Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment


 ,
,  , and
, and
Abstract
:1. Introduction
2. Advantages of Traditional Statistical Methods over ML
3. Advantages of ML over Traditional Statistical Techniques
4. Different Indications for the Two Computational Approaches
5. Integration between the Two Approaches
6. Applications of ML in Medicine
6.1. Diagnostic Process
6.2. Predicting Prognosis
6.3. Drug Discovery
6.4. Personalized Treatment
7. Discussion
8. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ngiam, K.Y.; Khor, I.W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Stanfill, M.H.; Marc, D.T. Health Information Management: Implications of Artificial Intelligence on Healthcare Data and Information Management. Yearb. Med. Inform. 2019, 28, 56–64. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Arcadu, F.; Benmansour, F.; Maunz, A.; Willis, J.; Haskova, Z.; Prunotto, M. Deep learning algorithm predicts diabetic retinopathy progression in individual patients. NPJ Digit. Med. 2019, 2. [Google Scholar] [CrossRef] [PubMed]
- Lam, C.; Yi, D.; Guo, M.; Lindsey, T. Automated Detection of Diabetic Retinopathy using Deep Learning. AMIA Jt. Summits Transl. Sci. 2018, 2017, 147–155. [Google Scholar]
- Hassabis, D.; Kumaran, D.; Summerfield, C.; Botvinick, M. Neuroscience-Inspired Artificial Intelligence. Neuron 2017, 95, 245–258. [Google Scholar] [CrossRef] [Green Version]
- Lee, C.S.; Tyring, A.J.; Wu, Y.; Xiao, S.; Rokem, A.S.; DeRuyter, N.P.; Zhang, Q.; Tufail, A.; Wang, R.K.; Lee, A.Y. Generating retinal flow maps from structural optical coherence tomography with artificial intelligence. Sci. Rep. 2019, 9, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Cattell, J.; Chilukuri, S.; Levy, M. How Big Data Can Revolutionize Pharmaceutical R&D. Available online: https://www.mckinsey.com/~/media/McKinsey/Industries/Pharmaceuticals%20and%20Medical%20Products/Our%20Insights/How%20big%20data%20can%20revolutionize%20pharmaceutical%20R%20and%20D/How%20big%20data%20can%20revolutionize%20pharmaceutical%20RD.pdf (accessed on 2 September 2020).
- Azzolina, D.; Baldi, I.; Barbati, G.; Berchialla, P.; Bottigliengo, D.; Bucci, A.; Calza, S.; Dolce, P.; Edefonti, V.; Faragalli, A.; et al. Machine learning in clinical and epidemiological research: Isn’t it time for biostatisticians to work on it? Epidemiol. Biostat. Public Heal. 2019, 16. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Corrao, G. Real World Evidence; Il Pensiero Scientifico Editore: Milano, Italy, 2019. [Google Scholar]
- Verlato, G.; Marrelli, D.; Accordini, S.; Bencivenga, M.; Di Leo, A.; Marchet, A.; Petrioli, R.; Zoppini, G.; Muggeo, M.; Roviello, F.; et al. Short-term and long-term risk factors in gastric cancer. World J. Gastroenterol. 2015, 21, 6434–6443. [Google Scholar] [CrossRef]
- Verlato, G.; Giacopuzzi, S.; Bencivenga, M.; Morgagni, P.; De Manzoni, G. Problems faced by evidence-based medicine in evaluating lymphadenectomy for gastric cancer. World J. Gastroenterol. 2014, 20, 12883–12891. [Google Scholar] [CrossRef]
- Fabris, A.; Bruschi, M.; Santucci, L.; Candiano, G.; Granata, S.; Dalla Gassa, A.; Antonucci, N.; Petretto, A.; Ghiggeri, G.M.; Gambaro, G.; et al. Proteomic-based research strategy identified laminin subunit alpha 2 as a potential urinary-specific biomarker for the medullary sponge kidney disease. Kidney Int. 2017, 91, 459–468. [Google Scholar] [CrossRef] [PubMed]
- de Manzoni, G.; Marrelli, D.; Verlato, G.; Morgagni, P.; Roviello, F. Western perspective and epidemiology of gastric cancer. In Gastric Cancer: Principles and Practice; Springer International Publishing: Cham, Switzerland, 2015; pp. 111–123. ISBN 9783319158266. [Google Scholar]
- Bencivenga, M.; Verlato, G.; Mengardo, V.; Scorsone, L.; Sacco, M.; Torroni, L.; Giacopuzzi, S.; de Manzoni, G. Is There Any Role for Super-Extended Limphadenectomy in Advanced Gastric Cancer? Results of an Observational Study from a Western High Volume Center. J. Clin. Med. 2019, 8, 1799. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Corrao, G.; Arfè, A.; Nicotra, F.; Ghirardi, A.; Vaghi, A.; De Marco, R.; Pesci, A.; Merlino, L.; Zambon, A. Persistence with inhaled corticosteroids reduces the risk of exacerbation among adults with asthma: A real-world investigation. Respirology 2016, 21, 1034–1040. [Google Scholar] [CrossRef] [PubMed]
- Arfè, A.; Nicotra, F.; Cerveri, I.; de Marco, R.; Vaghi, A.; Merlino, L.; Corrao, G. Incidence, Predictors, and Clinical Implications of Discontinuing Therapy with Inhaled Long-Acting Bronchodilators among Patients with Chronic Obstructive Pulmonary Disease. COPD J. Chronic Obstr. Pulm. Dis. 2016, 13, 540–546. [Google Scholar] [CrossRef] [PubMed]
- Bzdok, D.; Altman, N.; Krzywinski, M. Points of Significance: Statistics versus machine learning. Nat. Methods 2018, 15, 233–234. [Google Scholar] [CrossRef]
- Bencivenga, M.; Verlato, G.; Han, D.-S.; Marrelli, D.; Roviello, F.; Yang, H.-K.; de Manzoni, G. Validation of two prognostic models for recurrence and survival after radical gastrectomy for gastric cancer. Br. J. Surg. 2017, 104, 1235–1243. [Google Scholar] [CrossRef]
- Bruschi, M.; Granata, S.; Candiano, G.; Fabris, A.; Petretto, A.; Ghiggeri, G.M.; Gambaro, G.; Zaza, G. Proteomic analysis of urinary extracellular vesicles reveals a role for the complement system in medullary sponge kidney disease. Int. J. Mol. Sci. 2019, 20, 5517. [Google Scholar] [CrossRef] [Green Version]
- Kingslake, J.; Dias, R.; Dawson, G.R.; Simon, J.; Goodwin, G.M.; Harmer, C.J.; Morriss, R.; Brown, S.; Guo, B.; Dourish, C.T.; et al. The effects of using the PReDicT Test to guide the antidepressant treatment of depressed patients: Study protocol for a randomised controlled trial. Trials 2017, 18, 558. [Google Scholar] [CrossRef] [Green Version]
- Chen, C. Ascent of machine learning in medicine. Nat. Mater. 2019, 18, 407. [Google Scholar] [CrossRef]
- Saria, S.; Butte, A.; Sheikh, A. Better medicine through machine learning: What’s real, and what’s artificial? PLoS Med. 2018, 15. [Google Scholar] [CrossRef]
- Lanera, C.; Berchialla, P.; Baldi, I.; Lorenzoni, G.; Tramontan, L.; Scamarcia, A.; Cantarutti, L.; Giaquinto, C.; Gregori, D. Use of Machine Learning Techniques for Case-Detection of Varicella Zoster Using Routinely Collected Textual Ambulatory Records: Pilot Observational Study. JMIR Med. Inform. 2020, 8, e14330. [Google Scholar] [PubMed]
- Churpek, M.M.; Yuen, T.C.; Winslow, C.; Meltzer, D.O.; Kattan, M.W.; Edelson, D.P. Multicenter comparison of machine learning methods and conventional regression for predicting clinical deterioration on the wards. Crit. Care Med. 2016, 44, 368. [Google Scholar] [CrossRef] [Green Version]
- Hernesniemi, J.A.; Mahdiani, S.; Tynkkynen, J.A.; Lyytikäinen, L.-P.; Mishra, P.P.; Lehtimäki, T.; Eskola, M.; Nikus, K.; Antila, K.; Oksala, N. Extensive phenotype data and machine learning in prediction of mortality in acute coronary syndrome–the MADDEC study. Ann. Med. 2019, 51, 156–163. [Google Scholar] [CrossRef] [PubMed]
- Paik, E.S.; Lee, J.-W.; Park, J.-Y.; Kim, J.-H.; Kim, M.; Kim, T.-J.; Choi, C.H.; Kim, B.-G.; Bae, D.-S.; Seo, S.W. Prediction of survival outcomes in patients with epithelial ovarian cancer using machine learning methods. J. Gynecol. Oncol. 2019, 30. [Google Scholar] [CrossRef] [PubMed]
- Nudel, J.; Bishara, A.M.; de Geus, S.W.L.; Patil, P.; Srinivasan, J.; Hess, D.T.; Woodson, J. Development and validation of machine learning models to predict gastrointestinal leak and venous thromboembolism after weight loss surgery: An analysis of the MBSAQIP database. Surg. Endosc. 2020. [Google Scholar] [CrossRef]
- Shimoda, A.; Ichikawa, D.; Oyama, H. Prediction models to identify individuals at risk of metabolic syndrome who are unlikely to participate in a health intervention program. Int. J. Med. Inform. 2018, 111, 90–99. [Google Scholar] [CrossRef]
- Kim, S.; Kim, W.; Park, R.W. A comparison of intensive care unit mortality prediction models through the use of data mining techniques. Healthc. Inform. Res. 2011, 17, 232–243. [Google Scholar] [CrossRef]
- Frizzell, J.D.; Liang, L.; Schulte, P.J.; Yancy, C.W.; Heidenreich, P.A.; Hernandez, A.F.; Bhatt, D.L.; Fonarow, G.C.; Laskey, W.K. Prediction of 30-day all-cause readmissions in patients hospitalized for heart failure: Comparison of machine learning and other statistical approaches. JAMA Cardiol. 2017, 2, 204–209. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, S.; Yamashita, T.; Sakama, T.; Arita, T.; Yagi, N.; Otsuka, T.; Semba, H.; Kano, H.; Matsuno, S.; Kato, Y. Comparison of risk models for mortality and cardiovascular events between machine learning and conventional logistic regression analysis. PLoS ONE 2019, 14, e0221911. [Google Scholar] [CrossRef]
- Stokes, J.M.; Yang, K.; Swanson, K.; Jin, W.; Cubillos-Ruiz, A.; Donghia, N.M.; MacNair, C.R.; French, S.; Carfrae, L.A.; Bloom-Ackerman, Z. A deep learning approach to antibiotic discovery. Cell 2020, 180, 688–702. [Google Scholar] [CrossRef] [Green Version]
- Darcy, A.M.; Louie, A.K.; Roberts, L.W. Machine learning and the profession of medicine. JAMA J. Am. Med. Assoc. 2016, 315, 551–552. [Google Scholar] [CrossRef] [PubMed]
- Gulshan, V.; Peng, L.; Coram, M.; Stumpe, M.C.; Wu, D.; Narayanaswamy, A.; Venugopalan, S.; Widner, K.; Madams, T.; Cuadros, J.; et al. Development and validation of a deep learning algorithm for detection of diabetic retinopathy in retinal fundus photographs. JAMA J. Am. Med. Assoc. 2016, 316, 2402–2410. [Google Scholar] [CrossRef] [PubMed]
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.W.M.; Hermsen, M.; Manson, Q.F.; Balkenhol, M.; et al. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA J. Am. Med. Assoc. 2017, 318, 2199–2210. [Google Scholar] [CrossRef] [PubMed]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Steele, A.J.; Denaxas, S.C.; Shah, A.D.; Hemingway, H.; Luscombe, N.M. Machine learning models in electronic health records can outperform conventional survival models for predicting patient mortality in coronary artery disease. PLoS ONE 2018, 13, e0202344. [Google Scholar] [CrossRef] [Green Version]
- Esteva, A.; Kuprel, B.; Novoa, R.A.; Ko, J.; Swetter, S.M.; Blau, H.M.; Thrun, S. Dermatologist-level classification of skin cancer with deep neural networks. Nature 2017, 542, 115–118. [Google Scholar] [CrossRef]
- Beam, A.L.; Kohane, I.S. Big data and machine learning in health care. JAMA J. Am. Med. Assoc. 2018, 319, 1317–1318. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Hinton, G. Deep learning—A technology with the potential to transform health care. JAMA J. Am. Med. Assoc. 2018, 320, 1101–1102. [Google Scholar] [CrossRef]
- Van Calster, B.; McLernon, D.J.; Van Smeden, M.; Wynants, L.; Steyerberg, E.W.; Bossuyt, P.; Collins, G.S.; MacAskill, P.; McLernon, D.J.; Moons, K.G.M.; et al. Calibration: The Achilles heel of predictive analytics. BMC Med. 2019, 17. [Google Scholar] [CrossRef] [Green Version]
- Sekhar, H.; Rajula, R.; Mauri, M.; Fanos, V. Scale-free networks in metabolomics. Bioinformation 2018, 14, 140–144. [Google Scholar] [CrossRef]
- Bzdok, D. Classical statistics and statistical learning in imaging neuroscience. Front. Neurosci. 2017, 11, 543. [Google Scholar] [CrossRef] [PubMed]


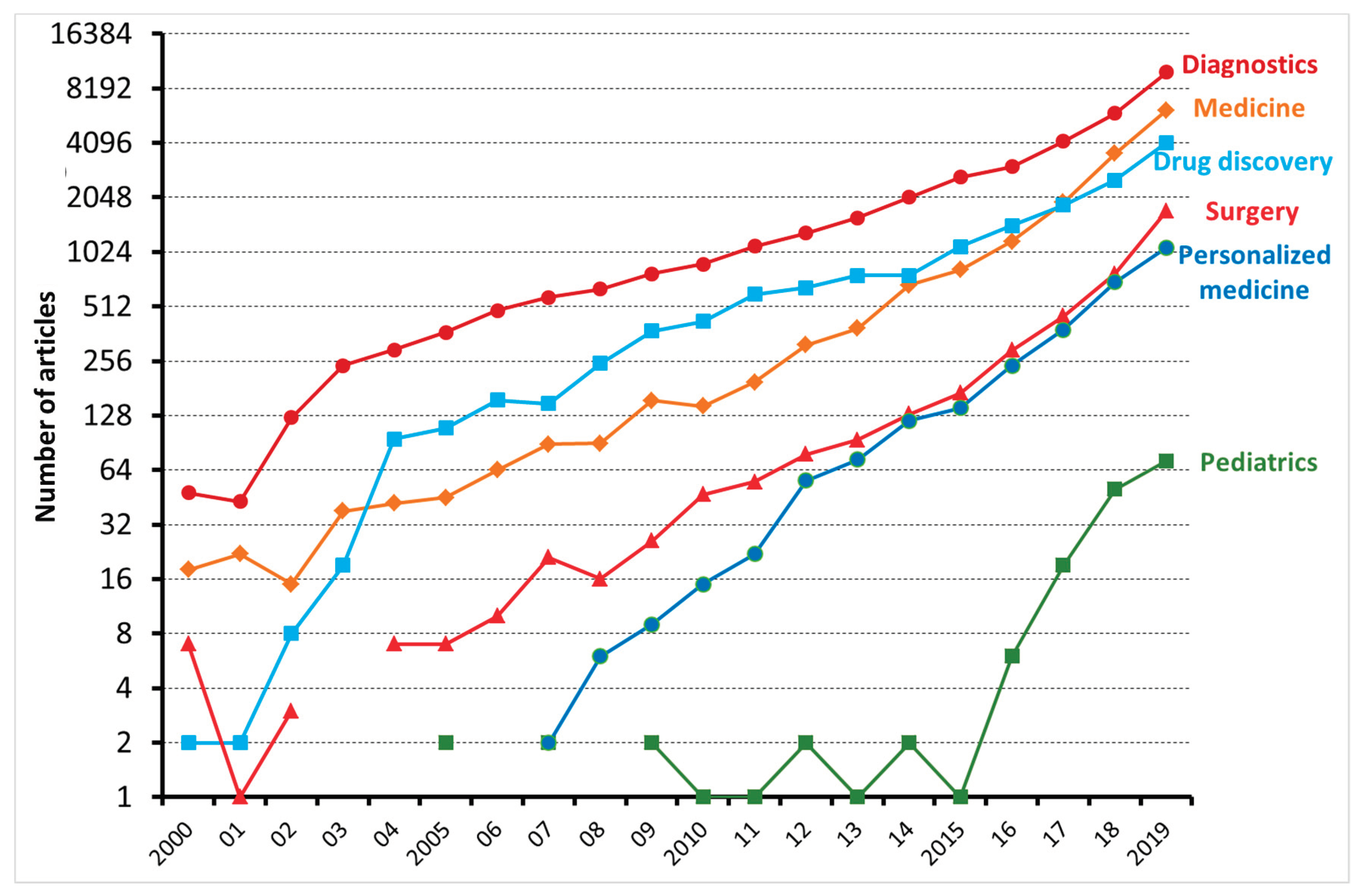{kind=link}
| Application | Areas |
|---|---|
| Diagnostic testing | Personalized diagnostics Parkinson’s disease progression prediction from mobile phone accelerometer data Predict viral failure in AIDS patients |
| Medical imaging | Clinical research: MRI and PET scans and deep learning Cellular image analysis: genotype, phenotype, classification, identification, cellular tracking |
| Oncology | Clinical research: Identify which genes are associated with breast cancer relapse. Prognosis: Predict probability of survival in 5 years |
| Remote patient monitoring | Real-time predictions using data from wearables Medication adherence monitoring |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rajula, H.S.R.; Verlato, G.; Manchia, M.; Antonucci, N.; Fanos, V. Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment. Medicina 2020, 56, 455. https://doi.org/10.3390/medicina56090455
Rajula HSR, Verlato G, Manchia M, Antonucci N, Fanos V. Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment. Medicina. 2020; 56(9):455. https://doi.org/10.3390/medicina56090455
Chicago/Turabian StyleRajula, Hema Sekhar Reddy, Giuseppe Verlato, Mirko Manchia, Nadia Antonucci, and Vassilios Fanos. 2020. "Comparison of Conventional Statistical Methods with Machine Learning in Medicine: Diagnosis, Drug Development, and Treatment" Medicina 56, no. 9: 455. https://doi.org/10.3390/medicina56090455