





Summary
Recent work by Reiss and Ogden provides a theoretical basis for sometimes preferring restricted maximum likelihood (REML) to generalized cross-validation (GCV) for smoothing parameter selection in semiparametric regression. However, existing REML or marginal likelihood (ML) based methods for semiparametric generalized linear models (GLMs) use iterative REML or ML estimation of the smoothing parameters of working linear approximations to the GLM. Such indirect schemes need not converge and fail to do so in a non-negligible proportion of practical analyses. By contrast, very reliable prediction error criteria smoothing parameter selection methods are available, based on direct optimization of GCV, or related criteria, for the GLM itself. Since such methods directly optimize properly defined functions of the smoothing parameters, they have much more reliable convergence properties. The paper develops the first such method for REML or ML estimation of smoothing parameters. A Laplace approximation is used to obtain an approximate REML or ML for any GLM, which is suitable for efficient direct optimization. This REML or ML criterion requires that Newton–Raphson iteration, rather than Fisher scoring, be used for GLM fitting, and a computationally stable approach to this is proposed. The REML or ML criterion itself is optimized by a Newton method, with the derivatives required obtained by a mixture of implicit differentiation and direct methods. The method will cope with numerical rank deficiency in the fitted model and in fact provides a slight improvement in numerical robustness on the earlier method of Wood for prediction error criteria based smoothness selection. Simulation results suggest that the new REML and ML methods offer some improvement in mean-square error performance relative to GCV or Akaike’s information criterion in most cases, without the small number of severe undersmoothing failures to which Akaike’s information criterion and GCV are prone. This is achieved at the same computational cost as GCV or Akaike’s information criterion. The new approach also eliminates the convergence failures of previous REML- or ML-based approaches for penalized GLMs and usually has lower computational cost than these alternatives. Example applications are presented in adaptive smoothing, scalar on function regression and generalized additive model selection.
1. Introduction
Given the λj, there is a unique minimizer of expression (3), , which is straightforward to compute by a penalized version of the iteratively reweighted least squares method that is used for GLM estimation (penalized iteratively reweighted least squares (PIRLS)) (see for example Wood (2006) or Section 3.2). To select values for the λj requires optimization of a separate criterion, , say, which must be chosen.
1.1. Smoothness selection: prediction error or likelihood?
The λi selection criteria that have been proposed fall into two main classes. The first group try to minimize model prediction error, by optimizing criteria such as Akaike’s information criterion (AIC), cross-validation or generalized cross-validation (GCV) (see for example Wahba and Wold (1975) and Craven and Wahba (1979)). The second group treat the smooth functions as random effects (Kimeldorf and Wahba, 1970), so that the λi are variance parameters which can be estim- ated by maximum (marginal) likelihood (ML) (Anderssen and Bloomfield, 1974), or restricted maximum likelihood (REML), which Wahba (1985) called ‘generalized maximum likelihood’.
Asymptotically prediction error methods give better prediction error performance than likelihood-based methods (e.g. Wahba (1985) and Kauermann (2005)) but also have slower convergence of smoothing parameters to their optimal values (Härdle et al., 1988). Reflecting this, published simulation studies (e.g. Wahba (1985), Gu (2002), Ruppert et al. (2003) and Kohn et al. (1991)) differ about the relative performance of the two classes, although there is agreement that prediction error criteria are prone to occasional severe undersmoothing. Reiss and Ogden (2009) provided a theoretical comparison of REML and GCV at finite sample sizes, showing that GCV is both more likely to develop multiple minima and to give more variable λj-estimates. Fig. 1 illustrates the basic issue. GCV penalizes overfit only weakly, with a minimum that tends to be very shallow on the undersmoothing side, relative to sampling variability. This can lead to an overfit. By contrast, REML (and also ML) penalizes overfit more severely and therefore tends to have a much more pronounced optimum, relative to sampling variability. In principle, extreme undersmoothing can also be avoided by use of modified prediction error criteria such as AICc (Hurvich et al., 1998), but in practice the use of low to intermediate rank bases for the fj already suppresses severe overfit, and AICc then offers little additional benefit relative to GCV, as Fig. 1 also illustrates.
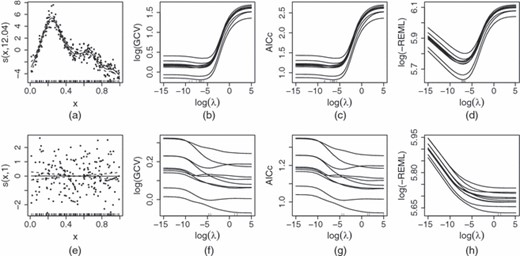
Example comparison of GCV, AICc and REML criteria: (a) some (x,y)-data modelled as yi = f(xi)+ɛi, ɛi independent and identically distributed N(0,σ2) where smooth function f was represented by using a rank 20 thin plate regression spline (Wood, 2003); (b)–(d) various smoothness selection criteria plotted against logarithmic smoothing parameters, for 10 replicates of the data (each generated from the same ‘truth’) (note how shallow the GCV and AICc minima are relative to the sampling variability, resulting in rather variable optimal λ-values (which are shown as a rug plot), and a propensity to undersmooth; in contrast the REML optima are much better defined, relative to the sampling variability, resulting in a smaller range of λ-estimates); (e)–(h) are equivalent to (a)–(d), but for data with no signal, so that the appropriate smoothing parameter should tend to ∞ (note GCV’s and AICc’s occasional multiple minima and undersmoothing in this case, compared with the excellent behaviour of REML; ML (which is not shown) has a similar shape to REML)
Greater resistance to overfit, less smoothing parameter variability and a reduced tendency to multiple minima suggest that REML or ML might be preferable to GCV for semiparametric GLM estimation. But these benefits must be weighed against the fact that existing computational methods for REML or ML estimation of semiparametric GLMs are substantially less reliable than their prediction error equivalents, as the remainder of this section explains.
There are two main classes of computational method for λj-estimation: those based on single iterations and those based on nested iterations. In the single-iteration case, each PIRLS step, which is used to update , is supplemented by a -update. The latter is based on improving a λ selection criterion , which depends on the estimate of at the start of the step. will be some sort of REML, GCV or similar criterion, but it is not a fixed function of λ, instead changing with from iterate to iterate. Consequently single-iteration methods do not guarantee convergence to a fixed , (see Gu (2002), page 154, Wood (2006), page 180, and Brezger et al. (2007), reference manual section 8.1.2).
In nested iteration, the smoothness selection criterion depends on β only via . An outer iteration updates to optimize , with each iterative step requiring an inner PIRLS iteration to find the current . Because nested iteration optimizes a properly defined function of λ, it is possible to guarantee convergence to a fixed optimum, provided that is bounded below, and expression (3) has a well-defined optimum (conditions which are rather mild, in practice). The disadvantage of nested iteration is substantially increased computational complexity.
To date only single-iteration methods have been proposed for REML or ML estimation of semiparametric GLMs (e.g. Wood (2004), using Breslow and Clayton (1993), or Fahrmeir et al. (2004), using Harville (1977)), and in practice convergence problems are not unusual: examples are provided in Wood (2004, 2008), and in Appendix A. Early prediction-error-based methods were also based on single iteration (e.g. Gu (1992) and Wood (2004)), and suffered similar convergence problems, but these were overcome by Wood’s (2008) nested iteration method for GCV, generalized approximate cross-validation, and AIC smoothness selection. Wood (2008) cannot be extended to REML or ML while maintaining good numerical stability, so the purpose of this paper is to provide an efficient and stable nested iteration method for REML or ML smoothness selection, thereby removing the major practical obstacle to use of these criteria.
2. Approximate restricted maximum likelihood or marginal likelihood for generalized linear model smoothing parameter estimation
Since the work of Kimeldorf and Wahba (1970), Wahba (1983) and Silverman (1985), it has been recognized that the penalized likelihood estimates are also the posterior modes of the distribution of β|y, if β∼N(0,S−φ), where S=Σi λiSi, and S− is an appropriate generalized inverse (see for example Wood (2006)). Once the elements of β are viewed as random effects in this way, it is natural to try to estimate the λi, and possibly φ, by ML or REML (Wahba, 1985).
This preliminary section uses standard methods to obtain an approximate REML expression that is suitable for efficient direct optimization to estimate the smoothing parameters of a semiparametric GLM. Rather than follow Patterson and Thompson (1971) directly, Laird and Ware’s (1982) approach to REML is taken, in which fixed effects are viewed as random effects with improper uniform priors and are integrated out. The key feature of the resulting expression is that it is relatively efficient to compute with and is suitable for optimizing as a properly defined function of the smoothing parameters, i.e., in contrast with previous single-iteration approaches to this problem, there is no need to resort to optimizing the REML score of a working model. Since a very similar approach obtains an approximate ML, this is also derived. ML can be useful for comparing models with different smooth terms included, for example (REML cannot be used for such a comparison because the alternative models will differ in fixed effect structure).
There are two approaches to the estimation of φ:
- (a)
estimate φ as part of lr-maximization, or
- (b)
use the Pearson statistic over n−Mp as , and optimize the resulting criterion, taking account of the derivatives of with respect to the smoothing parameters.
The only advantage of approach (b) is that it may sometimes allow the resulting REML score to be used as a heuristic method of smoothness selection with quasi-likelihood.
The simpler approach of using the expected Hessian in place of H was also investigated, but in simulations it gave worse performance than GCV when non-canonical links were used.
2.1. Marginal likelihood details
2.2. Accuracy of the Laplace approximation
For fixed dimension of β, the true REML or ML integral divided by its Laplace approximation is 1+O(n−1) (see for example Davison (2003), section 11.3.1). For consistency, it is usually necessary for the dimension of β to grow with n, which reduces this rate somewhat. However, for spline-type smoothers the dimension need only grow slowly with n (for example Gu and Kim (2002) showed that the rate need only be O(n2/9) for cubic-spline-like smooths), so convergence is still rapid. Kauermann et al. (2009) showed in detail that the Laplace approximation is well justified asymptotically for ML in the penalized regression spline setting.
Note that the Laplace approximation that is employed here does not suffer from the difficulties that are common to most penalized quasi-likelihood (PQL) (Breslow and Clayton, 1993) implementations when used with binary data. Most PQL implementations must estimate φ for the working model, even with binary data where this is not really satisfactory. In addition, PQL uses the expected Hessian in place of the exact Hessian when non-canonical links are used, which also reduces accuracy. That said, it should still be expected that the accuracy of equations (4) and (5) will reduce for binary or Poisson data when the expectation of the response variable is very low.
3. Optimizing the restricted maximum likelihood criterion
Equations (4) and (5) depend on the smoothing parameter vector λ via the dependence of S and (and hence W) on λ. The proposal here is to optimize equation (4) or (5) with respect to the ρi = log (λi), by using Newton’s method, with the usual modifications that
- (a)
some step length control will be used and
- (b)
the Hessian will be perturbed to be positive definite, if it is not (see Nocedal and Wright (2006) for an up-to-date treatment and computational details).
Each trial logarithmic smoothing parameter vector ρ, proposed as part of the Newton method iteration, will require a PIRLS iteration to evaluate the corresponding (and hence W). So the whole optimization consists of two nested iterations: an outer iteration to find , and an inner iteration to find the corresponding to any ρ. The outer iteration requires the gradient and Hessian of equation (4) or (5) with respect to ρ, and this in turn requires first and second derivatives of with respect to ρ.
Irrespective of the details of the optimization method, the major difficulty in minimizing equation (4) or (5) is that, if some λj is sufficiently large, then the ‘numerical footprint’ of the corresponding penalty term λjβTSjβ can extend well beyond the penalty’s range space, i.e. numerically the penalty can have marked effects in the subspace of the model parameter space for which, formally, βTSjβ=0. For example if ‖λjSj‖≫‖λkSk‖ then λjSj can have effects which are ‘numerically zero’ when judged relatively to ‖λjSj‖ (and would be exactly zero in infinite precision arithmetic), but which are larger than the strictly non-zero effects of λkSk. If left uncorrected, this problem leads to serious errors in evaluation of , |S|+ and |XTWX+S| and their derivatives with respect to ρ (see Section 3.1). Because multiple penalties often have overlapping range spaces (i.e. they penalize intersecting subspaces of the parameter space), no single reparameterization can solve this problem for all λ-values, but an adaptive reparameterization approach does work and is outlined in Section 3.1. Note that the Wood (2008) method, for dealing with numerical ill conditioning for prediction error criteria, is hopeless here. That method truncates the parameter space to deal with ill conditioning that is induced by changes in λ, but such an approach would lead to large erroneous and discontinuous changes in |S|+ and |XTWX+S| as λ changes. We shall of course still need to truncate the parameter space if some parameters would not be identifiable whatever the value of λ, but such a λ-independent truncation is not problematic.
A second question, when minimizing equation (4) or (5), is what optimization method to use to obtain the corresponding to any trial λ. If a PIRLS scheme is employed based on Newton (rather than Fisher) updates, then the Hessian that is required in equation (4) or (5) is conveniently obtained as a by-product of fitting, which also means that the same method can be used to stabilize both and REML or ML evaluation. Furthermore the required derivatives of with respect to ρ can be obtained directly from the information that is available as part of the PIRLS, using implicit differentiation, without the need for further iteration. Newton-based PIRLS also leads to more rapid convergence with non-canonical links.
As a result of the preceding considerations, this paper proposes that the following steps should be taken for each trial ρ proposed by the outer Newton iteration.
Step 1: reparameterize to avoid large norm λjSj-terms having effects outside their range spaces, thereby ensuring accurate computation with the current ρ (Section 3.1).
Step 2: estimate by Newton-based PIRLS, setting to 0 any elements of which would be unidentifiable irrespectively of the value ofρ (Sections 3.2 and 3.3).
Step 3: obtain first and second derivatives of with respect to ρ, using implicit differentiation and the quantities that are calculated as part of step 2 (Section 3.4).
Step 4: using the results from steps 2 and 3, evaluate the REML or ML criterion and derivatives with respect to ρ (Section 3.5).
After these four steps, all the ingredients are in place to propose a new ρ by using a further step of Newton’s method.
3.1. Reparameterization, log|S|+ and √S
log (|S|+) (where S=Σj λjSj) is the most numerically troublesome term in the REML or ML objective. Both λi→0 and λi→∞ can cause numerical problems when evaluating the determinant. The problem is most easily seen by considering the simple example of evaluating |λ1S1+λ2S2| when the q×q positive semidefinite dense matrices Sj are not full rank, but λ1S1+λ2S2 is. In what follows let ‖·‖ denote the matrix 2-norm (although the 1-, ∞- or Frobenius norms would serve as well), and let denote the computed version of any quantity x. Consider a similarity transform based on the eigendecomposition S1 = UΛUT, with computed version . Let Λ+ denote the vector of strictly positive eigenvalues, and Λ0 the vector of zero eigenvalues, and note that will have elements of typical magnitude ‖S1‖ɛm where ɛm is the computational machine precision (see for example Watkins (1991), section 5.5, or Golub and van Loan (1996), chapter 8).
In short, we can expect this ‘numerical zero leakage’ issue to spoil determinant calculations whenever the ratio of the largest strictly positive eigenvalue of λ1S1 (which sets the scale of the arbitrary perturbation, ) to the smallest strictly positive eigenvalue of λ2S2 is too great. However, the example also suggests a simple way of suppressing the problem. Reparameterize by using the computed eigenbasis of the dominant term S1, so that S1 becomes and S2 becomes . In the transformed space it is easy to ensure that the dominant term (now ) acts only within its range space, by setting (if the rank of S1 is known then identifying which eigenvalues should be 0 is trivial; if not, see step 3 in Appendix B).
Having reparameterized and truncated in this way, stable evaluation of |λ1Λ+λ2UTS2U| is straightforward. Only the first r1 columns of now depend on λ1S1. Forming a pivoted QR-decomposition maintains this column separation in (the decomposition acts on columns, without mixing between columns), with the result that can be accurately computed. Furthermore, pivoting ensures that is computable, which is necessary for derivative calculations. See Golub and van Loan (1996) for full discussion of QR-decomposition with pivoting.
The stable computation of , which was discussed in Section 3.3, will also require that a square root of S can be formed that maintains the required ‘column separation’ of the dominant terms in S (i.e. we must not end up with large magnitude elements in some column j>r1, just because λ1‖S1‖ is large). This is quite straightforward under the reparameterization that was just discussed. For example, let (with s ‘machine zeros’ set to true zeros) and be the diagonal matrix such that . Forming the Choleski decomposition , then is a matrix square root such that . Furthermore, λ1S1 affects only the size of the elements in ’s first r1 columns (this is easily seen, since, from the definition of , the squared Euclidean norm of its jth column is given by , which does not depend on λ1S1 if j>r1). The preconditioning (or ‘scaling’) matrix ensures that the Choleski factor can be computed in finite precision, however divergent the sizes of the components of S (see for example Watkins (1991), section 2.9). From now on no further purpose is served by distinguishing between ‘true’ and computed quantities, so circumflexes will be omitted.
Of course S=Σ λiSi generally contains more than two terms and is not full rank, but Appendix B generalizes the similarity-transform-based reparameterization, along with the (generalized) determinant and square-root calculations, to any number of components of a rank deficient S. It also provides the expressions for the derivatives of log (|S|+) with respect to ρ. The operations count for Appendix B is O(q3).
The stable matrix square root E, produced by the Appendix B method, is only useful if the rest of the model fitting adopts the Appendix B reparameterization, i.e. the transformed Si, S and E, computed by Appendix B, must be used in place of the original untransformed versions, along with a transformed version of the model matrix. To compute the latter, let Qs be the orthogonal matrix describing the similarity transform applied by Appendix B, i.e., if S is the transformed total penalty matrix, then formally is the untransformed original. Then the transformed model matrix should be XQs (obtained at O(nq2) cost). In what follows it is assumed that this reparameterization is always adopted, being recomputed for each new ρ-value. So the model matrix and penalty matrices are taken to be the transformed versions, from now on. If the coefficient estimates in this parameterization are , then the estimates in the original parameterization are .
Finally, reparameterization is preferable to simply limiting the working λ-range. To keep the non-zero eigenvalues of all λiSi within limits that guarantee computational stability usually entails unacceptably restrictive limits on the λi, i.e. limits that are sufficiently restrictive to ensure numerical stability have statistically noticeable effects.
3.2. Estimating the regression coefficients given smoothing parameters
Estimation of the coefficients β is performed by the modified IRLS scheme of iterating the following two steps to convergence (μ-estimates are initialized by using the previous , or directly from y).
Step 1: given the current estimate of μ (and hence η), evaluate z and w.
- Step 2: solve the weighted penalized least squares problem of minimizingwith respect to β, to obtain the updated estimate of β and hence μ (and η). See Section 3.3.(7)
At convergence of the Newton-type iteration the Hessian of the deviance with respect to β is given by 2XTWX, where W=diag(wi). Under Fisher scoring 2XTWX is the expected Hessian. See for example Green and Silverman (1994) or Wood (2006) for further information on (Fisher-based) PIRLS.
Several points should be noted.
- (a)
Step halving will be needed in the event that the penalized deviance increases at any iteration, but the Newton method should never require it at the end of the iteration.
- (b)
The Newton scheme tends to converge faster than Fisher scoring in non-canonical link situations, an effect which can be particularly marked when using Tweedie (1984) distributions.
- (c)
With non-canonical links, the wi need not all be positive for the Newton scheme, and in practice negative weights are encountered for perfectly reasonable models: the next section deals with this. Negative wi provide the second reason that the Wood (2008) method cannot be extended to REML.
3.3. Stable least squares with negative weights
This section develops a method for stable computation of weighted least squares problems when some weights are negative, as required by the Newton-based PIRLS that was described in Section 3.2. The method also deals with identifiability problems that do not depend on the magnitude of λ.
When weights are non-negative, a stable solution of equation (8) is based on orthogonal decomposition of √WX (e.g. Wood (2004)), but this does not work if some weights are negative. This section proposes a stable solution method, by starting with a ‘nearby’ penalized least squares problem, for which all the weights are non-negative, applying a stable orthogonal decomposition approach to this, but at the same time developing the correction terms that are necessary to end up with the solution to equation (8) itself.
At the end of model fitting, will need to have the pivoting that was applied at equation (10) reversed, and the elements of that were dropped by the truncation step after equation (9) will have to be reinserted as 0s. Note that the leading order cost of the method that is described here is the O(nq2) of the first QR-decomposition. LAPACK can be used for all decompositions (Anderson et al., 1999).
3.3.1. λ-independent rank deficiency
As mentioned above, it is necessary to deal with any rank deficiency of the weighted penalized least squares problem that is ‘structural’ to the problem, rather than being the numerical consequence of some smoothing parameter tending to 0 or ∞, i.e. we need to find which, if any, parameters β would be unidentifiable, even if the penalties and models matrix were all evenly scaled relative to each other.
3.4. Derivatives of with respect to the logarithmic smoothing parameters
3.5. The rest of the restricted maximum likelihood objective and its derivatives
Given and then the corresponding derivatives of μ and η follow immediately. The derivatives of D with respect to ρ are then routine to calculate (see Wood (2008) for full details). The remaining quantities in the REML (or ML) calculation are |XTWX+S|, and the log-saturated-likelihood. These are covered here.
3.5.1. Derivatives of log|XTWX+S|
3.5.2. Derivatives of
3.5.3. Scale-parameter-related derivatives
For known scale parameter cases, all the derivatives that are required for direct Newton optimization of the REML or ML criteria have now been obtained. However, when φ is unknown some further work is still needed (the dependence on φ has none of the exploitable linearity of the dependence on λi, which is why it must be treated separately).
The ML derivative expressions are identical to those given in this subsection, if we set Mp = 0 (for ML, the fixed effects are not integrated out, and in consequence the direct dependence on the number of fixed effects goes). Whichever version of REML or ML is used, derivatives of the saturated log-likelihood with respect to φ are required: Appendix G gives some common examples.
3.6. Other smoothness selection criteria
Although it was not possible to adapt the Wood (2008) method to optimize REML or ML reliably, the method that is proposed here can readily optimize prediction error criteria of the sort that were discussed in Wood (2008). In fact the new method has the advantage of eliminating a potential difficulty with the Wood (2008) method, namely that, when using a non-canonical link in the presence of outliers, the Fisher-based PIRLS could (rarely) require step length reduction at convergence, which could cause the subsequent derivative iterations to fail.
4. Some simulation comparisons
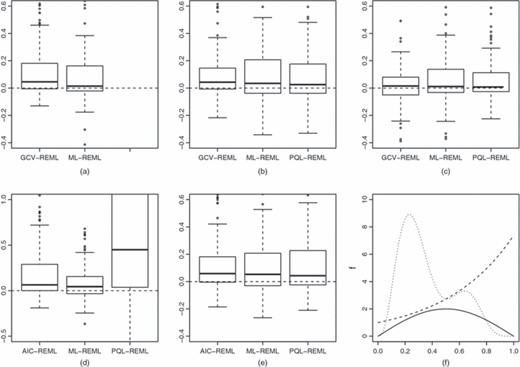
Mean-square error (MSE) comparisons between REML and other methods for five distributions: (a) normal; (b) gamma; (c) Tweedie; (d) binary; (e) Poisson; (f) components
Model performance was judged by calculating the mean-square error (MSE) in reconstructing the true linear predictor, at the observed covariate values. In the case of binary data, this measure is rather unstable for fitted probabilities in the vicinity of 0 or 1, so the probability scale was used in place of the linear predictor scale.
The results are summarized in Fig. 2. Boxplots show the distributions, over 200 replicates, of differences in MSE between each alternative method and REML. Before plotting, the MSEs are divided by the MSE for REML estimation, averaged over the the case being plotted. In all cases a Wilcoxon signed rank test indicates that REML has lower MSE than the competing method (p-value less than 10−3 except for the PQL–ML comparison for the Tweedie distribution where p = 0.04). The Tweedie variance power was 1.5. PQL failed in 16, 10, 22 and seven replicates, for the gamma, Tweedie, binary and Poisson data respectively. The other methods converged successfully for every replicate. The most dramatic difference is between REML and PQL for binary data, where PQL has a substantial tail of poor fits, reflecting the well-known fact that PQL is poor for binary data. Note also the skew in the GCV–REML comparisons: this seems to result from a smallish proportion of GCV- or AIC-based replicates substantially overfitting. The mean time per replicate for GCV or AIC, REML and ML was about 0.7 s on a 1.33-GHz Intel U7700 computer running LINUX (on a mid-range laptop). PQL took between 10 and 20 times longer. All computations were performed with R 2.9.2 (R Development Core Team, 2008) and R package mgcv version 1.6-1 (which includes a Tweedie family based on Dunn and Smith (2005)).
The experiment was repeated at lower noise levels: first for noise levels such that the r2-value between μi and yi was about 0.7 and then for still lower noise levels so that the r2-value was about 0.95. Fig. 3 shows the results for the lowest noise level. In this case ML gives the best MSE performance, although REML is not much worse and still better than the prediction error criteria. The intermediate noise level results are not shown, but indicate ML and REML to be almost indistinguishable, and both better than prediction error criteria. It seems likely that the superiority of ML over REML in the lowest noise case relates to Wahba’s (1985) demonstration that REML undersmooths, asymptotically: ML will of course smooth more but is still consistent (Kauermann et al., 2009). Similarly the failure of prediction error methods to show any appreciable catch-up as noise levels were reduced, despite their asymptotic superiority in MSE terms, presumably relates to the excruciatingly slow convergence rates for prediction-criteria-based estimates, obtained in Härdle et al. (1988).
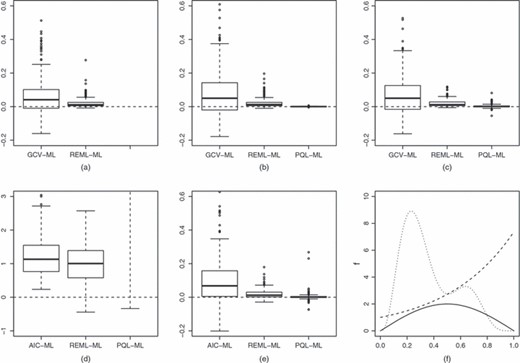
As for Fig. 2, but using data for which only 5% of the variance in the response was noise: in this case ML gave the best MSE performance and so has replaced REML as the reference method (all differences are significant at p<0.000 04 except the PQL–ML comparisons for the gamma, Tweedie and Poisson distributions for which the p-values are 0.01, 0.01 and 0.0006)
The two problematic examples from the introduction to Wood (2008), Figs 1 and 2, were also repeated with the methods that are developed here: convergence was unproblematic and reasonable fits were obtained. See Appendix A for some further comparisons with another alternative method.
The simulation evidence supports the implication of Reiss and Ogden’s (2009) work, that REML (and hence the structurally very similar ML) may have practical advantages over GCV or AIC for smoothing parameter selection, and reinforces the message from Wood (2008), that direct nested optimization is quicker and more reliable than selecting smoothing parameters on the basis of approximate working models.
5. Examples
This section presents three example applications which, as special cases of penalized GLMs, are straightforward given the general method that is proposed in this paper.
5.1. Simple P-spline adaptive smoothing
An important feature of the method proposed is that it is stable even when different penalties act on intersecting sets of parameters. Tensor product smooths that are used for smooth interaction terms are an obvious important case where this occurs (see for example Wood (2006), section 4.1.8), but adaptive smoothing provides a less-well-known example, as illustrated in this section, using adaptive P-splines.
The results are shown in Fig. 4, which also includes a fit in which a single-penalty rank 40 thin plate regression spline is used to represent f(t). The single-penalty case must use the same degree of penalization for all t, with the result that the curve at low and high times appears underpenalized and too bumpy, presumably to accommodate the high degree of variability at intermediate times. The adaptive fit took 1.3 s, compared with 0.15 s for the single-penalty fit (see Section 4, for computer details).
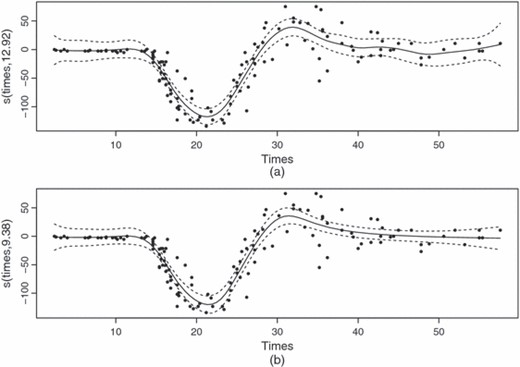
Two attempts to smooth the motorcycle crash data (all smoothing parameters were chosen by REML; note that the adaptive smoother uses fewer effective degrees of freedom and produces a fit which appears to show better adaptation to the data): (a) the smooth as a rank 40 penalized thin plate regression spline; (b) a simple adaptive smoother of the type discussed in Section 5.1
5.2. Generalized regression of scalars on functions
The fact that the method that is described in this paper has been developed for the rather general model (1) means that it can be used for models that superficially appear to be rather different from a GAM. To illustrate this, this section revisits an example from Reiss and Ogden (2009) but makes use of the new method to employ a more general model than theirs, based on non-Gaussian errors with multiple penalties.
As an example, consider trying to predict the octane rating of gasoline (or petrol) from its near infrared spectrum. For internal combustion engines in which a fuel–air mixture is compressed within the cylinders before combustion, it is important that the fuel–air mixture does not spontaneously ignite owing to compressive heating. Such early combustion results in ‘knocking’ and poor engine performance. The octane rating of fuel measures its resistance to knocking. It is a somewhat indirect measure: the lowest compression ratio at which the fuel causes knocking is recorded. The octane rating is the percentage of iso-octane in the mixture of n-heptane and iso-octane with the same lowest knocking compression ratio as the fuel sample. Measuring octane rating requires special variable compression test engines, and it would be rather simpler to measure the octane from spectral measurements on a fuel sample, if this were possible.
Fig. 5(a) shows near infrared spectra for 60 gasoline samples (from Kalivas (1997), as provided by Wehrens and Mevik (2007)). The octane rating of each sample has also been measured. Model (15) is a possibility for such data (where yi is octane rating, zi(x) is the ith spectrum and x is wavelength). The octane rating is positive and continuous (at least in theory), and there is some indication of increasing variance with mean (see Fig. 5(c)), so a gamma distribution with log-link is an appropriate initial model. The spectra themselves are rather spiky, with some smooth regions interspersed with regions of very rapid variation. It seems sensible to allow the coefficient function f(x) the possibility of behaving in a similar way, so representing f by using the same sort of adaptive smooth as was used in the previous section is appropriate. Estimation of this model is then just a case of estimating a GLM subject to multiple penalization. The remaining panels of Fig. 5 show the results of this fitting, with REML smoothness selection.
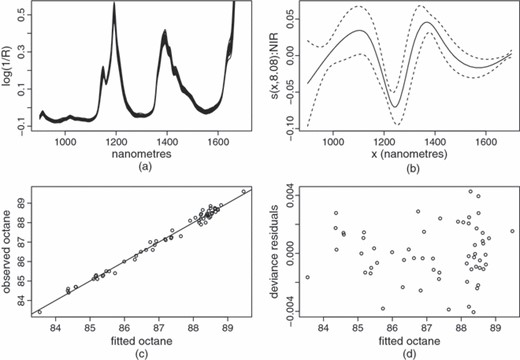
(a) Near infrared spectra for 60 samples of gasoline (the y-axis is the logarithm of the inverse of reflectance, which is measured every 2 nm; these spectra ought to be able to predict the octane rating of the samples; the spectra actually reach 1.2 at the right-hand end but, since this region turns out to have little predictive power, the y-axis has been truncated to show more detail at lower wavelengths); (b) estimated coefficient function for the model given in Section 5.2, with factor h absorbed (the inner product of this with the spectrum for a sample gives the predicted octane rating); (c) observed versus fitted ratings; (d) deviance residuals for the model versus fitted octane rating
Note that the coefficient function appears to be contrasting the two peak regions with the trough between them, with the extreme ends of the spectra apparently adding little. The model explains around 98% of the deviance in octane rating, and the residual plots look plausible (including a QQ-plot of deviance residuals, which is not shown).
5.3. Generalized additive model term selection and null space penalties
Smoothing parameter selection does most of the work in selecting between models of differing complexity, but it does not usually remove a term from the model altogether. If the smoothing parameter for a term tends to ∞, this usually causes the term to tend towards some simple, but non-zero, function of its covariate. For example, as its smoothing parameter tends to ∞, a cubic regression spline term will tend to a straight line. It seems logical to decide on whether or not terms should be included in the model by using the same criterion as used for smoothness selection, but how should this be achieved in practice? Tutz and Binder (2006) proposed one solution to the model selection problem, by using a boosting approach to perform fitting, smoothness selection and term selection simultaneously. They also provided evidence that in very data poor settings, with many spurious covariates, this approach can be much better than the alternatives. This section proposes a possible alternative to boosting, in which each smooth term is given an extra penalty, which will shrink to zero any functions that are in the null space of the usual penalty.
For example, consider a smooth with K coefficients β and penalty matrix , with null space dimension Ms, so that the wiggliness penalty is . Now consider the eigendecomposition . The first K−Ms eigenvalues Λi will be positive, and the last Ms will be 0. Writing Λ+ for the (K−Ms)×(K−Ms) diagonal matrix containing only the positive eigenvalues, and U+ for the K×(K−Ms) matrix of corresponding eigenvectors, then . Now let U− be the K×Ms matrix of the eigenvectors corresponding to zero eigenvalues. U+ forms a basis for the space of coefficients corresponding to the ‘wiggly’ component of the smooth, whereas U− is a basis for the components of zero wiggliness—the null space of the penalty. The two bases are orthogonal. So, if we want to produce a penalty which penalizes only the null space of the penalty, we could use where . If a smooth term is already subject to multiple penalties (e.g. a tensor product smooth or an adaptive smooth), the same basic construction holds, but the null space is obtained from the eigendecomposition of the sum of the original penalty matrices. Note that this construction is general and completely automatic.
This sort of construction could be used with any smoothing parameter selection method, not just REML or ML, but it is less appealing if used with a method which is prone to undersmoothing, as GCV seems to be.
As a small example, Poisson data were simulated assuming a log-link and a linear predictor made up of the sum of the three functions shown in Fig. 2(f) applied to three sets of 200 IID U(0,1) covariates. Six more IID U(0,1) nuisance covariates were simulated. A GAM was fitted to the simulated data, assuming a Poisson distribution and log-link, and with a linear predictor consisting of a sum of nine smooth functions of the nine covariates. Each smooth function was represented by using a rank 10 cubic regression spline (actually P-splines for GAM boosting). The model was fitted by using four different methods: the GAM boosting method of Tutz and Binder (2006), using version 1.1 of R package GAMBoost (with penalty set to 500 to ensure that each fit used well over the 50 boosting steps that were suggested as the minimum by Tutz and Binder (2006)); GCV smoothness selection, with the null space penalties that were suggested here, REML with no null space penalties and REML with null space penalties. 200 replicates of this experiment were run, and the MSE in the linear predictor at the covariate values was recorded for each method for each replicate.
Fig. 6 shows the results. REML with null space penalties achieves lower MSE than REML without null space penalties, and substantially better performance than GCV with null space penalties or GAM boosting. The success of the methods in identifying which components should be in the model at all was also recorded. For GAM boosting the methods given in the GAMBoost package were employed, whereas, for the null space penalties, terms with effective degrees of freedom greater than 0.2 were deemed to have been selected. On this basis the false negative selection rates (rates at which influential covariates were not selected) were 0.6% for boosting and 0.16% for the other methods. The false positive selection rates (rates at which spurious terms were selected) were 67%, 71% and 62% for boosting, GCV and REML respectively. REML with null space penalties took just under 6 s per fit, on average, whereas boosting took about 2.5 min per fit. Note that the example here has relatively high information content, relative to the scenarios that were investigated by Binder and Tutz (2006): with less information boosting is still appealing.
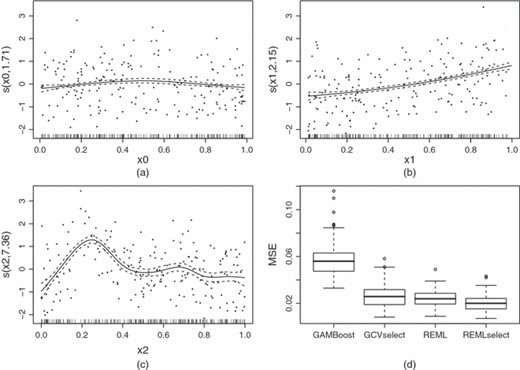
Model selection example (models were fitted to Poisson data simulated from a linear predictor made up of the three terms shown in Fig. 2(f); the linear predictors of the fitted models also included smooth functions of six additional nuisance predictors; four alternative fitting methods were used for each replicate simulation): (a)–(c) typical estimates of the terms that actually made up the true linear predictor, using REML, with selection penalties (partial Pearson residuals are shown for each smooth estimate); (d) distribution, over 200 replicates, of the MSE of the models fitted by each of the methods (‘GAMBoost’ is fitted by using Tutz and Binder’s (2006) boosting method, ‘GCVselect’ is for models with selection penalties under GCV smoothness selection, ‘REML’ is REML smoothness selection without selection penalties and ‘REMLselect’ is for REML smoothness selection with selection penalties)
6. Discussion
The method that was proposed in this paper offers a general computationally efficient way of estimating the smoothing parameters of models of the form (1), when the fj are represented by using penalized regression splines and the coefficients β are estimated by optimizing expression (3). With this method, REML- or ML-based estimation of semiparametric GLMs can rival the estimation of ordinary parametric GLMs for routine computational reliability. Previously such efficiency and reliability were only available for prediction error criteria, such as GCV. This means that the advantages of REML or ML estimation that were outlined in Section 1.1 need no longer be balanced against the more reliable fitting methods that are available for GCV or AIC. The cost of this enhancement is that the method proposed has a somewhat more complex mathematical structure than the previous prediction-error-based methods (e.g. Wood (2008)), but since the method is freely available in R package mgcv (from version 1.5) this is not an obstacle to its use.
Given that REML or ML estimation requires that we view model (1) as a generalized linear mixed model, then an obvious question is why should it be treated as a special case for estimation purposes, rather than estimated by general generalized linear mixed model software? The answer lies in the special nature of the λi. The fact that they enter the penalty or precision matrix linearly, facilitates both the evaluation of derivatives to computational accuracy and the ability to stabilize the computations via the method of Appendix B. In addition the λi are unusual precision parameters in that their ‘true’ value is often infinite. This behaviour can cause problems for general purpose methods, which cannot exploit the advantages of the linear structure. Conversely, the method that is proposed here can be used to fit any generalized linear mixed model where the precision matrix is a linear combination of known matrices but, since it is not designed to exploit the sparse structure that many random effects have, it may not be the most efficient method for so doing.
A limitation of the method that was presented here is that it is designed to be efficient when the fj are represented by using penalized regression splines as described in Wahba (1980), Parker and Rice (1985), Eilers and Marx (1996), Marx and Eilers (1998), Ruppert et al. (2003), Wood (2003) etc. These ‘intermediate rank’ smoothers have become very popular over the last decade, as researchers realized that many of the advantages of splines could be obtained without the computational expense of full splines: an opinion which turns out to be well founded theoretically (see Gu and Kim (2002), Hall and Opsomer (2005) and Kauermann et al. (2009)). But, despite its wide applicability, the penalized regression spline approach has limitations. The most obvious is that relatively low rank smooths are unsuitable for modelling short-range auto-correlation (particularly spatial). Where this deficiency matters, Rue et al. (2009) offer an attractive alternative approach, by directly estimating additive smooth components of the linear predictor, with very sparse Sj-matrices directly penalizing these components. The required sparsity can be obtained by modelling the smooth components as Markov random fields of some sort. Provided that the number of smoothing parameters is quite low, then the methods offer very efficient computation for this class of problem, as well as better inferences about the smoothing parameters themselves. When the model includes large numbers of random effects, but not all components have the sparsity that is required by Rue et al. (2009), or when the number of smoothing parameters or variance parameters is moderate to large, then the simulation-based Bayesian approach of Fahrmeir, Lang and co-workers (e.g. Lang and Brezger (2004), Brezger and Lang (2006) and Fahrmeir and Lang (2001)) is likely to be more efficient than the method that is proposed here, albeit applicable to a more restricted range of penalized GLMs, because of restrictions on the Sj that are required to maintain computational efficiency.
An interesting area for further work would be to establish relative convergence rates for the under REML, ML and GCV smoothness selection. It is not difficult to arrange for to be consistent under either approach, at least when spline-like bases are used for the fj in model (1). Without penalization, all that we require is that the basis dimension grows with sample size n sufficiently fast that the spline approximation error declines at a faster rate than the sampling variance of , but sufficiently slow that dim(β)/n→0 (so that the observed likelihood converges to its expectation). This is not difficult to achieve, given the good approximation theoretic properties of splines. If smoothing parameters are chosen to be sufficiently small, then penalization will reduce the MSE at any n, so consistency can be maintained under penalized estimation. In fact, asymptotically, GCV minimizes the MSE (or a generalized equivalent), so the will be consistent under GCV estimation. Since REML smooths less than GCV, asymptotically (Wahba, 1985), then the same must hold for REML. However, establishing the relative convergence rates that are actually achieved under the two alternatives appears to be more involved.
Acknowledgements
I am especially grateful to Mark Bravington for explanation of the implicit function theorem, and for providing the original fisheries modelling examples that broke Fisher-scoring-based approaches, and to Phil Reiss for first alerting me to the real practical advantages of REML and providing an early preprint of Reiss and Ogden (2009). The Commonwealth Scientific and Industrial Research Organisation paid for a visit to Hobart where the Tweedie work was done, and it became clear that the Wood (2008) method could not be extended to REML. Thanks also go to Mark Bravington, Merrilee Hurn and Alistair Spence for some helpful discussions during the painful process that led to the Section 3.1– Appendix B method. Phil Reiss, Mark Bravington, Nicole Augustin and Giampiero Marra all provided very helpful comments on an earlier draft of this paper. The Joint Editor, Associate Editor and two referees all made suggestions which substantially improved the paper, for which I am also grateful.
References
Appendix A: Convergence failures of previous restricted maximum likelihood schemes
Wood (2008) provides some examples of convergence failure for the PQL approach, in which smoothing parameters are estimated iteratively by REML or ML estimation of working linear mixed models. The alternative scheme that is proposed in the literature has been implemented by Brezger et al. (2007) in the BayesX package. Like PQL, this scheme need not converge (as Brezger et al. (2007) explicitly pointed out), but Brezger et al. (2007) employed an ingenious heuristic stabilization trick which seems to lead to superior performance to that of PQL in this regard. However, it is not difficult to find realistic examples that still give convergence problems. For example the following code was used in R version 2.7.1 to generate data with a relatively benign collinearity problem and a mild mean–variance relationship problem:
Appendix B: |∑iλiSi|+
As discussed in Section 3.1, a stable method for calculating log (|Σi λiSi|+) and its derivatives with respect to ρi = log (λi) is required, when the λi may be wildly different in magnitude. This appendix provides such a method by extending the simple approach that was described in Section 3.1.
Initialization: set K = 0, Q = q and . Set γ = {1…M}, where M is the number of Si-matrices.
Similarity transformation: the following steps are iterated until the termination criterion is met (at step 4).
Step 1: set .
Step 2: create α = {i:Ωi⩾ɛ max(Ωi),i ∈ γ} and γ′={i:Ωi<ɛ max(Ωi),i ∈ γ} where ɛ is, for example, the cube root of the machine precision. So α indexes the dominant terms out of those remaining.
Step 3: find the eigenvalues of and use these to determine the formal rank r of any summation of the form where the λi are positive. The rank is determined by counting the number of eigenvalues that are larger than ɛ times the dominant eigenvalue. ɛ is typically the machine precision raised to a power in [0.7,0.9].
Step 4: if r = Q then terminate. The current S is the S to use for determinant calculation.
Step 5: find the eigendecomposition , where the eigenvalues are arranged in descending order on the leading diagonal of D. Let Ur be the first r columns of U and Un the remaining columns.
- Step 6: write S in partitioned formwhere the subscripts denote dimensions (rows × columns). Then set B′ = BU andwhere . Thenand |S|=|S′|. The key point here is that the effect of the terms that are indexed by α has been concentrated into an r×r block, with rows and columns to the lower right of that block uncontaminated by ‘large machine 0s’ from the terms indexed by α.
- Step 7: defineand transformandThese transformations facilitate derivative calculations using the transformed S.
Step 8: transform .
Step 9: set K←K+r, Q←Q−r, S←S′ and γ←γ′. Return to step 1.
Note that the orthogonal matrix which similarity transforms the original S to the final transformed version can be accumulated as the algorithm progresses, to produce the Qs of Section 3.1.
The effect of the preceding iteration is to concentrate the dominant terms in S into the smallest possible block of leftmost columns, with these terms having no effect beyond those columns. Next the most dominant terms in the remainder are concentrated in the smallest possible number of immediately succeeding columns, again with no effect to the right of these columns. This pattern is repeated. Since QR-decomposition operates on columns of S, without mixing columns, it can now be used to evaluate stably the determinant of the transformed S. Alternative methods of determinant calculation (e.g. Choleski or symmetric eigendecomposition) would require an additional preconditioning step.
Appendix C: Derivatives of by using implicit differentiation
When full Newton optimization is used in place of Fisher scoring to obtain , then there is no computational advantage in iterating for the derivatives of with respect to ρ (as in Wood (2008)), rather than exploiting the implicit function theorem to obtain them directly by implicit differentiation. This is because Newton-based PIRLS requires exactly the same quantities as implicit differentiation. This appendix provides the details.
C.1. Partial derivatives of Dp
C.2. Derivatives of with respect to ρ
Appendix D: Derivatives of w
Appendix E: Marginal likelihood determinant term and derivatives
Appendix F: Pearson statistic
Appendix G: Derivatives of the saturated log-likelihood
When the scale parameter is fixed and known, as in the binomial and Poisson cases, then ls is irrelevant and its derivative with respect to φ is 0. Otherwise ls and derivatives are needed. Here are three common examples.
- (a)Gaussian:
- (b)Inverse Gaussian:
- (c)Gamma:Writing log Γ to mean the log-gamma function (to be differentiated as a whole):The lgamma, digamma and trigamma functions in R evaluate log Γ, log Γ′ and log Γ′′ respec-tively.
Appendix H: Derivatives of tr(F)
There is a strong argument for employing Fisher-scoring-based weights in place of Newton-based weights in the definition of F. This requires redefining W, Tk and Tjk and setting I+ to I, but otherwise the computations are identical. This change removes the possibility of XTWX having negative eigenvalues, which can occasionally lead to nonsensical computed effective degrees of freedom.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}