
Abstract
Over the past decades, a particular focus is given to research on machine learning techniques for speech processing applications. However, in the past few years, research has focused on using deep learning for speech processing applications. This new machine learning field has become a very attractive area of study and has remarkably better performance than the others in the various speech processing applications. This paper presents a brief survey of application deep learning for various speech processing applications such as speech separation, speech enhancement, speech recognition, speaker recognition, emotion recognition, language recognition, music recognition, speech data retrieval, etc. The survey goes on to cover the use of Auto-Encoder, Generative Adversarial Network, Restricted Boltzmann Machine, Deep Belief Network, Deep Neural Network, Convolutional Neural Network, Recurrent Neural Network and Deep Reinforcement Learning for speech processing. Additionally, it focuses on the various speech database and evaluation metrics used by deep learning algorithms for performance evaluation.








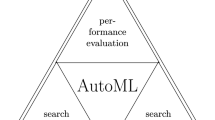
adopted from Arindam Jatti et al. [100])


Similar content being viewed by others


Data Availability
Enquiries about data availability should be directed to the authors.
References
Sarker, I. H. (2021). Deep learning: A comprehensive overview on techniques, taxonomy, applications and research directions. SN Computer Science, 2(6), 1–20.
Otter, D. W., Medina, J. R., & Kalita, J. K. (2020). A survey of the usages of deep learning for natural language processing. IEEE Transactions on Neural Networks and Learning Systems, 32(2), 604–624.
Alam, M., Samad, M. D., Vidyaratne, L., Glandon, A., & Iftekharuddin, K. M. (2020). Survey on deep neural networks in speech and vision systems. Neurocomputing, 417, 302–321.
Watanabe, S., & Araki, S. (2019). Introduction to the issue on far-field speech processing in the era of deep learning: speech enhancement, separation, and recognition. IEEE Journal of Selected Topics in Signal Processing, 13(4), 785–786.
Raj, D., Denisov, P., Chen, Z., Erdogan, H., Huang, Z., He, M., Watanabe, S., Du, J., Yoshioka, T., Luo, Y., & Kanda, N. (2021). Integration of speech separation, diarization, and recognition for multi-speaker meetings: System description, comparison, and analysis. In 2021 IEEE spoken language technology workshop (SLT), pp. 897–904. IEEE.
Suh, J. Y., Bennett, C. C., Weiss, B., Yoon, E., Jeong, J., & Chae, Y. (2021). Development of speech dialogue systems for social ai in cooperative game evironments. In IEEE region 10 symposium (TENSYMP 2021).
Hanifa, R. M., Isa, K., & Mohamad, S. (2021). A review on speaker recognition: Technology and challenges. Computers & Electrical Engineering, 90, 107005.
Ntalampiras, S. (2021). Speech emotion recognition via learning analogies. Pattern Recognition Letters, 144, 21–26.
Deng, L., Hassanein, K., & Elmasry, M. (1994). Analysis of the correlation structure for a neural predictive model with application to speech recognition. Neural Networks, 7(2), 331–339.
Cohen, J., Kamm, T., & Andreou, A. (1995). Vocal tract normalization in speech recognition: Compensation for system systematic speaker variability. The Journal of the Acoustical Society of America, 97(5), 3246–3247.
Schuster, M., & Paliwal, K. K. (1997). Bidirectional recurrent neural networks. IEEE Transactions on Signal Processing, 45(11), 2673–2681. https://doi.org/10.1109/78.650093
Hermansky, H., Ellis, D. P. W., & Sharma, S. (2000). Tandem connectionist feature extraction for conventional HMM systems. In 2000 IEEE international conference on acoustics, speech, and signal processing proceedings (Cat. No.00CH37100), Istanbul, Turkey, vol. 3, pp. 1635–1638. https://doi.org/10.1109/ICASSP.2000.862024.
Povey, D., Kingsbury, B., Mangu, L., Saon, G., Soltau, H., & Zweig, G. (2005). fPME: Discriminatively trained features for speech recognition. In Proceedings IEEE ICASSP’05, pp. 961–964.
Morgan, N., et al. (2005). Pushing the envelope: Aside [speech recognition]. IEEE Signal Processing Magazine, 22(5), 81–88. https://doi.org/10.1109/MSP.2005.1511826
Grezl, F., Karafiat, M., Kontar, S., & Cernocky, J. (2007). Probabilistic and bottle-neck features for LVCSR of meetings. In 2007 IEEE international conference on acoustics, speech and signal processing-ICASSP '07, Honolulu, HI, pp. IV-757-IV-760. https://doi.org/10.1109/ICASSP.2007.367023.
Morgan, N. (2012). Deep and wide: Multiple layers in automatic speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 20(1), 7–13. https://doi.org/10.1109/TASL.2011.2116010
Rabiner, L. R., & Schafer, R. W. (2007). Introduction to digital speech processing. Now Publishers Inc.
Van Gilse, P. H. G. (1948). Another method of speech without larynx. Acta Oto-Laryngologica, 36(sup78), 109–110.
Everest, F. A., & Pohlmann, K. (2009). Master handbook of acoustics. McGraw-Hill/TAB Electronics.
Haneche, H., Ouahabi, A., & Boudraa, B. (2021). Compressed sensing-speech coding scheme for mobile communications. Circuits, Systems, and Signal Processing. https://doi.org/10.1007/s00034-021-01712-x
Sonawane, A., Inamdar, M. U., & Bhangale, K. B. (2017). Sound based human emotion recognition using MFCC & multiple SVM. In 2017 international conference on information, communication, instrumentation and control (ICICIC), pp. 1–4. IEEE.
Bhangale, K. B., Titare, P., Pawar, R., & Bhavsar, S. (2018). Synthetic speech spoofing detection using MFCC and radial basis function SVM. IOSR Journal of Engineering (IOSRJEN), 8(6), 55–61.
Bhangale, K. B., & Mohanaprasad, K. (2021). A review on speech processing using machine learning paradigm. International Journal of Speech Technology, 24(2), 367–388.
Nirmal, J., Zaveri, M., Patnaik, S., & Kachare, P. (2014). Voice conversion using general regression neural network. Applied Soft Computing, 24, 1–12.
Amrouche, A., Taleb-Ahmed, A., Rouvaen, J. M., & Yagoub, M. C. E. (2009). Improvement of the speech recognition in noisy environments using a nonparametric regression. International Journal of Parallel, Emergent and Distributed Systems, 24(1), 49–67.
LeCun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature, 521, 436–444. https://doi.org/10.1038/nature14539
Bengio, Y., Courville, A., & Vincent, P. (2013). Representation learning: A review and new perspectives. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(8), 1798–1828. https://doi.org/10.1109/TPAMI.2013.50
Ng, A. Y., & Jordan, M. I. (2001). On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes. In Proceedings of the 14th international conference on neural information processing systems, Cambridge, MA, USA: MIT Press, 2001, pp. 841–848.
LeCun, Y., Kavukcuoglu, K., & Farabet, C. (2010). Convolutional networks and applications in vision. In Proceedings of 2010 IEEE international symposium on circuits and systems, pp. 253–256.
Purwins, H., Li, Bo., Virtanen, T., Schlüter, J., Chang, S.-Y., & Sainath, T. (2019). Deep learning for audio signal processing. IEEE Journal of Selected Topics in Signal Processing, 13(2), 206–219.
Chen, X. W., & Lin, X. (2014). Big data deep learning: Challenges and perspectives. IEEE Access, 2, 514–525.
Shrestha, A., & Mahmood, A. (2019). Review of deep learning algorithms and architectures. IEEE Access, 7, 53040–53065.
Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep learning. In Adaptive computation and machine learning series (p. 775). MIT Press. https://mitpress.mit.edu/books/deep-learning.
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., & Salakhutdinov, R. (2014). Dropout: A simple way to prevent neural networks from overfitting. The Journal of Machine Learning Research, 15(1), 1929–1958.
Strom, N. (2015). Scalable distributed DNN training using commodity GPU cloud computing. In Sixteenth annual conference of the international speech communication association.
Jolliffe, I. T. (2002). Mathematical and statistical properties of sample principal components. In: Principal Component Analysis. Springer Series in Statistics. Springer, New York. https://doi.org/10.1007/0-387-22440-8_3.
Noda, K. (2013). Multimodal integration learning of object manipulation behaviors using deep neural networks. In Proceedings of the IEEE/RSJ international conference on intelligent robots and systems, pp. 1728–1733.
Lu, X., Matsuda, S., Hori, C., & Kashioka, H. (2012). Speech restoration based on deep learning autoencoder with layer-wised pretraining. In 13th annual conference of the international speech communication association.
Lu, X., Matsuda, S., Hori, C., & Kashioka, H. (2012). Speech restoration based on deep learning autoencoder with layer-wised learning. In INTERSPEECH, Portland, Oregon, Sept. 2012.
Lu, X., Tsao, Y., Matsuda, S., & Hori, C. (2013). Speech enhancement based on deep denoising auto-encoder. In Proceedings of interspeech, pp. 436–440.
Lu, X., Tsao, Y., Matsuda, S., & Hori, C. (2014). Ensemble modeling of denoising autoencoder for speech spectrum restoration. In Proceedings of the annual conference of the international speech communication association, INTERSPEECH, pp 885–889.
Sun, M., Zhang, X., Van Hamme, H., & Zheng, T. F. (2016). Unseen noise estimation using separable deep auto encoder for speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(1), 93–104. https://doi.org/10.1109/TASLP.2015.2498101.
Safari, R., Ahadi, S. M., & Seyedin, S. (2017). Modular dynamic deep denoising autoencoder for speech enhancement. In 2017 7th international conference on computer and knowledge engineering (ICCKE), Mashhad, pp. 254–259. https://doi.org/10.1109/ICCKE.2017.8167886.
Agrawal, P., & Ganapathy, S. (2019). Modulation filter learning using deep variational networks for robust speech recognition. IEEE Journal of Selected Topics in Signal Processing, 13(2), 244–253.
Leglaive, S., Alameda-Pineda, X., Girin, L., & Horaud, R. (2020). A recurrent variational autoencoder for speech enhancement. In ICASSP 2020–2020 IEEE international conference on acoustics, speech and signal processing (ICASSP), Barcelona, Spain, pp. 371–375. https://doi.org/10.1109/ICASSP40776.2020.9053164.
Li, Y., Zhang, X., Li, X., Zhang, Y., Yang, J., & He, Q. (2018). Mobile phone clustering from speech recordings using deep representation and spectral clustering. IEEE Transactions on Information Forensics and Security, 13(4), 965–977. https://doi.org/10.1109/TIFS.2017.2774505
Zhang, Q., & Hansen, J. H. L. (2018). Language/dialect recognition based on unsupervised deep learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(5), 873–882.
Chorowski, J., Weiss, R. J., Bengio, S., & van den Oord, A. (2019). Unsupervised speech representation learning using WaveNet autoencoders. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(12), 2041–2053.
Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems, pp. 2672–2680.
Mirza, M., & Osindero, S. (2014). Conditional generative adversarial nets. arXiv preprint arXiv:1411.1784.
Qian, Y., Hu, Hu., & Tan, T. (2019). Data augmentation using generative adversarial networks for robust speech recognition. Speech Communication, 114, 1–9.
Pascual, S., Serra, J., & Bonafonte, A. (2019). Time-domain speech enhancement using generative adversarial networks. Speech Communication, 114, 10–21.
Kaneko, T., Kameoka, H., Hojo, N., Ijima, Y., Hiramatsu, K., & Kashino, K. (2017). Generative adversarial network-based postfilter for statistical parametric speech synthesis. In 2017 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 4910–4914. IEEE.
Kaneko, T., Takaki, S., Kameoka, H., & Yamagishi J. (2017). Generative adversarial network-based postfilter for STFT spectrograms. In Interspeech, pp. 3389–3393.
Hsu, C. C., Hwang, H. T., Wu, Y. C., Tsao, Y., & Wang H. M. (2017). Voice conversion from unaligned corpora using variational autoencoding wasserstein generative adversarial networks. arXiv preprint arXiv:1704.00849.
Mimura, M., Sakai, S., & Kawahara, T. (2017). Cross-domain speech recognition using nonparallel corpora with cycle-consistent adversarial networks. In 2017 IEEE automatic speech recognition and understanding workshop (ASRU), pp. 134–140. IEEE.
Hu, H., Tan, T., & Qian, Y. (2018). Generative adversarial networks based data augmentation for noise robust speech recognition. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 5044–5048. IEEE.
Freund, Y., & Haussler, D. (1992). Unsupervised learning of distributions on binary vectors using two layer networks. In Advances in neural information processing systems, pp. 912–919.
Larochelle, H., & Bengio, Y. (2008). Classification using discriminative restricted Boltzmann machines. In Proceedings of the 25th international conference on machine learning, pp. 536–543.
Wang, Y., & Wang, D. (2013). Towards scaling up classification-based speech separation. IEEE Transactions on Audio, Speech, and Language Processing, 21(7), 1381–1390. https://doi.org/10.1109/TASL.2013.2250961
Xu, Y., Du, J., Dai, L., & Lee, C. (2014). An experimental study on speech enhancement based on deep neural networks. IEEE Signal Processing Letters, 21(1), 65–68. https://doi.org/10.1109/LSP.2013.2291240
Shah, M., Chakrabarti, C., & Spanias, A. (2015). Within and cross-corpus speech emotion recognition using latent topic model-based features. EURASIP Journal on Audio, Speech, and Music Processing, 2015(1), 4.
Navamani, T. M. (2019). Efficient deep learning approaches for health informatics. In Deep learning and parallel computing environment for bioengineering systems (pp. 503–519). Elsevier. https://doi.org/10.1016/B978-0-12-816718-2.00014-2.
Rizk, Y., Hajj, N., Mitri, N., & Awad, M. (2019). Deep belief networks and cortical algorithms: A comparative study for supervised classification. Applied Computing and Informatics, 15(2), 81–93.
Mohamed, A. R., Dahl, G., & Hinton, G. (2009). Deep belief networks for phone recognition. In Nips workshop on deep learning for speech recognition and related applications, vol. 1, no. 9, p. 39.
Mohamed, A. R., Yu, D., & Deng L. (2010). Investigation of full-sequence training of deep belief networks for speech recognition. In Eleventh annual conference of the international speech communication association.
Mohamed, A.-R., Dahl, G. E., & Hinton, G. (2011). Acoustic modeling using deep belief networks. IEEE transactions on audio, speech, and language processing, 20(1), 14–22.
Zhang, X., & Wu, J. (2013). Deep belief networks based voice activity detection. IEEE Transactions on Audio, Speech, and Language Processing, 21(4), 697–710. https://doi.org/10.1109/TASL.2012.2229986
Sarikaya, R., Hinton, G. E., & Deoras, A. (2014). Application of deep belief networks for natural language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(4), 778–784. https://doi.org/10.1109/TASLP.2014.2303296
Wen, G., Li, H., Huang, J., Li, D., & Xun, E. (2017). Random deep belief networks for recognizing emotions from speech signals. Computational Intelligence and Neuroscience. https://doi.org/10.1155/2017/1945630
Wang, C., Wang, J., Santoso, A., Chiang, C., & Wu, C. (2018). Sound event recognition using auditory-receptive-field binary pattern and hierarchical-diving deep belief network. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(8), 1336–1351. https://doi.org/10.1109/TASLP.2017.2738443
Affonso, E. T., Rosa, R. L., & Rodríguez, D. Z. (2018). Speech quality assessment over lossy transmission channels using deep belief networks. IEEE Signal Processing Letters, 25(1), 70–74. https://doi.org/10.1109/LSP.2017.2773536
Hourri, S., & Kharroubi, J. (2020). A deep learning approach for speaker recognition. International Journal of Speech Technology, 23(1), 123–131.
Bengio, Y. (2009). Learning deep architectures for AI. Foundations and Trends in Machine Learning., 2(1), 1–127.
Kang, T. G., Kwon, K., Shin, J. W., & Kim, N. S. (2015). NMF-based Target source separation using deep neural network. IEEE Signal Processing Letters, 22(2), 229–233. https://doi.org/10.1109/LSP.2014.2354456
Nie, S., Liang, S., Liu, W., Zhang, X., & Tao, J. (2018). Deep learning based speech separation via NMF-style reconstructions. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(11), 2043–2055.
Zheng, N., & Zhang, X. (2019). Phase-aware speech enhancement based on deep neural networks. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(1), 63–76. https://doi.org/10.1109/TASLP.2018.2870742
Zhao, Y., Wang, Z., & Wang, D. (2019). Two-stage deep learning for noisy-reverberant speech enhancement. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(1), 53–62.
Dahl, G. E., Yu, D., Deng, L., & Acero, A. (2012). Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 20(1), 30–42. https://doi.org/10.1109/TASL.2011.2134090
Yu, D., Deng, L., & Seide, F. (2013). The deep tensor neural network with applications to large vocabulary speech recognition. IEEE Transactions on Audio, Speech, and Language Processing, 21(2), 388–396. https://doi.org/10.1109/TASL.2012.2227738
Narayanan, A., & Wang, D. (2014). Investigation of speech separation as a front-end for noise robust speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(4), 826–835. https://doi.org/10.1109/TASLP.2014.2305833
Wang, G., & Sim, K. C. (2014). Regression-based context-dependent modeling of deep neural networks for speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(11), 1660–1669. https://doi.org/10.1109/TASLP.2014.2344855
Xue, S., Abdel-Hamid, O., Jiang, H., Dai, L., & Liu, Q. (2014). Fast adaptation of deep neural network based on discriminant codes for speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(12), 1713–1725. https://doi.org/10.1109/TASLP.2014.2346313
Zhou, P., Jiang, H., Dai, L., Hu, Y., & Liu, Q. (2015). State-clustering based multiple deep neural networks modeling approach for speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(4), 631–642. https://doi.org/10.1109/TASLP.2015.2392944
Gao, J., Du, J., & Chen, E. (2019). Mixed-bandwidth cross-channel speech recognition via joint optimization of dnn-based bandwidth expansion and acoustic modeling. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(3), 559–571. https://doi.org/10.1109/TASLP.2018.2886739
Wu, C., Gales, M. J. F., Ragni, A., Karanasou, P., & Sim, K. C. (2018). Improving interpretability and regularization in deep learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(2), 256–265. https://doi.org/10.1109/TASLP.2017.2774919
Chen, K., & Salman, A. (2011). Learning speaker-specific characteristics with a deep neural architecture. IEEE Transactions on Neural Networks, 22(11), 1744–1756. https://doi.org/10.1109/TNN.2011.2167240
Tan, Z., Mak, M., & Mak, B. K. (2018). DNN-based score calibration with multitask learning for noise robust speaker verification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(4), 700–712.
Yu, H., Tan, Z., Ma, Z., Martin, R., & Guo, J. (2018). Spoofing detection in automatic speaker verification systems using DNN classifiers and dynamic acoustic features. IEEE Transactions on Neural Networks and Learning Systems, 29(10), 4633–4644.
Wang, Z., & Wang, D. (2019). Combining spectral and spatial features for deep learning based blind speaker separation. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(2), 457–468.
Lotfian, R., & Busso, C. (2019). Curriculum learning for speech emotion recognition from crowdsourced labels. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(4), 815–826.
Liu, B., Xu, Z., Sun, C., Wang, B., Wang, X., Wong, D. F., & Zhang, M. (2018). Content-oriented user modeling for personalized response ranking in chatbots. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(1), 122–133. https://doi.org/10.1109/TASLP.2017.2763243
Fukushima, K. (1988). Neocognitron: A hierarchical neural network capable of visual pattern recognition. Neural Networks, 1, 119–130.
LeCun, Y., Bottou, L., Bengio, Y., & Haffner, P. (1998). Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86, 2278–2324.
Hubel, D. H., & Wiesel, T. N. (1968). Receptive fields and functional architecture of monkey striate cortex. The Journal of Physiology., 195(1), 215–243.
Li, Z., Liu, F., Yang, W., Peng, S., & Zhou, J. (2021). A survey of convolutional neural networks: Analysis, applications, and prospects. IEEE Transactions on Neural Networks and Learning Systems. https://doi.org/10.1109/TNNLS.2021.3084827
Hou, J., Wang, S., Lai, Y., Tsao, Y., Chang, H., & Wang, H. (2018). Audio-visual speech enhancement using multimodal deep convolutional neural networks. IEEE Transactions on Emerging Topics in Computational Intelligence, 2(2), 117–128.
Luo, Y., Chen, Z., & Mesgarani, N. (2018). Speaker-independent speech separation with deep attractor network. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(4), 787–796.
Tan, T., Qian, Y., Hu, H., Zhou, Y., Ding, W., & Yu, K. (2018). Adaptive very deep convolutional residual network for noise robust speech recognition. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(8), 1393–1405.
Jati, A., & Georgiou, P. (2019). Neural predictive coding using convolutional neural networks toward unsupervised learning of speaker characteristics. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(10), 1577–1589.
An, N. N., Thanh, N. Q., & Liu, Y. (2019). Deep CNNs with self-attention for speaker identification. IEEE Access, 7, 85327–85337. https://doi.org/10.1109/ACCESS.2019.2917470
Nagrani, A., Chung, J. S., Xie, W., & Zisserman, A. (2020). Voxceleb: Large-scale speaker verification in the wild. Computer Speech & Language, 60, 101027.
Zhang, S., Zhang, S., Huang, T., & Gao, W. (2018). Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Transactions on Multimedia, 20(6), 1576–1590. https://doi.org/10.1109/TMM.2017.2766843
Zhao, J., Mao, X., & Chen, L. (2018). Learning deep features to recognise speech emotion using merged deep CNN. IET Signal Processing, 12(6), 713–721. https://doi.org/10.1049/iet-spr.2017.0320
Hossain, M. S., & Muhammad, G. (2019). Emotion recognition using deep learning approach from audio–visual emotional big data. Information Fusion, 49, 69–78.
Ocquaye, E. N. N., Mao, Q., Song, H., Xu, G., & Xue, Y. (2019). Dual exclusive attentive transfer for unsupervised deep convolutional domain adaptation in speech emotion recognition. IEEE Access, 7, 93847–93857.
Tripathi, S., Kumar, A., Ramesh, A., Singh, C., & Yenigalla, P. (2019). Deep learning based emotion recognition system using speech features and transcriptions. arXiv preprint arXiv:1906.05681.
Dinkel, H., Qian, Y., & Yu, K. (2018). Investigating raw wave deep neural networks for end-to-end speaker spoofing detection. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(11), 2002–2014.
DiPietro, R., & Hager, G. D. (2020). Deep learning: RNNs and LSTM. In Handbook of medical image computing and computer assisted intervention (pp. 503–519). Elsevier. https://doi.org/10.1016/B978-0-12-816176-0.00026-0.
Chung, J., Gulcehre, C., Cho, K., & Bengio, Y. (2014). Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555.
Graves, A., Mohamed, A., & Hinton, G. (2013). Speech recognition with deep recurrent neural networks. In 2013 IEEE international conference on acoustics, speech and signal processing, Vancouver, BC, pp. 6645–6649. https://doi.org/10.1109/ICASSP.2013.6638947.
Qin, C.-X., Dan, Qu., & Zhang, L.-H. (2018). Towards end-to-end speech recognition with transfer learning. EURASIP Journal on Audio, Speech, and Music Processing, 2018(1), 1–9.
de Benito-Gorron, D., Lozano-Diez, A., Toledano, D. T., & Gonzalez-Rodriguez, J. (2019). Exploring convolutional, recurrent, and hybrid deep neural networks for speech and music detection in a large audio dataset. EURASIP Journal on Audio, Speech, and Music Processing, 2019(1), 9.
Kang, J., Zhang, W.-Q., Liu, W.-W., Liu, J., & Johnson, M. T. (2018). Advanced recurrent network-based hybrid acoustic models for low resource speech recognition. EURASIP Journal on Audio, Speech, and Music Processing, 2018(1), 6.
Tang, Z., Wang, D., Chen, Y., Li, L., & Abel, A. (2018). Phonetic temporal neural model for language identification. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(1), 134–144.
Han, K., & Wang, D. (2014). Neural network based pitch tracking in very noisy speech. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 22(12), 2158–2168. https://doi.org/10.1109/TASLP.2014.2363410
Tan, K., & Wang, D. (2018). A convolutional recurrent neural network for real-time speech enhancement. In Interspeech, pp. 3229–3233.
Li, A., Yuan, M., Zheng, C., & Li, X. (2020). Speech enhancement using progressive learning-based convolutional recurrent neural network. Applied Acoustics, 166, 107347.
Vafeiadis, A., Fanioudakis, E., Potamitis, I., Votis, K., Giakoumis, D., Tzovaras, D., Chen, L., & Hamzaoui, R. (2019). Two-dimensional convolutional recurrent neural networks for speech activity detection. In International Speech Communication Association, pp. 2045–2049.
Shen, Z., Yong, B., Zhang, G., Zhou, R., & Zhou, Q. (2019). A deep learning method for Chinese singer identification. Tsinghua Science and Technology, 24(4), 371–378. https://doi.org/10.26599/TST.2018.9010121
Wu, Y., & Li, W. (2019). Automatic audio chord recognition with MIDI-trained deep feature and BLSTM-CRF sequence decoding model. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(2), 355–366.
Zhao, J., Mao, X., & Chen, L. (2019). Speech emotion recognition using deep 1D & 2D CNN LSTM networks. Biomedical Signal Processing and Control, 47, 312–323.
Yu, Y., Si, X., Changhua, Hu., & Zhang, J. (2019). A review of recurrent neural networks: LSTM cells and network architectures. Neural computation, 31(7), 1235–1270.
Goehring, T., Keshavarzi, M., Carlyon, R. P., & Moore, B. C. J. (2019). Using recurrent neural networks to improve the perception of speech in non-stationary noise by people with cochlear implants. The Journal of the Acoustical Society of America, 146(1), 705–718.
Sutton, R. S., Barto, A. G., & Williams, R. J. (1992). Reinforcement learning is direct adaptive optimal control. IEEE Control Systems, 12(2), 19–22.
Mnih,V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D., & Riedmiller, M. (2013). Playing atari with deep reinforcement learning. In NIPS deep learning workshop.
Sutton, R. S., McAllester, D., Singh, S., & Mansour, Y. (1999). Policy gradient methods for reinforcement learning with function approximation. In Proceedings of the 12th international conference on neural information processing systems, NIPS’99, pp. 1057–1063.
Weisz, G., Budzianowski, P., Su, P., & Gašić, M. (2018). Sample efficient deep reinforcement learning for dialogue systems with large action spaces. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(11), 2083–2097. https://doi.org/10.1109/TASLP.2018.2851664
Chen, L., Chang, C., Chen, Z., Tan, B., Gašić, M., & Yu, K. (2018). Policy adaptation for deep reinforcement learning-based dialogue management. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), Calgary, AB, pp. 6074–6078. https://doi.org/10.1109/ICASSP.2018.8462272.
Chen, L., Chen, Z., Tan, B., Long, S., Gašić, M., & Yu, K. (2019). AgentGraph: Toward universal dialogue management with structured deep reinforcement learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 27(9), 1378–1391. https://doi.org/10.1109/TASLP.2019.2919872
Shen, Y. L., Huang, C. Y., Wang, S. S., Tsao, Y., Wang, H. M., & Chi, T. S. (2019). Reinforcement learning based speech enhancement for robust speech recognition. In ICASSP 2019–2019 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 6750–6754. IEEE.
Rajapakshe, T., Rana, R., Latif, S., Khalifa, S., & Schuller, B. W. (2019). Pre-training in deep reinforcement learning for automatic speech recognition. arXiv preprint arXiv:1910.11256.
Kala, T., & Shinozaki, T. (2018). Reinforcement learning of speech recognition system based on policy gradient and hypothesis selection. In 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP), Calgary, AB, pp. 5759–5763, https://doi.org/10.1109/ICASSP.2018.8462656.
Lee, H., Chung, P., Wu, Y., Lin, T., & Wen, T. (2018). Interactive spoken content retrieval by deep reinforcement learning. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 26(12), 2447–2459.
Bui, H., & Chong, N. Y. (2019). Autonomous speech volume control for social robots in a noisy environment using deep reinforcement learning. In 2019 IEEE international conference on robotics and biomimetics (ROBIO), Dali, China, pp. 1263–1268. https://doi.org/10.1109/ROBIO49542.2019.8961810.
Su, M., Wu, C., & Chen, L. (2020). Attention-based response generation using parallel double Q-learning for dialog policy decision in a conversational system. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 28, 131–143. https://doi.org/10.1109/TASLP.2019.2949687
Zue, V., Seneff, S., & Glass, J. (1990). Speech database development at MIT: TIMIT and beyond. Speech Communication, 9(4), 351–356.
Panayotov, V., Chen, G., Povey, D., & Khudanpur, S. (2015). Librispeech: An asr corpus based on public domain audio books. In 2015 IEEE international conference on acoustics, speech and signal processing (ICASSP), pp. 5206–5210. IEEE.
Nagrani, A., Chung, J. S., & Zisserman, A. (2017). "Voxceleb: A large-scale speaker identification dataset. arXiv preprint arXiv:1706.08612.
Pearce, D., & Picone, J. (2002). Aurora working group: DSR front end LVCSR evaluation AU/384/02. In Institute for signal & information processing, Mississippi State University, Technical Report.
Sinha, R., Gales, M. J., Kim, D. Y., Liu, X. A., Sim, K. C., & Woodland, P. C. (2006). The CU-HTK mandarin broadcast news transcription system. In Proceedings of ICASSP 2006, May, 2006, pp. 1077–1080.
Barker, J., Watanabe, S., Vincent, E., & Trmal, J. (2018). The fifth'CHiME'speech separation and recognition challenge: Dataset, task and baselines. arXiv preprint arXiv:1803.10609.
Kinoshita, K., Delcroix, M., Gannot, S., Habets, E., Haeb-Umbach, R., Kellermann, W., Leutnant, V., Maas, R., Nakatani, T., Raj, B., Sehr, A., & Yoshioka, T. (2016). A summary of the REVERB challenge: state-of-the-art and remaining challenges in reverberant speech processing research. EURASIP Journal on Advances in Signal Processing. https://doi.org/10.1186/s13634-016-0306-6
Godfrey, J. J., Holliman, E. C., & McDaniel, J. (1992) SWITCHBOARD: telephone speech corpus for research and development. In [Proceedings] ICASSP-92: 1992 IEEE international conference on acoustics, speech, and signal processing, San Francisco, CA, USA, vol. 1, pp. 517–520. https://doi.org/10.1109/ICASSP.1992.225858.
Burkhardt, F., Paeschke, A., Rolfes, M., Sendlmeier, W. F., & Weiss, B. (2005). A database of German emotional speech. In Proceedings of Interspeech.
Busso, C., Bulut, M., Lee, C. C., Kazemzadeh, A., Mower, E., Kim, S., Chang, J. N., Lee, S., & Narayanan, S. S. (2008). IEMOCAP: Interactive emotional dyadic motion capture database. Journal of Language Resources and Evaluation, 42(4), 335–359.
Lotfian, R., & Busso, C. (2019). Building naturalistic emotionally balanced speech corpus by retrieving emotional speech from existing podcast recordings. IEEE Transactions on Affective Computing, 10(4), 471–483.
Black, D. (2014). Singing voice dataset.
Goto, M., Hashiguchi, H., Nishimura, T., & Oka, R. (2002). RWC music database: Popular, classical, and jazz music databases. In Proceedings of the 3rd international conference on music information retrieval (ISMIR 2002), pp. 287–288.
Hsu, C., & Jang, J. R. (2010). On the improvement of singing voice separation for monaural recordings using the MIR-1K dataset. IEEE Transactions on Audio, Speech, and Language Processing, 18(2), 310–319. https://doi.org/10.1109/TASL.2009.2026503
Varga, A., & Steeneken, H. J. M. (1993). Assessment for automatic speech recognition: II. NOISEX-92: A database and an experiment to study the effect of additive noise on speech recognition systems. Speech Communication, 12(3), 247–251.
Jensen, J., & Taal, C. H. (2016). An algorithm for predicting the intelligibility of speech masked by modulated noise maskers. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 24(11), 2009–2022.
Vincent, E., Gribonval, R., & Fevotte, C. (2006). Performance measurement in blind audio source separation. IEEE Transactions on Audio, Speech and Language Processing, 14(4), 1462–1469.
Funding
None.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Bhangale, K.B., Kothandaraman, M. Survey of Deep Learning Paradigms for Speech Processing. Wireless Pers Commun 125, 1913–1949 (2022). https://doi.org/10.1007/s11277-022-09640-y
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-022-09640-y