
Abstract
The operation of squaring (coproduct followed by product) in a combinatorial Hopf algebra is shown to induce a Markov chain in natural bases. Chains constructed in this way include widely studied methods of card shuffling, a natural “rock-breaking” process, and Markov chains on simplicial complexes. Many of these chains can be explicitly diagonalized using the primitive elements of the algebra and the combinatorics of the free Lie algebra. For card shuffling, this gives an explicit description of the eigenvectors. For rock-breaking, an explicit description of the quasi-stationary distribution and sharp rates to absorption follow.
Similar content being viewed by others


1 Introduction
A Hopf algebra is an algebra \(\mathcal{H}\) with a coproduct \(\Delta:\mathcal{H}\to\mathcal{H}\otimes\mathcal{H}\) which fits together with the product \(m:\mathcal{H}\otimes\mathcal{H}\rightarrow\mathcal{H}\). Background on Hopf algebras is in Sect. 2.2. The map \(m\Delta:\mathcal{H}\to\mathcal{H}\) is called the Hopf-square (often denoted Ψ 2 or x [2]). Our first discovery is that the coefficients of x [2] in natural bases can often be interpreted as a Markov chain. Specializing to familiar Hopf algebras can give interesting Markov chains: the free associative algebra gives the Gilbert–Shannon–Reeds model of riffle shuffling. Symmetric functions give a rock-breaking model of Kolmogoroff [54]. These two examples are developed first for motivation.
Example 1.1
(Free associative algebra and riffle shuffling)
Let x 1,x 2,…,x n be noncommuting variables and \(\mathcal {H}=k\langle x_{1},\ldots,x_{n}\rangle\) be the free associative algebra. Thus \(\mathcal{H}\) consists of finite linear combinations of words \(x_{i_{1}}x_{i_{2}}\cdots x_{i_{k}}\) in the generators with the concatenation product. The coproduct Δ is an algebra map defined by Δ(x i )=1⊗x i +x i ⊗1 and extended linearly. Consider
A term in this product results from a choice of left or right from each factor. Equivalently, for each subset S⊆{1,2,…,k}, there corresponds the term
Thus mΔ is a sum of 2k terms resulting from removing \(\{ x_{i_{j}}\}_{j\in S}\) and moving them to the front. For example,
Dividing mΔ by 2k, the coefficient of a word on the right is exactly the chance that this word appears in a Gilbert–Shannon–Reeds inverse shuffle of a deck of cards labeled by x i in initial order \(x_{i_{1}}x_{i_{2}}\cdots x_{i_{k}}\). Applying \(\frac{1}{2^{k}}m\Delta\) in the dual algebra gives the usual model for riffle shuffling. Background on these models is in Sect. 5. As shown there, this connection between Hopf algebras and shuffling gives interesting new theorems about shuffling.
Example 1.2
(Symmetric functions and rock-breaking)
Let us begin with the rock-breaking description. Consider a rock of total mass n. Break it into two pieces according to the symmetric binomial distribution:
Continue, at the next stage breaking each piece into {j 1,j−j 1}, {j 2,n−j−j 2} by independent binomial splits. The process continues until all pieces are of mass one when it stops. This description gives a Markov chain on partitions of n, absorbing at 1n.
This process arises from the Hopf-square map applied to the algebra Λ=Λ(x 1,x 2,…,x n ) of symmetric functions, in the basis of elementary symmetric functions {e λ }. This is an algebra under the usual product. The coproduct, following [38] is defined by
extended multiplicatively and linearly. This gives a Hopf algebra structure on Λ which is a central object of study in algebraic combinatorics. It is discussed in Sect. 2.4. Rescaling the basis elements to \(\{\hat{e}_{i}:=i!e_{i}\}\), a direct computation shows that mΔ in the {e λ } basis gives the rock-breaking process; see Sect. 4.1.
A similar development works for any Hopf algebra which is either a polynomial algebra as an algebra (for instance, the algebra of symmetric functions, with generators e n ), or is cocommutative and a free associative algebra as an algebra (e.g., the free associative algebra), provided each object of degree greater than one can be broken non-trivially. These results are described in Theorem 3.4.
Our second main discovery is that this class of Markov chains can be explicitly diagonalized using the Eulerian idempotent and some combinatorics of the free associative algebra. This combinatorics is reviewed in Sect. 2.3. It leads to a description of the left eigenvectors (Theorems 3.15 and 3.16) which is often interpretable and allows exact and asymptotic answers to natural probability questions. For a polynomial algebra, we are also able to describe the right eigenvectors completely (Theorem 3.19).
Example 1.3
(Shuffling)
For a deck of n distinct cards, the eigenvalues of the Markov chain induced by repeated riffle shuffling are 1,1/2,…,1/2n−1 [45]. The multiplicity of the eigenvalue 1/2n−i equals the number of permutations in S n with i cycles. For example, the second eigenvalue, 1/2, has multiplicity \(\binom{n}{2}\). For 1≤i<j≤n, results from Sect. 5 show that a right eigenvector f ij is given by
Summing in i<j shows that \(d(w)-\frac{n-1}{2}\) is an eigenvector with eigenvalue 1/2 (d(w)=# descents in w). Similarly \(p(w)-\frac {n-2}{3}\) is an eigenvector with eigenvalue 1/4 (p(w)=# peaks in w). These eigenvectors are used to determine the mean and variance of the number of carries when large integers are added.
Our results work for decks with repeated values allowing us to treat cases when, e.g., the suits do not matter and all picture cards are equivalent to tens. Here, fewer shuffles are required to achieve stationarity. For decks of essentially any composition we show that all eigenvalues 1/2i, 0≤i≤n−1, occur and determine multiplicities and eigenvectors.
Example 1.4
(Rock-breaking)
Consider the rock-breaking process of Example 1.2 started at (n), the partition with a single part of size n. This is absorbing at the partition 1n. In Sect. 4, this process is shown to have eigenvalues 1,1/2,…,1/2n−1 with the multiplicity of 1/2n−l the number of partitions of n into l parts. Thus, the second eigenvalue is 1/2 taken on uniquely at the partition 1n−22. The corresponding eigenfunction is
This is a monotone function in the usual partial order on partitions and equals zero if and only if λ=1n. If X 0=(n),X 1,X 2,… are the successive partitions generated by the Markov chain then
Using Markov’s inequality,
This shows that for k=2log2 n+c, the chance of absorption is asymptotic to 1−1/2c+1 when n is large. Section 4 derives all of the eigenvectors and gives further applications.
Section 2 reviews Markov chains (including uses for eigenvectors), Hopf algebras, and some combinatorics of the free associative algebra. Section 3 gives our basic theorems, generalizing the two examples to polynomial Hopf algebras and cocommutative, free associative Hopf algebras. Section 4 treats rock-breaking; Section 5 treats shuffling. Section 6 briefly describes other examples (e.g., graphs and simplicial complexes), counter-examples (e.g., the Steenrod algebra), and questions (e.g., quantum groups).
Two historical notes: The material in the present paper has roots in work of Patras [65–67], whose notation we are following, and Drinfeld [34]. Patras studied shuffling in a purely geometric fashion, making a ring out of polytopes in \(\mathbb{R}^{n}\). This study led to natural Hopf structures, Eulerian idempotents, and generalization of Solomon’s descent algebra in a Hopf context. His Eulerian idempotent maps decompose a graded commutative or cocommutative Hopf algebra into eigenspaces of the ath Hopf-powers; we improve upon this result, in the case of polynomial algebras or cocommutative, free associative algebras, by algorithmically producing a full eigenbasis. While there is no hint of probability in the work of Patras, it deserves to be much better known. More detailed references are given elsewhere in this paper.
We first became aware of Drinfeld’s ideas through their mention in Shnider–Sternberg [82]. Consider the Hopf-square, acting on a Hopf algebra \(\mathcal{H}\). Suppose that \(x\in\mathcal{H}\) is primitive, Δ(x)=1⊗x+x⊗1. Then mΔ(x)=2x so x is an eigenvector of mΔ with eigenvalue 2. If x and y are primitive then mΔ(xy+yx)=4(xy+yx) and, similarly, if x 1,…,x k are primitive then the sum of symmetrized products is an eigenvector of mΔ with eigenvector 2k. Drinfeld [34, Prop. 3.7] used these facts without comment in his proof that any formal deformation of the cocommutative universal enveloping algebra \(\mathcal{U}(\mathfrak{g})\) results already from deformation of the underlying Lie algebra \(\mathfrak{g}\). See [82, Sect. 3.8] and Sect. 3.4 below for an expanded argument and discussion. For us, a description of the primitive elements and their products gives the eigenvectors of our various Markov chains. This is developed in Sect. 3.
2 Background
This section gives notation and background for Markov chains (including uses for eigenvectors), Hopf algebras, the combinatorics of the free associative algebra and symmetric functions. All of these are large subjects and pointers to accessible literature are provided.
2.1 Markov chains
Let \(\mathcal{X}\) be a finite set. A Markov chain on \(\mathcal{X}\) may be specified by a transition matrix K(x,y) \((x,y\in\mathcal {X})\) with K(x,y)≥0, ∑ y K(x,y)=1. This is interpreted as the chance that the chain moves from x to y in one step. If the chain is denoted X 0,X 1,X 2,… and X 0=x 0 is a fixed starting state then
Background and basic theory can be found in [50] or [15]. The readable introduction [58] is recommended as close in spirit to the present paper. The analytic theory is developed in [75].
Let K 2(x,y)=∑ z K(x,z)K(z,y) denote the probability of moving from x to y in two steps. Similarly, K l is defined. Under mild conditions [58, Sect. 1.5] Markov chains have unique stationary distributions π(x): thus π(x)≥0, ∑ x π(x)=1, ∑ x π(x)K(x,y)=π(y), so π is a left eigenvector of K with eigenvalue 1. Set
Then K operates as a contraction on L 2 with Kf(x)=∑ y K(x,y)f(y). The Markov chains considered in this paper are usually not self-adjoint (equivalently reversible), nonetheless, they are diagonalizable over the rationals with eigenvalues \(1=\beta_{0}\geq \beta_{1}\geq\cdots\geq\beta_{|\mathcal{X}|-1}>0\). We have a basis of left eigenfunctions \(\{g_{i}\}_{i=0}^{|\mathcal{X}|-1}\) with g 0(x)=π(x) and ∑ x g i (x)K(x,y)=β i g i (y), and, in some cases, a dual basis of right eigenfunctions \(\{f_{i}\}_{i=0}^{|\mathcal {X}|-1}\) with f 0(x)≡1, Kf i (x)=β i f i (x), and ∑ x f i (x)g j (x)=δ ij . As is customary in discussions of random walks on algebraic structures, we will abuse notation and think of the eigenfunctions f i both as functions on the state space and as linear combinations of the states—in other words, ∑ x f i (x)x will also be denoted f i .
Throughout, we are in the unusual position of knowing β i , g i and possibly f i explicitly. This is rare enough that some indication of the use of eigenfunctions is indicated.
Use A
For any function \(f:\mathcal{X}\to\mathbb{R}\), expressed in the basis of right eigenfunctions {f i } as
the expectation of f after k steps, having started at x 0, is given by
For example, for shuffling, the normalized number of descents d(π)−(n−1)/2 is the sum of the 1/2-eigenfunctions for riffle shuffling; see Example 5.8. Thus, with x 0=id and all k, 0≤k<∞,
In [27, 28] it is shown that the number of descents in repeated riffle shuffles has the same distribution as the number of carries when n integers are added. Further, the square of this eigenfunction has a simple eigenfunction expansion leading to simple formulas for the variance and covariance of the number of carries.
Use B
If f is a right eigenfunction with eigenvalue β, then the self-correlation after k steps (starting in stationarity) is
This indicates how certain correlations fall off and gives an interpretation of the eigenvalues.
Use C
For f a right eigenfunction with eigenvalue β, let Y i =f(X i )/β i, 0≤i<∞. Then Y i is an \(\mathcal{F}_{i}\) martingale with \(\mathcal {F}_{i}=\sigma (X_{0},X_{1}, \ldots, X_{i} )\). One may try to use optional stopping, maximal and concentration inequalities and the martingale central limit theorem to study the behavior of the original X i chain.
Use D
One standard use of right eigenfunctions is to prove lower bounds for mixing times for Markov chains. The earliest use of this is the second moment method [26]. Here, one uses the second eigenfunction as a test function and expands its square in the eigenbasis to get concentration bounds. An important variation is Wilson’s method [95] which only uses the first eigenfunction but needs a careful understanding of the variation of this eigenfunction. A readable overview of both methods and many examples is in [76].
Use E
The left eigenfunctions come into computations since ∑ x g i (x)f j (x)=δ ij . Thus in (2.1), a i =〈g i |f/π〉. (Here f/π is just the density of f with respect to π.)
Use F
A second prevalent use of left eigenfunctions throughout this paper: the dual of a Hopf algebra is a Hopf algebra and left eigenfunctions of the dual chain correspond to right eigenfunctions of the original chain. This is similar to the situation for time reversal. If \(K^{*}(x,y)=\frac{\pi(y)}{\pi(x)}K(y,x)\) is the time-reversed chain (note K ∗(x,y) is a Markov chain with stationary distribution π), then g i /π is a right eigenfunction of K ∗.
Use G
The left eigenfunctions also come into determining the quasi-stationary distribution of absorbing chains such as the rock-breaking chain. A useful, brief introduction to quasi-stationarity is in [50]. The comprehensive survey [91] and annotated bibliography [68] are also useful. Consider the case where there is a unique absorbing state x • and the second eigenvalue β 1 of the chain satisfies 1=β 0>β 1>β 2≥⋯. This holds for rock-breaking. There are two standard notions of “the limiting distribution of the chain given that it has not been absorbed”:


In words, π 1(x) is the limiting distribution of the chain given that it has not been absorbed up to time k and π 2(x) is the limiting distribution of the chain given that it is never absorbed. These quasi-stationary distributions can be expressed in terms of the eigenfunctions:
These results follow from simple linear algebra and are proved in the references above. For rock-breaking, results in Sect. 4 show that π 1=π 2 is point mass at the partition 1n−22.
Use H
Both sets of eigenfunctions appear in the formula
This permits the possibility of determining convergence rates. It can be difficult to do for chains with large state spaces. See the examples and discussion in [29].
To conclude this discussion of Markov chains we mention that convergence is customarily measured by a few standard distances:



Here \(\|K_{x_{0}}^{l}-\pi\|_{\operatorname{TV}}\leq\operatorname{sep}_{x_{0}}(l)\leq l_{\infty}(l)\) and all distances are computable by determining the maximizing or minimizing values of A or y and using (2.5)–(2.8). See [58, Lemma 6.13] for further discussion of these distances.
2.2 Hopf algebras
A Hopf algebra is an algebra \(\mathcal{H}\) over a field k (usually the real numbers in the present paper). It is associative with unit 1, but not necessarily commutative. Let us write m for the multiplication in \(\mathcal{H}\), so m(x⊗y)=xy. Then \(m^{[a]}:\mathcal{H}^{\otimes a}\to\mathcal{H}\) will denote a-fold products (so m=m [2]), formally m [a]=m(ι⊗m [a−1]) where ι denotes the identity map.
\(\mathcal{H}\) comes equipped with a coproduct \(\Delta :\mathcal{H}\to\mathcal{H}\otimes\mathcal{H}\), written Δ(x)=∑(x) x (1)⊗x (2) in Sweedler notation [89]. The coproduct is coassociative in that
so there is no ambiguity in writing Δ[3](x)=∑(x) x (1)⊗x (2)⊗x (3). Similarly, \(\Delta ^{[a]}:\mathcal{H}\to\mathcal{H}^{\otimes a}\) denotes the a-fold coproduct, where Δ is applied a−1 times, to any one tensor-factor at each stage; formally Δ[a]=(ι⊗⋯⊗ι⊗Δ)Δ[a−1]. The Hopf algebra \(\mathcal{H}\) is cocommutative if ∑(x) x (1)⊗x (2)=∑(x) x (2)⊗x (1); in other words, an expression in Sweedler notation is unchanged when the indices permute. An element x of \(\mathcal{H}\) is primitive if Δ(x)=1⊗x+x⊗1.
The product and coproduct have to be compatible so Δ is an algebra homomorphism, where multiplication on \(\mathcal{H}\otimes \mathcal{H}\) is componentwise; in Sweedler notation this says Δ(xy)=∑(x),(y) x (1) y (1)⊗x (2) y (2). All of the algebras considered here are graded and connected, i.e., \(\mathcal{H}=\bigoplus_{i=0}^{\infty}\mathcal{H}_{i}\) with \(\mathcal {H}_{0}=k\) and \(\mathcal{H}_{n}\) finite-dimensional. The product and coproduct must respect the grading so \(\mathcal{H}_{i}\mathcal{H}_{j}\subseteq\mathcal{H}_{i+j}\), and \(x\in\mathcal{H}_{n}\) implies \(\Delta(x)\in\bigoplus_{j=0}^{n}\mathcal{H}_{j}\otimes\mathcal {H}_{n-j}\). There are a few more axioms concerning a counit map and an antipode (automatic in the graded case); for the present paper, the most important is that the counit is zero on elements of positive degree, so, by the coalgebra axioms, \(\bar{\Delta}(x):=\Delta(x) - 1 \otimes x - x \otimes1 \in\bigoplus_{j=1}^{n-1}\mathcal{H}_{j}\otimes\mathcal{H}_{n-j}\), for \(x\in\mathcal{H}_{n}\). The free associative algebra and the algebra of symmetric functions, discussed in Sect. 1, are examples of graded Hopf algebras.
The subject begins in topology when H. Hopf realized that the presence of the coproduct leads to nice classification theorems which allowed him to compute the cohomology of the classical groups in a unified manner. Topological aspects are still a basic topic [46] with many examples which may provide grist for the present mill. For example, the cohomology groups of the loops on a topological space form a Hopf algebra, and the homology of the loops on the suspension of a wedge of circles forms a Hopf algebra isomorphic to the free associative algebra of Example 1.1 [14].
Joni and Rota [49] realized that many combinatorial objects have a natural breaking structure which gives a coalgebra structure to the graded vector space on such objects. Often there is a compatible way of putting pieces together, extending this to a Hopf algebra structure. Often, either the assembling or the breaking process is symmetric, leading to commutative or cocommutative Hopf algebras, respectively. For example, the symmetric function algebra is commutative and cocommutative while the free associative algebra is just cocommutative.
The theory developed here is for graded commutative or cocommutative Hopf algebras with one extra condition: that there is a unique way to assemble any given collection of objects. This amounts to the requirement that the Hopf algebra is either a polynomial algebra as an algebra (and therefore commutative) or a free associative algebra as an algebra and cocommutative (and therefore noncommutative). (We write a free associate algebra to refer to the algebra structure only, as opposed to the free associative algebra which has a specified coalgebra structure—namely, the generating elements are primitive.)
Increasingly sophisticated developments of combinatorial Hopf algebras are described by [4, 77–80] and [1]. This last is an expansive extension which unifies many common examples. Below are two examples that are prototypes for their Bosonic Fock functor and Full Fock functor constructions, respectively [1, Ch. 15]; they are also typical of constructions detailed in other sources.
Example 2.1
(The Hopf algebra of unlabeled graphs) [79, Sect. 12] [35, Sect. 3.2]
Let \(\bar{\mathcal{G}}\) be the vector space spanned by unlabeled simple graphs (no loops or multiple edges). This becomes a Hopf algebra with product disjoint union and coproduct
where the sum is over subsets of vertices S with G S , \(G_{S^{\mathcal{C}}}\) the induced subgraphs. Graded by number of vertices, \(\bar{\mathcal{G}}\) is both commutative and cocommutative, and is a polynomial algebra as an algebra. The associated random walk is described in Example 3.1 below.
Example 2.2
(The noncommutative Hopf algebra of labeled graphs) [79, Sect. 13] [35, Sect. 3.3]
Let \(\mathcal{G}\) be the vector space spanned by the set of simple graphs where vertices are labeled {1,2,…,n}, for some n. The product of two graphs G 1 G 2 is their disjoint union, where the vertices of G 1 keep their labels, and the labels in G 2 are increased by the number of vertices in G 1. The coproduct is
where we again sum over all subsets S of vertices of G, and G S , \(G_{S^{\mathcal{C}}}\) are relabeled so the vertices in each keep the same relative order. For example,

where 1 denotes the empty graph. \(\mathcal{G}\) is noncommutative and cocommutative and a free associative algebra as an algebra; the associated random walk is detailed in Example 3.2. As the notation suggests, \(\bar{\mathcal{G}}\) is a quotient of \(\mathcal {G}\), obtained by forgetting the labels on the vertices.
Aguiar–Bergeron–Sottile [4] define a combinatorial Hopf algebra as a Hopf algebra \(\mathcal{H}\) with a character \(\zeta :\mathcal{H}\to k\) which is both additive and multiplicative. They prove a universality theorem: any combinatorial Hopf algebra has a unique character-preserving Hopf morphism into the algebra of quasisymmetric functions. They show that this unifies many ways of building generating functions. When applied to the Hopf algebra of graphs, their map gives the chromatic polynomial. In Sect. 3.7 we find that their map gives the probability of absorption for several of our Markov chains. See also the examples in Sect. 6.
A good introduction to Hopf algebras is in [82]. A useful standard reference is in [64] and our development does not use much outside of her Chap. 1. The broad-ranging text [62] is aimed towards quantum groups but contains many examples useful here. Quantum groups are neither commutative nor cocommutative and need special treatment; see Example 6.3.
A key ingredient in our work is the Hopf-square map Ψ 2=mΔ; Ψ 2(x) is also written x [2]. In Sweedler notation, Ψ 2(x)=∑(x) x (1) x (2); in our combinatorial setting, it is useful to think of “pulling apart” x according to Δ, then using the product to put the pieces together. On graded Hopf algebras, Ψ 2 preserves the grading and, appropriately normalized, gives a Markov chain on appropriate bases. See Sect. 3.2 for assumptions and details. The higher power maps Ψ a=m [a]Δ[a] will also be studied, since under our hypothesis, they present no extra difficulty. For example, Ψ 3(x)=∑(x) x (1) x (2) x (3). In the shuffling example, Ψ a corresponds to the “a-shuffles” of [10]. A theorem of [90] shows that, for commutative or cocommutative Hopf algebras, the power rule holds: (x [a])[b]=x [ab], or Ψ a Ψ b=Ψ ab. See also the discussion in [56]. In shuffling language this becomes “an a-shuffle followed by a b-shuffle is an ab-shuffle” [10]. In general Hopf algebras this power law often fails [51]. Power maps are actively studied as part of a program to carry over to Hopf algebras some of the rich theory of groups. See [44, 59] and their references.
2.3 Structure theory of a free associative algebra
The eigenvectors of our Markov chains are described using combinatorics related to the free associative algebra, as described in the self-contained [60, Chap. 5].
A word in an ordered alphabet is Lyndon if it is strictly smaller (in lexicographic order) than its cyclic rearrangements. So 1122 is Lyndon but 21 or 1212 are not. A basic fact [60, Th. 5.1.5] is that any word w has a unique Lyndon factorization, that is, w=l 1 l 2⋯l k with each l i a Lyndon word and l 1≥l 2≥⋯≥l k . Further, each Lyndon word l has a standard factorization: if l is not a single letter, then l=l 1 l 2 where l i is non-trivial Lyndon and l 2 is the longest right Lyndon factor of l. (The standard factorization of a letter is just that letter by definition.) Thus 13245=13⋅245. Using this, define, for Lyndon l, its standard bracketing λ(l) recursively by λ(a)=a for a letter and λ(l)=[λ(l 1),λ(l 2)] for l=l 1 l 2 in standard factorization. As usual, [x,y]=xy−yx for words x,y. Thus
and

Garsia and Reutenauer [37, Sect. 2] describes how to visualize the standard bracketing of a Lyndon word as a rooted binary tree: given a Lyndon word l with standard factorization l=l 1 l 2, inductively set T l to be the tree with \(T_{l_{1}}\) as its left branch and \(T_{l_{2}}\) as its right branch. T 13245 and T 1122 are shown below.

Observe that a word w appears in the expansion of λ(l) only if, after exchanging the left and right branches at some vertices of T l , the leaves of T l , when read from left to right, spell out w. The coefficient of w in λ(l) is then the signed number of ways to do this (the sign is the parity of the number of exchanges required). For example,
-
25413 has coefficient 1 in λ(13245) since the unique way to rearrange T 13245 so the leaves spell 25413 is to exchange the branches at the root and the highest interior vertex;
-
21345 does not appear in λ(13245) since whenever the branches of T 13245 switch, 2 must appear adjacent to either 4 or 5, which does not hold for 21345;
-
1221 has coefficient 0 in λ(1122) as, to make the leaves of T 1122 spell 1221, we can either exchange branches at the root, or exchange branches at both of the other interior vertices. These two rearrangements have opposite signs, so the signed count of rearrangements is 0.
A final piece of notation is the following symmetrized product: let w=l 1 l 2⋯l k in Lyndon factorization. Then set
Viewing \(\operatorname{sym}(w)\) as a polynomial in the letters w 1,w 2,…,w l will be useful for Theorem 3.16.
Garsia and Reutenauer’s tree construction can be extended to visualize \(\operatorname{sym}(w)\), using what Barcelo and Bergeron [9] call decreasing Lyndon hedgerows, which simply consist of \(T_{l_{1}},T_{l_{2}},\ldots,T_{l_{k}}\) placed in a row. Denote this as T w also. The example T 35142 is shown below.

We can again express the coefficient of w′ in \(\operatorname {sym}(w)\) as the signed number of ways to rearrange T w so the leaves spell w′. Now there are two types of allowed moves: exchanging the left and right branches at a vertex, and permuting the trees of the hedgerow. The latter move does not come with a sign. Thus 14253 has coefficient −1 in \(\operatorname{sym}(35142)\), as the unique rearrangement of T 35142 which spells 14253 requires transposing the trees and permuting the branches labeled 3 and 5.
It is clear from this pictorial description that every term appearing in \(\operatorname{sym}(w)\) is a permutation of the letters in w. Garsia and Reutenauer [37, Th. 5.2] shows that \(\{\operatorname{sym}(w)\}\) form a basis for a free associative algebra. This will turn out to be a left eigenbasis for inverse riffle shuffling, and similar theorems hold for other Hopf algebras.
2.4 Symmetric functions and beyond
A basic object of study is the vector space \(\varLambda_{k}^{n}\) of homogeneous symmetric polynomials in k variables of degree n. The direct sum \(\varLambda_{k}=\bigoplus_{n=0}^{\infty}\varLambda_{k}^{n}\) forms a graded algebra with familiar bases: the monomial (m λ ), elementary (e λ ), homogeneous (h λ ), and power sums (p λ ). For example, e 2(x 1,…,x k )=∑1≤i<j≤k x i x j and for a partition λ=λ 1≥λ 2≥⋯≥λ l >0 with λ 1+⋯+λ l =n, \(e_{\lambda}=e_{\lambda_{1}}e_{\lambda_{2}}\cdots e_{\lambda_{l}}\). As λ ranges over partitions of n, {e λ } form a basis for \(\varLambda_{k}^{n}\), from which we construct the rock-breaking chain of Example 1.2. Splendid accounts of symmetric function theory appear in [61] and [86]. A variety of Hopf algebra techniques are woven into these topics, as emphasized by [38] and [96]. The comprehensive account of noncommutative symmetric functions [39] and its follow-ups furthers the deep connection between combinatorics and Hopf algebras. However, this paper will only involve its dual, the algebra of quasisymmetric functions, as they encode informations about absorption rates of our chains, see Sect. 3.7. A basis of this algebra is given by the monomial quasisymmetric functions: for a composition α=(α 1,…,α k ), define \(M_{\alpha}=\sum_{i_{1} < i_{2} < \cdots<i_{k}} x_{i_{1}}^{\alpha_{1}} \cdots x_{i_{k}}^{\alpha_{k}}\). Further details are in [86, Sect. 7.19].
3 Theory
3.1 Introduction
This section states and proves our main theorems. This introduction sets out definitions. Section 3.2 develops the reweighting schemes needed to have the Hopf-square maps give rise to Markov chains. Section 3.3 explains that these chains are often acyclic. Section 3.4 addresses a symmetrization lemma that we will use in Sections 3.5 and 3.6 to find descriptions of some left and right eigenvectors, respectively, for such chains. Section 3.7 determines the stationary distributions and gives expressions for the chance of absorption in terms of generalized chromatic polynomials. Applications of these theorems are in the last three sections of this paper.
As mentioned at the end of Sect. 2.2, we will be concerned with connected, graded (by positive integers) Hopf algebras \(\mathcal{H}\) with a distinguished basis \(\mathcal{B}\) satisfying one of two “freeness” conditions (in both cases, the number of generators may be finite or infinite):
-
1.
\(\mathcal{H}=\mathbb{R} [c_{1},c_{2},\ldots ]\) as an algebra (i.e., \(\mathcal{H}\) is a polynomial algebra) and \(\mathcal {B}= \{ c_{1}^{n_{1}}c_{2}^{n_{2}}\cdots\mid n_{i}\in\mathbb{N} \}\), the basis of monomials. The c i may have any degree, and there is no constraint on the coalgebra structure. This will give rise to a Markov chain on combinatorial objects where assembling is symmetric and deterministic.
-
2.
\(\mathcal{H}\) is cocommutative, \(\mathcal{H}=\mathbb{R}\langle c_{1},c_{2},\ldots \rangle \) as an algebra, (i.e., \(\mathcal{H}\) is a free associative algebra) and \(\mathcal{B}= \{ c_{i_{1}}c_{i_{2}}\cdots \mid i_{j}\in\mathbb{N} \}\), the basis of words. The c i may have any degree, and do not need to be primitive. This will give rise to a Markov chain on combinatorial objects where pulling apart is symmetric, assembling is non-symmetric and deterministic.
By the Cartier–Milnor–Moore theorem [19, 63], any graded connected commutative Hopf algebra has a basis which satisfies the first condition. However, we will not make use of this, since the two conditions above are reasonable properties for many combinatorial Hopf algebras and their canonical bases. For example, the Hopf algebra of symmetric functions, with the basis of elementary symmetric functions e λ , satisfies the first condition.
Write \(\mathcal{H}_{n}\) for the subspace of degree n in \(\mathcal {H}\), and \(\mathcal{B}_{n}\) for the degree n basis elements. The generators c i can be identified as those basis elements which are not the non-trivial product of basis elements; in other words, generators cannot be obtained by assembling objects of lower degree. Thus, all basis elements of degree one are generators, but there are usually generators of higher degree; see Examples 3.1 and 3.2 below. One can view the conditions 1 and 2 above as requiring the basis elements to have unique factorization into generators, allowing the convenient view of \(b \in\mathcal{B}\) as a word b=c 1 c 2⋯c l . Its length l(b) is then well-defined—it is the number of generators one needs to assemble together to produce b. Some properties of the length are developed in Sect. 3.3. For a noncommutative Hopf algebra, it is useful to choose a linear order on the set of generators refining the ordering by degree: i.e. if deg(c)<deg(c′), then c<c′. This allows the construction of the Lyndon factorization and standard bracketing of a basis element, as in Sect. 2.3. Example 3.17 demonstrates such calculations.
The ath Hopf-power map is Ψ a:=m [a]Δ[a], the a-fold coproduct followed by the a-fold product. These power maps are the central object of study of [65–67]. Intuitively, Ψ a corresponds to breaking an object into a pieces (some possibly empty) in all possible ways and then reassembling them. The Ψ a preserve degree, thus mapping \(\mathcal{H}_{n}\) to \(\mathcal{H}_{n}\).
As noted in [66], the power map Ψ a is an algebra homomorphism if \(\mathcal{H}\) is commutative:
and a coalgebra homomorphism if \(\mathcal{H}\) is cocommutative:
Only the former will be necessary for the rest of this section.
3.2 The Markov chain connection
The power maps can sometimes be interpreted as a natural Markov chain on the basis elements \(\mathcal{B}_{n}\) of \(\mathcal{H}_{n}\).
Example 3.1
(The Hopf algebra of unlabeled graphs, continuing from Example 2.1)
The set of all unlabeled simple graphs gives rise to a Hopf algebra \(\bar{\mathcal{G}}\) with disjoint union as product and
where the sum is over subsets of vertices S with G S , \(G_{S^{\mathcal{C}}}\) the induced subgraphs. Graded by the size of the vertex set, \(\bar{\mathcal{G}}\) is a commutative and cocommutative polynomial Hopf algebra with basis \(\mathcal{B}\) consisting of all graphs. The generators are precisely the connected graphs, and the length of a graph is its number of connected components.
The resulting Markov chain on graphs with n vertices evolves as follows: from G, color the vertices of G red or blue, independently with probability 1/2. Erase any edge with opposite colored vertices. This gives one step of the chain; the process terminates when there are no edges. Observe that each connected component breaks independently; that Δ is an algebra homomorphism ensures that, for any Hopf algebra, the generators break independently. The analogous Hopf algebra of simplicial complexes is discussed in Sect. 6.
Example 3.2
(The noncommutative Hopf algebra of labeled graphs, continuing from Example 2.2)
Let \(\mathcal{G}\) be the linear span of the simple graphs whose vertices are labeled {1,2,…,n} for some n. The product of two graphs G 1 G 2 is their disjoint union, where the vertices of G 1 keep their labels, and the labels in G 2 are increased by the number of vertices in G 1. The coproduct is
where the sum again runs over all subsets S of vertices of G, and G S , \(G_{S^{\mathcal{C}}}\) are relabeled so the vertices in each keep the same relative order. An example of a coproduct calculation is in Example 2.2. \(\mathcal{G}\) is cocommutative and a free associative algebra; its distinguished basis \(\mathcal{B}\) is the set of all graphs. A graph in \(\mathcal{G}\) is a product if and only if there is an i such that no edge connects a vertex with label ≤i to a vertex with label >i. Thus, all connected graphs are generators, but there are non-connected generators such as

Each step of the associated random walk on \(\mathcal{B}_{n}\), the graphs with n vertices, has this description: from G, color the vertices of G red or blue, independently with probability 1/2. Suppose r vertices received the color red; now erase any edge with opposite colored vertices, and relabel so the red vertices are 1,2,…,r and the blue vertices are r+1,r+2,…,n, keeping their relative orders. For example, starting at the complete graph on three vertices, the chain reaches each of the graphs shown below with probability 1/8:

So, forgetting the colors of the vertices,

As with \(\bar{\mathcal{G}}\), the chain on \(\mathcal{G}_{n}\) stops when all edges have been removed.
When is such a probabilistic interpretation possible? To begin, the coefficients of mΔ(b) must be non-negative real numbers for \(b\in\mathcal{B}\). This usually holds for combinatorial Hopf algebras, but the free associative algebra and the above algebras of graphs have an additional desirable property: for any \(b\in\mathcal {B}\), the coefficients of Ψ 2(b) sum to 2deg(b), regardless of b. Thus the operator \(\frac{1}{2^{n}}\varPsi^{2}(b)=\sum_{b'}K(b,b')b'\) forms a Markov transition matrix on basis elements of degree n. Indeed, the coefficients of Ψ a(b) sum to a deg(b) for all a, so \(\frac{1}{a^{n}}\varPsi^{a}(b)=\sum_{b'}K_{a}(b,b')b'\) defines a transition matrix K a . For other Hopf algebras, the sum of the coefficients in Ψ 2(b) may depend on b, so simply scaling Ψ 2 does not always yield a transition matrix.
Zhou’s rephrasing [97, Lemma 4.4.1.1] of the Doob transform [58, Sect. 17.6.1] provides a solution: if K is a matrix with non-negative entries and ϕ is a strictly positive right eigenfunction of K with eigenvalue 1, then \(\hat{K}(b,b'):= \phi(b)^{-1}K(b,b')\phi(b')\) is a transition matrix. Here \(\hat{K}\) is the conjugate of K by the diagonal matrix whose entries are ϕ(b). Theorem 3.4 below gives conditions for such ϕ to exist, and explicitly constructs ϕ recursively; Corollary 3.5 then specifies a non-recursive definition of ϕ when there is a sole basis element of degree 1. The following example explains why this construction is natural.
Example 3.3
(Symmetric functions and rock-breaking)
Consider the algebra of symmetric functions with basis {e λ }, the elementary symmetric functions. The length l(e λ ) is the number of parts in the partition λ, and the generators are the partitions with a single part. The coproduct is defined by

with the sum over all compositions \(\lambda'=\lambda_{1}',\lambda _{2}',\ldots,\lambda_{l}'\) with \(0\leq\lambda'_{i}\leq\lambda_{i}\), and λ−λ′ is the composition \(\lambda_{1}-\lambda_{1}',\ldots ,\lambda_{l}-\lambda_{l}'\). When reordered, some parts may be empty and some parts may occur several times. There are (λ 1+1)⋯(λ l +1) possible choices of λ′, so the coefficients of Ψ 2(e λ ) sum to (λ 1+1)⋯(λ l +1), which depends on λ.
Consider degree 2, where the basis elements are \(e_{1^{2}}\) and e 2. For K such that \(\frac{1}{2^{2}}\varPsi^{2}(b)=\sum_{b'}K(b,b')b'\),
which is not a transition matrix as the second row does not sum to 1. Resolve this by performing a diagonal change of basis: set \(\hat {e}_{1^{2}}=\phi(e_{1^{2}})^{-1}e_{1^{2}}\), \(\hat{e}_{2}=\phi(e_{2})^{-1}e_{2}\) for some non-negative function \(\phi:\mathcal{B}\rightarrow\mathbb{R}\), and consider \(\hat{K}\) with \(\frac{1}{2^{2}}\varPsi^{2}(\hat {b})=\sum_{\hat{b}'}\hat{K}(\hat{b},\hat{b}')\hat{b}'\). Since the first row of K, corresponding to \(e_{1^{2}}\), pose no problems, set \(\phi(e_{1^{2}})=1\). In view of the upcoming theorem, it is better to think of this as \(\phi(e_{1^{2}})= (\phi (e_{1}) )^{2}\) with ϕ(e 1)=1. Equivalently, \(\hat{e}_{1^{2}} = \hat{e}_{1} ^{2}\) with \(\hat{e}_{1} =e_{1}\). Turning attention to the second row, observe that \(\Delta(\hat{e}_{2})=\phi(e_{2})^{-1}(e_{2}\otimes1+e_{1}\otimes e_{1}+1\otimes e_{2})\), so \(\varPsi^{2}(\hat{e}_{2})=\hat{e}_{2}+\phi(e_{2})^{-1}\hat {e}_{1^{2}}+\hat{e}_{2}\), which means
so \(\hat{K}\) is a transition matrix if \(\frac{1}{4}\phi (e_{2})^{-1}+\frac{1}{2}=1\), i.e. if \(\phi(e_{2})= \frac{1}{2}\).
Continue to degree 3, where the basis elements are \(e_{1^{3}}\), e 12 and e 3. Now define K such that \(\frac{1}{2^{3}}\varPsi ^{2}(b)=\sum_{b'}K(b,b')b'\);
Again, look for \(\phi(e_{1^{3}}),\phi(e_{12})\) and ϕ(e 3) so that \(\hat{K}\), defined by \(\frac{1}{2^{3}}\varPsi^{2}(\hat {b})=\sum_{\hat{b}'}\hat{K}(\hat{b},\hat{b}')\hat{b}'\), is a transition matrix, where \(\hat{e}_{1^{3}}=\phi(e_{1^{3}})^{-1}e_{1^{3}}\), \(\hat{e}_{12}=\phi(e_{12})^{-1}e_{12}\), \(\hat{e}_{3}\,{=}\,\phi (e_{3})^{-1}\!e_{3}\). Note that, taking \(\phi(e_{1^{3}})\,{=}\,(\phi(e_{1}) )^{3}\!\,{=}\,1\) and \(\phi(e_{12})\,{=}\,\phi(e_{2})\phi(e_{1})\,{=}\,\frac{1}{2}\), the first two rows of \(\hat{K}\) sum to 1. View this as \(\hat {e}_{1^{3}}=\hat{e}_{1} ^{3}\) and \(\hat{e}_{12}=\hat{e}_{2} \hat{e}_{1}\). Then, as \(\varPsi^{2}(\hat{e}_{3})=\phi (e_{3})^{-1}(e_{3}+e_{2}e_{1}+e_{1}e_{2}+e_{3})=\hat{e}_{3}+\frac {1}{2}\phi(e_{3})^{-1}\hat{e}_{2,1}+\frac{1}{2}\phi(e_{3})^{-1}\hat {e}_{2,1}+\hat{e}_{3}\), the transition matrix is given by
and choosing \(\phi(e_{3})=\frac{1}{6}\) makes the third row sum to 1.
Continuing, we find that \(\phi(e_{i})=\frac{1}{i!}\), so \(\hat {e}_{i}=i!e_{i}\), more generally, \(\hat{e}_{\lambda}=\prod (i!)^{a_{i}(\lambda)}e_{\lambda}\) with i appearing a i (λ) times in λ. Then, for example,
So, for any partition λ of n,
and the coefficients of \(m\Delta(\hat{e}_{\lambda})\) sum to \(\sum_{\lambda'\leq\lambda}\binom{\lambda_{1}}{\lambda '_{1}}\cdots\binom{\lambda_{l}}{\lambda'_{l}}=2^{\lambda_{1}}\cdots 2^{\lambda_{n}}=2^{n}\), irrespective of λ. Thus \(\frac{1}{2^{n}}m\Delta\) describes a transition matrix, which has the rock-breaking interpretation of Sect. 1.
The following theorem shows that this algorithm works in many cases. Observe that, in the above example, it is the non-zero off-diagonal entries that change; the diagonal entries cannot be changed by rescaling the basis. Hence the algorithm would fail if some row had all off-diagonal entries equal to 0, and diagonal entry not equal to 1. This corresponds to the existence of \(b \in\mathcal{B}_{n}\) with \(\frac {1}{2^{n}}\varPsi^{2} (b)=\alpha b\) for some α≠1; the condition \(\bar{\Delta}(c):=\Delta(c) - 1 \otimes c - c\otimes1 \neq0\) below precisely prevents this. Intuitively, we are requiring that each generator of degree greater than one can be broken non-trivially. For an example where this condition fails, see Example 6.5.
Theorem 3.4
(Basis rescaling)
Let \(\mathcal{H}\) be a graded Hopf algebra over \(\mathbb{R}\) which is either a polynomial algebra or a free associative algebra that is cocommutative. Let \(\mathcal{B}\) denote the basis of monomials in the generators. Suppose that, for all generators c with deg(c)>1, all coefficients of Δ(c) (in the \(\mathcal{B}\otimes\mathcal{B}\) basis) are non-negative and \(\bar{\Delta}(c)\neq0\). Let K a be the transpose of the matrix of a −n Ψ a with respect to the basis \(\mathcal{B}_{n}\); in other words, a −n Ψ a(b)=∑ b′ K a (b,b′)b′ (suppressing the dependence of K a on n). Define, by induction on degree,

where ϕ(b) satisfies \(b=\phi(b)\hat{b}\). Write \(\hat{\mathcal {B}}:=\{\hat{b}\mid b \in\mathcal{B}\}\) and \(\hat{\mathcal{B}}_{n}:=\{ \hat{b}\mid b \in\mathcal{B}_{n}\}\). Then the matrix of the ath power map with respect to the \(\hat{\mathcal{B}}_{n}\) basis, when transposed and multiplied by a −n, is a transition matrix. In other words, the operator \(\hat{K}_{a}\) on \(\mathcal{H}_{n}\), defined by \(a^{-n}\varPsi ^{a}(\hat{b})=\sum_{b'}\hat{K}_{a}(\hat{b},\hat{b}')\hat{b}'=\sum_{b'}\phi(b)^{-1}K_{a}(b,b')\phi(b')b'\), has \(\hat{K}_{a}(\hat{b},\hat {b}')\geq0\) and \(\sum_{b'}\hat{K}_{a}(\hat{b},\hat{b}')=1\) for all \(b\in\mathcal{B}_{n}\), and all a≥0 and n≥0 (the same scaling works simultaneously for all a).
Remarks
-
1.
Observe that, if b=xy, then the definition of \(\hat{b}\) ensures \(\hat{b}=\hat{x}\hat{y}\). Equivalently, ϕ is a multiplicative function.
-
2.
The definition of \(\hat{c}\) is not circular: since \(\mathcal {H}\) is graded with \(\mathcal{H}_{0}=\mathbb{R}\), the counit is zero on elements of positive degree so that \(\bar{\Delta}(c)\in\bigoplus_{j=1}^{\deg (c)-1} \mathcal{H}_{j}\otimes \mathcal{H}_{\deg(c)-j}\). Hence K 2(c,b) is non-zero only if b=c or l(b)>1, so the denominator in the expression for \(\hat{c}\) only involves ϕ(b) for b with l(b)>1. Such b can be factorized as b=xy with deg(x),deg(y)<deg(b), whence ϕ(b)=ϕ(x)ϕ(y), so \(\hat{c}\) only depends on ϕ(x) with deg(x)<deg(c).
Proof
First note that \(\hat{K}_{2}(c,c)=\phi(c)^{-1}K_{2}(c,c)\phi (c)=K_{2}(c,c)=2^{1-\deg(c)}\), since \(m\Delta(c)=2c+m\bar{\Delta}(c)\) and \(\bar{\Delta}(c) \in\bigoplus_{j=1}^{\deg(c)-1}\mathcal {H}_{j}\otimes\mathcal{H}_{\deg(c)-j}\) means no c terms can occur in \(m\bar{\Delta}(c)\). So
as desired.
Let \(\eta_{c}^{xy}\) denote the coefficients of Δ(c) in the \(\mathcal{B}\otimes\mathcal{B}\) basis, so \(\Delta(c)= \sum_{x,y\in \mathcal{B}}\eta_{c}^{xy}x\otimes y\). Then \(K_{2}(c,b)=2^{-\deg(c)}\sum_{xy=b}\eta_{c}^{xy}\), and
So, if b has factorization into generators b=c 1⋯c l , then
so
Thus
as desired, where the third equality is due to multiplicativity of ϕ.
The above showed each row of \(\hat{K}_{2}\) sums to 1, which means (1,1,…,1) is a right eigenvector of \(\hat{K}_{2}\) of eigenvalue 1. \(\hat{K}_{a}\) describes Ψ a in the \(\hat{\mathcal{B}}\) basis, which is also a basis of monomials/words, in a rescaled set of generators \(\hat{c}\), so, by Theorems 3.19 and 3.20, the eigenspaces of \(\hat{K}_{a}\) do not depend on a. Hence (1,1,…,1) is a right eigenvector of \(\hat{K}_{a}\) of eigenvalue 1 for all a, thus each row of \(\hat{K}_{a}\) sums to 1 also.
Finally, to see that the entries of \(\hat{K}_{a}\) are non-negative, first extend the notation \(\eta_{c}^{xy}\) so \(\Delta^{[a]}(c)=\sum_{b_{1},\ldots b_{a}}\eta_{c}^{b_{1},\ldots,b_{a}}b_{1}\otimes\cdots \otimes b_{a}\). As Δ[a]=(ι⊗⋯⊗ι⊗Δ)Δ[a−1], it follows that \(\eta_{c}^{b_{1},\ldots,b_{a}}=\sum_{x}\eta _{c}^{b_{1},\ldots,b_{a-2},x}\eta_{x}^{b_{a-1},b_{a}}\), which inductively shows that \(\eta_{c}^{b_{1},\ldots,b_{a}}\ge0\) for all generators c and all \(b_{i}\in\mathcal{B}\). So, if b has factorization into generators b=c 1⋯c l , then
where the sum is over all sets \(\{b_{i,j}\}_{i=1,j=1}^{i=l,j=a}\) such that the product b 1,1 b 2,1⋯b l,1 b 1,2⋯b l,2⋯b 1,a ⋯b l,a =b′. Finally, \(\hat{K}_{a}(\hat{b},\hat{b}')=\phi(b)^{-1}K_{a}(b,b')\phi (b')\geq0\). □
Combinatorial Hopf algebras often have a single basis element of degree 1—for the algebra of symmetric functions, this is the unique partition of 1; for the Hopf algebra \(\mathcal{G}\) of graphs, this is the discrete graph with one vertex. After the latter example, denote this basis element by •. Then there is a simpler definition of the eigenfunction ϕ, and hence \(\hat{b}\) and \(\hat{K}\), in terms of \(\eta_{b}^{b_{1},\ldots,b_{r}}\), the coefficient of b 1⊗⋯⊗b r in Δ[r](b):
Corollary 3.5
Suppose that, in addition to the hypotheses of Theorem 3.4, \(\mathcal{B}_{1} =\{\bullet\}\). Then \(\hat{b}=\frac{(\deg b)!}{\eta _{b}^{\bullet,\ldots,\bullet}}b\), so \(\hat{K}_{a}\) is defined by
Proof
Work on \(\mathcal{H}_{n}\) for a fixed degree n. Recall that ϕ is a right eigenvector of \(\hat{K}_{a}\) of eigenvalue 1, and hence, by the notation of Sect. 3.6, an eigenvector of Ψ ∗a of eigenvalue a n. By Theorems 3.19 and 3.20, this eigenspace is spanned by f b for b with length n. Then \(\mathcal{B}_{1} =\{\bullet\}\) forces b=•n, so \(f_{\bullet^{n}}(b')=\frac{1}{n!}\eta_{b'}^{\bullet,\ldots,\bullet}\) spans the a n-eigenspace of Ψ ∗a. Consequently, ϕ is a multiple of \(f_{\bullet^{n}}\). To determine this multiplicative factor, observe that Theorem 3.4 defines ϕ(•) to be 1, so ϕ(•n)=1, and \(f_{\bullet^{n}}(\bullet^{n})=1\) also, so \(\phi=f_{\bullet^{n}}\). □
3.3 Acyclicity
Observe that the rock-breaking chain (Examples 1.2 and 3.3) is acyclic—it can never return to a state it has left, because the only way to leave a state is to break the rocks into more pieces. More specifically, at each step the chain either stays at the same partition or moves to a partition which refines the current state; as refinement of partitions is a partial order, the chain cannot return to a state it has left. The same is true for the chain on unlabeled graphs (Example 3.1)—the number of connected components increases over time, and the chain never returns to a previous state. Such behavior can be explained by the way the length changes under the product and coproduct. (Recall that the length l(b) is the number of factors in the unique factorization of b into generators.) Define a relation on \(\mathcal{B}\) by b→b′ if b′ appears in Ψ a(b) for some a. If Ψ a induces a Markov chain on \(\mathcal{B}_{n}\), then this precisely says that b′ is accessible from b.
Lemma 3.6
Let b,b i ,b (i) be monomials/words in a Hopf algebra which is either a polynomial algebra or a free associative algebra that is cocommutative. Then
-
(i)
l(b 1⋯b a )=l(b 1)+⋯+l(b a );
-
(ii)
For any summand b (1)⊗⋯⊗b (a) in Δ[a](b), l(b (1))+⋯+l(b (a))≥l(b);
-
(iii)
if b→b′, then l(b′)≥l(b).
Proof
(i) is clear from the definition of length.
Prove (ii) by induction on l(b). Note that the claim is vacuously true if b is a generator, as each l(b (i))≥0, and not all l(b (i)) may be zero. If b factorizes non-trivially as b=xy, then, as Δ[a](b)=Δ[a](x)Δ[a](y), it must be the case that b (i)=x (i) y (i), for some x (1)⊗⋯⊗x (a) in Δ[a](x), y (1)⊗⋯⊗y (a) in Δ[a](y). So l(b (1))+⋯+l(b (a))=l(x (1))+⋯+l(x (a))+l(y (1))+⋯+l(y (a)) by (i), and by inductive hypothesis, this is at least l(x)+l(y)=l(b).
(iii) follows trivially from (i) and (ii): if b→b′, then b′=b (1)⋯b (a) for a term b (1)⊗⋯⊗b (a) in Δ[a](b). So l(b′)=l(b (1))+⋯+l(b (a))≥l(b). □
If \(\mathcal{H}\) is a polynomial algebra, more is true. The following proposition explains why chains built from polynomial algebras (i.e., with deterministic and symmetric assembling) are always acyclic; in probability language, it says that, if the current state is built from l generators, then, with probability a l−n, the chain stays at this state, otherwise, it moves to a state built from more generators. Hence, if the states are totally ordered to refine the partial ordering by length, then the transition matrices are upper-triangular with a l−n on the main diagonal.
Proposition 3.7
(Acyclicity)
Let \(\mathcal{H}\) be a Hopf algebra which is a polynomial algebra as an algebra, and \(\mathcal{B}\) its monomial basis. Then the relation → defines a partial order on \(\mathcal{B}\), and the ordering by length refines this order: if b→b′ and b≠b′, then l(b)<l(b′). Furthermore, for any integer a and any \(b \in\mathcal{B}\) with length l(b),
for some α bb′.
Proof
It is easier to first prove the expression for Ψ a(b). Suppose b has factorization into generators b=c 1 c 2⋯c l(b). As \(\mathcal{H}\) is commutative, Ψ a is an algebra homomorphism, so Ψ a(b)=Ψ a(c 1)⋯Ψ a(c l(b)). Recall from Sect. 2.2 that \(\bar{\Delta}(c)=\Delta(c)-1 \otimes c - c\otimes 1 \in\bigoplus_{i=1}^{deg(c)-1}\mathcal{H}_{i} \otimes\mathcal {H}_{deg(c)-i}\), in other words, 1⊗c and c⊗1 are the only terms in Δ(c) which have a tensor-factor of degree 0. As Δ[3]=(ι⊗Δ)Δ, the only terms in Δ[3](c) with two tensor-factors of degree 0 are 1⊗1⊗c, 1⊗c⊗1 and c⊗1⊗1. Inductively, we see that the only terms in Δ[a](c) with all but one tensor-factor having degree 0 are 1⊗⋯⊗1⊗c,1⊗⋯⊗1⊗c⊗1,…,c⊗1⊗⋯⊗1. So Ψ a(c)=ac+∑ l(b′)>1 α cb′ b′ for generators c. As Ψ a(b)=Ψ a(c 1)⋯Ψ a(c l ), and length is multiplicative (Lemma 3.6(i)), the expression for Ψ a(b) follows.
It is then clear that → is reflexive and antisymmetric. Transitivity follows from the power rule: if b→b′ and b′→b″, then b′ appears in Ψ a(b) for some a and b″ appears in Ψ a′(b′) for some a′. So b″ appears in Ψ a′ Ψ a(b)=Ψ a′a(b). □
The same argument applied to a cocommutative free associative algebra shows that all terms in Ψ a(b) are either a permutation of the factors of b, or have length greater than that of b. The relation → is only a preorder; the associated chains are not acyclic, as they may oscillate between such permutations of factors. For example, in the noncommutative Hopf algebra of labeled graphs, the following transition probabilities can occur:

(the bottom state is absorbing). The probability of going from b to some permutation of its factors (as opposed to a state of greater length, from which there is no return to b) is a l(b)−n.
Here is one more result in this spirit, necessary in Sect. 3.5 to show that the eigenvectors constructed there have good triangularity properties and hence form an eigenbasis:
Lemma 3.8
Let \(b,b_{i}, b_{i}'\) be monomials/words in a Hopf algebra which is either a polynomial algebra or a free associative algebra that is cocommutative. If b=b 1⋯b k and \(b_{i} \rightarrow b'_{i}\) for each i, then \(b \rightarrow b'_{\sigma(1)} \cdots b'_{\sigma(k)}\) for any σ∈S k .
Proof
For readability, take k=2 and write b=xy, x→x′, y→y′. By definition of the relation →, it must be that x′=x (1)⋯x (a) for some summand x (1)⊗⋯⊗x (a) of \(\bar{\Delta}^{[a]}(x)\). Likewise y′=y (1)⋯y (a′) for some a′. Suppose a>a′. Coassociativity implies that Δ[a](y)=(ι⊗⋯⊗ι⊗Δ[a−a′])Δ[a′](y), and y (a′)⊗1⊗⋯⊗1 is certainly a summand of Δ[a−a′](y (a′)), so y (1)⊗⋯⊗y (a′)⊗1⊗⋯⊗1 occurs in Δ[a](y). So, taking y (a′+1)=⋯=y (a)=1, we can assume a=a′. Then Δ[a](b)=Δ[a](x)Δ[a](y) contains the term x (1) y (1)⊗⋯⊗x (a) y (a). Hence Ψ a(b) contains the term x (1) y (1)⋯x (a) y (a), and this product is x′y′ if \(\mathcal{H}\) is a polynomial algebra.
If \(\mathcal{H}\) is a cocommutative, free associative algebra, the factors in x (1) y (1)⊗⋯⊗x (a) y (a) must be rearranged to conclude that b→x′y′ and b→y′x′. Coassociativity implies Δ[2a]=(Δ⊗⋯⊗Δ)Δ[a], and Δ(x (i) y (i))=Δ(x (i))Δ(y (i)) contains (x (i)⊗1)(1⊗y (i))=x (i)⊗y (i), so Δ[2a](b) contains the term x (1)⊗y (1)⊗x (2)⊗y (2)⊗⋯⊗x (a)⊗y (a). As \(\mathcal{H}\) is cocommutative, any permutation of the tensor-factors, in particular, x (1)⊗x (2)⊗⋯⊗x (a)⊗y (1)⊗⋯⊗y (a) and y (1)⊗y (2)⊗⋯⊗y (a)⊗x (1)⊗⋯⊗x (a), must also be summands of Δ[2a](b), and multiplying these tensor-factors together shows that both x′y′ and y′x′ appear in Ψ [2a](b). □
Example 3.9
(Symmetric functions and rock-breaking)
Recall from Example 3.3 the algebra of symmetric functions with basis {e λ }, which induces the rock-breaking process. Here, e λ →e λ′ if and only if λ′ refines λ. Lemma 3.8 for the case k=2 is the statement that, if λ is the union of two partitions μ and ν, and μ′ refines μ, ν′ refines ν, then μ′∐ν′ refines μ∐ν=λ.
3.4 The symmetrization lemma
The algorithmic construction of left and right eigenbases for the chains created in Sect. 3.2 will go as follows:
-
(i)
Make an eigenvector of smallest eigenvalue for each generator c;
-
(ii)
For each basis element b with factorization c 1 c 2⋯c l , build an eigenvector of larger eigenvalue out of the eigenvectors corresponding to the factors c i , produced in the previous step.
Concentrate on the left eigenvectors for the moment. Recall that the transition matrix K a is defined by a −n Ψ a(b)=∑ b′ K a (b,b′)b′, so the left eigenvectors for our Markov chain are the usual eigenvectors of Ψ a on \(\mathcal{H}\). Step (ii) is simple if \(\mathcal{H}\) is a polynomial algebra, because then \(\mathcal{H}\) is commutative so Ψ a is an algebra homomorphism. Consequently, the product of two eigenvectors is an eigenvector with the product eigenvalue. This fails for cocommutative, free associative algebras \(\mathcal{H}\), but can be fixed by taking symmetrized products:
Theorem 3.10
(Symmetrization lemma)
Let x 1,x 2,…,x k be primitive elements of any Hopf algebra \(\mathcal{H}\), then \(\sum_{\sigma\in S_{k}} x_{\sigma(1)} x_{\sigma (2)} \cdots x_{\sigma(k)}\) is an eigenvector of Ψ a with eigenvalue a k.
Proof
For concreteness, take a=2. Then

□
In Sects. 3.5 and 3.6, the fact that the eigenvectors constructed give a basis will follow from triangularity arguments based on Sect. 3.3. These rely heavily on the explicit structure of a polynomial algebra or a free associative algebra. Hence it is natural to look for alternatives that will generalize this eigenbasis construction plan to Hopf algebras with more complicated structures. For example, one may ask whether some good choice of x i exists with which the symmetrization lemma will automatically generate a full eigenbasis. When \(\mathcal{H}\) is cocommutative, an elegant answer stems from the following two well-known structure theorems:
Theorem 3.11
(Cartier–Milnor–Moore) [19, 63]
If \(\mathcal{H}\) is graded, cocommutative and connected, then \(\mathcal{H}\) is Hopf isomorphic to \(\mathcal {U}(\mathfrak{g})\), the universal enveloping algebra of a Lie algebra \(\mathfrak{g}\), where \(\mathfrak{g}\) is the Lie algebra of primitive elements of \(\mathcal{H}\).
Theorem 3.12
(Poincaré–Birkoff–Witt) [48, 60]
If {x 1,x 2,…} is a basis for a Lie algebra \(\mathfrak{g}\), then the symmetrized products \(\sum_{\sigma \in S_{k}} x_{i_{\sigma(1)}} x_{i_{\sigma(2)}} \cdots x_{i_{\sigma(k)}}\), for 1≤i 1≤i 2≤⋯≤i k , form a basis for \(\mathcal {U}(\mathfrak{g})\).
Putting these together reduces the diagonalization of Ψ a on a cocommutative Hopf algebra to determining a basis of primitive elements:
Theorem 3.13
(Strong symmetrization lemma)
Let \(\mathcal{H}\) be a graded, cocommutative, connected Hopf algebra, and let {x 1,x 2,…} be a basis for the subspace of primitive elements in \(\mathcal{H}\). Then, for each \(k \in\mathbb{N}\),
is a basis of the a k-eigenspace of Ψ a.
Much work [2, 3, 35] has been done on computing a basis for the subspace of the primitives of particular Hopf algebras, their formulas are in general more efficient than our universal method here, and using these will be the subject of future work. Alternatively, the theory of good Lyndon words [55] gives a Grobner basis argument to further reduce the problem to finding elements which generate the Lie algebra of primitives, and understanding the relations between them. This is the motivation behind our construction of the eigenvectors in Theorem 3.16, although the proof is independent of this theorem, more analogous to that of Theorem 3.15, the case of a polynomial algebra.
3.5 Left eigenfunctions
This section gives an algorithmic construction of an eigenbasis for the Hopf power maps Ψ a on the Hopf algebras of interest. If K a as defined by a −n Ψ a(b)=∑ b′ K a (b,b′)b′ is a transition matrix, then this eigenbasis is precisely a left eigenbasis of the associated chain, though the results below stand whether or not such a chain may be defined (e.g., the construction works when some coefficients of Δ(c) are negative, and when there are primitive generators of degree >1). The first step is to associate each generator to an eigenvector of smallest eigenvalue, this is achieved using the (first) Eulerian idempotent map
Here \(\bar{\Delta}(x)=\Delta(x) - 1 \otimes x - x \otimes1 \in\bigoplus_{j=1}^{n-1}\mathcal{H}_{j}\otimes\mathcal{H}_{n-j}\), as explained in Sect. 2.2. Then inductively define \(\bar{\Delta }^{[a]}=(\iota\otimes \cdots\otimes\iota\otimes\bar{\Delta})\bar{\Delta}^{[a-1]}\), which picks out the terms in Δ[a](x) where each tensor-factor has strictly positive degree. This captures the notion of breaking into a non-trivial pieces. Observe that, if \(x\in\mathcal{H}_{n}\), then \(\bar{\Delta}^{[a]}(x)=0\) whenever a>n, so e(x) is a finite sum for all x. (By convention, e≡0 on \(\mathcal{H}_{0}\).)
This map e is the first of a series of Eulerian idempotents e i defined by Patras [66]; he proves that, in a commutative or cocommutative Hopf algebra of characteristic zero where \(\bar{\Delta }\) is locally nilpotent (i.e. for each x, there is some a with \(\bar{\Delta}^{[a]} x=0\)), the Hopf-powers are diagonalizable, and these e i are orthogonal projections onto the eigenspaces. In particular, this weight decomposition holds for graded commutative or cocommutative Hopf algebras. We will not need the full series of Eulerian idempotents, although Example 3.18 makes the connection between them and our eigenbasis.
To deduce that the eigenvectors we construct are triangular with respect to \(\mathcal{B}\), one needs the following crucial observation (recall from Sect. 3.3 that b→b′ if b′ occurs in Ψ a(b) for some a):
Proposition 3.14
For any generator c,
for some real α cb′.
Proof
The summand \(\frac{(-1)^{a-1}}{a}m^{[a]}\bar{\Delta}^{[a]}(c)\) involves terms of length at least a, from which the second expression of e(c) is immediate. Each term b′ of e(c) appears in Ψ a(c) for some a, hence c→b′. Combine this with the knowledge from the second expression that c occurs with coefficient 1 to deduce the first expression. □
The two theorems below detail the construction of an eigenbasis for Ψ a in a polynomial algebra and in a cocommutative free associative algebra, respectively. These are left eigenvectors for the corresponding transition matrices. A worked example will follow immediately; it may help to read these together.
Theorem 3.15
Let \(\mathcal{H}\) be a Hopf algebra (over a field of characteristic zero) that is a polynomial algebra as an algebra, with monomial basis \(\mathcal{B}\). For \(b\in\mathcal{B}\) with factorization into generators b=c 1 c 2⋯c l , set
Then g b is an eigenvector of Ψ a of eigenvalue a l satisfying the triangularity condition
Hence \(\{ g_{b}\mid b\in\mathcal{B}_{n} \} \) is an eigenbasis for the action of Ψ a on \(\mathcal{H}_{n}\), and the multiplicity of the eigenvalue a l in \(\mathcal{H}_{n}\) is the coefficient of x n y l in \(\prod_{i} (1-yx^{i} )^{-d_{i}}\), where d i is the number of generators of degree i.
Theorem 3.16
Let \(\mathcal{H}\) be a cocommutative Hopf algebra (over a field of characteristic zero) that is a free associative algebra with word basis \(\mathcal{B}\). For \(b\in\mathcal{B}\) with factorization into generators b=c 1 c 2⋯c l , set g b to be the polynomial \(\operatorname{sym}(b)\) evaluated at (e(c 1),e(c 2),…,e(c l )). In other words, in the terminology of Sect. 2.3,
-
for c a generator, set g c :=e(c);
-
for b a Lyndon word, inductively define \(g_{b}: = [g_{b_{1}}, g_{b_{2}} ]\) where b=b 1 b 2 is the standard factorization of b;
-
for b with Lyndon factorization b=b 1⋯b k , set \(g_{b}:=\sum_{\sigma\in S_{k}} g_{b_{\sigma(1)}} g_{b_{\sigma(2)}}\cdots g_{b_{\sigma(k)}}\).
Then g b is an eigenvector of Ψ a of eigenvalue a k (k the number of Lyndon factors in b) satisfying the triangularity condition
Hence \(\{ g_{b}\mid b\in\mathcal{B}_{n} \} \) is an eigenbasis for the action of Ψ a on \(\mathcal{H}_{n}\), and the multiplicity of the eigenvalue a k in \(\mathcal{H}_{n}\) is the coefficient of x n y k in \(\prod_{i} (1-yx^{i} )^{-d_{i}}\), where d i is the number of Lyndon words of degree i in the alphabet of generators.
Remarks
-
1.
If Ψ a defines a Markov chain, then the triangularity of g b (in both theorems) has the following interpretation: the left eigenfunction g b takes non-zero values only on states that are reachable from b.
-
2.
The expression of the multiplicity of the eigenvalues (in both theorems) holds for Hopf algebras that are multigraded, if we replace all xs, ns and is by tuples, and read the formula as multi-index notation. For example, for a bigraded polynomial algebra \(\mathcal{H}\), the multiplicity of the a l-eigenspace in \(\mathcal{H}_{m,n}\) is the coefficient of \(x_{1}^{m} x_{2}^{n} y^{l}\) in \(\prod_{i,j} (1-yx_{1}^{i} x_{2}^{j} )^{-d_{i,j}}\), where d i,j is the number of generators of bidegree (i,j). This idea will be useful in Sect. 5.
-
3.
Theorem 3.16 essentially states that any cocommutative free associative algebra is in fact isomorphic to the free associative algebra, generated by e(c). But there is no analogous interpretation for Theorem 3.15; being a polynomial algebra is not a strong enough condition to force all Hopf algebras with this condition to be isomorphic. A polynomial algebra \(\mathcal{H}\) is isomorphic to the usual polynomial Hopf algebra (i.e. with primitive generators) only if \(\mathcal{H}\) is cocommutative; then e(c) gives a set of primitive generators.
Example 3.17
As promised, here is a worked example of this calculation, in the noncommutative Hopf algebra of labeled graphs, as defined in Example 3.2. Let b be the graph

which is the product of three generators as shown. (Its factors happen to be its connected components, but that’s not always true). Since the ordering of generators refines the ordering by degree, a vertex (degree 1) comes before an edge (degree 2), so the Lyndon factorization of b is

So g b is defined to be

The first Lyndon factor of b has standard factorization

so

The Eulerian idempotent map fixes the single vertex, and

thus substituting into the previous equation gives

Since

returning to the first expression for g b gives the following eigenvector of eigenvalue a 2

Proof of Theorem 3.15 (polynomial algebra)
By Patras [66], the Eulerian idempotent map is a projection onto the a-eigenspace of Ψ a, so, for each generator c, e(c) is an eigenvector of eigenvalue a. As \(\mathcal{H}\) is commutative, Ψ a is an algebra homomorphism, so the product of two eigenvectors is another eigenvector with the product eigenvalue. Hence g b :=e(c 1)e(c 2)⋯e(c l ) is an eigenvector of eigenvalue a l.
To see triangularity, note that, by Proposition 3.14,
Lemma 3.8 shows that \(b \rightarrow c_{1} ' \cdots c_{l}'\) in each summand, and the condition \(c_{i}' \neq c_{i}\) for some i means precisely that \(c_{1}' \cdots c_{l}' \neq b\). Also, by Proposition 3.14,
and thus \(l(c_{1}' \cdots c_{l}')>l\) as length is multiplicative.
The multiplicity of the eigenvalue a l is the number of basis elements b with length l. The last assertion of the theorem is then immediate from [94, Th. 3.14.1]. □
Example 3.18
We show that g b =e l(b)(b), where the higher Eulerian idempotents are defined by
By Patras [66], e i is a projection to the a i-eigenspace of Ψ a, so, given the triangularity condition of the eigenbasis {g b }, it suffices to show that b is the only term of length l(b) in e l(b)(b). Note that e l(b)(b) is a sum of terms of the form e(b (1))e(b (2))⋯e(b (l)) for some b (i) with b (1)⊗⋯⊗b (l) a summand of Δ[l](b). As e≡0 on \(\mathcal{H}_{0}\), the b i s must be non-trivial. Hence each term b′ of e l(b)(b) has the form \(b'=b_{(1)}'\cdots b_{(l)}'\), with \(b_{(i)}\rightarrow b_{(i)}'\) and b→b (1)⋯b (l). It follows from Lemma 3.8 that \(b_{(1)} \cdots b_{(l)} \rightarrow b_{(1)}' \cdots b_{(l)}'\), so b→b′ by transitivity, which, by Lemma 3.7 means l(b′)>l(b) unless b′=b.
It remains to show that the coefficient of b in e l(b)(b) is 1. Let b=c 1⋯c l be the factorization of b into generators. With notation from the previous paragraph, taking b′=b results in \(b \rightarrow b_{(1)} \cdots b_{(l)} \rightarrow b_{(1)}' \cdots b_{(l)}' =b\), so b=b (1)⋯b (l). This forces the b (i)=c σ(i) for some σ∈S l . As b (i) occurs with coefficient 1 in e(b (i)), the coefficient of b (1)⊗⋯⊗b (l) in (e⊗⋯⊗e)Δ[l](b) is the coefficient of c σ(1)⊗⋯⊗c σ(l) in Δ[l](b)=Δ[l](c 1)⋯Δ[l](c l ), which is 1 for each σ∈S l . Each occurrence of c σ(1)⊗⋯⊗c σ(l) in (e⊗⋯⊗e)Δ[l](b) gives rise to a b term in m [l](e⊗e⊗⋯⊗e)Δ[l](b) with the same coefficient, for each σ∈S l , hence b has coefficient l! in m [l](e⊗e⊗⋯⊗e)Δ[l](b)=l!e l (b).
The same argument also shows that, if i<l(b), then e i (b)=0, as there is no term of length i in e i (b). In particular, e(b)=0 if b is not a generator.
Proof of Theorem 3.16 (cocommutative and free associative algebra)
Schmitt [79, Thm. 9.4] shows that the Eulerian idempotent map e projects a graded cocommutative algebra onto its subspace of primitive elements, so g c :=e(c) is primitive. A straightforward calculation shows that, if \(x,y\in\mathcal{H}\) are primitive, then so is [x,y]. Iterating this implies that, if b is a Lyndon word, then g b (which is the standard bracketing of e(c)s) is primitive. Now apply the symmetrization lemma (Lemma 3.10) to deduce that, if \(b\in\mathcal{B}\) has k Lyndon factors, g b is an eigenvector of eigenvalue a k.
To see triangularity, first recall that \(\operatorname{sym}\) is a linear combination of the permutations of its arguments, hence g b is a linear combination of products of the form e(c σ(1))⋯e(c σ(l)) for some σ∈S l . Hence, by Proposition 3.14, each term in g b has the form \(c'_{\sigma(1)} \cdots c'_{\sigma(l)}\) with \(c_{i} \rightarrow c_{i}'\), and by Lemma 3.8, we have \(b \rightarrow c'_{\sigma(1)} \cdots c'_{\sigma(l)}\). Also, by Proposition 3.14,
and all terms of the sum have length greater than l, as length is multiplicative, and \(\operatorname{sym}\) is a linear combination of the permutations of its arguments.
The multiplicity of the eigenvalue a k is the number of basis elements with k Lyndon factors. The last assertion of the theorem is then immediate from [94, Th. 3.14.1]. □
3.6 Right eigenvectors
To obtain the right eigenvectors for our Markov chains, consider the graded dual \(\mathcal{H}^{*}\) of the algebras examined above. The multiplication Δ∗ and comultiplication m ∗ on \(\mathcal {H}^{*}\) are given by

for any \(x^{*},y^{*}\in\mathcal{H}^{*}\), \(z,w\in\mathcal{H}\). Then Ψ ∗a:=Δ∗[a] m ∗[a] is the dual map to Ψ a. So, if K a , defined by a −n Ψ a(b)=∑ b′ K a (b,b′)b′, is a transition matrix, then its right eigenvectors are the eigenvectors of Ψ ∗a. The theorems below express these eigenvectors in terms of {b ∗}, the dual basis to \(\mathcal{B}\). Dualizing a commutative Hopf algebra creates a cocommutative Hopf algebra, and vice versa, so Theorem 3.19 below, which diagonalizes Ψ ∗a on a polynomial algebra, will share features with Theorem 3.16, which diagonalizes Ψ a on a cocommutative free associative algebra. Similarly, Theorems 3.20 and 3.15 will involve common ideas. However, Theorems 3.19 and 3.20 are not direct applications of Theorems 3.16 and 3.15 to \(\mathcal{H}^{*}\) as \(\mathcal{H}^{*}\) is not a polynomial or free associative algebra—a breaking and recombining chain with a deterministic recombination does not dualize to one with a deterministic recombination. For example, the recombination step is deterministic for inverse shuffling (place the left pile on top of the right pile), but not for forward riffle shuffling (shuffle the two piles together).
The two theorems below give the eigenvectors of Ψ ∗a; exemplar computations are in Sect. 4.2. Theorem 3.19 gives a complete description of these for \(\mathcal{H}\) a polynomial algebra, and Theorem 3.20 yields a partial description for \(\mathcal{H}\) a cocommutative free associative algebra. Recall that \(\eta_{b}^{b_{1},\ldots,b_{a}}\) is the coefficient of b 1⊗⋯⊗b a in Δ[a](b).
Theorem 3.19
Let \(\mathcal{H}\) be a Hopf algebra (over a field of characteristic zero) that is a polynomial algebra as an algebra, with monomial basis \(\mathcal{B}\). For \(b\in\mathcal{B}\) with factorization into generators b=c 1 c 2⋯c l , set
where the normalizing constant A(b) is calculated as follows: for each generator c, let a c (b) be the power of c in the factorization of b, and set A(b)=∏ c a c (b)!. Then f b is an eigenvector of Ψ ∗a of eigenvalue a l, and
where the sum on the second line runs over all σ with (c σ(1),…,c σ(l)) distinct (i.e., sum over all coset representatives of the stabilizer of (c 1,…,c l )). The eigenvector f b satisfies the triangularity condition
Furthermore, {f b } is the dual basis to {g b }. In other words, f b (g b′)=0 if b≠b′, and f b (g b )=1. Yet another formulation: the change of basis matrix from {f b } to \(\mathcal{B}\), which has f b as its columns, is the inverse of the matrix with g b as its rows.
Remarks
-
1.
If \(\mathcal{H}\) is also cocommutative, then it is unnecessary to symmetrize—just define \(f_{b}=\frac {1}{A(b)}c_{1}^{*}c_{2}^{*}\cdots c_{l}^{*}\).
-
2.
If Ψ a defines a Markov chain on \(\mathcal{B}_{n}\), then the theorem says f b (b′) may be interpreted as the number of ways to break b′ into l pieces so that the result is some permutation of the l generators that are factors of b. In particular, f b takes only non-negative values, and f b is non-zero only on states which can reach b. Thus f b may be used to estimate the probability of being in states that can reach b, see Corollary 4.10 for an example.
Theorem 3.20
Let \(\mathcal{H}\) be a cocommutative Hopf algebra (over a field of characteristic zero) which is a free associative algebra as an algebra, with word basis \(\mathcal{B}\). For each Lyndon word b, let f b be the eigenvector of Ψ ∗a of eigenvalue a such that f b (g b )=1 and f b (g b′)=0 for all other Lyndon b′. In particular, f c =c ∗ and is primitive. For each basis element b with Lyndon factorization b=b 1⋯b k , let
where the normalizing constant A′(b) is calculated as follows: for each Lyndon basis element b′, let \(a'_{b'}(b)\) be the number of times b′ occurs in the Lyndon factorization of b, and set \(A'(b)=\prod_{b'}a'_{b'}(b)!\). Then f b is an eigenvector of Ψ ∗a of eigenvalue a k, and {f b } is the dual basis to {g b }. If b=c 1 c 2⋯c l with c 1≥c 2≥⋯≥c l in the ordering of generators, then
Proof of Theorem 3.19 (polynomial algebra)
Suppose b ∗⊗b′∗ is a term in m ∗(c ∗), where c is a generator. This means m ∗(c ∗)(b⊗b′) is non-zero. Since comultiplication in \(\mathcal{H}^{*}\) is dual to multiplication in \(\mathcal{H}\), m ∗(c ∗)(b⊗b′)=c ∗(bb′), which is only non-zero if bb′ is a (real number) multiple of c. Since c is a generator, this can only happen if one of b,b′ is c. Hence c ∗ is primitive. Apply the symmetrization lemma (Lemma 3.10) to the primitives \(c_{1}^{*}, \ldots, c_{l}^{*}\) to deduce that f b as defined above is an eigenvector of eigenvalue a l.
Since multiplication in \(\mathcal{H}^{*}\) is dual to the coproduct in \(\mathcal{H}\), \(c_{\sigma(1)}^{*} c_{\sigma(2)}^{*}\cdots c_{\sigma(l)}^{*}(b')=c_{\sigma (1)}^{*} \otimes c_{\sigma(2)}^{*} \otimes\cdots\otimes c_{\sigma(l)}^{*} (\Delta^{[l]}(b') )\), from which the first expression for f b (b′) is immediate. To deduce the second expression, note that the size of the stabilizer of (c σ(1),c σ(2),…,c σ(l)) under S l is precisely A(b).
It is apparent from the formula that b′∗ appears in f b only if c σ(1)⋯c σ(l)=b appears in Ψ l(b′), hence b′→b is necessary. To calculate the leading coefficient f b (b), note that this is the sum over S l of the coefficients of c σ(1)⊗⋯⊗c σ(l) in Δ[l](b)=Δ[l](c 1)⋯Δ[l](c l ). Each term in Δ[l](c i ) contributes at least one generator to at least one tensor-factor, and each tensor-factor of c σ(1)⊗⋯⊗c σ(l) is a single generator, so each occurrence of c σ(1)⊗⋯⊗c σ(l) is a product of terms from Δ[l](c i ) where one tensor-factor is c i and all other tensor-factors are 1. Such products are all l! permutations of the c i in the tensor-factors, so, for each fixed σ, the coefficient of c σ(1)⊗⋯⊗c σ(l) in Δ[l](b) is A(b). This proves the first equality in the triangularity statement. Triangularity of f b with respect to length follows, as ordering by length refines the relation → (Proposition 3.7).
To see duality, first note that, since Ψ ∗a is the linear algebra dual to Ψ a, f b (Ψ a g b′)=(Ψ ∗a f b )(g b′). Now, using that f b and g b are eigenvectors, it follows that
so f b (g b′)=0 if l(b′)≠l(b).
Now suppose l(b′)=l(b)=l. Then
which is 0 when b≠b′, and 1 when b=b′. □
Proof of Theorem 3.20 (cocommutative and free associative algebra)
\(\mathcal{H}^{*}\) is commutative, so the power map is an algebra homomorphism. Then, since f b is defined as the product of k eigenvectors each of eigenvalue a, f b is an eigenvector of eigenvalue a k.
For any generator c, c ∗ is primitive by the same reasoning as in Theorem 3.19, the case of a polynomial algebra. To check that c ∗(g c )=1 and c ∗(g b )=0 for all other Lyndon b, use the triangularity of g b :
Each summand c ∗(b′) in the second term is 0 as l(c)=1≤l(b)<l(b′). As \(\operatorname{sym}(b)\) consists of terms of length l(b), \(c^{*}(\operatorname{sym}(b))\) is 0 unless l(b)=1, in which case \(\operatorname{sym}(b)=b\). Hence \(c^{*}(g_{b})=c^{*}(\operatorname {sym}(b))\) is non-zero only if c=b, and \(c^{*}(g_{c})=c^{*}(\operatorname {sym}(c))=c^{*}(c)=1\).
Turn now to duality. An analogous argument to the polynomial algebra case shows that f b (g b′)≠0 only when they have the same eigenvalue, which happens precisely when b and b′ have the same number of Lyndon factors. So let b 1⋯b k be the decreasing Lyndon factorization of b, and let \(b'_{1}\cdots b'_{k}\) be the decreasing Lyndon factorization of b′. To evaluate
observe that
As \(g_{b'_{\sigma(i)}}\) is primitive, each term in \(\Delta^{[k]} (g_{b'_{\sigma(i)}} )\) has \(g_{b'_{\sigma(i)}}\) in one tensor-factor and 1 in the k−1 others. Hence the only terms of \(\Delta^{[k]} (g_{b'_{\sigma (1)}} )\cdots\Delta^{[k]} (g_{b'_{\sigma(k)}} )\) without 1s in any tensor factors are those of the form \(g_{b'_{\tau \sigma(1)}}\otimes\cdots\otimes g_{b'_{\tau\sigma(k)}}\) for some τ∈S k . Now \(f_{b_{i}}(1)=0\) for all i, so \(f_{b_{1}}\otimes\cdots\otimes f_{b_{k}}\) annihilates any term with 1 in some tensor-factor. Hence
As f b is dual to g b for Lyndon b, the only summands which contribute are when \(b_{i}=b'_{\sigma\tau(i)}\) for all i. In other words, this is zero unless the b i are some permutation of the \(b'_{i}\). But both sets are ordered decreasingly, so this can only happen if \(b_{i}=b'_{i}\) for all i, hence b=b′. In that case, for each fixed σ∈S k , the number of τ∈S k with b i =b στ(i) for all i is precisely A′(b), so f b (g b )=1.
The final statement is proved in the same way as in Theorem 3.19, for a polynomial algebra, since, when b=c 1 c 2⋯c l with c 1≥c 2≥⋯≥c l in the ordering of generators, \(f_{b}=\frac{1}{A'(b)}c_{1}^{*}c_{2}^{*}\cdots c_{l}^{*}\). □
3.7 Stationary distributions, generalized chromatic polynomials, and absorption times
This section returns to probabilistic considerations, showing how the left eigenvectors of Sect. 3.5 determine the stationary distribution of the associated Markov chain. In the absorbing case, “generalized chromatic symmetric functions”, based on the universality theorem in [4], determine rates of absorption. Again, these general theorems are illustrated in the three sections that follow.
3.7.1 Stationary distributions
The first proposition identifies all the absorbing states when \(\mathcal{H}\) is a polynomial algebra:
Proposition 3.21
Suppose \(\mathcal{H}\) is a polynomial algebra where K a , defined by a −n Ψ a(b)=∑ b′ K a (b,b′)b′, is a transition matrix. Then the absorbing states are the basis elements \(b\in\mathcal{B}_{n}\) which are products of n (possibly repeated) degree one elements, and these give a basis of the 1-eigenspace of K a .
Example 3.22
In the commutative Hopf algebra of graphs in Examples 2.1 and 3.1, there is a unique basis element of degree 1—the graph with a single vertex. Hence the product of n such, which is the empty graph, is the unique absorbing state. Similarly for the rock-breaking example (symmetric functions) on partitions of n, the only basis element of degree 1 is e 1 and the stationary distribution is absorbing at 1n (or \(e_{1^{n}}\)).
The parallel result for a cocommutative free associative algebra picks out the stationary distributions:
Proposition 3.23
Suppose \(\mathcal{H}\) is a cocommutative and free associative algebra where K a , defined by a −n Ψ a(b)=∑ b′ K a (b,b′)b′, is a transition matrix. Then, for each unordered n-tuple {c 1,c 2,…,c n } of degree 1 elements (some c i s may be identical), the uniform distribution on {c σ(1) c σ(2)⋯c σ(n)∣σ∈S n } is a stationary distribution for the associated chain. In particular, all absorbing states have the form •n, where \(\bullet\in\mathcal{B}_{1}\).
Example 3.24
In the free associative algebra \(\mathbb{R}\langle x_{1},x_{2},\ldots,x_{n}\rangle\), each x i is a degree 1 element. So the uniform distribution on x σ(1)⋯x σ(n) (σ∈S n ) is a stationary distribution, as evident from considering inverse shuffles.
Proof of Proposition 3.21
From Theorem 3.15, a basis for the 1-eigenspace is {g b ∣l(b)=n}. This forces each factor of b to have degree 1, so b=c 1 c 2⋯c n and g b =e(c 1)⋯e(c n ). Now \(e(c)=\sum_{a\geq1}\frac{(-1)^{a-1}}{a}m^{[a]}\bar{\Delta }^{[a]}(c)\), and, when deg(c)=1, \(m^{[a]}\bar{\Delta}^{[a]}(c)=0\) for all a≥2. So e(c)=c, and hence g b =c 1 c 2⋯c n =b, which is a point mass on b, so b=c 1 c 2⋯c n is an absorbing state. □
Proof of Proposition 3.23
From Theorem 3.16, a basis for the 1-eigenspace is {\(g _{b} \mid b\in\mathcal{B}_{n}, b\) has n Lyndon factors}. This forces each Lyndon factor of b to have degree 1, so each of these must in fact be a single letter of degree 1. Thus b=c 1 c 2⋯c n and \(g_{b}=\sum_{\sigma\in S_{n}} g_{c_{\sigma(1)}}\cdots g_{c_{\sigma(n)}}=\sum_{\sigma\in S_{n}} c_{\sigma(1)}\cdots c_{\sigma(n)}\), as g c =c for a generator c. An absorbing state is a stationary distribution which is a point mass. This requires c σ(1)⋯c σ(n) to be independent of σ. As \(\mathcal{H}\) is a free associative algebra, this only holds when c 1=⋯=c n =:•, in which case g b =n!•n, so •n is an absorbing state. □
3.7.2 Absorption and chromatic polynomials
Consider the case where there is a single basis element of degree 1; call this element • as in Sect. 3.2. Then, by Propositions 3.21 and 3.23, the K a chain has a unique absorbing basis vector \(\bullet^{n}\in\mathcal {H}_{n}\). The chance of absorption after k steps can be rephrased in terms of an analog of the chromatic polynomial. Note first that the property K a ∗K a′=K aa′ implies it is enough to calculate K a (b,•n) for general a and starting state \(b\in\mathcal {H}_{n}\). To do this, make \(\mathcal{H}\) into a combinatorial Hopf algebra in the sense of [4] by defining a character ζ that takes value 1 on • and value 0 on all other generators, and extend multiplicatively and linearly. In other words, ζ is an indicator function of absorption, taking value 1 on all absorbing states and 0 on all other states. By [4, Th. 4.1] there is a unique character-preserving Hopf algebra map from \(\mathcal{H}\) to the algebra of quasisymmetric functions. Define χ b to be the quasisymmetric function that is the image of the basis element b under this map. (If \(\mathcal{H}\) is cocommutative, χ b will be a symmetric function.) Call this the generalized chromatic quasisymmetric function of b since it is the Stanley chromatic symmetric function for the Hopf algebra of graphs [84]. We do not know how difficult it is to determine or evaluate χ b .
Proposition 3.25
With notation as above, the probability of being absorbed in one step of K a starting from b (that is, K a (b,•n)) equals
Proof
By definition of K a , the desired probability K a (b,•n) is a −n times the coefficient of •n in Ψ a(b). Every occurrence of •n in Ψ a(b)=m [a]Δ[a](b) must be due to a term of the form \(\bullet^{\alpha_{1}} \otimes\bullet^{\alpha_{2}} \otimes\cdots\otimes\bullet^{\alpha _{a}}\) in Δ[a](b), for some composition α=(α 1,…,α n ) of n (some α i may be 0). So, letting \(\eta_{b}^{b_{1},\ldots,b_{a}}\) denote the coefficient of b 1⊗⋯⊗b a in Δ[a](b),
where the sum runs over all α with a parts. To re-express this in terms of compositions with no parts of size zero, observe that
because Δ[a]=(ι⊗⋯⊗ι⊗Δ)Δ[a−1] implies \(\eta_{b}^{\bullet^{\alpha_{1}},\ldots , \bullet^{\alpha_{a-1}},1}= \sum_{b'}\eta_{b}^{\bullet^{\alpha _{1}},\ldots, \bullet^{\alpha_{a-2}}, b'}\eta_{b'}^{\bullet^{\alpha _{a-1}},1}\), but \(\eta_{b'}^{\bullet^{\alpha_{a-1}},1}\) is zero unless \(b=\bullet^{\alpha_{a-1}}\). Similar arguments show that \(\eta _{b}^{\bullet^{\alpha_{1}},\ldots, \bullet^{\alpha_{a}}}=\eta _{b}^{\bullet^{\bar{\alpha}_{1}},\ldots, \bullet^{\bar{\alpha }_{l(\bar{\alpha})}}}\), where \(\bar{\alpha}\) is α with all zero parts removed. So
summing over all \(\bar{\alpha}\) with at most a parts, and no parts of size zero.
Now, for all compositions \(\bar{\alpha}\) of n with no zero parts, the coefficient of the monomial quasisymmetric function \(M_{\bar {\alpha}}\) in χ b is defined to be the image of b under the composite
where in the middle map, \(\pi_{\bar{\alpha}_{i}}\) denotes the projection to the subspace of degree \(\bar{\alpha}_{i}\). As ζ takes value 1 on powers of • and 0 on other basis elements, it transpires that
summing over all compositions of n regardless of their number of parts. Since \(M_{\bar{\alpha}} (1,1,\ldots,1,0, \ldots)=\binom {a}{l(\bar{\alpha})}\), where a is the number of non-zero arguments, it follows that
with the first a arguments non-zero. □
Using a different character ζ, this same argument gives the probability of reaching certain sets of states in one step of the K a (b,−) chain. This does not require \(\mathcal{H}\) to have a single basis element of degree 1.
Proposition 3.26
Let \(\mathcal{C}\) be a subset of generators, and \(\zeta^{\mathcal {C}}\) be the character taking value 1 on \(\mathcal{C}\) and value 0 on all other generators (extended linearly and multiplicatively). Let \(\chi^{\mathcal{C}}_{b}\) be the image of b under the unique character-preserving Hopf map from \(\mathcal{H}\) to the algebra of quasisymmetric functions. Then the probability of being at a state which is a product of elements in \(\mathcal{C}\), after one step of the K a chain, starting from b, is
Example 3.27
(Rock-breaking)
Recall the rock-breaking chain of Example 3.3. Let \(\mathcal {C}= \{\hat{e}_{1}, \hat{e}_{2} \}\). Then \(\chi_{\hat {e}_{n}}^{\mathcal{C}} (2^{-k},2^{-k},\ldots,2^{-k},0,0,\ldots )\) measures the probability that a rock of size n becomes rocks of size 1 or 2, after k binomial breaks.
4 Symmetric functions and breaking rocks
This section studies the Markov chain induced by the Hopf algebra of symmetric functions. Section 4.1 presents it as a rock-breaking process with background and references from the applied probability literature. Section 4.2 gives formulas for the right eigenfunctions by specializing from Theorem 3.19 and uses these to bound absorption time and related probabilistic observables. Section 4.3 gives formulas for the left eigenfunctions by specializing from Theorem 3.15 and uses these to derive quasi-stationary distributions.
4.1 Rock-breaking
As in Examples 1.2 and 3.3, the Markov chain corresponding to the Hopf algebra of symmetric functions may be described as a rock-breaking process on partitions of n: at each step, break each part independently with a symmetric binomial distribution. The chain is absorbed when each part is of size one. Let P n (λ,μ) be the transition matrix or chance of moving from λ to μ in one step for λ,μ partitions of n. For n=2,3,4, these matrices are:

The ath power map Ψ a yields rock-breaking into a pieces each time, according to a symmetric multinomial distribution. To simplify things, we focus on a=2.
The mathematical study of rock-breaking was developed by Kolmogoroff [54] who proved a log normal limit for the distribution of pieces of size at most x. A literature review and classical applied probability treatment in the language of branching processes is in [7]. They allow more general distributions for the size of pieces in each break. A modern manifestation with links to many areas of probability is the study of fragmentation processes. Extensive mathematical development and good pointers to a large physics and engineering literature are in [11, 12]. Most of the probabilistic development is in continuous time and has pieces breaking one at a time. We have not seen previous study of the natural model of simultaneous breaking developed here.
The rock-breaking Markov chain has the following alternative “balls in boxes” description:
Proposition 4.1
The distribution on partitions of n induced by taking k steps of the chain P n starting at the one-part partition (n) is the same as the measure induced by dropping n balls into 2k boxes (uniform multinomial allocation) and considering the partition induced by the box counts in the non-empty cells. For λ a partition of n, written as \(1^{a_{1}(\lambda)}\cdots n^{a_{n}(\lambda)}\) with \(\sum_{i=1}^{n}ia_{i}(\lambda)=n\), set \(P_{n}^{k}((n),\lambda)=\frac{n!2^{k}}{2^{nk}\prod_{i=0}^{n}(a_{i}!)^{a_{i}}}\frac{1}{\prod_{i=1}^{n}(i!)^{a_{i}}}\). (Here, a 0(λ) is the number of empty cells.) Then, for any partition μ
Remarks
Because of Proposition 4.1, many natural functions of the chain can be understood, as functions of k and n, from known properties of multinomial allocation. This includes the distribution of the size of the largest and smallest piece, the joint distribution of the number of pieces of size i, and total number of pieces. See [8, 53].
Observe from the matrices for n=2,3,4 that, if the partitions are written in reverse-lexicographic order, the transition matrices are lower-triangular. This is because lexicographic order refines the ordering of partitions by refinement. Furthermore, the diagonal entries are the eigenvalues 1/2i, as predicted in Proposition 3.7. Specializing the counting formula in Theorem 3.15 to this case proves the following proposition.
Proposition 4.2
The rock-breaking chain P n (λ,μ) on partitions of size n has eigenvalues 1/2i, 0≤i≤n−1, with 1/2i having multiplicity p(n,i), the number of partitions of n into i parts.
Note
As noted by the reviewer, the same rock-breaking chain can be derived using the basis {h λ } of complete homogeneous symmetric functions instead of {e λ }, since the two bases have the same product and coproduct structures. The fact that the dual basis to {h λ } is the more recognizable monomial symmetric functions {m λ }, compared to \(\{e_{\lambda}^{*}\}\), is unimportant here as the calculations of eigenfunctions do not explicitly require the dual basis.
4.2 Right eigenfunctions
Because the operator P n (λ,μ) is not self-adjoint in any reasonable sense, the left and right eigenfunctions must be developed distinctly. The following description, a specialization of Theorem 3.19, may be supplemented by the examples and corollaries that follow. A proof is at the end of this section.
Proposition 4.3
Let μ, λ be partitions of n. Let a i (λ) denote the number of parts of size i in λ and l(λ) the total number of parts. Then the μth right eigenfunction for P n , evaluated at λ, is
where the sum is over all sets {μ j} such that μ j is a partition of λ j and the disjoint union ∐ j μ j=μ. The corresponding eigenvalue is 2l(μ)−n. f μ (λ) is always non-negative, and is non-zero if and only if μ is a refinement of λ. If \(\tilde{\lambda}\) is any set partition with underlying partition λ, then f μ (λ) is the number of refinements of \(\tilde{\lambda}\) with underlying partition μ.
Here is an illustration of how to compute with this formula:
Example 4.4
For n=5, μ=(2,1,1,1), λ=(3,2), the possible {μ j} are

Then
Example 4.5
For n=2,3,4, the right eigenfunctions f μ are the columns of the matrices:

For some λ,μ pairs, the formula for f μ (λ) simplifies.
Example 4.6
When λ=(n),
Example 4.7
\(f_{1^{n}} \equiv1\) has eigenvalue 1.
Example 4.8
As (n) is not a refinement of any other partition, f (n) is non-zero only at (n). Hence f (n)(λ)=δ (n)(λ).
Example 4.9
When μ=1n−r r (r≠1),
with eigenvalue 1/2r−1. Thus \(f_{1^{n-2}2}(\lambda)=\sum\binom {\lambda_{j}}{2}\) with eigenvalue 1/2 is the unique second-largest eigenfunction.
Example 4.9 can be applied to give bounds on the chance of absorption. The following corollary shows that absorption is likely after k=2log2 n+c steps.
Corollary 4.10
For the rock-breaking chain X 0=(n),X 1,X 2,…,
Proof
By Example 4.9, if μ=1n−22, then \(f_{\mu}(\lambda)=\sum \binom{\lambda_{i}}{2}\) is an eigenfunction with eigenvalue 1/2. Further, f μ (λ) is zero if and only if λ=1n; otherwise f μ (λ)≥1. Hence
where the last equality is a simple application of Use A in Sect. 2.1. □
Remarks
-
1.
From Proposition 4.1 and the classical birthday problem,
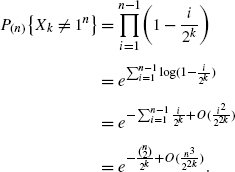
It follows that, for k=2log2 n+c (or 2k=2c n 2) the inequality in the corollary is essentially an equality.
-
2.
Essentially the same calculations go through for any starting state λ, since by Use A
$$E_\lambda \bigl\{f_\mu(X_k) \bigr\}= \frac{f_\mu(\lambda)}{2^k}. $$ -
3.
Other eigenfunctions can be similarly used. For example, when μ=1n−r r, \(f_{\mu}(\lambda)=\sum_{j}\binom{\lambda_{j}}{r}>0\) if and only if max j λ j ≥r, and f μ (λ)≥1 otherwise. It follows as above that
$$P_{(n)}\Bigl\{\max_i(X_k)_i \geq r\Bigr\}=P_{(n)}\bigl\{f_\mu(X_k)\geq1\bigr \}\leq E_{(n)}\bigl\{f_\mu(X_k)\bigr\}= \frac{\binom{n}{r}}{2^{(r-1)k}}. $$ -
4.
The right eigenfunctions with μ=1n−r r can be derived by a direct probabilistic argument. Drop n balls into 2k boxes. Let N i be the number of balls in box i. Then
$$E_{(n)} \Biggl\{\sum_{i=1}^{2^k} \binom{N_i}{r} \Biggr\} =2^kE_{(n)} \biggl\{ \binom{N_1}{r} \biggr\}=\frac{\binom{n}{r}}{2^{(r-1)k}}. $$The last equality follows because N 1 is binomial (n,1/2k) and, if X is binomial (n,p), E{X(X−1)⋯(X−r+1)}=n(n−1)⋯(n−r+1)p r. The other eigenvectors can be derived using more complicated multinomial moments.
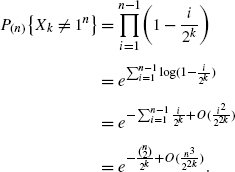
Proof of Proposition 4.3
For concreteness, take l(λ)=2 and l(μ)=3. Then Theorem 3.19 states that f μ (λ) is the coefficient of μ 1⊗μ 2⊗μ 3 in Δ[3](λ) (viewing μ i as a partition of single part), divided by ∏ i a i (μ)!. Recall that
So calculating f μ (λ) requires summing the coefficients of the terms where i 1∐i 2=μ 1, j 1∐j 2=μ 2, k 1∐k 2=μ 3. As μ 1 only has one part, it must be the case that either i 1=μ 1 and i 2=0, or i 1=0 and i 2=μ 1, and similarly for μ 2,μ 3. Thus, removing the parts of size 0 from (i 1,j 1,k 1,i 2,j 2,k 2) and reordering gives μ. So \(\binom{\lambda _{1}}{i_{1}j_{1}k_{1}}\binom{\lambda_{2}}{i_{2}j_{2}k_{2}}=\frac {\lambda_{1}!\lambda_{2}!}{\mu_{1}!\mu_{2}!\mu_{3}!}\). Also, if μ 1 denotes the partition obtained by removing 0s and reordering (i 1,j 1,k 1), and μ 2 from (i 2,j 2,k 2), then the disjoint union μ 1∐μ 2=μ. Given μ 1 and μ 2, the number of different sextuples (i 1,j 1,k 1,i 2,j 2,k 2) it could have come from is
Hence
which simplifies as desired. It is then an easy exercise to check that this is the number of refinements of the set partition \(\tilde{\lambda}\) of underlying partition μ. □
4.3 Left eigenfunctions and quasi-stationary distributions
This section gives two descriptions of the left eigenfunctions: one in parallel with Proposition 4.3 and the other using symmetric function theory. Again, examples follow the statement with proofs at the end.
Proposition 4.11
For the rock-breaking Markov chain P n on partitions of n, for each partition λ of n, there is a left eigenfunction g λ (μ) with eigenvalue 1/2n−l(λ),
where the sum is over sets {μ j} such that μ j is a partition of λ j and ∐μ j=μ. g λ (μ) is non-zero only if μ is a refinement of λ.
As previously, here is a calculational example.
Example 4.12
When μ=(2,1,1,1), λ=(3,2),
Example 4.13
For n=2,3,4, the left eigenfunctions g λ are the rows of the matrices:

Observe that these matrices are the inverses of those in Example 4.5, as claimed in Theorem 3.19.
The next three examples give some partitions λ for which the expression for g λ (μ) condenses greatly:
Example 4.14
If λ=(n) then g (n) is primitive and
with eigenvalue 1/2n−1.
Example 4.15
If λ=1n−r r (r≠1), g λ has eigenvalue 1/2r−1 and
if a 1(μ)≥a 1(λ), and 0 otherwise. In particular, \(g_{1^{n-2}2}\) puts equal mass at μ=1n and μ=1n−22 with mass 0 for other μ.
Example 4.16
Take λ=1n. As no other partition refines λ, \(g_{1^{n}}(\mu)=\delta_{1^{n}}(\mu)\), and this is the stationary distribution.
The left eigenfunctions can be used to determine the quasi-stationary distributions π 1, π 2 described in Sect. 2.1, Use G.
Corollary 4.17
For the rock-breaking Markov chain P n on partitions of n,
Proof
From (2.4), π 1 is proportional to \(g_{1^{n-2}2}\) on the non-absorbing states. The Perron–Frobenius theorem ensures that π 1 is non-negative. From Examples 4.15 and 4.16, \(\pi^{1}(\mu)=\delta_{1^{n-2}2}(\mu)\) for μ≠1n. Similarly, π 2 is proportional to the pointwise product \(g_{1^{n-2}2}(\mu)f_{1^{n-2}2}(\mu)=\delta_{1^{n-2}2}(\mu)\) for μ≠1n. □
From [38], the power sum symmetric functions p n are the primitive elements of the ring of symmetric functions and their products p λ give the left eigenfunctions of the Hopf-power chains. Up to scaling, p n is the only primitive element of degree n, so p n must be a scalar multiple of g (n). By Theorem 3.15, g (n) is normalized so that the coefficient of \(\hat {e}_{n}\) is 1 (recall \(\hat{e}_{n}=n!e_{n}\)), whilst the determinant formula [61, p. 28]:
shows that e n has coefficient (−1)n−1 n in p n . Comparing these shows g (n)=(−1)n−1(n−1)!p n , so the left eigenfunctions g λ are (−1)n−l(λ)∏ i (λ i −1)!p λ expressed in the \(\{\hat{e}_{\lambda}\}\) basis. Hence Proposition 4.11 may be rephrased as
For example, for λ=1n, p
1=e
1, and \(p_{1^{n}}=e_{1^{n}}=\hat{e}_{1^{n}}\) corresponding to the left eigenvector (1,0,…,0) with eigenvalue 1. For λ=21n−2, \(p_{2}=e_{1}^{2}-2e_{2}=\hat{e}_{1}^{2}-\hat{e}_{2}\), so \(p_{1^{n-2}2}=\hat{e}_{1^{n}}-\hat{e}_{1^{n-2}2}\) corresponding to the eigenvector (1,−1,0,…,0) with eigenvalue 1/2. For λ=1n−33,  . Multiplying by 2 gives the left eigenvector (2,−3,1,0,…,0) with eigenvalue 1/4.
. Multiplying by 2 gives the left eigenvector (2,−3,1,0,…,0) with eigenvalue 1/4.
The duality ∑ μ f λ (μ)g ν (μ)=δ λν implies that
so Proposition 4.3 gives
which also follows from [86, Prop. 7.7.1].
Proof of Proposition 4.11
g λ (μ) is the coefficient of μ in e(λ 1)e(λ 2)⋯e(λ l(λ)). Every occurrence of μ in e(λ 1)⋯e(λ l(λ)) is a product of a μ 1 term in e(λ 1), a μ 2 term in e(λ 2), etc., for some choice of partitions μ j of λ j with ∐ j μ j=μ. Hence it suffices to show that the coefficient of a fixed μ j in e(λ j ) is
Recall that \(e(\lambda_{j})=\sum_{a\geq1}\frac {(-1)^{a-1}}{a}m^{[a]}\bar{\Delta}^{[a]}(\lambda_{j})\), and observe that all terms of \(m^{[a]}\bar{\Delta}^{[a]}(\lambda_{j})\) are partitions with a parts. Hence μ j only occurs in the summand with a=l(μ j). So the number needed is \(\frac{(-1)^{l(\mu ^{j})-1}}{l(\mu^{j})}\) multiplied by the coefficient of μ j in \(m^{[a]}\bar{\Delta}^{[a]}(\lambda_{j})\). Each occurrence of μ j in \(m^{[a]}\bar{\Delta}^{[a]} (\lambda_{j} )\) is caused by \(\mu_{\sigma(1)}^{j} \otimes\cdots\otimes\mu_{\sigma(a)}^{j}\) in \(\bar{\Delta}^{[a]} (\lambda_{j} )\) for some σ∈S a . For each fixed σ, \(\mu_{\sigma(1)}^{j} \otimes\cdots \otimes\mu_{\sigma(a)}^{j}\) has coefficient
in \(\bar{\Delta}^{[a]} (\lambda_{j} )\), and the number of σ∈S a leading to distinct a-tuples \(\mu_{\sigma(1)}^{j}, \ldots, \mu_{\sigma(a)}^{j}\) is \(\frac{a!}{a_{1}(\mu^{j})!\cdots a_{\lambda_{j}}(\mu^{j})!}\). Hence the coefficient of μ j in \(m^{[a]}\bar{\Delta}^{[a]} (\lambda_{j} )\) is \(\binom{\lambda_{j}}{\mu_{1}^{j} \cdots\mu_{l(\mu^{j})}^{j}}\frac{l(\mu _{j})!}{a_{1}(\mu^{j})!\cdots a_{\lambda_{j}}(\mu^{j})!}\) as desired. □
Note
This calculation is greatly simplified for the algebra of symmetric functions, compared to other polynomial algebras. The reason is that, for a generator c, it is in general false that all terms of \(m^{[a]}\bar{\Delta}^{[a]}(c)\) have length a, or equivalently that all tensor-factors of a term of \(\bar{\Delta}^{[a]}(c)\) are generators. See the fourth summand of the coproduct calculation in Example 2.2 for an example. Then terms of length say, three, in e(c) may show up in both \(m^{[2]}\bar{\Delta}^{[2]}(c)\) and \(m^{[3]}\bar{\Delta }^{[3]}(c)\), so determining the coefficient of this length three term in e(c) is much harder, due to these potential cancelations in e(c). Hence much effort [2, 3, 35] has gone into developing cancelation-free expressions for primitives, as alternatives to e(c).
5 The free associative algebra and riffle shuffling
This section works through the details for the Hopf algebra k〈x 1,x 2,…,x N 〉 and riffle shuffling (Examples 1.1 and 1.3). Section 5.1 gives background on shuffling, Section 5.2 develops the Hopf connection, Section 5.3 gives various descriptions of right eigenfunctions. These are specialized to decks with distinct cards in Section 5.3.1 which shows that the number of descents\(-\frac {n-1}{2}\) and the number of peaks\(-\frac{n-2}{3}\) are eigenfunctions. The last section treats decks with general composition showing that all eigenvalues 1/2i, 0≤i≤n−1, occur as long as there are at least two types of cards. Inverse riffle shuffling is a special case of walks on the chambers of a hyperplane arrangement and of random walks on a left regular band. Saliola [74] and Denham [25] give a description of left eigenfunctions (hence right eigenfunctions for forward shuffling) in this generality.
5.1 Riffle shuffles
Gilbert–Shannon–Reeds introduced a realistic model for riffle shuffling a deck of n cards. It may be described in terms of a parameterized family of probability measures Q a (σ) for σ in the symmetric group S n and a∈{1,2,3,…} a parameter. A physical description of the a-shuffle begins by cutting a deck of n cards into a piles according to the symmetric multinomial distribution, so the probability of pile i receiving n i cards is \(\binom{n}{n_{1}n_{2}\cdots n_{a}}/a^{n}\). Then, the piles are riffled together by (sequentially) dropping the next card from pile i with probability proportional to pile size; continuing until all cards have been dropped. Usual riffle shuffles are 2-shuffles, and Bayer and Diaconis [10] show that Q a ∗Q b (σ)=∑ η Q a (η)Q b (ση −1)=Q ab (σ). Thus to study \(Q_{2}^{\ast k}(\sigma )=Q_{2^{k}}(\sigma)\) it is enough to understand Q a (σ). They also found the closed formula
Using this they proved that \(\frac{3}{2}\log_{2}n+c\) 2-shuffles are necessary and suffice to mix n cards.
The study of Q a (σ) has contacts with other areas of mathematics: to Solomon’s descent algebra [32, 83], quasisymmetric functions [36, 86, 87], hyperplane arrangements [6, 13, 16], Lie theory [69, 70], and, as the present paper shows, Hopf algebras. A survey of this and other connections is in [26] with [5, 22, 33] bringing this up to date. A good elementary textbook treatment is in [43].
Of course, shuffling can be treated as a Markov chain on S n with transition matrix K a (σ,π)=Q a (πσ −1), the chance of moving from σ to π after one a-shuffle. To check later calculations, when n=3, the transition matrix is 1/a 3 times

It is also of interest to study decks with repeated cards. For example, if suits do not matter, the deck may be regarded as having values 1,2,…,13 with value i repeated four times. Now, mixing requires fewer shuffles; see [5, 23, 24] for details. The present Hopf analysis works here, too.
5.2 The Hopf connection
Let \(\mathcal{H}=k\langle x_{1},x_{2},\ldots,x_{N}\rangle\) be the free associative algebra on N generators, with each x i primitive. As explained in Examples 1.1 and 1.3, the map x→Ψ a(x)/a degx is exactly inverse a-shuffling. Observe that the number of cards having each value is unchanged during shuffling. This naturally leads to the following finer grading on the free associative algebra: for each \(\nu=(\nu_{1},\nu_{2}, \ldots,\nu_{N})\in\mathbb{N}^{N}\), define \(\mathcal{H}_{\nu}\) to be the subspace spanned by words where x i appears ν i times. The ath power map \(\varPsi^{a}=m^{[a]}\Delta^{[a]}:\mathcal{H}\to \mathcal{H}\) preserves this finer grading. The subspace \(\mathcal {H}_{1^{N}}\subseteq k\langle x_{1},x_{2},\ldots,x_{N}\rangle\) is spanned by words of degree 1 in each variable. A basis is \(\{x_{\sigma}=x_{\sigma ^{-1}(1)}\cdots x_{\sigma^{-1}(n)}\}\). The mapping Ψ a preserves \(\mathcal{H}_{1^{n}}\) and \(\frac{1}{a^{n}}\varPsi^{a}(x_{\sigma})=\sum_{\pi}Q_{a}(\pi\sigma^{-1})x_{\pi}\). With obvious modification the same result holds for any subspace \(\mathcal{H}_{\nu}\). Working on the dual space \(\mathcal{H}^{*}\) gives the usual Gilbert–Shannon–Reeds riffle shuffles. Let us record this formally; say that a deck has composition ν if there are ν i cards of value i.
Proposition 5.1
Let ν=(ν 1,ν 2,…,ν N ) be a composition of n. For any a∈{1,2,…}, the mapping \(\frac{1}{a^{n}}\varPsi^{a}\) preserves \(\mathcal{H}_{\nu}\) and the matrix of this map in the monomial basis is the transpose of the transition matrix for the inverse a-shuffling Markov chain for a deck of composition ν. The dual mapping is the Gilbert–Shannon–Reeds measure (5.1) on decks with this composition.
Note
Since the cards behave equally independent of their labels, any particular deck of interest can be relabeled so that ν 1≥ν 2≥⋯≥ν N . In other words, it suffices to work with \(\mathcal{H}_{\nu}\) for partitions ν.
5.3 Right eigenfunctions
Theorem 3.16 applied to the free associative algebra gives a basis of left eigenfunctions for inverse shuffles, which are right eigenfunctions for the forward GSR riffle shuffles. By Remark 2 after Theorem 3.16, each word \(w\in\mathcal{H}_{\nu}\) corresponds to a right eigenfunction f w for the GSR measure on decks with composition ν. As explained in Example 1.3 and Sect. 2.3, these are formed by factoring w into Lyndon words, standard bracketing each Lyndon factor, then expanding and summing over the symmetrization. The eigenvalue is a k−n with k the number of Lyndon factors of w. The following examples should help understanding.
Example 5.2
For n=3, with ν=13, \(\mathcal{H}_{\nu}\) is six-dimensional with basis \(\{x_{\sigma}\}_{\sigma\in S_{3}}\). Consider w=x 1 x 2 x 3. This is a Lyndon word so no symmetrization is needed. The standard bracketing λ(x 1 x 2 x 3)=[λ(x 1),λ(x 2 x 3)]=[x 1,[x 2,x 3]]=x 1 x 2 x 3−x 1 x 3 x 2−x 2 x 3 x 1+x 3 x 2 x 1. With the labeling of the transition matrix K a of (5.1), the associated eigenvector is (1,1,0,−1,0,−1)T with eigenvalue 1/a 2.
For n=3,ν=(2,1), \(\mathcal{H}_{\nu}\) is three-dimensional with basis \(\{x_{1}^{2}x_{2},x_{1}x_{2}x_{1},x_{2}x_{1}^{2}\}\). Consider \(w=x_{2}x_{1}^{2}\). This factors into Lyndon words as x 2⋅x 1⋅x 1; symmetrizing gives the eigenvector \(x_{1}^{2}x_{2}+x_{1}x_{2}x_{1}+x_{2}x_{1}^{2}\) or (1,1,1)T with eigenvalue 1.
The description of right eigenvectors can be made more explicit. This is carried forward in the following two sections.
5.3.1 Right eigenfunctions for decks with distinct values
Recall from Sect. 2.3 that the values of an eigenfunction f w at w′ can be calculated graphically from the decreasing Lyndon hedgerow T w of w. When w has all letters distinct, this calculation simplifies neatly. To state this, extend the definition of f l (l a Lyndon word with distinct letters) to words longer than l, also with distinct letters: f l (w) is f l evaluated on the subword of w whose letters are those of l, if such a subword exists, and 0 otherwise. (Here, a subword always consists of consecutive letters of the original word.) Because w has distinct letters, there is at most one such subword. For example, f 35(14253)=f 35(53)=−1.
Proposition 5.3
Let w be a word with distinct letters and Lyndon factorization l 1 l 2⋯l k . Then, for all w′ with distinct letters and of the same length as w, \(f_{w}(w')=f_{l_{1}}(w')f_{l_{2}}(w')\cdots f_{l_{k}}(w')\) and f w takes only values 1, −1 and 0.
Example 5.4
f 35142(14253)=f 35(14253)f 142(14253)=−1⋅1=−1 as calculated in Sect. 2.3.
Proof
Recall from Sect. 2.3 that f w (w′) is the signed number of ways to permute the branches and trees of T w to spell w′. When w and w′ each consist of distinct letters, such a permutation, if it exists, is unique. This gives the second assertion of the proposition. This permutation is precisely given by permuting the branches of each \(T_{l_{i}}\) so they spell subwords of w′. The total number of branch permutations is the sum of the number of branch permutations of each \(T_{l_{i}}\). Taking parity of this statement gives the first assertion of the proposition. □
The example above employed a further shortcut that is worth pointing out: the Lyndon factors of a word with distinct letters start precisely at the record minima (working left to right, thus 35142 has minima 3,1 in positions 1,3), since a word with distinct letters is Lyndon if and only if its first letter is minimal. This leads to
Proposition 5.5
The multiplicity of the eigenvalue a n−k on \(\mathcal {H}_{1,1,\ldots, 1}\) is c(n,k), the signless Stirling number of the first kind.
Proof
By the above observation, the multiplicity of the eigenvalue a n−k on \(\mathcal{H}_{1,1, \ldots, 1}\) is the number of permutations with k record minima, which is also the number of permutations with k cycles, by [85, Prop. 1.3.1]. □
Example 5.6
(Invariance under reversal)
Let \(\bar{w}\) denote the reverse of w, then, for any σ, switching branches at every node shows that \(f_{\sigma}(\bar{w})=\pm f_{\sigma}(w)\) where the parity is n−# Lyndon factors in σ. Thus, each eigenspace of Ψ a is invariant under the map \(w\to \bar{w}\). For example, f 35142(35241)=f 35(35241)f 142(35241)=1⋅1=−f 35142(14253) when compared with Example 5.4 above. The quantity (n−# Lyndon factors in 35142) is 5−2=3, hence the change in sign.
Example 5.7
(Eigenvalue 1)
σ=n,n−1,…,1 is the only word with n Lyndon factors, so f σ (w)=1 spans the 1-eigenspace.
Example 5.8
(Eigenvalue 1/a and descents)
There are \(\binom{n}{2}\) permutations σ which have n−1 Lyndon factors. They may be realized by choosing i<j and taking σ=n,n−1,…,j+1,j−1,…,i+1,i,j,i−1,…,1. Then, all but j are record minima and the corresponding eigenfunctions are (in the notation at the start of this section),
Their sum is f(w):=∑ i<j f ij (w)=n−1−2d(w) with d(w) the number of descents in w. This is thus an eigenfunction with eigenvalue 1/a, as claimed in Example 1.4. This eigenfunction appears in the Markov chain recording the number of descents in successive a-shuffles, which is the same as the Markov chain of carries when n numbers are added in base a. The transition matrix of this Markov chain is Holte’s [47] “amazing matrix.” See [27–29]. The theory developed there shows that, with s(n,k) the Stirling numbers (x(x−1)⋯(x−n+1)=∑ k≥0 s(n,k)x k),
is a right eigenfunction with eigenvalue 1/a j, 0≤j≤n−1, and the eigenfunction f above is \(\frac{2}{n}h_{1}\).
Example 5.9
(Eigenvalue 1/a 2 and peaks)
Recall that a permutation w has a peak at position i, 1<i<n, if w(i−1)<w(i)>w(i+1), and a trough at position i, 1<i<n, if w(i−1)>w(i)<w(i+1). Call the remaining case a straight: w(i−1)<w(i)<w(i+1) or w(i−1)>w(i)>w(i+1). The number of peaks and the peak set have been intensively investigated [88, 92]. The following development shows that # \(\operatorname{peaks}(w)-\frac{n-2}{3}\) is an eigenfunction with eigenvalue 1/a 2, as is # troughs\((w)-\frac{n-2}{3}\). Indeed, a basis of this eigenspace is {f σ } where σ is obtained from n,n−1,…,1 by removing j and inserting it after i for i<j, and then removing k>j and inserting it further down also. Then, all but j,k are record minima. There are three places to insert k (in the examples, i=1,j=3,k=5):
- Case 1:
-
after l with l≠i, l≠j,l<k (e.g., 42513);
- Case 2:
-
after j, i.e., σ=n,n−1,…,k+1,k−1,…,j+1,j−1,…,i+1,i,j,k,i−1,…,1 (e.g., 42135);
- Case 3:
-
after i, i.e., σ=n,n−1,…,k+1,k−1,…,j+1,j−1,…,i+1,i,k,j,i−1,…,1 (e.g., 42153).
Then f σ (w) is, respectively,
- Case 1:
-
1 if ij and kl both occur as subwords of w, or if ji and lk both occur; −1 if ji and kl both occur, or if ij and lk both occur; 0 if i is not adjacent to j in w or if k is not adjacent to l (this is f ij f lk );
- Case 2:
-
1 if ijk or kji occur as subwords of w; −1 if ikj or jki occur; 0 otherwise (this is f ij f jk +f ik f jk );
- Case 3:
-
1 if ikj or jki occur as subwords of w; −1 if kij or jik occur; 0 otherwise (this is −f ik f jk +f ij f ik ).
Proposition 5.10
f ∧(w):= # peaks in \(w-\frac{n-2}{3}\), f ∨(w):= # troughs in \(w-\frac{n-2}{3}\) and f −(w):= # straights in \(w-\frac{n-2}{3}\) are right eigenfunctions with eigenvalue 1/a 2.
Proof
Let s r denote the sum of all eigenfunctions arising from case r, as defined in Example 5.9 above. Note that
Since each successive triple in w either forms a straight, a peak or a trough,
Hence \(f_{\wedge}=\frac{1}{3} (s_{3}-s_{2} )\), \(f_{\vee }=\frac{-1}{3} (s_{2}+2s_{3} )\), \(f_{-} = \frac{1}{3} (2s_{2} +s_{3} )\) are all in the 1/a 2-eigenspace. □
It may be possible to continue the analysis to patterns of longer length; in particular, one interesting open question is which linear combinations of patterns and constant functions give eigenfunctions.
5.3.2 Right eigenfunctions for decks with general composition
Recall from Proposition 5.1 that, for a composition ν=(ν 1,ν 2,…,ν N ) of n, the map \(\frac{1}{a^{n}}\varPsi ^{a}\) describes inverse a-shuffling for a deck of composition ν, i.e., a deck of n cards where ν i cards have value i. Theorem 3.16 applies here to determine a full left eigenbasis (i.e., a right eigenbasis for forward shuffles). The special case of ν=(n−1,1) (follow one labeled card) is worked out in [21] and used to bound the expected number of correct guesses in feedback experiments. His work shows that the same set of eigenvalues {1,1/a,1/a 2,…,1/a n−1} occur.
This section shows that this is true for all deck compositions (provided N>1). It also determines a basis of eigenfunctions with eigenvalue 1/a and constructs an eigenfunction which depends only on an appropriately defined number of descents, akin to Example 5.8.
The following proposition finds one “easy” eigenfunction for each eigenvalue of 1/a k. The examples that follow the proof show again that eigenfunctions can correspond to natural observables.
Proposition 5.11
Fix a composition ν of n. The dimension of the 1/a k-eigenspace for the a-shuffles of a deck of composition ν is bounded below by the number of Lyndon words in the alphabet {1,2,…,N} of length k+1 in which letter i occurs at most ν i times. In particular, 1/a k does occur as an eigenvalue for each k, 0≤k≤n−1.
Proof
By remark 2 after Theorem 3.16, the dimension of the 1/a k-eigenspace is the number of monomials in \(\mathcal{H}_{\nu }\) with n−k Lyndon factors. One way of constructing such monomials is to choose a Lyndon word of length k+1 in which letter i occurs at most ν i times, and leave the remaining n−k letters of ν as singleton Lyndon factors. The monomial is then obtained by putting these factors in decreasing order. This shows the lower bound.
To see that 1/a k is an eigenvalue for all k, it suffices to construct, for each k, a Lyndon word of length k+1 in which letter i occurs at most ν i times. For k>ν 1, this may be achieved by placing the smallest k+1 values in increasing order. For k≤ν 1, take the word with k 1s followed by a 2. □
Example 5.12
For ν=(3,2,1,2), the eight eigenfunctions constructed in the last step of the proof correspond to the words shown below in order 1/a k, 0≤k≤7. The bracketed term is the sole non-singleton Lyndon factor:

Example 5.13
For an n-card deck of composition ν, the second largest eigenvalue is 1/a. Our choice of eigenvectors correspond to words with n−1 Lyndon factors. Each such word must have n−2 singleton Lyndon factors and a Lyndon factor of length 2. Hence the bound in Proposition 5.11 is attained; furthermore it can be explicitly calculated: the Lyndon words of length 2 are precisely a lower value followed by a higher value, so the multiplicity of eigenvalue 1/a is \(\binom{N}{2}\). This does not depend on ν, only on the number N of distinct values.
Summing these eigenfunctions and arguing as in Example 5.8 gives
Proposition 5.14
For any n-card deck of composition ν, let a(w), d(w) be the number of strict ascents, descents in w, respectively. Then a(w)−d(w) is an eigenfunction of Ψ a with eigenvalue 1/a.
Proof
Fix two values i<j. Order the deck in decreasing order, then take a card of value j and put it after the first card of value i. In other words, let ij be the only non-singleton Lyndon factor. By inspection, the corresponding eigenvector is (up to scaling)
summing f ij over 1≤i<j≤N shows that {# ascents in w} − {# descents in w} is an eigenfunction with eigenvalue 1/a. □
Remarks
Under the uniform distribution, the expectation of a(w)−d(w) is zero. If initially the deck is arranged in increasing order w 0, a(w 0)−d(w 0)=N−1. If w k is the permutation after k a-shuffles, the proposition gives \(E\{a(w^{k})-d(w^{k})\}=\frac{1}{a^{k}}(N-1)\). Thus for a=2, k=log2(N−1)+θ shuffles suffice to make this expected value 2−θ. On the other hand, consider a deck with n cards labeled 1 and n cards labeled 2. If the initial order is w 0=11⋯12⋯21, a(w 0)−d(w 0)=0 and so E{a(w k)−d(w k)}=0 for all k.
Central limit theorems for the distribution of descents in permutations of multi-sets are developed in [24].
Example 5.15
Specialize Example 5.13 to ν=(1,n−1), so there is one exceptional card of value 1 in a deck of otherwise identical cards of value 2. Then there is a unique eigenfunction f 12 of eigenvalue 1/a:
6 Examples and counter-examples
This section contains a collection of examples where either the Hopf-square map leads to a Markov chain with a reasonable “real world” interpretation—Markov chains on simplicial complexes and quantum groups—or the constructions do not work out to give Markov chains—a quotient of the symmetric functions algebra, Sweedler’s Hopf algebra and the Steenrod algebra. Further examples will be developed in depth in future work.
Example 6.1
(A Markov chain on simplicial complexes)
Let \(\mathcal{X}\) be a finite set and \(\mathcal{C}\) a simplicial complex of subsets of \(\mathcal{X}\). Recall that this means that \(\mathcal{C}\) is a collection of non-empty subsets of \(\mathcal{X}\) such that \(c\in\mathcal{C}\) implies that all non-empty subsets of c are in \(\mathcal{C}\). As an example, consider the standard triangulation of the torus into 18 triangles:

Here the top and bottom edges are identified as are the left and right sides. This identifies several vertices and edges and \(\mathcal{X}\) consists of nine distinct vertices. The complex \(\mathcal{C}\) contains these nine vertices, the 24 distinct edges, and the 18 triangles.
The set of all simplicial complexes (on all finite sets \(\mathcal{X}\)) is a basis for a Hopf algebra, under disjoint union as product and coproduct
with the sum over subsets \(S\subseteq\mathcal{X}\), and \(\mathcal {C}_{S}=\{A\subseteq S:A\in\mathcal{C}\}\). By convention \(\mathcal {C}_{\emptyset}=1\) in this Hopf algebra so S=∅ is allowed in the sum. Graded by \(|\mathcal{X}|\), this gives a commutative, cocommutative Hopf algebra with basis given by all complexes \(\mathcal {C}\); the generators are the connected complexes.
The associated Markov chain, restricted to complexes on n vertices, is simple to describe: from a given complex \(\mathcal{C}\), color the vertices red or blue, independently, with probability 1/2. Take the disjoint union of the complex induced by the red vertices with the complex induced by the blue vertices. As usual, the process terminates at the trivial complex consisting of n isolated vertices.
This Markov chain is of interest in quantifying the results of a “topological statistics” analysis. There, a data set (n points in a metric space) gives rise to a family of complexes \(\mathcal {C}_{\epsilon}\), 0≤ϵ<∞, where the vertices of each \(\mathcal {C}_{\epsilon}\) are the data points, and k points form a simplex if the intersection of the ϵ balls around each point is non-empty in the ambient space. For ϵ small, the complex is trivial. For ϵ sufficiently large, the complex is the n-simplex. In topological statistics [17, 18] one studies things like the Betti numbers of \(\mathcal{C}_{\epsilon}\) as a function of ϵ. If these are stable for a range of ϵ this indicates interpretable structure in the data.
Consider now a data set with large n and ϵ fixed. If a random subset of k points is considered (a frequent computational ploy) the induced sub-complex essentially has the distribution of the “painted red” sub-complex (if the painting is done with probability k/n). Iterating the Markov chain corresponds to taking smaller samples.
If the Markov chain starts out at the n-simplex, every connected subset of the resulting Markov chain is a simplex. Thus, at each stage, all of the higher Betti numbers are zero and β 0 after k steps is 2k−X k , where X k is distributed as the number of empty cells if n balls are dropped into 2k boxes. This is a thoroughly studied problem [53]. The distribution of the Betti numbers for more interesting starting complexes is a novel, challenging problem. Indeed, consider the triangulation of the torus with 2n 2 initial triangles. Coloring the vertices red or blue with probability 1/2, the edges with red/red vertices are distributed in the same way as the “open sites” in site percolation on a triangular lattice. Computing the Betti number β 0 amounts to computing the number of connected components in site percolation. In the infinite triangular lattice, it is known that p=1/2 is the critical threshold and at criticality, the chance that the component containing the origin has size greater than k falls off as k −5/48. These and related facts about site percolation are among the deepest results in modern probability. See [42, 81, 93] for background and recent results. Iterates of the Markov chain result in site percolation with p below the critical value but estimating β 0 is still challenging.
It is natural to study the absorption of this chain started at the initial complex \(\mathcal{C}\). This can be studied using the results of Sect. 3.7.
Proposition 6.2
Let the simplicial complex Markov chain start at the complex \(\mathcal{C}\). Let G be the graph of the 1-skeleton of \(\mathcal{C}\). Suppose that the chromatic polynomial of G is p(x). Then the probability of absorption after k steps is p(2k)/2nk (with \(n=|\mathcal{X}|\)).
For example, if \(\mathcal{C}\) is the n-simplex, p(x)=x(x−1)⋯(x−n+1) and \(P\{\mbox{absorption after } k \mbox{ steps}\}=\prod_{i=1}^{n-1}(1-i/2^{k})\sim e^{-2^{-(2c-1)}}\) if k=2(log2 n+c) for n large. If \(\mathcal{C}\) is a tree, p(x)=x(x−1)n−1 and \(P\{\mbox{absorption after } k \mbox{ steps}\}=(1-1/2^{k})^{n-1}\sim e^{-2^{-c}}\) if k=log2 n+c for n large.
Using results on the birthday problem in non-standard situations [8, 20] it is possible to do similar asymptotics for variables such as the number of l-simplices remaining after k steps for more interesting starting \(\mathcal{C}\) such as a triangulation of the torus into 2(n−1)2 triangles.
As a final remark, note that the simplicial complex Markov chain induces a Markov chain on the successive 1-skeletons. The eigenvectors of this Markov chain are beautifully developed in [35]. These all lift to eigenvectors of the complex chain, so much is known.
Example 6.3
(Quantized shuffle algebras)
It is natural to seek useful deformations of processes like riffle shuffling. One route is via the quantized shuffle algebras of [40, 41] and [71–73]. These have become a basic object of study [52, 57]. Consider the vector space k〈x 1,…,x n 〉, and equip its degree 1 subspace with a symmetric \(\mathbb{Z}\) form x i ⋅x j . Turn this into an algebra with the product of concatenation. Take as coproduct Δ(x i )=1⊗x i +x i ⊗1. However, Δ is to be multiplicative with respect to the twisted tensor product \((x_{1}\otimes x_{2})(y_{1}\otimes y_{2})=q^{x_{2}\cdot y_{1}}(x_{1}x_{2}\otimes y_{1}y_{2})\). Green translates this into shuffling language. The upshot is if \(w=x_{i_{1}}x_{i_{2}}\cdots x_{i_{k}}\) is a word in k〈x 1,…,x n 〉 then
Here the sum is over all subsets (including the empty set), \(w_{S}w_{S^{\mathcal{C}}}\) is the inverse shuffle moving the letters in the positions marked by S to the front (keeping them in the same relative order). The weight \(\operatorname{wt}(S,w)\) is the sum of x j′⋅x j for \(j'\in S^{\mathcal{C}}\), j∈S, j′<j. Thus if w=ijklm and S={2,4}, we have \(w_{S}w_{S^{\mathcal{C}}}=jlikm\), and \(\operatorname{wt}(S,w)=i\cdot j+i\cdot l+k\cdot l\).
When q=1 this shuffle product gives Ree’s shuffle algebra and general values of q lead to elegant combinatorial formulations of quantum groups. For general q>0, there is also a naturally associated Markov chain. Work on the piece with multi-grading 1n, so each variable appears once and we may work with permutations in S n . For a starting permutation π, and 0≤j≤n, let \(\theta(j)=\sum_{|S|=j}q^{\operatorname{wt}(S,\pi)}\). Set \(\theta=\sum_{j=0}^{n}\theta(j)\). Choose j with probability θ(j)/θ and then S (with |S|=j) with probability \(q^{\operatorname {wt}(S,\pi)}/\theta(j)\). Move to \(\pi_{S}\pi_{S^{\mathcal{C}}}\). This defines a Markov transition matrix K q (π,π′) via \(\frac{1}{\theta}m\Delta(\pi)\). Note that the normalization θ depends on π.
We have not seen our way through this to nice mathematics. There is one case where progress can be made: suppose x i ⋅x j ≡1. Then \(\operatorname{wt}(S,\pi)=\operatorname{inv}(S)\), the minimum number of pairwise adjacent transpositions needed to move S to the left. (When n=5 and S={2,4}, \(\operatorname{inv}(S)=3\).) Since \(\operatorname{wt}(S,\pi)\) does not depend on π, neither does θ and the Markov chain becomes a random walk on S n driven by the measure
where z n is a normalizing constant.
The preceding description gives inverse riffle shuffles. It is straightforward to describe the q-analog of forward riffle shuffles by taking inverses. Let [j]
q
=1+q+⋯+q
j−1, [j]
q
!=[j]
q
[j−1]
q
⋯[1]
q
, and  , the usual q-binomial coefficient. We write I(w) for the number of inversions of the permutation w and R(w)=d(w
−1)+1 for the number of rising sequences.
, the usual q-binomial coefficient. We write I(w) for the number of inversions of the permutation w and R(w)=d(w
−1)+1 for the number of rising sequences.
Proposition 6.4
For q>0, the q-riffle shuffle measure has the following description on S n :
where
z
n
is the normalizing constant ∑
w:R(w)≤2
q
I(w). To generate
w
from
Q
q
, cut off
j
cards with probability
 and drop cards sequentially according to the following rule: if at some stage there are
A
cards in the left pile and
B
cards in the right pile, drop the next card
and drop cards sequentially according to the following rule: if at some stage there are
A
cards in the left pile and
B
cards in the right pile, drop the next card

Continue, until all cards have been dropped.
Proof
Equation (6.1) follows from the inverse description because I(w)=I(w
−1). For the sequential description, it is classical that  is the generating function for multi-sets containing j ones and n−j twos by number of inversion [85, Sect. 1.7]. For two piles with say, 1,2,…,j in the left and j+1,…,k in the right, in order, dropping j induces k−j inversions. Multiplying the factors in (6.2) results in a permutation with R(w)≤2, with probability
is the generating function for multi-sets containing j ones and n−j twos by number of inversion [85, Sect. 1.7]. For two piles with say, 1,2,…,j in the left and j+1,…,k in the right, in order, dropping j induces k−j inversions. Multiplying the factors in (6.2) results in a permutation with R(w)≤2, with probability  . Since the cut is made with probability
. Since the cut is made with probability  , the two-stage procedure gives (6.1). □
, the two-stage procedure gives (6.1). □
Remarks
When q=1, this becomes the usual Gilbert–Shannon–Reeds measure described in the introduction and in Sect. 5. In particular, for the sequential version, the cut is j with probability \(\binom{n}{j}/2^{n}\) and with A in the left and B in the right, drop from left or right with probability \(\frac{A}{A+B}\), \(\frac{B}{A+B}\), respectively. For general q, as far as we know, there is no closed form for z n . As q→∞, the cutting distribution is peaked at n/2 and most cards are dropped from the left pile. The most likely permutation arises from cutting off n/2 cards and placing them at the bottom. As q→0, the cutting distribution tends to uniform on {0,1,…,n} and most cards are dropped from the right pile. The most likely permutation is the identity. There is a natural extension to a q–a-shuffle with cards cut into a piles according to the q-multinomial distribution and cards dropped sequentially with probability “q-proportional” to packet size.
We hope to analyze this Markov chain in future work. See [30] for related q-deformations of a familiar random walk.
Example 6.5
(A quotient of the algebra of symmetric functions)
Consider \(\bar{\varLambda} = \varLambda/ e_{1} =k[e_{2}, e_{3}, \ldots]\), with
This is the Weyl group invariants of type A. It is a polynomial algebra, so the theory in Sect. 3 generates an eigenbasis of Ψ a and Ψ ∗a. One hopes this will induce a rock-breaking process where pieces of size one are not allowed; however, we cannot rescale the basis via Theorem 3.4 to obtain a transition matrix, as both e 2 and e 3 are primitive basis elements of degree greater than one. Hence \(e_{2}^{3}\), \(e_{3}^{2}\) have the same degree, but \(m\Delta(e_{2}^{3})=8e_{2}^{3}\) and \(m\Delta(e_{3}^{2})=4e_{3}^{2}\), so no rescaling can make the sum of the coefficients of \(m\Delta(e_{2}^{3})\) equal to that of \(m\Delta(e_{3}^{2})\).
Example 6.6
(Sweedler’s example)
The four-dimensional algebra
becomes a Hopf algebra with Δ(g)=g⊗g, Δ(x)=x⊗1+g⊗x, ϵ(g)=1, ϵ(x)=0. The antipode is s(g)=g −1, s(x)=−gx. It is discussed in [64] as an example of a Hopf algebra that is neither commutative nor cocommutative. With the given basis {1,g,x,gx}, mΔ(1)=1, mΔ(g)=1, mΔ(x)=x−gx, mΔ(gx)=−x+gx. The negative coefficients forestall our efforts to find a probabilistic interpretation. The element v=x−gx is an eigenvector for mΔ with eigenvalue 2 and high powers of \(\frac{1}{2} m\Delta\) applied to a general element a+bg+cx+dgx converge to (c−d)v. Of course, this example violates many of our underlying assumptions. It is not graded and is neither a polynomial algebra nor a free associative algebra.
Example 6.7
(The Steenrod algebra)
Steenrod squares (and higher powers) are a basic tool of algebraic topology [46]. They give rise to a Hopf algebra A 2 over \(\mathbb{F}_{2}\). Its dual \(A_{2}^{*}\) is a commutative, noncommutative Hopf algebra over \(\mathbb{F}_{2}\) with a simple description. As an algebra, \(A_{2}^{*}=\mathbb{F}_{2}[x_{1},x_{2},\ldots]\) (polynomial algebra in countably many variables) graded with x i of degree 2i−1. The coproduct is \(\Delta(x_{n})=\sum_{i=0}^{n}x_{n-i}^{2^{i}}\otimes x_{i}\) (x 0=1). Alas, because the coefficients are mod 2, we have been unable to find a probabilistic interpretation of mΔ. For example, \((A_{2}^{*})_{3}\) has basis \(\{x_{1}^{3},x_{2}\}\) and \(m\Delta(x_{1}^{3})=0\), \(m\Delta(x_{2})=x_{1}^{3}\) so (mΔ)2≡0. Of course, high powers of operators can be of interest without positivity [31, 44].
References
Aguiar, M., Mahajan, S.: Monoidal Functors, Species and Hopf Algebras. CRM Monograph Series, vol. 29. Am. Math. Soc., Providence (2010). With forewords by Kenneth Brown and Stephen Chase and André Joyal
Aguiar, M., Sottile, F.: Structure of the Malvenuto-Reutenauer Hopf algebra of permutations. Adv. Math. 191(2), 225–275 (2005)
Aguiar, M., Sottile, F.: Structure of the Loday-Ronco Hopf algebra of trees. J. Algebra 295(2), 473–511 (2006)
Aguiar, M., Bergeron, N., Sottile, F.: Combinatorial Hopf algebras and generalized Dehn–Sommerville relations. Compos. Math. 142(1), 1–30 (2006)
Assaf, S., Diaconis, P., Soundararajan, K.: A rule of thumb for riffle shuffling. Ann. Appl. Probab. 21, 843–875 (2011)
Athanasiadis, C.A., Diaconis, P.: Functions of random walks on hyperplane arrangements. Adv. Appl. Math. 45(3), 410–437 (2010)
Athreya, K.B., Ney, P.E.: Branching Processes. Springer, New York (1972). Die Grundlehren der mathematischen Wissenschaften, Band 196
Barbour, A.D., Holst, L., Janson, S.: Poisson Approximation. Oxford Studies in Probability., vol. 2. Clarendon, New York (1992). Oxford Science Publications
Barcelo, H., Bergeron, N.: The Orlik-Solomon algebra on the partition lattice and the free Lie algebra. J. Comb. Theory, Ser. A 55(1), 80–92 (1990)
Bayer, D., Diaconis, P.: Trailing the dovetail shuffle to its lair. Ann. Appl. Probab. 2(2), 294–313 (1992)
Bertoin, J.: The asymptotic behavior of fragmentation processes. J. Eur. Math. Soc. 5(4), 395–416 (2003)
Bertoin, J.: Random Fragmentation and Coagulation Processes. Cambridge Studies in Advanced Mathematics, vol. 102. Cambridge University Press, Cambridge (2006)
Bidigare, P., Hanlon, P., Rockmore, D.: A combinatorial description of the spectrum for the Tsetlin library and its generalization to hyperplane arrangements. Duke Math. J. 99(1), 135–174 (1999)
Bott, R., Samelson, H.: On the Pontryagin product in spaces of paths. Comment. Math. Helv. 27, 320–337 (1954). 1953
Brémaud, P.: Markov Chains. Texts in Applied Mathematics, vol. 31. Springer, Berlin (1999). Gibbs fields, Monte Carlo simulation, and queues
Brown, K.S., Diaconis, P.: Random walks and hyperplane arrangements. Ann. Probab. 26(4), 1813–1854 (1998)
Carlsson, G.: Topology and data. Bull. Am. Math. Soc. 46(2), 255–308 (2009)
Carlsson, E., Carlsson, G., de Silva, V.: An algebraic topological method for feature identification. Int. J. Comput. Geom. Appl. 16(4), 291–314 (2006)
Cartier, P.: A primer of Hopf algebras. In: Frontiers in Number Theory, Physics, and Geometry. II, pp. 537–615. Springer, Berlin (2007)
Chatterjee, S., Diaconis, P., Meckes, E.: Exchangeable pairs and Poisson approximation. Probab. Surv. 2, 64–106 (2005) (electronic)
Ciucu, M.: No-feedback card guessing for dovetail shuffles. Ann. Appl. Probab. 8(4), 1251–1269 (1998)
Conger, M.A., Howald, J.: A better way to deal the cards. Am. Math. Mon. 117(8), 686–700 (2010)
Conger, M., Viswanath, D.: Riffle shuffles of decks with repeated cards. Ann. Probab. 34(2), 804–819 (2006)
Conger, M., Viswanath, D.: Normal approximations for descents and inversions of permutations of multisets. J. Theor. Probab. 20(2), 309–325 (2007)
Denham, G.: Eigenvectors for a random walk on a hyperplane arrangement. Adv. Appl. Math. 48(2), 312–324 (2012)
Diaconis, P.: Mathematical developments from the analysis of riffle shuffling. In: Groups, Combinatorics & Geometry, Durham, 2001, pp. 73–97. World Scientific, River Edge (2003)
Diaconis, P., Fulman, J.: Carries, shuffling, and an amazing matrix. Am. Math. Mon. 116(9), 788–803 (2009)
Diaconis, P., Fulman, J.: Carries, shuffling, and symmetric functions. Adv. Appl. Math. 43(2), 176–196 (2009)
Diaconis, P., Fulman, J.: Foulkes characters, Eulerian idempotents, and an amazing matrix. J. Algebr. Comb. 1–16 (2012). doi:10.1007/s10801-012-0343-7
Diaconis, P., Ram, A.: Analysis of systematic scan Metropolis algorithms using Iwahori-Hecke algebra techniques. Mich. Math. J. 48, 157–190 (2000). Dedicated to William Fulton on the occasion of his 60th birthday
Diaconis, P., Saloff-Coste, L.: Convolution powers of complex functions on \(\mathbb{Z}\). ArXiv e-prints (2012)
Diaconis, P., Fill, J.A., Pitman, J.: Analysis of top to random shuffles. Comb. Probab. Comput. 1(2), 135–155 (1992)
Diaconis, P., Fulman, J., Holmes, S.: Analysis of Casino Shelf Shuffling Machines. ArXiv e-prints (2011)
Drinfeld, V.G.: Quasi-Hopf algebras. Algebra Anal. 1(6), 114–148 (1989)
Fisher, F.: CoZinbiel Hopf algebras in combinatorics. Ph.D. thesis, The George Washington University (2010)
Fulman, J.: Descent algebras, hyperplane arrangements, and shuffling cards. Proc. Am. Math. Soc. 129(4), 965–973 (2001)
Garsia, A.M., Reutenauer, C.: A decomposition of Solomon’s descent algebra. Adv. Math. 77(2), 189–262 (1989)
Geissinger, L.: Hopf algebras of symmetric functions and class functions. In: Combinatoire et Représentation du Groupe Symétrique, Actes Table Ronde C.N.R.S., Univ. Louis-Pasteur Strasbourg, Strasbourg, 1976. Lecture Notes in Math., vol. 579, pp. 168–181. Springer, Berlin (1977)
Gelfand, I.M., Krob, D., Lascoux, A., Leclerc, B., Retakh, V.S., Thibon, J.-Y.: Noncommutative symmetric functions. Adv. Math. 112(2), 218–348 (1995)
Green, J.A.: Hall algebras, hereditary algebras and quantum groups. Invent. Math. 120(2), 361–377 (1995)
Green, J.A.: Quantum groups, Hall algebras and quantized shuffles. In: Finite Reductive Groups, Luminy, 1994. Progr. Math., vol. 141, pp. 273–290. Birkhäuser Boston, Boston (1997)
Grimmett, G.: Percolation. Grundlehren der Mathematischen Wissenschaften [Fundamental Principles of Mathematical Sciences], vol. 321. Springer, Berlin (1999)
Grinstead, C.M., Snell, J.L.: Introduction to Probability, 2nd revised edn. Am. Math. Soc., Providence (1997)
Guralnick, R., Montgomery, S.: Frobenius–Schur indicators for subgroups and the Drinfeld double of Weyl groups. Trans. Am. Math. Soc. 361(7), 3611–3632 (2009)
Hanlon, P.: The action of S n on the components of the Hodge decomposition of Hochschild homology. Mich. Math. J. 37(1), 105–124 (1990)
Hatcher, A.: Algebraic Topology. Cambridge University Press, Cambridge (2002)
Holte, J.M.: Carries, combinatorics, and an amazing matrix. Am. Math. Mon. 104(2), 138–149 (1997)
Humphreys, J.E.: Introduction to Lie Algebras and Representation Theory. Graduate Texts in Mathematics, vol. 9. Springer, New York (1972)
Joni, S.A., Rota, G.-C.: Coalgebras and bialgebras in combinatorics. Stud. Appl. Math. 61(2), 93–139 (1979)
Karlin, S., Taylor, H.M.: A First Course in Stochastic Processes, 2nd edn. Academic Press, New York (1975)
Kashina, Y.: A generalized power map for Hopf algebras. In: Hopf Algebras and Quantum Groups, Brussels, 1998. Lecture Notes in Pure and Appl. Math., vol. 209, pp. 159–175. Dekker, New York (2000)
Kleshchev, A., Ram, A.: Representations of Khovanov-Lauda-Rouquier algebras and combinatorics of Lyndon words. Math. Ann. 349(4), 943–975 (2011)
Kolchin, V.F., Sevast’yanov, B.A., Chistyakov, V.P.: Random Allocations. V.H. Winston, Washington (1978). Translated from the Russian, Translation edited by A.V. Balakrishnan, Scripta Series in Mathematics
Kolmogoroff, A.N.: Über das logarithmisch normale Verteilungsgesetz der Dimensionen der Teilchen bei Zerstückelung. Dokl. Akad. Nauk SSSR 31, 99–101 (1941)
Lalonde, P., Ram, A.: Standard Lyndon bases of Lie algebras and enveloping algebras. Trans. Am. Math. Soc. 347(5), 1821–1830 (1995)
Landers, R., Montgomery, S., Schauenburg, P.: Hopf powers and orders for some bismash products. J. Pure Appl. Algebra 205(1), 156–188 (2006)
Leclerc, B.: Dual canonical bases, quantum shuffles and q-characters. Math. Z. 246(4), 691–732 (2004)
Levin, D.A., Peres, Y., Wilmer, E.L.: Markov Chains and Mixing Times. Am. Math. Soc., Providence (2009). With a chapter by James, Propp, G. and Wilson, David B.
Linchenko, V., Montgomery, S.: A Frobenius–Schur theorem for Hopf algebras. Algebr. Represent. Theory 3(4), 347–355 (2000). Special issue dedicated to Klaus Roggenkamp on the occasion of his 60th birthday
Lothaire, M.: Combinatorics on Words. Cambridge Mathematical Library. Cambridge University Press, Cambridge (1997). With a foreword by Roger Lyndon and a preface by Dominique Perrin; corrected reprint of the 1983 original, with a new preface by Perrin
Macdonald, I.G.: Symmetric Functions and Hall Polynomials, 2nd edn. Oxford Mathematical Monographs. Clarendon, New York (1995). With contributions by Zelevinsky, A., Oxford Science Publications
Majid, S.: Foundations of Quantum Group Theory. Cambridge University Press, Cambridge (1995)
Milnor, J.W., Moore, J.C.: On the structure of Hopf algebras. Ann. Math. 81, 211–264 (1965)
Montgomery, S.: Hopf Algebras and Their Actions on Rings. CBMS Regional Conference Series in Mathematics, vol. 82. (1993). Published for the Conference Board of the Mathematical Sciences, Washington, DC
Patras, F.: Construction géométrique des idempotents Eulériens. Filtration des groupes de polytopes et des groupes d’homologie de Hochschild. Bull. Soc. Math. Fr. 119(2), 173–198 (1991)
Patras, F.: La décomposition en poids des algèbres de Hopf. Ann. Inst. Fourier (Grenoble) 43(4), 1067–1087 (1993)
Patras, F.: L’algèbre des descentes d’une bigèbre graduée. J. Algebra 170(2), 547–566 (1994)
Pollett, P.K.: Quasi-stationary distributions: A bibliography (2011)
Reutenauer, C.: Free Lie Algebras. London Mathematical Society Monographs. New Series, vol. 7. Clarendon, New York (1993). Oxford Science Publications
Reutenauer, C.: Free lie algebras. In: Handbook of Algebra, vol. 3, pp. 887–903. North-Holland, Amsterdam (2003)
Rosso, M.: Some applications of quantum shuffles. In: Deformation Theory and Symplectic Geometry, Ascona, 1996. Math. Phys. Stud., vol. 20, pp. 249–258. Kluwer Academic, Dordrecht (1997)
Rosso, M.: Quantum groups and quantum shuffles. Invent. Math. 133(2), 399–416 (1998)
Rosso, M.: Groupes quantiques et algèbres de battage quantiques. C. R. Math. Acad. Sci. 320(2), 145–148 (1995)
Saliola, F.: Eigenvectors for a random walk on a left-regular band. Adv. Appl. Math. 48(2), 306–311 (2012)
Saloff-Coste, L.: Lectures on finite Markov chains. In: Lectures on Probability Theory and Statistics, Saint-Flour, 1996. Lecture Notes in Math., vol. 1665, pp. 301–413. Springer, Berlin (1997)
Saloff-Coste, L.: Total variation lower bounds for finite Markov chains: Wilson’s lemma. In: Random Walks and Geometry, pp. 515–532. Walter de Gruyter GmbH & Co. KG, Berlin (2004)
Schmitt, W.R.: Antipodes and incidence coalgebras. J. Comb. Theory, Ser. A 46(2), 264–290 (1987)
Schmitt, W.R.: Hopf algebras of combinatorial structures. Can. J. Math. 45(2), 412–428 (1993)
Schmitt, W.R.: Incidence Hopf algebras. J. Pure Appl. Algebra 96(3), 299–330 (1994)
Schmitt, W.R.: Hopf algebra methods in graph theory. J. Pure Appl. Algebra 101(1), 77–90 (1995)
Schramm, O., Smirnov, S., Garban, C.: On the scaling limits of planar percolation. Ann. Probab. 39(5), 1768–1814 (2011)
Shnider, S., Sternberg, S.: Quantum Groups: from Coalgebras to Drinfeld Algebras, a Guided Tour. Graduate Texts in Mathematical Physics, vol. II. International Press, Cambridge (1993)
Solomon, L.: A decomposition of the group algebra of a finite Coxeter group. J. Algebra 9, 220–239 (1968)
Stanley, R.P.: A symmetric function generalization of the chromatic polynomial of a graph. Adv. Math. 111(1), 166–194 (1995)
Stanley, R.P.: Enumerative Combinatorics. Vol. 1. Cambridge Studies in Advanced Mathematics, vol. 49. Cambridge University Press, Cambridge (1997). With a foreword by Gian-Carlo Rota, Corrected reprint of the 1986 original
Stanley, R.P.: Enumerative Combinatorics. Cambridge Studies in Advanced Mathematics. Vol. 2, vol. 62. Cambridge University Press, Cambridge (1999). With a foreword by Gian-Carlo Rota and appendix 1 by Sergey Fomin
Stanley, R.P.: Generalized riffle shuffles and quasisymmetric functions. Ann. Comb. 5(3–4), 479–491 (2001). Dedicated to the memory of Gian-Carlo Rota (Tianjin, 1999)
Stembridge, J.R.: Enriched P-partitions. Trans. Am. Math. Soc. 349(2), 763–788 (1997)
Sweedler, M.E.: Hopf Algebras. Mathematics Lecture Note Series. Benjamin, New York (1969)
Tate, J., Oort, F.: Group schemes of prime order. Ann. Sci. Éc. Norm. Super. 3, 1–21 (1970)
van Doorn, E.A.: Quasi-stationary distributions and convergence to quasi-stationarity of birth-death processes. Adv. Appl. Probab. 23(4), 683–700 (1991)
Warren, D., Seneta, E.: Peaks and Eulerian numbers in a random sequence. J. Appl. Probab. 33(1), 101–114 (1996)
Werner, W.: Lectures on two-dimensional critical percolation. In: Statistical Mechanics. IAS/Park City Math. Ser., vol. 16, pp. 297–360. Am. Math. Soc., Providence (2009)
Wilf, H.S.: Generating Functionology. Academic Press, Boston (1990)
Wilson, D.B.: Mixing times of Lozenge tiling and card shuffling Markov chains. Ann. Appl. Probab. 14(1), 274–325 (2004)
Zelevinsky, A.V.: Representations of Finite Classical Groups: a Hopf Algebra Approach. Lecture Notes in Mathematics, vol. 869. Springer, Berlin (1981)
Zhou, H.: Examples of Multivariate Markov Chains with Orthogonal Polynomial Eigenfunctions. ProQuest, Ann Arbor (2008). Ph.D. thesis, Stanford University
Acknowledgements
P. Diaconis was supported in part by NSF grant DMS 0804324. C.Y. Amy Pang was supported in part by NSF grant DMS 0652817. A. Ram was supported in part by ARC grant DP0986774.
We thank Marcelo Aguiar, Federico Ardila, Nantel Bergeron, Megan Bernstein, Dan Bump, Gunner Carlsson, Ralph Cohen, David Hill, Peter J. McNamara, Susan Montgomery and Servando Pineda for their help and suggestions, and the anonymous reviewer for a wonderfully detailed review.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Diaconis, P., Pang, C.Y.A. & Ram, A. Hopf algebras and Markov chains: two examples and a theory. J Algebr Comb 39, 527–585 (2014). https://doi.org/10.1007/s10801-013-0456-7
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10801-013-0456-7