
Abstract
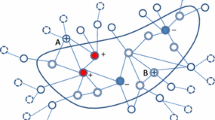
Active search on graphs focuses on collecting certain labeled nodes (targets) given global knowledge of the network topology and its edge weights (encoding pairwise similarities) under a query budget constraint. However, in most current networks, nodes, network topology, network size, and edge weights are all initially unknown. In this work we introduce selective harvesting, a variant of active search where the next node to be queried must be chosen among the neighbors of the current queried node set; the available training data for deciding which node to query is restricted to the subgraph induced by the queried set (and their node attributes) and their neighbors (without any node or edge attributes). Therefore, selective harvesting is a sequential decision problem, where we must decide which node to query at each step. A classifier trained in this scenario can suffer from what we call a tunnel vision effect: without any recourse to independent sampling, the urge to only query promising nodes forces classifiers to gather increasingly biased training data, which we show significantly hurts the performance of active search methods and standard classifiers. We demonstrate that it is possible to collect a much larger set of targets by using multiple classifiers, not by combining their predictions as a weighted ensemble, but switching between classifiers used at each step, as a way to ease the tunnel vision effect. We discover that switching classifiers collects more targets by (a) diversifying the training data and (b) broadening the choices of nodes that can be queried in the future. This highlights an exploration, exploitation, and diversification trade-off in our problem that goes beyond the exploration and exploitation duality found in classic sequential decision problems. Based on these observations we propose D\(^3\)TS, a method based on multi-armed bandits for non-stationary stochastic processes that enforces classifier diversity, which outperforms all competing methods on five real network datasets in our evaluation and exhibits comparable performance on the other two.








Similar content being viewed by others


Notes
The software and scripts to reproduce results presented in this work are available as an R package http://bitbucket.com/after-acceptance. All the data used in this work is publicly available from different sources.
Although the method proposed by Wang et al. (2013) is outperformed by a more recent proposal Ma et al. (2015) in active search problems, we found the opposite to be true when the graph is not fully observable. In addition to being highly sensitive to the parameterization, the most recent method computes and stores a dense correlation matrix between all visible nodes, which is hard to scale beyond \(10^5\) nodes.
Other seemingly obvious features (e.g., number of non-target neighbors) are not considered due to collinearity. Longer random walk paths are too expensive to be used in most real networks.
In comparison to other combinations of length and heuristic used in the “cold start” phase, this was found to work best.
We choose MOD in lieu of PNB because MOD is orders of magnitude faster. Among the base learners, we choose one representative of regression (SV Regression), classification (Random Forest) and ranking (ListNet) methods.
In general, rewards can be normalized to be in [0, 1].
The box extremes in our boxplots indicate lower and upper quartiles of a given empirical distribution; its median in marked in between them. Whiskers indicate minimum and maximum values.
We attempted to replace Random Forests by Mondrian Forests (Lakshminarayanan et al. 2014), but the only publicly available implementation is not optimized enough to be used in our application.
References
Ali A, Caruana R, Kapoor A (2014) Active learning with model selection. In: AAAI conference on artificial intelligence, pp 1673–1679
Attenberg J, Provost F (2011) Online active inference and learning. In: ACM SIGKDD international conference on knowledge discovery and data mining, pp 186–194
Attenberg J, Melville P, Provost F (2010) Guided feature labeling for budget-sensitive learning under extreme class imbalance. In: ICML workshop on budgeted learning
Auer P, Cesa-Bianchi N, Freund Y, Schapire RE (2002) The nonstochastic multiarmed bandit problem. SIAM J Comput 32(1):48–77
Avrachenkov K, Basu P, Neglia G, Ribeiro B (2014) Pay few, influence most: online myopic network covering. In: Computer communications workshops (INFOCOM WKSHPS), 2014 IEEE conference on, pp 813–818
Baram Y, El-Yaniv R, Luz K (2004) Online choice of active learning algorithms. J Mach Learn Res 5:255–291
Beygelzimer A, Dasgupta S, Langford J (2009) Importance weighted active learning. In: International conference on machine learning, ACM, pp 49–56
Beygelzimer A, Langford J, Li L, Reyzin L, Schapire RE (2011) Contextual bandit algorithms with supervised learning guarantees. In: International conference on artificial intelligence and statistics, pp 19–26
Bnaya Z, Puzis R, Stern R, Felner A (2013) Bandit algorithms for social network queries. In: Social computing (SocialCom), 2013 international conference on
Borgs C, Brautbar M, Chayes J, Khanna S, Lucier B (2012) The power of local information in social networks. Internet and network economics. Springer, Berlin, pp 406–419
Cao Z, Qin T, Liu TY, Tsai MF, Li H (2007) Learning to rank: from pairwise approach to listwise approach. In: International conference on machine learning, ACM, pp 129–136
Friedman J, Hastie T, Tibshirani R (2009) The elements of statistical learning. Springer series in statistics, vol 1. Springer, Berlin
Ganti R, Gray AG (2012) UPAL: unbiased pool based active learning. In: International conference on artificial intelligence and statistics, pp 422–431
Ganti R, Gray AG (2013) Building bridges: viewing active learning from the multi-armed bandit lens. In: Conference on uncertainty in artificial intelligence, pp 232–241
Garnett R, Krishnamurthy Y, Wang D, Schneider J, Mann R (2011) Bayesian optimal active search on graphs. In: Workshop on mining and learning with graphs
Garnett R, Krishnamurthy Y, Xiong X, Mann R, Schneider JG (2012) Bayesian optimal active search and surveying. In: International conference on machine learning, ACM, pp 1239–1246
Gouriten G, Maniu S, Senellart P (2014) Scalable, generic, and adaptive systems for focused crawling. In: ACM conference on hypertext and social media, pp 35–45
Gupta N, Granmo OC, Agrawala A (2011) Thompson sampling for dynamic multi-armed bandits. In: International conference on machine learning and applications and workshops, vol 1, pp 484–489
Helleputte T (2015) LiblineaR: linear predictive models based on the LIBLINEAR C/C++ library. R package version 1.94-2
Hothorn T, Hornik K, Zeileis A (2006) Unbiased recursive partitioning: a conditional inference framework. J Comput Graph Stat 15(3):651–674
Hsu WN, Lin HT (2015) Active learning by learning. In: AAAI conference on artificial intelligence, pp 2659–2665
Khuller S, Purohit M, Sarpatwar KK (2014) Analyzing the optimal neighborhood: algorithms for budgeted and partial connected dominating set problems. In: ACM-SIAM symposium on discrete algorithms, pp 1702–1713
Kuncheva LI (2003) That elusive diversity in classifier ensembles. In: Iberian conference on pattern recognition and image analysis, Springer, pp 1126–1138
Lakshminarayanan B, Roy DM, Teh YW (2014) Mondrian forests: efficient online random forests. In: Advances in neural information processing systems, pp 3140–3148
Leskovec J, Krevl A (2014) SNAP datasets: Stanford large network dataset collection. http://snap.stanford.edu/data
Liu W, Principe JC, Haykin S (2011) Kernel adaptive filtering: a comprehensive introduction, vol 57. Wiley, Hoboken
Ma Y, Huang TK, Schneider JG (2015) Active search and bandits on graphs using sigma-optimality. In: Conference on uncertainty in artificial intelligence, pp 542–551
Newman ME (2003) The structure and function of complex networks. SIAM Rev 45(2):167–256
Pant G, Srinivasan P (2005) Learning to crawl: comparing classification schemes. ACM Trans Inf Syst 23(4):430–462
Pfeiffer III JJ, Neville J, Bennett PN (2012) Active sampling of networks. In: Workshop on mining and learning with graphs
Pfeiffer III JJ, Neville J, Bennett PN (2014) Active exploration in networks: using probabilistic relationships for learning and inference. In: ACM international conference on information and knowledge management, pp 639–648
Robins G, Pattison P, Kalish Y, Lusher D (2007) An introduction to exponential random graph (\(p^*\)) models for social networks. Soc Networks 29(2):173–191
Robins G, Snijders T, Wang P, Handcock M, Pattison P (2007) Recent developments in exponential random graph (\(p^*\)) models for social networks. Soc networks 29(2):192–215
Schein AI, Ungar LH (2007) Active learning for logistic regression: an evaluation. Mach Learn 68(3):235–265
Settles B (2010) Active learning literature survey, vol 52(55–66). University of Wisconsin, Madison
Seung HS, Opper M, Sompolinsky H (1992) Query by committee. In: ACM workshop on computational learning theory, pp 287–294
Stapenhurst R (2012) Diversity, margins and non-stationary learning. Ph.D. thesis, University of Manchester
Tang EK, Suganthan PN, Yao X (2006) An analysis of diversity measures. Mach Learn 65(1):247–271
Wang X, Garnett R, Schneider J (2013) Active search on graphs. In: ACM SIGKDD International conference on knowledge discovery and data mining, ACM, pp 731–738
Xie P, Zhu J, Xing E (2016) Diversity-promoting bayesian learning of latent variable models. In: International conference on machine learning, PMLR, vol 48, pp 59–68
Acknowledgements
This work was sponsored by the ARO under MURI W911NF-12-1-0385, the U.S. Army Research Laboratory under Cooperative Agreement W911NF-09-2-0053, the CNPq, National Council for Scientific and Technological Development—Brazil, FAPEMIG, NSF under SES-1230081, including support from the National Agricultural Statistics Service. The views and conclusions contained in this document are those of the author and should not be interpreted as representing the official policies, either expressed or implied of the ARL or the U.S. Government. The U.S. Government is authorized to reproduce and distribute reprints for Government purposes notwithstanding any copyright notation hereon. The authors thank Xuezhi Wang and Roman Garnett for kindly providing code and datasets used in Wang et al. (2013).
Author information
Authors and Affiliations
Corresponding author
Additional information
Responsible editors: Andrea Passerini, Thomas Gaertner, Celine Robardet and Mirco Nanni.
Appendices
Appendix A: Complementary results
In Sect. 6.2 we presented results obtained when defining the target populations either as in prior work or as the largest subpopulation in the network. We extend these results by running simulations on ten additional datasets derived by taking the two largest subpopulations as targets (other than the original targets) from CiteSeer, DBpedia, Wikipedia, DonorsChoose and Kickstarter. These datasets are indicated by CS, DBP, WK, DC and KS, followed by 1 and 2, respectively. Table 8 shows performance results for five standalone models and for their combinations using round-robin and D\(^3\)TS. Except for DBP1 and WK1, D\(^3\)TS consistently figures among the two best performing methods.
Appendix B: Can we leverage diversity using a single classifier?
Intuitively, when a learning model is fitted to the nodes it chose to query, it tends to specialize in one region of the feature space and the search will consequently only explore similar parts of the graph, which can severely undermine its potential to find target nodes.
One potential way to mitigate this overspecialization would be to sample nodes probabilistically, as opposed to deterministically querying the node with the highest score. Clearly, we should not query nodes uniformly at random all the time. It turns out that querying nodes uniformly at random periodically does not help either, according to the following experiment. We implemented an algorithm for selective harvesting that samples at each step t, with probability p, an uniformly random node from \(\mathcal {B}(t)\), and with \(1-p\), the best ranked node according to a support vector regression (SVR) model. Table 9 shows the results for \(p=2.5\), 5.0, 10, 15 and \(20\%\).
We observe that the performance does not improve significantly for \(p \ge 2.5\)%, either because the diversity is not increasing in a way that translates into performance improvements or because all gains are offset by the samples wasted when querying nodes at random.
Instead of querying uniformly at random, we could query nodes according to a probability distribution that concentrates most of the mass on the top k nodes w.r.t. model scores. We experimented with several ways of mapping scores to a probability distribution P. In particular, we considered two classes of distributions:
-
truncated geometric distribution (\(0< q < 1\)):
$$\begin{aligned} P(v) \propto (1-q)^{\pi (v)-1} q, \quad \text {and} \end{aligned}$$ -
truncated Zeta distribution (\(r \ge 1\)):
$$\begin{aligned} P(v) \propto \pi (v)^{-r}, \end{aligned}$$
where \(\pi (v)\) is the rank of v based on the scores given by the model to \(v \in \mathcal {B}(t)\). In each experiment, we set q or r at each step in one of nine ways:
-
1.
Top 10 have \(x\%\) of the probability mass; for \(x \in \{70,90,99\}\).
-
2.
Top 10% nodes have \(x\%\) of the probability mass; for \(x \in \{90,99,99.9\}\).
-
3.
Top \(k(t) = \min \{10\times (1-t/T),1\}\) have \(x\%\) of the probability mass; for \(x \in \{70,90,99\}\).
None of the mappings was able to substantially increase the search’s performance. In contrast to almost \(20\%\) performance improvement seen by SVR under round-robin on CiteSeer at \(T=1500\) (Fig. 3), mapping scores to a probability distribution increased the number of targets nodes found by at most 3%.
Appendix C: Evaluation of MAB algorithms applied to Selective Harvesting
We experiment with representative algorithms of each of the following bandit classes:
-
Stochastic Bandits: UCB1, Thompson Sampling (TS), \(\epsilon \)-greedy,
-
Adversarial Bandits: Exp3 (Auer et al. 2002),
-
Non-stationary stochastic bandits: Dynamic Thompson Sampling (DTS) (Gupta et al. 2011),
-
Contextual Bandits: Exp4 (Auer et al. 2002) and Exp4.P (Beygelzimer et al. 2011).

Comparison between the best parameterizations of each MAB algorithm
UCB1 and TS are parameter-free. For \(\epsilon \)-greedy, Exp3 and Exp4.P we set the probability of uniformly random pulls, to \(\epsilon \in \{0.10,0.20,0.50\}\), \(\gamma \in \{0.10,0.20,0.50\}\) and \(Kp_{\min } \in \{0.01,0.05,0.10,0.20,0.50\}\) (respectively). We set parameter \(\gamma \) in Exp4 as \(K_p{\min }\) in Exp4.P. For DTS, we set the cap on the parameter sum \(C \in \{5,10, 20,50\}\). Interestingly, for each MAB algorithm, there was always one parameter value that outperformed all the others in almost all seven datasets. In Fig. 9 we show three representative plots of the performance comparison between the best parameterizations of each MAB algorithm. Since Exp4 was slightly outperformed by Exp4.P, Exp4 is not shown. These results corroborate our expectations (Sect. 5) that DTS would outperform other bandits in selective harvesting problems.
Rights and permissions
About this article

Cite this article
Murai, F., Rennó, D., Ribeiro, B. et al. Selective harvesting over networks. Data Min Knowl Disc 32, 187–217 (2018). https://doi.org/10.1007/s10618-017-0523-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10618-017-0523-0