
Abstract
The human eye is responsible for the visual reorganization of objects in the environment. The eye is divided into different layers and front/back areas; however, the most important part is the retina, responsible for capturing light and generating electrical impulses for further processing in the brain. Several manual and automated methods have been proposed to detect retinal diseases, though these techniques are time-consuming, inefficient, and unpleasant for patients. This research proposes a deep learning-based CSR detection employing two imaging techniques: OCT and fundus photography. These input images are manually augmented before classification, followed by training of DarkNet and DenseNet networks through both datasets. Moreover, pre-trained DarkNet and DenseNet classifiers are modified according to the need. Finally, the performance of both networks on their datasets is compared using evaluation parameters. After several experiments, the best accuracy of 99.78%, the sensitivity of 99.6%, specificity of 100%, and the F1 score of 99.52% were achieved through OCT images using the DenseNet network. The experimental results demonstrate that the proposed model is effective and efficient for CSR detection using the OCT dataset and suitable for deployment in clinical applications.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
The eye is a light-sensitive organ that provides vision in humans. The human eyes consist of the following parts: iris; which is the colored area of the eye and controls the amount of light entering the eye; cornea; which is the transparent layer on the front and assists in focusing the light; pupil; is the blackish round opening that allows the entry of light, conjunctive; is a thin tissue layer which covers front area except cornea, and lens focuses the light on the retina of the eye. However, most area of the eyeball is filled with a colorless gel called vitreous. Moreover, there is a lining consisting of light-sensing cells called the retina on the back of the eye. Photoreceptive cells in the retina, cone, and rod cells, can spot the light rays and transmit this information to the brain using the optic nerves. In the center of the retina, there is a small area called the macula, which is responsible for central vision [14]. While viewing an object, rays of light from that object pass through the vitreous and focus on the retina. Following that, the cells in the retina convert these light signals into impulses and send them through millions of optic nerve neurons. The cornea's irregular shape bends the light rays at different angles, which can sometimes form blurry images. Another function of the cornea is to protect the eye from other particles and start the refractive process. The cornea is an integral part of the eye, and minor damage can cause visual impairment [10]. Figure 1 [22] depicts the detailed anatomy of the human eye.

Human Eye Anatomy [22]
Any damage or disorder of the cornea, retina, pupil, or sclera can cause temporary or permanent vision loss. Some of the common visual disorders are macular degeneration, leading to central vision loss in old age, cataract or clouding of the lens, which causes blurry vision, glaucoma due to increased intraocular pressure with long-term visual impairment, optic neuritis occurs due to the inflammation of optic nerve because of multiple conditions including immune reaction, retinitis or the inflammation of the retina and central serous retinopathy (CSR) due to fluid builds up in the macula. CSR is the fourth most common disease of the retina and mostly affects men in the age range of 20 to 50, while the affected females are slightly older. The most common associated problems of CSR are hyperopic, myopic shift, micropsia, central scotoma, reduced central sensitivity, and metamorphopsia [34]. CSR is clinically diagnosed using multiple tests with techniques such as tonometry to measure the intraocular pressure, slit lamp, OCT, and fundoscopy to examine the retina, and fluorescein angiography for taking fluorescence-labeled retinal images.
OCT (optical coherence tomography) is an imaging method based on light, which is low coherence and generates 2D and 3D images dispersed from the biological tissues. However, this technique is routinely used in medical fields and nondestructive testing. Additionally, this imaging technique has attracted the interest of doctors and eye specialists as it produces morphology of tissues with high pixel resolution compared to other methods such as MRI and ultrasound.
The technology has evolved and improved diagnostics techniques in ophthalmology with the passage of time. The detection and diagnosis of disorders [6] such as hypertensive retinopathy [3, 4], diabetic retinopathy [1, 27, 30], CSR [18], and papilledema [2, 31] can be performed using Deep Learning and Machine Learning methodologies with fundus [5, 7] and OCT scans. The imaging of CSR using the fundus method is the process in which 3D images are represented by 2D employing reflected light for projecting the retina tissues on the imaging plane. The color areas of the fundus image represent the reflected light intensities of the waveband. Figure 2 [33] depicts the fundus image of the eye with landmarks.

Fundus Image with Landmarks [33]
The leakage site located in CSR is very crucial, and it is mainly done using fluorescein angiography. This method is widely used in clinical practice nevertheless has several drawbacks, including patients’ discomfort and time consumption. However, fundoscopy is a suitable method of analyzing CSR characteristics, but they are less specific than the angiogram.
Artificial intelligence (AI) technology has advanced in recent years, and it is currently used in every sphere of life for the benefit of humanity [35]. In healthcare, several attempts are being undertaken to integrate AI technology to improve medical treatments. Machine learning is developing new methods and techniques for disease identification at early stages to prevent further damage to disorder and reduce health-threatening factors worldwide [16, 19]. However, an automatic identification of CSR using the image processing of fundus images in patients without angiograms can improve the diagnosis. Image processing operations segment the main areas of the retina, such as the macula and optic disk and extract the area of interest for further classification purpose. Several recent investigations focus on the classification of normal and CSR patients using convolutional neural networks, support vector machines, ensemble classifier, and random forest. The diagnosis of the CSR using fundus images with the convolutional neural network improved the accuracy and reduced time consumption compared to the clinical diagnostic methods. Figure 3 shows different retinal layers in OCT image.

Different retinal layers in OCT image OPL: outer plexiform layer, ILM: inner limiting membrane, IS/OS: photoreceptor inner segment and outer segment layers, BM: Bruch’s membrane. RPE: retinal pigment epithelium layer [38]
This paper presents a convolutional neural network-based framework for the classification of normal and CSR using fundus images and OCT images. Furthermore, a comparative analysis of transfer learning-based models is performed on different networks, followed by data augmentation.
The rest of the paper is organized as follows. Section 2 analyzes the researches carried out in the past and their drawbacks. Section 3 evaluates the detailed discussion of the proposed method for classification of CSR. Section 4 discusses the experiment procedures of proposed method. Section 5 discusses the outcomes and findings of the proposed framework, and conclusion of the research is presented in section 6.
2 Literature review
The Convolutional Neural Network (CNN) is a deep learning (DL) architecture that requires unstructured data (such as scanned images) as inputs, that allocate learning weights and biases to different viewpoints/entities in the image and have the option to separate one from the other based on their significance. The development of the CNN declares the capacity to learn automatically specific to a training dataset as per the predictive modeling problem. However, the image classification can be the best example of CNN and their outcomes can easily be determined to specific features anywhere on input images. The input eye scan image goes through multiple convolutional layers which have the self-learning ability to focus on the CSR patch. After the final CNN layer, the model can accurately segment the image and determine the exact location and extent of the CSR patch. Similar to this patch, numerous other features related to various anomalies are focused on in different DL models. In this section, the use of various ML/DL techniques in the automatic detection of CSR disease has been reviewed, along with a brief description of the results and limitations.
The automatic identification of chorioretinopathy is helpful in clinical practices to save the patient eye sight; however, detecting a significant chorioretinopathy such as central serous chorioretinopathy using fundus images has not been explored frequently in recent literature.
Yang Wen et al. [39] designed a deep learning-based framework to detect CSR and classify acute and severe chorioretinopathy using fundus images. It was difficult to distinguish between the two groups of chorioretinopathy due to large similarities; however, this study employed a deep neural network and combined discriminative loss and focal loss to improve classification accuracy. Experimental results revealed that proposed method achieved 98.87% sensitivity, 97.69% accuracy, and 99.58% precision.
Carlos A. Ferreira et al. [13] proposed a subtraction method of images between early and late frames using vessel segmentation, vessel imprinting, image registration, early frames candidate selection, optic disc segmentation, optic disc, and background removal and leak segmentation. The proposed algorithm efficiently solved all problems to avoid compromise on performance and achieved a 0.87 precision value, 0.78 and 0.72 sensitivity value, and dice coefficient of 0.8 and 0.77 for the training and testing set.
Menglu Chen et al. [9], proposed a deep learning method to detect leakage areas of CSR using fundus angiography. The authors employed 2104 fundus images for processing in which macula and optic disk segmentation were performed using U-Net. However, leakage point segmentation was performed through an Attention Gated Network (AGN). The results showed that using AGN, 60.7% accuracy was achieved in correspondence to ground truth, and the dice value was 0.81; however, combining the elimination process to eliminate false positives, accuracy and dice value improved up to 93.4% and 0.949 respectively.
J. David et al. [11] proposed a framework to predict the changes produced due to CSR in the retina using the fundus images, and image processing methods. This study presented a solution to the growth in CSR cases and patient discomfort caused by fluorescein dye injection. The proposed method comprised of wavelet transform and contrast enhancement for removing noise and image enhancement and compensation in pre-processing stage, which is combined with a segmentation algorithm for the detection of CSR leakage area automatically.
Zhen, Yi MD et al. [42] proposed deep learning method for the detection of CSR using fundus images. A total of 2504 OCT images were acquired form a publically available dataset. The proposed method removed noise and normalized the dataset and split into 1:8:1 ratio for the testing, training and validation purpose. Moreover, Inception-V3 classifier was employed for training. For analyzing the algorithm's capability, non-parametric receiver operating characteristic analyses were performed along with two expert ophthalmologists independently reviewing the dataset to compare the performance of the proposed method employing Cohen's Kappa coefficients. The proposed method efficiently detects the CSR and attained an AUROC value of 0.934.
WJ Lee et al. [28] proposed a time domain-based assessment of CSR characteristics using fundus images. This study used different analytical methods such as leakage point intensity, staining patterns, and serous retinal detachment area with minimal variations. Moreover, the authors classified 52 cases into normal, chronic, and acute CSR classes. Results showed mixed patterns in fundus images with different intensities and patterns in retinal pigment epithelium areas and attained 97.61% accuracy.
Marta Zola et al. [44] conducted a pattern analysis of chronic central serous chorioretinopathy using fundus images. This study used the Heidelberg Retina Angiography with a cutoff barrier filter of 500 nm and excitation light of 488 nm. The changes in FAF patterns were investigated in 157 patients with chronic CSR. The most common alteration was changed in hyper-autofluorescence zones where hyper-reflective dots emerged or disappeard. The hypo-autofluorescence takes an average of 24 months to develop from granular hypo-autofluorescence. Hence, there were no patterns to anticipate the emergence of confluent CSR.
Tetsuju Sekiryu et al. [32] proposed a technique to investigate infrared fundus images for CSR detection. This research employed 83 eyes of 80 CSR patients from the same institution. The short-wave autofluorescence (SW-AF), infrared auto-fluorescence (IR-AF), optical coherence tomography, and fundus color images were assessed. Analysis revealed that granular hyper-SW-AF was observed in 64% of eyes, and granular hyper-IR-AF was observed in 27% of eyes.
Umut Asli Dinc et al. [12] evaluated chronic and acute CSR using fundus image patterns. The proposed investigation comprised of cross-sectional, prospective, and single-center using OCT images, fundus angiography images. A total of 42 eyes images with both chronic and acute CSR were acquired from Marine Care Hospital. The angiography's leakage point showed that 80% of acute and 88.2% of chronic cases had Hypo-autofluorescence. The fluid accumulation in subretinal areas corresponding to Hypo-autofluorescence was shown in 92% of acute and 82.3% of chronic CSR cases. Therefore, fundus autofluorescence can differentiate acute and chronic CSR using different analytical characteristics.
Quick and accurate identification of CSR preserves the macula from severe damage and serves as a foundation for detecting different retinal disorders. CSR uses Optical Coherence Tomographic (OCT) images; however, designing a computationally accurate and efficient method remains difficult. Hassan et al. [17] developed an automatic and accurate framework to detect CSR using OCT images employing pre-trained convolutional neural networks. The proposed method consists of image filtering, and enhancement to remove noise and improve contrast of OCT images. Pre-processed data was classified using three different CNN models; GoogleNet, ResNet-18, and AlexNet. The experimental results showed that AlexNet outperforms the other CNN models by achieving 99.64% accuracy.
S. Khalid et al. [25] proposed a machine learning-based method to detect CSR using the OCT images. This method consists of sparse de-noise of the retinal image followed by segmentation which generates the layers of the retina showing retinal thickness, followed by extraction of feature and the classification of processed using SVM. The proposed method utilized 90 OCT images to train the SVM classifier. This framework scored 99.86% specificity, 100% sensitivity, and 98.92% accuracy.
Z Ji et al. [23] proposed the Hessian-based Aggregate comprehensive Laplacian of Gaussian algorithm that identified CSR without retinal layers segmentation. A total of 23 OCT scans of longitudinal SD-OCT were used for the testing stage. In addition, the implementation process required B scans filtration into tiny mass regions reliant upon nearby convexity by storing the log-scale-normalized convolution reactions of each gLoG filter. Testing results showed that the proposed method achieved a positive predictive value of 93.65%, dice coefficient of 94.35%, and true positive value of 95.15%.
B. Hassan et al. [20] developed a rational technique for grading and segmentation of CSR as per medical requirements. The proposed method comprised of the five stages: pre-processing, segmentation of the retinal layer using a tensor graph, detection of retinal fluids, feature selection, and classification using SVM. The proposed method achieved a true negative rate of 100%, a true positive rate of 96.77%, and a precision of 97.7%.
Several researchers observed that combining ML algorithms and OCT images efficiently classify the CSR. R V Teja et al. [36] proposed a method which based on a combination of deep lab algorithm and random forest classifier for CSR detection. A total 768 scans were employed for testing the proposed method. The proposed method was compared to expert’s analysis achieving f1-score of 86.23%.
Table 1 summarizes the past papers for the detection of CR using OCT and fundus imaging methods.
This section significantly analyzes the researches carried out in the past to detect CSR and retinal fluid caused by CSR. In all instances, the quantity of the dataset is the most important factor in determining the validity of the results. According to some of the researchers, their results indicate an accurate diagnosis of the CSR disease based on models trained on OCT and fundus imaging datasets. However, there is still a room of improvement in terms of computational complexity, class imbalance issue, and data augmentation techniques. Additionally, most datasets are insufficient in size to fully train the models to detect any subsequent abnormalities in image data provided to them for evaluation.
In the field of machine learning and deep learning, one notable drawback is the reliance on private and local datasets for training and testing models. The use of such datasets raises concerns about the integrity and authenticity of the results obtained from these models. The lack of transparency regarding the data sources and the inability of independent researchers to replicate and verify the findings hinder the progress and trustworthiness of the research.
To address these limitations, this research introduces a novel framework that aims to detect Central Serous Retinopathy (CSR) using publicly available OCT and fundus images. The utilization of publicly accessible datasets enhances the transparency and reproducibility of the study. Researchers can easily access the same datasets and evaluate the proposed framework, which fosters collaboration and fosters the advancement of knowledge in the field.
The framework leverages two pre-trained neural networks: DenseNet and DarkNet. These networks have been extensively trained on large-scale datasets and have demonstrated high performance in various computer vision tasks. By utilizing these pre-trained models, the proposed framework can benefit from the learned representations and features extracted from diverse and extensive datasets.
The first component of the framework involves employing DenseNet, a powerful convolutional neural network architecture, to process OCT (Optical Coherence Tomography) images. OCT images provide detailed cross-sectional information about the retinal layers, enabling the detection of CSR-related abnormalities. The pre-trained DenseNet model can efficiently analyze the OCT images and extract relevant features indicative of CSR.
The second component utilizes DarkNet, another widely used deep neural network, to analyze fundus images. fundus images capture the overall appearance of the retina and provide valuable insights into various retinal conditions. By leveraging the pre-trained DarkNet model, the framework can effectively identify CSR-related patterns and abnormalities in the fundus images.
The combination of these two neural networks within the proposed framework enables comprehensive analysis and detection of CSR using publicly available OCT and fundus images. By utilizing pre-trained models and publicly accessible datasets, the research aims to enhance the integrity and authenticity of the results, allowing for greater collaboration, verification, and further advancements in the field of CSR detection.
It is important to note that while the utilization of public datasets improves transparency, the quality and representativeness of these datasets should still be carefully considered. Researchers must ensure that the public datasets adequately capture the diversity and complexity of real-world cases to achieve reliable and generalizable results.
The major advantages of this research are mentioned below:
-
1.
This paper presents an modified DenseNet, and DarkNet classifiers for the classification of CSR. However, the modification in the layers of the model has been performed according to the problem statement.
-
2.
The modified DenseNet classifier model stimulates the feature reuse but also minimizes the number of parameters which improves the overall accuracy of the detection of CSR. As a result, it demonstrates improved computational and overall memory performance.
-
3.
The modified architecture of the DarkNet consists of 61 layers including 5 blocks (1,2,4,4,2) which are a mixture of residual, 2 layers of 3 × 3 Conv, and 1 × 1 Conv. This modified architecture in terms of accuracy, outperformed other pre-trained classifiers.
-
4.
The data augmentation strategy improves the proposed system's efficiency and enhances the CSR detection rate.
-
5.
The proposed CSR detection model will give agility, sustainability flexibility, and cost effectiveness, allowing it to better serve humanity.
Table 2 shows advantages of the proposed work that is the limitations in the existing methods.
3 Proposed method
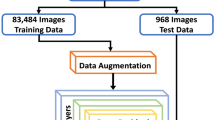
This research considers two different imaging techniques that are OCT, and fundus photography for CSR detection. Initially, both imaging modalities' input images are augmented to increase training and testing data so that the neural network can perform efficiently. Following that, two modified pre-trained convolutional neural networks DarkNet, and DenseNet were trained on OCT and fundus images. Subsequently, the trained networks were used to classify the testing dataset into normal and CSR-affected images. Moreover, the experimental results were compared using the evaluation parameters to assess the performance of proposed framework. Figure 4 shows the framework of the proposed comparative method for classifying CSR and normal class using fundus and OCT images.

Framework of Proposed Method
3.1 Dataset
Retinal disease can be diagnosed using imaging techniques such as MRI, angiography, OCT, and fundus images. This research employed different datasets for the training of proposed method, one of that is OCT imaging acquired from a publically available Optical Coherence Tomography Image Database (OCTID) [15]. These OCT images were gathered using a raster scan machine with a two mm scan length and 512 × 1024 pixel resolution. The employed dataset consists of 309 OCT images, of which normal images are 102, and CSR-affected images are 207. The fundus imaging dataset was acquired from a publicly available Kaggle repository [24]. There are 1000 fundus scans from 39 different classes, and they are part of the 209,494 fundus images used for testing and training the deep learning algorithms. Moreover, these images were collected from Joint Shantou International Eye Centre (JSIEC). This research utilized a total of 52 fundus images for two classes, of which 14 are CSR-affected images and 38 are normal images Fig. 5 shows the fundus images of CSR and normal class acquired form Kaggle dataset. However, Fig. 6 shows the OCT images of CSR-affected and normal class acquired form OCTID dataset.

Fundus Images of (a) normal eye (b) CSR-affected eye

OCT Images (a) normal eye (b) CSR-affected Eye
3.2 Data augmentation
Before classification of the training set, input images are augmented. In a convolutional neural network, a larger number of input images are required to obtain the required classification accuracy. Therefore, data augmentation is performed, which increases the total number of standard and CSR images of both the OCT and fundus database. The augmentation algorithm-generated five images from a single image dataset using image processing, which implies that the data sets increased five times [29, 43]. In classification problems, the training data is used for the training of the network, but testing data is different from training data and is used to test the efficiency of the trained network. Different data augmentation methods such as shearing, rotation, and horizontal and vertical flip were applied to attain several variants of the pre-processed images.
-
1
Shearing: Shearing alters the orientation of the original image. This approach shifts the pixels of the image in a clockwise direction by using specified angles. This study utilized a 45-degree shearing angle for image transformation.
-
2
Rotation: An image is rotated between 0 to 360 degrees in a clockwise direction in the rotation technique. The 120-degree rotation was used in this study for image transformation.
-
3
Horizontal and Vertical Flip: In this method of flipping, the pixels move either horizontally or vertically.
The original datasets OCT and fundus contains 116 and 245 images respectively, therefore, the data augmentation technique was much needed to train the deep learning architecture. However, after applying data augmentation techniques, the datasets size extended to 580 and 1220 for OCT and fundus dataset respectively. Figure 7 shows the graphical representation of normal and CSR-affected classes for both datasets before and after augmentation.

Graphical Representation of Data (a) before augmentation (b) after augmentation
3.3 Classification
The process of classifying two classes into their respective labels is known as classification. Two modified pre-trained networks DarkNet and DenseNet were trained using the real labels of the two classes, and assessed using validation data without the labels to obtain the output confusion matrix. The modification details of both networks are given below.
The weights in the filter of the pre-trained convolutional neural network can be calculated through the parameters given below.
Where h represents the height of the filter, w represents the width of the filter, and c represents number of channels in the input image.
Similarly, by putting zeros between each filter element, the layer widens the filters. The dilation factor controls the step size for sampling the input, or the filter's up-sampling factor. This function can be calculated through the following equation.
In addition, the total number of parameters in convolutional layer can be calculated as:
The output width and height of the convolutional layer is calculated by:
3.3.1 DenseNet
Each layer in the DenseNet design receives additional input from previous layers and passes its collection of features to all subsequent layers using concatenation technique. Each layer receives collective knowledge from the earlier layers as each layer inherits the function set from the earlier levels; the model can be thin and compact, with fewer channels. Moreover, the increase in rate k represents the extra number of channels for each layer. As a result, it demonstrates improved computational and memory performance.
In general, classic CNNs compute the output layers (lth) by applying a nonlinear transformation Hl (.) to the preceding layer's output Xl-1.
However, DenseNet concatenate the layer output functionality maps with the inputs rather than sum them. DenseNet provides a simple communication mechanism for enhancing information flow across layers: The lth layer accepts input from all preceding levels' features: The equation is then converted once again into:
where [X0, X1, X2, …, Xl−1] is a single tensor created by the concatenation of preceding layers' output maps. Hl (.) is a non-linear transformation function among the functions. There are three key operations in this function: batch normalization (BN), activation (ReLU), and pooling and convolution (CONV).
Batch Norm (BN) and ReLu with 3 × 3 convolution are finished for each layer of the composition, with an output vector of features of the k channels. After BN-ReLU-11 Conv, the BN-ReLU-33 Conv layer was used to reduce the size and complexity of the model. The layers are of 1 × 1 Conv after 2 × 2 average pooling, and the feature map size set the same in each DenseNet block. In addition, a softmax classifier is employed in the classification layer [21, 41]. The block diagram of the modified DenseNet is shown in Fig. 9, which consists of 4 dense block layers, originally, there were 3 dense blocks, and the third layer (BN + Relu + conv) was also removed from each dense block. Additionally, there are 60 layers in the model shown, a set of convolution and pooling layers after each dense block including four convolution and four pooling layers. In the dense block, there is a set of two layers, the first layer includes a batch normalization layer, a Relu layer, and 3 convolution layers, and the second layer includes the batch normalization layer, the Relu layer, 5 convolution layers, and transition layer. The modified network model stimulates the feature reuse but also minimizes the number of parameters which improves the overall accuracy of the detection of CSR. Figure 8 shows the modified architecture of DenseNet.

Modified Architecture of DenseNet
3.3.2 DarkNet
DarkNet is a fast and effective (depending upon the batch size, training data, and epochs) open source neural network framework. However, it may be used to recognize objects in real-time and classify images up to 1000 different categories. Convolution (Conv), a mixture of Relu layer, 2-D convolution, residual (consisting of 1 × 1 Conv and 3 × 3 Conv), and batch normalization are among the 32 layers that make up the DarkNet. The model consists of 5 blocks that are a mixture of (residual, 3 × 3 Conv, and 1 × 1 conv). The layers in each block increases as we proceed to the next block of DarkNet [37, 40]. In the existing DarkNet architecture, some modifications were made to enhance the accuracy of detection and preserve the necessary processing pace of the model. The modified architecture of the DarkNet consists of 61 layers including 5 blocks (1,2,4,4,2) which are a mixture of residual, 2 layers of 3 × 3 Conv, and 1 × 1 Conv. The number of blocks in the third and fourth layers were reduced from 8 to 4, and in the fifth block was reduced to two; however, the number of convolution layers of 3 × 3 in each block were increased up to 2 layers instead of one layer. Figure 9 shows the modified architecture of DarkNet.

Modified Architecture of DarkNet
4 Experiments
A deep learning-based binary classification model have been proposed in this study for CSR classification. Initially, CSR and fundus images were augmented to increase the number of images in the dataset. Following that, two pre-trained modified classifiers DenseNet and DarkNet were employed for the classification of normal and CSR-affected images. Moreover, evaluation parameters were used to compare the performance of both networks on OCT and fundus images.
4.1 Experiment setup
It is critical to properly train the model on the dataset before evaluating it. Therefore, the dataset employed for evaluating the efficiency of the proposed model is split into two sets i.e. training and testing. In this research, the dataset is divided into 70% for training and 30% into testing data. In neural network training, some parameters are usually the weights of the connections. However, during the training phase, these parameters are usually learned; therefore, the input dataset tunes the required parameters. These parameters usually include learning rate, epochs, and batch size. The parameters include learning rate of 0.0001, 12 epochs, and frequency of 18 for DarkNet and DenseNet training using fundus images. Similarly, the DarkNet and DenseNet training using OCT images utilized a learning rate of 0.0001, 12 epochs, and a frequency of 21. Table 3 shows the tabular representation of learning parameters.
4.2 Evaluation matrices
The metrics values used for the model performance quantification are termed as evaluation parameters. The selection of evaluation parameters depends upon machine learning tasks, such as regression, clustering, ranking, topic modeling, and classification. Regression and classification are the major tasks of supervised learning, that mostly consist of machine learning applications. Evaluation parameters for evaluating the classification models include F1 score, accuracy, confusion matrix, sensitivity, specificity, logarithmic loss, and area under curve. This study used the following parameters for evaluation; confusion matrix, accuracy, specificity, and sensitivity [8].
The confusion matrix is the detailed breakdown of every class's incorrect and correct classification outcome. When the confusion matrix is generated, four types of outputs can result.
-
1.
True Positive (TP): It predicts the observation of the class, which is the member of that class.
-
2.
True Negative (TN): It predicts that this observation is not a member of the class, and it is not also a member of that class.
-
3.
False Negative (FN): It predicts that this observation is not a member of the class but is a member of that class.
-
4.
False Positive (FP): It predicts that this observation is a member of a class that is not a member of that class.
-
5.
Accuracy: The correctly predicted data of testing set in percentage is called accuracy. It can be found by the division of correct predictions and total predictions.
$$\mathrm{Accuracy}=\frac{\mathrm{TN}+\mathrm{TP}}{\left(\mathrm{TN}+\mathrm{FP}+\mathrm{TP}+\mathrm{FN}\right)}\times 100$$(7) -
6.
F1 score: It is also the classification accuracy measure, which considers both recall and precision of the testing set to compute the result. Precision is the division of true positives by all predicted positive values, whereas recall is the division of true positives with all actual positives.
$$\mathrm F1-\mathrm{score}=2\mathrm x\frac{Precision\;x\;Recall}{Precision+Recall}$$(8) -
7.
Sensitivity: The proportionality measure of the actual positive observations is predicted as true positives. It implies that there is another actual positive observation proportion that can be predicted as incorrect as negatives.
$$\mathrm{Sensitivity}=\frac{\mathrm{TP}}{\mathrm{FN}+\mathrm{TP}}$$(9) -
8.
Specificity: The proportionality measure of the actual negative observations is predicted as true negatives. It implies that there is another actual negative observation proportion that can be predicted as incorrect as positives.
$$\mathrm{Specificity}=\frac{\mathrm{TP}}{\mathrm{FP}+\mathrm{TP}}$$(10)
In this research, two imaging modalities OCT and Fundus photography were compared in this research using two separate pre-trained neural networks, DarkNet and DenseNet. It can be observed that fundus images achieved the highest accuracy of 98.72%, the sensitivity of 98.28%, and an F1-score of 99.13% using the DenseNet neural network. CSR classification using OCT images has the highest accuracy of 99.78%, the sensitivity of 99.68%, and an F1 score of 99.84% for the DenseNet neural network. From the comparison of parameters of both imaging methods, it can be concluded that OCT image classification has slightly higher values compared to fundus image classification.
In the same way, DenseNet attained a good performance on both images compared to DarkNet based on the evaluation of parameters. It can be concluded that the proposed method using OCT images has outperformed in terms of efficiency and complexity even though pre-processing and segmentation was not utilized, that reduced the method's time complexity and space complexity.
Figures 10, 11, 12 and 13 shows the training curves of DenseNet on OCT images, DarkNet on OCT images, DenseNet on fundus images, and DarkNet on fundus images respectively with validation accuracy of 99.13%, 97.19%, 100%, and 100%, respectively.

Training Curve of Modified DarkNet using OCT Images
Figure 11 shows the accuracy and loss curve of DarkNet training using OCT images.

Training Curve of Modified DarkNet using Fundus Images
Figure 12 shows the accuracy and loss curve of DenseNet of fundus images.

Training Curve of Modified DenseNet using Fundus Images
Figure 13 shows the accuracy and loss curve of DarkNet using fundus images.

Training Curve of Modified DenseNet using OCT Images
Table 4 shows the ablation study of modified DenseNet architecture with data augmentation techniques.
In Table 5, ablation study is presented for the 4 experiments performed with modified versions of DenseNet network and augmentation of data. In experiment 1, total 3 layers of dense block, 2 layers of convolution layer and 4 layers of max pooling were used in the modified architecture of Dense Net with no data augmentation. This experiment attained a higher error rate and low f1-score. Similarly, in experiment 2, there are 3 dense blocks, 2 convolution layer, and 3 max pooling layers with 3 times data augmentation. This experiment showed a slightly better results than experiment 1. Experiment 3 involves 4 dense blocks, 4 convolutional layers, and 3 max pooling layers with 4 times data augmentation and achieved better results than experiment 2. In experiment 4, dense blocks, convolutional layers, and max pooling layers were set to 4 with 6 times data augmentation technique. However, it gives the same results as the proposed method. Hence the proposed method with 4 dense blocks, 4 max pooling layers, and 4 convolutional layer is suitable and finalized in the architecture of DenseNet, which performed better with error rate of 0.0022 and F1 score of 0.9984. Table 5 shows the ablation study of modified DarkNet architecture with data augmentation techniques.
Table 5 shows the summary of ablation study for the DarkNet experiments on different setups. In total, 4 experiments were performed by modifying the architecture of DarkNet and data augmentation. Experiment 1 employs 3 convolutional blocks, 4 convolutional layers with no data augmentation technique and attained high error rate and low f1-score. Similarly, experiment 2 was tested that includes 5 convolutional blocks, 5 convolutional layers without average pooling layer that slightly improved the efficiency. Furthermore, the third experiment consist of 5 convolutional blocks, 3 convolutional layers, and 1 average pooling layer with four times data augmentation and improved the results. In experiment 4, 5 convolutional blocks, 4 convolutional layers, and average pooling layers were set to 1 with 6 times data augmentation technique. However, it gives the same results as the proposed method. Hence the proposed method with 5 convolutional blocks, 5 convolutional layers, and 1 average pooling layer is suitable and finalized in the architecture of DarkNet, which performed better with error rate of 0.0065 and F1 score of 0.9952.
5 Results and discussion
Computationally advanced and automated reliable detection of CSR through retinal images has remained a challenge. This study proposed an efficient framework for advanced and accurate CSR detection deploying pre-trained Convolutional Neural Networks through retinal images. A data augmentation technique was used to increase the number of images in the datasets. Moreover, the pre-trained are utilized for image classification and further employed on publically available retinal images dataset. The classified images are of high quality and have little to no noise. The images were captured using a high-quality camera with good lighting conditions. Therefore, the noise levels are low enough that they neither need de-noising nor significantly impact the classification accuracy. In future, the techniques for de-noising [26] can be used on the noised images. The classification schemes and data augmentation method outperformed other proposed techniques in the literature. The results attained after experiments are given below. Figure 14 shows the confusion matrix for the testing set for DenseNet with OCT images, DarkNet with OCT images, DenseNet with fundus images, and DarkNet with fundus images.

Confusion Matrix of (a) DarkNet with Fundus Images (b) DenseNet with Fundus Images (c) DarkNet with OCT Images (d) DenseNet with OCT Images
Figure 15 depicts a graphical comparison of modified DenseNet and DarkNet for fundus images based on the evaluation parameters.

Comparison of Networks using Fundus Images
Figure 16 shows the graphical comparison of modified DenseNet and DarkNet for OCT images.

Comparison of Networks using OCT Images
5.1 Effect of learning parameters
5.1.1 Effect of change in epochs
Maximum number of epochs have a direct effect of accuracy up to some extent and then the curve normalizes. In case of both the DarkNet and DenseNet, accuracy rapidly increases with the increase in epochs from 0. The networks achieve their best accuracies at epoch 9 but more generalization is achieved at epoch 12 as seen in the curve below. Figure 17 shows the effect of change in epochs.

Accuracy vs Epochs
5.1.2 Effect of change in learning rate
In case of transfer learning, learning rate has a negligible effect on accuracy in transferable layers. On the other hand, learning rate can alter the decay in loss of training. As seen from the graph below, learning rate of 0.0001s is best suited for both the networks as both are pre-trained networks. Figure 18 shows the effect of change in learning rate.

Accuracy vs Learning Rate
5.1.3 Effect of change in batch size
Similar to learning rate, minimum batch size also exhibits same behavior for accuracy. Considering small number of images in database, a batch size of 62 is considered for experiments to have maximum results with acceptable computational complexity. Figure 19 shows effect of change in batch size.

Accuracy vs Batch Size
5.2 Comparative analysis
Table 6 presents the comparative analysis of the proposed methods with existing studies on both imaging techniques utilizing different detection algorithms.
The proposed model enhances the CSR detection rate, which means it can detect instances of CSR more accurately than other models. This is likely due to the use of efficient pre-processing techniques, implementation of modified DenseNet and DarkNet classification models, and data augmentation, as well as other techniques used in the model's design.
Moreover, the proposed CSR detection model is agile, sustainable, flexible, and cost-effective, which suggests that it may have advantages over other models in terms of accuracy, speed, resource usage, adaptability, and affordability.
6 Conclusion
Central serous retinopathy is a retinal disease that affects the macula in the eye's retina, damaging the vision and causing loss of vision if not detected at early stages, which may take preventive measures for aversion to impairment. Suffering from any impairment, we need assistance in daily work, which makes life difficult for everyone. However, an early diagnosis of a disease means more optimal treatment for CSR patients. Artificial intelligence is developing new innovative technologies for the development and welfare of the human race. Several automated systems have been proposed in the literature to detect CSR. However, they all possesses some drawbacks including time complexity, computational complexity, class imbalance issues, and low accuracy and proven to be inaccurate. In contrast, this research proposes a fully automatic detection of CSR using OCT and fundus images employing modified DenseNet and DarkNet deep learning classifiers. The framework of the proposed method consists of manual augmentation, training using DarkNet and DenseNet, and testing of the trained model. The comparative analysis revealed that DenseNet performed well compared to DarkNet and achieved 98.72% accuracy for fundus images and 99.78% accuracy for OCT images. This research significantly contributes to applying retinal images to advance the body of knowledge in detecting CSR from retinal images. Besides, it also constitutes as a decision support system to further advance the decision-making for clinicians and scientists.
This research has some limitations. First, the number of retinal images used for testing and training were limited. Therefore, data augmentation is performed. Moreover, this research used partially compatible hardware for experiments which resulted in utilizing more time. Nevertheless of above mentioned limitations, the developed methodology depicts a promising performance and put forward the need for further research.
This research demonstrates the suitability of the proposed framework for clinical use in assisting doctors and clinicians with diagnostic decisions related to retinal diseases. The efficiency of the system makes it capable of becoming a preference in the medical field for real-time applications. It can also help clinicians and doctors diagnose CSR and provide decision support for treatment planning. Moreover, the proposed method could be extended in early prediction of the CSR progression through retinal images. Therefore, in future designing, a combination of hardware and software to automatically detect CSR can be implemented with diversity of other CNN architectures and image processing techniques.
Data availability
Data sharing not applicable to this article as no datasets were generated or analyzed during the current study.
References
Abràmoff MD, Lavin PT, Birch M, Shah N, Folk JC (2018) Pivotal trial of an autonomous AI-based diagnostic system for detection of diabetic retinopathy in primary care offices. NPJ Digital Medicine 1:1–8. https://doi.org/10.1038/s41746-018-0040-6
Akbar S, Akram MU, Sharif M, Tariq A (2017) Decision support system for detection of papilledema through fundus retinal images. J Med Syst 41:1–16. https://doi.org/10.1007/s10916-017-0712-9
Akbar S, Akram MU, Sharif M, Tariq A, Khan SA (2018) Decision support system for detection of hypertensive retinopathy using arteriovenous ratio. Artif Intell Med 90:15–24. https://doi.org/10.1016/j.artmed.2018.06.004
Akbar S, Akram MU, Sharif M, Tariq A, Ullah Yasin U (2018) Arteriovenous ratio and papilledema based hybrid decision support system for detection and grading of hypertensive retinopathy. Comput Methods Programs Biomed 154:123–141. https://doi.org/10.1016/j.cmpb.2017.11.014
Akbar S, Hassan T, Akram MU, Yasin UU, Basit I (2017) AVRDB: annotated dataset for vessel segmentation and calculation of arteriovenous ratio. In Proceedings of the International Conference on Image Processing, Computer Vision, and Pattern Recognition (IPCV) (pp 129–134)
Akbar S, Sharif M, Akram MU, Saba T, Mahmood T, Kolivand M (2019) Automated techniques for blood vessels segmentation through fundus retinal images: A review. Microsc Res Tech 82:153–170. https://doi.org/10.1002/jemt.23172
Akram MU, Akbar S, Hassan T, Khawaja SG, Yasin U, Basit I (2020) Data on fundus images for vessels segmentation, detection of hypertensive retinopathy, diabetic retinopathy and papilledema. Data Brief 29:105282–105296. https://doi.org/10.1016/j.dib.2020.105282
Böger B, Fachi MM, Vilhena RO, Cobre AF, Tonin FS, Pontarolo R (2021) Systematic review with meta-analysis of the accuracy of diagnostic tests for COVID-19. Am J Infect Control 49:21–29. https://doi.org/10.1016/j.ajic.2020.07.011
Chen M, Jin K, You K, Xu Y, Wang Y, Yip CC, Ye J (2021) Automatic detection of leakage point in central serous chorioretinopathy of fundus fluorescein angiography based on time sequence deep learning. Graefes Arch Clin Exp Ophthalmol 259:2401–2411. https://doi.org/10.1007/s00417-021-05151-x
Coiner B, Pan H, Bennett ML, Bodien YG, Iyer S, O’Neil-Pirozzi TM, Stern E (2019) Functional neuroanatomy of the human eye movement network: a review and atlas. Brain Struct Funct 224:2603–2617. https://doi.org/10.1007/s00429-019-01932-7
David J, Kumar AS, Viji V (2009) Tracing of Central serous retinopathy from retinal fundus images. In 13th International Conference on Biomedical Engineering. Singapore, (pp 331–334)
Dinc UA, Tatlipinar S, Yenerel M, Görgün E, Ciftci F (2011) Fundus autofluorescence in acute and chronic central serous chorioretinopathy. Clin Exp Optom 94:452–457. https://doi.org/10.1111/j.1444-0938.2011.00598.x
Ferreira CA, Penas S, Silva J, Mendonca AM (2019) Quantitative assessment of central serous chorioretinopathy in angiographic sequences of retinal images. In 2019 IEEE 6th Portuguese Meeting on Bioengineering (ENBENG). Lisbon, Portugal, (pp 1–4)
Forrester JV, Dick AD, McMenamin PG, Roberts F, Pearlman E (2020) The eye e-book: basic sciences in practice. Elsevier Health Sciences, Amsterdam
Gholami P, Roy P, Parthasarathy MK, Lakshminarayanan V (2020) OCTID: Optical coherence tomography image database. Comput Electr Eng 81:106532–106547. https://doi.org/10.1016/j.compeleceng.2019.106532
Gull S, Akbar S (2021) Artificial intelligence in brain tumor detection through MRI scans: advancements and challenges. Artif Intell Internet of Things 241–276. https://doi.org/10.1201/9781003097204
Hassan SAE, Akbar S, Gull S, Rehman A, Alaska H (2021) Deep learning-based automatic detection of central serous retinopathy using optical coherence tomographic images. In 2021 1st International Conference on Artificial Intelligence and Data Analytics (CAIDA). Riyadh, Saudia Arabia, (pp 206–211)
Hassan SA, Akbar S, Rehman A, Saba T, Kolivand H, Bahaj SA (2021) Recent Developments in Detection of Central Serous Retinopathy through Imaging and Artificial Intelligence Techniques–A Review. IEEE Access 9:168731–168748. https://doi.org/10.1109/ACCESS.2021.3108395
Hassan SA, Gull S, Akbar S, Hanif I, Iqbal S, Aziz MW (2021) Artificial intelligence in coronavirus detection: Recent findings and future perspectives. Intell Comput Appl COVID-19 pp 23–48. https://doi.org/10.1201/9781003141105
Hassan B, Hassan T (2019). Fully automated detection, grading and 3D modeling of maculopathy from OCT volumes. In 2019 2nd International Conference on Communication, Computing and Digital systems (C-CODE). Islamabad, Pakistan, (pp. 252–257)
Huang Z, Zhu X, Ding M, Zhang X (2020) Medical image classification using a light-weighted hybrid neural network based on PCANet and DenseNet. IEEE Access 8:24697–24712. https://doi.org/10.1109/ACCESS.2020.2971225
Human Eye Anatomy (2022) National Keratoconus Foundation. https://nkcf.org/about-keratoconus/how-the-human-eye-works/. Accessed 13 Aug 2021
Ji Z, Chen Q, Wu M, Niu S, Fan W, Yuan S, Sun Q (2018) Beyond retinal layers: A large blob detection for subretinal fluid segmentation in sd-oct images. In International Conference on Medical Image Computing and Computer-Assisted Intervention.11071:372-380. https://doi.org/10.1007/978-3-030-00934-2_42
Kaggle Retinal Imaging Dataset (2021) https://www.kaggle.com/linchundan/fundusimage1000. Accessed 10 Aug 2021
Khalid S, Akram MU, Hassan T, Nasim A, Jameel A (2017) Fully automated robust system to detect retinal edema, central serous chorioretinopathy, and age related macular degeneration from optical coherence tomography images. Biomed Res Int 17:127–183. https://doi.org/10.1155/2017/7148245
Kumar M, Jindal MK, Kumar M (2021) A novel attack on monochrome and greyscale Devanagari CAPTCHAs. Trans Asian Low-Resour Lang Inf Process 20:1–30. https://doi.org/10.1145/3439798
Kumar S, Kumar B (2018) Diabetic retinopathy detection by extracting area and number of microaneurysm from colour fundus image. In 2018 5th International Conference on Signal Processing and Integrated Networks (SPIN). Noida, India, (pp 359–364)
Lee WJ, Lee JH, Lee BR (2016) Fundus autofluorescence imaging patterns in central serous chorioretinopathy according to chronicity. Eye 30(10):1336–1342. https://doi.org/10.1038/eye.2016.113
Li T, Zuo R, Xiong Y, Peng Y (2021) Random-drop data augmentation of deep convolutional neural network for mineral prospectivity mapping. Nat Resour Res 30:27–38. https://doi.org/10.1007/s11053-020-09742-z
Mohammadpoory Z, Nasrolahzadeh M, Mahmoodian N, Haddadnia J (2019) Automatic identification of diabetic retinopathy stages by using fundus images and visibility graph method. Measurement 140:133–141. https://doi.org/10.1016/j.measurement.2019.02.089
Saba T, Akbar S, Kolivand H, Ali Bahaj S (2021) Automatic detection of papilledema through fundus retinal images using deep learning. Microsc Res Tech 84:3066–3077. https://doi.org/10.1002/jemt.23865
Sekiryu T, Iida T, Maruko I, Saito K, Kondo T (2010) Infrared fundus autofluorescence and central serous chorioretinopathy. Invest Ophthalmol Vis Sci 51:4956–4962. https://doi.org/10.1167/iovs.09-5009
Sharib A et al (2014) Retinal Image Registration and Statistical Ethnicity ATLAS. https://www.researchgate.net/figure/Landmarks-in-Fundus-image_fig1_260332495. Accessed 12 Dec 2021
Sheeba O (2021) A review on imaging techniques and algorithms for the detection of central serous retinopathy. In 2021 5th International Conference on Computing Methodologies and Communication (ICCMC). Erode, India, (pp 1244–1248)
Shoukat A, Akbar S (2021) Artificial intelligence techniques for glaucoma detection through retinal images: State of the art. Artif Intell Internet Things, 209–240. https://doi.org/10.1201/9781003097204
Teja RV, Manne SR, Goud A, Rasheed MA, Dansingani KK, Chhablani J, Jana S (2019) Classification and quantification of retinal cysts in oct b-scans: efficacy of machine learning methods. In 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC). Berlin, Germeny, (pp 48–51)
Vasavi S, Priyadarshini NK, Harshavaradhan K (2020) Invariant feature-based darknet architecture for moving object classification. IEEE Sens J 21:11417–11426. https://doi.org/10.1109/JSEN.2020.3007883
Wang F, Zhang Q, Deegan AJ, Chang J, Wang RK (2018) Comparing imaging capabilities of spectral domain and swept source optical coherence tomography angiography in healthy subjects and central serous retinopathy. Eye Vision 5:1–9. https://doi.org/10.1186/s40662-018-0113-2
Wen Y, Chen L, Qiao L, Deng Y, Dai S, Chen J, Zhou C (2020) On automatic detection of central serous chorioretinopathy and central exudative chorioretinopathy in fundus images. In 2020 IEEE International Conference on Bioinformatics and Biomedicine (BIBM). Seoul, Korea (South), (pp 1161–1165)
Xiong J, Cui W, Zhang W, Zhang X (2019) YOLOv3-darknet with adaptive clustering anchor box for Intelligent dry and wet garbage identification and classification. In 2019 11th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC). Hangzhou, China, (pp 80–84)
Xu L, Bennamoun M, Boussaid F, An S, Sohel F (2019) Coral classification using densenet and cross-modality transfer learning. In 2019 International Joint Conference on Neural Networks (IJCNN). Budapest, Hungary, (pp 1–8)
Zhen Y, Chen H, Zhang X, Meng X, Zhang J, Pu J (2020) Assessment of central serous chorioretinopathy depicted on color fundus photographs using deep learning. Retina 40:1558–1564. https://doi.org/10.1097/IAE.0000000000002621
Zheng Q, Yang M, Tian X, Jiang N, Wang D (2020) A full stage data augmentation method in deep convolutional neural network for natural image classification. Discrete Dynamics in Nature and Society, 2020. https://doi.org/10.1155/2020/4706576
Zola M, Chatziralli I, Menon D, Schwartz R, Hykin P, Sivaprasad S (2018) Evolution of fundus autofluorescence patterns over time in patients with chronic central serous chorioretinopathy. Acta Ophthalmol 96:835–839. https://doi.org/10.1111/aos.13742
Acknowledgements
This work was supported by the Riphah Artificial Intelligence Research (RAIR) Lab, Riphah International University, Faisalabad Campus, Pakistan.
Funding
Open Access funding provided by the Qatar National Library. Qatar National Library and Qatar University Internal Grant IRCC-2021–010 funded this work.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors of this paper have no conflict of interest.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hassan, S.A., Akbar, S. & Khan, H.U. Detection of central serous retinopathy using deep learning through retinal images. Multimed Tools Appl 83, 21369–21396 (2024). https://doi.org/10.1007/s11042-023-16206-y
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-023-16206-y