
Abstract
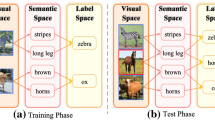
Zero-shot learning for visual recognition, e.g., object and action recognition, has recently attracted a lot of attention. However, it still remains challenging in bridging the semantic gap between visual features and their underlying semantics and transferring knowledge to semantic categories unseen during learning. Unlike most of the existing zero-shot visual recognition methods, we propose a stagewise bidirectional latent embedding framework of two subsequent learning stages for zero-shot visual recognition. In the bottom–up stage, a latent embedding space is first created by exploring the topological and labeling information underlying training data of known classes via a proper supervised subspace learning algorithm and the latent embedding of training data are used to form landmarks that guide embedding semantics underlying unseen classes into this learned latent space. In the top–down stage, semantic representations of unseen-class labels in a given label vocabulary are then embedded to the same latent space to preserve the semantic relatedness between all different classes via our proposed semi-supervised Sammon mapping with the guidance of landmarks. Thus, the resultant latent embedding space allows for predicting the label of a test instance with a simple nearest-neighbor rule. To evaluate the effectiveness of the proposed framework, we have conducted extensive experiments on four benchmark datasets in object and action recognition, i.e., AwA, CUB-200-2011, UCF101 and HMDB51. The experimental results under comparative studies demonstrate that our proposed approach yields the state-of-the-art performance under inductive and transductive settings.



Similar content being viewed by others


Notes
Our empirical study suggests that the random initialization in the K-mean clustering may lead to better performance but causes structured prediction to be unstable.
The dataset of all 30 splits are available online: http://staff.cs.manchester.ac.uk/~kechen/BiDiLEL.
The implementation of PCA and LDA used in our experiments is based on the open source available online: http://www.cad.zju.edu.cn/home/dengcai/Data/DimensionReduction.html.
An anonymous reviewer pointed out this fact and suggested this experiment.
The source code used in our experiments as well as more experimental results not reported in this paper are available on our project website: http://staff.cs.manchester.ac.uk/~kechen/BiDiLEL.
In our experiments, we use the pre-trained 300-dimensional word vectors available online: https://code.google.com/archive/p/word2vec, where 400-dimensional word vectors are unavailable.
References
Akata, Z., Lee, H., & Schiele, B. (2014). Zero-shot learning with structured embeddings. arXiv:1409.8403.
Akata, Z., Perronnin, F., Harchaoui, Z., & Schmid, C. (2013). Label-embedding for attribute-based classification. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 819–826).
Akata, Z., Perronnin, F., Harchaoui, Z., & Schmid, C. (2016). Label-embedding for image classification. IEEE Transactions on Pattern Analysis and Machine Intelligence, 38, 1425–1438.
Akata, Z., Reed, S., Walter, D., Lee, H., & Schiele, B. (2015). Evaluation of output embeddings for fine-grained image classification. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 2927–2936).
Al-Halah, Z., & Stiefelhagen, R. (2015). How to transfer? Zero-shot object recognition via hierarchical transfer of semantic attributes. In IEEE winter conference on applications of computer vision (WACV) (pp. 837–843). IEEE.
Andreopoulos, A., & Tsotsos, J. K. (2013). 50 years of object recognition: Directions forward. Computer Vision and Image Understanding, 117, 827–891.
Cai, D., He, X., & Han, J. (2007). Semi-supervised discriminant analysis. In International conference on computer vision (pp. 1–7). IEEE.
Changpinyo, S., Chao, W.-L., Gong, B., & Sha, F. (2016a). Synthesized classifiers for zero-shot learning. In IEEE conference on computer vision and pattern recognition (CVPR).
Changpinyo, S., Chao, W.-L., & Sha, F. (2016b). Predicting visual exemplars of unseen classes for zero-shot learning. arXiv:1605.08151.
Chatfield, K., Simonyan, K., Vedaldi, A., & Zisserman, A. (2014). Return of the devil in the details: Delving deep into convolutional nets. In British machine vision conference (BMVC).
Cheng, J., Liu, Q., Lu, H., & Chen, Y.-W. (2005). Supervised kernel locality preserving projections for face recognition. Neurocomputing, 67, 443–449.
Cox, T. F., & Cox, M . A. (2000). Multidimensional scaling. Boca Raton: CRC press.
Cristianini, N., & Shawe-Taylor, J. (2000). An introduction to support vector machines and other kernel-based learning methods. Cambridge: Cambridge University Press.
Dinu, G., Lazaridou, A., & Baroni, M. (2015). Improving zero-shot learning by mitigating the hubness problem. In International conference on learning representations workshop.
Elhoseiny, M., Elgammal, A., & Saleh, B. (2015). Tell and predict: Kernel classifier prediction for unseen visual classes from unstructured text descriptions. In IEEE conference on computer vision and pattern recognition (CVPR) workshop on language and vision.
Frome, A., Corrado, G. S., Shlens, J., Bengio, S., Dean, J., Mikolov, T. et al. (2013). Devise: A deep visual-semantic embedding model. In Advances in neural information processing systems (pp. 2121–2129).
Fu, Y., Hospedales, T. M., Xiang, T., & Gong, S. (2015). Transductive multi-view zero-shot learning. IEEE Transactions on Pattern Analysis and Machine Intelligence, 37, 2332–2345.
Fu, Y., & Huang, T. (2010). Manifold and subspace learning for pattern recognition. Pattern Recognition and Machine Vision, 6, 215.
Gan, C., Lin, M., Yang, Y., Zhuang, Y., & Hauptmann, A. G. (2015). Exploring semantic inter-class relationships (SIR) for zero-shot action recognition. In Twenty-ninth AAAI conference on artificial intelligence.
Gan, C., Yang, T., & Gong, B. (2016). Learning attributes equals multi-source domain generalization. In IEEE conference on computer vision and pattern recognition (CVPR).
Gong, Y., Ke, Q., Isard, M., & Lazebnik, S. (2014). A multi-view embedding space for modeling internet images, tags, and their semantics. International Journal of Computer Vision, 106, 210–233.
Griffin, G., Holub, A., & Perona, P. (2007). Caltech-256 object category dataset. Technical report 7694. California Institute of Technology. http://www.vision.caltech.edu/Image_Datasets/Caltech256/.
Hardoon, D. R., Szedmak, S., & Shawe-Taylor, J. (2004). Canonical correlation analysis: An overview with application to learning methods. Neural Computation, 16, 2639–2664.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 770–778).
Jayaraman, D., & Grauman, K. (2014). Zero-shot recognition with unreliable attributes. In Advances in neural information processing systems (pp. 3464–3472).
Jiang, Y.-G., Liu, J., Roshan Zamir, A., Toderici, G., Laptev, I., Shah, M., & Sukthankar, R. (2014). THUMOS challenge: Action recognition with a large number of classes. http://crcv.ucf.edu/THUMOS14/.
Jolliffe, I. (2002). Principal component analysis. Hoboken: Wiley Online Library.
Karpathy, A., & Fei-Fei, L. (2015). Deep visual-semantic alignments for generating image descriptions. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 3128–3137).
Kodirov, E., Xiang, T., Fu, Z., & Gong, S. (2015). Unsupervised domain adaptation for zero-shot learning. In IEEE international conference on computer vision (ICCV) (pp. 2452–2460).
Kuehne, H., Jhuang, H., Garrote, E., Poggio, T., & Serre, T. (2011). HMDB: a large video database for human motion recognition. In IEEE international conference on computer vision (ICCV) (pp. 2556–2563). IEEE.
Lampert, C. H., Nickisch, H., & Harmeling, S. (2009). Learning to detect unseen object classes by between-class attribute transfer. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 951–958). IEEE.
Lampert, C. H., Nickisch, H., & Harmeling, S. (2014). Attribute-based classification for zero-shot visual object categorization. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36, 453–465.
Liu, J., Kuipers, B., & Savarese, S. (2011). Recognizing human actions by attributes. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 3337–3344). IEEE.
Mensink, T., Gavves, E., & Snoek, C. (2014). COSTA: Co-occurrence statistics for zero-shot classification. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 2441–2448).
Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111–3119).
Niyogi, X. (2004). Locality preserving projections. In Neural information processing systems (Vol. 16, p. 153). MIT.
Norouzi, M., Mikolov, T., Bengio, S., Singer, Y., Shlens, J., Frome, A., Corrado, G. S., & Dean, J. (2014). Zero-shot learning by convex combination of semantic embeddings. In International conference on learning representations (ICLR).
Peng, X., Wang, L., Wang, X., & Qiao, Y. (2016). Bag of visual words and fusion methods for action recognition: Comprehensive study and good practice. Computer Vision and Image Understanding, 150, 109–125.
Radovanović, M., Nanopoulos, A., & Ivanović, M. (2010). Hubs in space: Popular nearest neighbors in high-dimensional data. The Journal of Machine Learning Research, 11, 2487–2531.
Reed, S., Akata, Z., Schiele, B., & Lee, H. (2016). Learning deep representations of fine-grained visual descriptions. In IEEE conference on computer vision and pattern recognition (CVPR).
Romera-Paredes, B., & Torr, P. (2015). An embarrassingly simple approach to zero-shot learning. In International conference on machine learning (ICML) (pp. 2152–2161).
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). Imagenet large scale visual recognition challenge. International Journal of Computer Vision, 115, 211–252.
Sammon, J. W. (1969). A nonlinear mapping for data structure analysis. IEEE Transactions on Computers, 18, 401–409.
Shao, L., Liu, L., & Yu, M. (2016). Kernelized multiview projection for robust action recognition. International Journal of Computer Vision, 118, 115–129.
Shao, L., Zhen, X., Tao, D., & Li, X. (2014). Spatio-temporal laplacian pyramid coding for action recognition. IEEE Transactions on Cybernetics, 44, 817–827.
Shigeto, Y., Suzuki, I., Hara, K., Shimbo, M., and Matsumoto, Y. (2015). Ridge regression, hubness, and zero-shot learning. In Machine learning and knowledge discovery in databases (pp. 135–151). Springer.
Simonyan, K., & Zisserman, A. (2014). Two-stream convolutional networks for action recognition in videos. In Advances in neural information processing systems (pp. 568–576).
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In International conference on learning representations.
Smola, A., & Vapnik, V. (1997). Support vector regression machines. Advances in Neural Information Processing Systems, 9, 155–161.
Solmaz, B., Assari, S. M., & Shah, M. (2013). Classifying web videos using a global video descriptor. Machine Vision and Applications, 24, 1473–1485.
Soomro, K., Zamir, A. R., & Shah, M. (2012). UCF101: A dataset of 101 human actions classes from videos in the wild. In CRCV-TR-12-01.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., Erhan, D., Vanhoucke, V., & Rabinovich, A. (2015). Going deeper with convolutions. In IEEE conference on computer vision and pattern recognition (pp. 1–9).
Tran, D., Bourdev, L., Fergus, R., Torresani, L., & Paluri, M. (2015). Learning spatiotemporal features with 3D convolutional networks. In International conference on computer vision (ICCV) (pp. 4489–4497).
Tsochantaridis, I., Joachims, T., Hofmann, T., & Altun, Y. (2005). Large margin methods for structured and interdependent output variables. Journal of Machine Learning Research, 6, 1453–1484.
Vedaldi, A., & Lenc, K. (2015). Matconvnet—Convolutional neural networks for matlab. In ACM international conference on multimedia.
Wah, C., Branson, S., Welinder, P., Perona, P., & Belongie, S. (2011). The caltech-ucsd birds-200-2011 dataset. Technical report CNS-TR-2010-001. California Institute of Technology. http://www.vision.caltech.edu/visipedia/CUB-200-2011.html.
Wang, H., & Schmid, C. (2013). Action recognition with improved trajectories. In IEEE international conference on computer vision (ICCV) (pp. 3551–3558). IEEE.
Wang, L., Xiong, Y., Wang, Z., Qiao, Y., & Van Gool, L. (2016). Temporal segment networks: Towards good practices for deep action recognition. In European conference on computer vision (ECCV).
Wu, Z., Jiang, Y.-G., Wang, X., Ye, H., Xue, X., & Wang, J. (2016). Multi-stream multi-class fusion of deep networks for video classification. In ACM multimedia (ACM MM).
Xian, Y., Akata, Z., Sharma, G., Nguyen, Q., Hein, M., & Schiele, B. (2016). Latent embeddings for zero-shot classification. In IEEE conference on computer vision and pattern recognition (CVPR).
Xu, X., Hospedales, T., & Gong, S. (2015a). Semantic embedding space for zero-shot action recognition. In IEEE international conference on image processing (ICIP) (pp. 63–67). IEEE.
Xu, X., Hospedales, T., & Gong, S. (2015b). Zero-shot action recognition by word-vector embedding. arXiv:1511.04458.
Yu, M., Liu, L., & Shao, L. (2015). Kernelized multiview projection. arXiv:1508.00430.
Zhang, H., Deng, W., Guo, J., & Yang, J. (2010). Locality preserving and global discriminant projection with prior information. Machine Vision and Applications, 21, 577–585.
Zhang, Z., & Saligrama, V. (2015). Zero-shot learning via semantic similarity embedding. In IEEE international conference on computer vision (ICCV) (pp. 4166–4174).
Zhang, Z., & Saligrama, V. (2016a). Zero-shot learning via joint latent similarity embedding. In IEEE conference on computer vision and pattern recognition (CVPR) (pp. 6034–6042).
Zhang, Z., & Saligrama, V. (2016b). Zero-shot recognition via structured prediction. In European conference on computer vision (pp. 533–548). Springer.
Zhao, S., Liu, Y., Han, Y., & Hong, R. (2015). Pooling the convolutional layers in deep convnets for action recognition. arXiv:1511.02126.
Zheng, Z., Yang, F., Tan, W., Jia, J., & Yang, J. (2007). Gabor feature-based face recognition using supervised locality preserving projection. Signal Processing, 87, 2473–2483.
Acknowledgements
The authors would like to thank the action editor and all the anonymous reviewers for their invaluable comments that considerably improve the presentation of this manuscript. Also the authors are grateful to Ziming Zhang at Boston University for providing their source code in structured prediction and Yongqin Xian at Max Planck Institute for Informatics for providing their GoogLeNet features for AwA dataset, which have been used in our experiments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Christoph Lampert.
Electronic supplementary material
Below is the link to the electronic supplementary material.
Appendices
Appendix A: Derivation of Gradient on the LSM Cost Function
In this appendix, we derive the gradient of \(E(B^u)\) defined in Eq. (7). To facilitate our presentation, we simplified our notation as follows: \(d^{lu}_{ij}, d^{uu}_{ij}, \delta ^{lu}_{ij}\) and \(\delta ^{uu}_{ij}\) denote \(d(\pmb {b}^l_i,\pmb {b}^u_j), d(\pmb {b}^u_i,\pmb {b}^u_j)\), \(\delta (\pmb {s}^l_i,\pmb {s}^u_j)\) and \(\delta (\pmb {s}^u_i,\pmb {s}^u_j)\), respectively, where \(d(\cdot , \cdot )\) and \(\delta (\cdot , \cdot )\) are distance metrics used in the latent and semantic spaces.
Based on the simplified notation, Eq. (7) is re-written as follows:
Let \(\pmb {b}^u_{j}=(b^u_{j1},\ldots ,b^u_{jd_y})\) denote the embedding of unseen class j in the latent space, where \({b}^u_{jk}\) is its k-th element. By applying the chain rule, we achieve
For the first term in Eq. (A.2), we have
and
Likewise, for the second term in Eq. (A.2), we have
and
Inserting Eqs. (A.3)–(A.6) into Eq. (A.2) leads to
Thus, we obtain the gradient of \(E(B^{u})\) with respect to \(B^{u}\) used in Algorithm 1: \(\nabla _{B^u} E(B^u)= \Big ( \frac{\partial E(B^{u})}{\partial b^u_{jk}} \Big )_{|{\mathcal {C}}^u| \times d_y }\).
Appendix B: Extension to the Joint Use of Multiple Visual Representations
In this appendix, we present the extension of our bidirectional latent embedding framework in the presence of multiple visual representations.
In general, different visual representations are often of various dimensionality. To tackle this problem, we apply the kernel-based methodology (Cristianini and Shawe-Taylor 2000) by mapping the original visual space \(\mathcal {X}\) to a pre-specified kernel space \(\mathcal {K}\). For the visual representations \(X^l\), the mapping leads to the corresponding kernel representations \(K^l \in {\mathbb {R}}^{n_l \times n_l}\) where \(K^l_i\) is the i-th column of the kernel matrix \(K^l\) and \(K^l_{ij} = k(\pmb {x}^l_i, \pmb {x}^l_j)\). \(k(\pmb {x}^l_i, \pmb {x}^l_j)\) stands for a kernel function of certain favorable properties, e.g., the linear kernel function used in our experiments is \(k(\pmb {x}^l_i, \pmb {x}^l_j)={\pmb {x}^l_i}^T\pmb {x}^l_j\). As there is the same dimensionality in the kernel space, the latent embedding can be learned via a joint use of the kernel representations of different visual representations regardless of their various dimensionality.
Given M different visual representations \(X^{(1)}, X^{(2)}, \ldots , X^{(M)}\), we estimate their similarity matrices \(W^{(1)}, W^{(2)}, \ldots , W^{(M)}\) with Eq. (1), respectively, and generate their respective kernel matrices \( K^{(1)}, K^{(2)}, \ldots , K^{(M)}\) as described above. Then, we combine similarity and kernel matrices with their arithmetic averages:
and
Here we assume different visual representations contribute equally. Otherwise, any weighted fusion schemes in Yu et al. (2015) may directly replace our simple averaging-based fusion scheme from a computational perspective. However, the use of different weighted fusion algorithms may lead to considerably different performance. How to select a proper weighted fusion algorithm is non-trivial but not addressed in this paper.
By substituting W and \(X^l\) in Eq. (2) with \(\widetilde{W}\) in Eq. (A.8) and \(\widetilde{K}\) in Eq. (A.9), the projection P can be learned from multiple visual representations with the same bottom–up learning algorithm (c.f. Eqs. (2–5). Applying the projection P to the kernel representation of any instance leads to its embedding in the latent space. Thus, we can embed all the training instances in \(X^l\) into the learned latent space by
where \(\widetilde{K}^l\) is the combined kernel representation of training data \(X^l\). For the same reason, the centralization and the \(l_2\)-normalization need to be applied to \(Y^l\) prior to the landmark generation and the top–down learning as presented in Sects. 3.2 and 3.3. As the joint use of multiple visual representations merely affects learning the projection P, the landmark generation and the top–down learning in our proposed framework keep unchanged in this circumstance.
After the bidirectional latent embedding learning, however, zero-shot recognition described in Sect. 3.4 has to be adapted for multiple visual representations accordingly. Given a test instance \(\pmb {x}_i^u\), its label is predicted in the latent space via the following procedure. First of all, its representation in the kernel space \(\mathcal {K}\) is achieved by
where \({\widetilde{k}}(\cdot ,\cdot )\) is the combined kernel function via the arithmetic averages of M kernel representations of this instance arising from its M different visual representations. Then we apply projection P to map it into the learned latent space:
After \(\pmb {y}_i^u\) is centralized and normalized in the same manner as done for all the training instances, its label, \(l^*\), is assigned to the class label of which embedding is closest to \(\pmb {y}_i^u\); i.e.,
where \(\pmb {b}^u_l\) is the latent embedding of l-th unseen class, and \(d(\pmb {x},\pmb {y})\) is a distance metric in the latent space.
Appendix C: Visual Representation Complementarity Measurement and Selection
For the success in the joint use of multiple visual representations, diversity yet complementarity of multiple visual representations play a crucial role in zero-shot visual recognition. In this appendix, we describe our approach to measuring the complementarity between different visual representations and a complementarity-based algorithm used in finding complementary visual representations to maximize the performance, which has been used in our experiments.
1.1 C.1: The Complementarity Measurement
The complementarity of multiple visual representations have been exploited in previous works. Although those empirical studies, e.g., the results reported by Shao et al. (2016), strongly suggest that the better performance can be obtained by combining multiple visual representations in human action classification, little has been done on a quantitative complementarity measurement. To this end, we propose an approach to measuring the complementarity of visual representations based on the diversity of local distribution in a representation space.
First of all, we define the complementarity measurement of two visual representations \(X^{(1)}\in {\mathbb {R}}^{d_1 \times n}\) and \(X^{(2)} \in {\mathbb {R}}^{d_2 \times n}\), where \(d_1\) and \(d_2\) are the dimensionality of the two visual representations, respectively, and n is the number of instances. For each instance \(\mathbf {x}_i, i = 1,2,\ldots ,n\), we denote its k nearest neighbours (kNN) in space \(\mathcal {X}^{(1)}\) and \(\mathcal {X}^{(2)}\) by \({\mathcal {N}}^{(1)}_k(i)\) and \({\mathcal {N}}^{(2)}_k(i)\), respectively. To facilitate our presentation, we simplify our notation of \({\mathcal {N}}^{(m)}_k(i)\) to be \({\mathcal {N}}^{(m)}_i\). According to the labels of the instances in the kNN neighborhood, the set \({\mathcal {N}}^{(m)}_i\) can be divided into two disjoint subsets:
where \({\mathcal {I}}^{(m)}_i\) and \(\mathcal {E}^{(m)}_i\) are the subsets that contain nearest neighbours of the same label as that of \(\mathbf {x}_i\) and of different labels, respectively. Thus, we define the complementarity between representations \(X^{(1)}\) and \(X^{(2)}\) as follows:
where \({\mathcal {I}}^{(m)} = \cup _{i=1}^n {\mathcal {I}}^{(m)}_i\) for \(m = 1, 2\), and \(|\cdot |\) denotes the cardinality of a set. The value of c ranges from 0 to 0.5. Intuitively, the greater the value of c is, the higher complementarity between two representations is.
In the presence of more than two visual representations, we have to measure the complementarity between one and the remaining representations instead of another single one as treated in Eq. (A.14). Fortunately, we can extend the measurement defined in Eq. (A.14) to this general scenario. Without loss of generality, we define the complementarity between representation \(X^{(1)}\) and a set of representations \(S = \{X^{(2)}, \ldots , X^{(M)}\}\) as follows:
where \(|{\mathcal {I}}^{2,\ldots ,M}|=|{\mathcal {I}}^{(2)}\cup {\mathcal {I}}^{(3)}\cdots \cup {\mathcal {I}}^{(M)}|\). Thus, Eq. (A.15) forms a generic complementarity measurement for multiple visual representations.
1.2 C.2: Finding Complementary Visual Representations
Given a set of representations \(\{X^{(1)}, X^{(2)}, \ldots , X^{(M)}\}\), we aim to select a subset of representations \(S_{selected}\) where the complementarity between each element and another is as high as possible. Assume we already have a set \(S_{selected}\) containing m complementary representations, and a set \(S_{candidate}\) containing \(M-m\) candidate representations, we can decide which representation in \(S_{candidate}\) should be selected to join \(S_{selected}\) by using the complementarity measurement defined in Eq. (A.15). In particular, we estimate the complementarity between each candidate representation and the set of all the representations in \(S_{selected}\), and the one of highest complementarity is selected. The selection procedure terminates when a pre-defined condition is satisfied. For example, a pre-defined condition may be a maximum number of representations to be allowed in \(S_{selected}\) or a threshold specified by a minimal value of complementarity measurement. The complementary representation selection procedure is summarized in Algorithm A.1.

1.3 C.3: Application in Zero-shot Human Action Recognition
Here, we demonstrate the effectiveness of our proposed approach to finding complementary visual representations for zero-shot human action recognition. We apply Algorithm A.1 to candidate visual representations ranging from handcrafted to deep visual representations on UCF101 and HMDB51. For the hand-crafted candidates, we choose the state-of-the-art improved dense trajectory (IDT) based representations. To distill the video-level representations, two different encoding methods, bag-of-features and Fisher vector, are employed to generate four different descriptors, HOG, HOF, MBHx and MBHy (Wang and Schmid 2013). Thus, there are a total of eight different IDT-based local representations. Besides, two global video-level representations, GIST3D (Solmaz et al. 2013) and STLPC (Shao et al. 2014), are also taken into account. For deep representations, we use the C3D (Tran et al. 2015) representation. Thus, all the 11 different visual representations constitute the candidate set, \(S_{candidate}\).

Results regarding the joint use of multiple visual representations (mean and standard error) on UCF101 (51/50 split)

Results regarding the joint use of multiple visual representations (mean and standard error) on UCF101 (81/20 split)

Results regarding the joint use of multiple visual representations (mean and standard error) on HMDB51
On UCF101 and HMDB51, we set the termination condition to be five visual representations at maximum in \(S_{selected}\) in Algorithm A.1. Applying Algorithm A.1 to 11 candidate representations on two datasets leads to the same \(S_{selected}\) consisting of C3D and four FV-based IDT representations. To verify this measured result, we use our bidirectional latent embedding framework working on incrementally added representations with the same settings described in Sect. 4. As illustrated in Figs. 4, 5 and 6, the performance of zero-shot human action recognition achieved in 30 trials is constantly improved as more and more selected representations are used, which suggests those selected representations are indeed complementary. In particular, the combination of the deep C3D representation and four IDT-based hand-crafted representations yields the best performance that is significantly better than that of using any single visual representations.
In conclusion, we anticipate that the technique presented in this appendix would facilitate the use of multiple visual representations in not only visual recognition but also other pattern recognition applications.
Rights and permissions
About this article

Cite this article
Wang, Q., Chen, K. Zero-Shot Visual Recognition via Bidirectional Latent Embedding. Int J Comput Vis 124, 356–383 (2017). https://doi.org/10.1007/s11263-017-1027-5
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-017-1027-5