
Abstract
Large-scale group decision-making (LSGDM) deals with complex decision- making problems which involve a large number of decision makers (DMs). Such a complex scenario leads to uncertain contexts in which DMs elicit their knowledge using linguistic information that can be modelled using different representations. However, current processes for solving LSGDM problems commonly neglect a key concept in many real-world decision-making problems, such as DMs’ regret aversion psychological behavior. Therefore, this paper introduces a novel consensus based linguistic distribution LSGDM (CLDLSGDM) approach based on a statistical inference principle that considers DMs’ regret aversion psychological characteristics using regret theory and which aims at obtaining agreed solutions. Specifically, the CLDLSGDM approach applies the statistical inference principle to the consensual information obtained in the consensus process, in order to derive the weights of DMs and attributes using the consensus matrix and adjusted decision-making matrices to solve the decision-making problem. Afterwards, by using regret theory, the comprehensive perceived utility values of alternatives are derived and their ranking determined. Finally, a performance evaluation of public hospitals in China is given as an example in order to illustrate the implementation of the designed method. The stability and advantages of the designed method are analyzed by a sensitivity and a comparative analysis.
Similar content being viewed by others
1 Introduction
Multi-attribute group decision making (MAGDM) problems have been widely applied in various fields, such as investment decision-making, project evaluation, quality evaluation, resource allocation and comprehensive evaluation of economic benefits, etc. (Zhang et al. 2019; Zhang et al. 2020a, b; Wan et al. 2020; Liu and You 2019). With the development of the natural and economic environment, MAGDM problems have evolved from individual decision-making and small-scale group decision-making (GDM) to complex large-scale GDM (LSGDM) (Zhang et al. 2014; Jin et al. 2020; Xu et al. 2019a, b). Generally, LSGDM problems have the following characteristics (Xu et al. 2015; Lu et al. 2021; Guo et al. 2020; Quesada et al. 2015):
-
(1)
Decision makers (DMs) can participate in decision-making at different times and places by using network tools;
-
(2)
Generally, more than 20 DMs are used to handle LSGDM problems (Chen and Liu 2006), including people in both the same organization and different organizations, and, the knowledge, skills, experience and personality characteristics of each DM often vary. Besides, DMs both cooperate and compete;
-
(3)
The relationship between attributes is not only interrelated but also contradictory;
-
(4)
DMs’ assessments are uncertain and diverse, and consequently often quite conflicting. Thus, group consensus is very important to be able to increase agreement among DMs.
In the twenty-first century, with the digitalization process, LSGDM has become the focus of complex decision-making problems, especially in emergency decision-making. It requires experts from different fields to participate in the decision-making process and obtain the most effective decision results within a short period of time (Tang et al. 2020; Zhang et al. 2020c; Ou et al. 2018; Lin et al. 2020, 2021). The characteristics of LSGDM problems differ from those of GDM problems. For instance, the large number of DMs that are involved in LSGDM, the non-cooperative behavior shown by and minority opinions given by DMs, etc. The traditional consensus and GDM methods face many challenges in dealing with complex LSGDM problems (Labella et al. 2018; Gou et al. 2021; Bain and Hansen 2020; Liu et al. 2020; Chu et al. 2020; Zheng et al. 2020; Rodríguez et al. 2021b; Tang and Liao 2021; Chen et al. 2021). Therefore, previous models must be developed/evolved to deal with large-scale groups and to define new solution processes for LSGDM (Xu 2009; Xu and Chen 2018).
Complex real-word LSGDM problems in modern society and the economy cannot always be effectively managed and solved using crisp assessments. Moreover, it is natural for DMs to provide their assessments with linguistic variables (Zadeh 1975), which are intuitive and flexible enough to describe a DM’s knowledge, uncertainty and subjectivity. Although DMs elicit information using linguistic terms from a linguistic term set (LTS) (Herrera and Martinez 2000), sometimes they need more than one term to express their opinions. However, LTS cannot clearly reflect the importance and distribution assessments of different linguistic terms. To overcome such limitation, Zhang et al. (2014) introduced the concepts of linguistic distribution term sets (LDTSs) and linguistic distribution preference relations (LDPRs) and discussed operation laws for LDTSs. DMs’ social experience and cultural background, however, can lead to conflicts arising among them. In this situation, the application of a consensus reaching processes in LSGDM to build consensual opinions was successfully applied (Gong et al. 2020a, b). Therefore, consensus reaching process (CRP) is a key stage in the process of obtaining an acceptable solution for all DMs. There are many proposals for CRP models (Wang et al. 2019; Wu and Xu 2018; Wu et al. 2019; Gou et al. 2018; Ding et al. 2019), including the satisfaction achieving approaches with CRP (Zhang et al. 2018), adaptive CRP methods (Rodríguez et al. 2018), minimum-cost CPR models (Labella et al. 2020a, b). By defining the individual consensus measure and group consensus measure, Zhang et.al (2020a, b) devised a feedback mechanism and a consensus reaching algorithm. Based on personalized individual semantics, Li et al. (2019) developed a consensus method for LSGDM problems, in which the DMs’ willingness is increased by using the new clustering process and opposing consensus groups. Du et al. (2020) constructed a mixed CRP model by integrating the independent and supervised consensus-reaching models. Xu et al. (2019a, b) proposed a CRP model with uncertain linguistic preference relations, in which the element with lowest consensus level is modified to achieve the predefined consensus level. In order to decrease the impact of internal disagreements among DMs, Rodríguez et al. (2021a) designed a CRP model with restricted equivalence functions under the hesitant fuzzy linguistic term set environment. With the help of the reliability of DMs and Dempster–Shafer evidence theory, Liu et al. (2021) presented a novel CRP model for hesitant fuzzy linguistic GDM problems. Du et al. (2021) proposed a large-scale multi-attribute GDM consensus-reaching method to reach satisfactory consensus levels by considering the DMs’ knowledge structures. Xiao et al. (2020) first constructed a classification-based consensus framework and then developed an optimization model to derive the weights of DMs by maximizing consensus degrees among DMs.
Extant LSGDM methods rank alternatives to the decision-making problem by assuming that DMs are completely rational and neglecting DMs’ psychological behavior, like regret aversion. However, for complex and high risk LSGDM problems, DMs not only focus on the utility of alternatives chosen, but also on the results they would have obtained if they had chosen different alternative/s, in order to avoid regretting their choice. Therefore, regret theory is key to dealing with the DMs’ behavior of regret aversion (Bell 1982; Loomes and Sugden 1982; Zhou et al. 2017; Wang et al. 2020).
The large number of experts involved in LSGDM problems will inevitably lead to a large number of assessments, which can be utilized to deduce valuable decision-making information with statistical inference (Gong et al. 2020a; Ma et al. 2020). To put this in context, we note that with respect to group evaluation problems, Bu (2007) introduced a parameter estimation method with statistical inference theory and the AHP method, and developed a mathematical model to derive efficient and practical GDM results. Liu (2015) regarded the expert’s judgment results as a random sample of statistical inference GDM opinions, and established a green building group evaluation method based on statistical inference. Therefore, to accurately extract expert’s effective evaluation information and obtain reliable LSGDM results that reflect the personal preference of each expert, the statistical inference principle must be used to deal with LSGDM evaluation data.
Yet, despite it being of interest to multiple real-world decision-making problems, there are few reports on the consensus based linguistic distribution LSGDM (CLDLSGDM) method that consider the regret aversion psychological characteristics of DMs (Song et al. 2017). Therefore, this paper proposes a new CLDLSGDM method with regret theory, in which DM assessments are elicited by means of linguistic distribution elements (LDEs) to reflect the importance of assessments of different linguistic terms and their regret aversion behavior. The main contributions of this paper are listed as follows:
-
A CLDLSGDM is presented to improve agreement among DMs under the linguistic distribution information environment in multi-attribute LSGDM (MALCGDM) problems.
-
Based on the statistical inference principle, we develop two weight allocation methods for DMs and attributes.
-
A novel CLDLSGDM that ranks alternatives is proposed based on regret theory, in which we capture DM regret aversion psychological behavior.
-
A numerical example for evaluating the performance of public hospitals in China and the comparative analysis are provided to show the advantages of the proposed method.
The rest of the paper is set out according to the following scheme. Section 2 offers some basic knowledge about LDTSs, regret theory and MALSGDM. In Sect. 3, a novel CLDLSGDM method is designed, including CRP, DMs’ weight derivation process, attributes’ weight generation process and desirable alternative selection process. An illustration of the developed methods’ ranking orders of the Chinese public hospitals is given in Sect. 4. In Sect. 4, both a sensitivity analysis and a comparative analysis are performed to assess the stability and advantages of the proposed novel CLDLSGDM method. In Sect. 5 we point out the conclusions of this paper.
2 Preliminaries
In this section, we review the related knowledge about LDTSs, regret theory and LSGDM.
2.1 Linguistic Distribution Term Sets (LDTSs)
Let \(S = \left\{ {s_{\xi } \left| {\xi = 0,1, \ldots ,2\tau } \right.} \right\}\) be a fuzzy discrete LTS with odd cardinality, \(s_{\xi }\) indicates the linguistic term in \(S\) (Zadeh 1975; Li et al. 2017; Martínez and Herrera 2014; Martínez et al. 2010; Liu et al. 2010; Rodríguez et al. 2012; Labella et al. 2020a, b), which satisfy the following characteristics (Rodríguez and Martínez 2013): (1) If \(\xi \ge \zeta\), then \(s_{\xi } \ge s_{\zeta }\); (2) \(neg\;(s_{\xi } ) = s_{2\tau - \xi }\), especially \(neg\;(s_{\tau } ) = s_{\tau }\).
As LTS cannot accurately depict the distribution assessments associated with linguistic variables, Zhang et al. (2014) have generalized the LTSs to the LDEs in order to deal with this limitation.
Definition 1
(Zhang et al. 2014) Let \(S = \left\{ {s_{\xi } \left| {\xi = 0,1, \ldots ,2\tau } \right.} \right\}\) be a LTS, then a LDE can be denoted as follows:
where \(s_{\xi } \in S\), \(p^{(\xi )} \in [0,1]\) is the corresponding probability of \(s_{\xi }\). LDE \(h\) can be seen as a discrete full probability distribution over the LTS \(S\).
Remark 1
In Definition 1, if \(\sum\nolimits_{\xi = 0}^{2\tau } {p^{(\xi )} } { = 1}\), then it means that all the probability information is considered in the LDE \(h\); If \(\sum\nolimits_{\xi = 0}^{2\tau } {p^{(\xi )} } { < 1}\), then LDE \(h\) can be normalized as (Zhang et al. 2014):
For convenience, the normalized LDE is still represented as \(h\) in this paper.
2.2 Regret Theory
In complex and risky decision-making problems, DMs are bounded rational and present different psychological behaviors, such as loss avoidance, decreasing sensitivity and distorted probability judgment. Regret theory (Bell 1982; Loomes and Sugden 1982) is an important behavioral decision-making theory, which can be applied to capture the DMs’ regret aversion.
Definition 2
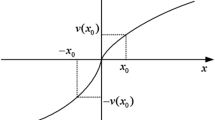
(Zhang et al. 2016) Assume that \(x\) and \(y\) are the evaluation values of alternatives \(A\) and \(B\), then the regret-rejoice function \(R( \cdot )\) is defined as:
where \(\delta\) is the regret aversion coefficient of DM, \(\vartriangle v = pu(x) - pu(y)\) indicates the perceived utility deviation between alternatives \(A\) and \(B\), \(pu(x)\) and \(pu(y)\) represent the perceived utility values of \(x\) and \(y\).
Remark 2
In Definition 2, if \(\vartriangle v > 0\), then \(R(\vartriangle v)\) indicates the rejoice value of the DM choosing alternative \(x\) and giving up \(y\). If \(\vartriangle v < 0\), then \(R (\vartriangle v)\) indicates the regret value of the DM choosing alternative \(x\) and giving up \(y\). In addition, the parameter \(\delta\) is the regret aversion degree of the DM. The graphical representation of \(R (\vartriangle v)\) with different \(\delta\) is shown in Fig. 1. Let \(f (\delta ) = |R ( - \vartriangle v)|\)\(- R (\vartriangle v) = exp\left( {\delta \vartriangle v} \right) + exp\left( { - \delta \vartriangle v} \right) - 2\), then.
thus, \(f(\delta )\) is an increasing function with respect to parameter \(\delta\). Therefore, the bigger the parameter \(\delta\) is, the greater the deviation between \(|R( - \vartriangle v)|\) and \(R(\vartriangle v)\) is, and the more regret aversive a DM is.

Regret-rejoice function \(R(\vartriangle v)\) with different \(\delta\)
2.3 Linguistic Distribution MALSGDM Problem
A MALSGDM problem with linguistic distribution preference information can be depicted as follows:
-
(i) Let \(E = \{ e_{1} ,e_{2} , \ldots ,e_{q} \}\) be a set of DMs and \(q(q \ge 20)\) be the number of DMs in the MALSGDM problem (Chen and Liu 2006). The weight vector of DMs is \(\omega = (\omega_{1} ,\omega_{2} , \ldots ,\omega_{q} )^{T}\), where \(\omega_{k} \ge 0,\sum\nolimits_{k = 1}^{q} {\omega_{k} } = 1\). The weight vector \(\omega\) is completely unknown.
-
(ii) A set of alternatives \(X = \{ x_{1} ,x_{2} , \ldots ,x_{m} \}\), a set of attributes \(A = \{ a_{1} ,a_{2} , \ldots ,a_{n} \}\). \(m(m \ge 2)\) and \(n(n \ge 1)\) are the number of alternatives and attributes in the MALSGDM problem, respectively. For DM \(e_{k}\), the weight vector of attributes is \(w_{k} = (w_{k1} ,w_{k2} , \ldots ,w_{kn} )^{T}\), where \(w_{kj} \ge 0,\sum\nolimits_{j = 1}^{n} {w_{kj} } = 1\). The weight vectors \(w_{k} (k = 1,2, \ldots ,q)\) are completely unknown.
-
(iii) DMs \(\{ e_{1} ,e_{2} , \ldots ,e_{q} \}\) evaluate the alternatives \(\{ x_{1} ,x_{2} , \ldots ,x_{n} \}\) with respect to attributes \(\{ a_{1} ,a_{2} , \ldots ,a_{m} \}\) with linguistic distribution information decision-making matrices \(H_{k} = (h_{ij}^{k} )_{m \times n} (k = 1,2, \ldots, q)\), where LDE \(h_{ij}^{k} = \left\{ {(s_{\xi } ,p_{ij(k)}^{(\xi )} )\left| {\xi = 0,1,\ldots, 2\tau } \right.} \right\}\) indicates the linguistic distribution preference information of alternative \(x_{i}\) with respect to attribute \(a_{j}\) provided by DM \(e_{k}\).
3 CLDLSGDM Method
In this section, a novel CLDLSGDM method is designed, including CRP, DM weight derivation process, attribute weight generation process and desirable alternative selection process. We first propose a LSGDM CRP with linguistic distribution information to achieve the consensus goal, then we develop DM and attribute weight allocation methods with a/the statistical inference principle. Based on the regret theory, the ranking order of the alternatives is eventually obtained, in which the regret aversion psychological characteristics of DMs are considered. The flow chart of the proposed CLDLSGDM method is shown in Fig. 2.

The developed CLDLSGDM method
3.1 CRP for CLDLSGDM (Phase I)
For MALSGDM problems, group consensus is an important step to be taken to avoid conflicting decision results (Labella et al. 2018; 2020a, b). In the process of consensus improvement, the original evaluation information provided by DMs will inevitably be modified, with the aim of increasing the level of agreement among DMs (Palomares et al. 2014). Thus, a CRP model must be developed with the aim of retaining as many expert preferences as possible. Therefore, a new CRP with linguistic distribution information is introduced in order to try and reach an agreement by retaining the DMs’ preferences as much as possible. The flow chart of the new CRP is shown in Fig. 3.

Phase I: CRP for CLDLSGDM
As DMs provide \(q\) linguistic distribution information decision-making matrices \(H_{k} =\) \((h_{ij}^{k} )_{m \times n} (k = 1,2,\ldots,q)\), where \(h_{ij}^{k} = \left\{ {(s_{\xi } ,p_{ij(k)}^{(\xi )} )\left| {\xi = 0,1,\ldots, 2\tau ,0 \le p_{ij(k)}^{(\xi )} \le 1,\sum\limits_{\xi = 0}^{2\tau } {p_{ij(k)}^{(\xi )} } = 1} \right.} \right\}\), then the similarity matrix \(SM^{kl} = (sm_{ij}^{kl} )_{m \times n}\) between DMs \(e_{k}\) and \(e_{l}\) can be obtained as follows:
where \(sm_{ij}^{kl} = 1 - \frac{1}{2}\sum\limits_{\xi = 0}^{2\tau } {\left| {p_{ij(k)}^{(\xi )} - p_{ij(l)}^{(\xi )} } \right|}\). It is obvious that \(0 \le sm_{ij}^{kl} \le 1,i = 1,2, \ldots ,m,j = 1,2, \ldots ,n\).
Therefore, there are \(q^{2}\) similarity matrices \(SM^{kl} (k,l = 1,2, \ldots ,q)\), and we can construct a super-similarity matrix \(SM = \left( {SM^{kl} } \right)_{q \times q}\) as follows:
As \(sm_{ij}^{kk} = 1 - \frac{1}{2}\sum\limits_{\xi = 0}^{2\tau } {\left| {p_{ij(k)}^{(\xi )} - p_{ij(k)}^{(\xi )} } \right|} = 1,sm_{ij}^{lk} = 1 - \frac{1}{2}\sum\limits_{\xi = 0}^{2\tau } {\left| {p_{ij(l)}^{(\xi )} - p_{ij(k)}^{(\xi )} } \right|} = 1 - \frac{1}{2}\sum\limits_{\xi = 0}^{2\tau } {\left| {p_{ij(k)}^{(\xi )} - p_{ij(l)}^{(\xi )} } \right|} = sm_{ij}^{kl}\), then we have \(SM^{kk} = \left( {\begin{array}{*{20}c} 1 & 1 & \cdots & 1 \\ 1 & 1 & \cdots & 1 \\ \vdots & \vdots & \ddots & \vdots \\ 1 & 1 & \cdots & 1 \\ \end{array} } \right)_{m \times n} ,k = 1,2, \cdots ,q\) and \(SM^{kl} = SM^{lk}\). Thus, super- similarity matrix \(SM\) is a symmetric matrix.
Based on the super-similarity matrix \(SM = \left( {SM^{kl} } \right)_{q \times q}\), we can derive the consensus matrix \(CM = \left( {cm_{kl} } \right)_{q \times q}\) as follows:
where \(cm_{kl} = \frac{1}{mn}\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {sm_{ij}^{kl} } } \in [0,1]\) is defined as the consensus degree between DMs \(e_{k}\) and \(e_{l}\). As \(sm_{ij}^{kk} = 1,sm_{ij}^{lk} = sm_{ij}^{kl}\), then.
-
(i) \(cm_{kk} = \frac{1}{mn}\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {sm_{ij}^{kk} } } = 1,\) which means that DM \(e_{k}\) has the highest degree of consensus DM \(e_{k}\) achieves is with themselves and is consistent with our intuitive perception.
-
(ii) \(cm_{kl} = \frac{1}{mn}\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {sm_{ij}^{kl} } } = \frac{1}{mn}\sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {sm_{ij}^{lk} } } = cm_{lk} ,k,l = 1,2,\ldots,q\), which indicates the consensus degree between DMs \(e_{k}\) and \(e_{l}\) is unique and unidirectional.
Therefore, consensus matrix \(CM = \left( {cm_{kl} } \right)_{q \times q}\) is a symmetric matrix and the diagonal elements are equal to 1.
Definition 3
Let \(CM = \left( {cm_{kl} } \right)_{q \times q}\) be a consensus matrix of DMs \(\{ e_{1} ,e_{2} ,\ldots, e_{q} \}\), then the group consensus index (\(GCI\)) among DMs is defined as:
Now, we present a consensus adjustment algorithm to improve the group consensus degree.
Algorithm I
Input The linguistic distribution information decision-making matrices \(H_{k} = (h_{ij}^{k} )_{m \times n} (k = 1,2, ldots, q)\), the group consensus index threshold \(\theta (0 < \theta < 1)\), the cost of changing DMs \(e_{k}\)’s opinion 1 unit \(c_{k} (k = 1,2, \ldots q)\).
Output The adjusted linguistic distribution information decision-making matrices \(\tilde{H}_{k} =\) \((\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots, q)\), the iterative times \(t\).
Step 1 Let \(t = 0\) and \(H_{k}^{(t)} = (h_{ij}^{k(t)} )_{m \times n} = H_{k} = (h_{ij}^{k} )_{m \times n} (k = 1,2,\ldots, q)\).
Step 2 Using Eqs. (5) and (7) to calculate similarity matrices \(SM^{kl(t)} (k,l = 1,2, \cdots ,q)\) and consensus matrix \(CM^{(t)} = \left( {cm_{kl}^{(t)} } \right)_{q \times q}\).
Step 3 Check the group consensus level with \(GCI^{(t)}\). If \(GCI^{(t)} \ge \theta\), then go to Step 8; Otherwise, go to Step 4.
Step 4Search for the lowest consensus level among DMs. Let \(cm_{{k^{*} ,l^{*} }}^{(t)} = \mathop {\min }\limits_{k < l} \{ cm_{kl}^{(t)} \}\), then the pair of DMs \((e_{{k^{*} }} ,e_{{l^{*} }} )\) has the lowest consensus level.
Step 5 Identifying the lowest similarity level in \(SM^{{k^{*} ,l^{*} ,(t)}}\). Let \(sm_{{i^{*} ,j^{*} }}^{{k^{*} ,l^{*} ,(t)}} = \mathop {\min }\limits_{i = 1,2,\ldots,m,j = 1,2,\ldots,n} \{ sm_{ij}^{{k^{*} ,l^{*} ,(t)}} \}\), then DMs \(e_{{k^{*} }}\) and \(e_{{l^{*} }}\) have the largest deviation on the judgement values of alternative \(x_{{i^{*} }}\) with respect to attribute \(a_{{j^{*} }}\), and we need to adjust LDE \(h_{{i^{*} ,j^{*} }}^{{k^{*} ,(t)}}\) or \(h_{{i^{*} ,j^{*} }}^{{l^{*} ,(t)}}\).
Step 6 Adjust the judgement values based on adjust cost. In order to decrease the deviation between \(h_{{i^{*} ,j^{*} }}^{{k^{*} ,(t)}}\) and \(h_{{i^{*} ,j^{*} }}^{{l^{*} ,(t)}}\), the adjustment direction is given as follows:
-
If \(c_{{k^{*} }} < c_{{j^{*} }}\), then DM \(e_{{k^{*} }}\) should change LDE \(h_{{i^{*} ,j^{*} }}^{{k^{*} ,(t)}}\) to \(h_{{i^{*} ,j^{*} }}^{{l^{*} ,(t)}}\).
-
If \(c_{{k^{*} }} > c_{{j^{*} }}\), then DM \(e_{{l^{*} }}\) should change LDE \(h_{{i^{*} ,j^{*} }}^{{l^{*} ,(t)}}\) to \(h_{{i^{*} ,j^{*} }}^{{k^{*} ,(t)}}\).
Step 7 Generate the new linguistic distribution information decision-making matrices \(H_{k}^{(t + 1)} = (h_{ij}^{k(t + 1)} )_{m \times n} (k = 1,2,\ldots,q)\). Let \(t = t + 1\), and go to Step 2.
Step 8 Let \(\tilde{H}_{k} = H_{k}^{(t)} (k = 1,2,\ldots,q)\), then output the adjusted linguistic distribution information decision-making matrices \(\tilde{H}_{k} (k = 1,2,\ldots,q)\), the iterative times \(t\).
Step 9 End.
Remark 3
From Algorithm I, it is clear that the obtained \(\tilde{H}_{k} = (\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots,q)\) has a high level of consensus, and the iterative times \(t\) can directly reflect the number of adjusted elements.
The importance of each DM and attribute in MALSGDM problems differs. Although the weight vector of DMs \(\omega = (\omega_{1} ,\omega_{2} , \ldots ,\omega_{q} )^{T}\) and weight vectors of attributes \(w_{k} = (w_{k1} ,w_{k2} ,\ldots,w_{kn} )^{T} (k = 1,2 \ldots,q)\) are completely unknown, it can be calculated based on the DMs’ judgements. Therefore, in Subsections 3.2 and 3.3, by utilizing the statistical inference principle (Bu 2007; Liu 2015), we propose two DM and attribute weight allocation methods based on \(\tilde{H}_{k} =\)\((\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\), obtained in Subsection 3.1.
3.2 Deriving DMs’ Weights Based on Statistical Inference (Phase II)
It is obvious that the greater the number of consensus degrees associated with a DM in a consensus matrix \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{q \times q}\), the closer the data distribution is to a normal distribution. Thus, the decision-making result is more accurate with the normal distribution method. For a MALSGDM problem, a large number of DMs participate in the complex decision-making problem. Therefore, in this subsection, we assume that the consensus data in the consensus matrix has normal distribution characteristics. Thus, we calculate the mathematical expectations and standard variances of these normal distribution data sequences. Finally, the normal distribution estimation is applied to calculate the DMs’ weights. The flow chart of Phase II can be seen in Fig. 4.

Phase II: Deriving DMs’ weights
First, based on the adjusted linguistic distribution information decision-making matrices \(\tilde{H}_{k} = (\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\) that were derived from Algorithm I, we can obtain a new consensus matrix \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{q \times q}\) by using Eqs. (5) and (7).
Based on the consensus matrix \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{q \times q}\), let \(c\tilde{m}_{k}^{L} = \mathop {\min }\limits_{l \ne k} \{ c\tilde{m}_{kl} \} ,c\tilde{m}_{k}^{U} = \mathop {\max }\limits_{l \ne k} \{ c\tilde{m}_{kl} \} ,\) \(k = 1,2 \ldots ,q\), we obtain a sequence of interval numbers as follows: \(\left\{ {[c\tilde{m}_{1}^{L} ,c\tilde{m}_{1}^{U} ],[c\tilde{m}_{2}^{L} ,} \right.c\tilde{m}_{2}^{U} ],\left. { \ldots ,[c\tilde{m}_{q}^{L} ,c\tilde{m}_{q}^{U} ]} \right\}\), which can be divided into two real number sequences:
\(c\tilde{m}^{L} = \left\{ {c\tilde{m}_{1}^{L} ,c\tilde{m}_{2}^{L} , \ldots ,c\tilde{m}_{q}^{L} } \right\}\;{\text{and}}\;c\tilde{m}^{U} = \left\{ {c\tilde{m}_{1}^{U} ,c\tilde{m}_{2}^{U} , \ldots ,c\tilde{m}_{q}^{U} } \right\}\),
thus, the mathematical expectations \(\overline{cm}^{L} ,\overline{cm}^{U}\) and standard variances \(\overline{sv}^{L} ,\overline{sv}^{U}\) of two real number sequences \(c\tilde{m}^{L}\) and \(c\tilde{m}^{U}\) are calculated as:
where \(q\) is the number of data in a normal distribution data sequence \(\left\{ {c\tilde{m}_{1}^{L} ,c\tilde{m}_{2}^{L} , \ldots ,c\tilde{m}_{q}^{L} } \right\}\) or a normal distribution data sequence \(\left\{ {c\tilde{m}_{1}^{U} ,c\tilde{m}_{2}^{U} , \cdots ,c\tilde{m}_{q}^{U} } \right\}\).
As the variance of the consensus degrees in \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{q \times q}\) is unknown, we apply a normal distribution estimation to compute the probability of interval number \([c\tilde{m}_{k}^{L} ,c\tilde{m}_{k}^{U} ]\), i.e.,
where (i) \(P(x \le c\tilde{m}_{k}^{L} ) = P\left( {\frac{{\overline{cm}^{L} - c\tilde{m}_{k}^{L} }}{{{{\overline{sv}^{L} } \mathord{\left/ {\vphantom {{\overline{sv}^{L} } {\sqrt q }}} \right. \kern-\nulldelimiterspace} {\sqrt q }}}}} \right)\), if \(c\tilde{m}_{k}^{L} < \overline{cm}^{L}\);
(ii) \(P(x \le c\tilde{m}_{k}^{L} ) = P\left( {\frac{{c\tilde{m}_{k}^{L} - \overline{cm}^{L} }}{{{{\overline{sv}^{L} } \mathord{\left/ {\vphantom {{\overline{sv}^{L} } {\sqrt q }}} \right. \kern-\nulldelimiterspace} {\sqrt q }}}}} \right)\), if \(c\tilde{m}_{k}^{L} > \overline{cm}^{L}\);
(iii) \(P(x \le c\tilde{m}_{k}^{U} ) = P\left( {\frac{{\overline{cm}^{U} - c\tilde{m}_{k}^{U} }}{{{{\overline{sv}^{U} } \mathord{\left/ {\vphantom {{\overline{sv}^{U} } {\sqrt q }}} \right. \kern-\nulldelimiterspace} {\sqrt q }}}}} \right)\), if \(c\tilde{m}_{k}^{U} < \overline{cm}^{U}\);
(iv) \(P(x \le c\tilde{m}_{k}^{U} ) = P\left( {\frac{{\overline{cm}^{U} - c\tilde{m}_{k}^{U} }}{{{{\overline{sv}^{U} } \mathord{\left/ {\vphantom {{\overline{sv}^{U} } {\sqrt q }}} \right. \kern-\nulldelimiterspace} {\sqrt q }}}}} \right)\), if \(c\tilde{m}_{k}^{U} > \overline{cm}^{U}\).
Let \(L_{{c\tilde{m}_{k} }} = c\tilde{m}_{k}^{U} - c\tilde{m}_{k}^{L} ,k = 1,2 \cdots ,q\). The larger value of \(L_{{c\tilde{m}_{k} }}\) is, the more scattered DM \(e_{k}\)’s consensus degrees is and the lower the consensus level of DM \(e_{k}\) is, which indicates that DM \(e_{k}\) is less important in MALSGDM problems. Therefore, one can derive DMs’ weights as follows:
and \(\omega_{k} \in [0,1],\sum\nolimits_{k = 1}^{q} {\omega_{k} } = 1\).
3.3 Generating Attribute Weights Based on Statistical Inference (Phase III)
Similar to the process of deriving DM weights in Subsection 3.2, this subsection utilizes the statistical inference principle to derive the attributes’ weights with \(\tilde{H}_{k} = (\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\). First, we transform the linguistic distribution information decision-making matrices \(\tilde{H}_{k} = (\tilde{h}_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\) into the utility matrices \(U_{k} = (u_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\) with a utility function. Then, we determine the attributes’ weights utilizing the mathematical expectations and standard variances obtained. The flow chart of Phase III can be seen in Fig. 5.

Phase III: Generating attribute weights
According to Definition 1, we know that a LDE can be viewed as a discrete full probability distribution over the LTS \(S = \{ s_{0} ,s_{1} , \ldots s_{\tau } , \ldots ,s_{2\tau } \}\). Therefore, for a LDE \(\tilde{h} = \left\{ {(s_{\xi } ,\tilde{p}_{{}}^{(\xi )} )\left| {\xi = } \right.} \right.\) \(\left. {0,1, \ldots ,2\tau ,0 \le \tilde{p}_{{}}^{(\xi )} \le 1,\sum\nolimits_{\xi = 0}^{2\tau } {\tilde{p}_{{}}^{(\xi )} } = 1} \right\}\), a utility function \(u(\tilde{h}) = \sum\nolimits_{\xi = 0}^{2\tau } {\Phi^{ - 1} (s_{\xi } ) \cdot \tilde{p}_{{}}^{(\xi )} } = \sum\nolimits_{\xi = 0}^{2\tau } {\xi \cdot \tilde{p}_{{}}^{(\xi )} }\) is used to calculate the utility value of LDE \(\tilde{h}\), and thus we can obtain the utility matrices \(U_{k} = (u_{ij}^{k} )_{m \times n} (k = 1,2 \ldots, q)\), where \(u_{ij}^{k} = \sum\nolimits_{\xi = 0}^{2\tau } {\xi \cdot \tilde{p}_{ij(k)}^{(\xi )} } ,i = 1,2, \ldots ,m,j = 1,2, \ldots ,n,k = 1,2 \ldots , q\).
Let \(u_{j}^{kL} = \mathop {\min }\limits_{i} \{ u_{ij}^{k} \} ,u_{j}^{kU} = \mathop {\max }\limits_{i} \{ u_{ij}^{k} \} ,j = 1,2, \ldots ,n,k = 1,2 \ldots ,q\), then we obtain the following interval matrix \(B = (b_{kj}^{{}} )_{q \times n} = \left( {[u_{j}^{kL} ,u_{j}^{kU} ]} \right)_{q \times n}\):
\(\begin{gathered} \;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;a_{1} \;\;\;\;\;\;\;\;\;\;\;\;\;\;a_{2} \;\;\;\;\;\;\;\; \cdots \;\;\;\;\;\;\;\;\;a_{n} \hfill \\ B = \begin{array}{*{20}c} {e_{1} } \\ {e_{2} } \\ {} \\ {e_{q} } \\ \end{array} \left( {\begin{array}{*{20}c} {[u_{1}^{1L} ,u_{1}^{1U} ]} & {[u_{2}^{1L} ,u_{2}^{1U} ]} & \cdots & {[u_{n}^{1L} ,u_{n}^{1U} ]} \\ {[u_{1}^{2L} ,u_{1}^{2U} ]} & {[u_{2}^{2L} ,u_{2}^{2U} ]} & \cdots & {[u_{n}^{2L} ,u_{n}^{2U} ]} \\ \vdots & \vdots & \ddots & \vdots \\ {[u_{1}^{qL} ,u_{1}^{qU} ]} & {[u_{2}^{qL} ,u_{2}^{qU} ]} & \cdots & {[u_{n}^{qL} ,u_{n}^{qU} ]} \\ \end{array} } \right) \hfill \\ \end{gathered}\).
We divide the interval sequence \(\left\{ {[u_{1}^{kL} ,u_{1}^{kU} ],[u_{2}^{kL} ,u_{2}^{kU} ], \ldots ,[u_{n}^{kL} ,u_{n}^{kU} ]} \right\}\) into the following two real number sequences \(\left\{ {u_{1}^{kL} ,u_{2}^{kL} , \ldots ,u_{n}^{kL} } \right\}\) and \(\left\{ {u_{1}^{kU} ,u_{2}^{kU} , \ldots ,u_{n}^{kU} } \right\}\). Therefore, their mathematical expectations \(\overline{u}^{kL} ,\overline{u}^{kU}\) and standard variances \(\overline{sv}^{kL} ,\overline{sv}^{kU}\) are calculated as:
where \(n\) is the number of data in the normal distribution data sequence \(\left\{ {u_{1}^{kL} ,u_{2}^{kL} , \ldots ,u_{n}^{kL} } \right\}\) or normal distribution data sequence \(\left\{ {u_{1}^{kU} ,u_{2}^{kU} , \ldots ,u_{n}^{kU} } \right\}\).
This is then followed by the generation of probability for the interval number \([u_{j}^{kL} ,u_{j}^{kU} ]\):
where (i) \(P\left( {x \le u_{j}^{kL} } \right) = P\left( {\frac{{\overline{u}^{kL} - u_{j}^{kL} }}{{{{\overline{sv}^{kL} } \mathord{\left/ {\vphantom {{\overline{sv}^{kL} } {\sqrt n }}} \right. \kern-\nulldelimiterspace} {\sqrt n }}}}} \right)\), if \(u_{j}^{kL} < \overline{u}^{kL}\);
(ii) \(P\left( {x \le u_{j}^{kL} } \right) = P\left( {\frac{{u_{j}^{kL} - \overline{u}^{kL} }}{{{{\overline{sv}^{kL} } \mathord{\left/ {\vphantom {{\overline{sv}^{kL} } {\sqrt n }}} \right. \kern-\nulldelimiterspace} {\sqrt n }}}}} \right)\), if \(u_{j}^{kL} > \overline{u}^{kL}\);
(iii) \(P\left( {x \le u_{j}^{kU} } \right) = P\left( {\frac{{\overline{u}^{kU} - u_{j}^{kU} }}{{{{\overline{sv}^{kU} } \mathord{\left/ {\vphantom {{\overline{sv}^{kU} } {\sqrt n }}} \right. \kern-\nulldelimiterspace} {\sqrt n }}}}} \right)\), if \(u_{j}^{kU} < \overline{u}^{kU}\);
(iv) \(P\left( {x \le u_{j}^{kU} } \right) = P\left( {\frac{{u_{j}^{kU} - \overline{u}^{kU} }}{{{{\overline{sv}^{kU} } \mathord{\left/ {\vphantom {{\overline{sv}^{kU} } {\sqrt n }}} \right. \kern-\nulldelimiterspace} {\sqrt n }}}}} \right)\), if \(u_{j}^{kU} > \overline{u}^{kU}\).
Let \(L_{kj} = u_{j}^{kU} - u_{j}^{kL} ,k = 1,2 \ldots, q,j = 1,2, \ldots, n\). In the process of MALSGDM problems, the larger the value of \(L_{kj} = u_{j}^{kU} - u_{j}^{kL}\) is, the more decentralized the attribute \(a_{j}\)’s utility values are, and the greater the difference of the utility values among different alternatives is with respect to attribute \(a_{j}\). Thus, the higher the degree of distinction among different alternatives occurs with attribute \(a_{j}\), which implies that attribute \(a_{j}\) provides the DMs with effective information, and that attribute \(a_{j}\) is more important in MALSGDM problems and should be assigned a bigger weight. Thus, the attributes’ weights are derived as follows:
thus \(\sum\nolimits_{j = 1}^{n} {w_{kj} } = 1\) and \(w_{kj} \in [0,1],k = 1,2 \ldots ,q,j = 1,2, \ldots ,n\).
3.4 Determining the Ranking of Alternatives with Regret Theory (Phase IV)
DMs are bounded rational under the complex risk decision-making environment. Therefore, based on the obtained weight vector of DMs \(\omega = (\omega_{1} ,\omega_{2} , \ldots ,\omega_{q} )^{T}\) and weight vectors of attributes \(w_{k} = (w_{k1} ,w_{k2} , \ldots ,w_{kn} )^{T} (k = 1,2 \ldots ,q)\), we first construct the reference utility values, then the perceived utility matrices are obtained, which is followed by the integration of the comprehensive perceived utility matrix. In the end, we obtain the ranking of alternatives \(\{ x_{1} ,x_{2} , \ldots ,x_{n} \}\). The flow chart of Phase IV can be seen in Fig. 6.

Phase IV: Desirable alternative selection process
Regret theory utilizes the regret-rejoice function to reflect the DM’s psychological perception that depends on the deviation of the utility values between the alternative they choose and the reference alternative. Now, we propose a decision-making approach to derive the ranking of alternatives with regret theory.
Algorithm II
Step 1. For the utility matrices \(U_{k} = (u_{ij}^{k} )_{m \times n} (k = 1,2 \ldots ,q)\), let \(u_{i}^{k} = \sum\nolimits_{j = 1}^{n} {w_{kj} u_{ij}^{k} } ,i = 1,2, \ldots ,m\), then \(\left( {u_{1}^{k} ,u_{2}^{k} , \ldots ,u_{m}^{k} } \right)^{T}\) can be deemed as a reference utility vector. According to regret-rejoice function (i.e., Eq. (4)), the perceived utility value of LDE \(\tilde{h}_{ij}^{k}\) is calculated as:
thus, the perceived utility matrices \(PU_{k} = \left( {pu(\tilde{h}_{ij}^{k} )} \right)_{m \times n} ,k = 1,2, \ldots ,q\) are constructed.
Step 2. By using the DMs’ weights \(\omega = (\omega_{1} ,\omega_{2} , \ldots ,\omega_{q} )^{T}\), we fuse these perceived utility matrices \(PU_{k} (k = 1,2, \cdots ,q)\) into a comprehensive perceived utility matrix \(PU =\) \(\left( {pu(\tilde{h}_{ij}^{{}} )} \right)_{m \times n}\), where
Step 3. Let \(\varpi = (\varpi_{1} ,\varpi_{2} , \ldots ,\varpi_{n} )^{T}\), where \(\varpi_{j} = \sum\limits_{k = 1}^{q} {\omega_{k} w_{kj} } ,j = 1,2, \cdots ,n\). As \(\varpi_{j} \ge 0\) and
thus, \(\varpi = (\varpi_{1} ,\varpi_{2} , \cdots ,\varpi_{n} )^{T}\) can be regarded as the attribute weight vector of the comprehensive perceived utility matrix \(PU = \left( {pu(\tilde{h}_{ij}^{{}} )} \right)_{m \times n}\).
Step 4. Calculate the comprehensive perceived utility value of alternative \(x_{i}\) as follows:
Step 5. Determine the ranking order of alternatives with \(U(x_{i} )(i = 1,2, \cdots ,m)\), and select/obtain the best alternative \(x^{*}\), which is represented as \(\mathop {\max }\limits_{i} \left\{ {U(x_{i} )} \right\}\).
4 Case Study
Now, we will apply the developed CLDLSGDM method to the hospital assessment problem, then the sensitivity analysis and comparative analysis will be performed to illustrate the advantages of the developed CLDLSGDM method.
4.1 Application to Evaluate the Performance of Hospitals in China
Emergency health management in China has been proposed to deal with the risk of major public health incidents, such as COVID-19. Emergency health management refers to the government and other public medical institutions taking a series of necessary and effective steps towards protecting the safety of public life, health and property, and promoting the harmonious development of the society by establishing necessary response mechanisms and by applying science, technology, planning and management to the process of prevention, response, disposal and recovery of major public health incidents.
An important aspect of emergency health management is the effective evaluation of hospitals, so that the government might be able to coordinate and direct hospital resources in order to deal with major public health events effectively as soon as they occur. In this section, we give a numerical example to evaluate the performance of 4 listed public hospitals in Hefei, China, which illustrates the practicability and validity of the proposed CLDLSGDM method. The 4 listed public hospitals are The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)), Anhui Provincial Hospital (\(x_{2}\)), The First Affiliated Hospital of Anhui Medical University (\(x_{3}\)) and The First Affiliated Hospital of Anhui University of Traditional Chinese Medicine (\(x_{4}\)). Three evaluation attributes of hospitals are considered as follows: fixed assets (\(a_{1}\)), the number of full-time employees (\(a_{2}\)) and patient evaluation index (\(a_{3}\)). The above 4 public hospitals compete with each other as they all engage in medical services. Let \(S = \left\{ {s_{0} :very\;poor,} \right.\) \(\left. {s_{1} :poor,s_{2} :medium,s_{3} :good,\;s_{4} :very\;good} \right\}\) be a LTS, with a group consensus index threshold of \(\theta = 0.85\), let the costs be \((c_{1} ,c_{2} , \cdots ,c_{20} ) = (3,6,1,2,1,5,4,6,2,3,2,2,5,3,2,7,2,6,5,1)\) (Ben-Arieh et al. 2009; Gong et al. 2021), and the regret aversion coefficient \(\delta = 0.3\) (Zhang et al. 2016). To evaluate the medical and health service capacities of these hospitals \(\{ x_{1} ,x_{2} ,x_{3} ,x_{4} \}\), 20 DMs \(\{ e_{1} ,e_{2} , \ldots ,e_{20} \}\) provide their evaluation opinions, with LDEs, on four hospitals with respect to three attributes. Due to the complexity and ambiguity of the human mind, it is impracticable to require DMs to provide numerical judgements about four public hospitals. Thus, they are required to provide their preference using LDEs. For example, after DM \(e_{1}\) compares The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) and The First Affiliated Hospital of Anhui Medical University (\(x_{3}\)), they think that the linguistic preference degree of The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) over The First Affiliated Hospital of Anhui Medical University (\(x_{3}\)) may be \( very\;poor^{\prime\prime},poor,medium\) or \( very\;good\), and the their corresponding probabilities are 30%, 30%, 30%, and 10%, respectively. Thus, the evaluation information of The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) over The First Affiliated Hospital of Anhui Medical University (\(x_{3}\)) from DM \(e_{1}\) can be depicted by LDE \( h_{{13}}^{1} = \{ (s_{0} ,0.3),(s_{1} ,0.3),(s_{2} ,0.3),(s_{3} ,0),(s_{4} ,0.1)\} \). Therefore, after interviewing 20 DMs and selecting the evaluation information in a similar way, twenty linguistic distribution information decision-making matrices \(H_{k} = (h_{ij}^{k} )_{4 \times 3} (k = 1,2, \cdots ,20)\) are obtained, which are shown in the Appendix.
We utilize the proposed CLDLSGDM method to appraise the relative performance of the 4 public hospitals and derive an overall ranking.
5 Phase I: CRP
By using Eqs. (5) and (7), we obtain the consensus matrix \(CM = \left( {cm_{kl} } \right)_{20 \times 20}\) as follows:
then we utilize Eq. (8) to get the DMs’ group consensus index \(GCI = 0.7936\). As \(GCI = 0.7936 < 0.85 = \theta\), we apply Algorithm I to improve the group consensus degree among DMs. As \(cm_{3,17}^{{}} = 0.40,cm_{3,10}^{{}} = 0.42\) and \(cm_{10,17}^{{}} = 0.41\) are the smallest three elements in consensus matrix \(CM = \left( {cm_{kl} } \right)_{20 \times 20}\), DMs \(e_{3} ,e_{10}\) and \(e_{17}\) need to adjust their evaluation opinions and another seventeen DMs do not need to modify their evaluation opinions, i.e., \(\tilde{H}_{k} = H_{k} (k = 1,2,4,5,6,7,8,9,11,12,13,14,15,16,18,19,20)\). The adjustment costs of DMs \(e_{3}\) and \(e_{10}\) are \(c_{3} = 1\) and \(c_{10} = 3\), respectively. According to Step 6 in Algorithm I, we have \(c_{3} < c_{10}\), and then we change DM \(e_{3}\)’s evaluation opinions toward to DM \(e_{10}\). Therefore, we obtain the adjusted linguistic distribution information decision-making matrices \(\tilde{H}_{3}\) as follows:

Similarly, one can obtain the adjusted linguistic distribution information decision-making matrices \(\tilde{H}_{k} (k = 10,17)\) which are derived as follows:

Then, one can determine the following new consensus matrix \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{20 \times 20}\):
and the group consensus index is \(GCI = 0.8515 > 0.85 = \theta\). Thus, DMs achieve an acceptable consensus level.
6 Phase II: Derive DM Weights
Based on the obtained consensus matrix \(C\tilde{M} = \left( {c\tilde{m}_{kl} } \right)_{20 \times 20}\), we utilize Eqs. (9)–(12) to calculate the weight vector of DMs:
7 Phase III: Generate Attribute Weights
According to the obtained linguistic distribution information decision-making matrices \(\tilde{H}_{k} (k = 1,2,\ldots,20)\), we can obtain the utility matrices \(U_{k} = (u_{ij}^{k} )_{m \times n} (k = 1,2 \ldots,20)\) as follows:
Then, we utilize Eqs. (13)–(16) to calculate the attribute weight vectors:
8 Phase IV: Determine the Ranking Order of Alternatives
First, with the perceived utility function (i.e., Eq. (17)), we construct perceived utility matrices \(PU_{k} = \left( {pu(\tilde{h}_{ij}^{k} )} \right)_{4 \times 3} (k = 1,2, \ldots ,20)\) as follows:
By using Eq. (18), one can derive the following comprehensive perceived utility matrix:
In addition, based on the obtained weight vector of DMs \(\omega = (\omega_{1} ,\omega_{2} , \cdots ,\omega_{20} )^{T}\) and attribute weight vectors \(w_{k} = (w_{k1} ,w_{k2} ,w_{k3} )^{T} (k = 1,2 \cdots ,20)\), we apply Eq. (19) to the attribute weight vector of comprehensive perceived utility matrix as follows:
Then, we calculate the comprehensive perceived utility values of public hospitals \(x_{i} (i = 1,2,3,4)\): \(U(x_{1} ) = 1.6730,U(x_{2} ) = 1.8887,U(x_{3} ) = 2.7874,U(x_{4} ) = 1.1864\). Therefore, we determine the ranking order of the four public hospitals to be \(x_{3} \succ x_{2} \succ x_{1} \succ x_{4}\).
8.1 Sensitivity Analysis
There is a parameter \(\delta\) in the developed CLDLSGDM method, where the parameter \(\delta > 0\) is the regret aversion coefficient of DMs and reflects the regret-rejoice psychological preference of DMs. Therefore, we have explored what impact the sensitivity analysis of parameter \(\delta\) might have on the complete ranking of the 4 public hospitals.
The sensitivity analyses of regret aversion coefficient \(\delta\) on the comprehensive perceived utility values of 4 public hospitals are shown in Table 1 and Fig. 7. The sensitivity analyses of regret aversion coefficient \(\delta\) on the complete ranking of 4 public hospitals are shown in Table 2 and Fig. 8.

Comprehensive perceived utility values with different \(\delta\)

Ranking results of 4 public hospitals with different \(\delta\)
From Table 1 and Fig. 7, it is shown that the comprehensive perceived utility values of 4 public hospitals monotonically decrease with respect to the regret aversion coefficient \(\delta\), which may lead to \(u_{ij}^{k} - \sum\limits_{j = 1}^{n} {w_{kj} u_{ij}^{k} } \le 0\). From Figs. 7 and 8, it can be observed that although the optimal public hospital remained unchanged, the complete ranking order of the 4 public hospitals has changed. Specifically, when regret aversion coefficient \(\delta \in (0,2.617)\), the complete ranking order of 4 public hospitals is \(x_{3} \succ x_{2} \succ x_{1} \succ x_{4}\), which indicates that the developed CLDLSGDM method has better robustness when \(\delta \in (0,2.617)\). The gap between public hospital \(x_{2}\) and public hospital \(x_{1}\) tended to decrease as the regret aversion coefficient \(\delta\) increased. When regret aversion coefficient \(\delta \in (2.617,4]\), the complete ranking order of the 4 public hospitals is \(x_{3} \succ x_{1} \succ x_{2} \succ x_{4}\), and the gap between public hospital \(x_{3}\) and public hospital \(x_{1}\) tended to decrease as the regret aversion coefficient \(\delta\) increased. When regret aversion coefficient \(\delta > 5.0493\), the ranking order of public hospital \(x_{3}\) and public hospital \(x_{1}\) changed. According to regret theory, it is known that the bigger the regret aversion coefficient \(\delta\) is, the greater the risk aversion of DMs is, and the more regret aversive a DM is.
8.2 Comparative Analysis
In this subsection, we present a comparison between our method and the methods used in Zhang et al. (2014), Liu and Li (2019), Zheng et al. (2020) and Liu et al. (2021). Differences between our method and the above literature have been summarized and are shown in Table 3.
Applying the methods proposed by Zhang et al. (2014), Liu and Li (2019), Zheng et al. (2020) and Liu et al. (2021), we derive the comprehensive evaluation values of 4 public hospitals, respectively, and then the ranking results of the 4 public hospitals are determined and displayed in Table 4 and Fig. 9.

Ranking results of 10 public hospitals with different methods
From Table 4 and Fig. 9, it is obvious that The First Affiliated Hospital of Anhui Medical University (\(x_{3}\)) is the public hospital with the best performance. Although the 4 public hospitals obtain different comprehensive evaluation values with the methods in Zhang et al. (2014), Zheng et al. (2021) and the proposed probabilistic linguistic MALSGDM method, the ranking results of the 4 public hospitals are same, i.e., the complete ranking results of the 4 public hospitals are \(x_{3} \succ x_{2} \succ x_{1} \succ x_{4}\). In addition, the comprehensive prospect evaluation values of the 4 public hospitals obtained using Liu and Li (2019)’s method, in which there are five unknown parameters, could lead to unstable GDM results. Thus, Liu and Li (2019)’s method produces a different ranking order between The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) and Anhui Provincial Hospital (\(x_{2}\)) than that obtained by the proposed probabilistic linguistic MALSGDM method. Liu et al. (2021)’s method is considered too complex to evaluate the relationship between DMs, thus Liu et al. (2021)’s method generates a different ranking order between The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) and The First Affiliated Hospital of Anhui University of Traditional Chinese Medicine (\(x_{4}\)) than that obtained by the proposed probabilistic linguistic MALSGDM method.
According to the above comparison and sensitivity analysis, the advantages of the developed CLDLSGDM method are summarized as follows:
-
(1)
As LDE is a useful modelling tool used to express complex information in GDM, subsequently the CLDLSGDM method seems more reasonable and better suited to coping with LSGDM problems, in which DMs can elicit their opinions with qualitative evaluation information. Therefore, the developed CLDLSGDM method is more practical and can be widely used.
-
(2)
Although both the proposed method and Zhang et al. (2014)’s method obtain the same ranking results for the 4 public hospitals, the proposed method is more reasonable and reliable. On the one hand, the method proposed in Zhang et al. (2014) does not consider DMs’ agreements before making decisions and directly utilizes the linguistic distribution weighted averaging operator to integrate the individual attribute values into the overall attribute values, which may lead to unreliable results. On the other hand, the method proposed in Zhang et al. (2014)/this method disregards the psychological perception of DMs in the process of GDM. The proposed method, however, is based on CRP and regret theory and reduces disagreement among DMs with the aim of obtaining an agreed solution. It also considers the DMs are bounded rational under the complex GDM environment. Therefore, the developed CLDLSGDM method is more reasonable and reliable.
-
(3)
It can be observed in Table 4 that the ranking results of the 4 public hospitals, derived from both our method and Liu and Li (2019)’s method, are different. The method proposed in Liu and Li (2019) is based on prospect theory, thus, in the process of determining the comprehensive prospect evaluation values of the 4 public hospitals, one must consider how to select the five parameters provided by DMs. These include risk aversion coefficient, risk attitude coefficient, loss-aversion coefficient, gain coefficient and loss coefficient, which may lead to unstable and inaccurate GDM results. However, the proposed method takes the regret aversion psychological characteristics of DMs with only one parameter into account, which reduces the computational complexity. Therefore, the developed CLDLSGDM method is simpler and more efficient.
-
(4)
Comparison with the method proposed in Zheng et al. (2021): Although the ranking order of the 4 public hospitals is the same for both the proposed method and the Zheng et al. (2021) method, the proposed method is simpler and more effective. According to the method in Zheng et al. (2021), first, we need to utilize the bi-objective clustering method to divide the experts into different clusters, which is followed by the generation of cluster weights. Then, the comprehensive evaluation values and comprehensive ranking of the 4 public hospitals are obtained, which disregard the regret aversion psychological characteristics of DMs. However, as more DMs become involved in the LSGDM, the clustering method in Zheng et al. (2021) will be much harder to implement. As the proposed method derives the weights of DMs and attributes with the statistical inference principle, the comprehensive ranking of the 4 public hospitals is easy to obtain when considering the regret aversion psychological characteristics of DMs. Therefore, the developed CLDLSGDM method is simpler and more practical.
-
(5)
Comparison with method in Liu et al. (2021): Note that the method in Liu et al. (2021) and the proposed method derive different ranking orders of the 4 public hospitals, i.e., the ranking between The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) and The First Affiliated Hospital of Anhui University of Traditional Chinese Medicine (\(x_{4}\)) is different. It can be observed that the method presented in Liu et al. (2021) is based on social network analysis in order to develop the consensus model and obtain a comprehensive ranking of the 4 public hospitals. However, although the social relationship among DMs perhaps improves the authenticity of GDM, it takes too much time and costs too much to analyze. In addition, in the original linguistic distribution information decision-making matrices \(H_{k} = (h_{ij}^{k} )_{4 \times 3} (k = 1,2, \ldots ,20)\) provided by DMs, it can be observed that \(h_{1j}^{k} \ge h_{4j}^{k} ,k = 1,2, \ldots ,20\), which indicates that The Second Affiliated Hospital of Anhui Medical University (\(x_{1}\)) is preferred to The First Affiliated Hospital of Anhui University of Traditional Chinese Medicine (\(x_{4}\)), i.e., \(x_{1} \succ x_{4}\). Therefore, the developed CLDLSGDM method in the paper is considered more reliable.
9 Conclusions
With the development of modern society and the economy, As LSGDM problems contain crisp data, the fact that DMs are generally provided qualitative evaluation information is not always effective. Therefore, this paper develops a CLDLSGDM method with linguistic distribution information based on statistical inference principle and regret theory. We first propose a LSGDM CRP with linguistic distribution information in a linguistic distribution information environment, in which the evaluation opinions of DMs are retained as much as possible, in order to improve the group consensus degree. Then, by utilizing the statistical inference principle, we develop two weight allocation methods for DMs and attributes. Furthermore, based on regret theory, we derive the comprehensively perceived utility values of alternatives and obtain the ranking order of alternatives, in which the regret aversion psychological characteristics of DMs are considered. Finally, a numerical example for evaluating the performance of the 4 public hospitals is presented to illustrate the implementation of the developed CLDLSGDM method. The stability analysis of the developed method is performed using a sensitivity analysis of parameter. The results of the comparative analysis demonstrate the advantages of the developed method.
However, the CLDLSGDM method sets a fixed group consensus index threshold and does not study how to determine appropriate group consensus index threshold. Therefore, in the future, based on the simulation experiment, we will further investigate the algorithm to determine the appropriate group consensus index thresholds. Also, the developed CLDLSGDM method can also be employed in other fields, such as social risk evaluation and hotel location selection.
References
Bain K, Hansen AS (2020) Strengthening implementation success using large-scale consensus decision-making—A new approach to creating medical practice guidelines. Eval Program Plann 79:101730
Bell DE (1982) Regret in decision making under uncertainty. Oper Res 30(5):961–981
Ben-Arieh D, Easton T, Evans B (2009) Minimum cost consensus with quadratic cost functions. IEEE Trans Syst Man Cybern Part A Syst Hum 39(1):210–217
Bu SY (2007) Design and implementation of group decision mathematical model. Sci Technol Inf 6:65–67
Chen XH, Liu R (2006) Improved clustering algorithm and its application in complex huge group decision-making. Syst Eng Electr 28(11):1695–1699
Chen ZS, Liu XL, Chin KS, Pedrycz W, Tsui KL, Skibniewski MJ (2021) Online-review analysis based large-scale group decision-making for determining passenger demands and evaluating passenger satisfaction: Case study of high-speed rail system in China. Inf Fus 69:22–39
Chu JF, Wang YM, Liu XW, Liu YC (2020) Social network community analysis based large-scale group decision making approach with incomplete fuzzy preference relations. Inf Fus 60:98–120
Ding RX, Wang XQ, Shang K, Herrera F (2019) Social network analysis-based conflict relationship investigation and conflict degree-based consensus reaching process for large scale decision making using sparse representation. Inf Fus 5:251–272
Du YW, Chen Q, Sun YL, Li CH (2021) Knowledge structure-based consensus-reaching method for large-scale multiattribute group decision-making. Knowl-Based Syst 219:106885
Du ZJ, Yu SM, Xu XH (2020) Managing noncooperative behaviors in large-scale group decision-making: Integration of independent and supervised consensus-reaching models. Inf Sci 531:119–138
Gong ZW, Guo WW, Herrera-Viedma E, Gong ZJ, Wei G (2020a) Consistency and consensus modeling of linear uncertain preference relations. Eur J Oper Res 283(1):290–307
Gong ZW, Wang H, Guo WW, Gong ZJ, Wei G (2020b) Measuring trust in social networks based on linear uncertainty theory. Inf Sci 508:154–172
Gong ZW, Xu XX, Guo WW, Herrera-Viedma E, Cabrerizo FJ (2021) Minimum cost consensus modelling under various linear uncertain-constrained scenarios. Inf Fus 66:1–17
Gou XJ, Xu ZS, Herrera F (2018) Consensus reaching process for large-scale group decision making with double hierarchy hesitant fuzzy linguistic preference relations. Knowl-Based Syst 157:20–33
Gou XJ, Xu ZS, Liao HC, Herrera F (2021) Consensus model handling minority opinions and noncooperative behaviors in large-scale group decision-making under double hierarchy linguistic preference relations. IEEE Trans Cybern 51(1):283–296
Guo WW, Gong ZW, Xu XX, Herrera-Viedma E (2020) Additive and multiplicative consistency modeling for incomplete linear uncertain preference relations and its weight acquisition. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2020.2965909
Herrera F, Martinez L (2000) A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans Fuzzy Syst 8(6):746–752
Jin FF, Ni ZW, Langari R, Chen HY (2020) Consistency improvement-driven decision-making methods with probabilistic multiplicative preference relations. Group Decis Negot 29:371–397
Labella Á, Liu HB, Rodríguez RM, Martínez L (2020a) A cost consensus metric for consensus reaching processes based on a comprehensive minimum cost model. Eur J Oper Res 281:316–331
Labella Á, Liu Y, Rodríguez RM, Martínez L (2018) Analyzing the performance of classical consensus models in large scale group decision making: A comparative study. Appl Soft Comput 67:677–690
Labella Á, Rodríguez RM, Martínez L (2020b) Computing with comparative linguistic expressions and symbolic translation for decision making: ELICIT information. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2019.2940424
Li CC, Dong YC, Herrera F (2019) A consensus model for large-scale linguistic group decision making with a feedback recommendation based on clustered personalized individual semantics and opposing consensus groups. IEEE Trans Fuzzy Syst 27(2):221–233
Li CC, Dong YC, Herrera F, Herrera-Viedma E, Martínez L (2017) Personalized individual semantics in computing with words for supporting linguistic group decision making: an application on consensus reaching. Inf Fus 33(1):29–40
Lin MW, Chen ZY, Xu ZS, Gou XJ, Herrera F (2021) Score function based on concentration degree for probabilistic linguistic term sets: an application to TOPSIS and VIKOR. Inf Sci 551:270–290
Lin MW, Wang HB, Xu ZS (2020) TODIM-based multi-criteria decision-making method with hesitant fuzzy linguistic term sets. Artif Intell Rev 53:3647–3671
Liu F, Zhang JW, Liu T (2020) A PSO-algorithm-based consensus model with the application to large-scale group decision-making. Complex Intell Syst 6:287–298
Liu J, Martínez L, Wang HM, Rodríguez RM, Novozhilov V (2010) Computing with words in risk assessment. Int J Comput Intell Syst 3:396–419
Liu PD, Li Y (2019) An extended MULTIMOORA method for probabilistic linguistic multicriteria group decision-making based on prospect theory. Comput Ind Eng 136:528–545
Liu PD, You XL (2019) Improved TODIM method based on linguistic neutrosophic numbers for multicriteria group decision-making. Int J Comput Intell Syst 12(2):544–556
Liu PD, Zhang XH, Pedrycz W (2021) A consensus model for hesitant fuzzy linguistic group decision-making in the framework of Dempster-Shafer evidence theory. Knowl-Based Syst 212:106559
Liu YP (2015) The research of group decision-making evaluation methods on green building based on statistical inference theory. Lanzhou Jiaotong University, Lanzhou
Loomes G, Sugden R (1982) Regret theory: an alternative theory of rational choice under uncertainty. Econ J 92(368):805–824
Lu YL, Xu YJ, Herrera-Viedma E, Han YF (2021) Consensus of large-scale group decision making in social network: the minimum cost model based on robust optimization. Inf Sci 547:910–930
Ma XJ, Gong ZW, Guo WW (2020) Optimisation of group consistency for incomplete uncertain preference relation. Int J Comput Intell Syst 13(1):130–141
Martínez L, Herrera F (2014) Challenges of computing with words in decision making. Inf Sci 258:218–219
Martínez L, Ruan D, Herrera F (2010) Computing with words in decision support systems: an overview on models and applications. Int J Comput Intell Syst 3(4):382–395
Ou Y, Yi LZ, Zou B, Pei Z (2018) The linguistic intuitionistic fuzzy set TOPSIS method for linguistic multi-criteria decision makings. Int J Comput Intell Syst 11(1):120–132
Palomares I, Estrella FJ, Martínez L, Herrera F (2014) Consensus under a fuzzy context: Taxonomy, analysis framework AFRYCA and experimental case of study. Inf Fus 20:252–271
Quesada FJ, Palomares I, Martínez L (2015) Managing experts behavior in large-scale consensus reaching processes with uninorm aggregation operators. Appl Soft Comput 35:873–887
Rodríguez RM, Labella L, Sesma-Sara M, Bustince H, Martinez L (2021a) A cohesion-driven consensus reaching process for large scale group decision making under a hesitant fuzzy linguistic term sets environment. Comput Ind Eng 155:107158
Rodríguez RM, Labella A, de Tré G, Martínez L (2018) A large scale consensus reaching process managing group hesitation. Knowl-Based Syst 159:86–97
Rodríguez RM, Martínez L (2013) An analysis of symbolic linguistic computing models in decision making. Int J Gen Syst 42(1):121–136
Rodríguez RM, Martínez L, Herrera F (2012) Hesitant fuzzy linguistic term sets for decision making. IEEE Trans Fuzzy Syst 20:109–119
Rodríguez RM, Labella L, Dutta B, Martínez L (2021b) Comprehensive minimum cost models for large scale group decision making with consistent fuzzy preference relations. Knowl-Based Syst 215:106780
Song Y, Yao H, Yao S, Yu DH, Shen Y (2017) Risky multicriteria group decision making based on cloud prospect theory and regret feedback. Math Prob Eng, 9646303.
Tang M, Liao HC (2021) From conventional group decision making to large-scale group decision making: What are the challenges and how to meet them in big data era? A state-of-the-art survey. Omega 100:102141
Tang M, Liao HC, Xu JP, Streimikiene D, Zheng XS (2020) Adaptive consensus reaching process with hybrid strategies for large-scale group decision making. Eur J Oper Res 282:957–971
Wan QF, Xu XH, Chen XH, Zhuang J (2020) A two-stage optimization model for large-scale group decision-making in disaster management: minimizing group conflict and maximizing individual satisfaction. Group Decis Negot 29:901–921
Wang HD, Pan XH, Yan J, Yao JL, He SF (2020) A projection-based regret theory method for multi-attribute decision making under interval type-2 fuzzy sets environment. Inf Sci 512:108–122
Wang P, Xu XH, Huang S (2019) An improved consensus-based model for large group decision making problems considering experts with linguistic weighted information. Group Decis Negot 28:619–640
Wu T, Liu XW, Qin JD, Herrera F (2019) Consensus evolution networks: A consensus reaching tool for managing consensus thresholds in group decision making. Inf Fus 52:375–388
Wu ZB, Xu JP (2018) A consensus model for large-scale group decision making with hesitant fuzzy information and changeable clusters. Inf Fus 41:217–231
Xiao J, Wang XL, Zhang HJ (2020) Managing classification-based consensus in social network group decision making: An optimization-based approach with minimum information loss. Inf Fus 63:74–87
Xu XH, Chen XH (2018) Research of a kind of method of multi-attributes and multi-schemes large group decision making. J Syst Eng 23(2):137–141
Xu XH, Du ZJ, Chen XH, Cai CG (2019a) Confidence consensus-based model for large-scale group decision making: A novel approach to managing non-cooperative behaviors. Inf Sci 477:410–427
Xu XH, Zhong XY, Chen XH, Zhou YJ (2015) A dynamical consensus method based on exit-delegation mechanism for large group emergency decision making. Knowl-Based Syst 86:237–249
Xu XS (2009) An automatic approach to reaching consensus in multiple attribute group decision making. Comput Ind Eng 56:1369–1374
Xu YJ, Zhang ZQ, Wang HM (2019b) A consensus-based method for group decision making with incomplete uncertain linguistic preference relations. Soft Comput 23(2):669–682
Zadeh LA (1975) The concept of a linguistic variable and its application to approximate reasoning. Inf Sci 8(2):99–249
Zhang C, Liao HC, Luo L, Xu ZS (2020a) Distance-based consensus reaching process for group decision making with intuitionistic multiplicative preference relations. Appl Soft Comput 88:106045
Zhang GQ, Dong YC, Xu YF (2014) Consistency and consensus measures for linguistic preference relations based on distribution assessments. Inf Fus 17:46–55
Zhang HJ, Dong YC, Chiclana F, Yu S (2019) Consensus efficiency in group decision making: A comprehensive comparative study and its optimal design. Eur J Oper Res 275(2):580–598
Zhang HJ, Dong YC, Herrera-Viedma E (2018) Consensus building for the heterogeneous large-scale GDM with the individual concerns and satisfactions. IEEE Trans Fuzzy Syst 28(2):884–898
Zhang HJ, Zhao SH, Kou G, Dong LCC, YC, Herrera F, (2020b) An overview on feedback mechanisms with minimum adjustment or cost in consensus reaching in group decision making: Research paradigms and challenges. Inf Fus 60:65–79
Zhang ST, Zhu JJ, Liu XD, Chen Y (2016) Regret theory method-based group decision-making with multidimensional preference and incomplete weight information. Inf Fus 31:1–13
Zhang Z, Gao Y, Li ZL (2020c) Consensus reaching for social network group decision making by considering leadership and bounded confidence. Knowl-Based Syst 204:106240
Zheng YH, Xu ZS, He Y, Tian YH (2020) A hesitant fuzzy linguistic bi-objective clustering method for large-scale group decision-making. Expert Syst Appl 168:114355
Zheng YH, Xu ZS, He Y, Tian YH (2021) A hesitant fuzzy linguistic bi-objective clustering method for large-scale group decision-making. Expert Syst Appl 168:114355
Zhou H, Wang JQ, Zhang HY (2017) Grey stochastic multi-criteria decision-making based on regret theory and TOPSIS. Int J Mach Learn Cybern 8:651–995
Acknowledgements
The work was supported by the National Natural Science Foundation of China (Nos. 71901001, 72071001, 71771001), the Spanish Research Project (No. PGC2018-099402-B-I00), the Humanities and Social Sciences Planning Project of the Ministry of Education (No. 20YJAZH066), Natural Science Foundation of Anhui Province (Nos. 2008085QG333, 2008085MG226, 2008085QG334), Key Research Project of Humanities and Social Sciences in Colleges and Universities of Anhui Province (Nos. SK2019A0013, SK2020A0038), Top Talent Academic Foundation for University Discipline of Anhui Province (No. gxbjZD2020056).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflicts of interest
None.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix


Rights and permissions
About this article

Cite this article
Jin, F., Liu, J., Zhou, L. et al. Consensus-Based Linguistic Distribution Large-Scale Group Decision Making Using Statistical Inference and Regret Theory. Group Decis Negot 30, 813–845 (2021). https://doi.org/10.1007/s10726-021-09736-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10726-021-09736-z