
Abstract
Three probabilistic methodologies are developed for predicting the long-term creep rupture life of 9–12 wt%Cr ferritic-martensitic steels using their chemical and processing parameters. The framework developed in this research strives to simultaneously make efficient inference along with associated risk, i.e., the uncertainty of estimation. The study highlights the limitations of applying probabilistic machine learning to model creep life and provides suggestions as to how this might be alleviated to make an efficient and accurate model with the evaluation of epistemic uncertainty of each prediction. Based on extensive experimentation, Gaussian Process Regression yielded more accurate inference (\(Pearson\;correlation\;coefficent> 0.95\) for the holdout test set) in addition to meaningful uncertainty estimate (i.e., coverage ranges from 94 to 98% for the test set) as compared to quantile regression and natural gradient boosting algorithm. Furthermore, the possibility of an active learning framework to iteratively explore the material space intelligently was demonstrated by simulating the experimental data collection process. This framework can be subsequently deployed to improve model performance or to explore new alloy domains with minimal experimental effort.
Similar content being viewed by others

Introduction
Advanced ultra-supercritical power plants require increased steam temperature and pressure, for higher efficiency and lower carbon emissions, to comply with environmental regulations. Without building new power plants this can be achieved by increasing the operating temperature and pressures of the existing power plants. To design ferritic-martensitic steels (the most common cost-effective alloys used in power plants today) in the 9–12 wt% Cr range that can withstand these higher operating temperatures and pressures, a predictive model needs to be developed that can reliably and accurately predict the lifetime of an alloy and its interrelation to the factors that govern the mechanical and chemical properties of the alloys1,2,3. In this effort, machine learning has lent itself quite well to develop models with unprecedented accuracy with inference time orders of magnitude shorter than the traditional first-principles density functional theory4,5,6, Monte Carlo simulations7, molecular dynamics8, or phase field modeling9,10,11. Neural Network has been successfully employed in the past by Cole et al.12 and Brun et al.13 to model the creep rupture strength from physical and processing parameters. In a recent article, it was shown that a Gradient Boosting Algorithm14 can be used to efficiently predict the rupture life15 and rupture strength16 of 9–12 wt% Cr ferritic-martensitic steels and austenitic stainless-steels. However, oftentimes the prediction is unreliable for low confidence modeling, where the data is either scarce and highly non-linear or the uncertainty associated with the prediction is not available. Specifically, long-term creep rupture life exhibits uncertainty that ranges from several years to decades17. For proper reliability analysis, it is imperative to quantify the uncertainty associated with each data point, i.e., Epistemic uncertainty. It should be noted that there are two types of uncertainty associated with data sets: (1) Aleatoric uncertainty (i.e., resulting from the intrinsic nature of the data generation process), and (2) Epistemic uncertainty (i.e., resulting from the limitation of the model itself). In this article, three probabilistic machine learning approaches were used to make an efficient prediction with epistemic uncertainty estimate, namely; (1) Quantile Regression, (2) Natural Gradient Boosting, and (3) Gaussian Process Regression.
As a general rule the time span between the initial discovery of a novel material (i.e., the idea for a new alloy and the research to support further development) and integrating it into existing infrastructure can take more than 20 years18. By using artificial intelligence and machine learning, the screening process of identifying new candidate alloys that need to be synthesized and tested in a laboratory can be sped up, thereby greatly reducing the time span of the entire process. In this pursuit, the uncertainty estimate, from the probabilistic machine learning model, of the individual data points yet to be explored, can guide the candidate selection process via Bayesian Optimization in order to optimize for a certain desired property, e.g., longer creep rupture life or high yield stress. Another utility of the uncertainty estimate is to improve the existing machine learning model performance by acquiring data points that lead to maximum information gain (or greatest minimization of the entropy). Active learning has been demonstrated to be very effective in the design of experiments for the classification problem19; however, its application to the regression problem is still limited, owing to the sequential nature of the algorithm. In classification, only the decision boundary needs to be learned which implies using only a fraction of data points to build a reliable model. On the other hand, the regression problem requires learning over the whole data range, leading to a very slow data acquisition rate in a sequential learning fashion. In this research, a batch-mode, pool-based active learning framework has been demonstrated where data can be acquired in a parallel manner at each iteration by selecting candidates from several clusters (i.e., learned using unsupervised techniques).
Probabilistic machine learning algorithms
Quantile regression
Quantile regression forests are a non-parametric way of estimating the conditional quantiles of high dimensional predictor variables20,21. For this approach Y is defined as the response variable while X represents an array of predictor variables. In standard formalism, the regression analysis provides an estimate \(\widehat{\mu }(x)\) of the conditional mean \((E(Y | X = x))\) for the response variable, which is obtained through learning the parameter of a regression model that minimizes the expected squared error loss:
However, the conditional mean only captures the point estimate of the response variable. It does not provide any information about the distribution of the response variable at a certain point. The conditional distribution of \(Y\) being smaller than \(y\) given the predictor variable \(X = x\) is given by,
The associated loss function to optimize this relation is given by the following equation,
here, \(\alpha\) ranges from 0 to 1 depending on the percentile that one wishes to achieve. To get the \(95\%\) prediction interval, two models are fit with \(\alpha =0.025\) and \(0.975\). In this work, in addition to the prediction interval, the median response variable is also computed using \(\alpha =0.5\). For quantile regression, Gradient Boosting Decision Tree (GBDT) is used which was the best performing non-probabilistic model in a previous study15. GBDT is an ensemble of weak decision tree models that iteratively fit data to minimize the error made in the previous iteration14.
Natural gradient boosting regression
Natural Gradient Boosting (NG Boosting) algorithm is another probabilistic GBDT based model; however, unlike quantile regression, or conditional mean estimation, it learns the full probability distribution by construction22. The key idea in NG Boosting is to use the natural gradients instead of the regular gradients, thus allowing the algorithm to fit a probability distribution over the outcome space, conditioned on the predictor variables. The algorithm consists of three distinct components: (1) Base learner, (2) Parametric distribution, and (3) Scoring rule. The base learner used in the algorithm is the GBDT. Instead of making a point estimate, a probability distribution learns by learning the parameter of the distribution, e.g., the mean and standard deviation in the case of Gaussian distribution. The scoring rule is selected in such a way that the forecasted probability distribution gets a high score if it matches the true distribution with respect to the observation \(y\). In the algorithm, negative log-likelihood is used as the scoring rule.
Gaussian process regression
Gaussian Process Regression (GPR) is a flexible class of non-parametric models23, where the non-linearity in the data can be modeled by incorporating different basis functions within the kernel to compute the covariance matrix. It can also include user-defined prior functions to take advantage of domain knowledge (which is crucial when data are scarce). The GPR prior is an infinite-dimensional, multi-variate distribution that can be completely described by a mean function \(\left(m\left(x\right)\right)\) and a covariance function \(k(x, x{^{\prime}})\),
The posterior predictive distribution is then obtained by computing the likelihood from the observed data within a Monte Carlo framework. However, it can also be posed as an optimization problem to minimize the analytical negative log-likelihood. Once the learning process is complete, the posterior distribution not only provides a point estimate for the prediction but also a standard deviation of the prediction.
Active learning
Active learning is a machine learning method that is used for optimal design of experiments by iteratively guiding the selection of the next unexplored data points to be acquired by using a suitable acquisition function19. These selected new data, when added to the already explored training data, will yield the maximum improvement in the model performance thus leading to a better model with fewer data points acquired. In this work, a pool-based Bayesian active learning method based on GPR as the base learner is used which selects the most useful samples from a pool of unlabeled samples. However, the traditional pool-based sequential active learning is not suitable for an iterative exploration of 9–12 wt% Cr ferritic-martensitic steel space, as each experiment is expensive and can take several days to years to complete. Instead of choosing one sample at each iteration, a batch mode is adapted which enables selecting multiple samples at each iteration. In Fig. 1, a schematic of the active learning loop is shown to illustrate the inner working of the active learning cycle adapted in this work. The algorithm used for active learning for batch mode in this study is the same as the standard approach; except, during the query stage, the unpooled data are clustered using k-means algorithm. At this point the variance reduction approach (i.e., selecting the most uncertain sample) is used to select one sample from each cluster. This approach is not only faster than the traditional sequential active learning, but it is also better in terms of informativeness (which represents the ability of the sample to reduce the generalization error in the adopted model and ensures lower uncertainty in the subsequent iteration), and diversity in the samples (meaning the data is the most dissimilar to the data already present in the training set). Since the data are clustered into several groups, each selected sample is diverse from another, and the variance reduction approach ensures that the samples are also very informative.

Active learning workflow of a batch-mode, pool-based method. In the query stage, candidates are selected from the pool of unlabled samples based on K-means algorithms and variance reduction approach. The selected samples are tested in the laboratory and added to the training data to make refined inference on the pool of unlabeled samples.
Methods
The dataset for 9–12 wt% Cr ferritic-martensitic steel was collected and compiled by the National Energy Technology Laboratory (NETL) as part of the Extreme Environment Materials (eXtremeMAT or XMAT), a DOE-funded project that seeks to reduce the time to bring new alloys to commercial readiness while at the same time providing the modeling framework necessary to describe its entire life in operation at all length scales. In Table 1, we show the mean, median, maximum and minimum value of each features used in the machine learning model. The dataset contains 875 rows of data corresponding to each unique composition and processing parameter set. The preprocessing step consists of imputation of missing data by mean values, normalization of the data using standard scaler approach. The creep rupture life, or the target variable, is always positive, resulting in inherent constraints that need to be incorporated into the machine learning algorithms. It is a particularly severe problem for probabilistic modeling as the response variable is allowed to have any value with certain probabilities, albeit very small for values outside the 95% confidence interval. Due to this freedom in probabilistic modeling, it is crucial to log-transform the data so that the predicted response variable is always positive. In Fig. 2, the distribution of response variables in their original space and their transformed space is shown. This transformation also makes the data more normally distributed which helps tackle the heteroscedasticity problem to some extent.

The distribution of rupture life in both original and transformed space.
For Quantile regression and NG Boosting, the predicted response variable was computed by taking the exponential of the prediction for all the quantiles. However, for GPR the mean and standard deviation of the log-transformed prediction of individual points must be transformed with the following formula to achieve the mean and standard deviation in the original space.
where \({\mu }_{\mathrm{log}\left(y\right)}\) and \({\sigma }_{\mathrm{log}\left(y\right)}\) are mean and standared deviation of the prediction in the log-transformed sapce, and \({\mu }_{y}\) and \({\sigma }_{y}\) are the mean and standard deviation of the prediction in the original space, respectively. For Quantile Regression, the CatBoost24 python package was used with scikit-learn API. For NG Boosting, the NGBoost22 python package was used. To perform GPR, scikit-learn25 python package was used. The code to reproduce the machine learning models and active learning results can be obtained from https://github.com/mamunm/uncertainty_quantification_creep_life.
To quantify the overall model performance for prediction, a five-fold, cross-validation scheme was used where in each iteration 80% data were used to train the model and 20% data were used to test the model performance. Pearson correlation coefficient (PCC) was used to measure the predictive performance and coverage (i.e., the fraction of data that lie within two (2) standard deviations) was used to quantify the reliability of the uncertainty estimate.
For active learning, \(20\%\) data were used as test data and then 20% of the remaining data were used as the initial training data. Kmeans clustering algorithm is used to fit the remaining data into 10 clusters. In each iteration, 10 new data points are added to the training data by selecting 1 point each from the 10 clusters. The correlation coefficient of the holdout test set is then calculated to determine the accuracy of the model at each iteration. The active learning technique is compared to a baseline random sample addition to indicate the relative efficiency of the active learning model.
Disclaimer
This manuscript was prepared as an account of work sponsored by an agency of the United States Government. Neither the United States Government nor any agency thereof, nor any of their employees, makes any warranty, express or implied, or assumes any legal liability or responsibility for the accuracy, completeness, or usefulness of any information, apparatus, product, or process disclosed, or represents that its use would not infringe privately owned rights. Reference therein to any specific commercial product, process, or service by trade name, trademark, manufacturer, or otherwise does not necessarily constitute or imply its endorsement, recommendation, or favoring by the United States Government or any agency thereof. The views and opinions of authors expressed therein do not necessarily state or reflect those of the United States Government or any agency thereof.
Results and discussion
Figure 3 illustrates the actual rupture life and the predicted rupture life with the \(95\%\) confidence interval for prediction on the hold-out test set. PCC for training and testing data is 0.\(980 \pm 0.006\) and 0.\(890\pm 0.050\), respectively, with the coverage ranging from \(95.34 \pm 0.77 \%\) and \(80.74 \pm 3.10 \%\), respectively. The accuracy of the model is quite satisfactory as discussed in our previous work15. In addition to that, the model can now provide a 95% prediction interval that contains about 80% of the test dataset. There are several problems associated with quantile regression that questions the reliability of the model for real-world applications.

Actual and Quantile Regression predicted creep rupture life (in log scale) of ferritic-martensitic steels in ascending order of the predicted creep rupture life. The green area indicates the 95% prediction interval.
The first and obvious problem is the lower prediction interval \((|{y}_{median}-{y}_{lower}|)\) is greater than the higher prediction interval \((|{y}_{higher}-{y}_{median}|)\) in the high rupture life area and vice versa in the low rupture life area. Due to the inherent nature of the loss function of the quantile regression, it overestimates the lower prediction interval for this dataset as there are significantly more data in that region. Another problem is that in a few instances the predicted median is not within the prediction interval. Since three models are being optimized for median and two (2) standard deviations in the interquartile range, each model optimizes the parameters irrespective of the other models. As a result, inconsistency appears in the prediction interval and predicted median. The third and final problem is the confidence interval is not well-calibrated which questions the reliability of the uncertainty estimate. For a well-calibrated model, 95% of the data should fall within two (2) standard deviations which is satisfied for the training data but only \(80.74 \pm 3.10 \%\) of the testing data are contained within two standard deviation leading to under-estimation of the confidence interval.
In Fig. 4, the actual and NG Boosting predicted rupture life along with the prediction interval is shown for the hold-out test set. The PCC for the training and testing set is \(0.980 \pm 0.002\) and \(0.920\pm 0.030\), respectively, with the coverage ranging from \(98.47 \pm 0.28 \%\) and \(84.08 \pm 2.03 \%\), respectively. Surprisingly, the model prediction is more accurate than the non-probabilistic Gradient Boosting approach. Furthermore, the uncertainty estimate is better behaved than the quantile regression. The prediction interval always contains the mean and the uncertainty is higher where the data is scarce, leading to a more faithful model that can be used for an iterative exploration of the materials space. However, the uncertainty is not well-calibrated as evident by this coverage of the testing data, i.e., \(84.08 \pm 2.03 \%\).

Actual and NG Boosting predicted creep rupture life (in log scale) of ferritic-martensitic steels in ascending order of the predicted creep rupture life. The green area indicates the 95% prediction interval.
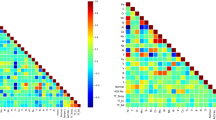
Next, the GPR model was trained with an additive kernel consisting of a Matern kernel, a white kernel, and a dot product kernel. The Matern kernel models the short-range interaction present in the data. The white kernel adds noise to the diagonal elements of the kernel matrix to make it more robust and generalizable to noise. The dot product kernel models any linear trends between the data points. In Fig. 5, the kernel matrix is illustrated for the training data. As expected, there is a high correlation between adjacent data points but the correlation slowly fades with increasing distance. Also, the data seem to be clustered naturally into about six (6) distinct clusters.

Components of kernel matrix for the additive kernel used in this study. The x and y axes represent the index of the samples and the color bar shows the magnitude of the kernel function.
Next, Fig. 6 illustrates the actual and predicted creep rupture life for the GPR along with the \(95\%\) prediction interval. The PCC for training and testing was set at \(0.990 \pm 0.001\) and \(0.970\pm 0.020\), respectively, with the coverage ranging from \(99.25 \pm 0.18 \%\) and \(96.40 \pm 1.52 \%\), respectively. Not only is the GPR highly accurate compared to the other two algorithms, but it also has very high coverage which means more than 96% of the data lies within the 95% prediction interval, as it should be for a well-calibrated uncertainty estimation.

Actual and Gaussian Process predicted creep rupture life (in log scale) of ferritic-martensitic steels in ascending order of the predicted creep rupture life. The green area indicates the 95% prediction interval.
Active learning for iterative exploration
The data used in this study were collected over 30 years of concerted efforts from government and non-government initiatives16. The overarching goal of probabilistic machine learning is to make reliable predictions for unknown alloys as well as to accelerate the data collection process to improve the model performance. This process exhaustively explores a material’s space with minimal experimental effort. To this end, the uncertainty of prediction provides valuable information about the knowledge gap present in the dataset, and by acquiring the data with the highest uncertainty, significant improvement in the model’s performance can be achieved. In Fig. 7, the correlation coefficient for the hold-out test data for both the random and the active data collection processes are shown. Not surprisingly, the active learning process can readily find the data points that lead to the most improvement in test set performance. This technique therefore can be used to design the experimentation necessary both to improve the model performance and to optimize the desired alloy properties. By incorporating this framework into the experimental/computational data collection process, significant improvement in materials discovery can be achieved.

Correlation coefficient of the hold-out test set for both random data acquisiton and active learning algorithm.
Conclusion
In this work, three approaches are described to determine the uncertainty associated with machine learning prediction of creep rupture life of ferritic-martensitic steels for each data point. The advantages and disadvantages of each approach was described with the accuracy of the prediction based on coverage of the 95% prediction interval. From this effort, the GPR was identified as the best algorithm for both accurate inference and uncertainty estimation. Implementing this uncertainty estimation technique in the machine learning workflow will enable researchers to estimate the variance in the predicted values and to understand the risk inherent in the model. This technique will further help to ensure model interpretability by providing a 95% confidence interval for the predicted values. Finally, a simulated design of experiments was used to iteratively collect data using an active learning framework to accelerate data collection for reliable and informative data acquisition. Implementing this technique will enable researchers to more efficiently explore the alloy design space, and optimize the experimentally collected data points for improving the model predictions. These methods will ultimately help optimize the desired properties of the alloys.
Data availability
The data used that support the findings of this study are available upon request to M. W. (Madison.Wenzlick@NETL.DOE.GOV).
References
Klueh, R. L. & Nelson, A. T. Ferritic/martensitic steels for next-generation reactors. J. Nucl. Mater. 371, 37–52 (2007).
Klueh, R. L. et al. Ferritic/martensitic steels—overview of recent results. J. Nucl. Mater. 307–311, 455–465 (2002).
Bischoff, J. et al. Corrosion of ferritic–martensitic steels in steam and supercritical water. J. Nucl. Mater. 441, 604–611 (2013).
Hohenberg, P. & Kohn, W. Inhomogeneous electron gas. Phys. Rev. 136, B864–B871 (1964).
Kohn, W. & Sham, L. J. Self-consistent equations including exchange and correlation effects. Phys. Rev. 140, A1133–A1138 (1965).
Mamun, O., Winther, K. T., Boes, J. R. & Bligaard, T. A Bayesian framework for adsorption energy prediction on bimetallic alloy catalysts. NPJ Comput. Mater. 6, 177 (2020).
Rahman, A. Correlations in the motion of atoms in liquid argon. Phys. Rev. 136, A405–A411 (1964).
Alder, B. J. & Wainwright, T. E. Studies in molecular dynamics. I. General method. J. Chem. Phys. 31, 459–466 (1959).
Chen, L.-Q. Phase-field models for microstructure evolution. Annu. Rev. Mater. Res. 32, 113–140 (2002).
Boettinger, W. J., Warren, J. A., Beckermann, C. & Karma, A. Phase-field simulation of solidification. Annu. Rev. Mater. Res. 32, 163–194 (2002).
Steinbach, I. Phase-field models in materials science. Modell. Simul. Mater. Sci. Eng. 17, 73001 (2009).
Cole, D., Martin-Moran, C., Sheard, A. G., Bhadeshia, H. K. D. H. & MacKay, D. J. C. Modelling creep rupture strength of ferritic steel welds. Sci. Technol. Weld. Joining 5, 81–89 (2000).
Brun, F. et al. Theoretical design of ferritic creep resistant steels using neural network, kinetic, and thermodynamic models. Mater. Sci. Technol. 15, 547–554 (1999).
Friedman, J. H. Stochastic gradient boosting. Comput. Stat. Data Anal. 38, 367–378 (2002).
Mamun, O., Wenzlick, M., Sathanur, A., Hawk, J. & Devanathan, R. Machine learning augmented predictive and generative model for rupture life in ferritic and austenitic steels. NPJ Mater. Degrad. 5, 20 (2021).
Mamun, O., Wenzlick, M., Hawk, J. & Devanathan, R. A machine learning aided interpretable model for rupture strength prediction in Fe-based martensitic and austenitic alloys. Sci. Rep. 11, 5466 (2021).
Hossain, M. A. & Stewart, C. M. A probabilistic creep model incorporating test condition, initial damage, and material property uncertainty. Int. J. Press. Vessels Piping 193, 104446 (2021).
Romanov, V. N. Deep-freeze graph training for latent learning. Comput. Mater. Sci. 199, 110757 (2021).
Kumar, P. & Gupta, A. Active learning query strategies for classification, regression, and clustering: A survey. J. Comput. Sci. Technol. 35, 913–945 (2020).
Meinshausen, N. & Ridgeway, G. Quantile regression forests. J. Mach. Learn. Res. 7, 2 (2006).
Koenker, R. & Hallock, K. F. Quantile regression. J. Econ. Perspect. 15, 143–156 (2001).
Duan, T. et al. NGBoost: Natural Gradient Boosting for Probabilistic Prediction. CoRR abs/1910.03225, (2019).
Rasmussen, C. E. Gaussian processes in machine learning. in Summer school on machine learning 63–71 (Springer, 2003).
Dorogush, A. V., Ershov, V. & Gulin, A. CatBoost: gradient boosting with categorical features support. arXiv preprint arXiv: 1810.11363 (2018).
Pedregosa, F. et al. Scikit-learn: Machine learning in python. J. Mach. Learn. Res. 12, 2825–2830 (2011).
Acknowledgements
This work was supported by the U.S. Department of Energy, Office of Fossil Energy, eXtreme environment MATerials (XMAT) consortium. This research used resources of the Pacific Northwest National Laboratory, which is supported by the U.S. Department of Energy.
Author information
Authors and Affiliations
Contributions
O.M and R.D conceptualized the study. J.H. provided the data. O.M. conducted the machine learning experiments and wrote the code to perform Active Learning. O.M., M.F.N.T., and M.W. analyzed the results. O.M. wrote the manuscript. R.D., J.H., M.F.N.T., and M.W. reviewed the manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare no competing interests.
Additional information
Publisher's note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mamun, O., Taufique, M.F.N., Wenzlick, M. et al. Uncertainty quantification for Bayesian active learning in rupture life prediction of ferritic steels. Sci Rep 12, 2083 (2022). https://doi.org/10.1038/s41598-022-06051-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1038/s41598-022-06051-8
This article is cited by
-
Uncertainty quantification in multivariable regression for material property prediction with Bayesian neural networks
Scientific Reports (2024)
-
Finite Element Analysis and Machine Learning Guided Design of Carbon Fiber Organosheet-Based Battery Enclosures for Crashworthiness
Applied Composite Materials (2024)
Comments
By submitting a comment you agree to abide by our Terms and Community Guidelines. If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
