
Additive Ensemble Neural Network with Constrained Weighted Quantile Loss for Probabilistic Electric-Load Forecasting

 ,
,  ,
,  and
and {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Related Works
- Review works: The work in [5] presents a comprehensive review of the techniques used to forecast electricity demand, analyzing the different types of forecasts, parameters affected, techniques used, together with a literature review and a taxonomy of the main variables involved in the problem. The work in [19] presents a detailed review of recent literature and techniques applied for building energy consumption modeling and forecasting.
- Quantile forecasting applied to SMTLF: The work in [10] presents theoretical bases on the effectiveness of the pinball loss function to achieve quantile estimations. A comparison of quantile regression techniques for weather forecasting is provided in [42] with a recommendation to use ensemble models. A gradient descent algorithm for quantile regression is proposed in [12]. The work proposes a special function to smooth the pinball loss. The technique is extended to a boosted quantile regression algorithm, and the results are obtained with simulated datasets. There are several works presenting probabilistic forecasting neural networks for load forecasting. In [43], a smoothed quantile loss with a CNN network is used to build a multi-quantile forecast estimator. The pinball loss is smoothed with a log-cosh function. The model is applied to residence load forecasting. A similar model is proposed in [44] with an NN based on ResNet with skip connections. The pinball loss is not smoothed. The work analyzes the impact of the network depth and the skip connections. The dataset used is the open-source GEFcom2014. In the same line of work, [45] obtains quantile forecasts with an NN based on an LSTM network. A Huber smooth function is applied to the pinball loss. The work presents results for residential and small businesses load forecasting using a public data set. The same smooth pinball loss proposed in [12] is used in [11] for quantile forecast of energy consumption using the GEFcom2014 dataset. To reduce quantile crossover, they propose a special weight initialization of the neural network. In [35] the quantile loss is regularized with an additional term to take into account the crossover quantile errors. The dataset used is also GEFcom2014. All the previously mentioned works apply variants of the quantile forecasting model, including neural networks, but none propose a constrained weighted quantile loss fully incorporated as learnable parameters in the network architecture and capable of extending any point-forecast NN into a quantile forecast model.
- Dynamic mode decomposition (DMD) applied to SMTLF: Considering related works corresponding to the alternative models used as comparison models for the CWQFNN (Section 4), there is a growing current interest in the application of dynamical systems analysis tools based on reduced-order models and, in particular, in the use of dynamic mode decomposition to SMTLF. The work in [24] provides a DMD study applied to electric load data from a utility operator in Queensland, Australia. They show better performance results using DMD vs. time-series autoregressive models. The forecasting is made for the following day using the data from the previous 4 days as predictors, presenting the best result for mean absolute percentage error (MAPE) for one-day ahead forecasting of 2.13. A similar application of DMD is done in [46] but applying DMD to predict forecast errors followed by an extreme value constraint method to further correct the forecasts. The algorithm is applied to actual load demand data from the grid in Tianjin, China, and the results obtained with DMD are compared with a series of additional techniques (autoregressive moving average, neural networks, support vector machines, extreme learning machines...). According to the authors, the proposed method shows greater accuracy and stability than alternative ones, with a best average root-mean-squared error (RMSE) of 476.17. In [47], the authors employ an empirical mode decomposition technique to extract different modes from the load signal and apply an independent deep belief network for each mode prediction, with a subsequent aggregation of results (ensemble) to obtain the final load forecast.
- Classic machine learning models applied to SMTLF: A substantial number of works have presented several classic machine learning models for SMTLF. A feed-forward neural network (FF-NN) is used in [48] to forecast the electricity consumption for residential buildings for the next 24 h. Results are compared with other models, including GTB and RF, selecting the best model at each forecast iteration. The best average result for the different test iterations is obtained for the neural network (NN) with an RMSE of 2.48. The work in [49] presents a theoretical review of the most commonly used ML methods for short-term load forecast (STLF), including NN and support vector for regression. Time-series statistical analysis models for SMTLF are discussed in detail in [4] with forecasts at an hour interval applied to load data from the Electric Reliability Council of Texas (ERCOT). The present results are applying ARIMA and seasonal autoregressive integrated moving average (SARIMA) models achieving an average MAPE between 4.36% to 12.41%. More classic ensemble techniques for forecasting electricity consumption in office buildings are investigated in [50], comparing gradient tree boosting (GTB), random forests (RF) and a specifically adapted Adaboost model that presents the best results.
- Sequence to sequence (Seq2seq) models applied to SMTLF: Seq2seq architectures that originated in the field of natural language processing (NLP) have been applied in recent works to STLF. Authors in [51] apply different Seq2seq architectures, comparing them with other DL models based on recurrent and convolutional layers. The models are applied to two different datasets (scenarios), one for an Individual household electric power consumption data set (IHEPC) and the other for the GEFCom2014 public dataset. The best results (RMSE between 17.2 and 0.75 depending on the scenario) are obtained with convolutional and recurrent architectures and deep neural networks with dense layers. Considering average results, the Seq2seq models do not provide the best results. The conclusions obtained in this work are consistent with the results obtained by the present study. A similar study is presented in [52], where research is conducted comparing a Seq2seq model (with and without attention) with alternative DL models based exclusively on different types of recurrent networks, such as long short-term memory networks (LSTM) and gated recurrent unit (GRU). In this case, the Seq2seq model presents the best results for short-term forecasting, also following the results obtained in the present work. A generic Seq2seq with a specific attention mechanism is proposed in [53] for multivariate time-series forecasting.
- Deep learning models applied to SMTLF: The work in [54] introduces a deep learning architecture based on an ensemble of convolutional blocks acting on segregated subsets of the input data. The model is applied for day-ahead forecasting of individual residential loads with data obtained from a smart metering electricity customer behavior trial (CBTs) in Ireland. The work focuses on achieving low training time and high accuracy, the proposed model being the best in both aspects with a mean absolute error (MAE) of 0.3469. Authors in [55] present an analysis of the influence of the number of layers, activation functions and optimization methods using neural networks to predict the Hellenic energy consumption. The work in [56] incorporates a wavelet denoising algorithm to a neural network for the short-term load forecast of the Bulgarian power system grid, showing that wavelet denoising improves the load signal quality and overall forecast performance.
- Models applied to the same dataset: Using the same dataset proposed for this work, [17] presents an NN model that works on a 24 h day-ahead forecasting of electric loads previously aggregated into clusters by consumption patterns. The patterns are obtained with a self-organizing map (SOM) followed by a k-means clustering algorithm.
- Application to cybersecurity: The impact of cybersecurity attacks on smart grids is well-known [57], these attacks can be addressed with intrusion detection tools, but there is a growing interest in identifying these attacks using indicators of indirect effects, such as deviations from normal consumption or customer revenues. In these alternative approaches, the application of accurate forecasting models is crucial. The detection of abnormalities in load consumption patterns to identify energy theft or other types of attacks is studied in [58], based on a hierarchical clustering and decision trees classification. A similar approach is presented in [59], which also uses a decision tree algorithm without prior clustering.
3. Materials and Methods
3.1. Selected Dataset
3.2. Models Description
- Obtain the training and validation sets using a sliding window method (Figure 1);
- Select the quantile probabilities used in the forecasts () (Figure 9)
- Apply the selected base model within the CWQFNN architecture (Figure 9);
- The output of the CWQFNN model will be quantile forecasts for each of the time-ahead predictions, along with the learned quantile weights () applied in the CWQLoss (Equation (2)).
4. Results
4.1. Point Forecasts
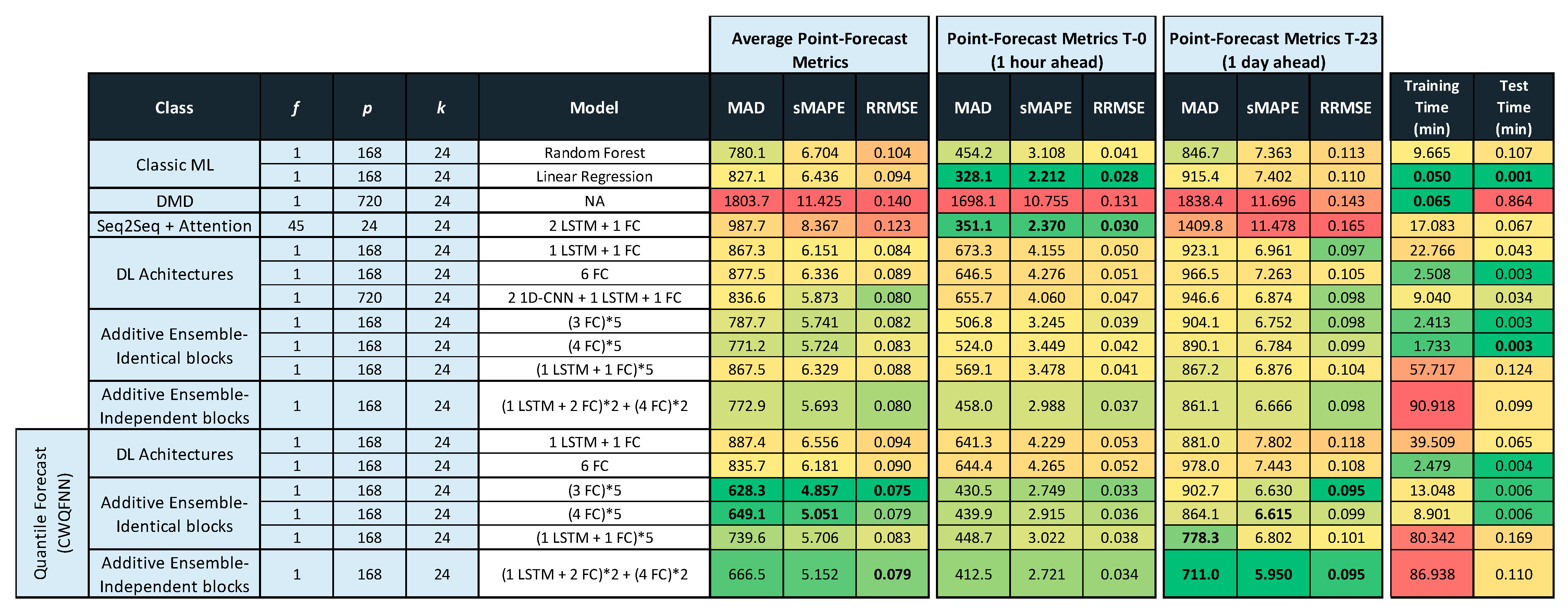
- (a).
- DMD models do not provide the best results under any configuration.
- (b).
- Classic ML models (linear regression) provide the best results for very short-term forecasts considering the maximum forecast time horizon in each scenario. For example, linear regression provides best results at T-0 for a forecast time-horizon of 24 h, the same happens for a time horizon of 168 h (Figure A2 in Appendix A), and is among the best result models for T-0, T-23 and T-167 for a time horizon of 720 h (Figure A3 in Appendix A).It is important to note that the ML models do not produce a multi-output prediction. Therefore, it is necessary to create a specific predictor for each predicted value. This is the reason for the good behavior of these models in short-term forecasts. The interesting point is that for long-term forecasts, a single DL, AE, or CWQFNN model can produce better forecasts than many ML models, each trained on a specific expected output. A possible explanation for this behavior is that the further the forecast is in time, the relationship between predictors and outputs is less linear, and the correlation between outputs is more relevant.
- (c).
- Seq2seq+ attention gives better results than Seq2seq. They present excellent results for very short-term forecasts and poor results for average and longer-term forecasts. Seq2seq models only have results for a value of equal to 45. For a value of equal to 1, the network had difficulties converging, and the results were poor (Figure A1 in Appendix A). The combination of CNN and LSTM layers provides poor results for Seq2seq models, while pure recurring networks with one or two LSTM layers provide the best results.
- (d).
- DL models provide good average performance metrics. The best models are simple combinations of LSTM and FC layers (e.g., 1 LSTM + 1 FC), sequences of a few FC layers (e.g., 6 FC), and simple combinations of 1D-CNN and LSTM layers (e.g., 2 1D-CNN+ 1 LSTM + 1 FC). The architectures with 2D-CNN layers provide poor results.
- (e).
- Additive ensemble (AE) deep learning models are excellent performance architectures for long-term forecasting and average results. There is not much difference in performance between the AE architecture with Identical and Independent blocks, but considering its greater simplicity, we can justify that the Identical blocks architecture is the one that offers the best results. AE models perform best with blocks composed of a few FC layers repeated a small number of times (e.g., (3 FC)*5) and simple combinations of LSTM and FC layers also repeated a small number of times (e.g., (1 LSTM + 1 FC)*5).The good behavior of the AE deep learning models is related to a better exploration in the solution space due to the independent random initialization of each block in the ensemble [36,37]. This explanation better justifies the good behavior that the ability of AE models to reduce overfitting given that all the regularization techniques used (drop-out, batch normalization, weight sharing) do not provide any performance improvement (Figure A1 in Appendix A), which indicates that the focus of this problem should not be on overfitting but on obtaining a sufficiently rich network structure that adjusts to the characteristics of the data.
- (f).
- CWQFNN architectures present the best results for average and long-term forecasting for almost all point forecast metrics. To achieve these results, the best base model is an AE-Identical blocks architecture with a small number of repeating blocks formed by a few FC layers (e.g., (3 FC)*5 or (4 FC)*5). The good behavior of this architecture is maintained for all forecast time horizons ( = 24, 168, 720).
4.2. Probabilistic Forecasts
4.3. Impact of Quantile-Weights Restrictions
4.4. Time Evolution of Point and Probabilistic Forecasts
4.5. Influence of the Sliding-Window Length
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A





References
- Hammad, M.A.; Jereb, B.; Rosi, B.; Dragan, D. Methods and Models for Electric Load Forecasting: A Comprehensive Review. Logist. Sustain. Transp. 2020, 11, 51–76. [Google Scholar] [CrossRef] [Green Version]
- Mohammed, A.A.; Aung, Z. Ensemble Learning Approach for Probabilistic Forecasting of Solar Power Generation. Energies 2016, 9, 1017. [Google Scholar] [CrossRef]
- Koenker, R. Quantile Regression; Cambridge University Press: Cambridge, UK, 2005; ISBN 9780521845731. [Google Scholar]
- Nguyen, H.; Hansen, C.K. Short-term electricity load forecasting with Time Series Analysis. In Proceedings of the 2017 IEEE International Conference on Prognostics and Health Management (ICPHM), Dallas, TX, USA, 19–21 June 2017; pp. 214–221. [Google Scholar] [CrossRef]
- Hernández, L.; Baladron, C.; Aguiar, J.M.; Carro, B.; Sanchez-Esguevillas, A.J.; Lloret, J.; Massana, J. A Survey on Electric Power Demand Forecasting: Future Trends in Smart Grids, Microgrids and Smart Buildings. IEEE Commun. Surv. Tutor. 2014, 16, 1460–1495. [Google Scholar] [CrossRef]
- Benidis, K.; Rangapuram, S.S.; Flunkert, V.; Wang, B.; Maddix, D.; Turkmen, C.; Gasthaus, J.; Bohlke-Schneider, M.; Salinas, D.; Stella, L.; et al. Neural forecasting: Introduction and literature overview. arXiv 2020, arXiv:2004.10240. [Google Scholar]
- Lim, B.; Zohren, S. Time Series Forecasting With Deep Learning: A Survey. arXiv 2020, arXiv:2004.13408. [Google Scholar]
- Wang, H.; Lei, Z.; Zhang, X.; Zhou, B.; Peng, J. A review of deep learning for renewable energy forecasting. Energy Convers. Manag. 2019, 198, 111799. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A. Neural network architecture based on gradient boosting for IoT traffic prediction. Futur. Gener. Comput. Syst. 2019, 100, 656–673. [Google Scholar] [CrossRef]
- Steinwart, I.; Christmann, A. Estimating conditional quantiles with the help of the pinball loss. Bernoulli 2011, 17, 211–225. [Google Scholar] [CrossRef]
- Hatalis, K.; Lamadrid, A.J.; Scheinberg, K.; Kishore, S. Smooth Pinball Neural Network for Probabilistic Forecasting of Wind Power. arXiv 2017, arXiv:1710.01720. [Google Scholar]
- Zheng, S. Gradient descent algorithms for quantile regression with smooth approximation. Int. J. Mach. Learn. Cybern. 2011, 2, 191–207. [Google Scholar] [CrossRef]
- Lang, C.; Steinborn, F.; Steffens, O.; Lang, E.W. Electricity Load Forecasting—An Evaluation of Simple 1D-CNN Network Structures. arXiv 2019, arXiv:1911.11536. [Google Scholar]
- Singh, N.; Vyjayanthi, C.; Modi, C. Multi-step Short-term Electric Load Forecasting using 2D Convolutional Neural Networks. In Proceedings of the 2020 IEEE-HYDCON, Hyderabad, India, 11–12 September 2020; pp. 1–5. [Google Scholar]
- Kong, W.; Dong, Z.Y.; Jia, Y.; Hill, D.J.; Xu, Y.; Zhang, Y. Short-Term Residential Load Forecasting Based on LSTM Recurrent Neural Network. IEEE Trans. Smart Grid 2019, 10, 841–851. [Google Scholar] [CrossRef]
- Park, M.; Lee, S.; Hwang, S.; Kim, D. Additive Ensemble Neural Networks. IEEE Access 2020, 8, 113192–113199. [Google Scholar] [CrossRef]
- Hernández, L.; Baladrón, C.; Aguiar, J.M.; Carro, B.; Sánchez-Esguevillas, A.; Lloret, J. Artificial neural networks for short-term load forecasting in microgrids environment. Energy 2014. [Google Scholar] [CrossRef]
- Bontempi, G.; Ben Taieb, S.; Le Borgne, Y.-A. Machine Learning Strategies for Time Series Forecasting BT—Business Intelligence: Second European Summer School. In Proceedings of the eBISS 2012, Brussels, Belgium, 15–21 July 2012; Tutorial Lectures. Aufaure, M.-A., Zimányi, E., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; pp. 62–77, ISBN 978-3-642-36318-4. [Google Scholar]
- Bourdeau, M.; Zhai, X.Q.; Nefzaoui, E.; Guo, X.; Chatellier, P. Modeling and forecasting building energy consumption: A review of data-driven techniques. Sustain. Cities Soc. 2019, 48, 101533. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. Statistical and Machine Learning forecasting methods: Concerns and ways forward. PLoS ONE 2018, 13, e0194889. [Google Scholar] [CrossRef] [Green Version]
- Martin, M.L.; Sanchez-Esguevillas, A.; Carro, B. Review of Methods to Predict Connectivity of IoT Wireless Devices. Ad. Hoc. Sens. Wirel. Netw. 2017, 38, 125–141. [Google Scholar]
- Schmid, P.J. Dynamic mode decomposition of numerical and experimental data. J. Fluid Mech. 2010, 656, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Tirunagari, S.; Kouchaki, S.; Poh, N.; Bober, M.; Windridge, D.; Dynamic, D.W. Dynamic Mode Decomposition for Univariate Time Series: Analysing Trends and Forecasting. 2017. Available online: https://hal.archives-ouvertes.fr/hal-01463744/ (accessed on 22 April 2021).
- Mohan, N.; Soman, K.P.; Sachin Kumar, S. A data-driven strategy for short-term electric load forecasting using dynamic mode decomposition model. Appl. Energy 2018, 232, 229–244. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A.; Lloret, J. Network Traffic Classifier with Convolutional and Recurrent Neural Networks for Internet of Things. IEEE Access 2017, 5. [Google Scholar] [CrossRef]
- Lopez-Martin, M.; Carro, B.; Lloret, J.; Egea, S.; Sanchez-Esguevillas, A. Deep Learning Model for Multimedia Quality of Experience Prediction Based on Network Flow Packets. IEEE Commun. Mag. 2018, 56. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2014, arXiv:1409.0473. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. arXiv 2014, arXiv:1409.3215. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. arXiv 2015, arXiv:1508.04025. [Google Scholar]
- Lopez-Martin, M.; Carro, B.; Sanchez-Esguevillas, A. IoT type-of-traffic forecasting method based on gradient boosting neural networks. Futur. Gener. Comput. Syst. 2020, 105, 331–345. [Google Scholar] [CrossRef]
- Fort, S.; Hu, H.; Lakshminarayanan, B. Deep Ensembles: A Loss Landscape Perspective. arXiv 2019, arXiv:1912.02757. [Google Scholar]
- Frankle, J.; Carbin, M. The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks. arXiv 2018, arXiv:1803.03635. [Google Scholar]
- Jain, S.; Liu, G.; Mueller, J.; Gifford, D. Maximizing Overall Diversity for Improved Uncertainty Estimates in Deep Ensembles. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2009. [Google Scholar]
- Cannon, A.J. Non-crossing nonlinear regression quantiles by monotone composite quantile regression neural network, with application to rainfall extremes. Stoch. Environ. Res. Risk Assess. 2018, 32, 3207–3225. [Google Scholar] [CrossRef] [Green Version]
- Hatalis, K.; Lamadrid, A.J.; Scheinberg, K.; Kishore, S. A Novel Smoothed Loss and Penalty Function for Noncrossing Composite Quantile Estimation via Deep Neural Networks. arXiv 2019, arXiv:1909.12122. [Google Scholar]
- Jiang, X.; Jiang, J.; Song, X. Oracle model selection for nonlinear models based on weighted composite quantile regression. Stat. Sin. 2012, 22, 1479–1506. [Google Scholar]
- Sun, J.; Gai, Y.; Lin, L. Weighted local linear composite quantile estimation for the case of general error distributions. J. Stat. Plan. Inference 2013, 143, 1049–1063. [Google Scholar] [CrossRef]
- Bloznelis, D.; Claeskens, G.; Zhou, J. Composite versus model-averaged quantile regression. J. Stat. Plan. Inference 2019, 200, 32–46. [Google Scholar] [CrossRef] [Green Version]
- Jiang, R.; Qian, W.-M.; Zhou, Z.-G. Weighted composite quantile regression for single-index models. J. Multivar. Anal. 2016, 148, 34–48. [Google Scholar] [CrossRef]
- Jiang, R.; Yu, K. Single-index composite quantile regression for massive data. J. Multivar. Anal. 2020, 180, 104669. [Google Scholar] [CrossRef]
- Wang, W.; Lu, Z. Cyber security in the Smart Grid: Survey and challenges. Comput. Netw. 2013, 57, 1344–1371. [Google Scholar] [CrossRef]
- Bogner, K.; Pappenberger, F.; Zappa, M. Machine Learning Techniques for Predicting the Energy Consumption/Production and Its Uncertainties Driven by Meteorological Observations and Forecasts. Sustainability 2019, 11, 3328. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.; Wang, B.; Guo, H.; Chai, C.; Wang, Y.; Zhu, Z. Unified Quantile Regression Deep Neural Network with Time-Cognition for Probabilistic Residential Load Forecasting. Complexity 2020, 2020, 9147545. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Quan, H.; Gandhi, O.; Rajagopal, R.; Tan, C.-W.; Srinivasan, D. Improving Probabilistic Load Forecasting Using Quantile Regression NN With Skip Connections. IEEE Trans. Smart Grid 2020, 11, 5442–5450. [Google Scholar] [CrossRef]
- Wang, Y.; Gan, D.; Sun, M.; Zhang, N.; Lu, Z.; Kang, C. Probabilistic individual load forecasting using pinball loss guided LSTM. Appl. Energy 2019, 235, 10–20. [Google Scholar] [CrossRef] [Green Version]
- Kong, X.; Li, C.; Wang, C.; Zhang, Y.; Zhang, J. Short-term electrical load forecasting based on error correction using dynamic mode decomposition. Appl. Energy 2020, 261, 114368. [Google Scholar] [CrossRef]
- Fan, C.; Ding, C.; Zheng, J.; Xiao, L.; Ai, Z. Empirical Mode Decomposition based Multi-objective Deep Belief Network for short-term power load forecasting. Neurocomputing 2020, 388, 110–123. [Google Scholar] [CrossRef]
- Oprea, S.; Bâra, A. Machine Learning Algorithms for Short-Term Load Forecast in Residential Buildings Using Smart Meters, Sensors and Big Data Solutions. IEEE Access 2019, 7, 177874–177889. [Google Scholar] [CrossRef]
- Jacob, M.; Neves, C.; Vukadinović Greetham, D. Short Term Load Forecasting BT—Forecasting and Assessing Risk of Individual Electricity Peaks; Jacob, M., Neves, C., Greetham, D.V., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 15–37. ISBN 978-3-030-28669-9. [Google Scholar]
- Pinto, T.; Praça, I.; Vale, Z.; Silva, J. Ensemble learning for electricity consumption forecasting in office buildings. Neurocomputing 2020. [Google Scholar] [CrossRef]
- Gasparin, A.; Lukovic, S.; Alippi, C. Deep Learning for Time Series Forecasting: The Electric Load Case. arXiv 2019, arXiv:1907.09207. [Google Scholar]
- Gong, G.; An, X.; Mahato, N.K.; Sun, S.; Chen, S.; Wen, Y. Research on Short-Term Load Prediction Based on Seq2seq Model. Energies 2019, 12, 3199. [Google Scholar] [CrossRef] [Green Version]
- Du, S.; Li, T.; Yang, Y.; Horng, S.-J. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, N.; Gao, W.; Guo, X.; Huang, C.; Hao, T.; Zhan, J. LoadCNN: A Low Training Cost Deep Learning Model for Day-Ahead Individual Residential Load Forecasting. arXiv 2019, arXiv:1908.00298. [Google Scholar]
- Karampelas, P.; Vita, V.; Pavlatos, C.; Mladenov, V.; Ekonomou, L. Design of artificial neural network models for the prediction of the Hellenic energy consumption. In Proceedings of the 10th Symposium on Neural Network Applications in Electrical Engineering, Osaka, Japan, 13–25 September 2010; pp. 41–44. [Google Scholar]
- Ekonomou, L.; Christodoulou, C.A.; Mladenov, V. A short-term load forecasting method using artificial neural networks and wavelet analysis. Int. J. Power Syst. 2016, 1, 64–68. [Google Scholar]
- Otuoze, A.O.; Mustafa, M.W.; Larik, R.M. Smart grids security challenges: Classification by sources of threats. J. Electr. Syst. Inf. Technol. 2018, 5, 468–483. [Google Scholar] [CrossRef]
- Jain, S.; Choksi, K.A.; Pindoriya, N.M. Rule-based classification of energy theft and anomalies in consumers load demand profile. IET Smart Grid 2019, 2, 612–624. [Google Scholar] [CrossRef]
- Cody, C.; Ford, V.; Siraj, A. Decision Tree Learning for Fraud Detection in Consumer Energy Consumption. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 1175–1179. [Google Scholar]
- Zarnani, A.; Karimi, S.; Musilek, P. Quantile Regression and Clustering Models of Prediction Intervals for Weather Forecasts: A Comparative Study. Forecasting 2019, 1, 169–188. [Google Scholar] [CrossRef] [Green Version]
- Pinson, P.; Kariniotakis, G.; Nielsen, H.A.; Nielsen, T.S.; Madsen, H. Properties of quantile and interval forecasts of wind generation and their evaluation. In Proceedings of the 2006 European Wind Energy Conference (EWEC 2006), Athènes, Greece, 27 February–2 March 2006; pp. 128–133. [Google Scholar]
- Roman, R.-C.; Precup, R.-E.; Petriu, E.M. Hybrid data-driven fuzzy active disturbance rejection control for tower crane systems. Eur. J. Control 2021, 58, 373–387. [Google Scholar] [CrossRef]
- Zhu, Z.; Pan, Y.; Zhou, Q.; Lu, C. Event-Triggered Adaptive Fuzzy Control for Stochastic Nonlinear Systems with Unmeasured States and Unknown Backlash-Like Hysteresis. IEEE Trans. Fuzzy Syst. 2020, 1. [Google Scholar] [CrossRef]
- Mann, J.; Kutz, J.N. Dynamic Mode Decomposition for Financial Trading Strategies. Quant. Financ. 2016, 16, 1643–1655. [Google Scholar] [CrossRef] [Green Version]
- Hartung, J.; Knapp, G. Multivariate Multiple Regression. In Encyclopedia of Statistics in Behavioral Science; John Wiley & Sons, Ltd.: Chichester, UK, 2005. [Google Scholar]
- Wolpert, D.H. Stacked generalization. Neural Netw. 1992, 5, 241–259. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Distributed Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Pedregosa, F.; Michel, V.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Vanderplas, J.; Cournapeau, D.; Pedregosa, F.; Varoquaux, G.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Jose, V.R.R.; Winkler, R.L. Evaluating Quantile Assessments. Oper. Res. 2009, 57, 1287–1297. [Google Scholar] [CrossRef] [Green Version]
- Winkler, R.L. A Decision-Theoretic Approach to Interval Estimation. J. Am. Stat. Assoc. 1972, 67, 187–191. [Google Scholar] [CrossRef]
- Ruder, S. An Overview of Multi-Task Learning in Deep Neural Networks. arXiv 2017, arXiv:1706.05098. [Google Scholar]
- Sener, O.; Koltun, V. Multi-Task Learning as Multi-Objective Optimization. arXiv 2018, arXiv:1810.04650. [Google Scholar]
- Désidéri, J.-A. Multiple-gradient descent algorithm (MGDA) for multiobjective optimization. Comptes Rendus Math. 2012, 350, 313–318. [Google Scholar] [CrossRef]




















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lopez-Martin, M.; Sanchez-Esguevillas, A.; Hernandez-Callejo, L.; Arribas, J.I.; Carro, B. Additive Ensemble Neural Network with Constrained Weighted Quantile Loss for Probabilistic Electric-Load Forecasting. Sensors 2021, 21, 2979. https://doi.org/10.3390/s21092979
Lopez-Martin M, Sanchez-Esguevillas A, Hernandez-Callejo L, Arribas JI, Carro B. Additive Ensemble Neural Network with Constrained Weighted Quantile Loss for Probabilistic Electric-Load Forecasting. Sensors. 2021; 21(9):2979. https://doi.org/10.3390/s21092979
Chicago/Turabian StyleLopez-Martin, Manuel, Antonio Sanchez-Esguevillas, Luis Hernandez-Callejo, Juan Ignacio Arribas, and Belen Carro. 2021. "Additive Ensemble Neural Network with Constrained Weighted Quantile Loss for Probabilistic Electric-Load Forecasting" Sensors 21, no. 9: 2979. https://doi.org/10.3390/s21092979