
Improving Comprehension: Intelligent Tutoring System Explaining the Domain Rules When Students Break Them †


Abstract
:1. Introduction
- Knowledge level of Bloom’s taxonomy “involves the recall of specifics and universals, the recall of methods and processes, or the recall of a pattern, structure, or setting” [1].
- Comprehension “refers to a type of understanding or apprehension such that the individual knows what is being communicated and can make use of the material or idea being communicated without necessarily relating it to other material or seeing its fullest implications” [1].
- Application refers to the “use of abstractions in particular and concrete situations” [1]. Its main difference from comprehension level is that when demonstrating comprehension, the student is hinted about the abstractions (concepts) he should use while the application level requires understanding the concepts involved in a particular task.
- Analysis represents the “breakdown of a communication into its constituent elements or parts such that the relative hierarchy of ideas is made clear and/or the relations between ideas expressed are made explicit” [1].
- Synthesis refers to the “putting together of elements and parts so as to form a whole” [1].
- Evaluation involves “judgments about the value of material and methods for given purposes” [1].
- Remembering implies learning the symbols and syntax of programming language to produce code.
- Comprehending implies understanding the nature of functions and statements of programming language.
- Applying means the ability to write the code according to the task requirements, and to define the objects and their behavior using programming language.
- Analyzing is associated with the abilities to find the logical or syntax errors in the program code.
- Synthesizing implies the ability to implement complex structures in programming language such as modules, classes, functions that interact with each other to solve some initial tasks.
- Evaluating is related to making choices about how to approach the given problem, what data structures, programming patterns, algorithms to apply for the task solution. To make such a choice, an appropriate level of experience is required.
2. Related Work
- Domain-independence requires using an open model for representing subject domains, including concepts, their relations, and laws.
- Question and task types. They affect learning objectives and the available feedback.
- Feedback type provided.
3. CompPrehension: Models, Architecture, and Workflow
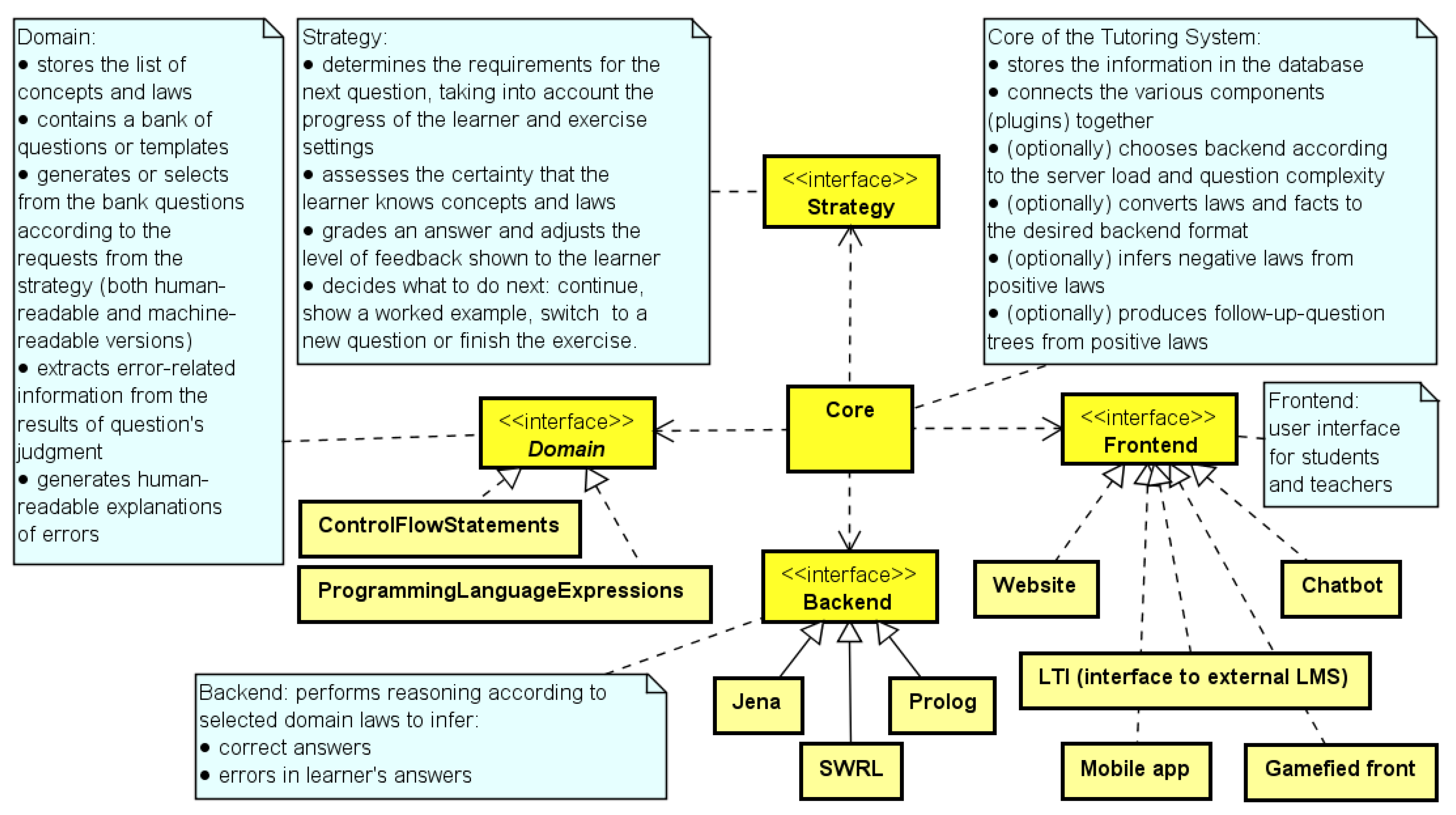
- Domain plug-ins encapsulate everything related to their subject domains, making the rest of the system domain-independent;
- Backend plug-ins allow interaction with different software reasoners, solving tasks by using provided laws and facts;
- Strategy plug-ins assess the level of demonstrated knowledge for the student, and choose the pedagogical interventions and the next question if necessary;
- Frontend plug-in encapsulates the user interface for teachers and students.
- Single choice (choosing one element from the given set);
- Multiple choice (choosing any number of elements from the given set);
- Match (matching each element from the given set with an element for another set);
- Order (ordering elements of a given set; elements may be omitted or used several times).
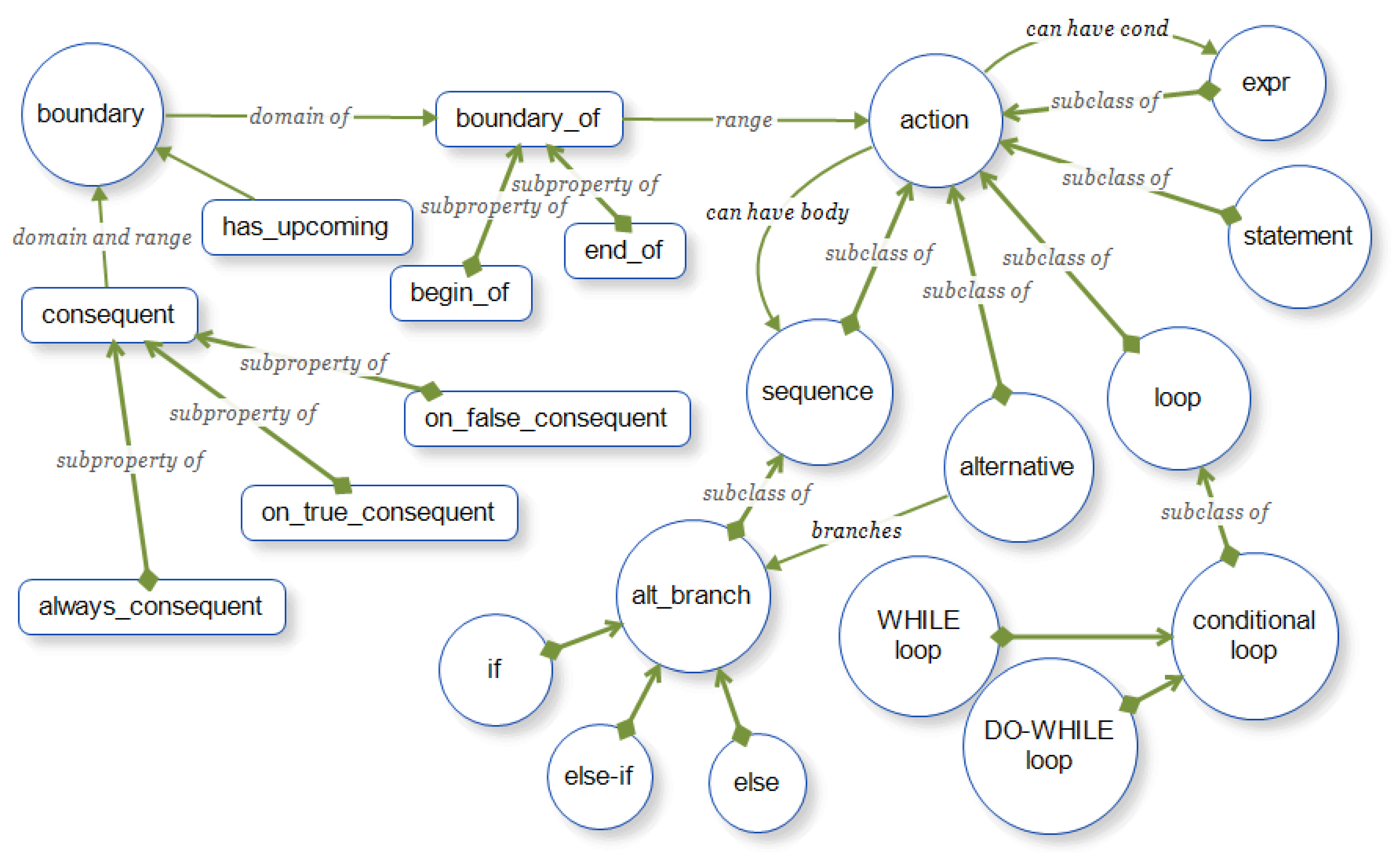
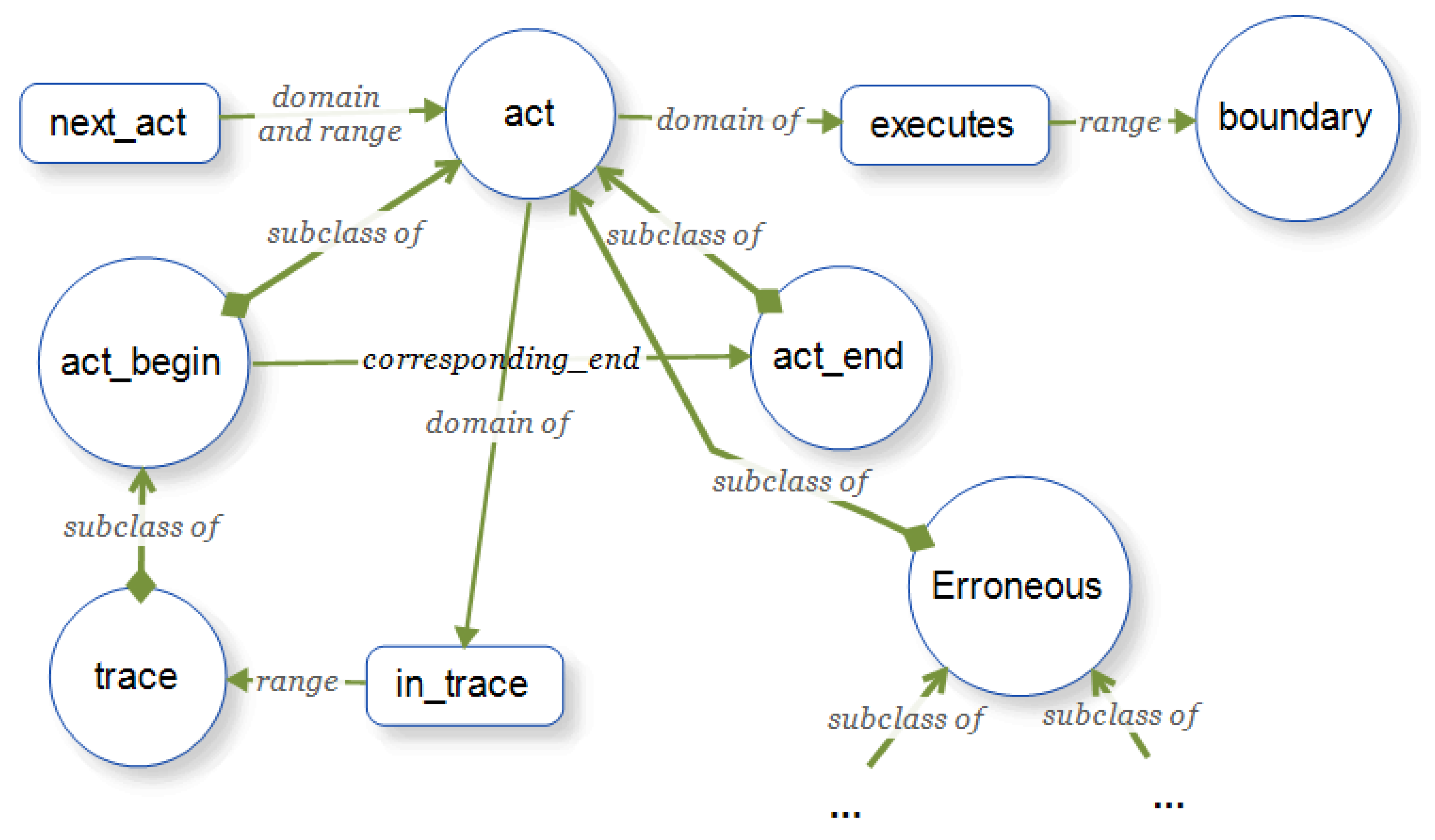
3.1. Comprehension-Level Model of Subject Domain
- Positive rules or productions allow inferring the correct answer from the formal problem definition;
- Negative rules or constraints allow catching errors in student’s answer.
3.2. Architecture
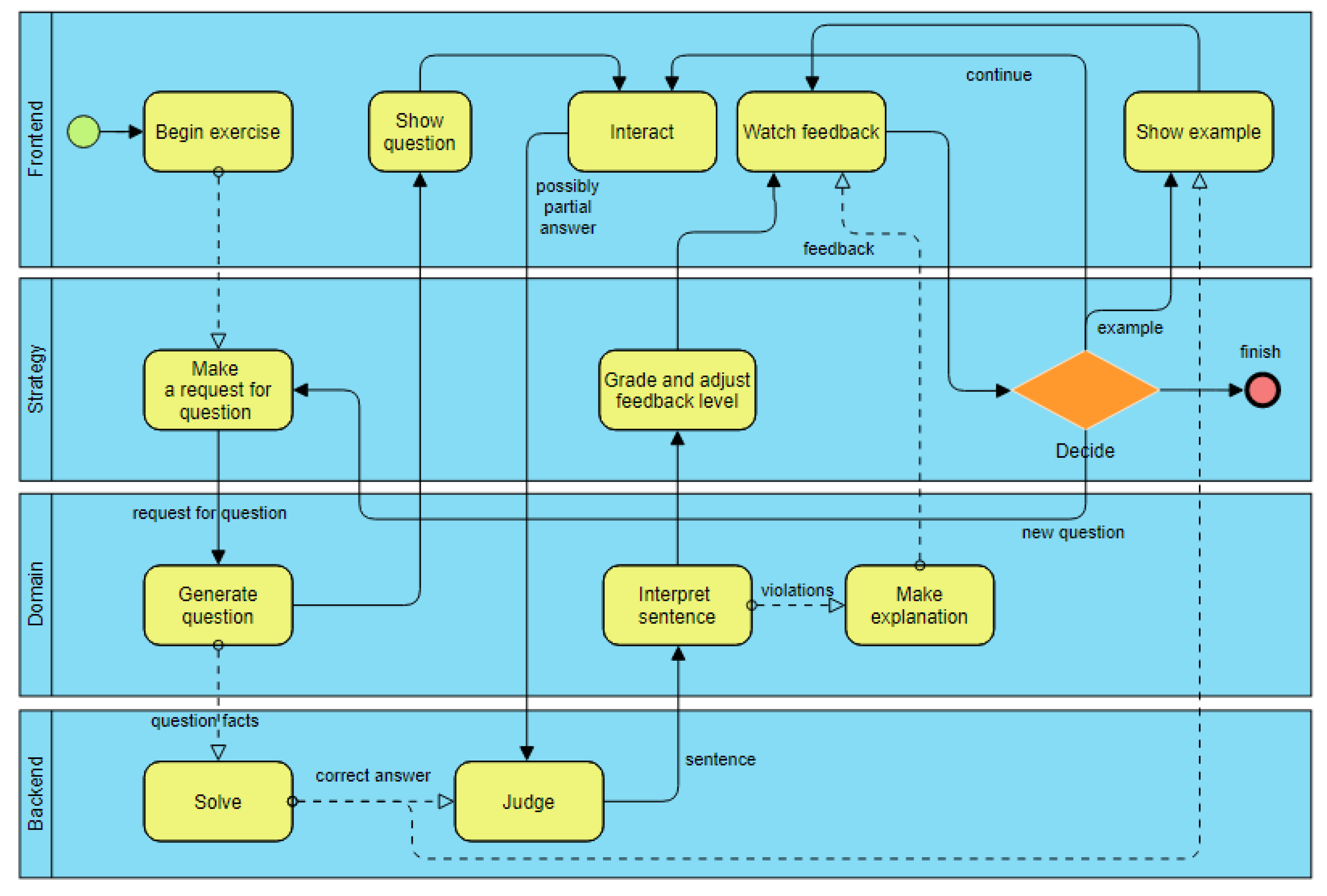
3.3. Typical Workflow
- The strategy creates a request for a question based on the exercise settings, student’s performance, and difficulty of the laws and concepts.
- The domain generates a question based on the strategy’s request, including machine-solvable and human-readable versions.
- The backend solves the question, finding the correct answer.
- The student reads the question and provides a (possibly partial) answer through the frontend.
- The core transforms the student’s answer to backend facts.
- The backend judges the answer, determining its correctness, errors, and their fault reasons (the sentence).
- The domain interprets this sentence, transforming backend facts to subject-domain law violations, and generates human-readable feedback (e.g., error explanation).
- The strategy adjusts the feedback level.
- The student watches the feedback, possibly requesting more feedback.
- The strategy chooses to show a worked example for the next step, to ask a follow-up question, to continue with the current question, to generate a new question, or consider the exercise completed (the strategy can also let the student choose among some of these options).
4. Developed Domains
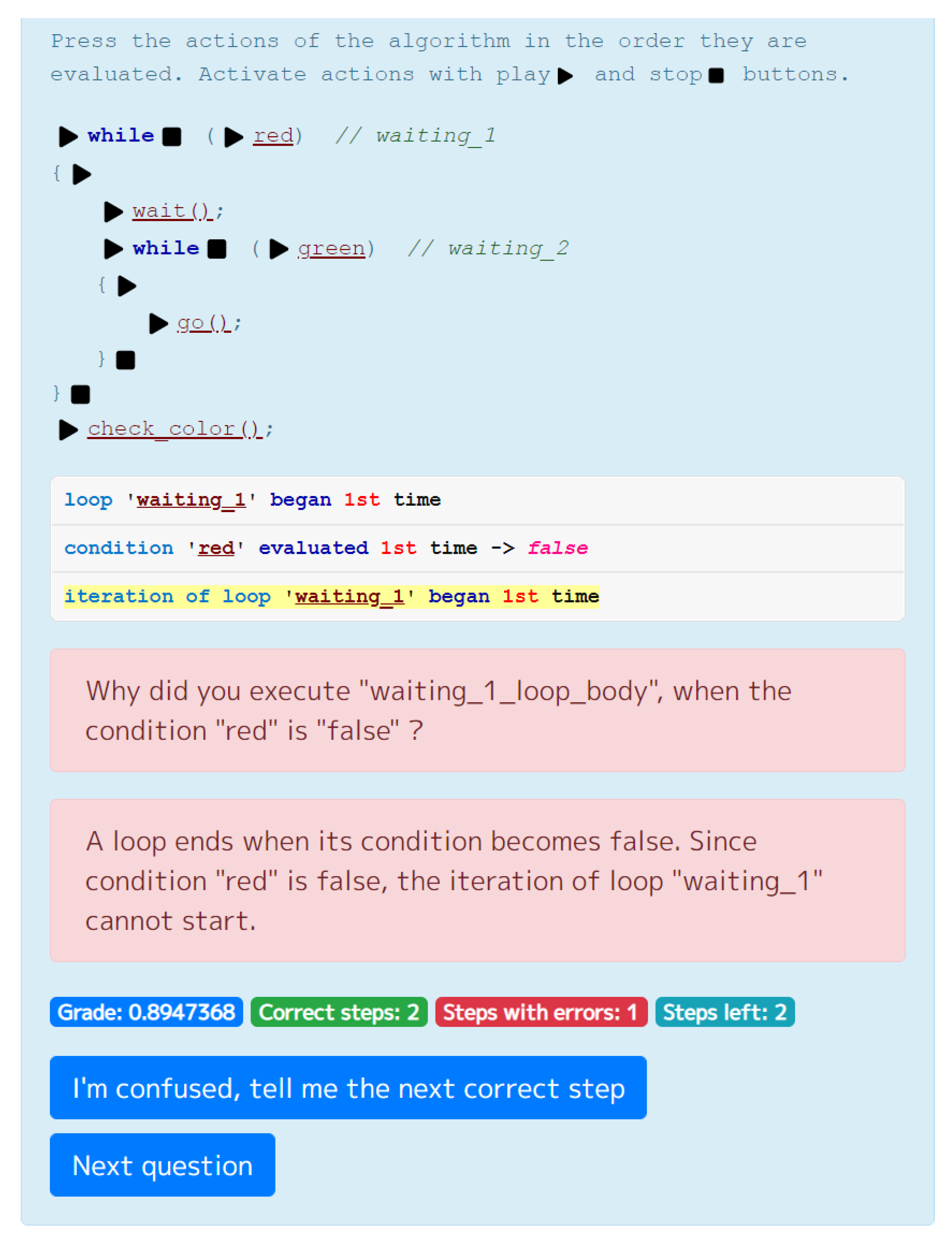
4.1. Control Flow Statements
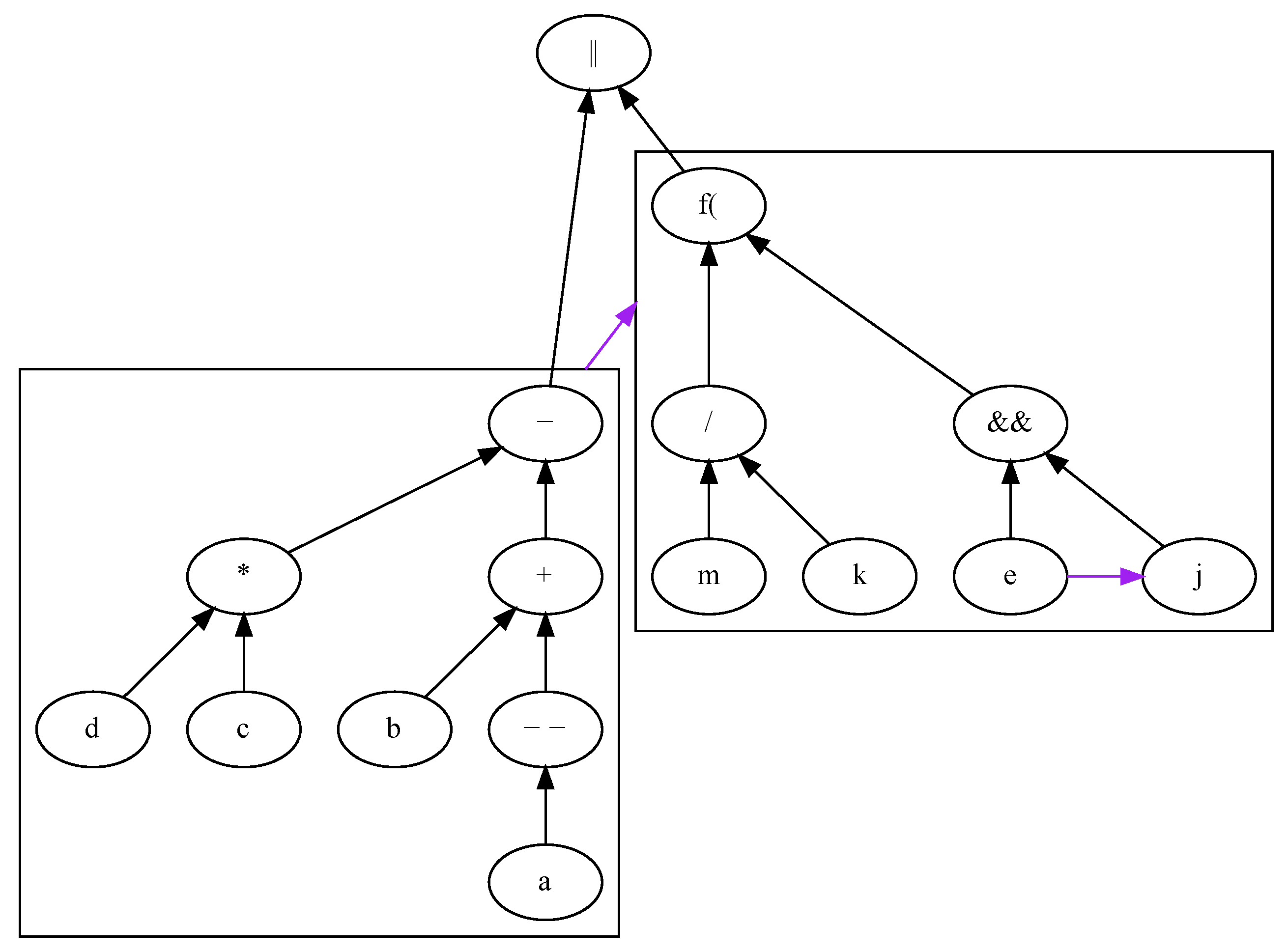
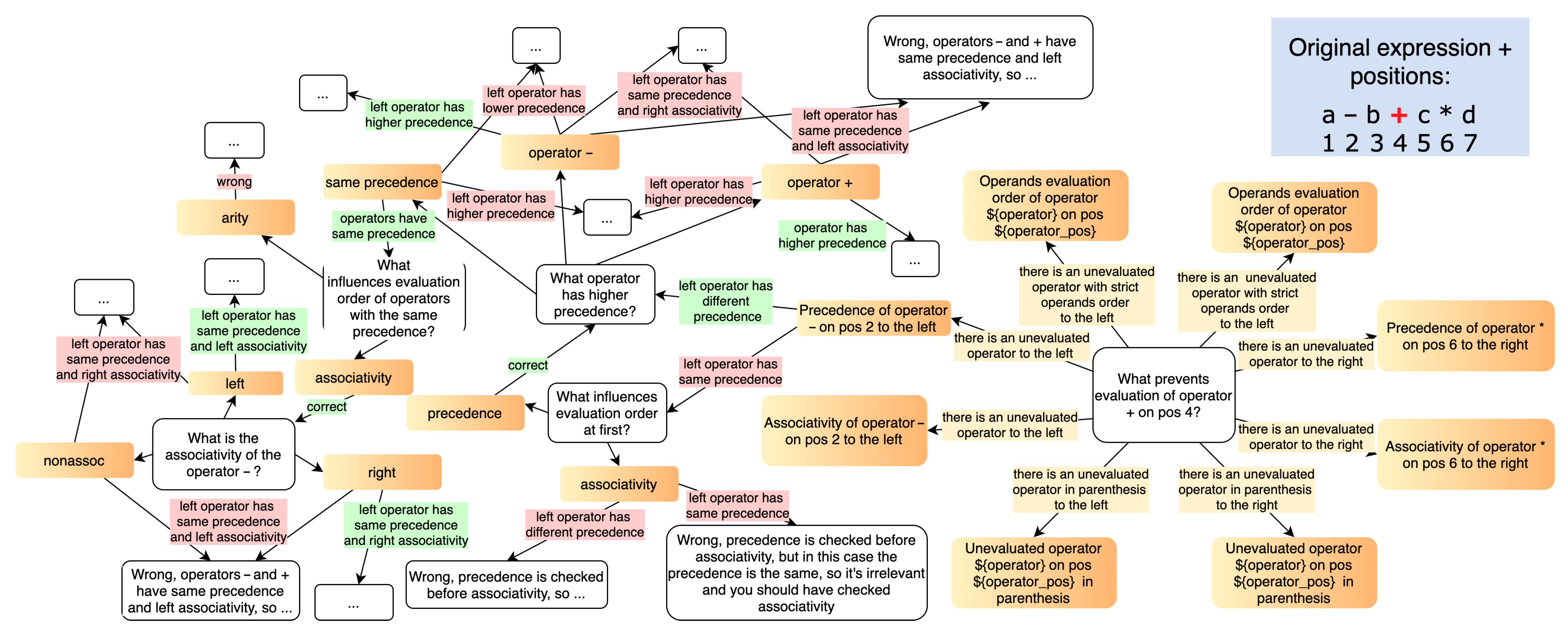
4.2. Expressions
- The student does not know that addition is left-associative;
- The student does not know that precedence must be checked before associativity;
- The student does not know the relative precedence of addition and multiplication.
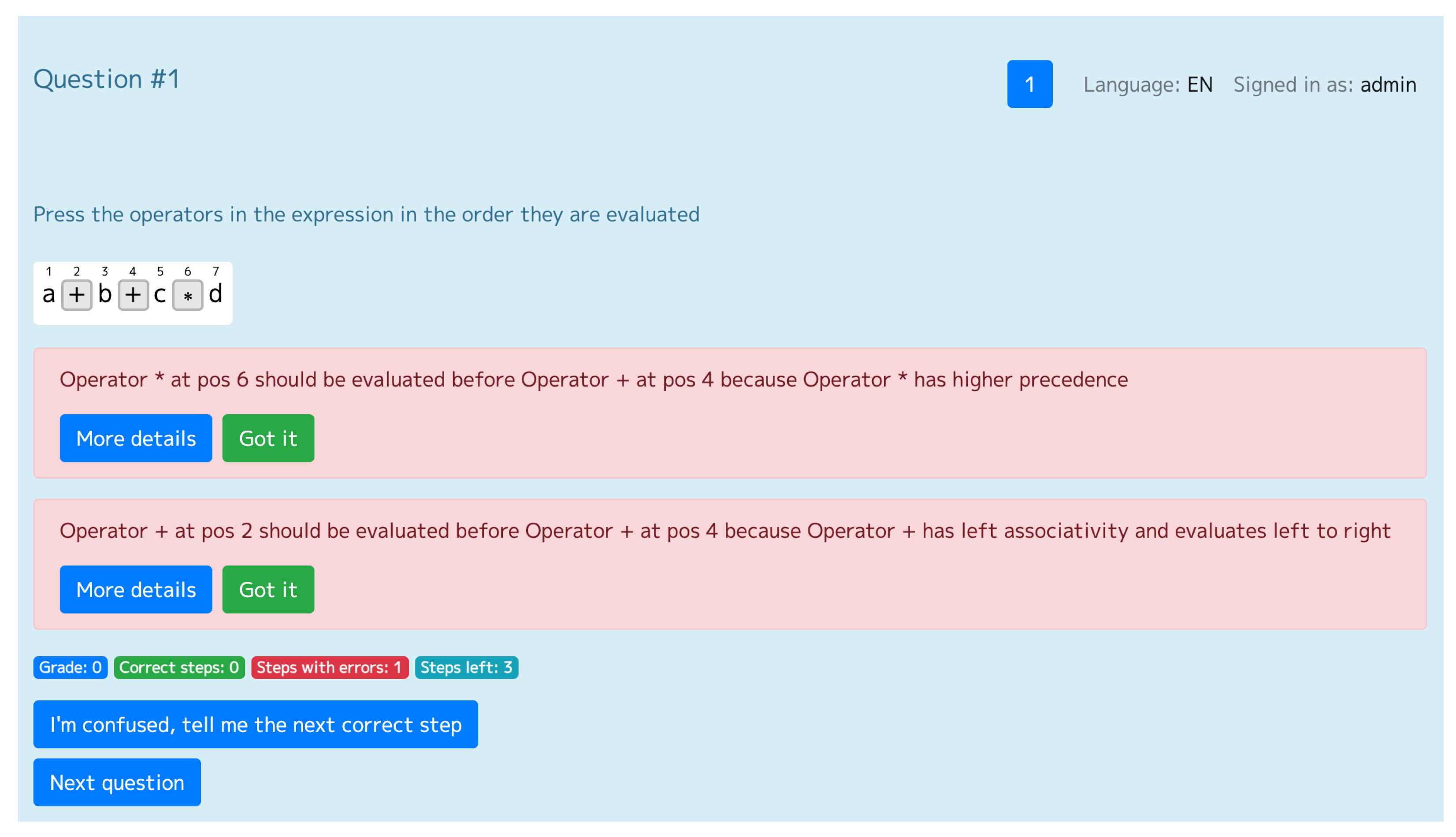
- Program: What prevents evaluation of operator + at pos 4?
- Student: Precedence of operator * at pos 6.
- Program: Correct.
- Program: Which operator has highest precedence: + or * ?
- Student: Operator +.
- Program: Wrong.
- Program: No, operator * has precedence over operator +, so the operator * at pos 6 should be evaluated before the operator + at pos 4.
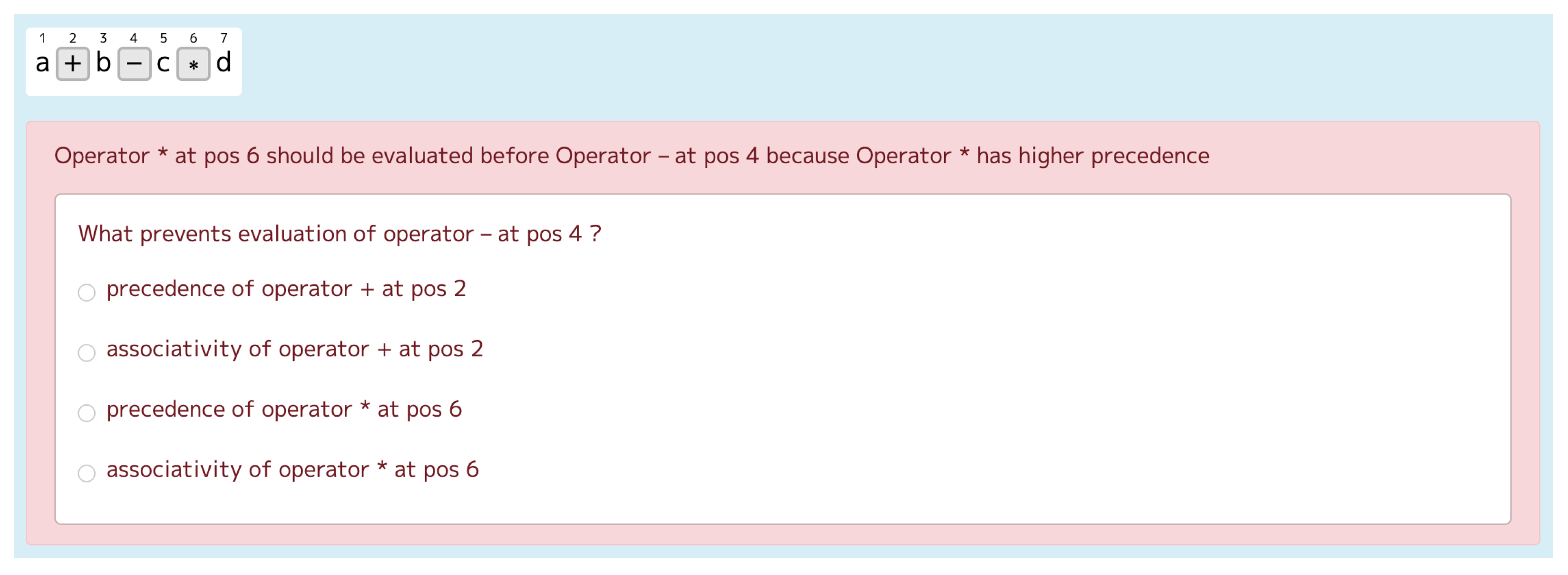
- Program: What prevents evaluation of operator − at pos 4?
- Student: Precedence of operator + at pos 2.
- Program: Wrong.
- Program: What influences evaluation order first: precedence or associativity?
- Student: Precedence.
- Program: Correct.
- Program: Which operator has highest precedence: − or + ?
- Student: The same precedence.
- Program: Correct.
- Program: What influences evaluation order of operators with the same precedence?
- Student: Associativity.
- Program: Correct.
- Program: What is the associativity of operator −?
- Student: Left.
- Program: Correct.
- Program: Yes, the operators + and − have the same precedence and left associativity, so the operator + at pos 2 should be evaluated first as it stands to the left of the operator − at pos 4.
5. Evaluation
- Pass a pre-test to measure their baseline knowledge (maximum grade is 10);
- Work with the CompPrehension system to learn more, preferably until the system tells that the exercise is complete;
- Pass a post-test to measure their learning gains (maximum grade is 10);
- Participate in a survey about the system they used.
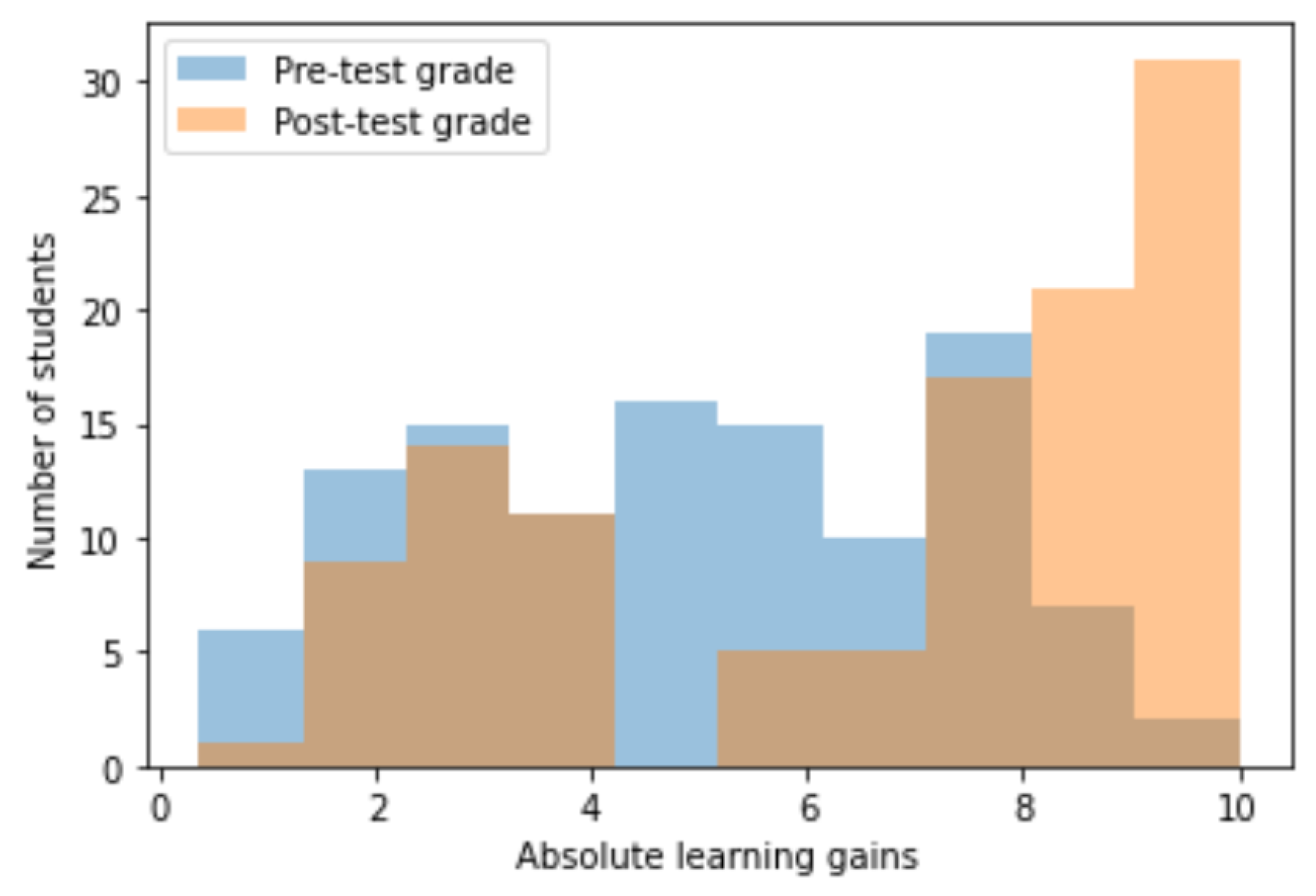
5.1. Expressions Domain
5.2. Control Flow Statements Domain
5.3. Survey
6. Discussion
- decoupling pedagogical strategies from subject-domain models;
- decoupling subject-domain-specific user interface from general question interface;
- systematic coverage of all the ways to violate subject-domain rules by negative laws;
- developing a question base to satisfy all possible requests for generating questions.
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| ASP | Answer Set Programming |
| AST | Abstract Syntax Tree |
| HTML | The HyperText Markup Language |
| ITS | Intelligent Tutoring System |
| IPTS | Intelligent Programming Tutoring System |
| LTI | Learning Tools Interoperability |
| SWRL | Semantic Web Rule Language |
References
- Bloom, B.S.; Engelhart, M.B.; Furst, E.J.; Hill, W.H.; Krathwohl, D.R. Taxonomy of Educational Objectives. The Classification of Educational Goals. Handbook 1: Cognitive Domain; Longmans Green: New York, NY, USA, 1956. [Google Scholar]
- Girija, V. Pedagogical Transitions Using Blooms Taxonomy. Int. J. Res. Eng. Soc. Sci. 2019, 9, 492–499. [Google Scholar]
- Ursani, A.A.; Memon, A.A.; Chowdhry, B.S. Bloom’s Taxonomy as a Pedagogical Model for Signals and Systems. Int. J. Electr. Eng. Educ. 2014, 51, 162–173. [Google Scholar] [CrossRef]
- Stanny, C. Reevaluating Bloom’s Taxonomy: What Measurable Verbs Can and Cannot Say about Student Learning. Educ. Sci. 2016, 6, 37. [Google Scholar] [CrossRef] [Green Version]
- Pikhart, M.; Klimova, B. Utilization of Linguistic Aspects of Bloom’s Taxonomy in Blended Learning. Educ. Sci. 2019, 9, 235. [Google Scholar] [CrossRef] [Green Version]
- Anderson, L.W.; Krathwohl, D.R.; Airasian, P.W.; Cruikshank, K.A.; Mayer, R.E.; Pintrich, P.R.; Raths, J.; Wittrock, M.C. A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom’s Taxonomy of Educational Objectives, abridged ed.; Allyn & Bacon: Boston, MA, USA, 2001. [Google Scholar]
- Churches, A. Bloom’s Digital Taxonomy. 2008. Available online: http://burtonslifelearning.pbworks.com/f/BloomDigitalTaxonomy2001.pdf (accessed on 5 November 2021).
- Mitrovic, A.; Koedinger, K.R.; Martin, B. A Comparative Analysis of Cognitive Tutoring and Constraint-Based Modeling. In Proceedings of the 9th International Conference on User Modeling, Johnstown, PA, USA, 22–26 June 2003; Brusilovsky, P., Corbett, A., de Rosis, F., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 313–322. [Google Scholar] [CrossRef] [Green Version]
- Taggart, M. Programming and Bloom’s Taxonomy. 2017. Available online: https://theforeverstudent.com/cs-ed-week-part-3-programming-and-blooms-taxonomy-151cfc0d550f (accessed on 5 November 2021).
- Omer, U.; Farooq, M.S.; Abid, A. Cognitive Learning Analytics Using Assessment Data and Concept Map: A Framework-Based Approach for Sustainability of Programming Courses. Sustainability 2020, 12, 6990. [Google Scholar] [CrossRef]
- Yoo, J.; Pettey, C.; Seo, S.; Yoo, S. Teaching Programming Concepts Using Algorithm Tutor. In EdMedia+ Innovate Learning; Association for the Advancement of Computing in Education: Waynesville, NC, USA, 2010; pp. 3549–3559. [Google Scholar]
- Skalka, J.; Drlík, M. Educational Model for Improving Programming Skills Based on Conceptual Microlearning Framework. In Proceedings of the International Conference on Interactive Collaborative Learning, Kos Island, Greece, 25–28 September 2018; Springer International Publishing: Cham, Switzerland, 2019; pp. 923–934. [Google Scholar] [CrossRef]
- Skalka, J.; Drlik, M.; Benko, L.; Kapusta, J.; del Pino, J.C.R.; Smyrnova-Trybulska, E.; Stolinska, A.; Svec, P.; Turcinek, P. Conceptual Framework for Programming Skills Development Based on Microlearning and Automated Source Code Evaluation in Virtual Learning Environment. Sustainability 2021, 13, 3293. [Google Scholar] [CrossRef]
- Sychev, O.; Denisov, M.; Terekhov, G. How It Works: Algorithms—A Tool for Developing an Understanding of Control Structures. In Proceedings of the 26th ACM Conference on Innovation and Technology in Computer Science Education V. 2, ITiCSE ’21, Paderborn, Germany, 26 June–1 July 2021; Association for Computing Machinery: New York, NY, USA, 2021; pp. 621–622. [Google Scholar] [CrossRef]
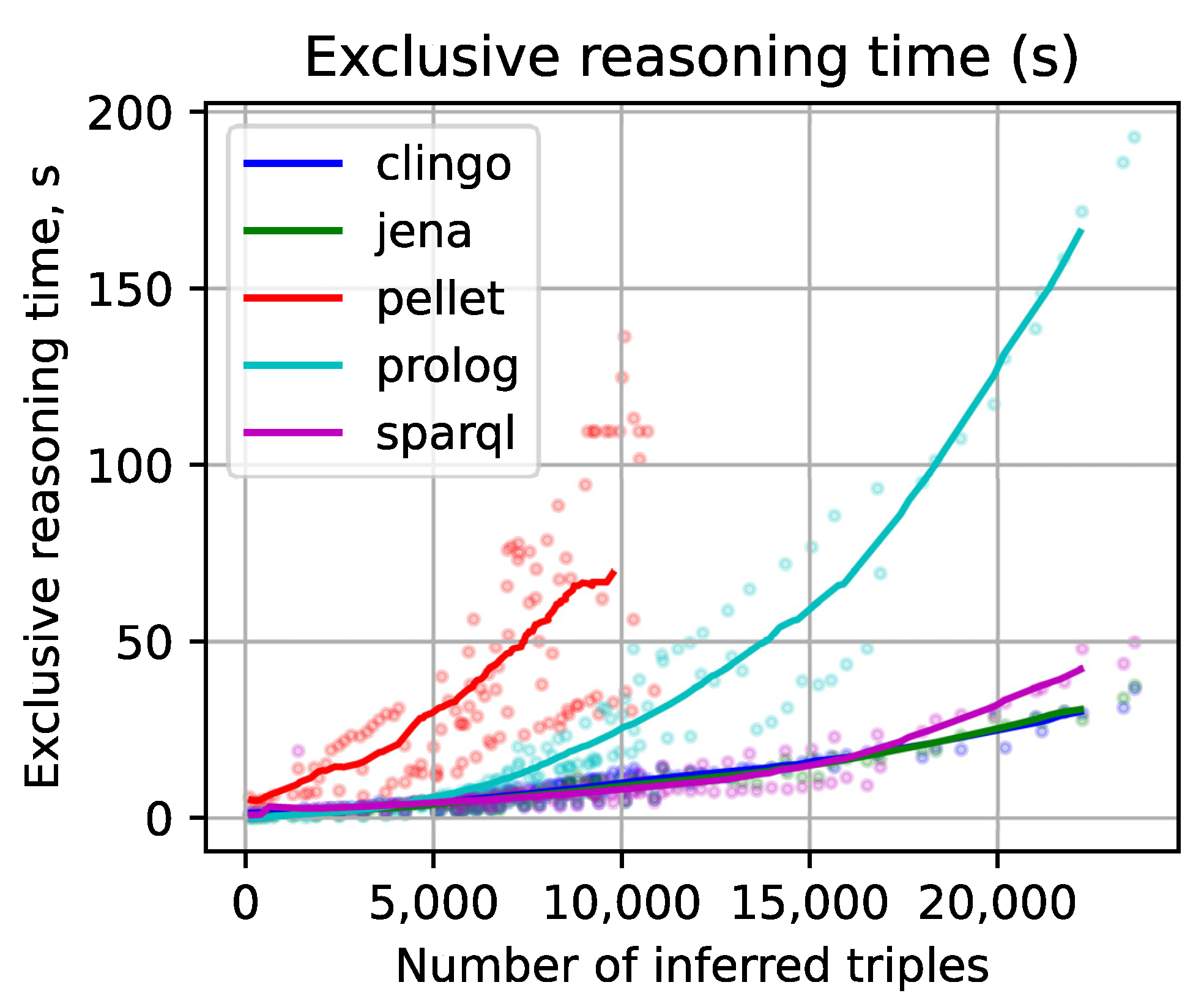
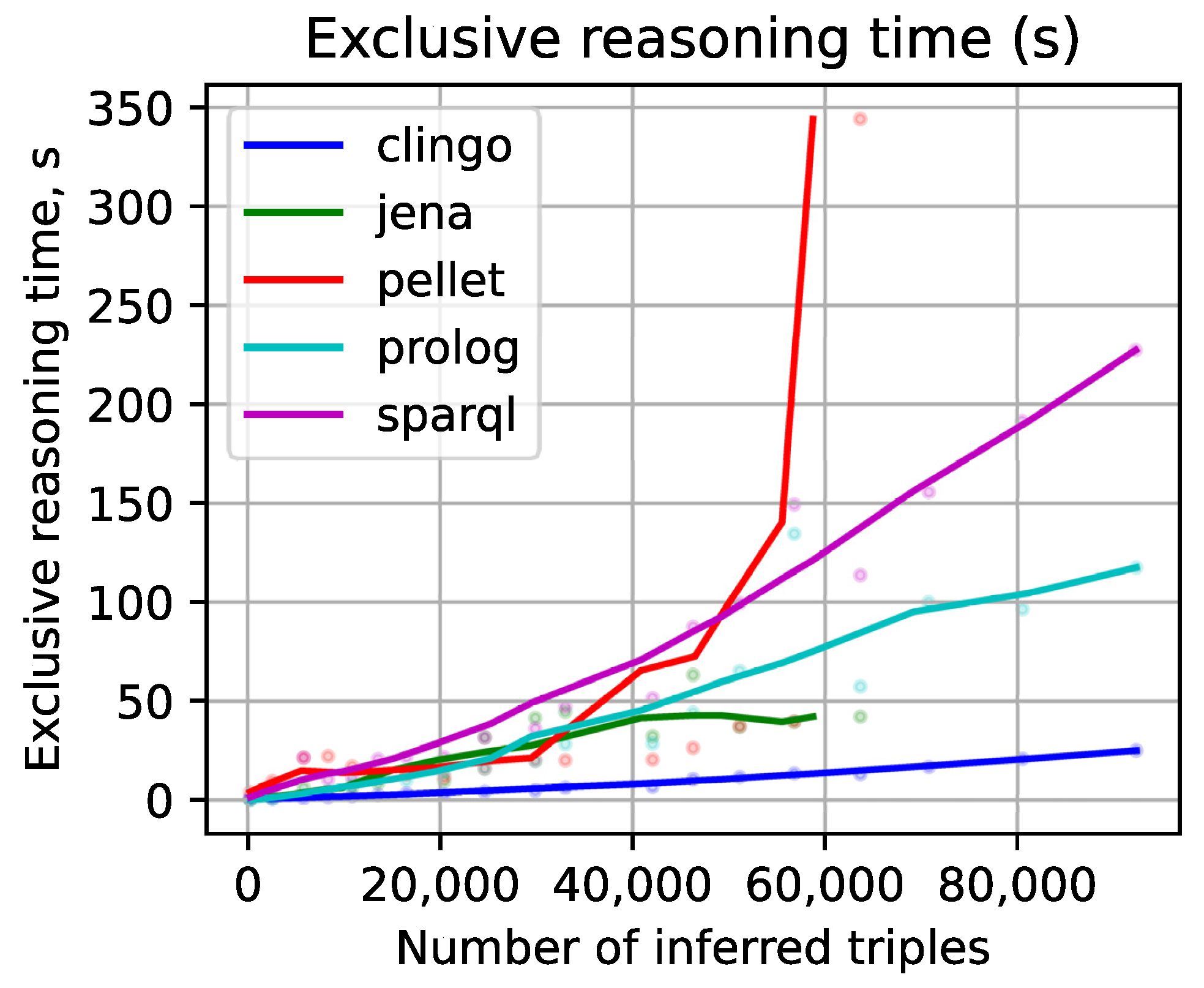
- Sychev, O.A.; Anikin, A.; Denisov, M. Inference Engines Performance in Reasoning Tasks for Intelligent Tutoring Systems. In Proceedings of the Computational Science and Its Applications—ICCSA 2021, Cagliari, Italy, 13–16 September 2021; Gervasi, O., Murgante, B., Misra, S., Garau, C., Blečić, I., Taniar, D., Apduhan, B.O., Rocha, A.M.A., Tarantino, E., Torre, C.M., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 471–482. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Ausin, M.; Azizsoltani, H.; Barnes, T.; Chi, M. Leveraging deep reinforcement learning for pedagogical policy induction in an intelligent tutoring system. In Proceedings of the EDM 2019—Proceedings of the 12th International Conference on EducationalData Mining, Montreal, QC, Canada, 2–5 July 2019; Lynch, C., Merceron, A., Desmarais, M., Nkambou, R., Eds.; International Educational Data Mining Society: Worcester, MA, USA, 2019; pp. 168–177. [Google Scholar]
- Crow, T.; Luxton-Reilly, A.; Wuensche, B. Intelligent tutoring systems for programming education. In Proceedings of the 20th Australasian Computing Education Conference—ACE’18, Brisbane, QLD, Australia, 30 January–2 February 2018; ACM Press: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Kumar, A.N. Generation of problems, answers, grade, and feedback—Case study of a fully automated tutor. J. Educ. Resour. Comput. 2005, 5, 3. [Google Scholar] [CrossRef]
- O’Rourke, E.; Butler, E.; Tolentino, A.D.; Popović, Z. Automatic Generation of Problems and Explanations for an Intelligent Algebra Tutor. In Proceedings of the 20th International Conference on Artificial Intelligence in Education, AIED, Chicago, IL, USA, 25–29 June 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 383–395. [Google Scholar] [CrossRef]
- Brusilovsky, P.; Su, H.D. Adaptive Visualization Component of a Distributed Web-Based Adaptive Educational System. In Intelligent Tutoring Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 229–238. [Google Scholar] [CrossRef] [Green Version]
- Fabic, G.V.F.; Mitrovic, A.; Neshatian, K. Adaptive Problem Selection in a Mobile Python Tutor. In Adjunct Publication of the 26th Conference on User Modeling, Adaptation and Personalization; ACM: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Jeuring, J.; Gerdes, A.; Heeren, B. A Programming Tutor for Haskell. In Proceedings of the Selected Papers of the 4th Central European Functional Programming School, Budapest, Hungary, 14–24 June 2011; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–45. [Google Scholar] [CrossRef]
- Lane, H.C.; VanLehn, K. Teaching the tacit knowledge of programming to novices with natural language tutoring. Comput. Sci. Educ. 2005, 15, 183–201. [Google Scholar] [CrossRef]
- Papadakis, S.; Kalogiannakis, M.; Zaranis, N. Developing fundamental programming concepts and computational thinking with ScratchJr in preschool education: A case study. Int. J. Mob. Learn. Organ. 2016, 10, 187. [Google Scholar] [CrossRef]
- Price, T.W.; Dong, Y.; Lipovac, D. iSnap. In Proceedings of the 2017 ACM SIGCSE Technical Symposium on Computer Science Education, Seattle, WA, USA, 8–11 March 2017; ACM: New York, NY, USA, 2017. [Google Scholar] [CrossRef] [Green Version]
- Barra, E.; López-Pernas, S.; Alonso, Á.; Sánchez-Rada, J.F.; Gordillo, A.; Quemada, J. Automated Assessment in Programming Courses: A Case Study during the COVID-19 Era. Sustainability 2020, 12, 7451. [Google Scholar] [CrossRef]
- Pillay, N. Developing intelligent programming tutors for novice programmers. ACM SIGCSE Bull. 2003, 35, 78–82. [Google Scholar] [CrossRef]
- Polito, G.; Temperini, M. A gamified web based system for computer programming learning. Comput. Educ. Artif. Intell. 2021, 2, 100029. [Google Scholar] [CrossRef]
- Sorva, J. Notional machines and introductory programming education. ACM Trans. Comput. Educ. 2013, 13, 1–31. [Google Scholar] [CrossRef]
- Fincher, S.; Jeuring, J.; Miller, C.S.; Donaldson, P.; du Boulay, B.; Hauswirth, M.; Hellas, A.; Hermans, F.; Lewis, C.; Mühling, A.; et al. Notional Machines in Computing Education: The Education of Attention. In Proceedings of the Working Group Reports on Innovation and Technology in Computer Science Education, ITiCSE-WGR ’20, Trondheim, Norway, 15–19 June 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 21–50. [Google Scholar] [CrossRef]
- Sorva, J.; Karavirta, V.; Malmi, L. A Review of Generic Program Visualization Systems for Introductory Programming Education. ACM Trans. Comput. Educ. 2013, 13, 1–64. [Google Scholar] [CrossRef]
- Schoeman, M.; Gelderblom, H. The Effect of Students’ Educational Background and Use of a Program Visualization Tool in Introductory Programming. In Proceedings of the Annual Conference of the South African Institute of Computer Scientists and Information Technologists on—SAICSIT’16, Johannesburg, South Africa, 26–28 September 2016; ACM Press: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Sychev, O.; Denisov, M.; Anikin, A. Verifying algorithm traces and fault reason determining using ontology reasoning. In Proceedings of the ISWC 2020 Demos and Industry Tracks: From Novel Ideas to Industrial Practice Co-Located with 19th International Semantic Web Conference (ISWC 2020), Globally Online, 1–6 November 2020 (UTC); CEUR Workshop Proceedings; Taylor, K.L., Gonçalves, R., Lécué, F., Yan, J., Eds.; CEUR-WS.org: Aachen, Germany, 2020; Volume 2721, pp. 49–54. [Google Scholar]
- Sychev, O.; Anikin, A.; Penskoy, N.; Denisov, M.; Prokudin, A. CompPrehension-Model-Based Intelligent Tutoring System on Comprehension Level. In Proceedings of the 17th International Conference on Intelligent Tutoring Systems, Virtual Event, 7–11 June 2021; Springer International Publishing: Cham, Switzerland, 2021; pp. 52–59. [Google Scholar] [CrossRef]
- Kumar, A.N. Allowing Revisions While Providing Error-Flagging Support: Is More Better? In Proceedings of the 21st International Conference on Artificial Intelligence in Education, Ifrane, Morocco, 6–10 July 2020; Springer International Publishing: Cham, Switzerland, 2020; pp. 147–151. [Google Scholar] [CrossRef]
- Kumar, A.N. Limiting the Number of Revisions while Providing Error-Flagging Support during Tests. In Proceedings of the 11th International Conference on Intelligent Tutoring Systems, Chania, Crete, Greece, 14–18 June 2012; Cerri, S.A., Clancey, W.J., Papadourakis, G., Panourgia, K., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 524–530. [Google Scholar] [CrossRef]
- Kumar, A.N. Generation of Demand Feedback in Intelligent Tutors for Programming. In Proceedings of the 17th Conference of the Canadian Society for Computational Studies of Intelligence, Canadian AI 2004, London, ON, Canada, 17–19 May 2004; Springer: Berlin/Heidelberg, Germany, 2004; pp. 444–448. [Google Scholar] [CrossRef] [Green Version]
- Anikin, A.; Sychev, O. Ontology-Based Modelling for Learning on Bloom’s Taxonomy Comprehension Level. In Proceedings of the Tenth Annual Meeting of the BICA Society, Seattle, WA, USA, 15–18 August 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 22–27. [Google Scholar] [CrossRef]
- Atzeni, M.; Atzori, M. CodeOntology: RDF-ization of Source Code. In Proceedings of the 16th International Semantic Web Conference, Vienna, Austria, 21–25 October 2017; d’Amato, C., Fernandez, M., Tamma, V., Lecue, F., Cudré-Mauroux, P., Sequeda, J., Lange, C., Heflin, J., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 20–28. [Google Scholar] [CrossRef]
- Barana, A.; Marchisio, M.; Sacchet, M. Interactive Feedback for Learning Mathematics in a Digital Learning Environment. Educ. Sci. 2021, 11, 279. [Google Scholar] [CrossRef]
- Elder, L.; Paul, R. The Role of Socratic Questioning in Thinking, Teaching, and Learning. Clear. House J. Educ. Strateg. Issues Ideas 1998, 71, 297–301. [Google Scholar] [CrossRef]
- Yenmez, A.A.; Erbas, A.K.; Cakiroglu, E.; Cetinkaya, B.; Alacaci, C. Mathematics teachers’ knowledge and skills about questioning in the context of modeling activities. Teach. Dev. 2018, 22, 497–518. [Google Scholar] [CrossRef]
- Kumar, A.N. Solving Code-Tracing Problems and Its Effect on Code-Writing Skills Pertaining to Program Semantics. In Proceedings of the 2015 ACM Conference on Innovation and Technology in Computer Science Education; Proceedings of the 20th Annual Conference on Innovation and Technology in Computer Science Education, Vilnius, Lithuania, 6–8 July 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 314–319. [Google Scholar] [CrossRef]
- Kumar, A.N. An Epistemic Model-Based Tutor for Imperative Programming. In Proceedings of the 22nd International Conference on Artificial Intelligence in Education, Utrecht, The Netherlands, 14–18 June 2021; Roll, I., McNamara, D., Sosnovsky, S., Luckin, R., Dimitrova, V., Eds.; Springer International Publishing: Cham, Switzerland, 2021; pp. 213–218. [Google Scholar] [CrossRef]
- Schneider, L.N.; Meirovich, A. Student Guided Learning-from Teaching to E-learning. Rev. Rom. Pentru Educ. Multidimens. 2020, 12, 115–121. [Google Scholar] [CrossRef]
- Burkšaitienė, N.; Lesčinskij, R.; Suchanova, J.; Šliogerienė, J. Self-Directedness for Sustainable Learning in University Studies: Lithuanian Students’ Perspective. Sustainability 2021, 13, 9467. [Google Scholar] [CrossRef]
- Chacon, I.A.; Barria-Pineda, J.; Akhuseyinoglu, K.; Sosnovsky, S.A.; Brusilovsky, P. Integrating Textbooks with Smart Interactive Content for Learning Programming. In Proceedings of the Third International Workshop on Inteligent Textbooks 2021 Co-located with 22nd International Conference on Artificial Intelligence in Education (AIED 2021), Online, 15 June 2021; CEUR Workshop Proceedings; Sosnovsky, S.A., Brusilovsky, P., Baraniuk, R.G., Lan, A.S., Eds.; CEUR-WS.org: Aachen, Germany, 2021; Volume 2895, pp. 4–18. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ITS | Open Subject-Domain Model | Rules Modelling | Bloom’s Taxonomy Levels | Question Types | Feedback Type | Tasks Generation |
|---|---|---|---|---|---|---|
| Fully automated tutor (A. N. Kumar) [19] | inner model for hypothetical language with Pascal syntax | Inner rules | Compre-hension | multiple-choice | automatic solving the generated problems, on-board answer generation, automatic partial credit, dynamic feedback generation and the ability to explain why an answer is incorrect | templates-based automatic problem generation for 5 pre-defined topics |
| Intelligent Algebra Tutor (Algebra Notepad) [20] | models valid algebraic operations using answer set programming (ASP) | logic programming language ASP to model if-then production rules | Application, Comprehension | Limited set of actions that students can apply to equations on every step of task solving | Automatically generates step-by-step explanations directly from the ASP model | Single underlying model to generate algebra problems, all valid solutions, and intelligent explanations |
| PyKinetic [22] | Inner model for Python language | Inner rules | Application, Analysis, Synthesis | Multiple choice, Drag and drop, Drop-down choices, Key in solution | Common feedback provided to help the student to fix the error, and task-oriented predefined hints (one hint for each task defined). | Predefined tasks (code fragments and test cases) |
| Programming Tutor for Haskell [23] | embedded domain-specific language for defining strategies (basic steps to incrementally construct a program) | refinement rules for Haskell functional language, used for reasoning | Synthesis | Works with program code | 6 feedback services generate hints derived from the strategy | no |
| AlgoTutor [11] | internal. C++ language and pseudo-code are supported for algorithmic structures learning and training | internal | Comprehension, Application | Single choice, multiple choice, code fragments | pass/fail result, errors highlighting, last correct line highlighting | no |
| Mistake Name | Message Example | |
|---|---|---|
| 1 | UpcomingNeighbour | Why did you skip loop “waiting”, action “get_ready()” ? |
| 2 | NotNeighbour | Why did you execute branch “if-green” ? |
| 3 | WrongCondNeighbour | Why did you execute branch “if-green”, when the condition “green” is false ? |
| 4 | BeginEndMismatch | Bad trace: loop “waiting” ended as selection “choose”. |
| 5 | EndedDeeper | An action ends only when all its nested actions have ended, so A cannot end until K ends as K is a part of A. |
| 6 | EndedShallower | Selection “choose” cannot end loop “waiting” as loop “waiting” contains selection “choose”. |
| 7 | WrongContext | A cannot be executed inside of B because A is not a direct part of B. |
| 8 | OneLevelShallower | A cannot be executed within C because A is an element of P, so start P first. |
| 9 | TooEarlyInSequence | A sequence executes its nested actions in order, so B cannot be executed before A. |
| 10 | TooLateInSequence | A sequence executes its nested actions in order, so A cannot be executed after B. |
| 11 | SequenceFinishedTooEarly | A sequence always executes all its actions. The sequence A cannot finish until actions: X, Y, Z are executed. |
| 12 | SequenceFinishedNotInOrder | Sequence “if-ready” cannot end until it starts. |
| 13 | DuplicateOfAct (of sequence) | A sequence executes each its action once, so each execution of P can contain only one execution of X. |
| 14 | NoFirstCondition | Selection statement “choose” should start with evaluating its first condition “red”. |
| 15 | BranchNotNextToCondition | Selection statement “choose” can execute the branch “if-red” right after condition “red” only. |
| 16 | ElseBranchNotNextToLastCondition | Selection statement “choose” cannot execute the branch “ELSE” until its condition “green” is evaluated. |
| 17 | ElseBranchAfterTrueCondition | Selection statement “choose” must not execute its branch “ELSE” since condition “green” is true. |
| 18 | CondtionNotNextToPrevCondition | Selection statement “choose” can evaluate its condition “green” right after the condition “red” only, if “red” is false. |
| 19 | ConditionTooEarly | Selection statement “choose” cannot evaluate its condition “green” until the condition “red” is evaluated. |
| 20 | ConditionTooLate | Selection statement “choose” should evaluate its condition “green” earlier, right after condition “red” is evaluated. |
| 21 | ConditionAfterBranch | Selection statement “choose” must not evaluate its condition “green” because the branch “if-red” was executed. |
| 22 | DuplicateOfCondition | Selection statement “choose” must not evaluate its condition “red” twice. |
| 23 | NoNextCondition | A selection statement evaluates its conditions in order up to the first true condition. Selection statement “choose” should evaluate its condition “green” next because the condition “red” is false. |
| 24 | BranchOfFalseCondition | A selection statement executes its branch only if its condition is true. Selection statement “choose” must not execute the branch “if-green” because its condition “green” is false. |
| 25 | AnotherExtraBranch | A selection statement executes only one branch. Selection statement “choose” must not start its branch “else” because the branch “if-red” was executed. |
| 26 | BranchWithoutCondition | A selection statement executes its branch when the branch condition evaluates to true. Selection statement “choose” must not execute the “if-red” without evaluating its condition “red” first. |
| 27 | NoBranchWhenConditionIsTrue | A selection statement executes its branch when the corresponding condition is true. Selection statement “choose” must execute the branch “if-red” because its condition “red” is true. |
| 28 | LastFalseNoEnd | When all conditions of a selection statement are false and “ELSE” branch does not exist, the selection does nothing. Selection statement “choose” does not have an “else” branch so it must finish because its condition “green” is false. |
| 29 | AlternativeEndAfterTrueCondition | When a condition of a selection statement evaluates to true, the selection executes the corresponding branch. Selection statement “choose” should not finish until the branch of successful condition “red” is executed. |
| 30 | NoAlternativeEndAfterBranch | A selection statement finishes after executing one branch. Selection statement “choose” executed its branch “if-green” and should finish. |
| 31 | LastConditionIsFalseButNoElse | A selection statement executes its “ELSE” branch only if all conditions are false. Selection statement “choose” must execute its branch “ELSE” because the condition “green” evaluated to false. |
| 32 | NoIterationAfter- SuccessfulCondition | A WHILE loop continues if its condition is true: its new iteration must begin. A new iteration of the loop “waiting” must begin because its condition “ready” is true. |
| 33 | LoopEndAfterSuccessfulCondition | A WHILE loop continues if its condition is true: its new iteration must begin. Its too early to finish the loop “waiting” because its condition “ready” is true. |
| 34 | NoLoopEndAfterFailedCondition | A WHILE loop ends when its condition becomes false. As the condition “ready” is false, the loop “waiting” must end. |
| 35 | LoopEndsWithoutCondition | Since the condition “ready” is not evaluated yet, the loop “waiting” must not end. |
| 36 | LoopStartIsNotCondition | A WHILE loop is a pre-test loop. So the loop “waiting” should start by evaluating its condition “ready”. |
| 37 | LoopStartIsNotIteration | A DO loop is a post-test loop. Therefore, loop “running” should begin with an iteration. |
| 38 | LoopContinuedAfterFailedCondition | A loop ends when its condition becomes false. Since condition “ready” is false, loop “running” cannot continue. |
| 39 | IterationAfterFailedCondition | A loop ends when its condition becomes false. Since condition “ready” is false, the iteration cannot start. |
| 40 | NoConditionAfterIteration | After an iteration of DO-WHILE loop, its condition must be evaluated to determine whether to continue the loop or finish it. After an iteration of loop “running”, its condition “ready” should be evaluated. |
| 41 | NoConditionBetweenIterations | After an iteration of DO-WHILE loop, it is to determine whether the loop continues or ends. Before proceeding to the next iteration of loop “running”, its condition “ready” should be evaluated. |
| Error Name | Message Example |
|---|---|
| HigherPrecedenceRight | Operator * at pos 4 should be evaluated before Operator + at pos 2 because Operator * has higher precedence |
| HigherPrecedenceLeft | Operator + at pos 4 should be evaluated before Operator < at pos 6 because Operator + has higher precedence |
| LeftAssociativityLeft | Operator + at pos 2 should be evaluated before Operator − at pos 4 because Operator + has the same precedence and left associativity and evaluates left to right |
| RightAssociativityRight | Operator = at pos 6 should be evaluated before Operator += at pos 4 because Operator = has the same precedence and right associativity and evaluates right to left |
| InComplex | Operator + at pos 2 should be evaluated before Operator * at pos 5 because expression in parenthesis is evaluated before the operators outside of them |
| Operator/ at pos 4 should be evaluated before parenthesis ( at pos 2 because function arguments are evaluated before function call | |
| StrictOperandsOrder | Operator< at pos 2 should be evaluated before Operator > at pos 6 because the left operand of the Operator || at pos 4 must be evaluated before its right operand |
| Domain | Pre-Test | Post-Test | Survey |
|---|---|---|---|
| Expressions | 151 | 135 | 88 |
| Control Flow Statements | 142 | 129 |
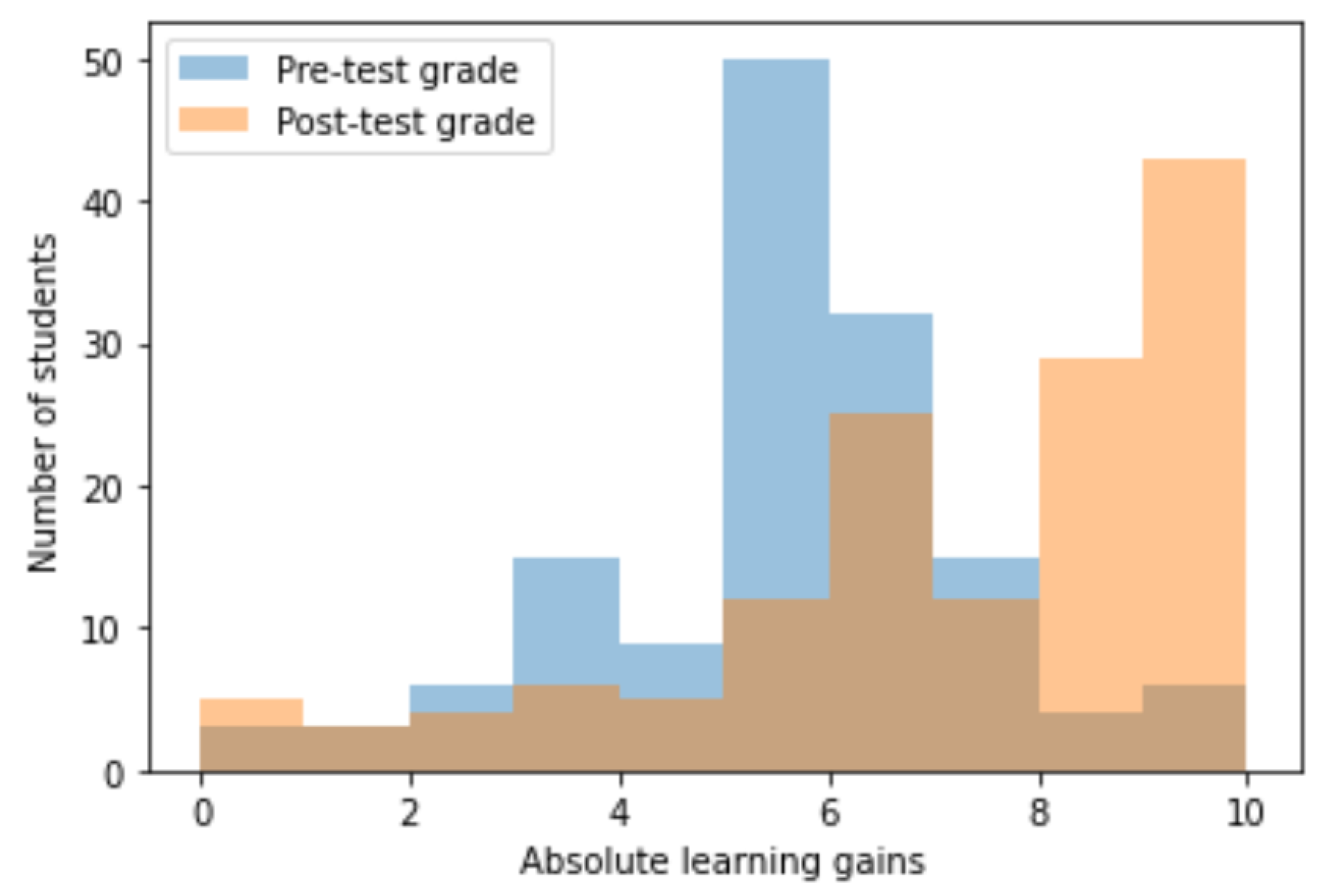
| Pre-Test | Post-Test | Gains | Significance | |
|---|---|---|---|---|
| Avg. | 5.62 | 7.17 | 1.6 | |
| Std. dev. | 1.9 | 2.48 |
| Low Pre-Test | High Pre-Test | Significance | |
|---|---|---|---|
| Number of students | 86 | 57 | |
| Avg. | 2.14 | 0.77 | |
| Std. dev. | 2.69 | 1.92 |
| Min | Max | Average | Std. Dev. | |
|---|---|---|---|---|
| Total questions | 1 | 136 | 13.98 | 18.44 |
| Completed questions | 1 | 14 | 4.71 | 2.59 |
| Total steps | 0 | 268 | 35.84 | 44.85 |
| Steps per question | 0 | 5 | 2.34 | 1.37 |
| Percent of the correct steps | 0 | 100% | 81.63% | 16.31 |
| Hinted steps | 1 | 57 | 4.04 | 8.98 |
| Follow-up questions usages | 0 | 10 | 0.69 | 1.45 |
| Pre-Test | Post-Test | Gains | Significance | |
|---|---|---|---|---|
| Avg. | 4.95 | 6.73 | 1.78 | |
| Std. dev. | 2.38 | 2.87 | 1.96 |
| Low Pre-Test | High Pre-Test | Significance | |
|---|---|---|---|
| Number of students | 84 | 44 | |
| Avg. | 2.12 | 1.16 | |
| Std. dev. | 2.22 | 1.31 |
| Min | Max | Average | Std. Dev. | |
|---|---|---|---|---|
| Total questions | 1 | 52 | 6.59 | 9.05 |
| Completed questions | 1 | 27 | 5.48 | 6.13 |
| Total steps | 0 | 540 | 64.51 | 98.7 |
| Steps per question | 0 | 32 | 7.31 | 6.80 |
| Percent of the correct steps | 0 | 100% | 68.93% | 21.4 |
| Hinted steps | 0 | 31 | 4.67 | 7.76 |
| Pre-Test | Post-Test | Absolute | Relative | |
|---|---|---|---|---|
| Grade | Grade | Learn. Gains | Learn. Gains | |
| Completed questions | −0.017 | 0.158 | 0.138 | 0.123 |
| Total questions | −0.103 | −0.098 | 0.023 | −0.059 |
| Percentage of completed | 0.139 | 0.567 | 0.285 | 0.433 |
| questions | ||||
| Failed interactions | −0.283 | −0.239 | 0.094 | 0.026 |
| Correct interactions | −0.083 | 0.106 | 0.164 | 0.151 |
| Total interactions | −0.130 | 0.043 | 0.161 | 0.135 |
| Percentage of failed | −0.369 | −0.518 | −0.029 | −0.271 |
| interactions | ||||
| Hinted steps | −0.290 | −0.182 | 0.146 | −0.065 |
| Question | Average | Std. Dev. |
|---|---|---|
| The interface was easy to understand and use | 3.86 | 1.07 |
| The exercise formulations were clearly stated | 3.25 | 1.22 |
| Some of the questions concerned the problems which were difficult to learn without this application | 3.15 | 1.20 |
| The tasks were repetitive and tiring | 2.50 | 1.18 |
| The explanations helped to solve the exercises | 3.48 | 1.18 |
| The explanations helped to understand the error and avoid it in the future | 3.63 | 1.03 |
| The exercises take too much time | 2.97 | 1.37 |
| I want to use this application to learn more about programming | 3.57 | 1.17 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sychev, O.; Penskoy, N.; Anikin, A.; Denisov, M.; Prokudin, A. Improving Comprehension: Intelligent Tutoring System Explaining the Domain Rules When Students Break Them. Educ. Sci. 2021, 11, 719. https://doi.org/10.3390/educsci11110719
Sychev O, Penskoy N, Anikin A, Denisov M, Prokudin A. Improving Comprehension: Intelligent Tutoring System Explaining the Domain Rules When Students Break Them. Education Sciences. 2021; 11(11):719. https://doi.org/10.3390/educsci11110719
Chicago/Turabian StyleSychev, Oleg, Nikita Penskoy, Anton Anikin, Mikhail Denisov, and Artem Prokudin. 2021. "Improving Comprehension: Intelligent Tutoring System Explaining the Domain Rules When Students Break Them" Education Sciences 11, no. 11: 719. https://doi.org/10.3390/educsci11110719