High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality


1
Department of Mathematics, University of Leicester, Leicester LE1 7RH, UK
2
Laboratory of Advanced Methods for High-Dimensional Data Analysis, Lobachevsky University, 603022 Nizhny Novgorod, Russia
3
Instituto de Matemática Interdisciplinar, Faculty of Mathematics, Universidad Complutense de Madrid, Avda Complutense s/n, 28040 Madrid, Spain
*
Author to whom correspondence should be addressed.
Entropy 2020, 22(1), 82; https://doi.org/10.3390/e22010082
Submission received: 9 December 2019
/
Revised: 2 January 2020
/
Accepted: 6 January 2020
/
Published: 9 January 2020
(This article belongs to the Special Issue Entropies: Between Information Geometry and Kinetics)
Abstract
:High-dimensional data and high-dimensional representations of reality are inherent features of modern Artificial Intelligence systems and applications of machine learning. The well-known phenomenon of the “curse of dimensionality” states: many problems become exponentially difficult in high dimensions. Recently, the other side of the coin, the “blessing of dimensionality”, has attracted much attention. It turns out that generic high-dimensional datasets exhibit fairly simple geometric properties. Thus, there is a fundamental tradeoff between complexity and simplicity in high dimensional spaces. Here we present a brief explanatory review of recent ideas, results and hypotheses about the blessing of dimensionality and related simplifying effects relevant to machine learning and neuroscience.
1. Introduction
During the last two decades, the curse of dimensionality in data analysis was complemented by the blessing of dimensionality: if a dataset is essentially high-dimensional then, surprisingly, some problems get easier and can be solved by simple and robust old methods. The curse and the blessing of dimensionality are closely related, like two sides of the same coin. The research landscape of these phenomena is gradually becoming more complex and rich. New theoretical achievements and applications provide a new context for old results. The single-cell revolution in neuroscience, phenomena of grandmother cells and sparse coding discovered in the human brain meet the new mathematical ‘blessing of dimensionality’ ideas. In this mini-review, we aim to provide a short guide to new results on the blessing of dimensionality and to highlight the path from the curse of dimensionality to the blessing of dimensionality. The selection of material and angle of view is based on our own experience. We are not trying to cover everything in the subject of review, but rather fill in the gaps in existing tutorials and surveys.
R. Bellman [1] in the preface to his book, discussed the computational difficulties of multidimensional optimization and summarized them under the heading “curse of dimensionality”. He proposed to re-examine the situation, not as a mathematician, but as a “practical man” [2], and concluded that the price of excessive dimensionality “arises from a demand for too much information”. Dynamic programming was considered a method of dimensionality reduction in the optimization of a multi-stage decision process. Bellman returned to the problem of dimensionality reduction many times in different contexts [3]. Now, dimensionality reduction is an essential element of the engineering (the “practical man”) approach to mathematical modeling [4]. Many model reduction methods were developed and successfully implemented in applications, from various versions of principal component analysis to approximation by manifolds, graphs, and complexes [5,6,7], and low-rank tensor network decompositions [8,9].
Various reasons and forms of the curse of dimensionality were classified and studied, from the obvious combinatorial explosion (for example, for n binary Boolean attributes, to check all the combinations of values we have to analyze cases) to more sophisticated distance concentration: in a high-dimensional space, the distances between randomly selected points tend to concentrate near their mean value, and the neighbor-based methods of data analysis become useless in their standard forms [10,11]. Many “good” polynomial time algorithms become useless in high dimensions.
Surprisingly, however, and despite the expected challenges and difficulties, common-sense heuristics based on the simple and the most straightforward methods “can yield results which are almost surely optimal” for high-dimensional problems [12]. Following this observation, the term “blessing of dimensionality” was introduced [12,13]. It was clearly articulated as a basis of future data mining in the Donoho “Millenium manifesto” [14]. After that, the effects of the blessing of dimensionality were discovered in many applications, for example in face recognition [15], in analysis and separation of mixed data that lie on a union of multiple subspaces from their corrupted observations [16], in multidimensional cluster analysis [17], in learning large Gaussian mixtures [18], in correction of errors of multidimensonal machine learning systems [19], in evaluation of statistical parameters [20], and in the development of generalized principal component analysis that provides low-rank estimates of the natural parameters by projecting the saturated model parameters [21].
Ideas of the blessing of dimensionality became popular in signal processing, for example in compressed sensing [22,23] or in recovering a vector of signals from corrupted measurements [24], and even in such specific problems as analysis and classification of EEG patterns for attention deficit hyperactivity disorder diagnosis [25].
There exist exponentially large sets of pairwise almost orthogonal vectors (‘quasiorthogonal’ bases, [26]) in Euclidean space. It was noticed in the analysis of several n-dimensional random vectors drawn from the standard Gaussian distribution with zero mean and identity covariance matrix, that all the rays from the origin to the data points have approximately equal length, are nearly orthogonal and the distances between data points are all about times larger [27]. This observation holds even for exponentially large samples (of the size for some , which depends on the degree of the approximate orthogonality) [28]. Projection of a finite data set on random bases can reduce dimension with preservation of the ratios of distances (the Johnson–Lindenstrauss lemma [29]).
Such an intensive flux of works ensures us that we should not fear or avoid large dimensionality. We just have to use it properly. Each application requires a specific balance between the extraction of important low-dimensional structures (‘reduction’) and the use of the remarkable properties of high-dimensional geometry that underlie statistical physics and other fundamental results [30,31].
Both the curse and the blessing of dimensionality are the consequences of the measure concentration phenomena [30,31,32,33]. These phenomena were discovered in the development of the statistical backgrounds of thermodynamics. Maxwell, Boltzmann, Gibbs, and Einstein found that for many particles the distribution functions have surprising properties. For example, the Gibbs theorem of ensemble equivalence [34] states that a physically natural microcanonical ensemble (with fixed energy) is statistically equivalent (provides the same averages of physical quantities in the thermodynamic limit) to a maximum entropy canonical ensemble (the Boltzmann distribution). Simple geometric examples of similar equivalence gives the ‘thin shell’ concentration for balls: the volume of a high-dimensional ball is concentrated near its surface. Moreover, a high-dimensional sphere is concentrated near any equator (waist concentration; the general theory of such phenomena was elaborated by M. Gromov [35]). P. Lévy [36] analysed these effects and proved the first general concentration theorem. Modern measure concentration theory is a mature mathematical discipline with many deep results, comprehensive reviews [32], books [33,37], advanced textbooks [31], and even elementary geometric introductions [38]. Nevertheless, surprising counterintuitive results continue to appear and push new achievements in machine learning, Artificial Intelligence (AI), and neuroscience.
This mini-review focuses on several novel results: stochastic separation theorems and evaluation of goodness of clustering in high dimensions, and on their applications to corrections of AI errors. Several possible applications to the dynamics of selective memory in the real brain and ‘simplicity revolution in neuroscience’ are also briefly discussed.
2. Stochastic Separation Theorems
2.1. Blessing of Dimensionality Surprises and Correction of AI Mistakes
D. Donoho and J. Tanner [23] formulated several ‘blessing of dimensionality’ surprises. In most cases, they considered M points sampled independently from a standard normal distribution in dimension n. Intuitively, we expect that some of the points will lie on the boundary of the convex hull of these points, and the others will be inside the interior of the hull. However, for large n and M, this expectation is wrong. This is the main surprise. With a high probability all M random points are vertices of their convex hull. It is sufficient that for some a and b that depend on only [39,40]. Moreover, with a high probability, each segment connecting a pair of vertices is also an edge of the convex hull, and any simplex with k vertices from the sample is a -dimensional face of the convex hull for some range of values of k. For uniform distributions in a ball, similar results were proved earlier by I. Bárány and Z. Füredi [41]. According to these results, each point of a random sample can be separated from all other points by a linear functional, even if the set is exponentially large.
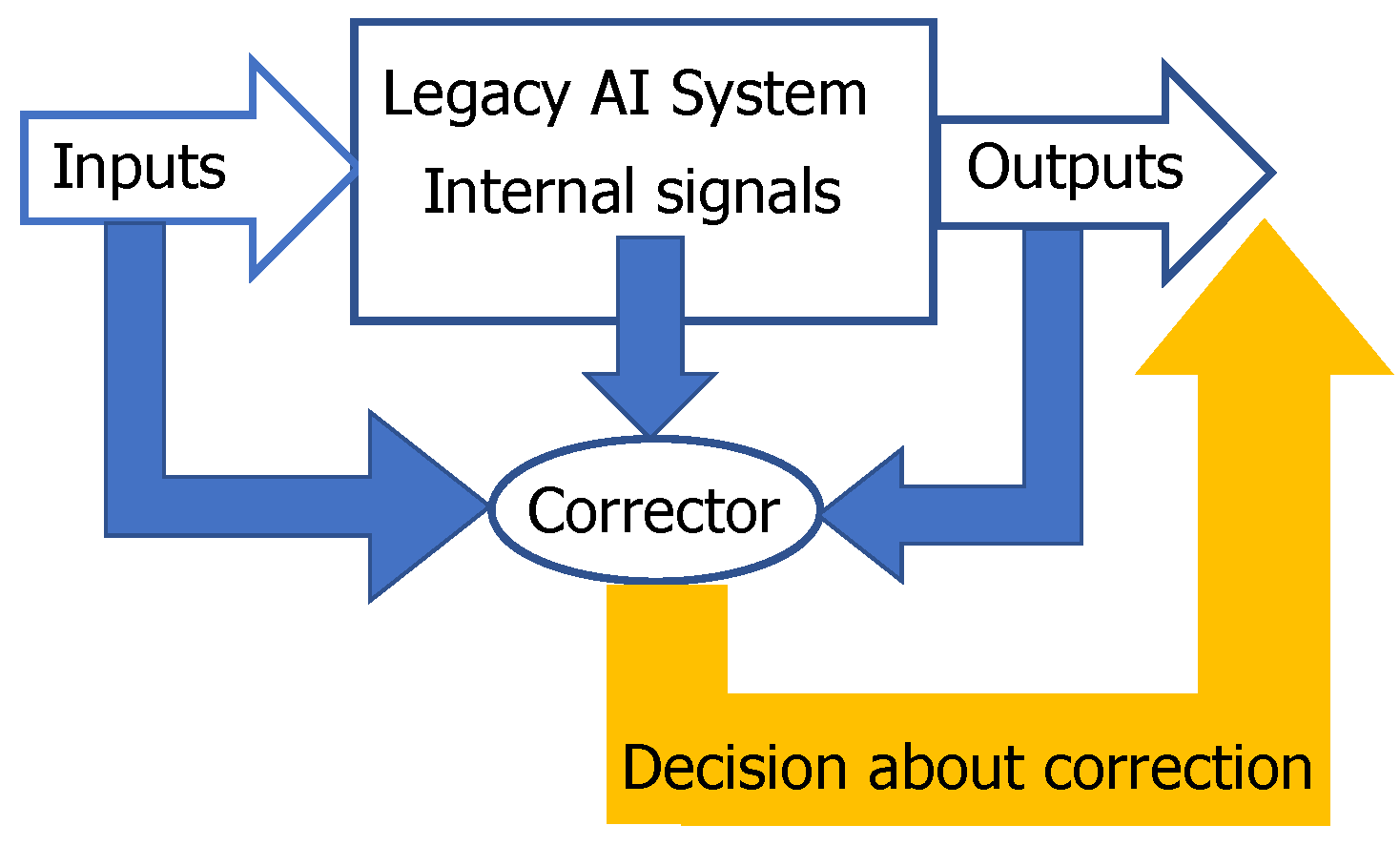
Such a separability is important for the solution of a technological problem of fast, robust and non-damaging correction of AI mistakes [30,39,40]. AI systems make mistakes and will make mistakes in the future. If a mistake is detected, then it should be corrected. The complete re-training of the system requires too much resource and is rarely applicable to the correction of a single mistake. We proposed to use additional simple machine learning systems, correctors, for separation of the situations with higher risk of mistake from the situations with normal functioning [19,42] (Figure 1). The decision rules should be changed for situations with higher risk. Inputs for correctors are: the inputs of the original AI systems, the outputs of this system and (some) internal signals of this system [39,40]. The construction of correctors for AI systems is crucial in the development of the future AI ecosystems.
Correctors should [30]:
- be simple;
- not damage the existing skills of the AI system;
- allow fast non-iterative learning;
- correct new mistakes without destroying the previous fixes.
Of course, if an AI system made too many mistakes then their correctors could conflict. In such a case, re-training is needed with the inclusion of new samples.
2.2. Fisher Separablity
Linear separation of data points from datasets [23,41] is a good candidate for the development of AI correctors. Nevertheless, from the ‘practical man’ point of view, one particular case, Fisher’s discriminant [45], is much more preferable to the general case because it allows one-shot and explicit creation of the separating functional.
Consider a finite data set Y without any hypothesis about the probability distribution. Let be the standard inner product in . Let us define Fisher’s separability following [39].
Definition 1.
A point is Fisher-separable from a finite set Y with a threshold α () if
This definition coincides with the textbook definition of Fisher’s discriminant if the data set Y is whitened, which means that the mean point is in the origin and the sample covariance matrix is the identity matrix. Whitening is often a simple by-product of principal component analysis (PCA) because, on the basis of principal components, whitening is just the normalization of coordinates to unit variance. Again, following the ‘practical’ approach, we stress that the precise PCA and whitening are not necessary but rather a priori bounded condition number is needed: the ratio of the maximal and the minimal eigenvalues of the empirical covariance matrix after whitening should not exceed a given number , independently of the dimension.
A finite set is called Fisher-separable, if each point is Fisher-separable from the rest of the set (Definition 3, [39]).
Definition 2.
A finite set is called Fisher-separable with threshold if inequality (1) holds for all such that . The set Y is called Fisher-separable if there exists some α () such that Y is Fisher-separable with threshold α.
2.3. Stochastic Separation for Distributions with Bounded Support
Let us analyse the separability of a random point from a finite set in the n-dimensional unit ball . Consider the distributions that can deviate from the equidistribution, and these deviations can grow with dimension n but not faster than the geometric progression with the common ratio , and, hence, the maximal density satisfies:
where constant C does not depend on n.
For such a distribution in the unit ball, the probability to find a random point in the excluded volume (Figure 2) tends to 0 as a geometric progression with the common ratio when .
Theorem 1.
Let us evaluate the probability that a random set Y is Fisher-separable. Assume that each point of Y is randomly selected from a distribution that satisfies (3). These distributions could be different for different .
Theorem 2.
The difference in conditions from Theorem 1 is that here and in Theorem 1 . Again, can grow exponentially with the dimension as the geometric progression with the common factor , while faster than the geometric progression with the common factor .
For illustration, if Y is an i.i.d. sample from the uniform distribution in the 100-dimensional ball and , then with probablity this set is Fisher-separable [42].
2.4. Generalisations
V. Kůrková [46] emphasized that many attractive measure concentration results are formulated for i.i.d. samples from very simple distributions (Gaussian, uniform, etc.), whereas the reality of big data is very different: the data are not i.i.d. samples from simple distributions. The machine learning theory based on the i.i.d. assumption should be revised, indeed [47]. In the theorems above two main restrictions were employed: the probability of a set occupying relatively small volume could not be large (3), and the support of the distribution is bounded. The requirement of identical distribution of different points is not needed. The independence of the data points can be relaxed [39]. The boundedness of the support of distribution can be transformed to the ‘not-too-heavy-tail’ condition. The condition ‘sets of relatively small volume should not have large probability’ remains in most generalisations. It can be considered as ‘smeared absolute continuity’ because absolute continuity means that the sets of zero volume have zero probability. Theorems 1 and 2 have numerous generalisations [39,40,48,49]. Let us briefly list some of them:
- Log-concave distributions (a distribution with density is log-concave if the set is convex and is a convex function on D). In this case, the possibility of an exponential (non-Gaussian) tail brings a surprise: the upper size bound of the random set , sufficient for Fisher-separability in high dimensions with high probability, grows with dimension n as , i.e., slower than exponential (Theorem 5, [39]).
- Strongly log-concave distributions. A log concave distribution is strongly log-concave if there exists a constant such thatIn this case, we return to the exponential estimation of the maximal allowed size of (Corollary 4, [39]). The comparison theorems [39] allow us to combine different distributions, for example the distribution from Theorem 2 in a ball with the log-concave or strongly log-concave tail outside the ball.
- The kernel versions of the stochastic separation theorem were found, proved and applied to some real-life problems [50].
- There are also various estimations beyond the standard i.i.d. hypothesis [39] but the general theory is yet to be developed.
2.5. Some Applications
The correction methods were tested on various AI applications for videostream processing: detection of faces for security applications and detection of pedestrians [39,44,51], translation of Sign Language into text for communication between deaf-mute people [52], knowledge transfer between AI systems [53], medical image analysis, scanning and classifying archaeological artifacts [54], etc., and even to some industrial systems with relatively high level of errors [43].
Application of the corrector technology to image processing was patented together with industrial partners [55]. A typical test of correctors’ performance is described below. For more detail of this test, we refer to [44]. A convolutional neural network (CNN) was trained to detect pedestrians in images. A set of 114,000 positive pedestrian and 375,000 negative non-pedestrian RGB images, re-sized to , were collected and used as a training set. The testing set comprised of 10,000 positives and 10,000 negatives. The training and testing sets did not intersect.
We investigated in the computational experiments if it is possible to take one of cutting edge CNNs and train a one-neuron corrector to eliminate all the false positives produced. We also look at what effect, this corrector had on true positive numbers.
For each positive and false positive we extracted the second to last fully connected layer from CNN. These extracted feature vectors have dimension 4096. We applied PCA to reduce the dimension and analyzed how the effectiveness of the correctors depends on the number of principal components retained. This number varied in our experiments from 50 to 2000. The 25 false positives, taken from the testing set, were chosen at random to model single mistakes of the legacy classifier. Several such samples were chosen. For data projected on more than the first 87 principal components one neuron with weights selected by the Fisher linear discriminant formula corrected 25 errors without doing any damage to classification capabilities (original skills) of the legacy AI system on the training set. For 50 or less principal components this separation is not perfect.
Single false positives were corrected successfully without any increase of the true positive rates. We removed more than 10 false positives at no cost to true positive detections in the street video data (Nottingham) by the use of a single linear function. Further increasing the number of corrected false positives demonstrated that a single-neuron corrector could result in gradual deterioration of the true positive rates.
3. Clustering in High Dimensions
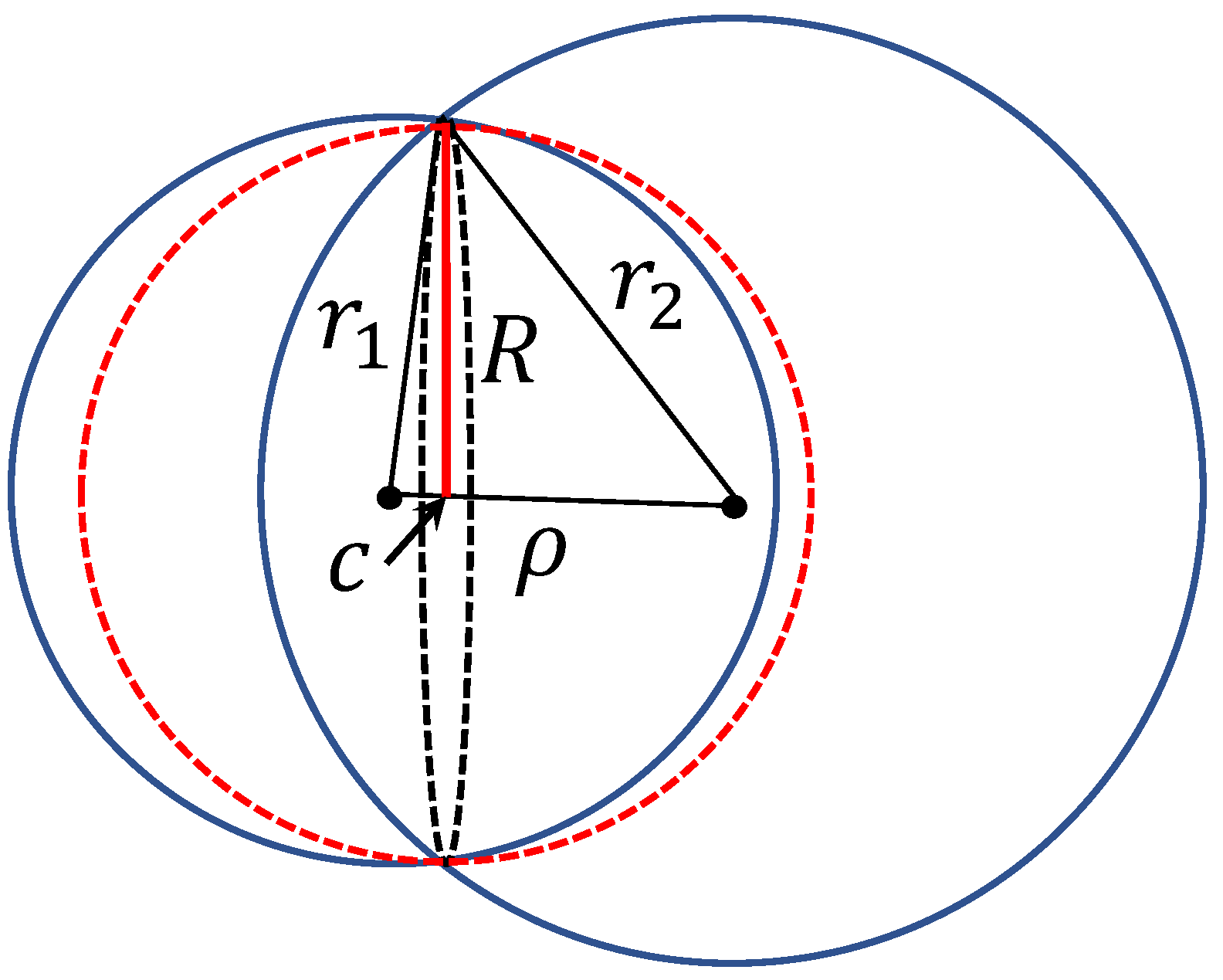
Producing a special corrector for every single mistake seems to be a non-optimal approach, despite some successes. In practice, happily, often one corrector improves performance and prevents the system from some new mistakes because they are correlated. Moreover, mistakes can be grouped in clusters and we can create correctors for the clusters of situations rather than for single mistakes. Here we meet another measure concentration ‘blessing’. In high dimensions, clusters are good (well-separated) even in the situations when one can expect their strong intersection. For example, consider two clusters and the distance-based clustering. Let and be the mean squared Euclidean distances between the centroids of the clusters and their data points, and be the distance between two centroids. The standard criteria of clusters’ quality [56] compare with and assume that for ‘good’ clusters . Assume the opposite, and evaluate the volume of the intersection of two balls with radii , . The intersection of the spheres (boundaries of the balls) is a -dimensional sphere with the centre c (Figure 3). Assume , which means that c is situated between the centers of the balls (otherwise, the biggest ball includes more than a half of the volume of the smallest one). The intersection of clusters belongs to a ball of radius R:
and the fractions of the volume of the two initial balls in the intersection is less then . These fractions evaluate the probability to confuse points between the clusters (for uniform distributions, for the Gaussian distributions the estimates are similar). We can measure the goodness of high-dimensional clusters by
Note that exponentially tends to zero with n increase. Small means ‘good’ clustering.
If then the probability to find a data point in the intersection of the balls (the ‘area of confusion’ between clusters) is negligible for uniform distributions in balls, isotropic Gaussian distributions and always when small volume implies small probability. Therefore, the clustering of mistakes for correction of high-dimensional machine learning systems gives good results even if clusters are not very good in the standard measures, and correction of clustered mistakes requires much fewer correctors for the same or even better accuracy [43].
We implemented the correctors with separation of clustered false-positive mistakes from the set of true positive and tested them on the classical face detection task [43]. The legacy object detector was an OpenCV implementation of the Haar face detector. It has been applied to video footage capturing traffic and pedestrians on the streets of Montreal. The powerful MTCNN face detector was used to generate ground truth data. The total number of true positives was 21,896, and the total number of false positives was 9372. The training set contained randomly chosen 50% of positives and false positives. PCA was used for dimensionality reduction with 200 principal components retained. Single-cluster corrector allows one to filter 90% of all errors at the cost of missing 5% percent of true positives. In dimension 200, a cluster of errors is sufficiently well-separated from the true positives. A significant classification performance gain was observed with more clusters, up to 100.
Further increase of dimension (the number of principal components retained) can even damage the performance because the number of features does not coincide with the dimension of the dataset, and the whitening with retained minor component can lead to ill-posed problems and loss of stability. For more detail, we refer to [43].
4. What Does ‘High Dimensionality’ Mean?
The dimensionality of data should not be naively confused with the number of features. Let us have n objects with p features. The usual data matrix in statistics is a 2D array with n rows and p columns. The rows give values of features for an individual sample, and the columns give values of a feature for different objects. In classical statistics, we assume that and even study asymptotic estimates for and p fixed. But, the modern ‘post-classical’ world is different [14]: the situation with (and even ) is not anomalous anymore. Moreover, it can be considered in some sense as the generic case: we can measure a very large number of attributes for a relatively small number of individual cases.
In such a situation the default preprocessing method could be recommended [57]: transform the data matrix with into the square matrix of inner products (or correlation coefficients) between the individual data vectors. After that, apply PCA and all the standard machinery of machine learning. New data will be presented by projections on the old samples. (Detailed description of this preprocessing and the following steps is presented in [57] with an applied case study for and .) Such a preprocessing reduces the apparent dimension of the data_space to .
PCA gives us a tool for estimating the linear dimension of the dataset. Dimensionality reduction is achieved by using only the first few principal components. Several heuristics are used for evaluation of how many principal components should be retained:
- The classical Kaiser rule recommends to retain the principal components corresponding to the eigenvalues of the correlation matrix (or where is a selected threshold; often is selected). This is, perhaps, the most popular choice.
- Control of the fraction of variance unexplained. This approach is also popular, but it can retain too many minor components that can be considered ‘noise’.
- Conditional number control [39] recommends to retain the principal components corresponding to , where is the maximal eigenvalue of the correlation matrix and is the upper border of the conditional number (the recommended values are [58]). This recommendation is very useful because it provides direct control of multicollinearity.
After dimensionality reduction, we can perform whitening of data and apply the stochastic separation theorems. This requires a hypothesis about the distribution of data: sets of a relatively small volume should not have a high probability, and there should be no ‘heavy tails’. Unfortunately, this assumption is not always true in the practice of big data analysis. (We are grateful to G. Hinton and V. Kůrková for this comment.).
The separability properties can be affected by various violations of i.i.d. structure of data, inhomogeneity of data, small clusters and fine-grained lumping, and other peculiarities [59]. Therefore, the notion of dimension should be revisited. We proposed to use the Fisher separability of data to estimate the dimension [39]. For regular probability distributions, this estimate will give a standard geometric dimension, whereas, for complex (and often more realistic) cases, it will provide a more useful dimension characteristic. This approach was tested [59] for many bioinformatic datasets.
For analysis of Fisher’s separability and related estimation of dimensionality for general distribution and empirical datasets, an auxiliary random variable is used [39,59]. This is the probability that a randomly chosen point is not Fisher-separable with threshold from a given data point by the discriminant (1):
where is the probability measure for .
If is selected at random (not compulsory with the same distribution as ) then is a random variable. For a finite dataset Y the probability that the data point is not Fisher-separable with threshold from Y can be evaluated by the sum of for :
Comparison of the empirical distribution of to the distribution evaluated for the high-dimensional sphere can be used as information about the ‘effective’ dimension of data. The probability is the same for all and exponentially decreases for large n. We assume that is sampled randomly from for the rotationally invariant distribution on the unit sphere . For large n the asymptotic formula holds [39,59]:
Here means that when (the functions here are strictly positive). It was noticed that the asymptotically equivalent formula with the denominator performs better in small dimensions [59].
The introduced measure of dimension performs competitively with other state-of-the-art measures for simple i.i.d. data situated on manifolds [39,59]. It was shown to perform better in the case of noisy samples and allows estimation of the intrinsic dimension in situations where the intrinsic manifold, regular distribution and i.i.d. assumptions are not valid [59].
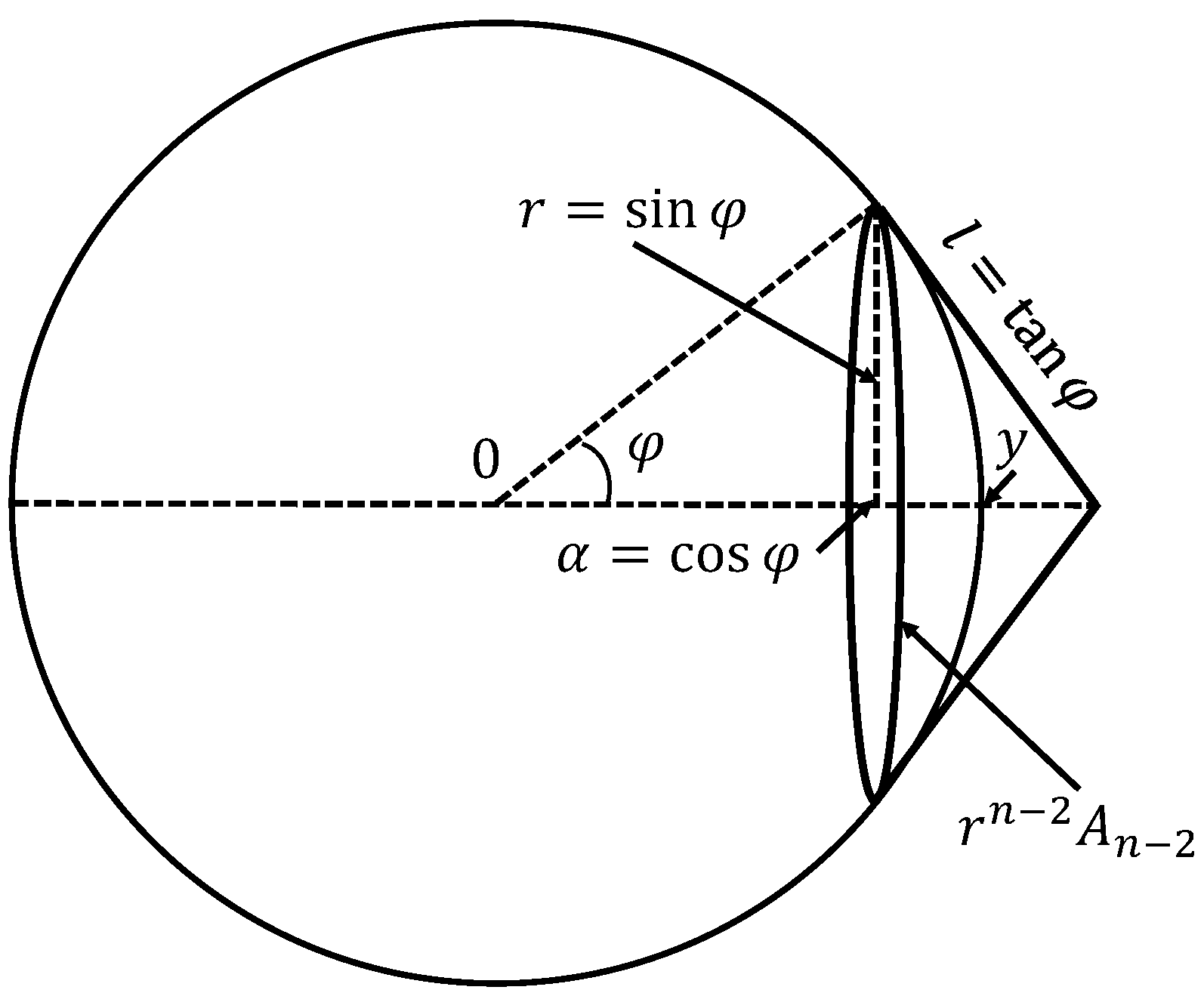
After this revision of the definition of data dimension, we can answer the question from the title of this section: What does ‘high dimensionality’ mean? The answer is given by the stochastic separation estimates for the uniform distribution in the unit sphere . Let . We use notation for the volume (surface) of . The points of , which are not Fisher-separable from y with a given threshold , form a spherical cap with the base radius (Figure 4). The area of this cap is estimated from above by the lateral surface of the cone with the same base, which is tangent to the sphere at the base points (see Figure 4). Therefore, the probability that a point selected randomly from the rotationally invariant distribution on is not Fisher-separable from y is estimated from above as
The surface area of is
where is Euler’s gamma-function.
Rewrite the estimate (8) as
Recall that is a monotonically increasing logarithmically convex function for [60]. Therefore, for
Take into account that (because ). After elementary transforms it gives us
Finally, we got an elementary estimate for from above
Compared to (7), this estimate from above is asymptotically exact.
Estimate from above a probability of a separability violations using (11) and an elementary rule: for any family of events ,
According to (11) and (12), if , Y is an i.i.d. sample from a rotationally invariant distribution on and
then all sample points with a probability greater than are Fischer-separable from a given point y with a threshold . Similarly, if
then with probability greater than each sample point is Fisher-separable from the rest of the sample with a threshold .
Estimates (13) and (14) provide sufficient conditions for separability. The Table 1 illustrates these estimates (the upper borders of in these estimates are presented in the table with three significant figures). For an illustration of the separability properties, we estimated from above the sample size for which the Fisher-separability is guaranteed with a probability 0.99 and a threshold value (Table 1). These sample sizes grow fast with dimension. From the Fisher-separability point of view, dimensions 30 or 50 are already large. The effects of high-dimensional stochastic separability emerge with increasing dimensionality much earlier than, for example, the appearance of exponentially large quasi-orthogonal bases [28].
5. Discussion: The Heresy of Unheard-of Simplicity and Single Cell Revolution in Neuroscience
V. Kreinovich [61] summarised the impression from the effective AI correctors based on Fisher’s discriminant in high dimensions as “The heresy of unheard-of simplicity” using quotation of the famous Pasternak poetry. Such a simplicity appears also in brain functioning. Despite our expectation that complex intellectual phenomena is a result of a perfectly orchestrated collaboration between many different cells, there is a phenomenon of sparse coding, concept cells, or so-called ‘grandmother cells’ which selectively react to the specific concepts like a grandmother or a well-known actress (‘Jennifer Aniston cells’) [62]. These experimental results continue the single neuron revolution in sensory psychology [63].
The idea of grandmother or concept cells was proposed in the late 1960s. In 1972, Barlow published a manifest about the single neuron revolution in sensory psychology [63]. He suggested: “our perceptions are caused by the activity of a rather small number of neurons selected from a very large population of predominantly silent cells.” Barlow presented many experimental evidences of single-cell perception. In all these examples, neurons reacted selectively to the key patterns (called ‘trigger features’). This reaction was invariant to various changes in conditions.
The modern point of view on the single-cell revolution was briefly summarised recently by R. Quian Quiroga [64]. He mentioned that the ‘grandmother cells’ were invented by Lettvin “to ridicule the idea that single neurons can encode specific concepts”. Later discoveries changed the situation and added more meaning and detail to these ideas. The idea of concept cells was evolved during decades. According to Quian Quiroga, these cells are not involved in identifying a particular stimulus or concept. They are rather involved in creating and retrieving associations and can be seen as the “building blocks of episodic memory”. Many recent discoveries used data received from intracranial electrodes implanted in the medial temporal lobe (MTL; the hippocampus and surrounding cortex) for patients medications. The activity of dozens of neurons can be recorded while patients perform different tasks. Neurons with high selectivity and invariance were found. In particular, one neuron fired to the presentation of seven different pictures of Jennifer Aniston and her spoken and written name, but not to 80 pictures of other persons. Emergence of associations between images was also discovered.
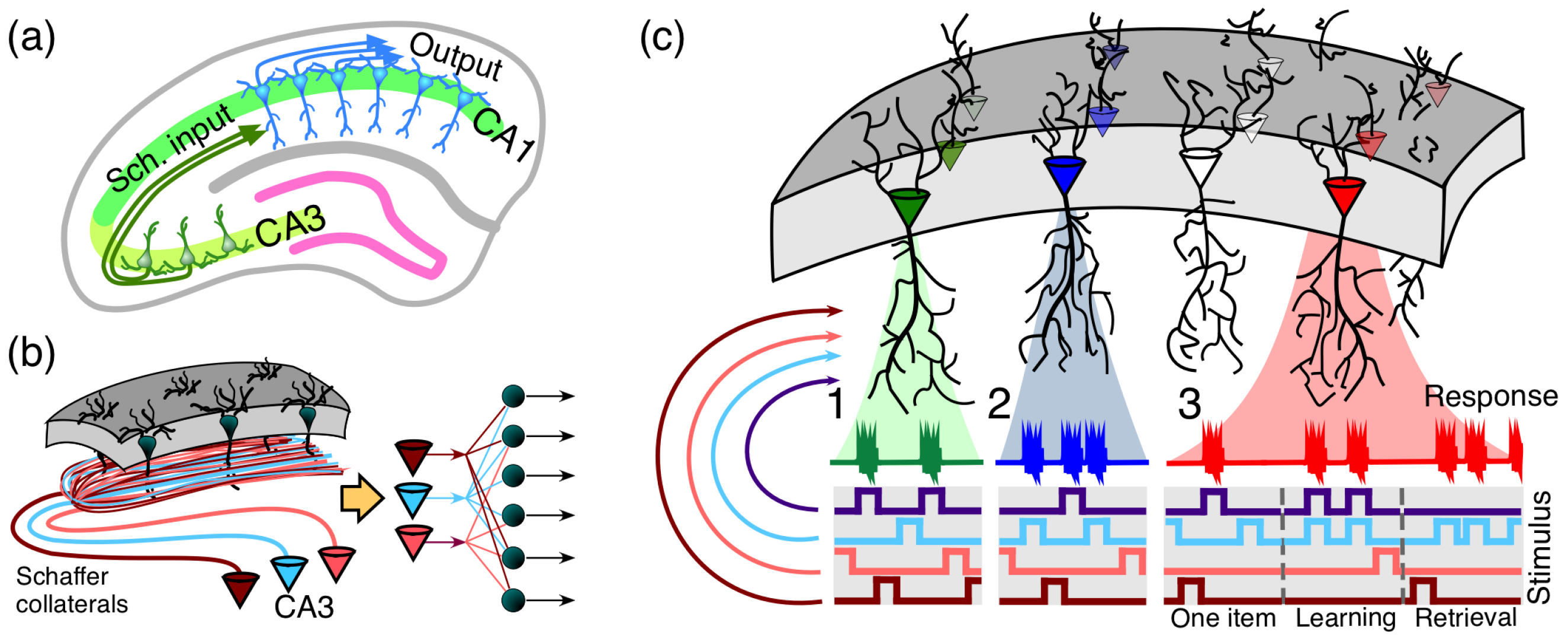
Some important memory functions are performed by stratified brain structures, such as the hippocampus. The CA1 region of the hippocampus includes a monolayer of morphologically similar pyramidal cells oriented parallel to the main axis (Figure 5). In humans, CA1 region of the hippocampus contains of pyramidal neurons. Excitatory inputs to these neurons come from the CA3 regions (ipsi- and contra-lateral). Each CA3 pyramidal neuron sends an axon that bifurcates and leaves multiple collaterals in the CA1 (Figure 5b). This structural organization allows transmitting multidimensional information from the CA3 region to neurons in the CA1 region. Thus, we have simultaneous convergence and divergence of the information content (Figure 5b, right). A single pyramidal cell can receive around 30,000 excitatory and 1700 inhibitory inputs (data for rats [65]). Moreover, these numbers of synaptic contacts of cells vary greatly between neurons [66]. There are nonuniform and clustered connectivity patterns. Such a variability is considered as a part of the mechanism enhancing neuronal feature selectivity [66]. However, anatomical connectivity is not automatically transferred into functional connectivity and a realistic model should decrease significantly (by several orders of magnitude) the number of functional connections (see, for example, [67]). Nevertheless, even several dozens of effective functional connections are sufficient for the application of stochastic separation theorems (see Table 1).
For sufficiently high-dimensional sets of input signals a simple enough functional neuronal model with Hebbian learning (the generalized Oja rule [40,68]) is capable of explaining the following phenomena:
- the extreme selectivity of single neurons to the information content of high-dimensional data (Figure 5(c1)),
- simultaneous separation of several uncorrelated informational items from a large set of stimuli (Figure 5(c2)),
- dynamic learning of new items by associating them with already known ones (Figure 5(c3)).
These results constitute a basis for the organization of complex memories in ensembles of single neurons.
Re-training large ensembles of neurons is extremely time and resources consuming both in the brain and in machine learning. It is, in fact, impossible to realize such a re-training in many real-life situations and applications. “The existence of high discriminative units and a hierarchical organization for error correction are fundamental for effective information encoding, processing and execution, also relevant for fast learning and to optimize memory capacity” [69].
The multidimensional brain is the most puzzling example of the ‘heresy of unheard-of simplicity’, but the same phenomenon has been observed in social sciences and in many other disciplines [61].
There is a fundamental difference and complementarity between analysis of essentially high-dimensional datasets, where simple linear methods are applicable, and reducible datasets for which non-linear methods are needed, both for reduction and analysis [30]. This alternative in neuroscience was described as high-dimensional ‘brainland’ versus low-dimensional ‘flatland’ [70]. The specific multidimensional effects of the ‘blessing of dimensionality’ can be considered as the deepest reason for the discovery of small groups of neurons that control important physiological phenomena. On the other hand, even low dimensional data live often in a higher-dimensional space and the dynamics of low-dimensional models should be naturally embedded into the high-dimensional ‘brainland’. Thus, a “crucial problem nowadays is the ‘game’ of moving from ‘brainland’ to ‘flatland’ and backward” [70].
C. van Leeuwen formulated a radically opposite point of view [71]: neither high-dimensional linear models nor low-dimensional non-linear models have serious relations to the brain.
The devil is in the detail. First of all, the preprocessing is always needed to extract the relevant features. The linear method of choice is PCA. Various versions of non-linear PCA can be also useful [6]. After that, nobody has a guarantee that the dataset is either essentially high-dimensional or reducible. It can be a mixture of both alternatives, therefore both extraction of reducible lower-dimensional subset for nonlinear analysis and linear analysis of the high dimensional residuals could be needed together.
Author Contributions
Conceptualization, A.N.G., V.A.M. and I.Y.T.; Methodology, A.N.G., V.A.M. and I.Y.T.; Writing—Original Draft Preparation, A.N.G.; Writing—Editing, A.N.G., V.A.M. and I.Y.T.; Visualization, A.N.G., V.A.M. and I.Y.T. All authors have read and agreed to the published version of the manuscript.
Funding
The work was supported by the Ministry of Science and Higher Education of the Russian Federation (Project No. 14.Y26.31.0022). Work of A.N.G. and I.Y.T. was also supported by Innovate UK (Knowledge Transfer Partnership grants KTP009890; KTP010522) and University of Leicester. V.A.M acknowledges support from the Spanish Ministry of Economy, Industry, and Competitiveness (grant FIS2017-82900-P).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Bellman, R. The theory of dynamic programming. Bull. Am. Math. Soc. 1954, 60, 503–515. [Google Scholar] [CrossRef] [Green Version]
- Bellman, R.; Kalaba, R. Reduction of dimensionality, dynamic programming, and control processes. J. Basic Eng. 1961, 83, 82–84. [Google Scholar] [CrossRef]
- Gorban, A.N.; Kazantzis, N.; Kevrekidis, I.G.; Öttinger, H.C.; Theodoropoulos, C. (Eds.) Model Reduction and Coarse–Graining Approaches for Multiscale Phenomena; Springer: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Jolliffe, I. Principal Component Analysis; Springer: Berlin/Heidelberg, Germany, 1993. [Google Scholar]
- Gorban, A.N.; Kégl, B.; Wunsch, D.; Zinovyev, A. (Eds.) Principal Manifolds for Data Visualisation and Dimension Reduction; Springer: Berlin/Heidelberg, Germany, 2008. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Zinovyev, A. Principal manifolds and graphs in practice: from molecular biology to dynamical systems. Int. J. Neural Syst. 2010, 20, 219–232. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cichocki, A.; Lee, N.; Oseledets, I.; Phan, A.H.; Zhao, Q.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 1 low-rank tensor decompositions. Found. Trends® Mach. Learn. 2016, 9, 249–429. [Google Scholar] [CrossRef] [Green Version]
- Cichocki, A.; Phan, A.H.; Zhao, Q.; Lee, N.; Oseledets, I.; Sugiyama, M.; Mandic, D.P. Tensor networks for dimensionality reduction and large-scale optimization: Part 2 applications and future perspectives. Found. Trends® Mach. Learn. 2017, 9, 431–673. [Google Scholar] [CrossRef]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When is “nearest neighbor” meaningful? In Proceedings of the 7th International Conference on Database Theory (ICDT), Jerusalem, Israel, 10–12 January 1999; pp. 217–235. [Google Scholar] [CrossRef] [Green Version]
- Pestov, V. Is the k-NN classifier in high dimensions affected by the curse of dimensionality? Comput. Math. Appl. 2013, 65, 1427–1437. [Google Scholar] [CrossRef]
- Kainen, P.C. Utilizing geometric anomalies of high dimension: when complexity makes computation easier. In Computer-Intensive Methods in Control and Signal Processing: The Curse of Dimensionality; Warwick, K., Kárný, M., Eds.; Springer: New York, NY, USA, 1997; pp. 283–294. [Google Scholar] [CrossRef]
- Brown, B.M.; Hall, P.; Young, G.A. On the effect of inliers on the spatial median. J. Multivar. Anal. 1997, 63, 88–104. [Google Scholar] [CrossRef] [Green Version]
- Donoho, D.L. High-Dimensional Data Analysis: The Curses and Blessings of Dimensionality. Invited Lecture at Mathematical Challenges of the 21st Century. In Proceedings of the AMS National Meeting, Los Angeles, CA, USA, 6–12 August 2000; Available online: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.329.3392 (accessed on 5 January 2020).
- Chen, D.; Cao, X.; Wen, F.; Sun, J. Blessing of dimensionality: High-dimensional feature and its efficient compression for face verification. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 3025–3032. [Google Scholar] [CrossRef]
- Liu, G.; Liu, Q.; Li, P. Blessing of dimensionality: Recovering mixture data via dictionary pursuit. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 47–60. [Google Scholar] [CrossRef]
- Murtagh, F. The remarkable simplicity of very high dimensional data: Application of model-based clustering. J. Classif. 2009, 26, 249–277. [Google Scholar] [CrossRef] [Green Version]
- Anderson, J.; Belkin, M.; Goyal, N.; Rademacher, L.; Voss, J. The More, the Merrier: The Blessing of Dimensionality for Learning Large Gaussian Mixtures. In Proceedings of the 27th Conference on Learning Theory, Barcelona, Spain, 13–15 June 2014; Balcan, M.F., Feldman, V., Szepesvári, C., Eds.; PMLR: Barcelona, Spain, 2014; Volume 35, pp. 1135–1164. [Google Scholar]
- Gorban, A.N.; Tyukin, I.Y.; Romanenko, I. The blessing of dimensionality: Separation theorems in the thermodynamic limit. IFAC-PapersOnLine 2016, 49, 64–69. [Google Scholar] [CrossRef]
- Li, Q.; Cheng, G.; Fan, J.; Wang, Y. Embracing the blessing of dimensionality in factor models. J. Am. Stat. Assoc. 2018, 113, 380–389. [Google Scholar] [CrossRef] [PubMed]
- Landgraf, A.J.; Lee, Y. Generalized principal component analysis: Projection of saturated model parameters. Technometrics 2019. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Donoho, D.; Tanner, J. Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processing. Phil. Trans. R. Soc. A 2009, 367, 4273–4293. [Google Scholar] [CrossRef] [PubMed]
- Candes, E.; Rudelson, M.; Tao, T.; Vershynin, R. Error correction via linear programming. In Proceedings of the 46th Annual IEEE Symposium on Foundations of Computer Science (FOCS’05), Pittsburgh, PA, USA, 23–25 October 2005; pp. 668–681. [Google Scholar] [CrossRef] [Green Version]
- Pereda, E.; García-Torres, M.; Melián-Batista, B.; Mañas, S.; Méndez, L.; González, J.J. The blessing of Dimensionality: Feature Selection outperforms functional connectivity-based feature transformation to classify ADHD subjects from EEG patterns of phase synchronisation. PLoS ONE 2018, 13, e0201660. [Google Scholar] [CrossRef] [PubMed]
- Kainen, P.; Kůrková, V. Quasiorthogonal dimension of Euclidian spaces. Appl. Math. Lett. 1993, 6, 7–10. [Google Scholar] [CrossRef] [Green Version]
- Hall, P.; Marron, J.; Neeman, A. Geometric representation of high dimension, low sample size data. J. R. Stat. Soc. B 2005, 67, 427–444. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.; Prokhorov, D.; Sofeikov, K. Approximation with random bases: Pro et contra. Inf. Sci. 2016, 364–365, 129–145. [Google Scholar] [CrossRef] [Green Version]
- Dasgupta, S.; Gupta, A. An elementary proof of a theorem of Johnson and Lindenstrauss. Random Sruct. Algorithms 2003, 22, 60–65. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Blessing of dimensionality: Mathematical foundations of the statistical physics of data. Philos. Trans. R. Soc. A 2018, 376, 20170237. [Google Scholar] [CrossRef] [Green Version]
- Vershynin, R. High-Dimensional Probability: An Introduction with Applications in Data Science; Cambridge Series in Statistical and Probabilistic Mathematics; Cambridge University Press: Cambridge, UK, 2018. [Google Scholar]
- Giannopoulos, A.A.; Milman, V.D. Concentration property on probability spaces. Adv. Math. 2000, 156, 77–106. [Google Scholar] [CrossRef] [Green Version]
- Ledoux, M. The Concentration of Measure Phenomenon; Number 89 in Mathematical Surveys & Monographs; AMS: Providence, RI, USA, 2005. [Google Scholar]
- Gibbs, J.W. Elementary Principles in Statistical Mechanics, Developed with Especial Reference to the Rational Foundation of Thermodynamics; Dover Publications: New York, NY, USA, 1960. [Google Scholar]
- Gromov, M. Isoperimetry of waists and concentration of maps. Geom. Funct. Anal. 2003, 13, 178–215. [Google Scholar] [CrossRef] [Green Version]
- Lévy, P. Problèmes Concrets D’analyse Fonctionnelle; Gauthier-Villars: Paris, France, 1951. [Google Scholar]
- Dubhashi, D.P.; Panconesi, A. Concentration of Measure for the Analysis of Randomized Algorithms; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Ball, K. An Elementary Introduction to Modern Convex Geometry. In Flavors of Geometry; Cambridge University Press: Cambridge, UK, 1997; Volume 31. [Google Scholar]
- Gorban, A.N.; Golubkov, A.; Grechuk, B.; Mirkes, E.M.; Tyukin, I.Y. Correction of AI systems by linear discriminants: Probabilistic foundations. Inf. Sci. 2018, 466, 303–322. [Google Scholar] [CrossRef] [Green Version]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. The unreasonable effectiveness of small neural ensembles in high-dimensional brain. Phys. Life Rev. 2019, 29, 55–88. [Google Scholar] [CrossRef] [PubMed]
- Bárány, I.; Füredi, Z. On the shape of the convex hull of random points. Probab. Theory Relat. Fields 1988, 77, 231–240. [Google Scholar] [CrossRef]
- Gorban, A.N.; Tyukin, I.Y. Stochastic separation theorems. Neural Netw. 2017, 94, 255–259. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; McEwan, A.A.; Meshkinfamfard, S. Blessing of dimensionality at the edge. arXiv 2019, arXiv:1910.00445. [Google Scholar]
- Gorban, A.N.; Burton, R.; Romanenko, I.; Tyukin, I.Y. One-trial correction of legacy AI systems and stochastic separation theorems. Inf. Sci. 2019, 484, 237–254. [Google Scholar] [CrossRef] [Green Version]
- Fisher, R.A. The Use of Multiple Measurements in Taxonomic Problems. Ann. Eugenics 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Kůrková, V. Some insights from high-dimensional spheres: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 98–100. [Google Scholar] [CrossRef]
- Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. Symphony of high-dimensional brain. Reply to comments on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain”. Phys. Life Rev. 2019, 29, 115–119. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Grechuk, B. Practical stochastic separation theorems for product distributions. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Kůrková, V.; Sanguineti, M. Probabilistic Bounds for Binary Classification of Large Data Sets. In Proceedings of the International Neural Networks Society, Genova, Italy, 16–18 April 2019; Oneto, L., Navarin, N., Sperduti, A., Anguita, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 1, pp. 309–319. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Gorban, A.N.; Grechuk, B. Kernel Stochastic Separation Theorems and Separability Characterizations of Kernel Classifiers. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef]
- Meshkinfamfard, S.; Gorban, A.N.; Tyukin, I.V. Tackling Rare False-Positives in Face Recognition: A Case Study. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS); IEEE: Exeter, UK, 2018; pp. 1592–1598. [Google Scholar] [CrossRef]
- Tyukin, I.Y.; Gorban, A.N.; Green, S.; Prokhorov, D. Fast construction of correcting ensembles for legacy artificial intelligence systems: Algorithms and a case study. Inf. Sci. 2019, 485, 230–247. [Google Scholar] [CrossRef] [Green Version]
- Tyukin, I.Y.; Gorban, A.N.; Sofeikov, K.; Romanenko, I. Knowledge transfer between artificial intelligence systems. Front. Neurorobot. 2018, 12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Allison, P.M.; Sofeikov, K.; Levesley, J.; Gorban, A.N.; Tyukin, I.; Cooper, N.J. Exploring automated pottery identification [Arch-I-Scan]. Internet Archaeol. 2018, 50. [Google Scholar] [CrossRef]
- Romanenko, I.; Gorban, A.; Tyukin, I. Image Processing. U.S. Patent 10,489,634 B2, 26 November 2019. Available online: https://patents.google.com/patent/US10489634B2/en (accessed on 5 January 2020).
- Xu, R.; Wunsch, D. Clustering; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Moczko, E.; Mirkes, E.M.; Cáceres, C.; Gorban, A.N.; Piletsky, S. Fluorescence-based assay as a new screening tool for toxic chemicals. Sci. Rep. 2016, 6, 33922. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dormann, C.F.; Elith, J.; Bacher, S.; Buchmann, C.; Carl, G.; Carré, G.; Marquéz, J.R.; Gruber, B.; Lafourcade, B.; Leitão, P.J.; et al. Collinearity: A review of methods to deal with it and a simulation study evaluating their performance. Ecography 2013, 36, 27–46. [Google Scholar] [CrossRef]
- Albergante, L.; Bac, J.; Zinovyev, A. Estimating the effective dimension of large biological datasets using Fisher separability analysis. In Proceedings of the IEEE IJCNN 2019—International Joint Conference on Neural Networks, Budapest, Hungary, 14–19 July 2019. [Google Scholar] [CrossRef] [Green Version]
- Artin, E. The Gamma Function; Courier Dover Publications: Mineola, NY, USA, 2015. [Google Scholar]
- Kreinovich, V. The heresy of unheard-of simplicity: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by A.N. Gorban, V.A. Makarov, and I.Y. Tyukin. Phys. Life Rev. 2019, 29, 93–95. [Google Scholar] [CrossRef]
- Quian Quiroga, R.; Reddy, L.; Kreiman, G.; Koch, C.; Fried, I. Invariant visual representation by single neurons in the human brain. Nature 2005, 435, 1102–1107. [Google Scholar] [CrossRef]
- Barlow, H.B. Single units and sensation: a neuron doctrine for perceptual psychology? Perception 1972, 1, 371–394. [Google Scholar] [CrossRef] [Green Version]
- Quian Quiroga, R. Akakhievitch revisited: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 111–114. [Google Scholar] [CrossRef]
- Megías, M.; Emri, Z.S.; Freund, T.F.; Gulyás, A.I. Total number and distribution of inhibitory and excitatory synapses on hippocampal CA1 pyramidal cells. Neuroscience 2001, 102, 527–540. [Google Scholar] [CrossRef]
- Druckmann, S.; Feng, L.; Lee, B.; Yook, C.; Zhao, T.; Magee, J.C.; Kim, J. Structured synaptic connectivity between hippocampal regions. Neuron 2014, 81, 629–640. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Brivanlou, I.H.; Dantzker, J.L.; Stevens, C.F.; Callaway, E.M. Topographic specificity of functional connections from hippocampal CA3 to CA1. Proc. Natl. Acad. Sci. USA 2004, 101, 2560–2565. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tyukin, I.; Gorban, A.N.; Calvo, C.; Makarova, J.; Makarov, V.A. High-dimensional brain: A tool for encoding and rapid learning of memories by single neurons. Bull. Math. Biol. 2019, 81, 4856–4888. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Varona, P. High and low dimensionality in neuroscience and artificial intelligence: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by A.N. Gorban et al. Phys. Life Rev. 2019, 29, 106–107. [Google Scholar] [CrossRef]
- Barrio, R. “Brainland” vs. “flatland”: how many dimensions do we need in brain dynamics? Comment on the paper “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 108–110. [Google Scholar] [CrossRef]
- Van Leeuwen, C. The reasonable ineffectiveness of biological brains in applying the principles of high-dimensional cybernetics: Comment on “The unreasonable effectiveness of small neural ensembles in high-dimensional brain” by Alexander N. Gorban et al. Phys. Life Rev. 2019, 29, 104–105. [Google Scholar] [CrossRef]
Figure 1.
A scheme of corrector. Corrector receives some input, internal, and output signals from the legacy artificial intelligence (AI) system and classifies the situation as ‘high risk’ or ‘normal’ one. For a high-risk situation, it sends the corrected output to users following the correction rules. The high risk/normal situation classifier is prepared by supervised training on situations with diagnosed errors (universal construction). The online training algorithm could be very simple like Fisher’s linear discriminants or their ensembles [30,39,40,43,44]. Correction rules for high-risk situations are specific to a particular problem.
Figure 1.
A scheme of corrector. Corrector receives some input, internal, and output signals from the legacy artificial intelligence (AI) system and classifies the situation as ‘high risk’ or ‘normal’ one. For a high-risk situation, it sends the corrected output to users following the correction rules. The high risk/normal situation classifier is prepared by supervised training on situations with diagnosed errors (universal construction). The online training algorithm could be very simple like Fisher’s linear discriminants or their ensembles [30,39,40,43,44]. Correction rules for high-risk situations are specific to a particular problem.

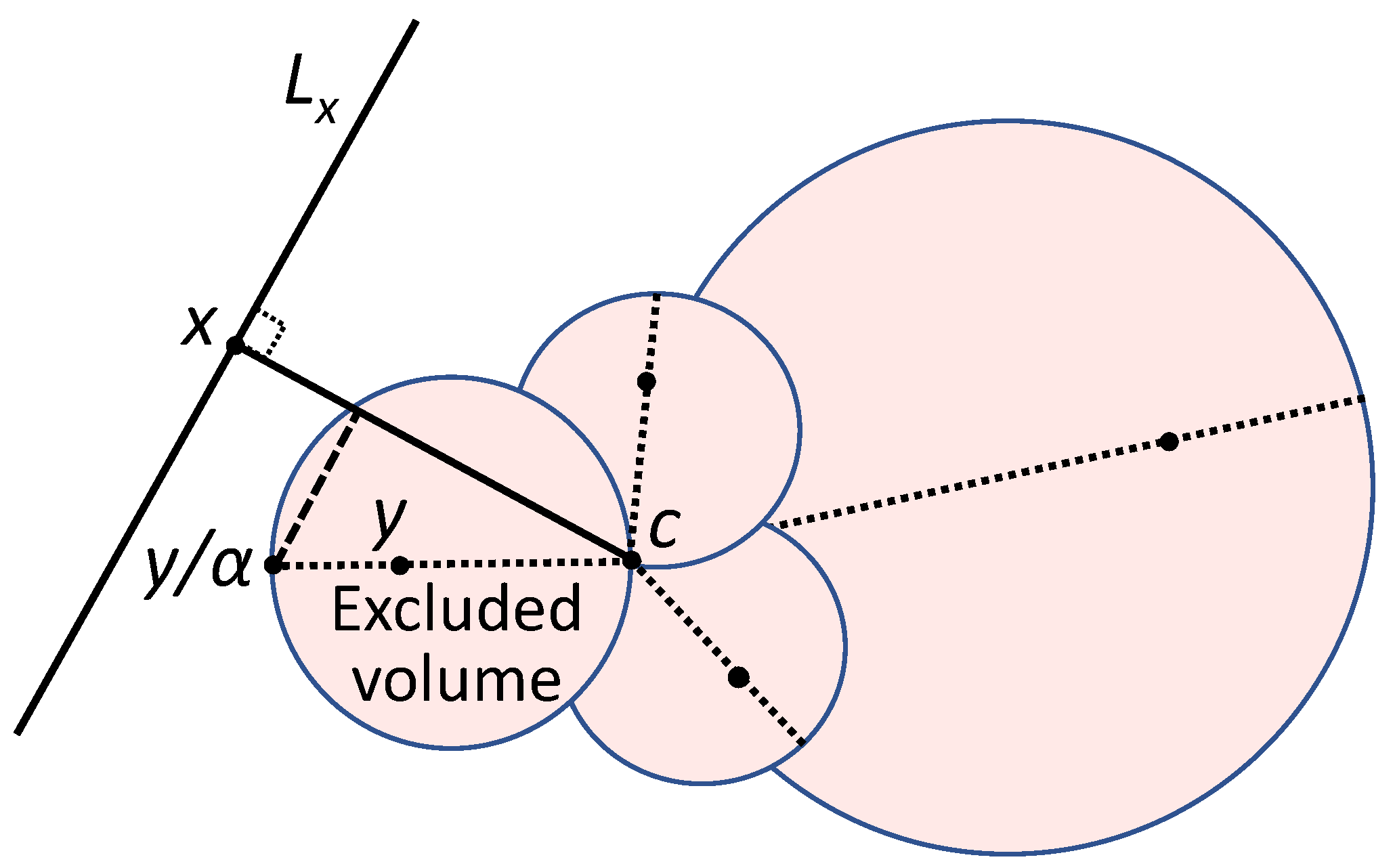
Figure 2.
Fisher’s separability of a point from a set Y. Diameters of the filled balls (excluded volume) are the segments (). Point should not belong to the excluded volume to be separable from by the linear discriminant (1) with threshold . Here, is the origin (centre), and is the hyperplane. A point should not belong to the union of such balls (filled) for all for separability from a set Y. The volume of this union, , does not exceed .
Figure 2.
Fisher’s separability of a point from a set Y. Diameters of the filled balls (excluded volume) are the segments (). Point should not belong to the excluded volume to be separable from by the linear discriminant (1) with threshold . Here, is the origin (centre), and is the hyperplane. A point should not belong to the union of such balls (filled) for all for separability from a set Y. The volume of this union, , does not exceed .

Figure 3.
Measure of clustering quality. Intersection of two balls with the radii , and the distance between centres is included in a ball with radius R (4) and centre c (colored in red).
Figure 3.
Measure of clustering quality. Intersection of two balls with the radii , and the distance between centres is included in a ball with radius R (4) and centre c (colored in red).

Figure 4.
Estimation of the area of the spherical cap. A point of is Fisher-separable from with the threshold if and only if it does not belong to the spherical cap with the base radius and the base plane orthogonal to y. The surface of this spherical cap is less than the lateral surface of the cone that is tangent to the base. The -dimensional surface of the base is . The lateral surface of the cone is .
Figure 4.
Estimation of the area of the spherical cap. A point of is Fisher-separable from with the threshold if and only if it does not belong to the spherical cap with the base radius and the base plane orthogonal to y. The surface of this spherical cap is less than the lateral surface of the cone that is tangent to the base. The -dimensional surface of the base is . The lateral surface of the cone is .

Figure 5.
Organisation of encoding memories by single neurons in laminar structures: (a) laminar organization of the CA3 and CA1 areas in the hippocampus facilitates multiple parallel synaptic contacts between neurons in these areas by means of Schaffer collaterals; (b) axons from CA3 pyramidal neurons bifurcate and pass through the CA1 area in parallel (left) giving rise to the convergence-divergence of the information content (right). Multiple CA1 neurons receive multiple synaptic contacts from CA3 neurons; (c) schematic representation of three memory encoding schemes: (1) selectivity. A neuron (shown in green) receives inputs from multiple presynaptic cells that code different information items. It detects (responds to) only one stimulus (purple trace), whereas rejecting the others; (2) clustering. Similar to 1, but now a neuron (shown in blue) detects a group of stimuli (purple and blue traces) and ignores the others; (3) acquiring memories. A neuron (shown in red) learns dynamically a new memory item (blue trace) by associating it with a known one (purple trace). ((Figure 13, [40]), published under CC BY-NC-ND 4.0 license.).
Figure 5.
Organisation of encoding memories by single neurons in laminar structures: (a) laminar organization of the CA3 and CA1 areas in the hippocampus facilitates multiple parallel synaptic contacts between neurons in these areas by means of Schaffer collaterals; (b) axons from CA3 pyramidal neurons bifurcate and pass through the CA1 area in parallel (left) giving rise to the convergence-divergence of the information content (right). Multiple CA1 neurons receive multiple synaptic contacts from CA3 neurons; (c) schematic representation of three memory encoding schemes: (1) selectivity. A neuron (shown in green) receives inputs from multiple presynaptic cells that code different information items. It detects (responds to) only one stimulus (purple trace), whereas rejecting the others; (2) clustering. Similar to 1, but now a neuron (shown in blue) detects a group of stimuli (purple and blue traces) and ignores the others; (3) acquiring memories. A neuron (shown in red) learns dynamically a new memory item (blue trace) by associating it with a known one (purple trace). ((Figure 13, [40]), published under CC BY-NC-ND 4.0 license.).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Stochastic separation on -dimensional spheres. For a sample size less than , all points of an i.i.d. sample with a probability greater than 0.99 are Fischer-separable from a given point y with a threshold . For a sample size less than , with probability greater than 0.99 an i.i.d. sample is Fisher-separable with a threshold (that is, each sample point is Fisher-separable from the rest of the sample with this threshold).
Table 1.
Stochastic separation on -dimensional spheres. For a sample size less than , all points of an i.i.d. sample with a probability greater than 0.99 are Fischer-separable from a given point y with a threshold . For a sample size less than , with probability greater than 0.99 an i.i.d. sample is Fisher-separable with a threshold (that is, each sample point is Fisher-separable from the rest of the sample with this threshold).
| n = 10 | n = 20 | n = 30 | n = 40 | n = 50 | n = 60 | n = 70 | n = 80 | |
|---|---|---|---|---|---|---|---|---|
| 5 | ||||||||
| 2 | 37 | 542 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Gorban, A.N.; Makarov, V.A.; Tyukin, I.Y. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy 2020, 22, 82. https://doi.org/10.3390/e22010082
AMA Style
Gorban AN, Makarov VA, Tyukin IY. High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality. Entropy. 2020; 22(1):82. https://doi.org/10.3390/e22010082
Chicago/Turabian StyleGorban, Alexander N., Valery A. Makarov, and Ivan Y. Tyukin. 2020. "High-Dimensional Brain in a High-Dimensional World: Blessing of Dimensionality" Entropy 22, no. 1: 82. https://doi.org/10.3390/e22010082
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.