1. Introduction
The deep learning (DL) computing paradigm has been deemed the gold standard in the medical image analysis field. It has been exhibiting excellent performance in several medical imaging areas, such as pathology [
1], dermatology [
2], radiology [
3,
4], and ophthalmology [
5,
6], which are the most competitive fields requiring human specialists. The recent approaches within DL being adapted to the direction of clinical alteration commonly depend on a large volume of highly reliable annotated images. Low-resource settings generate different issues, such as gathering highly reliable data, which turn out to be the bottleneck for advancing deep learning applications.
Learning from limited labeled images is a primary concern in the field of medical image analysis using DL since the image annotation process is cost-effective and time-consuming. On the other hand, DL requires a large number of medical images to perform well. Then, transfer learning (TL) has been proposed in this paper to overcome this challenging issue.
Transfer learning (TL) represents the key to success for a variety of effective DL models. Initially, these models are pretrained using a source dataset. They are then fine-tuned using the target task. It has been revealed to be an efficient method when there is a lack of target data. This is commonly found in medical imaging due to the difficulty of collecting medical image datasets. The ILSVRC-2012 competition of ImageNet [
7] is the most well-known pretraining dataset and has been extensively utilized to improve the performance of image processing tasks such as segmentation, detection, and classification [
8,
9,
10].
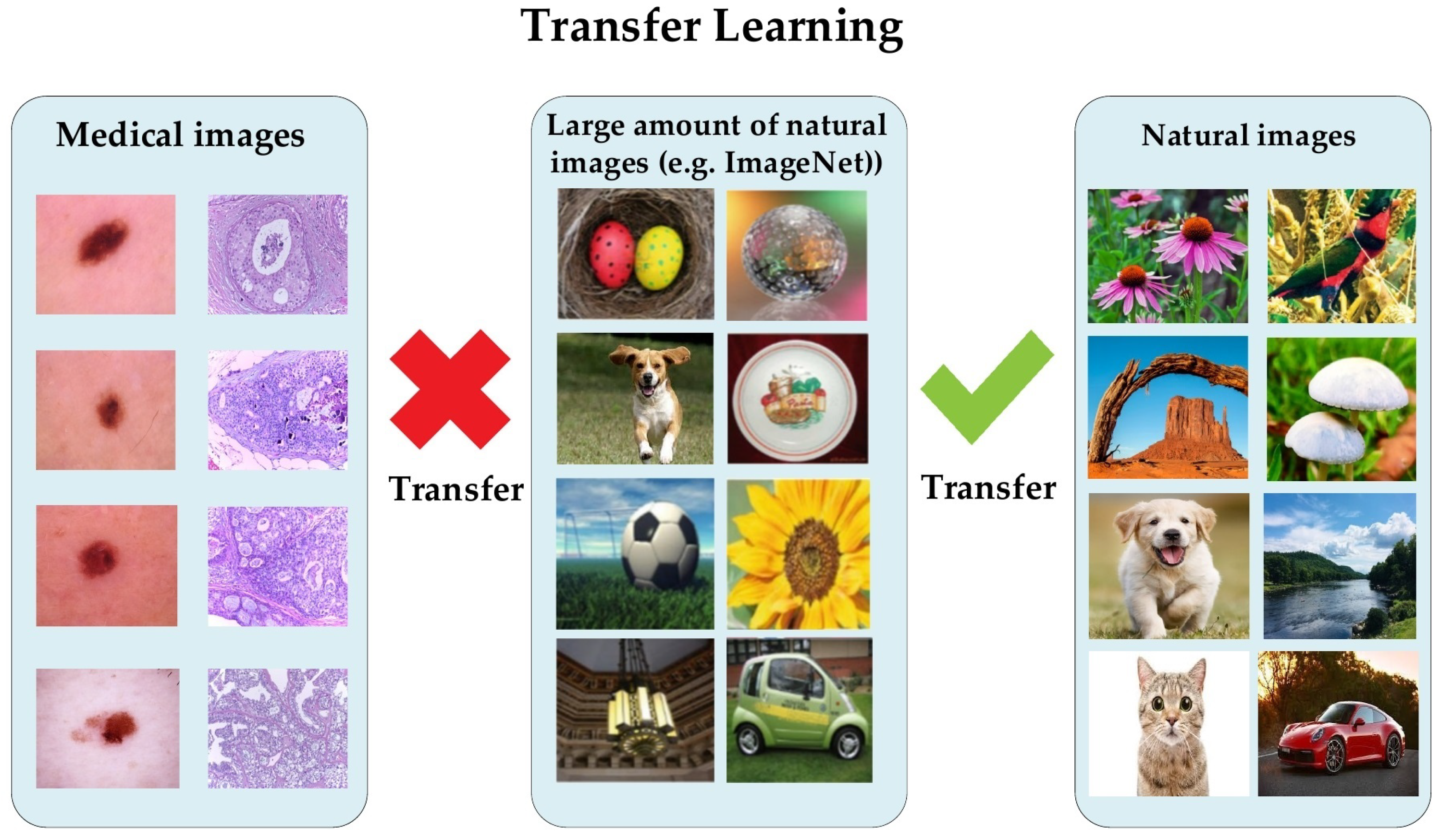
Conversely, it has been proven that a lightweight model trained from scratch on medical images performed nearly the same as a pretrained model on the ImageNet dataset [
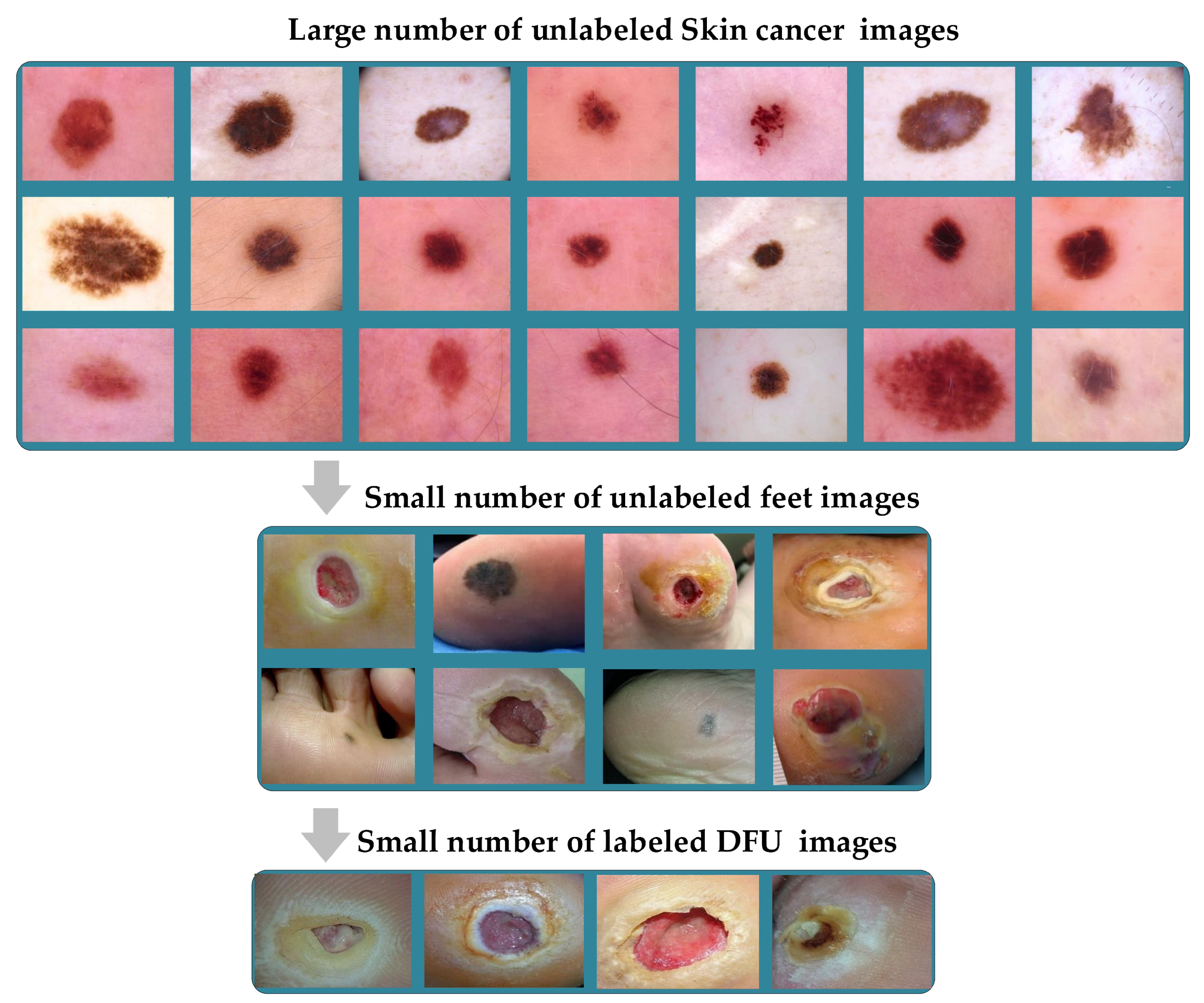
11]. The natural images of ImageNet are different from medical images in several aspects, regarding shapes, colors, resolution, and dimensionality (see
Figure 1). Recently, Alzubaidi et al. analyzed the benefits of using pretrained models and proved that they are limited in terms of performance improvement dealing with medical images. The authors empirically showed that in-domain TL can improve the performance against the pretrained ImageNet models [
12,
13,
14]. Moreover, it is unnecessary to utilize deeply elaborated models in order to achieve successful results tackling binary classification tasks.
In recent years, there has been significant growth in the amount of unlabeled medical image data facing several tasks. To take advantage of this, we propose transferring the learning knowledge from a large amount of unlabeled medical image data to the small amount of labeled image data of the target dataset. The proposed approach offers several benefits; (i) shortening the annotation process, (ii) benefitting from the availability of large unlabeled medical imaging datasets, (iii) reducing the effort and cost, (iv) guaranteeing that the deep learning model learns the relevant features, and (v) the ability to learn effectively with a small amount of labeled medical images. To prove the effectiveness of the proposed approach, we adopted in this paper two challenging medical imaging scenarios dealing with the skin and breast cancer.
One of the deadliest and fastest-spreading cancers in the world is skin cancer. Seventy-five percent of skin cancer patients die every year [
15,
16,
17,
18], while in the USA, there is a risk of skin cancer in every five people who mostly have pale skin and live in an extremely sunny area [
15]. In 2017, more than 87,000 emerging cases of melanoma are expected to be diagnosed in the USA [
18]. In Australia, 1520 people died from melanoma and 642 from non-melanoma in 2015. Early and accurate diagnosis of skin cancer can save a lot of people’s lives through early treatment [
15,
17,
19,
20].
On the other hand, breast cancer is not less dangerous than skin cancer. It is the leading cause of death for women around the world [
21,
22]. In 2018, the World Health Organization stated that, in its estimation, invasive breast cancer caused about 627,000 women to die. This number represents about 15% of all women cancer-related deaths. Globally, the rates of breast cancer are still progressively growing in most countries according to 2020 statistics [
23].
Briefly, the proposed approach is suitable for any medical imaging task that has plenty of unlabeled images with limited labeled images. Furthermore, it can also help to enhance the performance of tasks in the same domain, e.g., the pretrained model on histopathology images of the breast can be used for any task that uses the same image format, such as colon cancer and bone cancer. Another example of its application is that in which the pretrained model on skin cancer images can be used to improve the performance of any task related to skin diseases. To prove this, we fine-tuned the pretrained skin cancer model to be trained on feet skin images to classify them into two classes: either normal or abnormal (diabetic foot ulcer (DFU)). For medical imaging classification tasks with limited unlabeled and labeled images, we also present the concept of double-transfer learning on the diabetic foot ulcer (DFU) classification task. It is a technique that uses the pretrain model of the skin cancer task and then trains it on a small number of unlabeled feet images to improve the learned features. After that, the model is fine-tuned to train on the small labeled dataset. This approach helps in the tasks that have a small number of unlabeled and labeled images.
Our work reveals interesting contributions, as follows:
We demonstrate that the proposed approach of transfer learning from large unlabeled images can lead to excellent performance in medical imaging tasks.
We introduce a hybrid DCNN model that integrates parallel convolutional layers and residual connections along with global average pooling.
We train the proposed model with more than 200,000 unlabeled images of skin cancer and then fine-tune the model for a small dataset of labeled skin cancer to classify them into two classes, namely benign and malignant. We also train the proposed model with more than 200,000 unlabeled hematoxylin–eosin-stained breast biopsy images. We then fine-tune the model for a small dataset of labeled hematoxylin–eosin-stained breast biopsy images to classify them into four classes: invasive carcinoma, in situ carcinoma, benign tumor, and normal tissue.
We apply several data augmentation techniques to overcome the issue of unbalanced data.
We combine all contributions to improve the performance of two challenging tasks: skin and breast cancer classification tasks. In the skin cancer classification, the proposed model achieved an F1-score value of 89.09% when trained from scratch and 98.53% with the proposed approach on SIIM-ISIC Melanoma Classification 2020. The proposed model achieved an F1-score value of 85.29% when trained from scratch and 97.51% with the proposed approach ICIAR-2018 dataset for the breast cancer classification task. The results proved that the first and second contributions are effective in the medical imaging tasks.
We utilize the pretrained skin cancer model to improve the performance DFU classification task by fine-tuning it to train on feet skin images to classify them into two classes, either normal or abnormal. It attained an F1-score value of 86.0% when trained from scratch and 96.25% with transfer learning.
We introduce another type of transfer learning besides the proposed approach, which is double-transfer learning. We achieved an F1-score value of 99.25% with the DFU classification task using this technique.
We test our model trained with the double-transfer learning technique on unseen DFU test set images. Our model achieved an accuracy of 97.7%, which proves that our model is robust against overfitting.
The rest of the paper is organized as follows:
Section 2 describes the literature review.
Section 3 explains the materials and methods.
Section 4 reports the results. Lastly,
Section 5 concludes the paper.
3. Materials and Methods
This section consists of six parts: the proposed approach, the datasets, the data augmentation techniques, the proposed model, the training scenario, and double-transfer learning.
3.1. The Proposed Approach
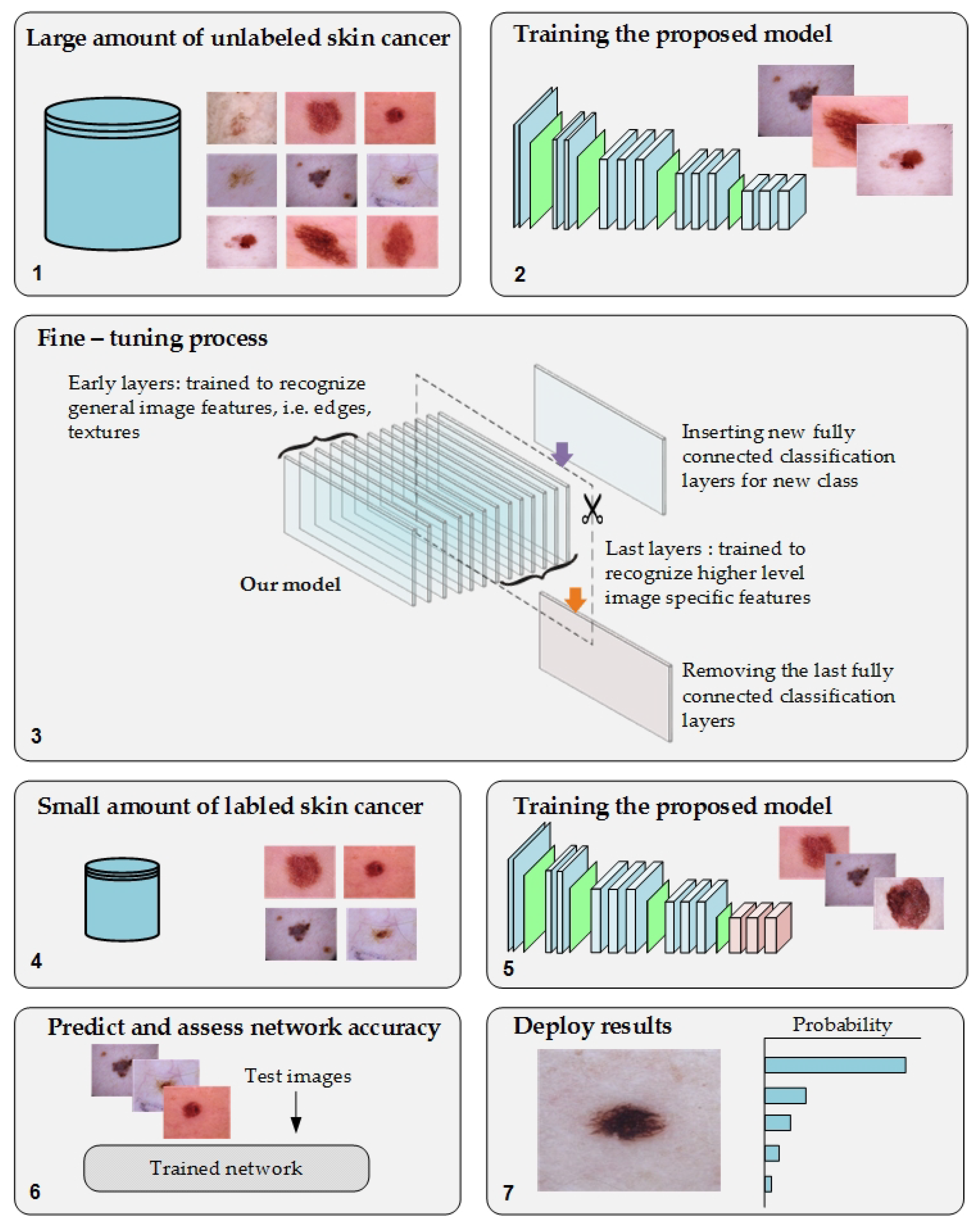
We propose a novel approach of TL to overcome the issues of transfer learning from pretrained models of the ImageNet dataset to medical imaging tasks and the annotation process of medical images. Moreover, it will help to address the issue of the lack of training in medical imaging tasks. The proposed approach was based on training the DL model on a large number of unlabeled images of specific tasks since there is significant growth in the unlabeled medical images. After the fine-tuning process, the model was trained on a small, labeled dataset for that same task.
Figure 2 depicts the workflow of the proposed approach.
This approach guarantees that the model will learn the relevant features and minimize the effort of the labeling process. To test the proposed approach, we employed two challenging medical imaging scenarios dealing with skin and breast cancer classification tasks. Both tasks have a large archive of images. To benefit from that, we used an archive of these tasks to improve the performance of recent datasets of the same tasks. In this paper, we used more than 200,000 unlabeled images of skin cancer to train the proposed model. The model was fine-tuned by considering a small dataset of labeled skin cancers to classify them into two classes, namely benign and malignant. Additionally, the proposed model was trained using more than 200,000 unlabeled hematoxylin–eosin-stained breast biopsy images and, next, fine-tuning the model for a small dataset of labeled hematoxylin–eosin-stained breast biopsy images to classify them in four classes: invasive carcinoma, in situ carcinoma, benign tumor, and normal tissue.
The main purpose of training the model with unlabeled images is to improve the learning stage of the model. Thus, the convergence of weights will be attainable. Since the purpose is for learning and not for the classification stage, the labels do not necessarily need to be accurate. Therefore, we assigned random labels such as giving each dataset in the source dataset the name of the dataset as a label.
The proposed approach is not limited to skin and breast cancer classification tasks. It can be utilized for any medical imaging task that has a large number of unlabeled images with a small number of labeled images. It can also improve the performance of medical imaging tasks in domain, as explained in the double-transfer learning section.
3.2. Dataset
This part consists of two main subparts. The first subpart describes the source datasets of both the skin and breast cancer tasks. The purpose of these datasets is to generate a pretrain model for the target dataset. The second subpart describes the target dataset of both the skin and breast cancer tasks.
3.2.1. Source Dataset
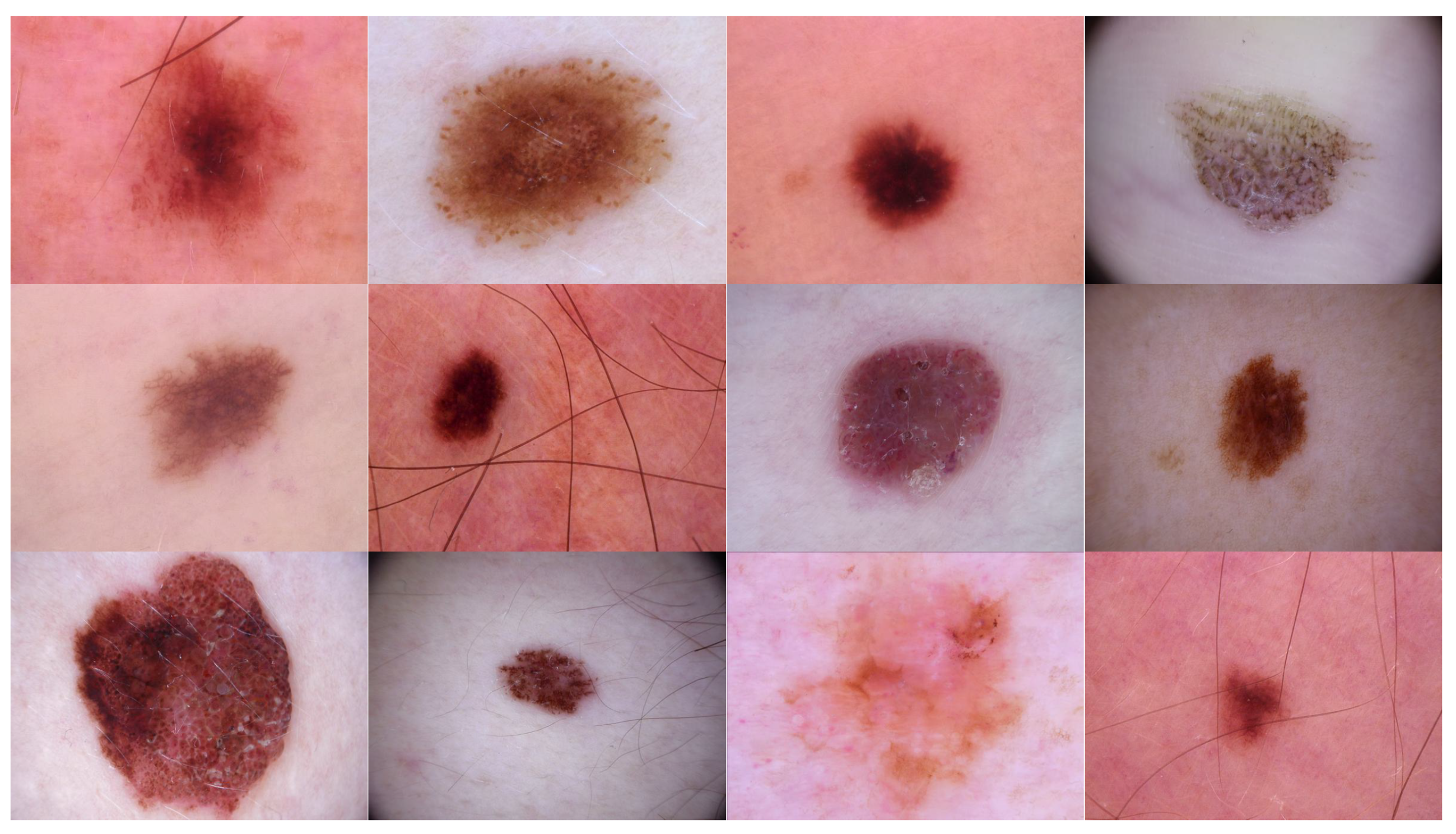
Source domain dataset of skin cancer: The main source of this dataset is the ISIC Challenges datasets (2016, 2017, 2018, 2019, and 2020) of skin lesion classification tasks [
20,
45,
46,
47,
48,
49]. The total number of images is 81,475. We added 100 melanoma and 70 naevus images of the MED-NODE dataset [
50]. The last source is the Dermofit dataset, which consists of 1300 skin lesion images of malignant and benign [
51]. All collected images were duplicated to more than 200,000 images by using data augmentation techniques.
Figure 3 shows some samples of the dataset.
Source domain dataset of breast cancer: we collected the histopathology images of breasts from various sources. The first source is the BreakHis dataset [
52]. This dataset is composed of 9109 microscopic images of breast tumor tissue with a size of 700 × 460 pixels. Each image was divided into two images of 350 × 230 and then resized to 512 × 512. The second source is the histopathological microscopy image dataset of IDC [
53]. It consists of 922 images with sizes of 2100 × 1574 and 1276 × 956 pixels. The third source is the breast cancer dataset, which is composed of 537 H&E-stained histopathological images with a size of 2200 × 2200 pixels [
54]. The fourth source is the BreCaHAD dataset [
55]. This dataset consists of 162 breast cancer histopathology images with a size of 1360 × 1024 pixels. The fifth source is the SPIE-AAPM-NCI BreastPathQ dataset [
56], which is composed of 2579 patches of histopathology images of the breast. These patches were extracted from 96 images with a size of 512 × 512. The sixth source is the image dataset from the bioimaging 2015 breast histology classification challenge [
57]. There are 249 images with a size of 2040 × 1536 pixels. All the images of sources two to six were divided into 12 nonoverlapping patches of 512 × 512 sizes. The total was 50,314 breast histology patches. All collected patches were duplicated to more than 200,000 images by using data augmentation techniques. It is worth mentioning that we cropped the images to 512 × 512 to fit the input size of the model. This guarantees that the proposed model detects the features that define the nucleus-localized organization and the overall tissue architecture required to distinguish between the classes. Conversely, taking a small size could result in a loss of information associated with the same assigned class of the entire image.
Figure 4 shows some samples of the dataset.
3.2.2. Target Dataset
Target dataset of skin cancer: The proposed model has been trained and tested after TL from the source skin cancer dataset on the SIIM-ISIC 2020 dataset [
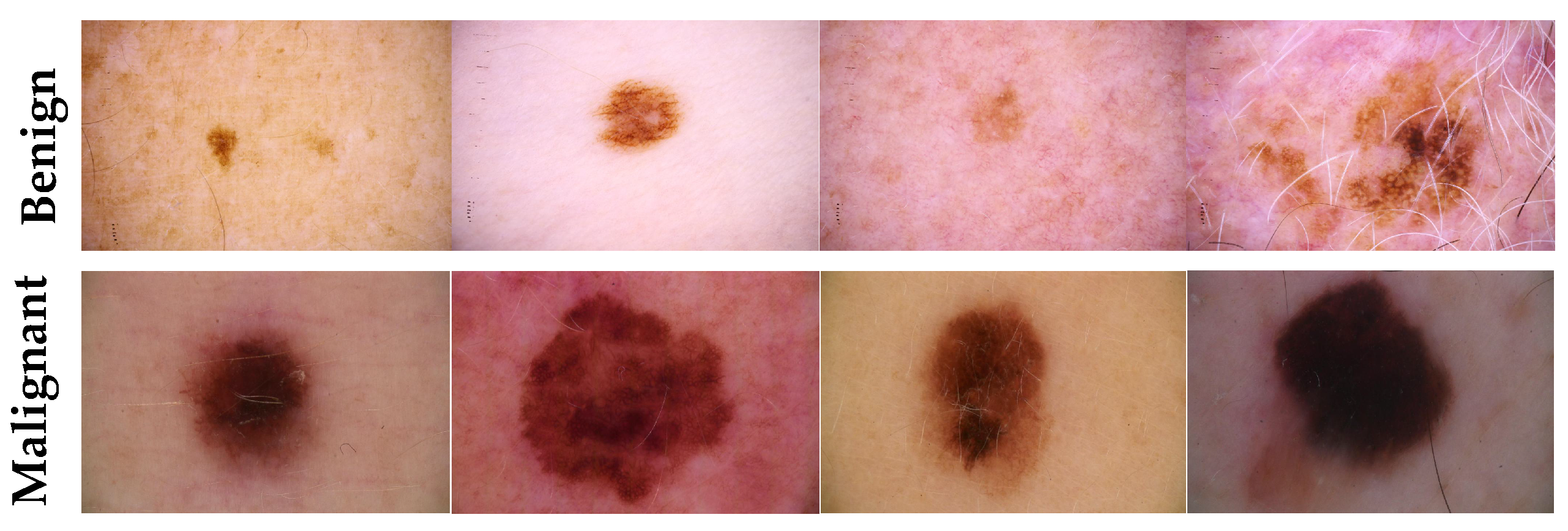
49]. The latter consists of 33,000 skin lesion samples classified into two categories: benign and malignant. We took part of the dataset, which was 9000 images, for the benign class, and the rest was added to the source dataset, with only 584 samples of the malignant class. To tackle the issue of imbalanced classes, we performed several data augmentation techniques on malignant class samples. The reason behind taking part of the dataset is to check how the proposed model with the proposed approach can perform when it trains on a small dataset. The part taken from the dataset was divided into 80% for training and 20% for testing. We resized all images to 500 × 375 to minimize the computational cost and to speed up the training process.
Figure 5 shows some samples of the dataset.
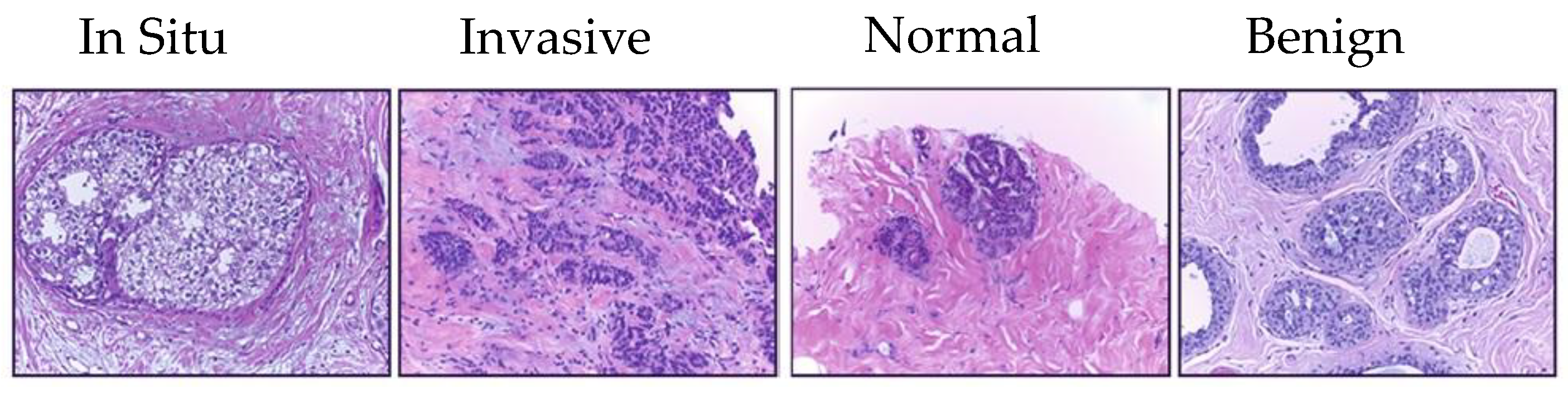
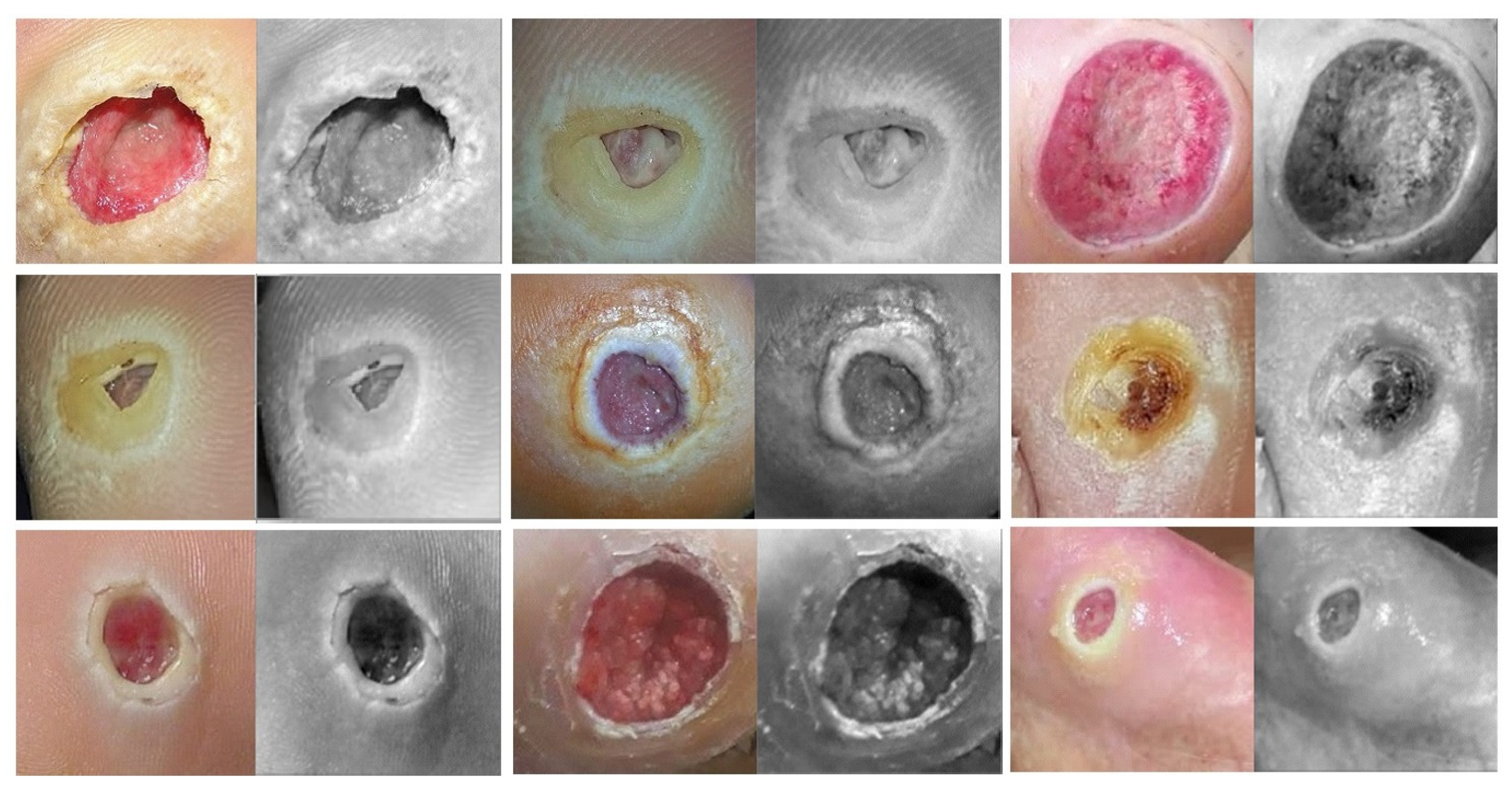
Target dataset of breast cancer: the ICIAR-2018 (BACH 2018) Grand Challenge provided this dataset [
58]. The images were uncompressed and in high-resolution mode (2040 × 1536 pixels). They consisted of H&E-stained breast histology microscopy images and were labeled as normal tissue, benign lesion, in situ carcinoma, or invasive carcinoma (see
Figure 6). The labeling stage was achieved by two medical steps, utilizing identical acquisition cases, with an enlargement of 200. A total of 400 images were used (100 samples in each class). These images were chosen so that the pathology recognition could be independently distinguished from the visible organization and the tissue structure. The dataset was divided into 300 images for the training set and 100 for the testing set. The original image was divided into 12 nonoverlapping patches of 512 × 512 pixels in size.
3.3. Augmentation Techniques
In this paper, we applied several data augmentation techniques to overcome the issue of unbalanced data and to increase the training set. These techniques are data-space solutions for any limited-data problem. Data augmentation incorporates a collection of methods that improve the attributes and size of training datasets. Thus, DL networks can perform better when these techniques are employed. Furthermore, these techniques help prevent the issue of overfitting. Next, we list some data augmentation techniques that we employed in this paper.
Random rotation between 45 and 315 degrees
Crop the region of interest (in the task of the skin and DFU)
Random brightness, random contrast
Zoom
Perform an erosion effect. The erosion is a morphological effect applied on the image that shrinks the object in the image and can be mathematically defined as in Equation (
1):
where
A is the image to be eroded and
B is the structuring element.
A dilation is an inverse of erosion that is performed on an image and can increase the area of the object. Here, we perform a double dilation effect. The dilation process can be described mathematically as in Equation (
2):
Add Gaussian Noise.
3.4. The Proposed Model
Our proposal is based on an effective DCNN model that combines several creative components to solve many issues, including better feature extraction, gradient-vanishing problem, and overfitting. These components can be summarized as follows:
Traditional convolutional layers at the beginning of the model to reduce the size of input images
Parallel convolutional layers with different filter sizes to extract different levels of features to guarantee that the model learns the small and large features
Residual connections and deep connections for better feature representation. These connections also handle the issue of gradient vanishing.
Batch normalization to expedite the training process
A rectified linear unit (ReLU) does not squeeze the input value, which helps minimize the effect of the vanishing gradient problem.
Dropout to avoid the issue of overfitting
Global average pooling makes an extreme dimensionality reduction by transforming the entire size to one dimension. This layer helps to reduce the effect of overfitting.
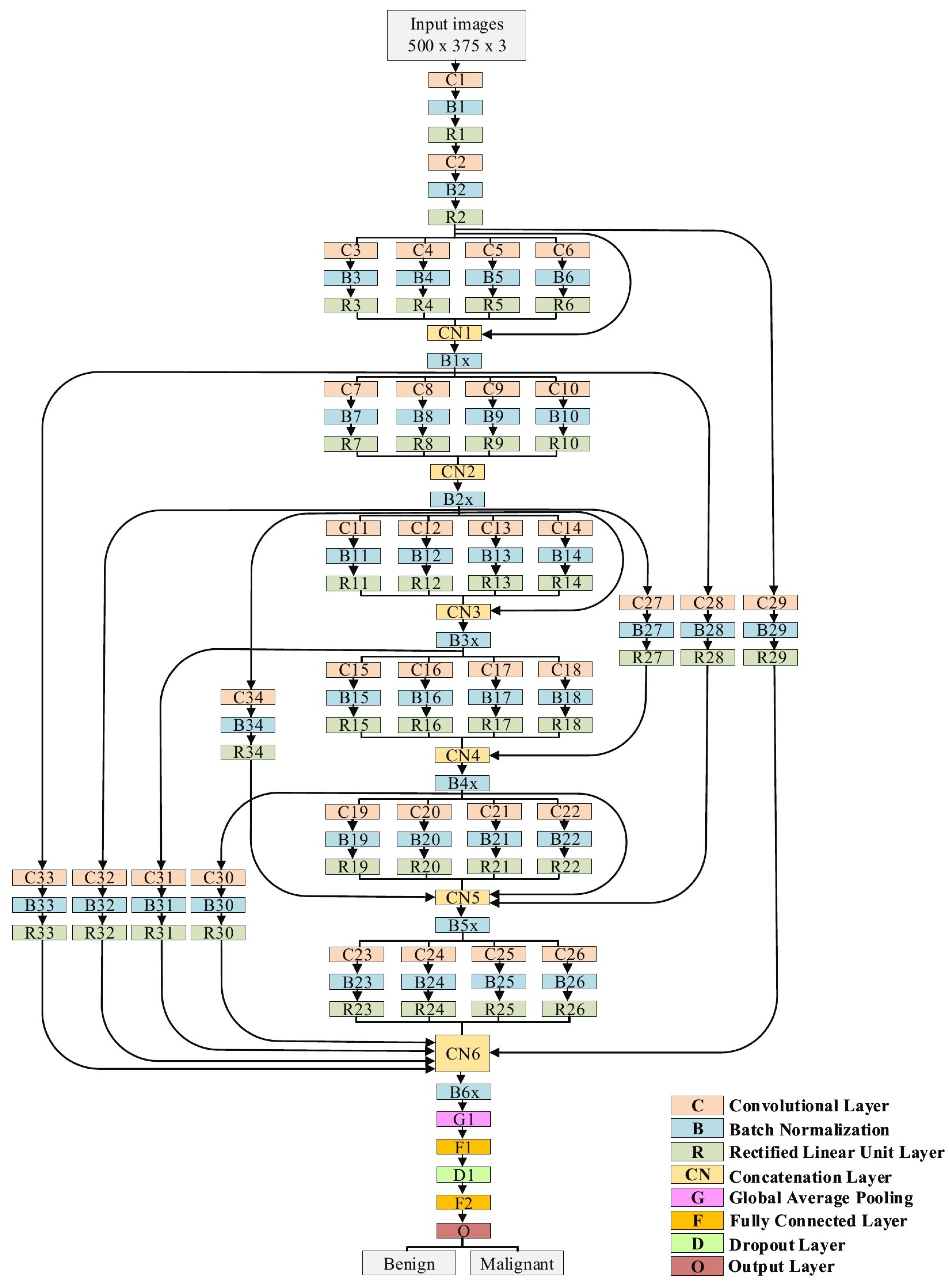
The proposed model is explained in detail in
Table 1 and
Figure 7. In the case of the skin cancer classification scenario, the input size of the proposed model is 500 × 375. Regarding the breast cancer scenario, the input size is modified to 512 × 512. The model starts with two traditional convolutional layers working in sequence. The first one has a filter size of 3 × 3, while the second convolution has a filter size of 5 × 5. Both convolutional layers are followed by BN and ReLU layers. We avoided utilizing small filters, such as 1 × 1, at the beginning of the model to prevent losing small features, which in the results, will perform as a bottleneck. Six blocks of parallel convolutional layers come after the traditional convolutional layers. Each block comprises four parallel convolutional layers with four distinct filter sizes (1 × 1, 3 × 3, 5 × 5, and 7 × 7). The output of these four layers is integrated into the concatenation layer to move to the following block. All convolutional layers in all six blocks are followed by BN and ReLU layers. There are ten connections between the blocks. Some of them are short and others are long, with a single convolutional layer. These connections maintain the model’s ability to have different levels of features for the purpose of better feature representation. Both parallel convolutions and the connections are extremely important for gradient propagation as the error can backpropagate from multiple paths. Finally, two fully connected layers are adopted with one dropout layer between them. Softmax is employed to finalize the output. In total, our proposed model consists of 34 convolutional layers.
3.5. Training Scenario
The training procedure of the proposed model is achieved in the following two phases:
We repeated phases #1 and #2 for the breast cancer classification task with respect to the breast cancer datasets (source + target).
Figure 9 and
Figure 10 show the learned filters from the first convolutional layer. The training options are listed as follows:
Stochastic gradient descent with a momentum set to 0.9
The mini-batch size was 64 and MaxEpochs was 100.
The learning rate was initially set to 0.001.
We ran our experiments on MATLAB 2020 software and a processor Intel (R) Core TM i7-5829K CPU at 3.30 GHz, 32 GB RAM, and 16 GB GPU.
3.6. Double-Transfer Learning Technique
The pretrained models on skin cancer and breast cancer are not limited to these tasks. They can also aid in further enhancing the performance of medical imaging tasks in the same domain. For example, the pretrained model on skin cancer images can be used to improve the performance of any task related to skin diseases. To test this, we worked on a DFU classification task. The aim of this task is to classify feet skin into two classes, namely normal (healthy skin) and abnormal (DFU). This experiment is significant for the task of DFU since this task suffers from a lack of images. We accomplished three training phases on the DFU classification task as follows:
Phase #1: Training our model from scratch using the DFU dataset [
59] that contained two classes, normal and abnormal
Phase #2: Fine-tuning the pretrained model of skin cancer task for the DFU classification task and then training it on the DFU dataset [
59].
Figure 11 shows the learned filters from the first convolutional layer.
Phase #3: First, fine-tuning the pretrained model of skin cancer task to train it on a small number of unlabeled feet skin images. We collected 2000 images of feet skin diseases including DFU from an internet search and part of the DermNet dataset [
60]. We increased this number to more than 10,000 using data augmentation techniques. Second, fine-tuning the pretrained model that results from the first step to train it on a small number of labeled DFU images [
59]: by doing that, we achieve a double-transfer learning technique.
Figure 12 shows the steps of the double-transfer learning technique.
For some of the medical imaging tasks, such as DFU, it is hard to obtain a large number of unlabeled images to train a pretrain model. At the same time, it is significantly harder to obtain labeled DFU images. To the best of our knowledge, there is only one public DFU dataset [
61] and a private dataset [
59] that we use in this paper.
The pretrained model using either skin cancer task or breast cancer task can behave as a base learned model for other medical imaging tasks in the same domain to obtain excellent learning. Furthermore, with the double-transfer learning technique, it is easy to turn the pretrained model for any medical imaging task in the domain. Both the proposed approach and double-transfer learning can be applied to many medical imaging tasks.
5. Conclusions
We can conclude by highlighting six major points in this paper. (i) We proposed a novel approach of TL to tackle the issue of the lack of training data in medical imaging tasks. The approach is based on training the DL models on a large number of unlabeled images of a specific task and then fine-tuning the model to train on a small number of labeled images for the same task. (ii) We designed a hybrid DCNN model based on several ideas, including parallel convolutional layers and residual connections along with global average pooling. (iii) We empirically proved the effectiveness of the proposed approach and model by applying them in two challenging tasks, skin and breast cancer. (iv) We utilized more than 200,000 unlabeled images of skin cancer to train the model, and then, we fine-tuned the model for a small dataset of labeled skin cancer to classify them into two classes, namely benign and malignant. We used the same procedure for the breast cancer task to classify histology breast images into four classes: invasive carcinoma, in situ carcinoma, benign tumor, and normal tissue. (v) We achieved excellent results in both tasks. In the skin cancer classification task, the proposed model achieved a F1-score value of 89.09% when trained from scratch and 98.53% with the proposed approach. The proposed model achieved a F1-score value of 85.29% when trained from scratch and 97.51% with the proposed approach for the breast cancer task. (vi) Additionally, we introduced another technique of transfer learning called double-transfer learning. We employed it to improve the performance DFU classification task, and we obtained a F1-score of 99.25%. Lastly, we aimed to use the learned features to improve the performance of other tasks, such as skin cancer segmentation.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}