

Abstract
This paper presents a deep learning method for faster magnetic resonance imaging (MRI) by reducing k-space data with sub-Nyquist sampling strategies and provides a rationale for why the proposed approach works well. Uniform subsampling is used in the time-consuming phase-encoding direction to capture high-resolution image information, while permitting the image-folding problem dictated by the Poisson summation formula. To deal with the localization uncertainty due to image folding, a small number of low-frequency k-space data are added. Training the deep learning net involves input and output images that are pairs of the Fourier transforms of the subsampled and fully sampled k-space data. Our experiments show the remarkable performance of the proposed method; only 29 of the k-space data can generate images of high quality as effectively as standard MRI reconstruction with the fully sampled data.
of the k-space data can generate images of high quality as effectively as standard MRI reconstruction with the fully sampled data.
Export citation and abstract BibTeX RIS

Original content from this work may be used under the terms of the Creative Commons Attribution 3.0 licence. Any further distribution of this work must maintain attribution to the author(s) and the title of the work, journal citation and DOI.
1. Introduction
Magnetic resonance imaging (MRI) produces cross-sectional images with high spatial resolution using strong nuclear magnetic resonances, gradient fields, and hydrogen atoms inside the human body (Lauterbur 1973, Seo et al 2014). MRI does not use damaging ionizing radiation like x-rays, but the scan takes a long time (Sodicson et al 1997, Haacke et al 1999) and involves confining the subject in an uncomfortable narrow bow. Shortening the MRI scan time might help increase patient satisfaction, reduce motion artifacts from patient movement, and reduce the medical cost. The MRI scan time is roughly proportional to the number of time-consuming phase-encoding steps in k-space. Many efforts have been made to expedite MRI scans by skipping the phase-encoding lines in k-space while eliminating aliasing, a serious consequence of the Nyquist criterion violation (Nyquist 1928) that is caused by skipping. Compressed sensing MRI and Parallel MRI are some of the techniques used to deal with these aliasing artifacts. Compressed sensing MRI uses prior information on MR images of the unmeasured k-space data to eliminate or reduce aliasing artifacts. Parallel MRI installs multiple receiver coils and uses space-dependent properties of receiver coils to reduce aliasing artifacts (Sodicson et al 1997, Pruessmann et al 1999, Larkman et al 2001). This paper focuses solely on single-channel MRI for simplicity; hence, parallel MRI is not discussed.
In undersampled MRI, we attempt to find an optimal reconstruction function  , which maps highly undersampled k-space data (
, which maps highly undersampled k-space data ( ) to an image (
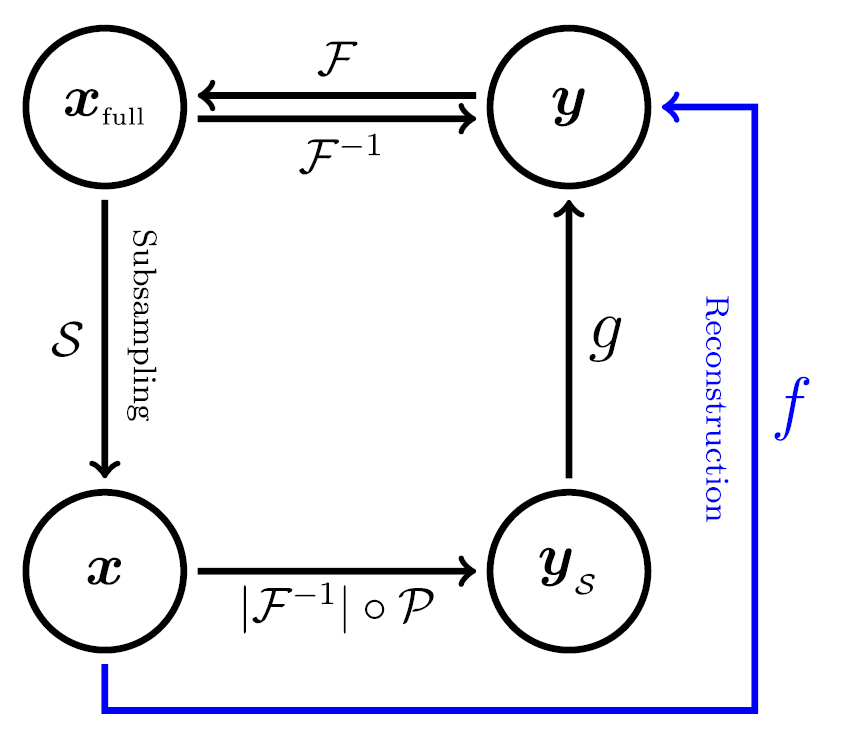
) to an image ( ) close to the MR image corresponding to fully sampled data. Undersampled MRI consists of two parts, subsampling and reconstruction, as shown in figure 1.
) close to the MR image corresponding to fully sampled data. Undersampled MRI consists of two parts, subsampling and reconstruction, as shown in figure 1.

Figure 1. General strategy for undersampled MRI reconstruction problem. The inverse Fourier transform of a fully sampled k-space data  produces a reconstructed MRI image
produces a reconstructed MRI image  . The goal is to find a subsampling function
. The goal is to find a subsampling function  and learn an undersampled MRI reconstruction f from the training dataset. Here,
and learn an undersampled MRI reconstruction f from the training dataset. Here,  is an aliased image caused by the violation of the Nyquist criterion. We use the U-net to find the function g that provides the mapping from the aliased image
is an aliased image caused by the violation of the Nyquist criterion. We use the U-net to find the function g that provides the mapping from the aliased image  to an anti-aliased image
to an anti-aliased image  .
.
Download figure:
Standard image High-resolution imageCompressive sensing (CS) MRI can be viewed as a sub-Nyquist sampling method in which the image sparsity is enforced to compensate for undersampled data (Donoho 2004, 2006, Candes et al 2006, Lustig et al 2007). CS-MRI can be described roughly as a model-fitting method to reconstruct the MR image  by adding a regularization term that enforces the sparsity-inducing prior on
by adding a regularization term that enforces the sparsity-inducing prior on  . It aims to reconstruct an image given by
. It aims to reconstruct an image given by

where  denotes the Fourier transform,
denotes the Fourier transform,  is a subsampling,
is a subsampling,  represents a transformation capturing the sparsity pattern of
represents a transformation capturing the sparsity pattern of  ,
,  is the symbol of composition, and λ is the regularization parameter controlling the trade-off between the residual norm and regularity. Here, the term
is the symbol of composition, and λ is the regularization parameter controlling the trade-off between the residual norm and regularity. Here, the term  forces the residual
forces the residual  to be small, whereas
to be small, whereas  enforces the sparsity of
enforces the sparsity of  . In CS-MRI, a priori knowledge of MR images is converted to a sparsity of
. In CS-MRI, a priori knowledge of MR images is converted to a sparsity of  with a suitable choice of
with a suitable choice of  . The most widely used CS method is total variation denoising (i.e.
. The most widely used CS method is total variation denoising (i.e.  ), which enforces piecewise constant images by uniformly penalizing image gradients. Although CS-MRI with random sampling has attracted a large amount of attention over the past decade, it has some limitations in the preservation of fine-scale details and noise-like textures that hold diagnostically important information in MR images.
), which enforces piecewise constant images by uniformly penalizing image gradients. Although CS-MRI with random sampling has attracted a large amount of attention over the past decade, it has some limitations in the preservation of fine-scale details and noise-like textures that hold diagnostically important information in MR images.
In contrast to the regularized least-squares approaches (1), our deep learning approach is a completely reversed paradigm. It aims to learn a function  using many training data
using many training data  . Roughly speaking, f is achieved by
. Roughly speaking, f is achieved by

where  is a deep convolutional neural network with some domain(or prior) knowledge determined by a training dataset that consists of pairs of fully sampled MR image and folded images. A U-net can provide a low-dimensional latent representation and preserve high-resolution features through concatenation in the upsampling process (Ronnerberger et al 2015). This reconstruction function f can be viewed as the inverse mapping of the forward model
is a deep convolutional neural network with some domain(or prior) knowledge determined by a training dataset that consists of pairs of fully sampled MR image and folded images. A U-net can provide a low-dimensional latent representation and preserve high-resolution features through concatenation in the upsampling process (Ronnerberger et al 2015). This reconstruction function f can be viewed as the inverse mapping of the forward model  subject to the constraint of MR images, which are assumed to exist in a low dimensional manifold. In the conventional regularized least-squares framework (1), it is very difficult to incorporate the very complicated MR image manifold into the regularization term. However, in the deep learning framework, the manifold constraint learned from the training set acts as highly nonlinear compressed sensing to obtain an useful reconstruction
subject to the constraint of MR images, which are assumed to exist in a low dimensional manifold. In the conventional regularized least-squares framework (1), it is very difficult to incorporate the very complicated MR image manifold into the regularization term. However, in the deep learning framework, the manifold constraint learned from the training set acts as highly nonlinear compressed sensing to obtain an useful reconstruction  by leveraging complex prior knowledge on
by leveraging complex prior knowledge on  .
.
There are several recent machine learning based methods for undersampled MRI (Hammernik et al 2017, Kwon et al 2017, Lee et al 2017) that were developed around the same time as our method. Hammernik et al developed an efficient trainable formulation for an accelerated Parallel Imaging(PI)-based method of learning variational framework to reconstruct MR images from accelerated multicoil MR data. The method is designed to learn a complete reconstruction procedure for multichannel MR data in the regularized least-squares framework. Their aim is to learn a set of parameters associated with the gradient of the regularization in the gradient decent scheme. Kwon et al applied the multilayer perceptron algorithm to reconstruct MR images from subsampled multicoil data. They reconstruct the image by using information from multiple receiver coils with different spatial sensitivities. In their method, the acceleration factor cannot be larger than the number of coils. Finally, Lee et al used a residual learning method to estimate aliasing artifacts from distorted images of undersampled data.
In this paper, a subsampling strategy for deep learning is explained using a separability condition in order to produce MR images with a quality that is as high as regular MR image reconstructed from fully sampled k-space data. The subsampling strategy is to preserve the information in  as much as possible, while maximizing the skipping rate. To be precise, we use uniform subsampling in the phase encoding direction so that the Fourier transform contains all detailed features in a folded image, according to the Poisson summation formula.
as much as possible, while maximizing the skipping rate. To be precise, we use uniform subsampling in the phase encoding direction so that the Fourier transform contains all detailed features in a folded image, according to the Poisson summation formula.
We include a few low-frequency sampling to learn the overall structure of MR images and to deal with anomaly location uncertainty in the uniform sampling. The experiments show the high performance of the proposed method.
2. Method
Let  be the MR image to be reconstructed, where N2 is the number of pixels and
be the MR image to be reconstructed, where N2 is the number of pixels and  is the set of complex numbers. In 2D Fourier imaging with Cartesian k-space sampling, the MR image
is the set of complex numbers. In 2D Fourier imaging with Cartesian k-space sampling, the MR image  can be reconstructed from the corresponding k-space data
can be reconstructed from the corresponding k-space data  : For
: For  ,
,

where  is the MR-signal received at k-space position
is the MR-signal received at k-space position  . The frequency-encoding is along the a-axis and the phase-encoding is along b-axis in the k-space as per our convention.
. The frequency-encoding is along the a-axis and the phase-encoding is along b-axis in the k-space as per our convention.
In undersampled MRI, we violate the Nyquist criterion and skip phase-encoding lines during the MRI acquisition to speed up the time-consuming phase encoding. However, sub-Nyquist k-space data yields aliasing artifacts in the image space. For example, suppose we skip two phase-encoding lines to obtain an acceleration factor of 2. Then, the k-space data with zero padding is given by

According to the Poisson summation formula, the discrete Fourier transform of the above uniformly subsampled data with factor 2 produces the following two-folded image (Seo et al 2012):

If the deep learning approach is able to find an unfolding map  , in this way we could accelerate the data acquisition speed. However, it is impossible to get this unfolding map even with sophisticated manifold learning for MR images. In the left panel of figure 2, we consider two different MR images y1 and y2 with small anomalies at the bottom
, in this way we could accelerate the data acquisition speed. However, it is impossible to get this unfolding map even with sophisticated manifold learning for MR images. In the left panel of figure 2, we consider two different MR images y1 and y2 with small anomalies at the bottom  and top
and top  , respectively. Here, the corresponding k-space data
, respectively. Here, the corresponding k-space data  and
and  are different. However, the corresponding uniformly subsampled k-space data with factor 2
are different. However, the corresponding uniformly subsampled k-space data with factor 2  and
and  are completely identical because
are completely identical because  . Here,
. Here,  and
and  are the sampling and zero-padding operator, respectively, so that
are the sampling and zero-padding operator, respectively, so that  is the subsampled k-space data with zero-padding given in (4). It is not possible to identify whether the anomaly is at the top or bottom. Deep learning cannot solve this unsolvable problem. We now explain our undersampling strategy for deep learning.
is the subsampled k-space data with zero-padding given in (4). It is not possible to identify whether the anomaly is at the top or bottom. Deep learning cannot solve this unsolvable problem. We now explain our undersampling strategy for deep learning.

Figure 2. Feasibility of deep learning methods. Learning f requires separability: 
 . The figure on the left shows why uniform subsampling does not satisfy the separability condition. We consider two different MR images with small anomalies at position
. The figure on the left shows why uniform subsampling does not satisfy the separability condition. We consider two different MR images with small anomalies at position  and
and  , respectively. The corresponding k-space data are different, but the corresponding uniformly subsampled k-space data with factor 2 are completely identical. It is hence not possible to identify whether the anomaly is at the top or bottom. In contrast, the figure on the right shows why separability can be achieved by adding low frequency data. Additional low frequency lines in the yellow box provides the location information of small anomalies.
, respectively. The corresponding k-space data are different, but the corresponding uniformly subsampled k-space data with factor 2 are completely identical. It is hence not possible to identify whether the anomaly is at the top or bottom. In contrast, the figure on the right shows why separability can be achieved by adding low frequency data. Additional low frequency lines in the yellow box provides the location information of small anomalies.
Download figure:
Standard image High-resolution imageRemark 2.1. Given the undersampled data  , let
, let  be the minimum norm solution, that is,
be the minimum norm solution, that is,

This  is
is  , the inverse Fourier transform of the data
, the inverse Fourier transform of the data  padded by zeros. This is because
padded by zeros. This is because  for all
for all  satisfying
satisfying  and the Fourier transform map is an isometry with respect to the
and the Fourier transform map is an isometry with respect to the  norm. Unfortunately, this minimum norm solution
norm. Unfortunately, this minimum norm solution  is undesirable in most cases. See appendix A.
is undesirable in most cases. See appendix A.
2.1. Subsampling strategy
Let  be a training set of undersampled and ground-truth MR images. The vectors
be a training set of undersampled and ground-truth MR images. The vectors  and
and  are in the space
are in the space  . Figure 1 shows a schematic diagram of our undersampled reconstruction method, where the corresponding inverse problem is to solve the underdetermined linear system
. Figure 1 shows a schematic diagram of our undersampled reconstruction method, where the corresponding inverse problem is to solve the underdetermined linear system

Given undersampled data  , there are infinitely many solutions
, there are infinitely many solutions  of (6) in
of (6) in  . It is impossible to invert the ill-conditioned system
. It is impossible to invert the ill-conditioned system  , where
, where  is the range space of operator
is the range space of operator  and its dimension is much lower than N2. We use the fact that the MR images of humans exist in a much lower-dimensional manifold
and its dimension is much lower than N2. We use the fact that the MR images of humans exist in a much lower-dimensional manifold  embedded in the space
embedded in the space  . With this constraint
. With this constraint  which is unknown, there is the possibility that there exists a practically meaningful inverse f in the sense that
which is unknown, there is the possibility that there exists a practically meaningful inverse f in the sense that

In the left of figure 2, we consider the case that  is the uniform subsampling of factor 2. With this choice of
is the uniform subsampling of factor 2. With this choice of  , two different images
, two different images  produce identical
produce identical  . This means the uniform subsampling of factor 2 is inappropriate for learning f satisfying (7). Here,
. This means the uniform subsampling of factor 2 is inappropriate for learning f satisfying (7). Here,  is the standard Logan phantom image and
is the standard Logan phantom image and  is a modified image of
is a modified image of  obtained by moving three small anomalies to their symmetric positions with respect to the middle horizontal line. In contrast, if we add a few low frequencies to the uniform subsampling of factor 2, as shown in the image on the right of figure 2, the situation is dramatically changed and separability (8) may be achieved.
obtained by moving three small anomalies to their symmetric positions with respect to the middle horizontal line. In contrast, if we add a few low frequencies to the uniform subsampling of factor 2, as shown in the image on the right of figure 2, the situation is dramatically changed and separability (8) may be achieved.

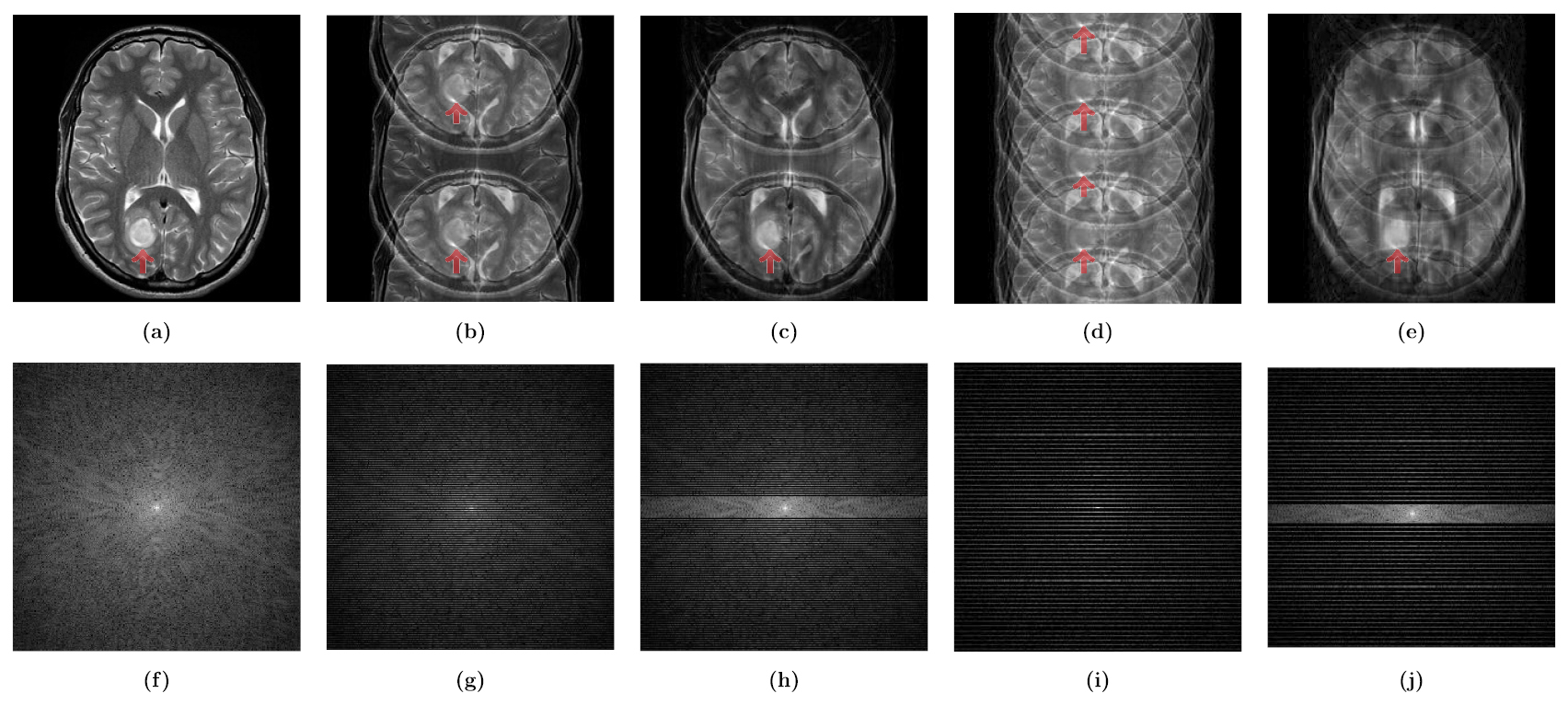
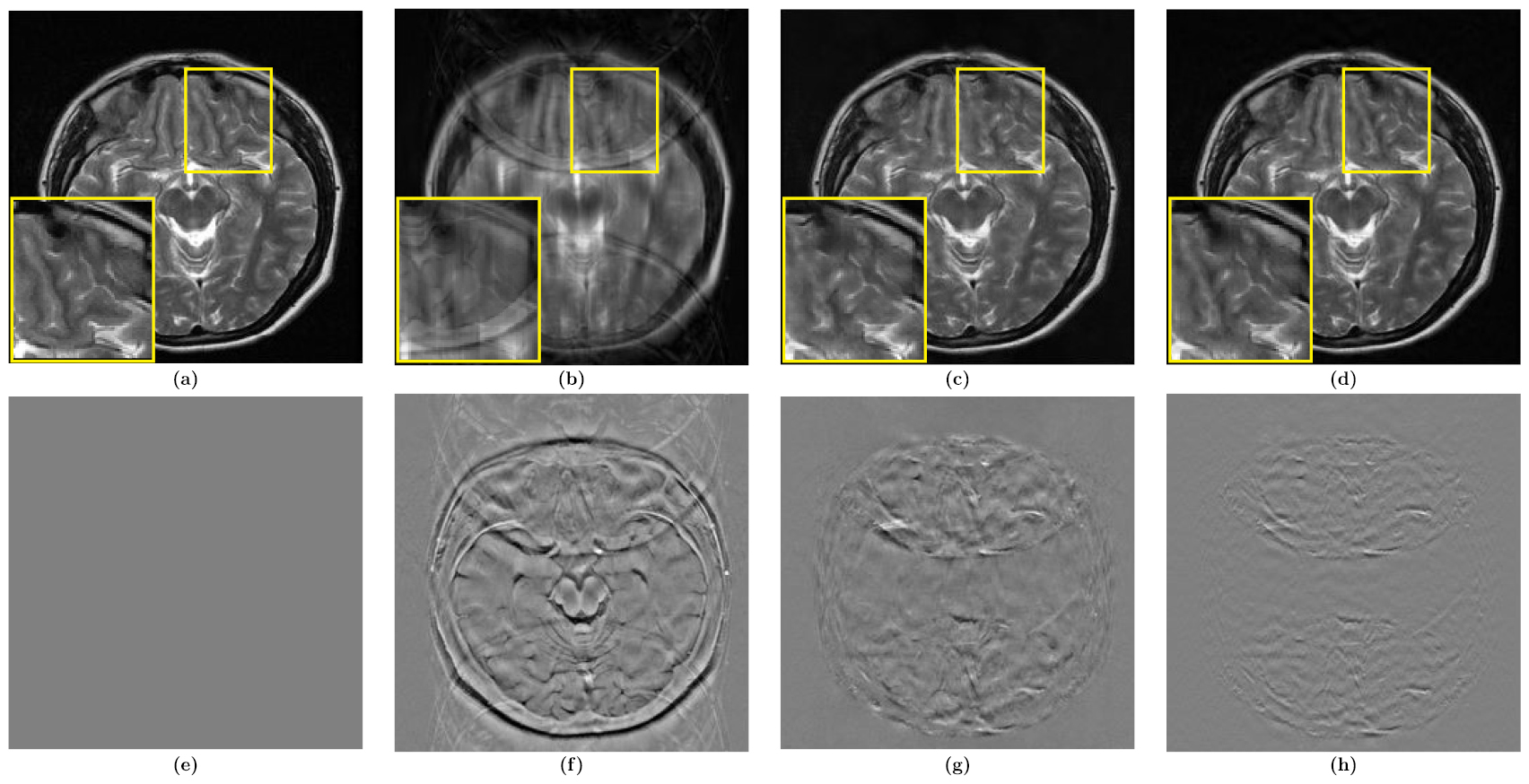
In figure 3, we demonstrate the separability condition again using the patient data. Figure 3(a) is the ground truth, where the tumor is at the bottom. Figures 3(b) and (d) are the reconstructed images using a uniform subsampling of factors 2 and 4, respectively; the tumors apear found at both the top and bottom, and the uniform subsampling of factor 2 and 4 are not separable. However, in the reconstructed images in figures 3(c) and (e) using the uniform subsampling of factosr 2 and 4 with added low frequencies, the tumors are clearly located at the bottom and separability (8) may be achieved. This crucial observation is validated by various numerical simulations as shown in figure 5.

Figure 3. MR images of human brain with a tumor at the bottom. Images (a)–(e) are reconstructed from (f) full sampling, (g) uniform subsampling of factor 2, (h) uniform subsampling of factor 2 with added some low frequencies, (i) uniform subsampling of factor 4, and (j) uniform subsampling of factor 4 with added low frequencies, respectively. In (b) and (d), tumor-like lesions are found at both the top and bottom; one is a copy of the other. Hence, a location uncertainty exists in the uniform sampling. However, in the reconstructed image (c) and (e) using the uniform subsampling of factor 2 and 4 with added low frequencies, the tumors are clearly located at the bottom. The location uncertainty can hence be addressed by adding a few low frequencies in k-space.
Download figure:
Standard image High-resolution imageIn the subsampling strategy, we use a uniform subsampling of factor 4 (25% k-space data—64 lines of a total 256 lines) with a few low frequencies(about  -space data—12 lines of a total 256 lines). Owing to the Poisson summation formula, the uniformly subsampled data with factor 4 provides the detailed structure of the folded image of
-space data—12 lines of a total 256 lines). Owing to the Poisson summation formula, the uniformly subsampled data with factor 4 provides the detailed structure of the folded image of  as
as

However, the folded image may not contain the location information of small anomalies. We fix the anomaly location uncertainty by adding a few amount of low frequency k-space data. (See appendix B for details.)
2.2. Image reconstruction function
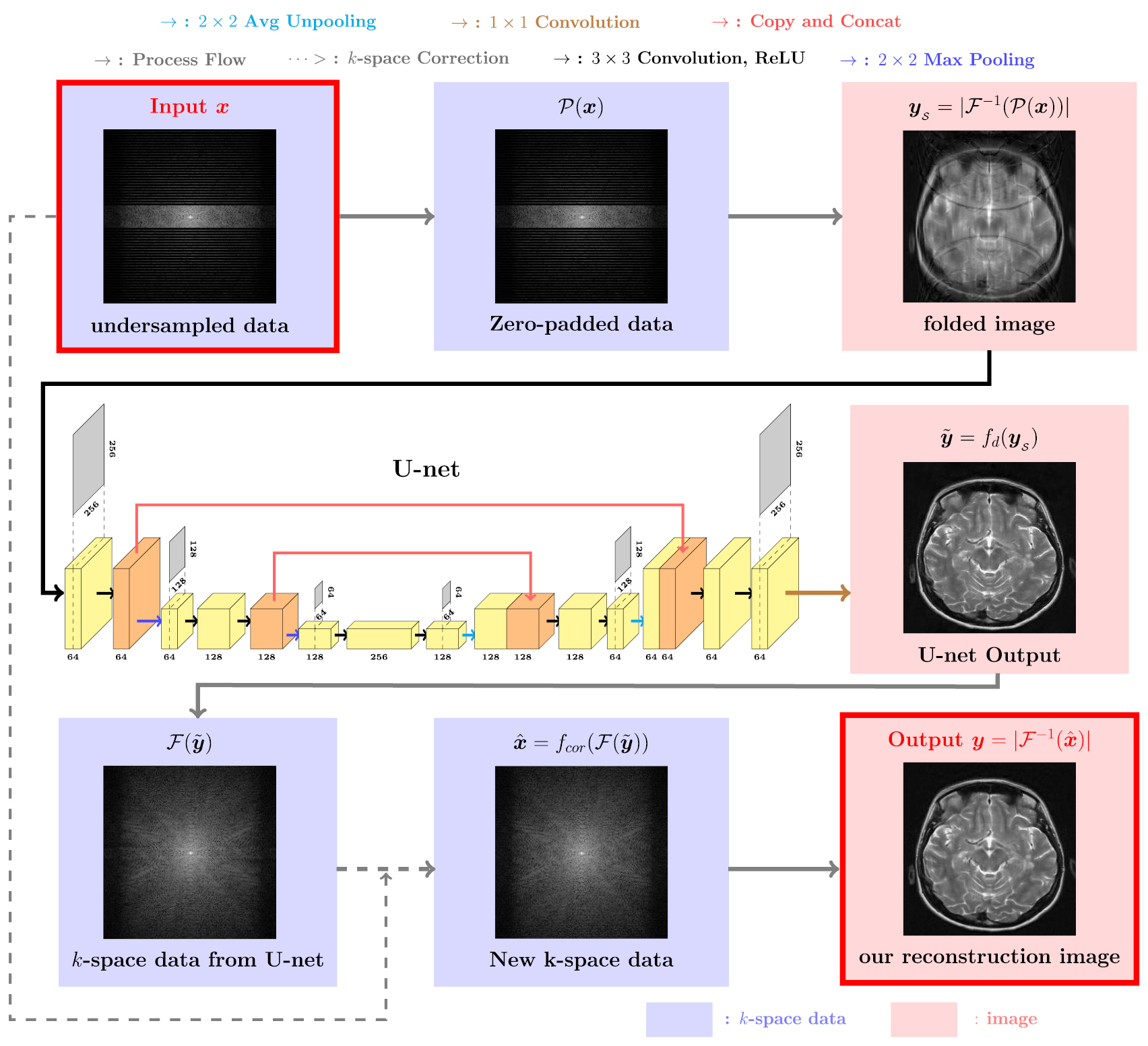
In this subsection, we describe the image reconstruction function f, which is schematically illustrated in figure 4. When we have an undersampled data  as an input of f, about 70% of
as an input of f, about 70% of  are not measured and not recorded. The first step of f is to fill in zeros for the unmeasured region of
are not measured and not recorded. The first step of f is to fill in zeros for the unmeasured region of  to obtain
to obtain  . After the zero padding has been added, we take the inverse Fourier transform of
. After the zero padding has been added, we take the inverse Fourier transform of  , take its absolute value, and obtain the folded image
, take its absolute value, and obtain the folded image  . We input this folded image
. We input this folded image  into the trained U-net and obtain the U-net output image
into the trained U-net and obtain the U-net output image  . We apply the Fourier transform to
. We apply the Fourier transform to  , which yields the k-space data
, which yields the k-space data  . The U-net recovers the zero-padded part of the k-space information. However, during this recovery, the unpadded parts of the data are distorted. We manually fix this unwanted distortion by placing the original
. The U-net recovers the zero-padded part of the k-space information. However, during this recovery, the unpadded parts of the data are distorted. We manually fix this unwanted distortion by placing the original  values in their corresponding positions in the k-space data
values in their corresponding positions in the k-space data  . We call this k-space correction as fcor and set
. We call this k-space correction as fcor and set  . Because the original input data is preserved, we expect to obtain a more satisfactory reconstruction image and, indeed, our experiments show that the k-space correction is very effective. Finally, we apply the inverse Fourier transform to
. Because the original input data is preserved, we expect to obtain a more satisfactory reconstruction image and, indeed, our experiments show that the k-space correction is very effective. Finally, we apply the inverse Fourier transform to  , take the absolute value and obtain our reconstruction image
, take the absolute value and obtain our reconstruction image  . In summary, our image reconstruction function
. In summary, our image reconstruction function  is given by
is given by

where fd is the trained U-net and fcor indicates the k-space correction. Here, fd should be determined by the following training process.

Figure 4. The proposed method consists of two major components : deep learning using U-net and k-space correction. As a preprecessing, we first fill in zeros for the unmeasured region of the undersampled data to get the zero-padded data. Then, we take the inverse Fourier transform, take its absolute value, and obtain the folded image. After the preprocess, we put this folded image into the trained U-net and produce the U-net output. The U-net recovers the zero-padded part of the k-space data. We take the Fourier transform and replace the unpadded parts by the original k-space data to preserve the original measured data. Finally, we obtain the final output image by applying the inverse Fourier transform and absolute value.
Download figure:
Standard image High-resolution imageTo train and test the U-net fd, we generate the training and test sets as follows. Given ground-truth MR images  , we take the Fourier transform of each
, we take the Fourier transform of each  , apply our subsampling strategy
, apply our subsampling strategy  , which yields
, which yields  . This provides a dataset
. This provides a dataset  of subsampled k-space data and ground-truth MR images. The dataset is divided into two subsets : a training set
of subsampled k-space data and ground-truth MR images. The dataset is divided into two subsets : a training set  and test set
and test set  . The input
. The input  of the image reconstruction function f is an undersampled k-space data and the output
of the image reconstruction function f is an undersampled k-space data and the output  is the ground truth image. Using the zero-padding operator, inverse Fourier transform, and absolute value, we obtain folded images
is the ground truth image. Using the zero-padding operator, inverse Fourier transform, and absolute value, we obtain folded images  . Our training goal is then to recover the ground-truth images
. Our training goal is then to recover the ground-truth images  from the folded images
from the folded images  . Note that
. Note that  is a set of pairs for training fd.
is a set of pairs for training fd.
The architecture of our U-net is illustrated in figure 4. The first half of the network is the contracting path and the last half is the expansive path. The size of the input and output images is 256 × 256. In the contracting path, we first apply the 3 × 3 convolutions with zero-padding so that the image size does not decrease after convolution. The convolution layers improve the performance of machine learning systems by extracting useful features, sharing parameters, and introducing sparse interactions and equivariant representations (Bengio et al 2015). After each convolution, we use a rectified linear unit(ReLU) as an activation function to solve the vanishing gradient problem (Glorot et al 2011). Then, we apply the 2 × 2 max pooling with a stride of 2. The max pooling helps to make the representation approximately invariant to small translations of the input (Bengio et al 2015). In the expansive path, we use the average unpooling instead of max-pooling to restore the size of the output. In order to localize more precisely, the upsampled output is concatenated with the correspondingly feature from the contracting path. At the last layer a 1 × 1 convolution is used to combine each the 64 features into one large feature (Ronnerberger et al 2015).
The input of the net is  , the weights are W, the net, as a function of weights W, is
, the weights are W, the net, as a function of weights W, is  , and the output is denoted as
, and the output is denoted as  . To train the net, we use the
. To train the net, we use the  loss and find the optimal weight set W0 with
loss and find the optimal weight set W0 with

Once the optimal weight W0 is found, we stop the training and denote the trained U-net as  .
.
In our experiment, the ground-truth MR image  was normalized to be in the range
was normalized to be in the range ![$[0, 1]$](https://content.cld.iop.org/journals/0031-9155/63/13/135007/revision2/pmbaac71aieqn121.gif) and the undersampled data
and the undersampled data  was subsampled to 29% k-space data as described in section 2. We trained our model using a training set of 1400 images from 30 patients. The MR images were obtained using a T2-weighted turbo spin-echo pulse sequence (repetition time = 4408 ms, echo time = 100 ms, echo spacing = 10.8 ms) (Loizou et al 2011). To train our deep neural network, all weights were initialized by a zero-centered normal distribution with standard deviation 0.01 without a bias term. The loss function was minimized using the RMSPropOptimize with learning rate 0.001, weight decay 0.9, mini-batch size 32, and 2000 epochs. RMSProp, which is an adaptive gradient method, was proposed by Tieleman and Hinton to overcome difficulties in the optimization process in practical machine learning implementations (Tieleman et al 2012). Training was implemented using TensorFlow (Google 2015) on an Intel(R) Core(TM) i7-6850K, 3.60GHz CPU and four NVIDIA GTX-1080, 8GB GPU system. The network required approximately six hours for training.
was subsampled to 29% k-space data as described in section 2. We trained our model using a training set of 1400 images from 30 patients. The MR images were obtained using a T2-weighted turbo spin-echo pulse sequence (repetition time = 4408 ms, echo time = 100 ms, echo spacing = 10.8 ms) (Loizou et al 2011). To train our deep neural network, all weights were initialized by a zero-centered normal distribution with standard deviation 0.01 without a bias term. The loss function was minimized using the RMSPropOptimize with learning rate 0.001, weight decay 0.9, mini-batch size 32, and 2000 epochs. RMSProp, which is an adaptive gradient method, was proposed by Tieleman and Hinton to overcome difficulties in the optimization process in practical machine learning implementations (Tieleman et al 2012). Training was implemented using TensorFlow (Google 2015) on an Intel(R) Core(TM) i7-6850K, 3.60GHz CPU and four NVIDIA GTX-1080, 8GB GPU system. The network required approximately six hours for training.
3. Result
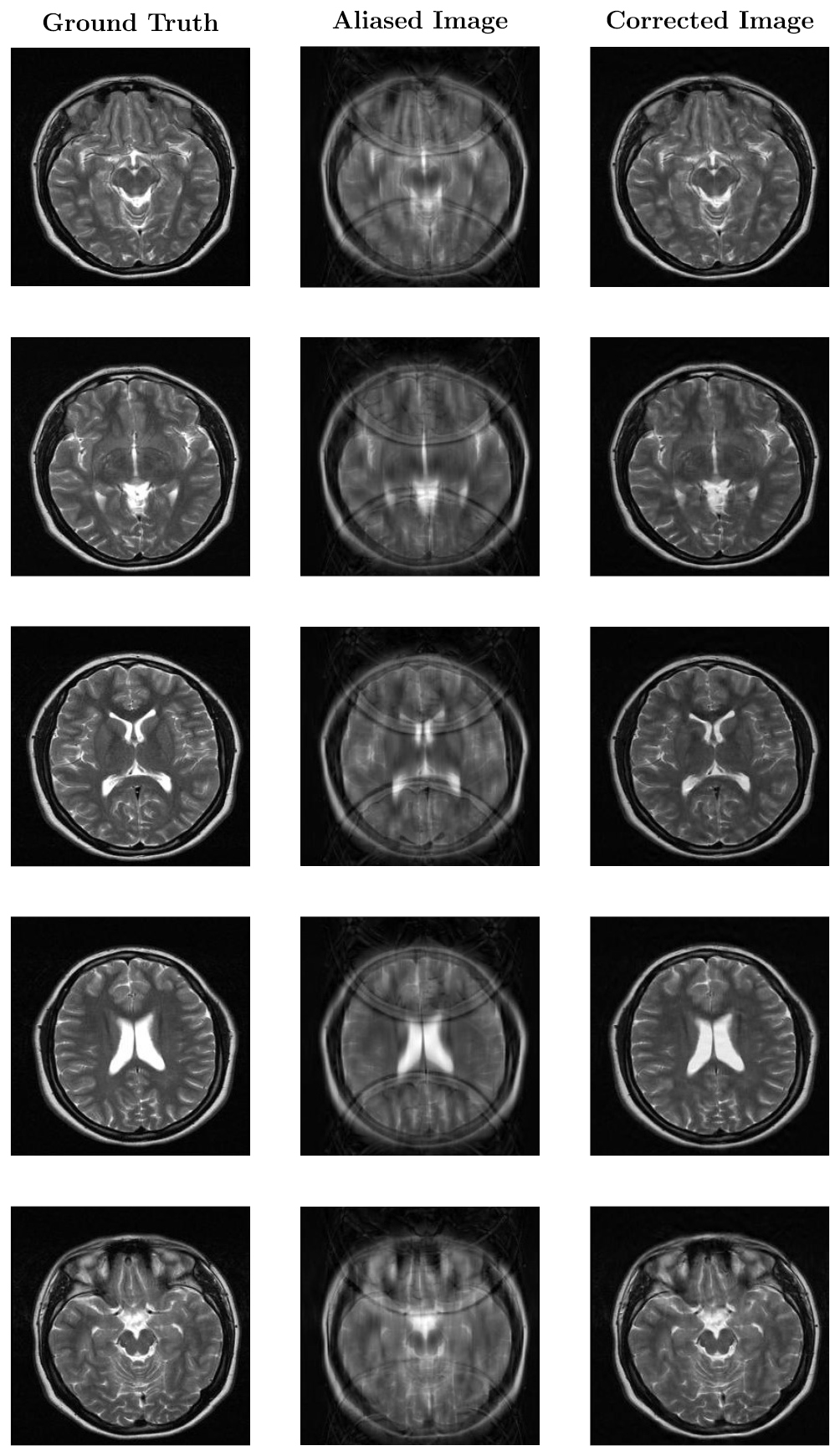
Figure 5 shows the performance of the proposed method for five different brain images in the test set. The first, second and third columns show the ground-truth, aliased and corrected images, respectively. The aliased images are folded four times. The proposed method suppresses these artifacts, but provides surprisingly sharp and natural-looking images.

Figure 5. Numerical simulation results of five different brain MR images. The first, second and third columns show the ground-truth, aliased and corrected images, respectively. The proposed method significantly reduces the undersampling artifacts while preserving morphological information.
Download figure:
Standard image High-resolution imageFigure 6 displays the impact of k-space correction. The four images in the first row are the ground truth (figure 6(a)), input (figure 6(b)) and output (figure 6(c)) of the U-net, and the final output after the k-space correction (figure 6(d)). In the second row, we subtract the ground truth from images in the first row. Images figure 6(c) before and figure 6(d) after k-space correction are visually indistinguishable. However, figures 6(g) and (h) displays the impact of k-space correction. The U-net almost completely removes the folding artifacts. However, one can still see a few folding artifacts. Hence, The k-space correction removes the remaining folding artifacts.

Figure 6. Simulation result using the proposed method : (a) ground-truth image, (b) aliased image, (c) output from the trained network, (d) k-space corrected image, figures (e)–(h) depict the difference image with respect to the image in (a).
Download figure:
Standard image High-resolution imageAll our qualitative observations are supported by the quantitative evaluation. After we trained our model by using 1400 images from 30 patients, we used a test set of 400 images from 8 other patients, and measure and report their mean-squared error (MSE) and structural similarity index (SSIM) in table 1.
Table 1. Quantitative evaluation results in terms of MSE and SSIM using the test set of 400 images. MSE is computed using  , where
, where  is normalized to the range
is normalized to the range ![$[0, 1]$](https://content.cld.iop.org/journals/0031-9155/63/13/135007/revision2/pmbaac71aieqn125.gif) . See Wang et al (2004) for definition of SSIM. As MSE approaches 0 or SSIM approaches 1, outputs are closer to labels.
. See Wang et al (2004) for definition of SSIM. As MSE approaches 0 or SSIM approaches 1, outputs are closer to labels.
| Aliased | U-net | U-net with k-space correction | |
|---|---|---|---|
| MSE |  |
 |
 |
| SSIM |  |
 |
 |
The results for these metrics support the effectiveness of both the U-net and k-space correction. In particular, the effectiveness of k-space correction is demonstrated.
4. Discussion and conclusion
Deep learning techniques exhibit surprisingly good performances in various challenging fields, and our case is not an exception. In this study, it generates the reconstruction function f using the U-net, providing a better performance than the existing methods.
Our inverse problem of undersampled MRI reconstruction is ill-posed in the sense that there are fewer equations than unknowns. The underdetermined system in section 3 has  unknowns and
unknowns and  equations. The dimension of the set
equations. The dimension of the set  is
is  , and therefore it is impossible to have an explicit reconstruction formula for solving (6), without imposing the strong constraint of a solution manifold. For the uniqueness, the Hausdorff dimension of the solution manifold must be less than the number of equations (i.e.
, and therefore it is impossible to have an explicit reconstruction formula for solving (6), without imposing the strong constraint of a solution manifold. For the uniqueness, the Hausdorff dimension of the solution manifold must be less than the number of equations (i.e.  ). Unfortunately, it is extremely hard to find a mathematical expression for the complex structure of MR images in terms of
). Unfortunately, it is extremely hard to find a mathematical expression for the complex structure of MR images in terms of  parameters, because of its highly nonlinearity characteristic. The deep learning approach is a feasible way to capture MRI image structure as dimensionality reduction.
parameters, because of its highly nonlinearity characteristic. The deep learning approach is a feasible way to capture MRI image structure as dimensionality reduction.
We learned the kind of subsampling strategy necessary to perform an optimal image reconstruction function after extensive effort. Initially, we used a regular subsampling with factor 4, but realized that it could not satisfy the separability condition. Because of wrap around artifact (a portion of the image is folded over onto some other portion of the image), it is impossible to specify the locations of small objects. We added low frequencies hoping to satisfy separability and this turned out to guarantee separability in a practical sense.
Once the data set satisfies the separability condition, we have many deep learning tools to recover the images from the folded images. We chose to use the U-net. The optimal choices may depend on the input image size, the number of training data, computer capacity, etc. It seems that the determination of optimal choice is difficult. Therefore, we empirically choose the number of layers, the number of convolution filters, and the filters' size. The trained U-net successfully unfolded and recovered the images from the folded images. The U-net removes most of the folding artifacts; however, one can still see them. Hence, The k-space correction is used to further reduce them.
The experiments show that our learned function f appears to have highly expressive representation capturing anatomical geometry as well as small anomalies. We tested the flexibility of the proposed method. We applied the proposed method to CT images that were never trained. It worked well for different types of images that were never trained. Our future research direction is to provide a more rigorous and detailed theoretical analysis to understanding why our method performs well. The proposed method can be extended to multi-channel complex data for parallel imaging, with suitable modifications to the sampling pattern and learning network. This is our ongoing research topic. In practice, owing to the large size of input data available for deep learning, we may face 'out of memory' problem. Indeed, we experienced out of memory problem when using input images of size  , with a four GPU (NVIDIA GTX-1080, 8GB) system. This memory limitation problem was the primary reason to use
, with a four GPU (NVIDIA GTX-1080, 8GB) system. This memory limitation problem was the primary reason to use  images, which were obtained by resizing
images, which were obtained by resizing  images. It is possible to develop more efficient and effective learning procedures for out of memory problem.
images. It is possible to develop more efficient and effective learning procedures for out of memory problem.
Acknowledgments
This research was supported by the National Research Foundation of Korea No. NRF-2017R1A2B20005661. Hyun, Lee and Seo were supported by Samsung Science &; Technology Foundation (No. SSTF-BA1402-01).
Appendix A. Minimum-norm solution of the underdetermined system
The minimum-norm solution of the underdetermined system  in Remark 2.1 is the solution of following optimization problem: Minimize
in Remark 2.1 is the solution of following optimization problem: Minimize  subject to the constraint
subject to the constraint  . This underdetermined system has infinitely many solutions. For example, the following images are solutions of
. This underdetermined system has infinitely many solutions. For example, the following images are solutions of  where
where  is an undersampled data with a reduction factor of 3.37.
is an undersampled data with a reduction factor of 3.37.

The first image is the minimum-norm solution, i.e.

This minimum-norm solution is improperly chosen; it does not look like a head MRI images. Then, can we deal with the complicated constraint problem: Solve  subject to the constraint that
subject to the constraint that  looks like a head MRI image? It seems to be very difficult to express this constraint in classical logic formalisms.
looks like a head MRI image? It seems to be very difficult to express this constraint in classical logic formalisms.
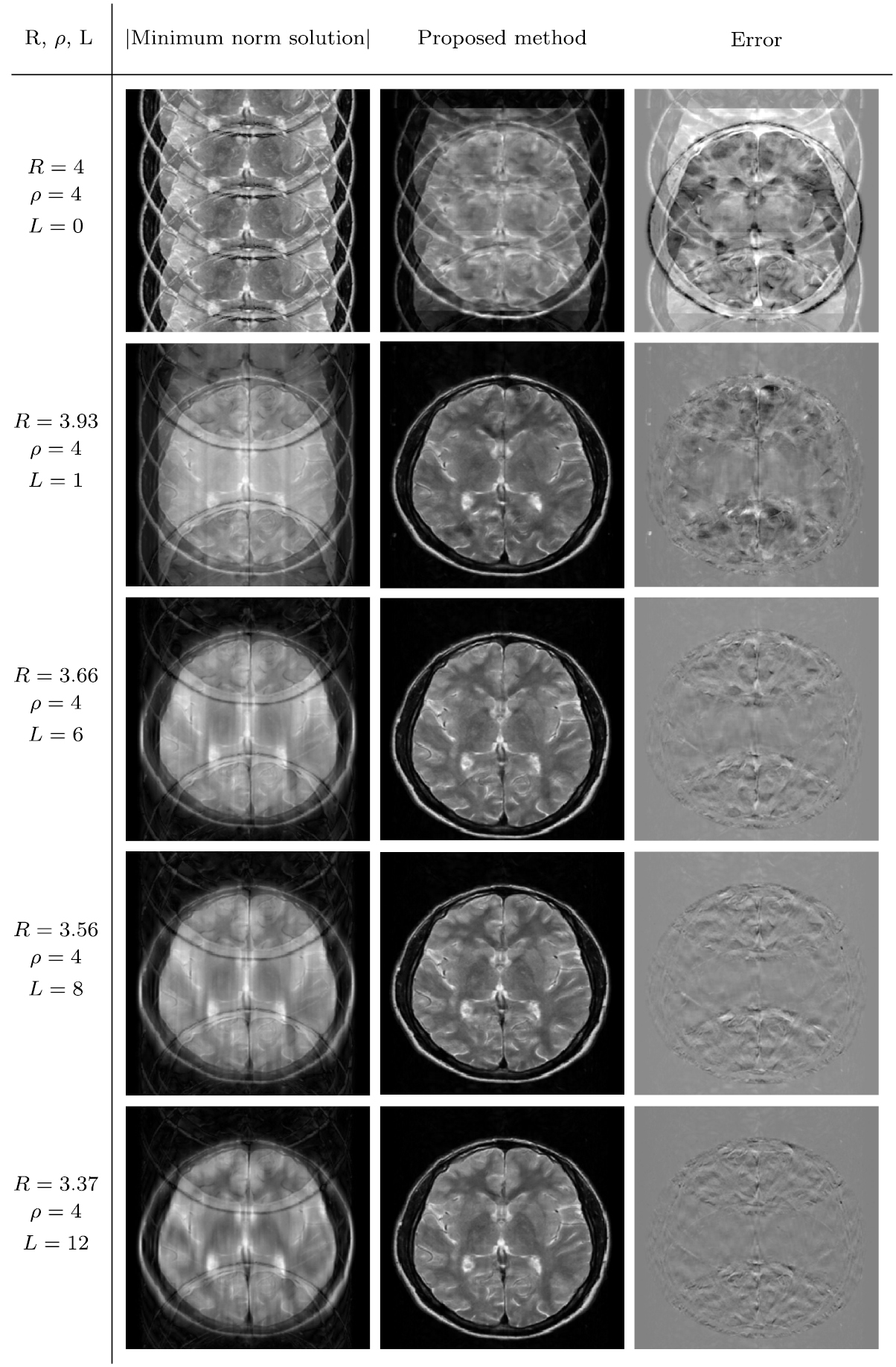
Appendix B. Performance of the proposed method with different reduction factors
We tested the proposed method with different reduction factors from R = 3.37 to R = 5.81. We performed two experiments by varying two factors ρ and L, where ρ denotes the uniform subsampling rate along the phase encoding direction (vertical direction) and L denotes the number of low frequency phase encoding lines to be added in our subsampling strategy.
In figure B1, we fix L = 12 and vary ρ from  to
to  . The proposed method provides the good reconstruction image, even if ρ is large
. The proposed method provides the good reconstruction image, even if ρ is large  . See the last row in figure B1.
. See the last row in figure B1.

Figure B1. In this experiment, we fix L = 12 and vary ρ :  .
.
Download figure:
Standard image High-resolution imageIn figure B2, we fix  and vary L from L = 0 to L = 12. In the case when the L = 0, the separability condition is violated and the proposed method fails (as shown in the first row of figure B2). When L = 1, our network starts to learn unfolding, dramatically. The proposed method with L = 12 provides excellent reconstruction capability.
and vary L from L = 0 to L = 12. In the case when the L = 0, the separability condition is violated and the proposed method fails (as shown in the first row of figure B2). When L = 1, our network starts to learn unfolding, dramatically. The proposed method with L = 12 provides excellent reconstruction capability.

Figure B2. In this experiment, we fix  and vary L :
and vary L :  .
.
Download figure:
Standard image High-resolution imageAppendix C. The reconstruction process
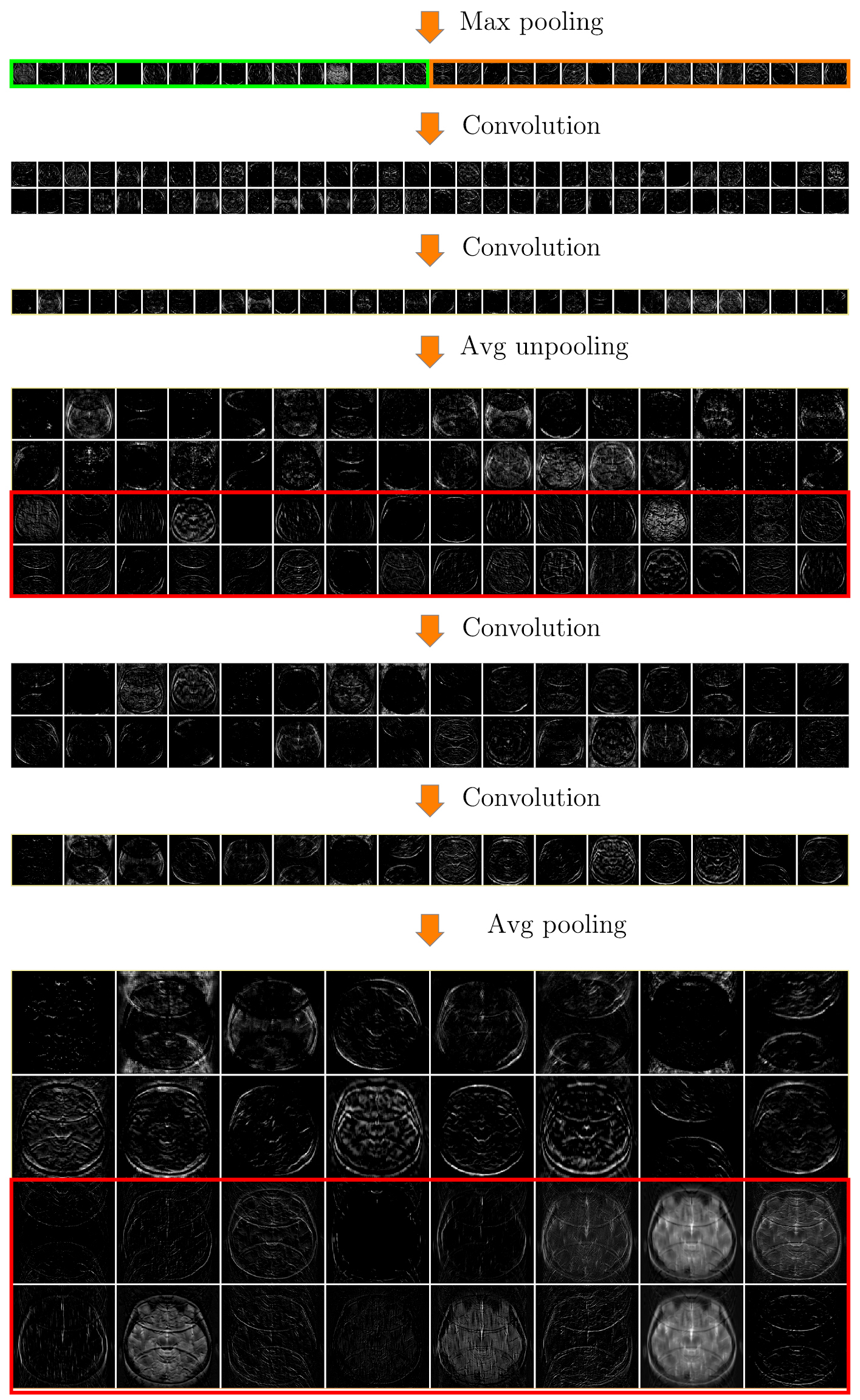
This appendix presents the reconstruction process intuitively using a simplified version of the U-net See figure C1, C2 and C3 for the detailed reconstruction process.

Figure C1. Reconstruction process (part 1).
Download figure:
Standard image High-resolution image
Figure C2. Reconstruction process (part 2).
Download figure:
Standard image High-resolution image
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Figure C3. Reconstruction process (part 3).
Download figure:
Standard image High-resolution image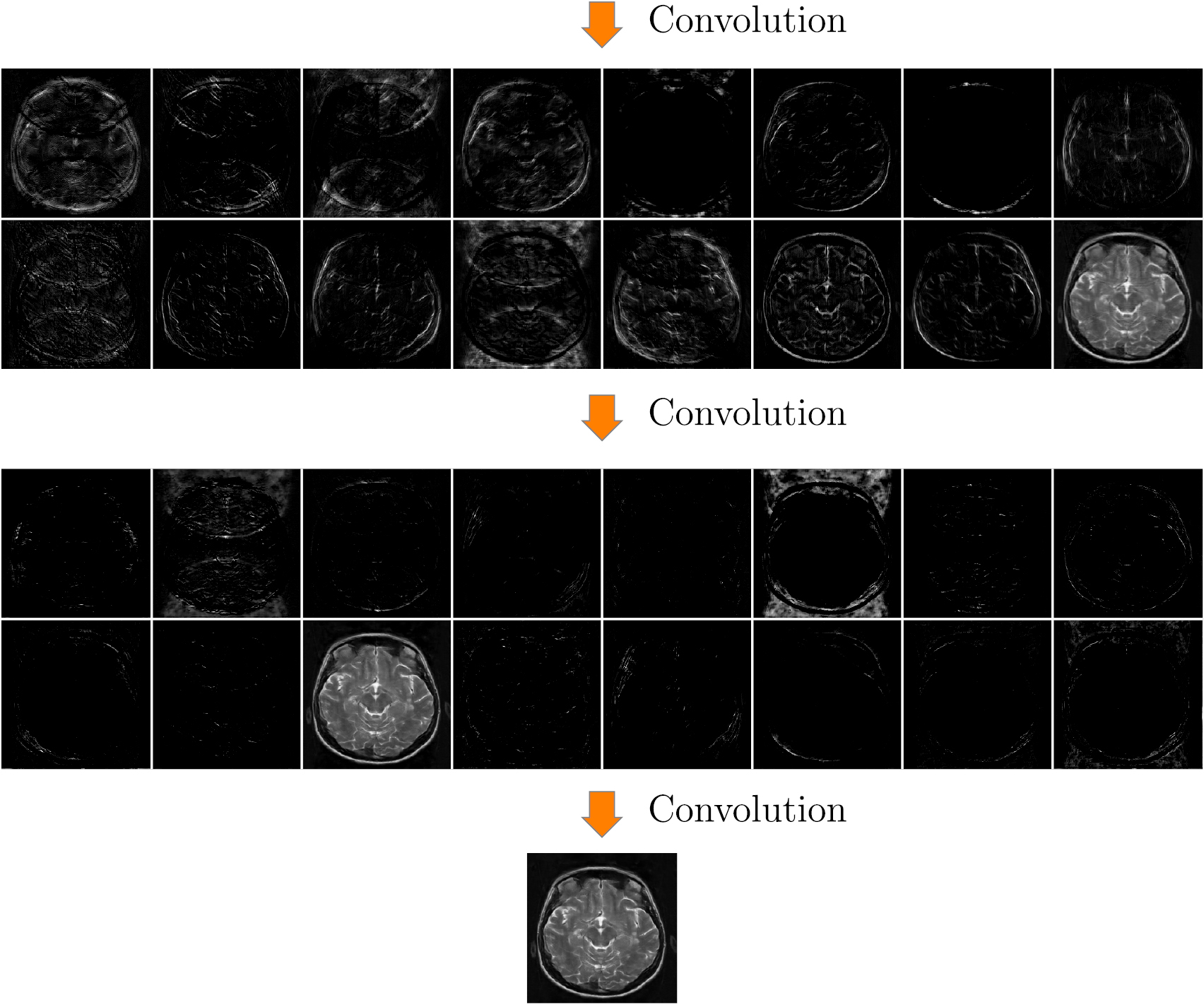{kind=link}