1. Introduction
Gestures and hand postures have been used for a long time as a way to express feelings and to communicate information between people. A gesture can represent a simple action, such as to allow people to cross a street, or complex body expressions belonging to a specific population language. Sign language uses both hand and body postures instead of sound patterns to establish communication. It is a very important type of language due to the fact that nine million people present some kind of hearing or speaking loss [
1], while most people do not speak sign language, as most of the hearing impaired are illiterate in their local language. Gesture recognition can work on this problematic by creating a bridge between the languages, recognizing a given gesture and translating it into words in real time [
2].
There are three types of gesture recognition systems: based on devices attached to the body [
3], based on gesture tracking [
4] and based on computer vision techniques [
5]. The first category uses sensors, such as wearable devices with accelerometers and markers, to capture a gesture and its corresponding movement. However, this invasive technology limits the normal execution of the gesture.
Gesture recognition systems based on tracking aim to follow the gesture trail, drawing a path through its execution using a marker. The limitation comes from the fact that these systems use only the traveled path, and they do not perform well with complex and very detailed movements, such as the ones involving different hand postures.
The last category, systems based on computer vision techniques, uses a camera device to capture the gesture and extract features, such as the speed, direction and intensity of a given gesture. Due to variations in gesture execution, people executing them and the environment, the accuracy of such systems can be degraded in specific scenarios, like reduced illumination, very fast movement or interference from other people [
6,
7]. However, it is the least invasive category, allowing a more natural iteration between the user and the system without impairing the gesture execution. Usually, some steps between the image capture and the classification output are followed by these systems: image segmentation, feature extraction and pattern classification [
8]. In the first step, the image background is removed, and only the body parts relevant to the gesture recognition are kept [
9]. In this scenario, the Microsoft Kinect [
10] appeared as an interesting solution to gesture recognition, presenting an important contribution in image segmentation for body detection. In the work of Tara
et al. [
11], the Microsoft Kinect is used to capture depth maps and to recognize static gestures. The depth maps are used to detect the hand through the definition of a distance threshold in which the hand is located. Lee
et al. [
12] proposed an approach with k-means and the convexity hull to find the fingers and provide a more accurate analysis of the gesture. The main proposition of Palacios
et al. [
13] consists of a segmentation algorithm where the user does not need to execute the gesture in the front of the body and near the depth sensor.
In the second step of gesture recognition systems based on computer vision techniques, descriptors are extracted in order to computationally represent the gesture pattern [
14]. Thus, the images are reduced to feature vectors by using mathematical models [
15]. Oreifej and Liu [
16] proposed a technique called Histogram of Oriented 4D Normals (Hon4d) that uses a 4D histogram approach for feature extraction, while Yang [
17] proposed an algorithm for 2D and 3D spaces that extracts some features from the executed gestures: the location of the left hand with respect to the signer’s face in 3D space; the angle from the face to the left hand; the position of the left hand with respect to the shoulder center; the occlusion of both hands. Doliotis
et al. [
18] proposed a feature extraction method using images generated by a Microsoft Kinect, retrieving a 3D pose orientation and full hand configuration parameters.
It is also important to note that there is a common issue between many feature extraction methods in gesture recognition: the curse of dimensionality [
19]. Some approaches have been proposed to solve this problem, like the reduction of the feature vectors [
20,
21] by selecting a smaller set of features that adequately keeps the original representation in order to distinguish the different gestures. Probabilistic models analyze the correlation between the features allowing their selection, like Principal Component Analysis (PCA) or Independent Component Analysis (ICA) [
22]. Moreover, optimization function techniques can also be used to reduce the feature vectors, aiming to minimize the model error rate, such as swarm methods [
23], which are designed to optimize high dimensionality functions.
In the last step of gesture recognition of systems based on computer vision techniques, a classifier is trained using the extracted descriptors in order to recognize the gestures [
24]. Barros
et al. [
5,
25] presented a gesture recognition system that achieved higher classification rates in comparison to other methods using dynamic time warping (DTW) [
26] and hidden Markov model (HMM) [
27] classifiers. Kim
et al. [
28] also used DTW as a classifier to recognize gestures captured by a depth sensor. Godoy
et al. [
29] proposed a gesture recognition method trained on a few samples with HMM, achieving high classification rates. Neverova
et al. [
30] proposed a framework based on a multi-scale and multi-modal deep learning architecture, which is able to detect, locate and recognize a gesture. To complete this task, they used information obtained from different data channels of a depth image, decomposing the gesture into multiple temporal and spatial scales. Wu
et al. [
31] proposed a multilayered gesture recognition system, dividing the recognition phase into three layers: the first layer for fast distinguishing types of gestures based on PCA; the second layer is a particle-based descriptor to extract and identify dynamic information from gestures in each frame using DTW with adaptive weights; and finally, the static hand shapes are recognized in the third layer. Their study achieved significant results in a large dataset with 50,000 gestures [
32].
In this paper, we propose a novel approach for dynamic gesture recognition with depth maps, called the hybrid approach for gesture recognition with depth maps (HAGR-D). HAGR-D uses a version of CIPBR (convex invariant position based on RANSAC) algorithm [
33] for feature extraction, a combination of the binary particle swarm optimization [
34] and a selector algorithm to make the feature selection and a hybridization between DTW and HMM classifiers for recognition. DTW is used to find the most probable gestures, while HMM refines DTW output.
This paper is organized as follows.
Section 2 describes the proposed model. In
Section 3, experiments with gesture images captured by the Microsoft Kinect are shown. Finally, in
Section 4, we present some concluding remarks.
2. Hybrid Approach for Gesture Recognition with a Depth Map
HAGR-D is an approach for gesture recognition that involves a method for feature extraction, a method for feature vector reduction and a hybrid classifier.
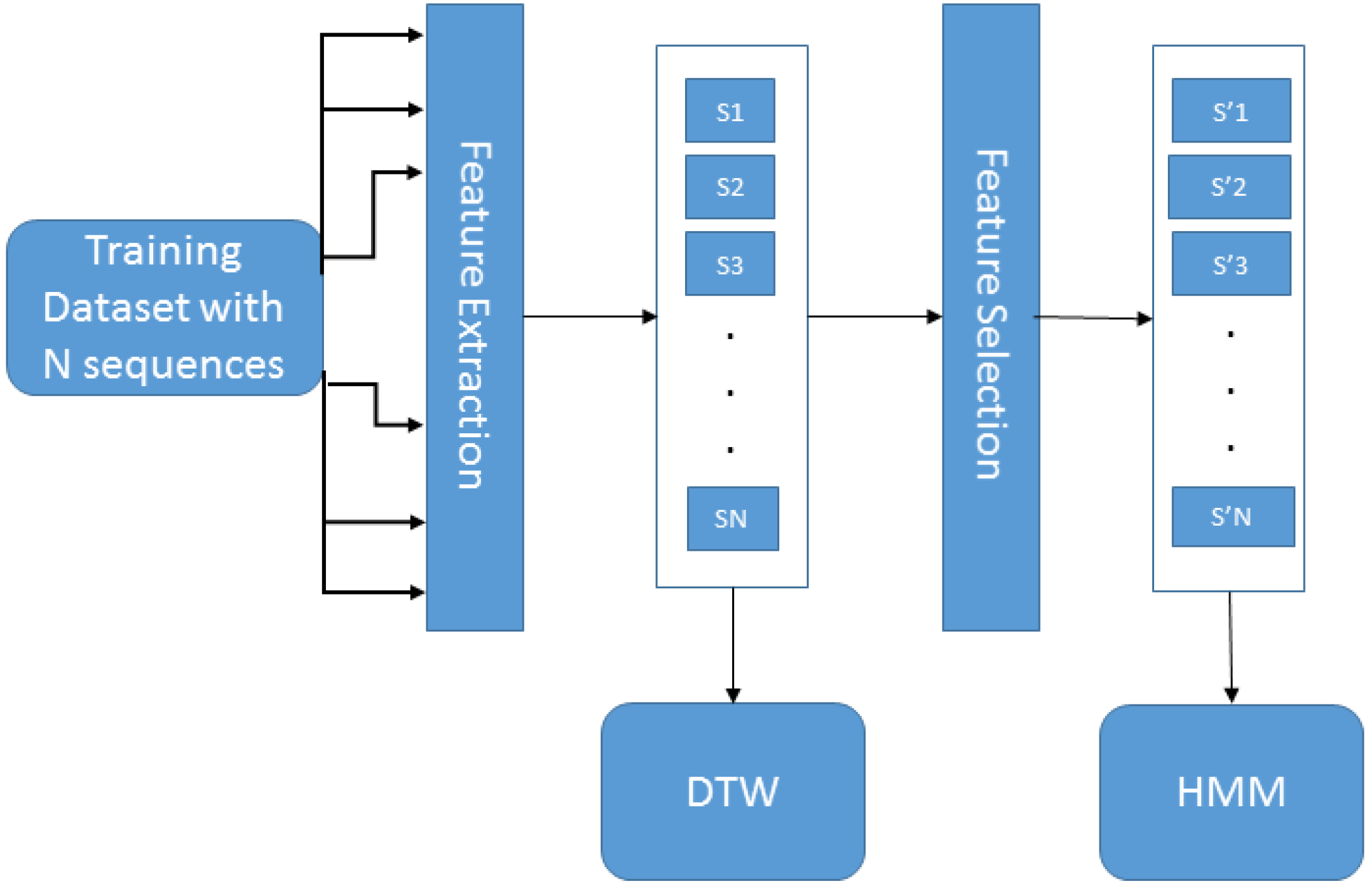
Figure 1 presents the training architecture for the HAGR-D system, which starts with feature extraction using a variation of the CIPBR algorithm for depth maps. These vectors are used to train the DTW classifier. The feature selection method uses a combination between binary particle swarm optimization [
34] and a selector algorithm [
25] to reduce the feature vector that is used by the HMM to refine the DTW classification result. We present the depth CIPBR algorithm in
Section 2.1, the feature selection method in
Section 2.2 and a description of DTW and HMM hybridization in
Section 2.3.
Table 1 presents the notations and definitions used to describe the HAGR-D.
Figure 1.
HAGR-D training architecture.
Figure 1.
HAGR-D training architecture.
Table 1.
Notations and definitions used to describe the HAGR-D.
Table 1.
Notations and definitions used to describe the HAGR-D.
| Symbol | Description |
|---|
| C | Hand contour center of mass |
| P | The hand contour highest point |
| The line segment between points P and C |
| Θ | Maximum circumcircle |
| Ψ | Convex hull points of the hand contour |
| Contour point of the convex hull Ψ |
| ω | Point of the Ψ set |
| Line segment calculated between the points ω and C |
| D | Set of distances |
| Q | Intersection between and Θ |
| d | Distance from the D set |
| distance d normalized |
| A | Set of angles |
| a | Angle from the A set |
| Angle a normalized |
| F | Final feature vector returned by depth CIPBR |
| X | Set of position in a search dimension |
| Position in a search dimension |
| V | Set of velocities in a search dimension |
| Velocity in a search dimension |
| Best position found by a particle |
| Best position found by the swarm |
| S | Feature vector |
| Reduced feature vector |
| k | Number of gestures candidates returned by DTW in classification time |
| Cost matrix generated for DTW to compare two patterns |
| i | Size of A pattern feature vector and position in a cost matrix row |
| j | Size of B pattern feature vector and position in a cost matrix column |
2.1. Depth CIPBR
The depth CIPBR algorithm is an approach composed of a sequence of tasks to reduce a depth map of a hand posture into two signature sets proposed by Keogh
et al. [
35]. To complete these tasks, there are four modules connected in cascade, as presented in
Figure 2.
Figure 2.
Depth CIPBR architecture.
Figure 2.
Depth CIPBR architecture.
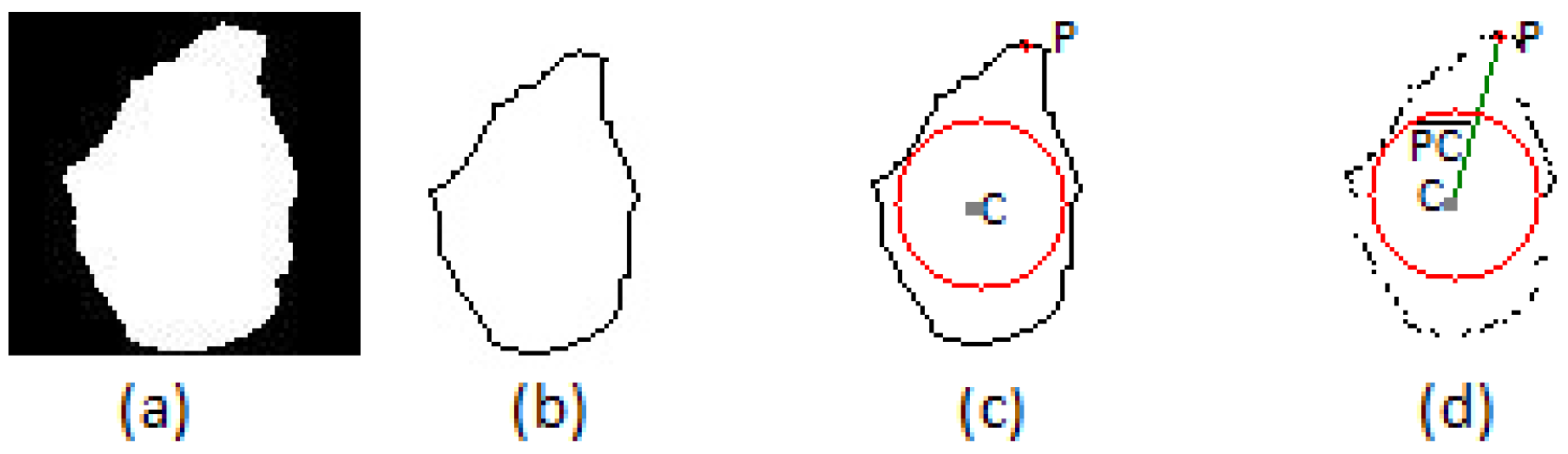
The first module, “radius calculation”, uses a hand posture image that is segmented from the depth map generated by the Microsoft Kinect;
Figure 3a. The hand posture contour is extracted from this image, generating the contour (
Figure 3b), and the center of mass (
C) of the hand posture is calculated from the image contour using the center moments [
36]. Then, the point that has the lower Y coordinate is found,
P;
Figure 3c. Finally, this module calculates the distance between the center of mass and point
P.
Figure 3d presents an output example of the “radius calculation” module. The dark gray point is the center of mass of the contour given by
C; the red point is the highest point of the contour given by
P; and the line connecting these points is given by
.
The second module of Depth CIPBR, “draw maximum circumcircle”, uses the line segment as radius to draw a circle inside the hand contour. If this circle exceeds the hand contour boundary, a triangle is calculated using the three most distant contour points from the point C, two of them being on opposite sides of the contour. The biggest circle inside this triangle is the maximum circumcircle Θ of the contour with the center at point C.
Figure 3.
(a) The hand segmented using the Microsoft Kinect; (b) the hand posture contour; (c) the mass center point drawn in the hand posture contour (dark gray point); (d) the convex hull points with the maximum circumcircle Θ (red circle), the center mass point(dark gray point), the highest point (red point) and the segment of line (green line).
Figure 3.
(a) The hand segmented using the Microsoft Kinect; (b) the hand posture contour; (c) the mass center point drawn in the hand posture contour (dark gray point); (d) the convex hull points with the maximum circumcircle Θ (red circle), the center mass point(dark gray point), the highest point (red point) and the segment of line (green line).
The third module of Depth CIPBR, “calculate signatures”, receives the maximum circumcircle Θ and points
P and
C as input. The hand contour points are substantially reduced using Andrew’s monotone chain convex hull algorithm [
37].
Andrew’s algorithm outputs a set
from convex hull points, which is used to generate two signature sets. The first signature set is composed of distances (D) calculated as follows:
For each point , the length of the line segment is calculated based on the Euclidean distance from ω to the point C;
Then, this length is subtracted from the circumcircle radius, in order to obtain the length, where point Qis the intersection between segment and Θ.
Therefore, the first signature set is composed of each distance
,
, calculated using the following Equation (1), where:
C is the center of mass of the hand posture contour;
are the x coordinates for points ω and C, respectively;
are the y coordinates for points ω and C, respectively;
is the radius of Θ calculated by the “draw maximum circumcircle” module.
The second signature set consists of a vector of angles obtained by calculating the angle between a line composed of each point of the convex hull hand shape point and the line segment . Both signature sets are obtained in a clockwise direction, always starting with point P.
Finally, in the last module, “feature vector normalization”, the signature sets are normalized. The first signature set is normalized dividing each distance by the radius calculated in the “draw maximum circumcircle” module. The normalized distance vector is represented by
:
The set of angles is normalized by dividing each angle by
:
Angle and distance sets are concatenated in the following order: angles first and distances at the end of the signature vector. Therefore, the final feature vector is .
2.2. Feature Selection Method
Some classifiers used for gesture recognition are more sensitive to the curse of dimensionality [
19], such as the HMM [
38,
39]. In order to overcome this obstacle, the feature selection method finds the smallest size possible for the feature vector and assigns the same size for the feature vectors of all gestures. This is also an important task, since many classifiers use inputs with the same predefined size.
In this study, binary particle swarm optimization (BPSO) [
34] finds the target size of the reduced feature vector, while the selector algorithm is used to resize the feature vectors. The objective that BPSO seeks to optimize is the minimum distance between the particle composed of zeros and ones and the gestures sequences. The number of ones in the particle denotes the size of the new feature vector.
The next subsections explain in detail how these algorithms work.
2.2.1. Particle Swarm Optimization
Particle swarm optimization [
40] solves an optimization problem with a swarm of simple computational elements, called particles, exploring a solution space to find an optimal solution. The position from each particle represents a candidate solution in
n-dimensional search space (D) defined as
, where each
is a position in the
n-dimension, and the particle velocity is represented by
.
The fitness function evaluates how well each particle presents itself in each iteration. When a particle moves and its new position has a better fitness value than the previous one, this value is saved in a variable called
. To guide the swarm to the best solution, the position, where a single particle found the best solution until the current execution, is stored in a variable called
. Therefore, to update the particle velocity and position, the following equations are used:
where
,
N is the size of the swarm,
represents the private experience or “cognitive experience” and
represents the ”social experience” interaction, usually used with a value of
[
40]. Variables
and
are random numbers between zero and one and represent how much
and
will influence the particle movement. The inertia factor
κ is used to control the balance of the search algorithm between exploration and exploitation. The
represents the particle position in the
i-th dimension. The recursive algorithm runs until the maximum number of iterations is reached.
2.2.2. Binary PSO
The binary PSO is a variation of the traditional PSO in discrete spaces. The major difference between this algorithm and its canonical version is the interpretation of velocity and position. In the binary version, the particle’s position and velocity are represented by zeros and ones only. This change requires a reformulation in how velocity is calculated, according to the following equation:
where
rand is a random number between zero and one.
Finally, to binarize all of the feature vectors, a threshold calculated through the mean of all of the feature vectors is used. BPSO calculates a distance from each
binary particle’s position to the same
j position in all binary vectors for the same gesture. After each iteration, all distances are added up to generate the fitness function output. Particles are improved as soon as the fitness values become smaller in comparison with the fitness obtained by the previous iteration. The particle fitness function is:
where
is the particle’s
i-th position and
is the
j-th features in all vectors.
2.2.3. Selector Algorithm
BPSO chooses the target size for the reduced feature vector
. Then, the selector algorithm [
25] reduces the CIPBR feature vector
S to
, producing the final vectors of the proposed approach. In this process, some rules must be respected. First, if any vector has fewer points than the target size of
, zeros are added to the feature vector until it matches the desired length. Second, feature vectors larger than the target size of
are redefined using a selection algorithm. This algorithm consists of calculating a window
W through the division of the current vector length by the target size of
. The current vector
S is parsed, and each value in the
W position is included in the new feature vector. If the new output vector
is even smaller than the desired length, the remaining positions are randomly visited in
S and used to compose the new output vector
until the desired length is reached.
2.3. DTW and HMM Hybridization
In order to classify the depth CIPBR feature vectors, a hybridization between two classifiers that generated good results in the literature of dynamic gesture classification is proposed: DTW and HMM [
5,
28,
29].
DTW gives the distance between two patterns that represents the degree of similarity between them using a cost matrix (). Given two patterns and , the cost matrix cell is the distance calculated between the element and . The similarity degree will be the sum of the lowest cost path in the matrix, which starts at and finishes at .
DTW works well in classifying grouped patterns, but it is not very sensitive to very close patterns and might commit some mistakes. We observed that in most DTW misclassifications, the right output was near the compared gesture of the training dataset. Thus, we propose to refine DTW output with HMM to reduce the number of mistakes.
A hidden Markov model (HMM) is a statistical Markov model in which the system being modeled is assumed to be a Markov process with unobserved (hidden) states. A simple way of observing an HMM is imagining it as a finite automaton deterministic with two alphabets, that is in every state, it will tell the likelihood of a hand posture change to another depending on the executed gesture. The HMM has the quality of being fast in training and running, but it can be very fragile in assertiveness, because all training depends on how likely matrices are initiated. Thus, with a higher initial matrix, or amount of the class involved, the HMM will loses some of its power.
DTW has no training phase, but retains a certain number of examples, so it can make the comparison between the kept examples and some input pattern, returning the class belonging to the closest example to the input pattern. Because of this proximity, DTW often confuses a class of a gesture with its closest neighboring class. The canonical DTW [
26], being the only classifier, faces the problem of proximity between classes of feature vectors generated by the CIPBR algorithm. Because of this proximity between classes, DTW has a greater tendency to return a foreign class present in the training set among the supposedly correct class examples.
To work around this problem, DTW is used in the hybrid classifier in order to return no longer a class, but the closest sequences to the input pattern belonging to training set. Thus, the correct class is more likely to be among the returned sequences. At this stage, the trained HMM has a higher probability of returning the correct class, avoiding the transition matrices outliers, since HMM only needs to classify between the sequences returned by DTW.
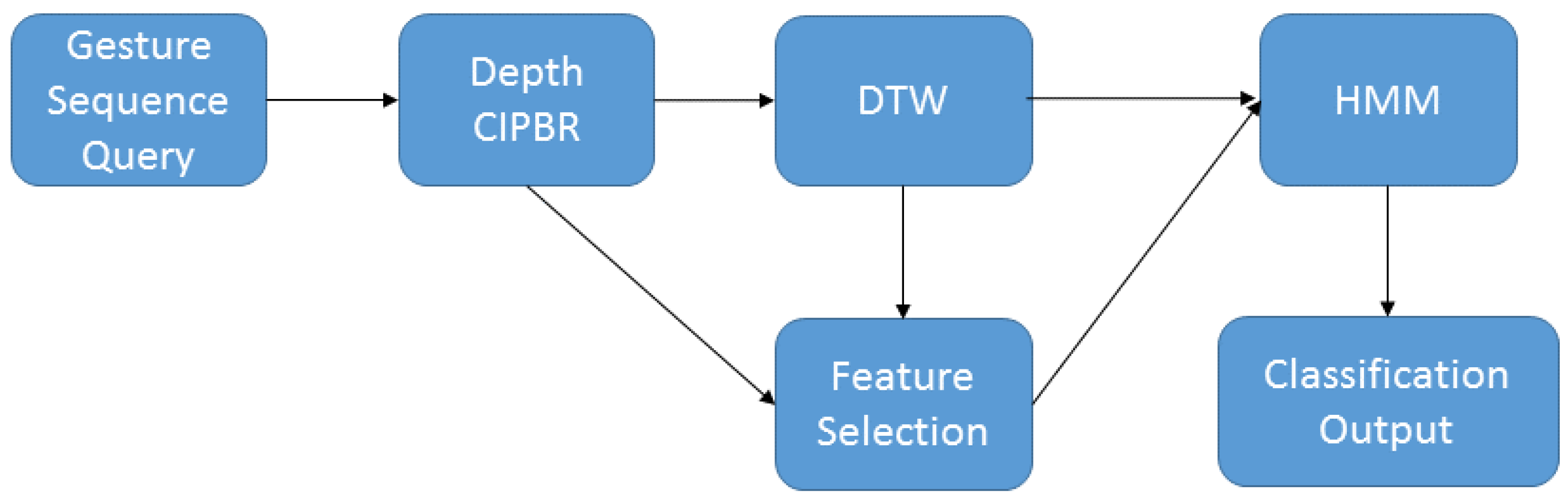
Figure 4 presents the sequence performed by the HAGR-D for gesture recognition. First, DTW classifies the gesture using the CIPBR algorithm for feature extraction and returns the
k nearest gestures of the input sequence as candidates. The input sequence is then resized by the selector algorithm using the best size found by the BPSO in training time, and HMM decides the classification of the input sequence between the
k candidate gestures returned by DTW.
Figure 4.
HAGR-D classification architecture.
Figure 4.
HAGR-D classification architecture.
Algorithm 1 presents a pseudo-code for DTW and HMM hybridization. The model starts receiving a set with images from a gesture at Line 1. The Depth CIPBR algorithm extracts the features of the hand postures in Line 2, and DTW classifies this feature vector and outputs another vector with the k nearest gestures from the training dataset, Line 3. Then, the input gesture and the outputs of DTW are resized by the selector algorithm using the size that the BPSO decided in the training time, Line 6. Finally, the HMM classifies each resized vector, and the hybrid classifier outputs the most incident class as returned by the HMM, Lines 7–9.
| Algorithm 1 Pseudo-Code from DTW and HMM Hybridization. |
| 1: Images ← gesture images of Image |
| 2: features ← depthCIPBR.extracts(Images) |
| 3: dtwOutputs ← dtw.classify (features) |
| 4: hmmOutpts |
| 5: for each gesture in dtwOutputs do |
| 6: resizedSequence ← selectorAlgorithm.resize(gesture, size) |
| 7: hmmOutpts ← hmm.classify(resizedSequence) |
| 8: classification ← mostIncidence(hmmOutputs) |
| 9: return classification |





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






