
Abstract
Estimates of the level of inequality of opportunity have traditionally been proposed as lower bounds due to the downward bias resulting from the partial observability of circumstances that affect individual outcome. We show that such estimates may also suffer from upward bias as a consequence of sampling variance. The magnitude of the latter distortion depends on both the empirical strategy used and the observed sample. We suggest that, although neglected in empirical contributions, the upward bias may be significant and challenge the interpretation of inequality of opportunity estimates as lower bounds. We propose a simple criterion to select the best specification that balances the two sources of bias. Our method is based on cross-validation and can easily be implemented with survey data. To show how this method can improve the reliability of inequality of opportunity measurement, we provide an empirical illustration based on income data from 31 European countries. Our evidence shows that estimates of inequality of opportunity are sensitive to model selection. Alternative specifications lead to significant differences in the absolute level of inequality of opportunity and to the re-ranking of a number of countries, which confirms the need for an objective criterion to select the best econometric model when measuring inequality of opportunity.

Source: EU-SILC, 2011

Source: EU-SILC, 2011
Similar content being viewed by others

Notes
Other well-established approaches can be used to measure IOp. Approaches differ in how they define the principle of equal opportunity and in the way the counterfactual distribution is constructed (Roemer 1998; Lefranc et al. 2009; Fleurbaey and Schokkaert 2009; Checchi and Peragine 2010). However, because the construction of these alternative counterfactual distributions generally requires the observation or identification of effort (an extremely difficult variable to measure), they are less frequently adopted in the empirical literature.
In principle, if cardinal circumstances are observed, regressors might be non-categorical. However, to the best of our knowledge in the empirical literature, this is never the case. Even if cardinal measures are available, i.e. parental income, authors tend to use categorical regressors for the quantiles of the continuous distribution (see, for example, Björklund et al. 2012).
Analogously to the Mincer equation, a log-linear specification is preferred by the majority of the authors. (Ferreira and Gignoux 2011)
Or, if adopting a parametric approach, regression with a larger number of controls and fewer degrees of freedom.
Note also that the approach proposed by Li Donni et al. (2015), although not explicitly discussed by the authors, represents a possible strategy to address this issue. They define Roemerian types using latent class analysis. That is, they assume that observable circumstances are manifestations of an unobservable membership to a number of latent groups. Their method reduces the number of types and hence avoids large sampling variance in the counterfactual distribution.
In a framework where the outcome is measured with error and the sampling variance of the counterfactual distribution is ignored, Wendelspiess (2015) predicts the opposite direction of bias.
Based on our conclusion Brunori et al. (2018) have recently compared popular econometric approaches to estimate IOp. Their analysis shows that conditional inference random forests, a machine learning algorithm introduced by Hothorn et al. (2006), outperforms other methods in predicting IOp out-of-sample.
We are aware that the number of alternative models exponentially increases when circumstances are interacted. Moreover, researchers might have the choice to consider some circumstances with different levels of aggregation, e.g. country/region/district of birth. In these cases, our method should be complemented with an algorithm that can restrict the number of models considered, for example, best subset selection or stepwise selection, see Gareth et al. (2013).
Austria (AT), Belgium (BE), Bulgaria (BG), Switzerland (CH), Cyprus (CY), Czech Republic (CZ), Germany (DE), Denmark (DK), Estonia (EE), Greece (EL), Finland (FI), France (FR), Croatia (HR), Hungary (HU), Ireland (IE), Italy (IT), Iceland (IS), Latvia (LV), Lithuania (LT), Luxembourg (LU), Malta (MT), the Netherlands (NL), Norway (NO), Poland (PL), Portugal (PT), Romania (RO), Spain (ES), Slovakia (SK), Slovenia (SI), Sweden (SE), and the United Kingdom (UK).
Those are based on the International Standard Classification of Occupations, published by the International Labour Office ISCO-08. Blue collar includes parents that who do not work or were occupied as: clerical support workers; service and sales workers; skilled agricultural, forestry and fish; craft and related trades workers; plant and machine operators; elementary occupations.
Education categories are based on the International Standard Classification of Education 1997 (ISCED-97). When coded into two, low includes ISCED below level 3.
ISCO-08 1-digit: armed forces occupations; managers; professionals; technicians and associate professionals; clerical support workers; service and sales workers; skilled agricultural, forestry and fish; craft and related trades workers; plant and machine operators; elementary occupations; did not work/unknown father/mother
Unknown father/mother, could neither read nor write; low level (ISCED 0-2); medium level (ISCED 3-4); high level (ISCED 5-6).
Note that these are the sample sizes used in the regression; they include only individuals with non-missing information.
References
Arlot S, Celisse A (2010) A survey of cross-validation procedures for model selection. Stat Surv 4:40–79
Athey S (2018) The impact of machine learning on economics. In: Agrawal AK, Gans J, Goldfarb A (eds) Chapter 21 in the economics of artificial intelligence: an agenda. University of Chicago Press, Chicago
Balcazar C (2015) Lower bounds on inequality of opportunity and measurement error. Econ Lett 137:102–105
Björklund A, Jäntti A, Roemer J (2012) Equality of opportunity and the distribution of long-run income in Sweden. Soc Choice Welf 39:675–696
Bourguignon F, Ferreira F, Ménendez M (2007) Inequality of opportunity in Brazil. Rev Income Wealth 53:585–618
Bourguignon F, Ferreira F, Ménendez M (2013) Inequality of opportunity in Brazil: a corrigendum. Rev Income Wealth 59:551–555
Brunori P, Ferreira F, Peragine V (2013) Inequality ofopportunity, income inequality and mobility: some internationalcomparisons. In: Paus E (ed) Getting development right: structural transformation, inclusion and sustainability in the post-crisis era. Palgrave Macmillan
Brunori P, Hufe P, Mahler GD (2018) The roots of inequality: estimating inequality of opportunity from regression trees. In: World bank policy research working papers 8349
Brunori P, Palmisano F, Peragine V (2016) Inequality of opportunity in Sub Saharan Africa. In: World bank policy research working papers 7782
Brzenziński M (2015) Inequality of opportunity in Europe before and after the Great Recession. In: Working Paper n. 2/2015 (150). Faculty of Economic Sciences, University of Warsaw
Chakravarty SR, Eichhorn W (1994) Measurement of income inequality: observed versus true data. In: Eichhorn W (ed) Models and measurement of welfare and inequality. Springer, Berlin
Checchi D, Peragine V (2010) Inequality of opportunity in Italy. J Econ Inequal 8:429–450
Checchi D, Peragine V, Serlenga L (2016) Inequality of opportunity in Europe: is there a role for institutions? In: Cappellari L, Polachek S, Tatsiramos K (eds) Inequality: causes and consequences, research in labor economics, vol 43. Emerald, Bingley
Daniels B (2012) “CROSSFOLD: stata module to perform k-fold cross-validation,” Statistical Software Components S457426. Boston College Department of Economics
Ferreira F, Gignoux J (2011) The measurement of inequality of opportunity: theory and an application to Latin America. Rev Income Wealth 57:622–657
Ferreira F, Peragine V (2016) Equality of opportunity: theory and evidence. In: Adler M, Fleurbaey M (eds) Oxford handbook of well-being and public policy. Oxford University Press, Oxford
Fleurbaey M, Schokkaert E (2009) Unfair inequalities in health and health care. J Health Econ 28:73–90
Gareth J, Witten D, Hastie T, Tibshirani R (2013) An introduction to statistical learning with applications in R. Springer, New York
Hastie T, Tibshirani R, Friedman J (2009) The elements of statistical learning data mining, inference, and prediction, 2nd edn. Springer
Hothorn T, Hornik K, Zeileis A (2006) Unbiased recursive partitioning: a conditional inference framework. J Comput Graph Stat 15(3):651–674
Hufe P, Peichl A, Roemer J, Ungerer M (2017) Inequality of income acquisition: the role of childhood circumstances. Soc Choice Welf 49:499–544
Hufe P, Peichl A (2015) Lower bounds and the linearity assumption in parametric estimations of inequality of opportunity. In: IZA working papers, DP No. 9605
Ibarra L, Martinez C, Adan L (2015) Exploring the sources of downward bias in measuring inequality of opportunity. In: World bank policy research working paper no. WPS 7458. Washington
Kanbur R, Wagstaff A (2016) How useful is inequality of opportunity as a policy construct? In: Basu K, Stiglitz JE (eds) Inequality and growth: patterns and policy. International economic association series. Palgrave Macmillan, London
Kohavi R (1995) A study of cross-validation and bootstrap for accuracy estimation and model selection. In: Proceedings of the 14th international joint conference on artificial intelligence, vol 2, pp 1137–1143
Larson SC (1931) The shrinkage of the coefficient of multiple correlation. J Educ Psychol 22(1):45–55
Lefranc A, Pistolesi N, Trannoy A (2009) Equality of opportunity and luck: definitions and testable conditions, with an application to income in France. J Public Econ 93(11–12):1189–1207
Li Donni P, Rodriguez JG, Rosa Dias P (2015) Empirical definition of social types in the analysis of inequality of opportunity: a latent classes approach. Soc Choice Welf 44:673–701
Luongo P (2011) The implication of partial observability of circumstances on the measurement of inequality of opportunity. In: Rodriguez J (ed) Research on economic inequality, vol 19, pp 23-49
Marrero G, Rodrguez J (2012) Inequality of opportunity in Europe. Rev Income Wealth 58:597–621
Mullainathan S, Spiess J (2017) Machine learning: an applied econometric approach. J Econ Perspect 31(2):87–106
Niehues J, Peichl A (2014) Upper bounds of inequality of opportunity: theory and evidence for Germany and the US. Soc Choice Welf 43:63–79
Rodríguez JD, Pérez A, Lozano JA (2010) Sensitivity analysis of kappa-fold cross validation in prediction error estimation. IEEE Trans Pattern Anal Mach Intell 32(3):569–575
Roemer J (1998) Equality of opportunity. Harvard University Press, Cambridge
Roemer J, Trannoy A (2015) Equality of Opportunity. In: Atkinson AB, Bourguignon F (eds) Handbook of income distribution, vol 2. Elsevier, New York
Shao J (1997) An asymptotic theory for linear model selection. Stat Sin 7(1997):221–264
Stone M (1977) An asymptotic equivalence of choice of model by cross-validation and akaike’s criterion. J R Stat Soc Ser B 39(1):44–47
Suárez AA, Menéndez AJL (2017) Income inequality and inequality of opportunity in Europe. Are they on the rise? ECINEQ WP 2017-436
Van de Gaer D, Ramos X (2016) Empirical approaches to inequality of opportunity: principles, measures, and evidence. J Econ Surv 30(5):855–883
Varian HR (2014) Big data: new tricks for econometrics. J Econ Perspect 28(2):3–27
Wendelspiess FCJ (2015) Measuring inequality of opportunity with latent variables. J Hum Dev Capab 16(1):106–121
Author information
Authors and Affiliations
Corresponding author
Appendices
A Upward bias when estimating IOp with survey data
Chakravarty and Eichhorn (1994) distinguish between the true distribution of income, y, and the observed distribution, \(\tilde{y}\), where \(\tilde{y}=\)\( y+e\) and e is commonly defined as the measurement error such that \(e\sim iid(0,\sigma ^{2})\). By considering a strictly concave von Neumann–Morgenstern utility function, U, they prove by analogy that if we measure inequality \(I(\tilde{y})\) with an inequality index I that satisfies symmetry and the Pigou-Dalton transfer principle, then the inequality of the true y distribution is smaller than inequality in the observed distribution.
Without loss of generality, we apply their result to the case of non-parametric IOp measurement (Eq. 2).
Proposition
Let \(\tilde{Y}\) be the counterfactual distribution estimated with Eq. 2. Assume that \(\tilde{Y}\) is estimated by observing the full set of circumstances and the entire population. Let \(\hat{\tilde{Y}}\) be the same counterfactual distribution estimated by observing the full set of circumstances but considering only a proper subsample of the entire population. Let IOp and \(\hat{IOp}\) be any measure of inequality that satisfies symmetry and the Pigou-Dalton transfer principle applied to \( \tilde{Y}\) and \(\hat{\tilde{Y}}\) respectively. Then, \(E(\hat{IOp})>IOp\).
Proof
Let \(\mathbf {M} =\mu _1, \ldots , \mu _T\) be the vector of types’ mean outcomes in the population. Let \(\hat{\mathbf {M}} =\hat{\mu _1}, \ldots , \hat{\mu _T}\) be the estimates of types’ means based on a proper subsample of the population. Then, for each \(t=1,\ldots ,n\), \(\hat{\mu }_{t}=\)\(\mu _{t}+\eta \), where \(\eta = \frac{\sigma }{\sqrt{N_{t}}}\sim (0, \chi ^2)\) is the standard error of \(\hat{ \mu }_{t}\).
Following Chakravarty and Eichhorn (1994), we assume that U is a strictly concave function. By Jensen’s inequality, we have
Note that \(E\left( \hat{\mathbf {M}}| \mathbf {M} \right) = \mathbf {M}\), so:
By taking expectations with respect to \(\mathbf {M} \) on both sides, (4) becomes:
Because \(E(\eta )=0\), the two distributions have the same mean. If U is a strictly concave function, then (5) is equivalent to saying that the distribution of \(\mathbf {M}\) Lorenz dominates the distribution of \(\hat{ \mathbf {M}}\), which implies that \(E(\hat{IOp})>IOp\). \(\square \)
Corollary
When one or more of the relevant circumstances is not used to partition the population into types (partial observability) and \( \tilde{Y}\) is estimated on a proper subsample of the population, \(\hat{{IOp}} \) cannot be interpreted as a lower bound of IOp.
B A simulation to assess the magnitude of the upward bias
The reader may wonder whether the upward bias discussed in this paper actually represents a non-negligible issue in empirical implementations. To provide an idea of the possible magnitude of the bias, we perform a simulation. When estimating inequality of opportunity, the data generating process is typically unknown. We therefore prefer to base the simulation on the entire EU-SILC dataset instead of creating an ad hoc dataset.
Assume that the entire EU-SILC dataset is our population of interest. A population composed of 202,843 individuals aged between 26 and 60 years (more than the same age population in Iceland and approximately the same population in Luxembourg). Additionally, assume that a few observable circumstances are the only circumstances that determine inequality of opportunity. Individual outcome is assumed to be the result of the interactions of three circumstances: parental education, parental occupation, and origin. Individuals in the same type share the same highest parental education (five values), same immigration history (a dummy that takes the value of one if the respondent is a first- or second-generation immigrant), and the same highest parental occupation (ISCO 1 digit).
Under our assumptions, we can observe the real partition of the population into types. The observed between-type inequality is then the real IOp in the population. The residual inequality is assumed to be due to effort. Measured by MLD, IOp in the entire sample is 0.0314, approximately 7% of the total variability.
Our aim is then to understand the circumstances under which an estimate of inequality of opportunity based on a random subsample of this population results in upward bias. To this end, we estimate IOp using samples of increasing size. We start with 500, which is approximately the sample size of the smallest country in EU-SILC (Sweden). We then add 500 observations in each step until we have a sample of 20,000 observations (not far from Italy’s sample size, the largest country in EU-SILC). Each sample is randomly drawn 500 times to obtain normalized bootstrap confidence intervals around the point estimate.
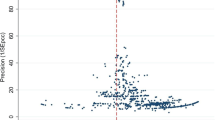
Figure 3 shows the IOp estimates for samples of increasing size. In grey, we provide a histogram showing the frequency of countries’ sample size (reported on the right y-axis) in EU-SILC 2011.Footnote 15
The estimates show a marked upward bias for the smallest samples. The average IOp based on the samples is more than 1.2 times higher than the IOp in the population for samples smaller than 4000. These are not unrealistically small samples: six of the 31 countries have smaller sample sizes. Interestingly, the confidence intervals of the estimates do not contain the population’s estimate for all samples smaller than 3000 (Sweden, Iceland, Denmark, and Norway have smaller sample sizes). Moreover, the upward bias is less than 10% only for sample sizes larger than 9000. Only France, Germany, Hungary, Poland, Spain, and Italy have larger sample sizes.
Estimates based on the samples approach the IOp in the population rather slowly; at the extreme right of the graph, the bias is approximately 4%. This may be considered a negligible distortion. Interestingly, the reader may recall that in Fig. 1 of Sect. 4, we found a relatively small difference between the IOp estimated with the two extreme specifications for countries with sample sizes larger than 10,000. However, in our simulation, a sample size of 20,000 observations is extremely large as it represents slightly less than 10% of the population.

Source: EU-SILC, 2011
IOp estimated on samples of increasing size
C Additional tables and figures

Rights and permissions
About this article

Cite this article
Brunori, P., Peragine, V. & Serlenga, L. Upward and downward bias when measuring inequality of opportunity. Soc Choice Welf 52, 635–661 (2019). https://doi.org/10.1007/s00355-018-1165-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00355-018-1165-x