
Abstract
Past research explored the relationship between personality, moral disengagement, and deception and found a general trend showing that the lower people score on the big five personality factors, but the higher they score on moral disengagement and Machiavellianism, the higher their lying tendency. However, a limitation of past research is that it has usually adopted a variable-centred approach, whereas a person-centred approach might describe people in more detail and provide further insight into the relationship between personality and morality. In the present study, we collected data from 316 participants and asked them to fill an on-line questionnaire which included measures on personality, moral disengagement, and lying tendency (perceived lying ability, frequency, negativity and contextuality). The latter was measured via the newly developed Structure of Deception (SoD) scale (Makowski et al., Current Psychology, 2021). We had to aims. First, to validate an Italian version of the SoD, which showed a good factor structure, gender measurement invariance, and good construct and criterion validity. Second, to explore the association between personal characteristics and lying tendency. Personality and morality scores were combined to obtain subpopulations of participants by a mean of cluster analysis. We obtained four clusters, one of which was marked by high Machiavellianism and moral disengagement but low scores on the personality factors, and one of which showed the opposite trend. The results also showed that cluster membership, and hence personal characteristics, was associated with lying tendency. The person-centred approach can be applied in research on lying. Limitations of the study and future suggestions are also discussed.
Similar content being viewed by others

Lying is a common behaviour that is frequently researched (Vrij, 2008). Studies adopting a variable-centred approach- which assumes that the relationship between the variables being studied is the same for the entire population- found that several factors influence lying. One is the role of personal characteristics (Caso et al., 2018; Levine, 2010). For example, if we look at personality traits, Hart et al. (2020) found that low scores on extraversion, agreeableness, conscientiousness, and openness to experience are all correlated with an increased tendency to lie, although Kashy and DePaulo (1996) and Weiss and Feldman (2006) found the opposite for extraversion. Vrij (2008) also reported that more extraverted people might lie more, even when taking into account the fact that they usually have more interaction than introverted people. Machiavellianism, a personality trait centred on lack of empathy, manipulativeness and indifference to morality also seems to be related to increased lying (Geis & Moon, 1981; Kashy & DePaulo, 1996; Muris et al., 2017; Vrij, 2008; Williams et al., 2010; Wright et al., 2017). Interestingly, people high in Machiavellianism openly admit that they are willing to lie in order to get what they want, and tend to treat people cynically (Vrij, 2008), which might also explain why they tend to tend more self-oriented lies compared to people low in Machiavellianism (Kashy & DePaulo, 1996). Also, people who score low on honesty/humility (part of the HEXACO model, Ashton et al., 2006 see below) tend to lie more, as people low in morality do (Barsky, 2011; Šukys, 2013; Tasa & Bell, 2017). Similarly, those who score high on moral disengagement- a process through which people can distance themselves from socially unacceptable behaviours by reframing immoral action as morally accepted, see (Bandura, 1999; Bandura et al., 1996, 2000; Caprara et al., 2006)- tend to lie more (Palena et al., 2021a). Personality is not only related to lying frequency, it also appears to be related to a negative perception of lying (Makowski et al., 2021) and to lying ability (for a recent review, see Semrad et al., 2019). For example, both high extraversion and Machiavellianism are thought to be related to better lie production (i.e., producing believable lies) (DePaulo & Rosenthal, 1979; Geis & Moon, 1981; Riggio & Friedman, 1983; Riggio et al., 1988; Vrij, 2008).
The available literature thus indicates that there is a link between personality, morality and deception (for a recent and complete review, see Semrad et al., 2019) as well as that deception can be seen as driven, at least in part, by personal characteristics (Markowitz & Levine, 2021). However, one of its limitations concerns the methodology that has been applied. If we focus on the role of each factor (e.g., personality, morality, etc.) on its own, we will miss important patterns. This is referred to as the variable-centred approach which, according to Palena et al. (2021a), might reduce the understanding of lying behaviour. It does not account for the characteristics of the individuals and assumes that the effect of one variable (e.g., morality) on an outcome variable (e.g., lying) is constant across people, regardless of other attributes (e.g., Machiavellianism). Palena et al. (2021a) thus suggested that the person-centred approach should be preferred where possible. The person-centred approach allows to study people in an integrative manner and accounts for the (cor)relation between several variables. Here, patterns of scores in the variables under investigation (e.g., personality and morality) are obtained via a data-drive approach, similar to a factor analysis. The difference is that in a factor analysis latent variables are obtained, whereas with the person-centred approach the goal is to obtain subpopulations (often referred to as groups, profiles, or clusters) of individuals who show a similar pattern of scores on the selected variables. This means that the person-centred approach can detect differences due to personal characteristics, and predict people’s future behaviour, better than the variable-centred approach (for a general description of the person-centred approach, or for a discussion on this topic in the investigative interviewing arena, see Magnusson, 1998; Palena & Caso, 2021). For example, a group obtained via the person-centred approach may be characterised by high scores on both extraversion and Machiavellianism (strong positive relation), a second group may score high on just one of the two variables (weaker positive relation) and a third group may show a high score on one of the variables and a low score on the other (negative relation). In this scenario people belonging to the first group should be more prone to lying than people belonging to the two other groups. Our goal was therefore to examine the relationship between personality, morality and deception using the person-centred approach.
Another issue in the available literature is that it usually focused on a specific aspect of lying, such as frequency or ability, and has done so in an unstandardised way. That is, different researchers have adopted different ways of operationalise and measure the variables of interest. Makowski et al. (2021) attempted to address this issue and developed a questionnaire aimed to explore, in a systematic way, several facets of lying. Their Structure of Deception (SoD) scale includes four factors: lying ability (perceived ability to produce believable lies), frequency (the subjective assessments of frequency of lying), negativity (the perception of unwillingness to tell lies, for reasons such as morality or emotional arousal associate with such a behaviour), and contextuality (perceived regulation of lying behaviour according to several factors, such as stakes) (Makowski et al., 2021).
Building on the above literature, the current study had two main goals. First, we aimed at validating an Italian version of the SoD (Makowski et al., 2021) and to explore its construct and criterion validity. Second, we aimed at exploring how personality and moral disengagement integrate to form specific clusters and how these are related to lying. When adopting the person-centred approach, it is difficult to hypothesize how many clusters would emerge (Palena et al., 2021a), as this analysis procedure is data-driven. This implies that in this sort of studies, liberal, rather than strict, hypotheses are made (Steca et al., 2016). Notwithstanding this, previous research suggests that we might expect the emergence of at least one cluster characterised by a pattern of scores linked to high proneness toward lying (e.g., high Machiavellianism and moral disengagement) and one to lying aversion (e.g., low Machiavellianism and moral disengagement) (H1). Further, we also predicted that the more a specific cluster was marked by a combination of variables associated with lying, the more people belonging to such cluster would report higher ability, frequency and contextuality but lower negativity than clusters with the opposite patterns. For example, a cluster characterised by high Machiavellianism and moral disengagement is expected to show a higher lying tendency than a cluster marked by a high score on one of these variables and a low score on the other (H2).
Method
Sample Size Calculation
We ran two a priori power analyses with GPower (Faul et al., 2007) to determine the required sample size, and set α at 0.05, power at 0.95 and f at 0.25, as we were interested in at least medium effect sizes. One analysis was conducted assuming two emerging clusters (N = 210) and one assuming five (N = 305). We did not explore the required sample size for more than five groups as we aimed for parsimoniousness and interpretability of the data (Boduszek et al., 2021; Palena et al., 2021a).
Participants
In total, 316 participants took part in the study. We searched for multivariate outliers with the R package performance (Lüdecke et al., 2019), which uses several algorithms to explore the presence of such outliers. Of the 316 participants, 29 were outliers, and were hence excluded from the analyses. Table 1 reports the demographics of both the complete and the reduced (used for all the analyses) dataset.
Variables and Instruments
Personality was measured via the Italian version of the 60-Items HEXACO questionnaire (Ashton & Lee, 2009; Ashton et al., 2006), a validated version of six personality domains: honesty-humility, emotionality, extraversion, agreeableness, conscientiousness, and openness to experience. Factor scores are computed as means of the items composing each of the six factors. The HEXACO showed good validity and reliability, also when comparing answers provided by the respondents themselves and by observers (Lee & Ashton, 2006).
Machiavellianism was measured via the Italian version of the Machiavellianism Personality Scale (MPS) (Bianchi & Mirkovic, 2020), a 16-items validated tool measuring four different facets of Machiavellianism: amorality, desire for control, desire for status, and distrust. Since previous research showed the presence of a higher-order Machiavellianism factor, it is possible to compute a total score, which we did by summing up the answers of the 16 items. The MPS scale showed good validity and reliability (Dahling et al., 2009).
Morality was measured via the Moral Disengagement Scale (MDS) (Caprara et al., 2006), a 32-item tool exploring eight dimensions of morality: moral justification, euphemistic labelling, advantageous comparison, displacement of responsibility, diffusion of responsibility, disregarding the consequences, dehumanisation, and attribution of blame. Total score was obtained by summing up all answers.
Lying was measured via the SoD (Makowski et al., 2021), and the Lie-Truth Ability Assessment Scale (LTAAS) (Zvi & Elaad, 2018). The former has been described above, and showed to possess good factor structure, validity, and reliability. The latter is a 16-items questionnaire exploring lie telling ability, truth telling ability, as well as the ability to perceive lies and to believe the others.
Procedure
The two questionnaires on lying were never translated in Italian before. Hence, an Italian researcher with high proficiency in English first translated the 32 items of the two questionnaires (16 for each) in Italian. The same researcher then translated the items back into English. Then, in alignment with the suggestions outlined in recent work on the translation issue (Behr & Shishido, 2016), the following procedure also used in previous research (Palena et al., 2021a) was applied. Two other researchers, Italian mother-tongue with high proficiency in English, evaluated the coherence between the original and the back translated English versions on a scale ranging from one (not coherent) to three (very much coherent). Agreement was obtained by a mean of Cohen’s k and was of 1 for both the SoD and the LTAAS. Following the translation, we created an online Google Module survey. The participants then read the consent form and, once accepting, they read the experimental instruction and completed the survey (filling in the questionnaire took about 8 min). We did not offer any incentive and the data were anonymous. The study was conducted in accordance with the Declaration of Helsinki (World Medical Association, 2004) and with the ethical guidelines for research provided by the Italian Psychological Association (Associazione Italiana di Psicologia, 2015).
Statistical Analyses
All the analyses were conducted with R (Version 4.0.3) (R Core Team, 2020) and R studio (Version 1.3.1093) (RStudio Team, 2020). To process the data, we used the R packages Lavaan (Rosseel, 2012), Psych (Ravelle, 2018), and Easystats (Lüdecke et al., 2019, 2020). To explore the fit of the Confirmatory Factor Analysis (CFA) we relied on the chi-square test statistics, the RMSEA, the SRMR and the CFI and the TLI. Measurement invariance of the gender of the respondent was conducted via Multigroup CFA, where three models were obtained and compared: configural invariance (the structure is assumed to be the same for the compared groups), metric invariance (loadings are fixed to be the same across groups) and scalar invariance (loadings and intercepts are fixed to be the same across groups). To compare the three models, we relied on the changes in RMSEA, SRMR and BIC, in addition to the Δχ2, as the latter is sensitive to sample size. ΔRMSEA ≤ 0.015, ΔSRMR ≤ 0.030, ΔCFI and ΔTLI ≤ 0.01, and non-significant Δχ2 are deemed to be indicative of measurement invariance, although Δχ2 are often disregarded as they are too sensitive to sample size (Cheung & Rensvold, 2002). Concerning the cluster analysis, we assessed the normality of the data and Hopkin’s H, which was obtained using the R package performance (Lüdecke et al., 2020), to assess whether the dataset was suitable for cluster analyses. Skewness <|2| and kurtosis <|7| are deemed as indicative of normally distributed data (West et al., 1995), whereas Hopkins’ H values close to 0 (below 0.5) indicate that the dataset is significantly clusterable (Lüdecke et al., 2020; Makowski et al., 2021). Further, the method agreement procedure (where 28 different clustering algorithms are aggregated), was used to explore what is the optimal number of clusters to be retained. As far as the maximum number of iterations for convergence concerned, we left it at the default value (n = 1000). No other assumption was tested as it has been suggested that such clustering method does not require any additional specific assumptions to be respected (Rupp, 2013). Clusters were then obtained via k-means analysis. Last, convergent validity was explored via Pearson’s correlations, whereas the association between the clusters and the other variables were explored via contingency table analyses and MANOVAs.
Results
First, we assessed whether the data were normally distributed. As shown in Table 3, none of the variables exceeded the limits of skewness |2| and kurtosis |7| (West et al., 1995).
Confirmatory Factor Analyses and Measurement Invariance and Validity
A CFA with ML estimator was conducted on the 16 items of the Structure of Deception scale. The fit was good, χ2(98) = 214.23, p < 0.001, RMSEA = 0.064, SRMR = 0.050, CFI = 0.96, TLI = 0.95. A second CFA with ML estimator was conducted on the 16 items LTAAS. The fit was acceptable, χ2(98) = 319.83, p < 0.001, RMSEA = 0.089, SRMR = 0.075, CFI = 0.92, TLI = 0.91. For both CFAs there was no correlated error for the relative items. Further, none of the Δχ2 was significant, (SoD: metric vs. configural, Δχ2 = 10.00, p = 0.61; scalar vs. metric, Δχ2 = 19.08, p = 0.08; LTAAS: metric vs. configural, Δχ2 = 15.73, p = 0.20; scalar vs. metric, Δχ2 = 15.64, p = 0.20). Also, Δs of the RMSEA, SRMR, CFI and TLI never exceeded the advisable thresholds (Table 2). Hence, both scales appeared to be gender invariant. Internal consistency was good (Table 3).
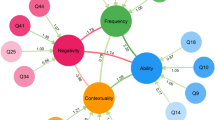
To explore validity, correlations between the SoD and the other questionnaires were conducted (Fig. 1).

Correlations among SoD, LTAAS, Hexaco, MDS (dm) and MPS scales. Warm colours indicate negative correlations, cold colours indicate positive correlations
Except for negativity and contextuality, all the correlations among the four factors of the SoD were significant. Also, ability, frequency and contextuality, negatively correlated with honesty-humility. Negativity also positively, but weakly, correlated with agreeableness and conscientiousness, whereas this latter negatively correlated with frequency. Concerning the LTAAS, lie ability correlated with all four factors of the SoD scale. Perceiving lies and believing others (LTAAS) correlated with ability (SoD). Last, except for negativity, the SoD factors also correlated with both the MPS and the MDS. Table 3 reports the descriptives of the MPS, the HEXACO, the MDS, the SoD and the LTAAS.
Cluster Analysis
In addition to the normality of the data, Hopkins’ H (0.36) also indicated that the data were suitable for clustering (Lüdecke et al., 2019, 2020; Makowski et al., 2021).
The method agreement procedure supported the presence of two (28.57%) or four (21.42%) clusters. The former accounted for 16.88% of the variance, the latter for 30.87%. Hence, we opted for the four-clusters solution. We then created the four clusters based on the standardised scores (z) of the total Machiavellianism (MPS), the total Moral Disengagement (MD), and the six factors of the HEXACO (Fig. 2). Such standardised scores are an indication of the distance between a particular cluster score and the grand mean. According to Steca et al. (2016), they can be interpreted in a similar way of d scores (0.2 small, 0.50 medium, 0.80 large). Within-clusters sum of squares, between clusters sum of squares and total sum of squares are reported in Fig. 2.

Cluster plot describing the scores of Moral Disengagement, Machiavellianism, and the six Hexaco factors. The scores are reported as z-scores and their deviation from the grand mean. Note. WSS = within sum of squares. Between sum of squares = 706.23, total sum of squares = 2288
Cluster 1
Cluster 1 (N = 56) was characterised by high scores on moral disengagement (M = 71.23; SD = 12.51) and Machiavellianism (M = 42.55; SD = 7.14), but low scores on all personality factors (honesty-humility M = 3.21, SD = 0.59; extraversion M = 3.00, SD = 0.63; agreeableness M = 2.74, SD = 0.48; conscientiousness M = 3.55, SD = 0.50; openness M = 3.01, SD = 0.58), except emotionality, which was close to the grand mean (M = 3.22; SD = 0.66).
Cluster 2
Cluster 2 (N = 73) showed high scores on Machiavellianism (M = 39.03; SD = 5.73), extraversion (M = 3.52; SD = 0.57), openness (M = 3.70; SD = 0.51) and, to a lesser degree, conscientiousness (M = 3.96; SD = 0.52), but low scores on honesty-humility (M = 3.49; SD = 0.51), emotionality (M = 2.77; SD = 0.60) and, to a lesser degree, agreeableness (M = 2.97; SD = 0.57). Further, they scored about the grand mean on moral disengagement (M = 55.64; SD = 10.54).
Cluster 3
Cluster 3 (N = 92) showed high scores on honesty-humility (M = 4.04; SD = 0.51) and emotionality (M = 3.63; SD = 0.52), but low scores on all the other variables (moral disengagement M = 50.74, SD = 9.82; Machiavellianism M = 30.50, SD = 5.04; extraversion M = 2.88, SD = 0.58; agreeableness M = 3.01, SD = 0.58; conscientiousness M = 3.77, SD = 0.56; openness M = 2.97, SD = 0.58).
Cluster 4
Last, Cluster 4 (N = 66) showed low scores on moral disengagement (M = 47.70; SD = 10.71), Machiavellianism (M = 27.64; SD = 5.78), and (to a lesser degree) emotionality (M = 3.08; SD = 0.68), but high scores on honesty-humility (M = 4.22; SD = 0.51), extraversion (M = 3.78; SD = 0.48), agreeableness (M = 3.65; SD = 0.51), conscientiousness (M = 4.08; SD = 0.54), and openness to experience (M = 3.82; SD = 0.56).
The presence of Clusters 1 and 4 support H1, as the former is marked by a combination of scores linked to a high lying tendency, whereas Cluster 4 is linked to a low tendency. Further, as shown in Fig. 2, those who belonged to Cluster 1 had mirrored scores of those who belonged to Cluster 4. The same appeared for participants from Cluster 2 and Cluster 3 (except for agreeableness).
Relating Cluster Membership to External Variables
The association between Cluster membership and gender, living status, education, job, and SES was explored via chi-square tests. There was an association between Cluster membership and gender, χ2(3) = 36.31, p < 0.001. The residuals showed that more males than expected belonged to Clusters 1 and 2. Further, more females and less males than expected belonged to Cluster 3 (Fig. 3).

Chi-squared and relative residuals between Sex and Cluster membership
The association between Cluster membership and living status (recoded as “alone” vs. “with other people” as there were several cells with low frequency), χ2(3) = 4.25, p = 0.23, education, (recoded as “university level” vs “below university level”), χ2(3) = 6.72, p = 0.08, and SES, χ2(3) = 4.47, p = 0.97 were not significant. Further, an ANOVA with age as the dependent variable and Cluster as the predictor was significant, F(3, 283) = 3.14, p < 0.05, η2 = 0.03. Pairwise comparisons with Bonferroni correction indicated that the only significant difference was between Cluster 2 (Mage = 38.14, SD = 16.60) and Cluster 4 (Mage = 46.27, SD = 17.07), p < 0.05.
MANOVA
Before comparing the SoD scores between the four clusters, it is useful to assess whether Cluster invariance is obtained. Both Δχ2 were significant, (SoD: metric vs. configural, Δχ2 = 63.87, p < 0.01; scalar vs. metric, Δχ2 = 93.03, p < 0.001). Yet, as reported above, χ2 are sensitive to sample size and cannot be used effectively to assess measurement invariance (Cheung & Rensvold, 2002). Δs of the RMSEA, SRMR, TLI never exceeded the advisable thresholds. ΔCFI only exceeded the threshold of 0.01 for the comparison between scalar and metric invariance (Table 2). Considering that: i) more lenient cut-offs such as ΔCFI of 0.02 have also been proposed (Putnick & Bornstein, 2016; Rutkowski & Svetina, 2014), ii) the BIC of the scalar-invariance model was lower than the previous two, and; iii) Cheung and Rensvold (2002) state that invariance is not hold only when ΔCFI values above the cut-off are supplemented by either ΔRMSEA or ΔSRMR also above their relative the cut-off, (see also Zercher et al., 2015) our results indicate that the SoD could be deemed as invariant across Clusters.
Regarding the MANOVA assumptions, Fig. 1 shows that multicollinearity was not an issue, as the highest correlation was moderate (r = 0.51). Multivariate normality, tested with the Shapiro–Wilk test, was not respected, W = 0.79, p < 0.001. Similarly, the Box’s M was also significant, χ2(30) = 56.00, p < 0.01. For these reasons, we report the Pillai’s trace (Field, 2009).
Considering the presence of an association between Cluster membership and both gender and age, a Manova was conducted to test the effect of Cluster membership on the four factors of the SoD, controlling for age and sex (see also Makowski et al., 2021). The effect was significant at a multivariate level, F(12, 837) = 5.16, p < 0.001.
For the univariate tests normality was not an issue (see Table 3). Homoscedasticity was violated for ability, F(3, 283) = 3.81, p < 0.05, and frequency, F(3, 283) = 5.25, p < 0.05, but not for negativity, F(3, 283) = 1.12, p = 0.34, and contextuality, F(3, 283) = 0.66, p = 0.57. For this reason, we ran univariate ANOVAs with Welch’s correction and the relative post-hoc via Games-Howell. We obtained significant results for all four variables: ability, F(3, 144.49) = 11.12, p < 0.001, ηp2 = 0.12; frequency, F(3, 144.56) = 11.27, p < 0.001, ηp2 = 0.13; negativity, F(3, 146.72) = 9.50, p < 0.001, ηp2 = 0.10; and contextuality, F(3, 146.32) = 4.99, p < 0.01, ηp2 = 0.06. Table 4 reports the descriptives and the post-hoc, conducted via Games-Howell comparisons due to unequal variances, for the SoD scores for each of the four clusters. Both participants from Cluster 1 and 2 scored higher than participants in Cluster 3 and 4 on ability, but the difference for both these pairs were non-significant. Participants belonging to Cluster 1 scored higher than all the others on frequency, whereas Cluster 3 did not differ from neither Cluster 2 nor 4. Concerning negativity, the comparisons between Clusters 1–2, 2–3 and 3–4 were not significant, whereas the other comparisons were. Last, concerning contextuality, only the differences between Cluster 4 and both Cluster 1 and 2 were significant. Taken together, the results support H2.
Discussion
Main Findings
One of the goals of this study was to validate the SoD questionnaire (Makowski et al., 2021) in Italian language. Our analyses showed that the original model fit with our Italian sample data. The fact that the SoD showed construct and criterion validity in our study further reinforces its usability for both theoretical and applied research, for example, for exploring what are the personal characteristics that are related to a higher lying tendency.
We also aimed at exploring how personal characteristics were related to lying. We extracted subpopulations of participants (clusters) based on personality and moral disengagement and obtained four clusters that showed to be associated with SoD scores. Below is a description of such clusters, which are also depicted in Fig. 2 (showing distance values, in z-scores, from the grand mean for each cluster and each variable).
Cluster 1
Cluster 1 scored high on moral disengagement and Machiavellianism but low on honesty-humility, extraversion, agreeableness, conscientiousness, and openness, and around the grand mean on emotionality. Cluster 1 hence appeared to include people who are not very honest, do not like much to interact with other people, are likely to be not open-minded and not very caring or empathetic to others. These people are likely to be self-oriented, and to pursue their goals regardless of the impact their actions have on others. Indeed, people from Cluster 1 showed higher lie frequency compared to the other clusters. Further, they scored higher on ability compared to Clusters 3 and 4, higher on contextuality compared to Cluster 4 and lower on negativity, compared Clusters 3 and 4. This makes people belonging to Cluster 1 likely skilled, and frequent, liars.
Cluster 2
Cluster 2 showed moral disengagement scores close to the grand mean (M = 55.64; SD = 10.54), high scores on Machiavellianism, extraversion, openness and, to a lesser degree, conscientiousness. Further, they scored low on honesty-humility, emotionality, and agreeableness. People in Cluster 2 thus show some features related to less empathetic and more deceptive behaviour, such as high scores on Machiavellianism and low scores on honesty-humility, emotionality and agreeableness (Hart et al., 2020). Yet, they did not show heightened moral disengagement, and, at the same time, they showed high conscientiousness (compared to the mean of the entire sample). This might explain our result whereby people belonging to this cluster obtained similar scores of those belonging to Cluster 1 on ability, negativity and contextuality, yet lower scores on lying frequency. In essence, Cluster 2 might include people who are skilled liars but, perhaps due to their higher morality and conscientiousness, might refrain from lying.
Cluster 3
Cluster 3 showed a pattern of scores that mirrored those of Cluster 2. People in Cluster 3 scored high on honesty-humility and emotionality, but low on moral disengagement, Machiavellianism, extraversion, agreeableness, conscientiousness, and on openness. Based on this pattern of scores we would expect people in this cluster to be less skilled and frequent liars that people belonging to the previous two clusters, in particular because of their low scores on moral disengagement and Machiavellianism and high scores on honesty-humility and emotionality. Indeed, people belonging to Cluster 3 scored, compared to people from Clusters 1 and 2, lower on ability. Further, they scored lower on frequency but higher on negativity than people from Cluster 1.
Cluster 4
Cluster 4 showed a pattern of personality and morality scores that mirrored those of people in Cluster 1. They scored low on Machiavellianism and moral disengagement, but high on honesty-humility, extraversion, agreeableness, conscientiousness, and openness. Since they appeared not to be morally disengaged nor Machiavellian but, at the same time, conscientious, agreeable, and honest according to their HEXACO scores, we would expect them to be the less skilled and frequent liars than people belonging to others. Indeed, we found that they showed lower ability, contextuality, and frequency, but higher negativity than people belonging to Clusters 1 and 2.
Comparisons With Other Studies and Implications of The Present Findings
Taken together, our results supported the idea, already stressed in previous work, that there might be a small proportion of people that shows a higher lying tendency than the rest of the population (prolific liars), and that there are other people that show more aversion toward such a behaviour (Markowitz & Levine, 2021; Serota & Levine, 2015). Further, in line with Palena et al. (2021a) the results also showed that it is important to study people in an integrative manner, such as via person-centred approaches so not to miss the impact of specific patterns of personality, which is likely to happen when applying the variable-centred approach. Take for example Clusters 1 and 2. They were both marked with high Machiavellianism, low honesty/humility, and low moral disengagement, yet they showed different scores on lying frequency. Similarly, both Clusters 1 and 3 were marked by low extraversion, openness, moral disengagement, and conscientiousness when compared to the grand mean of the whole sample. Yet, Cluster 1 obtained higher scores on ability and frequency, but lower scores on negativity, than Cluster 3. These differences only appear when using a person-centred approach.
Strengths, Future Directions and Limitations
Notwithstanding the above results, it is paramount not to fall in the mistake of labelling people as “born liars” or “born honest”, since there are several factors, other than those we explored, that might play a role when looking at lying (Markowitz & Levine, 2021). Yet, understanding what makes someone more prone, and perhaps even able, to lying, can be interesting for practical reasons, such as employee selection (Palena et al., 2021a; Semrad & Scott-Parker, 2020; Semrad et al., 2014, 2020). Further, studying people with this approach might help to tailor what interviewing technique investigators should apply according to the cluster membership of the interviewee. In essence, future studies could explore whether and how the efficacy in gathering information and discriminating between truth tellers and liars of the various interviewing techniques available to date- such as the Strategic Use of Evidence (Granhag & Hartwig, 2015) or Cognitive Credibility Assessment (Vrij et al., 2017)- depends on personal characteristics/cluster membership. Also, considering that previous attempts to examine the effect of personal characteristics on cues to deception showed limited results (Caso, et al., 2019a, 2019b), researchers could explore whether the person-centred approach might yield better results. For example, recent meta-analytic work has found that complications (occurrences that make the story provided by the interviewee more complex than necessary, see Vrij et al., 2021) and verifiable details (details provided by the interviewee that can be potentially verified by the investigators, see Palena et al., 2021b) can discriminate truth tellers from liars. Yet, it is possible that such cues are diagnostic veracity indicators in some people more than in others.
Our study had limitations. First, since we collect survey data, self-serving bias might be at play. Although relevant research in this topic is usually conducted via surveys or diary studies (Park et al., 2021; Serota & Levine, 2015; Serota et al., 2010), and although it has been previously suggested that good self-reported measures might be suitable (Makowski et al., 2021; Serota et al., 2010), there is the need for future studies to consider also objective criteria, such as objective count of lies told, or objective believability of senders (Caso et al., 2018) although this might be difficult (Makowski et al., 2021). Second, we did not collect data longitudinally. Even though personality is believed to be stable across life (Terracciano et al., 2010), future studies should consider longitudinal studies. In this regard, methods such as latent transition analysis might be of help (Palena & Caso, 2021). In such analyses, not only clusters are obtained, but shifts of membership from one cluster to another at different time points/contexts/states are also explored. Third, we did not account for genetic aspects related to personality, although they might be relevant as well. Future research should then try to include also such aspects (An et al., 2019). Last, future research should explore what the best predictors are to obtain clusters. That is, which variables maximise the differences between clusters. We have obtained clusters from personality and morality, but there may be other variables associated with lying, such as being a good actor and being expressive, being able to control emotions, being creative and intelligent (Vrij et al., 2010).
Data Availability
The datasets generated during and/or analysed during the current study are available from the corresponding author on reasonable request.
Change history
22 August 2022
The original version of this article was updated to add the Funding information.
References
An, L., Liu, C., Zhang, N., Chen, Z., Ren, D., Yuan, F., . . . Guo, Z. (2019). GRIK3 RS490647 is a common genetic variant between personality and subjective well-being in Chinese han population. Emerging Science Journal, 3(2), 78–87. https://doi.org/10.28991/esj-2019-01171
Ashton, M. C., & Lee, K. (2009). The HEXACO–60: A short measure of the major dimensions of personality. Journal of Personality Assessment, 91(4), 340–345. https://doi.org/10.1080/00223890902935878
Ashton, M. C., Lee, K., de Vries, R. E., Perugini, M., Gnisci, A., & Sergi, I. (2006). The HEXACO model of personality structure and indigenous lexical personality dimensions in Italian, Dutch, and English. Journal of Research in Personality, 40(6), 851–875. https://doi.org/10.1016/j.jrp.2005.06.003
Associazione Italiana di Psicologia. (2015). Codice Etico per la Ricerca in Psicologia. Retrieved from https://www.aipass.org/node/11560
Bandura, A. (1999). Moral disengagement in the perpetration of inhumanities. Personality and Social Psychology Review, 3(3), 193–209. https://doi.org/10.1207/s15327957pspr0303_3
Bandura, A., Barbaranelli, C., Caprara, G. V., & Pastorelli, C. (1996). Mechanisms of moral disengagement in the exercise of moral agency. Journal of Personality and Social Psychology, 71(2), 364–374. https://doi.org/10.1037/0022-3514.71.2.364
Bandura, A., Caprara, G.-V., & Zsolnai, L. (2000). Corporate transgressions through moral disengagement. Journal of Human Values, 6(1), 57–64. https://doi.org/10.1177/097168580000600106
Barsky, A. (2011). Investigating the effects of moral disengagement and participation on unethical work behavior. Journal of Business Ethics, 104(1), 59. https://doi.org/10.1007/s10551-011-0889-7
Behr, D., & Shishido, K. (2016). The translation of measurement instruments for cross-cultural surveys. In C. Wolf, D. Joye, T. Smith, & Y. Fu (Eds.), The SAGE Handbook of Survey Methodology (pp. 269–287). SAGE Publications Ltd.
Bianchi, R., & Mirkovic, D. (2020). Is Machiavellianism associated with depression? A cluster-analytic study. Personality and Individual Differences, 152, 109594. https://doi.org/10.1016/j.paid.2019.109594
Boduszek, D., Debowska, A., Sherretts, N., Willmott, D., Boulton, M., Kielkiewicz, K., . . . Hyland, P. (2021). Are prisoners more psychopathic than non-forensic populations? Profiling psychopathic traits among prisoners, community adults, university students, and adolescents. Deviant Behavior, 42(2), 232-244. https://doi.org/10.1080/01639625.2019.1665221
Caprara, G. V., Barbaranelli, C., Pastorelli, C., Iafrate, C., Beretta, M., Steca, P., & Bandura, A. (2006). La misura del disimpegno morale nel contesto delle trasgressioni dell’agire quotidiano. Giornale Italiano Di Psicologia, 33(1), 83–106. https://doi.org/10.1421/21961
Caso, L., Maricchiolo, F., Livi, S., Vrij, A., & Palena, N. (2018). Factors affecting observers’ accuracy when assessing credibility: The effect of the interaction between media, senders’ competence and veracity. The Spanish Journal of Psychology, 21, 1–10. https://doi.org/10.1017/sjp.2018.54
Caso, L., Palena, N., Carlessi, E., & Vrij, A. (2019a). Police accuracy in truth/lie detection when judging baseline interviews. Psychiatry, Psychology and Law, 1-10. https://doi.org/10.1080/13218719.2019.1642258
Caso, L., Palena, N., Vrij, A., & Gnisci, A. (2019b). Observers’ performance at evaluating truthfulness when provided with Comparable Truth or Small Talk Baselines. Psychiatry, Psychology and Law. https://doi.org/10.1080/13218719.2018.1553471
Cheung, G. W., & Rensvold, R. B. (2002). Evaluating goodness-of-fit indexes for testing measurement invariance. Structural Equation Modeling: A Multidisciplinary Journal, 9(2), 233–255. https://doi.org/10.1207/S15328007SEM0902_5
Dahling, J. J., Whitaker, B. G., & Levy, P. E. (2009). The development and validation of a new machiavellianism scale. Journal of Management, 35(2), 219–257. https://doi.org/10.1177/0149206308318618
DePaulo, B. M., & Rosenthal, R. (1979). Telling lies. Journal of Personality and Social Psychology, 37(10), 1713–1722. https://doi.org/10.1037/0022-3514.37.10.1713
Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007). G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods, 39(2), 175–191. https://doi.org/10.3758/BF03193146
Field, A. (2009). Discovering statistics using SPSS. SAGE Publications Ltd.
Geis, F. L., & Moon, T. H. (1981). Machiavellianism and deception. Journal of Personality and Social Psychology, 41(4), 766–775. https://doi.org/10.1037/0022-3514.41.4.766
Granhag, P. A., & Hartwig, M. (2015). The strategic use of evidence technique: A conceptual overview. In P. A. Granhag, V. Aldert, & B. Verschuere (Eds.), Detecting deception: Current challenges and cognitive approaches (pp. 231–251). Wiley.
Hart, C. L., Lemon, R., Curtis, D. A., & Griffith, J. D. (2020). Personality traits associated with various forms of lying. Psychological Studies, 65(3), 239–246. https://doi.org/10.1007/s12646-020-00563-x
Kashy, D. A., & DePaulo, B. M. (1996). Who lies? Journal of Personality and Social Psychology, 70(5), 1037–1051. https://doi.org/10.1037/0022-3514.70.5.1037
Lee, K., & Ashton, M. C. (2006). Further assessment of the HEXACO personality inventory: Two new facet scales and an observer report form. Psychological Assessment, 18(2), 182–191. https://doi.org/10.1037/1040-3590.18.2.182
Levine, T. R. (2010). A few transparent liars explaining 54% accuracy in deception detection experiments. Annals of the International Communication Association, 34(1), 41–61. https://doi.org/10.1080/23808985.2010.11679095
Lüdecke, D., Ben-Shachar, M. S., Patil, I., & Makowski, D. (2020). Extracting, computing and exploring the parameters of statistical models using R. Journal of Open Source Software, 5(53), 2445.
Lüdecke, D., Makowski, D., & Waggoner, P. (2019). Performance: Assessment of regression models performance (Vol. 4, p. 2). R Package Version 0.
Magnusson, D. (1998). The logic and implications of a person approach. In R. B. Cairns, L. R. Bergman, & J. Kagan (Eds.), Methods and Models for Studying the Individual (pp. 33–64). Sage.
Makowski, D., Pham, T., Lau, Z. J., Raine, A., & Chen, S. H. A. (2021). The structure of deception: Validation of the lying profile questionnaire. Current Psychology. https://doi.org/10.1007/s12144-021-01760-1
Markowitz, D. M., & Levine, T. R. (2021). It’s the situation and your disposition: A test of two honesty hypotheses. Social Psychological and Personality Science, 12(2), 213–224. https://doi.org/10.1177/1948550619898976
Muris, P., Merckelbach, H., Otgaar, H., & Meijer, E. (2017). The malevolent side of human nature: a meta-analysis and critical review of the literature on the dark triad (narcissism, machiavellianism, and psychopathy). Perspectives on Psychological Science, 12(2), 183–204. https://doi.org/10.1177/1745691616666070
Palena, N., & Caso, L. (2021). Investigative interviewing research: Ideas and methodological suggestions for new research perspectives. Frontiers in Psychology, 12(2675). https://doi.org/10.3389/fpsyg.2021.715028
Palena, N., Caso, L., Cavagnis, L., & Greco, A. (2021a). Profiling the Interrogee: Applying the person-centered approach in investigative interviewing research. Frontiers in Psychology, 12(5089). https://doi.org/10.3389/fpsyg.2021.722893
Palena, N., Caso, L., Vrij, A., & Nahari, G. (2021b). The verifiability approach: A meta-analysis. Journal of Applied Research in Memory and Cognition, 10(1), 155–166. https://doi.org/10.1016/j.jarmac.2020.09.001
Park, H. S., Serota, K. B., & Levine, T. R. (2021). In search of Korean outliars: “a few prolific liars” in South Korea. Communication Research Reports, 1-10. https://doi.org/10.1080/08824096.2021.1922374
Putnick, D. L., & Bornstein, M. H. (2016). Measurement invariance conventions and reporting: The state of the art and future directions for psychological research. Developmental Review : DR, 41, 71–90. https://doi.org/10.1016/j.dr.2016.06.004
R Core Team. (2020). R: A language and environment for statistical computing. Vienna: R Foundation for Statistical Computing. Available online at: https://www.R-project.org/.
Ravelle, W. (2018). Psych: Procedures for psychological, psychometric, and personality research: Northwestern University. Retrieved from https://CRAN.R-project.org/package=psych
Riggio, R. E., & Friedman, H. S. (1983). Individual differences and cues to deception. Journal of Personality and Social Psychology, 45(4), 899–915. https://doi.org/10.1037/0022-3514.45.4.899
Riggio, R. E., Salinas, C., & Tucker, J. (1988). Personality and deception ability. Personality and Individual Differences, 9(1), 189–191. https://doi.org/10.1016/0191-8869(88)90050-5
Rosseel, Y. (2012). Lavaan: An RPackage for structural equation modeling. Journal of Statistical Software, 48(2). https://doi.org/10.18637/jss.v048.i02.
RStudio Team. (2020). RStudio: Integrated development for R. Boston, MA: RStudio, PBC. Available online at: http://www.rstudio.com/.
Rupp, A. A. (2013). Clustering and classification The Oxford handbook of quantitative methods: Statistical analysis, Vol. 2 (pp. 517–550). New York, NY, US: Oxford University Press.
Rutkowski, L., & Svetina, D. (2014). Assessing the hypothesis of measurement invariance in the context of large-scale international surveys. Educational and Psychological Measurement, 74(1), 31–57. https://doi.org/10.1177/0013164413498257
Semrad, M., & Scott-Parker, B. (2020). Police, personality and the ability to deceive. International Journal of Police Science & Management, 22(1), 50–61. https://doi.org/10.1177/1461355719880568
Semrad, M., Scott-Parker, B., & Nagel, M. (2019). Personality traits of a good liar: A systematic review of the literature. Personality and Individual Differences, 147, 306–316. https://doi.org/10.1016/j.paid.2019.05.007
Semrad, M., Scott-Parker, B., & Vanags, T. (2020). DeceIT and personality: Which HEXACO traits make a convincing liar? Journal of Police and Criminal Psychology. https://doi.org/10.1007/s11896-020-09378-y
Semrad, M., Vanags, T., & Bhullar, N. (2014). Selecting witness protection officers: Developing a test battery for Australian police. Police Practice and Research, 15(1), 6–16. https://doi.org/10.1080/15614263.2012.710459
Serota, K. B., & Levine, T. R. (2015). A few prolific liars: Variation in the prevalence of lying. Journal of Language and Social Psychology, 34(2), 138–157. https://doi.org/10.1177/0261927x14528804
Serota, K. B., Levine, T. R., & Boster, F. J. (2010). The prevalence of lying in America: Three studies of self-reported lies. Human Communication Research, 36(1), 2–25. https://doi.org/10.1111/j.1468-2958.2009.01366.x
Steca, P., D’Addario, M., Magrin, M. E., Miglioretti, M., Monzani, D., Pancani, L., . . . Greco, A. (2016). A type A and type D combined personality typology in essential hypertension and acute coronary syndrome patients: Associations with demographic, psychological, clinical, and lifestyle indicators. PLOS ONE, 11(9), e0161840. https://doi.org/10.1371/journal.pone.0161840
Šukys, S. (2013). Athletes’ justification of cheating in sport: Relationship with moral disengagement in sport and personal factors. Baltic Journal of Sport and Health Sciences, 3(90), 70–77.
Tasa, K., & Bell, C. M. (2017). Effects of implicit negotiation beliefs and moral disengagement on negotiator attitudes and deceptive behavior. Journal of Business Ethics, 142(1), 169–183. https://doi.org/10.1007/s10551-015-2800-4
Terracciano, A., McCrae, R. R., & Costa, P. T., Jr. (2010). Intra-individual change in personality stability and age. Journal of Research in Personality, 44(1), 31–37. https://doi.org/10.1016/j.jrp.2009.09.006
Vrij, A. (2008). Detecting lies and deceit: Pitfalls and opportunities (2nd ed.). John Wiley and Sons.
Vrij, A., Fisher, R. P., & Blank, H. (2017). A cognitive approach to lie detection: A meta-analysis. Legal and Criminological Psychology, 22(1), 1–21. https://doi.org/10.1111/lcrp.12088
Vrij, A., Granhag, P. A., & Mann, S. (2010). Good liars. The Journal of Psychiatry & Law, 38(1–2), 77–98. https://doi.org/10.1177/009318531003800105
Vrij, A., Palena, N., Leal, S., & Caso, L. (2021). The relationship between complications, common knowledge details and self-handicapping strategies and veracity: A meta-analysis. The European Journal of Psychology Applied to Legal Context. https://doi.org/10.5093/ejpalc2021a7
Weiss, B., & Feldman, R. S. (2006). Looking good and lying to do it: Deception as an impression management strategy in job interviews. Journal of Applied Social Psychology, 36(4), 1070–1086. https://doi.org/10.1111/j.0021-9029.2006.00055.x
West, S. G., Finch, J. F., & Curran, P. J. (1995). Structural equation models with nonnormal variables: Problems and remedies Structural equation modeling: Concepts, issues, and applications. (pp. 56-75). Thousand Oaks: Sage Publications, Inc.
Williams, K. M., Nathanson, C., & Paulhus, D. L. (2010). Identifying and profiling scholastic cheaters: Their personality, cognitive ability, and motivation. Journal of Experimental Psychology: Applied, 16(3), 293–307. https://doi.org/10.1037/a0020773
World Medical Association. (2004). World medical association declaration of Helsinki ethical principles for medical research involving human subjects. Journal International de Bioéthique, 15(1), 124-129. https://doi.org/10.3917/jib.151.0124
Wright, J. P., Morgan, M. A., Almeida, P. R., Almosaed, N. F., Moghrabi, S. S., & Bashatah, F. S. (2017). Malevolent forces:self-control, the dark triad, and crime. Youth Violence and Juvenile Justice, 15(2), 191–215. https://doi.org/10.1177/1541204016667995
Zercher, F., Schmidt, P., Cieciuch, J., & Davidov, E. (2015). The comparability of the universalism value over time and across countries in the European Social Survey: exact vs. approximate measurement invariance. Frontiers in Psychology, 6(733). https://doi.org/10.3389/fpsyg.2015.00733
Zvi, L., & Elaad, E. (2018). Correlates of narcissism, self-reported lies, and self-assessed abilities to tell and detect lies, tell truths, and believe others. Journal of Investigative Psychology and Offender Profiling, 15(3), 271–286. https://doi.org/10.1002/jip.1511
Funding
Open access funding provided by Università degli studi di Bergamo within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Contributions
The first and the second author conceived the idea of the study and designed the experiment. The first, third and fourth authors conducted the analyses. All the authors interpreted the results, wrote and contributed to the article and approved the submitted version.
Corresponding author
Ethics declarations
Ethics Statement
The study was conducted in accordance with the Declaration of Helsinki (World Medical Association, 2004) and with the ethical guidelines for research provided by the Italian Psychological Association (Associazione Italiana di Psicologia, 2015). All the data were collected anonymously.
Competing Interests
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Palena, N., Caso, L., Cavagnis, L. et al. Exploring the relationship between personality, morality and lying: A study based on the person-centred approach. Curr Psychol 42, 20502–20514 (2023). https://doi.org/10.1007/s12144-022-03132-9
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12144-022-03132-9