
Abstract
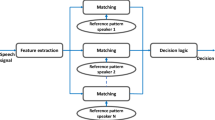
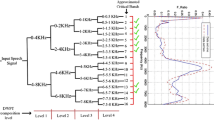
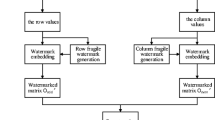
In this paper, a Multi-Factor Authentication (MFA) method is developed by a combination of Personal Identification Number (PIN), One Time Password (OTP), and speaker biometric through the speech watermarks. For this reason, a multipurpose digital speech watermarking applied to embed semi-fragile and robust watermarks simultaneously in the speech signal, respectively to provide tamper detection and proof of ownership. Similarly, the blind semi-fragile speech watermarking technique, Discrete Wavelet Packet Transform (DWPT) and Quantization Index Modulation (QIM) are used to embed the watermark in an angle of the wavelet’s sub-bands where more speaker specific information is available. For copyright protection of the speech, a blind and robust speech watermarking are used by applying DWPT and multiplication. Where less speaker specific information is available the robust watermark is embedded through manipulating the amplitude of the wavelet’s sub-bands. Experimental results on TIMIT, MIT, and MOBIO demonstrate that there is a trade-off among recognition performance of speaker recognition systems, robustness, and capacity which are presented by various triangles. Furthermore, threat model and attack analysis are used to evaluate the feasibility of the developed MFA model. Accordingly, the developed MFA model is able to enhance the security of the systems against spoofing and communication attacks while improving the recognition performance via solving problems and overcoming limitations.











Similar content being viewed by others
References
Akhaee MA, Kalantari NK, Marvasti F (2009) Robust multiplicative audio and speech watermarking using statistical modeling. In IEEE International Conference on Communications, ICC’09. 2009. IEEE
Akhaee MA, Kalantari NK, Marvasti F (2010) Robust audio and speech watermarking using Gaussian and Laplacian modeling. Signal Process 90(8):2487–2497
Al-Nuaimy W et al (2011) An SVD audio watermarking approach using chaotic encrypted images. Digit Sig Process 21(6):764–779
Baroughi AF, Craver S (2014) Additive attacks on speaker recognition. In IS&T/SPIE Electronic imaging. International Society for Optics and Photonics
Besacier L, Bonastre J-F, Fredouille C (2000) Localization and selection of speaker-specific information with statistical modeling. Speech Comm 31(2):89–106
Bimbot F et al (2004) A tutorial on text-independent speaker verification. EURASIP J Appl Sig Process 2004:430–451
Bolten JB (2003) E-authentication guidance for federal agencies. Office of Management and Budget, http://www.whitehouse.gov/omb/memoranda/fy04/m04-04.pdf. 2003
Brookes M (2006) VOICEBOX: a speech processing toolbox for MATLAB
Chaturvedi A, Mishra D, Mukhopadhyay S (2013) Improved biometric-based three-factor remote user authentication scheme with key agreement using smart card. In Information systems security, Springer, p 63–77
Dehak N et al (2011) Front-end factor analysis for speaker verification. Audio Speech Lang Process IEEE Trans 19(4):788–798
Faundez-Zanuy M, Hagmüller M, Kubin G (2006) Speaker verification security improvement by means of speech watermarking. Speech Comm 48(12):1608–1619
Faundez-Zanuy M, Hagmüller M, Kubin G (2007) Speaker identification security improvement by means of speech watermarking. Pattern Recogn 40(11):3027–3034
Garofolo JS, L.D. Consortium (1993) TIMIT: acoustic-phonetic continuous speech corpus, Linguistic Data Consortium
Hinkley DV (1969) On the ratio of two correlated normal random variables. Biometrika 56(3):635–639
Huber R, Stögner H, Uhl A (2011) Two-factor biometric recognition with integrated tamper-protection watermarking. In Communications and multimedia security, Springer
Hyon S (2012) An investigation of dependencies between frequency components and speaker characteristics based on phoneme mean F-ratio contribution. In Signal & Information Processing Association Annual Summit and Conference (APSIPA ASC), 2012. Asia-Pacific: IEEE
Kenny P (2012) A small foot-print i-vector extractor. In Proc. Odyssey
Khitrov M (2013) Talking passwords: voice biometrics for data access and security. Biom Technol Today 2013(2):9–11
Kim J-J, Hong S-P (2011) A method of risk assessment for multi-factor authentication. J Inf Process Syst (JIPS) 7(1):187–198
Kumar A, Lee HJ (2013) Multi-factor authentication process using more than one token with watermark security. In Future information communication technology and applications, Springer, p 579–587
Li C-T, Hwang M-S (2010) An efficient biometrics-based remote user authentication scheme using smart cards. J Netw Comput Appl 33(1):1–5
Li Q, Memon N, Sencar HT (2006) Security issues in watermarking applications-A deeper look. In Proceedings of the 4th ACM international workshop on Contents protection and security. ACM
Lu X, Dang J (2008) An investigation of dependencies between frequency components and speaker characteristics for text-independent speaker identification. Speech Comm 50(4):312–322
Mallat S (2008) A wavelet tour of signal processing: the sparse way. Academic press
McCool C et al (2012) Bi-modal person recognition on a mobile phone: using mobile phone data. In Multimedia and Expo Workshops (ICMEW), 2012 I.E. International Conference on, IEEE
Mohamed S et al (2013) A method for speech watermarking in speaker verification
Nematollahi MA, Akhaee MA, Al-Haddad SAR, Gamboa-Rosales H (2015) Semi-fragile digital speech watermarking for online speaker recognition. EURASIP J Audio Speech Music Process 2015(1):1–15
Nematollahi MA, Al-Haddad S (2015) Distant speaker recognition: an overview. Int J Humanoid Robot 12(03):1–45
Nematollahi MA, Gamboa-Rosales H, Akhaee MA, Al-Haddad SAR (2015) Robust digital speech watermarking for online speaker recognition. Mathematical Problems in Engineering, 2015
O’Gorman L (2003) Comparing passwords, tokens, and biometrics for user authentication. Proc IEEE 91(12):2021–2040
Pathak MA, Raj B (2013) Privacy-preserving speaker verification and identification using gaussian mixture models. Audio Speech Lang Process IEEE Trans 21(2):397–406
Reynolds DA (1995) Speaker identification and verification using Gaussian mixture speaker models. Speech Comm 17(1):91–108
Reynolds DA, Quatieri TF, Dunn RB (2000) Speaker verification using adapted Gaussian mixture models. Digit Sig Process 10(1):19–41
Roberts C (2007) Biometric attack vectors and defences. Comput Secur 26(1):14–25
Seyed Omid Sadjadi MS, Heck L (2013) MSR Identity toolbox v1.0: A MATLAB toolbox for speaker recognition research, IEEE
Simon J (2012) DataHash
Woo RH, Park A, Hazen TJ (2006) The MIT mobile device speaker verification corpus: data collection and preliminary experiments. In Speaker and Language Recognition Workshop, IEEE Odyssey 2006: The. 2006. IEEE
Wu Z et al (2015) Spoofing and countermeasures for speaker verification: a survey. Speech Comm 66:130–153
Acknowledgments
The authors would like to appreciate anonymous reviewers who have made helpful comments on this drafts of this paper.
Author information
Authors and Affiliations
Corresponding author
Appendix A
Appendix A
Discrete Fourier Transform (DFT) is assumed as Weibull distribution. However, the distribution of the DWPT sub-bands is assumed as a Generalized Gaussian Distribution (GGD) [2]. GGD can be defined as in Eq. (14), if μ 2 s = 0 and σ 2 s are assumed.
where Γ(.) corresponds to Gamma function which is expressed by \( \varGamma (x)={\displaystyle {\int}_0^{\infty }{t}^{x-1}{e}^{-t}dt\cong}\sqrt{2\pi }{x}^{x-\frac{1}{2}}{e}^{-x},v \) corresponds to the shape of the distribution which can be estimated by statistical moment of the signal.
If the watermarked speech signal is passing through AWGN channel, it is possible to formulate the watermarked speech signal at receiver based on Eqs. (15) and (16).
where n i corresponds to the amount of noise which is contaminated the watermarked speech signal. To estimate the probability of the watermark bits when it is 1, Eq. (17) is expressed:
As seen, the summation of different parameters in Eq. (17) are affected the amount of the detection threshold. By considering Central Limit Theorem (CLT), there is possible to compute different series in nominator and denominator based on Normal distribution. Due to large value for μ and long length of the speech frames, the Normal distribution is often generated positive numbers which can modeled parameters like ∑ A n 4 i which is always positive. Equations (18) and (19) are computed the mean and variance respectively.
where M corresponds to the length of each set of A and B. By applying the moment of GGD for r = 4 and r = 8, Eqs. (20) and (21) are estimated.
By considering Eqs. (18) and (19), Eq. (22) is formulated.
If the mean of the noise is assumed as zero, Eq. (23) can be expressed.
Then, the Normal distribution of 4 moment noise component can be estimated as in Eq. (24).
The other parameters in Eq. (17) can be computed from Eq. (25) to (27).
In order to simplify the computation, two free auxiliary parameters p and q are used in Eq. (28). Therefore, R|1,p,q can formulated as in Eq. (29).
where u and w are defined themselves by Eqs. (30) and (31).
The density of \( \frac{u}{w} \) is computed to estimate the pdf of R|1,p,q. By considering independency and normal distribution for two parameters of u and w, it is possible to express Eq. (32):
Also, if U and W are assumed as normal distribution and independent, then f U,W (u, w) is formulated as in Eq. (33):
Equation (34) is closed-form solution for Eq. (31) which has already discussed in literature [14].
Each parameter in Eq. (34) is defined based on Eqs. (35) to (38):
As a result, Eq. (39) formulate the density of R|1:
The lowest bound and the highest bound are applied to restrict the energy ration between two A and B sets within L and U which is stated as in Eq. (40):
Although Eq. (22) is expressed the density of parameter P, Eq. (41) is formulated the density of parameter q based on the ratio between independent and normal distribution.
With using same manner in Eq. (17), the probability of r|0 is also computable. Therefore, Eq. (42) can estimate the probability of detected error:
The threshold is estimated by minimizing the error as in Eq. (43):
Rights and permissions
About this article

Cite this article
Nematollahi, M.A., Gamboa-Rosales, H., Martinez-Ruiz, F.J. et al. Multi-factor authentication model based on multipurpose speech watermarking and online speaker recognition. Multimed Tools Appl 76, 7251–7281 (2017). https://doi.org/10.1007/s11042-016-3350-1
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-016-3350-1