
Abstract
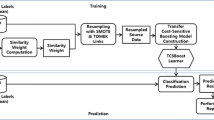
It is well-known that software defect prediction is one of the most important tasks for software quality improvement. The use of defect predictors allows test engineers to focus on defective modules. Thereby testing resources can be allocated effectively and the quality assurance costs can be reduced. For within-project defect prediction (WPDP), there should be sufficient data within a company to train any prediction model. Without such local data, cross-project defect prediction (CPDP) is feasible since it uses data collected from similar projects in other companies. Software defect datasets have the class imbalance problem increasing the difficulty for the learner to predict defects. In addition, the impact of imbalanced data on the real performance of models can be hidden by the performance measures chosen. We investigate if the class imbalance learning can be beneficial for CPDP. In our approach, the asymmetric misclassification cost and the similarity weights obtained from distributional characteristics are closely associated to guide the appropriate resampling mechanism. We performed the effect size A-statistics test to evaluate the magnitude of the improvement. For the statistical significant test, we used Wilcoxon rank-sum test. The experimental results show that our approach can provide higher prediction performance than both the existing CPDP technique and the existing class imbalance technique.







Similar content being viewed by others


References
Arcuri A, Briand L (2011) A practical guide for using statistical tests to assess randomized algorithms in software engineering. 2011 33rd Int Conf Softw Eng 1–10. doi: 10.1145/1985793.1985795
Arcuri A, Fraser G (2011) On parameter tuning in search based software engineering. Search Based Softw Eng 33–47
Arisholm E, Briand LC, Johannessen EB (2010) A systematic and comprehensive investigation of methods to build and evaluate fault prediction models. J Syst Softw 83:2–17. doi:10.1016/j.jss.2009.06.055
Bradley AP (1997) The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recogn 30:1145–1159. doi:10.1016/S0031-3203(96)00142-2
Chang C, Lin C (2013) LIBSVM: a library for support vector machines. 1–39
D’Ambros M, Lanza M, Robbes R (2011) Evaluating defect prediction approaches: a benchmark and an extensive comparison. Empir Softw Eng 17:531–577. doi:10.1007/s10664-011-9173-9
Dejaeger K (2013) Toward comprehensible software fault prediction models using bayesian network classifiers. Softw Eng IEEE Trans 39:237–257
Elish KO, Elish MO (2008) Predicting defect-prone software modules using support vector machines. J Syst Softw 81:649–660. doi:10.1016/j.jss.2007.07.040
Gao K, Khoshgoftaar T (2011) Software Defect Prediction for High-Dimensional and Class-Imbalanced Data. SEKE
Garcia EA (2009) Learning from imbalanced data. IEEE Trans Knowl Data Eng 21:1263–1284. doi:10.1109/TKDE.2008.239
Gray D, Bowes D, Davey N, et al. (2009) Using the support vector machine as a classification method for software defect prediction with static code metrics. Eng Appl Neural Networks 223–234
Grbac T, Goran M (2013) Stability of software defect prediction in relation to levels of data imbalance. SQAMIA
Hall M, Frank E, Holmes G (2009) The WEKA data mining software: an update. ACM SIGKDD Explor Newsl 11:10–18.
Hall T, Beecham S, Bowes D et al (2012) A systematic literature review on fault prediction performance in software engineering. IEEE Trans Softw Eng 38:1276–1304. doi:10.1109/TSE.2011.103
Hand DJ (2009) Measuring classifier performance: a coherent alternative to the area under the ROC curve. Mach Learn 77:103–123. doi:10.1007/s10994-009-5119-5
He Z, Shu F, Yang Y, et al. (2011) An investigation on the feasibility of cross-project defect prediction. Autom. Softw Eng 167–199
Hsu C, Chang C, Lin C (2010) A practical guide to support vector classification. 1:1–16
Kim S, Whitehead E, Zhang Y (2008) Classifying software changes: clean or buggy? Softw Eng IEEE Trans 34:181–196
Kim S, Zhang H, Wu R, Gong L (2011) Dealing with noise in defect prediction. Proceeding 33rd Int Conf Softw Eng - ICSE ’11 481. doi: 10.1145/1985793.1985859
Kullback S, Leibler R (1951) On information and sufficiency. Ann Math Stat
Lee T, Nam J, Han D, et al. (2011) Micro interaction metrics for defect prediction. Proc 19th ACM SIGSOFT Symp 13th Eur Conf Found Softw Eng - SIGSOFT/FSE ’11 311. doi: 10.1145/2025113.2025156
Ma Y, Luo G, Zeng X, Chen A (2012) Transfer learning for cross-company software defect prediction. Inf Softw Technol 54:248–256. doi:10.1016/j.infsof.2011.09.007
Mende T, Koschke R (2009) Revisiting the evaluation of defect prediction models. Proc 5th Int Conf Predict Model Softw Eng - PROMISE ’09 1. doi: 10.1145/1540438.1540448
Menzies T, Dekhtyar A, Distefano J, Greenwald J (2007) Problems with precision: a response to “comments on ‘data mining static code attributes to learn defect predictors. IEEE Trans Softw Eng 33:637–640. doi:10.1109/TSE.2007.70721
Menzies T, Milton Z, Turhan B et al (2010) Defect prediction from static code features: current results, limitations, new approaches. Autom Softw Eng 17:375–407. doi:10.1007/s10515-010-0069-5
Menzies T, Caglayan B, He Z, et al. (2012) The PROMISE repository of empirical software engineering data. http://promisedata.googlecode.com
Nam J, Pan SJ, Kim S (2013) Transfer defect learning. 2013 35th Int Conf Softw Eng 382–391. doi: 10.1109/ICSE.2013.6606584
Pan SJ, Yang Q (2010) A survey on transfer learning. IEEE Trans Knowl Data Eng 22:1345–1359. doi:10.1109/TKDE.2009.191
Peters F, Menzies T, Gong L, Zhang H (2013) Balancing privacy and utility in cross-company defect prediction. IEEE Trans Softw Eng 39:1054–1068. doi:10.1109/TSE.2013.6
Premraj R, Herzig K (2011) Network versus code metrics to predict defects: a replication study. Int Symp Empir Softw Eng Meas 2011:215–224. doi:10.1109/ESEM.2011.30
Ren J, Qin K, Ma Y, Luo G (2014) On software defect prediction using machine learning. J Appl Math 2014:1–8. doi:10.1155/2014/785435
Shatnawi R, Li W (2008) The effectiveness of software metrics in identifying error-prone classes in post-release software evolution process. J Syst Softw 81:1868–1882. doi:10.1016/j.jss.2007.12.794
Shepperd M (2011) NASA MDP software defect data sets. http://nasa-softwaredefectdatasets.wikispaces.com/
Singh Y, Kaur A, Malhotra R (2009) Empirical validation of object-oriented metrics for predicting fault proneness models. Softw Qual J 18:3–35. doi:10.1007/s11219-009-9079-6
Song L, Minku LL, Yao X (2013) The impact of parameter tuning on software effort estimation using learning machines. Proc 9th Int Conf Predict Model Softw Eng - PROMISE ’13 1–10. doi: 10.1145/2499393.2499394
Tan P-N, Steinbach M, Kumar V (2005) Introduction to data mining. J Sch Psychol 19:51–56. doi:10.1016/0022-4405(81)90007-8
Turhan B, Menzies T, Bener AB, Di Stefano J (2009) On the relative value of cross-company and within-company data for defect prediction. Empir Softw Eng 14:540–578. doi:10.1007/s10664-008-9103-7
Vargha A, Delaney HD (2000) A critique and improvement of the CL common language effect size statistics of McGraw and Wong. J Educ Behav Stat 25:101–132. doi:10.3102/10769986025002101
Wang BX, Japkowicz N (2009) Boosting support vector machines for imbalanced data sets. Knowl Inf Syst 25:1–20. doi:10.1007/s10115-009-0198-y
Wang S, Yao X (2013) Using class imbalance learning for software defect prediction. IEEE Trans Reliab 62:434–443. doi:10.1109/TR.2013.2259203
Wilcoxon F (1945) Individual comparisons by ranking methods. Biom Bull 1:80–83
Zheng J (2010) Cost-sensitive boosting neural networks for software defect prediction. Expert Syst Appl 37:4537–4543. doi:10.1016/j.eswa.2009.12.056
Zimmermann T, Nagappan N, Gall H, et al. (2009) Cross-project defect prediction. Proc 7th Jt Meet Eur Softw Eng Conf ACM SIGSOFT Symp Found Softw Eng 91. doi: 10.1145/1595696.1595713
Acknowledgments
This work was supported by a National Research Foundation of Korea (NRF) grant funded by the Korea government (MSIP) (No. NRF-2013R1A1A2006985).
Author information
Authors and Affiliations
Corresponding author
Additional information
Communicated by: Tim Menzies
Appendix
Appendix
Table 9 shows all features in each of the NASA and SOFTLAB datasets obtained from PROMISE repository (Shepperd 2011; Menzies et al. 2012).
Table 10 shows the parameter values used for tuning them. For SVM, Radial Basis Function (RBF) kernel is employed since it is widely used.
Table 11 shows the selected parameter values for each learner according to each dataset.
Figures 6, 7, 8, 9, 10, 11, 12, 13, 14 and 15 shows the result of the effect size A-statistics test between VCB-SVM and each classifier in terms of AUC, PD, PF, and H-measure over each test set. Figure 6 shows the effect size test result of AUC, PD, PF and H-measure when ar3 dataset is used as a test set. VCB-SVM is worse than other models in terms of PF. However, it is better than other models in terms of PD. The overall performance (AUC and H-measure) of VCB-SVM is better than those of other models except for LR. Similar results can be found over the other data sets.

Effect size test result of AUC, PD, PF and H-measure when ar5 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when kc1 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when mc2 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when kc3 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when mw1 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when kc2 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when pc1 dataset is used as a test set

Effect size test result of AUC, PD, PF and H-measure when cm1 dataset is used as a test set
Rights and permissions
About this article

Cite this article
Ryu, D., Choi, O. & Baik, J. Value-cognitive boosting with a support vector machine for cross-project defect prediction. Empir Software Eng 21, 43–71 (2016). https://doi.org/10.1007/s10664-014-9346-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10664-014-9346-4