
Abstract
In this contribution, we introduce a generalized Kalman filter with precision in recursive form when the stochastic model is misspecified. The filter allows for a relaxed dynamic model in which not all state vector elements are connected in time. The filter is equipped with a recursion of the actual error-variance matrices so as to provide an easy-to-use tool for the efficient and rigorous precision analysis of the filter in case the underlying stochastic model is misspecified. Different mechanizations of the filter are presented, including a generalization of the concept of predicted residuals as needed for the recursive quality control of the filter.
Similar content being viewed by others


1 Introduction
The recursive Kalman filter (Kalman 1960; Koch 1999; Simon 2006; Teunissen 2007; Grewal and Andrews 2008) is known to be a ‘best’ filter in the minimum variance sense in case the underlying model is correctly specified. In practical applications, however, it may be challenging to correctly specify the stochastic model. Due to a lack of information, for instance, one may be unsure about the variance matrices that need to be specified and thus be forced to make use of approximations, or alternatively, because of computational constraints, one may have to oversimplify the model, thereby neglecting particular stochastic contributions. An example of the first case occurs in the context of precise point positioning (PPP), where often the uncertainty in the PPP corrections is either neglected or approximated in the mechanization of the Kalman filter (Zumberge et al. 1997; Kouba and Heroux 2001; Li et al. 2014; Teunissen and Khodabandeh 2015). Examples of the latter can be found in the context of navigation, where the characteristics of the assumed system noise may be too simplistic to catch the actual uncertainty in the dynamic behaviour of the system (Salzmann 1993).

Estimation of relative code biases/clock offsets between two u-blox [ZED-F9P] receivers: (left) code-bias time series; (right) square root of the Kalman filter (KF) error variances. Assuming the code biases’ system noise is incorrectly specified to 0.2 \({\mathrm{nsec}}/\sqrt{\mathrm{sec}}\) (instead of 0.5 \({\mathrm{nsec}}/\sqrt{\mathrm{sec}}\)), the Kalman filter reports the ‘misspecified’ error variances (thick red lines) rather than the ‘actual’ ones (dashed green lines)
With an incorrectly specified stochastic model, the recursive Kalman filter loses its property of being ‘best’. Although this is a pitfall, a far more serious problem than not being ‘best’ is the lack of a proper quality description that goes along with it. With an incorrectly specified stochastic model, also all the error-variance matrices that are recursively produced by the Kalman filter become incorrect and thus fail to provide a means for describing the actual quality of the filter. As an illustrative example, consider a GNSS short-baseline set-up in which code measurements of two receivers are processed to deliver, next to other parameter solutions, also filtered solutions of the relative code biases of the two receivers. Their single-epoch time series are presented in the left panel of Fig. 1. The temporal behaviour of the code biases is assumed to follow a random-walk process, while the corresponding relative clock offsets are assumed unlinked in time (Odijk et al. 2015; Zhang et al. 2020). Let us now assume that the code biases’ system noise is incorrectly specified to 0.2 \({\mathrm{nsec}}/\sqrt{\mathrm{sec}}\) (instead of 0.5 \({\mathrm{nsec}}/\sqrt{\mathrm{sec}}\)). As shown in the right panel of Fig. 1, the Kalman filter would then report a ‘misspecified’ quality description of the filtered solutions (thick red lines) rather than the ‘actual’ ones (dashed green lines). The results also indicate that such misspecified choice does affect not only the quality description of the code-bias solutions, but also that of other parameters like the receiver clock offsets.
In this contribution, we show how in case of a misspecified stochastic model the actual error-variance matrices of the filter can be computed recursively and thus provide an efficient online way to describe and study the actual quality of the filter. This will be done for a generalized version of the Kalman filter, namely one in which the dynamic model is relaxed such that not all state-vector components are required to be linked in time. We believe this generalization to be necessary as the measurement model in many practical applications contains state-vector elements that are not connected in time. As such cannot be treated with the standard Kalman filter, the ‘engineering’ solution is often to set the corresponding part of the variance matrix of the system noise to very large values, thereby mimicking numerically an infinite system noise. As this is unsatisfactorily and clearly not rigorous, we show how a rigorous Kalman-filter-based solution to this problem can be formulated. Our solution is different from the information filter, which would use instead of the state-vector estimation, the information vector and information matrix (Khodabandeh et al. 2018). We thereby also show the need to generalize the concept of predicted residuals or ‘innovations’ (Kailath 1970), as the relaxed dynamic model now only allows certain functions of the observables to be predicted.
This contribution is organized as follows. In Sect. 2, we give a brief review of the standard Kalman filter with a special attention to its assumed stochastic model. In Sect. 3, we generalize the Kalman filter by allowing that not all state-vector components are linked in time. Its dynamic model is assumed valid for only some functions of the state vector, and these functions are permitted to vary in time. Different mechanizations of the corresponding recursive filters are presented. In Sect. 4, we study the error-variance matrices of the different state vectors in case the generalized filter is executed with an incorrect stochastic model. We show how they can be computed in recursive form and thus evaluated online parallel to the actual running of the filter. In Sect. 5, we pay special attention to the predicted residuals, the concept of which needs to be generalized since our relaxed dynamic model now only allows certain functions of the observables to be predicted. We show how they can be used in the recursive testing for the detection of model biases and how the incorrectly specified stochastic model affects the precision of predicted residuals and corresponding test statistics. We also show how the recursive form of the affected precision of the predicted residuals can be used to study how well biases can still be detected even under the usage of a misspecified stochastic model.
We make use of the following notation: We use the underscore to denote a random vector. Thus, \(\underline{x}\) is random, while x is not. \(\mathsf {E}(.)\) and \(\mathsf {D}(.)\) denote the expectation and dispersion operator, while \(\mathsf {C}(.,.)\) denotes the covariance operator. Thus, \(\mathsf {D}(\underline{x})=\mathsf {C}(\underline{x},\underline{x})\) represents the variance matrix of \(\underline{x}\). Error-variance matrices are denoted with the capital letter P. For two positive-definite matrices, \(M_{1}\) and \(M_{2}\), the matrix inequality \(M_{1} \ge M_{2}\) means that \(M_{1} - M_{2}\) is positive semi-definite.
2 Kalman filter and its assumptions
In this section, we briefly review the Kalman filter with a special attention to its underlying stochastic assumptions.
2.1 Model assumptions
First, we state the measurement and dynamic model assumptions.
The measurement model: The link between the random vector of observables \(\underline{y}_i\) and the random state vector \(\underline{x}_i\) is assumed given as
together with
and
with \(\delta _{ij}\) being the Kronecker delta. The time index and number of epochs after initialization are indicated by i and t, respectively. Thus, the zero-mean measurement noise \(\underline{n}_i\) is assumed to be uncorrelated in time and to be uncorrelated with the initial state vector \(\underline{x}_0\). The design matrices \(A_{i} \in \mathbb {R}^{m_{i} \times n}\) and variance matrices \(R_{i} \in \mathbb {R}^{m_{i} \times m_{i}}\) are assumed given, with \(A_{0}\) of full rank, \(\mathrm{rank}(A_{0})=n\), and all \(R_{i}\) positive definite. The design matrices \(A_{i}\) (\(i\ge 1\)) need not be of full rank. Note that we assume the mean \(x_{0}\) of the initial state vector to be unknown.
The dynamic model: The linear dynamic model, describing the time evolution of the random state vector \(\underline{x}_i\), is given as
with
and
where \(\varPhi _{i,i-1}\) denotes the transition matrix and the random vector \(\underline{d}_i\) is the system noise. The system noise \(\underline{d}_i\) is thus also assumed to have a zero mean, to be uncorrelated in time and to be uncorrelated with the initial state vector and the measurement noise.
2.2 The Kalman filter
The Kalman filter is a recursive best linear predictor (BLP) in case the means of \(\underline{x}_{i}\), \(i=0, \ldots , t\), are known and a recursive BLUP (best linear unbiased predictor) in case these means are unknown (Teunissen and Khodabandeh 2013). In our case, it is a recursive BLUP, since we assume \(x_{0}\) unknown.
As \(x_{0}\) is unknown, the initialization of the filter requires the BLUP of \(\underline{x}_{0}\), which is given as
Note that the variance (vc)-matrix of \(\underline{\hat{x}}_{0}-x_{0}\) is given as \(Q_{0|0} = (A^{T}R_{0}^{-1}A_{0})^{-1}+Q_{x_{0}x_{0}}\), in which \(Q_{x_{0}x_{0}}\) is the unknown vc-matrix of \(\underline{x}_{0}\). In our case, however, we do not need the vc-matrix of the estimation error \(\underline{\hat{x}}_{0}-x_{0}\), but rather the vc-matrix of the BLUP error \(\underline{\hat{x}}_{0}-\underline{x}\), which is given as
Following the initialization and any other measurement update, we have the time update (TU) in which the linear dynamic model is used to predict the state-vector one epoch ahead. The TU and its error-variance matrix are given as
With any measurement epoch, we have a measurement update (MU) to improve upon the state-vector TU. The MU and its error variance can be given in two different forms, the information form or the variance form. The MU information form is given as
with gain matrix \(K_{t}=P_{t|t}A_{t}^{T}R_{t}^{-1}\). The MU variance form is given as
with the gain matrix expressed as \(K_{t}=P_{t|t-1}A_{t}^{T}(R_{t}+A_{t}P_{t|t-1}A_{t}^{T})^{-1}\).
Although we will focus ourselves in the following on the first two moments of the Kalman filter, the random vectors \(\underline{x}_{0}\), \(\underline{n}_{i}\) and \(\underline{d}_{i}\) will be assumed normally distributed when required.
3 Generalized Kalman filter
In the standard Kalman filter, it is assumed that a dynamic model is available for the complete state vector \(\underline{x}_{t}\) (cf. 4). In many practical applications, however, this is not the case. It often happens that a dynamic model is only valid for a part of \(\underline{x}_{t}\). As the other part will then have to be modelled as unlinked in time, the ‘engineering’ solution is often to set the corresponding part of the vc-matrix \(S_{t}\) to very large values, thereby mimicking numerically an infinite system noise. This is rather unsatisfactorily and clearly not rigorous. Below we show how a rigorous solution to this problem can be formulated.
3.1 A relaxed dynamic model
Instead of the dynamic model (4), we assume that only of certain functions of the state vector,
a dynamic model is available,
Thus, \(\underline{z}_{i}\) denotes the ‘linked-in-time’ state vectors. As we assume the functions to be linearly independent, the matrices \(F_{i} \in \mathbb {R}^{n \times p_{i}}\) are all of full column rank. The simplest case of such functions occurs when a dynamic model is available for only one part of \(\underline{x}_{i}\), say for the first p components. Then, the functions take the simple form \(F_{i}^{T}=[I_{p}, 0]\). In the above formulation, we allow, however, general functions which may also be time dependent. They are therefore permitted to change over time.
As with (5) and (6), the system noise \(\underline{d}^{z}_{i}\) of (13) is assumed to obey
and
3.2 A reparametrized measurement model
For the purpose and ease of deriving the generalized Kalman filter, we reparametrize the observation equation \(\underline{y}_{i}=A_{i}\underline{x}_{i}+\underline{n}_{i}\) (cf. 1) so that it becomes parametrized in \(\underline{z}_{i}\) and in a part that is annihilated by \(F_{i}^{T}\).
Recall that for the standard Kalman filter, it was sufficient to assume \(A_{0}\) to be of full column rank. All the other design matrices \(A_{i}\), \(i \ne 0\), were allowed to be rank defect. For the present case, this is still allowed, provided that all the matrices \([F_{i}, A_{i}^{T}]^{T}\), \(i \ne 0\), are of full column rank. Note that this condition is automatically fulfilled if \(F_{i}=I_{n}\). The reparametrization that we choose is given as
with \(G_{i}\) being a basis matrix of the null space of \(F_{i}^{T}\). Thus, \(F_{i}^{T}G_{i}=0\) and matrix \([F_i,G_i]\) is square and nonsingular. Moreover,
Thus, \(\underline{u}_{i}\) denotes the ‘unlinked-in-time’ state vectors. Note, since \(F_{i}^{T}G_{i}=0\) and \(F_{i}^{T}F_{i}^{+}=I_{p_{i}}\), that (16) indeed satisfies \(F_{i}^{T}\underline{x}_{i}=\underline{z}_{i}\). Also note that \(A_{i}G_{i}\) is of full column rank, since \([F_{i}, A_{i}^{T}]^{T}\) is of full column rank and \(G_{i}\) is a basis matrix of the null space of \(F_{i}^{T}\). As \(A_{i}G_{i}\) is of full column rank, the inverse in the expression of \(M_{i}\) exists. Also note that \(M_{i}\) is idempotent, \(M_{i}M_{i}=M_{i}\). It is an oblique projector that projects along the range space of \(G_{i}\) and onto the null space of \(G_{i}^{T}A_{i}^{T}R_{i}^{-1}A_{i}\).
It is not difficult to verify that the square matrix \([M_{i}F_{i}^{+}, G_{i}]\) is invertible and thus that (16) is a genuine reparametrization. If we substitute the reparametrization into the observation equations \(\underline{y}_{i}=A_{i}\underline{x}_{i}+\underline{n}_{i}\), we obtain the reparametrized observation equations as
with
in which \(P_{A^{u}_{i}}^{\perp }A_{i}=A_{i}M_{i}\), \(P_{A^{u}_{i}}^{\perp }=I_{m_{i}}-P_{A^{u}_{i}}\) and \(P_{A^{u}_{i}}=A^{u}_{i}(A^{u T}_{i}R_{i}^{-1}A^{u}_{i})^{-1}A^{u T}_{i}R_{i}^{-1}\) is the orthogonal projector (idempotent matrix) that projects onto the range space (column space) of \(A^{u}_{i}=A_{i}G_{i}\). Orthogonality is here with respect to the metric of \(R_{i}^{-1}\), i.e. \(P_{A^{u}_{i}}^TR_{i}^{-1}P_{A^{u}_{i}}^{\perp }=0\). An important property of the reparametrized observation Eq. (18) is that the range spaces of its design matrices, \(A^{z}_{i}\) and \(A^{u}_{i}\), are mutually orthogonal in the metric of \(R_{i}^{-1}\). Hence,
This implies that the measurement updates for \(\underline{z}_{i}\) and \(\underline{u}_{i}\) can be determined independently from each other, thereby easing the derivation of the generalized Kalman filter. Hence, the solution \(\underline{\hat{u}}_{t|t}\) will then be solely driven by the observable \(\underline{y}_{t}\) and is thus given as
We will now first determine the filter for \(\underline{z}_{t}\) and then for \(\underline{x}_{t}\).
3.3 The filter for \(\underline{z}_{t}\)
In some applications, one may be interested solely in the recursive estimation of the state-vector components for which a dynamic model is available and, thus, in the recursive estimation of \(\underline{z}_{t}=F_{t}^{T}\underline{x}_{t}\), rather than in that of the complete state vector \(\underline{x}_{t}\). We present this recursive filter in information form and variance form.
The initialization of the z-filter takes (7) and (8) as input, to give
Following the initialization, we have the time update (TU) in which the linear dynamic model (13) is used to predict the state-vector components one epoch ahead. Similar to (9), the TU and its error-variance matrix are given as
To determine the measurement update (MU), we first formulate it in information form, whereby now good use can be made of the orthogonality property (20) of the reparametrized observation Eq. (18). Due to this orthogonality, it follows that \(\underline{\hat{z}}_{t|t}=[(P^{z}_{t|t-1})^{-1}+A^{z T}_{t}R_{t}^{-1}A^{z}_{t}]^{-1}[(P^{z}_{t|t-1})^{-1}\underline{\hat{z}}_{t|t-1}+A^{z T}_{t}R_{t}^{-1}\underline{y}_{t}]\), which can be written in the more familiar MU information form as
with \(K^{z}_{t}=P^{z}_{t|t}A^{z T}_{t}R_{t}^{-1}\). Similar to the variance form (11), the MU variance form of the z-filter is given as
with \(K^{z}_{t}=P^{z}_{t|t-1}A^{z T}_{t}[R_{t}+A^{z}_{t}P^{z}_{t|t-1}A^{z T}_{t}]^{-1}\). Note, since \(A^{z T}_{t}R_{t}^{-1}A^{z}_{t}=A^{z T}_{t}R_{t}^{-1}A_{t}F_{t}^{+}\), that \(K^{z}_{t}A^{z}_{t}=K^{z}_{t}A_{t}F_{t}^{+}\) and that therefore the residual \(\underline{y}_{t}-A^{z}_{t}\underline{\hat{x}}_{t|t-1}\) in (24) and (25) can be replaced by \(\underline{y}_{t}-A_{t}F_{t}^{+}\underline{\hat{x}}_{t|t-1}\).
The above shows that the whole cycling sequence of TUs and MUs can be done solely in terms of estimations of \(\underline{z}_{t}\), without the need to resort to an estimation of the complete state vector \(\underline{x}_{t}\). Note, however, although both (24) and (25) have the same structure as the MUs of the standard Kalman filter (cf. 10 and 11), that \(A^{z}_{t}{\hat{\underline{z}}}_{t|t-1}\) (or \(A_{t}F^{+}_{t}{\hat{\underline{z}}}_{t|t-1}\)) is not a predictor of \(\underline{y}_{t}\). The residual \(\underline{y}_{t}-A^{z}_{t}{\hat{\underline{z}}}_{t|t-1}\) (or \(\underline{y}_{t}-A_{t}F^{+}_{t}{\hat{\underline{z}}}_{t|t-1}\)) in (24) and (25) is therefore not a predicted residual, this in contrast to \(\underline{v}_{t}=\underline{y}_{t}-A_{t}\underline{\hat{x}}_{t|t-1}\), which is the predicted residual of the standard Kalman filter. We will come back to this in Sect. 5.

Flowchart of the generalized Kalman filter: x-filter (left) versus z-filter (right). The step inside the green box is optional
3.4 The filter for \(\underline{x}_{t}\)
As there is no dynamic model for the complete state vector \(\underline{x}_{t}\), time updates of it like (9) do not exist. However, for every epoch a solution \(\underline{\hat{x}}_{t|t}\) can be determined, either from \(\underline{\hat{z}}_{t|t-1}\) and \(\underline{y}_{t}\), or from \(\underline{\hat{z}}_{t|t}\) and \(\underline{y}_{t}\).
First, we present the information form of \(\underline{\hat{x}}_{t|t}\) based on \(\underline{\hat{z}}_{t|t-1}\) and \(\underline{y}_{t}\). As \([F_{t}, A_{t}^{T}]^{T}\) is of full column rank, we have \(\underline{\hat{x}}_{t|t}=P^{x}_{t|t}[F_{t}(P^{z}_{t|t-1})^{-1}\underline{\hat{z}}_{t|t-1}+A_{t}^{T}R_{t}^{-1}\underline{y}_{t}]\), with \(P^{x}_{t|t}=[F_{t}(P^{z}_{t|t-1})^{-1}F_{t}^{T}+A_{t}^{T}R_{t}^{-1}A_{t}]^{-1}\). This can be written in the more familiar update form as
with \(K^{x}_{t}=P^{x}_{t|t}A_{t}^{T}R_{t}^{-1}\). When one insists on using (26), for instance, because it automatically provides \(\underline{\hat{x}}_{t|t}\) for every epoch, one still will have to compute \(\underline{\hat{z}}_{t|t}\) in order to proceed with the next time update. Hence, when using (26), the MUs of the z-filter, (24) or (25), get replaced by (26) and
Note, when (26) is substituted into (27), that one indeed gets (24) again. This follows, since \(F_{t}^{T}F_{t}^{+}=I_{n}\), \(F_{t}^{T}K^{x}_{t}=K^{z}_{t}\) and \(K^{z}_{t}A^{z}_{t}=K^{z}A_{t}F^{+}\).
With (26) and (27), the computation of \(\underline{\hat{x}}_{t|t}\) is an integral part of the generalized Kalman filter. Its computation is needed to be able to proceed with the next time update. This can be avoided if one computes \(\underline{\hat{x}}_{t|t}\) from \(\underline{\hat{z}}_{t|t}\) and \(\underline{y}_{t}\), instead of from \(\underline{\hat{z}}_{t|t-1}\) and \(\underline{y}_{t}\). From the reparametrization, (16) follows \( \underline{\hat{x}}_{t|t} = \Pi _{t} F_{t}^{+}\underline{\hat{z}}_{t|t}+G_{t}\underline{\hat{u}}_{t|t} \), which, with (21) and by recognizing that \(\underline{\hat{z}}_{t|t}\) and \(\underline{\hat{u}}_{t|t}\) are uncorrelated, \(\mathsf {C}(\underline{\hat{z}}_{t|t}, \underline{\hat{u}}_{t|t})=0\), can be written, together with its error-variance matrix, in the update form
with \(M_{t}\!=\!I_{n}-G_{t}^{x}A_{t}\) and \(G^{x}_{t}\!=\!G_{t}(A^{u T}_{t}R_{t}^{-1}A^{u}_{t})^{-1}A_{t}^{u T}R_{t}^{-1}\). Note that the error variance \(P^{x}_{t|t}\) is the sum of two terms. In the first term, we recognize \(P^{z}_{t|t} \le P^{z}_{t|t-1}\), thus showing the improvement in precision that \(\underline{y}_{t}\) brings through \(\underline{\hat{z}}_{t|t}\). The addition of the positive semi-definite second term \(G^{x}_{t}R_{t}G^{x T}_{t}\), however, reflects the increase in uncertainty due to the presence of the additional state-vector components for which no dynamic model is available. Also note the flexibility in formulation (28). In contrast to (26), the continuation of the filter is not affected, whether one decides to compute \(\underline{\hat{x}}_{t|t}\) or not. Finally, note that the variance form of (26) is obtained if (25) is substituted into (28). For a summarizing flowchart and a comparison of the x-filter and z-filter, see Fig. 2.
4 State-vector error-variance matrices
In this section, we consider some of the basic stochastic assumptions of the Kalman filter misspecified. This will affect the precision description of the Kalman filter, and in particular, it will make the P-matrices fail to be the error-variance matrices of the executed filter. We determine the correct error-variance matrices and show how they can still be computed in recursive form.
4.1 Recursive error-variance matrices
We assume the vc-matrices \(R_{i}\) and \(S^{z}_{i}\) of the measurement and system noise, \(\underline{n}_{i}\) and \(\underline{d}^{z}_{i}\), to be misspecified. Their correct vc-matrices are denoted with an overbar, \({\bar{R}}_{i}\) and \({\bar{S}}^{z}_{i}\). Thus, we assume
With this assumption, the generalized Kalman filter of the previous section is executed using the wrong vc-matrices, namely \(R_{i}\) and \(S^{z}_{i}\), and will thus provide a precision description through its P-matrices that is incorrect. We denote the correct error-variance matrices using an overbar as \({\bar{P}}^{z}_{t|t-1}\), \({\bar{P}}^{z}_{t|t}\) and \({\bar{P}}^{x}_{t|t}\). The following lemma shows how they can be computed in recursive form, thereby making use of the information provided by the filter.
Lemma 1
(Error-variance matrix recursion) The error-variance matrices of the generalized Kalman filter, having misspecified vc-matrices for its measurement and system noise (cf. 29), are given in recursive form as
for \(t=1, \ldots \), with \(L^{z}_{t}=[I_{p_{t}}-K^{z}_{t}A^{z}_{t}]\), \(L^{x}_{t}=[I_{n}-K^{x}_{t}A_{t}]F^{+}\) and \(H^{x}_{t}=[I_{n}-G^{x}_{t}A_{t}]F^{+}\). The initial error-variance matrix is given as \({\bar{P}}^{z}_{0|0}=F_{0}^{T}A_{0}^{+}{\bar{R}}_{0}A_{0}^{+T}F_{0}\), with \(A_{0}^{+}=(A_{0}^{T}R_{0}^{-1}A_{0})^{-1}A_{0}^{T}R_{0}^{-1}\).
Proof
For the proof, see “Appendix”. \(\square \)
Note, in (30), that the gain matrices \(K^{z}_{t}\) and \(K^{x}_{t}\) are to be computed by the assumed (and not correct) variance matrices. The above result provides a very useful tool for the efficient precision analysis of Kalman filters. In many practical applications, one may either be not too sure about the vc-matrices that one needs to specify or one may be forced, for instance, because of numerical constraints, to oversimplify the model, thereby neglecting particular stochastic contributions. With the above lemma, one has an easy-to-use tool available to do an online recursive sensitivity analysis of the generalized Kalman filter, whereby the computations can be done in parallel to the recursion of the filter itself.

Relation between assumed (\(P_{t|t}\)), actual (\({\bar{P}}_{t|t}\)) and optimal (\(\bar{{\bar{P}}}_{t|t} \le {\bar{P}}_{t|t}\)) Kalman-filter error variances: (left) \(P_{t|t} \le {\bar{P}}_{t|t}\) since too optimistic assumed stochastic model; (middle) \(P_{t|t} \le \ge {\bar{P}}_{t|t}\) mixture of pessimistic and optimistic stochastic model; (right) \(P_{t|t} \ge {\bar{P}}_{t|t}\) since too pessimistic assumed stochastic model
It depends on the mechanization of the generalized Kalman filter which of the above error variances are used in the recursion. In case of only the z-filter, only (30)(a)+(b) are needed, giving the recursion \({\bar{P}}^{z}_{t-1|t-1} \rightarrow {\bar{P}}^{z}_{t|t-1} \rightarrow {\bar{P}}^{z}_{t|t}\). Would \(\underline{\hat{x}}_{t|t}\) be included based on (26) and (27), then (30)(a)+(c)+(d) are needed, giving the recursion \({\bar{P}}^{z}_{t-1|t-1} \rightarrow {\bar{P}}^{z}_{t|t-1} \rightarrow {\bar{P}}^{x}_{t|t} \rightarrow {\bar{P}}^{z}_{t|t}\). For \(\underline{\hat{x}}_{t|t}\) based on (28), however, the recursion is that of the z-filter, while (30)(e) is used to tap off \({\bar{P}}^{x}_{t|t}\) from \({\bar{P}}^{z}_{t|t}\).
In case of the standard Kalman filter, we have \(F_{t}=I_{n}\) and \(G_{t}\) absent, and the results of Lemma 1 reduce to
with \(L_{t}=[I_{n}-K_{t}A_{t}]\).
When comparing \({\bar{P}}_{t|t}\) of (31) with \(P_{t|t}\) of (10) or (11), and knowing that \(P_{t|t}\) is an incorrect error-variance matrix when \({\bar{R}}_{i} \ne R_{i}\) and/or \({\bar{S}}_{i} \ne S_{i}\), for some \(i \le t\), one should be careful not to draw the automatic conclusion that \(P_{t|t}\) gives a too optimistic precision description and that the actual precision is poorer. Only in two extreme cases can one make a definite statement concerning the relation between the assumed error variance \(P_{t|t}\) and the actual error variance \({\bar{P}}_{t|t}\). When comparing \(P_{t|t}\) with \({\bar{P}}_{t|t}\), one is comparing the error-variance of the same linear estimator \(\underline{\hat{x}}_{t|t}\) under two different stochastic regimes. The assumed error variance is therefore too optimistic (\(P_{t|t} \le {\bar{P}}_{t|t}\)) if the assumed stochastic model is too optimistic. Likewise, the assumed error variance is too pessimistic (\(P_{t|t} \ge {\bar{P}}_{t|t}\)) if the assumed stochastic model is too pessimistic. In all other cases, the assumed error variance \(P_{t|t}\) can be either too optimistic or too pessimistic.
Next to the assumed and actual error variance, we may also consider the optimal error variance \(\bar{{\bar{P}}}_{t|t}\), which is the error variance when the Kalman filter is based on the correct stochastic model, \({\bar{R}}_{i}\) and \({\bar{S}}_{i}\). Based on the filter’s ‘best’ property, we have \(\bar{{\bar{P}}}_{t|t} \le {\bar{P}}_{t|t}\). And when we compare \(P_{t|t}\) with \(\bar{{\bar{P}}}_{t|t}\), we can make use of the property that the error variance of a Kalman filter improves if its stochastic model improves. Therefore, \(P_{t|t} \le \bar{{\bar{P}}}_{t|t}\), if the stochastic model under which \(P_{t|t}\) is computed can be seen as an improvement of that under which \(\bar{{\bar{P}}}_{t|t}\) is computed, and vice versa. This is summarized in Table 1. Similar conclusions hold for the error-variance matrices of the generalized Kalman filter.

Square root of assumed (\(P_{t|t}\); left) and actual (\({\bar{P}}_{t|t}\); right) error variances for different choices of assumed stochastic model (\(R_{i}=\sigma ^{2}\), with half of them smaller than \({\bar{R}}_{i}={\bar{\sigma }}^{2}\) and the other half larger than \({\bar{\sigma }}^{2}\))
Example 1
(Assumed and actual precision compared) To illustrate the characteristics of the assumed (\(P_{t|t}\)), actual (\({\bar{P}}_{t|t}\)) and optimal (\(\bar{{\bar{P}}}_{t|t})\) error variances, we consider a simple Kalman filter based on one-dimensional position observables with a constant-velocity model, i.e. a model in which the velocity fluctuations are treated as zero-mean system noise. Then, the state vector consists of position and velocity, \(\underline{x}_k=[\underline{s}(t_k),\dot{\underline{s}}(t_k)]^{T}\), and the design matrix, transition matrix and vc-matrix of the system noise vector are given as (Teunissen 2007)
with \(q_{\ddot{s}}\) being the spectral density given and \(\varDelta t\) the measurement interval. Figure 3 shows in a qualitative sense how the actual error variances \({\bar{P}}_{t|t}\), computed using the recursions of Lemma 1, can differ from the assumed \(P_{t|t}\). Only in the strict case, when one knows that the assumed stochastic model is either too optimistic or too pessimistic, can one predict the relation between \(P_{t|t}\) and \({\bar{P}}_{t|t}\) beforehand, as shown in Fig. 3 (left and right). In the general case, however, this is not possible, as shown in Fig. 3 (middle). As this general case usually prevails in practice (in particular in regard to the settings of the system noise), one cannot rely on a priori formulated bounds on the relation between \(P_{t|t}\) and \({\bar{P}}_{t|t}\). This therefore underlines the practical usefulness of having the recursions of Lemma 1 available for an online and parallel precision analysis.
Example 2
(Designing for precision). The error-variance matrices of a (generalized) Kalman filter can be computed already in a designing phase, i.e. before the actual measurements and experiment are executed. Such computations only require knowledge about the design and transition matrices and the measurement and system noise vc-matrices. Hence, when for an application certain requirements are specified for the error-variance matrices, one can design a corresponding functional and stochastic model so as to meet these requirements. Such would then imply an analysis of the dependence of the error variances on changes in the assumed stochastic model. This can be done rather straightforwardly with the standard \(P_{t|t}\) output of the Kalman filter, and Fig. 4 (left) shows such example based on (32).
However, in case of a misspecified stochastic model, such an analysis may give a seriously wrong picture, since the behaviour of the actual error variance \({\bar{P}}_{t|t}\) for changes in the assumed stochastic model can be quite different from the dependence that \(P_{t|t}\) exhibits. As a case in point, assume that the designer for his/her current application has a properly designed filter, i.e. one for which the assumed stochastic model is identical to the actual stochastic model and thus \(P_{t|t}={\bar{P}}_{t|t}=\bar{{\bar{P}}}_{t|t}\). Now, a new application comes up and the designer believes that for this new application, a more optimistic stochastic model can be used and thus designs the filter accordingly to reach a smaller \(P_{t|t}\). But if in actual fact the actual stochastic model would have remained unchanged, the choice of taking a more optimistic stochastic model will lead to an actual precision that is poorer. Hence, the designer is then confronted with the case that \(P_{t|t} \downarrow \) (designer believes to get a better precision), while \({\bar{P}}_{t|t} \uparrow \) (the actual precision gets poorer). The reason for this unwanted change is that the designer unknowingly replaced a best filter with one that is not MMSE best and therefore to one that provides a poorer precision. This will happen, irrespective of whether the assumed stochastic model was chosen to be an improvement or a deterioration relative to the correct stochastic model, and Fig. 4 (right) shows such example based on (32).
5 Predicted residuals
Predicted residuals play an important role in the quality control of Kalman filters (Teunissen 1990; Salzmann 1993; Gillissen and Elema 1996; Tiberius 1998; Yang et al. 2001; Perfetti 2006; Teunissen and Khodabandeh 2013; Zhang and Lu 2021). In this section, we generalize the concept of predicted residuals, show how their properties are affected by the stochastic misspecification (29) and discuss its consequences.
5.1 The predicted residual defined
The predicted residual of the standard Kalman filter at epoch t is defined as \(\underline{y}_{t}-A_{t}\underline{\hat{x}}_{t|t-1}\). It derives its name from the fact that \(A_{t}\underline{\hat{x}}_{t|t-1}\) is a prediction of the observable \(\underline{y}_{t}\). In the case of the generalized Kalman filter, however, \(\underline{y}_{t}=A_{t}\underline{x}_{t}+\underline{n}_{t}=A_{t}^{z}\underline{z}_{t}+A_{t}^{u}\underline{u}_{t}+\underline{n}_{t}\) cannot be predicted, since \(\underline{\hat{u}}_{t|t-1}\), and therefore \(\underline{\hat{x}}_{t|t-1}\), does not exist. The residual \(\underline{y}_{t}-A^{z}_{t}\underline{\hat{z}}_{t|t-1}\) is therefore not a predicted residual. We can generalize the concept of the predicted residual however by considering functions of \(\underline{y}_{t}\) that can be predicted. These must be functions that annihilate the contribution of \(\underline{u}_{t}\). This leads therefore to the following definition.
Definition 1
(Predicted residual) Let \(\underline{w}_{t}=\underline{y}_{t}-A_{t}^{z}\underline{\hat{z}}_{t|t-1}\) and let \(U_{t} \in \mathbb {R}^{m \times (m_{t}-n+p_{t})}\) be any basis matrix of the null space of \(A_{t}^{u T}\) (i.e. \(U_{t}^{T}A^{u}_{t}=0\)). Then,
is a (generalized) predicted residual of epoch t. \(\square \)
Note that for the standard Kalman filter (i.e. \(F_{t}=I_{n}\)), we have \(F_{t}^{+}=I_{n}\), \(A^{u}_{t}=0\), \(\underline{\hat{z}}_{t|t-1}=\underline{\hat{x}}_{t|t-1}\) and \(U_{t}=I_{m_{t}}\), from which it follows that (33) will then reduce back to the standard predicted residual \(\underline{v}_{t}=\underline{y}_{t}-A_{t}\underline{\hat{x}}_{t|t-1}\). Also note, since \(U_{t}^{T}A^{u}_{t}=0\), that \(U_{t}^{T}A^{z}_{t}=U_{t}^{T}A_{t}F^{+}\) and that therefore \(\underline{w}_{t}=\underline{y}_{t}-A_{t}^{z}\underline{\hat{z}}_{t|t-1}\) in (33) may be replaced by \(\underline{y}_{t}-A_{t}F^{+}\underline{\hat{z}}_{t|t-1}\), which is the residual that occurs in all mechanizations of the generalized Kalman filter (cf. 24, 25, 26, 28).

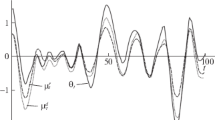
LOM test statistic \(T_{t}=v_{t}^{T}Q_{v_{t}v_{t}}^{-1}v_{t}/r_{t}\) under correctly (green) assumed and incorrectly (red) assumed stochastic model: (top-left) \(T_{t}\) time series; (top-right) \(T_{t}\) time correlation; (bottom) \(T_{t}\) histograms compared with \(\chi ^{2}(1,0)\)-PDF
5.2 Statistical testing
In standard Kalman filtering, the predicted residuals play an important role in the recursive execution of statistical tests for detecting and identifying potential biases in the underlying functional model (measurement and dynamic model). Their importance in executing such tests stems from their properties of being zero mean and being uncorrelated in time, thereby making recursive testing possible. These same properties also hold true for the predicted residual (33),
with \(Q_{v_{t}v_{t}} = U_{t}^{T}Q_{w_{t}w_{t}}U_{t}\) and \(Q_{w_{t}w_{t}}=R_{t}+A^{z}_{t}P^{z}_{t|t-1}A^{z T}_{t}\). This implies that the same recursive testing algorithms that are in use for the standard Kalman filter can be applied to its generalized version as well. This is the case, for instance, with Local and global overall model (LOM/GOM) testing. Their associated test statistics are given as (Teunissen and Salzmann 1989; Teunissen 1990),
and
in which \(r_{i}=m_{i}-n+p_{i}\) denotes the local redundancy. Under a correctly specified Kalman filter, these test statistics are centrally \(\mathcal {F}\)-distributed as
\(\mathcal {F}(\sum _{i=s}^{t} r_{i}, \infty , 0)\) denotes \(\mathcal {F}\)-distribution with \(\sum _{i=s}^{t} r_{i}\) and \(\infty \) degrees of freedom, and noncentrality parameter 0. Local and global biases are then, respectively, considered detected when \(T_{t} > \mathcal {F}_{\alpha _{l}}(r_{t}, \infty , 0)\) and \(T_{s, t} > \mathcal {F}_{\alpha _{g}}(\sum _{i=s}^{t}r_{i}, \infty , 0)\). The notations \(\mathcal {F}_{\alpha _{l}}(r_{t}, \infty , 0)\) and \(\mathcal {F}_{\alpha _{g}}(\sum _{i=s}^{t}r_{i}, \infty , 0)\) are the critical values having \(\alpha _{l}\) and \(\alpha _{g}\) as levels of significance, respectively.
5.3 On the precision of the predicted residuals
The distributional properties, stated in (37), fail to hold, once the underlying assumed properties of the predicted residuals fail to hold. Although with the misspecified stochastic model (29), the predicted residuals will still be normally distributed and will still have a zero mean, their second moments will change. The following result shows how (29) affects this change.
Lemma 2
(Predicted residual variance and between-epoch covariance). With the actual vc-matrices of the measurement and system noise (cf. 29), the variance matrix of the predicted residual (33) and its between-epoch covariance read
with \({\bar{K}}^{z}_{t}= {\bar{P}}^{z}_{t|t-1}A^{z T}_{t}{\bar{Q}}_{w_{t}w_{t}}^{-1}\) and \(K^{z}_{t}=P^{z}_{t|t-1}A^{z T}_{t}Q_{w_{t}w_{t}}^{-1}\).
Proof
For the proof, see “Appendix”. \(\square \)
This result shows that next to the change in vc-matrix of the predicted residual also time correlation is introduced. Thus, while the measurement noise and system noise are still assumed to be uncorrelated in time, the mere misspecification of their vc-matrices already introduces time correlation in the predicted residuals.
The change in the second moments of the predicted residuals will directly impact the statistics of \(\underline{T}_{t}\) as the example of Fig. 5, based on (32) (\(R_{i}=(0.5m)^{2}\), \(q_{\overset{..}{u}}=0\;m^{2}/s^{3}\), \({\bar{R}}_{i}=(1.0m)^{2}\), and \({\bar{q}}_{\overset{..}{u}}=3\cdot 10^{-8} m^{2}/s^{3}\)), illustrates. In case of an incorrect stochastic model, the LOM statistic will fail to have a mean equal one, as shown in Fig. 5 (top-left); will be time correlated, as shown in Fig. 5 (top-right); and will fail to follow the Chi-squared distribution, as shown in Fig. 5 (bottom).
The induced time correlation, \(\mathsf {C}(\underline{v}_{t}, \underline{v}_{t+1}) \ne 0\), due to the incorrectly assumed stochastic model, also implies that the GOM test statistic (36) cannot be used anymore as such. It will not have the \(\mathcal {F}(\sum _{i=s}^{t} r_{i}, \infty , 0)\) distribution and the assumed absence of time correlation under which it is constructed fails to hold. The situation with regard to the LOM test statistic is fortunately somewhat brighter. Although \(\underline{T}_{t}\) of (35) will also fail to be \(\mathcal {F}\)-distributed, knowledge of the correct vc-matrix of the predicted residuals allows one to construct a new LOM test statistic with the same \(\mathcal {F}\)-distribution. If we replace \(Q_{v_{t}v_{t}}\) in (35) by \({\bar{Q}}_{v_{t}v_{t}}\) of (38), we obtain
Hence, with knowledge of this distribution one can execute rigorous testing again.
5.4 Reliability analysis
Although \(\underline{{\bar{T}}}_{t}\) of (39) has the same distribution as \(\underline{T}_{t}\) of (37), it is important to realize that the performance of the testing with \(\underline{{\bar{T}}}_{t}\) will be different from that of testing with \(\underline{T}_{t}\) under a correctly specified Kalman filter. To illustrate this, we consider the standard Kalman filter and assume that under the alternative hypothesis the mean of the observable \(\underline{y}_{t}\) may be biased by \(C_{t}b_{t}\), with matrix \(C_{t}\) known and \(b_{t}\) unknown. In a GNSS context, such may represent the occurrence of outliers and/or slips in the GNSS observables. We then have the following null and alternative hypotheses
Then, \(\underline{v}_{t}|\mathcal {H}_{a} \sim \mathcal {N}(C_{t}b_{t}, Q_{v_{t}v_{t}})\) in case the stochastic model of the Kalman filter is correctly specified and \(\underline{v}_{t}|\mathcal {H}_{a} \sim \mathcal {N}(C_{t}b_{t}, {\bar{Q}}_{v_{t}v_{t}})\) in case (29) is true. This implies that \(\underline{T}_{t}\sim \mathcal {F}(m_{t}, \infty , \lambda )\) and \(\underline{{\bar{T}}}_{t} \sim \mathcal {F}(m_{t}, \infty , {\bar{\lambda }})\), with noncentrality parameters
Hence, under the alternative hypothesis \(\mathcal {H}_{a}\), the two test statistics, \(\underline{T}_{t}\) and \(\underline{{\bar{T}}}_{t}\), have different distributions. From a reliability analysis standpoint, it is then important to appreciate that the two noncentrality parameters of (41) have two very different usages. The noncentrality parameter \(\lambda \) can be used to analyse the minimal detectable biases (MDBs) in their dependence on the correctly specified vc-matrices \(R_{i}\) and \(S_{i}\) (\(i \le t\)). This is the usual way in which one studies the strength of the underlying model for detecting biases with the appropriate tests. The noncentrality parameter \({\bar{\lambda }}\), however, allows one to study the sensitivity of the MDBs in dependence of the incorrectly specified vc-matrices \(R_{i}\) and \(S_{i}\) (\(i \le t\)) and thus help answer questions like how well biases can still be detected even under the usage of a misspecified stochastic model.
In case of a single bias (i.e. \(C_{t} \rightarrow c_{t}\)) with (41), the corresponding MDBs are given as (Baarda 1968; Teunissen 2018)
in which the reference value of the noncentrality parameter \(\lambda ={\bar{\lambda }}\) is determined from the chosen level of significance and power of the test.
6 Summary and concluding remarks
In this contribution, we introduced a generalized Kalman filter with precision in recursive form when the stochastic model is misspecified. The filter allows for a relaxed dynamic model in which not all state vector elements are connected in time. The filter’s flexibility stems from the property that its dynamic model is assumed to hold for only some functions of the state vector and that these functions are permitted to vary in time. Different mechanizations of the corresponding recursive filters were presented.
Just like the standard Kalman filter, its generalization has the property of being ‘best’ in the MMSE sense. And just like with the standard Kalman filter, this property is lost in case the filter is based on an incorrectly specified stochastic model. Although losing this optimality property is a pitfall, we considered a far more serious problem the consequential lack of a proper quality description of the filter.
We therefore extended the filter with a recursion of its actual time-update and measurement-update error-variance matrices, to provide a tool for the efficient precision analysis of (generalized) Kalman filters. It allows for an easy-to-execute online recursive sensitivity analysis, whereby the computations can be done in parallel to the recursion of the filter itself. The relevance of having such tool available was further underlined by illustrating through several examples that the behaviour of the actual filter precision, in response to changes in the assumed stochastic model, is difficult to predict a priori.
Next to the error-variance matrices, also the predicted residuals play an important role in the quality control of recursive filters. Due to the relaxation of the dynamic model, the concept of predicted residuals had to be generalized to predictable functions of the observables. It was thereby shown how their precision is affected by a misspecified stochastic model. It was hereby also shown that while the measurement noise and system noise are uncorrelated in time, the mere misspecification of their vc-matrices will already introduce time correlation in the predicted residuals. This will therefore have its impact on the distributional properties of the test statistics used for the detection, identification and adaptation of the underlying models. In particular, the time correlation of the predicted residuals will affect the recursive global statistics as it invalidates the assumptions on which they are constructed. For the local statistics, fortunately the situation was shown to be brighter, as the usage of the given recursions of the actual vc-matrices still allows the construction of test statistics with known distributions. Finally, we demonstrated, differently from the traditional minimal detectable bias (MDB), which relies on a correctly specified model, how the recursive form of the affected precision of the predicted residuals can be used to study how well biases can still be detected even under the usage of a misspecified stochastic model.
7 Appendix
Proof of Lemma 1
The different error states can be written in their contributing factors as
where use has been made of \(K^{z}_{t}A^{u}_{t}=0\), \(F_{t}^{T}(\underline{x}_{t}-F_{t}^{+}\underline{z}_{t})=0\) and the fact that the null space of both \([K^{x}_{t}A_{t}-I_{n}]\) and \([G^{x}_{t}A_{t}-I_{n}]\) are spanned by the columns of \(G_{t}\). Application of the variance propagation law to the error states (43) gives the result. The error-variance matrix of the initial state follows from applying the variance propagation law to \(\underline{\hat{z}}_{0|0}-\underline{z}_{0} = F_{0}^{T}A_{0}^{+}\underline{n}_{0}\). \(\square \)
Proof of Lemma 2
For the predicted residuals \(\underline{v}_{t}=\underline{y}_{t}-A^{z}_{t}\underline{\hat{z}}_{t|t-1}\) and \(\underline{v}_{t+1}=\underline{y}_{t+1}-A^{z}_{t+1}\underline{\hat{z}}_{t+1|t}\), we may, with the help of \(\underline{z}_{t+1}=\varPhi ^{z}_{t+1,t}\underline{z}_{t}+\underline{d}^{z}_{t}\), \(\underline{\hat{z}}_{t+1|t}=\varPhi ^{z}_{t+1,t}\underline{\hat{z}}_{t|t}\), \(\underline{y}_{t}=A_{t}^{z}\underline{z}_{t}+A_{t}^{u}\underline{u}_{t}+\underline{n}_{t}\), and \(\underline{\hat{z}}_{t|t}=\underline{\hat{z}}_{t|t-1}+K^{z}_{t}[\underline{y}_{t}-A^{z}_{t}\underline{\hat{z}}_{t|t-1}]\), write
Application of the variance propagation law to the first equation gives \({\bar{Q}}_{v_{t}v_{t}}\). The covariance \(\mathsf {C}(\underline{v}_{t}, \underline{v}_{t+1})\) follows from the above two equations by recognizing that only the random vectors that the two equations have in common, \(\underline{n}_{t}\) and \(\underline{z}_{t}-\underline{\hat{z}}_{t|t-1}\), contribute to this covariance. \(\square \)
Data availability
Data are included in this published article, while further data are available from the corresponding author on reasonable request.
References
Baarda W (1968) A testing procedure for use in geodetic networks. Netherlands Geodetic Commission, Publ on geodesy, New Series 2(5)
Gillissen I, Elema I (1996) Test results of DIA: a real-time adaptive integrity monitoring procedure, used in an integrated navigation system. Int Hydrogr Rev 73(1):75–103
Grewal MS, Andrews AP (2008) Kalman filtering; theory and practice using MATLAB, 3rd edn. Wiley, New York
Kailath T (1970) The innovations approach to detection and estimation theory. Proc IEEE 58(5):680–695
Kalman RE (1960) A new approach to linear filtering and prediction problems. J Basic Eng 82(1):35–45
Khodabandeh A, Teunissen PJG, Zaminpardaz S (2018) Consensus-based distributed filtering for GNSS. Chapter 14 in Kalman filters—theory for advanced applications. InTech pp 273–304
Koch KR (1999) Parameter estimation and hypothesis testing in linear models. Springer, Berlin
Kouba J, Heroux P (2001) Review of code and phase biases in multi-GNSS positioning. GPS Solut 5(2):12–28
Li T, Wang J, Laurichesse D (2014) Modeling and quality control for reliable precise point positioning integer ambiguity resolution with GNSS modernization. GPS Solut 18:429–442
Odijk D, Zhang B, Khodabandeh A, Odolinski R, Teunissen PJG (2015) On the estimability of parameters in undifferenced, uncombined GNSS network and PPP-RTK user models by means of S-system theory. J Geod 90(1):15–44
Perfetti N (2006) Detection of station coordinate discontinuities within the Italian GPS fiducial network. J Geod 80(7):381–396
Salzmann M (1993) Least squares filtering and testing for geodetic navigation applications. Publications on Geodesy, Netherlands Geodetic Commission, p 37
Simon D (2006) Optimal state estimation, Kalman, H-infinity and nonlinear approaches. Wiley, New York
Teunissen PJG (1990) Quality control in integrated navigation systems. IEEE Aerosp Electron Syst Mag 5(7):35–41
Teunissen PJG (2007) Dynamic data processing: recursive least-squares, 2nd edn. Delft University Press, Delft
Teunissen PJG (2018) Distributional theory for the DIA method. J Geod 92(1):59–80
Teunissen PJG, Khodabandeh A (2013) BLUE, BLUP and the Kalman filter: some new results. J Geod 87(5):461–473
Teunissen PJG, Khodabandeh A (2015) Review and Principles of PPP-RTK methods. J Geod 89(3):217–240
Teunissen PJG, Salzmann M (1989) A recursive slippage test for use in state-space filtering. Manuscr Geod 14(6):383–390
Tiberius CCJM (1998) Recursive data processing for kinematic GPS surveying. Publications on Geodesy, Netherlands Geodetic Commission, p 45
Yang Y, He H, Xu G (2001) Adaptively robust filtering for kinematic geodetic positioning. J Geod 75:109–116
Zhang X, Lu X (2021) Recursive estimation of the stochastic model based on the Kalman filter formulation. GPS Solut. https://doi.org/10.1007/s10291-020-01060-4
Zhang X, Zhang B, Yuan Y, Zha J (2020) Extending multipath hemispherical model to account for time-varying receiver code biases. Adv Space Res 65(1):650–662
Zumberge JF, Heflin MB, Jefferson DC, Watkins MM, Webb FH (1997) Precise point positioning for the efficient and robust analysis of GPS data from large networks. J Geophys Res 102:5005–5017
Author information
Authors and Affiliations
Contributions
PT wrote the paper and developed the theory together with AK. DP provided numerical support, and both DP and AK validated the paper.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Teunissen, P.J.G., Khodabandeh, A. & Psychas, D. A generalized Kalman filter with its precision in recursive form when the stochastic model is misspecified. J Geod 95, 108 (2021). https://doi.org/10.1007/s00190-021-01562-0
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s00190-021-01562-0