
Abstract
Methods for efficiently controlling dynamics propagated on networks are usually based on identifying the most influential nodes. Knowledge of these nodes can be used for the targeted control of dynamics such as epidemics, or for modifying biochemical pathways relating to diseases. Similarly they are valuable for identifying points of failure to increase network resilience in, for example, social support networks and logistics networks. Many measures, often termed ‘centrality’, have been constructed to achieve these aims. Here we consider Katz centrality and provide a new interpretation as a steady-state solution to continuous-time dynamics. This enables us to implement a sensitivity analysis which is similar to metabolic control analysis used in the analysis of biochemical pathways. The results yield a centrality which quantifies, for each node, the net impact of its absence from the network. It also has the desirable property of requiring a node with a high centrality to play a central role in propagating the dynamics of the system by having the capacity to both receive flux from others and then to pass it on. This new perspective on Katz centrality is important for a more comprehensive analysis of directed networks.
Similar content being viewed by others

Introduction
Ranking nodes with respect to their degree often provides valuable information on their relative importance, but it can also neglect essential factors and, by definition, it cannot distinguish between nodes of the same degree. One of the major deficiencies of degree centrality is that while it counts the number of neighbours of a node, it does not account for how central or important those neighbours are. Centrality measures that directly address this deficiency include Katz centrality1, eigenvector centrality2, and the centrality known as PageRank which partly underpins the Google search engine3. We briefly summarise these here.
We consider a network represented by an \(n\) by \(n\) non-negative matrix \(A\) such that \({A}_{ij}\ne 0\) represents a connection (arc) from node \(j\) to node \(i\), and potentially \(A\) could be weighted and directed. Katz centrality1 is the earliest of these measures and can be defined by
where \({\bf{r}}={[{r}_{1},{r}_{2}\mathrm{,\; ...},{r}_{n}]}^{T}\) denotes Katz centrality at each node, 1 is an \(n\times 1\) column vector of ones and \(0 < a < \mathrm{1/}\rho (A)\) where \(\rho (A)\) is the spectral radius of matrix \(A\) (see methods). This has solution
where \(M={(I-aA)}^{-1}\) and I is the n by n identity matrix. This definition is slightly different to the original paper by Katz1, but it results in the same ranking of nodes. It can be interpreted as a sum of two contributions. One is an intrinsic centrality that each node has (first term on the right of (1)) and the other is the centrality passed to it in proportion to how important its neighbours are (second term on the right of (1)). PageRank3 can be viewed as a variant of Katz centrality4 in which the centrality contributed by a node to its neighbours is treated as a limited resource which is distributed evenly among them. Experience by Google suggests that this modification makes a better representation of the relative importance of internet pages.
Eigenvector centrality2 can be motivated in a similar way to Katz centrality and is defined as the principal right-eigenvector of \(A\), which we shall denote by u. Although there are clear similarities between (1) and the eigenvalue equation, and similarities with the motivations behind the two measures, they are mathematically distinct.
Complications arise in all of these centralities when we consider directed networks. In the context of eigenvector centrality, Kleinberg5 proposed a resolution by using two quantities to characterise a directed network. These are termed ‘hubs’ and ‘authorities’ where each node has a measure of the extent to which it is behaving like a hub (receiving centrality from its neighbours) and the extent to which it is behaving like an authority (passing centrality to its neighbours). The hub quantifier, which we shall denote by h, is defined by the principal right-eigenvector of matrix \({A}^{T}A\). The authority quantifier, which we shall denote by a, is defined as the principal right-eigenvector of \(A{A}^{T}\). For undirected networks, this distinction is unimportant and both reduce to standard eigenvector centrality.
On directed networks, Katz centrality, PageRank and eigenvector centrality favour hub-like nodes. This is evident from the form of (1) and from the eigenvalue equation where centrality is passed to a node from its inward-pointing neighbours. However, we argue here that a genuinely central node, in the sense that it is central to the ongoing dynamics, should be able to receive flux from others and be able to pass this on. In this sense, pure source or pure sink nodes are peripheral to sustaining the ongoing dynamics and so are not central, even though a sink node could attain a high centrality from the form of (2).
We first recast Katz centrality as a solution to a continuous-time dynamical system. Then, by investigating the idea that the importance or centrality of an individual to this system is determined by the net impact of their removal, with everything else remaining the same, we quantify the net worth or effect of that individual, both in terms of their intrinsic value as well as by the impact that they have on others. By making a linear approximation to this process of node deletion we derive a centrality measure that automatically accounts for both the hub-like and the authority-like properties of nodes and gives a different perspective on Katz centrality.
Methods
A linear continuous-time dynamical system
We can interpret centrality of the form (2) as the unique steady state of the following linear continuous-time dynamical system:
In this system, centrality is generated uniformly across the network at each node (first term on the right). It is also destroyed at each node at a rate given by the amount of centrality at the node (last term on the right). An individual’s centrality is increased by a flux from its neighboring nodes in proportion to their own centrality (middle term on the right). We shall refer to this system as Katz dynamics.
The steady-state solution coincides with (2) when \(0 < a < \mathrm{1/}{\mu }_{1}\) where \({\mu }_{1}\) denotes the largest eigenvalue of \(A\) (which may not be unique). We know that for non-negative \(A\), \({\mu }_{1}\) is non-negative and equal to the spectral radius \(\rho (A)\) 6.
To determine the stability of the steady-state solution, we form the Jacobian of (3). This is \(J=aA-I\), which has characteristic equation \(det(J-\lambda I)=0\) or
provided \(a\ne 0\). The eigenvalue \({\lambda }_{1}\) of \(J\) with the largest real part is therefore \({\lambda }_{1}=a{\mu }_{1}-1\) and it follows that the condition for stability of the steady state of (3) is \(a < \mathrm{1/}{\mu }_{1}\). This is also the condition for \(I-aA\) to be an M-matrix7 which implies that all elements of its inverse are non-negative; clearly this is a desirable property in forming a centrality measure. The stability of the steady state of (3) is also essential for our control analysis below.
Control analysis
When the condition \(a < \mathrm{1/}{\mu }_{1}\) is met, (3) is a structurally stable continuous-time dynamical system describing dynamics on a network with matrix \(A\) comprising \(n\) variables \({x}_{1},{x}_{2},\mathrm{...,}\,{x}_{n}\). We define the importance or centrality of a node by the net impact on the system of its absence8. So, the total impact of a node is the sum of the differences in the steady states of (3) before and after the node removal. This accounts both for the net effect of the flux passed to the node itself, but also the contribution it makes to others in the system.
Define \({{\bf{q}}}^{i}=[{q}_{1}^{i},{q}_{2}^{i},\,...,\,{q}_{n-1}^{i}{]}^{T}\) to be the steady-state solution (2) with node \(i\) removed from \(A\). Then define \({{\bf{r}}}^{i}={[{q}_{1}^{i},{q}_{2}^{i},\mathrm{...,}{q}_{i-1}^{i},\mathrm{0,}{q}_{i}^{i},{q}_{i+1}^{i},\mathrm{...,}{q}_{n-1}^{i}]}^{T}\); that is, each node in the steady-state solution of the perturbed network maintains the same position in the vector \({{\bf{r}}}^{i}\) as in r and \({r}_{i}^{i}=0\). Then we can define the total impact of node \(i\):
This needs to be repeated for each node in the network to form the full vector of centralities \({\bf{d}}=[{d}_{1},{d}_{2},\,...,\,{d}_{n}{]}^{T}\). It is important to observe that node deletion cannot lead to an increase in the principal eigenvalue6 and so the stability condition is never broken.
The computational complexity of assessing the impact of perturbations on this linear system is not generally reducible9 and typically requires that we solve as many linear systems of equations as there are nodes in the network. While we shall compare our numerical results with this direct deletion method, we shall now derive an approximation to this based on a linear sensitivity analysis similar to metabolic control analysis10,11,12, used in the analysis of biochemical networks. This reduces computational cost and yields some new perspectives.
We consider small perturbations to the steady state of (3) by targeting individual nodes. The resulting linear response of the steady states of all other nodes is then used to approximate the process of node deletion. To enable targeting of individual nodes, we rewrite (3) to introduce some node-specific parameters \({\boldsymbol{\gamma }}={[{\gamma }_{1},{\gamma }_{2},\mathrm{...,}{\gamma }_{n}]}^{T}\):
where \(\circ \) denotes the Hadamard (or component-wise) product. Now define
to be a vector-valued function of variables x and γ. Its zero values (\({\bf{f}}({{\bf{x}}}^{\ast },{\boldsymbol{\gamma }})={\bf{0}}\), where 0 is the column vector \({[0,0,\mathrm{...,}0]}^{T}\) of length \(n\)) define the steady state \({{\bf{x}}}^{\ast }=[{x}_{1}^{\ast },{x}_{2}^{\ast }\mathrm{,\; ...,}\,{x}_{n}^{\ast }]\) of the dynamical system (5).
We shall assume that \({\boldsymbol{\gamma }}={\bf{1}}\) because this is equivalent to the original system (3), and in this case \({{\bf{x}}}^{\ast }={\bf{r}}\). However we use this new vector of parameters to investigate small node-specific perturbations from this steady state. Specifically, we define the impact of one node \(i\) on another node \(j\) by:
where \({\gamma }_{i}\) provides a direct instantaneous perturbation to just the value \({x}_{i}^{\ast }\), followed by more complicated effects through the network as the system moves to a new state. Here, the linear response of the steady state to a change in \({\gamma }_{i}\) is given by \(d{x}_{j}^{\ast }/d{\gamma }_{i}\). The remaining factor determines the size of perturbation equivalent to the removal of node \(i\) and together they form a linear approximation to the removal of node \(i\).
To determine (6), we first solve (5) at the steady state for \({x}_{i}^{\ast }\):
from which we obtain:
So, the immediate impact of a small increase in \({\gamma }_{i}\) is that \({x}_{i}^{\ast }\) reduces in proportion to its size.
For \({\gamma }={\bf{1}}\) we have
After a small perturbation, the system returns to a new steady state near to the original one. Since \({\bf{f}}={\bf{0}}\) at both steady-state solutions, an infinitesimal perturbation between two steady states is described by
where \({{\bf{0}}}_{{\bf{n}}\times {\bf{n}}}\) is the \(n\) by \(n\) zero matrix. The total derivative of \({\bf{f}}\) with respect to γ is
Putting \(d{\bf{f}}/d{\boldsymbol{\gamma }}={{\bf{0}}}_{{\bf{n}}\times {\bf{n}}}\) and determining the relevant partial derivatives enables us to obtain C from (7):
where \(R\) is a diagonal matrix with diagonal elements \({R}_{ii}={r}_{i}\).
The element C ji describes the impact of node \(i\) on node \(j\). We can construct the total impact on the system of perturbing node \(i\) by computing \({\sum }_{j}{C}_{ji}\), and for all nodes, this can be determined by taking the column-sum of C:
Using (2) and the Hadamard product we obtain
which is the component-wise product of the row-sum and the column-sum of \(M\) which we shall refer to here as the linear approximation.
The row-sum of \(M\) corresponds to Katz centrality. The utility of the column-sum of \(M\) in describing the influence of nodes, or what we shall refer to as the ‘sender’ property, has been emphasised elsewhere13. Hence, using our knowledge of \({\bf{r}}\) as a measure of the hub-like or ‘receiver’ property gives the centrality \({\boldsymbol{\sigma }}\) as a product of measures of the extent to which a node is a sender or a receiver:
where
is a vector \({\bf{s}}={[{s}_{1},{s}_{2},\mathrm{...,}{s}_{n}]}^{T}\) denoting the sender property of each node. It is straightforward to see that s is also the steady-state solution to Katz dynamics on \({A}^{T}\).
Results
General observations
By making a linear approximation to the process of removing nodes from the steady state of Katz dynamics we obtain a product of two quantities, one quantifying the ‘sender’ property of a node and one quantifying the ‘receiver’ property. For our overall measure of centrality \({\boldsymbol{\sigma }}\) to be large, we typically require both the sender (s) and receiver (r) properties to be large.
We note that r and s describe very similar network properties to Kleinberg’s hubs (h) and authorities (a) respectively and also to the principal right (u) and principal left (v) eigenvectors of \(A\) respectively. Motivated by (9), it is also of interest to numerically investigate the analogous products \({\bf{h}}\,\circ \,{\bf{a}}\) and \({\bf{u}}\,\circ \,{\bf{v}}\) which we shall do in the following section.
The form of (8) means that \({\boldsymbol{\sigma }}\) is invariant with respect to taking the transpose of \(A\). Furthermore the sender and receiver properties are interchanged under this operation. As a special case of this, on undirected networks it follows that \({\bf{s}}={\bf{r}}\) and that consequently for each node \(i\), \({{\rm{\sigma }}}_{i}={r}_{i}^{2}={s}_{i}^{2}\). Due to this monotonic relationship, the node rankings for undirected networks are the same for \({\boldsymbol{\sigma }}\) as for Katz centrality; node rankings only differ on networks with directed links. It also follows from the definitions of the sender and receiver properties that, over the whole network, what is sent is also received; \({{\bf{1}}}^{{T}}{\bf{r}}={{\bf{1}}}^{{T}}{\bf{s}}\). So in this sense, the centrality flux is conserved. Analogous results to these also apply for \({\bf{h}}\,\circ \,{\bf{a}}\) and \({\bf{u}}\,\circ \,{\bf{v}}\).
For the original node deletion process, the form of (4) means that d is also invariant with respect to taking the transpose of \(A\), although in this case we did not propose an explicit separation into hub-like and authority-like properties.
Numerical evaluation on example networks
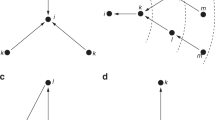
Table 1 shows the different centrality measures that we have considered applied to the example network in Fig. 1. For Katz dynamics, the impact of the deletion of the peripheral source and sink nodes is captured exactly by the linear approximation. Additionally, nodes 1 and 5 have the same centrality under the node deletion process and this is also captured qualitatively by the linear approximation, although the numerical values are quite different. The equal centrality of nodes 1 and 5 can be understood in terms of the invariance with respect to the matrix transpose discussed above. Observe that due to the structure of this network, nodes 1 and 5 interchange roles under the transpose of \(A\); this, together with the invariance under this operation, implies that they must have the same value.

A simple example network emphasising the effect of peripheral source and sink nodes and the symmetry of node deletion under matrix transposition.
For the hub and authority measures of Kleinberg, we see from Table 1 that each node acts as a pure hub or pure authority on this network. Consequently the product of these quantities is zero for each node and does not yield information about their relative importance. However, we could argue that nodes 1 and 5 act as a through-routes for the other nodes and in this sense, could usefully be allocated a centrality that acknowledges this. For the centrality formed by the product of the left and right principal eigenvectors, nodes 1 and 5 are given non-zero centrality. Again, the peripheral nodes are not given any centrality and are classed as pure source or sink nodes. Arguably this is reasonable, however, on other directed networks, nodes which have a role linking one node to another can also have zero eigenvector centrality4.
Figure 2 shows a directed network describing the advice structures between individuals in an organisation based on data compiled by Krackhardt14. The rankings of each node in this network are given in Table 2. For comparison, the in-degree and out-degree of each node is also given. The ranking with respect to hubs/authorities, right/left eigenvectors and receiver/sender have a high degree of consistency, as we would expect because node degree remains the main driver of each of these, but there are also significant differences.

The social interaction network of Krackhardt14 depicting advice structures within an organisation. The in-degree is easily seen from the number of arrow heads. The size of nodes is indicative of their out-degree (see Table 2 for actual in-degrees and out-degrees). This data is obtained by interviewing 21 members of an organisation and asking each one about how they perceive management or advice structures between all individuals. Here we use the network termed by Krackhardt as the Locally Aggregated Structure (LAS) formed from all of the links where both individuals at either end of a link agree that the link exists. A link from an individual \(i\) to an individual \(j\) indicates that \(i\) goes to \(j\) for help and advice.
Neither Katz centrality, nor the products \({\bf{a}}\,\circ \,{\bf{h}}\) and \({\bf{u}}\,\circ \,{\bf{v}}\) distinguish between the nodes 6,13,16 and 17, ranking them all as least important. However, for many purposes we would consider, for example, node 6, which only connects to node 21, to be less influential than node 17 which connects to five other individuals including node 21. Katz centrality and right-eigenvector centrality favour nodes which have large in-degree and this is particularly apparent in the top-ranking of node 2, in spite of it having a relatively low out-degree of only 3, meaning that it is close to resembling a sink. Node 18 is clearly very central in the sense of having the largest out-degree and a large in-degree and is identified as the most central node by the direct deletion method, the linear approximation and the combinations \({\bf{h}}\,\circ \,{\bf{a}}\) and \({\bf{u}}\,\circ \,{\bf{v}}\).
Figure 3 gives a visualisation of some of the information in Table 2. Here the rankings given by \({\bf{h}}\,\circ \,{\bf{a}}\) and \({\bf{u}}\,\circ \,{\bf{v}}\) are plotted against those given by the linear approximation (\({\boldsymbol{\sigma }}\)) since these are the two most directly comparable quantities. We have already noted the significant feature that nodes 6,13,16 and 17 are not differentiated by either \({\bf{h}}\,\circ \,{\bf{a}}\) or \({\bf{u}}\,\circ \,{\bf{v}}\), but they are ranked by \({\boldsymbol{\sigma }}\). From Fig. 3a, it is clear that the rankings of the linear approximation are similar to \({\bf{u}}\,\circ \,{\bf{v}}\) on this network, reflecting the close relationship between eigenvector centrality and Katz centrality4. More significant differences are apparent in the rankings by hubs and authorities in Fig. 3b.

Node rankings on the Krackhardt network (Fig. 2) given by a) the product of left and right principal eigenvectors and b) the product of hubs and authorities plotted against the node rankings from the linear approximation (\({\boldsymbol{\sigma }}\)). For Katz dynamics we used \(a=\mathrm{0.85/}{\mu }_{1}\) where \({\mu }_{1}\) is the largest eigenvalue of the adjacency matrix. Node identifiers correspond to those in Fig. 2.
Recalling that \({\boldsymbol{\sigma }}\) is obtained as a linear approximation to the node deletion process, it is of interest to investigate how accurate this approximation is. For the network in Fig. 1, some comparisons between d and its linear approximation \({\boldsymbol{\sigma }}\) are made in Table 1. For the Krackhardt network (Fig. 2), a comparison between the values of d and the linear approximation is given in Fig. 4. On this network, the linear approximation appears to accurately quantify the deletion process for the lower centrality nodes, but deviates for the higher-centrality nodes where the perturbation is larger. However, the almost monotonic relationship between the two means that the rankings of the nodes are almost identical, as can be seen in Table 2.

Plot of the linear approximation (\({\boldsymbol{\sigma }}\)) against direct deletion (\({\bf{d}}\)) for the Krackhardt network (Fig. 2). No scaling is applied to these values to enable a direct comparison. The line of equality is also plotted to assist in seeing the deviation. Here we used \(a=\mathrm{0.85/}{\mu }_{1}\) where \({\mu }_{1}\) is the largest eigenvalue of the adjacency matrix of the network. Node identifiers correspond to those in Fig. 2.
Discussion
We introduced a new interpretation of Katz centrality as the unique steady-state solution of an appropriate continuous-time dynamical system. We argued that by removing a node from the network and investigating the net impact on this steady state, both the direct value of the node as well as the impact that the node has on others is determined. This contrasts with some standard centrality measures such as Katz centrality and eigenvector centrality which only quantify the direct value of the node rather than its contribution to the whole system.
A linear approximation to this deletion process yielded a new centrality which is a product of two quantities, one of which quantifies the capacity of a node to receive flux from its neighbours (the receiver property) and the other which represents the capacity of a node to pass flux on to its neighbours (the sender property). The receiver property (2) is equal to the original Katz centrality and is formed from the row-sum of matrix \(M\). The sender quantity (10) corresponds to the column-sum of \(M\) and has been highlighted before as useful for capturing the influence of nodes on others13. In this sense, the centrality formed by the product of both requires that a central node is one that is able to receive flux and then pass it on to others and thereby contribute to the ongoing dynamics. Nodes that act just as sources or as sinks are not central to propagating and maintaining the dynamics of the system and in this sense are peripheral, resulting in a low overall centrality score. However, their separate sender or receiver properties could be large.
For the purposes of comparison, the form of the linear approximation to the node deletion process led us to define analogous measures given by the product of Kleinberg’s hubs and authorities and from the product of the left and right principal eigenvectors of the adjacency matrix. As expected, there is some correlation between these measures and with the linear approximation. However, a problem with both of these eigenvector methods is that they frequently yield zero centrality for some nodes on directed networks and so give no information on their relative importance. To determine eigenvector centrality unambiguously and with no zero values, we require that the adjacency matrix \(A\) is irreducible (strongly connected). For Kleinberg’s hubs and authorities, zero values can occur unless the matrices \(A{A}^{T}\) and \({A}^{T}A\) are irreducible. On directed networks this requirement is frequently broken, such as for both of our example networks.
In contrast, when defining the node deletion process d and its linear approximation \({\boldsymbol{\sigma }}\), we only require that the matrix \(I-aA\) is non-singular, which we ensure with a suitable choice for parameter \(a\). So, both the sender and receiver properties are non-zero and their product gives non-zero centralities for all nodes on any network, which is arguably advantageous. Indeed, Katz centrality itself has been viewed as a modification of right-eigenvector centrality to give each node an intrinsic self-centrality4 to resolve some of the problems on directed networks. Similarly, the sender property that we defined can be regarded as an equivalent modification of left-eigenvector centrality.
A natural question that arises is whether our original node deletion definition of centrality (d) can usefully be decomposed into sender and receiver properties in a similar way to its linear approximation. Other directions may include higher-order approximations to node deletion, a control analysis approach to modifications of Katz dynamics such as PageRank, or to a Katz-like variant of the hub and authority eigenvector equations4.
References
Katz, L. A new status index derived from sociometric analysis. Psychometrika 18, 39–43 (1953).
Bonacich, P. Factoring and weighting approaches to status scores and clique identification. J. Math. Sociol. 2, 113–120 (1972).
Brin, S. & Page, L. The anatomy of a large-scale hypertextual Web search engine. Comput. Netw. and ISDN Syst. 30, 107–117 (1998).
Newman, M. E. J. Networks: An Introduction. Oxford University Press (2010).
Kleinberg, J. M. Authoritative sources in a hyperlinked environment. J. ACM 46, 604–632 (1999).
Grantmacher, F. R. Applications of the Theory of Matrices. Interscience (1959).
Horn, R. A. & Johnson, C. R. Topics in Matrix Analysis. Cambridge University Press (1991).
Hadjichrysanthou, C. & Sharkey, K. J. Epidemic control analysis: designing targeted intervention strategies against epidemics propagated on contact networks. J. Theor. Biol. 365, 84–95 (2015).
Skeel, R. Scaling for numerical stability in Gaussian elimination. J. ACM 26, 494–526 (1979).
Kacser, H. & Burns, J. A. The control of flux. Symp. Soc. Exp. Biol. 27, 65–104 (1973).
Heinrich, R. & Rapoport, T. A. A linear steady-state treatment of enzymatic chains. General properties, control and effector strength. Eur. J. Biochem. 42, 89–95 (1974).
Reder, C. Metabolic control theory: a structural approach. J. Theor. Biol. 135, 175–201 (1988).
Taylor, M. Influence structures. Sociometry 32, 490–502 (1969).
Krackhardt, D. Cognitive social structures. Soc. Networks 9, 109–134 (1987).
Acknowledgements
This work was funded by the Leverhulme Trust Research Project Grant RPG-2014-341.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing Interests
The authors declare that they have no competing interests.
Additional information
Publisher's note: Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons license, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons license and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this license, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Sharkey, K.J. A control analysis perspective on Katz centrality. Sci Rep 7, 17247 (2017). https://doi.org/10.1038/s41598-017-15426-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-017-15426-1
This article is cited by
-
Accelerator-mediated access to investors among early-stage start-ups
Annals of Operations Research (2023)
-
Identification of potential microRNAs regulating metabolic plasticity and cellular phenotypes in glioblastoma
Molecular Genetics and Genomics (2023)
-
Network cartography of university students’ knowledge landscapes about the history of science: landmarks and thematic communities
Applied Network Science (2019)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
