Machine Learning Applications and Optimization of Clustering Methods Improve the Selection of Descriptors in Blackberry Germplasm Banks

 ,
,  , and
, and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Rubus spp. Accession Genotypes and Agronomic Management
2.2. Morphological Descriptors
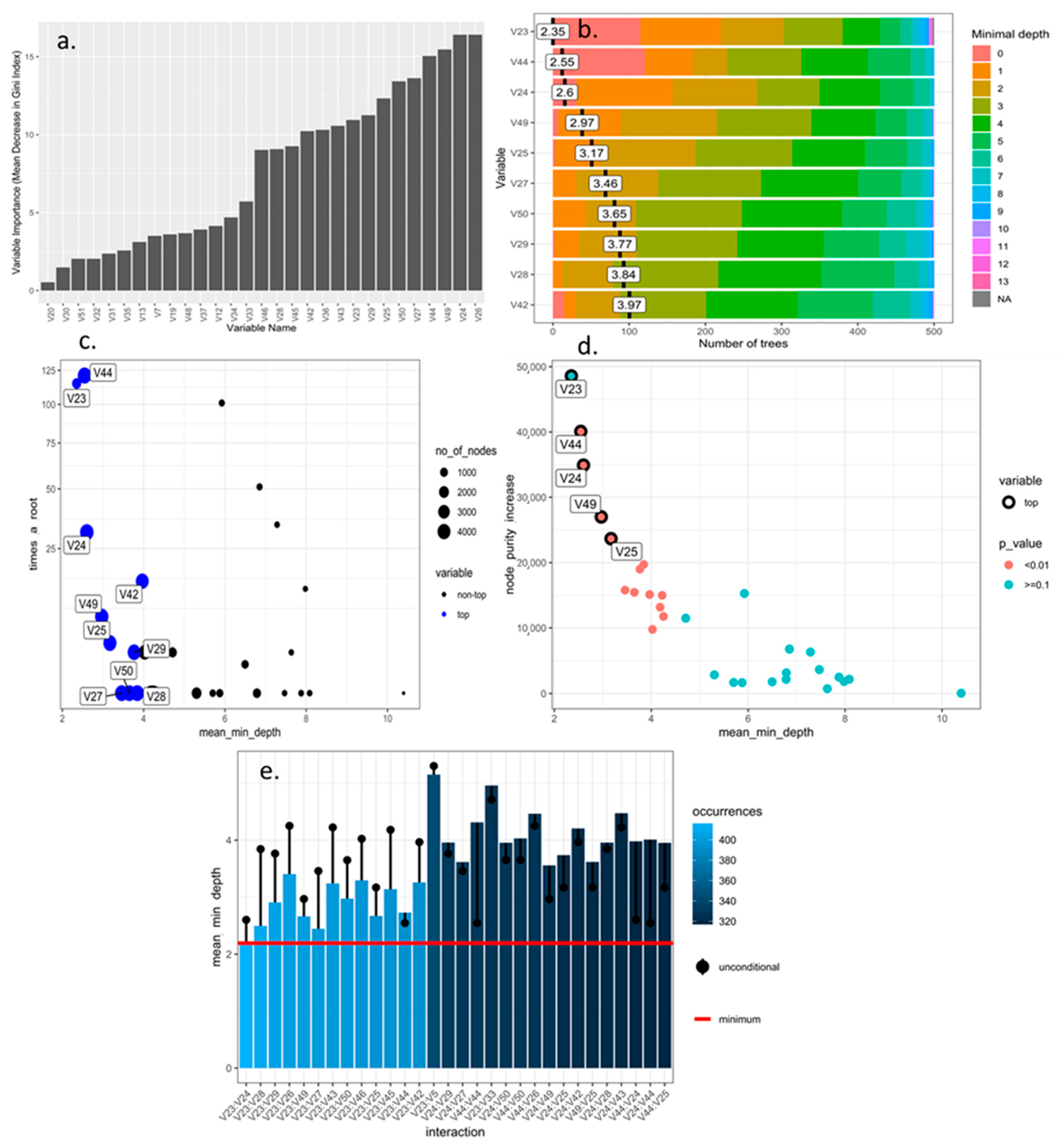
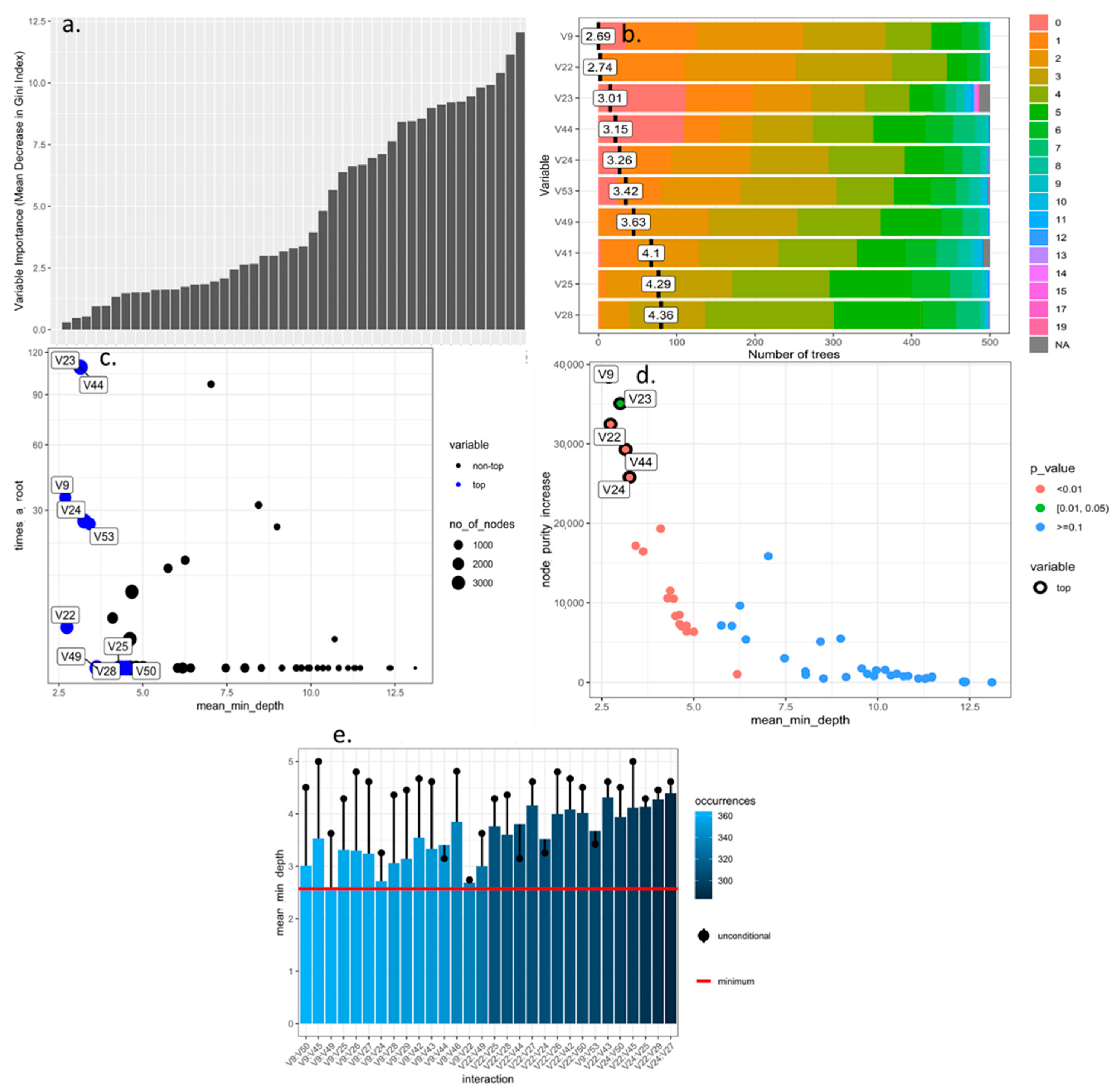
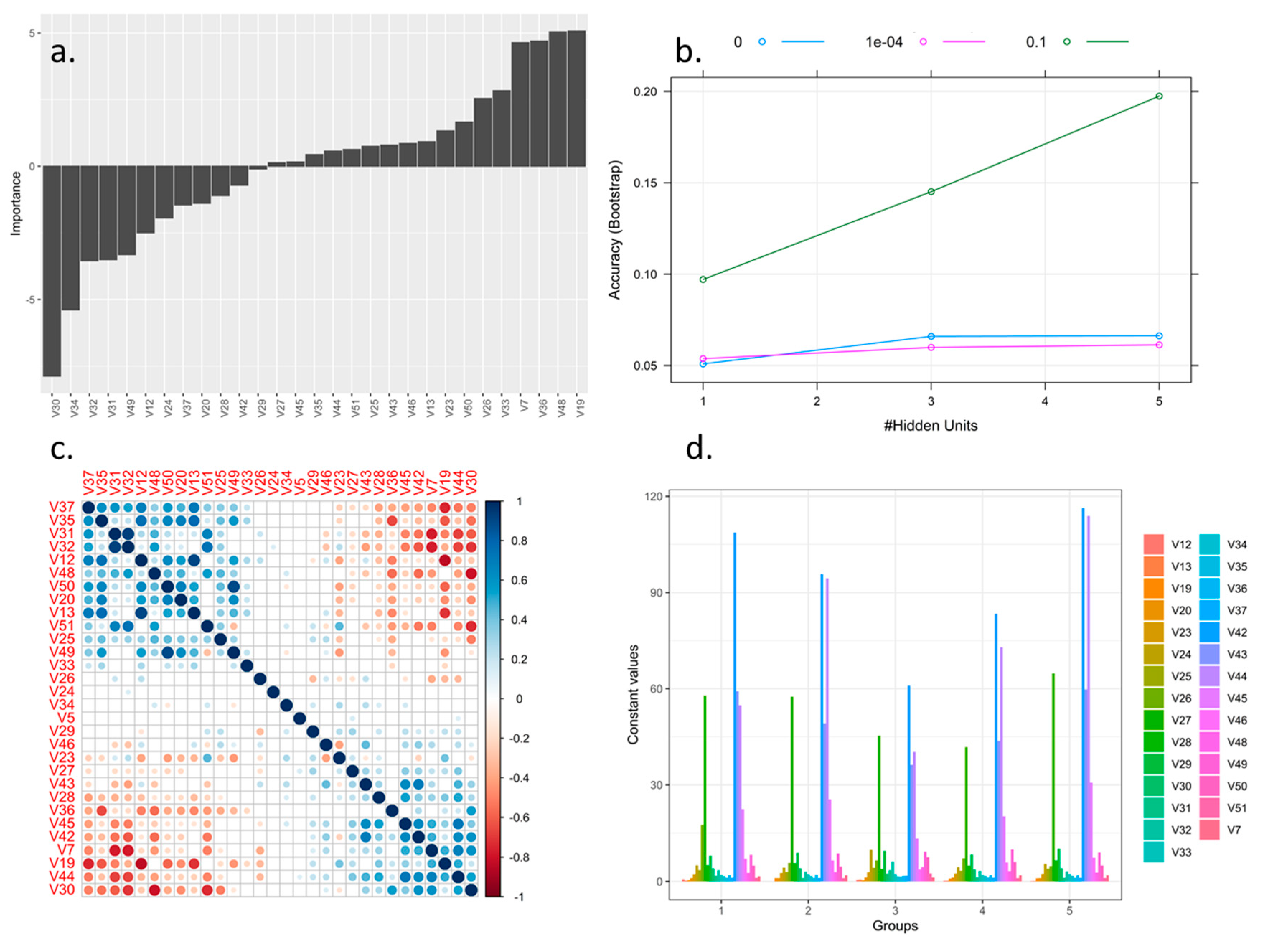
2.3. Selection and Optimization of Morphological Descriptors from the Rubus spp. Germplasm Bank Using Machine Learning Tools
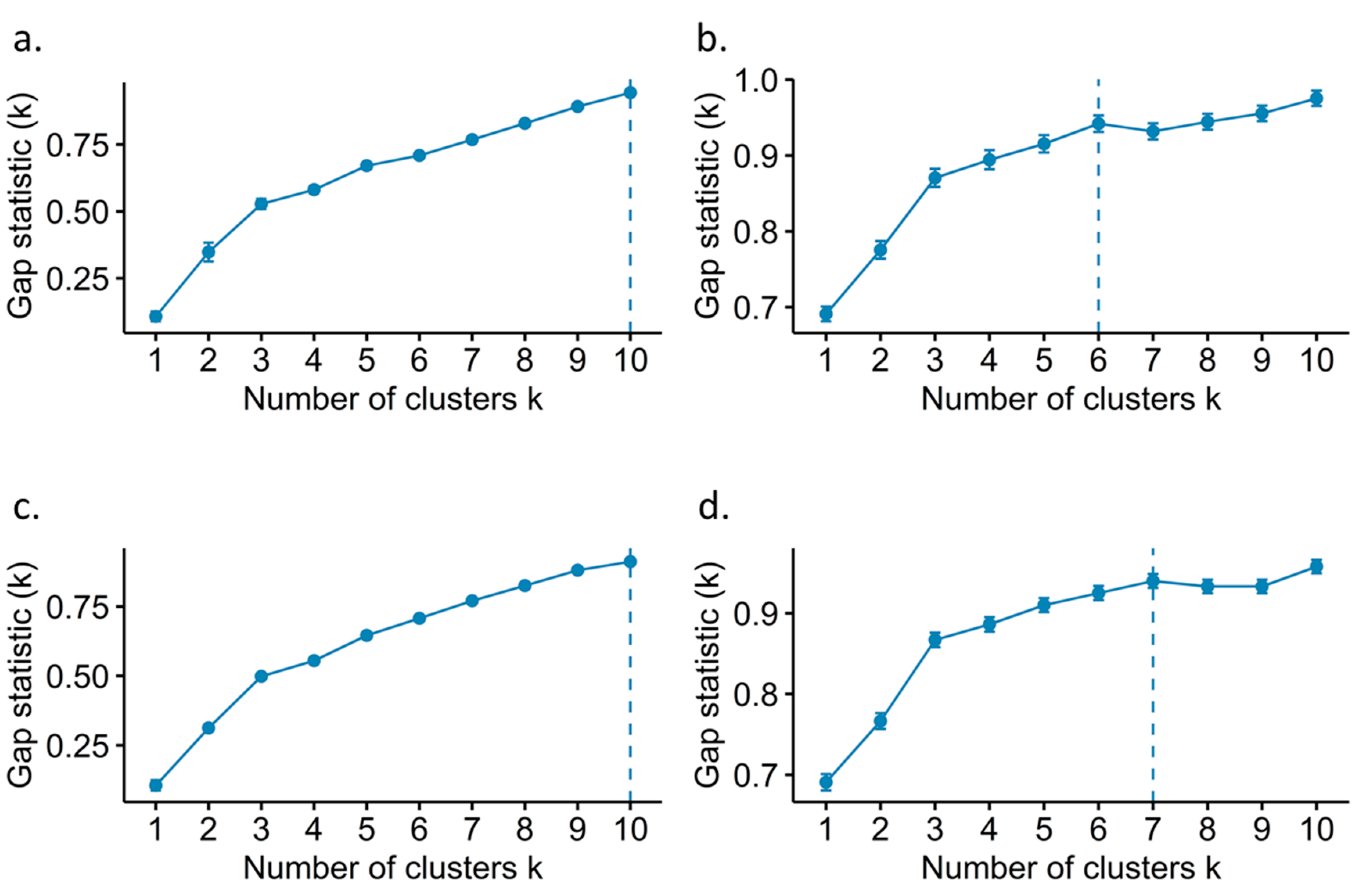
2.4. Rubus spp. Germplasm Bank k Genotype Clustering Methods
3. Results
3.1. Selection and Optimization of Machine Learning Algorithms for the Prioritization and Selection of Morphological Descriptors in Rubus spp.
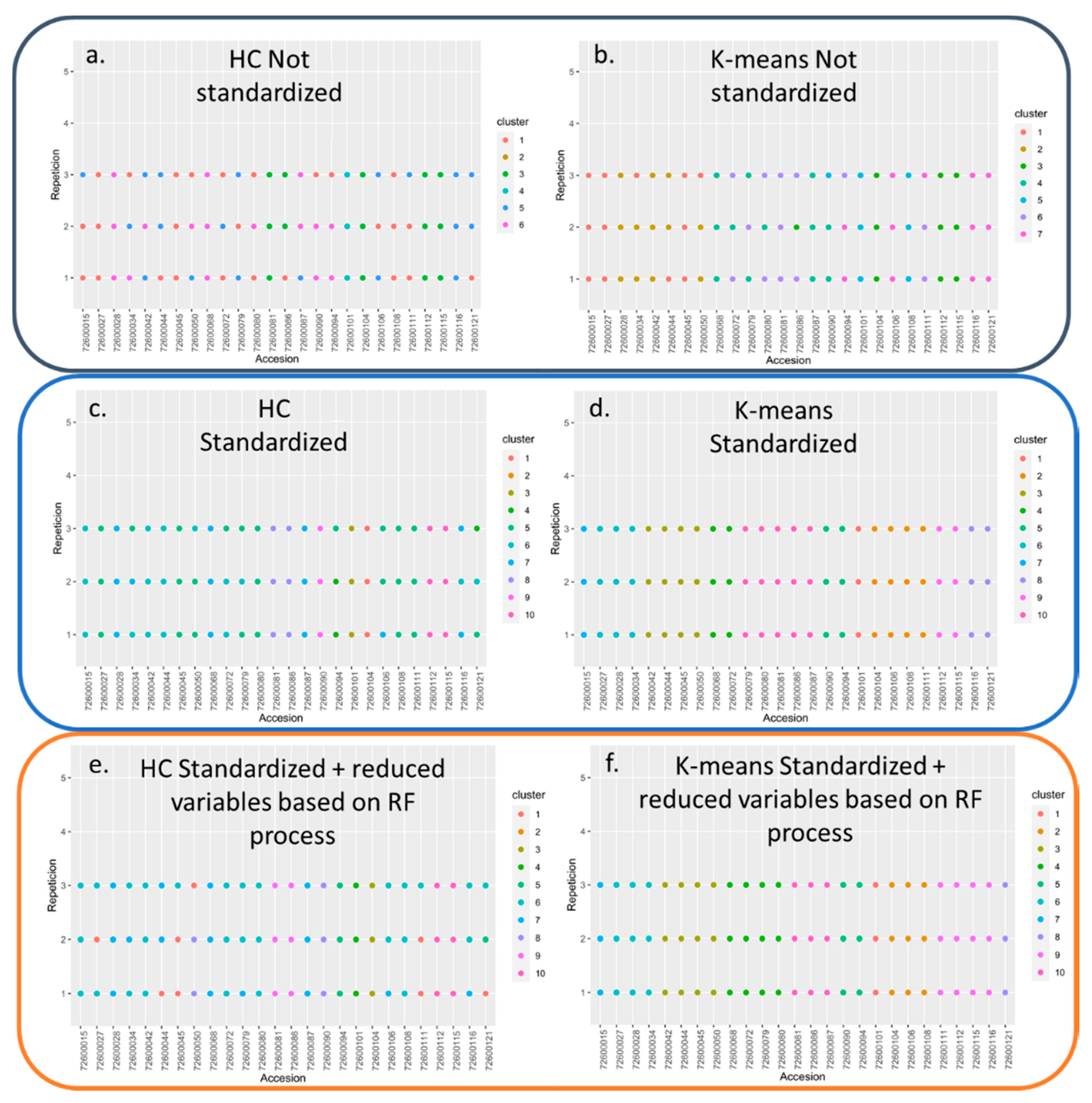
3.2. Genotype Discriminating Methods from the Rubus spp. Germplasm Bank
4. Discussion
4.1. Selection and Discrimination of Descriptors Applied to the Rubus spp. Germplasm Bank Using Machine Learning Tools
4.2. Selection of the Genotype Clustering Method of the Rubus spp. Germplasm Bank
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Data Availability Statement
References
- Paul, A.; Ghosh, S.; Das, A.K.; Goswami, S.; Choudhury, S.D.; Sen, S. A review on agricultural advancement based on computer vision and machine learning. In Emerging Technology in Modelling and Graphics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 567–581. [Google Scholar]
- Liakos, K.G.; Busato, P.; Moshou, D.; Pearson, S.; Bochtis, D. Machine learning in agriculture: A review. Sensors 2018, 18, 2674. [Google Scholar] [CrossRef] [Green Version]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Plant disease detection and classification by deep learning. Plants 2019, 8, 468. [Google Scholar] [CrossRef] [Green Version]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Rose, D.C.; Chilvers, J. Agriculture 4.0: Broadening responsible innovation in an era of smart farming. Front. Sustain. Food Syst. 2018, 2, 87. [Google Scholar] [CrossRef] [Green Version]
- Ramos, P.; Prieto, F.A.; Montoya, E.; Oliveros, C.E. Automatic fruit count on coffee branches using computer vision. Comput. Electron. Agric. 2017, 137, 9–22. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Plant Disease Classification: A Comparative Evaluation of Convolutional Neural Networks and Deep Learning Optimizers. Plants 2020, 9, 1319. [Google Scholar] [CrossRef]
- Kumar, M.; Gupta, S.; Gao, X.-Z.; Singh, A. Plant Species Recognition Using Morphological Features and Adaptive Boosting Methodology. IEEE Access 2019, 7, 163912–163918. [Google Scholar] [CrossRef]
- Sharma, R.; Kamble, S.S.; Gunasekaran, A.; Kumar, V.; Kumar, A. A systematic literature review on machine learning applications for sustainable agriculture supply chain performance. Comput. Oper. Res. 2020, 104926. [Google Scholar] [CrossRef]
- Jordan, M.I.; Mitchell, T.M. Machine learning: Trends, perspectives, and prospects. Science 2015, 349, 255–260. [Google Scholar] [CrossRef]
- Aldana-Domínguez, J.; Montes, C.; Martínez, M.; Medina, N.; Hahn, J.; Duque, M. Biodiversity and ecosystem services knowledge in the Colombian Caribbean: Progress and challenges. Trop. Conserv. Sci. 2017, 10, 1940082917714229. [Google Scholar] [CrossRef]
- Galeano, C.H.; Tehelen, K.; Jiménez, H.R.; Gonzalez, C.; Ceron-Souza, I. Opportunities and challenges for improving a Colombian public research program in plant breeding and plant genetic resources lead by Agrosavia. bioRxiv 2020. [Google Scholar] [CrossRef]
- Valencia-Ramírez, R.A.; Lobo-Arias, M.; Ligarreto, G.A. Estado del arte de los recursos genéticos vegetales en Colombia: Sistema de Bancos de Germoplasma. Cienc. Tecnol. Agropecu. 2010, 11, 85–94. [Google Scholar] [CrossRef]
- Arias, M.L. Recursos genéticos y mejoramiento de frutales andinos: Una visión conceptual. Cienc. Tecnol. Agropecu. 2006, 7, 40–54. [Google Scholar] [CrossRef] [Green Version]
- Lobo-Arias, M.; Medina, C.I. Conservación de recursos genéticos de la agrobiodiversidad como apoyo al desarrollo de sistemas de producción sostenibles. Cienc. Tecnol. Agropecu. 2009, 10, 33–42. [Google Scholar] [CrossRef] [Green Version]
- Gotor, E.; Alercia, A.; Rao, V.R.; Watts, J.; Caracciolo, F. The scientific information activity of Bioversity International: The descriptor lists. Genet. Resour. Crop Evol. 2008, 55, 757–772. [Google Scholar] [CrossRef]
- Ghosh, K. Normas Para Bancos de Germoplasma de Recursos Fitogenéticos Para la Alimentación y la Agricultura; FAO: Rome, Italy, 2013. [Google Scholar]
- Iza, M.; Viteri, P.; Hinojosa, M.; Martínez, A.; Sotomayor, A.; Viera, W. Morphological, phenological and pomological differentiation of commercial cultivars of blackberry (Rubus glaucus Benth.). Enfoque Ute 2020, 11, 47–57. [Google Scholar] [CrossRef] [Green Version]
- Mekonnen, F.; Mekbib, F.; Kumar, S.; Ahmed, S.; Sharma, T. Phenotypic variability and characteristics of lentil (Lens culinaris Medik.) germplasm of Ethiopia by multivariate analysis. J. Agric. Crop Res. 2014, 2, 104–116. [Google Scholar]
- Cancino-Escalante, G.O.; Sánchez-Montaño, L.R.; Quevedo-García, E.; Díaz-Carvajal, C. Caracterización fenotípica de accesiones de especies de Rubus L. de los municipios de Pamplona y Chitagá, región Nororiental de Colombia. Univ. Sci. 2011, 16, 219–233. [Google Scholar] [CrossRef]
- Ligarreto-Moreno, G.A.; Espinosa, N.; Barrero, L.S.; Medina, C.I. Variabilidad morfológica de variedades nativas de mora (Rubus sp.) en los Andes de Colombia. Rev. Colomb. Cienc. Hortic. 2016, 10, 211–221. [Google Scholar] [CrossRef] [Green Version]
- Evans, K.J.; Weber, H.E. Rubus anglocandicans (Rosaceae) is the most widespread taxon of European blackberry in Australia. Aust. Syst. Bot. 2003, 16, 527–537. [Google Scholar] [CrossRef]
- Voss, D.H. The Royal Horticultural Society Colour Chart 2001; Flower Council Of Holland: London, UK, 2002. [Google Scholar]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. randomForest: Breiman and Cutler’s Random Forests for classification and regression (R package). version 4.6. 2018. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Kenkel, B.; Team, R.C. Package ‘caret’. R J. 2020. [Google Scholar]
- Wright, M.N.; Wager, S.; Probst, P.; Wright, M.M.N. Package ‘ranger’. 2018. [Google Scholar]
- LeDell, E.; Poirier, S. H2O automl: Scalable automatic machine learning. In Proceedings of the 7th ICML Workshop on Automated Machine Learning; 2020; Volume 1, pp. 1–16. [Google Scholar]
- Müller, A.C.; Guido, S. Introduction to Machine Learning with Python: A Guide for Data Scientists; O’Reilly Media Inc.: Sebastopol, CA, USA, 2016. [Google Scholar]
- Hasmadi, M.; Pakhriazad, H.; Shahrin, M. Evaluating supervised and unsupervised techniques for land cover mapping using remote sensing data. Geogr. Malays. J. Soc. Space 2009, 5, 1–10. [Google Scholar]
- Paluszynska, A.; Biecek, P.; Jiang, Y. randomForestExplainer: Explaining and Visualizing Random Forests in Terms of Variable Importance. R Package version 0.10. 0. 2019. [Google Scholar]
- Ben-Hur, A.; Weston, J. A user’s guide to support vector machines. In Data Mining Techniques for the Life Sciences; Springer: Berlin/Heidelberg, Germany, 2010; pp. 223–239. [Google Scholar]
- Meyer, D.; Dimitriadou, E.; Hornik, K.; Weingessel, A.; Leisch, F.; Chang, C.; Lin, C. e1071: Misc functions of the Department of Statistics (e1071), TU Wien. R Package Version. 2014; Volume 1. [Google Scholar]
- Fan, R.-E.; Chen, P.-H.; Lin, C.-J. Working set selection using second order information for training support vector machines. J. Mach. Learn. Res. 2005, 6, 1889–1918. [Google Scholar]
- Beck, M.W. NeuralNetTools: Visualization and analysis tools for neural networks. J. Stat. Softw. 2018, 85, 1. [Google Scholar] [CrossRef]
- Ripley, B.; Venables, W. nnet: Feed-forward neural networks and multinomial log-linear models. R Package Version 2016, 7. [Google Scholar]
- Bergmeir, C.N.; Benítez Sánchez, J.M. Neural Networks in R Using the Stuttgart Neural Network Simulator: RSNNS; American Statistical Association: Alexandria, VA, USA. [CrossRef] [Green Version]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef] [Green Version]
- R Development Core Team. R: The R Project for Statistical Computing. R Found. Stat. Comput. 2020. [Google Scholar]
- Huang, J.; Ling, C.X. Using AUC and accuracy in evaluating learning algorithms. IEEE Trans. Knowl. Data Eng. 2005, 17, 299–310. [Google Scholar] [CrossRef] [Green Version]
- Murtagh, F.; Legendre, P. Ward’s hierarchical agglomerative clustering method: Which algorithms implement Ward’s criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef] [Green Version]
- Szoecs, E.; Wagner, H. Vegan: Community ecology package. R Package Version. 2019; Volume 2, 4–5. [Google Scholar]
- Suzuki, R.; Shimodaira, H.; Suzuki, M.R. Package ‘pvclust’. R Top. Doc. 2015, 14. [Google Scholar]
- Paradis, E.; Blomberg, S.; Bolker, B.; Brown, J.; Claude, J.; Cuong, H.S.; Desper, R. Package ‘ape’. Anal. Phylogenetics Evol. Version 2015, 2, 1–4. [Google Scholar]
- Adler, D.; Murdoch, M.D. Available online: https://cran.r-project.org/web/packages/rgl/ (accessed on 9 December 2020).
- Walesiak, M.; Dudek, A. mdsOpt–Searching for Optimal MDS Procedure for Metric and Interval-Valued Data, R package version 0.3-3. 2018. Available online: https://CRAN.R-project.org/package=mdsOpt (accessed on 9 December 2020).
- Aggarwal, S.; Phoghat, P.; Maitrey, S. Hierarchical clustering-an efficient technique of data mining for handling voluminous data. Int. J. Comput. Appl. 2015, 129, 31–36. [Google Scholar] [CrossRef]
- Milligan, G.W.; Cooper, M.C. A study of standardization of variables in cluster analysis. J. Classif. 1988, 5, 181–204. [Google Scholar] [CrossRef]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Kassambara, A.; Mundt, F. Factoextra: Extract and visualize the results of multivariate data analyses. R Package Version 1.0.7. 2020. [Google Scholar]
- Bolar, K. STAT: Interactive document for Working with Basic Statistical Analysis. R Package Version 0.1. 0. 2019. [Google Scholar]
- Vinh, N.X.; Epps, J.; Bailey, J. Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J. Mach. Learn. Res. 2010, 11, 2837–2854. [Google Scholar]
- Hennig, C. fpc: Flexible Procedures for Clustering. R package version 2.2-5 (2020). 2020. [Google Scholar]
- Chiquet, J.; Rigaill, G.; Dervieux, V. aricode: Efficient Computations of Standard Clustering Comparison Measures. 2019. Available online: https://rdrr.io/cran/aricode/ (accessed on 9 December 2020).
- Breiman, L. Using iterated bagging to debias regressions. Mach. Learn. 2001, 45, 261–277. [Google Scholar] [CrossRef] [Green Version]
- Christodoulou, M.D.; Battey, N.H.; Culham, A. Can you make morphometrics work when you know the right answer? Pick and mix approaches for apple identification. PLoS ONE 2018, 13, e0205357. [Google Scholar] [CrossRef] [Green Version]
- Rehman, T.U.; Mahmud, M.S.; Chang, Y.K.; Jin, J.; Shin, J. Current and future applications of statistical machine learning algorithms for agricultural machine vision systems. Comput. Electron. Agric. 2019, 156, 585–605. [Google Scholar] [CrossRef]
- Wang, Z.; O’Boyle, M. Machine learning in compiler optimization. Proc. IEEE 2018, 106, 1879–1901. [Google Scholar] [CrossRef] [Green Version]
- Tabarki, S.; Mechergui, K.; Khaldi, S.; Toumi, L.; Raies, A. Analysis of Morphological Variability in Five Spontaneous Populations of Rubus ulmifolius Schott in Tunisia. Asian J. Biol. 2017, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Guérin, J.; Gibaru, O.; Thiery, S.; Nyiri, E. Clustering for different scales of measurement-the gap-ratio weighted k-means algorithm. arXiv 2017, arXiv:1703.07625. [Google Scholar]
- Mereu, R.F. A note on the ratio of the moment magnitude scale to other magnitude scales: Theory and applications. Seismol. Res. Lett. 2017, 88, 193–205. [Google Scholar] [CrossRef]
- Oliva, C. Métodos para la Segmentación de Datos Longitudinales. Aplicación a Datos de Rendimientos de Cultivos en Argentina. Ph.D. Thesis, Universidad de Buenos Aires, Buenos Aires, Argentina, 2015; p. 72. [Google Scholar]
- Reichart, R.; Rappoport, A. The NVI clustering evaluation measure. In Proceedings of the Thirteenth Conference on Computational Natural Language Learning (CoNLL-2009), Boulder, CO, USA, 4–5 June 2009; pp. 165–173. [Google Scholar]
- Malik, A.; Tuckfield, B. Applied Unsupervised Learning with R: Uncover Hidden Relationships and Patterns with K-Means Clustering, Hierarchical Clustering, and PCA; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Ochieng, J.A.; Gesimba, R.M.; Oyoo, M.E.; Korir, P.C.; Owuoche, J.O.; Miheso, M. Morphological characterization of blackberry (Rubus subgenus Rubus Watson) genetic resources in Kenya. Afr. J. Plant Sci. 2019, 13, 297–308. [Google Scholar]
- Lauri, P.-É.; Normand, F. Are leaves only involved in flowering? Bridging the gap between structural botany and functional morphology. Tree Physiol. 2017, 37, 1137–1139. [Google Scholar] [CrossRef] [PubMed] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Specie | Unique Identification Code (CUI) | Specie | Unique Identification Code (CUI) |
|---|---|---|---|
| Rubus sp. (I) | 72600104 | Rubus glaucus (CN) | 72600111 |
| Rubus sp. (I) | 72600101 | Rubus glaucus (CN) | 72600087 |
| Rubus glaucus (CN) | 72600121 | Rubus glaucus (CN) | 72600079 |
| Rubus glaucus (CN) | 72600015 | Rubus sp. (I) | 72600086 |
| Rubus glaucus (CN) | 72600027 | Rubus glaucus (WN) | 72600072 |
| Rubus glaucus (CN) | 72600028 | Rubus sp. (CN) | 72600090 |
| Rubus glaucus (CN) | 72600034 | Rubus glaucus (CN) | 72600068 |
| Rubus glaucus (CN) | 72600042 | Rubus sp. (I) | 72600115 |
| Rubus glaucus (CN) | 72600044 | Rubus glaucus (CN) | 72600106 |
| Rubus glaucus (CN) | 72600045 | Rubus glaucus (CN) | 72600116 |
| Rubus sp. (WN) | 72600108 | Rubus glaucus (CN) | 72600080 |
| Rubus glaucus (CN) | 72600050 | Rubus sp. (I) | 72600081 |
| Rubus glaucus (CN) | 72600094 | Rubus sp. (I) | 72600112 |
| Plant and Organs | Morphological Variables |
|---|---|
| Plant growth habit | (V7) Plant size (types of plant growth) |
| Stem | (V8, V9) Primary color of the stem surface |
| (V10, V11) Secondary color of the stem surface | |
| (V12) Density of stem pubescence (tector hairs) | |
| (V13) Presence of trichomes on the stem (glandular hairs) | |
| (V14) Color of stem trichomes | |
| (V15) Number of trichomes on the stem [Area 0.5 cm2] | |
| (V16, V17, V18) Color of stem pubescence | |
| (V19) Stem waxiness | |
| (V20) Stem shape | |
| (V21, V22) Color of the base of the stinger on the stem | |
| (V23) Shape of the stinger on the stem | |
| (V24) Length of the base of the stinger on the stem [mm] | |
| (V25) Length of the stinger on the stem [mm] | |
| (V26) Number of stingers in the stem internode | |
| Leaf | (V27) Length of the internode on the stem [mm] |
| (V28) Stipule length (from leaf base and petiole) [mm] | |
| (V29) Stipule protrusion length on petiole [mm] | |
| (V30) Shape of stipules on petiole | |
| (V31) Blade shape | |
| (V32) Number of leaflets on the leaf | |
| (V33) Margin of terminal leaflet | |
| (V34) Shape of the base of the terminal leaflet | |
| (V35) Shape of terminal leaflet apex | |
| (V36) Terminal leaflet shape | |
| (V37) Pubescence of terminal leaflet (tector hairs) | |
| (V38, V39) Color of the terminal leaflet bundle | |
| (V40, V41) Color of the underside of the terminal leaflet | |
| (V42) Length of terminal leaflet [mm] | |
| (V43) Terminal leaflet width [mm] | |
| (V44) Petiole length at terminal leaflet [mm] | |
| (V45) Petiole length in terminal leaflet [mm] | |
| Flower | (V46) Number of stingers in the terminal leaflet |
| (V47) Type of inflorescence | |
| (V48) Petal shape | |
| (V49) Petal length [mm] | |
| (V50) Petal width [mm] | |
| (V51) Color distribution on the petals (pigmentation of certain areas) |
| Algorithm Type | Train Accuracy 1 | Train Missclass Error 1 | Validation Accuracy 1 | Validation Missclass Error 1 |
|---|---|---|---|---|
| Random Forest with numerical variables | 0.612 | 0.387 | 0.643 | 0.356 |
| Random Forest with all variables | 0.734 | 0.265 | 0.768 | 0.231 |
| Support Vector Machine linear | Na | Na | 0.0903 | 0.906 |
| Support Vector Machine radial | Na | Na | 0.218 | 0.781 |
| Neuronal Networks | Na | Na | 0.312 | 0.687 |
| Clustering Method type | NVI | ARI | IS | CH | EN | PG |
|---|---|---|---|---|---|---|
| HAC (not standardized) | 0.83189 | 0.06594 | 11.11800 | 147.1061 | 1.45703 | 0.45055 |
| K-means (not standardized) | 0.64981 | 0.19419 | 7.72195 | 103.6778 | 1.92456 | 0.31012 |
| HAC (standardized) | 0.64030 | 0.18111 | 8.03727 | 65.75058 | 1.96550 | 0.30829 |
| K-means (standardized) | 0.32366 | 0.45414 | 7.55724 | 24.58237 | 2.18674 | 0.12498 |
| HAC (standardized and with reduced variables based on random Forest process) | 0.65026 | 0.17933 | 1.36298 | 69.08629 | 1.94982 | 0.40440 |
| K-means (standardized and with reduced variables based on random Forest process) | 0.32122 | 0.46730 | 1.05589 | 20.30752 | 2.19465 | 0.14359 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Henao-Rojas, J.C.; Rosero-Alpala, M.G.; Ortiz-Muñoz, C.; Velásquez-Arroyo, C.E.; Leon-Rueda, W.A.; Ramírez-Gil, J.G. Machine Learning Applications and Optimization of Clustering Methods Improve the Selection of Descriptors in Blackberry Germplasm Banks. Plants 2021, 10, 247. https://doi.org/10.3390/plants10020247
Henao-Rojas JC, Rosero-Alpala MG, Ortiz-Muñoz C, Velásquez-Arroyo CE, Leon-Rueda WA, Ramírez-Gil JG. Machine Learning Applications and Optimization of Clustering Methods Improve the Selection of Descriptors in Blackberry Germplasm Banks. Plants. 2021; 10(2):247. https://doi.org/10.3390/plants10020247
Chicago/Turabian StyleHenao-Rojas, Juan Camilo, María Gladis Rosero-Alpala, Carolina Ortiz-Muñoz, Carlos Enrique Velásquez-Arroyo, William Alfonso Leon-Rueda, and Joaquín Guillermo Ramírez-Gil. 2021. "Machine Learning Applications and Optimization of Clustering Methods Improve the Selection of Descriptors in Blackberry Germplasm Banks" Plants 10, no. 2: 247. https://doi.org/10.3390/plants10020247