
An Enhanced Joint Hilbert Embedding-Based Metric to Support Mocap Data Classification with Preserved Interpretability

 , , and
, , and
Abstract
:1. Introduction
2. Methods
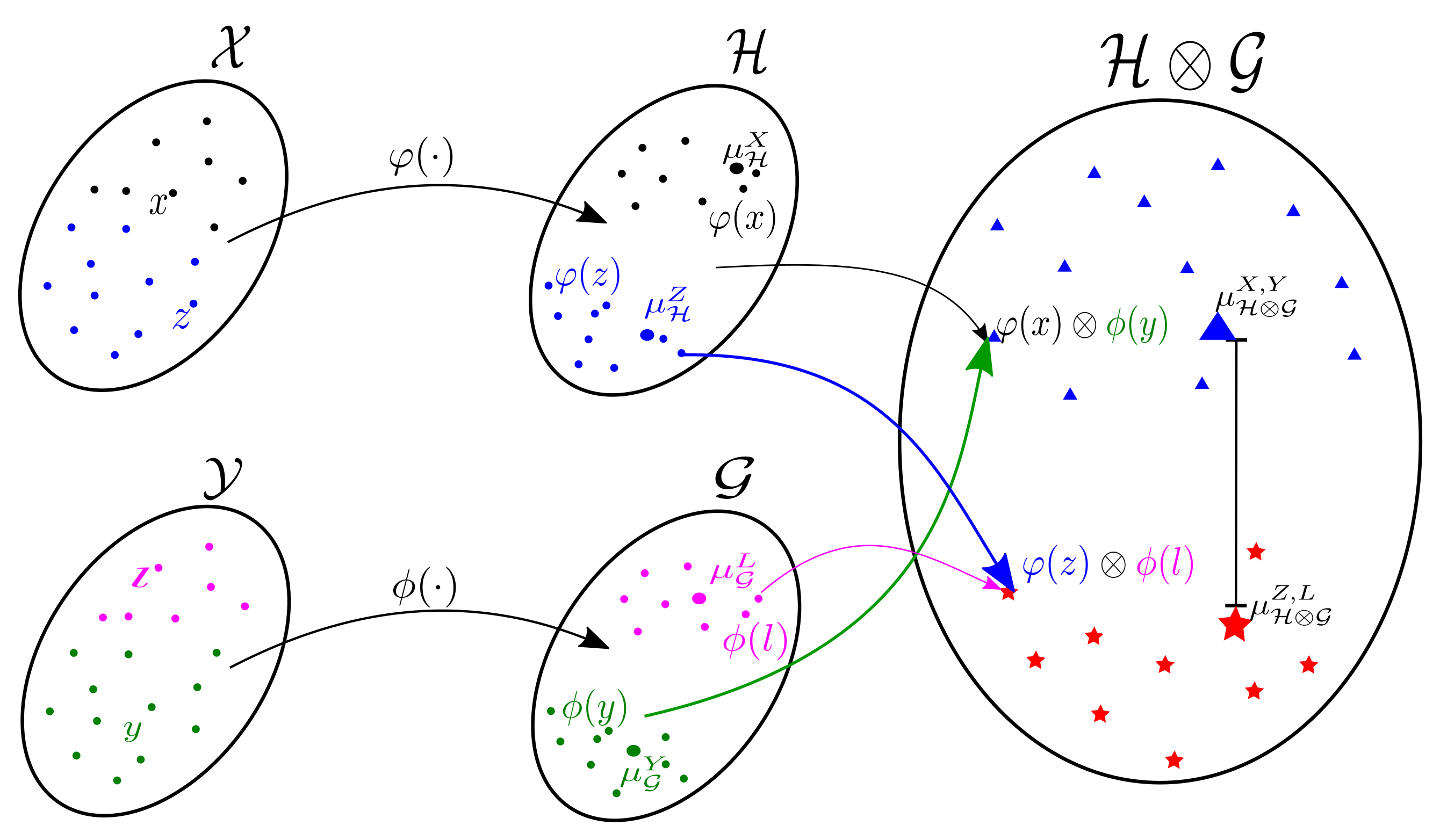
2.1. Marginal Embedding-Based Metric in RKHS
2.2. Enhanced Hilbert Embedding from Cross-Covariance Operator (EHECCO)
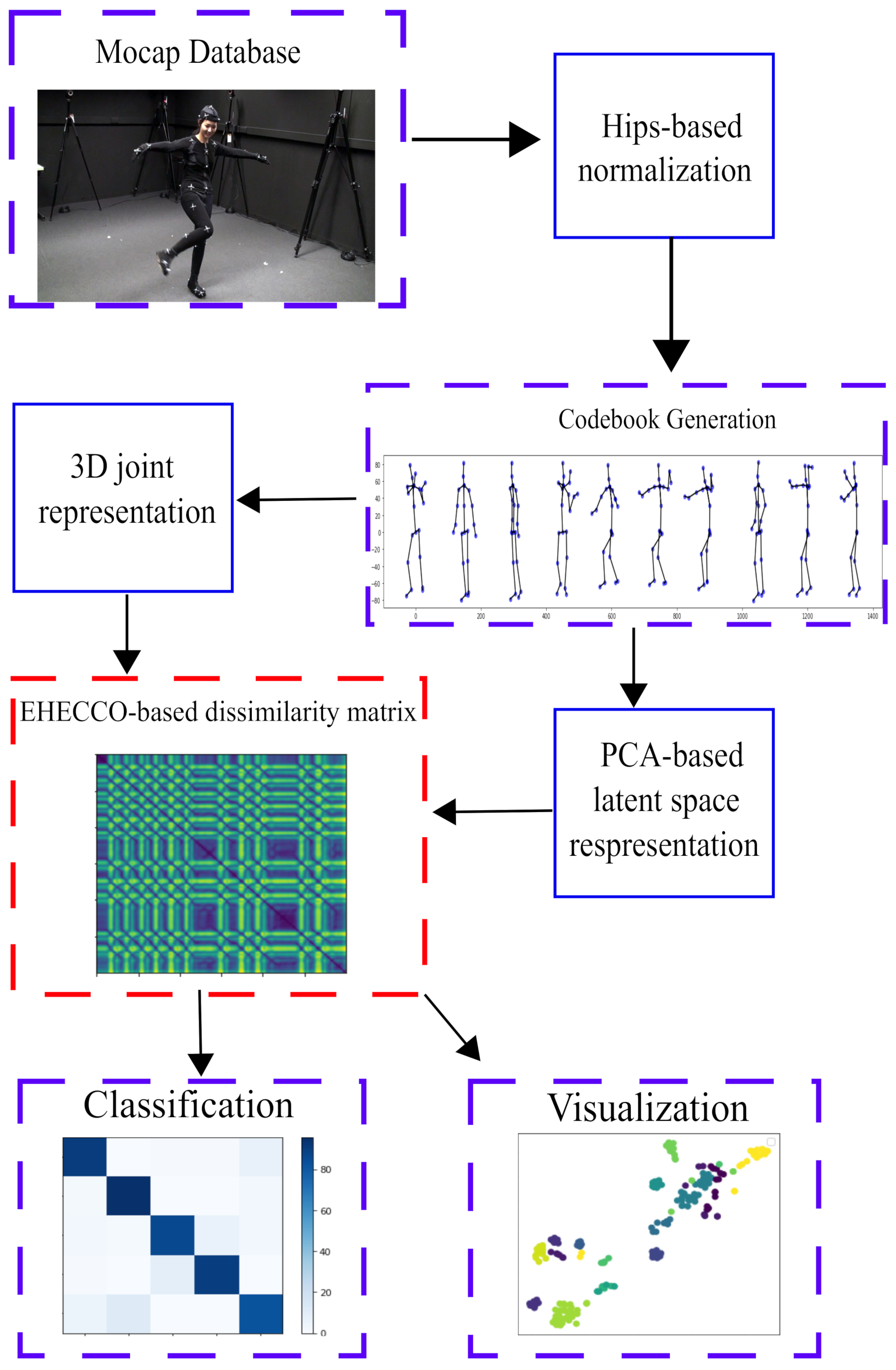
3. Experimental Setup
- –
- 3D joint normalization. A 3D joint representation is extracted from each Mocap record followed by a hip-based normalization [27].
- –
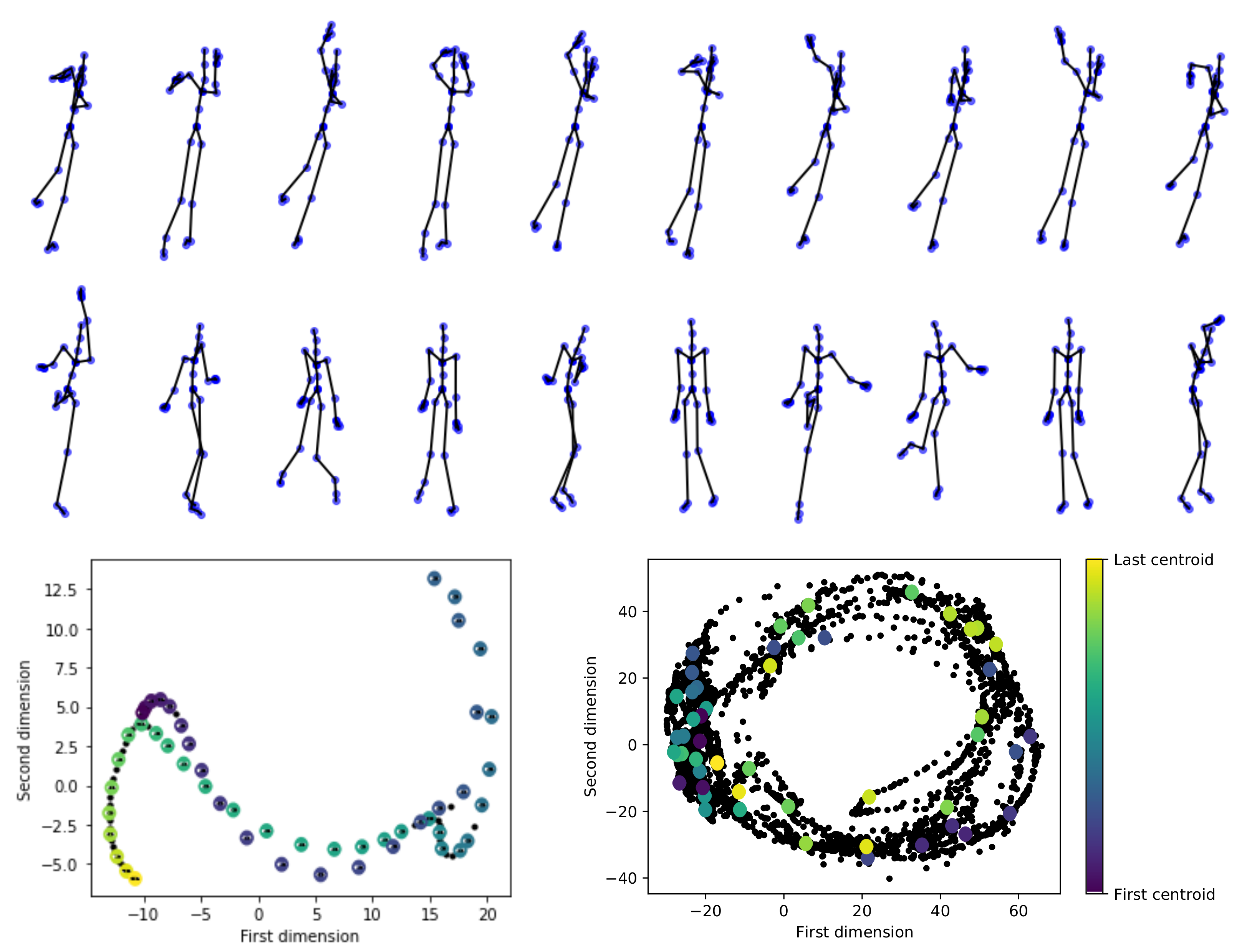
- Codebook generation. A codebook of Mocap frames is built to gather the most representative movement poses. Then, a set of clusters is computed using the well-known spectral clustering algorithm [54], from a vector-based concatenation of the 3D joints. The radial basis function is used as similarity, fixing the bandwidth as the median of the input Euclidean distances.
- –
- Joint and latent space-based representations. To code relevant patterns from provided codebooks, both the input joints and their latent space are considered to build a Mocap video input set: . Here, the well-known principal component analysis (PCA) algorithm is employed to compute a latent space coding the most relevant orthonormal basis concerning the preserved input channels’ variability [55]. In fact, for concrete testing, three principal components are considered (). According to our experiments, three components preserve at least of the input data variability. Note that the V value equals the number of Mocap joints times three (3D skeleton).
- –
- EHECCO-based dissimilarity representation and classification. Given a a pair of Mocap video sets: , , our EHECCO-based distance measure in Equation (9) is computed. In turn, a dissimilarity matrix is calculated as EHECCO-based pairwise Mocap video comparisons ( stands for the number of processed Mocap videos). For the tested databases, the probability vectors are fixed as , being the uniform distribution. Since the Gaussian kernel is preferred in pattern classification because of its universal approximating ability and mathematical tractability [56], and are fixed as Gaussians. Each kernel bandwidth is searched within the range concerning the final classification performance. equals the median of input Euclidean distances in accordance with each studied space (input Mocap joints) or (PCA-based latent projection). Finally, a support vector machine (SVM) classifier is trained on the EHECCO’s distance matrix. A radial basis function (nonlinear mapping) is set for the SVM, and the penalty and precision hyper-parameters are settled from the grids and , respectively, concerning the classification performance. In addition, 2D data projection is also provided from the EHECOO metric for visualization purposes.
3.1. Mocap Databases
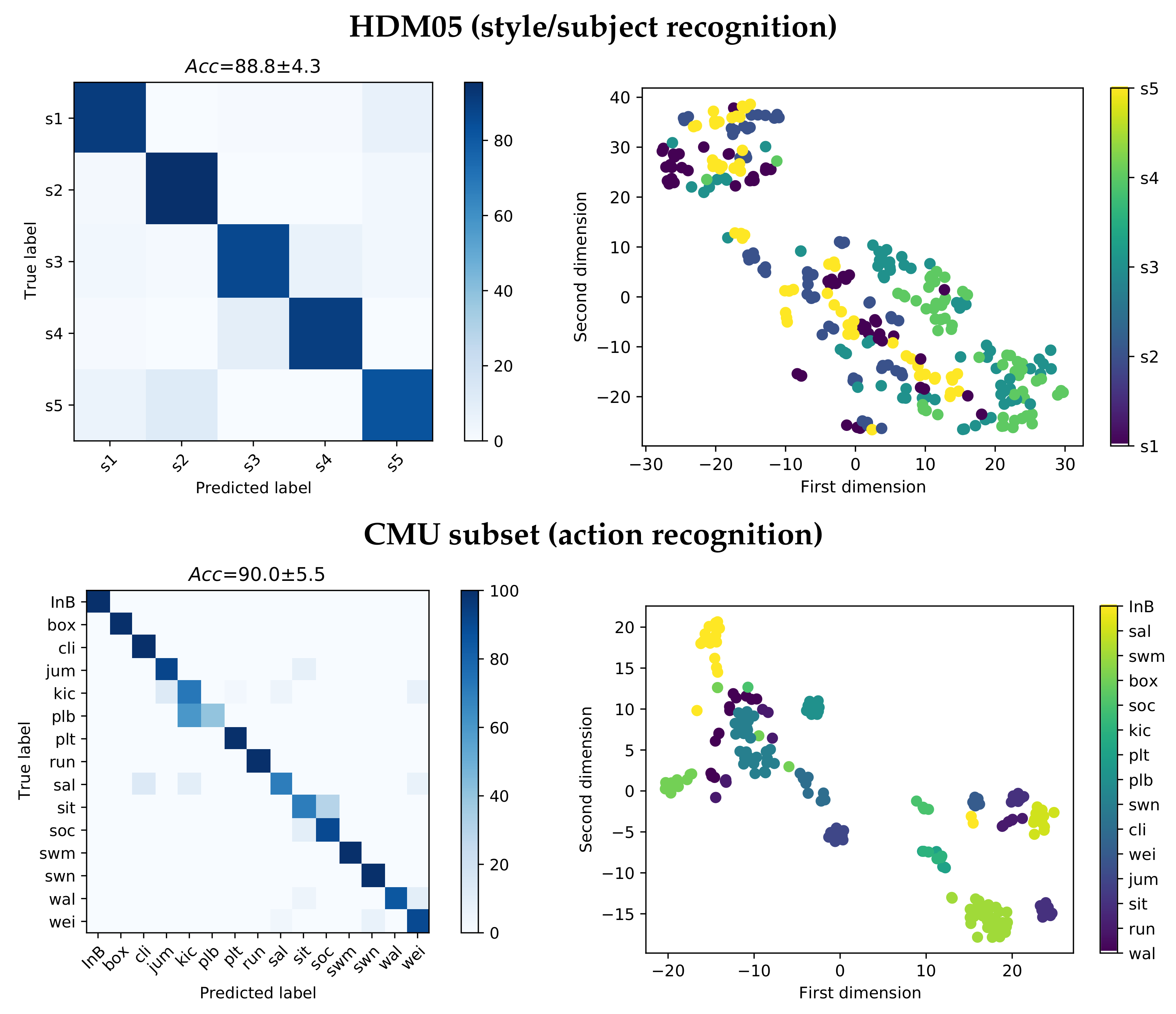
- HDM05 for style/subject recognition (http://resources.mpi-inf.mpg.de/HDM05/, accessed on 5 October 2020). This database includes 325 records (from 65 actions) performed by five different subjects. The dataset includes several recorded actions using a Vicon mocap system, where 31 reflective markers are placed on the subject’s bodies [57]. Then, multi-channel time series of BVH files at 120 frames per second is provided. Following the framework proposed by the authors in [27], we built a scheme for style classification (subject recognition). We relate the classes to each of the five subjects who perform the actions as follows: subject 1 (s1) and similarly for the other subjects.
- CMU subset for action recognition (http://mocap.cs.cmu.edu/info.php, accessed on 5 October 2020). Mocap data are obtained from the Carnegie Mellon Graphics Laboratory, holding 12 Vicon infrared MX-40 cameras at 120 Hz with images of four-megapixel resolution. The cameras are placed around a rectangular area, of approximately 3 m × 8 m, in the center of the room. In particular, multi-channel time series as BVH files with 38 markers are provided. In the same way, as in [26], an action recognition task is carried out from a subset of 150 clips of 15 different motion classes (performed by several subjects): walking (wal), running (run), sitting (sit), jumping (jum), weight-carrying (wei), climbing (cli), swinging (swn), placing a ball (plb), placing tee (plt), kicking (kic), soccer and basketball playing (soc), boxing (box), swimming (swm), salsa (sal), and Indian Bollywood dancing (InB).
- Tennis-Mocap for action recognition and anthropometric analysis (https://drive.google.com/file/d/1-3HAUP4vIBBMz21f7RRgA4b89uNrLxvr/view?usp=sharing, accessed on 5 October 2020). The data are collected from 17 players of the Caldas-Colombia tennis league. The employed motion capture protocol includes the placement of 34 markers for collecting information on body joints. Optitrack Flex V100 (100 Hz) infrared videography is collected from six cameras to acquire sagittal, frontal, and lateral planes. All subjects are encouraged to hit the ball with the same velocity and action as in a tennis match. Moreover, the players are instructed to hit one series continuously by 30 s of each indicated stroke: serve (Ser), forehand (For), backhand (Bac), volley (Vol), backhand volley (BaV), and smash (Sma). In addition, the Tennis database includes the anthropomorphic players’ measurements depicted in Table 1.
3.2. Method Comparison, Quality Assessment, and Implementation Details
4. Results and Discussion
4.1. HDM05 and CMU Results: Mocap Classification Benchmark
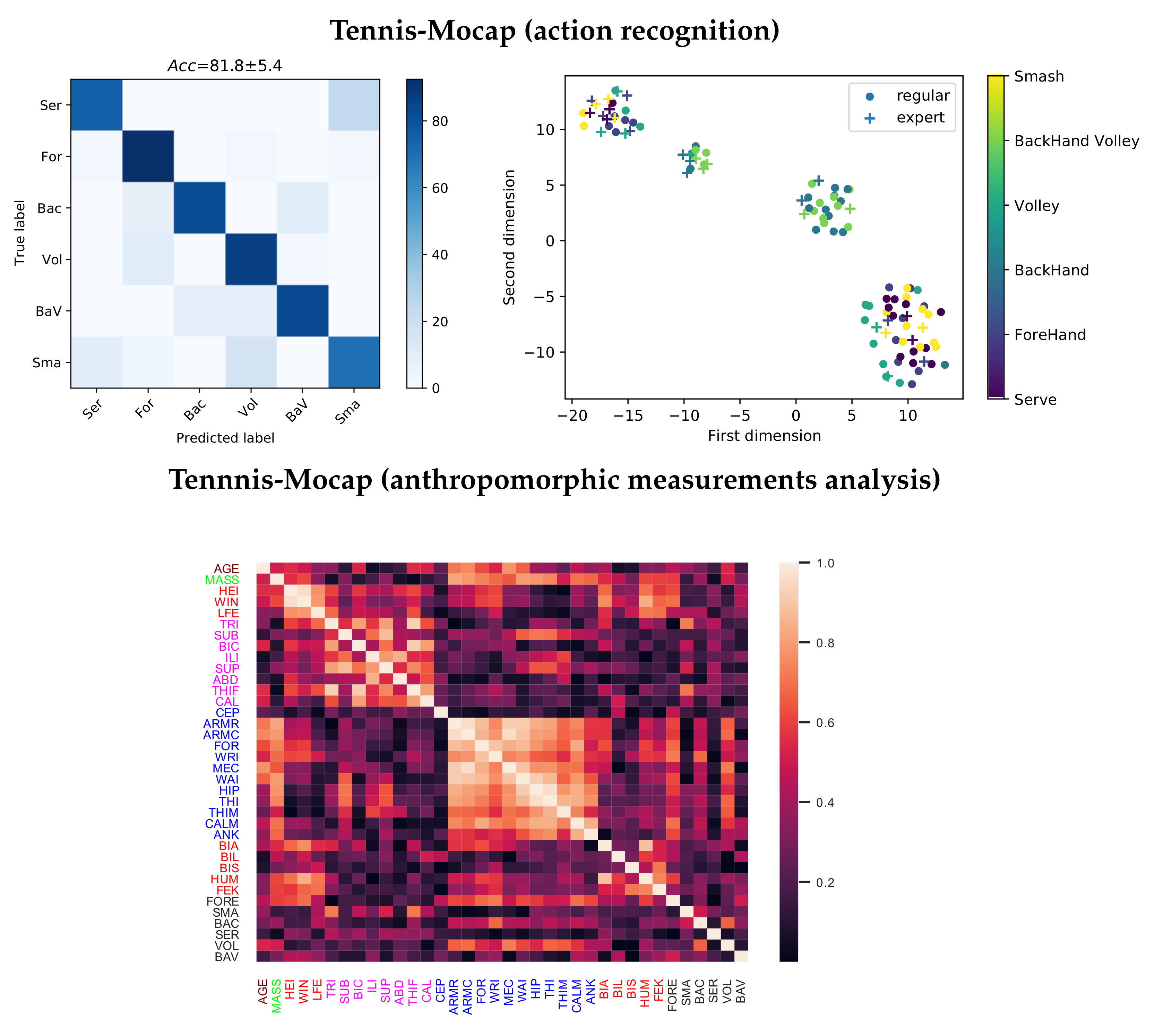
4.2. Tennis-Mocap Results: Classification and Anthropomorphic Analysis
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kadu, H.; Kuo, C. Automatic human mocap data classification. IEEE Trans. Multimed. 2014, 16, 2191–2202. [Google Scholar] [CrossRef]
- Kotsifakos, A. Case study: Model-based vs. distance-based search in time series databases. In Proceedings of the Exploratory Data Analysis (EDA) Workshop in SIAM International Conference on Data Mining (SDM), Philadelphia, PA, USA, 23–26 April 2014. [Google Scholar]
- Anantasech, P.; Ratanamahatana, C. Enhanced Weighted Dynamic Time Warping for Time Series Classification. In Proceedings of the Third International Congress on Information and Communication Technology, London, UK, 27–28 February 2019; pp. 655–664. [Google Scholar]
- Fawaz, H.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P. Deep learning for time series classification: A review. Data Min. Knowl. Discov. 2019, 33, 917–963. [Google Scholar] [CrossRef] [Green Version]
- Bicego, M.; Murino, V.; Figueiredo, M. Similarity-based classification of sequences using hidden Markov models. Pattern Recognit. 2004, 37, 2281–2291. [Google Scholar] [CrossRef]
- Bicego, M.; Murino, V. Investigating hidden Markov models’ capabilities in 2D shape classification. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 281–286. [Google Scholar] [CrossRef]
- Tanisaro, P.; Heidemann, G. Time series classification using time warping invariant echo state networks. In Proceedings of the 2016 15th IEEE International Conference on Machine Learning and Applications (ICMLA), Anaheim, CA, USA, 18–20 December 2016; pp. 831–836. [Google Scholar]
- Nurai, T.; Naqvi, W. A research protocol of an observational study on efficacy of microsoft kinect azure in evaluation of static posture in normal healthy population. Research Square. 2021, 1, 1–9. [Google Scholar]
- Yu, T.; Jin, H.; Tan, W.T.; Nahrstedt, K. SKEPRID: Pose and illumination change-resistant skeleton-based person re-identification. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2018, 14, 1–24. [Google Scholar] [CrossRef]
- Jiang, W.; Xue, H.; Miao, C.; Wang, S.; Lin, S.; Tian, C.; Murali, S.; Hu, H.; Sun, Z.; Su, L. Towards 3D human pose construction using wifi. In Proceedings of the 26th Annual International Conference on Mobile Computing and Networking, London, UK, 21–25 September 2020; pp. 1–14. [Google Scholar]
- Yang, C.; Wang, X.; Mao, S. RFID-Pose: Vision-Aided Three-Dimensional Human Pose Estimation With Radio-Frequency Identification. IEEE Trans. Reliab. 2020. [Google Scholar] [CrossRef]
- Božek, P.; Pivarčiová, E. Registration of holographic images based on the integral transformation. Comput. Inform. 2012, 31, 1369–1383. [Google Scholar]
- Jozef, C.; Bozek, P.; Pivarciová, E. A new system for measuring the deflection of the beam with the support of digital holographic interferometry. J. Electr. Eng. 2015, 66, 53–56. [Google Scholar] [CrossRef] [Green Version]
- de Souza, C.; Gaidon, A.; Cabon, Y.; Murray, N.; López, A. Generating human action videos by coupling 3D game engines and probabilistic graphical models. Int. J. Comput. Vis. 2019, 128, 1–32. [Google Scholar] [CrossRef] [Green Version]
- Alarcón-Aldana, A.; Callejas-Cuervo, M.; Bo, A. Upper Limb Physical Rehabilitation Using Serious Videogames and Motion Capture Systems: A Systematic Review. Sensors 2020, 20, 5989. [Google Scholar] [CrossRef]
- Jedlička, P.; Krňoul, Z.; Kanis, J.; Železnỳ, M. Sign Language Motion Capture Dataset for Data-driven Synthesis. In Proceedings of the LREC2020 9th Workshop on the Representation and Processing of Sign Languages: Sign Language Resources in the Service of the Language Community, Technological Challenges and Application Perspectives, Marseille, France, 11–16 May 2020; pp. 101–106. [Google Scholar]
- Protopapadakis, E.; Voulodimos, A.; Doulamis, A.; Camarinopoulos, S.; Doulamis, N.; Miaoulis, G. Dance pose identification from motion capture data: A comparison of classifiers. Technologies 2018, 6, 31. [Google Scholar] [CrossRef] [Green Version]
- Sun, C.; Junejo, I.; Foroosh, H. Motion retrieval using low-rank subspace decomposition of motion volume. In Computer Graphics Forum; Blackwell Publishing Ltd.: Oxford, UK, 2011; Volume 30, pp. 1953–1962. [Google Scholar]
- Sebernegg, A.; Kán, P.; Kaufmann, H. Motion Similarity Modeling–A State of the Art Report. arXiv 2020, arXiv:2008.05872. [Google Scholar]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I. A review of human activity recognition methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef] [Green Version]
- Gedat, E.; Fechner, P.; Fiebelkorn, R.; Vandenhouten, R. Human action recognition with hidden Markov models and neural network derived poses. In Proceedings of the 2017 IEEE 15th International Symposium on Intelligent Systems and Informatics (SISY), Subotica, Serbia, 14–16 September 2017; pp. 000157–000162. [Google Scholar]
- Principe, J. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Pulgarin-Giraldo, J.; Alvarez-Meza, A.; Van Vaerenbergh, S.; Santamaría, I.; Castellanos-Dominguez, G. Analysis and classification of MoCap data by hilbert space embedding-based distance and multikernel learning. In Proceedings of the 23rd Iberoamerican Congress on Pattern Recognition, Madrid, Spain, 19–22 November 2018; pp. 186–193. [Google Scholar]
- Williams, C.; Rasmussen, C. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Milios, D.; Camoriano, R.; Michiardi, P.; Rosasco, L.; Filippone, M. Dirichlet-based gaussian processes for large-scale calibrated classification. arXiv 2018, arXiv:1805.10915. [Google Scholar]
- Aristidou, A.; Cohen-Or, D.; Hodgins, J.; Chrysanthou, Y.; Shamir, A. Deep motifs and motion signatures. ACM Trans. Graph. (TOG) 2018, 37, 1–13. [Google Scholar] [CrossRef] [Green Version]
- Laraba, S.; Brahimi, M.; Tilmanne, J.; Dutoit, T. 3D skeleton-based action recognition by representing motion capture sequences as 2D-RGB images. Comput. Animat. Virtual Worlds 2017, 28, e1782. [Google Scholar] [CrossRef]
- Dridi, N.; Hadzagic, M. Akaike and bayesian information criteria for hidden markov models. IEEE Signal Process. Lett. 2018, 26, 302–306. [Google Scholar] [CrossRef]
- Singh, A.; Principe, J. Information theoretic learning with adaptive kernels. Signal Process. 2011, 91, 203–213. [Google Scholar] [CrossRef]
- Blandon, J.; Valencia, C.; Alvarez, A.; Echeverry, J.; Alvarez, M.; Orozco, A. Shape classification using hilbert space embeddings and kernel adaptive filtering. In International Conference Image Analysis and Recognition; Springer: Berlin/Heidelberg, Germany, 2018; pp. 245–251. [Google Scholar]
- Huang, Z.; Wan, C.; Probst, T.; Van Gool, L. Deep learning on lie groups for skeleton-based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6099–6108. [Google Scholar]
- Kamilaris, A.; Prenafeta-Boldú, F. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef] [Green Version]
- Duin, R.; Pekalska, E. Dissimilarity Representation For Pattern Recognition, The: Foundations And Applications; World Scientific: Hackensack, NJ, USA, 2005; Volume 64. [Google Scholar]
- García-Vega, S.; Álvarez-Meza, A.; Castellanos-Domínguez, G. MoCap Data Segmentation and Classification Using Kernel Based Multi-channel Analysis. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Springer: Berlin/Heidelberg, Germany, 2013; pp. 495–502. [Google Scholar]
- Müller, M. Dynamic time warping. Information Retrieval for Music and Motion; Springer: Cham, Switzerland, 2007; pp. 69–84. [Google Scholar]
- Jeong, Y.; Jeong, M.; Omitaomu, O. Weighted dynamic time warping for time series classification. Pattern Recognit. 2011, 44, 2231–2240. [Google Scholar] [CrossRef]
- Liu, X.; Sarker, M.; Milanova, M.; OGorman, L. Video-Based Monitoring and Analytics of Human Gait for Companion Robot. In Proceedings of the New Approaches for Multidimensional Signal Processing: Proceedings of International Workshop, NAMSP 2020, Sofia, Bulgaria, 9–11 July 2021; Volume 216, p. 15. [Google Scholar]
- Liu, L.; Li, P.; Chu, M.; Cai, H. Stochastic gradient support vector machine with local structural information for pattern recognition. Int. J. Mach. Learn. Cybern. 2021, 1, 1–18. [Google Scholar]
- Smola, A.; Gretton, A.; Song, L.; Schölkopf, B. Algorithmic Learning Theory. In Proceedings of the 18th International Conference, ALT 2007, Sendai, Japan, 1–4 October 2007; Chapter A Hilbert Space Embedding for Distributions. Springer: Berlin/Heidelberg, Germany, 2007; pp. 13–31. [Google Scholar]
- Huang, Z.; Van Gool, L. A riemannian network for spd matrix learning. arXiv 2016, arXiv:1608.04233. [Google Scholar]
- Vemulapalli, R.; Arrate, F.; Chellappa, R. Human action recognition by representing 3d skeletons as points in a lie group. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Vemulapalli, R.; Chellapa, R. Rolling rotations for recognizing human actions from 3d skeletal data. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4471–4479. [Google Scholar]
- Gretton, A.; Bousquet, O.; Smola, A.; Schölkopf, B. Measuring statistical dependence with Hilbert-Schmidt norms. In International Conference on Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2005; pp. 63–77. [Google Scholar]
- Song, L.; Fukumizu, K.; Gretton, A. Kernel embeddings of conditional distributions: A unified kernel framework for nonparametric inference in graphical models. IEEE Signal Process. Mag. 2013, 30, 98–111. [Google Scholar] [CrossRef]
- Zhao, J.; Xie, X.; Xu, X.; Sun, S. Multi-view learning overview: Recent progress and new challenges. Inf. Fusion 2017, 38, 43–54. [Google Scholar] [CrossRef]
- Shimizu, T.; Hachiuma, R.; Saito, H.; Yoshikawa, T.; Lee, C. Prediction of future shot direction using pose and position of tennis player. In Proceedings of the 2nd International Workshop on Multimedia Content Analysis in Sports, Nice, France, 21–25 October 2019; pp. 59–66. [Google Scholar]
- Muandet, K.; Fukumizu, K.; Sriperumbudur, B.; Schölkopf, B. Kernel mean embedding of distributions: A review and beyond. arXiv 2016, arXiv:1605.09522. [Google Scholar]
- Sriperumbudur, B.; Gretton, A.; Fukumizu, K.; Schölkopf, B.; Lanckriet, G. Hilbert space embeddings and metrics on probability measures. J. Mach. Learn. Res. 2010, 11, 1517–1561. [Google Scholar]
- Berlinet, A.; Thomas-Agnan, C. Reproducing Kernel Hilbert Spaces in Probability and Statistics; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Carter, T. An introduction to information theory and entropy. Complex Syst. Summer Sch. Santa Fe 2007, 1, 1–139. [Google Scholar]
- Smola, A.; Gretton, A.; Song, L.; Schölkopf, B. A Hilbert space embedding for distributions. International Conference on Algorithmic Learning Theory; Springer: Berlin/Heidelberg, Germany, 2007; pp. 13–31. [Google Scholar]
- Gretton, A.; Borgwardt, K.; Rasch, M.; Schölkopf, B.; Smola, A. A Kernel Two-sample Test. J. Mach. Learn. Res. 2012, 13, 723–773. [Google Scholar]
- Schölkopf, B.; Smola, A. Learning with Kernels; The MIT Press: Cambridge, MA, USA, 2002. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019. [Google Scholar]
- Jolliffe, I.; Cadima, J. Principal component analysis: A review and recent developments. Philos. Trans. R. Soc. Math. Phys. Eng. Sci. 2016, 374, 20150202. [Google Scholar] [CrossRef]
- Álvarez-Meza, A.; Cárdenas-Peña, D.; Castellanos-Dominguez, G. Unsupervised kernel function building using maximization of information potential variability. In Iberoamerican Congress on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2014; pp. 335–342. [Google Scholar]
- Müller, M.; Röder, T.; Clausen, M.; Eberhardt, B.; Krüger, B.; Weber, A. Documentation Mocap Database hdm05; University of Bonn: Bonn, Germany, 2007. [Google Scholar]
- Müller, M.; Röder, T. Motion templates for automatic classification and retrieval of motion capture data. In Proceedings of the 2006 ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Vienna, Austria, 2–4 September 2006; pp. 137–146. [Google Scholar]
- Kapadia, M.; Chiang, I.; Thomas, T.; Badler, N.; Kider, J. Efficient motion retrieval in large motion databases. In Proceedings of the ACM SIGGRAPH Symposium on Interactive 3D Graphics and Games, Orlando, FL, USA, 21–23 March 2013; pp. 19–28. [Google Scholar]
- Arora, S.; Hu, W.; Kothari, P.K. An analysis of the t-sne algorithm for data visualization. In Proceedings of the 31st Conference On Learning Theory, Stockholm, Sweden, 5–9 July 2018; pp. 1455–1462. [Google Scholar]
- Lee, J.A.; Renard, E.; Bernard, G.; Dupont, P.; Verleysen, M. Type 1 and 2 mixtures of Kullback–Leibler divergences as cost functions in dimensionality reduction based on similarity preservation. Neurocomputing 2013, 112, 92–108. [Google Scholar] [CrossRef]
- Landlinger, J.; Lindinger, S.; Stöggl, T.; Wagner, H.; Müller, E. Key factors and timing patterns in the tennis forehand of different skill levels. J. Sports Sci. Med. 2010, 9, 643. [Google Scholar]
- Delgado-Garcia, G.; Vanrenterghem, J.; Munoz-Garcia, A.; Molina-Molina, A.; Soto-Hermoso, V.M. Does stroke performance in amateur tennis players depend on functional power generating capacity? J. Sport. Med. Phys. Fit. 2019, 59, 760–766. [Google Scholar] [CrossRef] [PubMed]
- Fett, J.; Ulbricht, A.; Ferrauti, A. Impact of Physical Performance and Anthropometric Characteristics on Serve Velocity in Elite Junior Tennis Players. J. Strength Cond. Res. 2020, 34, 192–202. [Google Scholar] [CrossRef] [PubMed]
- Tsoulfa, K.; Dalamitros, A.; Manou, V.; Stavropoulos, N.; Kellis, S. Can a one-day field testing discriminate between competitive and noncompetitive preteen tennis players? J. Phys. Educ. Sport 2016, 16, 1075–1077. [Google Scholar] [CrossRef]
- Coulibaly, S.; Kouassi, F.; Beugré, J.B.; Kouadio, J.; Assi, A.; Sonan, N.; Kouamé, N.; Pineau, J.C. Left and right-hand correspondence of the anthropometrical parameters of the upper and manual lateral limb within professional tennis players. Gazz. Med. Ital. Arch. Per. Sci. Med. 2017, 176, 338–344. [Google Scholar]
- García-Murillo, D.G.; Alvarez-Meza, A.; Castellanos-Dominguez, G. Single-Trial Kernel-Based Functional Connectivity for Enhanced Feature Extraction in Motor-Related Tasks. Sensors 2021, 21, 2750. [Google Scholar] [CrossRef]
- Pomponi, J.; Scardapane, S.; Uncini, A. Bayesian neural networks with maximum mean discrepancy regularization. Neurocomputing 2021. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Age | Thigh cm (THI) | Height cm (HEI) | Medial calf mm (CAL) |
| Mass | Calf maximum cm (CALM) | Foot length cm (LFE) | Biceps mm (BIC) |
| Cephalic cm (CEP) | Relaxed arm cm (ARMR) | Biliocrestal cm (BIL) | Front thigh mm (THIF) |
| Minimum ankle cm (ANK) | Mesosternal chest cm (MEC) | Humerus cm (HUM) | Forehand (FORE) |
| Hip max cm (HIP) | Forearm cm (FOR) | Supraspinal mm (SUP) | Smash (SMA) |
| Contracted arm 90 cm (ARMC) | Bistyloid cm (BIS) | Subscapular mm (SUB) | Backhand (BAC) |
| Waist cm (WAI) | Biacromial cm (BIA) | Iliac crest mm (ILI) | Serve (SER) |
| Middle thigh cm (THIM) | Femur knee cm (FEK) | Triceps mm (TRI) | Volley (VOL) |
| Wrist cm (WRI) | Wingspan cm (WIN) | Abdominal mm (ABD) | Backhand Volley (BAV) |
| Method | Accuracy (%) |
|---|---|
| SPDNet [40] | 61.45 |
| SE [41] | 70.26 |
| SO [42] | 71.31 |
| LieNet [31] | 75.78 |
| Seq2Im+SVM [27] | 70.70 |
| Seq2Im+KNN [27] | 66.82 |
| Seq2IM+RF [27] | 80.62 |
| Seq2Im+CNN (fine-tuning) [27] | 83.33 |
| EHECCO+SVM | 88.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Valencia-Marin, C.K.; Pulgarin-Giraldo, J.D.; Velasquez-Martinez, L.F.; Alvarez-Meza, A.M.; Castellanos-Dominguez, G. An Enhanced Joint Hilbert Embedding-Based Metric to Support Mocap Data Classification with Preserved Interpretability. Sensors 2021, 21, 4443. https://doi.org/10.3390/s21134443
Valencia-Marin CK, Pulgarin-Giraldo JD, Velasquez-Martinez LF, Alvarez-Meza AM, Castellanos-Dominguez G. An Enhanced Joint Hilbert Embedding-Based Metric to Support Mocap Data Classification with Preserved Interpretability. Sensors. 2021; 21(13):4443. https://doi.org/10.3390/s21134443
Chicago/Turabian StyleValencia-Marin, Cristian Kaori, Juan Diego Pulgarin-Giraldo, Luisa Fernanda Velasquez-Martinez, Andres Marino Alvarez-Meza, and German Castellanos-Dominguez. 2021. "An Enhanced Joint Hilbert Embedding-Based Metric to Support Mocap Data Classification with Preserved Interpretability" Sensors 21, no. 13: 4443. https://doi.org/10.3390/s21134443