
Design of an Intelligent Tutoring System to Create a Personalized Study Plan Using Expert Systems


1
Department of Informatics and Computers, University of Ostrava, 30. Dubna 22, 701 03 Ostrava, Czech Republic
2
Elvac Company, a.s., Hasičská 930/53, 700 30 Ostrava, Czech Republic
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(12), 6236; https://doi.org/10.3390/app12126236
Submission received: 19 May 2022
/
Revised: 13 June 2022
/
Accepted: 15 June 2022
/
Published: 19 June 2022
Abstract
:The article is devoted to the issue of the construction of an intelligent tutoring system which was created by our university for implementing distance learning and combined forms of studies. Significantly higher demand for such tools occurred during the COVID-19 pandemic when distance learning was used by students in their full-time studies. Current Learning Management Systems (LMS) do not address students’ individuality regarding their various levels of input knowledge and skills or their different learning styles, which, in our case, are based on sensory preferences. Therefore, this article proposes a model of an intelligent tutoring system to control learning by accentuating the individual needs of a student. The foundation stones of this system are an expert system and adaptation mechanisms. The expert system acts as a tool for the identification of students’ needs from the point of view of input knowledge and sensory preferences. Sensory preferences influence the student’s learning style. The implemented adaptation mechanisms control the progress of the student through a study unit. The model was implemented in the LMS Moodle environment. Regarding the focus of the research content, our model is oriented on the study of the English language, where each student receives a unique study plan, which is continuously adapted based on achieved results. We consider the focus on the individuality of the student to be an innovative approach that can be achieved automatically on a mass scale.
1. Introduction
Online education has become very sought after worldwide, both in the public and private sectors [1]. Languages can be taught and learned through social networks [2] as well, but as [3] described in his work, with limited possibilities and results. Although it was as early as 1997 when [4] pointed out that e-learning a foreign language falls behind in areas of flexible feedback and an individualized approach, this complex problem has not been solved until now and is still a subject of numerous research questions, for example [5,6,7,8], and many others. Thus, various approaches and systems have been designed and developed in order to overcome this insufficiency, primarily concerned with systems that use a kind of intelligent tutoring methodology [8,9]. From the simple creation of a system offering the same educational content, path, and approach to all students, teachers and researchers have moved to a higher level, i.e., personalized e-learning. However, the idea of satisfying students’ educational needs individually, namely regarding e-learning studies, poses a complex problem and requires modifying the concept of the whole e-learning system, as was well outlined by [10].
2. Expert Systems for Educational Needs
Inaccuracy has characteristics that allow us to apply suitable tools to process a particular type of incompleteness. Inaccuracies appear while resolving decision-making processes. Their analysis often results in finding that the respective inaccuracy is represented by insufficient information. Thus, its foundation can be found in students’ incapability to specify what they know, i.e., their knowledge. Nevertheless, students’ knowledge cannot be detected by mere testing, as testing does not provide all the needed information. Insufficiency, in fact, is symbolized by the description of their knowledge in individual parts of the test. For instance, if a student is able to use the second and third conditional well, does it imply that the student can use them as mixed conditional? The second type of insufficient information is the use of a natural language that enters the decision-making process of a person and describes the decision-making process and its functioning. The insufficiency consists of the fact that a person is forced to use a finite set of words in a finite time to describe an infinite range of possible situations. Such a fact necessarily results in a situation when most verbal utterances have a wide range of meanings. These semantic uncertainties are caused by both semantic synonymies of words and a certain blurriness (fogginess, fuzziness) of the meaning of the keywords. Such fogginess results in a situation when traditional mathematics and exact sciences cannot appropriately deal with linguistically-defined situations. This situation has significantly improved over the last few years with the introduction of so-called fuzzy mathematics, which makes it possible to process such verbally described situations. Therefore, our approach is grounded in the capabilities of an expert system with incorporated fuzzy logic decision-making power.
As mentioned above, the basis of our methodology is conditional progress through a course. Such progress changes available study materials and activities based on the students’ preferences, their input knowledge, and continuous knowledge, which is acquired by tests that constitute an inseparable part of the course. From this perspective, we can claim that the basic mechanism controlling the educational process is a decision-making process.
Based on the sources [1,2,3,4,5,6,7,8,9,10] described above, the following groups of relevant uncertainties in the decision-making process of education have been identified:
- Uncertainties emerging from indefinite information. The source of uncertainty in this group is students’ “inability” to describe their knowledge and to determine its level objectively. As an example in English language education, this insufficiency can be represented by requiring knowledge of all parts of the language in a single test, e.g., if a student is able to use the Present Continuous tense in two of its uses (current action, future plan), does that mean that the student knows how to use it or not, or only partially? We know nothing about the student’s knowledge of using the Present Continuous as a temporary action or an annoying habit.
- The second group of uncertainties emerges from the use of natural language used by a person entering the decision-making process and who describes the process of decision-making and its functioning. The uncertainties of the semantic field of words are generated by a certain sharpness of the keyword’s meaning. Classical mathematics, and exact sciences in general, can hardly adequately tackle such linguistically defined situations.
- The third group of uncertainties influencing the decision-making process is the inexperience of students with sensory preferences, which influence the selection of the type of study materials.
The above-stated facts give evidence that a decision-making process controlling education must be adapted to such uncertainties. Omitting them would undoubtedly decrease the quality of the educational process. In the context of this perspective, it concerns a problem domain that offers an effective implementation of a fuzzy logic expert system into the control of an educational process.
3. Personalisation and Adaptivity in E-Learning and Language Learning—Research Context
In [11], the authors claim that personalized learning should involve activities of personal interest that are self-initiated. We cannot agree with this idea as this would result in a chaotic educational process. The process must be supervised by a teacher who knows what content, timing, etc., is suitable for achieving the right outcome. The student is in the center of the learning process, of course, but individual learning should provide freedom within the borders set by the teacher. All students should have the same outcome, which rather limits the freedom of a student to choose what and what not to learn. On the other hand, we can fully agree with [12], who believe that personalized learning should be carried out by recommending learning tasks and resources based on learners’ profiles.
Adaptivity of a system means a system’s ability to adapt to a change in the controlled system (in our case, a student), which the system reacts to with an appropriate change. Such adaptivity requires gathering user data and its analysis [13]. Current Learning Management Systems (LMSs) generally do not offer the possibility of adapting to the needs of individual users to such an extent, which would qualify them to be called adaptive systems. All activities are permanently supervised by a tutor, who guides the student through the course to achieve better results. It is fully up to the tutor to advise a student on the most suitable study materials, which might be often difficult as the tutor does not have much personal contact and time to analyze the students. This might result in a very time-consuming or even impossible process.
That is why the adaptivity of the educational system represents an important element of our approach. It means a condition that continuously, and if possible, immediately reacts to changes on the student’s side, aiming to adapt to their current needs as much as possible. Standard LMS systems do not offer this possibility to a sufficient extent, and a certain adaptivity is ensured by the tutor’s activity. However, the tutor’s interference has time limits, and reaction time is quite high. Relying on the state when the tutor ensures an educational process’s adaptivity in an LMS, the basic advantage of e-learning would be lost. The introduction of adaptivity in the LMSs environment is then a question of good mapping of the possibilities of current versions or the development of system modules that would bring the desired effect.
The research in the area of personalized/adaptive systems spreads into more specific areas. We can mention efforts for personalization/adaptation in the area of learning styles [14,15], improving the literacy of reading and writing [16,17], video content [18], recorded lectures [19], and many more, as the works of [20,21] summarize. An example of a more elaborated adaptive system is iSTART [22], which, however, focuses on reading comprehension only.
Regarding personalized e-learning in the area of second-language acquisition (namely English), there have been numerous attempts to create a system for language learning, for instance, [23], which focused on social networks and mobile devices, [24], which focused on primary-school English, and [25], which focused on a response system for classroom assessment. Nevertheless, they have not resulted in an adaptive system as we have defined the term adaptivity, nor have they covered the area to the extent to be able to be used for widespread public use.
The overview of possible approaches to e-learning adaptivity and language learning has brought us to the conclusion that it is essential to find a solution that (a) adapts the learning content of the course according to student’s needs, not only based on initial information about the student but based on his later study results as well, (b) is available for mass distribution using the open-source Moodle platform used in 251 countries with 211,000 installations and more than 250 million users [26], and (c) is simple to design and implement, while still offering the possibility for other parties to modify the proposed solution to meet their needs. In addition, for the solution to reach the masses, it should be versatile, i.e., usable for a large number of educational areas/subjects, not just limited to language area, reading skills, or mathematical operations. These features have not been found in the solution presented in the state-of-the-art analysis.
Therefore, to eliminate the above-described issues, it is suitable to take advantage of a system that makes it possible to process inaccurate information (as described in Section 1) and incorporate all features of a system satisfying the needs of personalized learning using adaptivity. Such a system is proposed below.
4. Proposed Model
Considering the work [27], we have similar goals to achieve: (1) using preferred study materials; (2) continuous assessment; (3) creating flexible learning outside school. We have deeply studied the possibility of proposing a model that would be adaptive and applicable to foreign language learning in an e-learning environment because one of the authors is a qualified and experienced university lecturer of English as a second language (ESL). We used the LMS Moodle platform as a tool to deploy the suggested methodology. The proposed learning model is split into two parallel threads that give us the basis for subsequent processes. One thread focuses on the educational area aimed at the student; in other words, we want to acquire information about how they learn and perceive information (sensory preferences). We also want to know their level of knowledge in the studied area (here, their language proficiency). A more in-depth study of this topic was introduced in [28]. The next thread applies the fuzzy logic expert system LFLC 2000 according to [29]. It is used to assess a didactic test. A more in-depth study of this topic was introduced in [30].
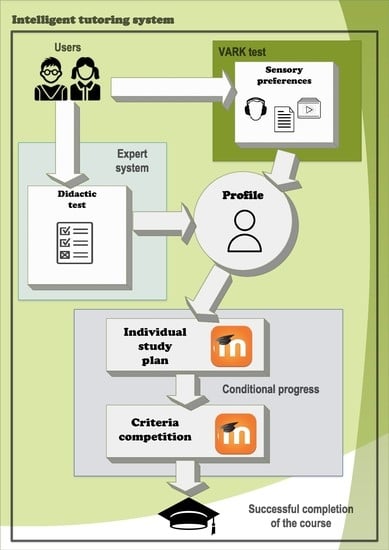
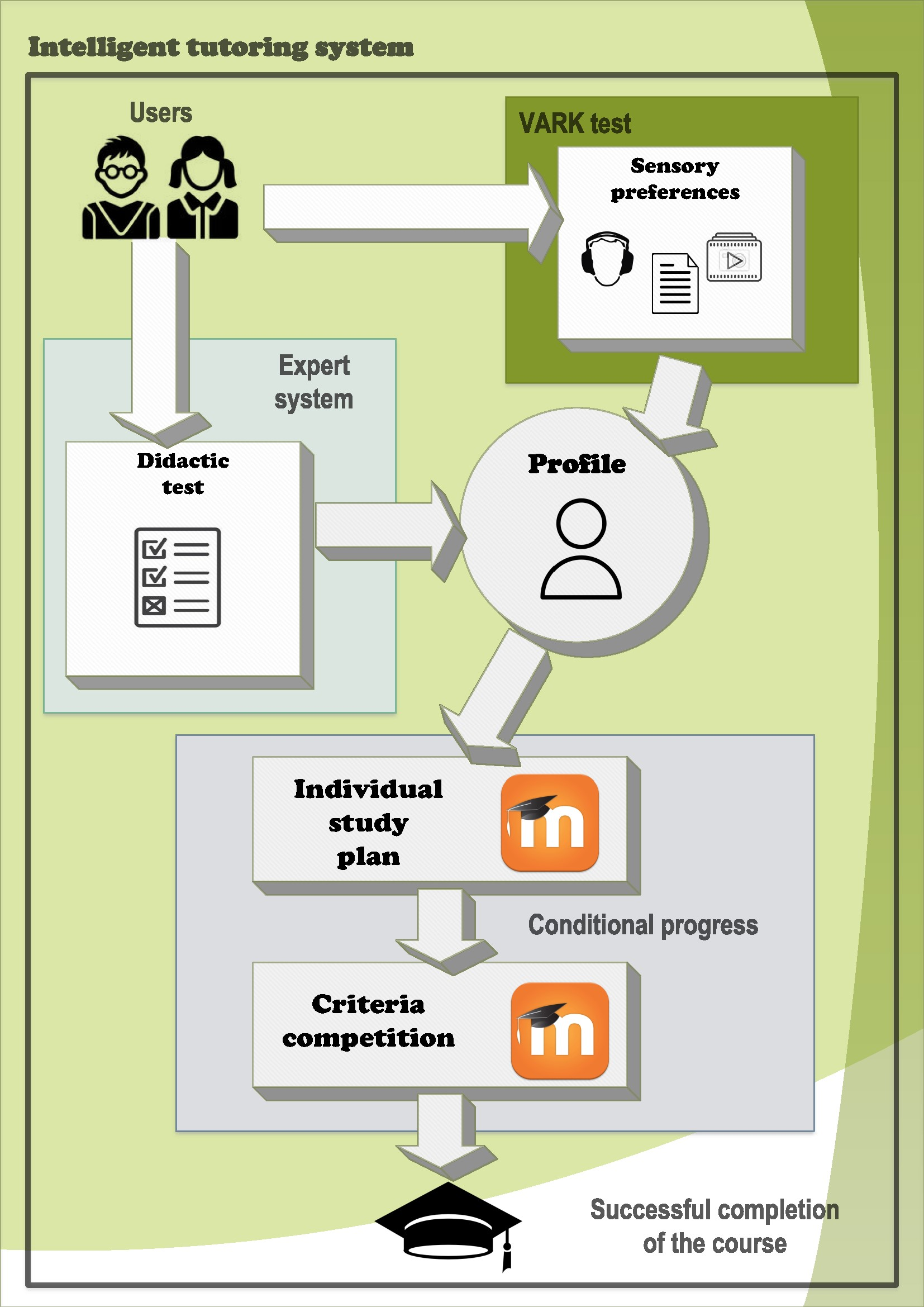
In this article, we want to focus more on the processes that follow after relevant information, which is unique for each student, is gathered and stored in a database. The student’s database is comprised of two sub-databases, see Figure 1. It is important to point out that there are no models of predefined student images in our database where a real student would be matched. Our idea considers that there is a unique portfolio for each student. This portfolio contains all their personal information.
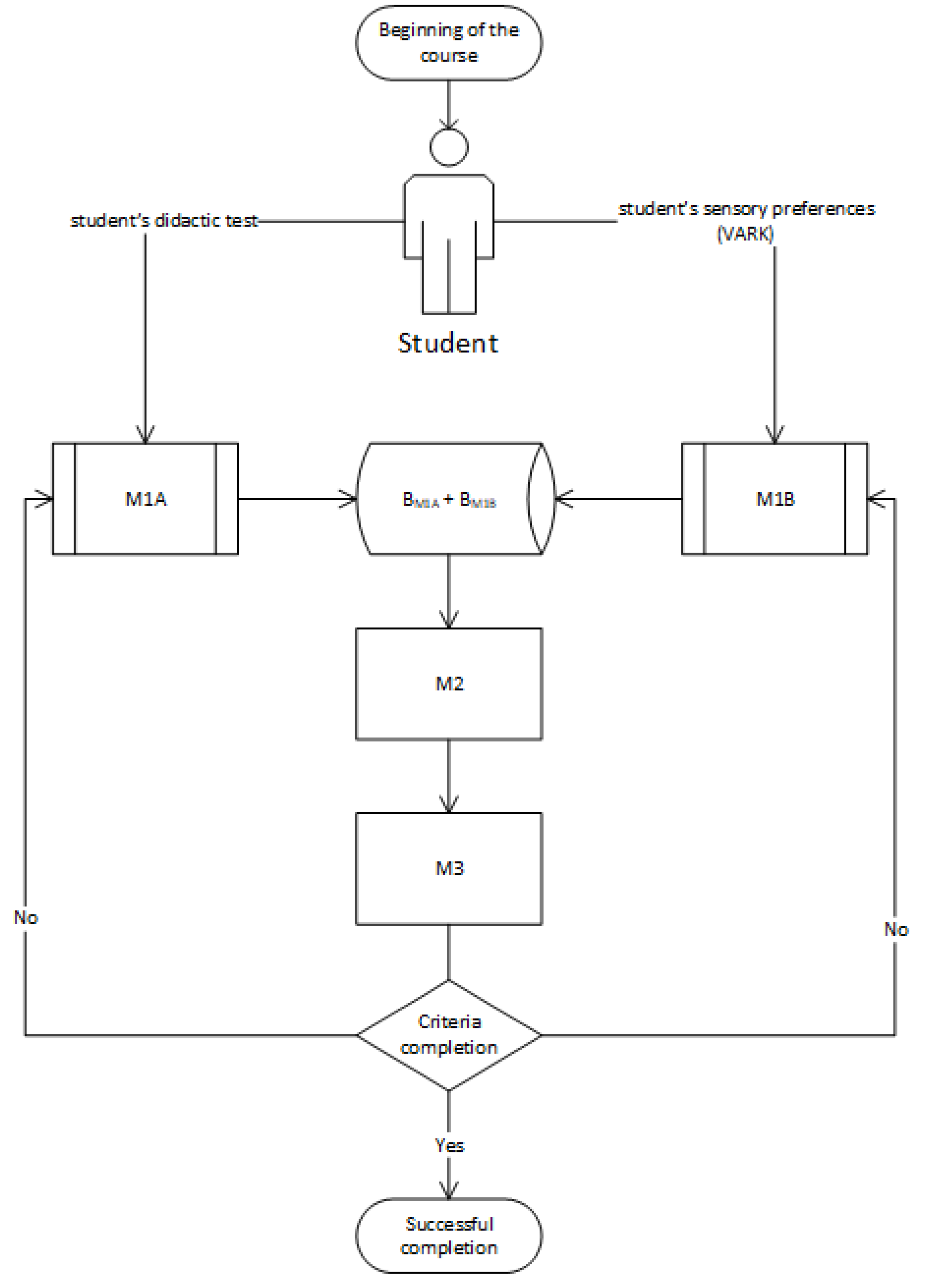
The proposed model consists of modules M1-M2-M3. The M1 module includes processes M1A and M1B. The role of the M1A module is to gather the student’s didactic test and assess it, which provides us with the input knowledge of the student when starting the learning process. A is a database that stores data from M1A. The M1B module, on the other hand, assesses and stores information about the student’s sensory preferences from the perspective of how they efficiently absorb information from their surroundings. Parallel to BM1A, BM1B denotes a database that holds data from the M1B module.
The main module during the learning phase is module M2. Its purpose is to adapt the learning objects, i.e., study materials, of the given e-learning course in order to meet the student’s needs as defined in M1A and M1B. The learning objects are modified in their content as well as form. A deeper-level adaptation within the M2 module requires that the learning objects are classified into learning units corresponding to the topics studied in the given course.
Concerning the pedagogical point of view, basic thematic areas are crucial for more advanced levels. Therefore, the control of the learning process does not only imply a change in the learning content but introduces conditional access to more advanced thematic areas on the basis of achieved results in previous thematic areas.
The next module, called M3, performs the operations of the final diagnostics. Such diagnostics are based on modifying the form of the learning objects. Such modification can be done repeatedly, yet the number of repetitions is limited as the forms of the learning content are also limited. If a student fails to meet the required learning outcomes, BM1B must be redefined to find more suitable learning content and form. If a student succeeds, the learning process is considered terminated.
4.1. Application of Module M1A
Module M1A deals with attributes in the student’s portfolio focused on the knowledge of the given studied area/topics. The outputs from this module are stored in BM1A. The studied area/topics are called Thematic group fields. Individual thematic groups give names to the fields. The groups are focused on grammatical issues and specific areas related to the study of information technology in English.
The fields hold values corresponding to individual fuzzy sets characterizing the current competencies of students in given thematic areas (categories). Linguistic value characterizing the level of a student’s competencies is a result of an initial test, which was subsequently processed in LFLC 2000. The categories were analyzed in order to assess the need for further study in the given category. The analysis and assessment were performed in LFLC 2000, which was designed to work with information burdened with indeterminacy.
The list below summarises the input variables entering the process for assessment of each individual category (including the linguistic expressions for the variables).
- Knowledge of the given category (V1)—small, medium, big;
- Weight of correct answers (V2)—small, medium, big;
- Importance of the category for further study (V3)—very small, small, medium, big, very big;
- Time spent on questions of the given category (V4)—small, medium, big.
4.1.1. Knowledge of the Given Category (V1)
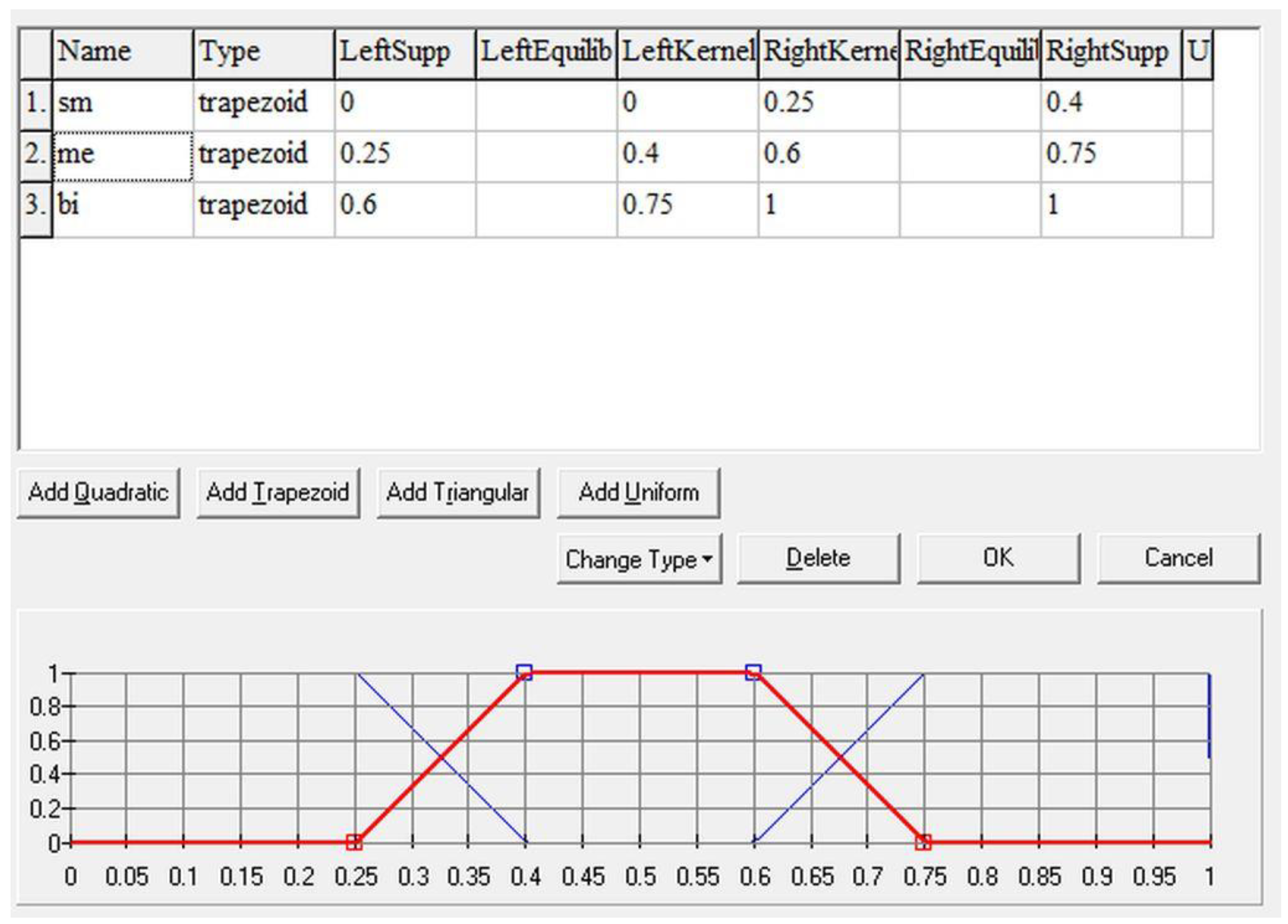
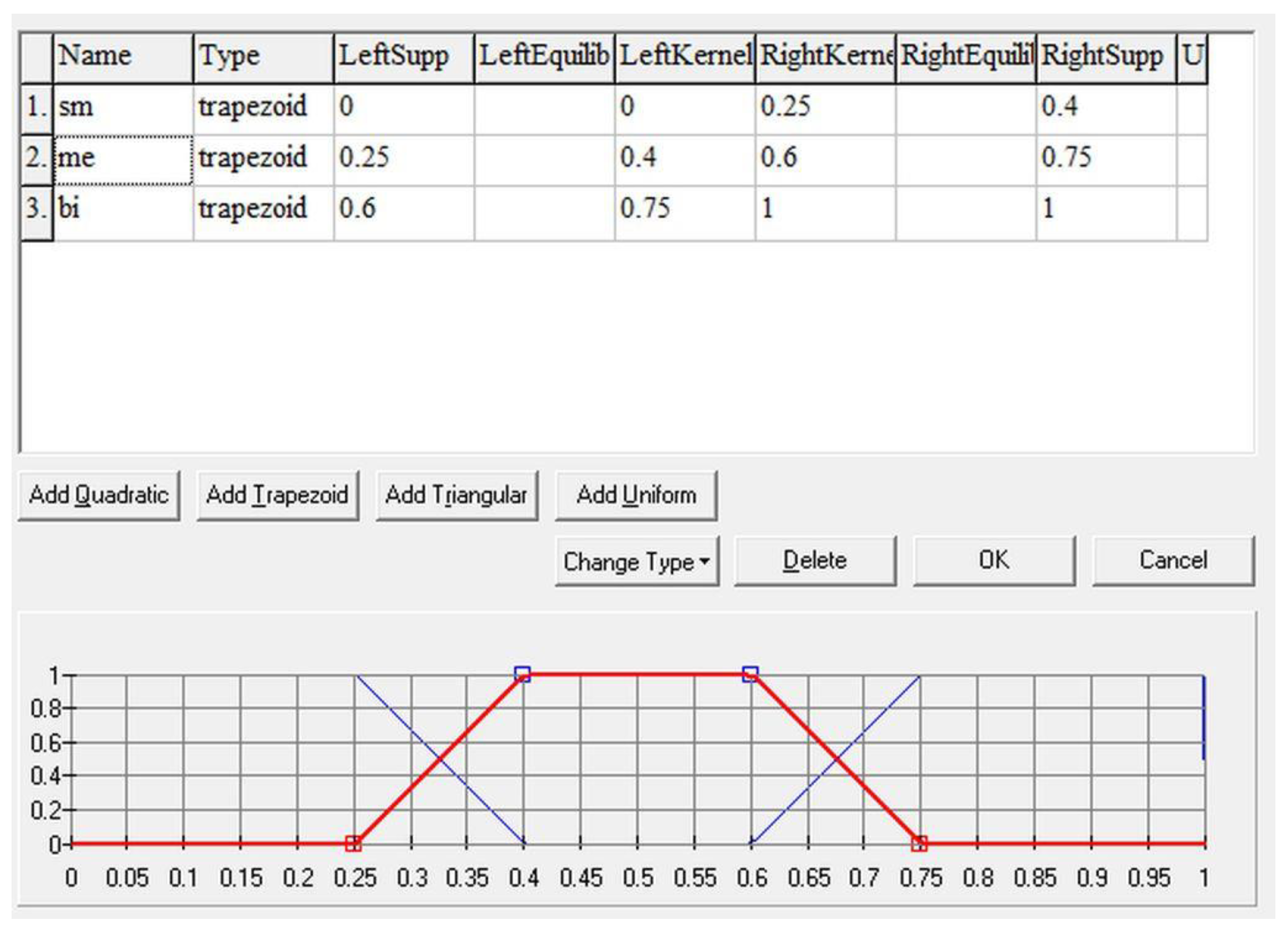
It determines the number of correctly answered questions. The lower the number of correct answers, the worse the knowledge is (Figure 2).
4.1.2. Weight of Correct Answers (V2)
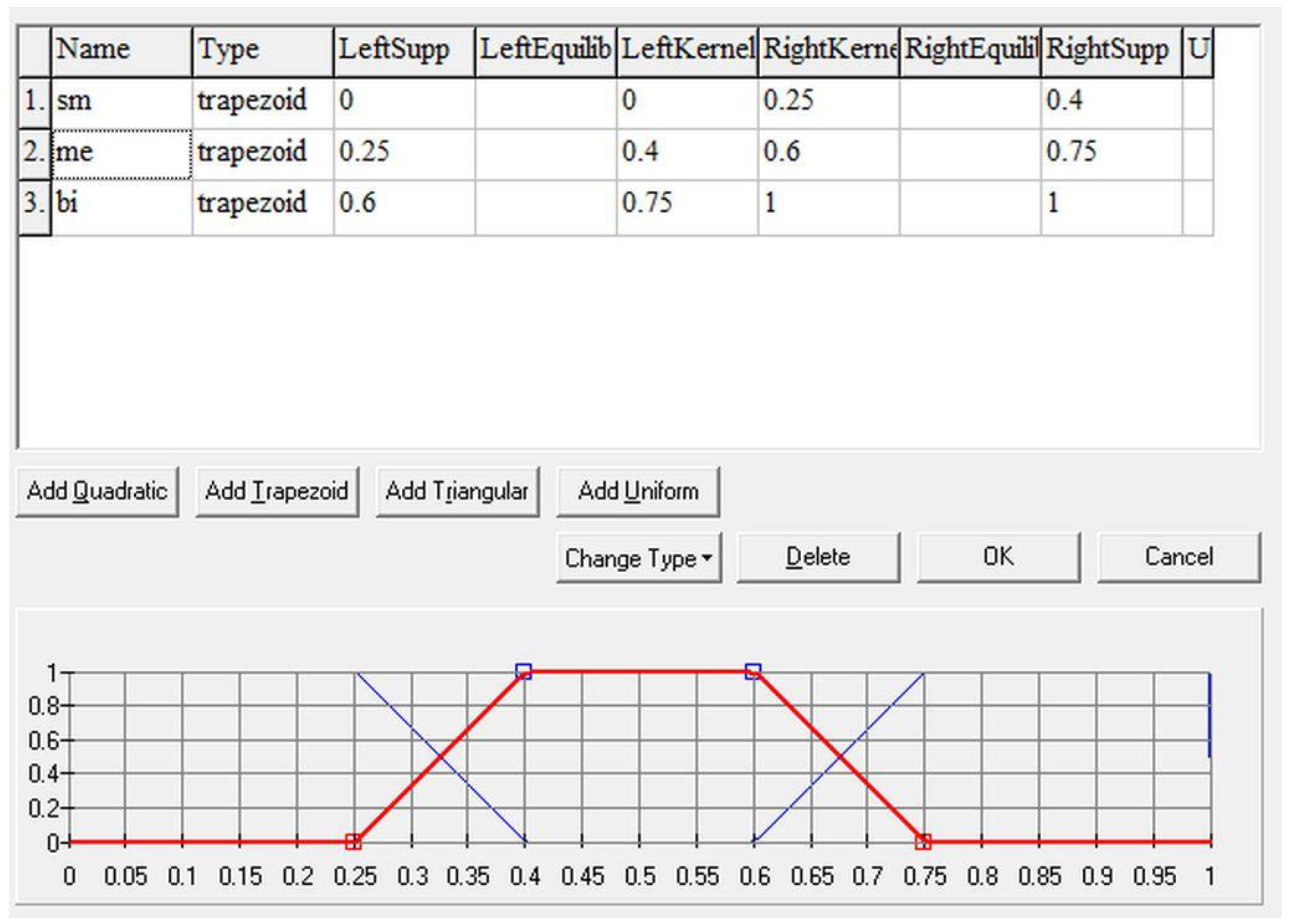
It determines whether the student answered easy or difficult questions. For instance, answering a question correctly on the first conditional is of a lower weight than answering a question on the third or even mixed conditional. Thus, all questions in the test are valued with a corresponding weight (Figure 3).
4.1.3. Importance of the Category for Further Study (V3)
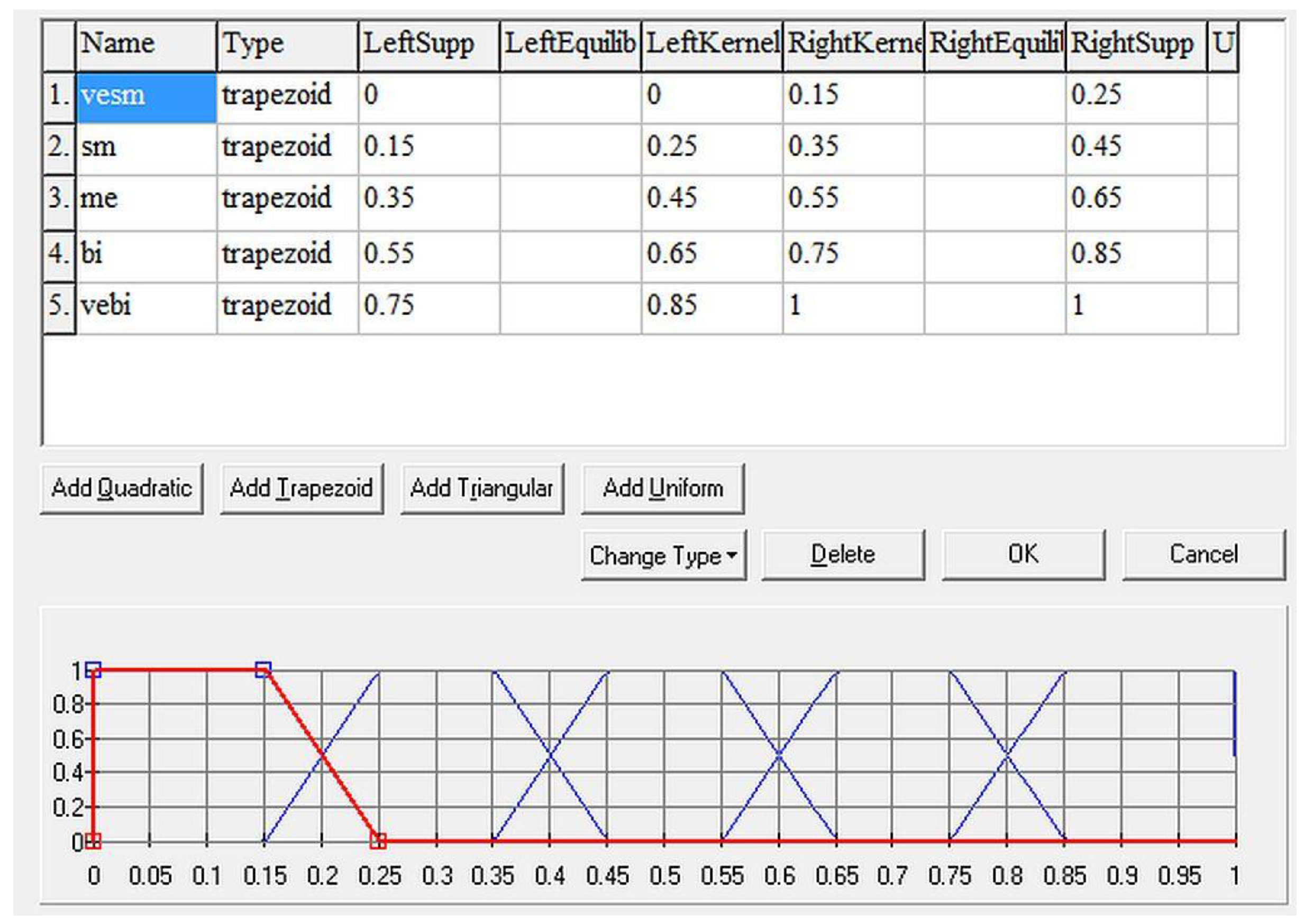
It determines the level of expected knowledge of a given student before entering the learning process. For instance, higher-level English courses usually expect that the students already know basic or pre-intermediate level grammar/vocabulary (the importance of the category is high or very high). However, when a student enters a beginner’s course, the knowledge of grammar/vocabulary is not expected as the student will learn it in this course (the importance for further study is medium). Considering the third conditional, for example, its importance for further studies is really very low as beginners do not need this at this level. However, if the student in a higher-level course proves to know the third conditional even before starting the course, the system evaluates it as a completed category, and the student can aim at those that are problematic for them (Figure 4).
4.1.4. Time Spent on Questions of the Given Category (V4)
It determines the total amount of time that the student needs to answer the question. Because the didactic test is limited to 40 min, it provides 20 s to answer one question, on average. The shorter the time and more correct answers, the better the assessment rate and vice versa (Figure 5).
4.1.5. Output Variable (V5)
Need for further studies of a given category (V5): extremely small, very small, small, more or less medium, medium, big, very big, extremely big.
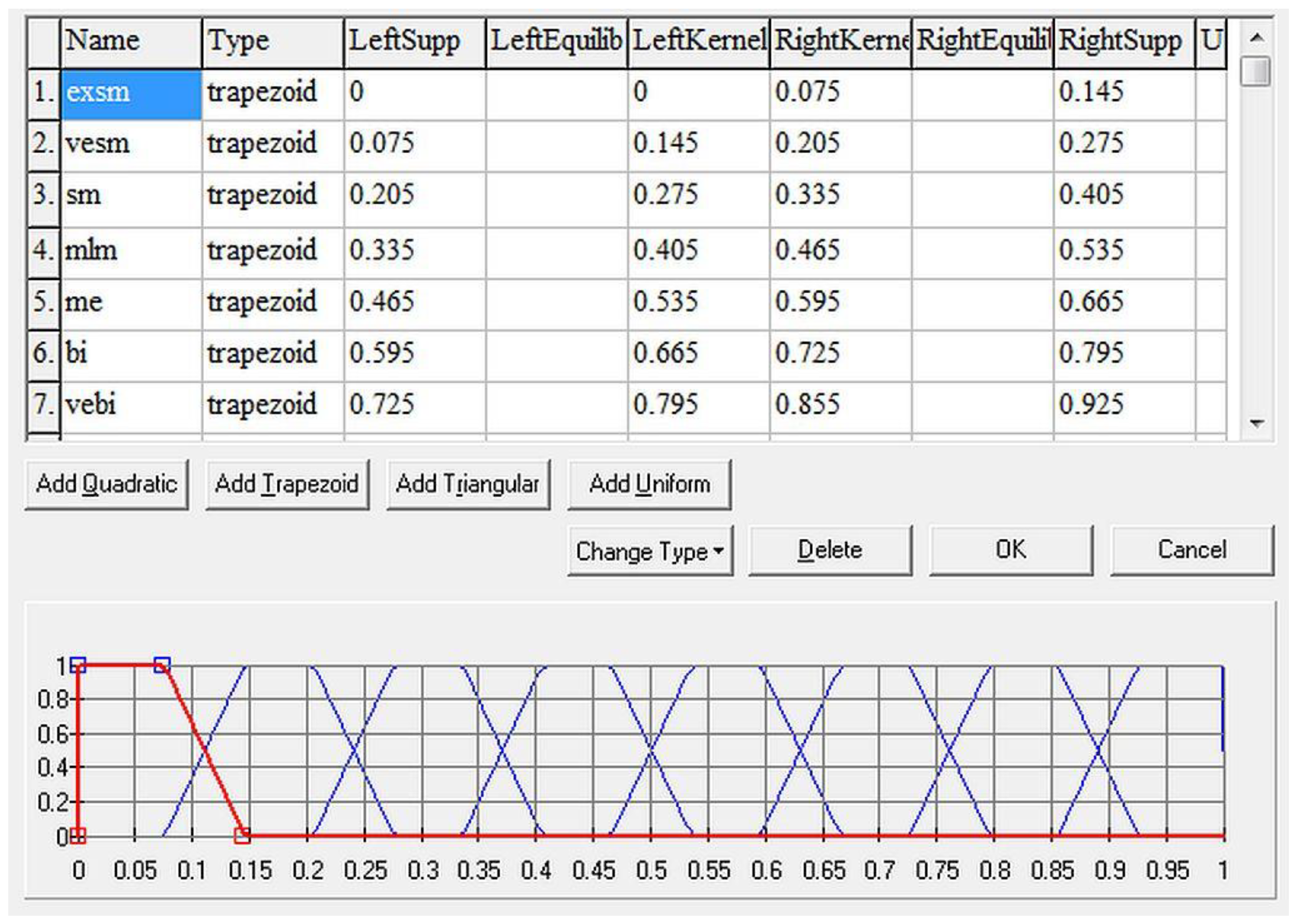
It determines the suggested intensity that the student should devote to studying the given category. The output variable represents the actual student’s knowledge and defines the necessity of studying individual categories within the course (Figure 6).
Variable V1, V2, and V4 use only 3 values since this classification is sufficient (knowledge of the category, weight of correct answers, and time spent). However, variable V3 requires a more detailed/smoother classification of the values into 5 values since the “Importance of the category for further study” is highly related to the output V5. The cutoffs are set to the default values in LFLC2000 software and can be seen in the provided figures <0,1>.
4.1.6. Assessing the Didactic Test Using LFLC 2000
The final phase before creating an individual study plan is to process the didactic test. The foundation lies in the use of an expert system and a knowledge base containing IF-THEN rules. Our knowledge base includes 135 rules. The software to process the test results is called LFLC 2000, where the rules were also created. Below are a few examples of linguistic rules that are stored in our database:
- IF (V1 is medium) and (V2 is small) and (V3 is very big) and (V4 is big) THEN (V5 is very big);
- IF (V1 is small) and (V2 is medium) and (V3 is medium) and (V4 is big) THEN (V5 is big);
- IF (V1 is big) and (V2 is small) and (V3 is big) and (V4 is big) THEN (V5 is medium);
- IF (V1 is medium) and (V2 is medium) and (V3 is small) and (V4 is medium) THEN (V5 is small);
- IF (V1 is big) and (V2 is big) and (V3 is small) and (V4 is medium) THEN (V5 is ex_small).
Before the test is processed, all answers from the test are clustered into categories (according to a given topic included in the test). The answers and their individual attributes for the input variables V1–V4 are gathered, processed in LFLC 2000, and the results in the form of the output variable V5 are stored in base BM1A.
4.2. Application of Module M1B
The LMS Moodle environment served as a means of applying the proposed learning model. The main principle of our approach was the uniqueness of each student. This idea was at the center of our focus when structuring the user’s (student’s) profile in Moodle. We created 25 new attributes that described the student’s sensory preferences and knowledge. Concerning the former, those areas were labeled as VARK. The attributes have values yes and no, as specified by a student in a questionnaire and which are stored in BM1B. VARK stands for:
- Visual—drawings, tables, maps, pictures, designs;
- Aural—any type of audio files;
- Read/write –any type of text;
- Kinaesthetic—practical work, learning by doing.
This methodology is used to identify how people absorb information and store it in their brains in the most efficient way. For instance, if a person wants to find a place in a town, they ask someone to tell/show/draw the way, according to how the person prefers to receive information. More details about the VARK methodology are found in [31].
The above-presented methodology is an easy, practical, yet very efficient method to test how people process new information. Nevertheless, no one can be 100% classified into a single VARK category (so-called preference). Each person possesses a certain mixture of preferences but always has one major one; the others are minor ones, which are influenced by a given situation, physical or mental condition, etc.
Among the positive features of this approach can be included: (a) there are only 4 dimensions, i.e., it is not unnecessarily complex; (b) its taxonomy is fixed, and the testing phase is standardized; and (c) study materials in an e-learning course are easy to assign to a corresponding preference (audio files, text files, pictures, charts, multimedia, etc.). If there is anything negative, we can state that the Kinaesthetic type is not yet very profoundly elaborated. It can be used in e-learning, but to a very limited extent.
The results from the VARK questionnaire are obtained by calculating the percentage ratio of each preference for a given student (see Table 1). The initial average ratio is set to 25-25-25-25 to be neutral. If any of the VARK preferences do not reach 20% (which means that some other(s) must increase in favor of that one), study materials related to the decreased preference are eliminated from the student’s study plan.
For instance, Student 1 clearly prefers the text type of study materials in combination with the audio type. The benefit of practical (kinaesthetic) exercises is neutral. Finally, this student does not favor the use of maps, schemes, etc., when studying.
4.3. Application of Module M2
Implementation of this extended version was applied in a new instance of LMS Moodle, which was installed in Linux Debian hosted on the VMWare technology. The Moodle version used was 3.9.14+. The experiment could not be implemented in the current Moodle of the University of Ostrava because the extension of the user field would affect all existing courses.
Access to individual diagnostic tools, tests, tasks, etc., uses values of individual thematic groups. As stated above, those values were acquired during initial testing. Rules controlling the student’s progress through the diagnostic tool of the course primarily take into consideration the values of the field but consider the didactic sequence of individual components within the course, as well.
When preparing a pilot e-learning course, we had to consider the possibility that a student should be able or will have to study the categories from potential previous courses, which regular Moodle at the UO does not allow. Each course has its electronic version, but electronic versions are not interconnected. Thus, it was necessary to import materials from the preceding courses, but only materials related to grammar, not topics. Having completed the import and extension of user fields, settings on how to progress through an e-course had to occur.
All of the student’s data was gathered, and the student’s database/portfolio was created. There are no predefined models of students created in our database where a real student would be matched. Our idea considers that there is an individual portfolio for each student. This portfolio contains all their personal information
4.3.1. Necessary Adaptation
The implementation of an adaptive e-learning model was tested in the LMS Moodle environment using its existing components. As stated above, the model focuses on the student’s individuality. This idea was reflected in the implementation, which concentrated on the student’s profile, primarily on optional fields in the user’s profile. This profile was extended with 25 new fields. The extension consisted of two groups. The first group of user’s fields served to define learning preferences for study materials; the second group focused on individual thematic groups/categories.
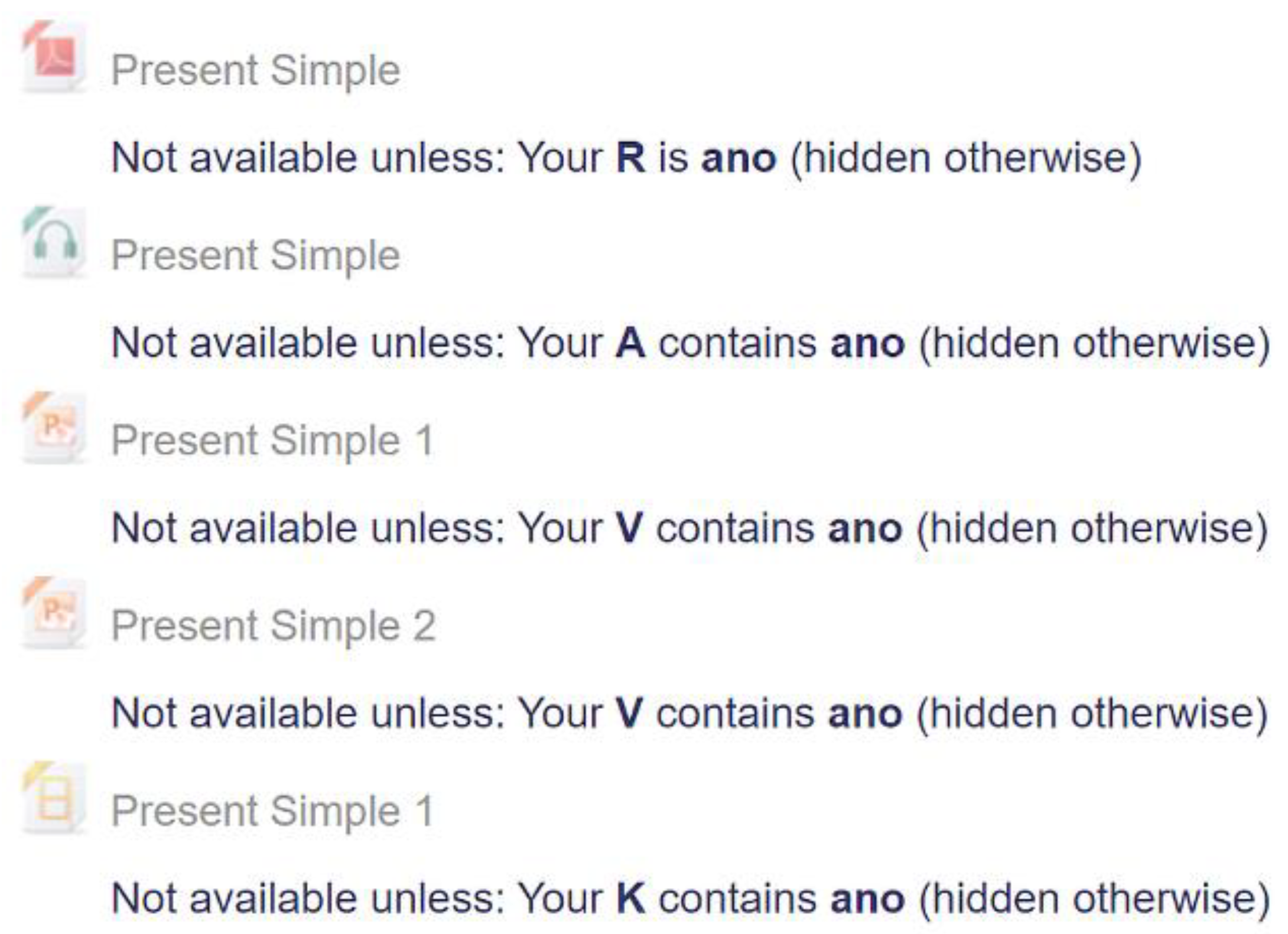
The LMS Moodle environment was extended with a set of rules which open the student to the most suitable form of study materials based on the VARK fields. This implies very simple rules. If the fields have value ANO (i.e., YES), the materials are accessible to the student. In the opposite case, NE (i.e., NO) means access denied (see Figure 7).
A prerequisite of implementing this adaptation is the existence of study materials that cover the whole subject matter in more formats (text, audio, video). The main benefit of this phase is making available such a material format that best suits the individual student, i.e., the student perceives it more effectively than the other forms. Moreover, the student is not flooded with a wide range of various types of study materials, which would make orientation in the course unclear and, after all, would decrease the effectiveness of learning.
4.3.2. Methodology of Student’s Progress through an E-Course
The progress through the e-course follows the methodology to ensure that the student takes a path corresponding to the assessment of the didactic test and the questionnaire. Such a progression should also respond to the student’s achievements or failures during the learning process.
The proposed methodology was tested on a lesson in the English language, which from the way of learning, seemed to be the optimal domain in which to implement the model. Progress through the course depended on both the initial diagnostics and continuous diagnostics. The model is characterized by its high level of process automation and minimizes demands on the tutor’s intervention.
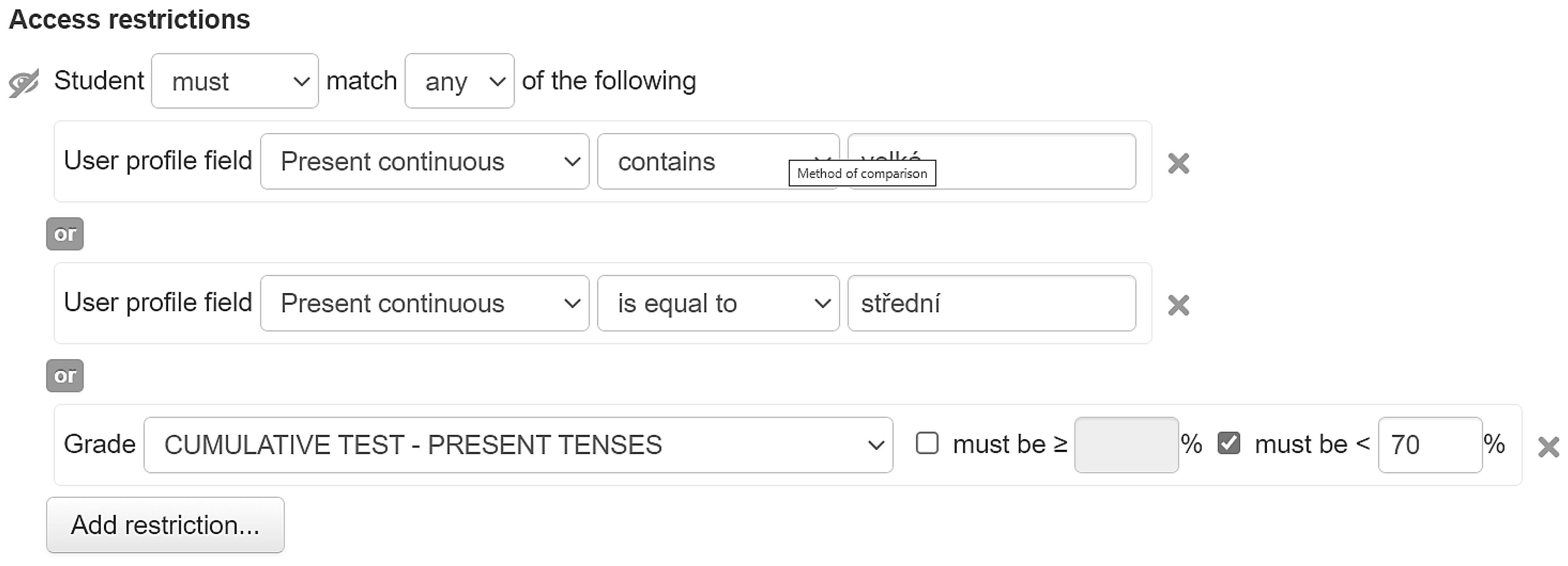
Based on the collected data about the students, the LMS Moodle platform makes it possible to set Access restrictions, see Figure 8. Taking into consideration the 25 fields of new attributes (see Table 2) in the student’s profile, each student receives an individually set study plan. Figure 9 provides us with the student’s perspective of the restrictions in Moodle.
Nevertheless, there might be a situation when a student does not have to study a certain unit (lesson), as the V5 assessment of this unit output was marked as “completed” based on the didactic test (V5 = 0–0.465). The only test that the student must take in a revision lesson is a Cumulative test. A Cumulative test ensures that the student was not lucky when taking the didactic test, i.e., if the student’s knowledge is consistent. In case a student fails the Cumulative test, the unit is retroactively opened. This is performed by a conditional access restriction. A grade lower than 70% results in opening the unit. For conditional restriction of a Cumulative test, see Figure 10.
Restrictions for Cumulative tests must be set as a complex batch of rules. In order to be allowed to take the Cumulative test, a student must comply with one of the following (here are described rules for the Present tenses Cumulative test):
- Output of variable V5 of both categories (Present tenses) is extremely big, very big, or big. The student takes the Cumulative test immediately without studying the 2 units.
- Output of variable V5 of one category is extremely big, very big, or big (meaning it is closed), but the other one is open. Before taking the Cumulative test, the student has to pass the Progress test of the open category.
- Output of variable V5 of both categories is extremely big, very big, or big. The two categories are open, and before taking the Cumulative test, the student has to pass the Progress test in both categories.
Once the student passes the Cumulative test, they are entitled to move on in the plan. This process is carried out iteratively until a successful termination. Personalized settings are grounded in the student’s results from the initial didactic test and the progress through the course.
The primary contribution of such a type of progression through a course is an emphasis on acquiring basic knowledge and skills in the area of the English language, which forms a foundation stone to develop higher “language constructions” later. The high autonomy of this model approaches a student in a very individual way and enables them to adapt time requirements to their abilities and possibilities. The implemented model also benefits students who cannot master the subject matter within a standard time in a semester and need to repeat it. Within the learning process, they concentrate on reinforcement of language bases.
4.4. Application of Module M3
Modifications to the created study plan are possible, primarily based on the student’s results during the progress through the e-course. No modifications are required or made if a student terminates the course with the required results. If a student fails any test repeatedly, there is the possibility of modifying the study materials, mainly their form (sensory preferences), i.e., BM1A must be changed, so a different way (form) of study materials is found.
5. Testing
5.1. Target Group of the Experiment
The target group testing the proposed model, including designing and structuring the didactic test and the pilot e-course, were students in a distance and combined form of Bachelor study program in Applied Informatics and Informatics at the Department of Informatics and Computers, Faculty of Science, University of Ostrava. The students enrolled in the course English for Specialisation Degree 3 (marked as XANG3). The length of the course was 13 weeks. The course XANG3 has two preceding optional courses, XANG1 and XANG2, which means that the students did not have to pass them. The reasons to test the students for a higher-level English were as follows:
- Selection of a course taught in the winter semester.
- Students were already used to the LMS Moodle environment.
- Students were required to have knowledge of XANG1 and XANG2.
- A wide spectrum of topics and grammar areas can be tested.
- There is a significantly lower number of students in XANG3 than in XANG1, lower by 72.3% (XANG1 = 243; XANG3 = 66), see Figure 11. Although it means that we had a smaller experimental group, the students of higher grades also have a higher motivation to complete their studies properly and thus a higher motivation to exploit the full potential of the new studying environment. However, the real number of tested students differs from the graph, which shows students officially registered in the distance and combined forms due to the influence of the COVID-19 pandemic when the full-time students joined the distance form of studies (years 2020/2021 and 2021/2022), see the Results section.
5.2. Evaluation of the Results
Our primary objective was not to perform an experiment to get a better educational outcome of the proposed methodology that would be justified by hard indicators, i.e., statistical comparison of the achieved results, but to show that the proposed methodology and structure of the e-course can provide an individualized study plan. Figure 12 and Figure 13 give an example of varied study materials according to the sensory preferences (Student 6 and Student 11) of the test group.
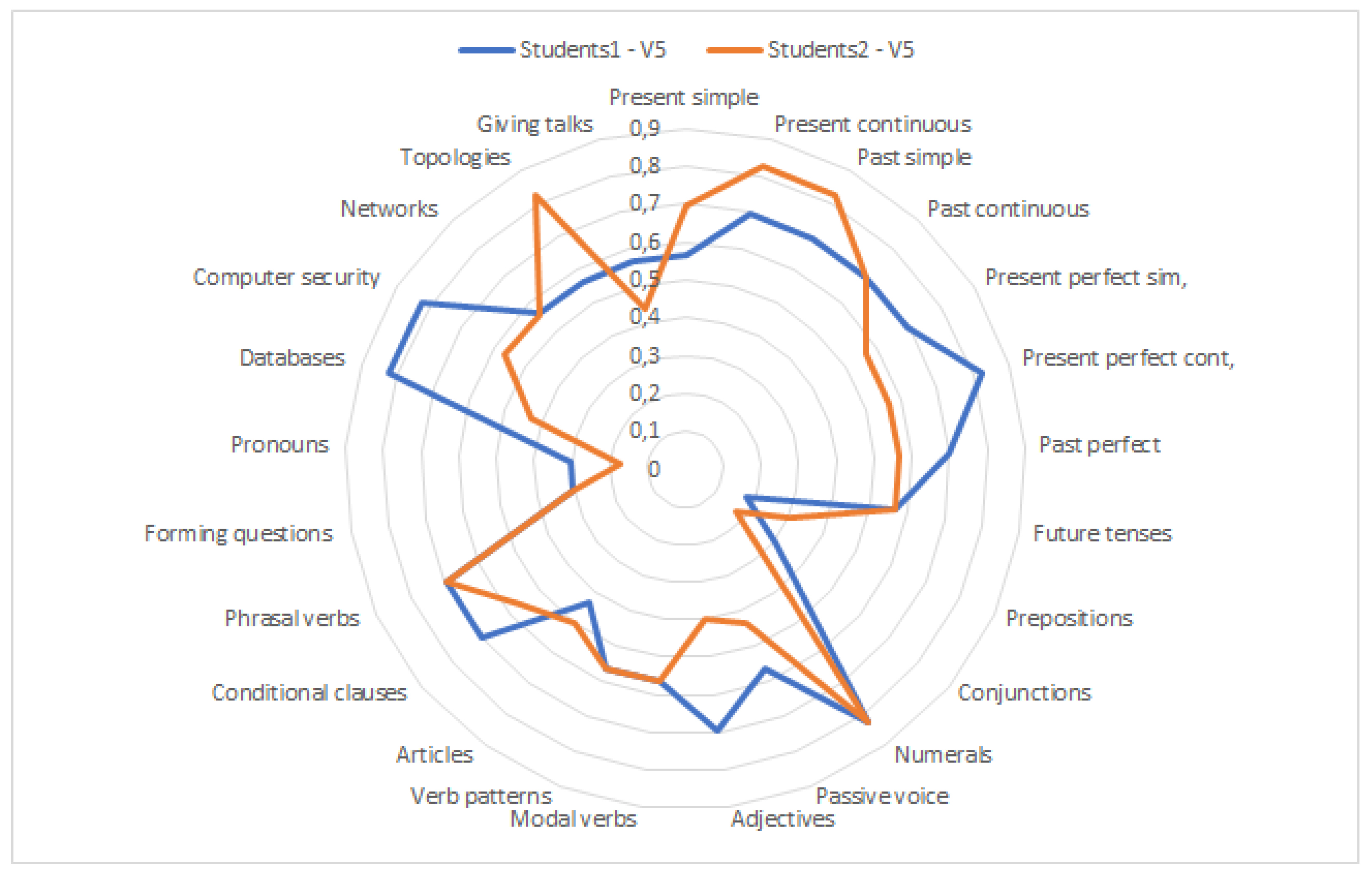
The second criterion to adapt students’ progress was their knowledge of the studied area divided into categories (corresponding to Moodle units). This part demonstrates the differences between the results of individual students and what the impact is on their study plans. Table 3 provides an example of two students’ results of the didactic test in the test group. Individual values of V1–V5 are computed by the expert system based on the input data. The membership function is <0;1>, and each value means how much it belongs to the given fuzzy set. It can be seen that the two students significantly differ in the V1–V4 in certain categories, while some are similar. It means that the assessment of the need to study a certain category (V5 value) will also differ, resulting in a different study plan. Bold formatting in the V5 value means that there is a difference higher than 10% in the result (in 16 out of 25 categories) of the two students.
Figure 14 shows the results of the two students in a graph that graphically demonstrates the differences between the results in individual categories. Based on the V5 value, the categories are either “not-completed” (need to study) or “completed” (no need to study).
The interpretation of Table 3 and Figure 14 is that students who achieved the V5 output of a category in the range 0–0.465 do not have to study the relevant categories (need to study this category is low). This means that the categories are assessed as completed, and the student can focus on those that were assessed as not-completed, i.e., V5 output ranges between 0.466–1.
The figures reveal that each student could benefit from a different learning path while heading towards the same educational outcome—the desired output from the course when students finish the course at the end of the semester. This was achieved by identification of students’ input data—sensory preferences (see Table 1) and knowledge of the subject matter (see Table 3)—setting the students’ profiles and further work with such data.
6. Results
The pilot verification of the proposed model was implemented in an experimental group of students who were exposed to the proposed methodology and a control group who went through a standard Moodle course without any modifications and adaptations.
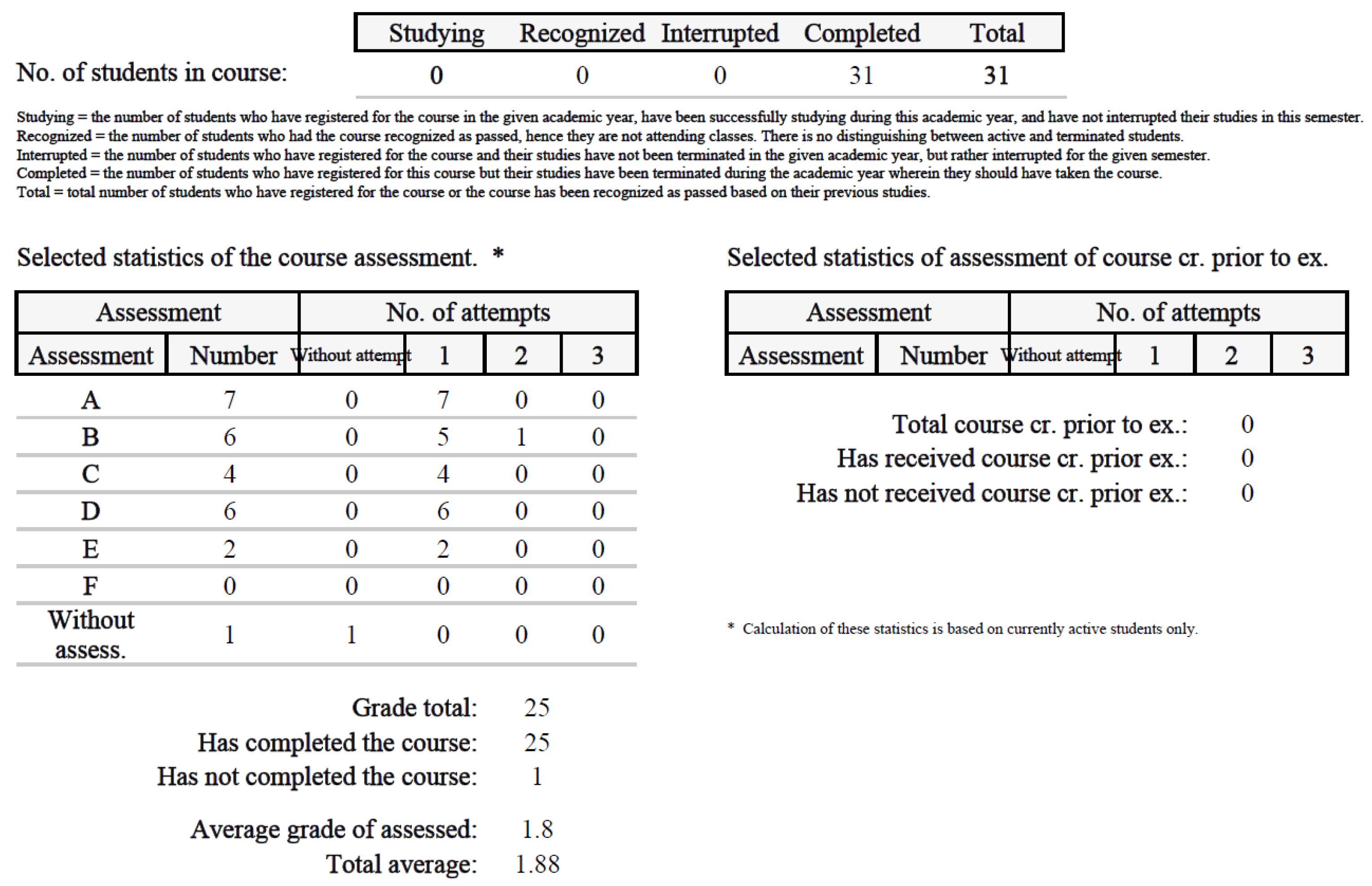
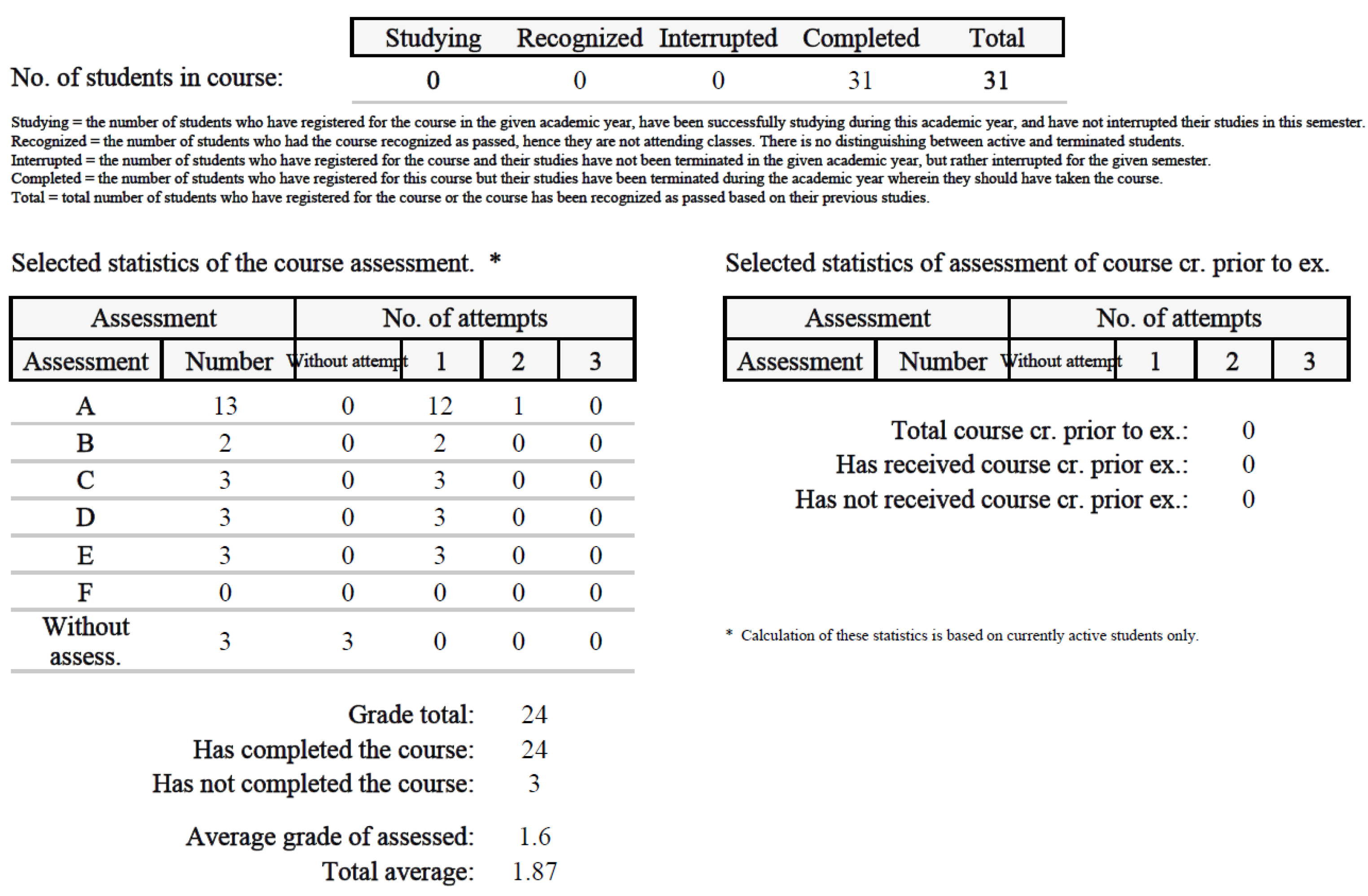
Figure 15 shows the students’ results during the first year of the COVID-19 pandemic (2020/2021). The XANG3 course included not only distance and combined forms of studies but full-time students as well, totaling 31 participants. The students studied in the standard Moodle environment without any modifications.
In the academic year 2020/2021, the course was not fully ready to implement the adaption in the LMS Moodle; therefore, the course was carried out in its standard way. However, in the academic year 2021/2022, we prepared the course for its pilot verification in the adapted form. Figure 16 shows students during the second year of the COVID-19 pandemic (2021/2022)—the XANG3 course in its adapted Moodle environment.
By coincidence, the number in both years totaled 31, so we can easily compare the results of both groups. The published results indicate that the LMS with the implemented adaptivity and the support of learning preferences offers the students more paths of study, which is reflected in the results (the average grade assessed is 1.8 for the control group and 1.6 for the experimental group). The main motivation of this approach is to improve skills and lower the ratio of worse results/grades (D, E).
7. Discussions and Conclusions
The article presented new tools and processes in e-learning to create the most effective path through a course for each student. Our investigated research question was how to create a smart solution that would be usable across an already used online educational platform. The main driving idea was that the development of an intelligent tutoring system for an already established educational platform could instantly address millions of users. Therefore, a new model has been designed to meet the current e-learning requirements. A methodology, in our case related to language learning, has been developed, and special components have been introduced, which enabled the creation of an individual study plan for each student. There are two new blocks of components. One block consisting of finding out the student’s language knowledge and one block of sensory preferences. In order to assess the student’s knowledge, we integrated an expert system into our model. The expert system provided the input values and information for creating a test e-course. A great benefit is that the proposed methodology used the possibilities of conditional progress through a course while introducing the new components and enabled the creation of individual study plans in an automated way. The above-described sequence of implemented tools and methods resulted in the transition of a traditional e-learning platform into an intelligent tutoring system.
The testing carried out on a sample set of students of the Bachelor’s study program in Applied Informatics at the Department of Informatics and Computers, Faculty of Science, University of Ostrava, proved that it is possible to successfully implement this model into real education using current LMSs and to make them smarter and more adaptive than they are today. A significant benefit of the testing is that this model is implementable at the level of conditional progress in current instances of LMS Moodle, meaning it can target millions of users. The result was that each student could benefit from an individually designed study plan, which was created automatically based on the input data. Such a created study plan was also modified if it had to be adapted to react to a student’s progress through the course.
We see the main contribution of the proposal and pilot verification of a model which can be implemented on a mass scale but provides an individual adaptation of the learning process to a particular student’s needs. The full implementation of the LMS Moodle environment is in progress.
Nevertheless, there has been an issue with the insufficiencies of a standard Moodle edition in the area of profile definition and redefinition for more courses. This is the area where we see space to develop a new module for LMS Moodle, which will transfer specific profile attributes from a Moodle global user profile to a local profile user in a given course. The next topics to be covered in our future research are verification of whether such a course structure leads to better educational results and verification if such a setting can be usable in other areas, not only a second-language education (i.e., to prove that the proposed methodology is independent of the studied subject). Moreover, in the future, we would like to focus on structuring students’ study plans considering the time demands of individual study materials and the e-learning course as a whole.
Our further research will focus on extending the proposed model to be implemented in other fields of study, not only language education. The goal is to gather a larger experimental group to verify and draw more accurate conclusions on the benefits and versatility of this system.
Author Contributions
Conceptualization, V.B. and M.K.; methodology, P.S. and V.B.; software, P.S. and T.P.; validation, P.S., V.B., T.P. and M.K.; data curation, V.B.; writing—original draft preparation, V.B., P.S. and M.K.; visualization, P.S., V.B., T.P. and M.K.; All authors have read and agreed to the published version of the manuscript.
Funding
This article was supported by the R&D project entitled “SMART Technologies for Improving Life in Cities and Regions” (reg. no. CZ.02.1.01/0.0/0.0/17_049/0008452). The base data in the article has been presented in the listed references, and the authors provide details of it.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Haythornthwaite, C.; Andrews, R.; Fransman, J.; Eric, M.M. The Sage Handbook of E-Learning Research; Sage: Thousand Oaks, CA, USA, 2016. [Google Scholar]
- Li, J.W.; Chang, Y.C.; Chu, C.P.; Tsai, C.C. A self-adjusting e-course generation process for personalized learning. Expert Syst. Appl. 2012, 39, 3223–3232. [Google Scholar] [CrossRef]
- Rudak, L. Susceptibility to e-teaching. In Proceedings of the IADIS International Conference E-Learning 2012, Lisbon, Portugal, 17–20 July 2012; pp. 10–16, ISBN 978-80-7248-731-8. [Google Scholar]
- Murphy, M.; McTear, M. Learner Modelling for Intelligent CALL. In Proceedings of the Sixth International Conference UM97; Springer: Vienna, Austria, 1997; pp. 301–312. [Google Scholar]
- Li, K.; Wong, B. The use of student response systems with learning analytics: A review of case studies (2008–2017). Int. J. Mob. Learn. Organ. 2018, 14, 63–79. [Google Scholar] [CrossRef]
- Pleines, C. Understanding vicarious participation in online language learning. Distance Educ. 2020, 41, 453–471. [Google Scholar] [CrossRef]
- Gelan, A.; Fastré, G.; Verjans, M.; Martin, N.; Janssenwillen, G.; Creemers, M.; Thomas, M. Affordances and limitations of learning analytics for computer assisted language learning a case study of the VITAL project. Comput. Assist. Lang. Learn. 2018, 31, 294–319. [Google Scholar] [CrossRef] [Green Version]
- Johnson, A.M.; Guerrero, T.A.; Tighe, E.L.; McNamara, D.S. iSTART-ALL: Confronting adult low literacy with intelligent tutoring for reading comprehension. In Proceedings of the 18th International Conference on Artificial Intelligence in Education, AIED, Wuhan, China, 28 June–1 July 2017; pp. 125–136. [Google Scholar]
- Klašnja-Milićević, A.; Vesin, B.; Ivanovic, M.; Budimac, Z.; Jain, L.C. E-Learning Systems: Intelligent Techniques for Personalization; Springer: Cham, Switzerland, 2016; Volume 112. [Google Scholar]
- Ferster, B. Teaching Machines: Learning from the Intersection of Education and Technology; John Hopkins University Press: Baltimore, MD, USA, 2014. [Google Scholar]
- Walkington, C.; Bernacki, M. Motivating students by “personalizing” learning around individual interests: A consideration of theory, design and implementation issues. Adv. Motiv. Achiev. 2014, 18, 139–176. [Google Scholar]
- Yu, Q.; Zao, Y. The value and practice of learning analytics in computer asssited language learning. Stud. Lit. Lang. 2015, 10, 90–96. [Google Scholar]
- Nguyen, Q.; Rinties, B.; Toetenel, L. Mixing and matching learning design and learning analytics. In Proceedings of the 4th International Conference, LCT 2017 Held as Part of HCI International 2017, Vancouver, BC, Canada, 9–14 July 2017. [Google Scholar]
- Kostolányová, K. Nová forma výuky–adaptivní e-learning. In Edukacja, Technika, Informatyka; Wydawnictwo Uniwersytetu Rzeszowskiego: Rzeszów, Poland, 2014; pp. 278–283. ISSN 2080-9069. [Google Scholar]
- Groff, J.S. Personalized Learning: The State of the Field & Future Direction; Center for Curriculum Redesign: Boston, MA, USA, 2017; 47p. [Google Scholar]
- McNamara, D. Self-Explanation and Reading Strategy Training (SERT) Improves low-knowledge students’. Discourse Process. 2017, 54, 479–492. [Google Scholar] [CrossRef]
- Passoneau, R.; McNamara, D.; Muresan, S.; Perin, D. Preface: Special issue on multidisciplinary. Int. J. Artif. Intell. Educ. 2017, 27, 665–670. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Hwang, D.; Park, S.; Lee, H.; Hong, C.; Kim, W. Personalized interactive e-learning system using expanded SCORM. Appl. Math. Inf. Sci. 2014, 8, 133–139. [Google Scholar] [CrossRef]
- Edwards, M.; Clinton, M. study exploring the impact of lecture capture availability. High. Educ. 2019, 77, 403–421. [Google Scholar] [CrossRef] [Green Version]
- Li, K.; Wong, B.M. Features and trends of peronalised learning: A review of journal publications from 2001 to 2018. Interact. Learn. Environ. 2020, 29, 182–195. [Google Scholar] [CrossRef]
- Lin, H.; Whang, G. Research trends of flipped classroom studies for medical courses: A review of journal publications from 2008 to 2017 based on the technology-enhanced learning model. Interact. Learn. Environ. 2019, 27, 1011–1027. [Google Scholar] [CrossRef]
- McCarthy, K.; Watanabe, M.; Dai, J.; McNamara, D.S. Personalized learning in iSTART Past modifications and future design. J. Res. Technol. Educ. 2020, 52, 301–321. [Google Scholar] [CrossRef]
- Gabarre, S.; Gabarre, C.; Din, R. Personalizing learning: A critical review of language learning with mobile phones and social networking sites. J. Adv. Res. Dyn. Control. Syst. 2018, 10, 1782–1786. [Google Scholar]
- Jewitt, C.; Clark, W.; Hadjithoma-Garstka, C. The use of learning platforms to organise learning in English primary and secondary schools. Learn. Media Technol. 2011, 36, 335–348. [Google Scholar] [CrossRef] [Green Version]
- Choi, S.; Lam, S.; Li, K.; Wong, B. Learning analytics at low-cost: At-risk student prediction with clicker data and systematic proactive interventions. Educ. Technol. Soc. 2018, 21, 273–290. [Google Scholar]
- Gamage, S.H.; Ayres, J.R.; Behrend, M.B. A systematic review on trends in using Moodle for teaching and learning. Int. J. STEM Educ. 2022, 9, 1–24. [Google Scholar] [CrossRef] [PubMed]
- Balakrishnan, B. Motivating engineering students learning via monitoring in personalized learning environment with tagging system. Comput. Appl. Eng. Educ. 2018, 26, 700–710. [Google Scholar] [CrossRef]
- Bradáč, V. Adaptive Model to Support Decision-Making in Language E-learning. In Proceedings of the 5th International Conference on Education and New Learning Technologies, Barcelona, Spain, 1–3 July 2013; pp. 4036–4045. [Google Scholar]
- Habiballa, H. Using software package LFLC 2000. In Proceedings of the 2nd International Conference Aplimat, Bratislava, Slovak Republic, 4–6 February 2003; pp. 355–358. [Google Scholar]
- Bradáč, V. Enhacing Assessment of Students’ Knowledge Using Fuzzy Logic in E-learning. In Proceedings of the 10th International Scientific Conference on Distance Learning in Applied Informatics, Sturovo, Slovakia, 5–7 May 2014; pp. 251–262. [Google Scholar]
- Fleming, N.D. VARK. A Guide to Learning Styles. Research and Statistics. 2009. Available online: http://vark-learn.com/home/ (accessed on 16 March 2020).
Figure 1.
Representation of modules to create student’s study plan.

Figure 2.
Graphic representation of the input value set V1.

Figure 3.
Graphic representation of the input value set V2.

Figure 4.
Graphic representation of the input value set V3.

Figure 5.
Graphic representation of the input value set V4.

Figure 6.
Graphic representation of the output value set V5.

Figure 7.
Illustration of conditional access to study materials according to VARK.

Figure 8.
Access restrictions to a lesson.

Figure 9.
Access restrictions as students see them.

Figure 10.
Conditional restriction of a Cumulative test.

Figure 11.
Number of combined and distance students enrolled in XANG1-3 in period 2016–2022.

Figure 12.
Student 11 sensory preferences: V + A.

Figure 13.
Student 6 sensory preferences: V + R + K.

Figure 14.
A graph showing students’ V5 assessment with subsequent impact on their personal study paths.
Figure 14.
A graph showing students’ V5 assessment with subsequent impact on their personal study paths.

Figure 15.
Results of all students during the academic year 2020/2021.

Figure 16.
Results of all students during the academic year 2021/2022.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Examples of VARK attributes in students’ portfolios in the test course.
| First Name | Last Name | Profile_ Field_V | Profile_ Field_A | Profile_ Field_R | Profile_ Field_K |
|---|---|---|---|---|---|
| Student 1 | Student 1 | NO (11.1) | YES (29.6) | YES (37) | YES (22.3) |
| Student 2 | Student 2 | NO (11.8) | YES (41.2) | NO (5.8) | YES (41.2) |
| Student 3 | Student 3 | NO (15.2) | YES (30.4) | YES (27.2) | YES (27.2) |
| Student 4 | Student 4 | YES (20.7) | YES (24.4) | YES (24.1) | YES (31.1) |
| Student 5 | Student 5 | NO (16.6) | YES (29.2) | YES (29.2) | YES (25) |
| Student 6 | Student 6 | YES (33.3) | NO (16.6) | YES (30.1) | YES (20) |
| Student 7 | Student 7 | YES (29.7) | YES (21.6) | YES (21.6) | YES (27.1) |
| Student 8 | Student 8 | YES (20.3) | YES (33.3) | NO (11.1) | YES (30.3) |
| Student 9 | Student 9 | NO (12.8) | YES (38.4) | YES (23.2) | YES (25.6) |
| Student 10 | Student 10 | YES (21.7) | YES (30.4) | YES (34.8) | NO (13.1) |
| Student 11 | Student 11 | YES (41.4) | YES (31) | NO (13.8) | NO (13.8) |
| Student 12 | Student 12 | YES (21.4) | YES (35.7) | NO (14.3) | YES (27.6) |
Table 2.
A general structure of the e-course.
| Lesson | Present simple |
| Lesson | Present continuous |
| Revision | Cumulative test (Present simple + Present continuous) |
| Lesson | Past Simple |
| Lesson | Past Continuous |
| Revision | Cumulative test (Past simple + Past continuous) |
| … | … |
Table 3.
Comparison of values achieved in the didactic test by two students. If V5 value is in red, the category is marked “not-completed”, if in black, the category is marked “completed”. Bold font means at least a 10% better achieved result.
Table 3.
Comparison of values achieved in the didactic test by two students. If V5 value is in red, the category is marked “not-completed”, if in black, the category is marked “completed”. Bold font means at least a 10% better achieved result.
| Student 1 | Student 2 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Category | V1 | V2 | V3 | V4 | V5 | V1 | V2 | V3 | V4 | V5 |
| Present simple | 1 | 0.5 | 0.9 | 0.55 | 0.565 | 1 | 0.5 | 0.9 | 0.84 | 0.695 |
| Present continuous | 0.75 | 0.5 | 0.9 | 1 | 0.695 | 0.5 | 0.5 | 0.9 | 1 | 0.825 |
| Past simple | 0.6 | 0.5 | 0.9 | 0.67 | 0.695 | 0.6 | 0.5 | 0.9 | 1 | 0.825 |
| Past continuous | 0.75 | 0.5 | 0.9 | 0.88 | 0.695 | 1 | 0.5 | 0.9 | 1 | 0.695 |
| Present perfect sim. | 0.67 | 0.5 | 0.7 | 0.64 | 0.695 | 0.5 | 0.5 | 0.7 | 1 | 0.565 |
| Present perfect cont. | 0 | 0.2 | 0.7 | 0.94 | 0.825 | 0.5 | 0.5 | 0.7 | 1 | 0.565 |
| Past perfect | 0 | 0.2 | 0.5 | 0.83 | 0.695 | 0.33 | 0.5 | 0.5 | 1 | 0.565 |
| Future tenses | 0.33 | 0.5 | 0.5 | 0.95 | 0.565 | 0.67 | 0.5 | 0.5 | 1 | 0.565 |
| Prepositions | 1 | 0.5 | 0.3 | 0.49 | 0.175 | 0.67 | 0.5 | 0.3 | 1 | 0.305 |
| Conjunctions | 0.4 | 0.5 | 0.3 | 0.79 | 0.305 | 0.8 | 0.5 | 0.3 | 1 | 0.175 |
| Numerals | 0.67 | 0.5 | 0.9 | 0.85 | 0.825 | 0.33 | 0.5 | 0.9 | 1 | 0.825 |
| Passive voice | 0.67 | 0.5 | 0.5 | 1 | 0.565 | 1 | 0.5 | 0.5 | 1 | 0.435 |
| Adjectives | 0.25 | 0.5 | 0.5 | 0.79 | 0.695 | 0.75 | 0.5 | 0.5 | 0.91 | 0.4 |
| Modal verbs | 0.38 | 0.5 | 0.5 | 0.84 | 0.565 | 0.63 | 0.5 | 0.5 | 1 | 0.565 |
| Verb patterns | 0.57 | 0.5 | 0.5 | 1 | 0.565 | 0.29 | 0.5 | 0.5 | 1 | 0.565 |
| Articles | 0.5 | 0.5 | 0.5 | 0.54 | 0.435 | 0.38 | 0.5 | 0.5 | 0.92 | 0.5 |
| Conditional clauses | 0 | 0.2 | 0.5 | 0.97 | 0.695 | 0.33 | 0.9 | 0.5 | 1 | 0.565 |
| Phrasal verbs | 0.2 | 0.5 | 0.5 | 1 | 0.695 | 0.2 | 0.5 | 0.5 | 1 | 0.695 |
| Forming questions | 0.5 | 0.5 | 0.3 | 0.46 | 0.305 | 0.5 | 0.5 | 0.3 | 0.6 | 0.305 |
| Pronouns | 0.6 | 0.5 | 0.3 | 0.58 | 0.305 | 1 | 0.5 | 0.3 | 0.69 | 0.175 |
| Databases | 0.2 | 0.5 | 0.7 | 0.75 | 0.825 | 0.8 | 0.5 | 0.7 | 0.93 | 0.43 |
| Computer security | 0.2 | 0.5 | 0.7 | 0.65 | 0.825 | 0.4 | 0.5 | 0.7 | 1 | 0.565 |
| Networks | 0.6 | 0.5 | 0.7 | 0.75 | 0.565 | 0.6 | 0.5 | 0.7 | 0.87 | 0.56 |
| Topologies | 0.6 | 0.5 | 0.7 | 1 | 0.565 | 0.2 | 0.5 | 0.7 | 1 | 0.825 |
| Giving talks | 0.33 | 0.5 | 0.7 | 1 | 0.565 | 1 | 0.5 | 0.7 | 1 | 0.435 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Bradáč, V.; Smolka, P.; Kotyrba, M.; Průdek, T. Design of an Intelligent Tutoring System to Create a Personalized Study Plan Using Expert Systems. Appl. Sci. 2022, 12, 6236. https://doi.org/10.3390/app12126236
AMA Style
Bradáč V, Smolka P, Kotyrba M, Průdek T. Design of an Intelligent Tutoring System to Create a Personalized Study Plan Using Expert Systems. Applied Sciences. 2022; 12(12):6236. https://doi.org/10.3390/app12126236
Chicago/Turabian StyleBradáč, Vladimír, Pavel Smolka, Martin Kotyrba, and Tomáš Průdek. 2022. "Design of an Intelligent Tutoring System to Create a Personalized Study Plan Using Expert Systems" Applied Sciences 12, no. 12: 6236. https://doi.org/10.3390/app12126236
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.