
A Novel Short-Term Residential Electric Load Forecasting Method Based on Adaptive Load Aggregation and Deep Learning Algorithms


 ,
,
Abstract
:1. Introduction
2. Power Consumption Analysis of Household Appliances
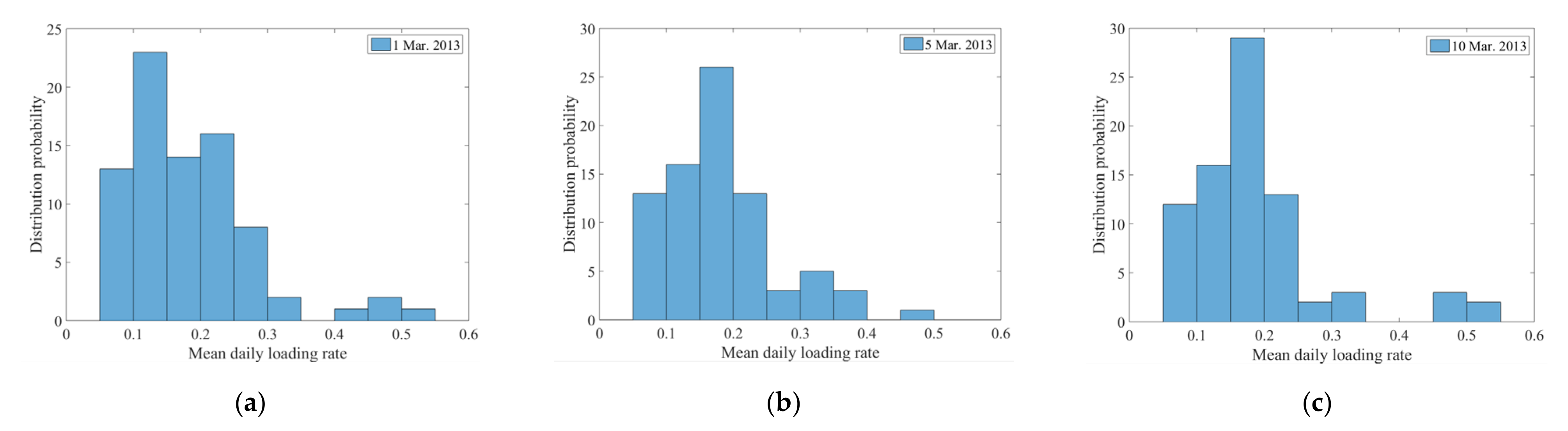
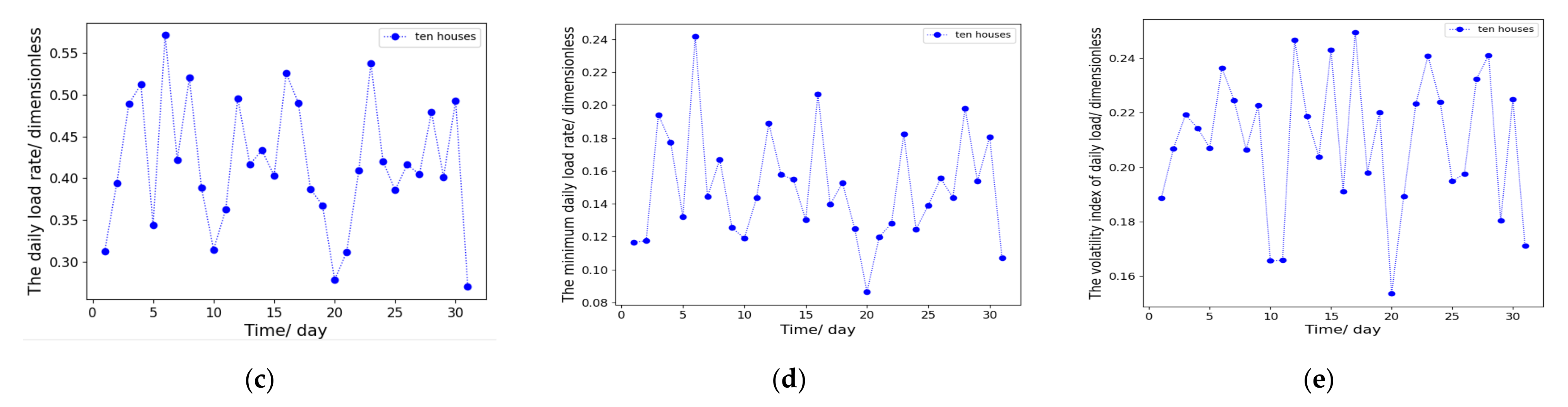
2.1. Quantitative Indicators of Residential Electric Loads
2.2. Characteristic Analysis of Residential Electric Loads
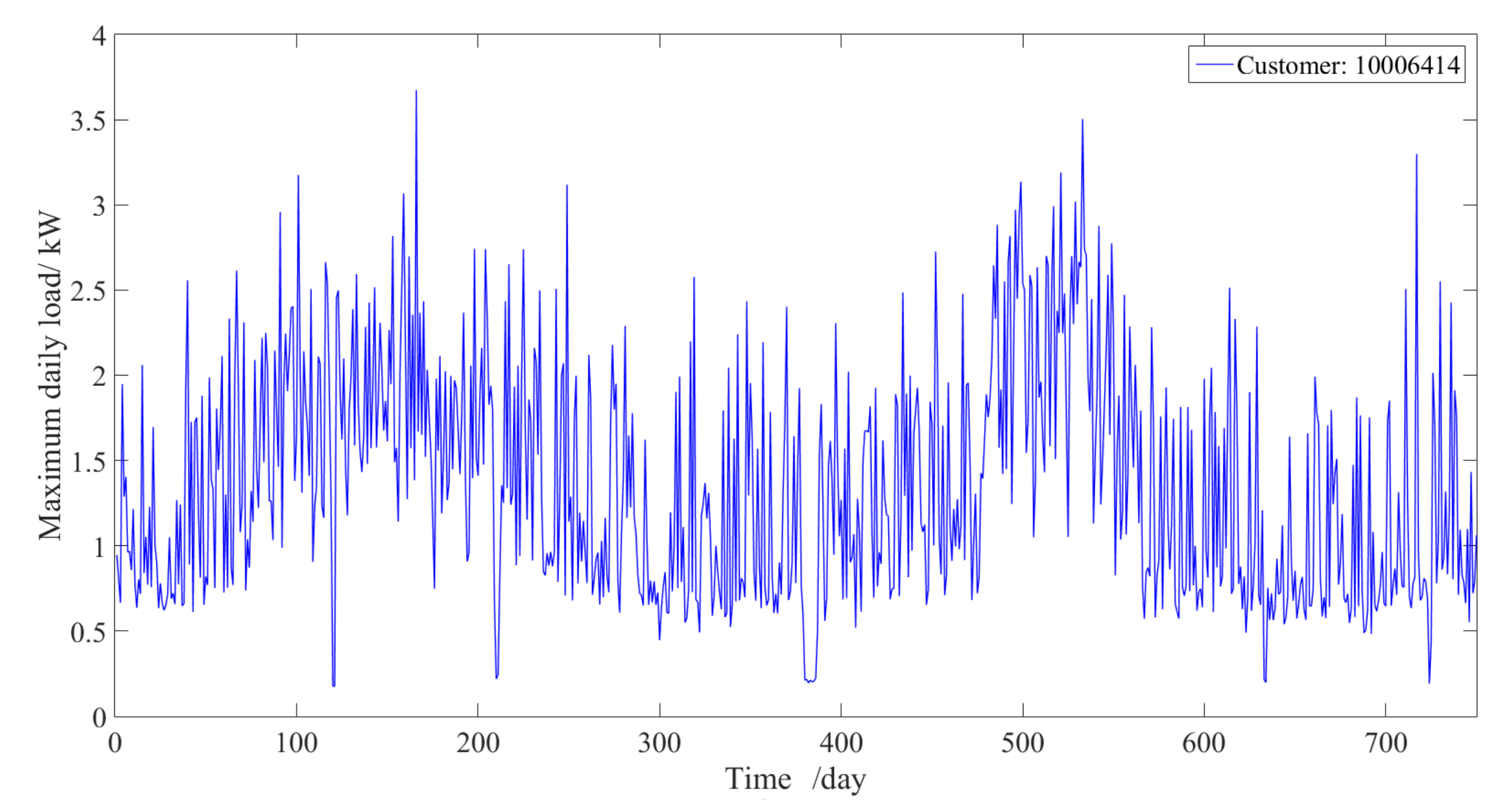
2.2.1. Electric Load Characteristics of a Single Unit
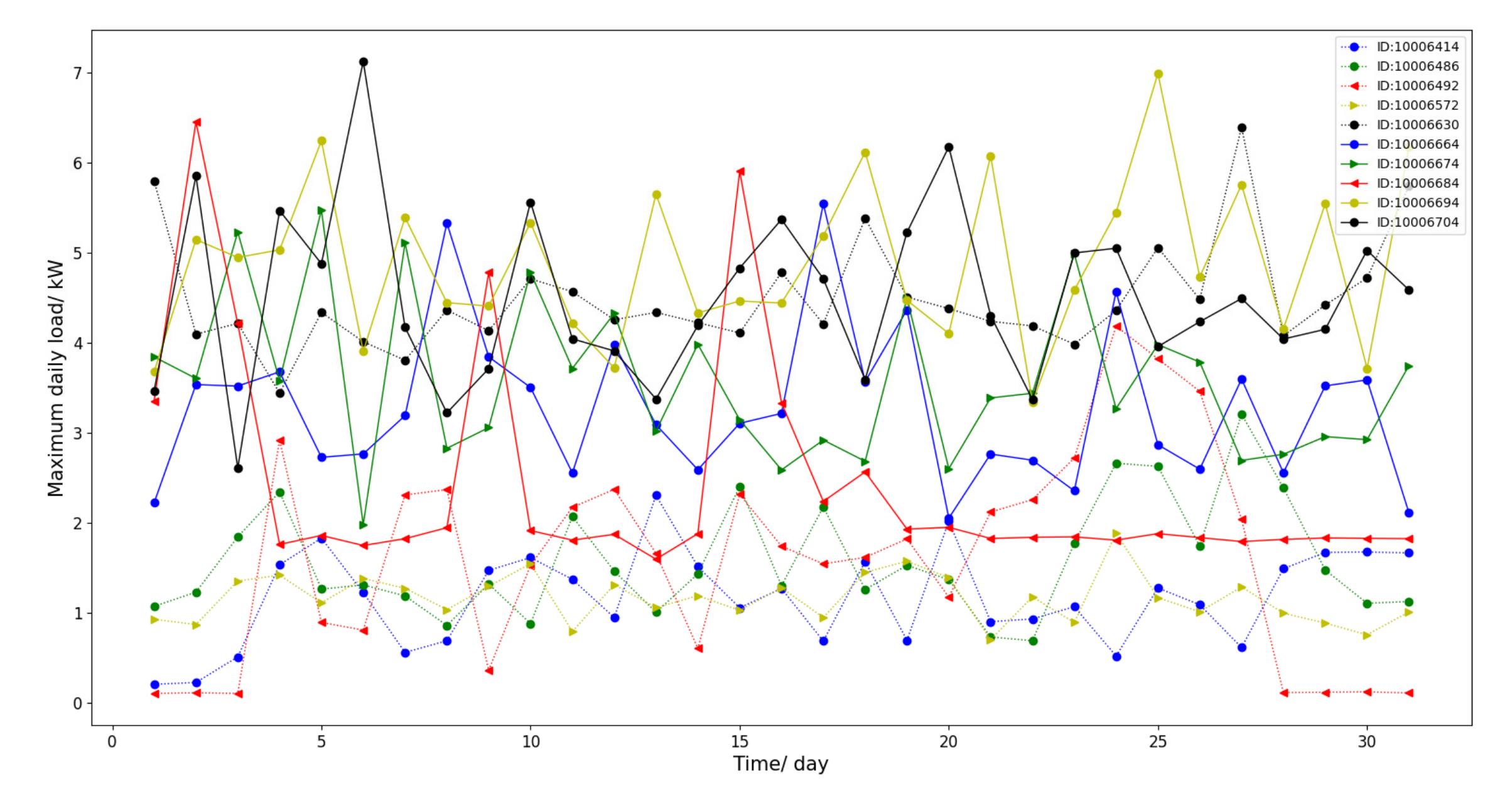
2.2.2. Electric Load Characteristics of Different Units
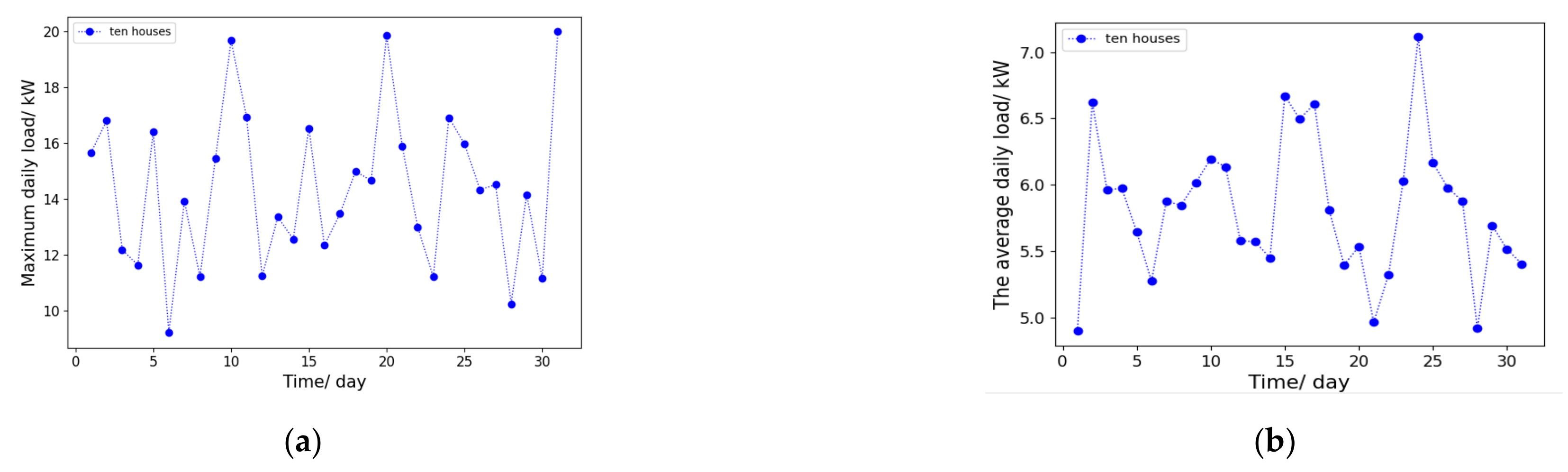
2.2.3. Electric Load Characteristics of a Single Unit and Total Loads of Multiple Units
3. A Novel Short-Term Residential Electric Load Forecasting Method
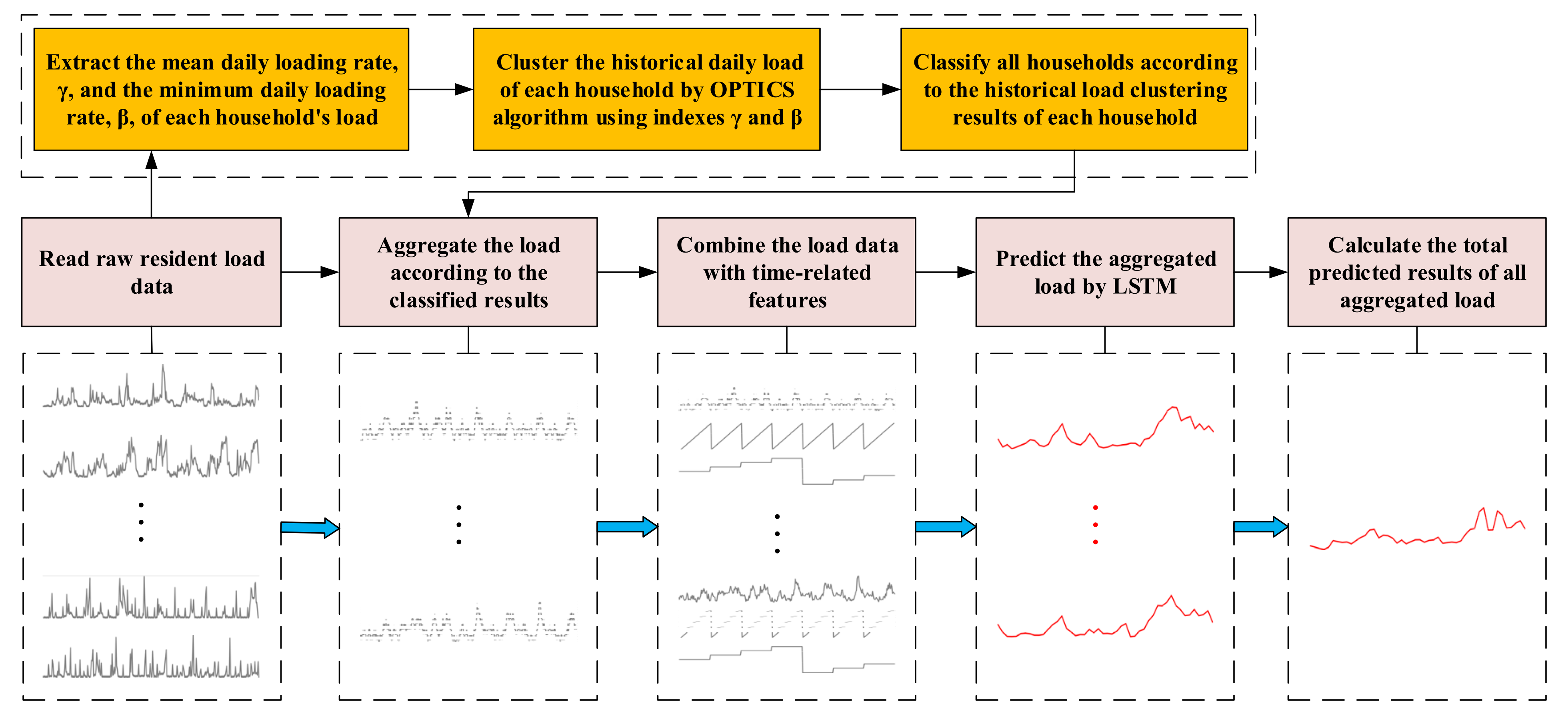
3.1. Basic Principle of Our Proposed Method
3.2. Optimal Number of Total Aggregated Households
3.3. Adaptive Density-Based Spatial Clustering Algorithm for the Residential Load
| Algorithm 1 The Clustering Subprocedure 1 |
| input: D: total number of historical days, dk,i,j: distance between the ith day and jth day of the kth household, MinPts: minimum samples in the neighborhood area, Ω: set of core samples, N: size of the set Ω, cd(o): the core distance of element o, rd(j, o): reachable distance from element j to element o. |
| output: results queue M. |
| 1 foreach item do |
| 2 Mark item o and put it into results queue M |
| 3 Calculate the reachable distance of any element j (): |
| 4 The unmarked elements belonging to the neighborhood area of o are sorted in ascending order. And put the elements into seeds queue P. |
| 5 If , then jump to the line 1 and move to the next element. |
| 6 If , foreach item , mark item q and put it into results queue M. |
| 7 If , the unmarked elements belonging to the neighborhood area of q are put into seeds queue P. And calculate the reachable distance of any elements belonging to queue P. |
| 8 If , do nothing |
| 9 end |
| 10 end |
| Algorithm 2 The Clustering Subprocedure 2 |
| input: M: results queue, dset: distance set value, ρset: set value for noise point treatment. |
| output: NCk subsets after the clustering process |
| 1 foreach item do |
| 2 If , item s is assigned to the current cluster |
| 3 If , item s is identified as an outlier |
| 4 If , item s is assigned to another cluster |
| 5 end |
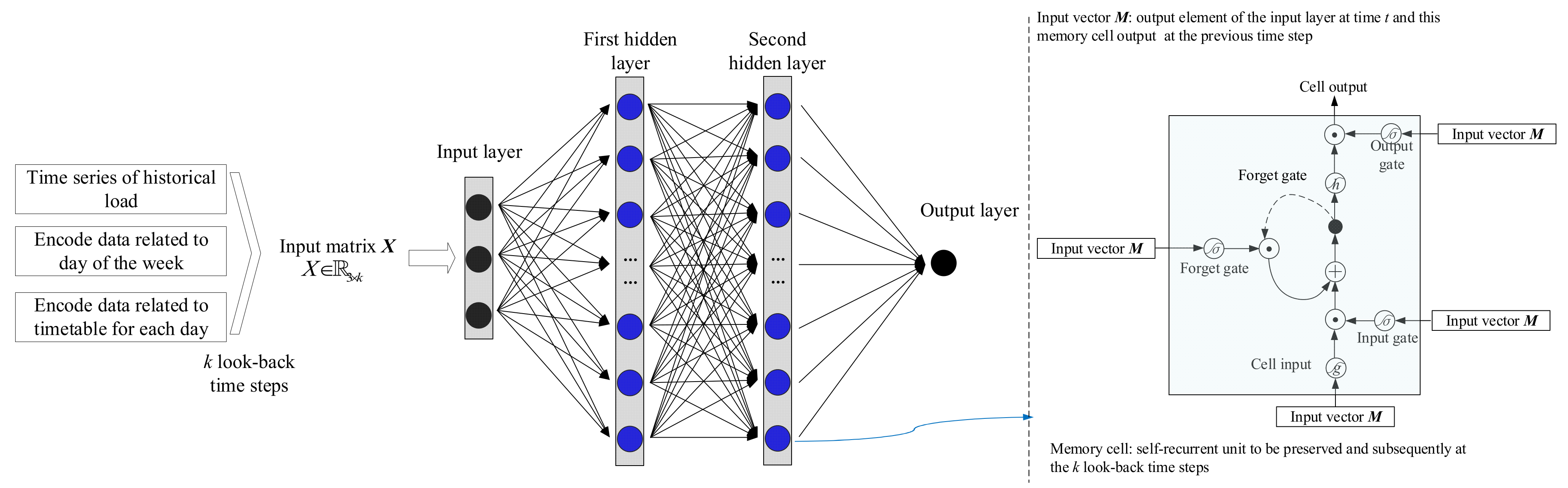
3.4. LSTM-Based Short-Term Data Prediction for Residential Load
- (a)
- The time series of historical load under selected K look-back time step, which is represented by E = {et−K, et−K+1, …, et−2, et−1};
- (b)
- The daily load data are related to the timetable each day. Hence, the time t in each day is encoded into t/dx according to the load sampling interval dx;
- (c)
- The pattern of historical data is related to human life routine, which is usually inextricably linked to the day of the week. Hence, the sorted number of days of the week related to the historical data is encoded into 0 to 6.
4. Simulation and Results Discussion
4.1. Experimental Datasets and Criteria in the Proposed Load Prediction Process
- a)
- Thirty-one history days are used in our experimental datasets, hence, the minimum number of points in the neighbors, MinPts, is set as five in the OPTICS clustering algorithm.
- b)
- The short-term load forecasting result is used for microgrid power dispatch. Hence, the high computational efficiency is needed in our scenario. The learning rate is set as 0.01 initially, with an Adam optimizer to reduce the LSTM network learning time. In the meantime, the number of iterations is set as 150 to avoid continuous oscillation. To effectively evaluate the load forecasting result, MAPE of the prediction load is used in the cost function.
- c)
- The sampling time interval of the historical load data is 30 min. Hence, there are 48 samples in a whole day. The look-back time step of the LSTM network is set as 48; therefore, the load at the same time of the previous day and the load before the prediction time can be both used to reveal the forecasting load value.
- d)
- The rolling load prediction strategy is adopted for the short-term residential load forecasting in this paper. In our following experiments, the constructed LSTM network outputs one prediction result after each prediction process without loss of generality.
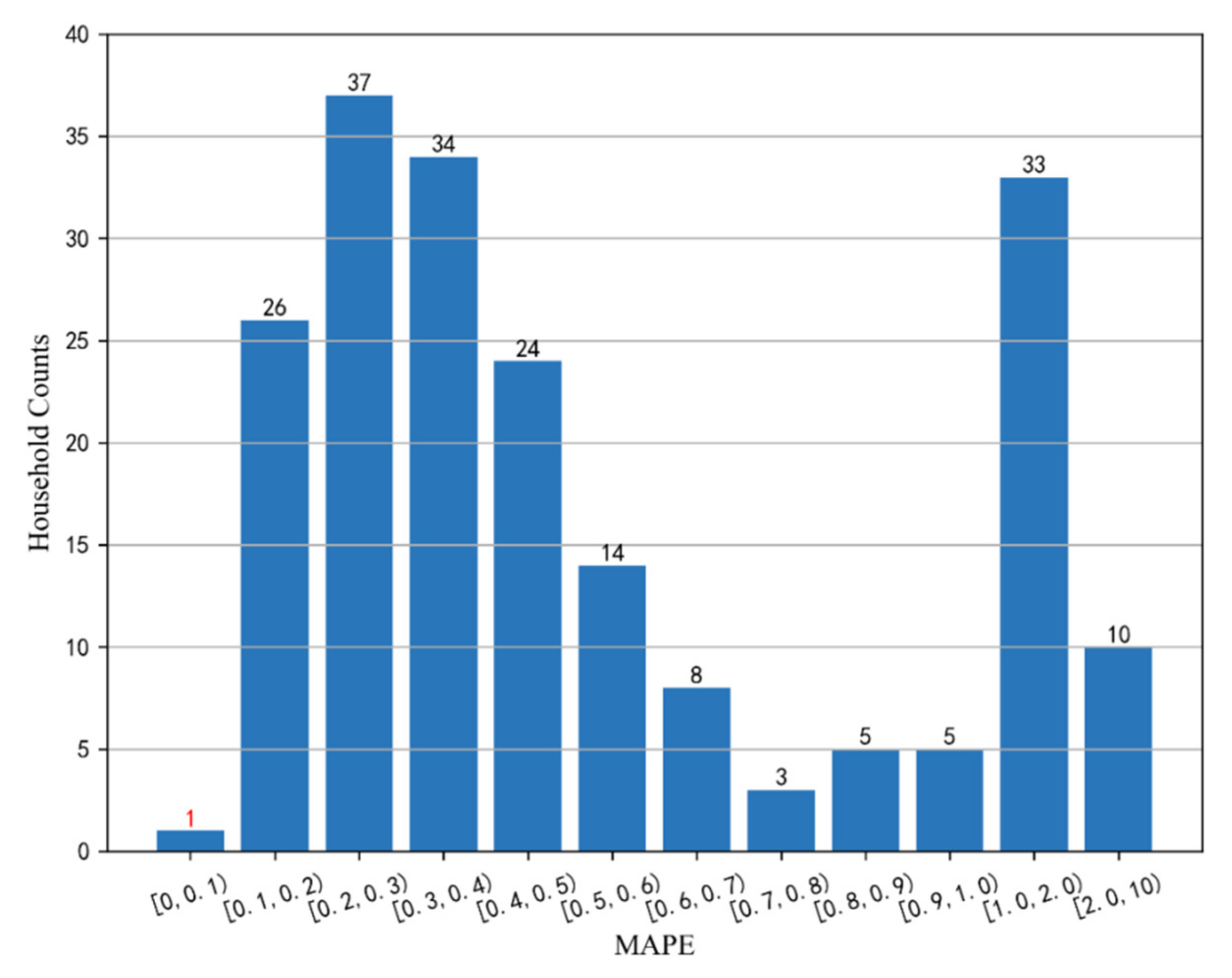
4.2. Short-Term Residential Load Forecasting Results of a Single Household
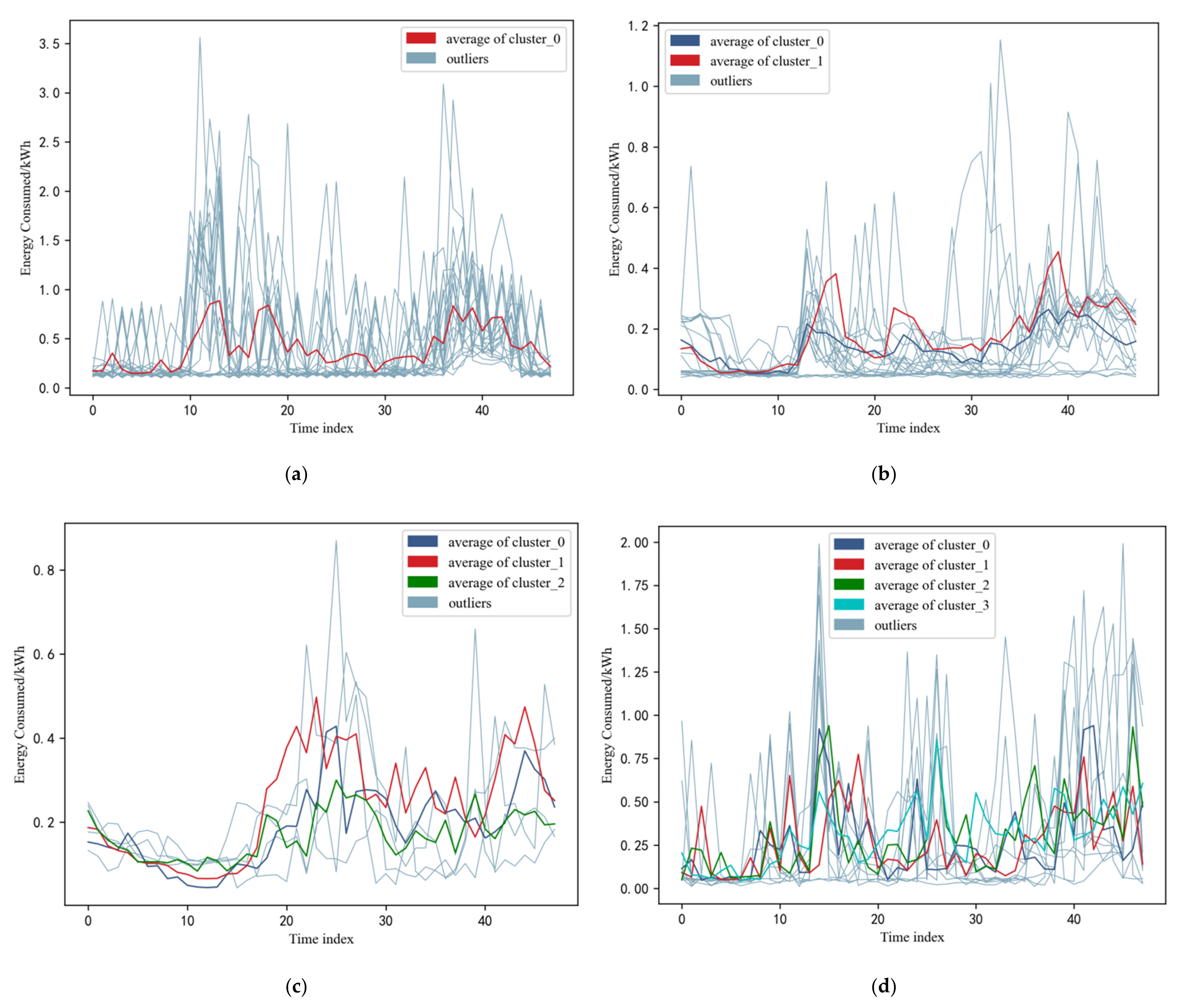
4.3. Results of Residential Load Clustering
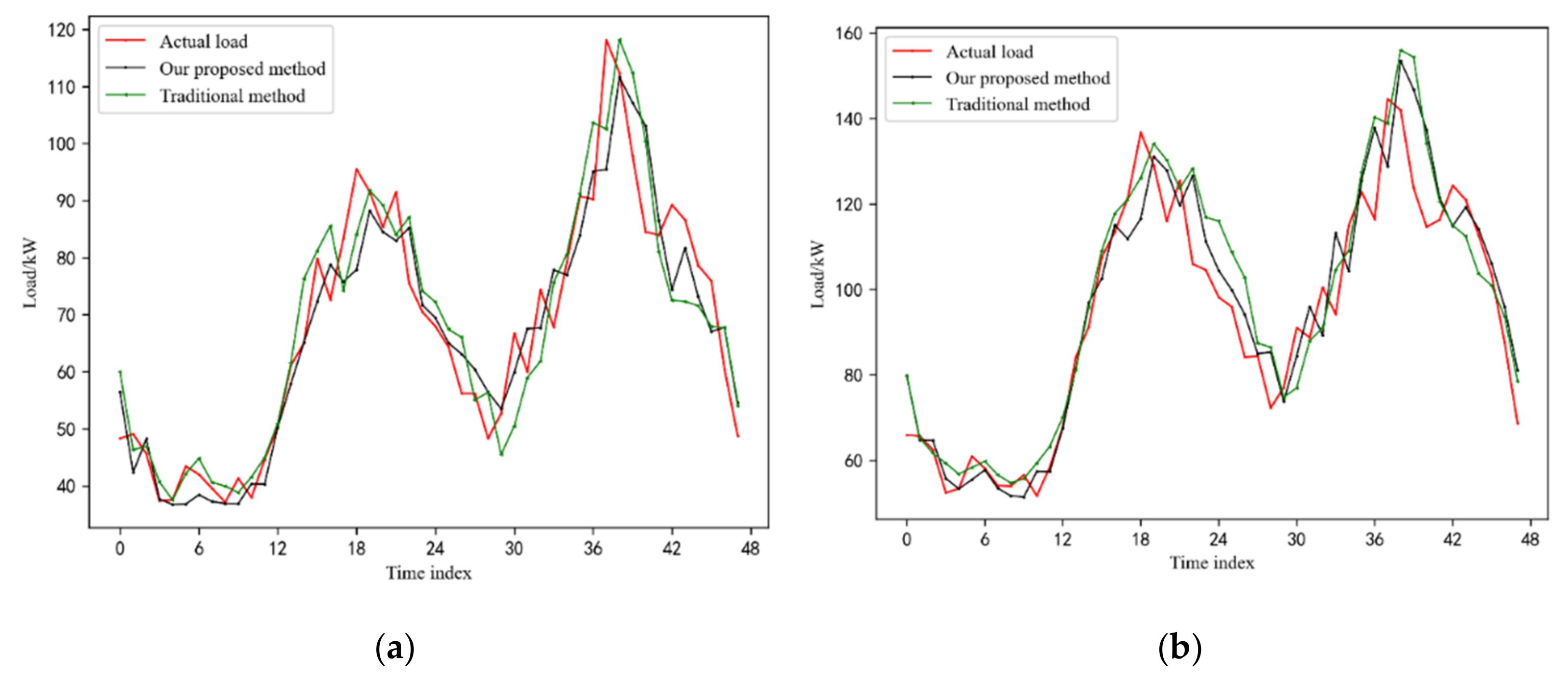
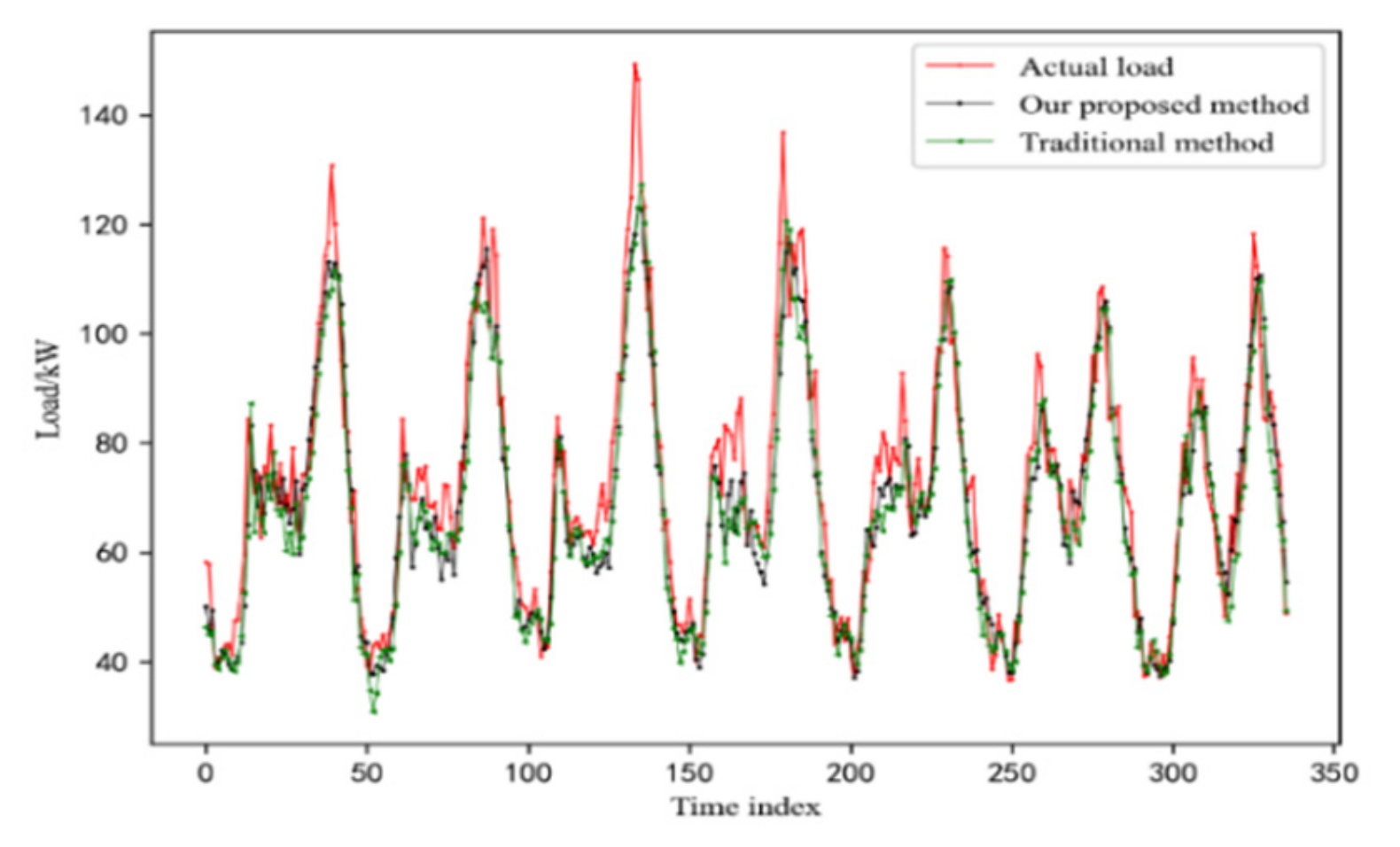
4.4. Results of Short-Term Residential Load Forecasting
4.5. Sensitivity of Look-Back Time Steps of the LSTM Network
4.6. Comparison with Traditional Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Koo, C.; Hong, T.; Lee, M.; Kim, J. An integrated multi-objective optimization model for determining the optimal solution in implementing the rooftop photovoltaic system. Renew. Sustain. Energy Rev. 2016, 57, 822–837. [Google Scholar] [CrossRef]
- Ondeck, A.D.; Edgar, T.F.; Baldea, M. Impact of rooftop photovoltaics and centralized energy storage on the design and operation of a residential CHP system. Appl. Energy 2018, 222, 280–299. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Xu, Y.; Wang, M.-H.; Li, J.; Xu, Z.; Chai, S.; He, Y. Data-Driven Game-Based Pricing for Sharing Rooftop Photovoltaic Generation and Energy Storage in the Residential Building Cluster Under Uncertainties. IEEE Trans. Ind. Inform. 2020, 17, 4480–4491. [Google Scholar] [CrossRef]
- Pazouki, S.; Haghifam, M.R. Optimal planning and scheduling of smart homes’ energy hubs. Int. Trans. Electr. Energy Syst. 2021, 31, e12986. [Google Scholar] [CrossRef]
- Singh, P.; Dhundhara, S.; Verma, Y.P.; Tayal, N. Optimal battery utilization for energy man-agement and load scheduling in smart residence under demand response scheme. Sustain. Energy Grids Netw. 2021, 26, 100432. [Google Scholar] [CrossRef]
- Kwon, Y.; Kim, T.; Baek, K.; Kim, J. Multi-Objective Optimization of Home Appliances and Electric Vehicle Considering Customer’s Benefits and Offsite Shared Photovoltaic Curtailment. Energies 2020, 13, 2852. [Google Scholar] [CrossRef]
- Khan, A.-N.; Iqbal, N.; Rizwan, A.; Ahmad, R.; Kim, D.-H. An Ensemble Energy Consumption Forecasting Model Based on Spatial-Temporal Clustering Analysis in Residential Buildings. Energies 2021, 14, 3020. [Google Scholar] [CrossRef]
- Aslam, S.; Herodotou, H.; Mohsin, S.M.; Javaid, N.; Ashraf, N.; Aslam, S. A survey on deep learning methods for power load and renewable energy forecasting in smart microgrids. Renew. Sustain. Energy Rev. 2021, 144, 110992. [Google Scholar] [CrossRef]
- Munkhammar, J.; Van Der Meer, D.; Widén, J. Very short term load forecasting of residential electricity consumption using the Markov-chain mixture distribution (MCM) model. Appl. Energy 2020, 282, 116180. [Google Scholar] [CrossRef]
- Liu, F.; Dong, T.; Hou, T.; Liu, Y. A Hybrid Short-Term Load Forecasting Model Based on Improved Fuzzy C-Means Clustering, Random Forest and Deep Neural Networks. IEEE Access 2021, 9, 59754–59765. [Google Scholar] [CrossRef]
- Tavassoli-Hojati, Z.; Ghaderi, S.; Iranmanesh, H.; Hilber, P.; Shayesteh, E. A self-partitioning local neuro fuzzy model for short-term load forecasting in smart grids. Energy 2020, 199, 117514. [Google Scholar] [CrossRef]
- Kyung-Bin, S.; Jeong-Do, P.; Rae-Jun, P. Short Term Load Forecasting Algorithm for Lunar New Year’s Day. J. Electr. Eng. Technol. 2018, 13, 591–598. [Google Scholar]
- Zhu, Y.; Zhang, B.; Dou, Z.; Zou, H.; Li, S.; Sun, K.; Liao, Q. Short-Term Load Forecasting Based on Gaussian Process Regression with Density Peak Clustering and Information Sharing Antlion Optimizer. IEEJ Trans. Electr. Electron. Eng. 2020, 15, 1312–1320. [Google Scholar] [CrossRef]
- Lee, C.-Y.; Wu, C.-E. Short-Term Electricity Price Forecasting Based on Similar Day-Based Neural Network. Energies 2020, 13, 4408. [Google Scholar] [CrossRef]
- Barman, M.; Choudhury, N.B.D.; Sutradhar, S. A regional hybrid GOA-SVM model based on similar day approach for short-term load forecasting in Assam, India. Energy 2018, 145, 710–720. [Google Scholar] [CrossRef]
- Bento, P.; Pombo, J.; Calado, M.D.R.; Mariano, S.J.P.S. A bat optimized neural network and wavelet transform approach for short-term price forecasting. Appl. Energy 2018, 210, 88–97. [Google Scholar] [CrossRef]
- Dou, C.; Zheng, Y.; Yue, D.; Zhang, Z.; Ma, K. Hybrid model for renewable energy and loads pre-diction based on data mining and variational mode decomposition. IET Gener. Transm. Distrib. 2018, 12, 2642–2649. [Google Scholar] [CrossRef]
- Lin, Y.; Luo, H.; Wang, D.; Guo, H.; Zhu, K. An Ensemble Model Based on Machine Learning Methods and Data Preprocessing for Short-Term Electric Load Forecasting. Energies 2017, 10, 1186. [Google Scholar] [CrossRef] [Green Version]
- Hu, Y.; Ye, C.; Ding, Y.; Xu, C. Short-term load forecasting utilizing wavelet transform and time series considering accuracy feedback. Int. Trans. Electr. Energy Syst. 2020, 30, e12455. [Google Scholar] [CrossRef]
- El-Hendawi, M.; Wang, Z. An ensemble method of full wavelet packet transform and neural network for short term electrical load forecasting. Electr. Power Syst. Res. 2020, 182, 106265. [Google Scholar] [CrossRef]
- Jawad, M.; Nadeem, M.S.A.; Shim, S.o.; Khan, I.R.; Shaheen, A.; Habib, N.; Hussain, L.; Aziz, W. Machine Learning Based Cost Effective Electricity Load Forecasting Model Using Correlated Meteorological Parameters. IEEE Access 2020, 8, 146847. [Google Scholar] [CrossRef]
- Zhao, W.; Zhang, H.; Zheng, J.; Dai, Y.; Huang, L.; Shang, W.; Liang, Y. A point prediction method based automatic machine learning for day-ahead power output of multi-region photovoltaic plants. Energy 2021, 223, 120026. [Google Scholar] [CrossRef]
- Si, Z.; Yu, Y.; Yang, M.; Li, P. Hybrid Solar Forecasting Method Using Satellite Visible Images and Modified Convolutional Neural Networks. IEEE Trans. Ind. Appl. 2021, 57, 5–16. [Google Scholar] [CrossRef]
- Zhang, G.; Guo, J. A Novel Method for Hourly Electricity Demand Forecasting. IEEE Trans. Power Syst. 2019, 35, 1351–1363. [Google Scholar] [CrossRef]
- Ghofrani, M.; Ghayekhloo, M.; Arabali, A. A hybrid short-term load forecasting with a new input selection framework. Energy 2015, 81, 777–786. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2017, 10, 841–851. [Google Scholar] [CrossRef]
- Richardson, I.; Thomson, M. Integrated simulation of photovoltaic micro-generation and domestic electricity demand: A one-minute resolution open-source model. Proc. Inst. Mech. Eng. Part A J. Power Energy 2012, 227, 73–81. [Google Scholar] [CrossRef]
- Han, T.; Muhammad, K.; Hussain, T.; Lloret, J.; Baik, S.W. An Efficient Deep Learning Framework for Intelligent Energy Management in IoT Networks. IEEE Internet Things J. 2020, 8, 3170–3179. [Google Scholar] [CrossRef]
- Sun, Y.; Haghighat, F.; Fung, B.C. A review of the-state-of-the-art in data-driven approaches for building energy prediction. Energy Build. 2020, 221, 110022. [Google Scholar] [CrossRef]
- Runge, J.; Zmeureanu, R. A Review of Deep Learning Techniques for Forecasting Energy Use in Buildings. Energies 2021, 14, 608. [Google Scholar] [CrossRef]
- Somu, N.; Gauthama Raman, M.R.; Ramamritham, K. A deep learning framework for building energy consumption forecast. Renew. Sustain. Energy Rev. 2021, 137, 110591. [Google Scholar] [CrossRef]
- Ding, Z.; Chen, W.; Hu, T.; Xu, X. Evolutionary double attention-based long short-term memory model for building energy prediction: Case study of a green building. Appl. Energy 2021, 288, 116660. [Google Scholar] [CrossRef]
- Bu, S.-J.; Cho, S.-B. Time Series Forecasting with Multi-Headed Attention-Based Deep Learning for Residential Energy Consumption. Energies 2020, 13, 4722. [Google Scholar] [CrossRef]
- Shakir, M.; Biletskiy, Y. Forecasting and optimization for microgrid in home energy management systems. IET Gener. Transm. Distrib. 2020, 14, 3458–3468. [Google Scholar] [CrossRef]
- Kong, W.; Dong, Z.; Hill, D.J.; Luo, F.; Xu, Y. Short-term residential load forecasting based on res-ident behavior learning. IEEE Trans. Power Syst. 2018, 33, 1087–1088. [Google Scholar] [CrossRef]
- Zang, H.; Xu, R.; Cheng, L.; Ding, T.; Liu, L.; Wei, Z.; Sun, G. Residential load forecasting based on LSTM fusing self-attention mechanism with pooling. Energy 2021, 229, 120682. [Google Scholar] [CrossRef]
- Haq, I.; Ullah, A.; Khan, S.; Khan, N.; Lee, M.; Rho, S.; Baik, S. Sequential Learning-Based Energy Consumption Prediction Model for Residential and Commercial Sectors. Mathematics 2021, 9, 605. [Google Scholar] [CrossRef]
- Shareef, H.; Ahmed, M.S.; Mohamed, A.; Al Hassan, E. Review on Home Energy Management System Considering Demand Responses, Smart Technologies, and Intelligent Controllers. IEEE Access 2018, 6, 24498–24509. [Google Scholar] [CrossRef]
- Alhussein, M.; Aurangzeb, K.; Haider, S.I. Hybrid CNN-LSTM Model for Short-Term Individual Household Load Forecasting. IEEE Access 2020, 8, 180544–180557. [Google Scholar] [CrossRef]
- Abdulla, K.; Steer, K.; Wirth, A.; Halgamuge, S. Improving the on-line control of energy storage via forecast error metric customization. J. Energy Storage 2016, 8, 51–59. [Google Scholar] [CrossRef] [Green Version]
- Barker, S.; Irwin, D.; Shenoy, P. Pervasive Energy Monitoring and Control through Low-Bandwidth Power Line Communication. IEEE Internet Things J. 2017, 4, 1349–1359. [Google Scholar] [CrossRef]
- Sinaga, K.P.; Yang, M.-S. Unsupervised K-Means Clustering Algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Yu, S.-H.; Chu, S.-W.; Wang, C.-M.; Chan, Y.-K.; Chang, T.-C. Two improved k-means algorithms. Appl. Soft Comput. 2018, 68, 747–755. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Quantitative Indexes | Customer Id: 10006414 | Customer Id: 10006486 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pmax/kW | Pv/kW | γ | β | FL | Pmax | Pv | γ | β | FL | |
| 10 March | 1.614 | 0.380 | 0.235 | 0.062 | 0.212 | 0.880 | 0.402 | 0.457 | 0.216 | 0.214 |
| 20 March | 2.020 | 0.313 | 0.155 | 0.045 | 0.158 | 1.368 | 0.310 | 0.226 | 0.045 | 0.248 |
| 30 March | 1.676 | 0.385 | 0.230 | 0.050 | 0.208 | 1.106 | 0.365 | 0.330 | 0.081 | 0.258 |
| Quantitative Indexes | Customer Id: 10006572 | Customer Id: 10006630 | ||||||||
| Pmax/kW | Pv/kW | γ | β | FL | Pmax/kW | Pv/kW | γ | β | FL | |
| 10 March | 1.546 | 0.507 | 0.328 | 0.132 | 0.152 | 4.710 | 1.009 | 0.214 | 0.042 | 0.252 |
| 20 March | 1.390 | 0.563 | 0.405 | 0.138 | 0.197 | 4.380 | 0.786 | 0.179 | 0.043 | 0.188 |
| 30 March | 0.756 | 0.428 | 0.566 | 0.278 | 0.200 | 4.720 | 0.835 | 0.177 | 0.040 | 0.224 |
| Quantitative Indexes | Ten Households | Twenty Households | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Pmax/kW | Pv/kW | γ | β | FL | Pmax/kW | Pv/kW | γ | β | FL | |
| 10 March | 19.674 | 6.194 | 0.315 | 0.119 | 0.166 | 23.278 | 8.950 | 0.384 | 0.156 | 0.163 |
| 20 March | 19.866 | 5.533 | 0.279 | 0.086 | 0.154 | 25.378 | 9.799 | 0.386 | 0.129 | 0.150 |
| 30 March | 11.178 | 5.512 | 0.493 | 0.181 | 0.225 | 17.448 | 9.410 | 0.539 | 0.203 | 0.180 |
| Clustering Algorithm | Basic Principle | Advantages | Disadvantages |
|---|---|---|---|
| K-means | The sample set is divided into K clusters according to the distance between the samples and core points of clusters. | It has low computational complexity, fast convergence, and strong interpretability. | a. The number of clusters, K, needs to be preset; b. It is difficult to converge when the algorithm is applied in non-convex datasets; c. It is sensitive to noise samples. |
| DBSCAN | It relies on a density-based notion of clusters. | a. It is suitable in discovering clusters of arbitrary shape; b. It is not sensitive to the noise samples. | a. The clustering quality is poor when the density of sample distribution is not uniform; b. Two parameters, including reachable distance threshold and sample number of clusters threshold, needs to be preset. |
| OPTICS | It is an extended DBSCAN algorithm for an infinite number of distance parameters. | It does not limit us to one global parameter setting in traditional density-based clustering algorithms. | The time complexity of this algorithm increased a little. |
| Clustering Results | Customer Id: 10006704 | Customer Id: 10006414 | |||||||
| Cluster id | 0 | outliers | 0 | 1 | outliers | ||||
| Number of clusters | 10 | 21 | 7 | 6 | 18 | ||||
| Clustering Results | Customer Id: 10006486 | Customer Id: 10006674 | |||||||
| Cluster id | 0 | 1 | 2 | outliers | 0 | 1 | 2 | 3 | outliers |
| Number of clusters | 11 | 9 | 7 | 4 | 6 | 6 | 5 | 5 | 9 |
| Households | 50 | 100 | 150 | 200 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Final Category id | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 | 1 | 2 | 3 |
| Number of households | 10 | 26 | 14 | 14 | 49 | 37 | 25 | 76 | 49 | 33 | 106 | 61 |
| Households | 50 | 100 | 150 | 200 |
|---|---|---|---|---|
| MAPE of the total load prediction | 15.6% | 11.5% | 9.1% | 8.5% |
| MAPE of the adaptive aggregated load prediction | 14.3% | 10.2% | 8.3% | 7.7% |
| Look-Back Time Steps | 50 | 100 | 150 | 200 |
|---|---|---|---|---|
| K = 48 | 14.3% | 10.2% | 8.3% | 7.7% |
| K = 6 | 18.3% | 11.9% | 9.4% | 7.8% |
| BPNN | hidden layers | hidden nodes | epochs |
| 2 | 20 | 150 | |
| SVR | kernel function | C | gamma |
| rbf | 1000 | 1 |
| Forecasting Method | Forecasting the Total Load Directly | Forecasting the Aggregated Load Separately and Summing |
|---|---|---|
| Our proposed method | 9.1% | 8.3% |
| SVR-based method | 9.4% | 11.2% |
| BPNN-based method | 10.9% | 10.2% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, T.; Fang, R.; Tang, J.; Ge, G.; Yang, D.; Liu, J.; Zhang, W. A Novel Short-Term Residential Electric Load Forecasting Method Based on Adaptive Load Aggregation and Deep Learning Algorithms. Energies 2021, 14, 7820. https://doi.org/10.3390/en14227820
Hou T, Fang R, Tang J, Ge G, Yang D, Liu J, Zhang W. A Novel Short-Term Residential Electric Load Forecasting Method Based on Adaptive Load Aggregation and Deep Learning Algorithms. Energies. 2021; 14(22):7820. https://doi.org/10.3390/en14227820
Chicago/Turabian StyleHou, Tingting, Rengcun Fang, Jinrui Tang, Ganheng Ge, Dongjun Yang, Jianchao Liu, and Wei Zhang. 2021. "A Novel Short-Term Residential Electric Load Forecasting Method Based on Adaptive Load Aggregation and Deep Learning Algorithms" Energies 14, no. 22: 7820. https://doi.org/10.3390/en14227820