
Abstract
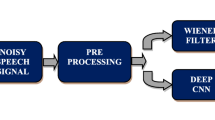
In this paper, novel early and late fusion convolutional neural networks (CNNs) are proposed for multi-channel speech enhancement. Two beamformers namely delay-and-sum and minimum variance distortionless response are used as prefilters to suppress the effect of noise in the input microphone array. Enhanced outputs of the two beamformers are to form two-channel input to the CNN and it is known as the early fusion CNN model. On the other hand, outputs of the beamformers are considered as inputs to the two individual CNNs separately. Further, outputs of CNNs are concatenated to form an input to the fully connected layers and it is known as the late fusion CNN model. Performance of the proposed early and late fusion CNNs is evaluated on the multi-conditional microphone array data simulated from the standard TIMIT dataset. Results demonstrate the superiority of our proposed models when compared to popular existing approaches.






Similar content being viewed by others

References
Allen, J.B., Berkley, D.A.: Image method for efficiently simulating small-room acoustics. J. Acoust. Soc. Am. 65(4), 943–950 (1979)
Araki, S., Hayashi, T., Delcroix, M., Fujimoto, M., Takeda, K., Nakatani, T.: Exploring multi-channel features for denoising-autoencoder-based speech enhancement. In: 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 116–120. IEEE (2015)
Bai, M.R., Ih, J.G., Benesty, J.: Acoustic Array Systems: Theory, Implementation, and Application. John Wiley & Sons (2013)
Buckley, K.: Spatial/spectral filtering with linearly constrained minimum variance beamformers. IEEE Trans. Acoust. Speech Signal Process. 35(3), 249–266 (1987)
Chen, J., Wang, D.: Long short-term memory for speaker generalization in supervised speech separation. J. Acoust. Soc. Am. 141(6), 4705–4714 (2017)
Cherry, E.C.: Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 25(5), 975–979 (1953)
Fu, S.W., Tsao, Y., Lu, X.: SNR-aware convolutional neural network modeling for speech enhancement. In: Interspeech, pp. 3768–3772 (2016)
Fu, S.W., Tsao, Y., Lu, X., Kawai, H.: Raw waveform-based speech enhancement by fully convolutional networks. In: 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), pp. 006–012. IEEE (2017)
Gannot, S., Cohen, I.: Speech enhancement based on the general transfer function GSC and postfiltering. IEEE Trans. Speech Audio Process. 12(6), 561–571 (2004)
Garofolo, J.S., Lamel, L.F., Fisher, W.M., Fiscus, J.G., Pallett, D.S.: Getting started with the DARPA TIMIT CD-ROM: an acoustic phonetic continuous speech database. National Institute of Standards and Technology (NIST), Gaithersburgh, MD, 107, p. 16 (1988)
Habets, E.A.P., Benesty, J., Cohen, I., Gannot, S., Dmochowski, J.: New insights into the MVDR beamformer in room acoustics. IEEE Trans. Audio Speech Lang. Process. 18(1), 158–170 (2009)
Hirsch, H.G., Pearce, D.: The Aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions. In: ASR2000-Automatic Speech Recognition: Challenges for the New Millenium ISCA Tutorial and Research Workshop (ITRW) (2000)
Hu, Y., Loizou, P.C.: Evaluation of objective quality measures for speech enhancement. IEEE Trans. Audio Speech Lang. Process. 16(1), 229–238 (2007)
Lee, B.K., Jeong, J.: Deep neural network-based speech separation combining with MVDR beamformer for automatic speech recognition system. In: IEEE International Conference on Consumer Electronics (ICCE), pp. 1–4. IEEE (2019)
Lu, X., Tsao, Y., Matsuda, S., Hori, C.: Speech enhancement based on deep denoising autoencoder. In: Interspeech, vol. 2013, pp. 436–440 (2013)
Masuyama, Y., Togami, M., Komatsu, T.: Consistency-aware multi-channel speech enhancement using deep neural networks. In: ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 821–825. IEEE (2020)
Niwa, K., Hioka, Y., Kobayashi, K.: Post-filter design for speech enhancement in various noisy environments. In: 14th International Workshop on Acoustic Signal Enhancement (IWAENC), pp. 35–39. IEEE (2014)
Nossier, S.A., Rizk, M.R.M., Moussa, N.D., el Shehaby, S.: Enhanced smart hearing aid using deep neural networks. Alex. Eng. J. 58(2), 539–550 (2019)
Nugraha, A.A., Liutkus, A., Vincent, E.: Multichannel audio source separation with deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 24(9), 1652–1664 (2016)
Pandey, A., Wang, D.: A new framework for CNN-based speech enhancement in the time domain. IEEE/ACM Trans. Audio Speech Lang. Process. 27(7), 1179–1188 (2019)
Perrot, V., Polichetti, M., Varray, F., Garcia, D.: So you think you can DAS? A viewpoint on delay-and-sum beamforming. Ultrasonics 111, 106309 (2021)
Shankar, N., Bhat, G.S., Panahi, I.: Comparison and real-time implementation of fixed and adaptive beamformers for speech enhancement on smartphones for hearing study. In: Proceedings of Meetings on Acoustics 178ASA, vol. 39, p. 055009. Acoustical Society of America (2019)
Taal, C.H., Hendriks, R.C., Heusdens, R., Jensen, J.: An algorithm for intelligibility prediction of time-frequency weighted noisy speech. IEEE Trans. Audio Speech Lang. Process. 19(7), 2125–2136 (2011)
Tan, K., Chen, J., Wang, D.: Gated residual networks with dilated convolutions for monaural speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 27(1), 189–198 (2018)
Tan, K., Zhang, X., Wang, D.: Real-time speech enhancement using an efficient convolutional recurrent network for dual-microphone mobile phones in close-talk scenarios. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 5751–5755. IEEE (2019)
Tu, Y.H., Du, J., Lee, C.H.: Speech enhancement based on teacher-student deep learning using improved speech presence probability for noise-robust speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 27(12), 2080–2091 (2019)
Tu, Y., Du, J., Xu, Y., Dai, L., Lee, C.H.: Speech separation based on improved deep neural networks with dual outputs of speech features for both target and interfering speakers. In: The 9th International Symposium on Chinese Spoken Language Processing, pp. 250–254. IEEE (2014)
Vincent, E., Gribonval, R., Févotte, C.: Performance measurement in blind audio source separation. IEEE Trans. Audio Speech Lang. Process. 14(4), 1462–1469 (2006)
Wang, D., Bao, C.: Multi-channel speech enhancement based on the MVDR beamformer and postfilter. In: 2020 IEEE International Conference on Signal Processing, Communications and Computing (ICSPCC), pp. 1–5. IEEE (2020)
Wang, Y., Narayanan, A., Wang, D.: On training targets for supervised speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 22(12), 1849–1858 (2014)
Wang, Z.Q., Wang, D.: Multi-microphone complex spectral mapping for speech dereverberation. In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 486–490. IEEE (2020)
Weninger, F., Erdogan, H., Watanabe, S., Vincent, E., Roux, J.L., Hershey, J.R., Schuller, B.: Speech enhancement with LSTM recurrent neural networks and its application to noise-robust ASR. In: International Conference on Latent Variable Analysis and Signal Separation, pp. 91–99. Springer (2015)
Williamson, D.S., Wang, Y., Wang, D.: Complex ratio masking for monaural speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 24(3), 483–492 (2015)
Xu, Y., Du, J., Dai, L.R., Lee, C.H.: An experimental study on speech enhancement based on deep neural networks. IEEE Signal Process. Lett. 21(1), 65–68 (2013)
Xu, Y., Du, J., Dai, L.R., Lee, C.H.: A regression approach to speech enhancement based on deep neural networks. IEEE/ACM Trans. Audio Speech Lang. Process. 23(1), 7–19 (2014)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Priyanka, S.S., Kumar, T.K. Multi-channel speech enhancement using early and late fusion convolutional neural networks. SIViP 17, 973–979 (2023). https://doi.org/10.1007/s11760-022-02301-4
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11760-022-02301-4