
Abstract
In this work novel results concerning Network-on-Chip-based turbo decoder architectures are presented. Stemming from previous publications, this work concentrates first on improving the throughput by exploiting adaptive-bandwidth-reduction techniques. This technique shows in the best case an improvement of more than 60 Mb/s. Moreover, it is known that double-binary turbo decoders require higher area than binary ones. This characteristic has the negative effect of increasing the data width of the network nodes. Thus, the second contribution of this work is to reduce the network complexity to support double-binary codes, by exploiting bit-level and pseudo-floating-point representation of the extrinsic information. These two techniques allow for an area reduction of up to more than the 40 % with a performance degradation of about 0.2 dB.














Similar content being viewed by others
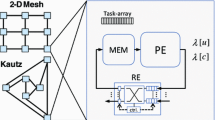
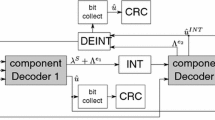

Notes
If Log-MAP algorithms are used the result is not actually the maximum among the input values due to \(f_{c}(x)\).
If we model a topology as a graph, a self-loop is an edge whose source and destination nodes coincide.
Since we use three fractional bits for data representation the integer values of K we considered correspond to 0.25, 0.75, 1 and so on.
The worst case corresponds to simulations where ABR is not applied
References
IEEE Std 802.16, part 16: air interface for fixed broadband wireless access systems, Oct. 2004.
TS 36.212 v8.0.0: Multiplexing and Channel Coding (FDD) (Release 8), 2007-09.
Berrou, C., Glavieux, A., Thitimajshima, P. (1993). Near Shannon limit error correcting coding and decoding: turbo codes. In IEEE international conference on communications (pp. 1064–1070).
Gallager, R.G. (1962). Low density parity check codes. IRE Transactions on Information Theory, IT-8(1), 21–28.
Boutillon, E., Douillard, C., Montorsi, G. (2007). Iterative decoding of concatenated convolutional codes: implementation issues. Proceedings of the IEEE, 95(6), 1201–1227.
Guilloud, F., Boutillon, E., Tousch, J., Danger, J.L. (2007). Generic description and synthesis of LDPC decoders. IEEE Transactions on Communications, 55(11), 2084–2091.
Martina, M., Masera, G., Moussa, H., Baghdadi, A. (2011). On chip interconnects for multiprocessor turbo decoding architectures. Elsevier Microprocessors and Microsystems, 35(2), 167–181.
Polydoros, A. (2008). Algorithmic aspects of radio flexibility. In IEEE international symposium on personal, indoor and mobile communications (pp. 1–5).
Vogt, T., & Wehn, N. (2008). Reconfigurable ASIP for convolutional and turbo decoding in an SDR environment. IEEE Transactions on VLSI, 16(10), 1309–1320.
Bougard, B., Priewasser, R., der Perre L.V., Huemer, M. (2008). Algorithm-architecture co-design of a multi-standard FEC decoder ASIP. In ICT mobile summit conference.
Martina, M., Nicola, M., Masera, G. (2008). A flexible UMTS-WiMax turbo decoder architecture. IEEE Transactions on Circuits and Systems II, 55(4), 369–373.
Rovini, M., Gentile, G., Fanucci, L. (2009). A flexible state-metric recursion unit for a multi-standard BCJR decoder. In IEEE international conference on signals circuits and systems (pp. 1–6).
Kim, J.H., & Park, I.C. (2009). A unified parallel radix-4 turbo decoder for mobile WiMAX and 3GPP-LTE. In IEEE custom integrated circuits conference (pp. 487–490).
Muller, O., Baghdadi, A., Jezequel, M. (2009). From parallelism levels to a multi-ASIP architecture for turbo decoding. IEEE Transactions on VLSI, 17(1), 92–102.
Reddy, P., Alkhayat, R., Clermidy, F., Baghdadi, A., Jezequel, M. (2010). Power consumption analysis and energy efficient optimization for turbo decoder implementation. In International symposium on sytem-on-chip (pp. 12–17).
Ilnseher, T., May, M., Wehn, N. (2010). A multi-mode 3GPP-LTE/HSDPA turbo decoder. In IEEE international conference on communication systems (pp. 336–340).
Gentile, G., Rovini, M., Fanucci, L. (2010). A multi-standard flexible turbo/LDPC decoder via ASIC design. In International symposium on turbo codes & iterative information processing (pp. 294–298).
Sun, Y., & Cavallaro, J.R. (2010). A flexible LDPC/turbo decoder architecture. Journal of Signal Processing Systems, 64(1), 1–16.
Murugappa, P., Al-Khayat, R., Baghdadi, A., Jezequel, M. (2011). A flexible high throughput multi-ASIP architecture for LDPC and turbo decoding. In Design, automation and test in Europe conference and exhibition (pp. 1–6).
Shin, M.C., & Park, I.C. (2007). SIMD processor-based turbo decoder supporting multiple third-generation wireless standards. IEEE Transactions on VLSI, 15(7), 801–810.
Sun, Y., Zhu, Y., Goel, M., Cavallaro, J.R. (2008). Configurable and scalable high throughput turbo decoder architecture for multiple 4G wireless standards. In IEEE international conference on application-specific systems, architectures and processors (pp. 209–214).
Lin, C.H., Chen, C.Y., Wu, A.Y. (2011). Area efficient scalable MAP processor design for high-throughput mulistandard convolutional turbo decoding. IEEE Transactions on VLSI, 19(2), 305–318.
Al-Khayat, R., Murugappa, P., Baghdadi, A., Jezequel, M. (2011). Area and throughput optimized ASIP for multi-standard turbo decoding. In IEEE international symposium on rapid system prototyping (pp. 79–84).
Hoffmann, A., Schliebusch, O., Nohl, A., Braun, G., Meyr, H. (2001). A methodology for the design of application specific instruction set processors (ASIP) using the machine description language LISA. In International conference on computer-aided-design.
Neeb, C., Thul, M.J., Wehn, N. (2005). Network-on-chip-centric approach to interleaving in high throughput channel decoders. In IEEE international symposium on circuits and systems (pp. 1766–1769).
Moussa, H., Muller, O., Baghdadi, A., Jezequel, M. (2007). Butterfly and Benes-based on-chip communication networks for multiprocessor turbo decoding. In Design, automation and test in Europe conference and exhibition (pp. 654–659).
Moussa, H., Baghdadi, A., Jezequel, M. (2008). Binary de Bruijn interconnection network for a flexible LDPC/turbo decoder. In IEEE international symposium on circuits and systems (pp. 97–100).
Martina, M., & Masera, G. (2010). Turbo NOC: a framework for the design of network on chip based turbo decoder architectures. IEEE Transactions on Circuits and Systems I, 57(10), 2776–2789.
Wang, G., Sun, Y., Cavallaro, J.R., Guo, Y. (2011). High-throughput contention-free concurrent interleaver architecture for multi-standard turbo decoder. In IEEE international conference on application-specific systems, architectures and processors (pp. 113–121).
Vacca, F., Moussa, H., Baghdadi, A., Masera, G. (2009). Flexible architectures for LDPC decoders based on network on chip paradigm. In Euromicro conference on digital system design (pp. 582–589).
Guerrier, P., & Greiner, A. (2000). A generic architecture for on-chip packet-switched interconnections. In Design, automation and test in Europe conference and exhibition (pp. 250–256).
Dally, W.J., & Towels, B. (2001). Route packets, not wires: On-chip interconnection networks. In Design automation conference (pp. 684–689).
Benini, L., & Micheli, G.D. (2002). Networks on chips: a new soc paradigm. IEEE Computer, 35(1), 70–78.
Kumar, S., Jantsch, A., Soininen, J.P., Forsell, M., Millberg, M., Oberg, J., Tiensyrja, K., Hemani, A. (2002). A network on chip architecture and design methodology. In IEEE computer society annual symposium on VLSI (pp. 105–112).
Awais, M., & Condo, C. (2012). Flexible LDPC decoder architectures. VLSI Design, 2012, 1–16.
Muller, O., Baghdadi, A., Jezequel, M. (2006). Bandwidth reduction of extrinsic information exchange in turbo decoding. IET Electronics Letters, 42(19), 1104–1105.
Park, S.M., Kwak, J., Lee, K. (2008). Extrinsic information memory reduced architecture for non-binary turbo decoder implementation. In IEEE vehicular technology conference (pp. 539–543).
Kim, J.H., & Park, I.C. (2009). Bit-level extrinsic information exchange method for double-binary turbo codes. IEEE Transactions on Circuits and Systems II, 56(1), 81–85.
Berrou, C., Jezequel, M., Douillard, C., Kerouedan, S. (2001). The advantages of non-binary turbo codes. In IEEE information theory workshop (pp. 61–63).
Bahl, L.R., Cocke, J., Jelinek, F., Raviv, J. (1974). Optimal decoding of linear codes for minimizing symbol error rate. IEEE Transactions on Information Theory, 20(3), 284–287.
Robertson, P., Villebrun, E., Hoeher, P. (1995). A comparison of optimal and sub-optimal MAP decoding algorithms operating in the Log domain. In IEEE ICC (pp. 1009–1013).
Robertson, P., Hoeher, P., Villebrun, E. (1997). Optimal and sub-optimal maximum a posteriori algorithms suitable for turbo decoding. European Transactions on Telecommunications, 8(2), 119–125.
Papaharalabos, S., Mathiopoulos, P.T., Masera, G., Martina, M. (2009). On optimal and near-optimal turbo decoding using generalized \(\max ^{*}\) operator. IEEE Communications Letters, 13(7), 522–524.
Flich, J., & Duato, J. (2008). Logic-based distributed routing for NoCs. IEEE Computer Architecture Letters, 7(1), 13–16.
Shi, Z., Yang, Y., Zeng, X., Yu, Z. (2011). A reconfigurable and deadlock-free routing algorithm for 2D Mesh Network-on-Chip. In IEEE international symposium of circuits and systems (pp. 2934–2937).
Moraveji, R., Sarbazi-Azad, H., Zomaya, A.Y. (2010). A general methodology for direction-based irregular routing algorithms. Journal of Parallel and Distributed Computing, 70(4), 363–370.
http://www.3gpp2.org. 2004.
Wang, Z., & Li, Q. (2007). Very low-complexity hardware interleaver for turbo decoding. IEEE Transactions on Circuits and Systems II, 54(7), 636–640.
Martina, M., Nicola, M., Masera, G. (2008). Hardware design of a low complexity, parallel interleaver for wimax duo-binary turbo decoding. IEEE Communications Letters, 12(11), 846–848.
Martina, M. (2012). Turbo NOC: Network On Chip based turbo decoder architectures, downloadable at http://personal.delen.polito.it/maurizio.martina/turbo.html.
Bang-Jensen, J., & Gutin, G. (2008). Digraphs, theory, algorithms and applications (2nd ed.). London: Springer-Verlag.
Imase, M., & Itoh, M. (1981). Design to minimize diameter on building-block network. IEEE Transactions on Computers, 30(6), 439–442.
Imase, M., & Itoh, M. (1983). A design for directed graphs with minimum diameter. IEEE Transactions on Computers, 32(8), 782–784.
Sabbaghi-Nadooshan, R., & Sarbazi-Azad, H. (2008). The kautz mesh: a new topology for socs. In IEEE international SoC design conference (pp. 300–303).
Sabbaghi-Nadooshan, R. (2011). Kautz mesh topology for on-chip networks. Journal of Computing, 3(2), 33–40.
Pulimeno, A., Graziano, M., Piccinini, G. (2012). UDSM trends, comparison: From technology roadmap to UltraSparc Niagara2. IEEE Transactions on VLSI Systems, 20(7), 1341–1346.
Angiolini, F., Meloni, P., Carta, S.M., Raffo, L., Benini, L. (2007). A layout-aware analysis of networks-on-chip and traditional inteconnects for MPSoCs. IEEE Transactions on Computer-aided Design of Integrated Circuits and Systems, 26(3), 421–434.
Meloni, P., Loi, I., Angiolini, F., Carta, S., Barbaro, M., Raffo, L., Benini, L. (2007). Area and power modeling for networks-on-chip with layout awareness. VLSI Design. special issue on Networks on Chip, Article ID 50285, 12 pages.
Hosseinabady, M., Kakoee, M.R., Mathew, J., Pradhan, D.K. (2007). Reliable network-on-chip based on generalized de Bruijn graph. In IEEE international high level design validation and test workshop (pp. 3–10).
Hosseinabady, M., Kakoee, M.R., Mathew, J., Pradhan, D.K. (2008). De Bruijn graph as a low latency scalable architecture for energy efficient massive NoCs. In Design, automation and test in Europe conference and exhibition (pp. 1370–1373).
Samatham, M.R., & Pradhan, D.K. (1989). The De Bruijn multiprocessor network: a versatile parallel processing and sorting network for VLSI. IEEE Transactions on Computers, 38(4), 567–581.
Cheng, C.C., Tsai, Y.M., Chen, L.G., Chandrakasan, A.P. (2010). A 0.077 to 0.168 nJ/bit/iteration scalable 3GPP LTE turbo decoder with an adaptive sub-block parallel scheme and an embedded DVFS engine. In IEEE custom integrated circuits conference (pp. 1–4).
Gentile, G., Rovini, M., Fanucci, L. (2010). Low-power techniques for flexible channel decoders. In International conference on applied electronics (pp. 1–4).
Reddy, P., Clermidy, F., Baghdadi, A., Jezequel, M. (2011). A low complexity stopping criterion for reducing power consumption in turbo decoders. In Design, automation and test in Europe conference and exhibition (pp. 1–6).
Kim, D.H., & Kim, S.W. (2006). Bit-level stopping of turbo decoding. IEEE Communications Letters, 10(3), 183–185.
Vogt, J., Ertel, J., Finger, A. (2000). Reducing bit width of extrinsic memory in turbo decoder realisations. IEE Electronics Letters, 36(20), 1714–1716.
Singh, A., Boutillon, E., Masera, G. (2008). Bit-width optimization of extrinsic information in turbo decoder. In International symposium on turbo codes & related topics (pp. 134–138).
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Martina, M., Masera, G. Improving Network-on-Chip-based Turbo Decoder Architectures. J Sign Process Syst 73, 83–100 (2013). https://doi.org/10.1007/s11265-013-0733-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11265-013-0733-7