
Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation


Abstract
:1. Introduction
- We provide a new benchmark database for HD-sEMG-based gesture recognition. The CapgMyo database consists of 3 sub-databases (DB-a, DB-b and DB-c); 8 isometric and isotonic hand gestures were obtained from 18 of the 23 subjects in DB-a and from 10 of the 23 subjects in DB-b, and 12 basic movements of the fingers were obtained from 10 of the 23 subjects in DB-c.
- We embedded a deep domain adaptation mechanism into the gesture classifier. When applied to new sessions/users, the adaptation starts working after the device is worn, and never stops until the user removes the device, going through the entire process of interaction (performing gesture recognition simultaneously).
Related Work
2. Materials and Methods
2.1. The CapgMyo Database
2.1.1. Participants
2.1.2. Acquisition Setup
2.1.3. Acquisition Protocol
2.1.4. Preprocessing
2.1.5. Data Records
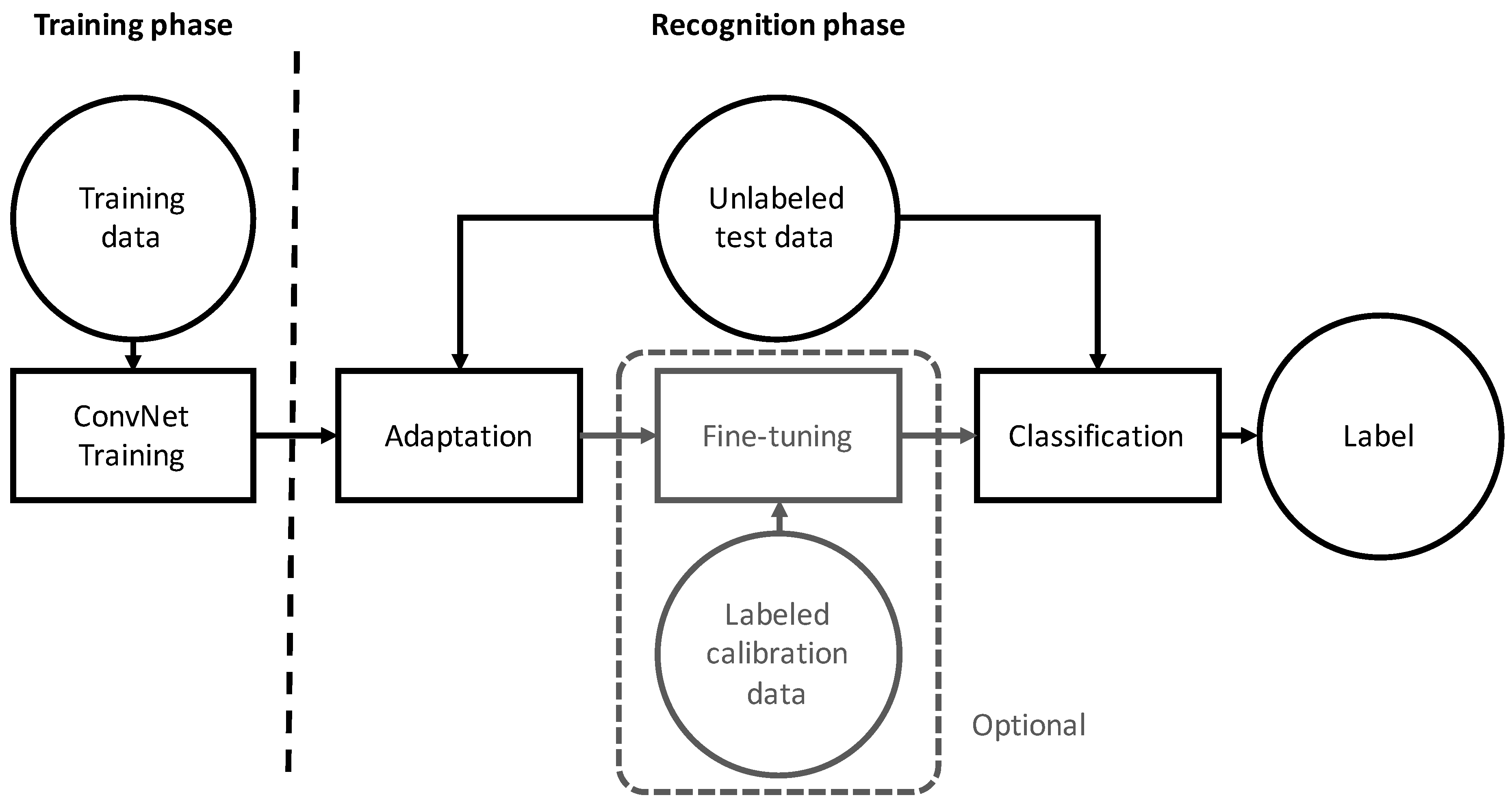
2.2. Inter-session Gesture Recognition by Deep Domain Adaptation
2.2.1. Problem Statement
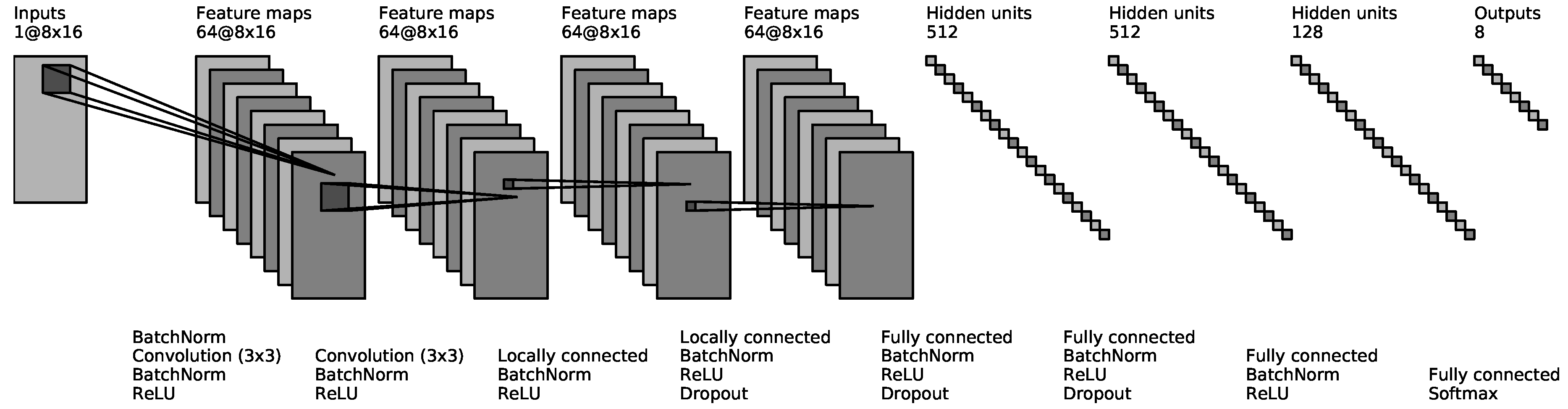
2.2.2. Gesture Recognition by Deep Convolutional Network
2.2.3. Deep Domain Adaptation
- In the training phase, the statistics and for each source domain are calculated independently. Because the statistics were calculated for each data batch in the training phase, we only need to ensure that the samples in each data batch are from the same session.
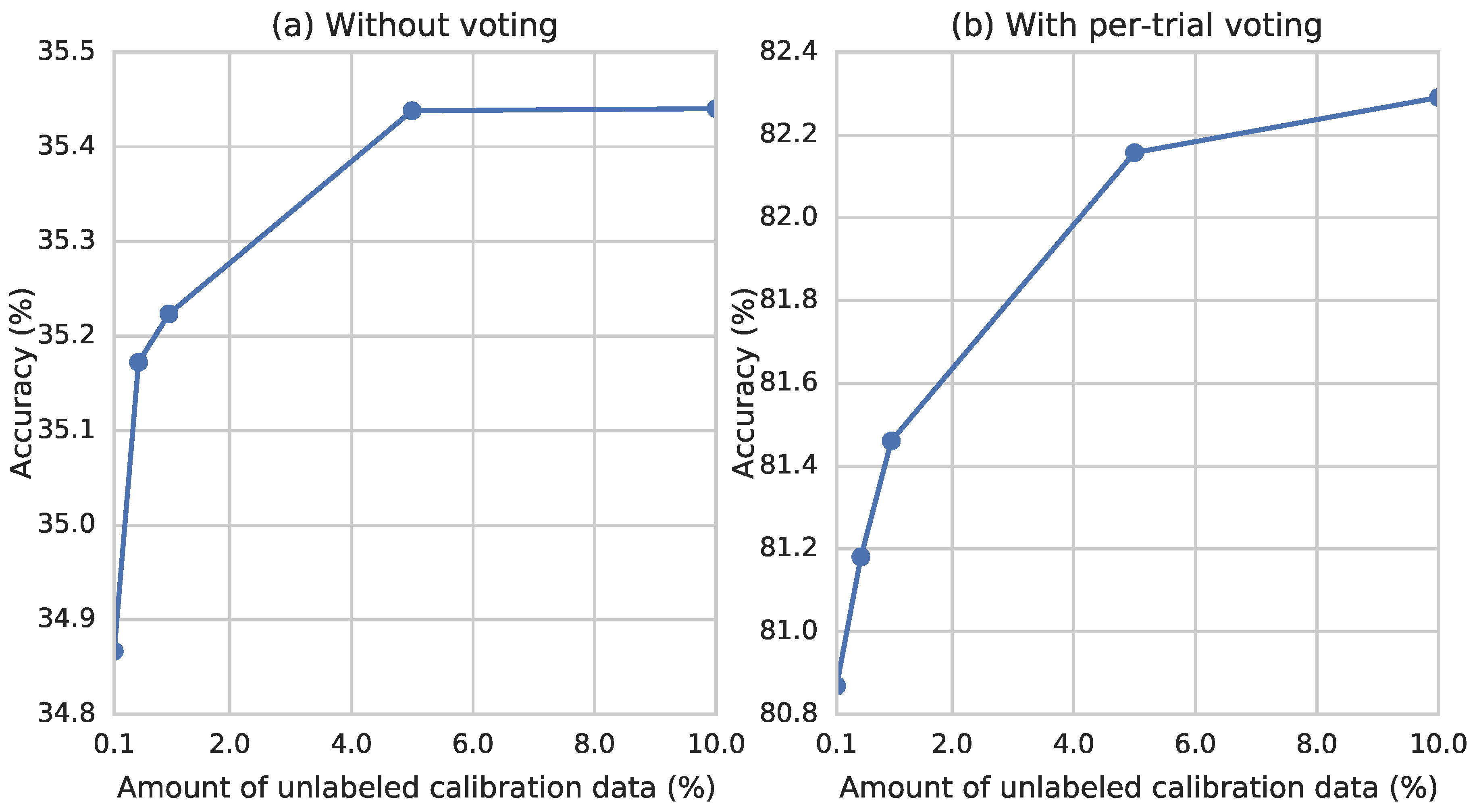
- In the recognition phase, given the unlabeled calibration data , AdaBN performs a forward pass, in which statistics and of BatchNorm are updated with and . The update is repeated for each BatchNorm, from bottom to top. If multiple batches of calibration data are presented, AdaBN performs multiple forward passes and calculate the statistics by moving average.
| Algorithm 1 Forward Pass of Multi-stream AdaBN in the traning phase |
| for do for do end for end for |
2.3. Experimental Setup
3. Results
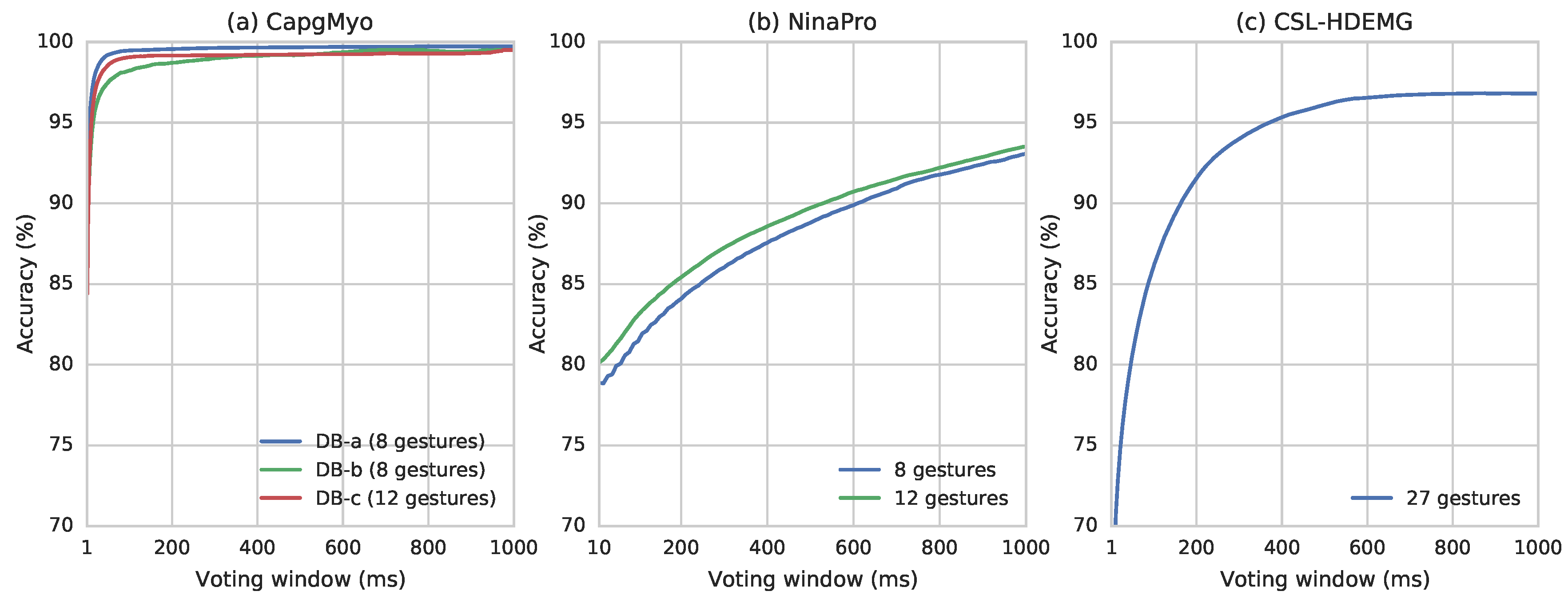
3.1. Technical Validation of CapgMyo
3.2. Evaluation using CSL-HDEMG
3.2.1. Intra-session evaluation
3.2.2. Inter-session evaluation
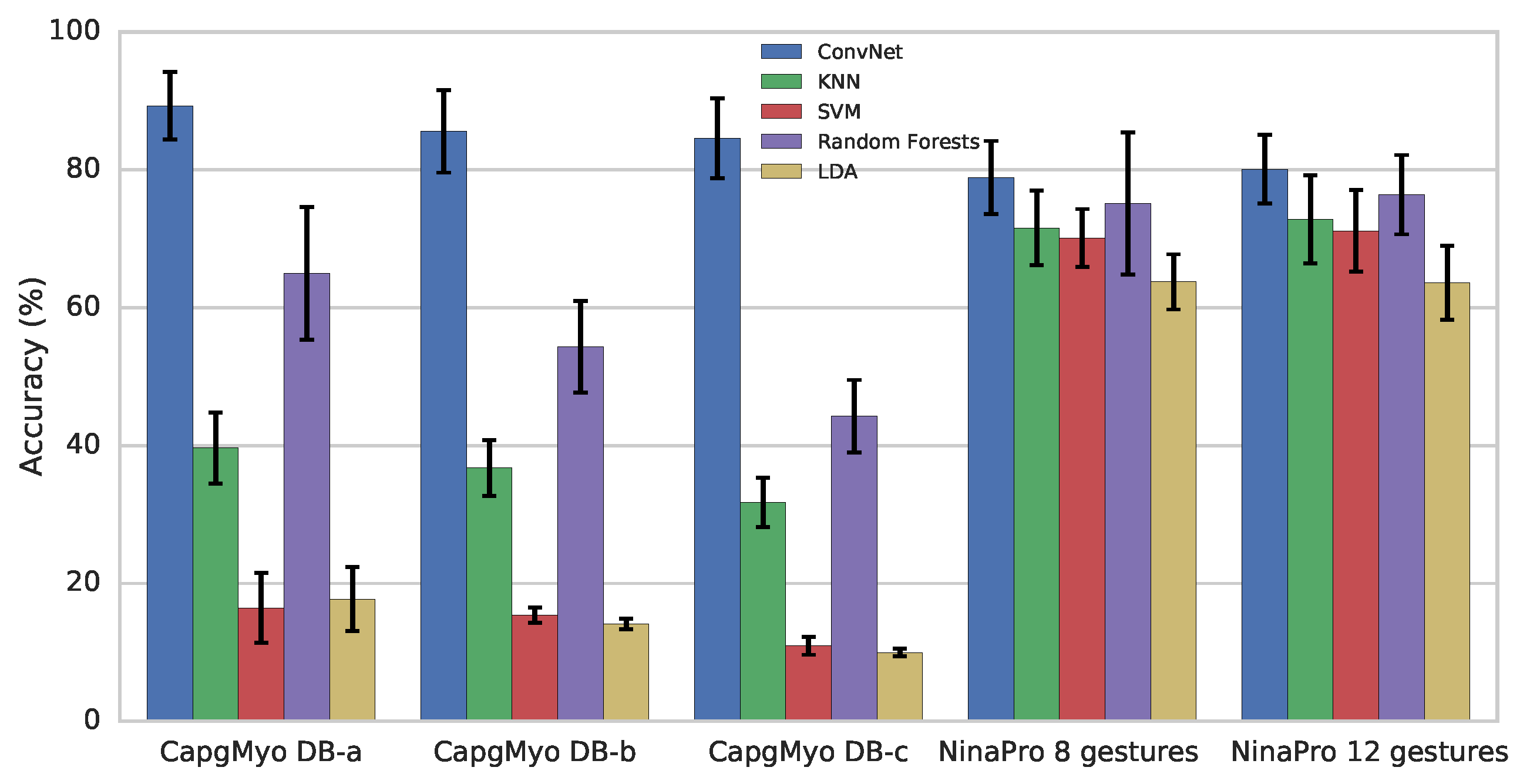
3.3. Evaluation using CapgMyo
3.4. Evaluation using NinaPro
4. Discussion
5. Conclusion and Further Works
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| MCI | muscle-computer interface |
| sEMG | surface electromyography |
| HD-sEMG | high-density surface electromyography |
| ConvNet | deep convolutional network |
| GMM | Gaussian mixture model |
| HMM | hidden Markov model |
| CCA | canonical correlation analysis |
| DAN | deep adaptation network |
| MK-MMD | multiple kernel variant of maximum mean discrepancies |
| GRL | gradient reverse layer |
| MVC | maximal voluntary contraction |
| BatchNorm | batch normalization |
| AdaBN | adaptive batch normalization |
| SGD | stochastic gradient descent |
| KNN | k-nearest neighbours |
| SVM | support vector machine |
| LDA | linear discriminant analysis |
References
- Saponas, T.S.; Tan, D.S.; Morris, D.; Balakrishnan, R. Demonstrating the feasibility of using forearm electromyography for muscle-computer interfaces. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Florence, Italy, 5–10 April 2008; pp. 515–524.
- Amma, C.; Krings, T.; Böer, J.; Schultz, T. Advancing muscle-computer interfaces with high-density electromyography. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 929–938.
- Casale, R.; Rainoldi, A. Fatigue and fibromyalgia syndrome: Clinical and neurophysiologic pattern. Best Pract. Res. Clin. Rheumatol. 2011, 25, 241–247. [Google Scholar] [CrossRef] [PubMed]
- Masuda, T.; Miyano, H.; Sadoyama, T. The propagation of motor unit action potential and the location of neuromuscular junction investigated by surface electrode arrays. Electroencephalogr. Clin. Neurophysiol. 1983, 55, 594–600. [Google Scholar] [CrossRef]
- Yamada, M.; Kumagai, K.; Uchiyama, A. The distribution and propagation pattern of motor unit action potentials studied by multi-channel surface EMG. Electroencephalogr. Clin. Neurophysiol. 1987, 67, 395–401. [Google Scholar] [CrossRef]
- Rojas-Martínez, M.; Mañanas, M.A.; Alonso, J.F. High-density surface EMG maps from upper-arm and forearm muscles. J. Neuroeng. Rehabil. 2012, 9, 1. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Rojas-Martínez, M.; Mañanas, M.; Alonso, J.; Merletti, R. Identification of isometric contractions based on high density EMG maps. J. Electromyogr. Kinesiol. 2013, 23, 33–42. [Google Scholar] [CrossRef] [PubMed]
- Zhang, X.; Zhou, P. High-density myoelectric pattern recognition toward improved stroke rehabilitation. IEEE Trans. Biomed. Eng. 2012, 59, 1649–1657. [Google Scholar] [CrossRef] [PubMed]
- Stango, A.; Negro, F.; Farina, D. Spatial correlation of high density EMG signals provides features robust to electrode number and shift in pattern recognition for myocontrol. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 189–198. [Google Scholar] [CrossRef] [PubMed]
- Castellini, C.; van der Smagt, P. Surface EMG in advanced hand prosthetics. Biol. Cybern. 2009, 100, 35–47. [Google Scholar] [CrossRef] [PubMed]
- Farina, D.; Jiang, N.; Rehbaum, H.; Holobar, A.; Graimann, B.; Dietl, H.; Aszmann, O.C. The extraction of neural information from the surface EMG for the control of upper-limb prostheses: Emerging avenues and challenges. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 797–809. [Google Scholar] [CrossRef] [PubMed]
- Hargrove, L.; Englehart, K.; Hudgins, B. A training strategy to reduce classification degradation due to electrode displacements in pattern recognition based myoelectric control. Biomed. Signal Process. Control 2008, 3, 175–180. [Google Scholar] [CrossRef]
- Boschmann, A.; Platzner, M. Reducing classification accuracy degradation of pattern recognition based myoelectric control caused by electrode shift using a high density electrode array. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), San Diego, CA, USA, 28 August–1 September 2012; pp. 4324–4327.
- Ju, P.; Kaelbling, L.P.; Singer, Y. State-based classification of finger gestures from electromyographic signals. In Proceedings of the International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 439–446.
- Khushaba, R.N. Correlation analysis of electromyogram signals for multiuser myoelectric interfaces. IEEE Trans. Neural Syst. Rehabil. Eng. 2014, 22, 745–755. [Google Scholar] [CrossRef] [PubMed]
- Patricia, N.; Tommasi, T.; Caputo, B. Multi-source adaptive learning for fast control of prosthetics hand. In Proceedings of the International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 2769–2774.
- Geng, W.; Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Li, J. Gesture recognition by instantaneous surface EMG images. Sci. Rep. 2016, 6, 36571. [Google Scholar] [CrossRef] [PubMed]
- Patel, V.M.; Gopalan, R.; Li, R.; Chellappa, R. Visual domain adaptation: A survey of recent advances. IEEE Signal Process. Mag. 2015, 32, 53–69. [Google Scholar] [CrossRef]
- Jin, W.; Li, Y.; Lin, S. Design of a novel non-invasive wearable device for array surface electromyogram. Int. J. Inf. Electron. Eng. 2016, 6, 139. [Google Scholar]
- Costanza, E.; Inverso, S.A.; Allen, R.; Maes, P. Intimate interfaces in action: Assessing the usability and subtlety of EMG-based motionless gestures. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, San Jose, CA, USA, 28 April–3 May 2007; pp. 819–828.
- Saponas, T.S.; Tan, D.S.; Morris, D.; Turner, J.; Landay, J.A. Making muscle-computer interfaces more practical. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 851–854.
- Lin, J.W.; Wang, C.; Huang, Y.Y.; Chou, K.T.; Chen, H.Y.; Tseng, W.L.; Chen, M.Y. BackHand: Sensing hand gestures via back of the hand. In Proceedings of the Annual ACM Symposium on User Interface Software & Technology, Daegu, Korea, 8–11 November 2015; pp. 557–564.
- McIntosh, J.; McNeill, C.; Fraser, M.; Kerber, F.; Löchtefeld, M.; Krüger, A. EMPress: Practical hand gesture classification with wrist-mounted EMG and pressure sensing. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Santa Clara, CA, USA, 7–12 May 2016; pp. 2332–2342.
- Matthies, D.J.; Perrault, S.T.; Urban, B.; Zhao, S. Botential: Localizing on-body gestures by measuring electrical signatures on the human skin. In Proceedings of the International Conference on Human-Computer Interaction with Mobile Devices and Services, Copenhagen, Denmark, 24–27 August 2015; pp. 207–216.
- Zhang, Y.; Harrison, C. Tomo: Wearable, low-cost electrical impedance tomography for hand gesture recognition. In Proceedings of the Annual ACM Symposium on User Interface Software & Technology, Daegu, Korea, 8–11 November 2015; pp. 167–173.
- Akhlaghi, N.; Baker, C.; Lahlou, M.; Zafar, H.; Murthy, K.; Rangwala, H.; Kosecka, J.; Joiner, W.; Pancrazio, J.; Sikdar, S. Real-time classification of hand motions using ultrasound imaging of forearm muscles. IEEE Trans. Biomed. Eng. 2016, 63, 1687–1698. [Google Scholar] [CrossRef] [PubMed]
- Blok, J.H.; van Dijk, J.P.; Drost, G.; Zwarts, M.J.; Stegeman, D.F. A high-density multichannel surface electromyography system for the characterization of single motor units. Rev. Sci. Instrum. 2002, 73, 1887–1897. [Google Scholar] [CrossRef]
- Lapatki, B.G.; van Dijk, J.P.; Jonas, I.E.; Zwarts, M.J.; Stegeman, D.F. A thin, flexible multielectrode grid for high-density surface EMG. J. Appl. Physiol. 2003, 96, 327–336. [Google Scholar] [CrossRef] [PubMed]
- Drost, G.; Stegeman, D.F.; van Engelen, B.G.M.; Zwarts, M.J. Clinical applications of high-density surface EMG: A systematic review. J. Electromyogr. Kinesiol. 2006, 16, 586–602. [Google Scholar] [CrossRef] [PubMed]
- Lynn, P.A. Direct on-line estimation of muscle fiber conduction velocity by surface electromyography. IEEE Trans. Biomed. Eng. 1979, 10, 564–571. [Google Scholar] [CrossRef]
- Muceli, S.; Farina, D. Simultaneous and proportional estimation of hand kinematics from EMG during mirrored movements at multiple degrees-of-freedom. IEEE Trans. Neural Syst. Rehabil. Eng. 2012, 20, 371–378. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, R.H.; Reaz, M.B.; Ali, M.A.B.M.; Bakar, A.A.; Chellappan, K.; Chang, T.G. Surface electromyography signal processing and classification techniques. Sensors 2013, 13, 12431–12466. [Google Scholar] [CrossRef] [PubMed]
- Ison, M.; Vujaklija, I.; Whitsell, B.; Farina, D.; Artemiadis, P. High-density electromyography and motor skill learning for robust long-term control of a 7-dof robot arm. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 24, 424–433. [Google Scholar] [CrossRef] [PubMed]
- Englehart, K.; Hudgins, B. A robust, real-time control scheme for multifunction myoelectric control. IEEE Trans. Biomed. Eng. 2003, 50, 848–854. [Google Scholar] [CrossRef] [PubMed]
- Crawford, B.; Miller, K.; Shenoy, P.; Rao, R. Real-time classification of electromyographic signals for robotic control. In Proceedings of the AAAI Conference on Artificial Intelligence, Pittsburgh, PA, USA, 9–13 July 2005; Volume 5, pp. 523–528.
- Oskoei, M.A.; Hu, H. Support vector machine-based classification scheme for myoelectric control applied to upper limb. IEEE Trans. Biomed. Eng. 2008, 55, 1956–1965. [Google Scholar] [CrossRef] [PubMed]
- Wheeler, K.R.; Chang, M.H.; Knuth, K.H. Gesture-based control and EMG decomposition. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2006, 36, 503–514. [Google Scholar] [CrossRef]
- Zhang, X.; Chen, X.; Li, Y.; Lantz, V.; Wang, K.; Yang, J. A framework for hand gesture recognition based on accelerometer and EMG sensors. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2011, 41, 1064–1076. [Google Scholar] [CrossRef]
- Lu, Z.; Chen, X.; Li, Q.; Zhang, X.; Zhou, P. A hand gesture recognition framework and wearable gesture-based interaction prototype for mobile devices. IEEE Trans. Hum.-Mach. Syst. 2014, 44, 293–299. [Google Scholar] [CrossRef]
- Phinyomark, A.; Phukpattaranont, P.; Limsakul, C. Feature reduction and selection for EMG signal classification. Expert Syst. Appl. 2012, 39, 7420–7431. [Google Scholar] [CrossRef]
- Phinyomark, A.; Quaine, F.; Charbonnier, S.; Serviere, C.; Tarpin-Bernard, F.; Laurillau, Y. A feasibility study on the use of anthropometric variables to make muscle—Computer interface more practical. Eng. Appl. Artif. Intell. 2013, 26, 1681–1688. [Google Scholar] [CrossRef]
- Phinyomark, A.; Quaine, F.; Charbonnier, S.; Serviere, C.; Tarpin-Bernard, F.; Laurillau, Y. EMG feature evaluation for improving myoelectric pattern recognition robustness. Expert Syst. Appl. 2013, 40, 4832–4840. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Kodagoda, S.; Takruri, M.; Dissanayake, G. Toward improved control of prosthetic fingers using surface electromyogram (EMG) signals. Expert Syst. Appl. 2012, 39, 10731–10738. [Google Scholar] [CrossRef]
- Khushaba, R.N.; Kodagoda, S. Electromyogram (EMG) feature reduction using mutual components analysis for multifunction prosthetic fingers control. In Proceedings of the International Conference on Control Automation Robotics & Vision, Guangzhou, China, 5–7 December 2012; pp. 1534–1539.
- Khushaba, R.N.; Kodagoda, S.; Liu, D.; Dissanayake, G. Muscle computer interfaces for driver distraction reduction. Comput. Methods Programs Biomed. 2013, 110, 137–149. [Google Scholar] [CrossRef] [PubMed]
- Al-Timemy, A.H.; Khushaba, R.N.; Bugmann, G.; Escudero, J. Improving the performance against force variation of EMG controlled multifunctional upper-limb prostheses for transradial amputees. IEEE Trans. Neural Syst. Rehabil. Eng. 2016, 24, 650–661. [Google Scholar] [CrossRef] [PubMed]
- Khushaba, R.N.; Al-Timemy, A.; Kodagoda, S.; Nazarpour, K. Combined influence of forearm orientation and muscular contraction on EMG pattern recognition. Expert Syst. Appl. 2016, 61, 154–161. [Google Scholar] [CrossRef]
- Atzori, M.; Gijsberts, A.; Castellini, C.; Caputo, B.; Hager, A.G.M.; Elsig, S.; Giatsidis, G.; Bassetto, F.; Müller, H. Electromyography data for non-invasive naturally-controlled robotic hand prostheses. Sci. Data 2014, 1, 140053. [Google Scholar] [CrossRef] [PubMed]
- Atzori, M.; Cognolato, M.; Müller, H. Deep learning with convolutional neural networks applied to electromyography data: A resource for the classification of movements for prosthetic hands. Front. Neurorobot. 2016, 10, 9. [Google Scholar] [CrossRef] [PubMed]
- Donahue, J.; Jia, Y.; Vinyals, O.; Hoffman, J.; Zhang, N.; Tzeng, E.; Darrell, T. DeCAF: A deep convolutional activation feature for generic visual recognition. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 647–655.
- Long, M.; Cao, Y.; Wang, J.; Jordan, M. Learning transferable features with deep adaptation networks. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 97–105.
- Tzeng, E.; Hoffman, J.; Darrell, T.; Saenko, K. Simultaneous deep transfer across domains and tasks. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 4068–4076.
- Ganin, Y.; Lempitsky, V. Unsupervised domain adaptation by backpropagation. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; pp. 1180–1189.
- Sun, B.; Feng, J.; Saenko, K. Return of frustratingly easy domain adaptation. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016.
- Li, Y.; Wang, N.W.; Shi, J.; Liu, J.; Hou, X. Revisiting batch normalization for practical domain adaptation. arXiv, 2016; arXiv:1603.04779. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: Montreal, QC, Canada, 8–13 December 2014; pp. 2672–2680. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6 July–11 July 2015; pp. 448–456.
- Šarić, M. Libhand: A library for hand articulation. Available online: http://www.libhand.org (accessed on 23 February 2017).
- Merletti, R.; Di Torino, P. Standards for reporting EMG data. J. Electromyogr. Kinesiol. 1999, 9, 3–4. [Google Scholar]
- Hermens, H.J.; Freriks, B.; Disselhorst-Klug, C.; Rau, G. Development of recommendations for sEMG sensors and sensor placement procedures. J. Electromyogr. Kinesiol. 2000, 10, 361–374. [Google Scholar] [CrossRef]
- Daley, H.; Englehart, K.; Hargrove, L.; Kuruganti, U. High density electromyography data of normally limbed and transradial amputee subjects for multifunction prosthetic control. J. Electromyogr. Kinesiol. 2012, 22, 478–484. [Google Scholar] [CrossRef] [PubMed]
- Hahne, J.M.; Rehbaum, H.; Biessmann, F.; Meinecke, F.C.; Muller, K.; Jiang, N.; Farina, D.; Parra, L.C. Simultaneous and proportional control of 2D wrist movements with myoelectric signals. In Proceedings of the IEEE International Workshop on Machine Learning for Signal Processing, Santander, Spain, 23–26 September 2012; pp. 1–6.
- Makowski, N.S.; Knutson, J.S.; Chae, J.; Crago, P.E. Control of robotic assistance using poststroke residual voluntary effort. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 221–231. [Google Scholar] [CrossRef] [PubMed]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. DeepFace: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 1701–1708.
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: South Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Srivastava, N.; Hinton, G.E.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Chen, T.; Li, M.; Li, Y.; Lin, M.; Wang, N.; Wang, M.; Xiao, T.; Xu, B.; Zhang, C.; Zhang, Z. Mxnet: A flexible and efficient machine learning library for heterogeneous distributed systems. arXiv, 2015; arXiv:1512.01274. [Google Scholar]
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the importance of initialization and momentum in deep learning. In Proceedings of the International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 1139–1147.
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1026–1034.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Farrell, T.R.; Weir, R.F. The optimal controller delay for myoelectric prostheses. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 111–118. [Google Scholar] [CrossRef] [PubMed]
- Smith, L.H.; Hargrove, L.J.; Lock, B.A.; Kuiken, T.A. Determining the optimal window length for pattern recognition-based myoelectric control: Balancing the competing effects of classification error and controller delay. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 186–192. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| label | Description | Instance | label | Description | Instance |
|---|---|---|---|---|---|
| 1 | Thumb up |  | 5 | Abduction of all fingers |  |
| 2 | Extension of index and middle, flexion of the others |  | 6 | Fingers flexed together in fist |  |
| 3 | Flexion of ring and little finger, extension of the others |  | 7 | Pointing index |  |
| 4 | Thumb opposing base of little finger |  | 5 | Adduction of extended fingers |  |
| label | Description | Instance | label | Description | Instance |
|---|---|---|---|---|---|
| 1 | Index flexion |  | 7 | Little finger flexion |  |
| 2 | Index extension |  | 8 | Little finger extension |  |
| 3 | Middle flexion |  | 9 | Thumb adduction |  |
| 4 | Middle extension |  | 10 | Thumb abduction |  |
| 5 | Ring flexion |  | 11 | Thumb flexion |  |
| 6 | Ring extension |  | 12 | Thumb extension |  |
| label | Description | Instance | label | Description | Instance |
|---|---|---|---|---|---|
| 100 | Abduction of all fingers |  | 102 | Fingers flexed together in fist |  |
| Name | Type | Description |
|---|---|---|
| data | matrix | SEMG signals, where n is the number of frames. |
| gesture | matrix | The gesture ID of each frame, where 0 denotes the rest posture. |
| subject | Scalar | The subject ID. |
| Name | Type | Description |
|---|---|---|
| data | matrix | SEMG signals. |
| gesture | Scalar | The gesture ID. |
| subject | Scalar | The subject ID. |
| trial | Scalar | The trial ID. |
| Subject ID | ID in DB-a | ID in DB-b | ID in DB-c | |
|---|---|---|---|---|
| Session 1 | Session 2 | |||
| 1 | - | - | - | 1 |
| 2 | 1 | 1 | 2 | 2 |
| 3 | 2 | 3 | 4 | - |
| 4 | - | 5 | 6 | 3 |
| 5 | 3 | - | - | - |
| 6 | 4 | 7 | 8 | 4 |
| 7 | 5 | 9 | 10 | - |
| 8 | - | 11 | 12 | - |
| 9 | 6 | 13 | 14 | - |
| 10 | 7 | - | - | - |
| 11 | 8 | - | - | - |
| 12 | - | 15 | 16 | 5 |
| 13 | 9 | - | - | 6 |
| 14 | - | - | - | 7 |
| 15 | 10 | - | - | - |
| 16 | 11 | - | - | 8 |
| 17 | 12 | 17 | 18 | - |
| 18 | 13 | - | - | - |
| 19 | 14 | - | - | - |
| 20 | 15 | - | - | - |
| 21 | 16 | - | - | 9 |
| 22 | 17 | - | - | - |
| 23 | 18 | 19 | 20 | 10 |
| CSL-HDEMG | CapgMyo DB-b | CapgMyo DB-c | |
|---|---|---|---|
| Intra-session | 96.8 (55.8) | 98.6 (85.6) | 99.2 (84.6) |
| Inter-session without adaptation | 62.7 (29.3) | 47.9 (35.0) | |
| Inter-session with adaptation | 82.3 (35.4) | 63.3 (41.2) | |
| Inter-subject without adaptation | 39.0 (31.4) | 26.3 (18.9) | |
| Inter-subject with adaptation | 55.3 (35.1) | 35.1 (21.2) |
| S1 | S2 | S3 | S4 | S5 | Avg | Std | |
|---|---|---|---|---|---|---|---|
| A | 93.7 | 97.8 | 98.1 | 98.9 | 99.6 | 97.6 | 2.3 |
| 85.2 | 90.7 | 95.2 | 94.8 | 90.7 | 91.3 | 4.0 | |
| B | 96.3 | 97.0 | 97.0 | 95.9 | 97.0 | 96.8 | 0.5 |
| 83.7 | 92.2 | 94.1 | 88.9 | 90.0 | 89.8 | 3.9 | |
| C | 97.8 | 97.0 | 96.3 | 94.8 | 91.5 | 95.5 | 2.5 |
| 88.9 | 93.3 | 92.6 | 92.2 | 88.9 | 91.2 | 2.1 | |
| D | 94.8 | 98.5 | 99.3 | 89.9 | 98.5 | 96.2 | 3.9 |
| 87.8 | 92.2 | 87.0 | 85.4 | 84.8 | 87.4 | 2.9 | |
| E | 97.0 | 98.5 | 99.3 | 98.1 | 94.8 | 97.6 | 1.7 |
| 91.5 | 89.6 | 96.3 | 94.1 | 90.4 | 92.4 | 2.8 | |
| 96.8 | 2.3 | ||||||
| 90.4 | 3.2 |
| A | B | C | D | E | Avg | |
|---|---|---|---|---|---|---|
| [2] | 60.6 | 73.0 | 62.3 | 53.3 | 45.3 | 58.9 |
| [2] with calibration | 83.9 | 77.2 | 71.0 | 66.5 | 78.4 | 75.4 |
| Ours | 69.9 | 71.3 | 61.2 | 59.4 | 51.8 | 62.7 |
| Ours with adaptation | 87.7 | 87.9 | 72.1 | 80.0 | 83.6 | 82.3 |
| DB | CSL | DB-b | DB-c | |
|---|---|---|---|---|
| Inter-Subject | Inter-Session | |||
| Training sessions | 4 | 9 | 1 | 9 |
| No AdaBN | 62.5 (29.3) | 39.0 (31.4) | 47.9 (35.0) | 26.3 (18.9) |
| Classical AdaBN | 82.0 (35.2) | 54.1 (33.8) | 63.0 (41.1) | 34.9 (20.9) |
| Multi-stream AdaBN | 82.3 (35.4) | 55.3 (35.1) | 63.3 (41.2) | 35.1 (21.2) |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Du, Y.; Jin, W.; Wei, W.; Hu, Y.; Geng, W. Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation. Sensors 2017, 17, 458. https://doi.org/10.3390/s17030458
Du Y, Jin W, Wei W, Hu Y, Geng W. Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation. Sensors. 2017; 17(3):458. https://doi.org/10.3390/s17030458
Chicago/Turabian StyleDu, Yu, Wenguang Jin, Wentao Wei, Yu Hu, and Weidong Geng. 2017. "Surface EMG-Based Inter-Session Gesture Recognition Enhanced by Deep Domain Adaptation" Sensors 17, no. 3: 458. https://doi.org/10.3390/s17030458