
Abstract
Subfossil pollen and plant macrofossil data derived from 14C-dated sediment profiles can provide quantitative information on glacial and interglacial climates. The data allow climate variables related to growing-season warmth, winter cold, and plant-available moisture to be reconstructed. Continental-scale reconstructions have been made for the mid-Holocene (MH, around 6 ka) and Last Glacial Maximum (LGM, around 21 ka), allowing comparison with palaeoclimate simulations currently being carried out as part of the fifth Assessment Report (AR5) of the Intergovernmental Panel on Climate Change. The synthesis of the available MH and LGM climate reconstructions and their uncertainties, obtained using modern-analogue, regression and model-inversion techniques, is presented for four temperature variables and two moisture variables. Reconstructions of the same variables based on surface-pollen assemblages are shown to be accurate and unbiased. Reconstructed LGM and MH climate anomaly patterns are coherent, consistent between variables, and robust with respect to the choice of technique. They support a conceptual model of the controls of Late Quaternary climate change whereby the first-order effects of orbital variations and greenhouse forcing on the seasonal cycle of temperature are predictably modified by responses of the atmospheric circulation and surface energy balance.
Similar content being viewed by others

1 Introduction
Climate models provide both the means to explore potential future climatic changes, and to test hypotheses concerning the causes of past climate. Although the former application has received the most publicity, the latter has the potential to provide challenging tests of modelling capability by providing a range of cases in which climate boundary conditions have varied well outside the limits of contemporary (or historically recent) observations (for further discussion on model benchmarking using palaeoclimate simulations see e.g. Braconnot et al. 2007a, b; Edwards et al. 2007; Schmidt 2010).
The Last Glacial Maximum (LGM, ca. 21,000 years ago, 21 ka) and middle Holocene (MH, ca. 6,000 years ago, 6 ka) have been the main target periods for the Palaeoclimate Modelling Intercomparison Project (PMIP http://pmip2.lsce.ipsl.fr/) and continue to be important standard benchmarks for model evaluation in the current phase of this project (Otto-Bliesner et al. 2009). Both time periods are included in the suite of simulations being carried out as part of the fifth Assessment Report (AR5) of the Intergovernmental Panel on Climate Change, and thus will contribute to the benchmarking of climate models used to predict potential future climate changes. At the LGM, large ice sheets covered substantial areas of the northern continents; the major greenhouse gases (carbon dioxide, methane and nitrous oxide) were at historic minimum atmospheric concentrations; and terrestrial ecosystems were less productive, of different composition, and generally shifted toward the equator. The MH was much more similar to the present than the LGM, and greenhouse gases were at levels close to those before the industrial revolution. However, the Earth’s orbital configuration differed from that of today, with perihelion in boreal summer/autumn (implying greater seasonality of insolation in the northern hemisphere) and greater obliquity, implying higher summer (and annual) insolation in high latitudes. Although neither period is a strict analogue or “anti-analogue” for future conditions, the LGM is of considerable interest as a period with strongly negative radiative forcing (including low carbon dioxide concentration) while the MH offers the possibility of studying a period with warmer conditions and longer growing seasons in many regions, comparable in some respects to climates expected as a result of increasing radiative forcing in the future.
The development of well-documented, quantitative global palaeodata sets portraying the spatial climatic patterns of the LGM and MH time periods is a central objective of the PMIP3 research programme (Otto-Bliesner et al. 2009). Terrestrial environments are diverse and many sources of palaeodata provide information on specific areas and ecosystems. Palaeovegetation (fossil pollen and plant macrofossil) data provide a unique combination of near-global coverage, multivariate responses (i.e. vegetation composition carries information about several distinct aspects of climate), and well-documented methods of providing quantitative palaeoclimatic estimates. This paper presents a global synthesis of reconstructed terrestrial climatic estimates for the LGM and MH, based on the application of common methods.
The palaeoceanographic community has recently completed a global reconstruction of LGM sea surface temperatures (MARGO Project Members 2009), which supersedes the widely used CLIMAP data set developed in the 1980s. Terrestrial environments are at least as diverse as marine environments, and as in the marine realm, many methods and data sources have been developed in order to generate palaeoclimate reconstructions that can be compared with modelling results. However, the most recent synthesis of quantitative climate reconstructions based on terrestrial palaeodata (COHMAP Members 1988; Wright et al. 1993) fell short of generating a unified global data set. Here we present such a data set, for the first time.
2 Methods
The MH and LGM reconstructions presented here were produced by combining existing quantitative reconstructions based on pollen and plant macrofossils that have been made for different regions of the world and using a variety of different methods. Although a few climate reconstructions have been made using other types of palaeoenvironmental records, such as chironomid or coleopteran assemblages (e.g. Atkinson et al. 1987; Heiri et al. 2003), only pollen and plant macrofossil data are extensive enough to provide quantitative palaeoclimate estimates at continental-to-regional scales. The procedure for selection, screening and combining the existing data sets is discussed in Sect. 2.6 after discussion of the general principles and specifics of the different quantitative reconstruction techniques.
2.1 Principles
Geographic distributions of plant species can be approximated by “envelopes” representing conterminous regions in climate space. The climate space required to describe species distributions is not a 1D space (i.e. species distributions cannot be represented accurately along a single axis such as mean annual temperature) but rather, at least a 2D (Iversen 1944; Hintikka 1963), 3D (Thompson et al. 1999) or 4D (Bartlein et al. 1998; Williams et al. 2001) space, with dimensions related to temperature seasonality and water availability. This situation is understood to arise because of the existence of bioclimatic limits on the distribution of taxa (Woodward 1987; Harrison et al. 2009). If these limits acted separately, they would define a volume in climate space, where the axes are provided by variables that relate to the relevant mechanisms (e.g. growing-degree days, GDD, rather than mean July temperature as an index of accumulated warmth during the growing-season, etc.) This assumption underpins the way in which the limits of population viability for taxa (Sykes et al. 1996; Smith et al. 2001) or plant functional types (PFTs, e.g. Sitch et al. 2003; Gerten et al. 2004; Prentice et al. 2007) are specified in regional and global modelling of vegetation dynamics.
Fossil pollen records provide evidence of changing plant distributions through time (e.g. Prentice et al. 2000; Bigelow et al. 2003; Pickett et al. 2004; Marchant et al. 2009). Pollen are often identifiable to genus and family level, but only rarely to species level. These higher taxa tend to have distributions as coherent as lower taxa or species in climate space, even when species from different continents are included: this was first noted by Huntley et al. (1989) for Fagus, and has been confirmed by more recent work which has established the general tendency for lineages to be evolutionarily conservative in terms of climate preferences (Ackerly 2003; Moles et al. 2005; Wake et al. 2009). Bioclimatic limits determine the fundamental niche of a taxon, but taxa (whether at species or higher level) commonly have overlapping fundamental niches. They also vary in abundance, with maximum values either near physiological optima, or displaced by competition. We therefore find more-or-less continuous variation in taxon abundance along environmental gradients in space, and we can construct relationships between composition and location in climate space (Jackson and Williams 2004).
In time, continuous changes in composition are observed. These can be explained by continuous changes in climate. The observed response in pollen assemblages is due in part to quantitative compositional shifts, and in part to range boundary shifts. When climate change is rapid, so is compositional change. The composition of pollen assemblages tracks the climate with lags of the order of 100 years or less (Gajewski 1987; Prentice et al. 1991; Birks and Ammann 2000; Davis and Shaw 2001; Tinner and Lotter 2001; Williams et al. 2002; Wehrli et al. 2007; Pross et al. 2009). Thus, climate changes (on multi-centennial to glacial-interglacial time scales) can be reconstructed by applying the modern spatial relationships between climate and plant assemblages to the “downcore” temporal variations in pollen, ignoring plant succession and persistence effects.
This substitution is usually done by using large surface sample data sets as “training sets” to establish empirical relationships between taxon abundances and climate variables, which can then be applied to fossil samples. It is also possible to start from contemporary species distribution directly (Kühl et al. 2002), which allows surface samples to be reserved for testing. Composition can also be predicted (most successfully in terms of plant functional types, PFTs) using process-based modelling (see e.g. Lischke et al. 2002; Koca et al. 2006; Miller et al. 2008), which is independent of either surface samples or species distributions.
2.2 Main categories of methods
2.2.1 Statistical methods
In inverse regression (Huntley and Prentice 1988; Bartlein et al. 1984), each climate variable is treated as a dependent variable in a multiple regression with the taxon abundances as predictors. (The regression is said to be “inverse”, in the sense that in nature climate is the control and taxon abundance is the response.) Improved fit can be obtained by Box-Cox transformation of the taxon abundances (Bartlein et al. 1984). The regression equations are developed on the surface sample data set, and then applied to the fossil samples directly.
Weighted averaging methods (ter Braak and Juggins 1993; Birks 1995) are a more recent type of regression, better suited to data (like pollen data, when large regions of climate space are considered) where the taxa display optima around which they decline in abundance. Optima are estimated from modern climate-abundance relationships, and estimates for fossil assemblages are made as a weighted average of the optima of all taxa found.
Artificial neural networks are widely used to calibrate the non-linear relationships between two or more parameters, and have been adapted to pollen-based climate reconstruction (e.g. by Peyron et al. 1998). A network is established as a series of coefficients or nodes that are adjusted during calibration to provide the closest possible fit, and then climate variables may be estimated from any pollen assemblage.
The modern analogue technique (Overpeck et al. 1985; Guiot 1990; Jackson and Williams 2004) searches through the surface sample data set to find the samples that give the lowest values of a dissimilarity measure, such as squared chord distance, between the fossil pollen sample and the modern ones. The method then attributes the average climate associated with these “modern analogues” to the fossil pollen sample.
The response surface technique (Bartlein et al. 1986) is conceptually related to the modern analogue technique. A response surface is a smooth surface fitted to each taxon’s abundance in climate space. The first applications fitted quadratic surfaces (paraboloids); later applications have used a more flexible surface-fitting procedure that allows more complicated shapes, and both procedures allow for mild extrapolation of the fitted surfaces. The technique seeks the point in climate space where the fossil-pollen sample shows lowest dissimilarity to the assemblage constructed from the fitted values of all of the taxa. The climate at this point is attributed to the fossil pollen sample. Waelbroeck et al. (1998) have extended this by combining response surfaces with a modern analogue approach to avoid excessive smoothing of the taxon abundances, and Gonzales et al. (2009) describe an approach for extrapolating the response surfaces by fitting symmetrical unimodal distributions to the taxon abundances in order to deal with the situation in which fossil-pollen samples have no analogues in the modern data set.
Inversion of species envelope models provides an alternative approach conceptually related to the response surface technique. Instead of using surface sample data as the training set, this approach starts with species range maps or biogeographic atlas data, usually recording species presence. Thompson et al. (2008) have used the modern analogue technique to select points from a continent-wide grid of species presence/absence distributions and associated climate that are the most similar to a fossil assemblage, assigning the associated climate as the reconstruction. The assignment may be weighted by an index of similarity such as the Jaccard coefficient. In the mutual climatic range approach, the climatic ranges for each species found in a fossil assemblage are superimposed, and the estimate is given as the climate interval common to all species (Atkinson et al. 1987). The reconstructed interval may be refined by using the 5–95 percentile range of the climate envelope to preferentially weight the estimated climate (Thompson et al. 2008) or, more rigorously, a probability density function (pdf) may be fitted to the species presence data (Kühl et al. 2002). The first applications of the pdf method fitted Gaussian surfaces; later applications have used a mixture model to obtain a more generalized form (e.g. Gavin and Hu 2006). As with response surfaces, the pdfs are fitted separately for each taxon, and fossil pollen samples are assigned the “most probable climate” to have produced the sample, based on multiplying together the pdfs of the constituent taxa.
2.2.2 Process-based methods
State-of-the-art biogeography models (Haxeltine and Prentice 1996; Kaplan et al. 2003) predict the geographic distribution and quantitative properties such as net primary production (NPP) and leaf area index (LAI) of plant functional types (PFTs), as a function of climate, soil properties (which affect water retention) and atmospheric CO2 content (which affects photosynthesis). When such models are “inverted” for climate reconstruction (Guiot et al. 2000), pollen taxa are assigned to PFTs using standard tables developed for the BIOME 6000 project and subsequent work in vegetation reconstruction (Prentice et al. 2000; Pickett et al. 2004; Marchant et al. 2009), or using independently generated bioclimatic affinity groups (Laurent et al. 2004). A climate space is constructed by systematically perturbing the input variables of the model. The method searches for the point in this climate space providing the best match between the PFT profile of the fossil pollen sample (in terms of abundances) and the PFT profiles generated by the model (in terms of NPP or LAI). A Monte Carlo Markov Chain algorithm has been used to accelerate the search and thus make the approach computationally tractable.
2.3 Advantages and problems of different methods
Inverse regression has difficulty in accommodating unimodal (as opposed to monotonic) taxon responses. As a result, it is necessary in practice to develop different regression equations applying to different regions of climate space (Bartlein and Webb 1985; Huntley and Prentice 1988). This leads to a degree of arbitrariness in the reconstruction because the best-fitting equation for a given point may not be the most suitable when applied to the same point in the past. It is encouraging that major features of early reconstructions using inverse regression have been upheld by newer techniques. But the method proved too cumbersome, and was abandoned.
Weighted averaging methods are designed to deal with unimodal responses and thus they deal with the most problematic features of conventional inverse regression. However, they have difficulty in handling more complex (e.g. bimodal) species responses. And in common with all regression methods they will always give an answer. This could be the wrong answer in no-analogue situations, i.e. when the pollen samples considered fall outside the compositional range represented by the training set.
Artificial neural networks adapt well to non-linear problems, such as vegetation climate relationships, but require a number of parameters to be chosen, including the number of nodes and the number of training iterations. Further, this remains a black-box approach in which the coefficients obtained are difficult to interpret.
Modern analogue and response surface methods can deal with arbitrarily complex niche shapes. Although conceptually simple, the application of the modern analogue technique requires several decisions that can affect the palaeoclimate estimates. These include decisions about the number of pollen taxa used to compute the squared chord distance, the threshold value of the squared chord distance that distinguishes a “good analogue” from a “no-analogue” fossil pollen sample, and the number of analogues averaged to compute the fossil palaeoclimate estimate (see e.g. Jackson and Williams 2004; Sawada et al. 2004; Viau et al. 2006, 2008; Williams and Shuman 2008). Although methods have been developed to identify “no-analogue” samples, e.g. comparison of between and within-vegetation zone dissimilarity values, the solutions depend on the vegetation classification scheme and taxonomic diversity (e.g. Overpeck et al. 1985; Anderson et al. 1989; Waelbroeck et al. 1998; Sawada et al. 2004; Williams and Shuman 2008). Assemblages dominated by widespread taxa may generate probably unrealistic “jumps” as analogues may be selected from geographically and climatically disparate regions (Brewer et al. 2008). These jumps can occur when a pollen taxon includes several species with highly distinct geographic and climatic distributions (Williams and Shuman 2008), and are also a problem when the modern calibration datasets are sparse. This feature may have led to misleading artifacts when the methods have been applied to continuous time series. No-analogue situations can be identified (by high dissimilarity values), but in these cases no reconstruction should be made; or at least the reconstruction has to have a caveat attached to it (Cheddadi et al. 1997). Furthermore, “wrong-analogue” situations can occur, and go undetected. These are situations where similar pollen assemblages occur across a wide range of a climate variable. The methods can then be biased by the available surface sample data, because it is possible that a close analogue will be found within the range of the surface samples even if the true palaeoclimate lies outside the range. Alternatively, wrong analogues can occur if the relative abundances of species represented by a particular pollen morphotype change substantially over time (Jackson and Williams 2004).
Inversion of species envelope models represents a partial solution to the no-analogue problem in that it uses species distributions only, rather than abundances, to produce the pdfs. No-analogue situations (in terms of species presence) will still produce no estimate, and wrong-analogue situations could still go undetected.
Inversion of process-based biogeographic models should, in principle, solve both the no-analogue and wrong-analogue problems by (a) using process-based logic to predict no-analogue assemblages, and (b) providing realistic error bars based on the full range of possible climates. A further strength of this approach is that it provides a way to include effects of CO2 concentration on competition between PFTs and therefore also the relative abundances of taxa (Harrison and Prentice 2003; Prentice and Harrison 2009). All other techniques are likely to give biased results for CO2 concentrations unlike those of the Late Holocene. An inevitable weakness however is that the method is model-dependent, and in practice, the forward-simulation requires the generation of potentially non-unique values of a large number of input variables (i.e., more than one reconstructed climate could correctly simulate a particular assemblage).
2.4 Including multiple data sources
Modern analogue methods can be easily adapted to apply constraints derived from another data source, e.g. lake level changes (Cheddadi et al. 1997). Inversion of biogeographic models can also be adapted in a natural way because process-based models predict ancillary variables such as runoff and plant δ13C (Hatté and Guiot 2005), the latter being a powerful additional indicator of C3 plant water status and C3/C4 plant competition (Harrison and Prentice 2003; Prentice and Harrison 2009). Hatté et al. (2009) showed that the use of δ13C as an additional constraint considerably reduces the uncertainties of climatic reconstructions obtained from inverse modelling compared to using pollen alone. Guiot et al. (2009) have indicated that inverse modelling could provide an elegant solution of combining multiple data types, including lake-levels, δ13C and pollen.
2.5 Comparative studies
Although these techniques have been employed in palaeoclimatology for a number of years, there are only a few studies in which different methods are used at the same site (see e.g. Bartlein and Whitlock 1993). In a recent study of the Eemian in Europe, Brewer et al. (2008) reconstructed climate for a set of sites using seven methods, include many of those described above. The methods were largely coherent during the interglacial period, characterised by quite diverse and information-rich assemblages. In glacial periods, however, there is increasing divergence between the values estimated by the different methods, and analogue-based methods show a marked increase in the variability of reconstructed values. These periods are characterised by information-poor assemblages that are often dominated by Pinus and Artemisia, both widespread taxa found in a range of environments. This situation poses problems for many of the methods: for example it becomes harder to obtain either true analogues or precise estimate from regression techniques. The level of agreement or divergence between different techniques does however provide a measure of the robustness of the reconstruction.
2.6 Methods used for the synthesis
We provide gridded reconstructions of climate variables for the MH (defined here as the period around 6,000 calendar years BP, 6 ka) and the LGM (defined here as the period around 21,000 calendar years BP, 21 ka) based on combining all existing quantitative reconstructions, subject to availability of the primary data (i.e. the reconstructions) and a transparent screening procedure. Quantitative estimates of past terrestrial climates were provided by the authors, from online public-access datasets, or from the literature.
Regional- to continental-scale palaeoclimate reconstructions have been made for Europe, Eurasia, North America and Africa (Table 1) using extensive archive pollen databases (the Global Pollen Database http://www.ncdc.noaa.gov/paleo/gpd.html, the North American Pollen Database http://www.ncdc.noaa.gov/paleo/napd.html, NEOTOMA http://www.neotomadb.org/, the European Pollen Database http://www.europeanpollendatabase.net/, the African Pollen Database http://medias3.mediasfrance.org/apd/) and modern calibration datasets (e.g. Gajewski et al. 2002; Whitmore et al. 2005). No large-scale regional climate reconstructions have been made for South America and Australasia, despite the existence of archive pollen databases for both regions (see http://www.ncdc.noaa.gov/paleo/lapd.html, http://palaeoworks.anu.edu.au/databases.html).
Several different reconstruction techniques have been applied to data sets extracted from the archival databases (Table 1; Fig. 1), ranging from simple regression through analogue techniques to inverse modelling methods. We made no attempt to select a single data set for a given region––in part because it would be difficult to evaluate regional patterns given that the maps would be based on different methods for different regions, and in part because (as will be demonstrated later) different techniques appear to yield remarkably similar results at least to first order.

Distribution of sites included in the benchmark data sets for 6 ka (upper panels) and 21 ka (middle panels) in geographic space by reconstruction method. Reconstructions made with different methods are available for some sites. The sites (shown as black dots) are also plotted in climate and vegetation space (lower panel), where climate space is represented by accumulated warmth during the growing season (GDD0) and the ratio of actual to potential evapotranspiration (AE/PE) and vegetation space by the distribution of major biomes within this climate space
The data coverage for Europe and North America is considerably denser than that for Russia, Asia and Africa. For regions with no large-scale reconstructions, we searched the literature for individual studies where researchers made time-series reconstructions for one or more individual cores based on an explicit statistical calibration method and a regional calibration dataset. These were retained only in regions from where we had no other reconstructions (Table 2).
We have used climate reconstructions based on pollen samples assigned by the original authors to 6 or 21 ka. In those cases where the original authors provide reconstructions for all pollen samples in a sequence, we have used the climate reconstructions based on the pollen sample closest to 6 ka, provided it fell within the range 5.5–6.5 ka. Some early datasets used the same convention in radiocarbon years, equivalent to 6.3–7.45 ka. As it was difficult to determine the age of the sample in order to calibrate them, we instead retained the original non-calibrated sample. In the worse case, this means the samples used could range in age from 5.5 to 7.45 ka. However the bulk of the samples (79%) definitely fall within the range of 5.5–6.5 ka, and only 3.5% of the samples definitely fall outside this range. A similar situation pertains to 21 ka, where we have taken the closest sample to 21 cal ka (±1 ka), but earlier studies would have been based on samples around 18,000 14C year BP, i.e. ranging from 20.25 to 22.9 cal year BP. In the worse case, this means the samples could range from 20 to 22.9 ka. Again, the majority of the samples (63%) definitely fall in the range 21 ± 1 cal ka.
Regional scale reconstructions have been mapped as values at individual sites (e.g. Jackson et al. 2000; Wu et al. 2007) or in some cases gridded (e.g. Cheddadi et al. 1997; Webb et al. 1998). Although in some cases only gridded fields were published, we obtained the original point data for this study. However, in one case (Webb et al. 1998), the reconstructions were done after the pollen data were gridded and thus point data reconstructions were not available. Gridding data involves interpolation and loss of the original data values, and in some cases extrapolation beyond the limits of the data (see discussion in Sawada et al. 2004). We have not used the gridded datasets in our analyses because we wanted a dataset that could subsequently be gridded at the appropriate scale for analysis and comparison with climate model output.
The datasets we have used in this study include reconstructions of many different climatic variables. However, in any one study, only a subset of these were typically reconstructed. Many climate variables are highly correlated; there are insufficient degrees of freedom to reconstruct all of the potential climate variables of interest. We retained those that are considered functionally important to plant growth (Harrison et al. 2009), generally called bioclimatic variables. Some climatic variables are functionally equivalent to these bioclimatic variables (e.g. July temperature in the northern hemisphere is functionally equivalent to mean temperature of the warmest month, MTWA: Harrison et al. 2009). So, in the northern hemisphere we have amalgamated July temperature (December temperature in the southern hemisphere) with reconstructions of MTWA. Similarly, we have amalgamated December temperature in the northern hemisphere (July temperature in the southern hemisphere) with its functional equivalent, mean temperature of the coldest month (MTCO). Six variables are included in the final analysis: mean temperature of the warmest month (MTWA), mean temperature of the coldest month (MTCO), accumulated temperature during the growing season (an index of growing season warmth) measure by growing degree days above a base level of 5°C (GDD5), mean annual temperature (MAT), mean annual precipitation (MAP) and a moisture index (alpha, α) defined as the ratio of actual to potential evaporation (Table 3).
We estimated climate anomalies (i.e. the difference between the target period and the present day, e.g. 6–0 ka) at each site. We do this because palaeoclimate reconstructions can differ from the present due to changes in the climate but also due to differences in the calibration set used as a baseline. The use of anomalies avoids this source of error. Wherever possible, we used the original climate reconstructions for 6 and 0 ka to estimate the climate anomaly. In the cases where modern values were not included in the database, we extracted the modern climate values from the Climate Research Unit (CRU) historical climatology data set (CRU CL 2.0, New et al. 2002).
Different studies have expressed reconstruction uncertainties in different ways. In this study, uncertainties are re-expressed as standard error of estimates where there was sufficient information to calculate these. Where the authors did not report uncertainty, or where it was impossible to compute it from available data, we have used the average global uncertainty (i.e. the RMSE of regression) for each bioclimatic variable derived from the regressions of observed versus reconstructed bioclimate variables shown in Fig. 2.

The number of sites in each grid cell contributing to the benchmark reconstructions of individual climatic variables, after the screening procedures, at 6 and 21 ka
There are a few instances where the reconstructions of modern climate variables are very different from the observed climate (i.e. CRU). These were most often sites in topographically diverse regions. We used the Mahalanobis Distance to identify points which differed significantly from the observations in an objective way (Bartlein et al. 1984). These sites were not included in the subsequent gridding procedure.
Finally, we produced gridded data sets of the anomalies of each bioclimatic variable. We used a regular latitude/longitude grid of 2° by 2°. The grid size was selected to be comparable to the grid size typical of the models used in state-of-the-art palaeoclimate simulations. This size of grid also avoids over-smoothing the resulting patterns of regional climate change and limits the number of grid cell values based on a single reconstruction. The grid-cell value of the anomaly was obtained by simple averaging, and that for the uncertainty as a pooled estimate of the standard error obtained in the usual way. The data (Electronic Supplementary Material) were plotted as symbols, where the colour reflects the magnitude of the anomaly and the symbol size reflects the significance of the grid-cell average of that anomaly: a large symbol is plotted when the absolute value of a t-statistic calculated using the anomaly values and the pooled standard error exceeds 2.0.
The product of our synthesis is a set of data sets each consisting of grid-point average anomalies, their uncertainties and associated t-statistics for a particular variable. This product is analogous to a “composite anomaly” map in synoptic climatology, and uses the same general concepts to establish robustness (i.e. invariance with respect to the inclusion of individual cases) and interpretability. At a particular location or grid-point on a composite-anomaly map, if the individual cases that are being composited produce anomalies that are similar in sign and magnitude, then the composite (usually the mean, but other statistics can be used) will take on that sign and magnitude, and change little if a single (or even several) cases are dropped. In contrast, if the individual anomalies differ from case to case in sign or magnitude, then they will cancel each other out in the composite. If the individual cases share the same map pattern (as well as anomaly values at individual grid cells) then that pattern will emerge in the composite-anomaly map, and again, will change little if a single (or several) cases are dropped; if the individual map patterns differ, than no resolvable (or interpretable) pattern emerges. In our analysis, if the individual reconstructions (from different sites and/or studies) are similar within a grid cell, then a significant anomaly will emerge, and if the reconstructions are similar among nearby grid cells, then a coherent map pattern will emerge. Conversely, if the reconstructions differ from one another within and among grid cells, then no discernable large-scale pattern will emerge. Note that there is no requirement that the individual grid-point anomalies that make up broad (regional-to-continental) scale anomaly patterns must individually be significant in order for the pattern as a whole to be interpretable; it would be extremely unlikely that broad-scale patterns would emerge by chance.
3 Results
3.1 Data in climate and vegetation space
The original data set contains 4,806 individual observations for 6 ka, of which 4,706 were used in the final data set after applying age-selection and statistical outlier criteria (Fig. 1; Table 1). For 21 ka, the original data set contains 357 individual observations, of which 349 were used in the final data set (Fig. 1; Tables 1, 2). Gridding results in the creation of climate estimates for 715 cells (out of a possible 3,687 non-ice-covered land cells) at 6 ka and for 153 cells (out of a possible 3,618 non-ice-covered land cells) at 21 ka. The number of individual reconstructions contributing to the estimate for each grid cell is shown in Fig. 2. These numbers reflect the number of sites, samples at each site, and individual studies that have produced reconstructions.
The spatial coverage is not even: there is very good coverage for Europe (north of 35N and west of 45E) (197 out of 354 non-ice-covered land cells at 6 ka) and North America (220 out of 735 non-ice-covered land cells at 6 ka) but coverage is sparse for Eurasia and Africa, and there is information for only one or at best a few cells for other tropical regions. There are no data from extratropical South America or Australia, and only seven points from New Zealand. Despite the uneven geographic coverage, the data set provides a reasonably comprehensive representation of modern climate and vegetation space (from tropical to tundra, and from maritime to continental climates, see Fig. 1, bottom panel). There is also uneven coverage of individual climate variables, with counts ranging from 1,408 for GDD5 to 4,232 for MTWA at 6 ka (yielding 516 and 628 gridded values, respectively) and from 163 for alpha to 333 for MTCO at 21 ka (yielding 88 and 145 gridded values, respectively). Thus, although the data set may fall short of providing a detailed picture of climate for every region of the globe, the data set encompasses a wide range of different climates at present, and so should provide an adequate sampling of the kinds of climate changes that we expect climate models to be able to reproduce.
3.2 Assessment of performance
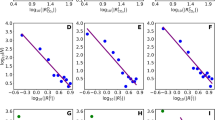
A basic test of any reconstruction method is to determine how well it predicts observed climates. Here, we compare the reconstructed modern climate variables at individual sites (using the results from all of the different reconstruction methods) with observations derived from the CRU historical climatology data set (CRU CL 2.0, New et al. 2002). The CRU data set provided mean monthly temperature and precipitation data for the period 1961–1990 on a 10′ grid. GDD5 was estimated by direct accounting and alpha was calculated using the approach described by Prentice et al. (1992a, b). The 0 ka reconstructed and CRU values are highly correlated (p ≪ 0.001) for all bioclimatic variables (Fig. 3). For those variables for which reconstructions are available from both North America and Europe/Africa (MTCO, MTWA, MAT and GDD5), the correlation between the 0 ka reconstructed and CRU values do not differ significantly. There are a small number of obvious outliers in the MTCO and MTWA plots; these are mostly from sites at higher elevations or at higher latitudes, where the climate data have been extrapolated from comparatively few climate stations and positional errors are greater.

Correlation between observed and reconstructed modern climate variables. The observed values are derived from the Climate Research Unit (CRU) historical climatology data set (CRU CL 2.0, New et al. 2002). The reconstructed values are derived from the various data sets included in the current synthesis which provided point-based estimates of modern climate. North America includes all sites between 0° and 75°N, and 50°–175° E), Europe and northern Africa includes sites between 0° and 75°N, and 2°E to 60°W, and all the remaining sites are included in the category “other regions”
The spatial variability of correlation for the data rich areas of North America and Europe/North Africa can be demonstrated by calculating Pearson’s correlation coefficient between the CRU data (Fig. 4, top panels) and the reconstruction using a moving spatial-window of 20° × 20° (Fig. 4, bottom panels). In North America, MTCO, MAT, MAP and GDD5 show high correlations with little spatial variability. On the other hand, the correlations for MTWA in the west are lower than those in the east, and for alpha are higher on the west, particularly at the mid latitudes (20°–60°N), than those on the east and in the arctic regions. These results indicate that MTWA reconstruction is less reliable in topographically complex regions (such as the American West) and also in regions where summer temperature does not limit vegetation, and that alpha is less reliable in regions where moisture is not a major limiting factor for vegetation. In Europe and North Africa, the correlations are generally high for MTCO, MTWA and MAT with little spatial variability. GDD5 in North Africa shows high correlations in the west and lower correlations to the east.

Maps showing regional climates (upper panels) based on data from the Climate Research Unit (CRU) historical climatology data set (CRU CL 2.0, New et al. 2002) and spatial variations in the strength of the correlations between observed and reconstructed climate variables (lower panels). The spatial variability of correlation is estimated by calculating Pearson’s correlation coefficient between the reconstruction and the CRU data using a moving spatial-window of 20° × 20°. The spatial window shifts 5° at each step in both longitudinal and latitudinal directions. The correlation coefficient is only calculated when the number of available 0 ka reconstruction estimates in each spatial window is equal to or larger than fifteen. The size of the squares are proportional to the correlation values; the center of each square is the location of the center of the corresponding 20° × 20° window
Standard goodness-of-fit statistics such as R 2 may overestimate the predictive power of climate reconstructions (especially those made with the modern analogue technique) due to unaccounted-for spatial autocorrelation in the response variables (e.g. Telford and Birks 2005). The extent of this effect in published pollen-based climate reconstructions cannot easily be quantified. However, it should be noted that the spatial autocorrelation of vegetation composition at a regional scale derives almost entirely from its causal relation to climate, provided that attention is confined to variables that influence the growth, establishment and regeneration of plants (Harrison et al. 2009). Spatial pattern in pollen data thus constitutes valuable information for the reconstruction, to be retained rather than rejected (Legendre 1993; Legendre and Legendre 1998). In any case, spatial autocorrelation in pollen data becomes non-significant at length scales of 200–300 km, and is slight at any scale when full taxon lists are used (Sawada et al. 2004). Guiot and de Vernal (2007) showed that the goodness-of-fit (as measured by the R 2 statistic) is an appropriate measure when spatial autocorrelation in the pollen data arises from the underlying climate and not from processes internal to the vegetation system.
3.3 Robustness and uncertainties
As a simple test of the robustness of the final reconstruction, we analysed an early version of the data set to determine whether the choice of sampling points and averaging period could have a substantial impact on the resulting reconstruction maps. We used palaeoclimatic anomalies from all sites in the database having at least three samples within each of the following time windows: 5.5–6.5, 6.5–7.5 and 5.5–7.45 cal kyr BP. Although there are 4,806 6 ka sites in the database, most of these sites only have a single reconstruction for 6 ka. The requirement that a site should have at least three samples within the 6 ka time windows therefore resulted in the use of a more limited number of sites for this analysis. In the first test, reconstructions from the single 6.0 ka sample used for mapping were compared to the average of all samples from that site within the broadest possible temporal envelope defined for ‘6.0 ka’ samples: 5.5–7.45 ka (total 1,097 sites). The second test compared the same 6.0 ka point with the average of all samples between 5.5 and 6.5 ka (1,046 sites). The third test was to compare the differences between average values from 5.5 to 6.5 and 6.5 to 7.5 ka (978 sites).
All three tests indicate a strong linear relationship between each of the sets of values compared (Table 4). Mean values for each of the climatic parameters indicate that sampling choice has a small overall impact on the results (Table 4). Large standard deviations are expected since the dataset includes sites from the tropics to the polar regions and 6 ka anomalies cannot be assumed to be similar in all areas of the globe. Generally the correlation between point and average data was better for temperature parameters than for mean annual precipitation. This is simply a data size issue, since temperature reconstructions exist for almost all sites, while precipitation has been reconstructed for about 15% of sites used in testing. These analyses demonstrate that uncertainties about the exact temporal window-width used in selecting samples have little impact on the final reconstructions.
Figure 5 exploits the overlap of reconstruction data sets to illustrate the robustness of reconstructed spatial patterns with respect to the choice of reconstruction technique. Cheddadi et al. (1997) used a modern analogue approach, while Wu et al. (2007) used model inversion to produce reconstructions of MH climate across Europe. The two data sets share ca. 85% of MH sites for the European window, although Wu et al. (2007) contains many more sites from Russia. The broad scale spatial patterns in GDD5 and alpha obtained in these two studies are surprisingly similar, and the correlations between the two sets of reconstructions at points where they overlap are significant (p < 0.001). Both show warmer than present growing-season conditions over most of Europe giving way to cooler than present conditions around the Mediterranean. Both show wetter than present conditions across Europe with the exception of a region centred on the Baltic Sea. However, there are consistent differences in the magnitude of reconstructed anomalies; for example, Wu et al. (2007) show a generally larger warming, and a greater increase in moisture availability, over northern Europe. There are also differences at smaller spatial scales, such as along the northwestern seaboard (for GDD) and southern Finland (for alpha). This comparison suggests that the robustness of the reconstructions is greater for broader spatial scales than for individual sites, and that analysis and model-data comparison should therefore focus on these scales.

Reconstructed climates (GDD5, alpha) for Europe at 6 ka using different data sets and two different methods: Cheddadi et al. (1997) used a constrained modern analogue approach, while Wu et al. (2007) use inverse modelling. Large symbols are used to indicate grid points with significant anomalies (i.e. those that exceed twice the standard error of the reconstructions) while small symbols are used to indicate anomalies that are not significant by this measure
3.4 Climate patterns at 6 ka
There are coherent large-scale patterns in the gridded reconstructions for 6 and 21 ka (Figs. 6, 7). The robustness of these patterns can be assessed in two ways: from the statistical significance of the individual grid cell values (shown by the size of the circle) and by the coherency of the sign and magnitude of the anomalies (shown by circle colour). Thus, features of these patterns which are non-significant statistically (because the change is small or there is no change, or because there are only a limited number of observations) may still be physically plausible and should be considered as robust features of the reconstructed changes in regional climate for the purposes of model evaluation.

Reconstructed a GDD5, b MTWA, c MTCO, d MAT, e MAP, and f alpha at 6 ka. Large symbols are used to indicate grid points with significant anomalies (i.e. those that exceed twice the pooled standard error of the reconstructions) while small symbols are used to indicate anomalies that are not significant by this measure. Note that the anomaly patterns are spatially coherent and include patches of both significant and not-significant values

Reconstructed a GDD5, b MTWA, c MTCO, d MAT, e MAP, and f alpha at 21 ka. Large symbols are used to indicate grid points with significant anomalies (i.e. those that exceed twice the pooled standard error of the reconstructions) while small symbols are used to indicate anomalies that are not significant by this measure. Note that the anomaly patterns are spatially coherent and include patches of both significant and not-significant values
The 6 ka GDD5 reconstructions (Fig. 6a) show large and spatially coherent differences from present. Northern Europe is characterised by an increase in growing season warmth compared to present, with anomalies in GDD5 of >500 kdays. In contrast, growing season warmth was reduced by >1,000 K day compared to present over most of southern Europe. A tri-partite latitudinal pattern is seen in Eurasia, with moderately increased growing season warmth compared to present along the Arctic coast, a reduction in GDD5 in the zone between ca. 45°–65°N, and increased growing season warmth in the continental interior. The northern coast of North America is also characterised by positive anomalies in GDD5, as is the Pacific Northwest away from the coast and most of the northeastern part of the continent. The American southwest and the southern part of the continent is characterised by a reduction in GDD5 compared to present, as is the coastal strip of the Pacific Northwest and the interior of northwestern Canada. Equatorial Africa and some sites in the western Sahara are characterised by reduced GDD5, whereas the surrounding zone including the eastern Sahara, eastern Africa and southern Africa was characterised by >1,000 K day increase in GDD5 compared to present.
The accumulated temperature sum during the growing season, as expressed by GDD5, is partially determined by changes in the length of the growing season and partially by changes in summer temperatures. It is therefore unsurprising that the 6 ka MTWA reconstructions (Fig. 6b) show similar, though somewhat less coherent, patterns of change relative to present to those evident in the GDD5 reconstructions. The similarity between the GDD and MTWA is clearly evident in Europe, Eurasia and Africa, and reflects the spatial coherence of the anomalies of both variables at a regional scale. The reconstructions of MTWA over much of North America have large uncertainties and this reduces the apparent coherence with the GDD5 reconstructions over this continent. Nevertheless, the contrast between warmer-than-present conditions in the northeast and colder-than-present conditions to the south and west is apparent in both data sets.
The reconstructed changes in 6 ka MTCO (Fig. 6c) are in general smaller and less significant than the changes in GDD5. Nevertheless, the spatial patterns are regionally coherent. The maritime region of western Europe is characterised by cooler conditions than present, by ca. 1°C in the north and up to 4°C in the south. The Mediterranean region as a whole is also significantly cooler (>2°C) than present. Central Europe and western Eurasia, however, are characterised by warmer conditions than today, with temperatures increased by as much as 2–4°C at some sites. The reconstructed MTCO changes in eastern Siberia are not significant but show a slight cooling compared to present. Reconstructed temperature changes in North America show a dipole structure, with positive MTCO anomalies in the northeastern part of the continent and negative MTCO anomalies in western and southern regions. In contrast to this regional pattern, however, some sites around Hudson Bay show a reduction in MTCO compared to present by ca. 1°C. Equatorial Africa is characterised by reduced MTCO, whereas the surrounding zone including the eastern Sahara, eastern Africa and southern Africa was characterised by an increase in MTCO.
In many regions of the northern extratropics, the differences between the MTWA and MTCO reconstructions show the expected impact of precession-driven insolation changes (i.e. increased seasonality). However, in some regions the reconstructions show no apparent change in seasonality or even changes in the opposite direction from expected (e.g. around Hudson Bay in eastern North America, the peri-Baltic region of Europe, and central Eurasia). As will be discussed later, these are predictable, second-order responses to atmospheric circulation changes.
The change in growing season conditions, as shown by GDD5, is the strongest influence on reconstructed changes in MAT (Fig. 6d). The largest and most significant changes in MAT occur where the changes in summer and winter temperatures are in the same direction: thus, the significant reduction in MAT in southern Europe compared to present reflects cooler conditions in both seasons, while the significant increase in MAT in central Europe reflects warmer conditions in both seasons. In the maritime regions of northeastern Europe and northern Scandinavia, the reconstructed change in MAT is smaller, because the seasonal changes in these regions are of opposite sign. A similar situation is apparent in North America, with large changes in MAT in regions where both seasons are characterised by warming or cooling compared to today, and smaller (or non-significant changes) in regions where the temperature changes result in increased seasonality. The changes in MAT across Africa reflect the changes in GDD5, with cooling (>2°C) compared to present in the western Sahara and the equatorial zone and warming elsewhere. Cooler conditions compared to present are shown by the MAT reconstructions over most of China; the exceptions mostly occur in the extreme north and northwest. In the absence of MTCO or MTWA reconstructions, it is unclear whether this is due to changes in both seasons but the coincidence of cooler conditions with increased precipitation (see below) suggests that the change in MAT reflects both orbitally induced winter cooling and summer cooling consequent on increased cloudiness in regions affected by the enhanced Asian monsoon during the MH.
The reconstructions show increased precipitation compared to present across Europe and Eurasia (MAP: Fig. 6e); the changes are small (<100 mm) and largely non-significant across most of Europe, but spatially very coherent. There are significant increases of between 100 and 500 mm compared than today in the Mediterranean region. Significantly wetter conditions (ca. 100 mm) than today are also registered across Eurasia. Increased precipitation is also shown across much of western and southern North America. The increase in the Great Basin is not significant although it is spatially coherent. Significant increases in precipitation compared to present, generally of >200 mm and in some localities of >500 mm, are registered across northern Africa. The equatorial zone is characterised by reduced precipitation compared to present, as is the northern part of the East African Rift Valley and Madagascar. Most of southern Africa is characterised by increased precipitation compared to present, except for sites near the south coast. An increase in precipitation compared to present is shown across most of China.
These reconstructed changes in precipitation are closely related to reconstructed changes in plant-available moisture (alpha: Fig. 6f). However, alpha is also affected by changes in growing-season temperature and evapotranspiration. Thus, the reconstructed patterns of change in alpha are in general less coherent and less significant than those shown by precipitation. Nevertheless, in regions characterised by very large changes in precipitation, there are congruent, large and significant changes in alpha. The Mediterranean region, for example, is characterised by a significant increase in precipitation compared to present and this translates into an increase in alpha of >0.2. Similarly, eastern North America is characterised by a decrease in precipitation compared to present, which translates into a decrease in alpha of ca. 0.5. The interplay between precipitation and temperature-controlled changes in evaporation, however, can result in significant changes in alpha. In southwestern North America, for example, the reconstructed increases in precipitation compared to today are small and non-significant. However, as a result of cooler temperature throughout the year, this negligible change in precipitation results in a significant increase in alpha.
One indication of the reliability and robustness of these climate reconstructions is the fact that the changes in individual variables are mutually consistent with one another, spatially coherent and statistically significant. Furthermore, the reconstructed changes are physically plausible and can be explained in terms of current understanding of the hierarchy of controls on regional climates (see e.g. Bartlein et al. 1998). The ultimate cause of changes in regional climate during the mid-Holocene is differences in the seasonal and latitudinal distribution of incoming solar radiation (insolation). Broadly speaking, as a result of changes in precession, insolation was higher during summer and lower during winter in the northern hemisphere. This resulted in increased summer temperatures in the mid- to high-latitudes of the northern hemisphere (see e.g. Braconnot et al. 2007a, b), a major feature of the reconstructions for northern Europe, and the Arctic coasts of both northern Eurasia and North America (Fig. 6a, b). Heating over the northern continents increased land–sea temperature contrast and resulted in the enhancement of the northern hemisphere monsoons (see e.g. Kutzbach et al. 2001: Braconnot et al. 2007a, b), again a major feature of the reconstructions from northern Africa and Asia, and apparent to a lesser extent in the increased precipitation found in southern and southwestern North America (Fig. 6e). Monsoon expansion in Africa results in a latitudinal shift in the rainbelts, and thus the reconstruction of reduced precipitation in the equatorial zone is consistent with orbitally induced changes in monsoon circulation. In North America, upward motion associated with the expanded monsoon is compensated by subsidence in the regions surrounding the monsoon core: thus the reconstruction of decreased precipitation (Fig. 6e) and moisture availability (Fig. 6f) in the Pacific Northwest and in the mid-continent of North America is consistent with orbitally induced circulation changes (Harrison et al. 2003).
Although the insolation-induced expansion of the northern hemisphere monsoons is apparent in reconstructed precipitation (Fig. 6e) and alpha (Fig. 6f), changes in summer temperature (measured either by GDD5 or MTWA) in the monsoon regions are less coherent. Increased summer temperature is registered at some sites in northern Africa but is not a noticeable feature of the American southwest. Furthermore, we have interpreted the reconstruction of cooler temperature year-round in China as indicating that the winter cooling associated with the stronger winter monsoon was not noticeably offset by a marked summer warming. The absence of a strong warming signal in the monsoon regions might seem surprising. However, although enhanced land-sea temperature contrast is a necessary prerequisite for monsoon enhancement (see e.g. Kutzbach et al. 2001), maintenance of monsoon precipitation is strongly dependent on latent heat flux and the energetics of the system, and their influence on atmospheric dynamics (Ramage 1971; Trenberth et al. 2000; Webster et al. 2002; Anderson et al. 2009; Taylor et al. 2010). Modern observations show that monsoon rains are accompanied by a strong regional temperature depression, and a similar phenomenon is presumably the cause of the weak and spatially less coherent structure of reconstructed summer temperature changes during the mid-Holocene.
One direct consequence of northern-hemisphere insolation changes during the mid-Holocene is increased seasonality in temperatures, but this is not a prominent feature of the reconstructions. Although the combination of colder winters and warmer summers is found in e.g. northwestern Europe, most regions show either an increase in temperature in both seasons (e.g. central Eurasia, northeastern North America) or a decrease in temperature in both seasons (e.g. southern Europe, southern and southwestern North America). In these regions, the direct effects of insolation changes are overwhelmed by changes in atmospheric circulation regimes. Thus, cooler temperatures year-round found in southern and southwestern North America reflect the impact of increased onshore flow of moist air and increased cloudiness associated with the strengthened North American monsoon (Harrison et al. 2003). Similarly, the increased winter temperatures characteristic of central Eurasia are a result of increased warm-air advection from the North Atlantic (Harrison et al. 1992; Bonfils et al. 2004).
At a more local scale, changes in land-sea geography also have an impact on regional climates that can be seen in the reconstructions. Both Hudson Bay and the Baltic Sea were more extensive during the mid-Holocene than they are today. In both regions, this resulted in local and year-round cooling (Fig. 6b, c) and, at least in the case of the peri-Baltic regions, it is likely that the enhancement of anticyclonic conditions over the region led to increased aridity (Fig. 6f).
Insolation changes in the northern and southern hemisphere between the mid-Holocene and today are not perfectly symmetrical. Although insolation is less in southern-hemisphere summer and more in southern-hemisphere winter, the largest increase in insolation occurs during the spring months (September through November). This asymmetry is reflected in the climate reconstructions for southern Africa, the only area of the southern hemisphere extratropics for which we have quantitative reconstructions. The increase in insolation during winter is responsible for the increase in MTCO relative to present (Fig. 6d). In general, the onset of the growing season is earlier when winter temperatures are higher, and this effect combined with a significant increase in insolation during the spring results in an increase in both GDD5 (Fig. 6a) and MTWA (Fig. 6b). Increased temperatures year-round offset, to some extent, the reconstructed increase in precipitation (Fig. 6e) such that the area which shows increased alpha compared to today (Fig. 6f) is less extensive than the area with increased precipitation. The reconstructed changes in southern Africa regional climates are, to first order, consistent with orbital forcing.
3.5 Climate patterns at 21 ka
The basic picture emerging from the 21 ka reconstructions is of colder conditions year-round across all regions (Fig. 7a–d). The change in MAT was largest (>8°C, Fig. 7d) close to the northern-hemisphere ice sheets and comparatively muted (<3°C, Fig. 7d) in the tropics. In general, the changes in winter temperatures as represented by MTCO (Fig. 7c) are larger than the changes in summer temperatures as represented by either GDD5 (Fig. 7a) or MTWA (Fig. 7b).
There are elements of the reconstructions that are not congruent with the general picture of year-round cooling: the reconstruction of MTWA warmer than today in Africa (Fig. 7b), and the reconstruction of warmer conditions than today as shown by one or more of the temperature-related variables at a few sites in the northern hemisphere extra-tropics, most noticeably in Alaska.
The MTWA reconstructions for Africa show temperatures between 1 and 4°C warmer than today (Fig. 7b, see also Wu et al. 2007). This is inconsistent with the reconstruction of reduced GDD5 (Fig. 7a) and MAT (Fig. 7d), unless the climate was characterised by a shift towards a short extremely hot summer in both hemispheres. The insolation patterns at 21 ka are inconsistent with such a change in seasonality in both hemispheres. The increased warm-season temperatures are unlikely to be a response to changes in advection, given the reconstruction of reduced precipitation compared to today across most of the continent (Fig. 7e). They are similarly unlikely to be a response to changes in the local partitioning of latent and sensible heat, due to reduction in cloudiness, because of their widespread expression. No physically plausible mechanism has been advanced to explain the warming.
The reconstruction of conditions similar or slightly warmer than today in Alaska during the LGM is registered chiefly in MTCO (Fig. 7c) and MAT (Fig. 7d) although single points show warmer values for other seasonal temperature variables. In contrast to the situation in Africa, there is a plausible mechanism for why this region might not experience the major cooling shown over the rest of the continent (Bartlein et al. 1998). The Laurentide ice sheet was sufficiently large to cause a major reorganisation in the atmospheric circulation pattern. This reorganisation could have resulted in more southerly onshore flow into Alaska, which would have produced advective warming of the region year-round.
The reconstructions (Fig. 7e) show a significant decrease in precipitation compared to present across Europe (>200 mm), Eurasia (>100 mm), the Pacific Northwest (>500 mm), eastern North America (>500 mm) and Africa (>200 mm) at 21 ka. Reduced vigour of the hydrological cycle and less precipitation are consistent with the colder glacial conditions at 21 ka. Despite the generally colder conditions, the reduction in precipitation was translated into a reduction in plant-available moisture (Fig. 7f). The only regions that appear to have registered an increase in both precipitation and plant-available moisture compared to today are the Great basin of North America and the southernmost part of southern Africa. Shifts in atmospheric circulation, specifically the displacement of the track of the westerlies by the Laurentide ice sheet, have been invoked to explain increased precipitation in the Great Basin during the LGM (Benson and Thompson 1987; Hostetler and Benson 1990). Changes in the southern westerlies have been invoked to explain increased precipitation during the LGM in southern Africa (e.g. Stuut and Lamyb 2004; Justino et al. 2005).
Low CO2 levels during the glacial affect vegetation by reducing the growth of C3 plants, and allowing C4 species to compete more successfully (Harrison and Prentice 2003: Prentice and Harrison 2009). This can lead to a shift towards more open vegetation, independent of climate change (Jolly and Haxeltine 1997; Cowling and Sykes 1999) and could result in reconstructions that are drier and/or colder than the true glacial climate (Prentice and Harrison 2009). The impact of CO2 has been taken into account in the inverse-modelling reconstructions for Europe, Eurasia and Africa (Wu et al. 2007) and China (Guiot et al. 2008). The impact of CO2 could mean that the reconstructions for North America, which are primarily based on analogue or response surface approaches, overestimate the degree of drying and cooling. Nevertheless, the magnitude of changes e.g. in eastern North America and Europe are similar. This suggests that the impact of CO2 does not dominate the reconstructed signals in North America, a conclusion consistent with recent palaeovegetation reconstructions for eastern North America based on pollen data and BIOME4 simulations (Gonzales et al. 2008; Williams et al. 2008).
4 Discussion and future perspectives
The data presented here are a resource for model-data comparison and are available at http://pmip3.lsce.ipsl.fr/. Comparisons should focus on the large-scale spatial patterns that are significant, robust and climatologically interpretable. Given that there is some redundancy among the reconstructed climate variables, we recommend focusing comparisons on GDD5, MTCO and MAP. GDD5 and MTCO represent independent controls on the distribution and abundance of plant taxa (Harrison et al. 2009). MTWA and MAT provide little additional information beyond what is already contained in GDD and MTCO. MAP reflects a third independent control (plant-available moisture) less directly, but we show here that it can be estimated with greater accuracy (Fig. 3) and that it yields more strongly coherent patterns than the alpha index (Figs. 6, 7), which might be preferred on theoretical grounds.
We have of necessity adopted rather broad time windows to represent the MH (potentially 5.5–7.45 ka) and LGM (potentially 20–22.9 ka) in order to include information from as many studies as possible. Some of the breadth is due to the inclusion of older data sets in which the time window had been defined around uncalibrated 14C ages, as well as data sets in which the time window had been defined around calendar ages. It would be desirable for future data compilations to be based on time windows defined around calendar ages only. It would also be desirable for a narrower window to be adopted for the LGM, to avoid potential inclusion of samples from associated Heinrich events (HS2 at 26.5–24.3 ka and HS1 at15.6–18 ka, Sanchez-Goñi and Harrison, in press).
A possible source of ambiguity in climate reconstruction is the choice of modern climate data for calibration. This has been recognized as an issue for the reconstruction of sea surface temperatures (Schäfer-Neth and Paul 2003) and it is equally an issue for climates over land. There is no strong basis for recommending one global climatology over others, but many analyses have used the CRU climatological data set for 1961–1990 as we have here. There is considerable merit in adopting a standard, even if it is imperfect. The CRU data set has the merits of applying to a consistent observation period and being widely used.
We have demonstrated that reconstructions made using different methods yield similar results for large-scale spatial patterns (Figs. 6, 7), even if the reconstructions for individual sites can differ. We suggest that the way forward is to use inverse modelling in preference to analogue or response-surface techniques, because inverse modelling (a) provides sound logic to cope with the no-analogue problem, (b) makes the wrong-analogue problem explicit, (c) allows the consequences of changing atmospheric CO2 concentration to be taken into account (Harrison and Prentice 2003; Prentice and Harrison 2009) and (d) allows the consequences of changing seasonality of climate forcing or climate responses to be taken into account (Guiot et al. 2000, 2009). However there are many detailed methodological choices to be made in this approach, such as the assignment of taxa to PFTs, choice of model, and the choice of model variable to compare with PFT abundance and more work is required before this technique will entirely supersede other methods.
An important limitation of the data presented here is the absence of quantitative reconstructions from South America and the southern-hemisphere extratropics generally (except for southern Africa). The primary pollen data, on which reconstructions are based, is also generally sparse in the tropics. To some extent, these limitations reflect the history of pollen analysis and the compilation of pollen data sets. However, the BIOME 6000 project (Prentice et al. 2000) has stimulated the compilation of new regional pollen data sets, e.g. from Australasia and southeast Asia (Pickett et al. 2004), South America (Marchant et al. 2009) and the Indian subcontinent (Sutra et al., in prep.). It is now possible and timely to exploit these compilations for the reconstruction of regional climate changes. There are additional ongoing efforts to expand pollen data coverage in some regions where existing data are sparse, such as central Asia (e.g. Cordova et al. 2007).
Although the greatest volume of quantitative climate reconstructions exists for the two time periods analysed here, some of the underlying data sets include reconstructions at more closely spaced time intervals; synthesis of these for, say, 1,000-year intervals would be worthwhile for comparison with a new generation of transient climate model simulations, as proposed in PMIP3. Further analyses of the data presented here are also possible, for example examination of elevational gradients in climate anomalies which can give further insight into underlying climate processes (cf. Farrera et al. 1999; Kageyama et al. 2005).
We have focused on quantitative reconstructions based on pollen and/or plant macrofossil data, but site-based climate reconstructions have been made using chironomid or coleopteran assemblages (e.g. Atkinson et al. 1987; Heiri et al. 2003), and using geochemical techniques (e.g. Stute et al. 1992; Jones et al. 2004). Synthesis of such data could provide a way of checking the reconstructions presented here, but more importantly of expanding the regional coverage of quantitative reconstructions.
The changes in regional climates inferred from pollen and/or plant macrofossil data could also be compared with records that provide more qualitative indications of past climate changes, for example lake-level records (see e.g. Street-Perrott and Harrison 1984; Harrison and Digerfeldt 1993; Harrison et al. 1996). However, some caution needs to be exercised here, to ensure that the sensors are responding to the same aspect of seasonal climate. Vegetation, for example, responds to plant-available moisture whereas lake-levels respond to runoff (i.e. precipitation in excess of that taken up by plants) (Cheddadi et al. 1997). In cases where there is a large enough change in precipitation, and/or plant growth is limited by seasonal temperatures, both plant-available moisture and runoff may increase and hence both sensors will appear to register wetter conditions (see e.g. Thompson et al. 1993; Yu and Harrison 1996; Jolly et al. 1998; Shuman et al. 2002). However, in some situations, lake levels may be high at the same time as the vegetation is registering drier conditions. The classic example is the co-existence of high lake levels and steppic vegetation in southern Europe during the Last Glacial Maximum (see Prentice et al. 1992a, b), where the vegetation is responding to a reduction of precipitation during the growing season while the lakes reflect increased runoff during the winter.
Finally, recent advances in data assimilation open up the possibility that palaeodata could be used to constrain the parameters of climate models and thereby improve reliability and realism, and assign quantitative uncertainties, in future climate prediction. Systematic approaches to data assimilation have been developed for present day climate and Earth system model components with reduced spatio-temporal resolution, simplified process representations, or reduced sets of parameters (e.g. Marotzke et al. 1999; Rayner et al. 2005). A system to apply these approaches to climate modelling has been demonstrated (Kaminski et al. 2007), and a further natural development of this system would allow fully coupled, dynamic climate system models to be constrained with palaeoclimate reconstructions using this variational approach. A rigorous method to combine models and palaeodata should help to provide a better understanding of the interactions between different components of the climate system, and establish a tighter link between palaeoclimate observation and Earth system modeling.
References
Ackerly DD (2003) Community assembly, niche conservatism, and adaptive evolution in changing environments. Int J Plant Sci 164(S3):S165–S184
Anderson PM, Bartlein PJ, Brubaker LB, Gajewski K, Ritchie JC (1989) Modern analogues of late-Quaternary pollen spectra from the western interior of North America. J Biogeogr 16:573–596
Anderson BT, Ruane AC, Roads JO, Kanamitsu M (2009) Estimating the influence of evaporation and moisture-flux convergence upon seasonal precipitation rates. Part II: an analysis for North America based upon the NCEP-DOE Reanalysis II Model. J Hydrometeorol 10:893–911
Atkinson TC, Briffa KR, Coope GR (1987) Seasonal temperatures in Britain during the last 22,000 years, reconstructed using beetle remains. Nature 325:587–593
Bartlein PJ, Webb T III (1985) Mean July temperature at 6000 yr B.P. in eastern North America: regression equations for estimates from fossil-pollen data. Syllogeus 55:301–342
Bartlein PJ, Whitlock C (1993) Paleoclimatic interpretation of the Elk Lake pollen record. In: Bradbury JP, Dean WE (eds) Evidence for rapid climate change in the North-Central, United States: The Elk Lake record. Geological Society of America Special Paper, vol 276, pp 275–293
Bartlein PJ, Webb T III, Fleri E (1984) Holocene climatic change in the northern Midwest: pollen-derived estimates. Quat Res 22:361–374
Bartlein PJ, Prentice IC, Webb T III (1986) Climatic response surfaces from pollen data for some eastern North American taxa. J Biogeogr 13:35–57
Bartlein PJ, Anderson KH, Anderson PM, Edwards ME, Mock CJ, Thompson RS, Webb RS, Webb T III, Whitlock C (1998) Paleoclimate simulations for North America over the past 21,000 years: features of the simulated climate and comparisons with paleoenvironmental data. Quat Sci Rev 17:549–585
Benson L, Thompson RS (1987) The physical record of lakes in the Great Basin. In: Ruddiman WF, Wright HE Jr (eds) North America and adjacent oceans during the last deglaciation. Geological Society of America, Boulder, pp 241–260
Bigelow NH, Brubaker LB, Edwards ME, Harrison SP, Prentice IC, Anderson PM, Andreev AA, Bartlein PJ, Christensen TR, Cramer W, Kaplan JO, Lozhkin AV, Matveyeva NV, Murray DF, McGuire AD, Razzhivin VY, Ritchie JC, Smith B, Walker DA, Gayewski K, Wolf V, Holmqvist BH, Igarashi Y, Kremenetskii K, Paus A, Pisaric MFJ, Volkova VS (2003) Climatic change and Arctic ecosystems I. Vegetation changes north of 55°N between the last glacial maximum, mid-Holocene, and present. J Geophys Res Atmos 108(D19):8170. doi:10.1029/2002JD002558
Birks HJB (1995) Quantitative palaeoenvironmental reconstructions. In: Maddy D, Brew JS (eds) Statistical modelling of quaternary science data. Quaternary Research Association, Cambridge, pp 161–254
Birks HH, Ammann B (2000) Two terrestrial records of rapid climatic change during the glacial–Holocene transition (14,000–9,000 calendar years B.P.) from Europe. Proc Natl Acad Sci USA 15:1390–1394
Bonfils C, de Noblet-Ducoudré N, Guiot J, Bartlein P, PMIP participants (2004) Some mechanisms of mid- Holocene climate change in Europe, inferred from comparing PMIP models to data. Clim Dyn 23:79–98
Bonnefille R, Chalié F (2000) Pollen-inferred precipitation time-series from equatorial mountains, Africa, the last 40 kyr BP. Glob Planetart Chang 26:25–50
Braconnot P, Otto-Bliesner B, Harrison SP, Joussaume S, Peterschmitt J-Y, Abe-Ouchi A, Crucifix M, Driesschaert E, Th Fichefet, Hewitt CD, Kageyama M, Kitoh A, Loutre M-F, Marti O, Merkel U, Ramstein G, Valdes P, Weber L, Yu Y, Zhao Y (2007a) Results of PMIP2 coupled simulations of the mid-Holocene and Last Glacial Maximum, Part 1: experiments and large-scale features. Clim Past 3:261–277
Braconnot P, Otto-Bleisner B, Harrison SP, Joussaume S, Peterschmitt J-Y, Abe-Ouchi A, Crucifix M, Fichefet Th, Hewitt CD, Kagayama M, Kitoh A, Loutre M-F, Marti O, Merkel U, Ramstein G, Valdes P, Weber L, Yu Y, Zhao Y (2007b) Results of PMIP2 coupled simulations of the mid-Holocene and Last Glacial Maximum, Part 2: feedbacks with emphasis on the location of the ITCZ and mid- and high latitudes heat budget. Clim Past 3:279–296
Brewer S, Guiot J, Sanchez-Goni M-F, Klotz S (2008) The climate in Europe during the Eemian: a multi-method approach using pollen data. Quat Sci Rev 27(25–26):2303–2315
Cheddadi R, Bar-Hen A (2009) Spatial gradient of temperature and potential vegetation feedback across Europe during the late Quaternary. Clim Dyn 32:371–379
Cheddadi R, Yu G, Guiot J, Harrison SP, Prentice IC (1997) The climate of Europe 6000 years ago. Clim Dyn 13:1–9
COHMAP Members (1988) Climatic changes of the last 18,000 years: observations and model simulations. Science 241:1043–1052
Connor SE, Kvavadze EV (2008) Modelling late Quaternary changes in plant distribution, vegetation and climate using pollen data from Georgia, Caucasus. J Biogeogr 36:529–545
Cordova CE, Harrison SP, Mudie PJ, Riehl S, Leroy SAG, Ortiz N (2007) Pollen, plant macrofossil and charcoal records for palaeovegetation reconstruction in the Mediterranean–Black Sea Corridor since the Last Glacial Maximum. Quat Int. doi:10.1016/j.quaint.2006.015
Cowling SA, Sykes MT (1999) Physiological significance of low atmospheric CO2 for plant–climate interactions. Quat Res 52:237–242
Davis MB, Shaw RG (2001) Range shifts and adaptive responses to Quaternary climate change. Science 292:673–679
Davis BAS, Brewer S, Stevenson AC, Guiot J, Juggins S (2003) The temperature of Europe during the Holocene reconstructed from pollen data. Quat Sci Rev 22:1701–1716
Edwards T, Crucifix M, Harrison SP (2007) Using the past to constrain the future: how the palaeorecord can improve estimates of global warming. Prog Phys Geogr 31:481–500
Farrera I, Harrison SP, Prentice IC, Ramstein G, Guiot J, Bartlein PJ, Bonnefille R, Bush M, Cramer W, von Grafenstein U, Holmgren K, Hooghiemstra H, Hope G, Jolly D, Lauritzen SE, Ono Y, Pinot S, Stute M, Yu G (1999) Tropical climates at the Last Glacial Maximum: a new synthesis of terrestrial palaeoclimate data. I. Vegetation, lake-levels and geochemistry. Clim Dyn 15:823–856
Frechette B, de Vernal A, Pierre JH, Richard PJH (2008) Holocene and Last Interglacial cloudiness in eastern Baffin Island, Arctic Canada. Can J Earth Sci 45:1221–1234
Gajewski K (1987) Climatic impacts on the vegetation of eastern North America during the past 2000 years. Vegetatio 68:179–190
Gajewski K, Vance R, Sawada M, Fung I, Gignac LD, Halsey L, John J, Maisongrande P, Mandell P, Mudie P, Richard P, Sherrin A, Soroko J, Vitt D (2000) The climate of North America and adjacent ocean waters ca. 6 ka. Can J Earth Sci 37:661–681
Gajewski K, Lezine A-M, Vincens A, Delestan A, Sawada M, The African Pollen Database (2002) Modern climate–vegetation–pollen relations in Africa and adjacent areas. Quat Sci Rev 21:1611–1631
Gavin DG, Hu FS (2006) Spatial variation of climatic and non-climatic controls on species distribution: the range limit of Tsuga heterophylla. J Biogeogr 33:1384–1396
Gerten D, Schaphoff S, Haberlandt U, Lucht W, Sitch S (2004) Terrestrial vegetation and water balance––hydrological evaluation of a dynamic global vegetation model. J Hydrol 286:249–270
Gonzales LM, Williams JW, Kaplan JO (2008) Variations in leaf area index in northern and eastern North America over the past 21,000 years: a data-model comparison. Quat Sci Rev 27:1453–1466
Gonzales LM, Williams JW, Grimm EC (2009) Expanded response-surfaces: a new method to reconstruct paleoclimates from fossil pollen assemblages that lack modern analogues. Quat Sci Rev 28:3315–3332. doi:10.1016/j.quascirev.2009.09.005
Guiot J (1990) Methodology of the last climatic cycle reconstruction in France from pollen data. Palaeogeogr Palaeoclimatol Palaeoecol 80:49–69
Guiot J, de Vernal A (2007) Transfer functions: methods for quantitative paleoceanography based on microfossils. In: Hillaire-Marcel C, de Vernal A (eds) Developments in marine geology, vol 1. Elsevier, Amsterdam. doi:10.1016/S1572-5480(07)01018-4
Guiot J, de Beaulieu JL, Cheddadi R, David F, Ponel P, Reille M (1993) The climate in western Europe during the last glacial/interglacial cycle derived from pollen and insect remains. Palaeogeogr Palaeoclimatol Palaeoecol 103:79–94
Guiot J, Torre F, Jolly D, Peyron O, Boreux JJ, Cheddadi R (2000) Inverse vegetation modeling by Monte Carlo sampling to reconstruct palaeoclimates under changed precipitation seasonality and CO2 conditions: application to glacial climate in Mediterranean region. Ecol Model 127:119–140
Guiot J, Wu H, Jiang WY, Luo YL (2008) East Asian Monsoon and paleoclimatic data analysis: a vegetation point of view. Clim Past 4:137–145
Guiot J, Wu H, Garreta V, Hatté C, Magny M (2009) A few prospective ideas on climate reconstruction: from a statistical single proxy approach towards a multi-proxy and dynamical approach. Clim Past 5:571–583
Harrison SP, Digerfeldt G (1993) European lakes as palaeohydrological and palaeoclimatic indicators. Quat Sci Rev 12:233–248
Harrison SP, Prentice IC (2003) Climate and CO2 controls on global vegetation distribution at the last glacial maximum: analysis based on palaeovegetation data, biome modelling and palaeoclimate simulations. Glob Chang Biol 9:983–1004
Harrison SP, Prentice IC, Bartlein PJ (1992) Influence of insolation and glaciation on atmospheric circulation in the North Atlantic sector: implications of general circulation model experiments for the Late Quaternary climatology of Europe. Quat Sci Rev 11:283–299
Harrison SP, Yu G, Tarasov PE (1996) Late Quaternary lake-level record from northern Eurasia. Quat Res 45:138–159
Harrison SP, Kutzbach JE, Liu Z, Bartlein PJ, Otto-Bliesner B, Muhs D, Prentice IC, Thompson RS (2003) Mid-Holocene climates of the Americas: a dynamical response to changed seasonality. Clim Dyn 20:663–688
Harrison SP, Prentice IC, Sutra J-P, Barboni D, Kohfeld KE, Ni J (2009) Towards a global scheme of plant functional types for ecosystem modelling, palaeoecology and climate impact research. J Veg Sci 21:300–317. doi:10.1111/j.1654-1103.2009.01144.x (on-line)
Hatté C, Guiot J (2005) Paleoprecipitation reconstruction by inverse modeling using the isotopic signal of loess organic matter: application to the Nussloch loess sequence (Rhine Valley, Germany). Clim Dyn 25:315–327
Hatté C, Rousseau D, Guiot J (2009) Climate reconstruction from pollen and δ13C records using inverse vegetation modelling–implication for past and future climates. Clim Past 5:147–156
Haxeltine A, Prentice IC (1996) BIOME3: An equilibrium terrestrial biosphere model based on ecophysiological constraints, resource availability, and competition among plant functional types. Global Biogeochem Cycles 10:693–709
Heiri O, Lotter AF, Hausmann S, Kienast F (2003) A chironomid-based Holocene summer air temperature reconstruction from the Swiss Alps. Holocene 13:477–484
Herzschuh U, Kürschner H, Mischke S (2006) Temperature variability and vertical vegetation belt shifts during the last ∼50,000 yr in the Qilian Mountains (NE margin of the Tibetan Plateau, China). Quat Res 66:133–146
Hintikka V (1963) Über das Grossklima einiger Pflanzenareale in zwei Klimakoordinatensystemen dargestellt. Ann Bot Soc Zool Botenn Vanamo 34:1–64
Hostetler SW, Benson LV (1990) Paleoclimatic implications of the high stand of Lake Lahontan derived from models of evaporation and lake level. Clim Dyn 4:207–217
Huntley B, Prentice IC (1988) July temperatures in Europe from pollen data 6000 years before present. Science 241:687–690
Huntley B, Bartlein PJ, Prentice IC (1989) Climatic control of the distribution and abundance of beech (Fagus L.) in Europe and North America. J Biogeogr 16:551–560
Iversen J (1944) Viscum, Hedera and Ilex as climate indicators. Geol Föreningen i Stockholm Förhandlingar 66:463–483
Jackson ST, Williams JW (2004) Modern analogs in Quaternary paleoecology: here today, gone yesterday, gone tomorrow? Annu Rev Earth Planet Sci 32:495–537
Jackson ST, Webb RS, Anderson KH, Overpeck JT, Webb T III, Williams J, Hansen BCS (2000) Vegetation and environment in unglaciated eastern North America during the last glacial maximum. Quat Sci Rev 19:489–508
Jiang W, Guo Z, Sun X, Wu H, Chu G, Yuan B, Hatté C, Guiot J (2006) Reconstruction of climate and vegetation changes of Lake Bayanchagan (Inner Mongolia): Holocene variability of the East Asian monsoon. Quat Res 65:411–420
Jolly D, Haxeltine A (1997) Effect of low glacial atmospheric CO2 on tropicalAfrican montane vegetation. Science 276:786–788
Jolly D, Harrison SP, Damnati B, Bonnefille R (1998) Simulated climate and biomes of Africa during the Late Quaternary: comparison with pollen and lake status data. Quat Sci Rev 17:629–657
Jones VJ, Leng MJ, Solovieva N, Sloane HJ, Tarasov P (2004) Holocene climate of the Kola Peninsula; evidence from the oxygen isotope record of diatom silica. Quat Sci Rev 23:833–839
Jost A, Lunt D, Kageyama M, Abe-Ouchi A, Peyron O, Valdes PJ, Ramstein G (2005) High-resolution simulations of the Last Glacial Maximum climate over Europe: a solution to discrepancies with continental palaeoclimatic reconstructions? Clim Dyn 24:577–590
Justino F, Timmermann A, Merkel U, Souza E (2005) Synoptic reorganisation of atmospheric flow during the Last Glacial Maximum. J Clim 18:2826–2846
Kageyama M, Harrison SP, Abe-Ouchi A (2005) The depression of tropical snowlines at the Last Glacial Maximum: what can we learn from climate model experiments? Quat Int 138–139:202–219
Kaminski T, Blessing S, Giering R, Scholze M, Vossbeck M (2007) Testing the use of adjoints for parameter estimation in a simple GCM on climate time-scales. Meteorol Z 16:643–652
Kaplan JO, Bigelow NH, Bartlein PJ, Christensen TR, Cramer W, Harrison SP, Matveyeva NV, McGuire AD, Murray DF, Prentice IC, Razzhivin VY, Smith B, Walker DA, Anderson PM, Andreev AA, Brubaker LB, Edwards ME, Lozhkin AV (2003) Climate change and Arctic ecosystems II: Modeling, palaeodata-model comparisons, and future projections. J Geophys Res Atmos 108(D19):8171
Kerwin MW, Overpeck JT, Webb RS, Anderson KH (2004) Pollen-based summer temperature reconstructions for the eastern Canadian boreal forest, subarctic, and Arctic. Quat Sci Rev 23:1901–1924
Koca D, Smith B, Sykes MT (2006) Modelling regional climate change effects on Swedish ecosystems. Clim Chang 78:381–406
Kühl N, Gerbhardt C, Litt T, Hense A (2002) Probability distribution functions as botanical–climatological transfer functions for climate reconstruction. Quat Res 58:381–392
Kutzbach JE, Harrison SP, Coe MT (2001) Land–ocean–atmosphere interactions and monsoon climate change: a paleo-perspective. In: Schulze E-D, Heimann M, Harrison SP, Holland E, Lloyd J, Prentice IC, Schimel D (eds) Global biogeochemical cycles in the climate system. Academic Press, London, pp 73–86
Laurent JM, Bar-Hen A, François L, Ghislain M, Cheddadi R (2004) Bioclimatic Affinity Groups of plants defined by climate seasonality: statistical refinements for vegetation modeling. J Veg Sci 15:739–746
Legendre P (1993) Spatial autocorrelation: trouble or new paradigm? Ecology 74:1659–1673
Legendre L, Legendre P (1998) Numerical ecology, 2nd edn. Elsevier, Amsterdam, p 853
Lischke H, Lotter AF, Fischlin A (2002) Untangling a Holocene pollen record with forest model simulations and independent climate data. Ecol Model 150:1–21
Magny M, Guiot J, Schoellammer P (2001) Quantitative reconstruction of Younger Dryas to Mid-Holocene paleoclimates at Le Locle, Swiss Jura, using pollen and lake-level data. Quat Res 56:170–180
Marchant RA, Harrison SP, Hooghiemstra H, Markgraf V, Boxel JH, Ager T, Almeida L, Anderson R, Baied C, Behling H, Berrio JC, Burbridge R, Björck S, Byrne R, Bush MB, Cleef AM, Duivenvoorden JF, Flenley JR, de Oliveira PE, van Geel B, Graf KJ, Gosling WD, Haberle S, van der Hammen T, Hansen BCS, Horn SP, Islebe GA, Kuhry P, Ledru M-P, Mayle FE, Leyden BW, Lozano-Garcia MS, Lozano-Garcia S, Melief ABM, Moreno P, Moar NT, Prieto A, van Reenan GB, Salgado-Labouriau ML, Schäbitz F, Schreve-Brinkamn EJ, Wille M (2009) Pollen-based biome reconstructions for Latin America at 0, 6000 and 18000 radiocarbon years. Clim Past Discuss 5:369–461
MARGO Project Members (2009) Constraints on the magnitude and patterns of ocean cooling at the Last Glacial Maximum. Nat Geosci. doi:10.1038/ngeo411
Marotzke JR, Giering QK, Zhang D, Stammer CN, Hill T, Lee V (1999) Construction of the adjoint MIT ocean general circulation model and application to Atlantic heat transport sensitivity. J Geophys Res 104:29529–29548
Miller PA, Giesecke T, Hickler T, Bradshaw RHW, Smith B, Seppä H, Valdes PJ, Sykes MT (2008) Exploring climatic and biotic controls on Holocene vegetation change in Fennoscandia. J Ecol 96:247–259
Moles AT, Ackerly DD, Webb CO, Tweddle JC, Dickie JB, Westoby M (2005) A brief history of seed size. Science 307:576–580
Nakagawa T, Tarasov PE, Nishida K, Gotanda K, Yasuda Y (2002) Quantitative pollen-based climate reconstruction in central Japan: application to surface and Late Quaternary spectra. Quat Sci Rev 21:2099–2113
New M, Lister D, Hulme M, Makin I (2002) A high-resolution data set of surface climate over global land areas. Clim Res 21:2217–2238
Ojala AEK, Alenius T, Seppä H, Giesecke T (2008) Integrated varve and pollen-based temperature reconstruction from Finland: evidence for Holocene seasonal temperature patterns at high latitudes. Holocene 18:529–538
Ortega-Rosas CI, Guiot J, Peñalba MC, Ortiz-Acosta ME (2008) Biomization and quantitative climate reconstruction techniques in northwestern Mexico—with an application to four Holocene pollen sequences. Glob Planet Chang 61:242–266
Otto-Bliesner BL, Joussaume S, Braconnot P, Harrison SP, Abe-Ouchi A (2009) Modeling and data synthesis of past climates. EOS 11:93
Overpeck JT, Webb T III, Prentice IC (1985) Quantitative interpretation of fossil pollen spectra: dissimilarity coefficients and the method of modern analogs. Quat Res 23:87–108
Peyron O, Guiot J, Cheddadi R, Tarasov P, Reille M, de Beaulieu J-L, Bottema S, Andrieu V (1998) Climatic reconstruction in Europe for 18000 yr BP from pollen data. Quat Res 49:183–196
Peyron O, Jolly D, Bonnefille R, Vincens A, Guiot J (2000) Climate of East Africa 6000 14C Yr B.P. as inferred from pollen data. Quat Res 54:90–101
Peyron O, Jolly D, Braconnot P, Bonnefille R, Guiot J, Wirrmann D, Chalie F (2006) Quantitative reconstructions of annual rainfall in Africa 6000 years ago: model-data comparison. J Geophys Res 111:D24110. doi:10.1029/2006JD007396
Pickett EJ, Harrison SP, Hope G, Harle K, Dodson JR, Kershaw AP, Prentice IC, Backhouse J, Colhoun EA, D’Costa D, Flenley J, Grindrod J, Haberle S, Hassell C, Kenyon C, Macphail M, Martin H, Martin AH, McKenzie M, Newsome JC, Penny D, Powell J, Raine JI, Southern W, Stevenson J, Sutra JP, Thomas I, van der Kaars S, Ward J (2004) Pollen-based reconstructions of biome distributions for Australia, Southeast Asia and the Pacific (SEAPAC region) at 0, 6000 and 18,000 14C yr B.P. J Biogeogr 31:1381–1444
Prentice IC, Harrison SP (2009) Ecosystem effects of CO2 concentration: evidence from past climates. Clim Past 5:297–307
Prentice IC, Bartlein PJ, Webb T III (1991) Vegetation and climate changes in eastern North America since the last glacial maximum. Ecology 72:2038–2056
Prentice IC, Guiot J, Harrison SP (1992a) Mediterranean vegetation, lake levels and palaeoclimate at the Last Glacial Maximum. Nature 360:658–660
Prentice IC, Cramer W, Harrison SP, Leemans R, Monserud RA, Solomon AM (1992b) A global biome model based on plant physiology and dominance, soil properties and climate. J Biogeogr 19:117–134
Prentice IC, Bondeau A, Cramer W, Harrison SP, Hickler T, Lucht W, Sitch S, Smith B, Sykes MT (2007) Dynamic vegetation modelling: quantifying terrestrial ecosystem responses to large-scale environmental change. In: Canadell J, Pitelka LF, Pataki D (eds) Terrestrial ecosystems in a changing world. Springer, Berlin, pp 175–192
Prentice IC, Jolly D, BIOME 6000 Participants (2000) Mid-Holocene and glacial-maximum vegetation geography of the northern continents and Africa. J Biogeogr 27:507–519
Pross J, Kotthoff U, Muller UC, Peyron O, Dormoy I, Schmiedl G, Kalaitzidis S, Smith AM (2009) Massive perturbation in terrestrial ecosystems of the Eastern Mediterranean region associated with the 8.2 kyr B.P. climatic event. Geology 37:887–890
Punyasena SW, Mayle FE, McElwain JC (2008) Quantitative estimates of glacial and Holocene temperature and precipitation change in lowland Amazonian Bolivia. Geology 36:667–670
Ramage C (1971) Monsoon meteorology. International Geophysics Series 15. Academic Press, San Diego, p 296
Rayner PJ, Scholze M, Knorr W et al (2005) Two decades of terrestrial carbon fluxes from a carbon cycle data assimilation system (CCDAS). Glob Biogeochem Cycles 19. doi:10.1029/2004GB002254
Rudaya N, Tarasov P, Dorofeyuk N, Solovieva N, Kalugin I, Andreev A, Daryin A, Diekmann B, Riedel F, Tserendash N, Wagner M (2009) Holocene environments and climate in the Mongolian Altai reconstructed from the Hoton-Nur pollen and diatom records: a step towards better understanding climate dynamics in Central Asia. Quat Sci Rev 28:540–554
Sawada M, Viau AE, Vettoretti G, Peltier WR, Gajewski K (2004) Comparison of North-American pollen-based temperature and global lake-status with CCCma AGCM2 output at 6 ka. Quat Sci Rev 23:225–244
Schäfer-Neth C, Paul A (2003) The Atlantic Ocean at the Last Glacial Maximum: 1. Objective mapping of the GLAMAP sea-surface conditions. In: Wefer G, Mulitza S, Ratmeyer V (eds) The South Atlantic in the Late Quaternary: reconstruction of material budgets and current systems. Springer, Berlin, pp 531–548
Schmidt G (2010) Enhancing the relevance of palaeoclimate model/data comparisons for assessements of future climate change. J Quat Sci 25:79–87
Seppä H, Poska A (2004) Holocene annual mean temperature changes in Estonia and their relationship to solar insolation and atmospheric circulation patterns. Quat Res 61:22–31
Seppä H, MacDonald GM, Birks HJB, Gervais BR, Snyder JA (2008) Late-Quaternary summer temperature changes in the northern-European tree-line region. Quat Res 69:404–412
Seppä H, Bjune AE, Telford RJ, Birks HJB, Veski S (2009) Last nine-thousand years of temperature variability in Northern Europe. Clim Past 5:523–535
Shuman B, Bartlein P, Logar N, Newby P, Webb T III (2002) Parallel climate and vegetation responses to the early-Holocene collapse of the Laurentide Ice Sheet. Quat Sci Rev 21:1793–1805
Sitch S, Smith B, Prentice IC et al (2003) Evaluation of ecosystem dynamics, plant geography and terrestrial carbon cycling in the LPJ Dynamic Global Vegetation Model. Glob Chang Biol 9:161–185
Smith B, Prentice IC, Sykes MT (2001) Representation of vegetation dynamics in modelling of terrestrial ecosystems: comparing two contrasting approaches within European climate space. Glob Ecol Biogeogr 10:621–637
Solovieva N, Tarasov PE, MacDonald G (2005) Quantitative reconstruction of Holocene climate from the Chuna Lake pollen record, Kola Peninsula, northwest Russia. Holocene 15:141–148
Street-Perrott FA, Harrison SP (1984) Temporal variations in lake levels since 30,000 yr BP––an index of the global hydrological cycle. Am Geophys Union Maurice Ewing Ser 5:118–129
Stute M, Schlosser P, Clark JF, Broecker WS (1992) Paleotemperatures in the Southwestern United States derived from noble gas measurements in groundwater. Science 256:1000–1003
Stuut J-BW, Lamyb F (2004) Climate variability at the southern boundaries of the Namib (southwestern Africa) and Atacama (northern Chile) coastal deserts during the last 120,000 yr. Quat Res 62:301–309
Sykes MT, Prentice IC, Cramer W (1996) A bioclimatic model for the potential distribution of northern European tree species under present and future climates. J Biogeogr 23:203–233
Tarasov PE, Guiot J, Cheddadi R, Andreev AA, Bezusko LG, Blyakharchuk TA, Dorofeyuk NI, Ludmila V, Filimonova LV, Volkova VS, Zernitskaya VP (1999) Climate in northern Eurasia 6000 years ago reconstructed from pollen data. Earth Planet Sci Lett 171:635–645
Taylor CM, Harris PP, Parker DJ (2010) Impact of soil moisture on the development of a Sahelian mesoscale convective system: a case-study from the AMMA Special Observing Period. Q J R Meteorol Soc 136:456–470
Telford RJ, Birks HJB (2005) The secret assumption of transfer functions: problems with spatial autocorrelation in evaluating model performance. Quat Sci Rev 24:2173–2179
ter Braak CJF, Juggins S (1993) Weighted averaging partial least squares regression (WA-PLS): an improved method for reconstructing environmental parameters from species assemblages. Hydrobiologia 269(270):485–502
Thompson RS, Whitlock C, Bartlein PJ, Harrison SP, Spaulding WG (1993) Climatic changes in the western United States since 18,000 yr BP. In: Wright HE Jr, Kutzbach JE, Webb T III, Ruddiman WF, Street-Perrott FA, Bartlein PJ (eds) Global climates since the last glacial maximum. University of Minnesota Press, Minneapolis, pp 468–513
Thompson RS, Anderson KH, Bartlein PJ (1999) Atlas of vegetation–climate relationships in North America. US Geological Survey Professional Paper 1650 A&B
Thompson RS, Anderson KH, Bartlein PJ (2008) Quantitative estimation of bioclimatic parameters from presence/absence vegetation data in North America by the modern analog technique. Quat Sci Rev 27:1234–1254
Tinner W, Lotter AF (2001) Central European vegetation response to abrupt climate change at 8.2 ka. Geology 29:551–554
Trenberth KE, Stepaniak DP, Caron JM (2000) The global monsoon as seen through the divergent atmospheric circulation. J Clim 13:3969–3993
Viau AE, Gajewski K (2009) Reconstructing millennial, regional paleoclimates of boreal Canada during the Holocene. J Clim 22:316–330
Viau A, Gajewski K, Sawada M, Fines P (2006) Mean-continental July temperature variability in North America during the past 14,000 years. J Geophys Res Atmos 111:D09102. doi:10.1029/2005JD006031
Viau AE, Gajewski K, Sawada MC, Bunbury J (2008) Low-and-high-frequency climate variability in Eastern Beringia during the past 25,000 years. Can J Earth Sci 45:435–1453
Vincens A, Chalié F, Bonnefille R, Guiot J, Tiercelin J-J (1993) Pollen-derived rainfall and temperature estimates from Lake Tanganyika and their implication for Late Pleistocene water levels. Quat Res 40:343–350
Waelbroeck C, Labeyrie L, Duplessy JC et al (1998) Improving past sea surface temperature estimates based on planktonic fossil faunas. Palaeoceanography 13:272–283
Wake DB, Hadly EA, Ackerly DD (2009) Biogeography, changing climates, and niche evolution: Biogeography, changing climates, and niche evolution. Proc Natl Acad Sci 106(Suppl 2):19631–19636
Webb T III, Bartlein PJ, Harrison SP, Anderson KH (1993) Vegetation, lake levels, and climate in eastern North America for the past 18,000 years. In: Wright HE Jr, Kutzbach JE, Webb T III, Ruddiman WF, Street-Perrott FA, Bartlein PJ (eds) Global climates since the last glacial maximum. University of Minnesota Press, Minneapolis, pp 415–467
Webb T III, Anderson KH, Bartlein PJ, Webb RS (1998) Late Quaternary climate change in eastern North America: a comparison of pollen-derived estimates with climate model results. Quat Sci Rev 17:587–606
Webster PJ, Clark C, Cherikova G, Fasullo J, Han W, Loschnigg J, Sahami K (2002) The monsoon as a self-regulating coupled ocean–atmosphere system. Meteorology at the Millennium. Int Geophys Ser 83:198–219
Wehrli M, Tinner W, Ammann B (2007) 16 000 years of vegetation and settlement history from Egelsee (Menzingen, central Switzerland). Holocene 17:747–761
Whitmore J, Gajewski K, Sawada M, Williams JW, Minckley T, Shuman B, Bartlein PJ, Webb T III, Viau AE, Shafer S, Anderson P, Brubaker L (2005) Modern pollen data from North America and Greenland for multi-scale paleoenvironmental Applications. Quat Sci Rev 24:1828–1848
Williams JW, Shuman B (2008) Obtaining accurate and precise environmental reconstructions from the modern analog technique and North American surface pollen dataset. Quat Sci Rev 27:669–687
Williams JW, Bartlein PJ, Webb III T (2000) Data-model comparisons for eastern North America––inferred biomes and climate values from pollen data. In: Proceedings of the Third Paleoclimate Modeling Intercomparison Project Workshop, Oct. 4–8, 1999. Montreal, Canada. Braconnot P (Ed), WCRP-111, WMO/TD-No. 1007
Williams JW, Shuman BN, Webb T (2001) Dissimilarity analyses of Late-Quaternary vegetation and climate in eastern North America. Ecology 82:3346–3362
Williams JW, Post DM, Cwynar LC, Lotter AF, Levesque AJ (2002) Rapid vegetation responses to past climate change. Geology 30:971–974
Williams JW, Gonzales LM, Kaplan JO (2008) Leaf area index for northern and eastern North America at the last glacial maximum: a data-model comparison. Glob Ecol Biogeogr 17:122–134
Wilmshurst JM, McGlone MS, Leathwick JR, Newnham RM (2007) A pre-deforestation pollen-climate calibration model for New Zealand and quantitative temperature reconstructions for the past 18000 years BP. J Quat Sci 22:535–547
Woodward FI (1987) Climate and plant distribution. Cambridge University Press, Cambridge
Wright HE, Kutzbach JE, Webb T, Ruddiman WF, Street-Perrott FA, Bartlein PJ (eds) (1993) Global climates since the last glacial maximum. University of Minnesota Press, Minneapolis
Wu H, Guiot J, Brewer S, Guo Z (2007) Climatic changes in Eurasia and Africa at the Last Glacial Maximum and mid-Holocene: reconstruction from pollen data using inverse vegetation modeling. Clim Dyn 29:211–229
Yu G, Harrison SP (1996) An evaluation of the simulated water balance of Eurasia and northern Africa at 6000 yr B.P. using lake status data. Clim Dyn 12:723–735
Zhu C, Chen X, Zhang GS, Ma CM, Zhu Q, Li ZX, Xu WF (2008) Spore–pollen–climate factor transfer function and paleoenvironment reconstruction in Dajiuhu, Shennongjia, Central China. Chin Sci Bull 53:42–49
Acknowledgments
This paper was initiated at a workshop funded by QUEST (Quantifying Uncertainties in the Earth System), a programme of the UK Natural Environment Research Council, and Project 0801 (Evaluation of PMIP Palaeoclimate Model Simulations) of the International Quaternary Association (INQUA). The paper is a contribution to ongoing work of the Palaeoclimate Modelling Intercomparison Programme. Regional dataset compilations and the work of individual co-authors has been funded by the QUEST (Quantifying Uncertainties in the Earth System) programme (SPH, ICP, TIH-P), the UK Natural Environment Research Council (SPH, ICP, MS), the US National Science Foundation (PJB, SB, BS, JWW), the Natural Sciences and Engineering Research Council of Canada (NSERC) and the Canadian Foundation for Climate and Atmospheric Sciences (CFCAS) (KEG, AV). We thank Tom Webb for his extensive review of the manuscript, and Pascale Braconnot for comments on the manuscript. The gridded data sets are available as text (.csv) or netCDF files in the Electronic Supplementary Material.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Bartlein, P.J., Harrison, S.P., Brewer, S. et al. Pollen-based continental climate reconstructions at 6 and 21 ka: a global synthesis. Clim Dyn 37, 775–802 (2011). https://doi.org/10.1007/s00382-010-0904-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00382-010-0904-1