
Abstract
This paper describes a strategy for a general search used by the ATLAS Collaboration to find potential indications of new physics. Events are classified according to their final state into many event classes. For each event class an automated search algorithm tests whether the data are compatible with the Monte Carlo simulated expectation in several distributions sensitive to the effects of new physics. The significance of a deviation is quantified using pseudo-experiments. A data selection with a significant deviation defines a signal region for a dedicated follow-up analysis with an improved background expectation. The analysis of the data-derived signal regions on a new dataset allows a statistical interpretation without the large look-elsewhere effect. The sensitivity of the approach is discussed using Standard Model processes and benchmark signals of new physics. As an example, results are shown for 3.2 fb\(^{-1}\) of proton–proton collision data at a centre-of-mass energy of 13 \(\text {TeV}\) collected with the ATLAS detector at the LHC in 2015, in which more than 700 event classes and more than \(10^5\) regions have been analysed. No significant deviations are found and consequently no data-derived signal regions for a follow-up analysis have been defined.
Similar content being viewed by others

1 Introduction
Direct searches for unknown particles and interactions are one of the primary objectives of the physics programme at the Large Hadron Collider (LHC). The ATLAS experiment at the LHC has thoroughly analysed the Run 1 \(pp\) collision dataset (recorded in 2010–2012) and roughly a quarter of the expected Run 2 dataset (2015–2018). No evidence of physics beyond the Standard Model (SM) has been found in any of the searches performed so far.
Searches that have been performed to date do not fully cover the enormous parameter space of masses, cross-sections and decay channels of possible new particles. Signals might be hidden in kinematic regimes and final states that have remained unexplored. This motivates a model-independentFootnote 1 analysis to search for physics beyond the Standard Model (BSM) in a structured, global and automated way, where many of the final states not yet covered can be probed.
General searches without an explicit BSM signal assumption have been been performed by the DØ Collaboration [1,2,3,4] at the Tevatron, by the H1 Collaboration [5, 6] at HERA, and by the CDF Collaboration [7, 8] at the Tevatron. At the LHC, preliminary versions of such searches have been performed by the ATLAS Collaboration at \(\sqrt{s} =7\), 8 and 13 \(\text {TeV}\), and by the CMS Collaboration at \(\sqrt{s} =7\) and 8 \(\text {TeV}\).
This paper outlines a strategy employed by the ATLAS Collaboration to search in a systematic and (quasi-)model-independent way for deviations of the data from the SM prediction. This approach assumes only generic features of the potential BSM signals. Signal events are expected to have reconstructed objects with relatively large momentum transverse to the beam axis. The main objective of this strategy is not to finally assess the exact level of significance of a deviation with all available data, but rather to identify with a first dataset those phase-space regions where significant deviations of the data from SM prediction are present for a further dedicated analysis. The observation of one or more significant deviations in some phase-space region(s) serves as a trigger to perform dedicated and model-dependent analyses where these ‘data-derived’ phase-space region(s) can be used as signal regions. Such an analysis can then determine the level of significance using a second dataset. The main advantage of this procedure is that it allows a large number of phase-space regions to be tested with the available resources, thereby minimizing the possibility of missing a signal for new physics, while simultaneously maintaining a low false discovery rate by testing the data-derived signal region(s) on an independent dataset in a dedicated analysis. The dedicated analysis with data-derived signal regions also allows an improved background prediction.
In this approach, events are first classified into different (exclusive) categories, labelled with the multiplicity of final-state objects (e.g. muons, electrons, jets, missing transverse momentum, etc.) in an event. These final-state categories are then automatically analysed for deviations of the data from the SM prediction in several BSM-sensitive distributions using an algorithm that locates the region of largest excess or deficit. Sensitivity tests for specific signal models are performed to demonstrate the effectiveness of this approach. The methodology has been applied to a subset of the \(\sqrt{s} =13\) \(\text {TeV}\) proton–proton collision data as reported in this paper. The data were collected with the ATLAS detector in 2015, and correspond to an integrated luminosity of 3.2 \(\text{ fb }^{-1}\).
The paper is organized as follows: the general analysis strategy is outlined in Sect. 2, while Sect. 3 provides specific details about its application to the ATLAS 2015 \(pp\) collision dataset. Conclusions are given in Sect. 4.
2 Strategy
The analysis strategy assumes that a signal of unknown origin can be revealed as a statistically significant deviation of the event counts in the data from the expectation in a specific data selection. A data selection can be any set of requirements on objects or variables needed to define a signal region (e.g. an event class or a specific range in one or multiple observables). In order to search for these signals a large variety of data selections need to be tested. This requires a high degree of automation and a categorization of the data events according to their main features. The main objective of this analysis is to identify selections for which the data deviates significantly from the SM expectation. These selections can then be applied as data-derived signal regions in a dedicated analysis to determine the level of significance using a new dataset. This has the advantage of a more reliable background expectation, which should allow an increase in signal sensitivity compared to a strategy that only relies on Monte Carlo expectations with a typically conservative evaluation of uncertainties. The strategy is divided into the seven steps described below.
2.1 Step 1: Data selection and Monte Carlo simulation
The recorded data are reconstructed via the ATLAS software chain. Events are selected by applying event-quality and trigger criteria, and are classified according to the type and multiplicity of reconstructed objects with high transverse momentum (\(p_{\text {T}}\)). Objects that can be considered in the classification are those typically used to characterize hadron collisions such as electrons, muons, \(\tau \)-leptons, photons, jets, \(b\text {-tagged}\) jets and missing transverse momentum. More complex objects, which were not implemented in the example described in Sect. 3, could also be considered. Examples are resonances reconstructed by a specific decay (e.g. \(Z\) or Higgs bosons decaying into two or four isolated leptons respectively, or decaying hadronically and giving rise to large radius jets with substructure) and displaced vertices. Event classes (or channels) are then defined as the set of events with a given number of reconstructed objects for each type, e.g. two muons and a jet.
Monte Carlo (MC) simulations are used to estimate the expected event counts from SM processes. To allow the investigation of signal regions with a low number of expected events it is important that the equivalent integrated luminosity of the MC samples significantly exceeds that of the data, and that all relevant background processes are included, in particular rare processes which might dominate certain multi-object event classes.
2.2 Step 2: Systematic uncertainties and validation
The particular nature of this analysis, in which a large number of final states are explored, makes the definition of control and validation regions difficult. In searches for BSM physics at the LHC, control regions are used to constrain MC-based background predictions with auxiliary measurements. Validation regions are used to test the validity of the background model prediction with data.
The simplest way to construct a background model is to obtain the background expectation from the MC prediction including the corresponding theoretical and experimental uncertainties. This approach, which is applied in the example in Sect. 3, has the advantage that it prevents the absorption of BSM signal contributions into a rescaling of the SM processes. Another possible approach is to automatically define, for each data selection and algorithmic hypothesis test, statistically independent control selections. The data in the control selections can be used to rescale the MC background predictions and to constrain the systematic uncertainties. This comes at the price of reduced sensitivity for the case in which a BSM model predicts a simultaneous effect in the signal region and control region, which would be absorbed in the rescaling.
To verify the proper modelling of the SM background processes, several validation distributions are defined using inclusive selections for which observable signals for new physics are excluded. If these validation distributions show problems in the MC modelling, either corrections to the MC backgrounds are applied or the affected event class is excluded.
Uncertainties in the background estimate arise from experimental effects, and the theoretical accuracy of the prediction of the (differential) cross-section and acceptance of the MC simulation. Their effect is evaluated for all contributing background processes as well as for benchmark signals.
2.3 Step 3: Sensitive variables and search algorithm
Distributions of observables in the form of histograms are investigated for all event classes considered in the analysis. Observables are included if they have a high sensitivity to a wide range of BSM signals. The total number of observables considered is, however, restricted to a few to avoid a large increase in the number of hypothesis tests, as the latter also increases the rate of deviations from background fluctuations. In high-energy physics this effect is commonly known as the ‘trial factor’ or ‘look-elsewhere effect’. Examples of such observables are the effective mass \(m_{\mathrm {eff}}\) (defined as the sum of the scalar transverse momenta of all objects plus the scalar missing transverse momentum), the total invariant mass \(m_{\mathrm {inv}}\) (defined as the invariant mass of all visible objects), the invariant mass of any combination of objects (such as the dielectron invariant mass in events with two electrons and two muons), event shape variables such as thrust [9, 10] or even more complicated variables such as the output of a machine-learning algorithm.
A statistical algorithm is used to scan these distributions for each event class and quantify the deviations of the data from the SM expectation. The algorithm identifies the data selection that has the largest deviation in the distribution of the investigated observable by testing many data selections to minimize a test statistic. An example of a possible test-statistic which has also been used in the analysis described in Sect. 3, is the local \(p_0\)-value, which gives the expected probability of observing a fluctuation that is at least as far from the SM expectation as the observed number of data events in a given region, if the experiment were to be repeated:
where n is the independent variable of the Poisson probability mass function (pmf), \(N_{\text {obs}}\) is the observed number of data events for a given selection, \(P(n \le N_{\text {obs}})\) is the probability of observing no more than the number of events observed in the data and \(P(n \ge N_{\text {obs}})\) is the probability of observing at least the number of events observed in the data. The quantity \(N_{\text {SM}}\) is the expectation for the number of events with its total uncertainty \(\delta N_{\text {SM}} \) for a given selection. The convolution of the Poisson pmf (with mean x) with a Gaussian probability density function (pdf), \(G (x;N_{\text {SM}},\delta N_{\text {SM}})\) with mean \(N_{\text {SM}}\) and width \(\delta N_{\text {SM}} \), takes the effect of both non-negligible systematic uncertainties and statistical uncertainties into account.Footnote 2 If the Gaussian pdf \(G\) is replaced by a Dirac delta function \(\delta (x-N_{\text {SM}})\) the estimator \(p_0\) results in the usual Poisson probability. The selection with the largest deviation identified by the algorithm is defined as the selection giving the smallest \(p_0\)-value. The smallest \(p_0\) for a given channel is defined as \(p_{\text {channel}}\), which therefore corresponds to the local \(p_0\)-value of the largest deviation in that channel.
Data selections are not considered in the scan if large uncertainties in the expectation arise due to a lack of MC events, or from large systematic uncertainties. To avoid overlooking potential excesses in these selections the \(p_0\)-values of selections with more than three data events are monitored separately. Single outstanding events with atypical object multiplicities (e.g. events with 12 muons) are visible as an event class. Single outstanding events in the scanned distributions are monitored separately.
The result of scanning the distributions for all event classes is a list of data selections, one per event class containing the largest deviation in that class, and their local statistical significance. Details of the procedure and the statistical algorithm used for the 2015 dataset are explained in Sect. 3.3.
2.4 Step 4: Generation of pseudo-experiments
The probability that for a given observable one or more deviations of a certain size occur somewhere in the event classes considered is modelled by pseudo-experiments. Each pseudo-experiment consists of exactly the same event classes as those considered when applying the search algorithm to data. However, the data counts are replaced by pseudo-data counts which are generated from the SM expectation using an MC technique. Pseudo-data distributions are produced taking into account both statistical and systematic uncertainties by drawing pseudo-random data counts for each bin from the convolved pmf used in Eqs. (1)–(3) to compute a \(p_0\)-value.
Correlations in the uncertainties of the SM expectation affect the chance of observing one or more deviations of a given size. The effect of correlations between bins of the same distribution or between distributions of different event classes are therefore taken into account when generating pseudo-data for pseudo-experiments. Correlations between distributions of different observables are not taken into account, since the results obtained for different observables are not combined in the interpretation.
The search algorithm is then applied to each of the distributions, resulting in a \(p_{\text {channel}}\)-value for each event class. The \(p_{\text {channel}}\) distributions of many pseudo-experiments and their statistical properties can be compared with the \(p_{\text {channel}}\) distribution obtained from data to interpret the test statistics in a frequentist manner. The fraction of pseudo-experiments having one of the \(p_{\text {channel}}\)-values smaller than a given value \(p_{\text {min}}\) indicates the probability of observing such a deviation by chance, taking into account the number of selections and event classes tested.

The fractions of pseudo-experiments (\(P_{\text {exp},i} (p_{\text {min}})\)) in the \(m_{\mathrm {inv}}\) scan, which have at least one, two or three \(p_{\text {channel}}\)-values smaller than a given threshold (\(p_{\text {min}}\)). Pseudo-datasets are generated from the SM expectation. Dotted lines are drawn at \(P_{\text {exp},i} =5\%\) and at the corresponding \(-\log _{10}(p_{\text {min}})\)-values
To illustrate this, Fig. 1 shows three cumulative distributions of \(p_{\text {channel}}\)-values from pseudo-experiments. The number of event classes (686) and the \(m_{\mathrm {inv}}\) distributions used to generate these pseudo-experiments coincide with the example application in Sect. 3. The distribution in Fig. 1 with circular markers is the fraction of pseudo-experiments with at least one \(p_{\text {channel}}\)-value smaller than \(p_{\text {min}}\). For example, about 15% of the pseudo-experiments have at least one \(p_{\text {channel}}\)-value smaller than \(p_{\text {min}}=10^{-4}\). Therefore, the estimated probability (\(P_{\text {exp},i}\)) of obtaining at least one \(p_{\text {channel}}\)-value (\(i=1\)) smaller than \(10^{-4}\) from data in the absence of a signal is about 15%, or \(P_{\text {exp},1}(10^{-4}) = 0.15\). To estimate the probability of observing deviations of a given size in at least two or three different event classes, the second or third smallest \(p_{\text {channel}}\)-value of a pseudo-experiment is compared with a given \(p_{\text {min}}\) threshold. From Fig. 1 it follows for instance that 2% of the pseudo-experiments have at least three \(p_{\text {channel}}\)-values smaller than \(10^{-4}\). Consequently, the probability of obtaining a third smallest \(p_{\text {channel}}\)-value smaller than \(10^{-4}\) from data in the absence of a signal is about 2%, or \(P_{\text {exp},3}(10^{-4}) = 0.02\)
In Fig. 1 a horizontal dotted line is drawn at a fraction of pseudo-experiments of 5% and corresponding vertical dotted lines are drawn at the three \(p_{\text {min}}\) thresholds. The observation of one, two or three \(p_{\text {channel}}\)-values in data below the corresponding \(p_{\text {min}}\) threshold, i.e. an observation with a \(P_{\text {exp},i} < 0.05\), promotes the selections that yielded these deviations to signal regions that can be tested in a new dataset.
2.5 Step 5: Evaluation of the sensitivity
The sensitivity of the procedure to a priori unspecified BSM signals can be evaluated with two different methods that either use a modified background estimation through the removal of SM processes or in which signal contributions are added to the pseudo-data sample.
In the first method, a rare SM process (with either a low cross-section or a low reconstruction efficiency) is removed from the background model. The search algorithm is applied again to test the data or ‘signal’ pseudo-experiments generated from the unmodified SM expectation, against the modified background expectation. The data samples would be expected to reveal excesses relative to the modified background prediction.
In the second method, pseudo-experiments are used to test the sensitivity of the analysis to benchmark signal models of new physics. The prediction of a model is added to the SM prediction, and this modified expectation is used to generate ‘signal’ pseudo-experiments. The search algorithm is applied to the pseudo-experiments and the distribution of \(p_{\text {channel}}\)-values is derived.
To provide a figure of merit for the sensitivity of the analysis, the fraction of ‘signal’ pseudo-experiments with \(P_{\text {exp},i} < 5\%\) for \(i=1,2,3\) is computed.
2.6 Step 6: Results
Finding one or more deviations in the data with \(P_{\text {exp},i} <5\%\) triggers a dedicated analysis that uses the data selection in which the deviation is observed as a signal region (step 7). If no significant deviations are found, the outcome of the analysis technique includes information such as: the number of events and expectation per event class, a comparison of the data with the SM expectation in the distributions of observables considered, the scan results (i.e. the location and the local \(p_0\)-value of the largest deviation per event class) and the comparison with the expectation from pseudo-experiments.
2.7 Step 7 (only in the case of \(P_{\text {exp},i} <5\%\)): Dedicated analysis of deviation
Dedicated analysis on original dataset Deviations are investigated using methods similar to those of a conventional analysis. In particular, the background prediction is determined using control selections to control and validate the background modelling. Such a procedure further constrains the background expectation and uncertainty, and reduces the dependence on simulation. If such a re-analysis of the region results in an insignificant deviation, it can be inferred that the deviation seen before was due to mismodellings or not well-enough understood backgrounds.
Dedicated analysis on an independent dataset If a deviation persists in a dedicated analysis using the original dataset, the data selection in which the deviation is observed defines a data-derived signal region that is tested in an independent new dataset with a similar or larger integrated luminosity. At this point, a particular model of new physics can be used to interpret the result of testing the data-derived signal region. Since the signal region is known, the corresponding data can be excluded (‘blinded’) from the analysis until the very end to minimize any possible bias in the analysis. Additionally, since only a few optimized hypothesis tests are performed on the independent dataset, the large look-elsewhere effect due to the large number of hypothesis tests performed in step 3 is not present in the dedicated analysis of the signal region(s). The assumptions of Gaussian uncertainties for the background models can also be tested in the dedicated analysis. If the full LHC data yields a significant deviation, the LHC running time may need to be increased, or the excess may have to be followed up at a future collider.
2.8 Advantages and disadvantages
The features of this strategy lead to several advantages and disadvantages that are outlined below.
Advantages:
-
It can find unexpected signals for new physics due to the large number of event classes and phase-space regions probed, which may otherwise remain uninvestigated.
-
A relatively small excess in two or three independent data selections, each of which is not big enough to trigger a dedicated analysis by itself (\(P_{\text {exp},1} > 5\%\)), can trigger one in combination (\(P_{\text {exp},2,3} < 5\%\)).
-
The approach is broad, and the scanned distributions can be used to probe the overall description of the data by the event generators for many SM processes.
-
The probability of a deviation occurring in any of the many different event classes under study can be determined with pseudo-experiments, resulting in a truly global interpretation of the probability of finding a deviation within an experiment such as ATLAS.
Disadvantages:
-
The outcome depends on the MC-based description of physics processes and simulations of the detector response. Event classes in which the majority of the events contain misreconstructed objects are typically poorly modelled by MC simulation and might need to be excluded from the analysis. Although step 2 validates the description of the data by the MC simulation, there is still a possibility of triggering false positives due to an MC mismodelling in a corner of phase space. Step 7 aims to minimize this by reducing the dependence on MC simulations in a dedicated analysis performed for each significant deviation. In future implementations a better background model could be constructed with the help of control regions or data-derived fitting functions. This might allow the detection of excesses that are small compared to the uncertainties in the MC-based description of the SM processes.
-
Since this analysis is not optimized for a specific class of BSM signals, a dedicated analysis optimized for a given BSM signal achieves a larger sensitivity to that signal. The enormous parameter space of possible signals makes an optimized search for each of them impossible.
-
The large number of data selections introduce a large look-elsewhere effect, which reduces the significance of a real signal. Step 7 circumvents this problem since the final discovery significance is determined with a dedicated analysis of one or a few data selection(s) and a statistically independent dataset. This can yield an improved signal sensitivity if the background uncertainty can be constrained in the dedicated analysis.
-
Despite being broad, the procedure might miss a certain signal because it does not show a localized excess in one of the studied distributions. This might be overcome with better observables, better event classification or modified algorithms, which may then be sensitive to such signals.
3 Application of the strategy to ATLAS data
This section describes the application of the strategy outlined in the previous section to the 13 \(\text {TeV}\) pp collision data recorded by the ATLAS experiment in 2015.
3.1 Step 1: Data selection and Monte Carlo simulation
3.1.1 ATLAS detector and dataset
The ATLAS detector [11] is a multipurpose particle physics detector with a forward-backward symmetric cylindrical geometry and a coverage of nearly \(4\pi \) in solid angle.Footnote 3 The inner tracking detector (ID) consists of silicon pixel and microstrip detectors covering the pseudorapidity region \(|\eta | < 2.5\), surrounded by a straw-tube transition radiation tracker which enhances electron identification in the region \(|\eta | < 2.0\). Between Run 1 and Run 2, a new inner pixel layer, the insertable B-layer [12], was inserted at a mean sensor radius of 3.3 cm. The inner detector is surrounded by a thin superconducting solenoid providing an axial 2 T magnetic field and by a fine-granularity lead/liquid-argon (LAr) electromagnetic calorimeter covering \(|\eta |<3.2\). A steel/scintillator-tile calorimeter provides hadronic coverage in the central pseudorapidity range (\(|\eta | < 1.7\)). The endcap and forward calorimeter coverage (\(1.5< |\eta | < 4.9\)) is completed by LAr active layers with either copper or tungsten as the absorber material. An extensive muon spectrometer with an air-core toroid magnet system surrounds the calorimeters. Three layers of high-precision tracking chambers provide coverage in the range \(|\eta | < 2.7\), while dedicated fast chambers provide a muon trigger in the region \(|\eta | < 2.4\). The ATLAS trigger system consists of a hardware-based level-1 trigger followed by a software-based high-level trigger [13].
The data used in this analysis were collected by the ATLAS detector during 2015 in \(pp\) collisions at the LHC with a centre-of-mass energy of 13 \(\text {TeV}\) and a 25 ns bunch crossing interval. After applying quality criteria for the beam, data and detector, the available dataset corresponds to an integrated luminosity of 3.2 \(\text{ fb }^{-1}\). In this dataset, each event includes an average of approximately 14 additional inelastic \(pp\) collisions in the same bunch crossing (pile-up).
Candidate events are required to have a reconstructed vertex [14], with at least two associated tracks with \(p_{\text {T}} > 400\) \(\text {MeV}\). The vertex with the highest sum of squared transverse momenta of the tracks is considered to be the primary vertex.
3.1.2 Monte Carlo samples
Monte Carlo simulated event samples [15] are used to describe SM background processes and to model possible signals. The ATLAS detector is simulated either by a software system based on Geant4 [16] or by a faster simulation based on a parameterization of the calorimeter response and Geant4 for the other detector systems. The impact of detector conditions on the simulation is typically corrected for as part of the calibrations and scale factors applied to the reconstructed objects.
To account for additional \(pp\) interactions from the same or nearby bunch crossings, a set of minimum-bias interactions generated using Pythia 8.186 [17], the MSTW2008LO [18] parton distribution function (PDF) set and the A2 set of tuned parameters (tune) [19] was superimposed onto the hard-scattering events to reproduce the observed distribution of the average number of interactions per bunch crossing.
Any further study of time-dependent detector variations would be part of the dedicated search following any interesting deviation.
In all MC samples, except those produced by Sherpa [20], the EvtGen v1.2.0 program [21] was used to model the properties of the bottom and charm hadron decays. The SM MC programs are listed in Table 1 and a detailed explanation can be found in Appendix A.1.
In addition to the SM background processes, two possible signals are considered as benchmarks. The first benchmark model considered is the production of a new heavy neutral gauge boson of spin 1 (\(Z'\)), as predicted by many extensions of the SM. Here, the specific case of the sequential extension of the SM gauge group (SSM) [22, 23] is considered, for which the couplings are the same as for the SM Z boson. This process was generated at leading order (LO) using Pythia 8.212 with the NNPDF23LO [24] PDF set and the A14 tune [25], as a Drell–Yan process, for five different resonant masses, covering the range from 2 \(\text {TeV}\) to 4 \(\text {TeV}\), in steps of 0.5 \(\text {TeV}\). The considered decays of \(Z'\) bosons are inclusive, covering the full range of lepton and quark pairs. Interference effects with SM Drell–Yan production are not included, and the \(Z'\) boson is required to decay into fermions only.
The second signal considered is the supersymmetric [26,27,28,29,30,31] production of gluino pairs through strong interactions. The gluinos are assumed to decay promptly into a pair of top quarks and an almost massless neutralino via an off-shell top squark \(\tilde{g}\rightarrow tt\tilde{\chi }^0_1\). Samples for this process were generated at LO with up to two additional partons using MG5_aMC@NLO 2.2.2 [32] with the CTEQ6L1 [33] PDF set, interfaced to Pythia 8.186 with the A14 tune. The matching with the parton shower was done using the CKKW-L [34] prescription, with a matching scale set to one quarter of the pair-produced resonance mass. The signal cross-sections were calculated at next-to-leading order (NLO) in the strong coupling constant, adding the resummation of soft gluon emission at next-to-leading-logarithm (NLL) accuracy [35,36,37].
3.1.3 Object reconstruction
Reconstructed physics objects considered in the analysis are: prompt and isolated electrons (e), muons (\(\mu \)) and photons (\(\gamma \)), as well as b-jets (b) and light (non-b-tagged) jets (j) reconstructed with the anti-\(k_t\) algorithm [38] with radius parameter \(R = 0.4\), and large missing transverse momentum (\(E_{\text {T}}^{\text {miss}} \)). Table 2 lists the reconstructed physics objects along with their \(p_{\text {T}}\) and pseudorapidity requirements. Jets and electrons misidentified as hadronically decaying \(\tau \)-leptons are difficult to model with the MC-based approach used in this analysis. Therefore, the identification of hadronically decaying \(\tau \)-leptons is not considered; they are mostly reconstructed as light jets. Details of the object reconstruction can be found in Appendix B.
After object identification, overlaps between object candidates are resolved using the distance variable \(\Delta R_y = \sqrt{(\Delta y)^2 + (\Delta \phi )^2}\). If an electron and a muon share the same ID track, the electron is removed. Any jet within a distance \(\Delta R_y=0.2\) of an electron candidate is discarded, unless the jet has a value of the b-tagging MV2c20 discriminant [39, 40] larger than that corresponding to approximately 85% b-tagging efficiency, in which case the electron is discarded since it probably originated from a semileptonic b-hadron decay. Any remaining electron within \(\Delta R_y = 0.4\) of a jet is discarded. Muons within \(\Delta R_y =0.4\) of a jet are also removed. However, if the jet has fewer than three associated tracks, the muon is kept and the jet is discarded instead to avoid inefficiencies for high-energy muons undergoing significant energy loss in the calorimeter. If a photon candidate is found within \(\Delta R_y=0.4\) of a jet, the jet is discarded. Photons within a cone of size \(\Delta R_y=0.4\) around an electron or muon candidate are discarded.
The missing transverse momentum (with magnitude \(E_{\text {T}}^{\text {miss}}\)) is defined as the negative vector sum of the transverse momenta of all selected and calibrated physics objects (electrons, photons, muons and jets) in the event, with an additional soft-term [41]. The soft-term is constructed from all tracks that are not associated with any physics object, but are associated with the primary vertex. The missing transverse momentum is reconstructed for all events; however, separate analysis channels are constructed for events with \(E_{\text {T}}^{\text {miss}} > 200\) \(\text {GeV}\). These events are taken exclusively from the \(E_{\text {T}}^{\text {miss}}\) trigger.
3.1.4 Event selection and classification
The events are divided into mutually exclusive classes that are labelled with the number and type of reconstructed objects listed in Table 2. The division can be regarded as a classification according to the most important features of the event. The classification includes all possible final-state configurations and object multiplicities, e.g. if a data event with seven reconstructed muons and no other objects is found, it is classified in a ‘7-muon’ event class (\(7\mu \)). Similarly an event with missing transverse momentum, two muons, one photon and four jets is classified and considered in the corresponding event class denoted \(E_{\text {T}}^{\text {miss}} 2\mu 1\gamma 4j\).

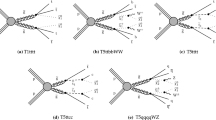
Flow diagram for the trigger and offline event selection strategy. The offline requirements are shown on the left of the dashed line and the trigger requirements are shown on the right of the dashed line
All events contributing to a particular event class are also required to be selected by a trigger from a corresponding class of triggers by imposing a hierarchy in the event selection. This avoids ambiguities in the application of trigger efficiency corrections to MC simulations and avoids variations in the acceptance within an event class. The flow diagram in Fig. 2 gives a graphical representation of the trigger and offline event selection, based on the class of the event. Since the thresholds for the single-photon and single-jet triggers are higher than the \(p_{\text {T}}\) requirements in the photon and jet object selection, an additional reconstruction-level \(p_{\text {T}}\) cut is imposed to avoid trigger inefficiencies. For the other triggers, the \(p_{\text {T}}\) requirements in the object definitions exceed the trigger thresholds by a sufficient margin to avoid additional trigger inefficiencies. Electrons are considered before muons in the event selection hierarchy because the electron trigger efficiency is considerably higher compared to the muon trigger efficiency.
Events with \(E_{\text {T}}^{\text {miss}} > 200\) \(\text {GeV}\) are required to pass the \(E_{\text {T}}^{\text {miss}}\) trigger which becomes fully efficient at 200 \(\text {GeV}\), otherwise they are rejected and not considered for further event selection. If the event has \(E_{\text {T}}^{\text {miss}} < 200\) \(\text {GeV}\) but contains an electron with \(p_{\text {T}} > 25\) \(\text {GeV}\) it is required to pass the single-electron trigger. However, events with more than one electron with \(p_{\text {T}} > 25\) \(\text {GeV}\) or with an additional muon with \(p_{\text {T}} > 25\) \(\text {GeV}\) can be selected by the dielectron trigger or electron-muon trigger respectively if the event fails to pass the single-electron trigger. Events with a muon with \(p_{\text {T}} > 25\) \(\text {GeV}\) but no reconstructed electrons or large \(E_{\text {T}}^{\text {miss}}\) are required to pass the single-muon trigger. If the event has more than one muon with \(p_{\text {T}} > 25\) \(\text {GeV}\) and fails to pass the single-muon trigger, it can additionally be selected by the dimuon trigger. Remaining events with a photon with \(p_{\text {T}} > 140\) \(\text {GeV}\) or two photons with \(p_{\text {T}} > 50\) \(\text {GeV}\) are required to pass the single-photon or diphoton trigger, respectively. Finally, any remaining event with no large \(E_{\text {T}}^{\text {miss}}\) , leptons, or photons, but containing a jet with \(p_{\text {T}} > 500\) \(\text {GeV}\) is required to pass the single-jet trigger.
In addition to the thresholds imposed by the trigger, a further selection is applied to event classes with \(E_{\text {T}}^{\text {miss}} <200\) \(\text {GeV}\) containing one lepton or one electron and one muon and possibly additional photons or jets (\(1\mu +X\), \(1e+X\) and \(1\mu 1e+X\)), to reduce the overall data volume. In these event classes, one lepton is required to have \(p_{\text {T}} > 100\) \(\text {GeV}\) if the event has less than three jets with \(p_{\text {T}} > 60\) \(\text {GeV}\).
To suppress sources of fake \(E_{\text {T}}^{\text {miss}} \), additional requirements are imposed on events to be classified in \(E_{\text {T}}^{\text {miss}} \) categories. The ratio of \(E_{\text {T}}^{\text {miss}}\) to \(m_{\mathrm {eff}}\) is required to be greater than 0.2, and the minimum azimuthal separation between the \(E_{\text {T}}^{\text {miss}}\) direction and the three leading reconstructed jets (if present) has to be greater than 0.4, otherwise the event is rejected.
3.2 Step 2: Systematic uncertainties and validation
3.2.1 Systematic uncertainties
Experimental uncertainties The dominant experimental systematic uncertainties in the SM expectation for the different event classes typically are the jet energy scale (JES) and resolution (JER) [42] and the scale and resolution of the \(E_{\text {T}}^{\text {miss}}\) soft-term. The uncertainty related to the modelling of \(E_{\text {T}}^{\text {miss}}\) in the simulation is estimated by propagating the uncertainties in the energy and momentum scale of each of the objects entering the calculation, with an additional uncertainty in the resolution and scale of the soft-term [41]. The uncertainties in correcting the efficiency of identifying jets containing b-hadrons in MC simulations are determined in data samples enriched in top quark decays, and in simulated events [39]. Leptonic decays of \(J/\psi \) mesons and Z bosons in data and simulation are exploited to estimate the uncertainties in lepton reconstruction, identification, momentum/energy scale and resolution, and isolation criteria [43,44,45]. Photon reconstruction and identification efficiencies are evaluated from samples of \(Z\rightarrow ee\) and \(Z+\gamma \) events [45, 46]. The luminosity measurement was calibrated during dedicated beam-separation scans, using the same methodology as that described in Ref. [47]. The uncertainty of this measurement is found to be 2.1%.
In total, 35 sources of experimental uncertainties are identified pertaining to one or more physics objects considered. For each source the one-standard-deviation \((1\sigma )\) confidence interval (CI) is propagated to a \(1\sigma \) CI around the nominal SM expectation. The total experimental uncertainty of the SM expectation is obtained from the sum in quadrature of these 35 \(1\sigma \) CIs and the uncertainty of the luminosity measurement.
Theoretical modelling uncertainties Two different sources of uncertainty in the theoretical modelling of the SM production processes are considered. A first uncertainty is assigned to account for our knowledge of the cross-sections for the inclusive processes. A second uncertainty is used to cover the modelling of the shape of the differential cross-sections. In order to derive the modelling uncertainties, either variations of the QCD factorization, renormalization, resummation and merging scales are used or comparisons of the nominal MC samples with alternative ones are used. For some SM processes additional modelling uncertainties are included. Appendix A.2 describes all theoretical uncertainties considered for the various SM processes. The total uncertainty is taken as the sum in quadrature of the two components and the statistical uncertainty of the MC prediction.
3.2.2 Validation procedures
The evaluated SM processes, together with their standard selection cuts and the studied validation distributions, are detailed in Table 3. These validation distributions rely on inclusive selections to probe the general agreement between data and simulation and are evaluated in restricted ranges where large new-physics contributions have been excluded by previous direct searches.
There are some cases in which the validation procedure finds modelling problems and MC background corrections are needed (multijets, \(\gamma (\gamma )\) + jets). In other cases, the affected event classes are excluded from the analysis as their SM expectation dominantly arises from object misidentification (e.g. jets reconstructed as electrons) which is poorly modelled in MC simulation. The excluded classes are: 1e1j, 1e2j, 1e3j, 1e4j, 1e1b, 1e1b1j, 1e1b2j, 1e1b3j. Event classes containing a single object, as well as those containing only \(E_{\text {T}}^{\text {miss}} \) and a lepton are also discarded from the analysis due to difficulties in modelling final states with one high energy object recoiling against many soft (non-reconstructed) ones.
3.2.3 Corrections to the MC background
The MC samples for multijet and \(\gamma +\text {jets}\) production, while giving a good description of kinematic variables, predict an overall cross-section and a jet multiplicity distribution that disagrees with data. Following step 2, correction procedures were applied.
In classes containing only j and b the multijet MC samples are scaled to data with normalization factors ranging between approximately 0.8 and 1.2. The normalization factors are derived separately in each exclusive jet multiplicity class by equating the expected total number of events to the observed number of events. Multijet production in other channels are not rescaled and found to be described by the MC samples within the theoretical uncertainties. If a channel contains less than four data events, no modifications are made.
For \(\gamma +\text {jets}\) event classes the same rescaling procedure is applied to classes with exactly one photon, no leptons or \(E_{\text {T}}^{\text {miss}}\), and any number of jets.
The Sherpa 2.1.1 MC generator has a known deficiency in the modelling of \(E_{\text {T}}^{\text {miss}}\) due to too large forward jet activity. This results in a visible mismodelling of the \(E_{\text {T}}^{\text {miss}}\) distribution in event classes with two photons, which also affects the \(m_{\mathrm {eff}}\) distribution. To correct for this mismodelling a reweighting [48] is applied to the background events containing two real photons (\(\gamma \gamma +\text {jets}\)). The diphoton MC events are reweighted as a function of \(E_{\text {T}}^{\text {miss}}\) and of the number of selected jets to match the respective distributions in the data for the inclusive diphoton sample in the range \(E_{\text {T}}^{\text {miss}} < 100\) \(\text {GeV}\). In no other event classes was the mismodelling large enough to warrant such a procedure.
The application of scale factors also outside the region where data to Monte Carlo comparisons are made would be cross-checked in the dedicated reanalysis of any deviation.
3.2.4 Comparison of the event yields with the MC prediction
After classification, 704 event classes are found with at least one data event or an SM expectation greater than 0.1 events. The data and the background predictions from MC simulation for these classes are shown in Fig. 3 and Appendix C. Agreement is observed between data and the prediction in most of the event classes. In events classes having more than two b-jets and where the SM expectation is dominated by \(t\bar{t}\) production, the nominal SM expectation is systematically slightly below the data. Data events are found in 528 out of 704 event classes. These include events with up to four leptons (muons and/or electrons), three photons, twelve jets and eight b-jets. There are 18 event classes with an SM expectation of less than 0.1 events; no more than two data events are observed in any of these, and they are not considered further in the analysis. No outstanding event was found in those channels. The remaining 686 classes are retained for statistical analysis.

The number of events in data, and for the different SM background predictions considered, for classes with large \(E_{\text {T}}^{\text {miss}}\) , one lepton and (b-)jets (no photons). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction. This figure shows 60 out of 704 event classes, the remaining event classes can be found in Figs. 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23 of Appendix C
3.3 Step 3: Sensitive variables and search algorithm
In order to quantitatively determine the level of agreement between the data and the SM expectation, and to identify regions of possible deviations, this analysis uses an algorithm for multiple hypothesis testing. The algorithm locates a single region of largest deviation for specific observables in each event class.
In the following, an algorithm derived from the algorithm used in Ref. [5] is applied to the 2015 dataset.
3.3.1 Choice of variables
For each event class, the \(m_{\mathrm {eff}}\) and \(m_{\mathrm {inv}}\) distributions are considered in the form of histograms. The invariant mass is computed from all visible objects in the event, with no attempt to use the \(E_{\text {T}}^{\text {miss}}\) information. These variables have been widely used in searches for new physics, and are sensitive to a large range of possible signals, manifesting either as bumps, deficits or wide excesses. Several other commonly used kinematic variables have also been studied for various models, but were not found to significantly increase the sensitivity. The approach is however not limited to these variables, as discussed in Sect. 2.
For each histogram, the bin widths h(x) as a function of the abscissa x are determined using:
where \(N_{\text {objects}}\) is the number of objects in the event class, k is the width of the bin in standard deviations, and \(\sigma _i(x/2)\) is the expected detector resolution in the central region for the \(p_{\text {T}}\) of object i evaluated at \(p_{\text {T}} =x/2\) to roughly approximate the largest \(p_{\text {T}}\)-scale in the event. An exception to this is the missing transverse momentum resolution (\(\sigma E_{\text {T}}^{\text {miss}} \)), which is a function of \(\sum E_{\text {T}} \), where \(\sum E_{\text {T}} \) is approximated by the effective mass minus the \(E_{\text {T}}^{\text {miss}}\) object requirement: \(\sigma E_{\text {T}}^{\text {miss}} \left( \sum E_{\text {T}} = x-200~\text {GeV}\right) \). The \(E_{\text {T}}^{\text {miss}}\) object is only considered in the binning of the effective mass histograms. A \(\pm 1 \sigma \) interval is used for the bin width (\(k=2\)) for all objects except for photons and electrons, for which a \(\pm 3 \sigma \) interval is used (\(k=6\)) to avoid having too finely binned histograms with few MC events. This results in variable bin widths with values ranging from 20 \(\text {GeV}\) to about 2000 \(\text {GeV}\). For a given event class, the scan starts at a value of the scanned observable larger than two times the sum of the minimum \(p_{\text {T}}\) requirement of each contributing object considered (e.g. 100 \(\text {GeV}\) for a \(2\mu \) class). This minimises spurious deviations which might arise from insufficiently well modelled threshold regions.
3.3.2 Algorithm to search for deviations of the data from the expectation
The algorithm identifies the single region with the largest upward or downward deviation in a distribution, provided in the form of a histogram, as the region of interest (ROI). The total number of independent bins is 36,936, leading to 518,320 combinations of contiguous bins (regionsFootnote 4) with an SM expectation larger than 0.01 events. For each region with an SM expectation larger than 0.01, the statistical estimator \(p_0\) is calculated as defined in Eqs. (1)–(3). Here, \(p_0\) is to be interpreted as a local \(p_0\)-value. The region of largest deviation found by the algorithm is the region with the smallest \(p_0\)-value. Such a method is able to find narrow resonances and single outstanding bins, as well as signals spread over large regions of phase space in distributions of any shape.

Example distributions showing the region of interest (ROI), i.e. the region with the smallest \(p_0\)-value, between the vertical dashed lines. a \(E_{\text {T}}^{\text {miss}} {} 1\gamma 3j\) channel, which has the largest deviation in the \(m_{\mathrm {inv}}\) scan. b \(1\mu 1e 4b 2j\) channel, which has the largest deviation in the \(m_{\mathrm {eff}}\) scan. c An upward fluctuation in the \(m_{\mathrm {inv}}\) distribution of the \(1e 1\gamma 2b 2j\) channel. d A downward fluctuation in the \(m_{\mathrm {eff}}\) distribution of the 6j channel. e A downward fluctuation in the \(m_{\mathrm {inv}}\) distribution of the \(E_{\text {T}}^{\text {miss}} {} 2\mu 1j\) channel. f An upward fluctuation in the \(m_{\mathrm {eff}}\) distribution of the \(E_{\text {T}}^{\text {miss}} 3j\) channel. The hatched band includes all systematic and statistical uncertainties from MC simulations. In the ratio plots the inner solid uncertainty band shows the statistical uncertainty from MC simulations, the middle solid band includes the experimental systematic uncertainty, and the hatched band includes the theoretical systematic uncertainty
To illustrate the operation of the algorithm, six example distributions are presented. Figure 4a shows the invariant mass distribution of the event class with one photon, three light jets and large missing transverse momentum (\(E_{\text {T}}^{\text {miss}} {} 1\gamma 3j\)), which has the smallest \(p_{\text {channel}}\) -value in the \(m_{\mathrm {inv}}\) scan. Figure 4b shows the effective mass distribution of the event class with one muon, one electron, four b-jets and two light jets (\(1\mu 1e 4b 2j\)), which has the smallest \(p_{\text {channel}}\) -value in the \(m_{\mathrm {eff}}\) scan. Figure 4c shows the invariant mass distribution of the event class with one electron, one photon, two b-jets and two light jets (\(1e 1\gamma 2b 2j\)). Figure 4d shows the effective mass distribution of the event class with six light jets (6j). Figure 4e shows the invariant mass distribution of the event class with two muons, a light jet and large missing transverse momentum (\(E_{\text {T}}^{\text {miss}} {} 2\mu 1j\)) and Fig. 4f shows the effective mass distribution of the event class with three light jets and large missing transverse momentum (\(E_{\text {T}}^{\text {miss}} 3j\)). The regions with the largest deviation found by the search algorithm in these distributions, an excess in Fig. 4a–c, f, and a deficit in Fig. 4d, e, are indicated by vertical dashed lines.
To minimize the impact of few MC events, 213,992 regions where the background prediction has a total relative uncertainty of over 100% are discarded by the algorithm. Discarding a region forces the algorithm to consider a different or larger region in the event class, or if no region in the event class satisfies the condition, to discard the entire event class.Footnote 5 For all discarded regions with \(N_{\text {obs}} >3\) a \(p_0\)-value is calculated. If the \(p_0\)-value is smaller than the \(p_{\text {channel}}\)-value (or if there is no ROI and hence no \(p_{\text {channel}}\)-value), it is evaluated manually by comparing it with the distribution of \(p_{\text {channel}}\)-values from the scan. This is done for 27 event classes among which the smallest \(p_0\)-value observed in a discarded region is 0.01. To model the analysis of discarded regions in pseudo-experiments, regions are allowed to have larger uncertainties if they fulfil the \(N_{\text {obs}} >3\) criterion.
In addition to monitoring regions discarded due to a total uncertainty in excess of 100%, regions discarded due to \(N_{\text {SM}} <0.01\) but with \(N_{\text {obs}} >3\) would also be monitored individually; however, no such region has been observed.
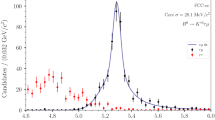
Tables 4 and 5 list the three event classes with the largest deviations in the \(m_{\mathrm {inv}}\) and \(m_{\mathrm {eff}}\) scans respectively. The largest deviation reported by a dedicated search using the same dataset was observed in an inclusive diphoton data selection at a diphoton mass of around 750 \(\text {GeV}\) with a local significance of \(3.9\sigma \) [49]. Due to the different event selections and background estimates the excess has a lower significance in this analysis. The excess was not confirmed in a dedicated analysis with 2016 data [50].
3.4 Step 4: Generation of pseudo-experiments
As described in Sect. 2.4, pseudo-experiments are generated to derive the probability of finding a \(p_0\)-value of a given size, for a given observable and algorithm. The \(p_{\text {channel}}\)-value distributions of the pseudo-experiments and their statistical properties can be compared with the \(p_{\text {channel}}\)-value distribution obtained from data. Correlations in the uncertainties of the SM expectation affect this probability and their effect is taken into account in the generation of pseudo-data as outlined in the following.
For the experimental uncertainties, each of the 35 sources of uncertainty is varied independently by drawing a value at random from a Gaussian pdf. This value is assumed to be 100% correlated across all bins and event classes. The uncertainty in the normalization of the various backgrounds is also considered as 100% correlated. Likewise, theoretical shape uncertainties, including those estimated from scale variations or the differences with alternative generators, are assumed to be 100% correlated, with the exception of the uncertainties which are used for some SM processes with small cross-sections. The latter uncertainties are assumed to be uncorrelated, both between event classes and between bins of the same event class. Scale variations are applied in the generation of pseudo-experiments by varying the renormalization, factorization, resummation and merging scales independently. The values for each scale of a given pseudo-experiment are 100% correlated between all bins and event classes. The scales are correlated between processes of the same type which are generated with a similar generator set-up, i.e. scales are correlated among the \(W/Z/\gamma +\text {jets}\) processes, among all the diboson processes, among the \(t\bar{t}+W/Z\) processes, and among the single-top processes.
Changing the size of the theoretical uncertainties by a factor of two leads to a change of less than 5% in the \(-\log _{10} (p_{\text {min}})\) thresholds at which a dedicated analysis is triggered. The correlation assumptions in the theoretical uncertainties were also tested. Figure 5 shows the effect of changing the correlation assumption for all theoretical shape uncertainties that are nominally taken as 100% correlated. This test decorrelates the bin-by-bin variations due to the theoretical shape uncertainties in the pseudo-data while retaining the correlation when summing over selected bins in the scan, thus testing the impact of an incorrect assumption in the correlation model. By comparing the nominal assumption of 100% correlation with a 50% correlated component, and a fully uncorrelated assumption, the threshold at which a dedicated analysis is triggered is changed by a negligible amount.

A comparison of different correlation assumptions for scale variations: 100% correlated; 50% correlated and 50% uncorrelated; and 100% uncorrelated. The fractions of pseudo-experiments in the scan of the \(m_{\mathrm {inv}}\) distribution having at least one \(p_{\text {channel}}\)-value smaller than \(p_{\text {min}}\) are shown on the left (a), while the fractions in the scan of the \(m_{\mathrm {eff}}\) distribution having at least three \(p_{\text {channel}}\)-values smaller than \(p_{\text {min}}\) are shown on the right (b)
3.5 Step 5: Evaluation of the sensitivity of the strategy
3.5.1 Sensitivity to standard model processes
The sensitivity of the procedure is evaluated with two different methods that either use a modified background estimation through the removal of SM processes or in which signal contributions are added to the pseudo-data sample. As a figure of merit, the fraction of ‘signal’ pseudo-experiments with \(P_{\text {exp},i} < 5\%\) for \(i=1,2,3\) is computed.

The fraction of pseudo-experiments which have at least one, two and three \(p_{\text {channel}}\)-values below a given \(p_{\min }\), given for both the pseudo-experiments generated from the nominal SM expectation and tested against the nominal expectation (dashed) and for those tested against the modified expectation (‘SM, WZ removed’) in which the WZ diboson process is removed (solid). The \(m_{\mathrm {inv}}\) scan is shown in a and the \(m_{\mathrm {eff}}\) scan in b. The horizontal dotted lines show the fractions of pseudo-experiments yielding \(P_{\text {exp},i} < 5\%\) when tested against the modified background prediction. The scan results of the data tested against the modified background prediction are indicated with solid arrows. For reference the scan results under the SM hypothesis are plotted as dashed arrows. The largest deviation after removing the WZ process from the background expectation is found in the \(m_{\mathrm {eff}}\) distribution of the \(3\mu \) event class. The distributions of the data and the expectation with both WZ included and WZ removed are shown in c and d respectively
Figure 6 shows how removing the WZ process from the background prediction affects the three smallest expected \(p_{\text {channel}}\)-values. In Fig. 6a, b, the dashed curves show the nominal expected \(p_{\text {channel}}\) distribution obtained from pseudo-experiments. These define the \(p_{\text {min}}\) thresholds for which \(P_{\text {exp},i} < 5\%\) and vertical dotted lines are drawn at the threshold values. The solid lines show the \(p_{\text {channel}}\) distributions obtained by testing pseudo-experiments generated from the SM prediction against the modified background prediction which has the WZ diboson process removed. It can be observed that in this case the \(m_{\mathrm {eff}}\) scan is more sensitive; the fraction of ‘signal’ pseudo-experiments with \(P_{\text {exp},i} < 5\%\) is about 80% in all three cases \(i=1,2,3\).
Additionally, in Fig. 6a, b, the three smallest \(p_{\text {channel}}\)-values observed in the data are shown by arrows, both when tested against the full SM prediction (dashed) and when tested against the modified prediction (solid). For all three cases (\(i=1,2,3\)), \(P_{\text {exp},i}<5\%\) is found again. This means that a dedicated analysis would be performed for the three event classes in which the \(p_{\text {channel}}\)-values are observed, i.e. \(3\mu \), \(1\mu 2e1j\), and \(2\mu 1e1j\), likely resulting in the discovery of an unexpected signal due to WZ production. Figures 6c, d shows the \(m_{\mathrm {eff}}\) distributions of the data with the full SM prediction and the modified prediction respectively. This test uses the conclusion from Sect. 3.6 and is performed in retrospect. In the case of a significant deviation, this test would be performed with pseudo-data to assess the sensitivity of the search to a missing background.

The fraction of pseudo-experiments which have at least one, two and three \(p_{\text {channel}}\)-values below a given \(p_{\text {min}}\), given for both the pseudo-experiments generated from the nominal SM expectation and tested against the nominal expectation (dashed) and for those tested against the modified expectation (‘SM, \(t\bar{t}\gamma \) removed’) in which the \(t\bar{t}\gamma \) process is removed (solid). The \(m_{\mathrm {inv}}\) scan is shown in a and the \(m_{\mathrm {eff}}\) scan in b. The horizontal dotted lines show the fractions of pseudo-experiments yielding \(P_{\text {exp},i} < 5\%\) when tested against the modified background prediction. The scan results of the data tested against the modified background prediction are indicated with solid arrows. For reference the scan results under the SM hypothesis are plotted as dashed arrows. The largest deviation after removing the \(t\bar{t}\gamma \) process from the background expectation is found in the \(m_{\mathrm {eff}}\) distribution of the \(1e1\gamma 1b2j\) event class. The distributions of the data and the expectation with both \(t\bar{t}\gamma \) included and \(t\bar{t}\gamma \) removed are shown in c and d respectively
Figure 7 shows the effect of removing the \(t \bar{t} + \gamma \) process. Again the \(m_{\mathrm {eff}}\) scan is slightly more sensitive, and about 70% of ‘signal’ pseudo-experiments have \(P_{\text {exp},i} < 5\%\) in all three cases \(i=1,2,3\). In the data, \(P_{\text {exp},i} < 5\%\) is found again for all three cases (\(i=1,2,3\)). A dedicated analysis would be performed for the three classes \(1\mu 1\gamma 2b1j\), \(1e1\gamma 2b2j\), and \(1\mu 1\gamma 1b3j\), likely resulting in the discovery of an unexpected signal due to \(t \bar{t} + \gamma \) production.
It is interesting to note that these discoveries would have been made without a priori knowledge of the existence of these processes.
3.5.2 Sensitivity to new-physics signals

The fraction of pseudo-experiments in which a deviation is found with a \(p_{\text {channel}}\)-value smaller than a given \(p_{\text {min}}\). Distributions are shown for pseudo-experiments generated from the SM expectation (circular markers), and after injecting signals of a inclusive \(Z'\) decays or b gluino pairs with \(\tilde{g} \rightarrow t\bar{t}\tilde{\chi }_1^0\) decays and various masses. The line corresponding to the injection of a \(Z'\) boson with a mass of 4 \(\text {TeV}\) and a gluino with a mass of 1600 \(\text {GeV}\) overlap with the line obtained from the SM-only pseudo-experiments due to the small signal cross-section
Figure 8 shows the sensitivity for the two benchmark signals considered as a function of the mass of the produced particle. For the \(Z'\) model, where the mass of the resonance can be reconstructed from its decay products, the sensitivity to the signal is found to be the largest in the scan of the \(m_{\mathrm {inv}}\) distribution. Gluinos undergo a cascade decay process to the lightest neutralino, which is undetected and leads to missing transverse momentum. It is not possible to fully reconstruct an event from gluino pair production due to the presence of neutralinos in the final state. The sensitivity to the gluino signal is therefore found to be the largest in the \(m_{\mathrm {eff}}\) scan, where a broad excess at large values of this quantity is expected.
Exclusion and discovery sensitivity have to be carefully distinguished when the results of this search are compared with model-based searches. An exclusion sensitivity at the 95% CL in a dedicated search roughly corresponds to a single class having a \(p_0\)-value for a discovery test smaller than 0.05. Consequently, the sensitivity to a benchmark signal corresponding to a given particle mass should be compared with the discovery sensitivity of other searches for a \(Z'\) boson or gluino.
As previously described, a deviation for which \(P_{\text {exp},i} <5\%\) promotes the selection to a signal region for a dedicated analysis. By applying this sensitivity criterion, it can be seen in Fig. 8 that this search is sensitive to a \(Z'\) boson with a mass of about 2.5 \(\text {TeV}\) as more than 90% of the signal-injected pseudo-experiments show a deviation for which \(P_{\text {exp},1}<5\%\). Similar sensitivity is expected for a gluino with a mass of about 1 \(\text {TeV}\). The probability of discovering a new-physics signal in a new dataset with a dedicated search in the selected event classes is estimated in the next section.
3.5.3 Sensitivity of a second independent dataset
In step 7 a dedicated analysis of a deviation is performed on an independent dataset. The sensitivity of step 7 is evaluated with pseudo-experiments.
A first pseudo-experiment emulates the original dataset on which this analysis is performed. The scan algorithm is applied after which eight different cases can be distinguished where \(P_{\text {exp},i}\) is either larger or smaller than 5% for \(i=1,2,3\). In seven cases at least one \(P_{\text {exp},i}<5\%\) and a new independent pseudo-experiment is generated to emulate a new independent dataset with the same integrated luminosity. The one, two or three data selections for which \(P_{\text {exp},i} <5\%\) are applied to the second pseudo-experiment to obtain the \(p_0\)-values for these selections. Although the systematic uncertainties may be reduced by applying data-driven estimates of the background, they were assumed to have the same size in the second pseudo-experiment to make a conservative estimate. The systematic uncertainties are also expected to be partially correlated between two datasets but here they were assumed to be uncorrelated.
In four of the seven cases \(P_{\text {exp},1}<5\%\) and these cases are grouped together into a ‘one signal region’ class. This class shows the sensitivity when there would be only a single data-derived signal region. The case where only \(P_{\text {exp},3}<5\%\) is called the ‘three signal region’ class. The two remaining cases where \(P_{\text {exp},2}<5\%\) define the ‘two signal region’ class. These classes show cases when a data-derived signal region is found only by a combination of two and three regions.

The fraction of cases in which the first pseudo-experiment has \(P_{\text {exp},i} <5\%\) and triggers a second pseudo-experiment which yields a value for \(-\sum _{k=1}^{n}\log _{10}({p_0}_k)\) smaller than a given value (\(-\sum _{k=1}^{n}\log _{10}(p_{\text {min},k})\)). Here n denotes the minimum number of event classes (1, 2 or 3) for which \(P_{\text {exp},i}<0.05\). The distribution is shown for pseudo-experiments generated from the SM expectation, and from an SM-plus-signal expectation of a inclusive decays of a \(Z'\) boson with mass \(m_{Z'} = 2.5\) \(\text {TeV}\) or b gluino pairs with mass \(m_{\tilde{g}} = 1.0\) \(\text {TeV}\) and \(g\rightarrow t\bar{t}\tilde{\chi }_1^0\) decays. The signal region tested in the follow-up pseudo-experiment is defined by the preceding pseudo-experiment. The \(5\sigma \) thresholds are obtained by extrapolating the SM-only fractions to \(5.7 \cdot 10^{-7}\) and are indicated at the top of the figure for \(n=1\) (left), \(n=2\) (middle) or \(n=3\) (right) event classes
For each of the three classes (\(n=1,2,3\)) the statistical estimator \(\prod _{k=1}^{n} {p_0}_k\) is computed. Figure 9 shows, as a function of the estimator in the logarithmic form \(-\sum _{k=1}^{n}\log _{10}({p_0}_k)\) the fraction of cases in which the first pseudo-experiment has \(P_{\text {exp},i} <5\%\) and triggers a second pseudo-experiment which yields a value for \(-\sum _{k=1}^{n}\log _{10}({p_0}_k)\) above a threshold given by the value on the horizontal axis. This is done for pseudo-experiments generated from the SM expectation (SM-only) and for pseudo-experiments generated from the SM expectation plus \(Z'\) or gluino signal contributions. The \(5\sigma \) lines are derived from the fractions given by the SM-only lines, as these correspond to the probability of false positives which defines the level of significance. It should be noted that the SM-only lines with circular markers start at a fraction of 0.05 by construction of the \(P_{\text {exp},i} <5\%\) definition. The \(n=2\) and \(n=3\) lines show the gain in sensitivity when a deviation in one or two channels, respectively, is not large enough to define a data-derived signal region. It does not show the gain in sensitivity from considering multiple channels when a single channel defines a signal region. Signals which produce one or more large deviations therefore lower the number of cases in the \(n=2\) and 3 categories, while signals producing deviations close to the \(P_{\text {exp},i} <5\%\) threshold (e.g. for higher \(Z'\) masses) would raise the number of cases in the \(n=2\) and 3 categories. A \(Z'\) boson with a mass of 2.5 \(\text {TeV}\) would yield a discovery in almost all cases.
In the case of a 1.0 \(\text {TeV}\) gluino the sensitivity is about \(5\sigma \). The sensitivity increases to about 1.1 \(\text {TeV}\) if the integrated luminosity of the two datasets combined is increased to about 10 \(\text{ fb }^{-1}\) by doubling the size of the second dataset to 6.4 \(\text{ fb }^{-1}\). ATLAS has determined the discovery sensitivity of the dedicated searches for gluinos decaying to quarks, a \(W\) boson and a neutralino. This dedicated search estimates a local significance (i.e. not corrected for trial factors of the dedicated searches) of \(5\sigma \) with a luminosity of 10 \(\text{ fb }^{-1}\) for gluinos with a mass of 1.35 \(\text {TeV}\) assuming a systematic uncertainty of 25% [51].
It should be noted that, with this strategy, these signals are found without any a priori assumptions about the model, including the mass and the decay chain of the gluinos or the \(Z'\) boson. It can therefore be concluded that this procedure could also be sensitive to possible unexpected signals for new physics.
3.6 Step 6: Results
In step 6 the \(p_{\text {channel}}\)-values found in the analysis of the 2015 ATLAS data are interpreted by comparing them with the \(p_{\text {channel}}\)-values found in the pseudo-experiments.

The fractions of pseudo-experiments (\(P_{\text {exp},i}(p_{\text {min}})\)) which have at least one, two or three \(p_{\text {channel}}\)-values (circular, square, and rhombic markers respectively) smaller than a given threshold (\(p_{\text {min}}\)) in the scans of a the \(m_{\mathrm {inv}}\) distributions, and of b the \(m_{\mathrm {eff}}\) distributions. The coloured arrows represent the three smallest \(p_{\text {channel}}\)-values observed in data. Dashed lines are drawn at \(P_{\text {exp},i}=5\%\) and at the \(p_{\text {min}}\)-values corresponding to \(1\sigma \), \(2\sigma \), \(3\sigma \), \(4\sigma \) and \(5\sigma \) local significances. Details of the deviations can be found in Tables 4 and 5
Figure 10 shows the fractions of pseudo-experiments that have at least one, two or three \(p_{\text {channel}}\)-values below a given threshold (\(p_{\text {min}}\)) in the scans of the \(m_{\mathrm {inv}}\) and the \(m_{\mathrm {eff}}\) distributions. The statistical tests in both distributions for the three leading \(p_{\text {channel}}\)-values are all consistent at the \(P_{\text {exp},i} >50\%\) level with the SM expectation of \(p_{\text {channel}}\)-values obtained from pseudo-experiments. Changing the size of the theoretical shape uncertainties by a factor of two leads to a change in the three smallest \(p_{\text {channel}}\)-values of a factor of two. It therefore does not lead to an appreciable change in the result.
In conclusion, no significant deviations are found in the 2015 dataset and consequently no dedicated analysis using data-derived signal regions (step 7) is initiated.
4 Conclusions
A strategy for a model-independent general search to find potential indications of new physics is presented. Events are classified according to their final state into many event classes. For each event class an automated search algorithm tests whether the data is compatible with the Monte Carlo simulated Standard Model expectation in several distributions sensitive to the effects of new physics. For each distribution the search algorithm is repeated on many pseudo-experiments to make a frequentist estimate of the statistical significance of the three largest deviations. A data selection in which a significant deviation is observed defines a data-derived signal region which will be tested on a new dataset in a dedicated analysis with an improved background model.
The strategy has been applied to the data collected by the ATLAS experiment at the LHC during 2015, corresponding to a total of 3.2 \(\text{ fb }^{-1}\) of 13 \(\text {TeV}\) \(pp\) collisions. In this dataset, exclusive event classes containing electrons, muons, photons, b-tagged jets, non-b-tagged jets and missing transverse momentum have been scanned for deviations from the MC-based SM prediction in the distributions of the effective mass and the invariant mass. Sensitivity studies with various toy signals (\(t\bar{t} + \gamma \), WZ, gluino, and \(Z'\) production) have shown that the strategy could discover signals for new physics without an a priori knowledge of the existence of the processes.
No significant deviations are found in the 2015 dataset and consequently no dedicated analysis using data-derived signal regions is performed. The strategy discussed in this paper will be useful to search for signals of unknown particles and interactions in the subsequent Run 2 datasets.
Data Availability Statement
This manuscript has no associated data or the data will not be deposited. [Authors’ comment: “All ATLAS scientific output is published in journals, and preliminary results are made available in Conference Notes. All are openly available, without restriction on use by external parties beyond copyright law and the standard conditions agreed by CERN.Data associated with journal publications are also made available: tables and data from plots (e.g. cross section values, likelihood profiles, selection efficiencies, cross section limits, ...) are stored in appropriate repositories such as HEPDATA (http://hepdata.cedar.ac.uk/). ATLAS also strives to make additional material related to the paper available that allows a reinterpretation of the data in the context of new theoretical models. For example, an extended encapsulation of the analysis is often provided for measurements in the framework of RIVET (http://rivet.hepforge.org/).” This information is taken from the ATLAS Data Access Policy, which is a public document that can be downloaded from http://opendata.cern.ch/record/413 [opendata.cern.ch].]
Notes
‘Model-independent’ refers to the absence of a beyond the Standard Model signal assumption. The analysis depends on the Standard Model prediction.
The second term in Eq. (2) gives the probability of observing no events given a negative expectation from downward variations of the systematic uncertainties. It can be derived as follows:
$$\begin{aligned}&\int _{-\infty }^{0} \mathrm {d}x \ G \left( x; N_{\text {SM}}, \delta N_{\text {SM}} \right) \cdot \sum _{n=0}^{N_{\text {obs}}} \ \lim _{\mu \rightarrow 0} \left( \frac{\text {e}^{-\mu }\mu ^n}{n!}\right) \\&\quad = \int _{-\infty }^{0} \mathrm {d}x \ G \left( x; N_{\text {SM}}, \delta N_{\text {SM}} \right) \cdot \sum _{n=0}^{N_{\text {obs}}} \delta _{n0} \\&\quad = \int _{-\infty }^{0} \mathrm {d}x \ G \left( x; N_{\text {SM}}, \delta N_{\text {SM}} \right) , \end{aligned}$$where \(\mu \) is the mean of the Poisson pmf and \(\delta _{n0} = \left\{ 1 \text { if } n=0 , \ 0 \text { if } n\ne 0 \right\} \) is the Kronecker delta. In Eq. (3) this term vanishes for \(N_{\text {obs}} >0\).
ATLAS uses a right-handed coordinate system with its origin at the nominal interaction point in the centre of the detector. The positive x-axis is defined by the direction from the interaction point to the centre of the LHC ring, with the positive y-axis pointing upwards, while the beam direction defines the z-axis. Cylindrical coordinates (r, \(\phi \)) are used in the transverse plane, \(\phi \) being the azimuthal angle around the z-axis. The pseudorapidity \(\eta \) is defined in terms of the polar angle \(\theta \) by \(\eta = - \ln \tan (\theta /2)\). The angular distance is defined as \(\Delta R = \sqrt{(\Delta \eta )^2 + (\Delta \phi )^2}\). Rapidity is defined as \(y = 0.5\cdot \ln [(E + p_z)/(E - p_z)]\) where E denotes the energy and \(p_z\) is the component of the momentum along the beam direction.
A histogram of n bins has 1 region of n contiguous bins, 2 regions of \(n-1\) contiguous bins, etc. down to n regions of single bins. Therefore, it has \(\sum _{i=1}^n i = n(n+1)/2\) regions. When combining bins, background uncertainties are conservatively treated as correlated among the bins with the exception of MC statistical uncertainties.
In the \(m_{\mathrm {inv}}\) and \(m_{\mathrm {eff}}\) scan respectively, 72 and 87 event classes are discarded since they have no ROI.
References
D0 Collaboration, Search for new physics in \(e\mu X\) data at DØ using SLEUTH: A quasi-model-independent search strategy for new physics. Phys. Rev. D 62, 092004 (2000). arXiv:hep-ex/0006011
D0 Collaboration, Quasi-model-independent search for new physics at large transverse momentum. Phys. Rev. D 64, 012004 (2001). arXiv:hep-ex/0011067
D0 Collaboration, Quasi-Model-Independent Search for New High \(p_T\) Physics at D0. Phys. Rev. Lett. 86, 3712 (2001). arXiv:hep-ex/0011071
D0 Collaboration, Model independent search for new phenomena in \(p\bar{p}\) collisions at \(\sqrt{s} = 1.96\) TeV. Phys. Rev. D 85, 092015 (2012). arXiv:1108.5362 [hep-ex]
H1 Collaboration, A general search for new phenomena in \(ep\) scattering at HERA. Phys. Lett. B 602, 14 (2004). arXiv:hep-ex/0408044
H1 Collaboration, A general search for new phenomena at HERA. Phys. Lett. B 674, 257 (2009). arXiv:0901.0507 [hep-ex]
CDF Collaboration, Model-independent and quasi-model-independent search for new physics at CDF. Phys. Rev. D 78, 012002 (2008). arXiv:0712.1311 [hep-ex]
CDF Collaboration, Global search for new physics with 2.0 fb\(^{-1}\) at CDF, Phys. Rev. D 79, 011101 (2009). arXiv:0809.3781 [hep-ex]
S. Brandt, C. Peyrou, R. Sosnowski, A. Wroblewski, The principal axis of jets: an attempt to analyse high-energy collisions as two-body processes. Phys. Lett. 12, 57 (1964)
E. Farhi, Quantum chromodynamics test for jets. Phys. Rev. Lett. 39, 1587 (1977)
ATLAS Collaboration, The ATLAS Experiment at the CERN Large Hadron Collider. JINST 3, S08003 (2008)
ATLAS Collaboration, ATLAS Insertable B-Layer Technical Design Report, ATLAS-TDR-19 (2010). https://cds.cern.ch/record/1291633
ATLAS Collaboration, Performance of the ATLAS trigger system in 2015. Eur. Phys. J. C 77, 317 (2017). arXiv:1611.09661 [hep-ex]
ATLAS Collaboration, Vertex reconstruction performance of the ATLAS Detector at \(\sqrt{s}\) = 13 TeV, ATL-PHYS-PUB-2015-026 (2015). https://cds.cern.ch/record/2037717
ATLAS Collaboration, The ATLAS simulation infrastructure. Eur. Phys. J. C 70, 823 (2010). arXiv:1005.4568 [physics.ins-det]
S. Agostinelli et al., Geant4 a simulation toolkit. Nucl. Instrum. Meth. A 506, 250 (2003)
T. Sjöstrand, S. Mrenna, P.Z. Skands, A brief introduction to PYTHIA 8.1. Comput. Phys. Commun. 178, 852 (2008). arXiv:0710.3820 [hep-ph]
A. Martin, W. Stirling, R. Thorne, G. Watt, Parton distributions for the LHC. Eur. Phys. J. C 63, 189 (2009). arXiv:0901.0002 [hep-ph]
ATLAS Collaboration, Summary of ATLAS Pythia 8 tunes, ATL-PHYS-PUB-2012-003 (2012). https://cds.cern.ch/record/1474107
T. Gleisberg, Event generation with SHERPA 1.1. JHEP 02, 007 (2009). arXiv:0811.4622 [hep-ph]
D.J. Lange, The EvtGen particle decay simulation package. Nucl. Instrum. Methods A 462, 152 (2001)
D. London, J.L. Rosner, Extra gauge bosons in E6. Phys. Rev. D 34, 1530 (1986)
P. Langacker, The physics of heavy \(Z^{\prime }\) gauge bosons. Rev. Mod. Phys. 81, 1199 (2009). arXiv:0801.1345 [hep-ph]
R.D. Ball, Parton distributions with LHC data. Nucl. Phys. B 867, 244 (2013). arXiv:1207.1303 [hep-ph]
ATLAS Collaboration, ATLAS Pythia 8 tunes to 7 TeV data, ATL-PHYS-PUB-2014-021 (2014). https://cds.cern.ch/record/1966419
Y.A. Golfand, E.P. Likhtman, Extension of the algebra of Poincare group generators and violation of \(p\) invariance. JETP Lett. 13, 323 (1971) [Pisma Zh. Eksp. Teor. Fiz. 13 , 452 (1971)]
D.V. Volkov, V.P. Akulov, Is the neutrino a goldstone particle? Phys. Lett. B 46, 109 (1973)
J. Wess, B. Zumino, Supergauge transformations in four-dimensions. Nucl. Phys. B 70, 39 (1974)
J. Wess, B. Zumino, Supergauge invariant extension of quantum electrodynamics. Nucl. Phys. B 78, 1 (1974)
S. Ferrara, B. Zumino, Supergauge invariant Yang–Mills theories. Nucl. Phys. B 79, 413 (1974)
A. Salam, J. Strathdee, Super-symmetry and non-Abelian gauges. Phys. Lett. B 51, 353 (1974)
J. Alwall, The automated computation of tree-level and next-to-leading order differential cross sections, and their matching to parton shower simulations. JHEP 07, 079 (2014). arXiv:1405.0301 [hep-ph]
J. Pumplin, New generation of parton distributions with uncertainties from global QCD analysis. JHEP 07, 012 (2002). arXiv:hep-ph/0201195
L. Lonnblad, S. Prestel, Matching tree-level matrix elements with interleaved showers. JHEP 03, 019 (2012). arXiv:1109.4829 [hep-ph]
W. Beenakker, M. Kramer, T. Plehn, M. Spira, P.M. Zerwas, Stop production at hadron colliders. Nucl. Phys. B 515, 3 (1998). arXiv:hep-ph/9710451
W. Beenakker, Supersymmetric top and bottom squark production at hadron colliders. JHEP 08, 098 (2010). arXiv:1006.4771 [hep-ph]
W. Beenakker, Squark and gluino hadroproduction. Int. J. Mod. Phys. A 26, 2637 (2011). arXiv:1105.1110 [hep-ph]
M. Cacciari, G.P. Salam, G. Soyez, The anti-\(k_{t}\) jet clustering algorithm. JHEP 04, 063 (2008). arXiv:0802.1189 [hep-ph]
ATLAS Collaboration, Performance of b-jet identification in the ATLAS experiment. JINST 11, P04008 (2016). arXiv:1512.01094 [hep-ex]
ATLAS Collaboration, Expected performance of the ATLAS \(b\)-tagging algorithms in Run-2, ATL-PHYS-PUB-2015-022 (2015). https://cds.cern.ch/record/2037697
ATLAS Collaboration, Performance of missing transverse momentum reconstruction with the ATLAS detector using proton–proton collisions at \(\sqrt{s} = 13\) TeV (2018). arXiv:1802.08168 [hep-ex]
ATLAS Collaboration, Jet energy scale measurements and their systematic uncertainties in proton–proton collisions at \(\sqrt{s}\) = 13 TeV with the ATLAS detector. Phys. Rev. D 96, 072002 (2017). arXiv:1703.09665 [hep-ex]
ATLAS Collaboration, Muon reconstruction performance of the ATLAS detector in proton–proton collision data at \(\sqrt{s}\) = 13 TeV. Eur. Phys. J. C 76, 292 (2016). arXiv:1603.05598 [hep-ex]
ATLAS Collaboration, Electron efficiency measurements with the ATLAS detector using the 2015 LHC proton–proton collision data, ATLAS-CONF-2016-024 (2016). https://cds.cern.ch/record/2157687
ATLAS Collaboration, Electron and photon energy calibration with the ATLAS detector using data collected in 2015 at \(\sqrt{s}\) = 13 TeV, ATL-PHYS-PUB-2016-015 (2016). https://cds.cern.ch/record/2203514
ATLAS Collaboration, Photon identification in 2015 ATLAS data, ATL-PHYS-PUB-2016-014 (2016). https://cds.cern.ch/record/2203125
ATLAS Collaboration, Luminosity determination in \(pp\) collisions at \(\sqrt{s}\) = 8 TeV using the ATLAS detector at the LHC. Eur. Phys. J. C 76, 653 (2016). arXiv:1608.03953 [hep-ex]
ATLAS Collaboration, Search for supersymmetry in a final state containing two photons and missing transverse momentum in \(\sqrt{s}\) = 13 TeV pp collisions at the LHC using the ATLAS detector. Eur. Phys. J. C 76, 517 (2016). arXiv:1606.09150 [hep-ex]
ATLAS Collaboration, Search for resonances in diphoton events at \(\sqrt{s}\) = 13 TeV with the ATLAS detector. JHEP 09, 001 (2016). arXiv:1606.03833 [hep-ex]
ATLAS Collaboration, Search for new phenomena in high-mass diphoton final states using \(37 {\rm fb}^{-1}\) of proton–proton collisions collected at \(\sqrt{s}\) = 13 TeV with the ATLAS detector. Phys. Lett. B 775 105 (2017). arXiv:1707.04147 [hep-ex]
ATLAS Collaboration, Expected sensitivity studies for gluino and squark searches using the early LHC 13 TeV Run-2 dataset with the ATLAS experiment, ATL-PHYS-PUB-2015-005 (2015).http://cds.cern.ch/record/2002608
ATLAS Collaboration, ATLAS Computing Acknowledgements, ATL-GEN-PUB-2016-002 (2016). https://cds.cern.ch/record/2202407
G. Corcella, HERWIG 6: an event generator for hadron emission reactions with interfering gluons (including supersymmetric processes). JHEP 01, 010 (2001). arXiv:hep-ph/0011363
H.-L. Lai, New parton distributions for collider physics. Phys. Rev. D 82, 074024 (2010). arXiv:1007.2241 [hep-ph]
S. Schumann, F. Krauss, A parton shower algorithm based on Catani–Seymour dipole factorisation. JHEP 03, 038 (2008). arXiv:0709.1027 [hep-ph]
ATLAS Collaboration, Monte Carlo generators for the production of a \(W\) or \(Z/\gamma ^{*}\) boson in association with jets at ATLAS in Run 2, ATL-PHYS-PUB-2016-003 (2016). https://cds.cern.ch/record/2120133
T. Gleisberg, S. Höche, Comix, a new matrix element generator. JHEP 12, 039 (2008). arXiv:0808.3674 [hep-ph]
F. Cascioli, P. Maierhöfer, S. Pozzorini, Scattering amplitudes with open loops. Phys. Rev. Lett. 108, 111601 (2012). arXiv:1111.5206 [hep-ph]
S. Höche, F. Krauss, M. Schönherr, F. Siegert, QCD matrix elements + parton showers. The NLO case. JHEP 04, 027 (2013). arXiv:1207.5030 [hep-ph]
R. Gavin, Y. Li, F. Petriello, S. Quackenbush, FEWZ 2.0: A code for hadronic Z production at next-to-next-to-leading order. Comput. Phys. Commun. 182, 2388 (2011). arXiv:1011.3540 [hep-ph]
R. Gavin, Y. Li, F. Petriello, S. Quackenbush, W physics at the LHC with FEWZ 2.1. Comput. Phys. Commun. 184, 208 (2013). arXiv:1201.5896 [hep-ph]
J.M. Campbell, R.K. Ellis, Update on vector boson pair production at hadron colliders. Phys. Rev. D 60, 113006 (1999). arXiv:hep-ph/9905386
J.M. Campbell, R.K. Ellis, C. Williams, Vector boson pair production at the LHC. JHEP 07, 018 (2011). arXiv:1105.0020 [hep-ph]
S. Alioli, P. Nason, C. Oleari, E. Re, A general framework for implementing NLO calculations in shower Monte Carlo programs: the POWHEG BOX. JHEP 10, 043 (2010). arXiv:1002.2581 [hep-ph]
ATLAS Collaboration, Simulation of top-quark production for the ATLAS experiment at \(\sqrt{s} = 13\) TeV, ATL-PHYS-PUB-2016-004 (2016). https://cds.cern.ch/record/2120417
P. Artoisenet, R. Frederix, O. Mattelaer, R. Rietkerk, Automatic spin-entangled decays of heavy resonances in Monte Carlo simulations. JHEP 03, 015 (2013). arXiv:1212.3460 [hep-ph]
T. Sjöstrand, S. Mrenna, P. Skands, PYTHIA 6.4 physics and manual. JHEP 05, 026 (2006). arXiv:hep-ph/0603175
P.Z. Skands, Tuning Monte Carlo generators: The Perugia tunes. Phys. Rev. D 82, 074018 (2010). arXiv:1005.3457 [hep-ph]
N. Kidonakis, Two-loop soft anomalous dimensions for single top quark associated production with a \(W^{-}\) or \(H^{-}\). Phys. Rev. D 82, 054018 (2010). arXiv:1005.4451 [hep-ph]
N. Kidonakis, Next-to-next-to-leading logarithm resummation for s-channel single top quark production. Phys. Rev. D 81, 054028 (2010). arXiv:1001.5034 [hep-ph]
N. Kidonakis, Next-to-next-to-leading-order collinear and soft gluon corrections for t-channel single top quark production. Phys. Rev. D 83, 091503 (2011). arXiv:1103.2792 [hep-ph]
M. Czakon, A. Mitov, Top++: A program for the calculation of the top-pair cross-section at hadron colliders. Comput. Phys. Commun. 185, 2930 (2014). arXiv:1112.5675 [hep-ph]
M. Czakon, D. Heymes, A. Mitov, High-precision differential predictions for top-quark pairs at the LHC. Phys. Rev. Lett. 116, 082003 (2016). arXiv:1511.00549 [hep-ph]
M. Czakon, D. Heymes, A. Mitov, Dynamical scales for multi-TeV top-pair production at the LHC. JHEP 04, 071 (2017). arXiv:1606.03350 [hep-ph]
ATLAS Collaboration, Multi-boson simulation for 13 TeV ATLAS analyses, ATL-PHYS-PUB-2016-002 (2016). https://cds.cern.ch/record/2119986
ATLAS Collaboration, Modelling of the \(t\bar{t}H\) and \(t\bar{t}V(V = W,Z)\) processes for \(\sqrt{s} = 13\) TeV ATLAS analyses, ATL-PHYS-PUB-2016-005 (2016). https://cds.cern.ch/record/2120826
ATLAS Collaboration, Measurement of the \(Z/\gamma^*\) boson transverse momentum distribution in pp collisions at \(\sqrt{s} = 7\) TeV with the ATLAS detector. JHEP 09, 145 (2014). arXiv:1406.3660 [hep-ex]
M. Bahr, Herwig++ physics and manual. Eur. Phys. J. C 58, 639 (2008). arXiv:0803.0883 [hep-ph]
LHC Higgs Cross Section Working Group, Handbook of LHC Higgs Cross Sections: 2. Differential distributions, CERN-2012-002. arXiv:1201.3084 [hep-ph]
S. Frixione, E. Laenen, P. Motylinski, B.R. Webber, C.D. White, Single-top hadroproduction in association with a W boson. JHEP 07, 029 (2008). arXiv:0805.3067 [hep-ph]
ATLAS Collaboration, Measurements of \(W\gamma\) and \(Z\gamma\) production in \(pp\) collisions at \(\sqrt{s} = 7\) TeV with the ATLAS detector at the LHC. Phys. Rev. D 87, 112003 (2013). arXiv:1302.1283 [hep-ex] [Erratum: Phys. Rev. D 91, 119901 (2015)]
ATLAS Collaboration, Search for supersymmetry at \(\sqrt{s}\) = 13 TeV in final states with jets and two same-sign leptons or three leptons with the ATLAS detector. Eur. Phys. J. C 76, 259 (2016). arXiv:1602.09058 [hep-ex]
ATLAS Collaboration, Electron efficiency measurements with the ATLAS detector using 2012 LHC proton–proton collision data. Eur. Phys. J. C 77, 195 (2017). arXiv:1612.01456 [hep-ex]
ATLAS Collaboration, Measurement of the photon identification efficiencies with the ATLAS detector using LHC Run-1 data (2016). arXiv:1606.01813 [hep-ex]
M. Cacciari, G.P. Salam, G. Soyez, FastJet user manual. Eur. Phys. J. C 72, 1896 (2012). arXiv:1111.6097 [hep-ph]
ATLAS Collaboration, Topological cell clustering in the ATLAS calorimeters and its performance in LHC Run 1. Eur. Phys. J. C 77, 490 (2017). arXiv:1603.02934 [hep-ex]
ATLAS Collaboration, Monte Carlo calibration and combination of in-situ measurements of jet energy scale, jet energy resolution and jet mass in ATLAS, ATLAS-CONF-2015-037 (2015). https://cds.cern.ch/record/2044941
ATLAS Collaboration, Performance of pile-up mitigation techniques for jets in pp collisions at \(\sqrt{s}\) = 8 TeV using the ATLAS detector. Eur. Phys. J. C 76, 581 (2016). arXiv:1510.03823 [hep-ex]
ATLAS Collaboration, Selection of jets produced in 13 TeV proton–proton collisions with the ATLAS detector, ATLAS-CONF-2015-029 (2015). https://cds.cern.ch/record/2037702
Acknowledgements
We thank CERN for the very successful operation of the LHC, as well as the support staff from our institutions without whom ATLAS could not be operated efficiently. We acknowledge the support of ANPCyT, Argentina; YerPhI, Armenia; ARC, Australia; BMWFW and FWF, Austria; ANAS, Azerbaijan; SSTC, Belarus; CNPq and FAPESP, Brazil; NSERC, NRC and CFI, Canada; CERN; CONICYT, Chile; CAS, MOST and NSFC, China; COLCIENCIAS, Colombia; MSMT CR, MPO CR and VSC CR, Czech Republic; DNRF and DNSRC, Denmark; IN2P3-CNRS, CEA-DRF/IRFU, France; SRNSFG, Georgia; BMBF, HGF, and MPG, Germany; GSRT, Greece; RGC, Hong Kong SAR, China; ISF and Benoziyo Center, Israel; INFN, Italy; MEXT and JSPS, Japan; CNRST, Morocco; NWO, Netherlands; RCN, Norway; MNiSW and NCN, Poland; FCT, Portugal; MNE/IFA, Romania; MES of Russia and NRC KI, Russian Federation; JINR; MESTD, Serbia; MSSR, Slovakia; ARRS and MIZŠ, Slovenia; DST/NRF, South Africa; MINECO, Spain; SRC and Wallenberg Foundation, Sweden; SERI, SNSF and Cantons of Bern and Geneva, Switzerland; MOST, Taiwan; TAEK, Turkey; STFC, United Kingdom; DOE and NSF, United States of America. In addition, individual groups and members have received support from BCKDF, CANARIE, CRC and Compute Canada, Canada; COST, ERC, ERDF, Horizon 2020, and Marie Skłodowska-Curie Actions, European Union; Investissements d’ Avenir Labex and Idex, ANR, France; DFG and AvH Foundation, Germany; Herakleitos, Thales and Aristeia programmes co-financed by EU-ESF and the Greek NSRF, Greece; BSF-NSF and GIF, Israel; CERCA Programme Generalitat de Catalunya, Spain; The Royal Society and Leverhulme Trust, United Kingdom.
The crucial computing support from all WLCG partners is acknowledged gratefully, in particular from CERN, the ATLAS Tier-1 facilities at TRIUMF (Canada), NDGF (Denmark, Norway, Sweden), CC-IN2P3 (France), KIT/GridKA (Germany), INFN-CNAF (Italy), NL-T1 (Netherlands), PIC (Spain), ASGC (Taiwan), RAL (UK) and BNL (USA), the Tier-2 facilities worldwide and large non-WLCG resource providers. Major contributors of computing resources are listed in Ref. [52].
Author information
Authors and Affiliations
Consortia
Appendices
Appendix
Details of the Monte Carlo samples
1.1 Monte Carlo programs and settings
Samples of multijet production were simulated with \(2\rightarrow 2\) matrix elements (ME) at leading order (LO) using the Pythia 8.186 generator [17]. The A14 [25] set of shower and multiple parton interactions parameters (tune) was used together with the NNPDF2.3LO PDF set [24]. Alternative multijet samples with \(2\rightarrow 2\) ME at LO were generated with Herwig++ 2.7.1 [53] with the UEEE5 underlying-event tune and the CTEQ6L1 [33] PDF set, and with Sherpa 2.1.1 [20] with ME for \(2\rightarrow 2\) and \(2\rightarrow 3\) partons at LO merged using the ME+PSLO prescription. All Sherpa samples use the CT10 [54] PDF set and the Sherpa parton shower [55] with a dedicated shower tuning developed by the Sherpa authors.
Events containing leptonic decays of a W or Z bosons with associated jets (W/\(Z+\text {jets}\)) were simulated using the Sherpa 2.1.1 generator [56]. Matrix elements were calculated using the Comix [57] and Open-Loops [58] generators. They include up to two partons at NLO and four partons at leading order (LO), merged using the ME+PS@NLO prescription [59]. Samples with W and Z decaying hadronically are also generated with Sherpa 2.1.1 including up to four partons at LO. The W/\(Z+\text {jets}\) events were normalized to their inclusive next-to-next-to-leading-order (NNLO) cross-sections [60, 61]. Simulated samples of massive vector bosons produced in association with one or two real photons were also generated with Sherpa 2.1.1 with a ME calculated at LO for up to three partons. They are scaled to their NLO cross-sections computed with MCFM [62, 63].
Samples of prompt photon production in association with jets (\(\gamma +\text {jets}\)) were generated using Sherpa 2.1.1. For these samples up to four real parton emissions are included at LO. Events containing two prompt photons (\(\gamma \gamma +\text {jets}\)) were also generated with Sherpa 2.1.1. Matrix elements were calculated with up to two partons at LO. The gluon-induced box process is also included. These samples were scaled to data following the procedure described in Sect. 3.2.3.
Top-quark pair production events, and single top quarks in the Wt- and s-channels, were simulated using the Powheg-Box v2 [64] generator with the CT10 PDF set, as detailed in Ref. [65]. The top quark mass was set to 172.5 \(\text {GeV}\). The \(h_{\text {damp}}\) parameter, which regulates the transverse momentum of the first extra emission beyond the Born configuration and thus controls the \(p_{\text {T}}\) of the \(t\bar{t}\) system, was set to the mass of the top quark. Electroweak t-channel single-top-quark events were generated using the Powheg-Box v1 generator. This generator uses the four-flavour scheme for the NLO matrix-element calculations together with the fixed four-flavour PDF set CT10f4. For all top-quark processes, top-quark spin correlations are preserved (for the single-top t-channel, top quarks were decayed using MadSpin [66]). An alternative sample of \(t\bar{t}\) was generated with the Sherpa 2.1.1 generator, including up to one additional parton at NLO and up to four additional partons at LO accuracy, interfaced to the parton shower using the ME+PS@NLO prescription. The parton shower (PS), fragmentation, and the underlying event of the Powheg-Box samples were simulated using Pythia 6.428 [67] with the CTEQ6L1 PDF set and the corresponding Perugia 2012 tune (P2012) [68]. The \(t\bar{t}\) and single-top-quark events were normalized to the NNLO cross-section including the resummation of soft gluon emission at next-to-next-to-logarithm accuracy [69,70,71] using Top++2.0 [72]. Both the default and the alternative \(t\bar{t}\) samples were corrected to reproduce the NNLO prediction [73, 74] of the top quark \(p_{\text {T}}\) and the \(p_{\text {T}}\) of the \(t\bar{t}\) system. The contribution of \(t\bar{t}+b\bar{b}\) was generated separately with Sherpa 2.1.1 at NLO; the calculation was performed in the four-flavour scheme and with the CT10f4 PDF set.
Diboson samples were generated with the Sherpa 2.1.1 generator, and are described in Ref. [75]. The matrix elements contain the WW, WZ and ZZ processes and all other diagrams with four or six electroweak vertices (such as same-electric-charge W boson production in association with two jets, \(W^{\pm }W^{\pm }jj\)). Fully leptonic triboson processes (WWW, WWZ, WZZ and ZZZ) with on-shell bosons and up to six charged leptons were also simulated using Sherpa 2.1.1. The ME for the ZZ processes were calculated at NLO for up to one additional parton; final states with two and three additional partons were calculated at LO. The WZ and WW processes were calculated at NLO with up to three extra partons at LO using the ME+PS@NLO prescription. The WW final states were generated without bottom quarks in the hard-scattering process, to avoid contributions from top-quark-mediated processes. The triboson processes were calculated with the same configuration and with up to two extra partons at LO. The generator cross-sections were used for the normalization of these backgrounds.
Samples of top quark production in association with vector bosons [76] (W, Z, \(\gamma \) and WW, including the non-resonant \(\gamma ^*/~Z\) contributions) were generated at LO with MG5_aMC@NLO 2.2.2 [32] interfaced to Pythia 8.186, with up to two (\(t\bar{t}W\)), one (\(t\bar{t}Z\)) or no (\(t\bar{t}WW\), \(t\bar{t}\gamma \)) extra partons included in the matrix element. The A14 tune was used together with the NNPDF2.3LO PDF set. The \(t\bar{t}\gamma \) sample uses a fixed QCD renormalization and factorization scale of \(2 m_{t}\), and the top decay was performed in MG5_aMC@NLO to account for hard photon radiation from the top decay products. The same generator was also used to simulate the tZ, 3-top and 4-top quarks processes. The \(t\bar{t}W\), \(t\bar{t}Z\), \(t\bar{t}WW\) and 4-top samples were normalized to their NLO cross-sections [32] while the LO cross-section from the generator was used for tZ and 3-top quarks.
The Higgs boson mass was set to 125 \(\text {GeV}\) and all SM Higgs boson decay modes were considered. The production of the SM Higgs boson in the gluon–gluon fusion (ggF) and vector-boson fusion (VBF) channels was modelled using the Powheg-Box v2 generator with the CT10 PDF set. It was interfaced to Pythia 8.186 with the CTEQ6L1 PDF set and the AZNLO tune [77]. Production of a Higgs boson in association with a pair of top quarks was simulated using MG5_aMC@NLO 2.2.2 interfaced to Herwig++ 2.7.1 [78] for showering and hadronization. The UEEE5 underlying-event tune was used together with the CT10 (matrix element) and CTEQ6L1 (parton shower) PDF sets. Simulated samples of SM Higgs boson production in association with a W or Z boson were produced with Pythia 8.186, using the A14 tune and the NNPDF2.3LO PDF set. Events were normalized to their most accurate cross-sections calculations (typically NNLO) [79].
To avoid double counting, events with a hard photon from final-state radiation were removed from the multijet, \(t\bar{t}\) and W/\(Z+\text {jets}\) samples.
1.2 Theoretical uncertainties
The inclusive W and Z cross-sections are known at NNLO, with an uncertainty of about 5% [60, 61]. Modelling uncertainties for \(W+\text {jets}\) and \(Z+\text {jets}\) are determined by varying the renormalization, factorization and resummation scales in the ME by factors 0.5 and 2, together with a change of the merging scale from 20 \(\text {GeV}\) to 15 \(\text {GeV}\) or 30 \(\text {GeV}\).
For top quark pair or single-top production, processes known to NNLO+NNLL [72] or approximate NNLO [69,70,71], respectively, the cross-section uncertainty is 7%. The modelling uncertainty for \(t\bar{t}\) is determined by comparing the nominal Powheg+Pythia NLO+PS sample with an alternative sample generated with Sherpa including up to two partons at NLO and four at LO accuracy in the ME. The single-top quark uncertainty is estimated by varying the renormalization and factorization scales, and by changing the \(h_{\text {damp}}\) parameter and the shower tune of the Powheg+Pythia sample. An uncertainty in the interference between the Wt and \(t\bar{t}\) production is estimated by comparing the nominal Wt sample, where all doubly resonant NLO Wt diagrams are removed, with a sample where the cross-section contribution from Feynman diagrams containing two top quarks is subtracted [80].
Diboson cross-sections (WW, WZ and ZZ) are calculated at NLO, and a 6% uncertainty, evaluated with the MCFM program [62, 63], is applied to their cross-sections. Their modelling uncertainty is evaluated analogously to \(V+\text {jets}\) by varying the scales used to perform the calculation. For \(W+\gamma \) and \(Z+\gamma \) samples, which are computed at LO, a 20% uncertainty in the cross-section is assumed, with a further 20% modelling uncertainty assigned in accord with the measurement in Ref. [81].
The cross-sections for top-quark pair production in association with one or two vector bosons are calculated at NLO and an uncertainty of 15% is used [32]. Their modelling uncertainty is evaluated from variations of the renormalization and factorization scales, together with a change in the merging scale. For \(t\bar{t}+\gamma \), an additional 12% uncertainty in the normalization is assumed, while a uniform 30% uncertainty is assigned to the modelling [76].
Multijet and \(\gamma +\text {jets}\) processes are scaled to data following the procedure described in Sect. 3.2.2. Therefore, no uncertainty is applied to their normalization. For multijets the maximum bin-by-bin difference between the Pythia 8 nominal sample and alternative samples generated with Sherpa and Herwig++ is considered as a shape uncertainty. In addition the standard deviation of the 100 replica sets of the NNPDF2.3LO PDF is used. The modelling uncertainty for \(\gamma +\text {jets}\) is estimated from scale variations with the same methodology as for the \(V+\text {jets}\) samples. The uncertainty in the \(\gamma \gamma +\text {jets}\) modelling is instead taken to be 30% from parton-level comparisons of samples with varied scales.
A conservative uncertainty of 20% [79] is assumed for Higgs production in the ggF, VBF and VH channels. A further uncertainty of 20% is assigned as a shape uncertainty.
For the subdominant triboson (including \(V+\gamma \gamma \)), ttH, 3-top, 4-top and tZ production processes a 50% uncertainty is assigned to the event yields, similarly to Ref. [82]. Uncertainties associated to PDFs are found to be small in all channels compared to the modelling uncertainties of the MC simulations.
Details of the object reconstruction
Electron candidates are reconstructed from an isolated electromagnetic calorimeter energy deposit matched to an ID track and are required to have \(|\eta |<2.47\), a transverse momentum \(p_{\text {T}} > 10\) \(\text {GeV}\), and to pass a loose likelihood-based identification requirement [44, 83]. The likelihood input variables include measurements of calorimeter shower shapes and measurements of track properties from the ID. The candidate electrons are selected if the matched tracks have a transverse impact parameter significance relative to the reconstructed primary vertex of \(|d_0|/\sigma (d_0) < 5\). Candidates within the transition region between the barrel and endcap electromagnetic calorimeters, \(1.37<|\eta |< 1.52\), are removed.
Muon candidates are reconstructed in the region \(|\eta |< 2.7\) from muon spectrometer tracks matched to ID tracks. The muon candidates are selected if they have a transverse momentum above 10 \(\text {GeV}\) and pass the medium identification requirements defined in Ref. [43], based on selections on the number of hits in the different ID and muon spectrometer subsystems, and the significance of the charge to momentum ratio q / p.
All candidate leptons (electrons and muons) are used for the object overlap removal, as discussed in Sect. 3.1.3. Tighter requirements on the lepton candidates are imposed, which are then referred to as ‘signal’ electrons or muons and are used further in the analysis, i.e. to establish the accuracy of the background modelling processes or to classify the events. Signal electrons must satisfy a tight likelihood-based identification requirement [44, 83]. Signal muons must fulfil the requirement of \(|d_0|/\sigma (d_0) < 3\). The track associated with a signal lepton must have a longitudinal impact parameter relative to the reconstructed primary vertex, \(z_0\), satisfying \(|z_0\cdot \sin \theta | < 0.5\) mm. Isolation requirements are applied to both the signal electrons and muons. The calorimeter isolation is computed as the sum of the energies of calorimeter energy clusters in a cone of size \(\Delta R =0.2\) around the lepton. Track isolation is defined as the scalar sum of the \(p_{\text {T}}\) of tracks within a variable-size cone around the lepton, in a cone of size \(\Delta R = 0.2\) (0.3) for electron (muon) transverse momenta \(p_{\text {T}} < 50\) \(\text {GeV}\) (\(p_{\text {T}} < 33\) \(\text {GeV}\)) and of size \(\Delta R = 10~\text {GeV}/p_{\text {T}} \) for \(p_{\text {T}} > 50\) \(\text {GeV}\) (\(p_{\text {T}} > 33\) \(\text {GeV}\)). The efficiency of these criteria increases with the lepton transverse momentum, reaching 95% at 25 \(\text {GeV}\) and 99% at 60 \(\text {GeV}\), as determined in a control sample of Z decays into leptons selected with a tag-and-probe technique [43, 44]. Corrections are applied to the MC samples to match the leptons’ trigger, reconstruction and isolation efficiencies in data.
Photon candidates are reconstructed from an isolated electromagnetic calorimeter energy deposit and are required to satisfy the tight identification criteria described in Refs. [46, 84]. Furthermore, photons are required to have \(p_{\text {T}} > 25\) \(\text {GeV}\) and \(|\eta | < 2.37\), excluding the barrel–endcap calorimeter transition in the range \(1.37< |\eta | < 1.52\). Photons must further satisfy isolation criteria based on both track and calorimeter information [46]. After correcting for contributions from pile-up, the energy within a cone of \(\Delta R = 0.4\) around the cluster barycentre is required to be less than \(2.45~\text {GeV}+ 0.022 \times p_{\text {T}} ^{\gamma }\), where \(p_{\text {T}} ^{\gamma }\) is the transverse momentum of the photon candidate. The energy of tracks in a cone of \(\Delta R = 0.2\) should be less than \(0.05\times p_{\text {T}} ^{\gamma }\).
Jet candidates are reconstructed with the anti-\(k_t\) algorithm [38] implemented in the FastJet package [85] with a radius parameter of \(R = 0.4\), using as input three-dimensional energy clusters in the calorimeter [86] calibrated to the electromagnetic scale. The reconstructed jets are then calibrated to the jet energy scale (JES) derived from simulation and in situ corrections based on 13 TeV data [42, 87]. For all jets the expected average energy contribution from pile-up clusters is subtracted according to the jet area prescription [88]. Quality criteria are imposed to identify jets arising from non-collision sources or detector noise and any event containing such a jet is removed [89]. All jet candidates are required to have \(p_{\text {T}} >20~\text {GeV}\) and \(|\eta | < 2.8\).
Identification of jets containing b-hadrons (b-tagging) is performed with a multivariate discriminant, MV2c20, making use of track impact parameters, the b- and c-hadron flight paths inside the jet and reconstructed secondary vertices [39, 40]. The algorithm working point used corresponds to a 77% average efficiency obtained for b-jets in simulated \(t\bar{t}\) events. The rejection factors for light-quark jets, c-quark jets and hadronically decaying \(\tau \)-leptons in simulated \(t\bar{t}\) events are approximately 140, 4.5 and 10, respectively [40]. Jets with \(|\eta |<2.5\) which satisfy this b-tagging requirement are identified as b-jet candidates. To compensate for differences between data and MC simulation in the b-tagging efficiencies and mistag rates, correction factors are applied to the simulated samples [40].
Event yields for all event classes

The number of events in data, and for the different SM background predictions considered, for classes with at least one photon and (b-)jets (no leptons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. In event classes with four or more data events, the \(\gamma +\text {jets}\) and \(\gamma \gamma +\text {jets}\) MC samples are scaled to data in the single-photon and diphoton event classes respectively. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with one electron and (b-)jets (no muons, photons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with one muon and (b-)jets (no electrons, photons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with one muon, one electron and (b-)jets (no photons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with two same-flavour leptons and (b-)jets (no photons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with three or four leptons and (b-)jets (no photons or \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with one lepton, at least one photon and (b-)jets (no \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with at least two leptons, at least one photon and (b-)jets (no \(E_{\text {T}}^{\text {miss}}\) ). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with large \(E_{\text {T}}^{\text {miss}}\) and (b-)jets (no leptons or photons). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with large \(E_{\text {T}}^{\text {miss}}\) , at least one photon, leptons and (b-)jets. The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with large \(E_{\text {T}}^{\text {miss}}\) , one muon, one electron and (b-)jets (no photons). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with large \(E_{\text {T}}^{\text {miss}}\) , at least one pair of same flavour leptons and (b-)jets (no photons). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. The hatched bands indicate the total uncertainty of the SM prediction

The number of events in data, and for the different SM background predictions considered, for classes with (b-)jets (no \(E_{\text {T}}^{\text {miss}}\) , leptons or photons). The classes are labelled according to the multiplicity and type (e, \(\mu \), \(\gamma \), j, b, \(E_{\text {T}}^{\text {miss}} \)) of the reconstructed objects for the given event class. In event classes with four or more data events, the multijet MC sample is scaled to data. The hatched bands indicate the total uncertainty of the SM prediction
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
Funded by SCOAP3
About this article

Cite this article
Aaboud, M., Aad, G., Abbott, B. et al. A strategy for a general search for new phenomena using data-derived signal regions and its application within the ATLAS experiment. Eur. Phys. J. C 79, 120 (2019). https://doi.org/10.1140/epjc/s10052-019-6540-y
Received:
Accepted:
Published:
DOI: https://doi.org/10.1140/epjc/s10052-019-6540-y