Remaining Useful Life Estimation of Insulated Gate Biploar Transistors (IGBTs) Based on a Novel Volterra k-Nearest Neighbor Optimally Pruned Extreme Learning Machine (VKOPP) Model Using Degradation Data


Abstract
:1. Introduction
2. Aging Experiment
2.1. Parametric Investigation of IGBT Module Degradation
2.2. IGBT Experimental Data Acquisition
3. Data Transformation Based on the Phase Space Reconstruction
4. Developing the VKOPP Model
4.1. VKOPP Complete Structure
4.2. Training for VKOPP Complete Structure
4.2.1. Original OPELM Algorithm
4.2.2. VKOPP Training Algorithm
- Step 1.
- The number of training set as D, construct the ELM models with N as the number of neurons. Randomly assign the input weights and bias of hidden layer . Record the output matrix of hidden layers as H and the output weight matrix as .
- Step 2.
- Rank nodes of hidden layers by the MRSR algorithm [21] as , where subscript and superscript represent the serial number of hidden layer nodes before and after sorting.
- Step 3.
- Select the optimized number of neurons by the LOO method based on the ranked order.
- Step 4.
- Update the input weights and threshold parameter after pruning. Calculate the output matrix of the hidden layer further.
- Step 5.
- Use the output matrix from the least square estimation of the traditional OPELM to access the initial regression residual and standardize as .
- Step 6.
- Obtain the initial weight of the training samples by .
- Step 7.
- Use of Equations (22) instead of the to achieve the new regression residual , and the new weights of the output weight matrix of each training samples based on the new regression residual.
- Step 8.
- Return to step 6, and so on, calculate the output weight parameter . Continue the iteration until the absolute value of the differences between the estimated values of two adjacent steps meet up with the given standard error, that is .
4.3. Network Output Prediction
- Step 1.
- As shown in Figure 7, at this moment, , the initial input vector of the VKOPP model is . After performing the input selection strategy, the input is denoted as . The hidden layer output matrix is then calculated.
- Step 2.
- Calculate the Euclidean distance between and each vector of the matrix of Equation (13); that is:
- Step 3.
- Sequence all distances in , and find the l + 10 nearest neighbor from of Equation (13) to form a new hidden-layer output matrix and the corresponding expected output , to obtain the output weights:The predicted value of the VKOPP model can then be presented as:In practice, multistep data can also be predicted at a time (i.e., data at moment ) by taking the predicted values as known data to predict the next ones and continue the process. Hence, the value for the future moments is then predicted in the following form:That is, we obtain the q-step-ahead predicted value:
- Step 4.
- At each next one-step-ahead (or q-step-ahead) prediction, update and ; then, calculate the predicted value.
5. VKOPP Model-Based IGBT’s RUL Prediction
- Step 1.
- Pre-treat the IGBT degradation data: the original dataset is normalized as , where is the number of sample data. Take the difference between adjacent data as the input, and then obtain new dataset and mark it as .
- Step 2.
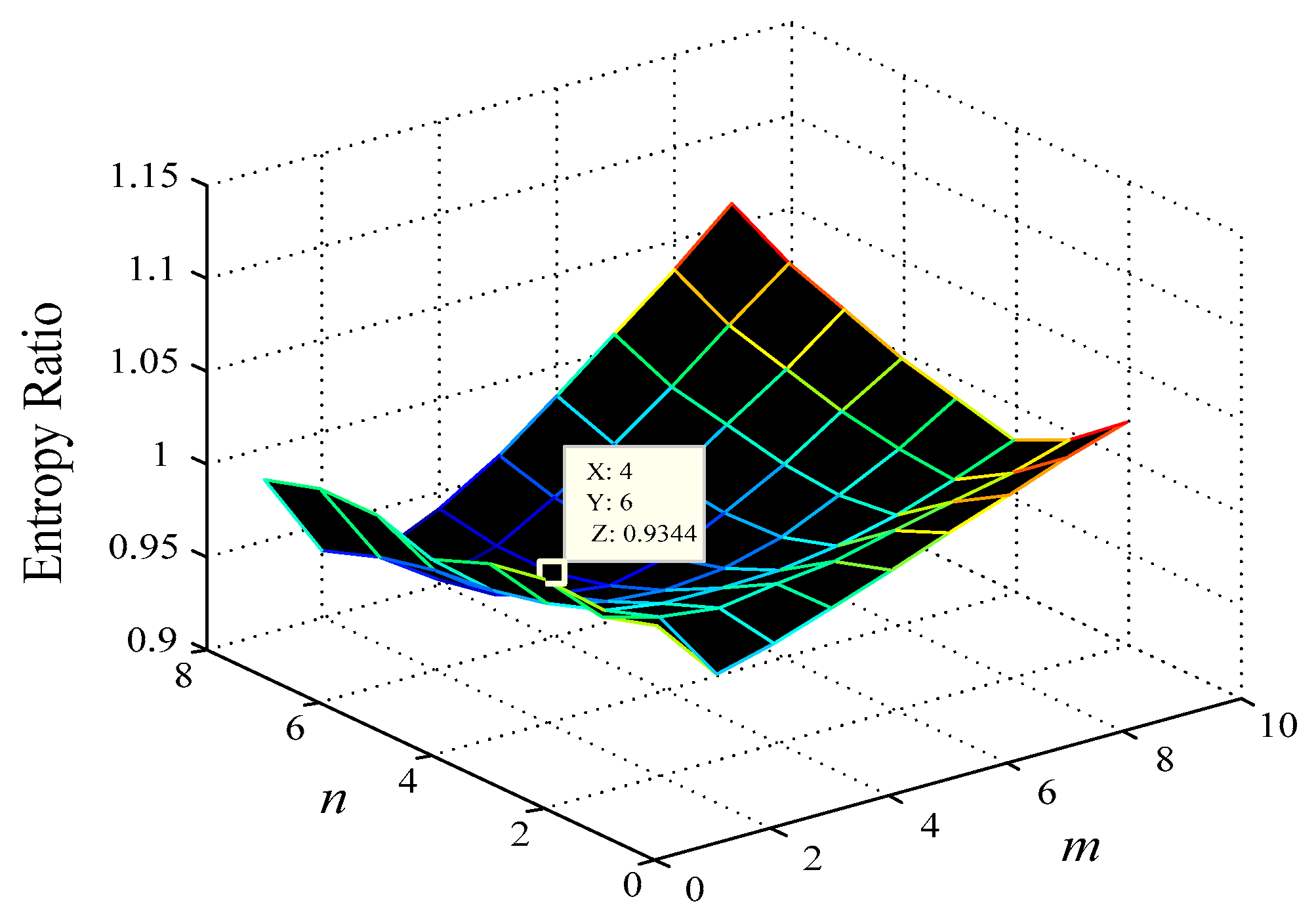
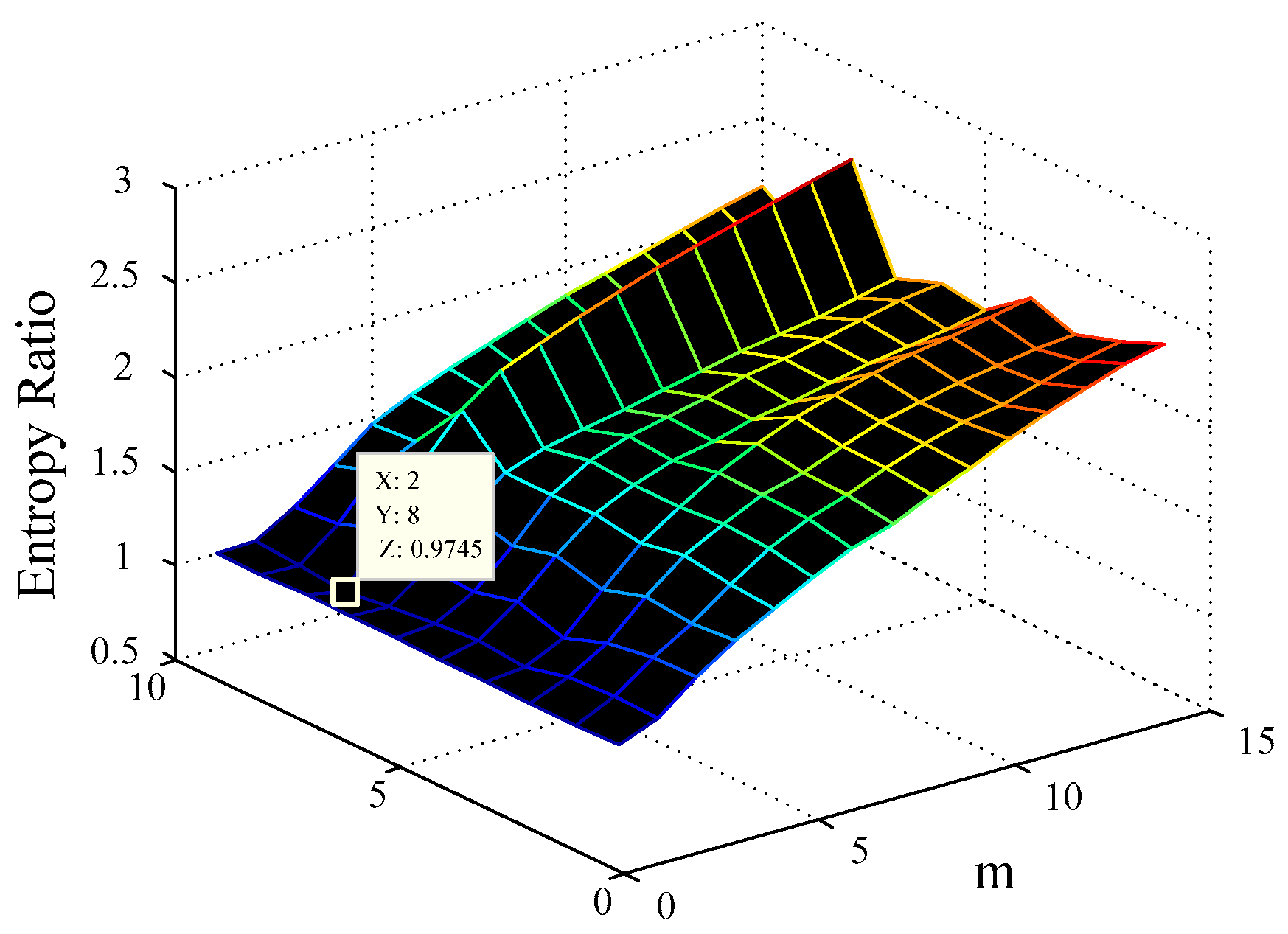
- Adopt the minimal differential entropy ratio method to optimize embedding dimension and delay time τ on dataset at the same time. Map the data to the d-dimensional feature space by using the windowize function in Matlab to obtain the input vector , where . To facilitate the calculations, a two-order truncated discretization Volterra model is taken as an example in the following. Thus, the input vector can be expressed as:where the vector dimensions of Xt is (d+1)(d+2)/2. The training expected output is , with .
- Step 3.
- When the input selection strategy (i.e., FB or LARS) is used, the input vector of hidden units can be expressed as . where , with . Suppose the vector dimension of is denoted as ; then, can be simplified as .
- Step 4.
- Construct an ELM model with N hidden neurons, and . Take obtained by Step3 as the input vector, with the input weights and biases of the ELM model . At moment , the input of the hidden unit is , which falls within the interval [−a, a] (the effective interval of Taylor expansion; if the activation function is different, the interval will be different, and the default is [−1, 1]). Withal, the input weights and biases are initialized randomly in the interval while satisfying when is not within the interval [−a, a].
- Step 5.
- Rank neurons by using the MRSR algorithm; the N hidden-layer nodes via ranking can be expressed as , where subscript and superscript represent the serial number of hidden layer nodes before and after sorting, respectively. Further, we select the optimal number of neurons by LOO for the model as .
- Step 6.
- Update the input weights and the biases of remaining hidden neurons as and , respectively; then, compute the OPELM hidden-layer output matrix .
- Step 7.
- Utilize the KNN and LSE methods to calculate the output weights of OPELM and prediction. The process is as follows:
- (1)
- As shown in Figure 7, to predict , the initial input vector of the VKOPP model is according to Step2. After performing the input selection strategy, the input is denoted as . Then, calculate the hidden-layer output matrix .
- (2)
- Calculate the Euclidean distance between and each vector of the matrix in Step 6; that is, .
- (3)
- Sequence all distances in , and find the l + 10 nearest neighbor from in Step 6 to form a new hidden-layer output matrix and the corresponding expected output , to obtain the output weights .
The predicted value of VKOPP model can then be presented as:Further, obtain the q-step-ahead predicted value:At each next one-step-ahead (or q-step-ahead) prediction, update hi and , and then calculate the predicted value. - Step 8.
- The metabolism processing technology [38] is employed to update the training data until the predictive value exceeds the IGBT acceptable performance threshold. Once the prediction is completed, obtain the IGBT RUL prediction results, and exit the program.
6. Experimental Results and Analysis of IGBT RUL Prediction
6.1. Algorithm Performance Validation and Assessment
6.1.1. Datasets
6.1.2. Experiments
6.2. IGBT’s RUL Prediction Results and Analysis
- (1)
- Prediction Accuracy: With the life prediction results of different prediction steps for the proposed and conventional prediction methodologies tested from Table 8 and Figure 11, the proposed prognostic approach can predict the life of IGBT modules with less error than other algorithms, and with increasing number of prediction steps, the advantage is more obvious.
- (2)
- Time-consumption: Table 9 reports the time consumption of 50-step-ahead prediction for experimental dataset IGBT3. The results of Table 9 show the interesting fact that the proposed VKOPP algorithm is computationally efficient, within approximately 1.747 s, to predict the RUL when 2000 samples are used as the training data. Furthermore, compared with some typical machine learning algorithms (i.e., WHMAR, OPELM, LLpruned, and LSSVM), the VKOPP algorithm has an obvious advantage in computational time.
7. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Choi, U.M.; Blaabjerg, F.; Jorgensen, S.; Munk-Nielsen, S.; Rannestad, B. Reliability improvement of power converters by means of condition monitoring of IGBT modules. IEEE Trans. Power Electr. 2017, 32, 7990–7997. [Google Scholar] [CrossRef]
- Alghassi, A.; Perinpanayagam, S.; Samie, M. Stochastic RUL calculation enhanced with TDNN-based IGBT failure modeling. IEEE Trans. Reliab. 2016, 65, 558–573. [Google Scholar] [CrossRef]
- Huang, X.J.; Chang, W.B.; Trillion, Q. Study of the protection and driving characteristics for high voltage high power IGBT modules used in traction convertor. In Proceedings of the IEEE 10th Conference on Industrial Electronics and Applications, Auckland, New Zealand, 15–17 June 2015; pp. 1335–1339. [Google Scholar]
- Cheng, Y.; Fu, G.C.; Jiang, M.G.; Xue, P. Investigation on intermittent life testing program for IGBT. J. Power Electron. 2017, 17, 811–820. [Google Scholar] [CrossRef]
- Xu, L.; Wang, M.C.; Zhou, Y.; Qian, Z.; Liu, S. Effect of silicone gel on the reliability of heavy aluminum wire bond for power module during thermal cycling test. In Proceedings of the IEEE 66th Electronic Components and Technology Conference, Las Vegas, NV, USA, 31 May–3 June 2016; pp. 1005–1010. [Google Scholar]
- Choi, U.M.; Frede, B.; Stig, M.N.; Søren, J.; Bjørn, R. Condition monitoring of IGBT module for reliability improvement of power converters. In Proceedings of the IEEE Transportation Electrification Conference and Expo, Asia-Pacific, Busan, Korea, 1–4 June 2016; pp. 602–607. [Google Scholar]
- Pecht, M. Prognostics and Health Management of Electronics; Wiley Online Library: Hoboken, NJ, USA, 2008. [Google Scholar]
- Chen, N.; Deng, Y.; Wu, J.; He, X. An efficient semi-mathematical model for co-pack IGBT. In Proceedings of the IEEE Applied Power Electronics Conference and Exposition, Fort Worth, TX, USA, 6–11 March 2011; pp. 1833–1837. [Google Scholar]
- Yin, C.Y.; Lu, H.; Musallam, M.; Bailey, C.; Johnson, C.M. A prognostic assessment method for power electronics modules. In Proceedings of the 2nd Electronics System-Integration Technology Conference, Greenwich, UK, 1–4 September 2008; pp. 1353–1358. [Google Scholar]
- Alghassi, A.; Perinpanayagam, S.; Jennions, I.K. A simple state-based prognostic model for predicting remaining useful life of IGBT power module. In Proceedings of the 15th European Conference on Power Electronics and Applications, Lille, France, 2–6 September 2013; pp. 1–7. [Google Scholar]
- Li, M.; Zhu, J.J.; Long, B. Particle filter approach for IGBT remaining useful life. Adv. Mater. 2014, 981, 86–89. [Google Scholar] [CrossRef]
- Thakur, A.; Thakur, Y.S. Modeling of IGBT using temperature prediction method. Int. J. Adv. Res. Comp. Eng. Tech. 2013, 2, 2595–2597. [Google Scholar]
- Wu, J.; Zhou, L.; Du, X.; Sun, P. Junction temperature prediction of IGBT power module based on BP neural network. J. Electr. Eng. Tech. 2014, 9, 970–977. [Google Scholar] [CrossRef]
- Mominul, A.; Stoyan, S.; Chris, B. Data driven prognostics for predicting remaining useful life of IGBT. In Proceedings of the 39th International Spring Seminar on Electronics Technology, Pilsen, Czech Republic, 18–22 May 2016; pp. 273–278. [Google Scholar]
- Ghasemi, M.; Tavassoli, K.M.; Babolian, E. Numerical solutions of the nonlinear Volterra–Fredholm integral equations by using homotopy perturbation method. Appl. Math. Comput. 2007, 188, 446–449. [Google Scholar] [CrossRef]
- Kobayakawa, S.; Yokoi, H. Evaluation of prediction capability of non-recursion type 2nd-order Volterra neuron network for electrocardiogram. In Proceedings of the 15th International Conference on Neural Information Processing of the Asia-Pacific Neural Network Assembly, Auckland, New Zealand, 25–28 November 2008; pp. 679–686. [Google Scholar]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Miche, Y.; Sorjamaa, A.; Bas, P.; Simula, O.; Jutten, C.; Lendasse, A. OP-ELM: Optimally Pruned Extreme Learning Machine. IEEE Trans. Neural Netw. 2010, 21, 158–170. [Google Scholar] [CrossRef] [PubMed]
- Grigorievskiy, A.; Miche, Y.; Ventela, A.M.; Séverin, E.; Lendasse, A. Long-term time series prediction using OP-ELM. Neural Netw. 2014, 51, 50–56. [Google Scholar] [CrossRef] [PubMed]
- Sovilj, D.; Sorjamaa, A.; Yu, Q.; Miche, Y.; Séverin, E. OPELM and OPKNN in long-term prediction of time series using projected input data. Neurocomputing 2010, 73, 1976–1986. [Google Scholar] [CrossRef]
- Yin, L.S.; He, Y.G.; Dong, X.P. Multi-step prediction of Volterra neural network for traffic flow based on chaos algorithm. In Proceedings of the 3rd International Conference on Information Computing and Applications, Chengde, China, 14–16 September 2012; pp. 232–241. [Google Scholar]
- Sarkany, Z.; Vass-Varnai, A.; Rencz, M. Effect of power cycling parameters on predicted IGBT lifetime. In Proceedings of the IEEE Aerospace Conference, Big Sky, MT, USA, 7–14 March 2015; pp. 1–9. [Google Scholar]
- Xiang, D.; Ran, L.; Tavner, P.; Bryant, A.; Yang, S.; Mawby, P. Monitoring solder fatigue in a power module using case-above-ambient temperature rise. IEEE Trans. Ind. Appl. 2011, 47, 2578–2591. [Google Scholar] [CrossRef]
- Rodriguez, M.A.; Claudio, A.; Theilliol, D.; Vela, L.G. A new fault detection technique for IGBT based on gate voltage monitoring. In Proceedings of the IEEE Power Electronics Specialists Conference, Orlando, FL, USA, 17–21 June 2007; pp. 1001–1005. [Google Scholar]
- Farokhzad, B. Method for Early Failure Recognition in Power Semiconductor Modules. U.S. Patent 6,145,107, 7 November 2000. [Google Scholar]
- Xiong, Y.; Cheng, X.; Shen, Z.J.; Mi, C.; Wu, H.; Garg, V.K. Prognostic and warning system for power-electronic modules in electric, Hybrid Electric, and Fuel-Cell Vehicles. IEEE Trans. Ind. Electron. 2008, 55, 2268–2276. [Google Scholar] [CrossRef]
- Chung, H.S.; Wang, H.; Blaabjerg, F.; Pecht, M. Reliability of Power Electronic Converter Systems; IET Press: London, UK, 2015. [Google Scholar]
- Patil, N.; Das, D.; Goebel, K.; Pecht, M. Identification of failure precursor parameters for Insulated Gate Bipolar Transistors (IGBTs). In Proceedings of the International Conference on Prognostics & Health Management, Denver, CO, USA, 6–9 October 2008; pp. 1–5. [Google Scholar]
- Dai, J.; Das, D.; Pecht, M. Prognostics-based risk mitigation for telecom equipment under free air cooling conditions. Appl. Energy 2012, 99, 423–429. [Google Scholar] [CrossRef]
- Packard, N.H.; Crutchfield, J.P.; Farmer, J.D.; Shaw, R.S. Shaw geometry from a time series. Phys. Rev. Lett. 1980, 45, 712–716. [Google Scholar] [CrossRef]
- Takens, F. Determining strange attractors in turbulence. Lect. Notes Math. 1981, 898, 361–381. [Google Scholar]
- Qiao, M.Y. Chaos Time-series prediction based on reconstructed phase space using the entropy rate. Micro Appl. 2014, 30, 31–34. [Google Scholar]
- Sorjamaa, A.; Hao, J.; Reyhani, N.; Ji, Y.; Lendasse, A. Methodology for long-term prediction of time series. Neurocomputing 2007, 70, 2861–2869. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T.; Johnstone, I.; Tibshirani, R. Least angle regression. Ann. Stat. 2004, 32, 407–499. [Google Scholar]
- Huber, P.J. Robust Statistics; Wiley Press: New York, NY, USA, 1981. [Google Scholar]
- Christopher, M.B. Pattern Recognition and Machine Learning; Springer Press: Boston, MA, USA, 2010. [Google Scholar]
- Rao, C.R.; Toutenburg, H. Linear Models: Least Squares and Alternatives, 3rd ed.; Springer Series in Statistics; Springer: Berlin, Germany, 2008; ISBN 978-3-540-74226-5. [Google Scholar]
- Long, B.; Xian, W.; Jiang, L.; Liu, Z. An improved autoregressive model by particle swarm optimization for prognostics of lithium-ion batteries. Microelectron. Reliab. 2013, 53, 821–831. [Google Scholar] [CrossRef]
- Mackey, M.C.; Glass, L. Oscillations and chaos in physiological control systems. Science 1977, 197, 287–289. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Wang, H.J.; Long, B.; Zhang, Z. Research on condition trend prediction based on weighed hidden markov and autoregressive model. Acta Electron. Sin. 2009, 37, 2113–2118. [Google Scholar]
- Liu, Z.; Huang, J.G.; Wang, H.J.; Luo, X. A novel weighed hidden markov autoregressive approach for trend prediction of electronic systems. In Proceedings of the IEEE International Conference on Electronic Measurement and Instruments, Beijing, China, 16–19 August 2009; pp. 182–186. [Google Scholar]
- Gebraeel, N. Sensory-updated residual life distributions for components with exponential degradation patterns. IEEE Trans. Autom. Sci. Eng. 2006, 3, 382–393. [Google Scholar] [CrossRef]
- Lendasse, A.; Verleysen, M.; Sorjamaa, A. Pruned lazy learning models for time series prediction. In Proceedings of the European Symposium on Artificial Neural Networks, Bruges, Belgium, 27–29 April 2005; pp. 509–514. [Google Scholar]
- Suykens, J.A.K.; Gestel, T.V.; Brabanter, J.D.; Moor, B.D.; Vandewalle, J. Least squares support vector machines. World Sci. 2002, 2, 1–27. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Typical Failure Mechanisms | External Characteristic Parameters |
|---|---|
| Thermal stress (solder fatigue) | Junction-case thermal resistance |
| Electrical Stress (wire-bond) | Gate voltage |
| Thermal stress (wire-bond, solder fatigue) | Turn-off time |
| Thermal stress/Electrical Stress | Saturation voltage |
| Junction-Case Thermal Resistance | Gate Voltage | Turn-Off Time | Saturation Voltage | |
|---|---|---|---|---|
| Pros | Direct response module aging condition | Basically unaffected by the device working point | Direct response status change | Simple measurement, high accuracy |
| Cons | The junction temperature is essential for calculating thermal resistance, but it is difficult to access. Direct measurement uses a sensor close to the junction, but this is intrusive and the accuracy is affected by sensor positioning and thermal inertia. | The real-time measurement of high requirements, vulnerable to the influence of the stray capacitance of the circuit. | Request the sensor response time as the nanosecond level, project cost is too high | Affected by the case temperature and collector current |
| Number | Frequency (Hz) | Swing ΔT (°C) |
|---|---|---|
| IGBT1 | 1 k | 100 |
| IGBT2 | 5 k | 100 |
| IGBT3 | 1 k | 50 |
| IGBT4 | 5 k | 50 |
| MG | Laser | DMT | ED | CATS_B | SN | RDD | MG_S | |
|---|---|---|---|---|---|---|---|---|
| AR | 0.00 | 11.00 | 9.70 | 0.88 | 0.46 | 2.90 | 1.80 | 0.14 |
| 5.60 | 400.00 | 520.00 | 100.00 | 110.00 | 290.00 | 260.00 | 57.00 | |
| WHMAR | 0.00 | 10.00 | 10.00 | 0.91 | 0.45 | 2.90 | 1.90 | 130.00 |
| 3.80 | 380.00 | 530.00 | 100.00 | 110.00 | 290.00 | 260.00 | 1800.00 | |
| RBFNN | 0.00 | 340.00 | 71.00 | 430.00 | 3100.00 | 690.00 | 13,000 | 0.68 |
| 3.60 | 2200.00 | 1400.00 | 2300.00 | 9100.00 | 4500.00 | 22,000 | 120.00 | |
| OPELM | 0.00 | 7100.00 | 1100.00 | 810,000.00 | 130,000.00 | 190,000.00 | 270.00 | 0.16 |
| 5.60 | 430.00 | 640.00 | 100.00 | 110.00 | 310.00 | 250.00 | 56.00 | |
| Volterra | 0.00 | 33.00 | 21.00 | 3.40 | 2.50 | 16.00 | 2800.00 | 0.11 |
| 11.00 | 680.00 | 770.00 | 200.00 | 260.00 | 670.00 | 1000.00 | 51.00 | |
| LLpruned | 0.00 | 1.60 | 11.00 | 0.93 | 0.74 | 3.90 | 3.00 | 0.03 |
| 8.30 | 150.00 | 560.00 | 110.00 | 140.00 | 340.00 | 340.00 | 26.00 | |
| LSSVM | 0.00 | 13.00 | 21.00 | 24.00 | 140.00 | 6.00 | 7.70 | 0.07 |
| 8.90 | 420.00 | 760.00 | 540.00 | 1900.00 | 420.00 | 530.00 | 40.00 | |
| VKOPP | 0.00 | 0.76 | 9.40 | 0.78 | 0.48 | 2.80 | 1.60 | 0.02 |
| 0.39 | 100.00 | 510.00 | 97.00 | 110.00 | 280.00 | 240.00 | 23.00 |
| MG | Laser | DMT | ED | CATS_B | SN | RDD | MG_S | |
|---|---|---|---|---|---|---|---|---|
| AR | 3.70 | 20.00 | 15.00 | 9.90 | 2.00 | 5.30 | 2.10 | 4.40 |
| 290.00 | 540.00 | 640.00 | 350.00 | 230.00 | 390.00 | 280.00 | 320.00 | |
| WHMAR | 5.30 | 17.00 | 15.00 | 10.00 | 2.20 | 5.30 | 2.00 | 11,000.00 |
| 350.00 | 490.00 | 660.00 | 350.00 | 240.00 | 390.00 | 270.00 | 16,000.00 | |
| RBFNN | 5.90 | ∞ | 800,000.00 | ∞ | ∞ | ∞ | ∞ | ∞ |
| 370.00 | 690,000.00 | 150,000.00 | 1,800,000.00 | ∞ | 6,500,000.00 | 7,000,000.00 | 2,300,000.00 | |
| OPELM | 0.38 | 2,200,000.00 | 15,000.00 | ∞ | 1,100,000.00 | 550,000.00 | 300.00 | 2.90 |
| 83.00 | 740.00 | 790.00 | 490.00 | 320.00 | 520.00 | 270.00 | 230.00 | |
| Volterra | 4.60 | 67.00 | 32.00 | 11.00 | 360.00 | ∞ | ∞ | 6.80 |
| 320.00 | 970.00 | 950.00 | 370.00 | 3100.00 | ∞ | ∞ | 390.00 | |
| LLpruned | 0.03 | 36.00 | 21.00 | 16.00 | 6.10 | 9.40 | 3.80 | 0.24 |
| 27.00 | 710.00 | 770.00 | 440.00 | 410.00 | 520.00 | 380.00 | 74.00 | |
| LSSVM | 0.01 | 16.00 | 25.00 | 40.00 | 140.00 | 8.20 | 17.00 | 0.10 |
| 11.00 | 480.00 | 840.00 | 690.00 | 1900.00 | 490.00 | 930.00 | 48.00 | |
| VKOPP | 0.00 | 7.50 | 15.00 | 4.70 | 2.30 | 4.20 | 1.60 | 0.09 |
| 1.20 | 320.00 | 650.00 | 230.00 | 250.00 | 350.00 | 240.00 | 45.00 |
| Cycle Test Conditions | Training Cycles | Life Prediction (Cycles) | Actual Life (Cycles) | Prediction Error (Cycles) | Relative Error (%) | |
|---|---|---|---|---|---|---|
| IGBT1 | f = 1 kHz, ΔT = 100 °C | 500 | 1774 | 1784 | 10 | 0.561 |
| 1000 | 1775 | 9 | 0.504 | |||
| 1506 | 1776 | 8 | 0.448 | |||
| 1600 | 1775 | 9 | 0.504 | |||
| IGBT2 | f = 5 kHz, ΔT = 100 °C | 500 | 1614 | 1615 | 1 | 0.062 |
| 1000 | 1613 | 2 | 0.124 | |||
| 1488 | 1617 | 2 | 0.124 | |||
| 1550 | 1613 | 2 | 0.124 | |||
| IGBT3 | f = 1 kHz, ΔT = 50 °C | 500 | 2650 | 2646 | 4 | 0.151 |
| 1000 | 2649 | 3 | 0.113 | |||
| 2000 | 2649 | 3 | 0.113 | |||
| 2400 | 2644 | 2 | 0.076 | |||
| IGBT4 | f = 5 kHz, ΔT = 50 °C | 500 | 1463 | 1474 | 11 | 0.746 |
| 1000 | 1465 | 9 | 0.611 | |||
| 1348 | 1461 | 13 | 0.882 | |||
| 1400 | 1464 | 10 | 0.678 |
| Cycle Test Conditions | Prediction Steps (Cycles) | Training Cycles | Life Prediction (Cycles) | Actual Life (Cycles) | Prediction Error (Cycles) | Relative Error (%) | |
|---|---|---|---|---|---|---|---|
| IGBT1 | f = 1 kHz, ΔT = 100 °C | 1 | 1506 | 1784 | 1784 | 0 | 0 |
| 10 | 1782 | 2 | 0.112 | ||||
| 50 | 1776 | 8 | 0.448 | ||||
| 100 | 1771 | 13 | 0.729 | ||||
| IGBT2 | f = 5 kHz, ΔT = 100 °C | 1 | 1488 | 1616 | 1615 | 1 | 0.062 |
| 10 | 1612 | 3 | 0.186 | ||||
| 50 | 1617 | 2 | 0.124 | ||||
| 100 | 1620 | 5 | 0.309 | ||||
| IGBT3 | f = 1 kHz, ΔT = 50 °C | 1 | 2000 | 2646 | 2646 | 0 | 0 |
| 10 | 2648 | 2 | 0.076 | ||||
| 50 | 2649 | 3 | 0.113 | ||||
| 100 | 2652 | 6 | 0.227 | ||||
| IGBT4 | f = 5 kHz, ΔT = 50 °C | 1 | 1348 | 1473 | 1474 | 1 | 0.068 |
| 10 | 1474 | 0 | 0 | ||||
| 50 | 1461 | 13 | 0.882 | ||||
| 100 | 1457 | 17 | 1.153 |
| Life Prediction Error (IGBT3 Experimental Dataset) | ||||
|---|---|---|---|---|
| 1-Step | 10-Step | 50-Step | 100-Step | |
| AR | 1 | 13 | 13 | 40 |
| WHMAR | 1 | 11 | 17 | 42 |
| OPELM | 12 | 21 | 61 | 111 |
| Volterra | 1 | 9 | 9 | 154 |
| LLpruned | 0 | 4 | 112 | 86 |
| LSSVM | 8 | 68 | 102 | 128 |
| VKOPP | 0 | 2 | 3 | 6 |
| Time Consumption (50-Step-Ahead) (s) | |
|---|---|
| AR | 0.6 |
| WHMAR | 37.8 |
| OPELM | 4.5 |
| Volterra | 0.799 |
| LLpruned | 90.23 |
| LSSVM | 223 |
| VKOPP | 1.747 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Z.; Mei, W.; Zeng, X.; Yang, C.; Zhou, X. Remaining Useful Life Estimation of Insulated Gate Biploar Transistors (IGBTs) Based on a Novel Volterra k-Nearest Neighbor Optimally Pruned Extreme Learning Machine (VKOPP) Model Using Degradation Data. Sensors 2017, 17, 2524. https://doi.org/10.3390/s17112524
Liu Z, Mei W, Zeng X, Yang C, Zhou X. Remaining Useful Life Estimation of Insulated Gate Biploar Transistors (IGBTs) Based on a Novel Volterra k-Nearest Neighbor Optimally Pruned Extreme Learning Machine (VKOPP) Model Using Degradation Data. Sensors. 2017; 17(11):2524. https://doi.org/10.3390/s17112524
Chicago/Turabian StyleLiu, Zhen, Wenjuan Mei, Xianping Zeng, Chenglin Yang, and Xiuyun Zhou. 2017. "Remaining Useful Life Estimation of Insulated Gate Biploar Transistors (IGBTs) Based on a Novel Volterra k-Nearest Neighbor Optimally Pruned Extreme Learning Machine (VKOPP) Model Using Degradation Data" Sensors 17, no. 11: 2524. https://doi.org/10.3390/s17112524