
Abstract
Low-level details and high-level semantics are both essential to the semantic segmentation task. However, to speed up the model inference, current approaches almost always sacrifice the low-level details, leading to a considerable decrease in accuracy. We propose to treat these spatial details and categorical semantics separately to achieve high accuracy and high efficiency for real-time semantic segmentation. For this purpose, we propose an efficient and effective architecture with a good trade-off between speed and accuracy, termed Bilateral Segmentation Network (BiSeNet V2). This architecture involves the following: (i) A detail branch, with wide channels and shallow layers to capture low-level details and generate high-resolution feature representation; (ii) A semantics branch, with narrow channels and deep layers to obtain high-level semantic context. The detail branch has wide channel dimensions and shallow layers, while the semantics branch has narrow channel dimensions and deep layers. Due to the reduction in the channel capacity and the use of a fast-downsampling strategy, the semantics branch is lightweight and can be implemented by any efficient model. We design a guided aggregation layer to enhance mutual connections and fuse both types of feature representation. Moreover, a booster training strategy is designed to improve the segmentation performance without any extra inference cost. Extensive quantitative and qualitative evaluations demonstrate that the proposed architecture shows favorable performance compared to several state-of-the-art real-time semantic segmentation approaches. Specifically, for a \(2048\times 1024\) input, we achieve 72.6% Mean IoU on the Cityscapes test set with a speed of 156 FPS on one NVIDIA GeForce GTX 1080 Ti card, which is significantly faster than existing methods, yet we achieve better segmentation accuracy. The code and trained models are available online at https://git.io/BiSeNet.











Similar content being viewed by others
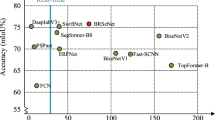


Notes
For running on GTX 1080Ti, we use FP32 data precision to compare with other methods.
References
Achanta, R., Shaji, A., Smith, K., Lucchi, A., Fua, P., & Süsstrunk, S. (2012). Slic superpixels compared to state-of-the-art superpixel methods. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(11), 2274–2282.
Badrinarayanan, V., Kendall, A., & Cipolla, R. (2017). SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(12), 2481–2495.
Bilinski, P., & Prisacariu, V. (2018). Dense decoder shortcut connections for single-pass semantic segmentation. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 6596–6605.
Boykov, Y. Y., Jolly, M. P. (2001) Interactive graph cuts for optimal boundary and region segmentation of objects in nd images. In: Proc. IEEE International Conference on Computer Vision, vol 1, pp. 105–112.
Brostow, G. J., Shotton, J., Fauqueur, J., & Cipolla, R. (2008a). Segmentation and recognition using structure from motion point clouds. In: Proc. European Conference on Computer Vision, pp. 44–57.
Brostow, G. J., Shotton, J., Fauqueur, J., & Cipolla, R. (2008b). Segmentation and recognition using structure from motion point clouds. In: Proc. European Conference on Computer Vision.
Caesar, H., Uijlings, J., & Ferrari, V. (2018). Coco-stuff: Thing and stuff classes in context. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, pp. 1209–1218.
Chandra, S., Couprie, C., & Kokkinos, I. (2018). Deep spatio-temporal random fields for efficient video segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 8915–8924.
Chen LC, Papandreou G, Schroff F, Adam H (2017) Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587.
Chen, L. C., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2015). Semantic image segmentation with deep convolutional nets and fully connected crfs. In: Proceedings of the International Conference on Learning Representations.
Chen, L. C., Zhu, Y., Papandreou, G., Schroff, F., & Adam, H. (2018). Encoder-decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision, pp. 801–818.
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., & Yuille, A. L. (2018). Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Transactions on Pattern Analysis and Machine Intelligence, 40(4), 834–848. https://doi.org/10.1109/TPAMI.2017.2699184.
Chetlur, S., Woolley, C., Vandermersch, P., Cohen, J., Tran, J., Catanzaro, B., & Shelhamer, E. (2014). cudnn: Efficient primitives for deep learning. arXiv preprint arXiv:1410.0759.
Chollet, F. (2017). Xception: Deep learning with depthwise separable convolutions. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1251–1258.
Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., & Schiele, B. (2016). The cityscapes dataset for semantic urban scene understanding. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3213–3223.
Fu, J., Liu, J., Tian, H., Li, Y., Bao, Y., Fang, Z., & Lu, H. (2019). Dual attention network for scene segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 3146–3154.
Geiger, A., Lenz, P., & Urtasun, R. (2012). Are we ready for autonomous driving? The kitti vision benchmark suite. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, pp. 3354–3361.
Ghiasi, G., & Fowlkes, C. C. (2016). LLaplacian pyramid reconstruction and refinement for semantic segmentation. In: Proceedings of the European Conference on Computer Vision, Springer, pp. 519–534.
Glorot, X., Bordes, A., & Bengio, Y. (2011). Glorot, X., Bordes, A., Bengio, Y. (2011) Deep sparse rectifier neural networks. In: Proceedings of the fourteenth international conference on artificial intelligence and statistics, pp. 315–323.
Hariharan, B., Arbeláez, P., Girshick, R., & Malik, J. (2015). Hypercolumns for object segmentation and fine-grained localization. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 447–456.
He, K., Zhang, X., Ren, S., & Sun, J. (2015). Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1026–1034.
He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861.
Howard, A., Sandler, M., Chu, G., Chen, L. C., Chen, B., Tan, M., Wang, W., Zhu, Y., Pang, R., Vasudevan, V., et al. (2019). Searching for mobilenetv3. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1314–1324.
Huang, P. Y., Hsu, W. T., Chiu, C. Y., Wu, T. F., & Sun, M. (2018). Efficient uncertainty estimation for semantic segmentation in videos. In: Proceedings of the European Conference on Computer Vision, pp. 520–535.
Huang, G., Liu, Z., Van Der Maaten, L., & Weinberger, K. Q. (2017). Densely connected convolutional networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4700–4708.
Iandola, F. N., Moskewicz, M. W., Ashraf, K., Han, S., Dally, W. J., Keutzer, K. (2016) Squeezenet: Alexnet-level accuracy with 50x fewer parameters and<1mb model size. arXiv preprint arXiv:1602.07360.
Ioffe, S., & Szegedy, C. (2015). Batch normalization: Accelerating deep network training by reducing internal covariate shift. In: Proceedings of the International Conference on Machine Learning, pp. 448–456.
Krizhevsky, A., Sutskever, I., Hinton, G. E. (2012) Imagenet classification with deep convolutional neural networks. In: Proceedings of the Advances in Neural Information Processing Systems, vol. 25, pp. 1097–1105.
Li, X., Liu, Z., Luo, P., Change Loy, C., & Tang, X. (2017). Not all pixels are equal: Difficulty-aware semantic segmentation via deep layer cascade. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3193–3202.
Li, H., Xiong, P., Fan, H., & Sun, J. (2019b). Dfanet: Deep feature aggregation for real-time semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9522–9531.
Li, G., Yun, I., Kim, J., & Kim, J. (2019a). Dabnet: Depth-wise asymmetric bottleneck for real-time semantic segmentation. In: Proceedings of the British Machine Vision Conference.
Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Dollár, P., & Zitnick, C. L. (2014). Microsoft coco: Common objects in context. In: Proceedings of the European Conference on Computer Vision, Springer, pp. 740–755.
Lin, G., Milan, A., Shen, C., & Reid, I. (2017). Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 1925–1934.
Liu, W., Rabinovich, A., Berg, A. C. (2016) Parsenet: Looking wider to see better. arXiv preprint arXiv:1506.04579.
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3431–3440.
Ma, N., Zhang, X., Zheng, H. T., & Sun, J. (2018). Shufflenet v2: Practical guidelines for efficient cnn architecture design. In: Proceedings of the European Conference on Computer Vision, pp. 116–131.
Mazzini, D. (2018). Guided upsampling network for real-time semantic segmentation. In: Proceedings of the British Machine Vision Conference.
Mehta, S., Rastegari, M., Caspi, A., Shapiro, L., & Hajishirzi, H. (2018). Espnet: Efficient spatial pyramid of dilated convolutions for semantic segmentation. In: Proceedings of the European Conference on Computer Vision, pp. 552–568.
Mehta, S., Rastegari, M., Shapiro, L. G., & Hajishirzi, H. (2019). spnetv2: A light-weight, power efficient, and general purpose convolutional neural network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9190–9200.
Orsic, M., & Segvic, S. (2021). Efficient semantic segmentation with pyramidal fusion. Pattern Recognition, 110, 107611.
Orsic, M., Kreso, I., Bevandic, P., & Segvic, S. (2019). In defense of pre-trained imagenet architectures for real-time semantic segmentation of road-driving images. In: Proceeding of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 12607–12616.
Otsu, N. (1979). A threshold selection method from gray-level histograms. IEEE Transactions on Systems, Man, and Cybernetics, 9(1), 62–66.
Paszke A, Chaurasia A, Kim S, Culurciello E (2016) Enet: A deep neural network architecture for real-time semantic segmentation. arXiv preprint arXiv:1606.02147
Peng, C., Zhang, X., Yu, G., Luo, G., & Sun, J. (2017). Large kernel matters–improve semantic segmentation by global convolutional network. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4353–4361.
Pohlen, T., Hermans, A., Mathias, M., & Leibe, B. (2017). Full-resolution residual networks for semantic segmentation in street scenes. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4151–4160.
Poudel, R. P., Bonde, U., Liwicki, S., & Zach, C. (2018). Contextnet: Exploring context and detail for semantic segmentation in real-time. In: Proceedings of the British Machine Vision Conference.
Poudel, R. P., Liwicki, S., & Cipolla, R. (2019). Fast-scnn: Fast semantic segmentation network. In: Proc. British Machine Vision Conference.
Ren, X., & Malik, J. (2003). Learning a classification model for segmentation. In: Proceedings of the IEEE International Conference on Computer Vision, p. 10–17.
Romera, E., Alvarez, J. M., Bergasa, L. M., & Arroyo, R. (2018). Erfnet: Efficient residual factorized convnet for real-time semantic segmentation. IEEE Transactions on Intelligent Transportation Systems, 19(1), 263–272.
Ronneberger, O., Fischer, P., & Brox, T. (2015). U-net: Convolutional networks for biomedical image segmentation. In: International Conference on Medical image computing and computer-assisted intervention, Springer, pp. 234–241.
Rother, C., Kolmogorov, V., & Blake, A. (2004). Grabcut: Interactive foreground extraction using iterated graph cuts. ACM Transactions on Graphics (TOG), 23, 309–314.
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., & Chen, L. C. (2018). Mobilenetv2: Inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510–4520.
Selvaraju, R. R., Cogswell, M., Das, A., Vedantam, R., Parikh, D., & Batra, D. (2017). Grad-cam: Visual explanations from deep networks via gradient-based localization. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 618–626.
Shelhamer, E., Long, J., & Darrell, T. (2017). Fully convolutional networks for semantic segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39(4), 640–651.
Shen, Z., Liu, Z., Li, J., Jiang, Y. G., Chen, Y., & Xue, X. (2017). Dsod: Learning deeply supervised object detectors from scratch. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1919–1927.
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In: Proceedings of the International Conference on Learning Representations.
Sturgess, P., Alahari, K., Ladicky, L., & Torr, P. H. S. (2009). Combining appearance and structure from motion features for road scene understanding. In: Proceedings of the British Machine Vision Conference.
Szegedy, C., Ioffe, S., Vanhoucke, V., Alemi, A. (2017). Inception-v4, inception-resnet and the impact of residual connections on learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol 31.
Tan, M., Chen, B., Pang, R., Vasudevan, V., Sandler, M., Howard, A., & Le, Q. V. (2019). Mnasnet: Platform-aware neural architecture search for mobile. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 2820–2828.
Treml, M., Arjona-Medina, J., Unterthiner, T., Durgesh, R., Friedmann, F., Schuberth, P., Mayr, A., Heusel, M., Hofmarcher, M., Widrich, M., et al. (2016). Speeding up semantic segmentation for autonomous driving. Proceeding of the Neural Information Processing Systems Workshops.
Van den Bergh, M., Boix, X., Roig, G., de Capitani, B., & Van Gool, L. (2012). Seeds: Superpixels extracted via energy-driven sampling. In: Proceedings of the European Conference on Computer Vision, pp. 13–26.
Vincent, L., & Soille, P. (1991). Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Transactions on Pattern Analysis and Machine Intelligence, 13(6), 583–598.
Wang, P., Chen, P., Yuan, Y., Liu, D., Huang, Z., Hou, X., & Cottrell, G. (2018a). Understanding convolution for semantic segmentation. In: Proceedings of the IEEE Winter Conference on Applications of Computer Vision, IEEE, pp. 1451–1460.
Wang, R. J., Li, X., & Ling, C. X. (2018b). Pelee: A real-time object detection system on mobile devices. Proc (pp. 1967–1976). Advances in Neural Information Processing Systems: Curran Associates Inc.
Wang, J., Sun, K., Cheng, T., Jiang, B., Deng, C., Zhao, Y., Liu, D., Mu, Y., Tan, M., Wang, X., et al. (2020). Deep high-resolution representation learning for visual recognition. IEEE Transactions on Pattern Analysis and Machine Intelligence. https://doi.org/10.1109/TPAMI.2020.2983686.
Wu, Z., Shen, C., Hengel Avd (2016) High-performance semantic segmentation using very deep fully convolutional networks. arXiv preprint arXiv:1604.04339
Xie, S., & Tu, Z. (2015). Holistically-nested edge detection. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1395–1403.
Yu, F., & Koltun, V. (2016). Multi-scale context aggregation by dilated convolutions. In: Proceedings of the International Conference on Learning Representations.
Yu, C., Liu, Y., Gao, C., Shen, C., & Sang, N. (2020a). Representative graph neural network. In: Proceedings of the European Conference on Computer Vision, Springer, pp. 379–396.
Yu, C., Wang, J., Gao, C., Yu, G., Shen, C., & Sang, N. (2020b). Context prior for scene segmentation. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition, pp. 12416–12425.
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., & Sang, N. (2018a). Bisenet: Bilateral segmentation network for real-time semantic segmentation. In: Proceedings of the European Conference on Computer Vision, pp. 325–341.
Yu, C., Wang, J., Peng, C., Gao, C., Yu, G., & Sang, N. (2018b). Learning a discriminative feature network for semantic segmentation. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 1857–1866.
Yu, C., Xiao, B., Gao, C., Yuan, L., Zhang, L., Sang, N., & Wang, J. (2021). Lite-hrnet: A lightweight high-resolution network. In: Proc. IEEE Conference on Computer Vision and Pattern Recognition. pp. 10440–10450.
Yuan, Y., Huang, L., Guo, J., Zhang, C., Chen, X., & Wang, J. (2021). Ocnet: Object context network for scene parsing. International Journal of Computer Vision, 129, 2375–2398.
Zhang, H., Dana, K., Shi, J., Zhang, Z., Wang, X., Tyagi, A., & Agrawal, A. (2018a). Context encoding for semantic segmentation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7151–7160.
Zhang, X., Zhou, X., Lin, M., & Sun, J. (2018b). Shufflenet: An extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6848–6856.
Zhao, H., Qi, X., Shen, X., Shi, J., & Jia, J. (2018a). Icnet for real-time semantic segmentation on high-resolution images. In: Proceedings European Conference on Computer Vision, pp. 405–420.
Zhao, H., Shi, J., Qi, X., Wang, X., & Jia, J. (2017). Pyramid scene parsing network. In: Proceedings IEEE Conference on Computer Vision and Pattern Recognition, pp. 2881–2890.
Zhao, H., Zhang, Y., Liu, S., Shi, J., Loy, C. C., Lin, D., & Jia, J. (2018b). PSANet: Point-wise spatial attention network for scene parsing. In: Proceedings of the European Conference on Computer Vision, pp. 267–283.
Zheng, S., Jayasumana, S., Romera-Paredes, B., Vineet, V., Su, Z., Du, D., Huang, C., & Torr, P. H. (2015). Conditional random fields as recurrent neural networks. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1529–1537.
Zhou, B., Zhao, H., Puig, X., Xiao, T., Fidler, S., Barriuso, A., et al. (2019). Semantic understanding of scenes through the ade20k dataset. International Journal of Computer Vision, 127(3), 302–321.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (No. 61433007 and 61876210).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by Laurent Najman.
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Yu, C., Gao, C., Wang, J. et al. BiSeNet V2: Bilateral Network with Guided Aggregation for Real-Time Semantic Segmentation. Int J Comput Vis 129, 3051–3068 (2021). https://doi.org/10.1007/s11263-021-01515-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11263-021-01515-2