Abstract
Parametrized quantum circuits serve as ansatze for solving variational problems and provide a flexible paradigm for the programming of near-term quantum computers. Ideally, such ansatze should be highly expressive, so that a close approximation of the desired solution can be accessed. On the other hand, the ansatz must also have sufficiently large gradients to allow for training. Here, we derive a fundamental relationship between these two essential properties: expressibility and trainability. This is done by extending the well-established barren plateau phenomenon, which holds for ansatze that form exact 2-designs, to arbitrary ansatze. Specifically, we calculate the variance in the cost gradient in terms of the expressibility of the ansatz, as measured by its distance from being a 2-design. Our resulting bounds indicate that highly expressive ansatze exhibit flatter cost landscapes and therefore will be harder to train. Furthermore, we provide numerics illustrating the effect of expressibility on gradient scalings and we discuss the implications for designing strategies to avoid barren plateaus.
- Received 12 February 2021
- Accepted 30 November 2021
DOI:https://doi.org/10.1103/PRXQuantum.3.010313
Published by the American Physical Society under the terms of the Creative Commons Attribution 4.0 International license. Further distribution of this work must maintain attribution to the author(s) and the published article's title, journal citation, and DOI.
Published by the American Physical Society
Physics Subject Headings (PhySH)
Popular Summary
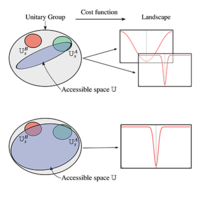
Variational quantum algorithms (VQAs) have gathered attention as a strategy for making the most of noisy quantum hardware. In VQAs, a problem-specific cost function is evaluated on a quantum computer, while a classical optimizer trains a parametrized quantum circuit (PQC) to minimize this cost. Central to the success of VQAs is the construction of the PQC, which serves as an ansatz to explore the space of solutions to the problem. The ansatz should ideally be highly expressive so that the solution can be accessed. On the other hand, the ansatz must also have a sufficiently featured cost landscape (i.e., sufficiently large gradients) to allow for training. Here, we derive a fundamental relationship between these two desirable properties: expressibility and trainability. Specifically, we show that the more expressive the ansatz, the flatter is the cost landscape, i.e., you cannot have both.
The origin of this trade-off is essentially that both expressivity and trainability are closely connected to randomness. An expressive ansatz is one that uniformly explores the space of unitaries. However, typical cost gradients for such random unitaries vanish with high probability. Combining these ideas, we have that higher expressibility leads to a flatter cost landscape.
Our work paves the way for a discussion of how reducing expressibility can be traded for increased trainability. We provide numerics proposing several possible strategies, including correlating parameters and initializing close to the solution. Further exploration of these, as well as other strategies, is an important direction for future research.