Recognition of Activities of Daily Living Based on Environmental Analyses Using Audio Fingerprinting Techniques: A Systematic Review

 , ,
, ,  ,
,  , and
, and 
Abstract
:1. Introduction
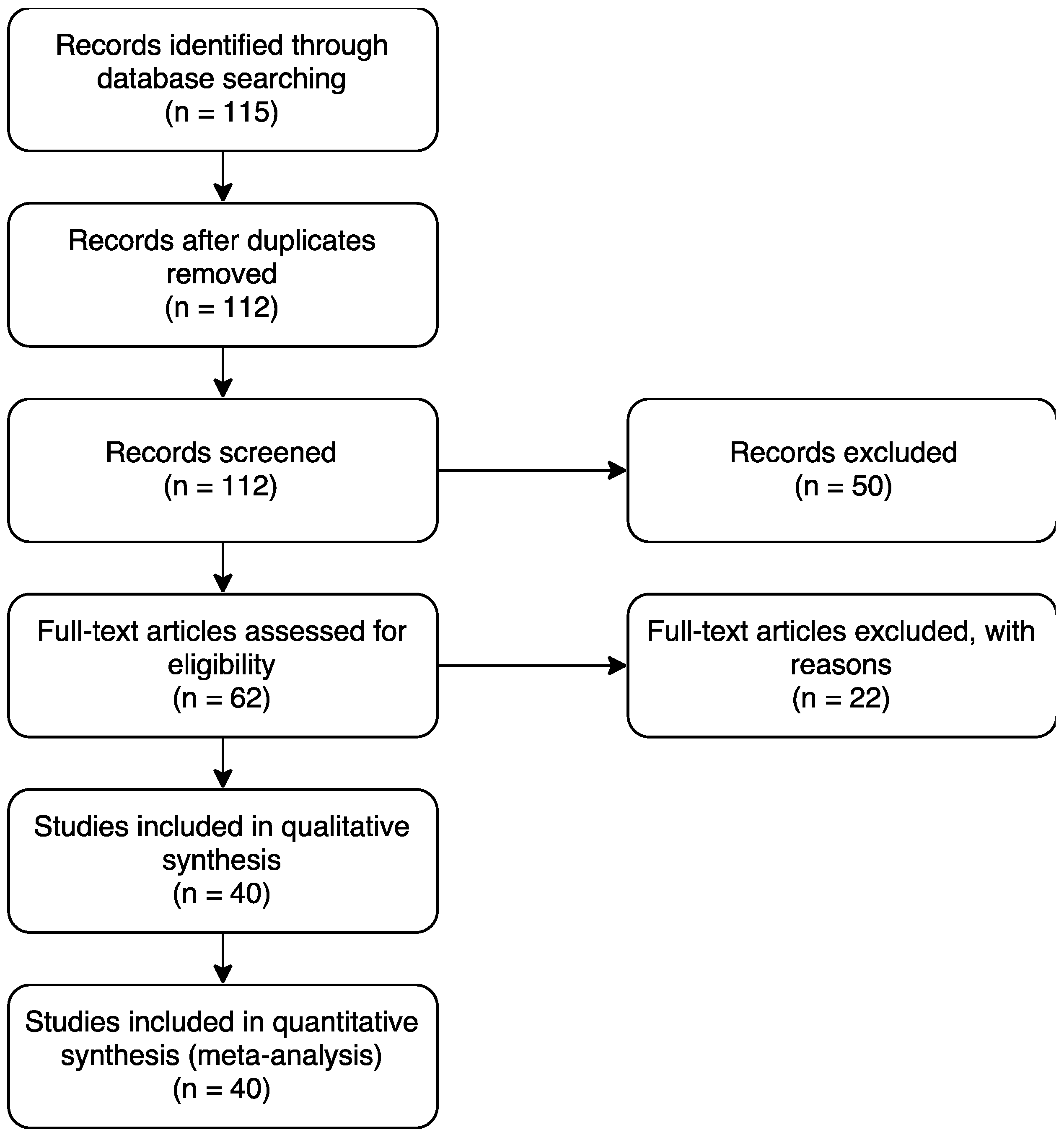
2. Methodology
2.1. Research Questions
2.2. Inclusion Criteria
2.3. Search Strategy
2.4. Extraction of Study Characteristics
3. Results
Methods for Audio Fingerprinting
4. Discussion
5. Conclusions
- (RQ1) the audio fingerprinting is defined as the ability to recognize the scenario in which a given audio was collected and involved in, based on various methods.
- (RQ2) Several techniques have been applied to implement audio fingerprinting methods, including Fast Fourier Transform (FFT). Support Vector Machine (SVM), QUery Context (QUC)-tree, spectral subband centroid (SSC), Streaming Audio Fingerprinting (SAF), Human Auditory System (HAS), Gaussian mixture models (GMM) modelling, likelihood estimation, linear discriminant analysis (LDA), Compressive Sampling (CS) theory, Philips robust hash (PRH), Asymmetric Fingerprint Matching, and TO-Combo-SAD (Threshold Optimized Combo SAD). These techniques yield high accuracy, and the use of mobile devices does not influence the predictive performance, allowing the use of these techniques anywhere, anytime.
- (RQ3) All of the methods presented in RQ2 can be implemented on mobile devices, but the methods that require lower computational resources are FFT with the CUFFT library, divide and locate (DAL) audio fingerprint method, and sub-fingerprint masking based on the predominant pitch extraction.
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Foti, D.; Koketsu, J.S. Pedretti’s Occupational Therapy: Practical Skills for Physical Dysfunction, 7th ed.; Activities of daily living; Mosby: St. Louis, MI, USA, 2013; pp. 157–232. [Google Scholar]
- Garcia, N.M.; Rodrigues, J.J.P. Ambient Assisted Living; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar]
- Dobre, C.; Mavromoustakis, C.X.; Goleva, R.L. Ambient Assisted Living and Enhanced Living Environments: Principles, Technologies and Control; Butterworth-Heinemann: Oxford, UK, 2016; p. 552. [Google Scholar]
- Garcia, N.M. A Roadmap to the Design of a Personal Digital Life Coach. In ICT Innovations 2015; Springer: Cham, Switzerland, 2016. [Google Scholar]
- Da Silva, J.R.C. Smartphone Based Human Activity Prediction; Faculdade de Engenharia: Porto, Portugal, 2013. [Google Scholar]
- Bieber, G.; Luthardt, A.; Peter, C.; Urban, B. The Hearing Trousers Pocket—Activity Recognition by Alternative Sensors. In Proceedings of the 4th International Conference on PErvasive Technologies Related to Assistive Environments, Crete, Greece, 25–27 May 2011. [Google Scholar]
- Kazushige, O.; Miwako, D. Indoor-outdoor activity recognition by a smartphone. In Proceedings of the 2012 ACM Conference on Ubiquitous Computing, Pittsburgh, PA, USA, 5–8 September 2012; p. 537. [Google Scholar]
- Ganti, R.K.; Srinivasan, S.; Gacic, A. Multisensor Fusion in Smartphones for Lifestyle Monitoring. In Proceedings of the 2010 International Conference on Body Sensor Networks, Singapore, 7–9 June 2010. [Google Scholar]
- Pires, I.M.; Garcia, N.M.; Pombo, N.; Flórez-Revuelta, F. From Data Acquisition to Data Fusion: A Comprehensive Review and a Roadmap for the Identification of Activities of Daily Living Using Mobile Devices. Sensors 2016, 16, 184. [Google Scholar] [CrossRef] [PubMed]
- Pires, I.M.; Garcia, N.M.; Flórez-Revuelta, F. Multi-sensor data fusion techniques for the identification of activities of daily living using mobile devices. In Proceedings of the ECMLPKDD 2015 Doctoral Consortium, European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015. [Google Scholar]
- Pires, I.M.; Garcia, N.M.; Pombo, N.; Flórez-Revuelta, F. Identification of Activities of Daily Living Using Sensors Available in off-the-shelf Mobile Devices: Research and Hypothesis. In Ambient Intelligence-Software and Applications, Proceedings of the 7th International Symposium on Ambient Intelligence (ISAmI 2016), Seville, Spain, 1–3 June 2016; Springer International Publishing: Cham, Switzerland, 2016. [Google Scholar]
- Sui, D.; Ruan, L.; Xiao, L. A Two-level Audio Fingerprint Retrieval Algorithm for Advertisement Audio. In Proceedings of the 12th International Conference on Advances in Mobile Computing and Multimedia, Kaohsiung, Taiwan, 8–10 December 2014; pp. 235–239. [Google Scholar]
- Liu, C.-C.; Chang, P.-F. An efficient audio fingerprint design for MP3 music. In Proceedings of the 9th International Conference on Advances in Mobile Computing and Multimedia, Ho Chi Minh City, Vietnam, 5–7 December 2011; pp. 190–193. [Google Scholar]
- Liu, C.-C. MP3 sniffer: A system for online detecting MP3 music transmissions. In Proceedings of the 10th International Conference on Advances in Mobile Computing, Bali, Indonesia, 3–5 December 2012; pp. 93–96. [Google Scholar]
- Tsai, T.J.; Stolcke, A. Robust and efficient multiple alignment of unsynchronized meeting recordings. IEEE/ACM Trans. Audio Speech Lang. Proc. 2016, 24, 833–845. [Google Scholar] [CrossRef]
- Casagranda, P.; Sapino, M.L.; Candan, K.S. Audio assisted group detection using smartphones. In Proceedings of the 2015 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Torino, Italy, 29 June–3 July 2015. [Google Scholar]
- Nagano, H.; Mukai, R.; Kurozumi, T.; Kashino, K. A fast audio search method based on skipping irrelevant signals by similarity upper-bound calculation. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- Ziaei, A.; Sangwan, A.; Kaushik, L.; Hansen, J.H.L. Prof-Life-Log: Analysis and classification of activities in daily audio streams. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brisbane, Australia, 19–24 April 2015. [Google Scholar]
- George, J.; Jhunjhunwala, A. Scalable and robust audio fingerprinting method tolerable to time-stretching. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015. [Google Scholar]
- Kim, H.G.; Cho, H.S.; Kim, J.Y. TV Advertisement Search Based on Audio Peak-Pair Hashing in Real Environments. In Proceedings of the 2015 5th International Conference on IT Convergence and Security (ICITCS), Kuala Lumpur, Malaysia, 24–27 August 2015. [Google Scholar]
- Seo, J.S. An Asymmetric Matching Method for a Robust Binary Audio Fingerprinting. IEEE Signal Process. Lett. 2014, 21, 844–847. [Google Scholar]
- Rafii, Z.; Coover, B.; Han, J. An audio fingerprinting system for live version identification using image processing techniques. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Naini, R.; Moulin, P. Fingerprint information maximization for content identification. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Yang, G.; Chen, X.; Yang, D. Efficient music identification by utilizing space-saving audio fingerprinting system. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo (ICME), Chengdu, China, 14–18 July 2014. [Google Scholar]
- Yin, C.; Li, W.; Luo, Y.; Tseng, L.-C. Robust online music identification using spectral entropy in the compressed domain. In Proceedings of the Wireless Communications and Networking Conference Workshops (WCNCW), Istanbul, Turkey, 6–9 April 2014. [Google Scholar]
- Wang, C.C.; Jang, J.S.R.; Liou, W. Speeding up audio fingerprinting over GPUs. In Proceedings of the 2014 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 7–9 July 2014. [Google Scholar]
- Lee, J.Y.; Kim, H.G. Audio fingerprinting to identify TV commercial advertisement in real-noisy environment. In Proceedings of the 2014 14th International Symposium on Communications and Information Technologies (ISCIT), Incheon, South Korea, 24–26 September 2014. [Google Scholar]
- Shibuya, T.; Abe, M.; Nishiguchi, M. Audio fingerprinting robust against reverberation and noise based on quantification of sinusoidality. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo (ICME), San Jose, CA, USA, 15–19 July 2013. [Google Scholar]
- Bisio, I.; Delfino, A.; Lavagetto, F.; Marchese, M. A Television Channel Real-Time Detector using Smartphones. IEEE Trans. Mob. Comput. 2015, 14, 14–27. [Google Scholar] [CrossRef]
- Lee, S.; Yook, D.; Chang, S. An efficient audio fingerprint search algorithm for music retrieval. IEEE Trans. Consum. Electron. 2013, 59, 652–656. [Google Scholar] [CrossRef]
- Bisio, I.; Delfino, A.; Luzzati, G.; Lavagetto, F.; Marchese, M.; Fra, C.; Valla, M. Opportunistic estimation of television audience through smartphones. In Proceedings of the 2012 International Symposium on Performance Evaluation of Computer and Telecommunication Systems (SPECTS), Genoa, Italy, 8–11 July 2012. [Google Scholar]
- Anguera, X.; Garzon, A.; Adamek, T. MASK: Robust Local Features for Audio Fingerprinting. In Proceedings of the 2012 IEEE International Conference on Multimedia and Expo, Melbourne, Australia, 9–13 July 2012. [Google Scholar]
- Duong, N.Q.K.; Howson, C.; Legallais, Y. Fast second screen TV synchronization combining audio fingerprint technique and generalized cross correlation. In Proceedings of the 2012 IEEE International Conference on Consumer Electronics (ICCE-Berlin), Berlin, Germany, 3–5 September 2012. [Google Scholar]
- Wang, H.; Yu, X.; Wan, W.; Swaminathan, R. Robust audio fingerprint extraction algorithm based on 2-D chroma. In Proceedings of the 2012 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–18 July 2012. [Google Scholar]
- Xiong, W.; Yu, X.; Wan, W.; Swaminathan, R. Audio fingerprinting based on dynamic subband locating and normalized SSC. In Proceedings of the 2012 International Conference on Audio, Language and Image Processing (ICALIP), Shanghai, China, 16–18 July 2012. [Google Scholar]
- Jijun, D.; Wan, W.; Yu, X.; Pan, X.; Yang, W. Audio fingerprinting based on harmonic enhancement and spectral subband centroid. In Proceedings of the IET International Communication Conference on Wireless Mobile and Computing (CCWMC 2011), Shanghai, China, 14–16 November 2011. [Google Scholar]
- Pan, X.; Yu, X.; Deng, J.; Yang, W.; Wang, H. Audio fingerprinting based on local energy centroid. In Proceedings of the IET International Communication Conference on Wireless Mobile and Computing (CCWMC 2011), Shanghai, China, 14–16 November 2011. [Google Scholar]
- Martinez, J.I.; Vitola, J.; Sanabria, A.; Pedraza, C. Fast parallel audio fingerprinting implementation in reconfigurable hardware and GPUs. In Proceedings of the 2011 VII Southern Conference on Programmable Logic (SPL), Cordoba, Argentina, 13–15 April 2011. [Google Scholar]
- Cha, G.H. An Effective and Efficient Indexing Scheme for Audio Fingerprinting. In Proceedings of the 2011 5th FTRA International Conference on Multimedia and Ubiquitous Engineering (MUE), Crete, Greece, 28–30 June 2011. [Google Scholar]
- Schurmann, D.; Sigg, S. Secure Communication Based on Ambient Audio. IEEE Trans. Mob. Comput. 2013, 12, 358–370. [Google Scholar] [CrossRef]
- Son, W.; Cho, H.-T.; Yoon, K.; Lee, S.-P. Sub-fingerprint masking for a robust audio fingerprinting system in a real-noise environment for portable consumer devices. IEEE Trans. Consum. Electron. 2010, 56, 156–160. [Google Scholar] [CrossRef]
- Chang, K.K.; Pissis, S.P.; Jang, J.-S.R.; Iliopoulos, C.S. Sub-nyquist audio fingerprinting for music recognition. In Proceedings of the Computer Science and Electronic Engineering Conference (CEEC), Colchester, UK, 8–9 September 2010. [Google Scholar]
- Umapathy, K.; Krishnan, S.; Rao, R.K. Audio Signal Feature Extraction and Classification Using Local Discriminant Bases. IEEE Trans. Audio Speech Lang. Proc. 2007, 15, 1236–1246. [Google Scholar] [CrossRef]
- Kim, H.G.; Kim, J.Y.; Park, T. Video bookmark based on soundtrack identification and two-stage search for interactive-television. IEEE Trans. Consum. Electron. 2007, 53, 1712–1717. [Google Scholar]
- Sert, M.; Baykal, B.; Yazici, A. A Robust and Time-Efficient Fingerprinting Model for Musical Audio. In Proceedings of the 2006 IEEE International Symposium on Consumer Electronics, St Petersburg, Russia, 28 June–1 July 2006. [Google Scholar]
- Ramalingam, A.; Krishnan, S. Gaussian Mixture Modeling of Short-Time Fourier Transform Features for Audio Fingerprinting. IEEE Trans. Inf. Forensics Secur. 2006, 1, 457–463. [Google Scholar] [CrossRef]
- Ghouti, L.; Bouridane, A. A fingerprinting system for musical content. In Proceedings of the 2006 14th European Signal Processing Conference, Florence, Italy, 4–8 September 2006. [Google Scholar]
- Cook, R.; Cremer, M. A Tunable, Efficient, Specialized Multidimensional Range Query Algorithm. In Proceedings of the 2006 IEEE International Symposium on Signal Processing and Information Technology, Vancouver, BC, Canada, 28–30 August 2006. [Google Scholar]
- Seo, J.S.; Jin, M.; Lee, S.; Jang, D.; Lee, S.; Yoo, C.D. Audio fingerprinting based on normalized spectral subband centroids. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 05), Philadelphia, PA, USA, 23 March 2005. [Google Scholar]
- Haitsma, J.; Kalker, T. Speed-change resistant audio fingerprinting using auto-correlation. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP 03), Hong Kong, China, 6–10 April 2003. [Google Scholar]
- Haitsma, J.; Kalker, T.; Oostveen, J. An efficient database search strategy for audio fingerprinting. In Proceedings of the 2002 IEEE Workshop on Multimedia Signal Processing, St.Thomas, VI, USA, 9–11 December 2002. [Google Scholar]


{kind=link}
| Paper | Year of Publication | Population | Purpose of the Study | Devices | Raw Data Available | Source Code Available |
|---|---|---|---|---|---|---|
| ACM | ||||||
| Sui et al. [12] | 2014 | 2500 pieces of 8 s advertisement audios, and randomly select 200 pieces of audio in the existing database and 50 pieces of other irrelevant audio as test audio | To search for audio in the database by the content rather than by name | Mobile Phone (Android) | No | No |
| Liu [13] | 2012 | 100,000 MP3 fragments | To create an MP3 sniffer system that includes audio fingerprinting | Not mentioned | Yes | Only for feature extraction |
| Liu et al. [14] | 2011 | 10,000 MP3 fragments | Proposes an MP3 fingerprint system for the recognition of several clips | Not mentioned | The same data as [13] | The same source code as [13] |
| IEEE | ||||||
| Tsai et al. [15] | 2016 | Multi-channel audio recordings of 75 real research group meetings, approximately 72 h of meetings in total | Proposes an adaptive audio fingerprint based on spectrotemporal eigenfilters | Mobile phones, tablets or laptop computers | Yes | No |
| Casagranda et al. [16] | 2015 | 1024 samples | Proposes an audio fingerprinting method that uses GPS and acoustic fingerprints | Smartphone | No | No |
| Nagano et al. [17] | 2015 | Approximately 1,518,177 min (25,303 h) of songs | Proposes a method to accelerate audio fingerprinting techniques by skipping the search for irrelevant signal sections | Not mentioned | Yes | No |
| Ziaei et al. [18] | 2015 | 1062 10 s clips | Proposes a method to analyze and classify daily activities in personal audio recordings | Not mentioned | Yes | No |
| George et al. [19] | 2015 | 1500 audio files | Proposes an audio fingerprinting method based on landmarks in the audio spectrogram | Computer | No | No |
| Kim et al. [20] | 2015 | 6000 television advertisements with a total time of 1110 h | Proposes a television advertisement search based on audio fingerprinting in real environments | Television | No | No |
| Seo [21] | 2014 | 1000 songs with classic, jazz, pop, rock, and hip-hop | Proposes a binary audio fingerprint matching, using auxiliary information | Not mentioned | No | No |
| Rafii et al. [22] | 2014 | Several songs with a duration between 6 and 9 s | Proposes an audio fingerprinting method for recognition of some clips | Computer and Smartphone | No | No |
| Naini et al. [23] | 2014 | 1000 songs | Proposes an audio fingerprinting method based on maximization of the mutual information across the distortion channel | Not mentioned | No | No |
| Yang et al. [24] | 2014 | 200,000 songs | Proposes a music identification system based on space-saving audio fingerprints | Not mentioned | No | No |
| Yin et al. [25] | 2014 | 958 randomly chosen query excerpts | Proposes an audio fingerprinting algorithm that uses compressed-domain spectral entropy | Not mentioned | No | No |
| Wang et al. [26] | 2014 | 100,000 songs | Proposes an audio fingerprinting method that uses GPUs | Not mentioned | No | No |
| Lee et al. [27] | 2014 | 3000 TV advertisements | Proposes a high-performance audio fingerprint extraction method for identifying Television commercial advertisement | Television | No | No |
| Shibuya et al. [28] | 2013 | 1374 television programs (792 h in total) | Proposes a method of identifying media content from an audio signal recorded in reverberant and noisy environments using a mobile device | Smartphone, tablet, notebook, desktop, or another mobile device | No | No |
| Bisio et al. [29] | 2013 | 20 sounds | Proposes the Improved Real-Time TV-channel Recognition (IRTR) method | Smartphone | No | No |
| Lee et al. [30] | 2013 | 1000 songs as positive samples and 999 songs as negatives | Proposes a method that speeds up the search process, reducing the number of database accesses | Not mentioned | No | No |
| Bisio et al. [31] | 2012 | 100,000 songs | Proposes an audio fingerprint algorithm adapted to mobile devices | Smartphone | No | No |
| Anguera et al. [32] | 2012 | Several datasets | Proposes an audio fingerprinting algorithm that encodes the local spectral energies around salient points selected among the main spectral peaks in a given signal | Not mentioned | No | No |
| Duong et al. [33] | 2012 | 300 real-world recordings in a living room | Proposes an audio fingerprinting method that combines the Fingerprinting technique with Generalized cross correlation | iPad | No | No |
| Wang et al. [34] | 2012 | 20 music clips with 5 s | Proposes an audio fingerprinting algorithm for recognition of some clips | Not mentioned | No | No |
| Xiong et al. [35] | 2012 | 835 popular songs | Proposes an audio fingerprinting algorithm based on dynamic subband locating and normalized spectral subband centroid (SSC) | Not mentioned | No | No |
| Deng et al. [36] | 2011 | 100 audio files | Proposes an audio fingerprinting algorithm based on harmonic enhancement and SSC of audio signal | Not mentioned | No | No |
| Pan et al. [37] | 2011 | 62-h audio database of 1000 tracks | Proposes an audio feature in spectrum, local energy centroid, for audio fingerprinting | Not mentioned | No | No |
| Martinez et al. [38] | 2011 | 3600 s of several real-time tests | Presents an audio fingerprinting method with a low-cost embedded reconfigurable platform | Computer | No | No |
| Cha [39] | 2011 | 1000 songs | Proposes an indexing scheme and a search algorithm based on the index | Computer | No | Only pseudo-code for fingerprint matching |
| Schurmann et al. [40] | 2011 | 7500 experiments | Proposes an audio fingerprinting method for the recognition of some clips | Computer | No | No |
| Son et al. [41] | 2010 | 500 popular songs | Proposes an audio fingerprinting method using sub-fingerprint masking based on the predominant pitch extraction | Mobile devices | Yes | No |
| Chang et al. [42] | 2010 | 17,208 audio clips | Presents a sub-Nyquist audio fingerprinting system for music recognition, which utilizes Compressive Sampling (CS) theory | Not mentioned | No | No |
| Umapathy et al. [43] | 2007 | 213 audio signals | Proposes an audio feature extraction and a multi-group classification using the local discriminant bases (LDB) technique | Not mentioned | No | No |
| Kim et al. [44] | 2007 | 100 Korean broadcast TV programs | Proposes an audio fingerprinting method for identification of bookmarked audio segments | Computer | No | No |
| Sert et al. [45] | 2006 | approximately 45 min of pop, rock, and country songs | Proposes an audio fingerprinting method from the most representative section of an audio clip | Not mentioned | No | No |
| Ramalingam et al. [46] | 2006 | 250 audio files | Proposes and audio fingerprinting method using several features | Not mentioned | No | No |
| Ghouti et al. [47] | 2006 | Two audio contents perceptually similar | Proposes an audio fingerprinting algorithm that uses balanced multiwavelets (BMW) | Not mentioned | No | No |
| Cook et al. [48] | 2006 | 7,106,069 fingerprints | Proposes an audio fingerprinting algorithm for the fast indexing and searching of a metadata database | PDA or computer | Yes | No |
| Seo et al. [49] | 2005 | 8000 classic, jazz, pop, rock, and hip-hop songs | Proposes an audio fingerprinting method based on normalized SSC | Not mentioned | No | No |
| Haitsma et al. [50] | 2003 | 256 sub-fingerprints | Proposes to solve larger speed changes by storing the fingerprint at multiple speeds in the database or extracting the fingerprint query at multiple speeds and then to perform multiple queries on the database | Not mentioned | No | No |
| Haitsma et al. [51] | 2002 | 256 sub-fingerprints | Proposes an audio fingerprinting system for recognition of some clips | Not mentioned | No | No |
| Paper | Outcomes |
|---|---|
| ACM | |
| Sui et al. [12] | The authors propose a two-level audio fingerprint retrieval algorithm to satisfy the demand of accurate and efficient search for advertisement audio. Based on clips with 8 s of advertisements, the authors build a database with 2500 audio fingerprints. The results show that the algorithm implemented with parallel processing yields a precision of 100%. |
| Liu [13] | The authors create an MP3 sniffer system and test it with multi-resolution local descriptions. The system has a database of 100,000 MP3 tones and authors report that the system has high performance, because 100 queries for identifying unknown MP3 tones took less than 2 s to be processed |
| Liu et al. [14] | The authors describe an MP3 fingerprinting system that compares the normalized distance between two MP3 fingerprints to detect a false identification. The authors identify the possible features of the song and build a large database. For the identification, the authors test the near neighbor searching schemes and compare with the indexing scheme, which utilizes the PCA technique, the QUery Context (QUC)-tree, and the MP3 signatures. The conclusions show that the system has a maximum average error equals to 4.26%. |
| IEEE | |
| Tsai et al. [15] | The authors propose a method for aligning a set of overlapping meeting recordings, which uses an audio fingerprint representation based on spectrotemporal eigenfilters that are learned on-the-fly in an unsupervised manner. The proposed method is able to achieve more than 99% alignment accuracy at a reasonable error tolerance of 0.1 s. |
| Casagranda et al. [16] | The authors propose an audio fingerprinting algorithm based on the spectral features of the audio samples. The authors reported that the algorithm is noise tolerant, which is a key feature for audio based group detection. |
| Nagano et al. [17] | The authors propose an approach to accelerate fingerprinting techniques and apply it to the divide-and-locate (DAL) method. The reported results show that DAL3 can reduce the computational cost of DAL to approximately 25%. |
| Ziaei et al. [18] | The authors propose a method to analyze and classify daily activities in personal audio recordings (PARs), which uses speech activity detection (SAD), speaker diarization, and a number of audio, speech and lexical features to characterize events in daily audio streams. The reported overall accuracy of the method is approximately 82%. |
| George et al. [19] | The authors propose an audio fingerprinting method that is tolerant to time-stretching and is scalable. The proposed method uses three peaks in the time slice, unlike Shazam, which uses only one. The additive noise deteriorates the lowest frequency bin, decreasing the performance of the algorithm at higher additive noise, compared to other algorithms. |
| Kim et al. [20] | The authors propose a Television advertisement search based on audio peak-pair hashing method. The reported results show that the proposed method has respectable results compared to other methods. |
| Seo [21] | The authors propose an asymmetric fingerprint matching method which utilizes an auxiliary information obtained while extracting fingerprints from the input unknown audio. The experiments carried out with one thousand songs against various distortions compare the performance of the asymmetric matching with the conventional Hamming distance. Reported results suggest that the proposed method has better performance than the conventional Hamming distance. |
| Rafii et al. [22] | The authors propose an audio fingerprinting system with two stages: fingerprinting and matching. The system uses CQT and a threshold method for fingerprinting stage, and the Hamming similarity and the Hough Transform for the matching stage, reporting an accuracy between 61% and 81%. |
| Naini et al. [23] | The authors present a method for designing fingerprints that maximizes a mutual information metric, using a greedy optimization method that relies on the information bottleneck (IB) method. The results report a maximum accuracy around 65% in the recognition. |
| Yang et al. [24] | The authors propose an efficient music identification system that utilizes a kind of space-saving audio fingerprints. The experiments were conducted on a database of 200,000 songs and a query set of 20,000 clips compressed in MP3 format with different bit rates. The author’s report that compared to other methods, this method reduces the memory consumption and keeps the recall rate at approximately 98%. |
| Yin et al. [25] | The authors propose a compressed-domain audio fingerprinting algorithm for MP3 music identification in the Internet of Things. The algorithm achieves promising results on robustness and retrieval precision rates under various time-frequency audio signal distortions including the challenging pitch shifting and time-scale modification. |
| Wang et al. [26] | The authors propose parallelized schemes for audio fingerprinting over GPU. In the experiments, the speedup factors of the landmark lookup and landmark analysis are verified and the reported overall response time has been reduced. |
| Lee et al. [27] | The authors propose a salient audio peak pair fingerprint extraction based on CQT. The reported results show that the proposed method has better results compared to other methods, and is suitable for many practical portable consumer devices. |
| Shibuya et al. [28] | The authors develop a method that uses the quadratically interpolated FFT (QIFFT) for the audio fingerprint generation in order to identify media content from an audio signal recorded in a reverberant or noisy environment with an accuracy around 96%. |
| Bisio et al. [29] | The authors present an improvement of the parameter configuration used by the Philips audio fingerprint computation algorithm in order to reduce the computational load and consequent energy consumption in the smartphone client. The results show a significant reduction of computational time and power consumption of more than 90% with a limited decrease in recognition performance. |
| Lee et al. [30] | The authors propose an audio fingerprint search algorithm for music retrieval from large audio databases. The results of the proposed method achieve 80–99% search accuracy for input audio samples of 2–3 s with signal-to-noise ratio (SNR) of 10 dB or above. |
| Bisio et al. [31] | The authors present an optimization of the Philips Robust Hash audio fingerprint computation algorithm, in order to adapt it to run on a smartphone device. In the experiments, the authors report that the proposed algorithm has an accuracy of 95%. |
| Anguera et al. [32] | The authors present a novel local audio fingerprint called Masked Audio Spectral Keypoints (MASK) that is able to encode, with few bits, the audio information of any kind in an audio document. MASK fingerprints encode the local energy distribution around salient spectral points by using a compact binary vector. The authors report an accuracy around 58%. |
| Duong et al. [33] | The authors presented a new approach based on audio fingerprinting techniques. The results of this study indicate that a high level of synchronization accuracy can be achieved for a recording period as short as one second. |
| Wang et al. [34] | The authors present an audio fingerprinting algorithm, where the audio fingerprints are produced based on 2-Dimagel, reporting an accuracy between 88% and 99%. |
| Xiong et al. [35] | The authors propose an improved audio fingerprinting algorithm based on dynamic subband locating and normalized Spectral Subband Centroid (SSC). The authors claim that the algorithm can recognize unknown audio clips correctly, even in the presence of severe noise and distortion. |
| Deng et al. [36] | The authors propose an audio fingerprinting algorithm based on harmonic enhancement and Spectral Subband Centroid (SSC). The authors build a database with 100 audio files, and also implement several techniques to reduce the noise and other degradations, proving the reliability of the method when severe channel distortion is present. The results report an accuracy between 86% and 93%. |
| Pan et al. [37] | The authors propose a method for fingerprinting generation using the local energy centroid (LEC) as a feature. They report that the method is robust to different noise conditions and, when the linear speed is not changed, the audio fingerprint method based on LEC obtains an accuracy of 100%, reporting better results than Shazam’s fingerprinting. |
| Martinez et al. [38] | The authors present a music information retrieval algorithm based on audio fingerprinting techniques. The size of frame windows influences the performance of the algorithm, e.g., the best size of the frame window for shorts audio tracks is between 32 ms to 64 ms, and the best size of the frame window for audio tracks is 128 ms. |
| Cha [39] | The author proposes an indexing scheme for large audio fingerprint databases. The method shows a higher performance than the Haitsma-Kalker method with respect to accuracy and speed. |
| Schurmann et al. [40] | The authors propose a fuzzy-cryptography scheme that is adaptable in its noise tolerance through the parameters of the error correcting code used and the audio sample length. In a laboratory environment, the authors utilized sets of recordings for five situations at three loudness levels and four relative positions of microphones and audio source. The authors derive the expected Hamming distance among audio fingerprints through 7500 experiments. The fraction of identical bits is above 0.75 for fingerprints from the same audio context, and below 0.55 otherwise. |
| Son et al. [41] | The authors present an audio fingerprinting algorithm to recognize songs in real noisy environments, which outperforms the original Philips algorithm in recognizing polyphonic music in real similar environments. |
| Chang et al. [42] | The authors introduce the Compressive Sampling (CS) theory to the audio fingerprinting system for music recognition, by proposing a CS-based sub-Nyquist audio fingerprinting system. Authors claim that this system achieves an accuracy of 93.43% in reducing the sampling rate and in the extraction of musical features. |
| Umapathy et al. [43] | The authors present a novel local discriminant bases (LDB)-based audio classification scheme covering a wide range of audio signals. After the experiments, the obtained results suggest significant potential for LDB-based audio classification in auditory scene analysis or environment detection. |
| Kim et al. [44] | The authors develop a system that retrieves desired bookmarked video segments using audio fingerprint techniques based on the logarithmic modified Discrete Cosine Transform (DCT) modulation coefficients (LMDCT-MC) feature and two-stage bit vector searching method. The author’s state that the search accuracy obtained is 99.67%. |
| Sert et al. [45] | The authors propose an audio fingerprinting model based on the Audio Spectrum Flatness (ASF) and Mel Frequency Cepstral Coefficients (MFCC) features, reporting and accuracy of 93% and 91%, respectively. |
| Ramalingam et al. [46] | The authors propose a method to create audio fingerprints by Gaussian Mixtures using features extracted from the short-time Fourier transform (STFT) of the signal. The experiments were performed on a database of 250 audio files, obtaining the highest identification rate of 99.2% with spectral centroid. |
| Ghouti et al. [47] | The authors propose a framework for robust identification of audio content by using short robust hashing codes, which applies the forward balanced multiwavelet (BMW) to transform each audio frame using 5 decomposition levels, and after the distribution of the subbands’ coefficients into 32 different blocks, the estimation quantization (EQ) scheme and the hashes are computed. |
| Cook et al. [48] | The authors propose a system that allows audio content identification and association of metadata in very restricted embedded environments. The authors report that the system has better performance than the method based on a more traditional n-dimensional hashing scheme, but it achieves results with 2% less accuracy. |
| Seo et al. [49] | The authors propose an audio fingerprinting method based on the normalized Spectral Subband Centroid (SSC), where the match is performed using the square of the Euclidean distance. The normalized SSC obtains better results than the widely-used features, such as tonality and Mel Frequency Cepstral Coefficients (MFCC). |
| Haitsma et al. [50] | The authors present an approach to audio fingerprinting, but it has negligible effects on other aspects, such as robustness and reliability. They proved that the developed method is robust in case of linear speed changes. |
| Haitsma et al. [51] | The authors present an approach to audio fingerprinting, in which the fingerprint extraction is based on the extraction of a 32-bit sub-fingerprint every 11.8 millis. They also develop a fingerprint database and implement a two-phase search algorithm, achieving an excellent performance, and allowing the analytical modeling of false acceptance rates. |
| Features | Average Accuracy of Features | Number of Studies |
|---|---|---|
| Fast Fourier Transform (FFT) | 93.85% | 16 |
| Thresholding | 90.49% | 6 |
| Normalized spectral subband centroid (SSC) | 93.44% | 5 |
| Mel-frequency cepstrum coefficients (MFCC) | 97.30% | 4 |
| Maximum | 87.57% | 3 |
| Local peaks and landmarks | 82.32% | 3 |
| Shannon entropy | 99.10% | 2 |
| Rényi entropy | 99.10% | 2 |
| MPEG-7 descriptors | 97.50% | 2 |
| Spectral bandwidth | 97.10% | 2 |
| Spectral flatness measure | 97.10% | 2 |
| Modified discrete cosine transform (MDCT) | 93.00% | 2 |
| Constant Q transform (CQT) | 85.40% | 2 |
| Short-time Fourier transform (STFT) | 84.50% | 2 |
| Average | 83.00% | 2 |
| Minimum | 83.00% | 2 |
| Sum of the spectrum modulus of every frame | 100.00% | 1 |
| Sum of global spectrum modulus in two stages | 100.00% | 1 |
| Local energy centroid (LEC) | 100.00% | 1 |
| Time-frequency power spectral | 100.00% | 1 |
| Long-term logarithmic modified discrete cosine transform (DCT) modulation coefficients (LMDCT-MC) | 99.67% | 1 |
| Bit packing | 99.20% | 1 |
| Spectral band energy | 99.20% | 1 |
| Spectral crest factor | 99.20% | 1 |
| Spectral similarity | 99.00% | 1 |
| Timbral texture | 99.00% | 1 |
| Band periodicity | 99.00% | 1 |
| Linear prediction coefficient derived cepstral coefficients (lpccs) | 99.00% | 1 |
| Zero crossing rate | 99.00% | 1 |
| Octaves | 99.00% | 1 |
| Single local description | 96.00% | 1 |
| Multiple local description | 96.00% | 1 |
| Chroma vectors | 96.00% | 1 |
| MP3 signatures | 96.00% | 1 |
| Time averaging | 96.00% | 1 |
| Quadratic interpolation | 96.00% | 1 |
| Sinusoidal quantification | 96.00% | 1 |
| Frequency-axial discretization | 96.00% | 1 |
| Time-axial warping | 96.00% | 1 |
| Logarithmic moduled complex lapped transform spectral peaks | 86.50% | 1 |
| Correlation coefficient | 70.00% | 1 |
| Matching score | 70.00% | 1 |
| Methods | Average Accuracy of Methods | Number of Studies |
|---|---|---|
| Other methods | 90.78% | 15 |
| Two level search algorithm | 99.84% | 2 |
| Likelihood estimation | 97.10% | 3 |
| Principal Component Analysis (PCA) | 90.13% | 2 |
| Hamming distances between each fingerprint | 83.50% | 2 |
| Streaming audio fingerprinting (SAF) | 100.00% | 1 |
| Human auditory system (HAS) | 100.00% | 1 |
| Divide and locate (DAL) | 100.00% | 1 |
| Gaussian mixture models (GMM) modelling | 99.20% | 1 |
| Local discriminant bases (LDBS)-based automated multigroup audio classification system | 99.00% | 1 |
| Linear discriminant analysis (LDA) | 99.00% | 1 |
| Local maximum chroma energy (LMCE) | 99.00% | 1 |
| Expanded hash table lookup method | 97.40% | 1 |
| Query Context (QUC)-tree | 96.00% | 1 |
| Improved Real-Time TV-channel Recognition (IRTR) | 95.00% | 1 |
| Sub-Nyquist fudio fingerprinting system | 93.43% | 1 |
| Logarithmic moduled complex lapped transform (LMCLT) peak pair | 86.50% | 1 |
| TO-Combo-SAD (Threshold Optimized Combo SAD) algorithm | 84.25% | 1 |
| Support vector machine (SVM) | 84.25% | 1 |
| Hough Transform between each fingerprint | 81.00% | 1 |
| Masked audio spectral keypoints (MASK) | 58.00% | 1 |
| SAF | HAS | DAL | TLS | GMM | LDBS | LDA | LMCE | ||
|---|---|---|---|---|---|---|---|---|---|
| 100.00% | 100.00% | 100.00% | 99.84% | 99.20% | 99.00% | 99.00% | 99.00% | ||
| Local energy centroid (LEC) | 100.00% | 100.00% | 100.00% | 100.00% | 99.92% | 99.60% | 99.50% | 99.50% | 99.50% |
| Sum of global spectrum modulus in two stages | 100.00% | 100.00% | 100.00% | 100.00% | 99.92% | 99.60% | 99.50% | 99.50% | 99.50% |
| Sum of the spectrum modulus of every frame | 100.00% | 100.00% | 100.00% | 100.00% | 99.92% | 99.60% | 99.50% | 99.50% | 99.50% |
| Time-frequency power spectral | 100.00% | 100.00% | 100.00% | 100.00% | 99.92% | 99.60% | 99.50% | 99.50% | 99.50% |
| Long-term logarithmic modified discrete cosine transform (DCT) modulation coefficients (LMDCT-MC) | 99.67% | 99.84% | 99.84% | 99.84% | 99.76% | 99.44% | 99.34% | 99.34% | 99.34% |
| Bit packing | 99.20% | 99.60% | 99.60% | 99.60% | 99.52% | 99.20% | 99.10% | 99.10% | 99.10% |
| Spectral band energy | 99.20% | 99.60% | 99.60% | 99.60% | 99.52% | 99.20% | 99.10% | 99.10% | 99.10% |
| Spectral crest factor | 99.20% | 99.60% | 99.60% | 99.60% | 99.52% | 99.20% | 99.10% | 99.10% | 99.10% |
| Rényi entropy | 99.10% | 99.55% | 99.55% | 99.55% | 99.47% | 99.15% | 99.05% | 99.05% | 99.05% |
| Shannon entropy | 99.10% | 99.55% | 99.55% | 99.55% | 99.47% | 99.15% | 99.05% | 99.05% | 99.05% |
| Band periodicity | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
| Linear prediction coefficient derived cepstral coefficients (lpccs) | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
| Octaves | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
| Spectral similarity | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
| Timbral texture | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
| Zero crossing rate | 99.00% | 99.50% | 99.50% | 99.50% | 99.42% | 99.10% | 99.00% | 99.00% | 99.00% |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pires, I.M.; Santos, R.; Pombo, N.; Garcia, N.M.; Flórez-Revuelta, F.; Spinsante, S.; Goleva, R.; Zdravevski, E. Recognition of Activities of Daily Living Based on Environmental Analyses Using Audio Fingerprinting Techniques: A Systematic Review. Sensors 2018, 18, 160. https://doi.org/10.3390/s18010160
Pires IM, Santos R, Pombo N, Garcia NM, Flórez-Revuelta F, Spinsante S, Goleva R, Zdravevski E. Recognition of Activities of Daily Living Based on Environmental Analyses Using Audio Fingerprinting Techniques: A Systematic Review. Sensors. 2018; 18(1):160. https://doi.org/10.3390/s18010160
Chicago/Turabian StylePires, Ivan Miguel, Rui Santos, Nuno Pombo, Nuno M. Garcia, Francisco Flórez-Revuelta, Susanna Spinsante, Rossitza Goleva, and Eftim Zdravevski. 2018. "Recognition of Activities of Daily Living Based on Environmental Analyses Using Audio Fingerprinting Techniques: A Systematic Review" Sensors 18, no. 1: 160. https://doi.org/10.3390/s18010160