5G SLAM Using the Clustering and Assignment Approach with Diffuse Multipath
by
 , , , , ,
, , , , ,
Yu Ge
1,* ,
,
Fuxi Wen
1,
Hyowon Kim
2,
Meifang Zhu
3,
Fan Jiang
1,
Sunwoo Kim
2,
Lennart Svensson
1 and
Henk Wymeersch
1 1
Department of Electrical Engineering, Chalmers University of Technology, 412 96 Gothenburg, Sweden
2
Department of Electronic Engineering, Hanyang University, 04763 Seoul, Korea
3
Department of Electrical and Information Technology, Lund University, 221 00 Lund, Sweden
*
Author to whom correspondence should be addressed.
Sensors 2020, 20(16), 4656; https://doi.org/10.3390/s20164656
Submission received: 16 July 2020
/
Revised: 13 August 2020
/
Accepted: 14 August 2020
/
Published: 18 August 2020
(This article belongs to the Special Issue Sensor Network Signal Processing)
Abstract
:5G communication systems operating above 24 GHz have promising properties for user localization and environment mapping. Existing studies have either relied on simplified abstract models of the signal propagation and the measurements, or are based on direct positioning approaches, which directly map the received waveform to a position. In this study, we consider an intermediate approach, which consists of four phases—downlink data transmission, multi-dimensional channel estimation, channel parameter clustering, and simultaneous localization and mapping (SLAM) based on a novel likelihood function. This approach can decompose the problem into simpler steps, thus leading to lower complexity. At the same time, by considering an end-to-end processing chain, we are accounting for a wide variety of practical impairments. Simulation results demonstrate the efficacy of the proposed approach.
1. Introduction
Progressive generations of cellular communication systems have a common property—each generation relies on a larger bandwidth and higher carrier frequency than the previous one. This is particularly noticeable in 5G, where in Frequency Range 2 (FR2), carriers above 24 GHz are utilized in combination with contiguous bandwidths of up to 400 MHz. Early commercial deployments in the US have demonstrated data rates beyond 1 Gbps [1]. The same increases in bandwidth and carrier frequency also have direct benefits for positioning [2]. This has led to intense research activities into 5G positioning as well as a dedicated study item in 3GPP. The final report of this study in 3GPP [3] revealed that by using both delay and angle measurements, it is possible to satisfy commercial positioning performance requirements. Beyond positioning, the sparse nature of the channel at higher carriers allows the receiver to resolve the multipath components, which transforms them from foe to friend [4,5]. In particular, the geometric nature of the channel at mmWave frequencies leads to a relation between the multipath parameters and the physical environment, as the parameters are related to the location of the user (UE) with respect to the base station (BS) and the propagation environment. The simultaneous localization and mapping problem is then invoked to invert multipath parameters into geometric information that determines the user’s position and the locations of objects, based on the signal from a single base station. Several papers have addressed this problem, exploiting both line-of-sight (LOS) and non-LOS (NLOS) paths for position estimation, synchronization, and mapping in mmWave multiple-input multiple-output (MIMO) [6,7,8] and mmWave multiple-input single-output (MISO) [9,10] contexts. However, this inversion is challenging due to a number of reasons: (i) estimation of the channel parameters involves solving a high-dimensional problem; (ii) the association between the objects in the environment and the measurements is not available; (iii) an object may give rise to multiple measurements, due to diffuse multipath; (iv) the measurements per object are not clustered. We will now treat each of these four challenges in turn.
Channel estimation for mmWave is a rich research area, which we cannot cover in detail here. Rather, we categorize these methods as search-based and search-free. Search-based methods, such as those using maximum likelihood (ML) [11] and compressed sensing (CS) techniques [12,13], require an exhaustive search in the high-dimensional space of channel parameters, which entails high complexity. On the other-hand, search-free methods [14], such as matrix or tensor decomposition based subspace methods, directly provide estimates of the channel parameters [15] or rely on low-dimensional search [16], thus avoiding the need for high-dimensional optimization. An important challenge of channel estimation for SLAM is that the different dimensions (angles of arrival and departure, delays and gains) should be correctly matched.
The unknown association between measurements and objects is a common problem in SLAM, and powerful methods to address it can be found in the literature [17,18]. SLAM with radio-based measurements has been considered in the context of ultra-wideband (UWB) communication [19,20] using only distance measurements, which is referred to multipath-assisted SLAM, or channel SLAM. Focusing on the application of SLAM in a 5G mmWave context (which we designate ’5G SLAM’), message passing-based estimators were introduced in References [7,21], based on the concept of non-parametric belief propagation, without the data association (DA). Extension of such methods to include the hidden DAs is possible, following the approaches from Reference [22]. In Reference [23], the probability hypothesis density (PHD) filter, which is a random-finite-set filter, was used to solve the 5G SLAM problem, considering only one measurement per object. In Reference [24], a more powerful random-finite-set filter, Poisson multi-Bernoulli mixture (PMBM) filter, was used, which enumerates all possible DAs.
Multiple measurements per object, while common in the SLAM and extended object tracking literature [25], have been generally ignored in the above 5G SLAM works. The multiple measurements per object are caused by diffuse multipath due to object roughness with respect to the wavelength, depicted in Figure 1. In Reference [5], diffuse multipath is seen as a perturbation, leading to false measurements. In Reference [26], exploitation of the diffuse multipath in radar is proposed by means of diffuse multipath statistics. In Reference [27], surface roughness was considered in radar applications, modeled as a number of sub-reflectors, in an environment with known wall geometry. A similar model with random sub-reflectors was evaluated in Reference [28], where the estimated diffuse paths were used for positioning and mapping, using a simple geometric approach.
Finally, when measurements from an object are not clustered, the unknown grouping can be considered within the SLAM filter [29,30,31], though this comes at a high computational cost. In Reference [28], a K-means clustering was utilized, but this requires a priori knowledge of the number of clusters. In Reference [32], K-power-means was proposed, as well as several criteria to decide the number of clusters. In Reference [24], the perfect clustering was assumed.
In this paper, we address the aforementioned challenges, building on the extensive literature in each of the above research areas in order to provide an end-to-end framework for SLAM harnessing diffuse multipath. The proposed end-to-end framework provides a general approach for user localization and environment mapping in 5G downlink transmissions from a single BS. Therefore, the purposed framework can be utilized in many application areas, including personal navigation [4], localization of cars and robots [33], smart homes [34], indoor location analysis [35], immersive customer experiences [36], location-aided communication [37], personal radar [38], to name but a few. Moreover, the proposed framework can form a foundation for future Beyond 5G and 6G localization and sensing approaches [39]. Our framework is built on a layered approach, comprising three main parts (channel estimation, clustering, and SLAM), which are evaluated separately and end-to-end. The main contributions of this paper are as follows:
- The description of an end-to-end framework for SLAM harnessing diffuse multipath and its performance evaluation.
- The evaluation of clustering and assignment methods, which is suitable for estimated channel parameters under both specular and diffuse multipath, as well as a method to utilize the estimated channel gains for improving the clustering in the 5G SLAM problem.
- The extension of the 5G SLAM likelihood function, in order to harness both specular and diffuse multipath components and to classify different object types according to their roughness, while accounting for clustering errors.
The novelty of the proposed approach compared to the existing random finite set (RFS) based 5G SLAM work [23,40] is three-fold—first of all, References [23,40] did not use a real channel estimator, which makes the problem easier. Secondly, they assumed at most one measurement from an object, which is not the real case. Finally, the PHD filter is not optimal, which does not contain the enumeration of the different data associations. In Reference [24], although the measurements are from the ESPRIT channel estimator and the diffuse multipath is considered, the channel gain is still ignored and the channel estimation results are assumed to be well grouped based on the source. In the current paper, we study the whole framework, from downlink signals to SLAM filter. We also fully use the information given by the channel estimator, including diffuse multipath and channel gain. The PMBM filter is used, which is optimal and enumerates all possible data associations.
The remainder of this paper is structured as follows. The system model is described in Section 2, including the signal model, environment model, sensor, and measurement model. The end-to-end framework is then presented in Section 3, specifying the components that will be detailed in the subsequent sections, starting with channel estimation in Section 4, clustering in Section 5, and the novel likelihood in Section 6. Simulation results are presented in Section 7, followed by our conclusions in Section 8. The paper also contains several appendices describing the geometric expressions of the channel parameters, as well as the details of the SLAM method.
Notations
Scalars (e.g., x) are denoted in italic, vectors (e.g., ) in bold, matrices (e.g., ) in bold capital letters, sets (e.g., ) in calligraphic, tensors (e.g., ) in bold calligraphic. Transpose and Hermetian are denoted by and , and . Furthermore, denotes the absolute value of a scalar, or the cardinality of a set; denotes the Euclidean norm of a vector. A Gaussian density with mean and covariance , evaluated in value is denoted by . Finally, the notations of important variables are summarized in Table 1.
2. System Model
In this section, we describe the basic models of the user, the environment, the propagation channel, and the observed waveform. We use the 5G positioning reference signals (PRS) [41] as pilot signals. These signals are broadcast by the BS, and used for positioning according to the 3GPP standards [3,42]. Since the signals are broadcast, there is no multi-user issue or interference, so that we only focus on a single UE, where the proposed algorithms can be assumed to be executed per UE.
2.1. User Model
In this paper, we only consider the single-user scenario, so the cooperation between different users is beyond the scope of this paper. The dynamic state of the user at time step k is denoted by , which contains the position of the user , heading , translation speed , turn rate and clock bias . The dynamic model of is
where denotes a known transition function; is the process noise, modeled as a zero-mean Gaussian with known covariance . The above dynamic model can be expressed, equivalently, in terms of a transition density .
2.2. Environment Model
We consider an environment with a few landmarks. There is a fixed and known BS, located at . The other unknown landmarks are modeled as different types of surfaces (see Figure 2). A surface can be described with an extended state comprising:
- A point on a corner of the surface and a vector normal to the surface.
- The size of the surface in length l and height h. The width w is not relevant.
- The smoothness of the surface, denoted by .
- The scattering attenuation and reflection attenuation , with , in which the remaining power is absorbed in the surface.
To avoid dealing with such a high-dimensional surface state description, we use a simplified state, containing a fixed virtual anchor (VA) with location , which is the reflection of the BS with respect to the surface, that is,
Note that the VA location is surface-specific. We only consider 3 different types of surfaces: smooth surface (SM, with , , ), medium rough surface (MR, with ) and very rough surface (VR, with ). Signals from the base station can only be reflected via SM to the receiver; while they can be reflected and diffused via MR to the receiver; whereas VR can only diffuse signals. This allows us to have a compact state representation, with the landmark state , where and for , while , for [24].
2.3. Channel Model
At time step k, the channel from the BS to the user in the frequency domain is given by [11]:
where is the delta Dirac function, f is the frequency, is the angle of arrival (AOA), is the angle of departure (AOD), is the number of landmarks in the environment ( represents the BS); is the number of paths from each landmark ( represents the specular path). For each surface, there is at most one deterministic specular component among the paths, while all remaining paths are diffuse components and thus random [28]. We denote the total number of paths by . Each path can be described by a complex gain , a time of arrival (TOA) , an AOA pair in both azimuth and elevation, and an AOD pair in both azimuth and elevation. The generative model for each of these parameters is described as
- LOS path: When , , the gain has uniform phase and has powerwhere is the wavelength, and the TOA, AOA, and AOD follow the geometric relations between the BS and the UE. They are given in Appendix A.
- Specular path from surface i: For , , the point of incidence on the i-th surface (denoted by with virtual anchor ) is the intersection of the surface and the line between the i-th virtual anchor and the UE . The specular path gain has uniform phase and powerThe TOA, AOA, and AOD follow the relative position of the UE, BS, and the incidence point on the surface. They are given in Appendix A.
- Diffuse paths from surface i: For , , the number of paths per surface and their spread in angle and delay, as well as the channel gains, depend on the roughness of that surface. These paths can be interpreted as coming from random points on the surface, with a spatial distribution that depends on the roughness, where is the random variable that describes the position of the diffuse point. The diffuse points are generated from the distribution ([43],Chapter 3)where denotes the set of points that make the i-th surface, is the deviation of the scattering angle with respect to the angle of the specular path (i.e,. when is the incidence point of the specular path), is the angle between the impinging ray (i.e., from the transmitter to ) and the surface normal, and is the angle between the departing ray and the surface normal. The diffuse paths have uniform and independent phases and equal powerThe locations of the diffuse points fully determine their corresponding TOA, AOA, and AOD, provided in Appendix A.
2.4. Signal Model
We will assume a transmitter and receiver with uniform rectangular arrays (URAs) with (i.e., columns and rows) and elements, respectively. The corresponding steering vectors are
and
in which ⊗ is the Kronecker product.
In addition, we consider OFDM transmission with subcarriers and subcarrier spacing . The received signal at subcarrier s at time step k is then [44]
where is the pilot signal over subcarrier s (spanning T OFDM symbols), is white Gaussian noise with , and is the channel frequency response,
3. Methodology and End-to-End Framework
Using the raw measurements directly in SLAM is challenging, due to the high dimensionality of the measurement, the complex nonlinear relation to the user and landmark states, and the fact that not all paths may be resolvable, due to a limited number of transmitter and receiver antennas and bandwidth. While such direct localization has performance benefits [45,46,47], we instead consider a layered approach, visualized in Figure 3, comprising the following steps after downlink transmission of the signals .
- First of all, channel estimation is performed to recover the channel parameters (angles, delays, gains). Due to the finite resolution at the receiver side, not all paths are resolvable. Hence, the number of estimated paths (denoted by ) will be much smaller than . The channel estimator thus provides a set of channel parameter estimates at time k, . Each element is either a clutter, which is caused by noise peaks that are detected as paths during channel estimation, with clutter intensity or followswhere denotes the measurement noise; is for LOS, the incidence point of the deterministic specular components, or a (random) point on the surface for a NLOS component. We recall that the underlying geometric relation can be found in Appendix A. We describe the channel estimator in Section 4.
- After channel estimation, we group the unordered elements in in clusters , where each cluster should correspond to one landmark. This removes the need to consider all possible partitions of the measurements in the SLAM method, drastically reducing overall complexity. Clustering is challenging as measurement clusters may be non-convex. In addition, diffuse paths may be far away from the specular paths, leading to possible miss-classifications. The proposed clustering method is described in Section 5.
- Finally, after clustering, the SLAM method requires a likelihood function that expresses the statistical relation between the state and the clustered measurements, . The SLAM method is deferred to Appendix B, while in the main text we focus on the proposed likelihood function in Section 6. The SLAM filter follows a Rao-Blackwellized approach, where we use a set of particles (indexed by n) to represent the user state, and use PMBM densities conditioned on each particle to represent the map. Clustering and likelihood computation are conditioned in the user state and are thus performed per particle.
4. Channel Estimation
In this section, the ESPRIT channel estimator is introduced.
4.1. Background
The standard formulation of the channel estimation problem is an ML problem, where
in which contains the delays, gains, and angles of all the paths, as well as the number of paths. Since the number of paths is unknown and paths are not all resolvable, model order selection techniques can be applied, for example, by adding a regularizer to (17) ([11], Section 5.2), for example, following the minimum description length (MDL) or Akaike information criterion (AIC). The dense multipath can be treated as a stochastic process, by writing (14) as
where is the dense multipath containing all the contributions from the diffuse paths. The dense multipath is then modeled as complex Gaussian process with zero mean and covariance , possibly with unknown elements. Then the entire noise process has covariance . Alternatively, we can estimate the geometric parameters of the dominant diffuse multipath components from MIMO channel measurements, which leads to a multidimensional harmonic retrieval (HR) problem [48]. Numerous HR techniques have been developed, ranging from multidimensional searching or optimization based, such as multiple signal classification (MUSIC), ML and CS techniques [49], and polynomial-rooting or matrix-shifting based search-free methods, such as root-MUSIC [14] and estimation of parameters by rotational invariant techniques (ESPRIT) and their multidimensional extensions [50]. Due to its simplicity and high-resolution capability, ESPRIT-type algorithms have become one of the popular HR techniques [51].
4.2. ESPRIT Channel Estimator
For notational convenience, we drop the time index k. From (14), the received signal on subcarrier s is of the form
where is the channel frequency response, is a known pilot signal with orthogonality property (), and is i.i.d. Gaussian noise. Then we have
where is also i.i.d. Gaussian noise with a scaled covariance matrix.
4.2.1. Observations in Tensor Form
We utilize a Tensor framework to exploit the R-D grid structure inherent in the data, as well as the Vandermonde structure in angle and delay domains. To this end, we map from geometric channel parameters to spatial frequencies by
For subcarrier i, and are matrices. We convert these matrices (one per subcarrier) to a 5D tensor of suitable dimension, , and . For the p-th path, the equivalent 5D array steering tensor can be written as
where ∘ represents the outer product (Note that , and with .), is the spatial frequency of the p-th source in the r-th dimension, is equivalent to the uniform linear array steering vector composed of sensors, , where P is the total number of paths, and . This allows us to express the observation as
where denotes the complex path gain of the p-th path.
4.2.2. Shift Invariance
We now introduce the multidimensional shift invariant structure in each dimension r, in order to apply Tensor-ESPRIT. We first introduce so-called selection matrices , which select out of elements belonging to the first and the second subarray in the r-th mode, respectively. For example, when , we have
where and denote the identity matrix and zero vector, respectively, and the sizes are defined in subscripts. Secondly, we introduce , which has the shift invariance property
where is a diagonal matrix that contains the unknown parameters , in dimension r.
4.2.3. Tensor-ESPRIT
In order to obtain the subspace spanned by , we take CANDECOMP/PARAFAC (CP) decomposition on [52]. Because the total number of paths P is unknown, model order selection techniques [53] can be utilized to estimate . In general, the estimated for rough surfaces with hundreds of closely located diffuse paths.
where are the estimated path gains, and is the estimated signal subspace with normalized column vectors . Note that after taking CP decomposition, the path gains and channel parameter associations are achieved synchronously. In other words, corresponds to a unique in each dimension r, so that the output of (26) is .
Since and span the same subspace, , where is a non-singular transform matrix. Entering this relation in (25), we obtain
where . In (27), only is unknown, but can be estimated via the least squares method:
where denotes the pseudo-inverse. Since the matrix is similar to the diagonal matrix , they share the same eigenvalues. Hence, the spatial frequency can be recovered as , where are the eigenvalues of . The , map to delay , AOA pair , and AOD pair via (21).
Finally, each tuple , for is returned as the output of the channel estimator. We denote this combined output as .
The most computationally demanding part of channel parameter estimation is the CP decomposition. In (Reference [54], Table 1), the complexities of major computations in popular CP decomposition algorithms is summarized. For example, the alternating least squares (ALS) algorithm with line search has a complexity of order , where and and denotes the total number of paths.
5. Channel Parameter Clustering
At time step k, the channel estimator provides a set of channel parameter estimates , , and we need to cluster based on different landmarks. However, clustering is challenging, since is in a 6D space, and the delay, angle, and gain are in different scales and spaces, so that they should be properly weighted. We also do not have any advance knowledge of the number of landmarks in the environment. In this section, we try to address these challenges. For brevity, we will omit the time index k.
5.1. Background
As a general term, a cluster is defined as a collection of objects that are similar to each other in some agreed-upon sense [55]. In radio channel analysis, a cluster is usually described as a group of multipath components (MPCs) with the same parameter distribution. The MPCs that have similar values in delay and angular domain are jointly classified as a single cluster, which reflects the physical environment, as similar MPCs are usually spatially close to each other, for example, reach the receiver via the same landmark.
Clustering methodology in radio channel analysis has been expanded from visual clustering to automatic clustering, where the visual clustering is usually valid for data with limited dimensions [55,56], while the automatic clustering can handle data with more than three dimensions [57]. Automatic clustering algorithms, focusing on the parameter space of MPCs, such as Hierarchical, K-means, and Gaussian mixture, have been widely used in radio channel characterizations [32,58,59,60,61]. Hierarchical clustering algorithms cluster the data based on a binary cluster tree, which is limited by the data size, and therefore limited to small data sets. K-means [62] assumes a known number of clusters and iteratively assigns data to each cluster and computes cluster centroids until the cluster centroids are converged. While K-means is a widely used clustering method, it suffers from several drawbacks: (i) the number of clusters is predefined, which limits the capabilities to reflect the reality of the environment; (ii) it cannot cope with outliers, which implies all the observed data will eventually be part of some clusters, even observations that are far away in 6D space and should be considered as outliers; (iii) it usually gives spherical-like shape clusters. MPCs that reflect other physical properties can be assigned as the edge of a spherical cluster, which has notable effects on the cluster properties, that is, cluster centroids, and loses the ability to link to physical reality. The more sophisticated affinity propagation [63] partially avoids these problems, but still leads to circular clusters and has very high complexity. Gaussian mixture clustering [57] gives more variation to the shapes of the clusters extracted with K-means, and follows the similar structure of K-means. It can give clusters in different shape if the original data is not distributed circularly. However, the method is complex and converges slowly.
Density-based spatial clustering of applications with noise (DBSCAN) [64] is one of the most widely applied clustering methods for data sorting. Without a predefined number of clusters, DBSCAN utilizes two critical parameters—the minimum number of points clustered together for a region to be considered dense, and a distance measure to locate the points in the neighborhood of any point. The density-based clustering method has no limitations on the number of clusters, uses a dense distance, and gives more freedom regarding the shape of clusters. While we have evaluated different methods in Section 7, here we only present the best performing method, which is an extension of the DBSCAN algorithm.
5.2. Modified DBSCAN
In this section, we will present the DBSCAN clustering method with the obtained channel estimates. The method involves three phases—(i) the mapping of the geometric channel parameters (delay and angles) to a 3D point; (ii) clustering with DBSCAN; (iii) refinement by using the channel gain.
5.2.1. Phase 1: 5D to 3D Mapping
Distinct from existing work where the channel parameters are used as features for clustering [28,61], we transform the 5D channel parameter into a 3D position. In the absence of noise, this point should be on the surface of a landmark for NLOS paths, while in the presence of noise, the most likely estimation of the point can be founded close to the surface. The transformation reduces the dimensionality, and avoids different scales and spaces problems. Hence, the 5D parameters, that is, the delay , the AOA pair and the AOD pair can be converted to a point .
The general idea to transform the 5D parameters into a 3D point is illustrated in Figure 4. Specifically, for the p-th diffuse multipath, a virtual anchor position can be estimated as
where c is the speed of light, is the estimated clock bias, is the unit vector pointing along with the direction of arrival, given by
Given and , a hypothesized surface can be defined via a point on the surface and the normal vector to the surface . With knowledge of and the surface, the incidence point location can be computed from from Snell’s law of reflection as
Note that this method also works for the LOS path, and it will return a point near , since and are both approximate to . From , we obtain the corresponding 3D points . Next, we will perform the clustering methods with the 3D positions of points.
5.2.2. Phase 2: Clustering with DBSCAN
In DBSCAN [64], all points are classified into either clusters or identified as noise. In a specific cluster , the core points have an -neighbourhood with points. We define a distance measure from which the –neighbourhood of the p-th point is defined as
In this paper, we use . The main idea of DBSCAN is that clusters are not characterized by their variance (as in K-means), but by density-reachability. In particular, is directly density-reachable from , if and only if and . In addition, is density-reachable from , if there exists an ordered sequence of points in , where is directly density-reachable from . If the sphere of contains at least points, that is, , the point will be a core point of a cluster. The border points can have a smaller size -neighbourhood, but can be density-reachable from the core points.
Given the parameters and , we can discover a cluster in a two-step approach: (i) choose an arbitrary point from the database satisfying the core point conditions as a seed; (ii) find all points that are density-reachable from the seeds [64]. We follow these two steps, that is, to identify a core point, to find a cluster with the core point, and to find all clusters. The algorithms are provided in Algorithm 1. Note that Algorithm 2 is used in Algorithm 1 to find all points in each cluster. The output of the clustering is a partitioning of (or ) into clusters and a set of noise points .
| Algorithm 1: DBSCAN for Clustering |
| Input: Points , threshold , and ; |
| Output: All clusters and the associated points. |
|
| Algorithm 2: Find All Points in Cluster l |
| Input: Cluster index l, point index p and its -neighbourhood ; |
| Output: The associated points in cluster l. |
|
5.2.3. Phase 3: Extract Isolated Specular Paths and Outliers Using Channel Gain
The DBSCAN clustering has two drawbacks in our application:
- The tensor ESPRIT channel estimator from Section 4 can generate estimates, whose 3D points (as obtained in Section 5.2.1) are still on or near the corresponding surfaces, but are far away from the cluster centers. Hence, they are informative for the SLAM algorithm, but are part of , so they are not clustered correctly. We have observed that the channel gains of these paths are very small.
- The LOS path and specular paths from smooth surfaces are not part of any cluster, as such landmarks have one or few associated paths. We have observed that the channel gains of these paths are very large (approximately following the path loss models from Section 2.3).
To solve these problems, we use the estimated channel gains. We partition into two sets according to the channel gains.
where is a predefined threshold, is the estimated clock bias, and c is the speed of light. The scaling with is added to compensate for the path loss. For each of the high-gain paths in , we create a new cluster. For each of the low-gain paths in , we find the nearest cluster as
and add p to cluster .
The overall computations in channel parameter clustering consist of three parts, that is, the computations in each phase. Given the number of paths , the transition from 5D to 3D mapping requires computations. According to Reference [64], the complexity of the DBSCAN algorithm without the use of index structure for acceleration is . The last phase requires computations. Therefore, the overall complexity is .
6. Likelihood Function for SLAM
After clustering, the measurements are grouped into clusters , using Algorithm 1, where is the number of estimated clusters. The clustered measurements will be the input into the SLAM filter during the update process, via an appropriate likelihood function. For brevity, we omit the time index k again. We work with the compact representation of the landmark state from Section 2.2. Hence, our goal is to determine , where is the landmark position (i.e., the BS location or a virtual anchor location) and is the landmark state. This likelihood function will influence the probabilities of different associations between landmarks and clusters, and it will also influence the particle weight and the distribution of the landmark given a state and the association.
6.1. Background
In previous 5G SLAM works, Reference [21] assumed there is at most one measurement from each source; the channel gain is not used, and the inter-path interference is not considered. The measurements are only generated by known multivariate Gaussian distributions, then the likelihood function falls into the likelihood of the signal measurements, which follows the Gaussian format. According to the PMBM formalism, multiple measurements per source should follow a Poisson or Bernoulli distribution. Under the standard point model, the likelihood function corresponds to a Bernoulli distribution, with [65]
where is the detection probability. Under the extended target model, the likelihood function corresponds to a Poisson point process (PPP) ([25], Equation (5)):
where is the Poisson rate for surfaces of type m. For both (36) and (37), it has been proven that the PMBM density is a conjugate prior.
6.2. Likelihood Function
In this section, we describe the proposed likelihood function. We here assume that the measurements within each cluster are independent, as diffuse points are generated independently. We also assume the number of paths only depends on the source type m. It is important to note that for measurements from diffuse paths, a measurement is a function of a random incidence point on the surface. In order to express the measurements as a function of the compact state, we propose the following approach.
We first separate into two parts, the path with the shortest delay , which is the closest path to the specular component, and any remaining paths , which we view as diffuse multipath. We associate the deterministic incidence point with the assumed specular component, which can be derived by (31) using and . Therefore, we can write , for , which is in the desired form (16). Hence
In other words, the object may be miss-detected with probability . If the object is detected, then the likelihood contains a contribution from the first arriving path (the specular path, which is directly related to the VA location or BS location) and from the set of all remaining paths.
Note that as a special case for there can be at most one associated measurement, so that
which is in the desired form. Hence, we can focus on the diffuse paths. As the measurements contain both a specular component and diffuse paths, the likelihood function does not follow the standard models (36)–(37). Nevertheless, we use the likelihood in the PMBM filter without any proof of conjugacy or optimality.
6.2.1. Likelihood for Diffuse Paths
We recall from Section 2.3 that diffuse multipath originates from random points on the surface and from Section 4 that the estimates points will differ from those from Section 2.3, due to the finite resolution of the receiver. Hence, it is fundamentally impossible to estimate the original random incidence points from the observations . To avoid estimating , we propose estimating an artificial incidence point from as the projection of (obtained using the method in Section 5.2.1) onto the surface. The projection point can be derived by
where is a point on the surface, and is a normal to the surface. Then, can be expressed in the desired form , where is the artificial incidence point that gave rise to measurement . The likelihood can be further simplified by noticing the error component of , which is only due to the the projection distance of to the surface. We therefore use this distance directly as a compressed measurement to replace the delay and angles
Figure 5 shows the principle of calculating .
We thus have a general model for the likelihood function associated with the diffuse paths, where the cardinality distribution is arbitrary and (cf. (Reference [18], Equation (1))
in which all constituent distributions can be obtained from the simulation of a channel estimator or provided directly in closed-form by a channel estimator. In (42), the first term represents the cardinality distribution, is a normalization constant to ensure that integrates to one over . The element in are represented in compressed format through and are modeled as independent and identically distributed.
6.2.2. Clustering Errors and Marginal Likelihood Function
Due to clustering errors and channel estimator errors, it is possible that the specular path is not associated with the set of the specular paths. Then the shortest path in may be a diffuse path, leading to low likelihood , so that the SLAM method is likely to view the source of this measurement cluster as a new landmark, which is not desirable. In order to solve this problem, we introduce , which is the probability that the first path in a cluster is in fact the specular path. This probability can be determined by observation of the overall clustering performance. By marginalizing over the event of missing the specular path in a cluster, the likelihood function can be written as
where the factor is due to there being an additional specular path, which was not present in the cluster. The complexity of the likelihood function is , as we consider paths.
7. Results
In the implementation, all the codes are written in MATLAB, and the simulations and experiments are run on a MacBook Pro (15-inch, 2019) with a 2.6 GHz 6-Core Intel Core i7 processor and 16 Gb memory.
7.1. Simulation Parameters
We consider a scenario with a single vehicle with the initial state , a BS located at , a SM, with the VA at , two MRs, with VAs at and a VR, with the VA at . The BS and the receiver are both equipped with a URA with antennas. The vehicle moves around the BS with a known constant turn rate. Every time step, the BS sends OFDM symbols to the vehicle with 200 subcarriers using the transmit power of 5.05 W at carrier frequency of 28 GHz. The subcarrier spacing is 0.5 MHz. The transmitted signals are disturbed by the noise with power spectral density of mW/Hz. The transition function of the movement, the initial vehicle state, the landmark locations, the process noise, the initial prior, the survival probability, the detection probability, the birth rate, the clutter intensity, and pruning thresholds are the same as in Reference [23].
7.2. Channel Estimation Results
In this section, we show the results of the tensor ESPRIT channel estimator for a MR surface, which generated one specular path and 100 diffuse paths. To visualize the channel estimator output, we transform the estimated TOAs, AOAs, AODs into 3D points. The result is shown in Figure 6, where the original diffuse points are marked with blue dots and the estimated diffuse points with red discs. We observe that the channel estimator returns only 5 paths, much less than the original 101 paths, due to the finite resolution of the receiver. All projected points are close to the surface and there is a projected point very close to the deterministic reflection point. This is because the specular path of the MR has larger power than the other diffuse paths, so it is less affected by inter-path interference.
7.3. Clustering Performance Evaluation
To evaluate the clustering performance, we generate 40 snapshots of the channel with known landmarks. We then obtain the channel estimates with 5D geometric parameters, and transform them into 3D point positions. The DBSCAN clustering algorithm is applied to each snapshot, with m and . Then we use the estimated channel gain to modify the results, with . As a comparison, we also compare with other clustering methods, including the well-known K-means, gap statistics (‘GS’) [66], and affinity propagation (’AP’) [63] on the same data set. For the K-means, we assume that the number of clusters, K, is known, while for the remaining methods this priori knowledge is not needed.
To evaluate the clustering performance, we consider the following performance metrics, which use as ground-truth hand-labeled data: the clustering accuracy (CA), which is the percentage of correctly clustered points, and the impurity (IMP), which is the percentage of points clustered into a wrong cluster
where is the set of all possible assignments; is the ground truth clusters; is the cluster results provided by the clustering algorithm; is the number of all target points. The performance is presented in Table 2. The proposed clustering method based on DBSCAN provides the best clustering performance, with an average clustering accuracy over 99%. The modified DBSCAN goes through all noise points using channel gain and refines the results, so it performs slightly better. K-means achieves an average accuracy of 94.63%. GS-based clustering method has an average accuracy of only 68.64% since the estimated value of the number of clusters can be erroneous. The AP clustering method has an average accuracy of 84.35% since it still based on space partition and the estimated value of the number of clusters can be erroneous either. In terms of impurity, the last three algorithms cluster measurements from different sources together when errors occur, but for DBSCANs this never happens, so that all points in each cluster correspond to one landmark. By observing the clustering results of modified DBSCAN, losing the shortest path from the same landmark happens rarely, and we have estimated .
Though the K-means algorithm shows good average clustering performance, it suffers from a few limitations as indicated in Section 5.1. This can be demonstrated in Figure 7, where we present the clustering results with DBSCAN and K-means with the data from the 33rd snapshot. We use different colors to indicate the different clusters obtained from the corresponding clustering methods. The proposed DBSCAN can correctly cluster the measurements into the right clusters shown in Figure 7a; however, K-means shows unstable clustering performance indicated in Figure 7b–d. This is because the clustering performance of K-means is highly dependent on the initialization of the partitions. In addition, we observe from Figure 7b,d that in K-means, the data points from the same cluster can be divided into separated clusters, and the points from different clusters can be clustered in a single cluster. All these mismatches will cause performance degradation in SLAM, which will be further demonstrated in Section 7.5.
7.4. Estimated Likelihoods
Given the channel estimation and the clustering performance, we now describe the obtained likelihood functions. For simplicity, we consider all dimensions independent and report the observed distributions of the number of paths and error of the specular path gain, delay and 4 angles. For diffuse paths, we report the distribution of the distances and the channel gains. All these distributions are based on gathered channel estimation and clustering results in various vehicle locations. We use the setting in Section 7.1, and run the channel estimator many times, collect all channel estimation results and study statistics of collected data. Since the channel gains are strongly affected by path loss, (4)–(7) reduce the impact of the distance dependence by considering
We first focus on the case as an example, and study , , , , and in Figure 8. Figure 8a shows the histogram of the number of paths, as well as a Poisson approximation. We observe that there are always a (assumed) specular path and 1 to 5 diffuse paths, and the existing of more than one diffuse path follows a Poisson distribution. Figure 8b shows the histogram of the delay error of the first estimated path (i.e., subtracted with the delay of the specular path and multiple by the speed of light c) as well as a Gaussian fit. We observe that there is a shift of delay of 0.17 m, which is caused by inter-path interference. Figure 8c shows the histogram of the elevation AOD error of first estimated path (i.e., subtracted with the angle of the specular path) as well as a Gaussian fit. We observe that inter-path interference does not influence the angle so much. Figure 8d shows the histogram and Gaussian fit of the distances . As the inter-path interference leads to a positive delay shift, the estimated diffuse points are more likely to be behind the surface. Finally, Figure 8e,f shows the histogram of and as well as Gaussian fits. We observe that the specular path is stronger than diffuse paths, as the mean of is larger, and diffuse paths are influenced by inter-path interference more seriously, as the distribution of is more spread.
Table 3 provides a complete overview of the likelihood function for all landmark types. Based on all components of the likelihood functions for all landmarks, we have the following observations: for both cases and , there is always one path presents and all the angles, delays and follow Gaussian distributions. For case , apart from the assumed specular path, there are 3 to 12 more paths present, and angles, delays, and also follow Gaussian distributions. We also find that the smoother surface has a higher gain for the specular path and lower gain for the diffuse path.
However, since the clustering algorithm is not perfect, it is possible that the cluster associated with a landmark may have fewer or more paths than the ground truth cluster. For example, the cluster associated with the MR may only have a specular path, due to the clustering error. We therefore set those possibility none zero in manually, in order to increase the tolerance of the wrong clustering, as shown in Table 3.
7.5. SLAM Performance Evaluation
7.5.1. Mapping Performance
Firstly, we study the performance of the proposed 5G SLAM scheme in mapping, conditioned on the true vehicle state. We use the generalized optimal subpattern assignment (GOSPA) distance [67] as the metric to evaluate the mapping result. The GOSPA metric considers the estimation error, which is the error between the estimated positions with the real positions of landmarks, the miss-detection error, which is the error of miss-detecting the existing landmarks, and the false alarm error, which is the error of detecting non-existing landmarks. The GOSPA between the estimate landmark position set and the real landmark position set is defined as
where is the set of all possible assignments; is the number of miss detection of assignment ; is the number of false alarm of assignment . The cardinality penalty factor , the cut-off distance , and the exponent factor are set as 20, 2, and 2, respectively.
We make two comparisons: (i) we compare different clustering methods (SLAM filter using modified DBSCAN which is the proposed method, DBSCAN without channel gains, and K-means); (ii) we compare SLAM filters with different numbers of paths (using all paths in every signal cluster based on the proposed likelihood function, which is the proposed method; using all paths but without using channel gains [24]; using the single (specular) path in every cluster based on the proposed likelihood function; using the single (specular) path in every cluster but without using channel gains, which is the PMBM extension of Reference [23]).
Figure 9 shows the outcome of the first comparison. We observe that the SLAM filter with K-means clustering performs poorly, even though the number of clusters is already known. Although the K-means performance in Table 2 seems good, grouping measurements from different sources leads to significant errors. The reason is that K-means only divides the space linearly and cannot handle complicated shapes. It often groups projected points from different sources into the same clusters; for example, at time step 17, it groups the measurements from BS and SM together. Modified DBSCAN and simple DBSCAN perform much better, as the blue and red lines are much lower, since both of them never group measurements from different sources together. The tensor ESPRIT channel estimator may create measurements that are far away from the specular path, and have low gains but still contain location information. Treating those outliers individually as single-element clusters in DBSCAN loses some information, and also forces the SLAM filter to create a new landmark, when similar outliers appear in successive time steps. This is apparent in the peak at time step 37–39 in Figure 9a, since there are some clutters pointing to a similar region between time step 36–39. With the help of the channel gains, the modified DBSCAN groups those measurements into the right clusters, which helps in mapping. That is the reason why the blue line is lower than the red line, for example at time step 2 in Figure 9c and time step 3 in Figure 9d.
Figure 10 shows the comparison of the GOSPA results among 4 different settings (with or without using diffuse multipath, with or without using channel gain). We observe that SLAM filter has better performance when using diffuse multipath, as the solid lines are lower than the dashed lines, and it can also help the system to identify the landmark types, as there are no sharp peaks in solid lines, which is because more paths provide more information. We also observe the gain can improve the performance, especially in helping the SLAM filter to recognize the surface type, as the blue lines are lower than the red lines. Without information from channel gains, the SLAM filter has trouble to distinguish SM and MR when only using the specular path, as indicated by the sharp peaks of red dashed lines in Figure 10b,c and the red solid line dropping more slowly than the blue solid line in Figure 10b. This is because the distributions of delays and angles of specular paths from SM and MR are very close to each other, and some disturbance may cause a wrong identification. The information from channel gains will alleviate this problem. However, the channel gain is usually disturbed by inter-path interference, which increases with the roughness of the surface. Therefore, the gain is more informative for paths from SM and MR, but less informative for paths from VR, so the blue dashed lines are much lower than the red dashed lines in Figure 10b,c, but only slightly lower than the red dashed line in Figure 10d.
7.5.2. Localization Performance
Next, we study the performance of the proposed 5G SLAM scheme in vehicle state estimation and compare the estimation results among the SLAM filter with different settings (with or without using diffuse multipath, with or without using channel gain). The landmarks are unknown and are mapped with tracking the vehicle state. We add bias to the initial state, and the initial covariance is set as . We use 2000 particles to represent the vehicle state, and obtain the mean absolute error (MAE) between the real vehicle state and the estimated vehicle state after time step 5 until the simulation ends at time step 40
as shown in Figure 11. The clock bias is multiplied with the speed of light c for evaluation. Overall, when using diffuse multipath, the SLAM filter has better performance in positioning, as MAEs are lower. The reason is that diffuse multipath provides more information than the single path. Using channel gain also improves the positioning performance, especially very helpful to estimate the clock bias, since gain contains information about propagation distance directly without being affected by the clock bias.
7.5.3. Complexity Evaluation
We also evaluate the complexity of the proposed framework by measuring the execution time for each phase—channel estimation, clustering, mapping, SLAM (per particle), as shown in Figure 12. We measured a runtime per time step of 8.12 s for the channel estimation. The reason for taking a long time is that the ESPRIT channel estimator is based on a high dimensional tensor decomposition with high complexity. We measured the modified DBSCAN takes 0.21 ms per snapshot. For mapping, it takes 110 ms per time step. Although the proposed SLAM filter considers all possible data associations, as there are not too many landmarks under the simulation scenario, the number of all possible data associations is not large. However, the runtime will increase with more data associations. For SLAM, the proposed SLAM filter takes 149 ms per each particle (298.52 s in total) per time step. As 2000 particles are used and we need to fuse maps of all particles, the complexity is much higher than mapping, where the true vehicle state is given.
8. Conclusions
In this paper, we have treated the 5G SLAM problem from an end-to-end perspective, including downlink data transmission, channel estimation, clustering, and the SLAM filter. In the 5G SLAM problem, we aim to localize and synchronize a user while mapping the propagation environment, with the help of downlink signals from a single base station. We have proposed a novel method to cluster the MPCs by projecting the high-dimensional data into 3D points and then cluster the points based on the DBSCAN algorithm, which we augmented to account for the channel gains. We have also proposed a novel likelihood function in the 5G SLAM filter, which accounts for both the specular path as well as the diffuse multipath components.
Our results show that the ESPRIT channel estimator can estimate the channel parameters of both specular and diffuse multipath, and that the proposed system can directly use the raw un-clustered channel estimation results by applying the proposed clustering algorithms. With the help of the novel likelihood function, the proposed scheme can accurately estimate the number of landmarks, their types (i.e., roughness), and positions, and the channel gain is helpful in clustering and mapping and positing. The results also confirm that the proposed method can handle mapping and vehicle state estimation simultaneously, and highlight the benefit of considering both specular and diffuse multipath. In addition, the channel gains turn out the be highly informative for synchronizing the user to the base station.
The proposed framework has two computational bottleneck—the ESPRIT channel estimator and the particle filter used in the PMBM SLAM. In order to enable real-time execution, there is a need for faster solutions for both the channel estimation and the SLAM filter. The solutions could be either in the form of new algorithms, or by offloading the computation to more powerful edge computing systems, where edge servers can provide high-performance computing capability closer to end users [68,69,70].
Author Contributions
Y.G. has led the paper, drafted the main parts, derived the likelihood functions, and performed the simulations. F.W. has led the work related to channel estimation and relation between channel parameters and the location parameters. H.K. derived the SLAM methods. M.Z. provided expertise on clustering and channel estimation. F.J. has supported the work on clustering and proof-reading of the paper. S.K., L.S., and H.W. were supervisors of the research and acquired the funding. They have also proof-read and edited the paper. All authors have read and agreed to the published version of the manuscript.
Funding
This work was partially supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by Knut and Alice Wallenberg Foundation, the Vinnova 5GPOS project under grant 2019-03085, by the Swedish Research Council under grant 2018-0370, by the MSIP, Korea, under the ITRC support program IITP-2020-2017-0-01637, and by the IITP grant funded by the Korea government No. 2019-0-01325.
Acknowledgments
The authors are grateful to Kamran Keykhosravi, Zohair Abu Shaban and M. Furkan Keskin for their comments on this manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Geometric Relations
The geometric relations are as follows. For LOS, returns
- TOA:
- AOD pair: ,
- AOA pair: ,
For the case of a specular component, returns
- TOA:
- AOD pair: ,
- AOA pair: , .
where is the incident point, which can be calculated by (31). For the case of a diffuse component with diffuse point , returns
- TOA:
- AOD pair: ,
- AOA pair: , .
Appendix B. PMBM SLAM Filter
Appendix B.1. Representation of PMBM Density
We adopt the finite set statistic (FISST) for the multi-target tracking [71], and we introduce RFS for a multi-target state, which consists of the undetected targets that have never been detected before and detected targets that have been detected at least once. The PMBM density is denoted by [65]
where ⊎ denotes the union of mutually disjoint sets, denotes a Poisson point process (PPP) density, and denotes an multi-Bernoulli mixture (MBM) density. The PPP density is defined as
where is the intensity function called as probability hypotheses density [72], n is the cardinality of . The MBM density is represented as
where h indicates the hypotheses index [18], n is the number of potentially detected objects, and denotes the Bernoulli density of the object j under the global hypothesis h, and is its weight. Each Bernoulli density follows
where is the existence probability and is the state density. Then, (A2) can be parameterized by , and (A3) can be parameterized by , where is the index set.
Appendix B.2. Implementation of PMBM SLAM Filter
The PMBM SLAM filter goes through prediction and update steps of the Bayesian filtering recursion as in [23]. For implementation, we adopt the Rao-Blackwellized approach; particles represent the user state, and PMBM densities conditioned on each particle indicate the landmarks. At the beginning of time k, is given, where and , and we have a PMBM density with PPP parameter and MBM parameters for all particle n. For notation simplicity, we omit the particle index n in the PPP and MBM parameters.
- User Prediction: Using (1), the user particle is predicted as , where and .
- Map Prediction: Since the targets are static, the PPP parameter is predicted as , where is the survival probability, is the birth intensity. For the MBM components, , , and .
- Map Update: The map update is divided into the following four cases [65]
- (a)
- Missed detections for undetected objects: The undetected objects remain as the undetected objects, and thus is given bywhere indicates the detection probability.
- (b)
- Detections for the first time: Using the grouped measurement and the PPP parameter , we newly generate the MBM parameters aswhere .
- (c)
- Missed detections for the previously detected objects: The detected objects also remain as the detected objects, and then the MBM parameters have no measurement update
- (d)
- Detections for the previously detected objects: Using , the MBM parameters are computed as
- User Update: Each particle weight is updated aswhere is the weight for the updated global hypothesis h and particle n. Then, the user state is estimated by .
Given the number of particles N, the user state prediction requires computations. For each particle, the map prediction requires computations (if there are unique Bernoulli components for the given particle), and the map update process requires computations for updating Bernoulli components and for updating data associations and their weights (if there are measurement clusters and global hypotheses in total for the given particle), where A represents the permutation operation and C represents the combination operation. The complexity of the particle weight updating is for each particle, and the complexity of state estimation is . Note: each particle may have different and .
Appendix B.3. Map Fusion
We need to create a map using these particles. Since there is a different MBM for each particle, and an MB represents a possible map, a best map needs to be computed. Firstly, we need to compute an MB for each particle. The MBM with parameters can be written as , where is the probability of the global hypothesis h, which follows
The existence probability of each new MB component will be [18]
and the density becomes
Then, we have an MB with parameters for particle n. When considering all particles, we would create a larger MB by concatenating all MBs of different particles together, with parameters . Finally, we merge components with Euclidean distances smaller than the given threshold in the new MB, and the finial MB is the best map. The map fusion requires computations, when considering the merging process.
References
- Narayanan, A.; Ramadan, E.; Carpenter, J.; Liu, Q.; Liu, Y.; Qian, F.; Zhang, Z.L. A first look at commercial 5G performance on smartphones. In Proceedings of the Web Conference, Taipei, Taiwan, 20–24 April 2020; pp. 894–905. [Google Scholar]
- Del Peral-Rosado, J.A.; Raulefs, R.; López-Salcedo, J.A.; Seco-Granados, G. Survey of cellular mobile radio localization methods: From 1G to 5G. IEEE Commun. Surv. Tutorials 2017, 20, 1124–1148. [Google Scholar] [CrossRef]
- 3GPP TR 38.855 V16.0.0; Study on NR Positioning Support; Technical Report. Available online: https://www.3gpp.org (accessed on 18 August 2020).
- Del Peral-Rosado, J.; Granados, G.; Raulefs, R.; Leitinger, E.; Grebien, S.; Wilding, T.; Dardari, D.; Lohan, E.; Wymeersch, H.; Floch, J.; et al. White Paper on New Localization Methods for 5G Wireless Systems and the Internet-of-Things. In COST Action CA15104. Available online: http://www.iracon.org/wp-content/uploads/2018/03/IRACON-WP2.pdf (accessed on 18 August 2020).
- Witrisal, K.; Meissner, P.; Leitinger, E.; Shen, Y.; Gustafson, C.; Tufvesson, F.; Haneda, K.; Dardari, D.; Molisch, A.F.; Conti, A.; et al. High-accuracy localization for assisted living: 5G systems will turn multipath channels from foe to friend. IEEE Signal Process. Mag. 2016, 33, 59–70. [Google Scholar] [CrossRef]
- Talvitie, J.; Valkama, M.; Destino, G.; Wymeersch, H. Novel algorithms for high-accuracy joint position and orientation stimation in 5G mmWave systems. In Proceedings of the IEEE Globecom Workshops (GC Wkshps), Singapore, 4–8 December 2017. [Google Scholar]
- Mendrzik, R.; Wymeersch, H.; Bauch, G. Joint localization and mapping through millimeter wave MIMO in 5G systems. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018. [Google Scholar]
- Li, X.; Leitinger, E.; Oskarsson, M.; Åström, K.; Tufvesson, F. Massive MIMO-based localization and mapping exploiting phase information of multipath components. IEEE Trans. Wirel. Commun. 2019, 18, 4254–4267. [Google Scholar] [CrossRef] [Green Version]
- Fascista, A.; Coluccia, A.; Wymeersch, H.; Seco-Granados, G. Millimeter-wave downlink positioning with a single-antenna receiver. IEEE Trans. Wirel. Commun. 2019, 18, 4479–4490. [Google Scholar] [CrossRef] [Green Version]
- Fascista, A.; Coluccia, A.; Wymeersch, H.; Seco-Granados, G. Downlink single-snapshot localization and mapping with a single-antenna receiver. arXiv 2020, arXiv:2007.14679. [Google Scholar]
- Richter, A. Estimation of Radio Channel Parameters: Models and Algorithms. Ph.D. Thesis, Ilmenau University of Technology, Ilmenau, Germany, 2005. [Google Scholar]
- Alkhateeb, A.; El Ayach, O.; Leus, G.; Heath, R.W. Channel estimation and hybrid precoding for millimeter wave cellular systems. IEEE J. Sel. Top. Signal Process. 2014, 8, 831–846. [Google Scholar] [CrossRef] [Green Version]
- Venugopal, K.; Alkhateeb, A.; Prelcic, N.G.; Heath, R.W. Channel estimation for hybrid architecture-based wideband millimeter wave systems. IEEE J. Sel. Areas Commun. 2017, 35, 1996–2009. [Google Scholar] [CrossRef]
- Gershman, A.B.; Rübsamen, M.; Pesavento, M. One- and two-dimensional direction-of-arrival estimation: An overview of search-free techniques. Signal Process. 2010, 90, 1338–1349. [Google Scholar] [CrossRef]
- Wen, F.; Garcia, N.; Kulmer, J.; Witrisal, K.; Wymeersch, H. Tensor decomposition based beamspace ESPRIT for millimeter wave MIMO channel estimation. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Abu Dhabi, UAE, 9–13 December 2018. [Google Scholar]
- Zhou, Z.; Fang, J.; Yang, L.; Li, H.; Chen, Z.; Blum, R.S. Low-rank tensor decomposition-aided channel estimation for millimeter wave MIMO-OFDM systems. IEEE J. Sel. Areas Commun. 2017, 35, 1524–1538. [Google Scholar] [CrossRef]
- Mullane, J.; Vo, B.N.; Adams, M.D.; Vo, B.T. A random-finite-set approach to Bayesian SLAM. IEEE Trans. Robot. 2011, 27, 268–282. [Google Scholar] [CrossRef]
- Williams, J.L. Marginal multi-Bernoulli filters: RFS derivation of MHT, JIPDA, and association-based MeMBer. IEEE Trans. Aerosp. Electron. Syst. 2015, 51, 1664–1687. [Google Scholar] [CrossRef] [Green Version]
- Leitinger, E.; Meyer, F.; Hlawatsch, F.; Witrisal, K.; Tufvesson, F.; Win, M.Z. A belief propagation algorithm for multipath-based SLAM. IEEE Trans. Wirel. Commun. 2019, 18, 5613–5629. [Google Scholar] [CrossRef] [Green Version]
- Gentner, C.; Jost, T.; Wang, W.; Zhang, S.; Dammann, A.; Fiebig, U.C. Multipath assisted positioning with simultaneous localization and mapping. IEEE Trans. Wirel. Commun. 2016, 15, 6104–6117. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Wymeersch, H.; Garcia, N.; Seco-Granados, G.; Kim, S. 5G mmWave vehicular tracking. In Proceedings of the 52nd IEEE Asilomar Conference on Signals, Systems, and Computers, Pacific Grove, CA, USA, 28–31 October 2018; pp. 541–547. [Google Scholar]
- Meyer, F.; Braca, P.; Willett, P.; Hlawatsch, F. A scalable algorithm for tracking an unknown number of targets using multiple sensors. IEEE Trans. Signal Process. 2017, 65, 3478–3493. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.; Granström, K.; Gao, L.; Battistelli, G.; Kim, S.; Wymeersch, H. 5G mmWave cooperative positioning and mapping using multi-model PHD filter and map fusion. IEEE Trans. Wirel. Commun. 2020. [Google Scholar] [CrossRef] [Green Version]
- Ge, Y.; Kim, H.; Wen, F.; Svensson, L.; Kim, S.; Wymeersch, H. Exploiting diffuse multipath in 5G SLAM. arXiv 2020, arXiv:2006.15603. [Google Scholar]
- Granström, K.; Baum, M.; Reuter, S. Extended object tracking: Introduction, overview and applications. arXiv 2016, arXiv:1604.00970. [Google Scholar]
- Aubry, A.; De Maio, A.; Foglia, G.; Orlando, D. Diffuse multipath exploitation for adaptive radar detection. IEEE Trans. Signal Process. 2015, 63, 1268–1281. [Google Scholar] [CrossRef]
- Setlur, P.; Negishi, T.; Devroye, N.; Erricolo, D. Multipath exploitation in non-LOS urban synthetic aperture radar. IEEE J. Sel. Top. Signal Process. 2013, 8, 137–152. [Google Scholar] [CrossRef] [Green Version]
- Wen, F.; Kulmer, J.; Witrisal, K.; Wymeersch, H. 5G positioning and mapping with diffuse multipath. arXiv 2019, arXiv:1912.08697. [Google Scholar]
- Fatemi, M.; Granström, K.; Svensson, L.; Ruiz, F.J.; Hammarstrand, L. Poisson multi-Bernoulli mapping using Gibbs sampling. IEEE Trans. Signal Process. 2017, 65, 2814–2827. [Google Scholar] [CrossRef] [Green Version]
- Granström, K.; Svensson, L.; Reuter, S.; Xia, Y.; Fatemi, M. Likelihood-based data association for extended object tracking using sampling methods. IEEE Trans. Intell. Veh. 2017, 3, 30–45. [Google Scholar] [CrossRef]
- Granström, K.; Lundquist, C.; Orguner, O. Extended target tracking using a Gaussian-mixture PHD filter. IEEE Trans. Aerosp. Electron. Syst. 2012, 48, 3268–3286. [Google Scholar] [CrossRef] [Green Version]
- Czink, N.; Cera, P.; Salo, J.; Bonek, E.; Nuutinen, J.P.; Ylitalo, J. A framework for automatic clustering of parametric MIMO channel data including path powers. In Proceedings of the IEEE Vehicular Technology Conference, Melbourne, Australia, 7–10 May 2006. [Google Scholar]
- 5GPPP Association. 5G Automotive Vision, 5GPPP; White Paper. Available online: https://5g-ppp.eu (accessed on 18 August 2020).
- Ahvar, E.; Daneshgar-Moghaddam, N.; Ortiz, A.M.; Lee, G.M.; Crespi, N. On analyzing user location discovery methods in smart homes: A taxonomy and survey. J. Netw. Comput. Appl. 2016, 76, 75–86. [Google Scholar] [CrossRef] [Green Version]
- Yaeli, A.; Bak, P.; Feigenblat, G.; Nadler, S.; Roitman, H.; Saadoun, G.; Ship, H.J.; Cohen, D.; Fuchs, O.; Ofek-Koifman, S.; et al. Understanding customer behavior using indoor location analysis and visualization. IBM J. Res. Dev. 2014, 58, 1–3. [Google Scholar] [CrossRef]
- Hwangbo, H.; Kim, Y.S.; Cha, K.J. Use of the smart store for persuasive marketing and immersive customer experiences: A case study of Korean apparel enterprise. Mob. Inform. Syst. 2017, 2017, 4738340. [Google Scholar]
- Taranto, R.D.; Muppirisetty, S.; Raulefs, R.; Slock, D.; Svensson, T.; Wymeersch, H. Location-aware communications for 5G networks. IEEE Signal Process. Mag. 2014, 31, 102–112. [Google Scholar] [CrossRef] [Green Version]
- Guidi, F.; Guerra, A.; Dardari, D. Personal mobile radars with millimeter-wave massive arrays for indoor mapping. IEEE Trans. Mob. Comput. 2015, 15, 1471–1484. [Google Scholar] [CrossRef]
- Bourdoux, A.; Barreto, A.N.; van Liempd, B.; de Lima, C.; Dardari, D.; Belot, D.; Lohan, E.S.; Seco-Granados, G.; Sarieddeen, H.; Wymeersch, H.; et al. 6G white paper on localization and sensing. arXiv 2020, arXiv:2006.01779. [Google Scholar]
- Kim, H.; Granström, K.; Kim, S.; Wymeersch, H. Low-complexity 5G SLAM with CKF-PHD filter. In IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP); IEEE: Piscataway, NJ, USA, 2020; pp. 5220–5224. [Google Scholar]
- Ferre, R.M.; Seco-Granados, G.; Lohan, E.S. Positioning Reference Signal Design for Positioning Via 5G; National Committee for Radiology in Finland: Tampere, Finland, 2019. [Google Scholar]
- 3GPP TS 38.211 NR V15.8.0; Physical Channels and Modulation; Technical Report. Available online: https://www.3gpp.org (accessed on 18 August 2020).
- Kulmer, J. High-Accuracy Positioning Exploiting Multipath for Reducing the Infrastructure. Ph.D. Thesis, Graz University of Technology, Graz, Austria, 2019. [Google Scholar]
- Heath, R.W.; Gonzalez-Prelcic, N.; Rangan, S.; Roh, W.; Sayeed, A.M. An overview of signal processing techniques for millimeter wave MIMO systems. IEEE J. Sel. Top. Signal Process. 2016, 10, 436–453. [Google Scholar] [CrossRef]
- Vukmirović, N.; Erić, M.; Janjić, M.; Djurić, P.M. Direct wideband coherent localization by distributed antenna arrays. Sensors 2019, 19, 4582. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, P.; Pajovic, M.; Koike-Akino, T.; Sun, H.; Orlik, P.V. Fingerprinting-based indoor localization with commercial mmWave WiFi-part II: Spatial beam SNRs. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Waikoloa, HI, USA, 9–13 December 2019. [Google Scholar]
- Guerra, A.; Guidi, F.; Dardari, D. Single-anchor localization and orientation performance limits using massive arrays: Mimovs. beamforming. IEEE Trans. Wirel. Commun. 2018, 17, 5241–5255. [Google Scholar] [CrossRef] [Green Version]
- Liu, X.; Sidiropoulos, N.D.; Jiang, T.; Gershman, A. Multidimensional harmonic retrieval with applications in MIMO wireless channel sounding. In Space-Time Processing for MIMO Communications; Wiley Online Library: Hoboken, NJ, USA, 2005; pp. 41–75. [Google Scholar]
- Yang, Z.; Li, J.; Stoica, P.; Xie, L. Sparse methods for direction-of-arrival estimation. In Academic Press Library in Signal Processing; Elsevier: Amsterdam, The Netherlands, 2018; Volume 7, pp. 509–581. [Google Scholar]
- Haardt, M.; Pesavento, M.; Roemer, F.; El Korso, M.N. Subspace methods and exploitation of special array structures. In Academic Press Library in Signal Processing; Elsevier: Amsterdam, The Netherlands, 2014; Volume 3, pp. 651–717. [Google Scholar]
- Haardt, M.; Roemer, F.; Del Galdo, G. Higher-order SVD-based subspace estimation to improve the parameter estimation accuracy in multidimensional harmonic retrieval problems. IEEE Trans. Signal Process. 2008, 56, 3198–3213. [Google Scholar] [CrossRef]
- Kolda, T.G.; Bader, B.W. Tensor decompositions and applications. SIAM Rev. 2009, 51, 455–500. [Google Scholar] [CrossRef]
- Liu, K.; da Costa, J.P.C.; So, H.C.; Huang, L.; Ye, J. Detection of number of components in CANDECOMP/PARAFAC models via minimum description length. Digit. Signal Process. 2016, 51, 110–123. [Google Scholar] [CrossRef]
- Phan, A.; Tichavský, P.; Cichocki, A. CANDECOMP/PARAFAC decomposition of high-order tensors through tensor reshaping. IEEE Trans. Signal Process. 2013, 61, 4847–4860. [Google Scholar] [CrossRef]
- Han, J.; Kamber, M.; Pei, J. Data Mining, Concepts and Techniques; Morgan Kaufmann Publishers: San Mateo, CA, USA, 2011. [Google Scholar]
- Foerster, J.R.; Pendergrass, M.; Molisch, A.F. A UWB channel model for ultra wideband indoor communications. In Proceedings of the International Symposium on Wireless Personal Multimedia Communications, Yokosuka, Japan, 19–22 October 2003. [Google Scholar]
- Czink, N. The Random-Cluster Model. Ph.D. Thesis, Technische Universitäat Wien, Vienna, Austria, 2007. [Google Scholar]
- Wyne, S.; Czink, N.; Karedal, J.; Almers, P.; Tufvesson, F.; Molisch, A.F. A cluster-based analysis of outdoor-to-indoor office MIMO measurements at 5.2 GHz. In Proceedings of the IEEE Vehicular Technology Conference, Melbourne, Australia, 7–10 May 2006. [Google Scholar]
- Salo, J.; Salmi, J.; Czink, N.; Vainikainen, P. Automatic clustering of nonstationary MIMO channel parameter estimates. In Proceedings of the Information and Communications Technologies, Cape Town, South Africa, 3–6 May 2005. [Google Scholar]
- Czink, N.; Yin, X.; Ozcelik, H.; Herdin, M.; Bonek, E.; Fleury, B.H. Cluster characteristics in a MIMO indoor propagation environment. IEEE Trans. Wirel. Commun. 2007, 6, 1465–1475. [Google Scholar] [CrossRef]
- He, R.; Ai, B.; Molisch, A.F.; Stuber, G.L.; Li, Q.; Zhong, Z.; Yu, J. Clustering enabled wireless channel modeling using big data algorithms. IEEE Commun. Mag. 2018, 56, 177–183. [Google Scholar] [CrossRef]
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Frey, B.J.; Dueck, D. Clustering by passing messages between data points. Science 2007, 315, 972–976. [Google Scholar] [CrossRef] [Green Version]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. In Proceedings of the International Conference on Knowledge Discovery and Data Mining, Portland, OR, USA, 2–4 August 1996; pp. 226–231. [Google Scholar]
- García-Fernández, Á.F.; Williams, J.L.; Granström, K.; Svensson, L. Poisson multi-Bernoulli mixture filter: Direct derivation and implementation. IEEE Trans. Aerosp. Electron. Syst. 2018, 54, 1883–1901. [Google Scholar] [CrossRef] [Green Version]
- Tibshirani, R.; Walther, G.; Hastie, T. Estimating the number of clusters in a data set via the gap statistic. J. R. Stat. Soc. Ser. B Stat. Methodol. 2001, 63, 411–423. [Google Scholar] [CrossRef]
- Rahmathullah, A.S.; García-Fernández, Á.F.; Svensson, L. Generalized optimal sub-pattern assignment metric. In Proceedings of the 20th IEEE International Conference on Information Fusion (Fusion), Xi’an, China, 10–13 July 2017. [Google Scholar]
- Mitsis, G.; Tsiropoulou, E.E.; Papavassiliou, S. Data offloading in UAV-assisted multi-access edge computing systems: A resource-based pricing and user risk-awareness approach. Sensors 2020, 20, 2434. [Google Scholar] [CrossRef] [PubMed]
- Mitsis, G.; Apostolopoulos, P.A.; Tsiropoulou, E.E.; Papavassiliou, S. Intelligent dynamic data offloading in a competitive mobile edge computing market. Future Internet 2019, 11, 118. [Google Scholar] [CrossRef] [Green Version]
- Ferdowsi, A.; Challita, U.; Saad, W. Deep learning for reliable mobile edge analytics in intelligent transportation systems: An overview. IEEE Veh. Technol. Mag. 2019, 14, 62–70. [Google Scholar] [CrossRef]
- Mahler, R.P. Advances in Statistical Multisource-Multitarget Information Fusion; Artech House: Norwood, MA, USA, 2014. [Google Scholar]
- Mahler, R.P. Multitarget Bayes filtering via first-order multitarget moments. IEEE Trans. Aerosp. Electron. Syst. 2003, 39, 1152–1178. [Google Scholar] [CrossRef]
- Murty, K.G. An algorithm for ranking all the assignments in order of increasing cost. Oper. Res. 1968, 16, 682–687. [Google Scholar] [CrossRef]
Figure 1.
In mmWave simultaneous localization and mapping (SLAM) applications, each object can give rise to a specular path as well as multiple diffuse paths. The number and spread of these diffuse paths depend on the roughness of the object. At the receiver side, diffuse paths from an object have similar delays and angles, so that they can only be resolved with sufficient bandwidth and number of antennas.
Figure 1.
In mmWave simultaneous localization and mapping (SLAM) applications, each object can give rise to a specular path as well as multiple diffuse paths. The number and spread of these diffuse paths depend on the roughness of the object. At the receiver side, diffuse paths from an object have similar delays and angles, so that they can only be resolved with sufficient bandwidth and number of antennas.

Figure 2.
Two different surface models: (a) shows a high-dimensional model, while (b) is a compact model that expresses the location of the surface via a virtual anchor.
Figure 2.
Two different surface models: (a) shows a high-dimensional model, while (b) is a compact model that expresses the location of the surface via a virtual anchor.

Figure 3.
Proposed layered approach for SLAM from the observations . The time index k is omitted.

Figure 4.
Illustration of the 3D transformation from the 5D parameters: from the channel estimates, a hypothesized landmark (a virtual anchor) location is determined. From the landmark and BS locations, the incidence point is derived.
Figure 4.
Illustration of the 3D transformation from the 5D parameters: from the channel estimates, a hypothesized landmark (a virtual anchor) location is determined. From the landmark and BS locations, the incidence point is derived.

Figure 5.
The principle of finding and calculating using , and .

Figure 6.
The 3D projection of channel estimation results of 100 diffuse path and a specular path from an MR.
Figure 6.
The 3D projection of channel estimation results of 100 diffuse path and a specular path from an MR.

Figure 7.
The clustering performance of DBSCAN and K-means.

Figure 8.
Some components of the likelihood for MR.

Figure 9.
Comparison of GOSPA results among three clustering algorithms.

Figure 10.
Comparison of GOSPA results among four different settings.

Figure 11.
Comparison of vehicle state estimation performance, considering the utilization of channel gains and different sets of estimated propagation paths.
Figure 11.
Comparison of vehicle state estimation performance, considering the utilization of channel gains and different sets of estimated propagation paths.

Figure 12.
The execution times for each phase of the proposed framework.


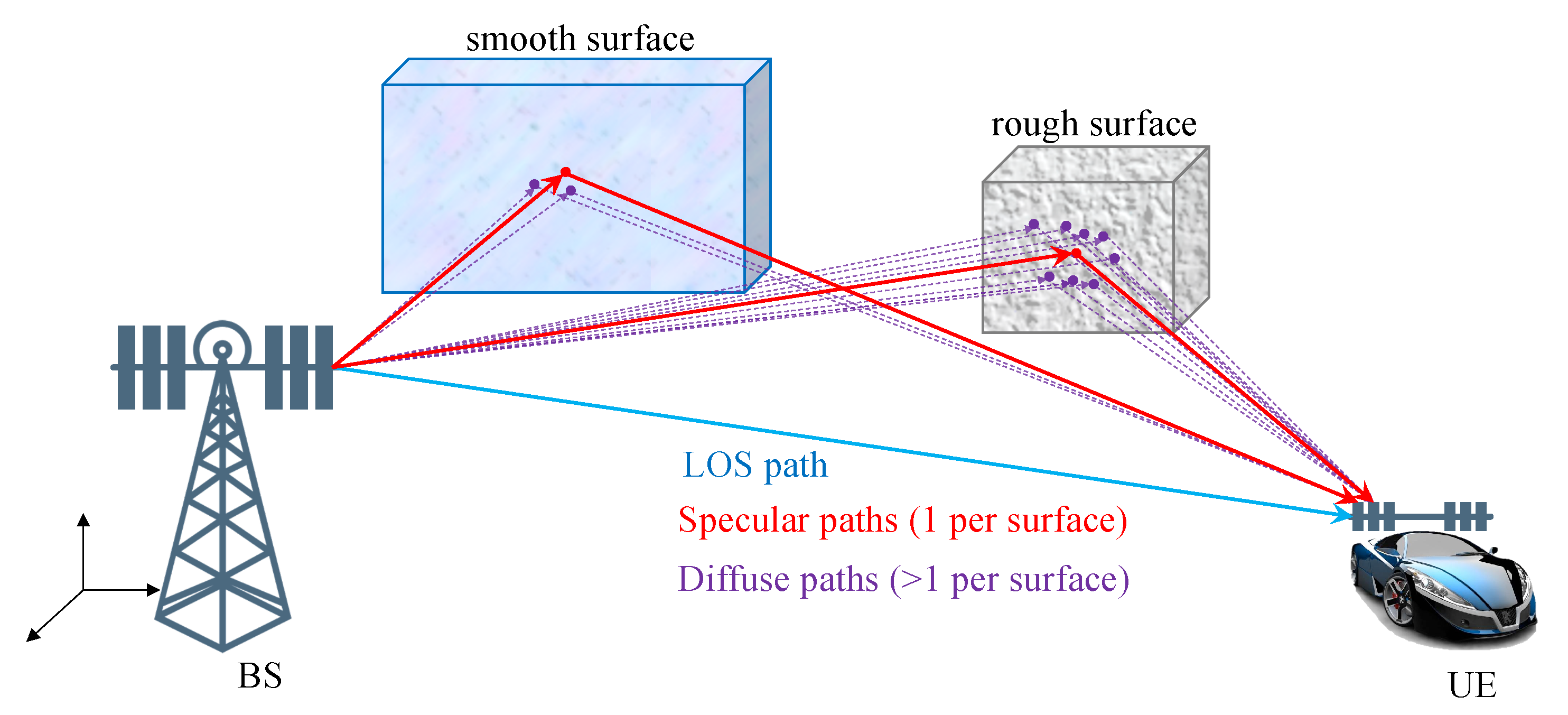{kind=link}
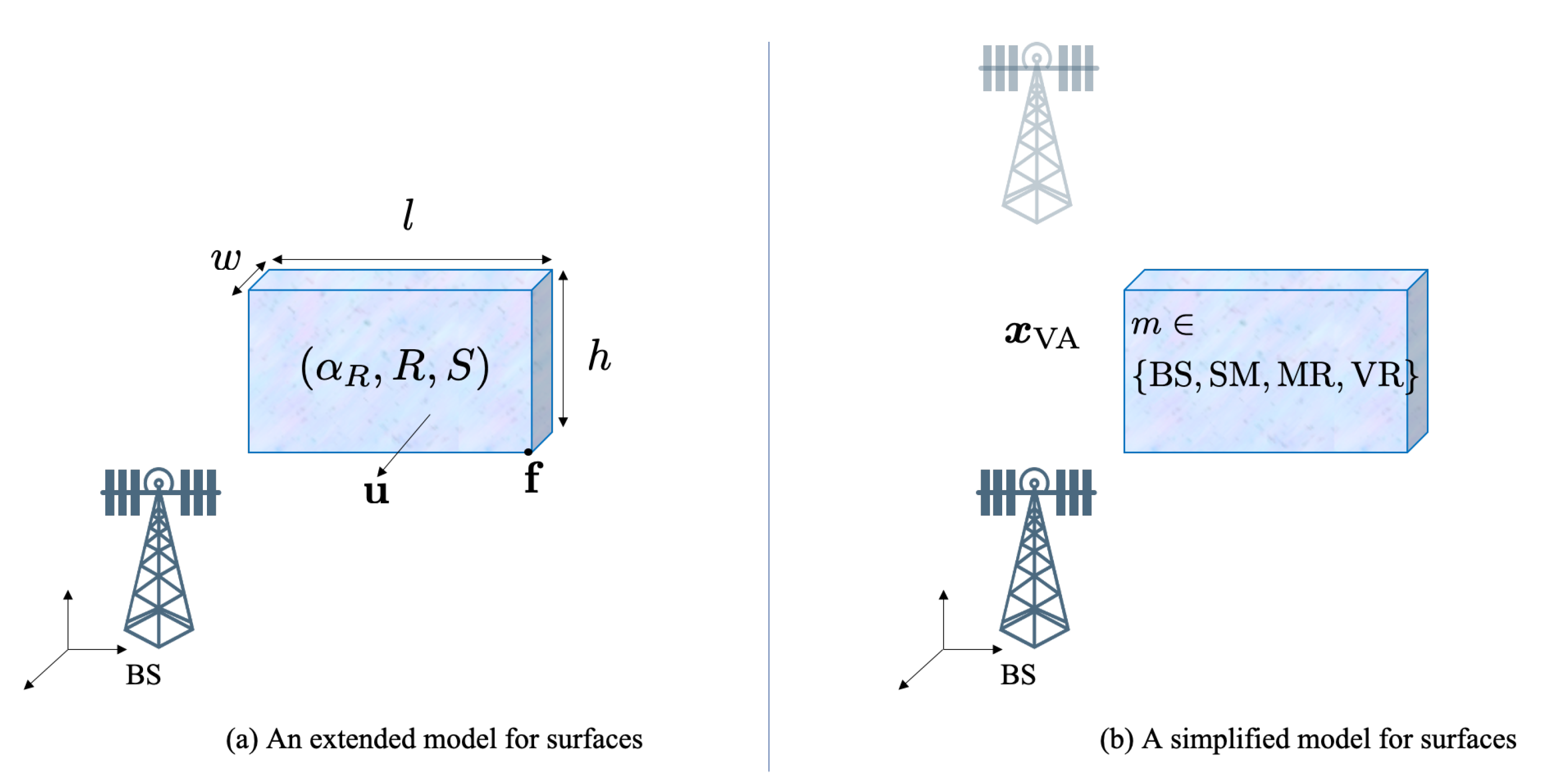{kind=link}
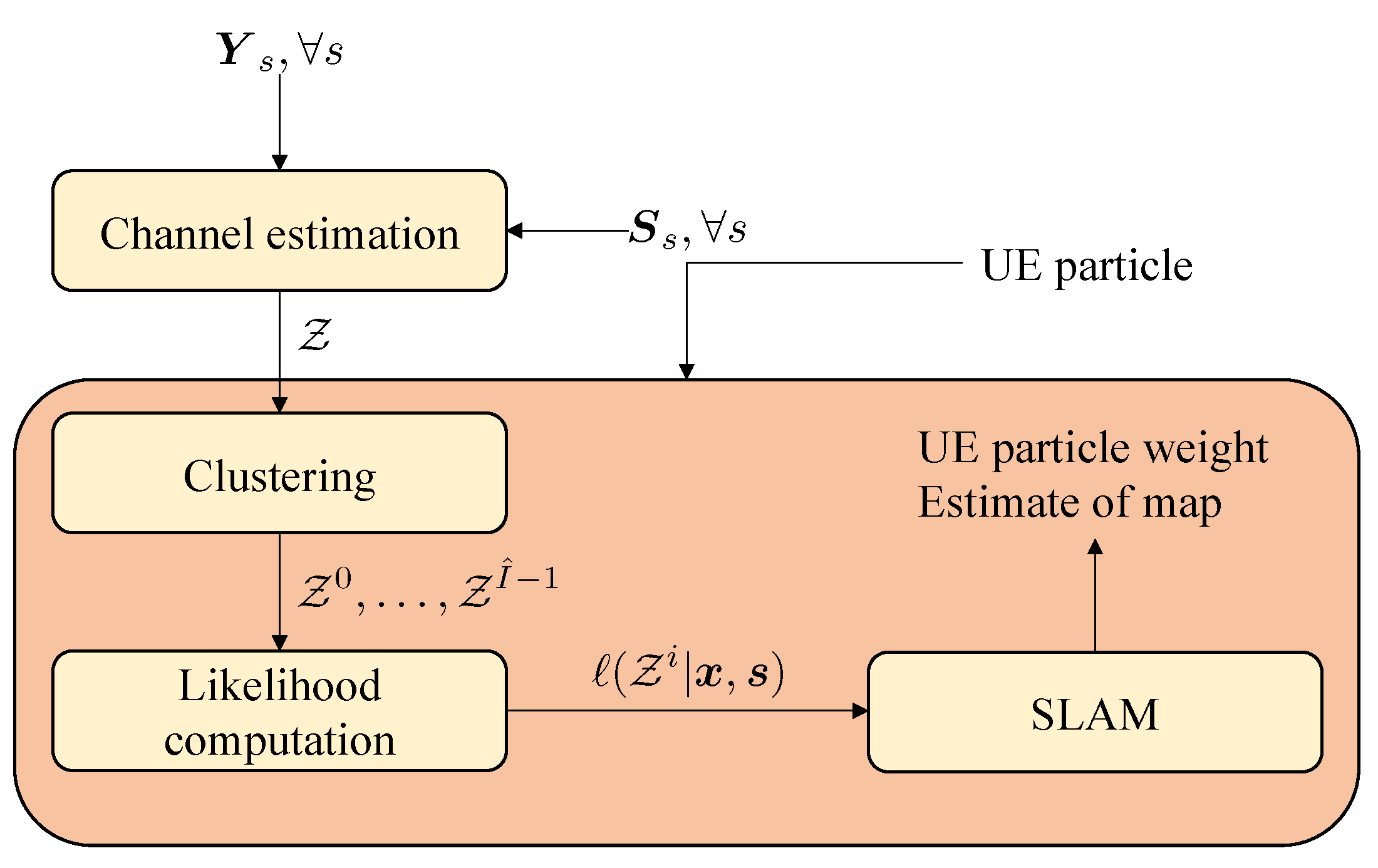{kind=link}
{kind=link}
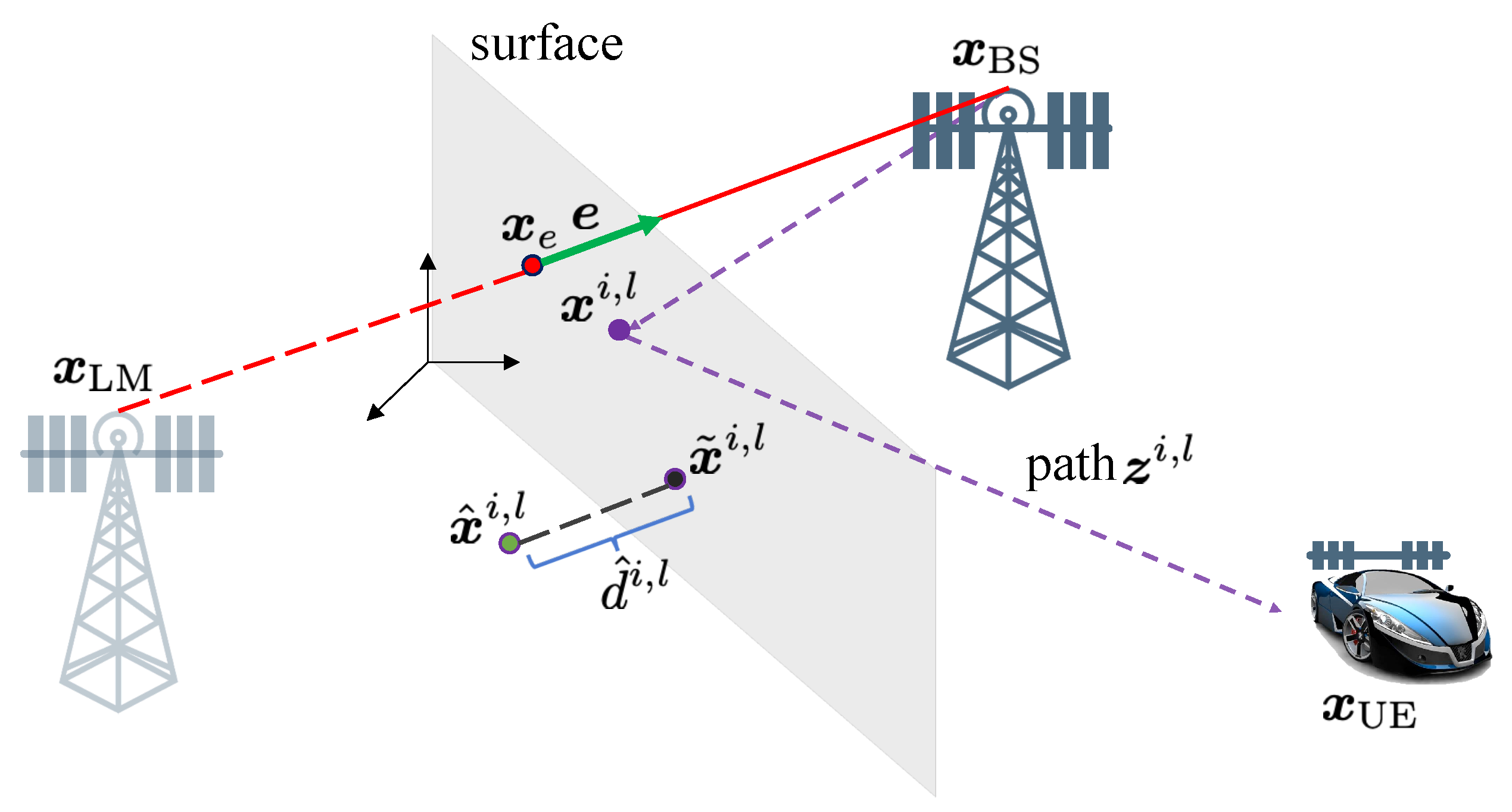{kind=link}
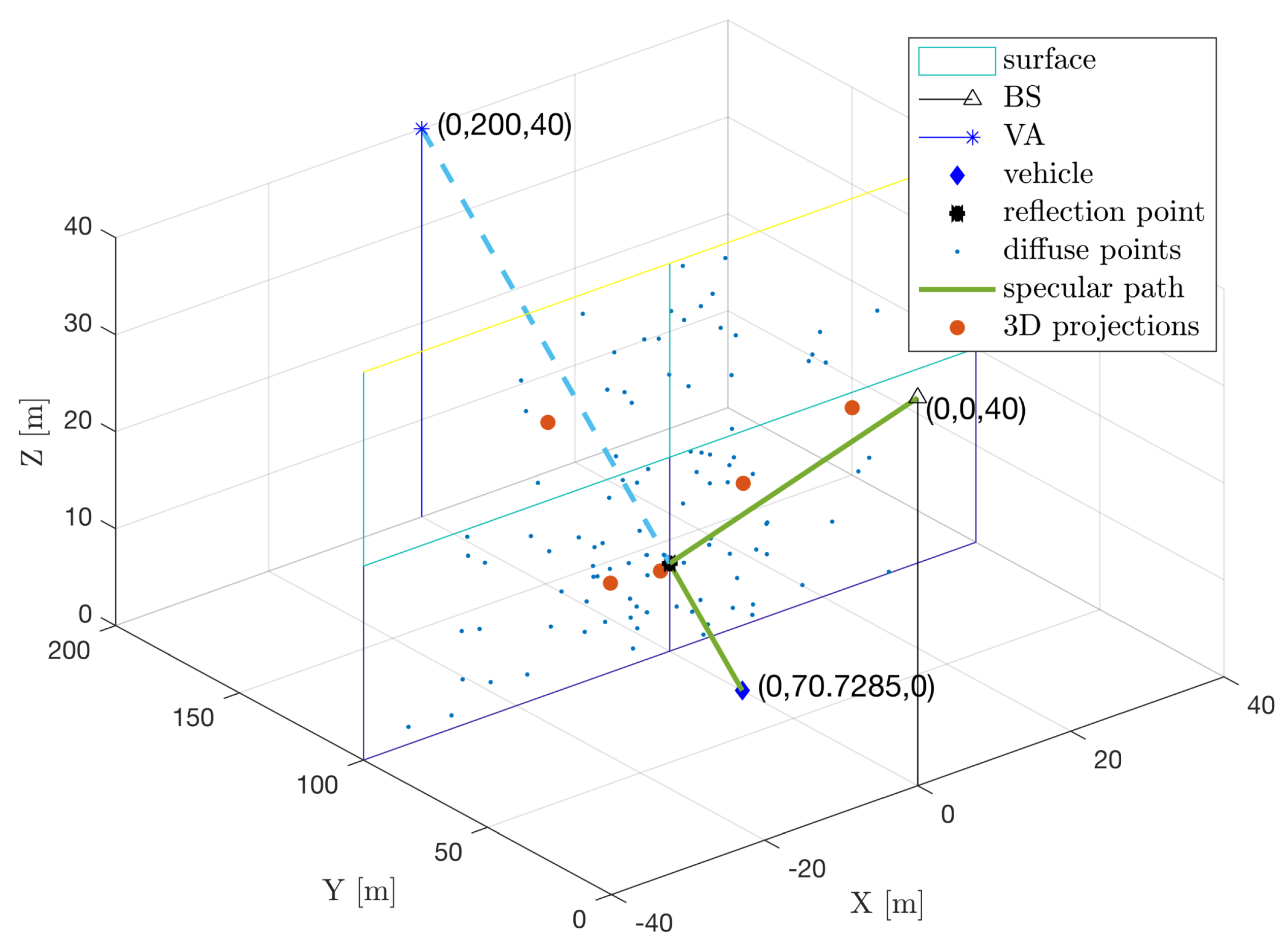{kind=link}
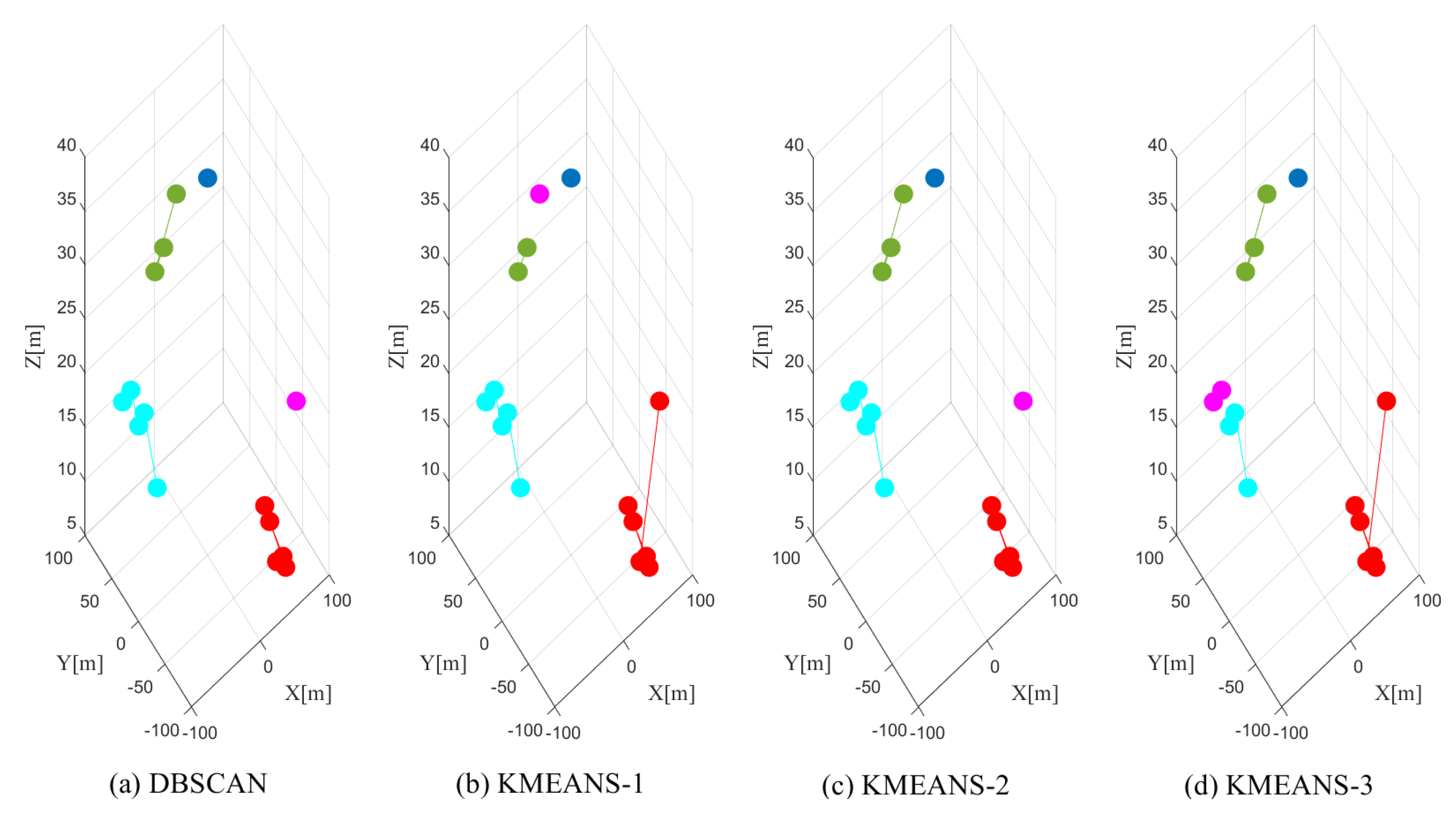{kind=link}
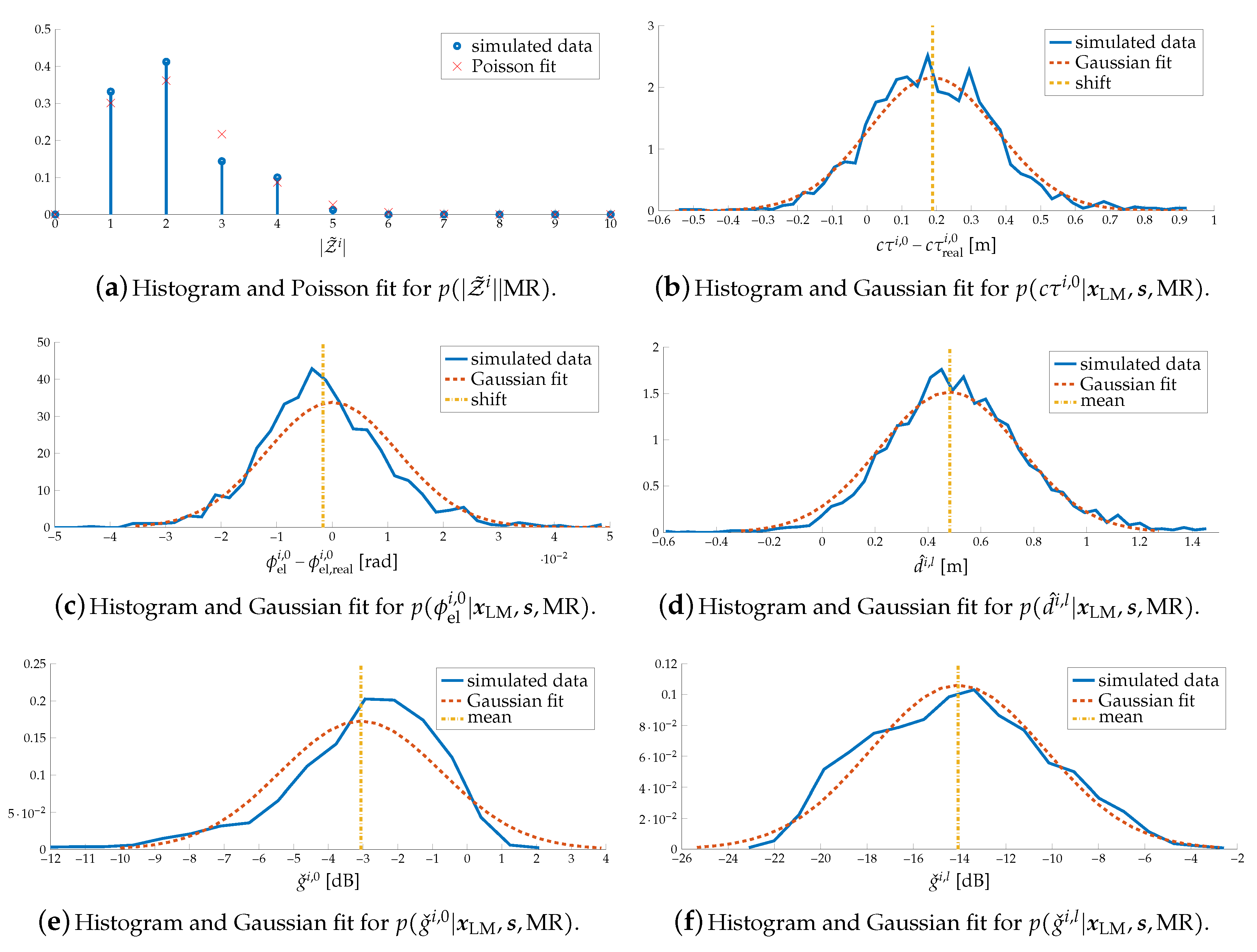{kind=link}
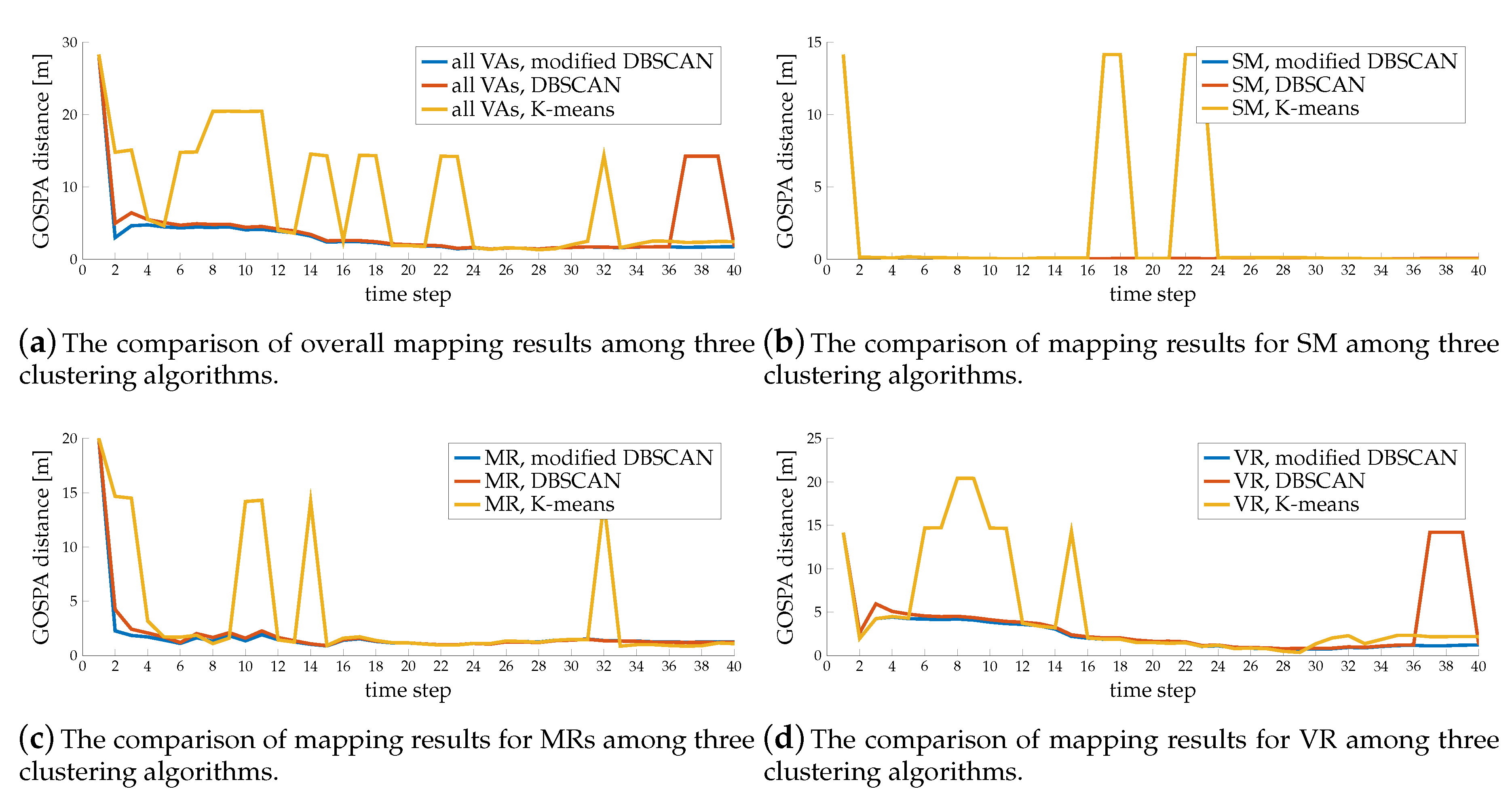{kind=link}
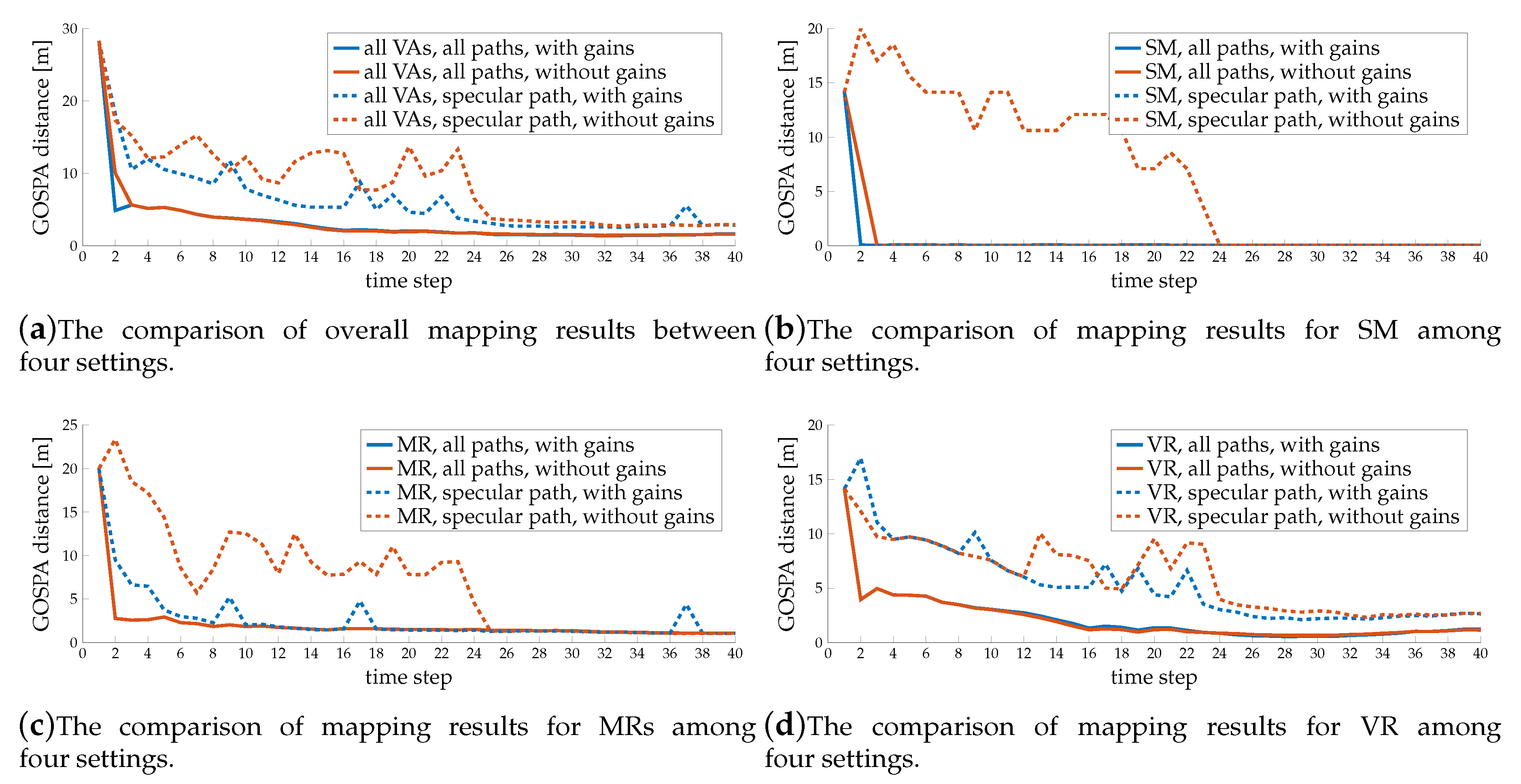{kind=link}
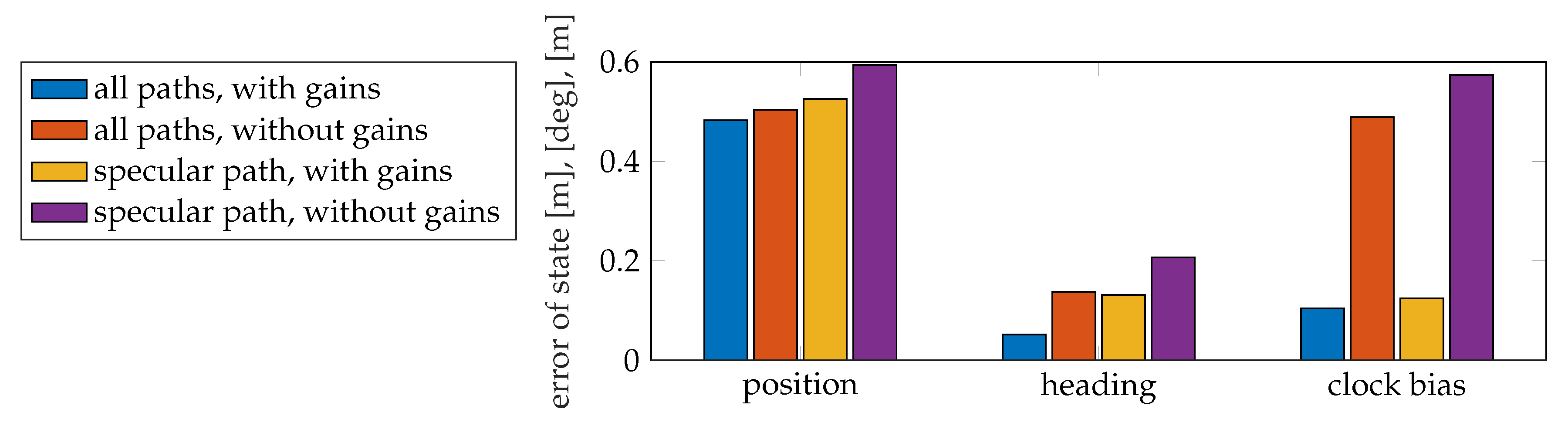{kind=link}
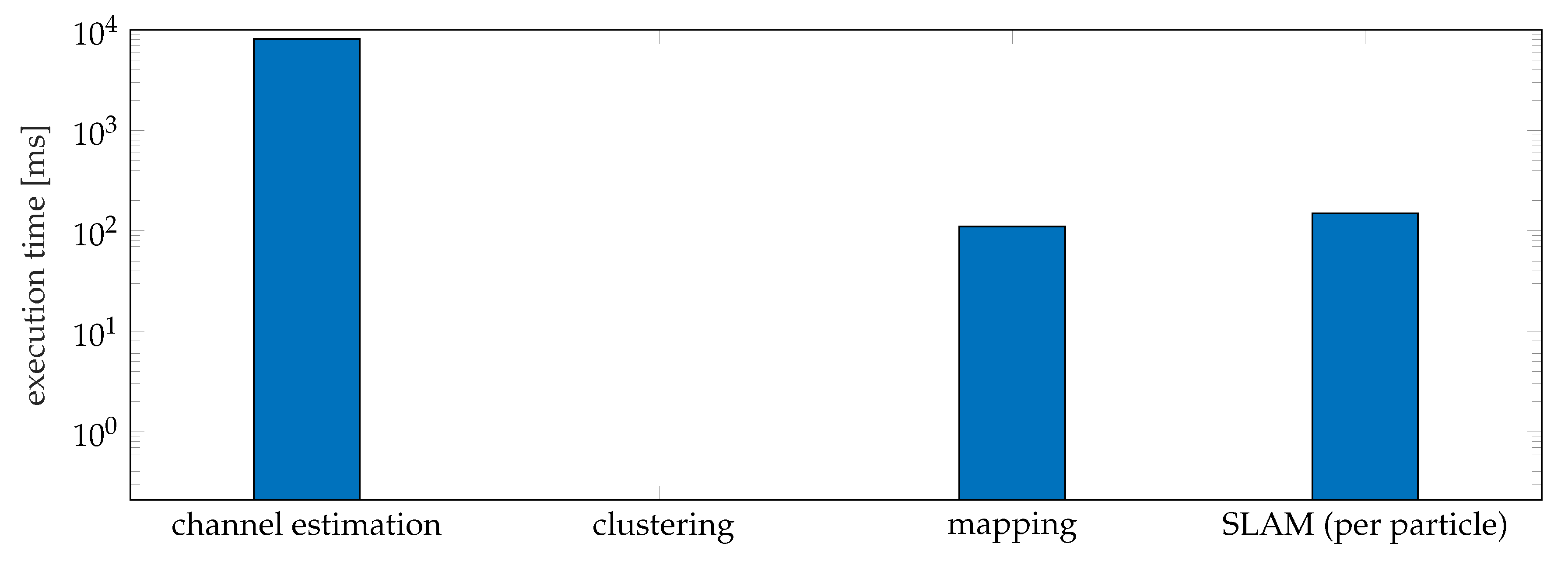{kind=link}
Table 1.
Notations of important variables.
| Notation | Definition | Notation | Definition |
|---|---|---|---|
| state of the user | landmark location | ||
| m | landmark type | angle of arrival (AOA) pair | |
| angle of departure (AOD) pair | time of arrival (TOA) | ||
| g | channel gain | measurement set | |
| single measurement | c | speed of light | |
| detection probability | k | time index | |
| i | surface index | path index | |
| s | subcarrier index | r | dimension index |
Table 2.
Performance comparison of different clustering methods.
| Clustering Method | Clustering Accuracy | Impurity |
|---|---|---|
| Modified DBSCAN | 99.61% | 0 |
| DBSCAN | 99.07% | 0 |
| K-means | 94.63% | 5.37% |
| Gap Statistics (GS) | 68.64% | 27.19% |
| Affinity Propagation (AP) | 84.35% | 12.54% |
Table 3.
Likelihood function for 5G SLAM for different types of landmarks.
| Type m | ||
|---|---|---|
| BS | N/A | |
| SM | N/A | |
| MR | ||
| VR | ||
| BS | ||
| SM | ||
| MR | ||
| VR | ||
* means that is equal to M plus a random variable drawn from a discrete mixture distribution with two components: one with mass p at value n and one that is a scaled Geometric distribution (with scaling ). represents a Poisson distribution. denotes . , are the geometric relations and , which can be found in Appendix A.
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Ge, Y.; Wen, F.; Kim, H.; Zhu, M.; Jiang, F.; Kim, S.; Svensson, L.; Wymeersch, H. 5G SLAM Using the Clustering and Assignment Approach with Diffuse Multipath. Sensors 2020, 20, 4656. https://doi.org/10.3390/s20164656
AMA Style
Ge Y, Wen F, Kim H, Zhu M, Jiang F, Kim S, Svensson L, Wymeersch H. 5G SLAM Using the Clustering and Assignment Approach with Diffuse Multipath. Sensors. 2020; 20(16):4656. https://doi.org/10.3390/s20164656
Chicago/Turabian StyleGe, Yu, Fuxi Wen, Hyowon Kim, Meifang Zhu, Fan Jiang, Sunwoo Kim, Lennart Svensson, and Henk Wymeersch. 2020. "5G SLAM Using the Clustering and Assignment Approach with Diffuse Multipath" Sensors 20, no. 16: 4656. https://doi.org/10.3390/s20164656
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.