1. Introduction
Emotions are complex states that result in psychological and physiological changes that influence our behaving and thinking [
1]. The main assumption is that there are objectively measurable physiological responses to the autonomic nervous system activity that can be used for recognizing the human emotional state [
2]. For example, the emotional state of fear usually initiates rapid heartbeat, rapid breathing, sweating, and muscle tension. These physiological changes can be captured by sensors embedded into wearable devices that can measure [
3]:
electrocardiography (ECG), which represents cardiac electrical activity,
electroencephalography (EEG), brain electrical activity,
electromyography (EMG), muscle activity,
Blood Volume Pulse (BVP), cardiovascular dynamics,
Electrodermal activity (EDA), sweating level,
electrooculography (EOG), eye movements,
respiration rate (RESP),
facial muscle activation (EMO), emotional activation, and
body temperature (TEMP).
Signals were provided by some behavioral sensors such as an accelerometer (ACC), a gyroscope (GYRO), and environmental sensors. A barometer, an altimeter, ambient light, temperature sensors, and GPS may also be useful as additional data sources.
With the advancement of technology and the penetration of information systems into our everyday life, the emotional awareness of systems is becoming crucial. For example, in the domain of human–computer interaction (HCI), an emotion-aware system would enable a more natural interaction and better user experience [
4]. In the mobile health domain, a system for monitoring affective states can contribute to the timely detection and treatment of emotional and mental disorders such as depression, bipolar disorders, and post-traumatic stress disorder (PTSD) [
5]. Affect recognition systems can also be beneficial from an economic point of view. For example, the cost of work-related depression in Europe has been estimated to be €617 billion annually (EU report on mental health:
https://ec.europa.eu/healt).
Unfortunately, three decades after establishing Affective Computing as a scientific field, emotionally intelligent systems are still not part of our everyday life. One reason is that relations between the wearable sensor data and the human psychophysiological states are not as explicit as is the relation between the wearable sensor data and human physical states. For example, smartphones can count steps and recognize human physical activities (e.g., running vs. walking) [
6] but cannot recognize emotions and related affective states (e.g., cognitive load) with high accuracy [
7,
8].
In the last decade, deep learning (DL) dominated the artificial intelligence (AI) domain by achieving breakthroughs in image processing [
9,
10,
11,
12], natural language processing [
13,
14,
15], and reinforcement learning [
16,
17]. Conversely to those domains, DL methods for sensor data are relatively scarce, and the appropriate DL methods and architectures are yet to be discovered [
18]. In particular, the end-to-end approach, which can significantly simplify the classification flow, is not well investigated.
The classical feature-based approach requires domain-specific, expert knowledge about the sensors and signals to extract meaningful and informative features. For example, the R-peaks are used to compute the R-R Intervals (RRI) from the ECG signal, while the systolic peaks, maximum slopes, or onsets can be used to obtain the Heart Rate Variability (HRV) from the BVP signal [
19]. Furthermore, feature extraction is time and computationally demanding, signal-dependent (each signal requires dedicated features), nonstandardized, and unsystematic (the number of features for each signal can vary from only a few for the skin temperature to hundreds for the EEG signal). To extract features, an advanced signal preprocessing is very often necessary. What is more, a great number of extracted features lead to the curse of dimensionality and require feature selection and feature reduction stages, which, in turn, may lead to the loss of information.
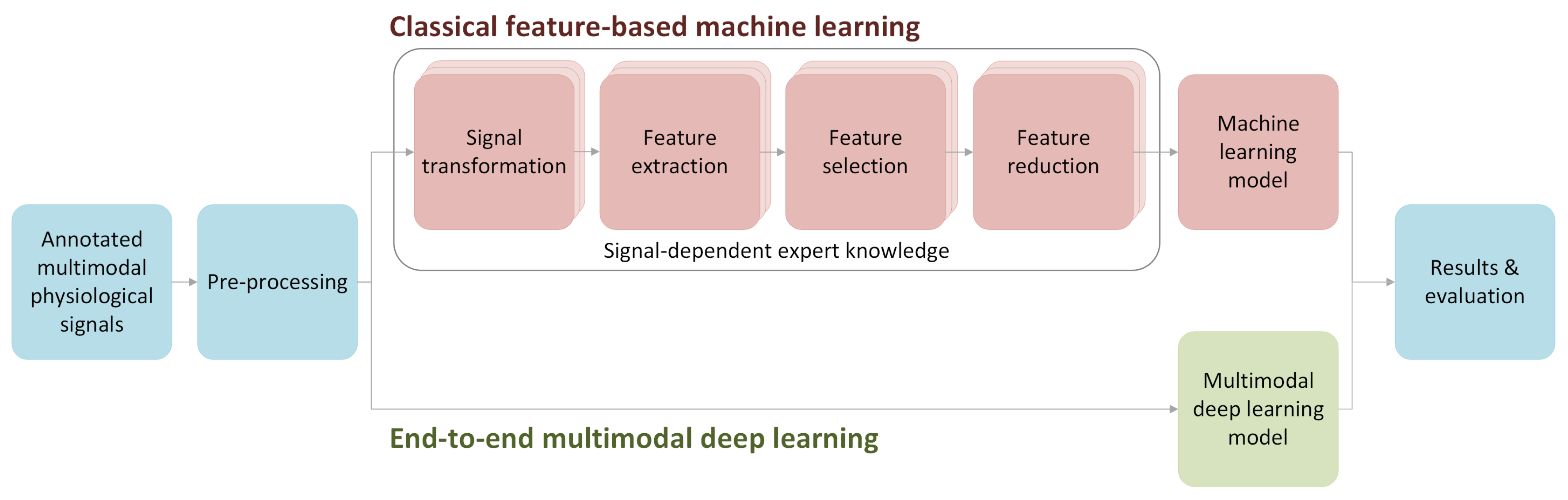
On the other hand, the end-to-end deep learning approach assumes that deep neural network architectures are able to extract the necessary information on their own, thus significantly reducing the complexity of the flow and amount of the work but also increasing the chance of extracting the appropriate information, unobtainable even for the domain experts. See
Figure 1 for an illustrative comparison between the classical feature-based approach and the end-to-end DL techniques to the affect recognition problem.
Having that in mind, we present in this paper an extensive analysis of the end-to-end deep learning architectures for affect recognition from physiological sensor data. Our study has been inspired by the recent work by Ismail et al. [
20], who presented a comprehensive overview of DL methods for time-series classification.
The main contribution of our work is as follows:
Enhanced existing DL methods for time-series classification to work with multimodal data, i.e., the methods can simultaneously learn from several data sources (sensors), each having its own sampling frequency.
Extensive comparison of ten end-to-end DL architectures for affect recognition on four publicly available datasets, three for emotion recognition, and one for stress recognition. To enable a fair comparison between the methods, Bayesian optimization was utilized.
The implementation of the deep learning architectures (the source code), alongside the processed datasets, which are publicly available to enable replication, comparison, and further research.
3. Materials and Methods
DL architectures for signal processing have not yet realized any outstanding breakthrough, and designing them remains challenging, especially for problems with limited data for training. The main aim of the experiments was to compare ten end-to-end DL architectures (see
Section 3.1):
Architectures 1–6 were taken from a review of DL architectures for time-series classification [
20]. We enhanced them for multimodal data. Twiesen architecture was not implemented in Keras, so it was omitted. t-LeNet and MCNN were the worst performing models, so they were left out. In our comparison, we also included the Stresnet architecture from our prior work, as well as InceptionTime [
49]. Additionally, we implemented two LSTM networks, one of which (CNN-LSTM) was inspired by [
5].
All the above architectures were tested on four reference emotion and affect datasets (
Section 3.4) as an emotion/affect classification task (
Section 3.6). To enable fair comparison, hyperparameters of each architecture were tuned (
Section 3.3), and each architecture was validated using 5-fold subject-independent cross-validation (
Section 3.7). The details of implementation together with a publicly available code are described in
Section 3.8.
3.1. Deep Learning Architectures
The layer-based structure of the NNs facilitates the construction of a variety of DL architectures by combining layers. For example, CNN layers can be stacked on top of LSTM layers, namely, the input is received by the CNN layers and propagated to the LSTM layers. In addition to the vertical stacking, one can also experiment with horizontal branching. For example, for a 2-signal dataset (2 modes), one can use a separate DL branch for each signal (mode) and later fuse the two outputs. Such fusion can simply be performed by using the concatenation layer and its further processing with other layers, e.g., a fully connected (dense) layer.
Which DL architecture is most suitable for end-to-end learning on multimodal physiological signals may depend on the dataset; thus, extensive experimentation is required [
48]. They are described in the subsequent sections.
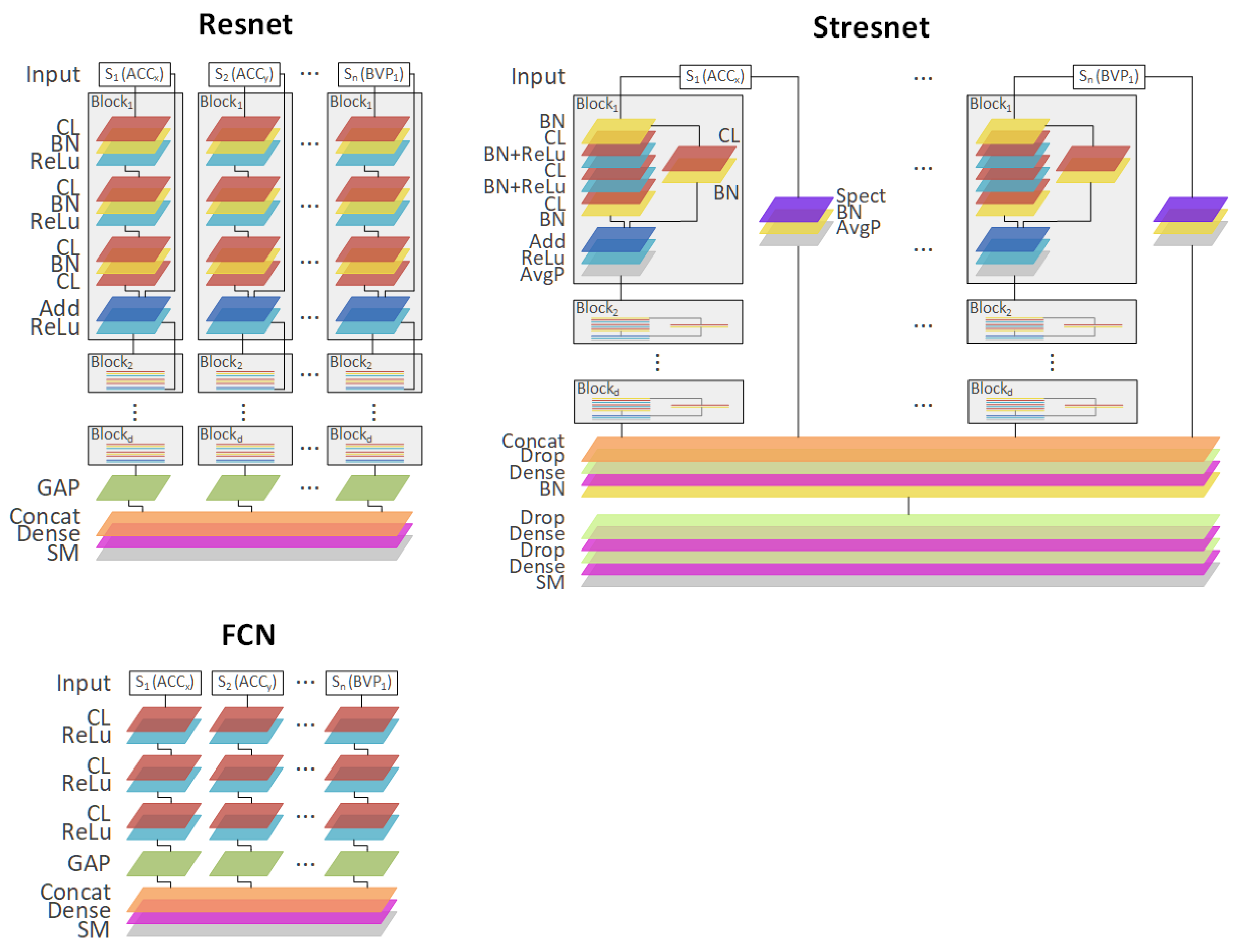
The three best-performing architectures are presented in
Figure 2: the spectrotemporal residual network (Stresnet), the fully convolutional neural network (FCN), and the residual network (Resnet). Additionally,
Table 1 contains a short summary of all DL architectures used in the experiments.
MLP contains
d fully connected layers (FCL; dense) for each signal/mode (
N signals) and a final FCL, which provides the output. FCN consists of three convolutional layers (CLs) for each signal and the final FCL layer. The Encoder is similar to FCN but with an additional attention layer (Att) between the final CLs and the FCL. Time-CNN is quite similar to FCN architecture. CNN-LSTM was partially based on the description of architecture presented in [
5]. MLP-LSTM extends the MLP with an additional LSTM layer. MCDCNN trains in two parallel CNN layers for each modality (sensor signal). The last three architectures, Resnet, Stresnet, and Inception are the most complex ones. They all are based on residual connections, i.e., short-cut connections that bind two nonconsecutive layers and reduce the vanishing gradient problem [
50]. The Resnet contains
N branches (one branch per signal) that have
d residual blocks (e.g., three residual blocks), and each block contains 3 CLs. Stresnet is a network in which each signal is associated with two branches: a Resnet that analyzes the raw sensor signal in the time domain and another branch processing a spectral representation of the signal. Towards the end of the network, the two branches of each signal, namely, the spectral and the temporal ones, are merged using FCL. The Inception network, similarly to Resnet and Stresnet, includes the residual blocks, but it additionally uses Inception modules that (1) apply multiple filters of different sizes simultaneously to the same input; and (2) exploit “bottleneck” layers, which reduce the dimensionality of the input as well as the model’s complexity and thus potentially avoid overfitting problems for small datasets.
3.2. Bayesian Optimization Methods
When the term hyperparameters is used, it usually refers to parameters of the model (e.g., DL architecture), which is trained in contrast to parameters (weights) derived directly from the training dataset.
Very often, hyperparameters are chosen by a human supervisor based on their expert knowledge and experience. Alternatively, a random search is often performed. It evaluates a randomly chosen configuration x from a set of all correct configurations . Moreover, a grid search can be applied. It tests all possible configurations from in a given sequence.
In contrast, Bayesian optimization is a process of evaluating possible configurations, but each following configuration is picked based on the history of the previous evaluations.
Bayes’ theorem describes a way of calculating the conditional probability of event A happening assuming that B is true, i.e.,
. It assumes that knowledge about probability of observing events A (
) and B (
) while also being able to assess the probability of event B assuming that A is true:
. It is also sometimes referred to as a measure of the “degree of belief” in a given statement [
51]. In many cases, the component probabilities are easy to obtain. Mathematically, it is stated as [
51]:
Sequential Model-based Global Optimization (SMBO) algorithms optimize configuration
for a given model for which we can compute a fitness function (
). This class of algorithms picks a “promising” configuration
in each iteration based on history
of the already evaluated configurations with their respective results of calculated fitness function, i.e.,
[
52]. Therefore, they can be seen as an implementation of the Bayesian optimization.
Tree-structured Parzen Estimator approach (TPE) is an SMBO algorithm, which returns a set of configurations with the highest Expected Improvement beyond a given threshold
. Instead of directly calculating the probability of a given score
y for a given configuration
x (
), it computes
,
, and
[
52].
In this study, the TPE method was utilized for hyperparameter optimization. This kind of Bayesian optimization enables us a more fair comparison of the methods because
it exploits history to make more informed guesses about hyperparameters,
it does not need or use any prior knowledge about tuned architectures, and
the hyperparameter search space is defined at the beginning of the experiments, which prevents the researchers from making a tuning decision based on their preliminary test results, thus reducing the researchers’ bias and minimizing the possibility of overfitting [
53,
54].
3.3. Hyperparameters Search Space
The hyperparameters search space ensures that the default hyperparameters (i.e., the hyperparameters used in previous studies) are in the center of the search space for each architecture. These default hyperparameters were taken from said studies [
5,
20,
48]. Please note that the hyperparameter set was fixed and actually determines the architecture itself.
Each parameter was given an interval of values, which, based on our previous experience, had a chance to significantly influence architecture evaluation scores.
In order to describe the hyperparameter search space, the null distribution specification language [
55] was used with two extensions:
—the joint distribution of two null distributions related to expressions A and B;
—the joint distribution of n null distributions referring to n signals, e.g., ECG, BVP, EEG, EDA, RESP, TEMP, and ACC.
Hyperparameters defined by the second notation enable us to adjust the hyperparameters separately for each signal. Therefore, the inferred hyperparameters can be tailored according to the profile and importance of each signal.
The individual hyperparameters are as follows:
: a dimensionality of the output space of dense layers for signal i
: a dimensionality of the output space of convolution layers for signal i
: a multiplier of a dimensionality of the output space of convolution layers for signal i, applicable when different filters are used in different layers.
: a multiplier specifying the length of the convolution window for signal i, used when different layers have different kernel sizes.
: output space of the LSTM layer for signal i.
: for Resnet and Stresnet, the number of residual blocks; for Inception, the number of inception blocks.
For MLP and MLP-LSTM, the following hyperparameter search space was considered (
hyperparameters):
where
means that the hyperparameter
may be chosen from three possible values:
.
For MCDCNN, Time-CNN, Encoder, and FCN, there are
hyperparameters:
For CNN-LSTM (
hyperparameters),
For Inception (
),
For Stresnet (
),
Additionally, four hyperparameters related to the optimizer itself were tuned for each architecture:
where
means that hypeparameter
can be an integer in the range [−7, −1);
and
are the learning rate (
) and decay in the Adam optimizer, respectively;
is a factor by which the learning rate is reduced after
number of epochs with no improvement.
3.4. Datasets
Four datasets were included in our experiments. The first three, AMIGOS [
56], ASCERTAIN [
26], and DECAF [
57], are related to emotion recognition. The fourth dataset, WESAD [
38], focuses on stress recognition.
AMIGOS is a multimodal dataset for affect recognition, personality traits, and mood on individuals and groups. It contains data of 40 participants who watched 16 short affective videos (51–150 s each) and 37 participants who watched four long affective videos (14–24 min each). The participants’ signals, namely, EEG, ECG, and EDA, were recorded using wearable sensors, i.e., Emotiv EPOC Neuroheadset (EEG), Shimmer 2R (ECG), and an extension to the Shimmer 2R platform placed on the left hand’s middle and index fingers (EDA). Participants’ emotions were annotated with both self-assessment (valence, arousal, control, familiarity, liking, and basic emotions) as well as an external assessment of valence and arousal.
ASCERTAIN is a multimodal dataset for personality and affect recognition using commercial physiological sensors. It contains data from 58 subjects who watched 36 short videos (51–128 s each). The participants’ physiological signals were also recorded, including frontal EEG, ECG, EDA, and Facial Emotional Activation Features (EMO). Additionally, the participants rated each video in terms of the levels of arousal, valence, engagement, liking, and familiarity. The authors of the paper did not provide any information about which devices they used, except for description of their placement.
DECAF is a multimodal dataset for affect recognition. It contains data of 30 participants that watched 40 music-video segments (60 s each) and 36 movie clips (51–128 s each). It also contains EEG data, Facial Emotional Activation Features (EMO), horizontal Electrooculogram (EOG), ECG, and trapezius EMG. Additionally, the participants rated the affective stimuli in terms of the levels of arousal, valence, and dominance. ELEKTA Neuromag was used to record EEG, but other devices were not explicitly specified, except for their position on the body.
The WESAD dataset [
38] was collected in a study focused on stress, where the subjects experienced both an emotional and stress stimuli. More specifically, WESAD contains data from 15 subjects. Each subject underwent three sessions: a baseline session (neutral reading task; 20 min), an amusement session (watching a set of funny video clips; 392 s), and a stress session (being exposed to the Trier Social Stress Test [
58]; about 10 min). The amusement and stress sessions were followed by a guided meditation. The participants’ physiological response was recorded using both a wrist and chest device. The sensor data includes BVP, ECG, EDA, EMG, respiration, body temperature, and three-axis acceleration collected with two wearables, i.e., Empatica E4 (wristband) and RespiBAN (chest device).
3.5. Datasets Preprocessing
The signals synchronized by the datasets’ authors were exploited as an initial input to the methods we tested. Additionally, the sensor data from each dataset, each subject, and each signal was preprocessed using the following:
3–97% winsorization, which removes extreme values form the signal data;
Butterworth low-pass filter with a 10 Hz cut-off which removes components above the threshold frequency of 10 Hz;
downsampling, which reduces the dimensionality of the inputs and consequently decreases the number of learning parameters in the DL models (see
Table 2 for more details);
min-max normalization.
For the emotion datasets (AMIGOS, ASCERTAIN, and DECAF), each subject had many short sessions, in which the affective stimuli were presented. Each session was used as an input window to the DL methods. Windows were created from the last 50 s of the signals from each session, as it was the minimum session length. The long sessions from AMIGOS were discarded.
In the WESAD dataset, each subject had only a few long sessions. To segment the long sessions into input windows, each signal was divided into 60 s windows with 30 s slides, i.e., each window overlapped the previous and next window for 30 s. Each window was assigned to the dominant class in its time span.
3.6. Classification Task
The ASCRTAIN, AMIGOS, and DECAF datasets contain information about self-reported valance and arousal. These values were mapped to 4 classes:
low-arousal-low-valence (LALV),
low-arousal-high-valence (LAHV),
high-arousal-low-valence (HALV), and
high-arousal-high-valence (HAHV).
This is a common method of discretization of Russell’s
arousal-valence model [
8].
Table 3 describes which values of arousal/valence where considered as high/low. The representation (imbalance) of classes is depicted in
Table 4.
3.7. Validation
A 5-fold cross-validation was utilized. All datasets were pseudo-randomly divided into five test sets with approximately equal sizes. For each test set, the train and validation sets were created from the rest of the subjects. These subjects were pseudo-randomly split into a train and validation set with a ratio of 4:1. This assignment was constant during the whole experiment in order to discard any differences due to the better or worse division of the data.
The general goal of learning is to maximize performance on the training data. However, we utilized a validation set, separate from the test set, to avoid overfitting on the training data. The validation data was used for evaluation purposes of the trained model. The best performing models on the validation data were the final models applied to the test sets and are reported in
Section 4.
For each dataset, architecture, test set, and given hyperparameter combination, five training iterations were conducted, and the results were averaged over them. During training, a maximum of 150 epochs were run with early stopping implemented with a patience of 15, i.e., if validation loss had not improved for 15 epochs, the training stopped.
3.8. Method Implementation
Methods were implemented in Python using Tensorflow 1.13.1, keras 2.2.4, SciPy 1.4.1, and scikit-learn 0.22.1.
Each architecture implementation (except for MCDCNN and Stresnet) was adopted for multimodal data by creating separate branches for each signal. Details are presented in
Section 3.1. The code was made publicly available at
https://github.com/Emognition/dl-4-tsc.
4. Results
To compare the results of different architectures, the macro F1-score was utilized. The F1-score (Equation (
10)) is a harmonic mean of precision (Equation (
11)) and recall (see Equation (
12)). The macro F1-score is defined as the arithmetic mean for F1-scores of N classes calculated separately (Equation (
9)). While reporting the Area Under the Receiver Operating Characteristic Curve (ROC AUC), we also used the ROC AUC averaged over all classes. There were five iterations of each fold from which we obtained the average F1-score, accuracy, ROC AUC, as well as standard deviations of these metrics. Then, all metrics from five folds were averaged and the final values are reported in
Table 5,
Table 6,
Table 7 and
Table 8.
Table 5 presents the experimental results for the AMIGOS dataset. It can be seen that none of the DL classifiers achieved better F1-score results compared to the random guess classifiers. To the best of our knowledge, there is no study on the AMIGOS dataset that has incorporated the same 4-class problem. Harper at al. [
39], using CNN with LSTM and heart rate, achieved an F1-score of 0.78 and an accuracy of 0.79 for high/low valence detection (but with different thresholds) for their non-Bayesian approach, i.e., for all samples. The authors of the dataset achieved F1-scores of 0.57 and 0.59 for valence and arousal, respectively, using only short films.
Table 6 presents the experimental results for the DECAF dataset. The best performing models are built using FCN, Stresnet and Encoder. These three models are slightly better than the random guess classifier. The highest F1-score of 0.26 was achieved by the FCN classifier. To the best of our knowledge, there is no study on the DECAF dataset with the same 4-class problem. The authors of the dataset reported F1-scores of 0.58 and 0.56 for arousal and valence independently. They applied classical feature extraction methods.
Table 7 presents the experimental results for the ASCERTAIN dataset. The three best performing models are built using Inception, Resnet, and FCN. We have not found any study on the ASCERTAIN dataset that addresses the same 4-class problem. In the original paper of the ASCERTAIN dataset [
26], F1-scores were 0.71 and 0.67 for valence and arousal, respectively. They utilized classical feature extraction methods.
Table 8 presents the experimental results for the WESAD dataset. It can be seen that all of the DL classifiers outperformed the baseline classifiers (random guess and majority class). The best performing model achieved F1-score equal to 0.73 and is built using the FCN architecture. The authors of the dataset achieved an accuracy of 0.80 and an F1-score of 0.69 for all modalities using feature extraction, AdaBoost, and leave-one-subject-out validation [
38]. Lin at al. achieved an accuracy of 0.83 using DL, but they used different input data (1 s windows) and a different validation method [
59].
In
Table 9, the detailed results for the best architecture for each dataset in our study are shown. There are substantial differences in F1-score between classes for some datasets.
Our results (
Table 10) are consistent with the results originally obtained on multivariate time series by [
20]. The only differences are between the rank of MLP and MCDCNN. In our study, the MCDCNN performed better than MLP.
5. Discussion
A general observation that can be made from the results for the emotion datasets (AMIGOS, ASCERTAIN, and DECAF), is that end-to-end DL classifiers performed rather poorly. This does not refer to stress recognition (the WESAD dataset), where the FCN DL classifier achieved an F1-score equal to 0.73 and an ROC AUC of 0.91. One reason for such behavior may be the fact that physiological responses induced by the emotional videos used in the emotion datasets are generally less significant than responses invoked by the Trier Social Stress Test used in WESAD. The difficulty of recognizing subtle affective stimuli using physiological sensors has also been recognized in the related work [
7]. This is also confirmed by the baseline results reported by the creators of the datasets, i.e., the F1-score for binary classification of low vs. high arousal and low vs. high valence are between 0.55 and 0.60 [
26,
56,
57]. The relatively low separation of binary classes is also visible in Figure 4 in [
56], where classes are very close to each other. On the contrary, the WESAD dataset contains the class-label
stress, which is easier to be recognized compared to the class labels defined only by the arousal and valence levels in the emotion datasets.
Therefore, our classifier built using the multimodal end-to-end FCN architecture achieved results comparable to the original WESAD paper. It reveals that end-to-end DL can be efficiently used instead of the classical feature-based approaches for some affect recognition tasks operating on physiological data. It is also in line with the results from [
37].
It is also worth noting that, among the “simple” CNNs (i.e., FCN, Time-CNN, and MCDCNN), the best performing was FCN, which includes layers with the highest number of filters. It may indicate that DL architectures potentially need to accommodate many features to fully learn a signal representation. Furthermore, consistency with the results presented in [
20] may indicate that there might be more to incorporate from time series classification into affective computing and end-to-end DL physiological signals classification in order to achieve better results.
Regarding different DL architectures tested by us, CNN layers outperformed the architectures based on LSTM layers in all of the experiments. This indicates that CNN-based architectures may be more suitable than LSTM for affect recognition from physiological signals. This is counterintuitive, especially because the LSTMs were originally developed for handling sequences in the input data. Our intuition for such results is that the CNNs may be more robust to noise, e.g., the CNN filters can perform a moving average on the input sensor data; thus, they can remove some noise. The above raises a new question: can additional preprocessing methods increase DL performance? It, however, goes in the opposite direction than the general idea of end-to-end learning: put anything in the input and let the model deal with that.
In our work, we carried out simple preprocessing tasks such as winsorization, downsampling, filtering, and normalization (see
Section 3.5). We are aware that the application of the low-pass filter with a 10 Hz threshold could have removed some potentially valuable information, especially for EEG signals, e.g., beta waves belong to the 15–32 Hz range and gamma ≥ 32 Hz. On the other hand, we wanted to test DL architectures in the signal-agnostic environment, i.e., without any specific knowledge about individual signals. This enabled us to test end-to-end multimodal approaches, in which each signal was processed by a separate deep neural network branch (
Figure 2).
In principle, there is an open issue as to what
end-to-end machine learning is and which processing tasks, if any, may be performed before model training. Yet another problem for deep learning models are the quantities of the learning samples. In total, we had at our disposal only 620–2280 cases, depending on the dataset (
Table 4). It is a rather insufficient amount of data for properly training deep learning architectures.
Concluding, the main benefit of end-to-end learning is that expert knowledge about the nature of the physiological signals and their relations to affective states are not necessary (
Figure 1). Signals may be processed by the same types of branches, which, while learning, adapt to the specific profile of individual signals.
This work establishes a base for further development of end-to-end DL architectures for affect recognition from physiological sensor data. Building on this work, one can easily analyze the influence of different signal (pre)processing techniques or the impact of signal selection. For example, Gjoreski et al. showed that Stresnet builds better models for monitoring driving distractions and monitoring human locomotion modes when the input sensor modalities are preselected, e.g., using information gain [
6,
48].

 ,
, 



{kind=link}
{kind=link}