
SOPRENE: Assessment of the Spanish Armada’s Predictive Maintenance Tool for Naval Assets

 , , , ,
, , , ,  and
and
Abstract
:1. Introduction
2. Problem Statement
2.1. Equipment Selection and Scalability
2.2. Data Availability and Management
3. State of the Art
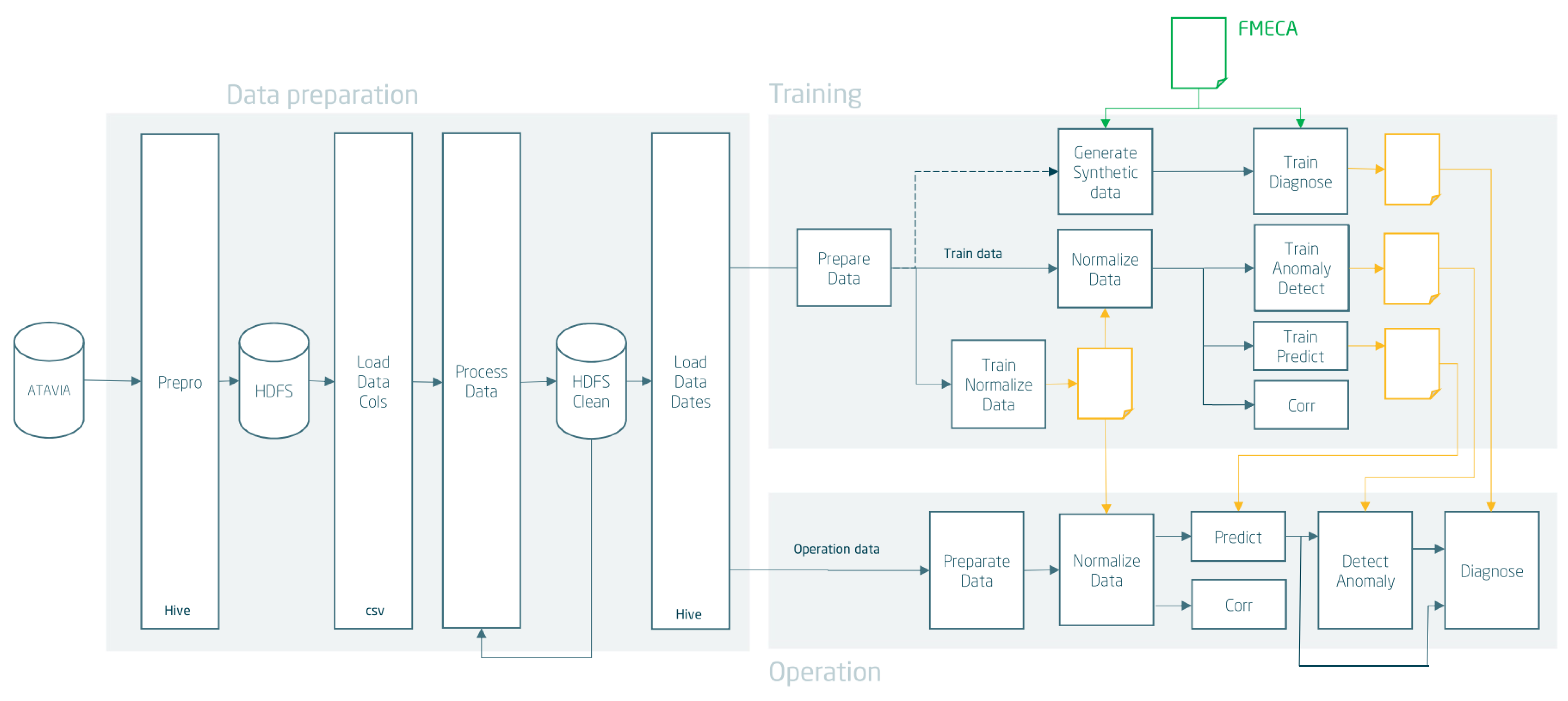
4. Unified Architecture
4.1. Behavioural Prediction
4.2. Anomaly Detection
- Detect anomalies: To determine which datum is normal or anomalous, a first filter is carried out by using the mean square error. Based on a precalculated threshold error, the data that exceed this error are classified as anomalous and the rest as normal. The user can choose whether the calculation of this threshold error is carried out using the interquartile range technique [60] (a statistical dispersion measure that allows the threshold to be calculated automatically) or by establishing a percentage of anomalous data in the set of data.
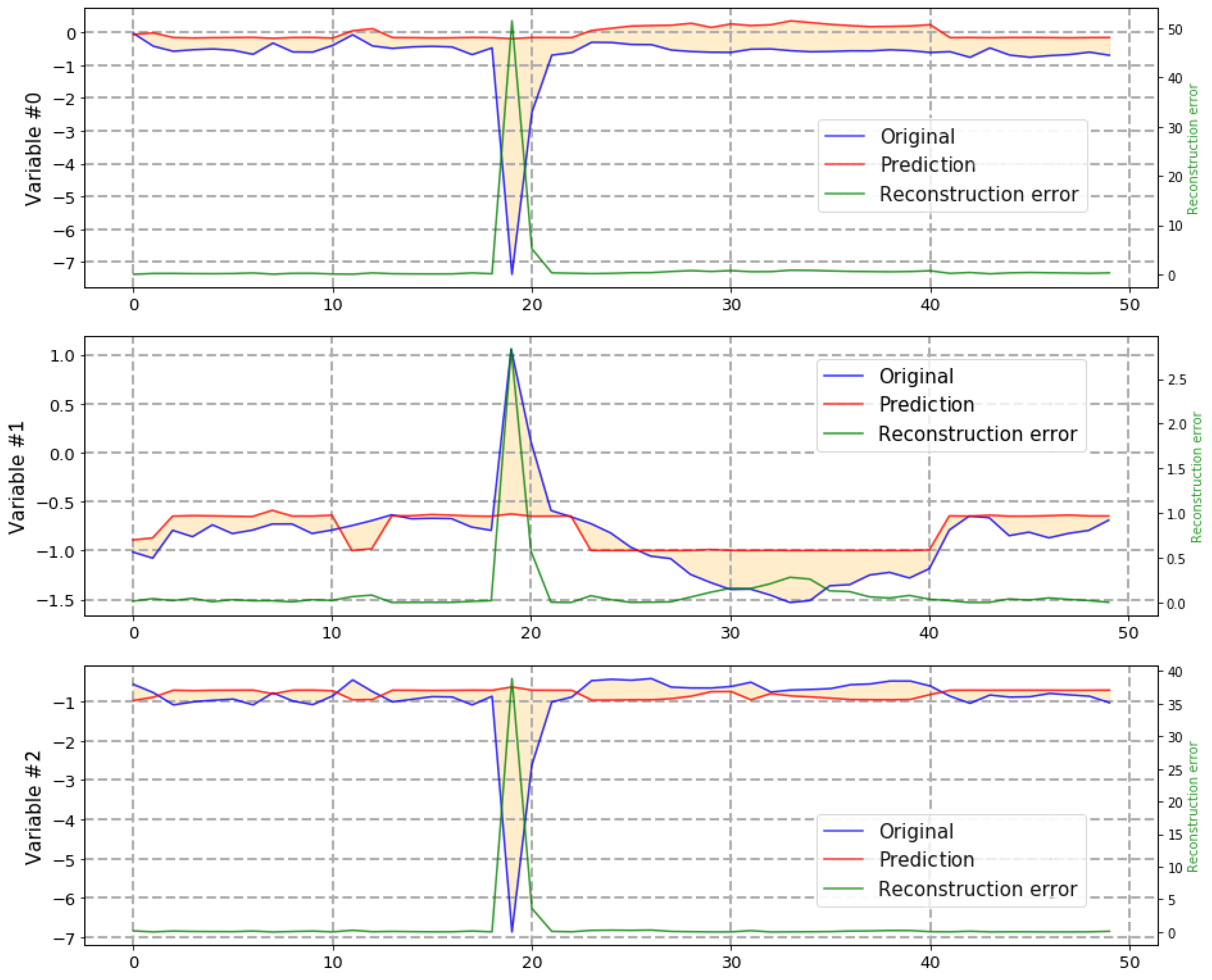
- Independent contributions: To determine which specific variables have caused the appearance of the anomaly in the data classified in the previous phase as anomalous, the decomposition of the reconstruction error is used (see Figure 2). Taking into account that the data are now normalized, this allows us to order the variables by their reconstruction error. To determine which variables have contributed the most to the formation of the anomaly, the system uses a method that automatically selects the most anomalous variables. The method is called the Elbow Method [61] and allows starting from a set of variables and their reconstruction errors by automatically selecting those that deviate the most.
- Build anomaly mask: From the selection of the previous phase, a matrix or output mask of dimensions is built and m is the number of rows or records and n is the number of columns or variables, where the anomalous variables are marked with a one and the normal variables with a zero. This information will be used by the subsequent diagnostic module.
4.3. Failure Diagnose
4.3.1. Artificial Failure Mode Generator
4.3.2. Classification Model
5. Results
5.1. Diesel Engine for Propulsion
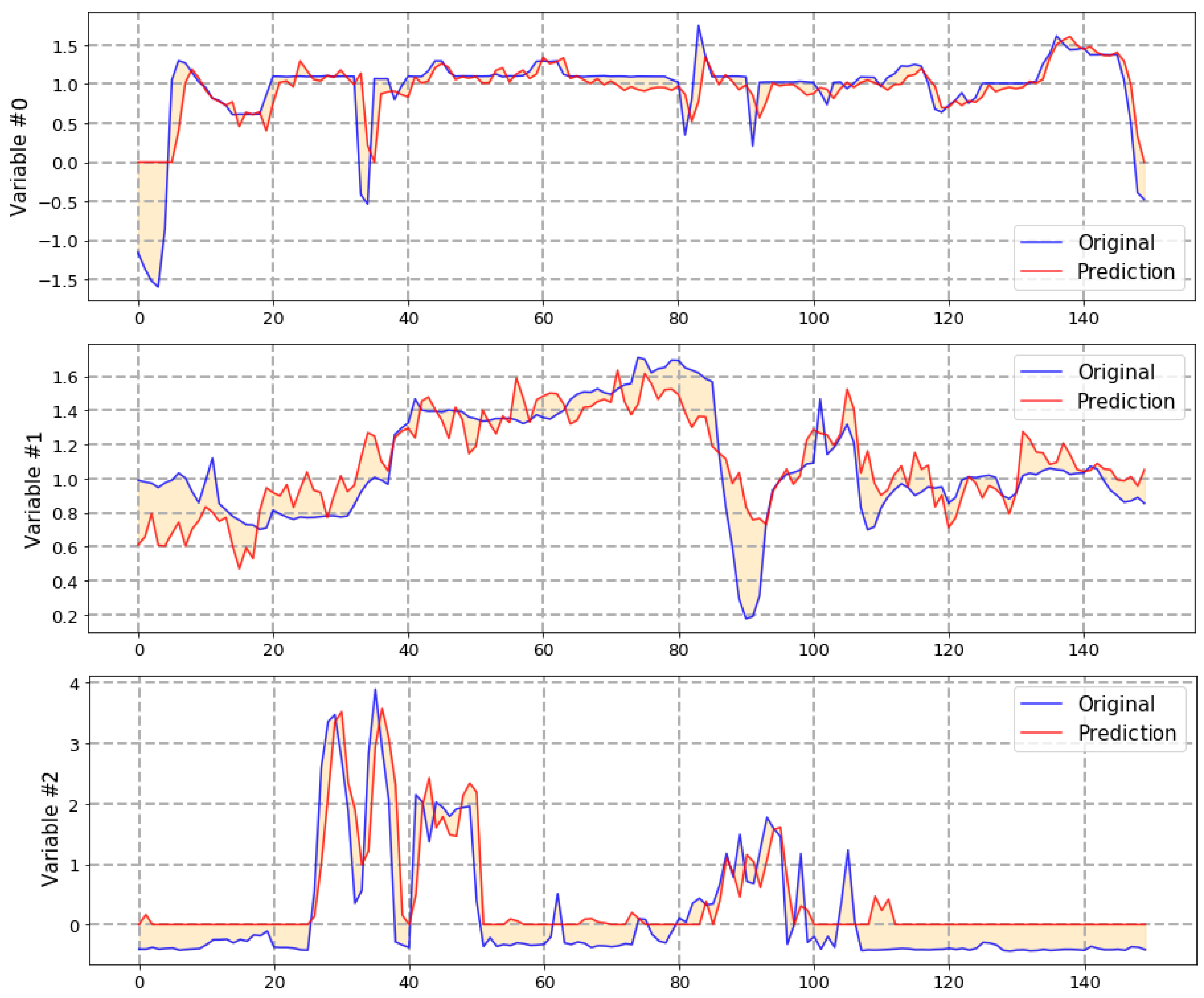
- Prediction: Despite the large data pools available, the RPM filtering rules out a significant piece of data when the engine was off. Due to this, when a large grouping is carried out (for example, 1 data/week or 1 data/month), very few data results. As stated in Section 4.1, it disables the correct convergence of certain models, making each one of them suitable for a specific scenario. Table 2 compares the different techniques and methods, collecting the mean squared errors by using different grouping modes and horizons.As it is possible to observe in the table, LSTM-based methods provide better performances with the lower degree of aggregation. Figure 4 depicts an example of prediction by using a recurrent neural network, where both sudden events and tendencies are correctly predicted. Please note that Figure 4 contains a prediction, while Figure 2 represents the reconstruction error in an autoencoder. On the other hand, Table 2 also illustrates that long-term behaviors are better estimated by simpler regression methods.The prediction system is very sensitive to both the grouping of the data and the sizes of the window and horizon. Furthermore, it has been found that, in general, there is a strong correlation between the variables that pass the selection process. A window size of approximately twice the forecast horizon has been found to be sufficient to achieve good results in most scenarios.
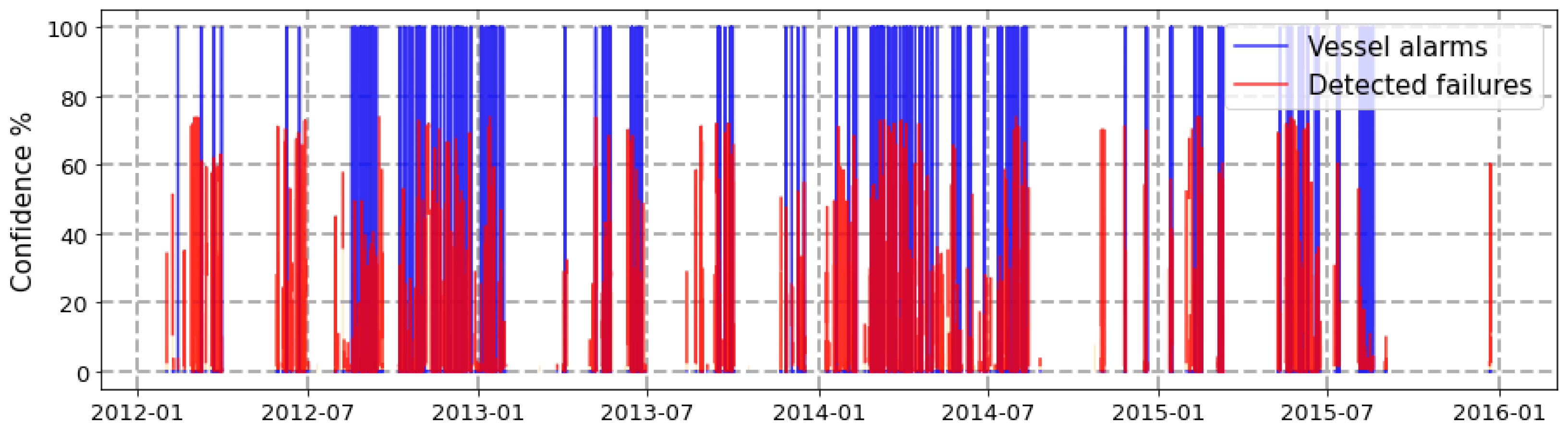
- Anomaly detection: For this stage, two metrics have been used to qualitatively measure the performance of the model during an interval of four years: on the one hand, the anomalies detected by the model have been correlated with the warship’s engine alarm system. Although, this system does not collect malfunctions but operative conditions, it is possible to observe an indirect relation between them (see Figure 5). On the other hand, the results have been analyzed by maintenance experts which focused on specific known events. The unsupervised trained autoencoder model has been tested and the results have been satisfactory. The model was able to detect most of these anomalies, as can be observed in Figure 6. The value of this graph is found in the coincidences between signals along the x-axis.It should also be noted that this process is very sensitive to parameterization and can be configured to allow the passage of more or less anomalies through the reconstruction threshold and, within these, select a greater or lesser number of variables involved by using the Elbow Method parameters.
- Failure diagnose: Using artificial datasets based on the engine’s design values (described in the Failure mode effects and criticality analysis, FMECA) has allowed us to build classification models that determine which failure modes are occurring. However, this theoretical behavior of the engine does not have to always correspond to reality, since its operation may vary with the use, replacement or repair of parts, etc. The training of diagnostic models depends directly on this generator and so it is necessary to build a sufficiently large and varied dataset.
5.2. Diesel Engine for Power Generation
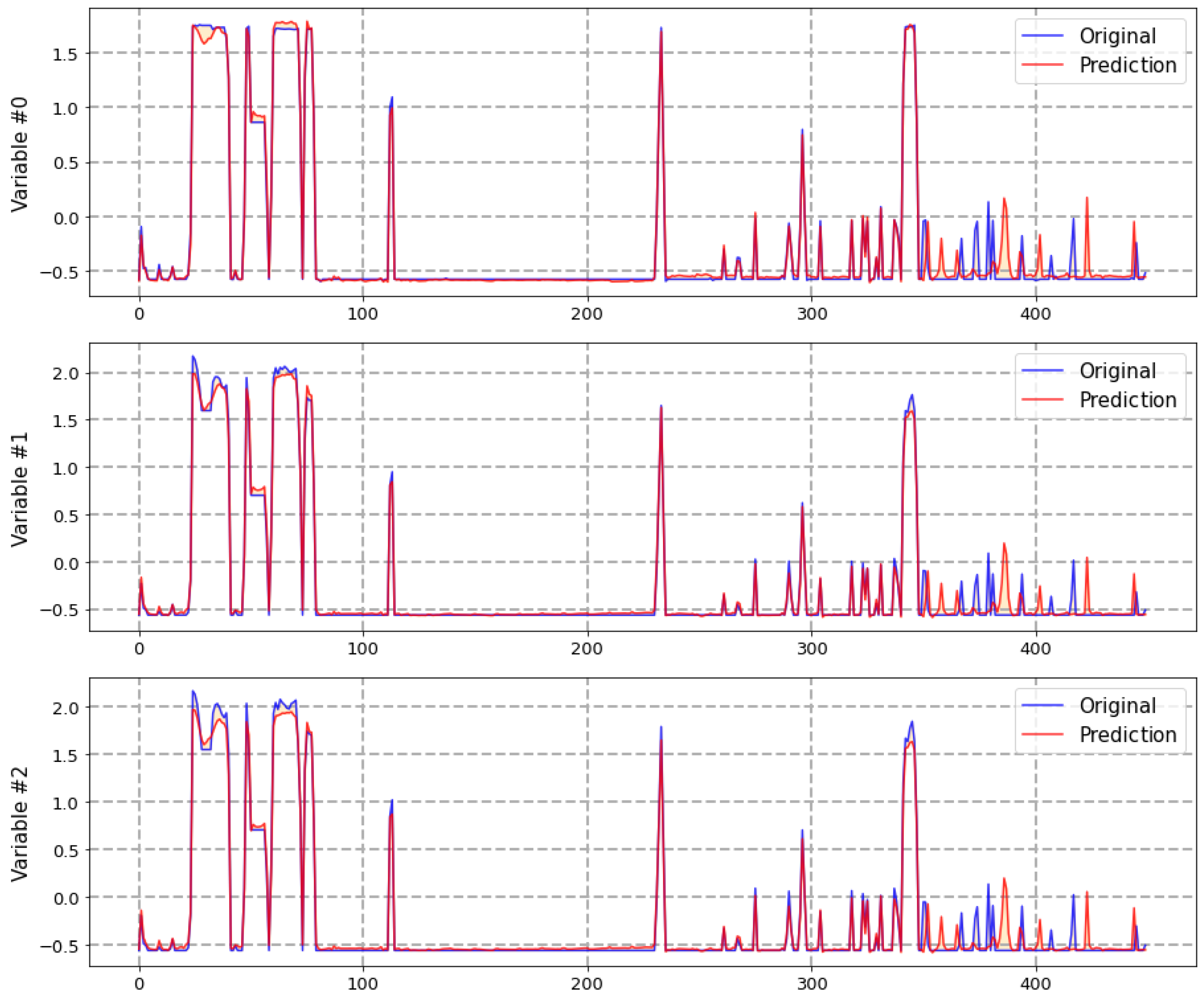
- Prediction: Similarly to the propulsion engine, data grouping has a large impact on the amount of data available for training and validation of the diesel generator models. This happens even though the availability of a large amount of data (five ships with four engines each one) after aggregation and filtering the amount of available data for training and validation is limited. The flexibility of the SOPRENE architecture allowed the application of two types of models depending on the data aggregation: Deep LSTM networks for data grouped by days and weeks and regularized (L1, L2 and ElasticNet) lineal models for weeks and months. Linear models showed a strong tendency to underfit data grouped by days, while there were insufficient data to train LSTM networks with data grouped by months. Table 3 summarizes a comparison of the MSE measured in validation for lineal models and LSTM-based network for a 10 units prediction horizon; the best results are marked in bold. An example of prediction with a LSTM network can be observed in Figure 7 that shows three normalized variables corresponding to a certain FMECA failure mode.
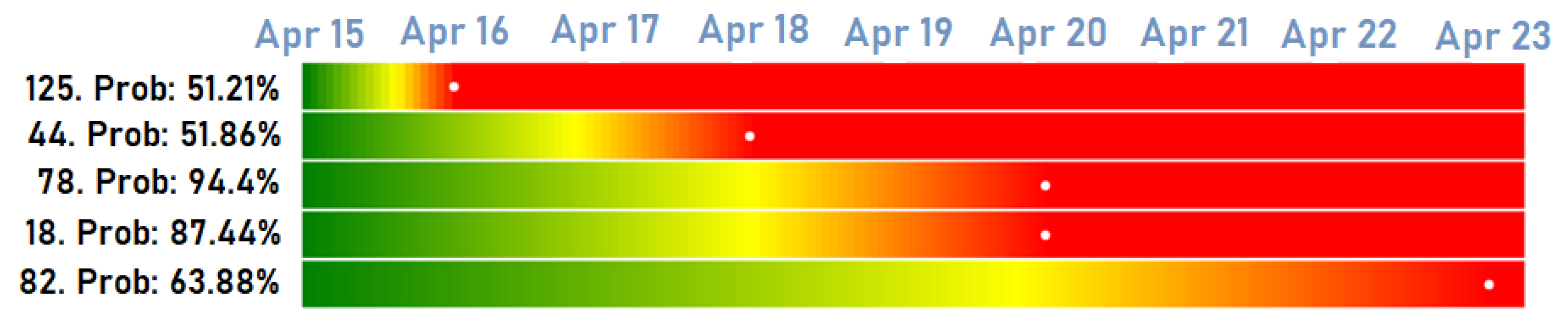
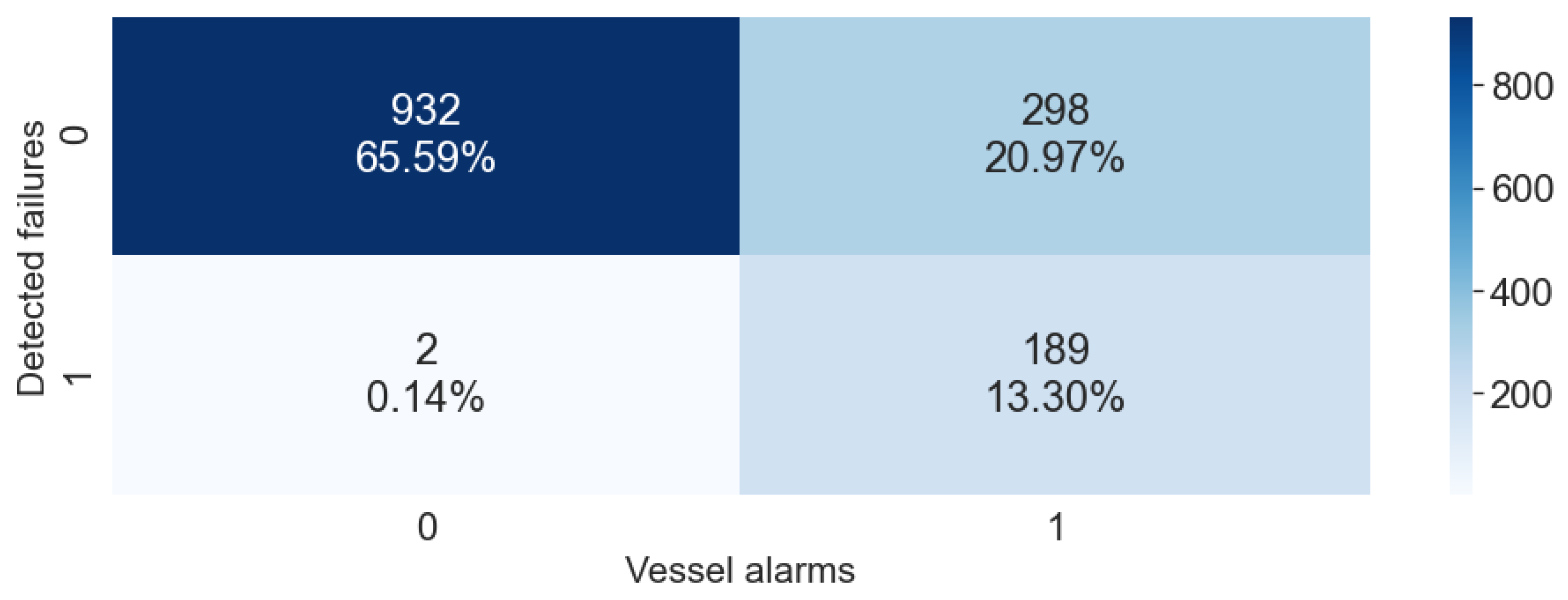
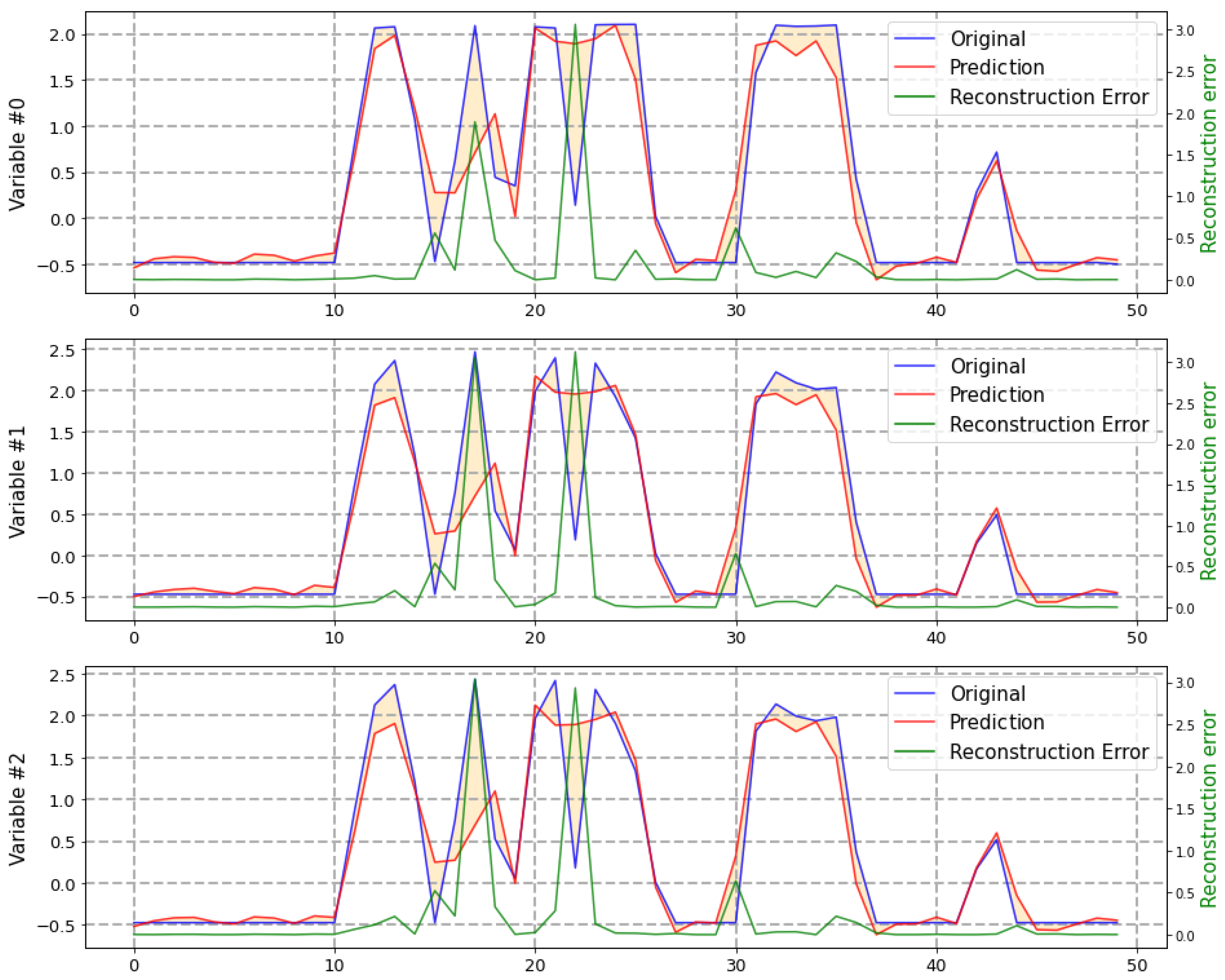
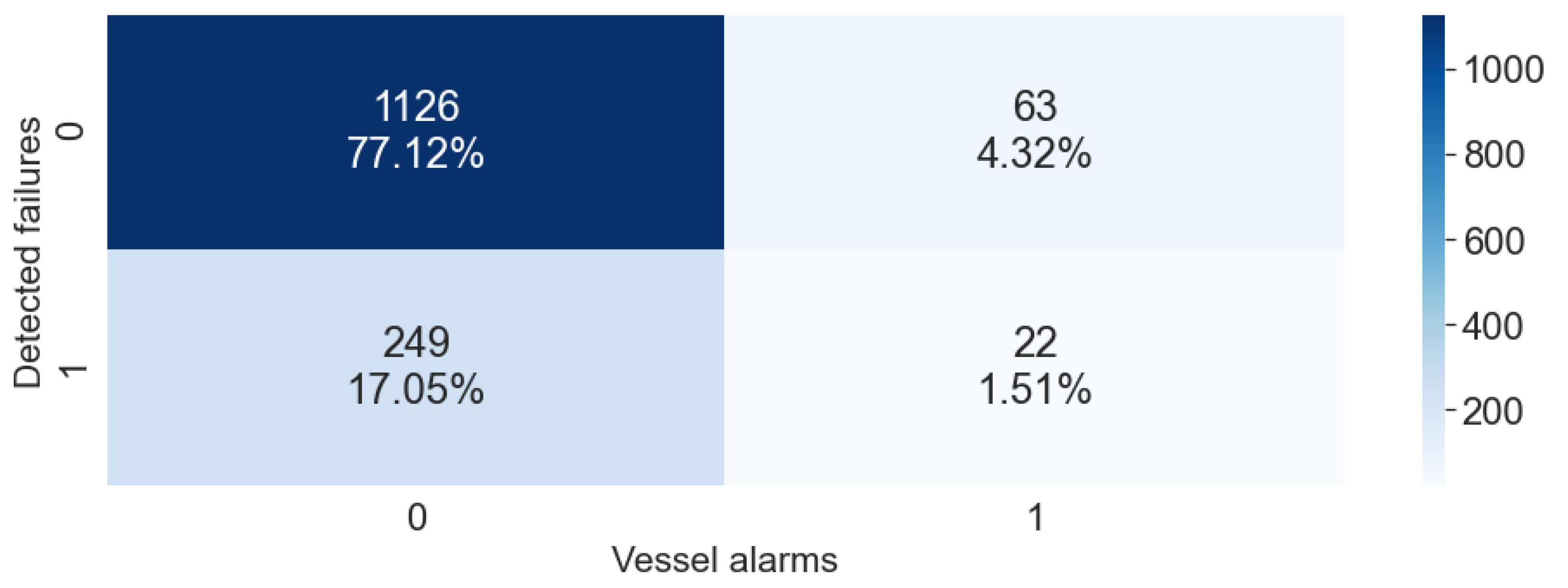
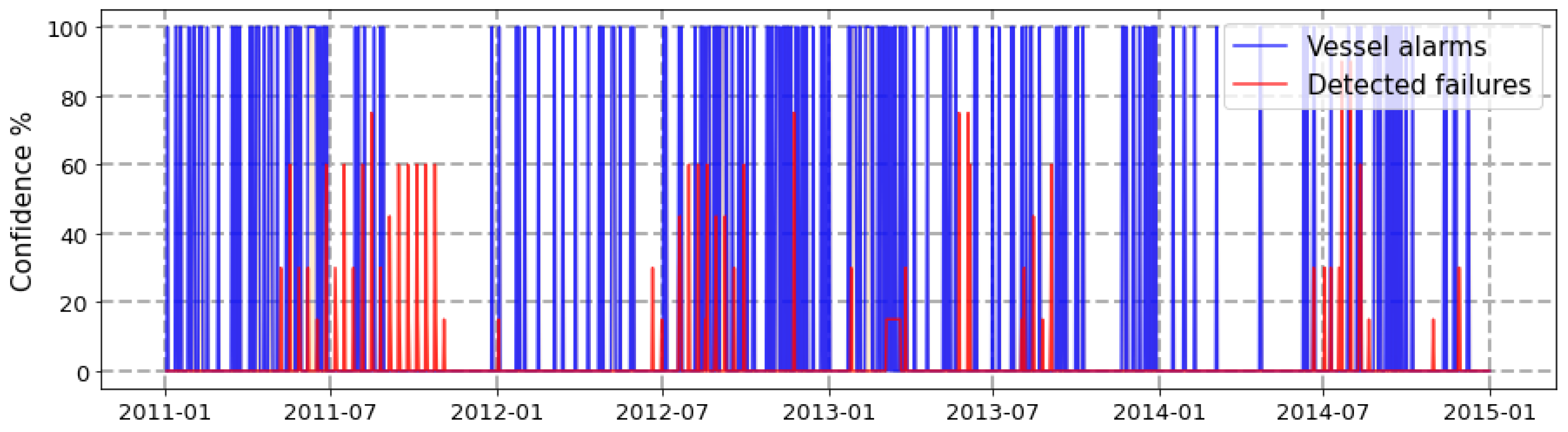
- Anomaly detection: Given the lack of labeled data and the need to quantify the contribution of each attribute to the overall reconstruction error, we implemented the anomaly detection subsystem based on a deep LSTM autoencoder. The autoencoder input is composed by the signals identified by FMECA for a certain failure mode and the output is the reconstruction error of each one of this attributes. Figure 8 shows an example of the real values of three attributes compared with the output given by the autoconder. In this manner, the solution gains in interpretability while the overall reconstruction error is easily computed. Figure 9 shows a confusion matrix comparing the anomalies detected automatically with vessel alarms. Despite the unsupervised nature of the anomaly detector, it is able to detect anomalies that actually correspond to vessel alarms to a great extent. Figure 10 shows a different perspective of the anomaly detector. It shows a timeline with the vessels detected by human experts (blue) with the automatic anomaly detector (red). There is an evident difference in the level of confidence given by each detection method, but it is easily adjusted by a threshold.
- Failure diagnosis: The main challenge in training the diagnosis model is to obtain a significant amount of data corresponding to the failure modes that are to be identified. Even though the datasets involved four years and five vessels, the presence of failure modes is limited in the extreme sense. A potential solution is to simulate the failure modes with thermodynamic models, but this was not an option in this context. The solution adopted was to synthesize data in each of the failure modes of interest by using the domain knowledge contained in FMECA. Of course the resulting synthetic dataset will not conserve all the complex behavior found in the engine, but the goal is actually to capture the information contained in FMECA with some variability to avoid overfitting. The system in charge of diagnosing the engine state for each failure mode identified in the FMECA is a MLP for which its input is the engine state and its output is a probability of occurrence of the given failure mode.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Mobley, K. An Introduction to Predictive Maintenance; Elsevier: Amsterdam, The Netherlands, 2002. [Google Scholar]
- Huda, A.N.; Taib, S. Application of infrared thermography for predictive/preventive maintenance of thermal defect in electrical equipment. Appl. Therm. Eng. 2013, 61, 220–227. [Google Scholar] [CrossRef]
- Durocher, D.B.; Feldmeier, G.R. Predictive versus preventive maintenance. IEEE Ind. Appl. Mag. 2004, 10, 12–21. [Google Scholar] [CrossRef]
- Selcuk, S. Predictive maintenance, its implementation and latest trends. Proc. Inst. Mech. Eng. Part B J. Eng. Manuf. 2017, 231, 1670–1679. [Google Scholar] [CrossRef]
- Motaghare, O.; Pillai, A.S.; Ramachandran, K.I. Predictive Maintenance Architecture. In Proceedings of the 2018 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 13–15 December 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Kanawaday, A.; Sane, A. Machine learning for predictive maintenance of industrial machines using IoT sensor data. In Proceedings of the 2017 8th IEEE International Conference on Software Engineering and Service Science (ICSESS), Beijing, China, 24–26 November 2017; pp. 87–90. [Google Scholar]
- Canizo, M.; Onieva, E.; Conde, A.; Charramendieta, S.; Trujillo, S. Real-time predictive maintenance for wind turbines using Big Data frameworks. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 70–77. [Google Scholar]
- Wang, J.; Liang, Y.; Zheng, Y.; Gao, R.X.; Zhang, F. An integrated fault diagnosis and prognosis approach for predictive maintenance of wind turbine bearing with limited samples. Renew. Energy 2020, 145, 642–650. [Google Scholar] [CrossRef]
- Budai, G.; Huisman, D.; Dekker, R. Scheduling preventive railway maintenance activities. J. Oper. Res. Soc. 2006, 57, 1035–1044. [Google Scholar] [CrossRef] [Green Version]
- Byington, C.S.; Roemer, M.J.; Galie, T. Prognostic enhancements to diagnostic systems for improved condition-based maintenance [military aircraft]. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 9–16 March 2002; Volume 6, p. 6. [Google Scholar]
- Fernández Jove, A.; Mackinlay, A.; Riola, J.M. Optimization of the Life Cycle in the Warships: Maintenance Plan and Monitoring for Costs Reduction. In Proceedings of the VI International Ship Design & Naval Engineering Congress (CIDIN) and XXVI Pan-American Congress of Naval Engineering, Maritime Transportation and Port Engineering (COPINAVAL); Springer: Cham, Switzerland, 2019; pp. 391–401. [Google Scholar]
- Lamas-López, F. Evolution of logistical support in the Spanish Navy through 4.0 technologies. In Proceedings of the 18th Conference of the Spanish Association for Artificial Intelligence (CAEPIA), Granada, Spain, 23–26 October 2018; pp. 1345–1350. [Google Scholar]
- IEC. Failure Modes and Effects Analysis (FMEA and FMECA); Technical Report, IEC Standard Number 60812:2018; International Electrotechnical Commission: London, UK, 2018. [Google Scholar]
- Ran, Y.; Zhou, X.; Lin, P.; Wen, Y.; Deng, R. A Survey of Predictive Maintenance: Systems, Purposes and Approaches. arXiv 2019, arXiv:1912.07383. [Google Scholar]
- He, Y.; Han, X.; Gu, C.; Chen, Z. Cost-oriented predictive maintenance based on mission reliability state for cyber manufacturing systems. Adv. Mech. Eng. 2018, 10, 1687814017751467. [Google Scholar] [CrossRef] [Green Version]
- Lin, L.; Luo, B.; Zhong, S. Multi-objective decision-making model based on CBM for an aircraft fleet with reliability constraint. Int. J. Prod. Res. 2018, 56, 4831–4848. [Google Scholar] [CrossRef]
- Zhao, J.; Yang, L. A bi-objective model for vessel emergency maintenance under a condition-based maintenance strategy. Simulation 2018, 94, 609–624. [Google Scholar] [CrossRef]
- Xiang, Y.; Coit, D.; Zhu, Z. A Multi-objective Joint Burn-in and Imperfect Condition-based Maintenance Model for Degradation-based Heterogeneous Populations. Qual. Reliab. Eng. Int. 2016, 32, 2739–2750. [Google Scholar] [CrossRef]
- Song, S.; Coit, D.W.; Feng, Q. Reliability analysis of multiple-component series systems subject to hard and soft failures with dependent shock effects. IIE Trans. 2016, 48, 720–735. [Google Scholar] [CrossRef]
- Gravette, M.A.; Barker, K. Achieved availability importance measure for enhancing reliability-centered maintenance decisions. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2015, 229, 62–72. [Google Scholar] [CrossRef]
- Konys, A. An Ontology-Based Knowledge Modelling for a Sustainability Assessment Domain. Sustainability 2018, 10, 300. [Google Scholar] [CrossRef] [Green Version]
- Peng, Y.; Dong, M.; Zuo, M.J. Current status of machine prognostics in condition-based maintenance: A review. Int. J. Adv. Manuf. Technol. 2010, 50, 297–313. [Google Scholar] [CrossRef]
- Chen, N.; Ye, Z.S.; Xiang, Y.; Zhang, L. Condition-based mainte-nance using the inverse gaussian degradation model Assessment Domain. Eur. J. Oper. Res. 2015, 243, 190–199. [Google Scholar] [CrossRef]
- Lucifredi, A.; Mazzieri, C.; Rossi, M. Application of multiregressive linear models, dynamic kriging models and neural network models to predictive maintenance of hydroelectric power systems. Mech. Syst. Signal Process. 2000, 14, 471–494. [Google Scholar] [CrossRef]
- Calder, M.; Sevegnani, M. Stochastic Model Checking for Predicting Component Failures and Service Availability. IEEE Trans. Dependable Secur. Comput. 2019, 16, 174–187. [Google Scholar] [CrossRef] [Green Version]
- Samanta, B.; Al-Balushi, K. Artificial Neural Network based fault diagnostics of rolling element bearings using time-domain features. Mech. Syst. Signal Process. 2003, 17, 317–328. [Google Scholar] [CrossRef]
- Quinlan, J.R. Improved Use of Continuous Attributes in C4.5. J. Artif. Intell. Res. 1996, 4, 77–90. [Google Scholar] [CrossRef] [Green Version]
- Shi, J.; Niu, N.; Zhu, X. A Fault Diagnosis Method for Multi-Condition System Based on Random Forest. In Proceedings of the 2019 Prognostics and System Health Management Conference (PHM-Paris), Paris, France, 2–5 May 2019; pp. 350–355. [Google Scholar]
- Chen, Y.; He, Y.; Li, Z.; Chen, L.; Zhang, C. Remaining Useful Life Prediction and State of Health Diagnosis of Lithium-ion Battery based on Second-order Central Difference Particle Filter. IEEE Access 2020, 8, 37305–37313. [Google Scholar] [CrossRef]
- Ratsch, G.; Mika, S.; Scholkopf, B.; Muller, K. Constructing boosting algorithms from SVMs: An application to one-class classification. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 1184–1199. [Google Scholar] [CrossRef] [Green Version]
- Susto, G.A.; Schirru, A.; Pampuri, S.; McLoone, S.; Beghi, A. Machine Learning for Predictive Maintenance: A Multiple Classifier Approach. IEEE Trans. Ind. Inform. 2015, 11, 812–820. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Mei, W.; Zeng, X.; Yang, C.; Zhou, X. Remaining Useful Life Estimation of Insulated Gate Biploar Transistors (IGBTs) Based on a Novel Volterra k-Nearest Neighbor Optimally Pruned Extreme Learning Machine (VKOPP) Model Using Degradation Data. Sensors 2017, 17, 2524. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, X.L.; Wang, P.H.; Hao, Y.S.; Zhao, M. Evidential KNN-based condition monitoring and early warning method with applications in power plant. Neurocomputing 2018, 315, 18–32. [Google Scholar] [CrossRef]
- Ma, M.; Sun, C.; Chen, X. Deep Coupling Autoencoder for Fault Diagnosis With Multimodal Sensory Data. IEEE Trans. Ind. Inform. 2018, 14, 1137–1145. [Google Scholar] [CrossRef]
- Yuan, J.; Tian, Y. An Intelligent Fault Diagnosis Method Using GRU Neural Network towards Sequential Data in Dynamic Processes. Processes 2019, 7, 152. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Huang, M.; Lu, Q.; Zhong, M. Rotating Machinery Fault Diagnosis Using Long-short-term Memory Recurrent Neural Network. IFAC PapersOnLine 2018, 51, 228–232. [Google Scholar] [CrossRef]
- Simões, A.; Viegas, J.M.; Farinha, J.T.; Fonseca, I. The State of the Art of Hidden Markov Models for Predictive Maintenance of Diesel Engines. Qual. Reliab. Eng. Int. 2017, 33, 2765–2779. [Google Scholar] [CrossRef]
- Nixon, S.; Weichel, R.; Reichard, K.; Kozlowski, J. A machine learning approach to diesel engine health prognostics using engine controller data. In Proceedings of the PHM2018—Annual Conference of the Prognostics and Health Management Society, Philadelphia, PA, USA, 24–27 September 2018. [Google Scholar]
- Hong, C.W.; Lee, C.; Lee, K.; Ko, M.S.; Kim, D.E.; Hur, K. Remaining useful life prognosis for turbofan engine using explainable deep neural networks with dimensionality reduction. Sensors 2020, 20, 6626. [Google Scholar] [CrossRef]
- UNCTAD. Review of Maritime Transport; Technical Report UNCTAD/RMT/2015; United Nations Conference on Trade and Development: New York, NY, USA, 2015. [Google Scholar]
- Karatuğ, Ç.; Arslanoğlu, Y. Importance of early fault diagnosis for marine diesel engines: A case study on efficiency management and environment. Ships Offshore Struct. 2020. [Google Scholar] [CrossRef]
- Lazakis, I.; Gkerekos, C.; Theotokatos, G. Investigating an SVM-driven, one-class approach to estimating ship systems condition. Ships Offshore Struct. 2019, 14, 432–441. [Google Scholar] [CrossRef]
- Stopford, M. Maritime Economics 3e; Routledge: London, UK, 2008. [Google Scholar]
- Park, P.; Marco, P.D.; Shin, H.; Bang, J. Fault detection and diagnosis using combined autoencoder and long short-term memory network. Sensors 2019, 19, 4612. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tsitsilonis, K.M.; Theotokatos, G. Engine malfunctioning conditions identification through instantaneous crankshaft torque measurement analysis. Appl. Sci. 2021, 11, 3522. [Google Scholar] [CrossRef]
- Bampoula, X.; Siaterlis, G.; Nikolakis, N.; Alexopoulos, K. A Deep Learning Model for Predictive Maintenance in Cyber-Physical Production Systems Using LSTM Autoencoders. Sensors 2021, 21, 972. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.G.; Choi, J.Y. Optimization of Design Parameters in LSTM Model for Predictive Maintenance. Appl. Sci. 2021, 11, 6450. [Google Scholar] [CrossRef]
- Wu, J.Y.; Wu, M.; Chen, Z.; Li, X.L.; Yan, R. Degradation-Aware Remaining Useful Life Prediction With LSTM Autoencoder. IEEE Trans. Instrum. Meas. 2021, 70, 1–10. [Google Scholar] [CrossRef]
- Liu, Q.; Liu, S.; Dai, Q.; Yu, X.; Teng, D.; Wei, M. Data-Driven Approaches for Diagnosis of Incipient Faults in Cutting Arms of the Roadheader. Shock Vib. 2021, 2021, 8865068. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Yin, Q. The Temperature Forecast of Ship Propulsion Devices from Sensor Data. Information 2019, 10, 316. [Google Scholar] [CrossRef] [Green Version]
- Coraddu, A.; Oneto, L.; Ghio, A.; Savio, S.; Anguita, D.; Figari, M. Machine learning approaches for improving condition-based maintenance of naval propulsion plants. Proc. Inst. Mech. Eng. Part M J. Eng. Marit. Environ. 2016, 230, 136–153. [Google Scholar] [CrossRef]
- Cai, B.; Sun, X.; Wang, J.; Yang, C.; Wang, Z.; Kong, X.; Liu, Z.; Liu, Y. Fault detection and diagnostic method of diesel engine by combining rule-based algorithm and BNs/BPNNs. J. Manuf. Syst. 2020, 57, 148–157. [Google Scholar] [CrossRef]
- Gkerekos, C.; Lazakis, I.; Theotokatos, G. Machine learning models for predicting ship main engine Fuel Oil Consumption: A comparative study. Ocean Eng. 2019, 188, 106282. [Google Scholar] [CrossRef]
- Uyanık, T.; Karatuğ, Ç.; Arslanoğlu, Y. Machine learning approach to ship fuel consumption: A case of container vessel. Transp. Res. Part D Transp. Environ. 2020, 84, 102389. [Google Scholar] [CrossRef]
- Cheliotis, M.; Gkerekos, C.; Lazakis, I.; Theotokatos, G. A novel data condition and performance hybrid imputation method for energy efficient operations of marine systems. Ocean Eng. 2019, 188, 106220. [Google Scholar] [CrossRef]
- Tan, Y.; Niu, C.; Tian, H.; Lin, Y.; Zhang, J. Decay detection of a marine gas turbine with contaminated data based on isolation forest approach. Ships Offshore Struct. 2021, 16, 546–556. [Google Scholar] [CrossRef]
- Makridis, G.; Kyriazis, D.; Plitsos, S. Predictive maintenance leveraging machine learning for time-series forecasting in the maritime industry. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Tan, Y.; Niu, C.; Tian, H.; Hou, L.; Zhang, J. A one-class SVM based approach for condition-based maintenance of a naval propulsion plant with limited labeled data. Ocean Eng. 2019, 193, 106592. [Google Scholar] [CrossRef]
- Smart, E.; Grice, N.; Ma, H.; Garrity, D.; Brown, D. One class classification based anomaly detection for marine engines. In Intelligent Systems: Theory, Research and Innovation in Applications; Studies in Computational Intelligence; Springer International Publishing: Cham, Switzerland, 2020; Volume 864, pp. 223–245. [Google Scholar] [CrossRef]
- Frey, B.B. (Ed.) The SAGE Encyclopedia of Educational Research, Measurement, and Evaluation; AGE Publications, Inc.: Thousand Oaks, CA, USA, 2018. [Google Scholar]
- Bholowalia, P.; Kumar, A. Article: EBK-Means: A Clustering Technique based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 17–24. [Google Scholar]
- Marius, P.; Balas, V.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Id | Signal | Nominal Value | Threshold Value | Tendency |
|---|---|---|---|---|
| 31 | Variable 1 | 1.3 | 2 | ↑ |
| Variable 2 | 5.4 | 5 | ↓ | |
| Variable 3 | 55 | 60 | ↑ |
| Horizon = 5 | Horizon = 10 | |||||
|---|---|---|---|---|---|---|
| Algorithm | D | W | M | H | D | W |
| Linear Regression | 0.65 | 0.36 | 0.22 | 0.64 | 0.35 | 0.27 |
| L1 | 0.62 | 0.36 | 0.22 | 0.61 | 0.32 | 0.25 |
| L2 | 0.60 | 0.33 | 0.20 | 0.64 | 0.31 | 0.24 |
| Elastic Net | 0.56 | 0.32 | 0.15 | 0.57 | 0.33 | 0.06 |
| LSTM | 0.41 | 0.28 | 0.16 | 0.40 | 0.27 | 0.16 |
| Algorithm | D | W | M |
|---|---|---|---|
| Linear Regression | - | ||
| L1 | - | 0.49 | |
| L2 | - | ||
| Elastic Net | - | ||
| LSTM | 0.31 | 0.59 | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fernández-Barrero, D.; Fontenla-Romero, O.; Lamas-López, F.; Novoa-Paradela, D.; R-Moreno, M.D.; Sanz, D. SOPRENE: Assessment of the Spanish Armada’s Predictive Maintenance Tool for Naval Assets. Appl. Sci. 2021, 11, 7322. https://doi.org/10.3390/app11167322
Fernández-Barrero D, Fontenla-Romero O, Lamas-López F, Novoa-Paradela D, R-Moreno MD, Sanz D. SOPRENE: Assessment of the Spanish Armada’s Predictive Maintenance Tool for Naval Assets. Applied Sciences. 2021; 11(16):7322. https://doi.org/10.3390/app11167322
Chicago/Turabian StyleFernández-Barrero, David, Oscar Fontenla-Romero, Francisco Lamas-López, David Novoa-Paradela, María D. R-Moreno, and David Sanz. 2021. "SOPRENE: Assessment of the Spanish Armada’s Predictive Maintenance Tool for Naval Assets" Applied Sciences 11, no. 16: 7322. https://doi.org/10.3390/app11167322