
Abstract
Despite the steady progress in video analysis led by the adoption of convolutional neural networks (CNNs), the relative improvement has been less drastic as that in 2D static image classification. Three main challenges exist including spatial (image) feature representation, temporal information representation, and model/computation complexity. It was recently shown by Carreira and Zisserman that 3D CNNs, inflated from 2D networks and pretrained on ImageNet, could be a promising way for spatial and temporal representation learning. However, as for model/computation complexity, 3D CNNs are much more expensive than 2D CNNs and prone to overfit. We seek a balance between speed and accuracy by building an effective and efficient video classification system through systematic exploration of critical network design choices. In particular, we show that it is possible to replace many of the 3D convolutions by low-cost 2D convolutions. Rather surprisingly, best result (in both speed and accuracy) is achieved when replacing the 3D convolutions at the bottom of the network, suggesting that temporal representation learning on high-level “semantic” features is more useful. Our conclusion generalizes to datasets with very different properties. When combined with several other cost-effective designs including separable spatial/temporal convolution and feature gating, our system results in an effective video classification system that that produces very competitive results on several action classification benchmarks (Kinetics, Something-something, UCF101 and HMDB), as well as two action detection (localization) benchmarks (JHMDB and UCF101-24).
You have full access to this open access chapter, Download conference paper PDF
Similar content being viewed by others


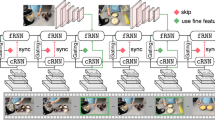
1 Introduction
The resurgence of convolutional neural networks (CNNs) has led to a wave of unprecedented advances for image classification using end-to-end hierarchical feature learning architectures [1,2,3,4]. The task of video classification, however, has not enjoyed the same level of performance jump as in image classification. In the past, one limitation was the lack of large-scale labeled video datasets. However, the recent creation of Sports-1M [5], Kinetics [6], Something-something [7], ActivityNet [8], Charades [9], etc. has partially removed that impediment.
Now we face more fundamental challenges. In particular, we have three main barriers to overcome: (1) how best to represent spatial information (i.e., recognizing the appearances of objects); (2) how best to represent temporal information (i.e., recognizing context, correlation and causation through time); and (3) how best to tradeoff model complexity with speed, both at training and testing time.

Our goal is to classify videos into different categories, as shown in the top row. We focus on two qualitatively different kinds of datasets: Something-something which requires recognizing low-level physical interactions, and Kinetics, which requires recognizing high-level activities. The main question we seek to answer is what kind of network architecture to use. We consider 4 main variants: I2D, which is a 2D CNN, operating on multiple frames; I3D, which is a 3D CNN, convolving over space and time; Bottom-Heavy I3D, which uses 3D in the lower layers, and 2D in the higher layers; and Top-Heavy I3D, which uses 2D in the lower (larger) layers, and 3D in the upper layers.
In this paper, we study these three questions by considering various kinds of 3D CNNs. Our starting point is the state of the art approach, due to Carreira and Zisserman [10], known as “I3D” (since it “inflates” the 2D convolutional filters of the “Inception” network [2] to 3D). Despite giving good performance, this model is very computationally expensive. This prompts several questions, which we seek to address in this paper:
-
Do we even need 3D convolution? If so, what layers should we make 3D, and what layers can be 2D? Does this depend on the nature of the dataset and task?
-
Is it important that we convolve jointly over time and space, or would it suffice to convolve over these dimensions independently?
-
How can we use answers to the above questions to improve on prior methods in terms of accuracy, speed and memory footprint?
To answer the first question, we apply “network surgery” to obtain several variants of the I3D architecture. In one family of variants, which we call Bottom-Heavy-I3D, we retain 3D temporal convolutions at the lowest layers of the network (the ones closest to the pixels), and use 2D convolutions for the higher layers. In the other family of variants, which we call Top-Heavy-I3D, we do the opposite, and retain 3D temporal convolutions at the top layers, and use 2D for the lower layers (see Fig. 1). We then investigate how to trade between accuracy and speed by varying the number of layers that are “deflated” (converted to 2D) in this way. We find that the Top-Heavy-I3D models are faster, which is not surprising, since they only apply 3D to the abstract feature maps, which are smaller than the low level feature maps due to spatial pooling. However, we also find that Top-Heavy-I3D models are often more accurate, which is surprising since they ignore low-level motion cues.
To answer the second question (about separating space and time), we consider replacing 3D convolutions with spatial and temporal separable 3D convolutions, i.e., we replace filters of the form \(k_t \times k \times k\) by \(1 \times k \times k\) followed by \(k_t \times 1 \times 1\), where \(k_t\) is the width of the filter in time, and k is the height/width of the filter in space. We call the resulting model S3D, which stands for “separable 3D CNN”. S3D obviously has many fewer parameters than models that use standard 3D convolution, and it is more computationally efficient. Surprisingly, we also show that it also has better accuracy than the original I3D model.
Finally, to answer the third question (about putting things together for an efficient and accurate video classification system), we combine what we have learned in answering the above two questions with a spatio-temporal gating mechanism to design a new model architecture which we call S3D-G. We show that this model gives significant gains in accuracy over baseline methods on a variety of challenging video classification datasets, such as Kinetics, Something-something, UCF-101 and HMDB, and also outperforms many other methods on other video recognition tasks, such as action localization on JHMDB.
2 Related work
2D CNNs have achieved state of the art results for image classification, so, not surprisingly, there have been many recent attempts to extend these successes to video classification. The Inception 3D (I3D) architecture [10] proposed by Carreira and Zisserman is one of the current state-of-the-art models. There are three key ingredients for its success: first, they “inflate” all the 2D convolution filters used by the Inception V1 architecture [2] into 3D convolutions, and carefully choose the temporal kernel size in the earlier layers. Second, they initialize the inflated model weights by duplicating weights that were pre-trained on ImageNet classification over the temporal dimension. Finally, they train the network on the large-scale Kinetics dataset [6].
Unfortunately, 3D CNNs are computationally expensive, so there has been recent interest in more efficient variants. In concurrent work, [11] has recently proposed a variety of models based on top of the ResNet architecture [4]. In particular, they consider models that use 3D convolution in either the bottom or top layers, and 2D in the rest; they call these “mixed convolutional” models. This is similar to our top-heavy and bottom-heavy models. They conclude that bottom heavy networks are more accurate, which contradicts our finding. However, the differences they find between top heavy and bottom heavy are fairly small, and are conflated with changes in computational complexity. By studying the entire speed-accuracy tradeoff curve (of Inception variants), we show that there are clear benefits to using a top-heavy design for a given computational budget (see Sect. 4.2).
Another way to save computation is to replace 3D convolutions with separable convolutions, in which we first convolve spatially in 2D, and then convolve temporally in 1D. We call the resulting model S3D. This factorization is similar in spirit to the depth-wise separable convolutions used in [12,13,14], except that we apply the idea to the temporal dimension instead of the feature dimension. This idea has been used in a variety of recent papers, including [11] (who call it “R(2+1)D”), [15] (who call it “Pseudo-3D network”), [16] (who call it “factorized spatio-temporal convolutional networks”), etc. We use the same method, but combine it with both top-heavy and bottom-heavy designs, which is a combination that leads to a very efficient video classification system. We show that the gains from separable convolution are complementary to the gains from using a top-heavy design (see Sect. 4.4).
An efficient way to improve accuracy is to use feature gating, which captures dependencies between feature channels with a simple but effective multiplicative transformation. This can be viewed as an efficient approximation to second-order pooling as shown in [17]. Feature gating has been used for many tasks, such as machine translation [18], VQA [19], reinforcement learning [20], image classification [21, 22], and action recognition [23]. We consider a variant of the above techniques in which we place the feature gating module after each of the temporal convolutions in an S3D network, and show that this results in substantial gains in accuracy (see Sect. 4.6).
Another way to improve accuracy (at somewhat higher cost) is to use precomputed optical flow features. This idea was successfully used in [24], who proposed a two-stream architecture where one CNN stream handles raw RGB input, and the other handles precomputed optical flow. Since then, many video classification methods follow the same multi-stream 2D CNN design, and have made improvements in terms of new representations [25, 26], different backbone architecture [17, 27,28,29], fusion of the streams [30,31,32,33] and exploiting richer temporal structures [34,35,36]. We will study the benefits of using optical flow in Sect. 5.1.
3 Experiment Setup
3.1 Datasets
In this paper, we consider two large video action classification datasets. The first one is Kinetics [6], which is a large dataset collected from YouTube, containing 400 action classes and 240 K training examples. Each example is temporally trimmed to be around 10 seconds. Since the full Kinetics dataset is quite large, we have created a smaller dataset that we call Mini-Kinetics-200.Footnote 1 Mini-Kinetics-200 consists of the 200 categories with most training examples; for each category, we randomly sample 400 examples from the training set, and 25 examples from the validation set, resulting in 80 K training examples and 5 K validation examples in total. The splits are publicly released to enable future comparisons. We also report some results on the original Kinetics dataset, which we will call Kinetics-Full for clarity.
The second main dataset is Something-something [7]. It consists of 110 k videos of 174 different low-level actions, each lasting between 2 to 6 s. In contrast to Kinetics, this dataset requires making fine-grained low-level distinctions, such as between “Pushing something from left to right” and “Pushing something from right to left”. It is therefore an interesting question whether the same principles will hold and the same architectures will work well on both datasets.
We also consider two smaller action classification datasets to test the transferability of our model, which we discuss in Sect. 5.2, as well as two action detection datasets, which we discuss in Sect. 5.3.
3.2 Model Training
Our training procedure largely follows [10]. During training, we densely sample 64 frames from a video and resize input frames to \(256\times 256\) and then take random crops of size \(224\times 224\). During evaluation, we use all frames and take \(224\times 224\) center crops from the resized frames. Our models are implemented with TensorFlow and optimized with a vanilla synchronous SGD algorithm with momentum of 0.9 and on 56 GPUs, batch size is set to 6 per GPU. For Mini-Kinetics-200, we train our model for 80 k steps with an initial learning rate of 0.1. We decay the learning rate at step 60k to 0.01, and step 70 k to 0.001. Since Something-something is a smaller dataset, we reduce the number of GPUs to 16 and train at learning rate of 0.1 for 10 k steps.
3.3 Measuring Speed and Accuracy
We report top-1 and top-5 accuracy. To measure the computational efficiency of our models, we report theoretical FLOPS based on a single input video sequence of 64 frames and spatial size \(224\times 224\). We pad the total number of frames to 250 for Mini-Kinetics-200 and 64 for Something-something when evaluating.
4 Network Surgery
In this section, we report the results of various “network surgery” experiments, where we vary different aspects of the I3D model to study the effects on speed and accuracy (Fig. 2).

Network architecture details for (a) I3D, (b) I2D, (c) Bottom-Heavy and (d) Top-Heavy variants. K indexes the spatio-temporal convolutional layers. The “2D Inc.” and “3D Inc.” blocks refer to 2D and 3D inception blocks, defined in Fig. 3.

(a) 2D Inception block; (b) 3D Inception block; (c) 3D temporal separable Inception block used in S3D networks.
4.1 Replacing all 3D Convolutions with 2D
In this section, we seek to determine how much value 3D convolution brings, motivated by the surprising success of 2D CNN approaches to video classification (see e.g., [36]). We do this by replacing every 3D filter in the I3D model with a 2D filter. This yields what we will refer to as the I2D model.Footnote 2
Theoretically, the I2D network should be invariant to the temporal reversal of the input frames, since it is not capable of incorporating global signals. To verify this, we train I2D and the original I3D model on the Kinetics-Full and Something-something datasets with normal frame order, and apply the trained models on validation data in which the frames are in normal order and reversed temporal order. The results of the experiment are shown in Table 1. We see that I2D has the same performance on both versions during testing, as is to be expected. However, we notice an interesting difference between the Kinetics dataset and the Something-something dataset. In the former case, the performance of I3D is indifferent to the “arrow of time” [37], whereas in the latter case, reversing the order hurts performance. We believe this is because Something-something dataset requires fine-grained distinctions between visually similar action categories.
4.2 Replacing some 3D Convolutions with 2D
Although we have seen that 3D convolution can boost accuracy compared to 2D convolution, it is computationally very expensive. In this section, we investigate the consequences of only replacing some of the 3D convolutions with 2D. Specifically, starting with an I2D model, we gradually inflate 2D convolutions into 3D, from low-level to high-level layers in the network, to create what we call the Bottom-Heavy-I3D model. We also consider the opposite process, in which we inflate the top layers of the model to 3D, but keep the lower layers 2D; we call such models Top-Heavy-I3D models.
We train and evaluate the Bottom-Heavy-I3D and Top-Heavy-I3D models on Mini-Kinetics-200 and Something-something, and show the results in Fig. 4. We see that the solid blue lines (top heavy I3D) are much better than the dotted blue lines (bottom heavy I3D) under the same FLOPS, which indicates that top heavy models are faster and more accurate. The speed increase is expected, since in a top-heavy model, the feature maps are reduced in size using spatial pooling before being convolved in 3D. For fixed computation budget, Top-Heavy-I3D is often significantly more accurate than Bottom-Heavy-I3D. This suggests that 3D convolutions are more capable and useful to model temporal patterns amongst high level features that are rich in semantics.
4.3 Analysis of Weight Distribution of Learned Filters
To verify the above intuition, we examined the weights of an I3D model which was trained on Kinetics-Full. Fig. 5 shows the distribution of these weights across 4 layers of our model, from low-level to high-level. In particular, each boxplot shows the distribution of \(W_l(t,:,:,:)\) for temporal offset t and layer l. We use \(t=0\) to indicate no offset in time, i.e., the center in the temporal kernel. At initialization, all the filters started with the same set of (2D convolution) weights (derived from an Inception model pre-trained on Imagenet) for each value of \(t \in \{-1,0,1\}.\) After training, we see that the temporally offset filters (i.e., for \(t \ne 0\)) have a weight distribution that is still closely centered on zero in the lower layers (see left panel), whereas the variance of the distribution increases in higher layers (see right panel). This suggests once again that the higher level temporal patterns are more useful for the Kinetics action classification task.

Accuracy vs number of FLOPS needed to perform inference on 64 RGB frames. Left: Mini-Kinetics-200 dataset. Right: Something-something dataset. Solid lines denote top-heavy models, dotted lines denote bottom-heavy models. Orange denotes spatial and temporal separable 3D convolutions, blue denotes full 3D convolutions.

Statistics of convolutional filter weights of an I3D model trained on Kinetics-Full. Each boxplot shows the distribution of \(W_l(t,:,:,:)\) for temporal offset t, with \(t=0\) being in the middle. Results for different layers l are shown in different panels, with lowest layers on the left. All filters with different temporal offset are initialized with the same set of weights. Low-level filters essentially ignore the temporal dimension, unlike higher level filters, where the weights distributed nicely across different temporal offsets.
4.4 Separating Temporal Convolution from Spatial Convolutions
In this section, we study the effect of replacing standard 3D convolution with a factored version which disentangles this operation into a temporal part and a spatial part. In more detail, our method is to replace each 3D convolution with two consecutive convolution layers: one 2D convolution layer to learn spatial features, followed by a 1D convolution layer purely on the temporal axis. This can be implemented by running two 3D convolutions, where the first (spatial) convolution has filter shape [1, k, k] and the second (temporal) convolution has filter shape [k, 1, 1]. By applying this factorization to I3D, we obtain a model which we refer to as S3D. For a detailed illustration of the architecture, please refer to Fig. 6.Footnote 3

An illustration of the S3D model. Dark red boxes are temporal separable convolutions (sep-conv), and pink boxes are temporal separable inception blocks, shown in Fig. 3c.
Table 2 compares the results of S3D and I3D on Kinetics-Full. Table 3 shows that S3D also outperforms I3D on the Something-something dataset. The results show that, despite a substantial compression in model size (12.06M parameters for I3D reduced to 8.77M for S3D), and a large speed-up (107.9 GFLOPS for I3D reduced to 66.38 GFLOPS for S3D), the separable model is even more accurate (top-1 accuracy improved from 71.1% to 72.2% for Kinetics-Full, and from 45.8% to 47.3% for Something-something). We believe the gain in accuracy is because the spatio-temporal factorization reduces overfitting, in a way without sacrificing the expressiveness of the representation, as we find that simply reducing the parameters of the network does not help with the performance.
Note that we can apply this separable transformation to any place where 3D convolution is used; thus this idea is orthogonal to the question of which layers should contain 3D convolution, which we discussed in Sect. 4.1. We denote the separable version of the Bottom-Heavy-I3D models by Bottom-Heavy-S3D, and the separable version of the Top-Heavy-I3D models by Top-Heavy-S3D, thus giving us 4 families of models.
We plot the speed vs accuracy of these models in Fig. 4. We see that separable top-heavy models offer the best speed-accuracy trade-off. In particular, the model in which we keep the top 2 layers as separable 3D convolutions, and make the rest 2D convolutions, seems to be a kind of “sweet spot”. We call this model “Fast-S3D”, since it is is 2.5 times more efficient than I3D (43.47 vs 107.9 GFLOPS), and yet has comparable accuracy (78.0% vs 78.4% on Mini-Kinetics-200).

tSNE projection of activation maps derived from images in the Something-something dataset. Colors and numbers represent the 10 action groups defined in [7]. The top row shows increasing semantic separation as we move to higher layers of S3D. The bottom row shows activations at level Max5a for 4 different models. We see that Top-Heavy-S3D has better semantic separation than Bottom-Heavy-S3D, especially for visually similar categories inside the red box.
4.5 tSNE Analysis of the Features
Here we explore the spatiotemporal representations learned by different levels of the S3D model on the Something-something dataset, using the tool of tSNE projection [38]. The behavior of the I3D models is very similar. Instead of using samples from all 174 categories, we use a smaller vocabulary, namely the “10 action groups” defined in [7].Footnote 4 We sample 2,200 data points from the validation set. In Fig. 7, the top row shows representations learned by a S3D model, at levels from Max3a to Max5c. The class separation becomed increasingly clearer at higher levels.
The bottom row shows representations learned at a certain feature level (Max5a), but across different models including I2D, Bottom-Heavy-S3D and Top-Heavy-S3D (both have a 2D-3D transition point at Max4b layer), as well as a full S3D model. Comparing the bottom-heavy and top-heavy models, for subtle actions such as “3: Picking”, “4: Putting” and “5: Poking” something, representations learned with a top-heavy model are more discriminative than that in a bottom-heavy model, thus leading to better class separations with the tSNE projection (highlighted with the red box). A top-heavy model can learn features that are as good as those learned with a full 3D model, and significantly better than those from the 2D model, without much sacrifice in processing speed. This observation further supports our hypothesis that temporal information modeling is most effective at top levels in the feature hierarchy for action classification tasks.
4.6 Spatio-Temporal Feature Gating
In this section we further improve the accuracy of our model by using feature gating. We start by considering the context feature gating mechanism first used for video classification in [23]. They consider an unstructured input feature vector \(x \in \mathcal {R}^n\) (usually learned at final embedding layers close to the logit output), and produce an output feature vector \(y \in \mathcal {R}^n\) as follows:
where \(\odot \) represents elementwise multiplication, \(W \in \mathcal {R}^{n \times n}\) is a weight matrix, and \(b \in \mathcal {R}^n\) is the bias term. This mechanism allows the model to upweight certain dimensions of x if the context model \(\sigma (W x +b)\) predicts that they are important, and to downweight irrelevant dimensions; this can be thought of as a “self-attention” mechanism.
We now extend this to feature tensors, with spatio-temporal structure. Let \(X \in \mathcal {R}^{T \times W \times H \times D}\) be the input tensor, and let Y be an output tensor of the same shape. We replace the matrix product Wx with \(W \mathrm {pool}(X)\), where the pooling operation averages the dimensions of X across space and time. (We found that this worked better than just averaging across space or just across time.) We then compute \(Y = \sigma (W \mathrm {pool}(X) + b) \odot X\), where \(\odot \) represents multiplication across the feature (channel) dimension, (i.e., we replicate the attention map \(\sigma (W \mathrm {pool}(X) + b)\) across space and time).
We can plug this gating module into any layer of the network. We experimented with several options, and got the best results by applying it directly after each of the [k, 1, 1] temporal convolutions in the S3D network. We call the final model (S3D with gating) S3D-G. We see from Table 2 that this results in a healthy gain in accuracy compared to S3D on the Kinetics-Full dataset (72.2% top-1 to 74.7%) at a very modest cost increase (66.38 GFLOPS to 71.38). Table 3 shows that S3D-G also outperforms S3D and I3D on Something-something. We also significantly outperform the current state of the art method, which is the Multi-scale TRN of [39], improving top-1 accuracy from 33.6% to 42.0%.
5 Generalization to Other Modalities, Data and Tasks
In this section, we evaluate the generality and robustness of the proposed S3D-G architecture by conducting transfer learning experiments on different input modalities, video datasets, and tasks.
5.1 Using Optical Flow Features
We first verify if S3D-G also works with optical flow inputs. For these experiments, we follow the standard setup as described in [10] and extract optical flow features with the TV-L1 approach [40]. We truncate the flow magnitude at \([-20, 20]\) and store them as encoded JPEG files. Other experiment settings are the same as the RGB experiments. From Table 4, we can see that the improvement of S3D-G over I3D is consistent with the gain we saw with RGB inputs, bringing the performance up from \(63.91\%\) to \(68.00\%\). By ensembling the two streams of RGB and flow, we obtain a performance of 77.22%, which is a 3% boost over the I3D network when trained on the same data. We note that even though we focus on the speed-accuracy trade-offs in action classification network design, the performance is competitive compared with recent Kinetics Challenge winners and concurrent works; notably [41, 42] use heavier backbone architectures (e.g. ResNet 101 has 8.5x more FLOPS than our S3D-G architecture)
5.2 Fine-Tuning on Other Video Classification Datasets
Next we conduct transfer learning experiments from Kinetics to other video classification datasets, namely HMDB-51 [44] and UCF-101 [45]. HMDB-51 contains around 7,000 videos spanning over 51 categories, while UCF-101 has 13,320 videos spanning over 101 categories. Both datasets consist of short video clips that are temporally trimmed, and contain 3 training and validation splits. We follow the standard setup as used in previous work and report average accuracy across all splits.
For our transfer learning experiments, we use the same setup as training on Kinetics, but change the number of GPUs to 8 and lower the learning rate to 0.01 for 6 K steps, and 0.001 for another 2K steps. For simplicity, we only use RGB (no optical flow).
Table 5 shows the results of this experiment. On UCF-101, our proposed S3D-G architecture, which only uses Kinetics for pretraining, outperforms I3D, and matches R(2+1)D, both of which use largescale datasets (Kinetics and Sports-1M) for pretraining. On HMDB-51, we outperform all previous methods published to date.
5.3 Spatio-Temporal Action Detection in Video
Finally, we demonstrate the effectiveness of S3D-G on action detection tasks, where the inputs are video frames, and the outputs are bounding boxes associated with action labels on the frames. Similar to the framework proposed in [48], we use the Faster-RCNN [49] object detection algorithm to jointly perform person localization and action recognition. We use the same approach as described in [50] to incorporate temporal context information via 3D networks. To be more specific, the model uses a 2D ResNet-50 [4] network that takes the annotated keyframe (frame with box annotations) as input, and extract features for region proposal generation on the keyframe. We then use a 3D network (such as I3D or S3D-G) that takes the frames surrounding the keyframe as input, and extract feature maps which are then pooled for bounding box classification. The 2D region proposal network (RPN) and 3D action classification network are jointly trained end-to-end. Note that we extend the ROIPooling operation to handle 3D feature maps by simply pooling at the same spatial locations over all time steps.
We report performance on two widely adopted video action detection datasets: JHDMB [51] and UCF-101-24 [45]. JHMDB dataset is a subset of HMDB-51, it consists of 928 videos for 21 action categories, and each video clip contains 15–40 frames. UCF-101-24 is a subset of UCF-101 with 24 labels and 3207 videos; we use the cleaned bounding box annotations from [52]. We report performance using the standard frame-AP metric defined in [53], which is computed as the average precision of action detection over all individual frames, at the intersection-over-union (IoU) threshold of 0.5. As commonly used by previous work, we report average performance over three splits of JHMDB and the first split for UCF-101-24.
Our implementation is based on the TensorFlow Object Detection API [54]. We train Faster-RCNN with asynchronous SGD on 11 GPUs for 600 K iterations. We fix the input resolution to be \(320\times 400\) pixels. For both training and validation, we fix the size of temporal context to 20 frames. All the other model parameters are set based on the recommended values from [54]. The ResNet-50 networks are initialized with ImageNet pre-trained models, and I3D and S3D-Gare pre-trained from Kinetics. We extract 3D feature maps from the “Mixed 4e” layer which has a spatial stride of 16.
Table 6 shows the comparison between I3D, S3D-G, and other state-of-the-art methods. We can see that both 3D networks outperform previous architectures by large margins, while S3D-G is consistently better than I3D.
6 Conclusion
We show that we can significantly improve on the previous state of the art 3D CNN video classification model, known as I3D, in terms of efficiency, by combining 3 key ideas: a top-heavy model design, temporally separable convolution, and spatio-temporal feature gating. Our modifications are simple and can be applied to other architectures. We hope this will boost performance on a variety of video understanding tasks.
Notes
- 1.
The original “Mini-Kinetics” dataset used in [6] contains videos that are no longer available. We created the new Mini-Kinetics-200 dataset in collaboration with the original authors.
- 2.
To reduce the memory and time requirements, and to keep the training protocol identical to I3D (in terms of the number of clips we use for training in each batch, etc), we retain two max-pooling layers with temporal stride 2 between Inception modules. Hence, strictly speaking, I2D is not a pure 2D model. However, it is very similar to a single-frame 2D classification model.
- 3.
There are 4 branches in an Inception block, but only two of them have 3x3 convolutions (the other two being pointwise 1x1 convolutions), as shown in Fig. 3. As such, when I3D inflates the convolutions to 3D, only some of the features contain temporal information. However, by using separable temporal convolution, we can add temporal information to all 4 branches. This improves the performance from \(78.4\%\) to \(78.9\%\) on Mini-Kinetics-200. In the following sections, whenever we refer to an S3D model, we mean S3D with such configuration.
- 4.
The labels are as follows. 0: Dropping [something], 1: Moving [something] from right to left, 2: Moving [something] from left to right, 3: Picking [something], 4:Putting [something], 5: Poking [something], 6: Tearing [something], 7: Pouring [something], 8: Holding [something], 9: Showing [something].
References
Krizhevsky, A., Sutskever, I., Hinton, G.E.: Imagenet classification with deep convolutional neural networks. In: NIPS (2012)
Szegedy, C., et al.: Going deeper with convolutions. In: CVPR (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. In: ICLR (2015)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., Fei-Fei, L.: Large-scale video classification with convolutional neural networks. In: CVPR (2014)
Kay, W., et al.: The kinetics human action video dataset. In: CVPR (2017)
Goyal, R., et al.: The something something video database for learning and evaluating visual common sense. In: ICCV (2017)
Caba Heilbron, F., Escorcia, V., Ghanem, B., Niebles, J.C.: ActivityNet: A large-scale video benchmark for human activity understanding. In: CVPR (2015)
Sigurdsson, G.A., Varol, G., Wang, X., Farhadi, A., Laptev, I., Gupta, A.: Hollywood in homes: crowdsourcing data collection for activity understanding. In: ECCV (2016)
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the kinetics dataset. In: CVPR (2017)
Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., Paluri, M.: A closer look at spatiotemporal convolutions for action recognition. In: CVPR (2018)
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: CVPR (2017)
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications (2017). arXiv:1704.04861
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: CVPR (2017)
Qiu, Z., Yao, T., Mei, T.: Learning spatio-temporal representation with pseudo-3D residual networks. In: ICCV (2017)
Sun, L., Jia, K., Yeung, D.Y., Shi, B.E.: Human action recognition using factorized spatio-temporal convolutional networks. In: ICCV (2015)
Girdhar, R., Ramanan, D.: Attentional pooling for action recognition. In: NIPS (2017)
Dauphin, Y.N., Fan, A., Auli, M., Grangier, D.: Language modeling with gated convolutional networks. In: ICML (2017)
Perez, E., Strub, F., de Vries, H., Dumoulin, V., Courville, A.: Film: visual reasoning with a general conditioning layer. In: AAAI (2018)
Elfwing, S., Uchibe, E., Doya, K.: Sigmoid-weighted linear units for neural network function approximation in reinforcement learning. Neural Netw. (2018)
Ramachandran, P., Zoph, B., Le, Q.V.: Swish: a self-gated activation function (2017). arXiv:1710.05941
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR (2018)
Miech, A., Laptev, I., Sivic, J.: Learnable pooling with context gating for video classification (2017). arXiv:1706.06905
Simonyan, K., Zisserman, A.: Two-stream convolutional networks for action recognition in videos. In: INIPS (2014)
Bilen, H., Fernando, B., Gavves, E., Vedaldi, A., Gould, S.: Dynamic image networks for action recognition. In: CVPR (2016)
Bilen, H., Fernando, B., Gavves, E., Vedaldi, A.: Action recognition with dynamic image networks. IEEE PAMI (2017)
Feichtenhofer, C., Pinz, A., Wildes, R.P.: Temporal residual networks for dynamic scene recognition. In: CVPR (2017)
Wang, L., Xiong, Y., Wang, Z., Qiao, Y.: Towards good practices for very deep two-stream convnets (2015). arXiv:1507.02159
Ng, J.Y., Hausknecht, M.J., Vijayanarasimhan, S., Vinyals, O., Monga, R., Toderici, G.: Beyond short snippets: deep networks for video classification. In: CVPR (2015)
Feichtenhofer, C., Pinz, A., Zisserman, A.: Convolutional two-stream network fusion for video action recognition. In: CVPR (2016)
Feichtenhofer, C., Pinz, A., Wildes, R.: Spatiotemporal multiplier networks for video action recognition. In: CVPR (2017)
Feichtenhofer, C., Pinz, A., Wildes, R.P.: Spatiotemporal residual networks for video action recognition. In: NIPS (2016)
Zolfaghari, M., Oliveira, G.L., Sedaghat, N., Brox, T.: Chained multi-stream networks exploiting pose, motion, and appearance for action classification and detection. In: ICCV (2017)
Donahue, J., et al.: Long-term recurrent convolutional networks for visual recognition and description. In CVPR (2015)
Wang, X., Farhadi, A., Gupta, A.: Actions transformations. In: CVPR (2016)
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., Lin, D., Tang, X., Van Gool, L.: Temporal segment networks: Towards good practices for deep action recognition. In: ECCV (2016)
Pickup, L.C., et al.: Seeing the arrow of time. In: CVPR (2014)
Maaten, L.V.D., Hinton, G.: Visualizing data using t-SNE. JMLR (2008)
Zhou, B., Andonian, A., Torralba, A.: Temporal relational reasoning in videos (2017). arXiv:1711.08496
Zach, C., Pock, T., Bischof, H.: A duality based approach for realtime tv-l1 optical flow. Pattern Recognit. (2007)
Bian, Y., et al.: Revisiting the effectiveness of off-the-shelf temporal modeling approaches for large-scale video classification (2017). arXiv:1708.03805
Wang, X., Girshick, R., Gupta, A., He, K.: Non-local neural networks. In: CVPR (2018)
Wang, L., Li, W., Li, W., Gool, L.V.: Appearance-and-relation networks for video classification. In: CVPR (2018)
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., Serre, T.: HMDB: A large video database for human motion recognition. In: ICCV (2011)
Soomro, K., Zamir, A., Shah, M.: UCF101: a dataset of 101 human actions classes from videos in the wild. Technical Report CRCV-TR-12-01 (2012)
Tran, D., Bourdev, L.D., Fergus, R., Torresani, L., Paluri, M.: C3D: Generic features for video analysis (2014). arXiv:1412.0767
Tran, D., Ray, J., Shou, Z., Chang, S., Paluri, M.: Convnet architecture search for spatiotemporal feature learning (2017). arXiv:1708.05038
Peng, X., Schmid, C.: Multi-region two-stream R-CNN for action detection. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 744–759. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_45
Ren, S., He, K., Girshick, R., Sun, J.: Faster R-CNN: Towards real-time object detection with region proposal networks. In: NIPS (2015)
Gu, C., et al.: AVA: A video dataset of spatio-temporally localized atomic visual actions. In: CVPR (2018)
Jhuang, H., Gall, J., Zuffi, S., Schmid, C., Black, M.: Towards understanding action recognition. In: ICCV (2013)
Saha, S., Sing, G., Cuzzolin, F.: AMTnet: Action-micro-tube regression by end-to-end trainable deep architecture. In: ICCV (2017)
Gkioxari, G., Malik, J.: Finding action tubes. In: CVPR (2015)
Huang, J., et al.: Speed/accuracy trade-offs for modern convolutional object detectors. In: CVPR (2017)
Weinzaepfel, P., Harchaoui, Z., Schmid, C.: Learning to track for spatio-temporal action localization. In: ICCV (2015)
Kalogeiton, V., Weinzaepfel, P., Ferrari, V., Schmid, C.: Action tubelet detector for spatio-temporal action localization. In: ICCV (2017)
Acknowledgment
We would like to thank the authors of [6] for the help on the Kinetics dataset and the baseline experiments, especially Joao Carreira for many constructive discussions. We also want to thank Abhinav Shrivastava, Jitendra Malik, and Rahul Sukthankar for valuable feedbacks. S.X. is supported by Google. Z.T. is supported by NSF IIS-1618477 and NSF IIS-1717431.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer Nature Switzerland AG
About this paper

Cite this paper
Xie, S., Sun, C., Huang, J., Tu, Z., Murphy, K. (2018). Rethinking Spatiotemporal Feature Learning: Speed-Accuracy Trade-offs in Video Classification. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), vol 11219. Springer, Cham. https://doi.org/10.1007/978-3-030-01267-0_19
Download citation
DOI: https://doi.org/10.1007/978-3-030-01267-0_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-01266-3
Online ISBN: 978-3-030-01267-0
eBook Packages: Computer ScienceComputer Science (R0)