
Abstract
Thermal conductivity is an important thermophysical property of nanofluids in many practical heat transfer applications. In this study, a novel approach is proposed to predict the thermal conductivity of nanofluids under multiple operating parameters. The proposed approach may be extended to be used to other thermophysical properties of nanofluids. The Kohonen’s self-organizing maps (SOM), as an unsupervised artificial neural network (ANN), is used to provide an accurate prediction tool for the problem in hand. Furthermore, SOM, similar to any ANN-based approach, can handle nonlinear and complex input–output relationships with high generalization ability. Comparison of the SOM predicted values with corresponding available theoretical results as well as experimental data implies high prediction capability of the developed approach. The proposed approach was utilized to predict thermal conductivity ratio of oxide (Al2O3, CuO and TiO2)/water nanofluids under various operating conditions (nanoparticle size, temperature, and nanoparticle volume fraction).
Similar content being viewed by others

1 Introduction
Nanomaterials have shown promising applications in different engineering sectors [1,2,3]. Adding nanoparticles (1–100 nm) into a base fluid in heating and cooling processes is one of the methods to increase the overall heat transfer coefficient between the fluid and the surrounding surfaces [4,5,6]. The main reason of this phenomenon is the significant increasing of the thermal conductivity of the nanofluid (with nanoparticles) compared with the base fluid (without nanoparticles) [7,8,9,10,11]. Effects of different parameters, such as temperature, volume fraction, particle shape and particle size) on the thermal conductivity ratio (TCR) of the nanofluid and that of its base fluid studied in many articles [12,13,14]. Thermophysical properties of different nanofluids types have been investigated including different nanoparticles types such as CuO [15], TiO2 [16], Fe3O4 [17], Al2O3 [18], and Ag [19] as well as different base fluid types such as water [20] and ethylene glycol [21].
Over the last three decades, nanofluids have attracted more and more attention. The main driving force for nanofluids research lies in a wide range of applications [22,23,24,25].
Various theoretical and experimental studies have been conducted on enhancement and prediction of the TCR of different types of nanofluids. The first theoretical investigation of the TCR can be traced back by Maxwell [26]. In this pioneering work, Maxwell presented a general equation to predict the thermal conductivity of dilute suspensions with micro particles. Then, several convenient and compact analytical and empirical equations for predicting TCR of nanofluids have been presented in the literature [27].
Available methods of measuring nanofluids thermal conductivity experimentally, is too costly and time-consuming task. Furthermore, the presented empirical and theoretical correlations in the literature are reliable for some operating parameters with limited ranges. Therefore, due to the nonlinear behavior the thermal conductivity, determining a practical correlation of it as a function of multiple operating parameters is often complicated and sometimes impossible. So, the application of intelligent systems based techniques such as ANNs was proposed by some researchers. ANNs show very important features such as generalization, mapping capabilities, fault tolerance, robustness, and high speed data processing. They also have the ability to learn by examples and detect complex inherent nonlinear relationships between the inputs and the outputs. ANN may be used as an excellent alternative to numerical and analytical based approaches without involving in solving complex mathematical models [28,29,30,31]. Hence, ANN is used as powerful tool to solve complex engineering problems in different real-world applications with a significant reduction in cost and time [32,33,34,35,36,37,38].
Ahmadloo et al. [39] presented a 5-input multi-layer perception (MLP) as an ANN model for the estimation of the TCR of various nanofluids. Fifteen nanofluids with different types of nanoparticles and base fluids were used to develop the MLP model using experimental data reported in the literature. Ariana et al. [40] presented a study to develop and validate MLP model to estimate the TCR of alumina/water nanofluids as a function of volume fraction, temperature and diameter of the nanoparticle. Papari et al. [41] employed MLP model to estimate TCR of nanofluids consisting of multi-walled carbon nanotubes suspended in different base fluids. Hemmat et al. [42] investigated the efficiency of MLP neural network in modeling TCR of water/EG (40–60%) nanofluid with Al2O3 nanoparticles. The measurement of nanofluid thermal conductivity at different volume fractions and temperatures was taken using KD2 Pro.. Longo et al. [43] presented a 3-input and a 4-input MLP ANN for predicting the TCR of oxide–water nanofluids. Both models employed for investigating the effect of nanoparticle thermal conductivity, nanoparticle volume fraction, and temperature, whereas the 4-input MLP model also considers the effect of the average size of nanoparticle cluster. Hemmat et al. [44] modeled the TCR of Al2O3–water nanofluid at different solid volume fractions and temperatures by ANN.
All the above-mentioned studies focused on prediction of the TCR of nanofluids using a limited number of input parameters and only one unknown target parameter (TCR). In this study, a general approach is proposed to predict multiple unknown parameters including TCR based on any number of known input parameters. To check the validity of the approach, it is applied to three different nanofluids using both theoretical and experimental data available in literature.
2 Self-organizing approach
In this article, self -organizing maps (SOM), as one an unsupervised ANN, is used to predict the TCR of nanofluids based on both theoretical and experimental literature data. As other ANNs approaches, SOM shows many important features such as generalization, data exploration, mapping capabilities, robustness, fault tolerance, and high speed data processing. Additionally, they have the ability to detect complex nonlinear relationships between the outputs and the inputs. Once the training process is accomplished, SOM can be utilized to predict the unknown outputs which are not used during training process. SOM is a powerful tool that used to convert the complex relationships into simple relationships. It is used in many engineering applications such as inverse dynamic control of industrial robots [45], unmanned aerial vehicle control [46], aircraft dynamics [47], and image processing [48].
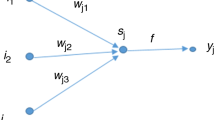
SOM is formed by creating a two-dimensional network consists of many interconnected nodes Fig. 1; the two-dimensional network is the common used arrangement of the output neurons. First, the synaptic weight vector for each node (neuron) in the map is initialized by assigning them proper values selected randomly from the training data using the principal component initialization to achieve exact reproducibility of the obtained results [49]. Secondly, a random selected input vector from the input space is presented to the network and the response of each node is evaluated and the one which produces the maximum response, as well as those adjacent to it in the network, are adapted so as to produce a stronger response to that input. After a number of iterations of each input pattern the system should ideally reach a state where an ordered image of the inputs stored in the network. More details about the training process of the SOM as summarized here:

SOM network architecture
2.1 Training algorithm
At each iteration, the value of a predefined discriminant function for each node is calculated using an input vector chosen randomly from the training dataset. The node that has the largest value of the discriminant function, at each iteration, is stated as the winner of the competition process [50, 51].
Let \(\bar{x}\) (with \(m\) space dimension) denotes input vector selected randomly from the input domain
The vector of synaptic weight (reference vector) of each node in the output layer has the same dimension of the input space (\(m\)). Let the synaptic weight vector of a node \(j\) be denoted by
where \(l\) is the number of nodes in the map. To determine the best match node (BMN) of \(\bar{x}\) that has a synaptic weight of \(\bar{w}_{j}\), the algorithm computes the inner products \(\bar{w}_{j}^{T} \bar{x}\) for \(j = 1,2, \ldots ,l\), then the node with the leading inner product value is selected as BMN.
The best matching condition, \(\bar{w}_{j}^{T} \bar{x}\) is maximized, is expressed mathematically as Euclidean distance minimization between \(\bar{x}\) and \(\bar{w}_{j}\). If \(i(\bar{x})\) defines the BMN for \(\bar{x}\), \(i(\bar{x})\) could be computed by [50]
The BMN locates of a topological neighborhood of cooperating nodes on the map. Then, more nodes surrounding the BMN are adjusted. Mathematically, let \(h_{ki}\) denotes the topological neighborhood centered on the wining node \(i\), and \(k\) denotes a typical node of a set of excited (cooperating) nodes around wining node \(i\). The distance between wining node \(i\) and excited cooperating \(k\) is defined by \(d_{ik}\). Then, the topological neighborhood \(h_{ki}\) is defined as a function of the distance \(d_{ik}\), such that it satisfies two different conditions:
-
1.
\(h_{ki}\) has a peak value at the BMN \(i\) for which the distance \(d_{ik}\) is diminished; in other words, it is symmetric about \(d_{ik} = 0\)
-
2.
The topological neighborhood \(h_{ki}\) amplitude decreases monotonically with increasing lateral distance \(d_{ik}\), decaying to zero for \(d_{ik}\) approaches infinity; this is an important condition to obtain a better convergence.
A typical choice of \(h_{ki}\) that fulfills the aforementioned conditions is the well-known Gaussian function [50]
which is independent of the BMN location. Where \(\sigma\) is a parameter defines the effective width of the topological neighborhood. It measures the degree of participation in the learning process between the BMN and its excited neighbors.
The lateral distance \(d_{ik}\) between winning neuron \(i\) and excited neuron \(k\) is defined as [52]
where the vector \(\bar{r}_{k}\) defines the position of excited node \(k\) and \(\bar{r}_{i}\) defines the position of winning node \(i\).
In addition, the topological neighborhood size shrinks with time based on the following exponential decay function [52]
where \(\sigma_{o}\) is the initial value of \(\sigma\) and is equal to the lattice radius, \(n\) is the discrete time parameter and \(\tau\) is a time constant through the entire learning process which may be evaluated from [52]
By definition, for unsupervised and self-organizing ANN, \(\bar{w}_{j}\) of neuron \(j\) should be adjusted according to its relation to the input vector \(\bar{x}\); namely, \(\bar{w}_{j}\) is changed towards the input vector \(\bar{x}\). The synaptic weight vectors of all nodes are updated according to the following algorithm is [53]
where \(\alpha (n)\) denotes the learning rate which decayed exponentially and evaluated by
where \(\alpha_{o}\) is the initial learning rate and be chosen by experience to be less than 0.5 and \(\tau\) is a time constant.
These training procedures are repeated using a random selected input vector at each step to ensure that every input vector has been selected as an input pattern. It ensures the good formulation of feature areas on the lattice (map). Termination of the training process takes place after passing pre-specified number of training epochs.
2.2 SOM offline learning
Offline learning of SOM is accomplished using training data found in the literature according to the procedures described in the previous sections. The training vector is comprised of the nanofluid code (\(\chi_{ij}\)); where \(\chi\) is the code of the nanofluid number, \(i\), \(i = 1,2, \ldots ,m\), \(m\) is the number nanofluids, \(j = 1,2, \ldots ,n\), and \(n\) is the total number of the experimental data, \(\varphi_{ij}\) is the volume fraction of nanofluid \(i\) at instant \(j\), \(T_{ij}\) the accordance temperature at each experiment, \(d_{ij}\) is the nanoparticle diameter, and \(r_{ij}\) is the TCR between the nanofluid and base fluid, then the resultant vector will be
2.3 SOM online testing
After the off-line learning of the SOM, the trained SOM is tested online. TCR, at least, is the unknown parameter, while nanofluid code, volume fraction, temperature and nanoparticles diameters are the known parameters. SOM is provided by a subspace of the input vector to compute the target output. This can be accomplished by using a projection matrix defined in Eq. (11) [54] that pre-multiplied by the input vector and defined as:
where \(I_{d}\) denotes the identity matrix. Then the input vector \(x_{kj}\) is pre-multiplied by the projection matrix \(P\) to get the new input vector \(x_{kj}^{'}\)
It worthy mentioned that the minimization of the Euclidean distance will be calculated between the modified input vector \(x_{ij}^{'}\) and the modified weight vectors \(Pw_{j}\).
To get the TCR, the winning node output weight vector \(w_{j}\) is pre-multiplied the difference between the projection matrix and its corresponding identity matrix \((I - P)\). Then the required subspace of the weight vector \(w_{j}^{'}\) which represents the required heat fluxes and their position is calculated as follows
2.4 SOM quality estimation
Herein, the quantization error \(Q_{\text{e}}\) as a well-known criterion to investigate the map resolution of the SOM [55], is introduced to represent the SOM fitting to a given training data. The quantization error is evaluated by calculating the average distance between the input training vectors and the corresponding BMN’s. For any given training dataset, the quantization error can be simply reduced by increasing the number of map nodes, thus the training data are distributed more sparsely inside the map. The error of quantization is computed by:
where \(N\), \(w_{{x_{ij} }}\), and \(x_{ij}\) denote the number of the training datasets, the BMN, the input vector, respectively. Our goal is to decrease the \(Q_{e}\) as much as possible (may be this is constrained by the available commercial computing hardware).
3 Results and discussions
In this section, two different examples will be illustrated to demonstrate the validity of the proposed method to predict the TCR for three types of water based nanofluids using three different nanoparticles, namely, aluminum oxide (Al2O3), copper oxide (CuO), and titanium oxide (TiO2). The goal is the prediction of the unknown TCR of the nanofluids based on measured data available in the literature. Both theoretical and experimental data are used as training data to the SOM. After SOM formation and training, unused data in the training process is used to test the validity of the approach.
SOM network with two-dimensional structure is used. The training process of the SOM is performed according to the procedures described in Sect. 2. The initial value of the learning rate \(\alpha_{o} = 0.3\) and decreases gradually up to \(\alpha_{f} \simeq 0.01\) with time constant \(\tau = 1000\);while the Gaussian function width parameter \(\sigma\) starts with \(\sigma_{o}\) equal to the lattice radius and decreases gradually with time constant calculated according to Eq. (7). The quantization error \(Q_{e}\) of different simulation results is ranged from 0.735 to 0.956 which is considered to be agreeable.
3.1 Example 1
In this illustrated example we will consider two types of nanofluids (Al2O3/water and CuO/water). The training data are generated from the theoretical model developed by [56] based on their experimental results. The main goal of this example, as the first step, is to investigate the validity of the proposed method to solve the problem understudy and avoiding the measuring errors which appeared during experiments and may affect the training process. According to their study, CuO and Al2O3 nanoparticles with average diameters of 29 and 36 nm, respectively, were mixed with water at volume fractions of 2%, 4%, 6%, and 10% and the experiments carried out at temperatures ranging from 27.5 to 34.7 °C. The empirical formulas of the TCR as a function in the volume fraction and the temperature for Al2O3/water and CuO/water nanofluids are given by:
where \(r\), \(\varphi\), and \(T\) denote the TCR, volume fraction and temperature in Celsius, respectively; and the subscripts \(A\) and \(B\) are used for Al2O3/water and CuO/water nanofluids, respectively.
For both nanofluids, the training data was taken at volume fraction ranged from 2 to 10% with step equal to 0.5% and temperature ranged from 27.5 to 32.5 °C with step equal to 0.5 °C with total number of data for each nanofluid equal to 255 as shown in Fig. 2. In this figure, CuO/water exhibits a better thermal conductivity ratio compared with Al2O3/water at all investigated conditions. However, it is worth to mention that CuO is unstable and is oxidized in water at T > 150 °C, so Al2O3/water nanofluid is a better choice for high temperature applications. All the training data elements, i.e., \(\chi_{ij}\), \(\varphi_{ij}\), \(T_{ij}\), \(d_{ij}\), and \(r_{ij}\), are normalized, before given to the SOM, to be ranged from − 1 to 1 with unitary variance and zero mean. So that the efficiency of the training process is enhanced by preventing the data dispersion to take place, as all input elements have the same importance regardless the magnitude of their values. After the learning process is finished, all data including the weights of SOM nodes are reverse-normalized.

Effect of the temperature and the volume fraction on the variation of TCR of: a Al2O3/water nanofluids, b CuO/water nanofluids
To check the validity of the proposed method to solve the problem in hand, the network is tested using a new data which did not give to the network in the training process. Then, the SOM accuracy, as an estimation model, is evaluated by two different error related performance criteria, i.e., mean squared error (MSE) and mean absolute percent error (MAPE), between the exact (actual) and predicted values from the SOM which can be evaluated from the following relationships:
where \(t\) is the number of test points, \(x_{exact}\) are the exact values obtained from literature and \(x_{pred}\) are the predicted values obtained from the SOM model.
Smaller values of MSE and MAPE indicate better performance of the network.
Figure 3a, b shows the scatter plot of the predicted values obtained from the SOM model versus the exact values obtained from literature for Al2O3/water and CuO/water nanofluids, respectively. The known parameters fed to the network in the this test were \(\chi_{ij}\), \(\varphi_{ij}\), \(T_{ij}\), and \(d_{ij}\) which picked up randomly from the literature data to predict the corresponding unknown \(r_{ij}\) values. It is observed from this figure that the obtained results are acceptable. The MSE for Al2O3/water and CuO/water nanofluids are 9.4402e−06 and 8.2908e−05, respectively. While, the MAPE for Al2O3/water and CuO/water nanofluids are 0.2354% and 0.5358%, respectively.

Predicted versus exact values of TCR over the test datasets: a Al2O3/water nanofluids, b CuO/water nanofluids
Figure 4a, b shows a comparative plot between the predicted values and the corresponding exact values of the TCR for Al2O3/water and CuO/water nanofluids, respectively, as a function of the temperature at different volume fractions (3.2, 5.8, and 8.4%). While, Fig. 5a, b shows a comparative plot between the predicted values and the corresponding exact values of the TCR for Al2O3/water and CuO/water nanofluids, respectively, as a function of the volume fraction at different temperature values (26.6, 30.2, and 33.8 °C). These two figures demonstrate the capability of the proposed method to predict the target values of the TCR regardless the nature of the input test datasets as long as the training process is achieved in a correct manner with sufficient and effective training datasets.

Effect of variations of the temperature on the TCR for three different volume fractions and the predicted values of the proposed ANN model. a Al2O3/water nanofluids, b CuO/water nanofluids

Effect of variations of the volume fraction on the TCR for three different temperature values and the predicted values of the proposed ANN model. a Al2O3/water nanofluids, b CuO/water nanofluids
3.2 Example 2
Herein, the proposed method will be applied to predict the TCR of TiO2/water nanofluid. The SOM performance will be investigated using training and test datasets from the available experimental results in the literature as reported in Table 1. This table shows the thermal conductivity of TiO2 reported in previous studies [57,58,59,60,61,62,63,64,65,66,67,68,69,70,71]. Three different parameters have been included in this table: particle size, particle volume fraction, and temperature. The training data was taken at volume fraction ranged from 0.2 to 9.77%, temperature ranged from 1 to 70 °C, and particle diameters ranged from 5 to 100 nm with total number of 150 training vectors. After normalization of the training data components, i.e., \(\varphi_{ij}\), \(T_{ij}\), \(d_{ij}\), and \(r_{ij}\), the data are fed to the network. Finally, after finishing the learning process, all data including the weights of SOM nodes are reverse-normalized.
Figure 6 shows the scatter plot of the predicted values obtained from the SOM model versus the exact values found in literature TiO2/water nanofluid. The known parameters fed to the network in the this test were \(\varphi_{ij}\), \(T_{ij}\), and \(d_{ij}\) which picked up randomly from the literature data to predict the corresponding unknown \(r_{ij}\) values. The MSE and the MAPE for the resulted data were 5.5381e−05 and 0.5978%, respectively.

Predicted versus exact values of TCR over the test datasets for TiO2/water nanofluids
The predicted results in this study imply that ANN may be used as a robust tool to predict the thermal conductivity of nanofluids. Moreover, it is recommended to apply different metaheurestic methods [72,73,74,75,76] to select the optimal nanofluids parameters that maximize their utilization as heat transfer fluid.
4 Conclusion
A general and accurate SOM model is used to predict TCR of oxide (Al2O3, CuO and TiO2)/water nanofluids under various operating conditions. The network was trained using both theoretical and experimental data available in literature. The model can not only learn multiple input parameters, such as nanofluid type, TCR, nanoparticle size, temperature, nanoparticle volume fraction, but also can be tested using multiple unknown parameters. The maximum mean squared error (MSE) of the SOM model is only 8.2908e−05; and the mean absolute percent error (MAPE) is 0.5978%. The proposed approach is accurate, fast, simple, robust, and applicable for any type of nanofluids. Furthermore, it can also be readily extended to predict any other thermo-physical properties of the nanofluids, which is our future work.
Abbreviations
- \(k\) :
-
Thermal conductivity (W/(m K))
- \(T\) :
-
Temperature (°C)
- \(\bar{x}\) :
-
Input vector
- \(\bar{w}_{j}\) :
-
Synaptic weight vector
- \(h_{ki}\) :
-
Topological neighborhood
- \(d_{ik}\) :
-
Euclidean distance
- \(r\) :
-
Thermal conductivity ratio
- \(\sigma\) :
-
Effective width of the topological neighborhood
- \(\bar{r}\) :
-
Position vector
- \(\tau\) :
-
Time constant
- \(P\) :
-
Projection matrix
- \(I_{g}\) :
-
Identity matrix
- \(\varphi\) :
-
Volume fraction (%)
References
Ali MKA, Xianjun H, Abdelkareem MAA, Gulzar M, Elsheikh AH (2018) Novel approach of the graphene nanolubricant for energy saving via anti-friction/wear in automobile engines. Tribol Int 124:209–229. https://doi.org/10.1016/j.triboint.2018.04.004
Ahmed Ali MK, Xianjun H, Abdelkareem MAA, Elsheikh AH (2019) Role of nanolubricants formulated in improving vehicle engines performance. IOP Conf Ser Mater Sci Eng 563:022015. https://doi.org/10.1088/1757-899x/563/2/022015
Fadl AE, Jingui Y, Ammar HE, Tawfik MM (2019) A new M50 matrix composite sintered with a hybrid Sns/Zno nanoscale solid lubricants: an experimental investigation. Mater Res Express 6:116523
Sudarsana Reddy P, Chamkha AJ (2016) Influence of size, shape, type of nanoparticles, type and temperature of the base fluid on natural convection MHD of nanofluids. Alex Eng J 55(1):331–341. https://doi.org/10.1016/j.aej.2016.01.027
Zayed M, Sharshir S, Elsheikh AH, Shaibo J, Hammad F, Ali MKA, Sargana S, Kh S, Edreis EM, Zhao J (2019) Applications of nanofluids in direct absorption solar collectors. In: Subramanian KRV, Nageswara Rao T, Balakrishnan A (eds) Nanofluids and its engineering applications. CRC-Taylor and Francis, Boca Raton, p 405429
Elsheikh AH, Sharshir SW, Mostafa ME, Essa FA, Ahmed Ali MK (2018) Applications of nanofluids in solar energy: a review of recent advances. Renew Sustain Energy Rev 82:3483–3502. https://doi.org/10.1016/j.rser.2017.10.108
Huminic A, Huminic G, Fleaca C, Dumitrache F, Morjan I (2015) Thermal conductivity, viscosity and surface tension of nanofluids based on FeC nanoparticles. Powder Technol 284:78–84. https://doi.org/10.1016/j.powtec.2015.06.040
Sharshir SW, Peng G, Elsheikh AH, Edreis EMA, Eltawil MA, Abdelhamid T, Kabeel AE, Zang J, Yang N (2018) Energy and exergy analysis of solar stills with micro/nano particles: a comparative study. Energy Convers Manag 177:363–375. https://doi.org/10.1016/j.enconman.2018.09.074
Sharshir SW, Kandeal AW, Ismail M, Abdelaziz GB, Kabeel AE, Yang N (2019) Augmentation of a pyramid solar still performance using evacuated tubes and nanofluid: experimental approach. Appl Therm Eng 160:113997. https://doi.org/10.1016/j.applthermaleng.2019.113997
Sharshir SW, Peng G, Wu L, Yang N, Essa FA, Elsheikh AH, Mohamed SIT, Kabeel AE (2017) Enhancing the solar still performance using nanofluids and glass cover cooling: experimental study. Appl Therm Eng 113:684–693. https://doi.org/10.1016/j.applthermaleng.2016.11.085
Zayed ME, Zhao J, Elsheikh AH, Du Y, Hammad FA, Ma L, Kabeel AE, Sadek S (2019) Performance augmentation of flat plate solar water collector using phase change materials and nanocomposite phase change materials: a review. Process Saf Environ Prot 128:135–157. https://doi.org/10.1016/j.psep.2019.06.002
Sundar LS, Venkata Ramana E, Graça MPF, Singh MK, Sousa ACM (2016) Nanodiamond-Fe3O4 nanofluids: preparation and measurement of viscosity, electrical and thermal conductivities. Int Commun Heat Mass Transf 73:62–74. https://doi.org/10.1016/j.icheatmasstransfer.2016.02.013
Agarwal R, Verma K, Agrawal NK, Singh R (2017) Sensitivity of thermal conductivity for Al2O3 nanofluids. Exp Therm Fluid Sci 80:19–26. https://doi.org/10.1016/j.expthermflusci.2016.08.007
Kim HJ, Lee S-H, Lee J-H, Jang SP (2015) Effect of particle shape on suspension stability and thermal conductivities of water-based bohemite alumina nanofluids. Energy 90. Energy 90(2):1290–1297. https://doi.org/10.1016/j.energy.2015.06.084
Sarafraz MM, Nikkhah V, Madani SA, Jafarian M, Hormozi F (2017) Low-frequency vibration for fouling mitigation and intensification of thermal performance of a plate heat exchanger working with CuO/water nanofluid. Appl Therm Eng 121:388–399. https://doi.org/10.1016/j.applthermaleng.2017.04.083
Salari E, Peyghambarzadeh SM, Sarafraz MM, Hormozi F (2016) Boiling thermal performance of TiO2 aqueous nanofluids as a coolant on a disc copper block. Period Polytech Chem Eng 60(2):106–122
Sheikhbahai M, Esfahany MN, Etesami N (2012) Experimental investigation of pool boiling of Fe3O4/ethylene glycol–water nanofluid in electric field. Int J Therm Sci 62:149–153
Salari E, Peyghambarzadeh M, Sarafraz MM, Hormozi F (2016) Boiling heat transfer of alumina nano-fluids: role of nanoparticle deposition on the boiling heat transfer coefficient. Period Polytech Chem Eng 60(4):252–258
Nakhjavani M, Nikkhah V, Sarafraz MM, Shoja S, Sarafraz M (2017) Green synthesis of silver nanoparticles using green tea leaves: experimental study on the morphological, rheological and antibacterial behaviour. Heat Mass Transf 53(10):3201–3209. https://doi.org/10.1007/s00231-017-2065-9
Nikkhah V, Sarafraz M, Hormozi F (2015) Application of spherical copper oxide (II) water nano-fluid as a potential coolant in a boiling annular heat exchanger. Chem Biochem Eng Q 29(3):405–415
Kamalgharibi M, Hormozi F, Zamzamian SAH, Sarafraz MM (2016) Experimental studies on the stability of CuO nanoparticles dispersed in different base fluids: influence of stirring, sonication and surface active agents. Heat Mass Transf 52(1):55–62. https://doi.org/10.1007/s00231-015-1618-z
Sharshir SW, Elsheikh AH, Peng G, Yang N, El-Samadony MOA, Kabeel AE (2017) Thermal performance and exergy analysis of solar stills—a review. Renew Sustain Energy Rev 73:521–544. https://doi.org/10.1016/j.rser.2017.01.156
Elsheikh AH, Sharshir SW, Ahmed Ali MK, Shaibo J, Edreis EMA, Abdelhamid T, Du C, Haiou Z (2019) Thin film technology for solar steam generation: a new dawn. Sol Energy 177:561–575. https://doi.org/10.1016/j.solener.2018.11.058
Sharshir SW, Ellakany YM, Algazzar AM, Elsheikh AH, Elkadeem MR, Edreis EMA, Waly AS, Sathyamurthy R, Panchal H, Elashry MS (2019) A mini review of techniques used to improve the tubular solar still performance for solar water desalination. Process Saf Environ Prot 124:204–212. https://doi.org/10.1016/j.psep.2019.02.020
Zayed ME, Zhao J, Elsheikh AH, Hammad FA, Ma L, Du Y, Kabeel AE, Shalaby SM (2019) Applications of cascaded phase change materials in solar water collector storage tanks: a review. Sol Energy Mater Sol Cells 199:24–49. https://doi.org/10.1016/j.solmat.2019.04.018
Maxwell JC (1904) A treatise on electricity and magnetism, 2nd edn. Oxford University Press, Cambridge
Mukesh Kumar P, Kumar J, Tamilarasan R, Sendhilnathan S, Suresh S (2015) Review on nanofluids theoretical thermal conductivity models. Eng J 19(1):17. https://doi.org/10.4186/ej.2015.19.1.67
Sivarajah U, Kamal MM, Irani Z, Weerakkody V (2017) Critical analysis of Big Data challenges and analytical methods. J Bus Res 70:263–286. https://doi.org/10.1016/j.jbusres.2016.08.001
Elsheikh AH, Guo J, Huang Y, Ji J, Lee K-M (2018) Temperature field sensing of a thin-wall component during machining: numerical and experimental investigations. Int J Heat Mass Transf 126:935–945. https://doi.org/10.1016/j.ijheatmasstransfer.2018.06.006
Abdelhamid T, Elsheikh AH, Elazab A, Sharshir SW, Selima ES, Jiang D (2018) Simultaneous reconstruction of the time-dependent Robin coefficient and heat flux in heat conduction problems. Inverse Probl Sci Eng 26(9):1231–1248. https://doi.org/10.1080/17415977.2017.1391243
Elsheikh AH, Guo J, Lee K-M (2019) Thermal deflection and thermal stresses in a thin circular plate under an axisymmetric heat source. J Therm Stress 42(3):361–373. https://doi.org/10.1080/01495739.2018.1482807
Siami-Irdemoosa E, Dindarloo SR (2015) Prediction of fuel consumption of mining dump trucks: a neural networks approach. Appl Energy 151:77–84. https://doi.org/10.1016/j.apenergy.2015.04.064
Elsheikh AH, Sharshir SW, Abd Elaziz M, Kabeel AE, Guilan W, Haiou Z (2019) Modeling of solar energy systems using artificial neural network: a comprehensive review. Sol Energy 180:622–639. https://doi.org/10.1016/j.solener.2019.01.037
Elsheikh A, Showaib E, Asar A (2013) Artificial neural network based forward kinematics solution for planar parallel manipulators passing through singular configuration. Adv Robot Autom 2(106):2
Elaziz MA, Elsheikh AH, Sharshir SW (2019) Improved prediction of oscillatory heat transfer coefficient for a thermoacoustic heat exchanger using modified adaptive neuro-fuzzy inference system. Int J Refrig 102:47–54. https://doi.org/10.1016/j.ijrefrig.2019.03.009
Ahmed AAM (2017) Prediction of dissolved oxygen in Surma River by biochemical oxygen demand and chemical oxygen demand using the artificial neural networks (ANNs). J King Saud Univ Eng Sci 29(2):151–158. https://doi.org/10.1016/j.jksues.2014.05.001
Babikir HA, Elaziz MA, Elsheikh AH, Showaib EA, Elhadary M, Wu D, Liu Y (2019) Noise prediction of axial piston pump based on different valve materials using a modified artificial neural network model. Alex Eng J. https://doi.org/10.1016/j.aej.2019.09.010
Shehabeldeen TA, Elaziz MA, Elsheikh AH, Zhou J (2019) Modeling of friction stir welding process using adaptive neuro-fuzzy inference system integrated with harris hawks optimizer. J Mater Res Technol. https://doi.org/10.1016/j.jmrt.2019.09.060
Ahmadloo E, Azizi S (2016) Prediction of thermal conductivity of various nanofluids using artificial neural network. Int Commun Heat Mass Transf 74:69–75. https://doi.org/10.1016/j.icheatmasstransfer.2016.03.008
Ariana MA, Vaferi B, Karimi G (2015) Prediction of thermal conductivity of alumina water-based nanofluids by artificial neural networks. Powder Technol 278:1–10. https://doi.org/10.1016/j.powtec.2015.03.005
Papari MM, Yousefi F, Moghadasi J, Karimi H, Campo A (2011) Modeling thermal conductivity augmentation of nanofluids using diffusion neural networks. Int J Therm Sci 50(1):44–52. https://doi.org/10.1016/j.ijthermalsci.2010.09.006
Hemmat Esfe M, Ahangar MRH, Toghraie D, Hajmohammad MH, Rostamian H, Tourang H (2016) Designing artificial neural network on thermal conductivity of Al2O3–water–EG (60–40%) nanofluid using experimental data. J Therm Anal Calorim. https://doi.org/10.1007/s10973-016-5469-8
Longo GA, Zilio C, Ceseracciu E, Reggiani M (2012) Application of Artificial Neural Network (ANN) for the prediction of thermal conductivity of oxide–water nanofluids. Nano Energy 1(2):290–296. https://doi.org/10.1016/j.nanoen.2011.11.007
Hemmat Esfe M, Afrand M, Yan W-M, Akbari M (2015) Applicability of artificial neural network and nonlinear regression to predict thermal conductivity modeling of Al2O3–water nanofluids using experimental data. Int Commun Heat Mass Transf 66:246–249. https://doi.org/10.1016/j.icheatmasstransfer.2015.06.002
Vachkov G, Kiyota Y, Komatsu K (2003) Solving the inverse dynamics problem by self-organizing maps. In: Proceedings. 2003 IEEE international symposium on computational intelligence in robotics and automation, 16–20 July 2003, vol 1533, pp 1533–1538. https://doi.org/10.1109/cira.2003.1222225
Jeongho C, Principe JC, Erdogmus D, Motter MA (2006) Modeling and inverse controller design for an unmanned aerial vehicle based on the self-organizing map. IEEE Trans Neural Netw 17(2):445–460. https://doi.org/10.1109/TNN.2005.863422
Jeongho C, Jing L, Thampi GK, Principe JC, Motter MA (2002) Identification of aircraft dynamics using a SOM and local linear models. In: Circuits and systems, 2002. MWSCAS-2002. The 2002 45th midwest symposium on, 4–7 Aug 2002, vol 142, pp II-148–II-151. https://doi.org/10.1109/mwscas.2002.1186819
da Costa FM, de Araújo SA, Sassi RJ (2013) Inverse Halftoning by means of self-organizing maps. In: Estévez AP, Príncipe CJ, Zegers P (eds) Advances in self-organizing maps: 9th international workshop, WSOM 2012 Santiago, Chile, December 12–14, 2012 Proceedings. Springer, Berlin, pp 145–152. https://doi.org/10.1007/978-3-642-35230-0_15
Ciampi A, Lechevallier Y (2000) Clustering large, multi-level data sets: an approach based on Kohonen self organizing maps. In: Zighed DA, Komorowski J, Żytkow J (eds) Principles of data mining and knowledge discovery: 4th European conference, PKDD 2000 Lyon, France, September 13–16, 2000 Proceedings. Springer, Berlin, pp 353–358. https://doi.org/10.1007/3-540-45372-5_36
Kohonen T (1990) The self-organizing map. Proc IEEE 78(9):1464–1480
Bayat P, Ahmadi A, Kordi A (2008) A new simulation of distributed mutual exclusion on neural networks. In: 2008 IEEE conference on innovative technologies in intelligent systems and industrial applications, 12–13 July 2008, pp 80–91. https://doi.org/10.1109/citisia.2008.4607340
Kohonen T (ed) (2001) The basic SOM. In: Self-organizing maps. Springer, Berlin, pp 105–176
Obermayer K, Sejnowski TJ, Poggio TA (2001) Self-organizing map formation: foundations of neural computation, vol 93, no 9125. MIT Press, Cambridge
Barreto GDA, Araújo AFR, Ritter HJ (2003) Self-organizing feature maps for modeling and control of robotic manipulators. J Intell Rob Syst 36(4):407–450. https://doi.org/10.1023/a:1023641801514
Sun Y (2000) On quantization error of self-organizing map network. Neurocomputing 34(1–4):169–193. https://doi.org/10.1016/S0925-2312(00)00292-7
Li CH, Peterson GP (2006) Experimental investigation of temperature and volume fraction variations on the effective thermal conductivity of nanoparticle suspensions (nanofluids). J Appl Phys 99(8):084314. https://doi.org/10.1063/1.2191571
Longo GA, Zilio C (2011) Experimental measurement of thermophysical properties of oxide–water nano-fluids down to ice-point. Exp Therm Fluid Sci 35(7):1313–1324. https://doi.org/10.1016/j.expthermflusci.2011.04.019
Turgut A, Tavman I, Chirtoc M, Schuchmann HP, Sauter C, Tavman S (2009) Thermal conductivity and viscosity measurements of water-based TiO2 nanofluids. Int J Thermophys 30(4):1213–1226. https://doi.org/10.1007/s10765-009-0594-2
Wang ZL, Tang DW, Liu S, Zheng XH, Araki N (2007) Thermal-conductivity and thermal-diffusivity measurements of nanofluids by 3ω method and mechanism analysis of heat transport. Int J Thermophys 28(4):1255–1268. https://doi.org/10.1007/s10765-007-0254-3
Zhang X, Gu H, Fujii M (2007) Effective thermal conductivity and thermal diffusivity of nanofluids containing spherical and cylindrical nanoparticles. Exp Therm Fluid Sci 31(6):593–599. https://doi.org/10.1016/j.expthermflusci.2006.06.009
Kim SH, Choi SR, Kim D (2006) Thermal conductivity of metal-oxide nanofluids: particle size dependence and effect of laser irradiation. J Heat Transf 129(3):298–307. https://doi.org/10.1115/1.2427071
Dongsheng W, Yulong D (2006) Natural convective heat transfer of suspensions of titanium dioxide nanoparticles (nanofluids). IEEE Trans Nanotechnol 5(3):220–227. https://doi.org/10.1109/TNANO.2006.874045
Duangthongsuk W, Wongwises S (2009) Measurement of temperature-dependent thermal conductivity and viscosity of TiO2-water nanofluids. Exp Therm Fluid Sci 33(4):706–714. https://doi.org/10.1016/j.expthermflusci.2009.01.005
Yoo D-H, Hong KS, Yang H-S (2007) Study of thermal conductivity of nanofluids for the application of heat transfer fluids. Thermochim Acta 455(1–2):66–69. https://doi.org/10.1016/j.tca.2006.12.006
Nisha MR, Philip J (2012) Dependence of particle size on the effective thermal diffusivity and conductivity of nanofluids: role of base fluid properties. Heat Mass Transf 48(10):1783–1790. https://doi.org/10.1007/s00231-012-1032-8
Pak BC, Cho YI (1998) Hydrodynamic and heat transfer study of dispersed fluids with submicron metallic oxide particles. Exp Heat Transf 11(2):151–170. https://doi.org/10.1080/08916159808946559
Reddy M, Rao V, Sarada S, Reddy B (2012) Temperature dependence of thermal conductivity of water based TiO2 nanofluids. Int J Micro Nano Scale Transp 3(1–2):43–52. https://doi.org/10.1260/1759-3093.3.1-2.43
Hussein AM, Bakar RA, Kadirgama K, Sharma KV (2013) Experimental measurement of nanofluids thermal properties. Int J Automot Mech Eng 7:850–863
Murshed SMS, Leong KC, Yang C (2005) Enhanced thermal conductivity of TiO2—water based nanofluids. Int J Therm Sci 44(4):367–373. https://doi.org/10.1016/j.ijthermalsci.2004.12.005
Azari A, Kalbasi M, Moazzeni A, Rahman A (2014) A thermal conductivity model for nanofluids heat transfer enhancement. Pet Sci Technol 32(1):91–99. https://doi.org/10.1080/10916466.2010.551808
Zhang X, Gu H, Fujii M (2006) Experimental study on the effective thermal conductivity and thermal diffusivity of nanofluids. Int J Thermophys 27(2):569–580. https://doi.org/10.1007/s10765-006-0054-1
Oliva D, Elaziz MA, Elsheikh AH, Ewees AA (2019) A review on meta-heuristics methods for estimating parameters of solar cells. J Power Sources 435:126683. https://doi.org/10.1016/j.jpowsour.2019.05.089
Hemmat Esfe M, Kiannejad Amiri M, Bahiraei M (2019) Optimizing thermophysical properties of nanofluids using response surface methodology and particle swarm optimization in a non-dominated sorting genetic algorithm. J Taiwan Inst Chem Eng 103:7–19. https://doi.org/10.1016/j.jtice.2019.07.009
Elsheikh AH, Abd Elaziz M (2019) Review on applications of particle swarm optimization in solar energy systems. Int J Environ Sci Technol 16(2):1159–1170. https://doi.org/10.1007/s13762-018-1970-x
Salman K, Elsheikh AH, Ashham M, Ali MKA, Rashad M, Haiou Z (2019) Effect of cutting parameters on surface residual stresses in dry turning of AISI 1035 alloy. J Braz Soc Mech Sci Eng 41(8):349. https://doi.org/10.1007/s40430-019-1846-0
Sergeyev YD, Kvasov DE, Mukhametzhanov MS (2018) On the efficiency of nature-inspired metaheuristics in expensive global optimization with limited budget. Sci Rep 8(1):453. https://doi.org/10.1038/s41598-017-18940-4
Acknowledgements
Funding was provided by National Natural Science Foundation of China (Grant Nos. E050902, E041604).
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors of the manuscript declared that there is no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Elsheikh, A.H., Sharshir, S.W., Ismail, A.S. et al. An artificial neural network based approach for prediction the thermal conductivity of nanofluids. SN Appl. Sci. 2, 235 (2020). https://doi.org/10.1007/s42452-019-1610-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s42452-019-1610-1