
Abstract
Monitoring progress towards the Sustainable Development Goals by 2030 requires the global community to disaggregate targets along socio-economic lines, but little has been published critically analyzing the appropriateness of wealth indices to measure socioeconomic status in low- and middle-income countries. This critical interpretive synthesis analyzes the appropriateness of wealth indices for measuring social health inequalities and provides an overview of alternative methods to calculate wealth indices using data captured in standardized household surveys. Our aggregation of all published associations of wealth indices indicates a mean Spearman’s rho of 0.42 and 0.55 with income and consumption, respectively. Context-specific factors such as country development level may affect the concordance of health and educational outcomes with wealth indices and urban–rural disparities can be more pronounced using wealth indices compared to income or consumption. Synthesis of potential future uses of wealth indices suggests that it is possible to quantify wealth inequality using household assets, that the index can be used to study SES across national boundaries, and that technological innovations may soon change how asset wealth is measured. Finally, a review of alternative approaches to constructing household asset indices suggests lack of evidence of superiority for count measures, item response theory, and Mokken scale analysis, but points to evidence-based advantages for multiple correspondence analysis, polychoric PCA and predicted income. In sum, wealth indices are an equally valid, but distinct measure of household SES from income and consumption measures, and more research is needed into their potential applications for international health inequality measurement.
Similar content being viewed by others
1 Introduction
To evaluate global progress in achieving the Sustainable Development Goals (SDG) by 2030, there is a need to disaggregate key indicators according to the socioeconomic status (SES) of households. Goals of ending poverty in all its forms everywhere and of reducing income inequality within and among countries take aim at SES directly, while several goals targeting health and education outcomes now aim to reduce socioeconomic inequalities (United Nations 2015). Nevertheless, in many countries, and especially among neglected populations and low- and middle-income countries (LMICs), reliable and timely data on income and consumptionFootnote 1 are not always available. In addition to missing data, there are challenges in using income or consumption measures in many LMICs, since income can be highly variable from month to month or difficult to accurately measure (Bollen et al. 2002). Alternatively, consumption data, such as that measured by the Living Standards and Measurement Studies, can be extremely time consuming and expensive to collect (Sahn and Stifel 2003).
Given the challenges in measuring SES with income and consumption, proxy indicators have been developed. In global health, the key proxy measure is the wealth index. Wealth indices use information about household durable assets, such as housing materials, toilet or latrine access, phone ownership, or agricultural land and livestock, which are regularly collected in most household surveys to create an index of household wealth. Their use has become widespread in large part because of the pre-existing availability of data measuring household durable assets in key standardized household surveys which span decades and cover nearly all LMICs of the world, such as the Demographic and Health Survey (DHS) and Multiple Indicator Cluster Surveys (MICS). Despite the near ubiquity of use of the wealth index in global health research, debates over which calculation method results in the best proxy for income or consumption, and even whether wealth indices should be considered as SES measures that are fundamentally distinct from income or consumption remain open questions (Howe et al. 2009; Sahn and Stifel 2003).
Hundreds of manuscripts have used the wealth index to examine topics ranging from malnutrition (Mohsena et al. 2010; Sahn and Stifel 2003), educational attainment (Booysen et al. 2008; Nwaru et al. 2012), malaria transmission (Chuma and Molyneux 2009; Rohner et al. 2012), and poverty (Harttgen and Vollmer 2013; Zeller et al. 2006). For fifteen years, the overwhelming majority of researchers creating these indices have followed the method developed by Filmer and Pritchett (2001) that summarizes multi-dimensional information on ownership of various household assets using principal components analysis (PCA) (Filmer and Scott 2012). This innovative application of PCA to the measurement of household wealth using DHS surveys allowed researchers to convert a series of ownership variables, many of which were binary (yes/no) or categorical (roof material, e.g.), into a continuous SES gradient (Rutstein 2008).
The PCA approach provides a way to go beyond simple sums of asset ownership by orthogonally layering linear combinations of the variables with maximum variation. More precisely stated, the covariance matrix underlying the structure of the data is used to solve for coefficient vectors for each independent variable such that each layer (or principal component) produces the direction of greatest variance. Other applications of PCA, such as factor reduction techniques, make use of several of these layered combinations ordered by the degree of underlying data variance (i.e. eigenvalues), sometimes visually inspecting a scree plot for changes in slope to decide how many components to keep. In calculating asset wealth, however, only the first principal component (which extracts the largest amount of information from the underlying asset data) is typically used as a measure of the “size” of the underlying structure of SES and ordinal data is often recoded as several binary dummy variables (Kolenikov and Angeles 2009).
Since the publication of Filmer and Pritchett’s (2001) foundational study, many researchers have focused on proving the utility and improving the process of this original method, while others have proposed alternative methods of wealth index construction. The only systematic review yet published on the topic of whether wealth indices function as effective proxies for household consumption found only weak to moderate association between the two measures (Howe et al. 2009). Other studies have compared different methods of calculating wealth indices in isolation (Filmer and Scott 2012; Kolenikov and Angeles 2009), but have not extended findings of strength of association between different SES measures to the theoretical questions of what exactly wealth indices are measuring and under what conditions they are appropriate measures. In sum, there has been no comprehensive synthesis of the evidence and debates surrounding the method which continues to be the standard for constructing a proxy for household SES in lieu of consumption or income data.
This study systematically collected and synthesized information from the diverse bodies of literature examining wealth indices to evaluate two primary research questions. First, under what conditions is the use of wealth indices appropriate when measuring health inequalities using household surveys in LMICs? Second, what alternative methods of calculating wealth indices are available and how do they compare to the most commonly used wealth index calculation method? This study does not aim to rank the various methods used to measure SES or select a method that dominates the others under all circumstances, but does aim to map these tools to normative choices and values. The findings of this study should be of particular interest to global health researchers, who should be aware that there is no gold standard for measuring household SES and that the choices they make regarding how to measure this latent and disputed concept have significant implications for the research they conduct, the policies they inform, and ultimately, the SDGs we aim to achieve.
2 Methods
This critical interpretive synthesis (CIS) integrates the diverse literatures informing the theoretical foundations of the wealth index, the appropriateness of its use in the field, and alternative methods of wealth index calculation. Since many of the constructs underpinning this research have yet to achieve universal definitions and the relevant literature is dispersed throughout field-specific journals of economics, demography, epidemiology, global health, and sociology; a systematic review is neither ideal or appropriate (Gough et al. 2017; Higgins and Green 2011). This is because asset wealth is defined and calculated in a multitude of ways, the “gold standard” it is evaluated against is highly field-dependent, and even when the same methodology and comparator are used, methods used to evaluate performance can be incomparable from study to study. In other words, what is needed is an interpretive synthesis rather than an aggregative synthesis. Because of these challenges, CIS—a method created to assemble findings from a complex body of evidence to inform policy in a theoretically grounded manner (Dixon-Woods et al. 2005, 2006)—was used following established norms within the health policy literature (Ako-Arrey et al. 2016; Boyko et al. 2012; Ellen et al. 2018; Moat et al. 2013).
The compass questions guiding the initial search and article evaluation were whether the standard DHS wealth index should retain its status as the primary method for estimating asset wealth in LMICs and whether the different contexts in which it is used affect its concordance with alternative SES measures. Constant reflexivity in the search and evaluation process resulted in the incorporation of several emerging themes, including delving into the ways in which wealth indices differ from income and consumption measures, a specific focus on how the urban–rural divide affects the choice of SES measure, and the possibilities, challenges, and advances in the effort to extend the use of wealth indices to the study of international health inequalities.
Guided by these compass questions, an initial search strategy broadly targeted articles comparing different methodologies for constructing wealth indices—especially as they related to the DHS wealth index. Specifically, initial searches of EconLit, Database of Abstracts of Reviews of Effects, PubMed, and Google Scholar in September 2015 focused on terms of “wealth index” “asset index” “principal components analysis”, “survey”, and “wealth” restricting searches to years following the publication of Filmer and Pritchett’s foundational article in 2001. Articles focused on the use of PCA in clinical research, imaging research, and any other unrelated applications were excluded from the review. In addition, applied studies that use wealth indices without comparing results with at least one other measure of SES were excluded. After evaluating titles and abstracts for relevance, bibliographies were combed for any studies that were not identified through database searches.
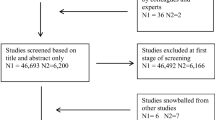
This stage of literature search was followed by a first stage of synthesis, workshopping of initial findings at the McMaster University Centre for Health Economics and Policy Analysis (CHEPA), and consulting with content experts. Following this stage of article evaluation, a second systematic search was conducted in September 2018 following the search strategy outlined in Fig. 1 and the same inclusion and exclusion criteria as the first search. A comprehensive screen of titles and abstracts was possible for each database except for Google Scholar, which was screened until saturation was reached and article titles were no longer relevant. This resulted in a total of 53 articles included for synthesis, of which 11 articles could be used for the quantitative comparison of wealth indices, income, and consumption. Detailed information from each article, including SES measures investigated, countries of study, academic discipline, key themes, and evidenced used for synthesis were extracted into a table presented in Appendix Table 3.

Flow chart of article inclusion process
2.1 Analysis
The data gathered through the systematic search strategy were analyzed through a multistage process. Specifically, measures of SES, discipline, study design, countries of study, key ideas, and specific contributions to CIS were first extracted into Appendix Table 3, and then organized and synthesized according to emergent themes. These emergent themes led to the division of results into four sections—the utility of the wealth index as a proxy for income and consumption, the performance of the wealth index as a measure of social welfare, the appropriateness of use of wealth indices in the field, and alternative methods of constructing wealth indices. Within each of these sections, the extracted information is presented according to established CIS practices in a format that was originally adapted from meta-ethnographic review (Ako-Arrey et al. 2016; Boyko et al. 2012; Dixon-Woods et al. 2005, 2006; Ellen et al. 2018; Moat et al. 2013). Key themes and concepts for each subsection are presented (reciprocal translational analysis), then contradictions between studies are examined (refutational synthesis), and finally, a general interpretation of findings grounded in the literature is proposed (lines-of-argument synthesis). In practice, this means synthesizing key introductory information, presenting qualitative data supporting and opposing the concept under study, and proposing an overall interpretation of the state of published research for each subsection. The content of the study data extracted was also continually evaluated against the credibility of each study, as determined by the strength of supporting data, methods used to generate results, and appropriateness of conclusions with regards to the results.
In order to synthesize data on alternatives to the standard PCA approach of calculating asset indices, the merits of alternative asset indices were evaluated for their statistical validity, ease of calculation, and validity of results; all of which had to be supported by empirical research in a diversity of settings. Statistical validity examined issues such as the statistical assumptions underlying each method and issues that categorical, ordinal, and interval variables could have on the calculation of the index. Ease of calculation evaluated how much training was necessary to begin using the method, how dependent the method was on human judgement, and whether the method was supported by statistical packages. Validity of results do not rely on any one gold standard, but rather synthesize information from alternative SES measures, health outcomes, and contextual social factors. This resulted in an evaluation framework that could be consistently applied to asset index calculation methods, despite some methods having more published evaluations than others.
The results of the CIS are presented according to the themes that emerged from this analysis. The complex relation of wealth indices with income and consumption measures is discussed first, including the most complete compilation of quantitative comparisons of these three SES measures yet assembled. Once wealth indices’ relation to these traditional measures of household SES is established, a synthesis of studies evaluating the performance of the wealth index as a measure of social welfare is presented. This is followed by a discussion of the appropriateness of use of wealth indices with a special focus on urban–rural issues (i.e. are wealth indices applicable across the urban–rural divide?), alterations to the standard approach, extension to the study of multiple countries, and emerging trends and opportunities for future research. The final section then evaluates all major alternatives to the DHS wealth index, with a critical interpretation of the merits and weaknesses of each method.
3 Results
3.1 Income, Consumption, and Wealth Indices
Wealth indices are generally viewed as a measure of long-term wealth or SES, but not of short-term poverty, income, or consumption (Filmer and Pritchett 2001; Howe et al. 2012) because the household assets on which they are based are accumulated gradually over time and are unlikely to change rapidly even in periods of shifting income or consumption patterns. This confers the advantage of an index which is far more stable than income and consumption, but may also obscure real improvements (or declines) in household living standards over the short and medium term (Booysen et al. 2008). The inclusion of spending on household durables in the calculation of consumption measures means that there is overlap what is being measured, but there is a notable difference between the amount a household is willing to pay for an asset, and the implicit utility derived from the ownership of that asset.
Despite these distinctions, wealth indices are frequently compared to consumption data based on the argument that it is the most accessible and closely related comparator with which to measure their performance (Aryeetey et al. 2010; Howe et al. 2012). Even though many authors default to household consumption as a gold standard measure of SES, reporting errors are known to affect even the most carefully planned and executed surveys due to recall error, exclusion of some expenses, choice of deflator, and currency exchange fluctuations (Bollen et al. 2002; Kolenikov and Angeles 2009; Moser and Felton 2007; Sahn and Stifel 2003). In addition to being compared to income and consumption, wealth index data has even been used as a counterpoint to national accounts data. A heated debate over whether an African growth “miracle” occurred in the 1990s was sparked due to comparisons of well-being based on asset indices, which had grown considerably, with well-being based on national accounts, which had not. Further analysis of this mystery revealed that factors such as new cheap imports of household durables from Asia and the tendency of household asset prices to drop over time were driving this discrepancy, but to this day there are many dissenting opinions and uncertainty over whether welfare has truly improved (Johnston and Abreu 2016).
A major difference between the wealth index and other measures of SES is that the former is based on household assets and cannot be expressed in per-capita units. Other measures of SES are not necessarily superior in this regard, since intrafamilial distribution of income is often highly unequal and consumption is usually inexactly divided into household equivalents using one of several methods (Aaberge and Melby 1998). This means that the wealth index is more closely related to household economies of scale models than per-capita consumption models, reinforcing the idea that it is tracking a separate, but equally valid construction of SES (Filmer and Scott 2012). Nevertheless, there is evidence that some conditions improve the concordance of the two measures. There is evidence, for example, that consumption data tracks wealth indices more closely in middle income countries, and especially if a greater variety of assets are included (Howe et al. 2009). Similar findings suggest that asset indices and consumption expenditure are more closely related when a higher percentage of consumption is captured by assets included in DHS surveys and that they are more highly correlated in countries where the average share of non-food expenditures is high (Filmer and Scott 2012). Despite the paucity of knowledge about the degree of concordance between income, consumption, and wealth indices, few studies have quantified this relationship in a systematic manner.
In general, there are two approaches to comparing income and consumption rakings with wealth index rankings—comparison of ordered subgroups such as quintilesFootnote 2 or terciles, or comparison of entire distributions. Studies opting for the first approach may use consumption or income as a “gold standard” and quantify the percentage of households missing from the poorest subdivision as errors of exclusion (Aryeetey et al. 2010). As one example, this was done in Turkey, finding that a wealth index was moderately associated with consumption and income, with 54.1% being in the lowest quintile for both wealth index and consumption, and 47.1% in the lowest quintile for both wealth index and income (Ucar 2015). For the second approach, the most common method of measuring distributional associations in this literature is Spearman rank correlation, which is a nonparametric measure of association varying between −1 and +1 for two variables across a ranked distribution (Spearman 1904). The second distributional approach was chosen as the measure of interest for this CIS because rank correlations take the entire distribution into account rather than losing granularity of data through grouping. Additionally, direct comparison of population groupings would not have been possible because the construction of subgroups varied too much for systematic comparison. Therefore, only the studies explicitly reporting Spearman correlation coefficients were included in the meta-analytic tables (Tables 1, 2).
The results of the pooled Spearman rank correlation coefficients (Table 1) indicate wide variability and overall moderate agreement of wealth indices with consumption or income. Spearman’s rho values ranged from 0.34 to 0.84, with a sample-size weighted average of 0.55 for consumption data and 0.42 for income data. Since wealth index constructions can differ even when the same data source and method are used because of decisions such as asset inclusion, and income and consumption comparators can also vary according to the calculation methods used, a range of correlation coefficient magnitudes is not unexpected. It is notable that besides Ferguson et al.’s (2003) two country comparison, no one has yet examined the relationship between all three SES measures in more than one country. There appears to be a moderate association between wealth indices and both income and consumption, allowing us to move on to understanding more about how the index relates to health and social welfare outcomes, when it is appropriate to use, and the alterations to the index that are possible for researchers.
3.2 The Wealth Index and Social Welfare
Rather than using consumption or income comparators, many researchers appraise the performance of wealth indices by examining their relationship with health or educational outcomes. Decades of research spanning nearly every country of the world have documented inequalities in health and educational outcomes associated with SES. Some have claimed that wealth indices may be more directly associated with these outcomes than household consumption or income because health and education outcomes are more significantly affected by long-run household SES than by monetary highs or lows (Mohanty 2009). This reasoning is often applied to outcomes such as childhood stunting which take many years to develop, but also applies to other social welfare outcomes (Filmer and Pritchett 2001; Sahn and Stifel 2003).
One of the first multi-country comparative studies suggested that the use of wealth indices resulted in smoother declines in stunting by wealth quintiles when compared to household consumption in 10 LMICs (Sahn and Stifel 2003). This evidence is supported by the correlation of wealth index quintiles with low birthweight, education level, and occupation in the Vietnamese context, indicating that the index was capturing both a measure of social class and health outcomes (Vu et al. 2011). Another evaluation used Bayesian information criterion to predict fertility rates with several SES proxies, finding that a wealth index performed better than all other measures, including consumption measures (which predicted almost no variation in fertility) (Bollen et al. 2002). There is weaker evidence from a wealth index of a Chinese community, finding only low to moderate correlation with maternal and child health indicators; although both an occupational index and educational index found equally weak associations (Nwaru et al. 2012).
In general, there is some evidence that asset measures may increase the magnitude of social health inequalities. Pro-rich inequalities in immunizations, maternity care, institutional deliveries, and hospital visits were greater when measured with a wealth index than consumption data in Mozambique (Lindelow 2006). In Tanzania, the use of a wealth index instead of household expenditure resulted in a statistically significant change in concentration index for AIDS mortality in men, but the effect was small and made no difference for women (Opuni et al. 2011). A focused review of SES ranking specifically for tuberculosis surveys concluded that wealth indices more consistently identified inequities in health than income or consumption surveys (Van Leth et al. 2011). Another team investigating insecticide-treated net ownership in Kenya found a mixed picture of larger inequalities in urban areas using a wealth index compared to consumption, but smaller inequalities in rural areas (possibly due to free net distributions in rural areas), concluding that neither the wealth index or consumption index approach is superior for health research in LMICs (Chuma and Molyneux 2009).
The evidence supporting larger social health inequality magnitudes when using asset measures did not translate to the outcome of seeking medical care, with wealth indices and consumption levels generating almost identical results in a large cross-sectional country comparison (Filmer and Scott 2012). There was greater health-seeking behavior found among the relatively poor in these countries, although this is hypothesized to be a product of the poorest quintile’s disproportionate share of illness. This theory is supported by the finding that the highest levels of child mortality are not uniformly found in the poorest quintiles of the consumption model, but are always found in the poorest quintiles of wealth index models—a statistically significant difference-in-difference (Filmer and Scott 2012). In general, the tendency of publicly-provided services tending to be of more importance in the lower end of the SES gradient and private goods tending to be more important for the upper end (Booysen et al. 2008) may have some impact on inequalities in health and healthcare seeking behaviour.
The outcome of educational attainment has similarly mixed results. One study using wealth index and consumption data to rank households in a multi-country data exercise found a statistically significant educational inequality in 7 of 11 countries included, with the DHS wealth index most often resulting in larger inequalities (Filmer and Scott 2012). In Ghana, however, the wealth index was modestly correlated to parental education levels (maternal r = 0.32, paternal r = 0.36), explaining only 14% of parental education and occupation variance (Doku et al. 2010). Using education as a ranking variable rather than an outcome yields similarly mixed results. A multi-country study found that wealth indices are not statistically different than maternal education as a ranking variable for quantifying inequalities in vaccination coverage, although wealth index inequalities were slightly smaller,Footnote 3 and some countries had much larger inequalities using one or the otherFootnote 4 (Arsenault et al. 2017).
Considering these results as a whole, we can conclude that the widespread practice of comparing wealth indices to income or consumption in studies of social inequalities of health and educational outcomes produces some contradictory outcomes, but generally points in the same direction as income and consumption research. That is, poor health and educational attainment is found among lower SES populations regardless of how SES is measured. However, there is an undeniably tautological reasoning underlying many comparisons. Even if wealth indices are an equally valid, but separate measure of household SES than income and consumption; then verifying both the validity of wealth indices through the presence of health and educational inequalities and confirming the presence of health and educational inequalities using wealth indices risks being dismissed as circular and baseless evidence. Larger inequalities in health outcomes such as child mortality clearly lend face validity to a measure of SES, but the many causal pathways that may lead one context to have larger inequalities using wealth indices, consumption, or income should be explored in all their complexity rather than relying on the unidimensional logic of a “true” effect size being the largest.
3.3 Challenges and Opportunities
3.3.1 Urban–Rural Considerations
Since the DHS wealth index was first developed, there have been concerns over comparability of results between urban and rural areas (Filmer and Pritchett 2001). Many have expressed concerns that since urban households are more likely to own many assets and are more likely to benefit from publicly provided assets such as piped water, they will be inappropriately classified as wealthier than comparable rural households (Booysen et al. 2008). Others counter that this is not misclassification, but an accurate representation of the relative affluence of urban households (Vyas and Kumaranayake 2006). Adding to this complexity, there are indications that unmet healthcare need can be underestimated in rural areas and overestimated in urban areas (Mohanty 2009). Beyond misclassification errors, the issue is complicated by the fact that assets like chickens or bicycles are an indicator of relative wealth in rural areas, while also being an indicator of relative poverty in urban areas (Chuma and Molyneux 2009).
Regardless of whether it is an accurate representation of household SES or not, urban–rural disparities appear to be larger when SES is measured using a wealth index than income or consumption measures. The difference in urbanization between the poorest and richest quintiles can be as large as 75% in a wealth index compared to 22% in an expenditure model in Albania, with several other countries also having large discrepancies in SES ranking due to urban status (Filmer and Scott 2012). Perhaps the most dramatic example of these vast differences was demonstrated in Kenya, where a wealth index placed no rural households in the richest quintile and only one rural household in the second richest (Chuma and Molyneux 2009).
The mechanism for this urban divide can largely be attributed to a combination of rural households having fewer assets, more commonly owned assets, and agricultural assets often being assigned negative factor loadings. As one illustrative example, there is a village in Guinea-Bissau where (unlike the rest of the country) portable gas stoves are highly desired, and therefore behave as a normal good,Footnote 5 but because that village is relatively poor compared to other villages, the wealth index scoring of gas stoves is negative (Johnston and Abreu 2016). Similarly, owning a common asset will usually imply a negative scoring, which could perversely rank a household as poorer than one lacking the asset at all (Wittenberg and Leibbrandt 2017). Even obtaining reliable information on rural assets is complicated by survey respondents often having difficulty answering questions about the number of hectares of agricultural land owned or even whether they live in an urban or rural area (Chakraborty et al. 2016).Footnote 6 In response to these concerns, a variety of strategies to identify and address urban–rural issues with wealth indices have been proposed.
One common strategy to identify relative affluence in both urban and rural areas is simply to split the sample into two groups and calculate a rural wealth index and an urban wealth index. In fact, the standard DHS approach to dealing with urban–rural issues is to regress both an urban-only sample and a rural-only sample against the complete sample to obtain a modified index influenced by all three factor loadings (Rutstein 2008). This strategy can lead to agricultural assets having positive weights for rural households and negative weights for urban households (Ward 2014), but the magnitude of effect appears to depend heavily on the setting. One study comparing a rural-only sample wealth index to one calculated for the full sample in Zimbabwe found a Spearman rank correlation coefficient of 0.862 (95% CI 0.854–0.869) between the two indices, indicating a fairly high association (Chasekwa et al. 2018). A Ghanaian study using consumption as a comparator found a weaker concordance: the wealth index “misclassified” 63% of consumption-poor households in urban settings compared to 46% in semi-urban settings, and 53% in rural settings (Aryeetey et al. 2010). Another Chinese study using income as a comparator found the same relatively weak association to household income (Spearman’s rho 0.27) in both a rural and peri-urban village, and a similar proportion of variation captured by the wealth index (27.8% vs. 24.3%) for both villages (Balen et al. 2010).
The different strategies used to address urban–rural biases also appear to have a moderate effect. One small Zambian study found that dropping all assets which are more likely to be found in an urban household did not significantly affect the overall variance explained by the wealth index (Boccia et al. 2013). Another large multiyear pooled analysis in China that found negative factor weights for all agricultural assets suggested that secondary principal components weights (which were positive) could be used in these cases, although dropping all agricultural assets appeared to make little difference, with 90% of households being classified in the same quintile (Ward 2014). A study designed to evaluate this approach in India found 39% of households to be classified in the same quintile, 50% to have moved to an adjacent quintile, and 10% to have moved to the farthest quintile (Mohanty 2009). Alternatively Ngo and Christiaensen (2018) have proposed adding a small number of binary consumption variables such as food and clothing purchases, finding that it increased identification of consumption-poor households in rural settings by 9%, but made no difference in urban settings. In sum, urban–rural differences should always be monitored and can be addressed through a number of approaches, but do not present an insurmountable obstacle to the use of wealth indices.
3.3.2 Robustness to Changes in the Asset Mix
Another common criticism of wealth indices relates to their reliance on assets which have direct impact on health, such as water and sanitation quality or food availability in research on the associations of SES and health (Homenauth et al. 2017). There is some evidence for this effect, with one study finding that dropping household construction variables from a wealth index in Uganda resulted in a significant association with mosquito human biting rate becoming insignificant, even though the two indices are highly correlatedFootnote 7 (Tusting et al. 2016). Another set of researchers in Zambia built an alternative index without food-related variables (which may have affected tuberculosis outcomes of interest directly) and found no significant difference with the wealth index using all variables (Boccia et al. 2013). A low-to-moderate effect is supported by a 10-country World Bank comparison of three alternative indices that exclude direct determinants of health and factors provided at the community-level, in which only 18% of households were categorized in a different wealth quintile with most of these shifting to an adjacent quintile (Houweling et al. 2003); as well as the use of a simplified asset list dropping various country-specific, urban–rural specific, and agricultural questions with 16 surveys finding inter-quintile agreement ranging from 75 to 83% (Chakraborty et al. 2016).
Despite relatively strong concordance of indices based on difference assets, some measures of social health inequality may be sensitive to these changes. One study found up to a 60% change in the relative index of inequality for five health outcomes with alternative wealth indices, although the direction of change appeared to be random and was not significant in some countries (Houweling et al. 2003). Dropping assets can also be motivated by time and resource savings for survey collection teams. In one example comparing two simplified asset indices to the full index, there was almost perfect agreement (kappa value greater than 0.61) after reducing the number of variables from 111 to 24 variables in Honduras and from 111 to 21 variables in Senegal using an iterative ranking of factor loadings (Ergo et al. 2016). The limited effect of dropping variables is mirrored by an expanded set of assets collected to measure progress in the Millennium Villages Project failing to predict income poverty more effectively than the standard DHS asset mix (Michelson 2013). Nevertheless, the variables that matter most vary according to the country context and reducing the number of accepted answers might not reduce the amount of time needed to survey a household because each variable may still require a separate question. In sum, changing the asset mix included in surveys may have a smaller effect than many anticipate, meaning that avoiding appearance of endogeneity with health-related variables or simplifying a survey instrument can be done with appropriate care.
3.3.3 Future Applications
Research on the use of wealth indices is not limited to refining existing applications. One emerging area of research concerns extending the wealth index to the study of economic inequality research. Care must be taken before applying inequality measures to asset indices, however, because Gini coefficients can only be applied to the absence or presence of real assets, due to the inherent lack of scale for categorical variables (Wittenberg and Leibbrandt 2017). One of the earliest investigations into whether wealth index inequalityFootnote 8 was correlated to expenditure-based inequality in 31 Mexican states found a Spearman’s rho of 0.566 (about the same strength of association as food expenditure), and slightly stronger association than either a housing-based wealth index or a utility-based wealth index (McKenzie 2005). This method was recreated in China and evaluated ecologically against known consumption inequality, appearing to track the same pattern of rising inequality through the 1990s until a peak was reached around 2000, suggesting broadly shared growth and an eventual decline in urban and rural wealth inequality (Ward 2014). A more recent application in South Africa found wealth index inequality fell from a Gini coefficient of 0.47 to 0.29 from 1993 to 2008, but cautions that the use of a negatively loaded first eigenvalue in the calculation of wealth index inequality could lead to this method performing poorly (Wittenberg and Leibbrandt 2017). Although there is clearly more research to be done on the limitations of wealth index inequality, this is an area of research which could grow rapidly given the increasing public interest on this topic.
Another commonly cited limitation of the wealth index is the perceived inability to make comparisons in wealth across countries. Since the wealth index in any given country is a relative measure, comparisons across countries may neglect important differences in cultural and social values associated with household assets. Much of the reasoning behind this skepticism lies on claims that the assets contained in standardized household surveys cannot be relied upon in countries that traditionally value assets differently than others. Despite this assertion, a “traditional wealth index” constructed to represent Kenyan cultural constructions of wealth was nearly identical to standard PCA of household assets (Opuni et al. 2011). Further support comes from a finding that a wealth index is more strongly correlated with locally identified factors indicating poverty (female-headedness of household, dependency ratios, and household food insecurity) than household income (Michelson 2013). Another effort to construct a wealth index applicable to 21 Latin American and Caribbean countries using telephone survey data found generally encouraging results. Pooling wealth indices resulted in broadly applicable SES rankings from poorer countries like Peru to richer countries like Costa Rica, and the resulting relative wealth quintiles were strongly correlated with years of schooling and self-reported income (Córdova 2008).
The largest effort to construct an asset index of worldwide comparability with wealth indices, however, comes from a team that overcame the difficulty of incomparability of many survey items by grouping accessories into cheap and expensive utensil categories (Smits and Steendijk 2013).Footnote 9 This approach results in a wealth index applicable to 165 household surveys across 97 LMIC and is robust to removal of any region from analysis (Pearson correlation coefficient ≥ 0.996), removal of any time period (Pearson correlation coefficient ≥ 0.997), and removal of any one asset (Pearson correlation coefficient ≥ 0.986).Footnote 10 Furthermore, there is good agreement between the international wealth index and country-specific wealth indices, country-specific poverty levels, life expectancy, and most strong agreement with the Human Development Index. Finally, the authors assert that reasonable estimates of purchasing power parity (PPP) poverty levels can be placed at 30th percentile of the index equivalent to PPP$1.25 a day and 50th percentile at PPP$2.00 a day (Smits and Steendijk 2013). This international poverty line can be coupled with the finding that transitions out of poverty occur at the same rate using asset indices and household income, with approximately 12–20% of the lowest quartile households transitioning to the highest quartile households after two years (Michelson 2013). These studies are breaking new ground, but it appears that international poverty studies using wealth indices are becoming increasingly possible.
Lastly, there are several research teams attempting to proxy wealth indices using new technologies. One team has developed a machine learning algorithm that can be used to roughly approximate wealth indices using phone usage characteristics in Rwanda and Afghanistan, although the models must be developed separately for each country and cannot be applied naively across borders (Blumenstock 2018). Another team has created a convolutional neural network trained on ground imagery that is able to predict 37–55% of variation in consumption and 55–75% of variation in asset wealth if trained separately for each country, although this drops to 19–52% and 24–71% if applied to other countries (Jean et al. 2016). This ground imagery method is slightly more predictive than phone-use estimation models, and the difference in estimation is likely due to the area’s wealth itself rather than directly identifying household features such as roofing materials directly. The fact that ground imagery is more highly correlated with a wealth index than with consumption also provides further evidence that a separate, but equally valid construct of SES is being captured by the method. In sum, ground-breaking research is being conducted into new ways to apply wealth indices to measuring SES inequality, to constructing high-quality cross-country pooled sample analysis, and to using new technologies to measure household SES.
3.4 Alternative Approaches
The standard wealth index constructed using PCA is not the only method used to measure SES using information of assets collected by household survey data. What follows is a short summary of the intersection of alternative approaches and a DHS-style wealth index, evaluating statistical validity, ease of calculation, and consistency of results supported by empirical research in a diversity of settings.
3.4.1 Count Measures
The most basic asset indices used for household survey data are simple asset counts. One Albanian team found that a wealth index was more highly correlated with consumption than a count measure consisting of water and sanitation provision, adequate housing provision, less crowded dwellings, and minimum education of household head (Azzarri et al. 2005). Similarly, an early comparison of the DHS wealth index, consumption measures, and count measures as predictors of fertility rate found the simple count measures to have the second-best fit (after the wealth index) using Bayesian Information Criterion (Bollen et al. 2002). These outcomes are contradicted by a team in Bangladesh, asserting that using a basic count measure outperforms the DHS wealth index in discriminating households more at risk for stunting, wasting, and underweight (Mohsena et al. 2010). Their use of a simple count of radio, television, bicycle, motorcycle, telephone, and electricity to construct wealth quintiles resulted in 49.1% of households in the lowest SES quintile and only 4.2% of the highest SES quintile having all three outcomes of interest, while the wealth index produced equivalent percentages of 28.6% and 11.4%, respectively. However, this study was strongly disputed by another team using the same indices in Cote d’Ivoire with rigorous biometric measures of nutritional status while accounting for the effect of malarial infection, age, and residency; where the wealth index resulted in larger socioeconomic inequalities in anemia, stunting, and wasting in children and women of reproductive age than the count score (Rohner et al. 2012). In sum, count measures may present an easily constructed and persuasive SES measure, but results are highly dependent on the judgement of the analyst of which household assets to include and may not be transferable to other contexts.
3.4.2 Multiple Correspondence Analysis
Many researchers have pointed out a fundamental flaw in the application of PCA to the types of variables needed to construct a wealth index; namely, that the technique is not meant to be applied to binary and categorical variables (Howe et al. 2012; Kolenikov and Angeles 2009). Since an average of 60% of household survey questions used to construct asset indices are binary, this is no minor limitation (Kolenikov and Angeles 2009). This limitation is commonly skirted by applying a qualitative judgement of superiority by an analyst recoding variables, possibly introducing bias and most likely affecting the fidelity of the final data. A long-standing alternative to PCA which does not have these inherent weaknesses is Multiple Correspondence Analysis (MCA), which has a similar approach of using a correlation matrix to determine “principal inertias” of the assets included for analysis and can be calculated using modules for most statistical packages (Booysen et al. 2008).
A large seven-country analysis of DHS data opted to use MCA rather than PCA because of these limitations, but found that despite some differences in variable weight orders, there was no significant difference between both indices (r = 0.953, p < 0.01) and the few households that were classified into different quintiles were restricted to one level higher or lower (Booysen et al. 2008). Another application of MCA in Kenya found it to be highly correlated to the DHS wealth index (r = 0.997, p < 0.01) with 93% of households placed in the same quintiles, although it explained the highest total variation of variables (47.3%) (Amek et al. 2015). Yet another comparison of MCA and the DHS wealth index found that they were not significantly different in year over year change and were both more strongly autocorrelated to themselves than to household income in several sub-Saharan countries (Michelson 2013). In this case we conclude that although MCA has yet to significantly differentiate itself empirically from the DHS wealth index when applied in the field, its theoretical superiority in handling a diverse set of variables makes MCA a valid alternative measure of household SES.
3.4.3 Item Response Theory/Latent Trait Modeling
Seizing on the controversial application of PCA to non-continuous data, other researchers have advocated the adoption of Item Response Theory (IRT), which is also referred to as Latent Trait Modeling (LTM). At a basic level, observed assets (whether they are dichotomous, polytomous, nominal, or ordinal) which demonstrate the most discrimination according to a latent trait (SES) are given larger weights, and are then assessed for reliability with a non-parametric bootstrap (Vandemoortele 2014). Despite claims of differentiation, an independent 11 country comparison found rank correlations for the DHS wealth index and IRT between 0.95 and 1.00—the most highly correlated alternative measure in the study (Filmer and Scott 2012). Another empirical evaluation of this technique by a strong advocate of IRT on Malawian DHS data also found high correlation with a PCA index (Spearman rank correlation = 0.88) (Vandemoortele 2014). Furthermore, the two key assumptions of normal distribution of data and independence of variables offer no improvement to the existing PCA approach, and its calculation is acknowledged to be more time consuming (Vandemoortele 2014). Given these disadvantages and the lack of significant difference in the field, the DHS wealth index remains the more viable option until evidence of superiority can be presented.
3.4.4 Mokken Scale Analysis
Mokken Scale Analysis (MSA) is a nonparametric technique which relies on Guttman scales of items which are statistically determined to be increasingly “harder” to answer. Using a combination of positive ownership of assets with the difficulty of eliciting a positive response, MSA is able to rank households along a latent SES gradient (Reidpath and Ahmadi 2014). Key assumptions include unidimensionality of SES, local independence of variables, monotonicity of responses, and invariant item ordering. An empirical application of the technique found very high Pearson product moment correlation with a polychoric PCA index (r = 0.96) and a lower correlation to household expenditure (r = 0.59) (Reidpath and Ahmadi 2014), a result which the authors concluded was similar to the pattern observed for the DHS wealth index. The real or perceived downside of complexity of the technique with only marginal statistical effect may limit the widespread adoption of MSA, so the DHS wealth index also remains the more viable option of the two options at this time.
3.4.5 Polychoric PCA
As a response to the primary statistical vulnerability levelled against the DHS wealth index—its inappropriate application to non-continuous variables—an improved polychoric PCA was proposed by Kolenikov and Angeles (2009). Criticizing Filmer and Pritchett’s technique for creating spurious correlation through the introduction of dummy variables and for losing directionality of ordinal data, Kolenikov and Angeles propose the use of a slightly amended multivariate technique, originally derived by the same statistician as ordinary PCA. Not only is there greater statistical fidelity, but the status of not owning an asset is also taken into account. This additional information can be important in cases like indoor plumbing, which may only be missing from a small percentage of the poorest households of a population (Moser and Felton 2007). The key findings of the proof-of-concept study were that polychoric PCA demonstrated lower misclassification rates compared to consumption, explained a higher proportion of variance in asset ownership, was more robust to the number of categories used, and was more robust to changes in variable coding scheme than the Filmer and Pritchett PCA procedure (Kolenikov and Angeles 2009).
Interestingly, the standard PCA and polychoric PCA methods demonstrate divergent classifications at the lower end of the SES spectrum with increasing agreement of classification on the upper end of the SES spectrum (Kolenikov and Angeles 2009). An independent comparison of the DHS wealth index with polychoric PCA using Bangladeshi DHS data also concluded that the DHS index lacks the ability to discriminate at the lower end of the spectrum due to its under-emphasis of common assets (Benini 2007). Despite this lower-end discrepancy, agreement remains very high. A Kenyan study found polychoric PCA to be closely correlated with standard PCA (r = 0.991, p < 0.01) and to even more closely mirror MCA (r = 0.991, p < 0.01), while placing 87% of households in the same quintiles as standard PCA and 91% in the same quintiles as MCA (Amek et al. 2015). Another comparison conducted using Zimbabwean data found a Spearman rank coefficient of 0.910 (95% CI 0.904–0.915) and 94% agreement between wealth quintiles between the DHS wealth index and polychoric PCA (Chasekwa et al. 2018). Similarly, Filmer and Scott’s 11 country comparison found both indices to be generally comparable (2012). There may be evidence of lack of robustness to variable loss, however, with an attempt to reduce a 17 item asset index to 11 items using polychoric PCA in Vietnam resulting in much lower concordance with both expenditure (r = 0.57 vs. r = 0.41) and an MSA-derived asset index (r = 0.98 vs. r = 0.68) (Reidpath and Ahmadi 2014).
As the only other method systematically compared to income and consumption by several studies, all available Spearman correlation coefficients between polychoric PCA wealth indices and either household consumption or income encountered in the literature search are presented in Table 2. The results are not as robust as those presented in Table 1 due to both income and consumption comparisons being based on one study,Footnote 11 but polychoric PCA appears to have an almost identical association as the DHS wealth index for both consumption (0.57) and income (0.40). Given that polychoric PCA overcomes the challenges relating to variable types, overcomes issues of “clumping” through greater discriminatory power at the lower end of the SES spectrum, and is integrated into several statistical packages, there is a strong case to be made for the superiority of this approach.
3.4.6 Predicted Income
A newly emerging technique overcomes the limits imposed by the ordinal nature of wealth indices by linking a country and year-specific predicted income to households according to their relative standing, as determined by a wealth index. An early application of a similar method using regressed prediction of consumption based on household assets found that it resulted in inequality levels in between those predicted by a wealth index approach and actual consumption, and that rankings of Mexican states by inequality were more similar to consumption than using a wealth index (McKenzie 2005). Since this early application, Harttgen and Vollmer (2013) have proposed a streamlined method, in which any wealth index is used to rank households into centiles or quintiles, and the resulting ordering is linked to an open access dataset estimating household income for 88 LMICs from 1993 to 2014.
The strength of this method is supported by studies finding more variation in stunting prevalence using the predicted income approach (38%) compared to wealth quintiles (20%) (Fink 2016), and predicted income better predicting skilled birth delivery in a large 100-country study, with log-normalized predicted income explaining 51.6% of variation, wealth quintiles predicting 22.0%, and the raw wealth index predicting 12.8% (Joseph et al. 2018). It is also possible to compare health outcomes taking predicted income inequality into account using tools such as equiplots with this approach, revealing countries which have similar outcomes at any given income level, and others that are performing poorly at a given income level (Fink 2016). Furthermore, comparisons of all countries over time reveals important trends such as countries that have succeeded in increasing skilled birth attendance in spite of stalled income growth, and those that have not improved outcomes even in times of sustained economic growth (Joseph et al. 2018). More study of this emerging method is clearly needed including whether the predicted income is more closely associated to actual household income or the wealth index on which it is based, but the new avenues of research made possible by the approach warrants its inclusion in future studies.
4 Conclusion
The construction of a wealth index using household survey data must be conducted with an awareness that the methodology chosen to quantify SES using assets contained in the survey data has a significant effect on the results. More straightforward alternatives to constructing asset indices like count measures offer simplicity but may overly depend on context and analyst expertise. While more complex methods of MCA, IRT, MSA, polychoric PCA, and predicted income offer varying degrees of improvement of statistical validity, they may do so at the expense of simplicity with only marginal improvement in outcomes compared to the standard DHS wealth index. Taking all published alternatives and evidence into account, analysts striving for an alternative to constructing a wealth index from household survey data can consider polychoric PCA as a method which meets the standards of statistical validity, ease of calculation, and validity of results, with MCA as another valid alternative. If wealth rankings in a meaningful scale are needed, the predicted income approach based on either the DHS wealth index or any comparable alternative offers great promise but must also be investigated in a greater diversity of settings and applications.
Evidence gathered in this review lends support to the idea that wealth indices represents a related, but distinct measure of latent SES from consumption or income measures. There is robust evidence linking the wealth index to health and educational outcomes at least as strongly as household consumption and income throughout the world. However, interpreting wealth indices as having a causal effect on health and educational outcomes cannot be taken as a given; especially with the knowledge that wealth indices, income, and consumption measures take aim at entirely separate models of SES. Long-known vulnerabilities to urban–rural distortions or changes in the asset mix included in surveys should always be considered, but with proper care, these vulnerabilities can be seen as ultimately informative rather than confounding. Future applications to inequality research, large-scale international studies, and the use of new technologies are promising prospects for which the groundwork has yet to be fully laid.
The main limitations of these conclusions stem from the paucity of research designed to answer these methodological issues specifically, rather than as a secondary research question dispersed throughout many fields. We are further limited by highly variable and sometimes inconsistent definitions of key concepts, which in many cases such as asset wealth, even lack a commonly agreed-upon name. These limitations can only be overcome with greater research intensity and debate. Because of these limitations, a critical interpretive synthesis was the most appropriate choice to present the debates surrounding this methodology in all its complexity. This presentation of key concepts, exploration of contradictions in the literature, and proposal of lines-of-argument synthesis aims to promote a shared understanding of an emerging field of study across the multitude of disciplines that are involved in its development. Further strengths of the study include our inclusion and synthesis of more studies than any prior work on wealth indices, and the first systematic search and compilation of Spearman correlation coefficients between wealth indices and both consumption and income.
The implications of these findings to measuring progress in achieving the SDGs cannot be understated. Developing countries and neglected populations which lack consumption and income data will necessarily be studied using wealth indices as a proxy for SES. If we are to adequately measure progress in achieving equity-focused SDGs around the world for these populations, we must acknowledge the challenges in developing reproducible, rigorous, and easily implemented methodologies for constructing asset indices using household surveys. However, we can also look to the many strengths of the method, not the least of which is the increasingly real possibility of worldwide comparability of SES among all populations of the world. Further study of this possibility must account for the many potential pitfalls in conducting research across national boundaries. Finally, it is remarkable that with the hundreds of studies using the wealth indices to measure health and social welfare outcomes, no study has yet systematically examined whether inequalities in health or social outcomes are larger in magnitude than would be measured using income or consumption in more than one country. Wealth indices have become the dominant method to measure SES in LMICs in the field of global health. Researchers using the method to develop surveys, analyze data, or interpret data for policymakers must understand its strengths, its limitations, the normative choices associated with the tool, and the potential to improve and extend the method to new areas of research.
Notes
Also referred to as household expenditure or consumption expenditure.
All sampled households divided into fifths in order of the raw wealth index score. Wealth index quintiles are included in all DHS survey datasets and are commonly used as the primary measure of household SES.
Haiti had larger inequalities using education [SII = 0.34 95% CI = 0.20, 0.48] than the wealth index [SII = 0.10 95% CI = 0.04, 0.24].
Mozambique had larger inequalities using wealth index [SII = 0.30 95% CI = 0.22, 0.37] than maternal education [SII = 0.16, 95% CI = 0.09, 0.24].
i.e. a good for which demand increases as when SES increases.
This can be resolved by having survey teams classify urban and rural areas rather than eliciting the information from survey respondents.
Spearman's rho = 0.93.
Wealth index inequality is calculated as the proportion of variation of wealth explained by the first eigenvalue.
Incidentally, this approach has also been used to compare assets over time for variables like landlines and cell phones, which can be combined into one "phone" asset in response to criticisms that the social significance of certain assets such as landlines, radios, and bicycles changes significantly over time (Wittenberg and Leibbrandt 2017; Harttgen and Vollmer 2013).
Although these results were obtained with ordinary PCA, sensitivity checks with MCA, factor analysis, and categorical PCA did not change the results.
Even so, the income comparisons include seven separate survey comparisons.
References
Aaberge, R., & Melby, I. (1998). The sensitivity of income inequality to choice of equivalence scales. Review of Income and Wealth,44, 565–569. https://doi.org/10.1111/j.1475-4991.1998.tb00299.x.
Ako-Arrey, D. E., Brouwers, M. C., Lavis, J. N., Giacomini, M. K., Haines, A., Dolea, C. M., et al. (2016). Health systems guidance appraisal—A critical interpretive synthesis. Implementation Science,11, 9. https://doi.org/10.1186/s13012-016-0373-y.
Amek, N., Vounatsou, P., Obonyo, B., Hamel, M., Odhiambo, F., Slutsker, L., et al. (2015). Using health and demographic surveillance system (HDSS) data to analyze geographical distribution of socio-economic status; an experience from KEMRI/CDC HDSS. Acta Tropica,144, 24–30. https://doi.org/10.1016/j.actatropica.2015.01.006.
Arsenault, C., Harper, S., Nandi, A., Mendoza Rodríguez, J. M., Hansen, P. M., & Johri, M. (2017). Monitoring equity in vaccination coverage: A systematic analysis of demographic and health surveys from 45 Gavi-supported countries. Vaccine,35, 951–959. https://doi.org/10.1016/j.vaccine.2016.12.041.
Aryeetey, G. C., Jehu-Appiah, C., Spaan, E., D’Exelle, B., Agyepong, I., & Baltussen, R. (2010). Identification of poor households for premium exemptions in Ghana’s National Health Insurance Scheme: Empirical analysis of three strategies. Tropical Medicine & International Health,15, 1544–1552. https://doi.org/10.1111/j.1365-3156.2010.02663.x.
Azzarri, C., Carletto, G., Davis, B., & Zezza, A. (2005). Monitoring poverty without consumption data: An application using the Albania Panel Survey. ESA working paper. https://doi.org/10.2753/EEE0012-8755440103.
Balen, J., McManus, D. P., Li, Y. S., Zhao, Z. Y., Yuan, L. P., Utzinger, J., et al. (2010). Comparison of two approaches for measuring household wealth via an asset-based index in rural and peri-urban settings of Hunan province, China. Emerging Themes in Epidemiology,7, 7. https://doi.org/10.1186/1742-7622-7-7.
Benini, A. (2007). The wealth of the poor: Simplifying living standards measurements with Rasch scales? [Unpublished Manuscript], Washington, DC.
Blumenstock, B. J. E. (2018). Estimating economic characteristics with phone data † 72–76. https://doi.org/10.1257/pandp.20181033.
Boccia, D., Hargreaves, J., Howe, L. D., De Stavola, B. L., Fielding, K., Ayles, H., et al. (2013). The measurement of household socio-economic position in tuberculosis prevalence surveys: A sensitivity analysis. The International Journal of Tuberculosis and Lung Disease,17, 39–45. https://doi.org/10.5588/ijtld.11.0387.
Bollen, K. A., Glanville, J. L., & Stecklov, G. (2002). Economic status proxies in studies of fertility in developing countries: Does the measure matter? Population Studies (NY),56, 81–96. https://doi.org/10.1080/00324720213796.
Booysen, F., van der Berg, S., Burger, R., Maltitz, M. Von, & Rand, G Du. (2008). Using an asset index to assess trends in poverty in seven Sub-Saharan African countries. World Development,36, 1113–1130. https://doi.org/10.1016/j.worlddev.2007.10.008.
Boyko, J. A., Lavis, J. N., Abelson, J., Dobbins, M., & Carter, N. (2012). Deliberative dialogues as a mechanism for knowledge translation and exchange in health systems decision-making. Social Science and Medicine,75, 1938–1945. https://doi.org/10.1016/j.socscimed.2012.06.016.
Chakraborty, N. M., Fry, K., Behl, R., & Longfield, K. (2016). Simplified asset indices to measure wealth and equity in health programs: A reliability and validity analysis using survey data from 16 countries. Global Health: Science and Practice,4, 141–154. https://doi.org/10.9745/GHSP-D-15-00384.
Chasekwa, B., Maluccio, J. A., Ntozini, R., Moulton, L. H., Wu, F., Smith, L. E., et al. (2018). Measuring wealth in rural communities: Lessons from the sanitation, hygiene, infant nutrition efficacy (SHINE) trial. PLoS ONE,13, 1–19. https://doi.org/10.1371/journal.pone.0199393.
Chuma, J., & Molyneux, C. (2009). Estimating inequalities in ownership of insecticide treated nets: Does the choice of socio-economic status measure matter? Health Policy Plan.,24, 83–93. https://doi.org/10.1093/heapol/czn050.
Córdova, A. (2008). Methodological note: Measuring relative wealth using household asset indicators. AmericasBarometer Insights. https://www.vanderbilt.edu/lapop/insights/I0806en_v2.pdf.
Dixon-Woods, M., Agarwhal, S., Jones, D., Young, B., & Sutton, A. (2005). Synthesising qualitative and quantitative evidence: A review of possible methods. Journal of Health Services Research & Policy,10, 45–53. https://doi.org/10.1258/1355819052801804.
Dixon-Woods, M., Cavers, D., Agarwal, S., Annandale, E., Arthur, A., Harvey, J., et al. (2006). Conducting a critical interpretive synthesis of the literature on access to healthcare by vulnerable groups. BMC Medical Research Methodology,6, 35. https://doi.org/10.1186/1471-2288-6-35.
Doku, D., Koivusilta, L., & Rimpelä, A. (2010). Indicators for measuring material affluence of adolescents in health inequality research in developing countries. Child Indicators Research,3, 243–260. https://doi.org/10.1007/s12187-009-9045-7.
Ellen, M. E., Wilson, M. G., Vélez, M., Shach, R., Lavis, J. N., Grimshaw, J. M., et al. (2018). Addressing overuse of health services in health systems: A critical interpretive synthesis. Health Research Policy and Systems,16, 1–14. https://doi.org/10.1186/s12961-018-0325-x.
Ergo, A., Ritter, J., Gwatkin, D. R., & Binkin, N. (2016). measurement of health program equity made easier: Validation of a simplified asset index using program data from Honduras and Senegal. Global Health: Science and Practice,4, 155–164.
Ferguson, B. D., Tandon, A., Gakidou, E., & Murray, C. J. L. (2003). Estimating permanent income using indicator variables, evidence and information for policy cluster. Geneva: World Health Organization.
Filmer, D., & Pritchett, L. H. (2001). Estimating wealth effects without expenditure data—or tears: An application to educational enrollment in states of India. Demography,38, 115–132. https://doi.org/10.1353/dem.2001.0003.
Filmer, D., & Scott, K. (2012). Assessing asset indices. Demography,49, 359–392. https://doi.org/10.1007/s13524-011-0077-5.
Fink, G. (2016). Estimated household income for DHS and MICS surveys [WWW Document]. Percentile level predictions for all countries. https://www.hsph.harvard.edu/gunther-fink/data/. Accessed August 18, 2018.
Fink, G., Victora, C. G., Harttgen, K., Vollmer, S., Vidaletti, L. P., & Barros, A. J. D. (2017). Measuring socioeconomic inequalities with predicted absolute incomes rather than wealth quintiles: A comparative assessment using child stunting data from national surveys. American Journal of Public Health, 107(4), 550–555. https://doi.org/10.2105/AJPH.2017.303657.
Gough, D., David, A., Oliver, S., & Thomas, J. (2017). An introduction to systematic reviews (2nd ed.). London: Sage.
Harttgen, K., & Vollmer, S. (2013). Using an asset index to simulate household income. Economic Letters,121, 257–262. https://doi.org/10.1016/j.econlet.2013.08.014.
Higgins, J. P., & Green, S. (2011). Cochrane handbook for systematic reviews of interventions (5.1.0.). Chichester: The Cochrane Collaboration. https://doi.org/10.1002/9780470712184.
Homenauth, E., Kajeguka, D., & Kulkarni, M. A. (2017). Principal component analysis of socioeconomic factors and their association with malaria and arbovirus risk in Tanzania: A sensitivity analysis. Journal of Epidemiology and Community Health,71, 1046–1051. https://doi.org/10.1136/jech-2017-209119.
Houweling, T. A. J., Kunst, A. E., & Mackenbach, J. P. (2003). Measuring health inequality among children in developing countries: Does the choice of the indicator of economic status matter? International Journal for Equity in Health,2, 8.
Howe, L. D., Galobardes, B., Matijasevich, A., Gordon, D., Johnston, D., Onwujeke, O., et al. (2012). Measuring socio-economic position for epidemiological studies in low- and Middle-income countries: A methods of measurement in epidemiology paper. International Journal of Epidemiology,41, 871–886. https://doi.org/10.1093/ije/dys037.
Howe, L. D., Hargreaves, J. R., Gabrysch, S., & Huttly, S. R. (2009). Is the wealth index a proxy for consumption expenditure? A systematic review. Journal of Epidemiology and Community Health,63, 871–877. https://doi.org/10.1136/jech.2009.088021.
Jean, N., Burke, M., Xie, M., Davis, W. M., Lobell, D. B., & Ermon, S. (2016). Machine learning to predict poverty. Science (80-.),353, 790–794.
Johnston, D., & Abreu, A. (2016). The asset debates: How(not) to use asset indices to measure well-being and the middle class in Africa. African Affairs (Lond),115, 399–418. https://doi.org/10.1093/afraf/adw019.
Joseph, G., da Silva, I. C. M., Fink, G., Barros, A. J. D., & Victora, C. G. (2018). Absolute income is a better predictor of coverage by skilled birth attendance than relative wealth quintiles in a multicountry analysis: Comparison of 100 low- and middle-income countries. BMC Pregnancy Childbirth,18, 104. https://doi.org/10.1186/s12884-018-1734-0.
Kolenikov, S., & Angeles, G. (2009). Socioeconomic status measurement with discrete proxy variables: Is principal component analysis a reliable answer? Review of Income and Wealth,55, 128–165.
Lindelow, M. (2006). Sometimes more equal than others: How health inequalities depend on the choice of welfare indicators. Health Economics,15, 263–279. https://doi.org/10.1002/hec.1058.
Manthalu, G., Nkhoma, D., & Kuyeli, S. (2010). Simple versus composite indicators of socioeconomic status in resource allocation formulae: The case of the district resource allocation formula in Malawi. BMC Health Services Research, 10, 6. https://doi.org/10.1186/1472-6963-10-6.
McKenzie, D. J. (2005). Measuring inequality with asset indicators. Journal of Population Economics,18, 229–260. https://doi.org/10.1007/s00148-005-0224-7.
Michelson, H. C. (2013). Measuring poverty in the millennium villages: The effect of asset index choice. World Development,49, 917–935.
Moat, K. A., Lavis, J. N., & Abelson, J. (2013). How contexts and issues influence the use of policy-relevant research syntheses: A critical interpretive synthesis. Milbank Quarterly,91, 604–648. https://doi.org/10.1111/1468-0009.12026.
Mohanty, S. K. (2009). Alternative wealth indices and health estimates in India. Genus,65, 113–137. https://doi.org/10.4402/genus-61.
Mohsena, M., Mascie-Taylor, C. G. N., & Goto, R. (2010). Association between socio-economic status and childhood undernutrition in Bangladesh; a comparison of possession score and poverty index. Public Health Nutrition,13, 1498–1504. https://doi.org/10.1017/S1368980010001758.
Moser, C., & Felton, A. (2007). The construction of an asset index measuring asset accumulation in Ecuador. Chronic Poverty Research Centre working paper 87. The Brookings Institution, Washington, DC.
Ngo, D., & Christiaensen, L. (2018). The performance of a consumption augmented asset index in ranking households and identifying the poor. World Bank Policy Research working paper.
Nkonki, L. L., Chopra, M., Doherty, T. M., Jackson, D., & Robberstad, B. (2011). Explaining household socio-economic related child health inequalities using multiple methods in three diverse settings in South Africa. International Journal for Equity in Health, 10(1), 13. https://doi.org/10.1186/1475-9276-10-13.
Nwaru, B. I., Klemetti, R., Kun, H., Hong, W., Yuan, S., Wu, Z., et al. (2012). Maternal socio-economic indices for prenatal care research in rural China. The European Journal of Public Health,22, 776–781. https://doi.org/10.1093/eurpub/ckr182.
Opuni, M., Peterman, A., & Bishai, D. (2011). Inequality in prime-age adult deaths in a high AIDS mortality setting: Does the measure of economic status matter. Health Economics,20, 1298–1311. https://doi.org/10.1002/hec.1671.
Reidpath, D. D., & Ahmadi, K. (2014). A novel nonparametric item response theory approach to measuring socioeconomic position: A comparison using household expenditure data from a Vietnam health survey, 2003. Emerging Themes in Epidemiology, 11(1), 9. https://doi.org/10.1186/1742-7622-11-9.
Rohner, F., Tschannen, A. B., Northrop-Clewes, C., Kouassi-Gohou, V., Bosso, P. E., & Nicholas Mascie-Taylor, C. G. (2012). Comparison of a possession score and a poverty index in predicting anaemia and undernutrition in pre-school children and women of reproductive age in rural and urban Côte d’Ivoire. Public Health Nutrition,15, 1620–1629. https://doi.org/10.1017/S1368980012002819.
Rutstein, S. O. (2008). The DHS Wealth Index: Approaches for rural and urban areas. Demographic and Health Survey working papers, Calverton, Maryland.
Sahn, D. E., & Stifel, D. (2003). Exploring alternative measures of welfare in the absence of expenditure data. Review of Income and Wealth,49, 463–489. https://doi.org/10.1111/j.0034-6586.2003.00100.x.
Smits, J., & Steendijk, R. (2013). The International Wealth Index (IWI) (No. 12–107). NiCE working paper, Nijmengen, The Netherlands. https://doi.org/10.1007/s11205-014-0683-x.
Spearman, C. (1904). The proof and measurement of association between two things. American Journal of Psychology,15, 72–101. https://doi.org/10.1177/036354657800600604.
Tusting, L. S., Rek, J. C., Arinaitwe, E., Staedke, S. G., Kamya, M. R., Bottomley, C., et al. (2016). Measuring socioeconomic inequalities in relation to malaria risk: A comparison of metrics in Rural Uganda. American Journal of Tropical Medicine and Hygeine,94, 650–658. https://doi.org/10.4269/ajtmh.15-0554.
Ucar, B. (2015). The usability of asset index as an indicator of household economic status in Turkey: Comparison with expenditure and income data. Social Indicators Research,121, 745–760. https://doi.org/10.1007/s11205-014-0670-2.
United Nations. (2015). Transforming our world: The 2030 agenda for sustainable development, A/RES/70/1. https://doi.org/10.1007/s13398-014-0173-7.2.
Van Leth, F., Guilatco, R. S., Hossain, S., Van’t Hoog, A. H., Hoa, N. B., Van Der Werf, M. J., et al. (2011). Measuring socio-economic data in tuberculosis prevalence surveys. The International Journal of Tuberculosis and Lung Disease,15, S58–S63. https://doi.org/10.5588/ijtld.10.0417.
Vandemoortele, M. (2014). Measuring household wealth with latent trait modelling: An application to Malawian DHS data. Social Indicators Research,118, 877–891. https://doi.org/10.1007/s11205-013-0447-z.
Vu, L., Tran, B., & Le, A. (2011). The use of total assets as a proxy for socioeconomic status in Northern Vietnam. Asia-Pacific Journal of Public Health,23, 996–1004. https://doi.org/10.1177/1010539510361638.
Vyas, S., & Kumaranayake, L. (2006). Constructing socio-economic status indices: How to use principal components analysis. Health Policy and Planning,21, 459–468. https://doi.org/10.1093/heapol/czl029.
Ward, P. (2014). Measuring the level and inequality of wealth: An application to China. Review of Income and Wealth,60, 613–635. https://doi.org/10.1111/roiw.12063.
Wittenberg, M., & Leibbrandt, M. (2017). Measuring inequality by asset indices: A general approach with application to South Africa. Review of Income and Wealth,63, 706–730. https://doi.org/10.1111/roiw.12286.
Zeller, M., Houssou, N., Alcaraz, G. V, Schwarze, S., & Johannsen, J. (2006). Developing poverty assessment tools based on principal component analysis: Results from Bangladesh, Kazakhstan, Uganda, and Peru. In International association of agricultural economists conference, Gold Coast, Australia, (pp. 1–24).
Acknowledgements
I gratefully acknowledge Dr. Emmanuel Guindon for helpful comments in the formulation and review of this research, members of the Centre for Health Economics and Policy Analysis (CHEPA) at McMaster University for contributions to the design of the study, and Dr. Michelle Dion for her insightful revisions.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Poirier, M.J.P., Grépin, K.A. & Grignon, M. Approaches and Alternatives to the Wealth Index to Measure Socioeconomic Status Using Survey Data: A Critical Interpretive Synthesis. Soc Indic Res 148, 1–46 (2020). https://doi.org/10.1007/s11205-019-02187-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-019-02187-9