
Abstract
We present our results on the adoption of a set-theoretic framework for granular computing to situation awareness. The proposed framework guarantees a high degree of flexibility in the process of creation of granules and granular structures allowing to satisfy the wide variety of requirements for perception and comprehension of situations where some elements must be perceived per similarity, others per spatial proximity, some must be fused to improve their comprehension, and so on. A second value is the support for approximate reasoning in situation awareness. A granular structure in particular represents a snapshot of a situation, and is a building block for the development of tools and techniques to reason on situation in order to reduce situation awareness errors and accelerate the process of decision-making. To this purpose, we show a technique to support operators in the analysis of conformity between a recognized situation and an expected one. A third value is the fact that we can support operators in having rapid and indicative measures of how two situations, e.g. a recognized and a projected, may differ. A preliminary evaluation instantiating our approach with self-organizing maps is reported and discussed. The results are encouraging with respect to the capability of improving perception and comprehension of a situation, reducing comprehension errors and supporting projection of situations.
Similar content being viewed by others


1 Introduction
Situation awareness (SA) is an essential construct supporting decision-making in complex and dynamic environments. In software systems for SA individual pieces of raw information (e.g. sensor data) are interpreted into a higher, domain-relevant concept called situation, which is an abstract state of affairs interesting to specific applications. The power of using situations lies in their ability to provide a simple, human understandable representation of the elements of the environment and support informed decision-making.
SA is being aware of what is happening around you and understanding what that information means to you now and in the future. The concept of SA is applied to operational situations, where humans or agents (from now on, we refer to these entities as SA operators) must have SA for a specified reason (e.g. to drive a car, treat a patient, control air traffic). However, achieving a good SA is not easy and software systems for SA have to be properly designed following a clear set of principles that are discussed by Endsley (2011). Among these we recall the importance of organizing information around goals and providing a proper level of abstraction of information, supporting the alternation between goal-driven and data-driven information processing, supporting patterns matching to schemata (i.e. prototypical states of the mental model) to allow rapid retrieval of comprehension and projection for the recognized situation.
Loia et al. (2016) present a detailed overview of how granular computing (GrC) can enforce SA and discussed how GrC methods and techniques can address requirements and design principles of SA systems. In proposing this study we were motivated by the recognition that GrC and SA share some important concepts and principles but, currently, are two separate areas that have not been investigated in a systemic way. In this paper, we take a step forward along this systemic integration with the adoption of a set-theoretic framework for GrC that fits well with SA requirements, and the definition of a technique to reason on granular structure in SA applications.
Specifically, the framework is based on the concepts of granule, granular structure, information granulation and distance between granular structures. We use the concept of granule as a way to improve the perception of the elements of an environment by clumping together these elements per proximity, similarity, indistinguishably, or other requirements that the specific SA application demands. However, in most cases, it is quite impossible to properly represent situations with stand-alone granules. A situation can be represented better with the support of a granular structure. The criteria that guide the creation of a granular structure depend on the specific SA application. As situations usually evolve over time, an SA operator must have the capability of projecting in the near future a recognized situation. This capability includes also the assessment of diversity between a recognized situation and a possible evolution. This can be supported by evaluating a distance between two granular structures representing, respectively, the situation recognized and a possible evolution.
Besides the need for a systemic integration of GrC and SA, an additional motivation to investigate GrC for SA relates to rapid decision-making and reduction of errors and biases. Usually, SA operational scenarios are mission critical requiring accurate and rapid decisions with minimum processing time. SA operators work in complex environments and take decisions under time pressure, information uncertain and changing conditions. GrC is gaining attention as a paradigm for decision-making under uncertainty (Pedrycz 2014) and several GrC methods have been applied with success to support multi-attribute decision-making (Wang et al. 2016), multi-criteria decision-making (Das et al. 2016), group decision-making (Xu and Wang 2016), and three way decisions (Cai et al. 2016; Ciucci 2016; Yao 2013), showing the benefits and added value of reasoning and taking decision with granules and granular structures in several domains such as power energy (Ekel et al. 2016), risk management (Skowron et al. 2016), aircraft landing control problem (Ahmad and Pedrycz 2016).
To show the potentiality of reasoning with granular structures in SA, we have defined a technique to analyse the conformity of a recognized situation with respect to the one that is expected by an SA operator. This information is of great importance for decision-making. It is quite clear, in fact, that a different level of attention is required by SA operators if they are processing a situation that conforms to their expectations with respect to a corresponding one that does not conform or unexpected. This can reduce some SA level 2 errors and biases.
Our contribution is thus twofold. First, we enhance the synergistic view of GrC and SA with the adoption of GrC framework along all the levels of SA, showing the benefits of reasoning with granules in SA in terms of improved comprehension of situation, support for projection, reduction of biases. Second, we rely on the foundational concepts of the framework to define and develop tools and techniques to enforce SA. In this paper, we focus on the conformity analysis.
The paper is organized as follows. Section 2 reports background on GrC and SA. Section 3 reports in a descriptive way how we can represent situations and their evolutions with granules and granular structures, and how we can reason on granular structures to reduce some SA errors. Section 4 presents our approach, that is based on the adoption of a theoretical framework to be used as foundation for the development of tools and techniques to reason on situations. Section 5 formally defines the framework and Sect. 6 reports the conformity analysis. Section 7 presents the results of a preliminary evaluation using self-organizing map (SOM) (Kohonen 1998) as a technique to build granules and granular structures. Section 8 lastly draws conclusions and presents future works.
2 Background
2.1 Granular computing
GrC is an information-processing paradigm focused on representing and processing basic chunks of information, namely granules, and finds its origin in the works of Zadeh (1997) that defines a granule as a clump of points (objects) drawn together by indistinguishability, similarity, proximity or functionality. Granules can be decomposed into smaller or finer granules called subgranules. Granules and subgranules can be organized by means of levels, hierarchies and granular structures. In order to construct or decompose granules we need to employ a specific operation called granulation. An overall picture of GrC that considers all its different perspectives is given by Yao et al. (2013).
There are different formal settings for GrC: set theory, interval calculus, fuzzy sets, rough sets, shadowed sets, probabilistic granules. In each of these environments, granules and granulation are defined in different ways and a tentative one to find similarity and bridge the gap between these settings is described in Dubois and Prade (2016).
In general, all the formal settings allow for the creation of granular structures. Multi-level structures where high-level granules represent more abstract concepts and low-level granules represent more specific concepts are used in human reasoning, and such granular structures are fundamental for our objectives. There is a wide set of relationships in GrC (Yao et al. 2013; Yao 2016) that can be used to organize granules in hierarchies, trees, networks, and so on. Formally, a granule g is a refinement of G (or G is a coarsening of g), denoted with \(g \preceq G\), if every data or subgranules of g is contained in some subgranules of G. Refinement (Coarsening) can be also partial when not every but only some data or subgranules of g is contained in some subgranules of G, and is denoted as \(g \sqsubseteq G\).
Building granules in a correct and appropriate way is an open issue that has been investigated by several scholars and partially depends on the requirements of the application. Pedrycz et al. (2015), Pedrycz and Homenda (2013) has proposed the principle of justifiable granularity as a way to evaluate the performance of informative granules. This principle is based on a trade-off between two measures that do not strictly depend on the specific application: coverage and specificity. A correct expression of these two measures depends on the nature of the set created (e.g. crisp as for k-means or fuzzy as for the fuzzy c-means) but, in general, coverage is related to the ability of covering data and specificity deals with the level of abstraction of the granule prototype by considering its size. As an example, for crisp sets a measure of coverage can be \(\mathrm{Cov}(P)= \frac{1}{N} \; \mathrm{card} \lbrace X_{k} \vert x_{k} \epsilon P \rbrace \) while for fuzzy sets we can sum the degree of memberships of the elements \(\mathrm{Cov}(P)= \frac{1}{N} \sum _{k=1} ^{N} \mu _{P} (X_{k})\). Ideally \(\mathrm{Cov}(P)\) should be 1 that means all data are covered by the prototype. Specificity requires that the intervals are as narrow (specific) as possible. The specificity of an interval can be evaluated in numerous ways. A specificity measure has to satisfy two requirements: it attains a maximal value for single-element, and the broader the interval, the lower the specificity measure. Coverage and specificity are in conflict. A proposal to visualize their relationship is to arrange them together in the form of a coverage-specificity plot, which can be also parametrized, and to evaluate the area under the curve to have a global measure of quality.
Another criterion to design granules is the principle of uncertainty level preservation (Livi and Sadeghian 2015, 2016) that is mainly focused on evaluating the quality of the granulation itself. By considering information granulation as a mapping between some input and output, this principle considers the quantification of the uncertainty as an invariant property to be preserved during the process of granulation. The difference among the input and output entropy is considered as an error to be reduced for a proper granulation of information.
2.2 Situation awareness
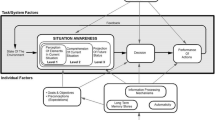
Endsley (1995c) defines situation awareness (SA) as “the perception of elements in the environment within a volume of time and space, the comprehension of their meaning, and the projection of their status in the near future”. The SA model proposed by Endsley is shown in Fig. 1. The model has three levels (Endsley 2011): (1) perception, which involves the capability to perceive the status, attributes and dynamics of the relevant elements of the environment; (2) comprehension, which refers to the understanding of what data and cues perceived mean in relation to goals and objectives; and (3) projection, which relates to the capability of projecting in near future the elements recognized. Endsley’s model is not linear but iterative, with understanding driving the search for new data and new data coming together to feed understanding. Furthermore, it must not be understood as a pure data-driven process since factors such as goals, mental models, attention, working memory, expectations play a significant role in SA.

Endsley’s model (from Endsley 2011)
A fundamental component of SA is the goal directed task analysis (GDTA) that is a form of cognitive task analysis focusing on the goals that SA operators must achieve and the information requirements at the levels of perception (SA L1), comprehension (SA L2) and projection (SA L3) that are needed in order to make appropriate decisions. Information is, step-by-step, decomposed until reaching finer elements that cannot be further decomposed. The result of GDTA is an abstract and hierarchical structure (see Fig. 2) establishing the requirements needed at the three levels of SA.

Results of a GDTA
GDTA plays a pivotal role in achieving good SA and it is important to underline that GDTA focuses on dynamic information requirements rather than static system knowledge. When experts build a GDTA structure they consider information needed to perform well a specific task, that has to be acquired and analysed by an operator in a certain domain during the execution of such task. In other words, a GDTA structure embeds subject matter knowledge (and to some extent also expectations) that is required by SA operators to perform well and achieve good SA.
A GDTA can also be seen as a result of a granulation process. Usually, in fact, experts perform a top-down analysis of the domain decomposing a whole into its parts. This kind of goal-driven approach to information processing is balanced by a data-driven one that develop a bottom-up analysis of the domain via integration of low-level elements into a whole. These two approaches (goal-driven and data-driven) essentially resemble two human cognitive capabilities that are analysis (i.e. from whole to parts) and synthesis (i.e. from parts to whole). A GDTA is at the same time a value and an issue if we regard SA from a computational perspective. The value is that a well formalized GDTA gives correct requirements and can avoid most of SA errors. The issue is that GDTA poses serious challenges in the way we must process and present data and information, and demands a highly flexible computational support.
3 Representing situations with granules and granular structures
With reference to Fig. 3, we present in a descriptive way the process of granulation and creation of granular structures in the context of SA. A more formal description is deepened in Sect. 5.
Starting from data registered by sensors, we can create type 1 granules g on the basis of the requirements at the perception level of the GDTA, i.e. SA L1 requirements, giving information on what are the elements to perceive for the specific SA objective. The number and level of abstraction of granules to be created depend on several factors such as the number and kind of elements to be perceived, and their relative importance for the objective. At this level, common issues relate to object recognition, feature reduction and outlier detection. We refer to (Loia et al. 2016) for an overview of GrC techniques that can be used to solve these issues. Once created, granules g can be optimized with criteria such as Coverage and Specificity introduced in Sect. 2.1. Type 1 granules can be abstracted and fused to create type 2 granules G to accommodate SA L2 requirements for comprehension. Coarsening or partial coarsening relationships can be used depending on the specific SA L2 requirements. It is worth evidencing that we could also start with creation of type 2 granules using techniques such as multi-sensor data fusion (Xu and Yu 2017) and use refinement or partial refinement relationships to accommodate SA L1 requirements. The decision of using a bottom-up or a top-down approach for creation of type 1 and type 2 granules depends on the application.

Granular structure at time t
As we already mentioned, a granular structure is a representation of the elements of the environment created following SA L1 and L2 requirements. It comes with a degree of imprecision and uncertainty that can be measured with the concept of information granulation, IG. The information granulation gives a measure of how much information is granulated in a structure. It takes its minimal value when the granulation is finest. In this case the granular structure is a precise representation of the elements of an environment that, however, is not optimal for SA applications requiring information fusion. The correct level of information granulation depends of course on the GDTA but also on behavioural determinants of the human operator such as attention, memory, and so on, that give information on the capabilities that a human operator owns for perceiving and understanding a granulated information. A discussion on how to design SA systems considering these and other factors is in (Endsley 2011) and an investigation on how to take into account all the human factors required is out of the scope of this paper. However, the information granularity associated with a granular structure is an interesting information for SA operators that can be considered as a degree of abstraction of the situation represented by the structure.
3.1 Evolving situations
So far we have created a hierarchical granular structure resembling the hierarchies existing between SA L1 and SA L2 requirements of a GDTA. This structure gives a snapshot of a situation at a specific time. To accommodate SA L3 requirements for the projection phase, we can leverage on the concept of evolvable granules (Antonelli et al. 2016; Pedrycz 2010).
If we recall the definition of SA, we recognize the importance of coupling Time and Space domain granulation processes for a correct creation of granules and granular structures for SA. In (Leite et al. 2012), it is suggested that time granulation is earlier than space granulation. In processing data from sensor networks, sensor readings are analysed over a fixed time window. Very simply, we can fix a time window, \(\gamma \), where we expect a slice of data and perform space granulation on this data. Space granulation results in a granular structure, a granular tree of two levels of granularity, \(\varepsilon \) and \(\varepsilon ^{I}\), corresponding to the two levels of SA requirements for perception and comprehension. Selecting a different time window, \(\gamma ^{I}\), can lead to a different granular structure where some granules can be merged, split or new granules can be created. This is the behaviour of evolvable granules (Pedrycz 2010).
With reference to Fig. 4 the bottom of the figure shows some objects registered by sensors in three time slices, the top of the figure shows three consequential granular structures, where granules report the position of the objects in the space. Starting with the first snapshot of data in the first time slice, we can create type 1 granules a, b, and c. In the next time slice objects d and e are recognized and can be merged into existing granules to form higher level granules \(\lbrace a, d \rbrace \) and \(\lbrace b, e \rbrace \). This process iterates in the subsequent time slices and, as output, granular structures evolve with granules that can be merged, split, removed or new granules created. (Pedrycz 2010) reported on a complete formalism to deal with splitting and merging criteria in the case of granules created with Fuzzy c-means.

Time and space domain granulation
To accommodate SA L3 requirements on the projection, we should reason on the evolution of granular structures. To this purpose, let us take a look at Fig. 5 that reports the case depicted in Fig. 4 in the form of a granular graph that combines time and space domain granulation. The tree in the middle of the figure reports time granulation. It is a lattice of partitions of indistinguishable objects in time slices of different width. Its semantics is that objects a, b, and c are indistinguishable with respect to time in a time window of width \(\gamma \). With respect to time, they are a single granule \(\lbrace a, b, c \rbrace \). The same is for d and e, as well as for f, g, and h. If we consider a larger time slice, e.g. \(2 \gamma \), we have coarser granules of indistinguishable objects, e.g. \(\lbrace a, b, c, d, e \rbrace \) or \(\lbrace d, e, f, g, h \rbrace \). The grey ellipses show the results of space granulation for the case reported in Fig. 4. Each ellipse gives a snapshot of a situation at a specific time-slot represented by a granular structure such as the ones of Fig. 3. Intuitively, to accommodate in a correct way SA L3 requirements, SA operators have to reason on the transitions \(\mathrm{GS}(S_{0}) \rightarrow \mathrm{GS}(S_{1}) \rightarrow \mathrm{GS}(S_{2})\). This can be done in a more or less difficult way depending on previous knowledge about the rules that govern the evolution of phenomena under observations and/or the actions that can enable situations transitions.

Evolution of granular structures
In many cases, however, SA operators can have good mental models, knowledge and expertise to foresee some probable evolutions of a situation and in these cases information on how much a projected situation differs from the recognized one can be useful to take decisions in SA. To this purpose, we use the concept of distance between granular structures to evaluate the dissimilarity between two granular structures representing consequential snapshots of a situation.
3.2 How to reduce SA errors
To clarify how GrC can concretely support SA, let us look the Fig. 6 that shows the taxonomy of SA errors described by Endsley (1995b). Reasoning on situations represented as granular structures can support reduction of several of these SA errors.

Taxonomy of SA errors (our elaboration from Endsley 1995b)
Specifically, SA L1 errors related to difficulty to perceive data and operators failures to observe data can be reduced with a proper granulation process that creates granules according to the GDTA requirements. We need to assure flexibility to accommodate requirements but, if granulated and properly organized, data becomes more easy to be perceived and understood.
SA L2 errors are related to difficulty in comprehending situations, i.e. information is correctly perceived, but its significance or meaning is not comprehended. Poor mental models do not allow operators to understand part of data and information and, thus, they defer or take wrong decisions. The capability of zooming in-out granules can help in reducing these errors, because it allows operators to have different views (more fine or more abstract) of the same information. The adoption of wrong mental models is a different story. In this case, an operator is not able to comprehend because his mental model is not correct with respect to the current situation. Sometimes, this may be due because of his expectations, and we will show in Sect. 6 a technique that can support reduction of errors in this case, as well as reduction of errors due to misinterpretation of information and over-reliance of the operators. At other times, a wrong mental model is due to the incomplete knowledge of models and schema of the current situation. GrC and granular structures have been widely studied for the problem of concept formation, and abductive reasoning (Skowron et al. 2016) may be considered a suitable strategy for L2 errors due to wrong mental models.
An operator may be aware of what is happening, but have a poor mental model to project the situation in the near future. This is a common error at L3. As discussed, evolvable granular structures and the capability to reason and compare current situation with possible evolutions is useful to support reduction of this type of error and to enforce mental models for projection.
Lastly, failure to maintain multiple goals and adoption of habitual schema are two general problems in SA. In the first case, an operator can have problems in maintaining multiple goals in memory and in assessing their relative importance. Techniques to compare and rank granular structures with regard to the different goals can lighten the operator effort. By comparing different granular structures, we can also clearly show the differences and this can avoid the trap of using habitual schemas that do not fit with the current situation.
4 The proposed approach to use GrC for SA
To enable the process of information granulation and reasoning described in Sect. 3 and related subsections, we propose the adoption of a framework for GrC and the development of a set of tools and techniques implementing capabilities to support human-oriented reasoning and cognition. The approach we propose is shown in Fig. 7.

The proposed approach
The framework for GrC is devoted at the creation of granules and granular structures, and offers functionalities to operate with granules (e.g. refinement, coarsening, zooming-in and zooming out). Functionalities to assess the performance of the created granules, such as implementation of trade-off between coverage and specificity mentioned in Sect. 2.1, can be part of the framework. The granulation process and organization of granules in structures is done principally following the GDTA requirements. The framework is described in Sect. 5 and is based on the results of Yao (1999) on GrC using neighbourhood systems.
On the top of this framework a set of techniques to support human-oriented reasoning and cognition can be developed. The objective of these techniques is to reason on granular structures that represent situations in order to reduce SA errors and improve decision-making. As an example, we propose in this paper the conformity analysis to reduce SA L2 errors that is based on the results on finding interesting patterns proposed in (Liu et al. 1999). The conformity analysis is reported in Sect. 6.
5 The theoretical framework
Let us give a more formal definition of granule, granular structure, information granulation and distance between granular structures. We use the concepts of neighbour and neighbourhood systems described by Yao (1999). As discussed by Yao both rough sets and fuzzy sets can be understood in the context of the proposed framework.
For each element x of an universe U, we can define a subset \(n(x) \subseteq U\) that we call neighbourhood of x. More formally, given a distance function \(D\colon U \times U \rightarrow R^{+}\), for each \(d \in R^{+}\) we can define the neighbourhood of x:
We define (1) as a (type 1) granule. A cluster containing the element x can be considered as (1). Equation (1) is generic enough to support also other types of granulation besides spatial proximity. For instance, if D is a similarity function \(D\colon U \times U \rightarrow [0,1]\), then (1) defines a granule of similar elements. If D is an equivalence relation, (1) denotes an equivalence class. Using a fuzzy binary relationship, we can define a neighbourhood (1) as a fuzzy set.
From (1) high-order granules and granular structures may be constructed. Let us consider a neighbourhood system of x as a non empty family of neighbourhoods:
Neighbourhood systems like (2) can be used to create multi-layered granulations. Specifically, a nested system NS\((x) = \lbrace n_{1}(x), n_{2}(x), \ldots, n_{j}(x) \rbrace \) with \(n_{1}(x) \subset n_{2}(x) \subset \cdots \subset n_{j}(x)\) can induce a hierarchy such that we can define refinement and coarsening relationships on granules \(n_{1}(x) \prec n_{2}(x) \prec ... \prec n_{j}(x)\). The union of neighbourhood systems for all the elements of an universe defines a granular structure:
If NS\((x_{i})\) is a hierarchy, GS is a hierarchical granular structure.
For a granular structure GS we define the information granularity as:
For the information granularity the two extremes (finest and coarser granularity) are \(\frac{1}{|U|} \le \mathrm{IG} \le 1\).
The last concept that we need to formalize is the distance between two granular structures. This concept has been proposed in GrC based on rough sets (Liang 2011) and fuzzy sets (Qian et al. 2015). Given two granular structures GS\(_{1}\) and GS\(_{2}\), we define their distance as follows:
where |.| is a cardinality, and \(|\mathrm{NS}_{1}(x_{i}) \bigtriangleup \mathrm{NS}_{2}(x_{i})|\) is the cardinality of a symmetric difference between the neighbourhood systems: \(|\mathrm{NS}_{1}(x_{i}) \cup \mathrm{NS}_{2}(x_{i})| - |\mathrm{NS}_{1}(x_{i}) \cap \mathrm{NS}_{2}(x_{i})|\). It is easy to understand that the operation \(\bigtriangleup \) removes the elements that are common between two sets and, thus, can be considered as a sort of dissimilarity. Formula (5) considers the accumulated dissimilarity between the granules of two granular structures. A distance defined as (5) is clearly a measure of dissimilarity, so conversely we can define the similarity between two granular structures as:
Illustrative example Before continuing, we present an illustrative example to show how to create granular structures and evaluating information granularity and distance between structures. This example is partially based on some operational scenarios reported in Newman (2002) for the assessment of SA.
A flight air traffic controller has to monitor flight paths in order to assess rare events or unusual situations. In our specific case, the unusual situation to recognize is a splitting manoeuvre that occurs when one aircraft staying close in a group suddenly moves away from a predefined trajectory.
Let us suppose \(U = \lbrace a, b, c, d \rbrace \) is the universe of all aircrafts an operator has to monitor. Let us suppose the situation recognized at \(t=t_{0}\) is S with four objects separated. Let us suppose that from S the SA operator expects two probable projections, let us call P1(S) and P2(S), where three objects group together. The example is graphically shown in Fig. 8.
Let us see how to create granular structures that can support reasoning on this scenario.

Situations and granular structures—example
For S we have the following neighbourhood systems:
In this case, the granular structure GS\(_{S}\) is the union of four singletons corresponding the four objects of the universe.
For P1(S) we have the following neighbourhood systems:
with NS(a), NS(b) and NS(c) that are nested systems and induce the hierarchy we can see in GS\(_{\mathrm{P1}(S)}\) with the creation of a coarse granule \(\lbrace a, b, c \rbrace \) reporting information on groups of aircrafts.
For P2(S) we have the following neighbourhood systems:
and the granular structure for this second projection GS\(_{\mathrm{P2}(S)}\) “appears” to be in some way similar to GS\(_{\mathrm{P1}(S)}\) for what concern the number of the object aggregated.
Let us calculate the information granularity of these structures
and the distance between these structures:
5.1 What is the value for SA?
In our illustrative example, the scenario requires granulation of data per spatial proximity. In this case, the formalism of (1) fits well since SA L1 requirements demand the perception of elements that are spatial closed. However, as mentioned in the previous section, if SA L1 requirements demand the perception of similar objects, a proper similarity function can be defined, and if SA L1 requirements demand the perception of objects that are indistinguishable with respect to some attributes, an equivalence relation can be defined to induce the creation of granules.
In other words, the value of defining granules as done in the framework lies in the flexibility we gain in the creation of type 1 granules according to the different granulation criteria that match the criteria a GDTA indicates for SA L1 requirements.
At comprehension level, SA L2 requirements usually give indications on what are the elements of L1 to be fused and/or abstracted in order to improve the comprehension. In our illustrative example, we need to comprehend if objects are spatially close together to assess the situation. We can support the comprehension with the creation of more abstract information fusing low-level information (in our scenario about the position of groups of objects), and this can be done with the adoption of neighbourhood systems such as (2). Neighbours of an element may be considered high-order granules and can be aggregated into a single multi-layered hierarchical structure, which is a granular structure such as (3). A granular structure such as (3) can be considered as an approximated representation of a situation at a particular time. A measure of the uncertainty associated with this representation is given by the information granularity (4).
A granular structure is such to organize the elements of an environment according to the SA L2 requirements improving the comprehension of a situation and, at the same time, is a building block for reasoning on situations and support projections of situations.
We evidence that to reason on situations, information granularity (4) and distance between granular structures (5) are useful for an SA operator. The first allows to measure the degree of uncertainty associated with a situation represented by a granular structure, the second allows to understand how two situations may differ. So these measures can be considered as building blocks of some interesting application we mentioned in Sect. 3.2 such as the comparison and ranking of situations.
However, this is not sufficient for an SA operator to take informed decision, since SA model demands the capability to project into near future the recognized situation, i.e. satisfying SA L3 requirements. To this purpose (4) and (5) can be used to give early indications on how projected situations differ with respect to a recognized one.
Let us look at the three situations of the illustrative example in terms of IG and D. The situation S is represented by GS\(_{S}\) with a value of IG\((GS_{S}) = \frac{1}{|U|}\) that is the finest granulation. The SA operator in this case has precise information on the position of the four objects. We can appreciate that there is a difference between the situation S and its two projections P1(S) and P2(S) because of the different values of IG. This means that both the projected situations bring a different and additional information that, intuitively, is the creation of an higher order granule. However, with IG we are not able to differentiate between the two projections since the information granularity is the same, i.e. IG\((\mathrm{GS}_{\mathrm{P1}(S)}) = \mathrm{IG}(\mathrm{GS}_{\mathrm{P2}(S)})\).
In this case, we can say to an SA operator that the projected situations bring a new kind of information (that is the high-order granule), but we cannot support the operator with early warnings on the fact that the two projections are, indeed, representative of different situations. Also the values of the distances between S and the projections is the same, i.e. \(D(\mathrm{GS}_{S}, \mathrm{GS}_{\mathrm{P1}(S)}) = D(\mathrm{GS}_{S}, \mathrm{GS}_{P2(S)})\). On these bases one could be tempted to consider the two projections as similar. But the two projections are different and the distance between the two projections \(D(\mathrm{GS}_{\mathrm{P1}(S)}, \mathrm{GS}_{\mathrm{P2}(S)}) \ne 0\) clearly evidences this fact.
When two granular structures have the same information granulation, the distance between granular structures is the only way to measure dissimilarity. In SA applications, in most cases, granules and levels of granulations are strongly related to the hierarchies defined in the GDTA, and situations can evolve during the time without changing the information granulation of the correlated granular structures. In these cases the distance between structures appears the only indicator of dissimilarity between situations.
Information granulation and distance between granular structures may be used to support projection by giving indications on new kind of information that can be available into a projected situation and/or how the projected situations differ from the recognized one. These measures can be considered by an SA operator as early indicators of informative and structural differences between a recognized situation and a possible projection.
6 Conformity analysis
We have seen that information granularity and distance are useful indicators that show how two granular structures representing situations can differ or be similar from an informative and structural perspective. However, these indicators do not state anything about classification or interpretation (e.g. good, bad, expected, etc.) of a specific situation. The conformity analysis presented in this section is devoted to understand if a recognized situation conforms to the expectations of an SA operator. Conformity analysis is inspired by the fuzzy pattern matching technique proposed by Liu et al. (1999). The idea is simple: we provide a linguistic description of the granules in a granular structure and then compare these descriptions with a set of expectations formalized with fuzzy if-then rules.
Let us suppose we granulate per spatial proximity using centroid-based clustering. A granule is a cluster of observations that are close in the space and can be regarded as fuzzy pattern in the form \(x_{1} \; is \; A_{1} \; \mathrm{AND} \; \cdots \; x_{k} \; is \; A_{k}\), where \(x_{k}\) is the kth attribute of the centroid of the cluster and \(A_{k}\) is a family of linguistic variables. We can also evaluate a confidence degree of the linguistic description as a t-norm \(\sigma = \mathrm{min}(\mu _{A_{1}}, \ldots, \mu _{A_{k}})\). \(\sigma \) gives information on the strength of the linguistic description associated with a granule. If we have a classification of this pattern, we can write this as an association rules in the form
where \(C_{i}\) can be a fuzzy set or a categorical value. If we cannot classify the pattern, we should not assume anything on its classification.
A granular structure is the union of all the granules and thus can be succinctly formalized as:
where \(i\in [1, n]\) with n the number of granules of the structure.
Let us suppose we have another set of fuzzy patterns or rules that are formalized by SA operators based on their knowledge and expectations:
where y are attributes, B linguistic variables, and C fuzzy sets or categorical values. The set of expected rules is:
with \(j<i\), since usually experts do not provide a high number of rules.
We can rank a granular structure with respect to a set of expectations of an operator comparing (7) and (8). In Liu et al. (1999) weights \(w_{i,j}\) between \(R_{i}\) and \(E_{j}\) are calculated in order to rank the discovered patterns with regard to conformity and unexpectedness. While conformity may be quite clear to understand, unexpectedness indeed is more challenging and can be considered as any kind of deviation with respect to expectations. We refer to the original work of Liu et al. (1999) for additional details on this aspect.
In Liu et al. (1999) the basic idea is to compute a set of weights \(w_{(i,j)}\) in two phases:
-
evaluating a degree of matching between the attribute names of \(R_{i}\) and \(E_{j}\). This degree is evaluated via the formula
$$\begin{aligned} L_{i,j} \; = \; \frac{|A_{(i,j)}|}{\max (|e_{j}|, |r_{i}|)}, \end{aligned}$$(9)where \(|A_{(i,j)}|\) is the size of the set of attribute names that are common to the conditional parts of \(R_{i}\) and \(E_{j}\), and \(|e_{j}|\), \(|r_{i}|\) are the numbers of attribute names in the conditional parts of, respectively, \(E_{j}\) and \(R_{i}\). For the consequential parts, we suppose the name of the class is the same so it does not account in (9);
-
Evaluating the degrees of matching between the attribute values, via \(V_{(i,j)k}\) that is the degree of matching between the kth attribute value of conditional parts, and \(Z_{(i,j)}\) that is the degree of value match of consequential parts. If we do not have the correct classification, we consider 1 the degree of value matches of the consequential parts.
On the basis of \(L_{(i,j)}\), \(V_{(i,j)k}\) and \(Z_{(i,j)}\), the weights \(w_{(i,j)}\) for the conformity ranking can be calculated via:
if \(|A_{(i,j)}| \; \ne 0\). \(w{(i,j)} = 0\) if \(|A_{(i,j)}| = 0\).
The degree of match of a rule \(R_{i} \in R\) with respect to the set of expected rules \(E_{j} \in E\) is defined as:
If E is a set of expected rules of a specific SA operator, then \(W_{i}\) represents a degree of conformity of a granule within a granular structure with respect to the expectations of the operator. In SA terms, this means a degree of conformity of information (granule) characterizing a recognized situation (granular structure) with the expectations of the operators.
Let us now define how to calculate \(V_{(i,j)k}\) and, if we have a classification, also \(Z_{(i,j)}\). In Liu et al. (1999) different cases to evaluate similarity between attribute values are presented that depend also on the specific operators \(\lbrace < \; > \; = \; \ne \; ... \rbrace \) involved in the rules. In fact, Liu et al. (1999) treat the case where patterns are discovered with knowledge mining technique, such as C4.5 (Quinlan 2014), so they need to compare cases such as Age \(<65\) in the discovered patterns with fuzzy statements such as \(\mathrm{Age} \; \mathrm{is} \; \mathrm{Young}\) of the user expectations. In our case, attribute values are represented by fuzzy sets in both \(R_{i}\) and \(E_{j}\), so we need to find a similarity between two fuzzy sets and we can do this via the mutual subsethood (Kosko 1997). Given two fuzzy sets A and B, the mutual subsethood measures the extent to which A equals B and can be evaluated via:
where |.| is the cardinality of the fuzzy set. In the case of Gaussian membership function, \(|A|=\int _{- \mathrm{inf}}^{+ \mathrm{inf}} a(x) \; =\int _{- \mathrm{inf}}^{+ \mathrm{inf}} \exp ^{- (\frac{x-c}{\sigma })^{2}}\), and \(|A \cap B|\) can be easily calculated based on the crossover points. Let us take a look at Fig. 9 from Paul and Kumar (2003) reporting an example of mutual subsethood for two Gaussian membership functions, with \(c_{1} > c_{2}\) and \(\sigma _{1} > \sigma _{2}\).

Mutual subsethood (from Paul and Kumar (2003))
The crossover points are evaluated as follows:
Equations (13) and (14) are used to calculate \(|A \cap B|\) in all the cases for which \(c_{1} \ne c_{2}\). If \(c_{1} = c_{2}\) there are no crossover points and \(h_{1}=h{2}=c\). In this case, \(|A \cap B| = \min (\sigma _{1} , \sigma _{2}) \sqrt{\pi }\). Details on the formulas, which are Gaussian integrals, to evaluate \(|A \cap B|\) in the other cases are available in literature, for instance in annex of Paul and Kumar (2003).
7 Evaluation
The objectives of our evaluation are related to a preliminary assessment of some of the benefits we envision for GrC in SA, specifically: to support comprehension and projection, and reduce L2 errors. The term preliminary here indicates the fact that we do not use a methodology for assessment of situation awareness, such as SAGAT (Endsley 1995a), in a real scenario with real operators. We have instantiated the proposed framework using a clustering technique and used a synthetic data set to simulate an evolving situation, and evaluated how granular structures can be used to reason on evolving situations.
7.1 Using SOM to create granules and granular structures
To create granules and granular structures we decided to use SOM as a clustering technique. The Kohonen SOM (Kohonen 1998) is an unsupervised neural network method particularly useful for data exploration and discovery of novel inputs. An SOM performs a topology-preserving mapping of the input data to the output units, enabling a reduction in the dimensionality of the input. This aspect gives SOM an added value related to visualization and visual inspections of the formed clusters. An SOM learns in a competitive way: the output neurons compete for the classification of the input patterns that are presented in the training phase. The output neuron with the nearest weight vector is classified as the winner. An output neuron is activated according to \( \mathrm{Out}_{j} = F_{\mathrm{min}}\sum _{i} (x_{i} - w_{ji})^2\), where \(F_\mathrm{min}\) is a threshold function, and \(w_{ji}\) is a connection weight between nodes j and i. Several works have compared SOM with other clustering techniques. In Mingoti and Lima (2006) SOM has been compared with k-means, fuzzy c-means and hierarchical clustering. Results show that SOMs generally have lower performance and are very sensitive to input data structure. In deciding to use SOMs for granulation in SA we accept a trade-off: to pay the cost of non-optimal clusters formation in favour of intuitive visualization features and easy data/pattern exploration that can offer benefits for SA.
7.2 Scenario for evaluation
To evaluate our approach, we refer to the already introduced surveillance scenario devoted to recognize anomalous situations, such as a splitting manoeuver. Let us suppose that two out of the four aircrafts are approaching the destination and the SA operator has to assess if they are proceeding close. Latitude and longitude of the objects are mapped on a bi-dimensional area that has to be monitored by the operator. The normal situation is defined by a trajectory that the aircraft objects have to follow in approaching the destination. Figure 10 shows an example of the normal trajectory from A to B that two aircrafts (depicted with red and blue points) have to follow in approaching B. The normal situation is when both the objects are approximatively in the area marked with two straight lines. When two objects are close and, at a certain time, one of the two suddenly changes, there is a split situation that is circled with an ellipse in the figure.

Area under observation
In our scenario, to reason with granules we have to induce a partition of the area under observation of Fig. 10 in several sub-areas that can group together per proximity the objects under surveillance. Figure 11 shows a partition in 9 sub-areas of proximity that can be induced using three fuzzy sets and linguistic labels on the x and y dimensions of the area. The 9 partitions can be classified with respect to normal (N) or anomalous (A) positions that the objects can take in the area under observation. For each axis, we used Gaussian functions centred at 0, 0.5 and 1, with variance 0.175.

Partition of the area under observation
Starting from a data set of observations \(o_ {j} =(x_{j}, y_{j})\) of positions of an aircraft, we can create granules \(g = \lbrace o_{j}, o_ {k} \vert o_{j} \approx o_ {k} \rbrace \), where \(\approx \) is a proximity relation. A granule g groups a set of observations that are close together.
7.3 Preparation of granular structure
To create granular structure we fuse granules g for aircrafts under observations. In our example, we limit to two objects and use a \(3 \times 2\) SOM (where \(\times \) refers to the multiplication sign) to fuse positions of the two objects. To train the SOM, we use the data set graphically shown in Fig. 10 and is representative of an evolutionary situation (the two objects are moving towards the destination) that includes a split manoeuvre. The trained map is shown in Fig. 12. Each neuron of the map is a granular structure fusing the position of two objects and the figure shows also the situations associated with the granular structures.

Granular structures created with the SOM
As we can see there are three granular structures that represent the situation GS2. The other three situations are represented by different granular structures. This is due to the fact that the partition we have done is larger in the middle of the area. Let us provide a linguistic description of the granular structures in the map and evaluate the conformity with respect to the expectations of the SA operators that can be succinctly described as \(\mathrm{Ob}_{1} \, \mathrm{is} \, N \, \mathrm{AND} \, \mathrm{Ob}_{2} \, \mathrm{is} \, N\), i.e. the two aircrafts move close together along a normal trajectory. The set of expectations can be formalized as follows, where FAR, MED and CLO are fuzzy sets with Gaussian membership functions previously reported:
The results shown in Table 1 reports the linguistic description of each granular structure, the confidence degree \(\sigma \) associated with the description, and the rank of conformance with the set of expectations evaluated with (10) and (11). We report as separated the three different granular structures associated with the situation GS2, i.e. GS2\(_{1}\), GS2\(_{3}\) and GS2\(_{3}\).
As mentioned, an SOM map allows visual inspection of the data. In Fig. 12 we used a fan diagram style where, for all the granular structures created, the size of each variable for the two objects is clearly understandable. Another advantage of using SOM for spatial granulation is that the position of the neurons reflects proximity in the data. This means that granular structures positioned around a neuron represents probable projections of the granular structure represented by the neuron. The data set for our scenario in fact reports observations of a spatio-temporal evolution of the two objects. This has allowed us to replicate a case similar to the spatio-temporal granulation shown in Fig. 4, with the four granular structures resembling the case of an evolvable granular structure. This simplification is useful for our objectives that aim to show the benefits of reasoning with granular structures.
7.4 Reasoning with the created granular structures
Now let us monitor the positions of \(\mathrm{ob}_{1}\) and \(\mathrm{ob}_{2}\) during three time windows. Table 2 reports the observations for the two objects in [t1, t2], and the associated granular structures of the map, i.e. GS1. If we review Table 1, an SA operator processing this information can easily perceive that the two objects are in a proximity region that is quite far from the destination. This information has an associated degree of confidence sufficiently high. At comprehension level, the operator recognizes the situation in this time window as in line with expectations, i.e. rank is 1. In summary, Table 2 reports a set of observations for which no anomalous situations are recognized. Also in terms of projections, looking at the neighbours of GS1, that are GS2\(_{1}\) and GS2\(_{3}\), an SA operator does not expect changes in the situations. The indicators of information granularity IG of the current situation GS1 and of its probable projections are the same, and the distance D between GS1 and its probable projections is zero. This means that the situations are similar from an informative and structural perspective. Also the ranking of the projections with respect to the expectations is 1 meaning the situations projected conform to the expectations.
Table 3 reports the observations for the two objects in another time window, i.e. [t4, t5], and the associated granular structures. Similar arguments can be provided for perception and comprehension levels. However, in this case a SA operator can receive early warnings on one of the probable projections of the situation recognized with the last observations. In fact, if we evaluate the IG of GS2\(_{2}\) and of its projection GS3, we can see that are different and their distance is not zero. This indicates that the situation is changing in this projection, and also the ranking value indicates that this projection is not so conform to the expectations.
Table 4 lastly reports the observations for the two objects in [t5, t6]. In this case, as anticipated in the previous slice, the situation changes and does not fully conform to the expectations. A deeper look at the finer granules for the two objects clearly shows that object ob\(_{1}\) is moving away from the normal trajectory.
8 Conclusions and future works
In this paper, we presented a GrC framework based on the results of Yao on granular computing using neighbourhood systems. The set-theoretic framework adopted defines the concepts of granule, granular structure, information granulation and distance between granular structures that are used as building blocks for representing situations and reasoning on them. The conformity analysis is an example of how we can reason on granular structures in order to reduce errors at comprehension level and biases, by adding information on how much a situation conforms to domain knowledge or expectations of an SA operator. Furthermore, it can support multiple views for different SA operators. This can be done via conformity analysis with different sets of fuzzy rules that represent different SA operators expectations. A preliminary evaluation has been done in the context of a surveillance scenario.
The results achieved need further investigations that we are going to execute also in additional scenarios such as airport security (Fenza et al. 2010), blended commerce (D’Aniello et al. 2014) and green fleet management (D’Aniello et al. 2016b), but are encouraging in the perspective of a systemic integration of SA and GrG, and are a good basis for the development of our perception-oriented SA framework delineated in Benincasa et al. (2015) and Loia et al. (2016).
The preliminary evaluation reported in this paper was not devoted to show how to create good granular structures with SOM but, instead, used an SOM as a rapid way to create granular structures resembling a case of evolvable granular structures for an evolving situation. This allowed us to show the benefits of our approach for comprehension and projection. However, the study of evolvable granular structure for evolutionary situations needs further conceptual development which we left for future works.
As example, in general, projecting into a near future requires the capability to perceive and comprehend evolutions of a granular structure. Given an universe U the number of granular structures we can create is limited by the number of partitions of the universe. Furthermore, in real cases not all the partitions of the universe can be admissible projections of a situation. Knowing the rules that govern phenomena under observation can help in selecting the granular structures that can be considered as admissible projections. Moreover, the projection of a situation may depend also on the actions executed by actors of the situation. Having a clear view of the actions that are admissible in a specific situation can give a strong support to SA operators for the SA L3 issue. Formal languages to model transitions between situations, such as situation calculus (Lin 2008), can be useful to model transitions between situations on the basis of admissible actions. Figure 13 shows how we can combine GDTA and a formal representation of transition between situations. GDTA L1 and L2 requirements are used as described in this paper to create granules and granular structures. L3 requirements are used to create a graph of transitions between situations. This graph is created taking into account also what we need to project. Each circle in the graph is a situation (a granular structure) and the transition between situations can be governed by simple rules such as \( \mathrm{if} \, \mathrm{do}(a, S_{i}) \, \mathrm{then} \, S_{j}\) where a is an admissible action.

Projection of the situations on the basis of actions
With the combined application of the information granularity, distance and conformance analysis an operator may be aware of the differences between the situations represented in the graph. If an SA operator is able to classify good or expected situations (e.g. green circle in the Fig. 13) from bad or unexpected ones (red circles), he can be aware of how much the projections are similar to bad or good situations. The combined adoption of action-based rules and granular structures may bring additional interesting applications in SA, such as the development of decision support systems based on SA D’Aniello et al. (2016a) that can recommend a flow of actions that operators have to execute to reach a particular situation of interest.
References
Ahmad SSS, Pedrycz W (2016) The development of granular rule-based systems: a study in structural model compression. Granul Comput. doi:10.1007/s41066-016-0022-5
Antonelli M, Ducange P, Lazzerini B, Marcelloni F (2016) Multi-objective evolutionary design of granular rule-based classifiers. Granul Comput 1(1):37–58
Benincasa G, D’Aniello G, De Maio C, Loia V, Orciuoli F (2015) Towards perception-oriented situation awareness systems. In: Angelov P, Atanassov K, Doukovska L, Hadjiski M, Jotsov V, Kacprzyk J, Kasabov N, Sotirov S, Szmidt E, Zadrony S (eds) Intelligent systems’ 2014, advances in intelligent systems and computing, vol 322. Springer, New York, pp 813–824
Cai M, Li Q, Lang G (2016) Shadowed sets of dynamic fuzzy sets. Granul Comput. doi:10.1007/s41066-016-0029-y
Ciucci D (2016) Orthopairs and granular computing. Granul Comput 1(3):159–170. doi:10.1007/s41066-015-0013-y
D’Aniello G, Gaeta M, Orciuoli F, Tomasiello S, Loia V (2014) A dialogue-based approach enhanced with situation awareness and reinforcement learning for ubiquitous access to linked data. In: International Conference on In Intelligent Networking and Collaborative Systems (INCoS), 2014. IEEE, pp 249–256
D’Aniello G, Gaeta A, Gaeta M, Lepore M, Orciuoli F, Troisi O et al (2016a) A new dss based on situation awareness for smart commerce environments. J Ambient Intell Humaniz Comput 7(1):47–61
D’Aniello G, Gaeta A, Loia V, Orciuoli F (2016b) Integrating gso and saw ontologies to enable situation awareness in green fleet management. In: 2016 IEEE international multi-disciplinary conference on cognitive methods in situation awareness and decision support (CogSIMA), pp 138–144
Das S, Kar S, Pal T (2016) Robust decision making using intuitionistic fuzzy numbers. Granul Comput. doi:10.1007/s41066-016-0024-3
Dubois D, Prade D (2016) Bridging gaps between several forms of granular computing. Granul Comput 1(2): 115–126. ISSN 2364-4974
Ekel P, Kokshenev I, Parreiras R, Pedrycz W, Pereira J Jr (2016) Multiobjective and multiattribute decision making in a fuzzy environment and their power engineering applications. Inf Sci 361:100–119
Endsley MR (1995a) Measurement of situation awareness in dynamic systems. Hum Factors J Hum Factors Ergon Soc 37(1):65–84
Endsley MR (1995b) A taxonomy of situation awareness errors. Hum Factors Aviat Oper 3(2):287–292
Endsley MR (1995c) Toward a theory of situation awareness in dynamic systems. Hum Factors J Hum Factors Ergon Soc 37(1):32–64
Endsley MR (2011) Designing for situation awareness: an approach to user-centered design. CRC Press, Boca Raton
Fenza G, Furno D, Loia V, Veniero M (2010) Agent-based cognitive approach to airport security situation awareness. In: 2010 international conference on complex, intelligent and software intensive systems (CISIS). IEEE, pp 1057–1062
Kohonen T (1998) The self-organizing map. Neurocomputing 21(1):1–6
Kosko B (1997) Fuzzy engineering. Prentice-Hall Inc, Upper Saddle River. ISBN 0-13-124991-6
Leite D, Costa P, Gomide F (2012) Interval approach for evolving granular system modeling. In: Learning in non-stationary environments. Springer, Berlin, pp 271–300
Liang J (2011) Uncertainty and feature selection in rough set theory. Springer, Berlin, pp 8–15
Lin F (2008) Situation calculus. Found Artif Intell 3:649–669
Liu B, Hsu W, Mun L-F, Lee H-Y (1999) Finding interesting patterns using user expectations. IEEE Trans Knowl Data Eng 11(6):817–832
Livi L, Sadeghian A (2015) Data granulation by the principles of uncertainty. Pattern Recognit Lett 67:113–121
Livi L, Sadeghian A (2016) Granular computing, computational intelligence, and the analysis of non-geometric input spaces. Granul Comput 1(1): 13–20. ISSN 2364-4974
Loia V, D’Aniello G, Gaeta A, Orciuoli F (2016) Enforcing situation awareness with granular computing: a systematic overview and new perspectives. Granul Comput 1(2): 127–143. ISSN 2364-4974
Mingoti SA, Lima JO (2006) Comparing som neural network with fuzzy c-means, k-means and traditional hierarchical clustering algorithms. Eur J Oper Res 174(3):1742–1759
Newman RL (2002) Scenarios for rare event simulation and flight testing. Crew Systems TR-02-07A, Monterey Technologies Inc
Paul S, Kumar S (2003) Subsethood based adaptive linguistic networks for pattern classification. IEEE Trans Syst Man Cybern Part C Appl Rev 33(2):248–258
Pedrycz W (2010) Evolvable fuzzy systems: some insights and challenges. Evol Syst 1(2):73–82
Pedrycz W (2014) Allocation of information granularity in optimization and decision-making models: towards building the foundations of granular computing. Eur J Oper Res 232(1):137–145
Pedrycz W, Homenda W (2013) Building the fundamentals of granular computing: a principle of justifiable granularity. Appl Soft Comput 13(10):4209–4218
Pedrycz W, Gacek A, Wang X (2015) Clustering in augmented space of granular constraints: a study in knowledge-based clustering. Pattern Recognit Lett 67:122–129
Qian Y, Li Y, Liang J, Lin G, Dang C (2015) Fuzzy granular structure distance. IEEE Transa Fuzzy Syst 23(6):2245–2259
Quinlan JR (2014) C4. 5: programs for machine learning. Elsevier, San Francisco
Skowron A, Jankowski A, Dutta S (2016) Interactive granular computing. Granul Comput 1(2):95–113
Wang C, Fu X, Meng S, He Y (2016) Spifgia operators and their applications to decision making. Granul Comput. doi:10.1007/s41066-016-0025-2
Xu W, Yu J (2017) A novel approach to information fusion in multi-source datasets: a granular computing viewpoint. Inf Sci 378:410–423
Xu Z, Wang H (2016) Managing multi-granularity linguistic information in qualitative group decision making: an overview. Granul Comput 1(1): 21–35. ISSN 2364-4974
Yao JT, Vasilakos AV, Pedrycz W (2013) Granular computing: perspectives and challenges. IEEE Trans Cybern 43(6):1977–1989
Yao Y (1999) Granular computing using neighborhood systems. In: Advances in soft computing. Springer, London, pp 539–553
Yao Y (2013) Granular computing and sequential three-way decisions. In: International conference on rough sets and knowledge technology. Springer, Heidelberg, pp 16–27
Yao Y (2016) A triarchic theory of granular computing. Granul Comput 1(2): 145–157. ISSN 2364-4974
Zadeh LA (1997) Toward a theory of fuzzy information granulation and its centrality in human reasoning and fuzzy logic. Fuzzy Sets Syst 90(2):111–127
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
D’Aniello, G., Gaeta, A., Loia, V. et al. A granular computing framework for approximate reasoning in situation awareness. Granul. Comput. 2, 141–158 (2017). https://doi.org/10.1007/s41066-016-0035-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41066-016-0035-0