
Abstract
In this paper, we introduce a regularized mean-field game and study learning of this game under an infinite-horizon discounted reward function. Regularization is introduced by adding a strongly concave regularization function to the one-stage reward function in the classical mean-field game model. We establish a value iteration based learning algorithm to this regularized mean-field game using fitted Q-learning. The regularization term in general makes reinforcement learning algorithm more robust to the system components. Moreover, it enables us to establish error analysis of the learning algorithm without imposing restrictive convexity assumptions on the system components, which are needed in the absence of a regularization term.



Similar content being viewed by others
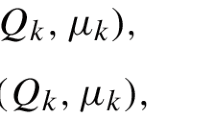


Notes
In classical mean-field game literature, the exogenous behaviour of the other agents is in general modelled by a state-measure flow \(\{\mu _t\}\), \(\mu _t \in \mathcal {P}(\mathsf {X})\) for all t, which means that total population behaviour is non-stationary. In this paper, we only consider the stationary case; that is, \(\mu _t = \mu \) for all t. Establishing a learning algorithm for the non-stationary case is more challenging.
References
Adlakha S, Johari R, Weintraub G (2015) Equilibria of dynamic games with many players: existence, approximation, and market structure. J Econ Theory 156:269–316
Anahtarci B, Kariksiz C, Saldi N (2019) Fitted Q-learning in mean-field games. arXiv:1912.13309
Anahtarci B, Kariksiz C, Saldi N (2020) Value iteration algorithm for mean field games. Syst Control Lett 143
Antos A, Munos R, Szepesvári C (2007) Fitted Q-iteration in continuous action-space MDPs. In: Proceedings of the 20th international conference on neural information processing systems, pp 9–16
Antos A, Munos R, Szepesvári C (2007) Fitted Q-iteration in continuous action-space MDPs. Tech. rep. inria-00185311v1
Bensoussan A, Frehse J, Yam P (2013) Mean field games and mean field type control theory. Springer, New York
Biswas A (2015) Mean field games with ergodic cost for discrete time Markov processes. arXiv:1510.08968
Cardaliaguet P (2011) Notes on mean-field games. Technical report, p 120
Carmona R, Delarue F (2013) Probabilistic analysis of mean-field games. SIAM J Control Optim 51(4):2705–2734
Carmona R, Lauriere M, Tan Z (2019) Linear-quadratic mean-field reinforcement learning: convergence of policy gradient methods. arXiv:1910.04295
Elie R, Perolat J, Lauriere M, Geist M, Pietquin O (2019) Approximate fictitious play for mean-field games. arXiv:1907.02633
Elliot R, Li X, Ni Y (2013) Discrete time mean-field stochastic linear-quadratic optimal control problems. Automatica 49:3222–3233
Fu Z, Yang Z, Chen Y, Wang Z (2019) Actor-critic provably finds Nash equilibria of linear-quadratic mean-field games. arXiv:1910.07498
Geist M, Scherrer B, Pietquin O (2019) A theory of regularized Markov decision processes. arXiv:1901.11275
Georgii H (2011) Gibbs Measures and Phase Transitions. De Gruyter studies in mathematics. De Gruyter
Gomes D, Mohr J, Souza R (2010) Discrete time, finite state space mean field games. J Math Pures Appl 93:308–328
Gomes D, Saúde J (2014) Mean field games models: a brief survey. Dyn Games Appl 4(2):110–154
Guo X, Hu A, Xu R, Zhang J (2019) Learning mean-field games. arXiv:1901.09585
Huang M (2010) Large-population LQG games involving major player: the nash certainty equivalence principle. SIAM J Control Optim 48(5):3318–3353
Huang M, Caines P, Malhamé R (2007) Large-population cost coupled LQG problems with nonuniform agents: individual-mass behavior and decentralized \(\epsilon \)-Nash equilibria. IEEE Trans Autom Control 52(9):1560–1571
Huang M, Malhamé R, Caines P (2006) Large population stochastic dynamic games: closed loop McKean-Vlasov systems and the Nash certainty equivalence principle. Commun Inform Syst 6:221–252
Kara AD, Yüksel S (2019) Robustness to incorrect priors in partially observed stochastic control. SIAM J Control Optim 57(3):1929–1964
Kara AD, Yüksel S (2020) Robustness to incorrect system models in stochastic control. SIAM J Control Optim 58(2):1144–1182
Kontorovich L, Ramanan K (2008) Concentration inequalities for dependent random variables via the martingale method. Ann Probab 36(6):2126–2158
Lasry J, Lions P (2007) Mean field games. Japan J Math 2:229–260
Mehta P, Meyn S (2009) Q-learning and Pontryagin’s minimum principle. In: Proceedings of the 48h IEEE Conference on Decision and Control (CDC) held jointly with 2009 28th Chinese Control Conference, pp 3598–3605
Moon J, Başar T (2015) Discrete-time decentralized control using the risk-sensitive performance criterion in the large population regime: a mean field approach. In: ACC 2015. Chicago
Moon J, Başar T (2016) Discrete-time mean field Stackelberg games with a large number of followers. In: CDC 2016. Las Vegas
Moon J, Başar T (2016) Robust mean field games for coupled Markov jump linear systems. Int J Control 89(7):1367–1381
Neu G, Jonsson A, Gomez V (2017) A unified view of entropy-regularized Markov decision processes. arXiv:1705.07798
Nourian M, Nair G (2013) Linear-quadratic-Gaussian mean field games under high rate quantization. In: CDC 2013. Florence
Saldi N (2019) Discrete-time average-cost mean-field games on Polish spaces. arXiv:1908.08793 (accepted to Turkish Journal of Mathematics)
Saldi N, Başar T, Raginsky M (2018) Markov-Nash equilibria in mean-field games with discounted cost. SIAM J Control Optim 56(6):4256–4287
Saldi N, Başar T, Raginsky M (2019) Approximate Markov-Nash equilibria for discrete-time risk-sensitive mean-field games. to appear in Mathematics of Operations Research
Saldi N, Başar T, Raginsky M (2019) Approximate Nash equilibria in partially observed stochastic games with mean-field interactions. Math Oper Res 44(3):1006–1033
Shalev-Shwartz S (2007) Online learning: theory, algorithms, and applications. Ph.D. thesis, The Hebrew University of Jerusalem
Tembine H, Zhu Q, Başar T (2014) Risk-sensitive mean field games. IEEE Trans Autom Control 59(4):835–850
Vidyasagar M (2010) Learning and generalization: with applications to neural networks, 2nd edn. Springer, New York
Wiecek P (2020) Discrete-time ergodic mean-field games with average reward on compact spaces. Dyn Games Appl 10:222–256
Wiecek P, Altman E (2015) Stationary anonymous sequential games with undiscounted rewards. J Optim Theory Appl 166(2):686–710
Yang J, Ye X, Trivedi R, Hu X, Zha H (2018) Learning deep mean field games for modelling large population behaviour. arXiv:1711.03156
Yin H, Mehta P, Meyn S, Shanbhag U (2014) Learning in mean-field games. IEEE Trans Autom Control 59:629–644
Acknowledgements
This work was partly supported by the BAGEP Award of the Science Academy.
Funding
Funding was provided by Bilim Akademisi (Grant No. BAGEP 2021).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the topical collection “Multi-agent Dynamic Decision Making and Learning” edited by Konstantin Avrachenkov, Vivek S. Borkar and U. Jayakrishnan Nair.
Appendix
Appendix
1.1 Duality of Strong Convexity and Smoothness
Suppose that \(\mathsf {E}= \mathbb {R}^d\) for some \(d \ge 1\) with an inner product \(\langle \cdot ,\cdot \rangle \). We denote \(\mathbb {R}^{*} = \mathbb {R}\, \bigcup \, \{\infty \}\). Let \(f:\mathsf {E}\rightarrow \mathbb {R}^{*}\) be a differentiable convex function with the domain \(S :=\{x \in \mathsf {E}: f(x) \in \mathbb {R}\}\), which is necessarily convex subset of \(\mathsf {E}\). The Fenchel conjugate of f is a convex function \(f^*:\mathsf {E}\rightarrow \mathbb {R}^*\) that is defined as
Now, we will state duality result between strong convexity and smoothness. To this end, we suppose that f is \(\rho \)-strongly convex with respect to a norm \(\Vert \cdot \Vert \) on \(\mathsf {E}\) (not necessarily Euclidean norm); that is, for all \(x,y \in S\), we have
To state the result, we need to define the dual norm of \(\Vert \cdot \Vert \). The dual norm \(\Vert \cdot \Vert _*\) of \(\Vert \cdot \Vert \) on \(\mathsf {E}\) is defined as
For example, \(\Vert \cdot \Vert _{\infty }\) is the dual norm of \(\Vert \cdot \Vert _{1}\).
Proposition 3
([36, Lemma 15]) Let \(f:\mathsf {E}\rightarrow \mathbb {R}^*\) be a differentiable \(\rho \)-strongly convex function with respect to the norm \(\Vert \cdot \Vert \) and let S denote its domain. Then,
-
1.
\(f^*\) is differentiable on \(\mathsf {E}\).
-
2.
\(\nabla f^*(y) = \mathop {\mathrm{arg\, max}}_{x \in S} \langle x,y \rangle - f(x)\).
-
3.
\(f^*\) is \(\frac{1}{\rho }\)-smooth with respect to the norm \(\Vert \cdot \Vert _*\) ; that is,
$$\begin{aligned} \Vert \nabla f^*(y_1) - \nabla f^*(y_2)\Vert \le \frac{1}{\rho } \Vert y_1-y_2\Vert _* \,\, \text {for all} \,\, y_1,y_2 \in \mathsf {E}. \end{aligned}$$
In the paper, we make use of the properties 2 and 3 of Proposition 3 to establish the Lipschitz continuity of the optimal policies, which enables us to prove the main results of our paper.
1.2 Proof of Proposition 1
Fix any \(x,\hat{x}, u,\hat{u}, \mu , \hat{\mu }\). Let us recall the following fact about \(l_1\) norm on the set probability distributions on finite sets [15, p. 141]. Suppose that there exists a real valued function F on a finite set \(\mathsf {E}\). Let \(\lambda (F) :=\sup _{e \in \mathsf {E}} F(e) - \inf _{e \in \mathsf {E}} F(e)\). Then, for any pair of probability distributions \(\mu ,\nu \) on \(\mathsf {E}\), we have
Using this fact, we now have
where the last inequality follows from the following fact in view of (6):
Similarly, we have
To show that (I) follows from Assumption 1-(b), let us define the transition probability \(M:\mathsf {A}\rightarrow \mathcal {P}(\mathsf {X})\) as
Let \(\xi \in \mathcal {P}(\mathsf {A}\times \mathsf {A})\) be the optimal coupling of u and \(\hat{u}\) that achieves total variation distance \(\Vert u-\hat{u}\Vert _{TV}\). Similarly, for any \(a,\hat{a} \in \mathsf {A}\), let \(K(\cdot |a,\hat{a}) \in \mathcal {P}(\mathsf {X}\times \mathsf {X})\) be the optimal coupling of \(M(\cdot |a)\) and \(M(\cdot |\hat{a})\) that achieves total variation distance \(\Vert M(\cdot |a)-M(\cdot |\hat{a})\Vert _{TV}\). Note that
where
and
Let us define \(\nu (\cdot ) :=\sum _{(a,\hat{a}) \in \mathsf {A}\times \mathsf {A}} K(\cdot |a,\hat{a}) \, \xi (a,\hat{a})\), and so, \(\nu \) is a coupling of uM and \(\hat{u} M\). Therefore, we have
Hence, (I) follows. This completes the proof.
1.3 Proof of Lemma 1
Fix any \(\mu \). If a function \(f: \mathsf {X}\rightarrow \mathbb {R}\) is K-Lipschitz continuous for some K, then \(g = \frac{f}{K}\) is 1-Lipschitz continuous. Hence, for all \(u \in \mathsf {U}\) and \(z,y \in \mathsf {X}\) we have
since \(\sup _x g(x) - \inf _x g(x) \le 1\). Hence, the contraction operator \(T_{\mu }\) maps K-Lipschitz functions to \(L_1+\beta K K_1/2\)-Lipschitz functions, since, for all \(z,y \in \mathsf {X}\)
Now we apply \(T_{\mu }\) recursively to obtain the sequence \(\{T_{\mu }^n f\}\) by letting \(T_{\mu }^n f = T_{\mu } (T_{\mu }^{n-1} f )\), which converges to the value function \(Q^{\mathop {\mathrm{reg}},*}_{\mu ,\max }\) by the Banach fixed point theorem. Clearly, by mathematical induction, we have for all \(n\ge 1\), \(T_{\mu }^n f\) is \(K_n\)-Lipschitz continuous, where \(K_n = L_1 \sum _{i=0}^{n-1} (\beta K_1/2)^i + K (\beta K_1/2)^n\). If we choose \(K < L_1\), then \(K_n \le K_{n+1}\) for all n and therefore, \(K_n \uparrow \frac{ L_1}{1-\beta K_1/2}\). Hence, \(T_{\mu }^n f\) is \( \frac{L_1}{1-\beta K_1/2}\)-Lipschitz continuous for all n, and therefore, \(Q^{\mathop {\mathrm{reg}},*}_{\mu ,\max }\) is also \( \frac{L_1}{1-\beta K_1/2}\)-Lipschitz continuous.
1.4 Proof of Lemma 2
Under Assumption 1, it is straightforward to prove that \(H_1\) maps \(\mathcal {P}(\mathsf {X})\) into \({\mathcal {C}}\). Indeed, the only non-trivial fact is the \(\left( K_{\mathop {\mathrm{Lip}}}+L_{\mathop {\mathrm{reg}}}\right) \)-Lipschitz continuity of \(H_1(\mu ) =:Q_{\mu }^{\mathop {\mathrm{reg}},*}\). This can be proved as follows: For any (x, u) and \((\hat{x},\hat{u})\), we have
where the last inequality follows from (6) and Lemma 1. Hence, \(Q_{\mu }^{\mathop {\mathrm{reg}},*}\) is \(\left( K_{\mathop {\mathrm{Lip}}}+L_{\mathop {\mathrm{reg}}}\right) \)-Lipschitz continuous.
Now, for any \(\mu ,{\hat{\mu }}\in \mathcal {P}(\mathsf {X})\), we have
where the last inequality follows from (6) and Lemma 1. This completes the proof.
1.5 Proof of Lemma 3
For any \(\mu \in \mathcal {P}(\mathsf {X})\), we have
where \( q_{x}^{\mu }(\cdot ) :=r(x,\cdot ,\mu ) + \beta \sum _{y \in \mathsf {X}} Q_{\mu ,\max }^{\mathop {\mathrm{reg}},*}(y) \, p(y|x,\cdot ,\mu ). \) By \(\rho \)-strong convexity of \(\varOmega \), \(Q_{\mu }^{\mathop {\mathrm{reg}},*}(x,\cdot )\) has a unique maximizer \(f_{\mu }(x) \in \mathsf {U}\) for any \(x \in \mathsf {X}\), which is the optimal policy for \(\mu \). By Property 2 of Proposition 3, we have
where \(\varOmega ^*\) is the Fenchel conjugate of \(\varOmega \), and \(\varOmega ^*(q_x^{\mu }) = Q_{\mu ,\max }^{\mathop {\mathrm{reg}},*}(x)\).
Moreover, for any \(\mu ,{\hat{\mu }}\in \mathcal {P}(\mathsf {X})\) and \(x,\hat{x}\in \mathsf {X}\), by property 3 of Proposition 3 and by noting the fact that \(\Vert \cdot \Vert _{\infty }\) is the dual norm of \(\Vert \cdot \Vert _1\) on \(\mathsf {U}\), we obtain the following bound:
Note that we have
Therefore, we obtain
1.6 Proof of Theorem 1
Let \(\mu _{\varepsilon } \in \varLambda ^{\mathop {\mathrm{reg}}}(\pi _{\varepsilon })\). Then, we have
Note that Lemma 3 and Proposition 1 lead to
Hence, (I) follows from [24, Lemma A2]. Therefore, we have:
where \(C_1 :=\left( \frac{3 \, K_1}{2} + \frac{K_1 \, K_{H_1}}{2\rho } \right) \). Note that by Assumption 2, \(C_1 < 1\). Now, fix any policy \(\pi \in \varPi \). Then, we have
Here, (II) follows from (6) and the fact that \(J_{\mu _*}^{\mathop {\mathrm{reg}}}(\pi ,\cdot )\) is \(K_{\mathop {\mathrm{Lip}}}\)-Lipschitz continuous, which can be proved as in Lemma 1. Therefore, we obtain
where \(C_2 :=\left( L_1+\frac{\beta K_1 K_{\mathop {\mathrm{Lip}}}}{2}\right) \frac{K_1}{1-C_1}\).
Note that we also have
Here, (III) follows from (6) and the fact that \(J_{\mu _*}^{\mathop {\mathrm{reg}}}(\pi _*,\cdot )\) is \(K_{\mathop {\mathrm{Lip}}}\)-Lipschitz continuous, which can be proved as in Lemma 1. Therefore, we obtain
where \(C_3 :=\left( L_1+L_{\mathop {\mathrm{reg}}}+\frac{\beta K_1 K_{\mathop {\mathrm{Lip}}}}{2}\right) \).
Note that we must prove that
for each \(i=1,\ldots ,N\), when N is sufficiently large. As the transition probabilities and the one-stage reward functions are the same for all agents, it is sufficient to prove (9) for Agent 1 only. Given \(\delta > 0\), for each \(N\ge 1\), let \({\tilde{\pi }}^{(N)} \in \varPi _1\) be such that
Then, by [33, Theorem 4.10], we have

Therefore, there exists \(N(\delta )\) such that
for all \(N\ge N(\delta )\).
Rights and permissions
About this article

Cite this article
Anahtarci, B., Kariksiz, C.D. & Saldi, N. Q-Learning in Regularized Mean-field Games. Dyn Games Appl 13, 89–117 (2023). https://doi.org/10.1007/s13235-022-00450-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13235-022-00450-2