
A Security-Enhanced Query Result Verification Scheme for Outsourced Data in Location-Based Services
by
 ,
,
Guangcan Yang
1, 
Jiayang Li
1,
Yunhua He
1,
Ke Xiao
1,*,
Yang Xin
2,
Hongliang Zhu
2 and
Chen Li
1 1
School of Information Science and Technology, North China University of Technology, Beijing 100144, China
2
School of Cyberspace Security, Beijing University of Posts and Telecommunications, Beijing 100876, China
*
Author to whom correspondence should be addressed.
Appl. Sci. 2022, 12(16), 8126; https://doi.org/10.3390/app12168126
Submission received: 17 July 2022
/
Revised: 7 August 2022
/
Accepted: 8 August 2022
/
Published: 13 August 2022
(This article belongs to the Section Computing and Artificial Intelligence)
Abstract
:Location-based services (LBSs) facilitate people’s lives; location-based service providers (LBSPs) usually outsource services to third parties to provide better services. However, the third party is a dishonest entity that might return incorrect or incomplete query results under the consideration of saving storage space and computation resources. In this paper, we propose a security-enhanced query result verification scheme (SEQRVS) for the outsourced data in a LBS. Specifically, while retaining fine-grained query result verification, we improve the construction process of verification objects to enhance the security of the outsourced data. To prevent the third party from deducing the knowledge of the outsourced data stored in itself (statistically), our scheme designs a novel storage structure to enhance the ability of privacy preservation for the outsourced data. Furthermore, based on the secure keyword search and query result verification mode proposed in our scheme, the user cannot only verify the correctness and completeness of the query result but also achieve consistency verification by the blockchain. Finally, the security analysis and extensive simulation results show the security and practicality of the proposed scheme.
1. Introduction
Location-based services (LBSs) are pervasive in people’s social lives. With the increase in LBS applications, users can enjoy many convenient social services, such as map navigation, restaurant recommendations, and taxi reservations. One typical LBS is the point of interest (POI) information query system. By inputting locations and POI types, users can reach relevant POI information [1]. However, since the location-based service provider (LBSP) has to maintain exponentially-growing POI data to provide a better service, storing and computing data have been burdens for LBSP.
Outsourcing a service, as a prevalent service mode, has many advantages, such as cost saving, quick deployment, and flexible resource configuration [2]. In this mode, enterprises could migrate their service data to a third party, such as the cloud or fog side, and outsource their services to the cloud or fog server. Motivated by the rich benefits brought about by outsourcing services, the LBSP could reduce its burden by utilizing the computing and storage resources of a third party [3,4,5]. However, how to guarantee the confidentiality of outsourced data has become a key problem (due to the separation from the direct control of outsourced data) [6].
To address this problem, one common way is to encrypt the service data before outsourcing. Therefore, many research studies focus on how to search for encrypted data. Searchable encryption, as a method that enables the outsourced data to be searched without decrypting, has been adopted in many research studies [4,7,8]. For example, searchable encryption is used in [7] to store electronic health records, allowing different participating healthcare organizations and individuals (e.g., physicians, hospitals, medical laboratories, and insurance companies) to securely access electronic health records, enabling efficient data sharing. However, driven by illegal profits, such as saving storage costs, the third party may behave dishonestly.
Therefore, many researchers have designed query result verification mechanisms to guarantee the correctness and completeness of query results. For example, researchers in [9] proposed a fine-grained query result verification scheme. In this scheme, the verification object of the query result was constructed by the Bloom filter, and a user who received the query result can check the correctness and completeness by verifying the corresponding verification object. Although the scheme achieves a fine-grained query result verification, the construction process is not perfect. Specifically, the structure of the certain verification object has an exceptional layout, which will provide additional knowledge to the third party and further lead to the privacy disclosure of the outsourced data. For example, if the LBSP outsources its service data to the cloud side and adopts this query result verification mechanism, the cloud side could easily figure out which is the largest number of encrypted outsourced POI type data.
The schemes [10,11,12] also provide verification solutions to support the check of the query result. Although the confidentiality of the query index and the outsourced data can be guaranteed by the method of encryption, the relationship between the encrypted query index and corresponding encrypted query objects (e.g., the verification object) is one-to-one. That is, the above query result verification mechanisms will provide additional statistical information to the third party and further lead to the information leakage of the encrypted outsourced data. For example, if the LBSP outsources its service data to the cloud side and adopts the above query result verification mechanisms, the cloud side could infer the meaning of the encrypted POI type by counting the frequency of the query indexes and popularity of POI types.
Although current schemes have proposed various query result verification mechanisms to prevent the third party from returning erroneous or incomplete query results, there is little research on the non-repudiation of the returned data. In practice, the third party may blame the situation of returning erroneous or incomplete query result on the communication process. For example, when the user finds out the erroneous or incomplete query result by verifying the corresponding verification object, the third party may claim that it has returned the correct and complete query result and the reason for missing data in other aspects such as the network communication problem.
To address the above problems, we designed a Security Enhanced Query Result Verification Scheme (SEQRVS) for the outsourced data in LBS. Specifically, the contribution of our paper can be summarized as follows.
- (1)
- Based on the outsourcing service of LBS, a secure keyword search and query result verification mode over encrypted outsourced data were constructed. In this mode, we improved the construction process of the verification object on the basis of analyzing the deficiency of the scheme [9]. Therefore, while retaining fine-grained query result verification, our scheme can effectively prevent the third party (i.e., the fog side) from obtaining additional knowledge from the structure of the verification object, and further enhance the security of the outsourced data.
- (2)
- To prevent the third party (i.e., the fog side) from deducing the meaning of the outsourced data stored in itself by the way of statistics, we designed the one-to-n lookup table as the storage structure of the outsourced data. By implementing this storage structure, the fog side not only knows nothing about what data are requested by the user and which query object is returned to the user, but also cannot determine the correspondence between the query index and the corresponding query object, which further enhances the ability of privacy preservation for the outsourced data.
- (3)
- To prevent the third party (i.e., the fog side) from attributing dishonest behaviors (e.g., storage errors) to the unreliability of network communication, we introduced the blockchain to guarantee the non-repudiation of the query result from the third party.
- (4)
- A comprehensive security analysis is provided to show the security of the mode and the storage structure adopted in our scheme, and extensive simulation results also demonstrate the security and practicality of the proposed scheme.
The rest of this paper is organized as follows. We review the related work in Section 2. The background, including the system model, threat model, and preliminary techniques to be used in the paper are described in Section 3. We propose the process of data outsourcing, data retrieval, and data verification of the scheme in Section 4. Then, we analyze the security and evaluate the performance of our proposed scheme in Section 5 and Section 6. In Section 7, we conclude the paper.
2. Related Works
In this section, we review some recent research work on privacy preservation, including secure storage, query, verifiable search, and methods to resist dishonest behavior.
2.1. Secure Storage and Query
Since the introduction of technologies, such as storage and computing in the cloud to LBS, many researchers have conducted work on how to ensure secure storage and query of outsourced data. Based on attribute encryption, linear encryption, and RSA encryption, Huang et al. [13] introduced a private-protected spatial–temporal LBS searchable framework, which effectively solved the problem of an expressive and practical search over encrypted LBS data. In [14], Wang et al. designed a secure dynamic spatial keyword query (SDSKQ) structure and proposed cryptographic text-signed quad-trees to improve search security, satisfying the requirements in practical applications, such as dynamic updates and diverse query type queries. Zhang et al. [15] also adopted the structure of quad-trees to build the index for the POI database, solving the secure problem of linear region search, and bridging the gap in research on linear region search. In [16], Guo et al. improved on the existing k-anonymity algorithm, compensating for the fact that the existing algorithm can leak some contents of POIs, providing a foundation for subsequent research on the security of the k-anonymity algorithm. Manju et al. [17] proposed a fog-assisted privacy protection scheme for LBS to process the users’ query in the fog server, efficiently protecting privacy security, solving the problem of double identity attacks in mobile phones. All of the above studies have addressed the issue of secure data storage and query to some extent; however, few papers have considered the pitfalls of the cloud as a potential attacker, which may leak or forge the outsourced data to reach illegal benefits.
2.2. Verifiable Search
To ensure that LBS works without a hitch, verifying the outsourced data returned from the cloud is also an essential part of the process. Yin et al. [9] constructed a data verification object using the Bloom filter to verify the correctness and completeness of data, realizing fine-grained and efficient verification of data. In [18], Zhu et al. implemented fine-grained access control based on blind signatures and key policy attribute-based encryption (KPABE), and used function hidden inner product encryption (FHIPE) to encrypt Bloom filters for data file authentication, achieving secure and efficient data validation. In [19], Zhou et al. devised a lightweight and secure comparison protocol LSCP without interactions between the cloud and users. By using this protocol, users can easily eliminate duplicate and useless encrypted LBS messages during the authentication process, making the verification process in VANETs much faster. Benarous et al. [20] proposed a privacy-preserving scheme for verifying location data transmission for the Internet of Vehicles, improving the security of privacy for LBS of vehicles. All of the above studies on data verifiability have certain flaws. There is no guarantee that dishonest clouds will not obtain useful information from them, and they cannot be directly applied to the data verification process in LBS either.
2.3. Resistance to Dishonest Behavior
How to prevent dishonest behavior in the cloud is also a current area of research. Liao et al. [21] designed the continuous query KAT algorithm to prevent the cloud from analyzing the user’s privacy based on the user’s trajectory. By using this algorithm, the situation that the user’s privacy may be compromised by the continuous query can be effectively solved. To further protect privacy, Kuang et al. [22] designed double-hidden regions in k-anonymity algorithms to prevent the cloud from accessing user privacy. In previous research, scholars have never really looked at the cloud as an attacker, to disrupt the entire LBS system, to examine the implementation options. However, in practical situations, especially when massive amounts of location data are increasingly and profoundly affecting people’s lives, it is necessary to consider the cloud as an entity that threatens the security of the entire LBS system.
Therefore, in this work, we use the Paillier cryptosystem and lookup table technology to guarantee storage and query privacy. We use verification objects to provide a fine-grained and reliable verification of fog nodes and outsourced data. Moreover, we use blockchain technology to effectively prevent dishonest behaviors of fog nodes.
3. Background
In this section, the techniques used in the scheme are introduced firstly, then the system model and threat model are illustrated.
3.1. Preliminaries
To better illustrate our scheme, we briefly introduce several key techniques used in the scheme, including the Voronoi diagram used to divide the fog nodes, the counting Bloom filter used to construct the verification objects, and so on.
3.1.1. Voronoi Diagram
A Voronoi diagram [23] is composed of several geometries in a plane, and each geometric is known as the Voronoi polygon. These Voronoi polygons are generated by a set of generator points, and the generation process is as follows. Given a set of generator points specified beforehand, by making perpendicular bisectors for the straight lines composed of generator points, the whole plane can be divided into several regions. For each point x in the region R, the distance between x and generator point is less than that between x and any other generator points, i.e., , where . According to the properties of the Voronoi diagram, if fog nodes can be seen as generator points, then a two-dimensional map can be divided into a Voronoi diagram. Figure 1 is an example of a Voronoi diagram based on fog nodes.
3.1.2. Counting Bloom Filter
The counting Bloom filter [24] is an improved version of the Bloom filter, which can support elemental addition and deletion operations. Before introducing the counting Bloom filter, it is necessary to explain the Bloom filter. The structure of a Bloom filter is a bit array of m bits, where each bit is set to 0 initially. The Bloom filter is usually used to determine whether an element is in or not in certain sets. Suppose that there is a set of t elements. To enable an element, can be represented in the Bloom filter; it needs to use l independent hash functions to hash s to obtain l different positions in the Bloom filter, and these hash functions are with the same output range . Then these l different positions in the structure of the Bloom filter are set to be 1. To decide whether , it needs to examine whether all the positions in the structure of the Bloom filter corresponding to are equal to 1, where . Therefore, if one of these corresponding positions is 0, . If all the corresponding positions are 1, then or a false positive. To minimize the impact of the false positive, our scheme adopts the same way as the paper [9]. That is, the parameter l is set to be , which will result in the minimum probability of the false positive (i.e., ). However, since each position of the standard Bloom filter only represents a single bit, it does not support element addition and deletion operations. Thus, the counting Bloom filter uses fixed size counters to represent an element instead of single bits. In this case, the corresponding counters are added by 1 when an element is inserted and the corresponding counters are decreased by 1 when an element is deleted.
3.1.3. Paillier Cryptosystem
The Paillier cryptosystem is a classic homomorphic encryption and is usually used to implement addition operations over the ciphertext domain [25]. In general, it consists of three polynomial-time algorithms (i.e., , , and ).
: Firstly, two independent large prime numbers p and q are randomly selected. Then we compute and , where is the least common multiple function. Finally, the public key and private key can be obtained, where .
: Assume m is a plaintext to be encrypted. Firstly, a random number is selected. Then the encrypted result c can be computed by Equation (1):
: To obtain the plaintext m, the encrypted result c can be recovered with the private key by Equation (2):
3.2. System Model
As shown in Figure 2, the proposed scheme has four entities: the LBSP, the fog node, the user, and the blockchain, which describe the following scenario: due to the storage and computing advantages of fog computing, the LBSP outsources its private data to the fog nodes. However, to guarantee data security, the outsourced data need to be encrypted and the storage structures of outsourced data also need to be constructed to support the secure keyword search over the encrypted outsourced data. When a user requests a certain type of POI information in a specified query region, s/he can send a POI query request to the third party (i.e., the fog node) based on some parameters obtained from the LBSP. Similar to [9], the third party (i.e., the fog node) is considered to be a dishonest entity that could maliciously delete the stored outsourced data or tamper with the user’s query result; the secure verification objects should be constructed and contained in the outsourced data. When a query ends, the query result along with the corresponding verification objects are returned to the user. Finally, the user can implement the correctness and completeness verification based on the received verification objects, taking a step towards consistency verification under the support of the blockchain.
3.3. Threat Model
Our threat model is mostly consistent with work in [9]. The LBSP and the blockchain are assumed to be honest; that is, they honestly behave similar to the scheme designed. To some extent, they can be regarded as reliable entities without leaking any privacy of users or colluding with the fog side. The fog side is assumed to be dishonest and curious; that is, they may maliciously discard or tamper with outsourced data to obtain improper benefits while attempting to analyze not only the users’ queries themselves and their frequencies but also the outsourced encrypted data. The two threat models are described as follows:
Given two fog node verification objects of two different fog node identifiers , the attackers cannot tell the difference between the above two verification objects. The semantic security (i.e., fog node verification object indistinguishability security) of the fog node verification object is defined by a game between probabilistic polynomial-time adversary and challenger .
()
- (1)
- Setup.
- (2)
- Phase 1. asks to return the fog node verification objects after submitting different fog node identifiers many times.
- (3)
- Challenge. sends two challenge fog node identifiers to , which have not been sent in Phase 1. asks for the challenge fog node verification object. After receiving two challenge fog node identifiers , fairly chooses a bit and returns the challenge fog node verification object of to .
- (4)
- Phase 2. continues to ask to return the fog node verification objects after submitting different fog node identifiers many times. The only restriction is that the fog node identifiers are different from the identifiers sent in Phase 1 and Challenge.
- (5)
- Guess. The adversary outputs a guess of b. If , wins the game.
As the space of b is only two, can choose the correct number with the probability of 50% if taking a random guess.
Definition 1.
The advantage of the probabilistic polynomial-time adversary wins () is
If is negligible in the game, the fog node verification object is semantically secure and achieves indistinguishability.
Given two description file verification objects of set for two different keywords , the attackers cannot tell the difference between the above two verification objects. The semantic security (i.e., the description file verification object achieving indistinguishability) of the description file verification object is defined by a game between probabilistic polynomial-time adversary and challenger .
()
- (1)
- Setup.
- (2)
- Phase 1. asks to return the corresponding description file verification objects after submitting different keywords many times.
- (3)
- Challenge. sends two challenge keywords to , which have not been sent in Phase 1. asks for the challenge description file verification objects. After receiving two challenge keywords, , fairly chooses a bit and returns the challenge description file verification object of to .
- (4)
- Phase 2. continues to ask to return the corresponding location data file verification objects after submitting different keywords many times. The only restriction is that the keywords are different from the keywords sent in Phase 1 and Challenge.
- (5)
- Guess. The adversary outputs a guess of b. If , wins the game.
As the space of b is only two, can choose the correct number with the probability of 50% if taking a random guess.
Definition 2.
The advantage of the probabilistic polynomial-time adversary winning () is
If is negligible in the game, the description file verification object is semantically secure and achieves indistinguishability.
4. Proposed Scheme
In this section, we first describe the overview of our scheme. Then, based on three main processes, the proposed scheme is explained in detail. The summary of notations is presented in Table 1.
4.1. Overview
In brief, the design goal of our scheme was to support the security verification of query results on the basis of providing a secure query over the outsourced data. That is, when a query ends, both the query result and corresponding verification objects are returned to the user by the fog node. Upon receiving these returned data, the user can obtain the query result that corresponds to his/her query index as well as verify the completeness and correctness of the query result according to the verification objects and check the consistency of the query result based on the blockchain.
Our scheme is mainly composed of three processes: data outsourcing process, data retrieval process, and data verification process. (1) The data outsourcing process: given a flat map (e.g., a city), the LBSP constructs a Voronoi diagram mentioned in Section 3.1. Then, according to the fog node in each Voronoi cell, the LBSP forms the original database, shown in Table 2. Note that the fog nodes can vary based on the frequency layers or in case the user devices are connected to some local Wi-Fi hotspots. Based on the original database, the LBSP begins to construct the encrypted outsourced data, such as the retrieval index, the query result, and the corresponding verification objects. While introducing the construction process of outsourced data, Section 4.2 explains the improved construction process of verification objects to fix the deficiency of the scheme [9]. (2) The data retrieval process: based on encrypted outsourced data constructed in the data outsourcing process, the storage structure of the outsourced data (i.e, one-to-n lookup table) stored in each fog node is illustrated. When a user specifies a query region, the fog nodes contained in the query region will be in charge of the user’s query service. Based on the one-to-n lookup table, Section 4.3 states how the user obtains the query service from the fog nodes and how to prevent the fog nodes from deducing the meaning of the outsourced data stored in themselves by the way of statistics. (3) The data verification process: after obtaining the returned data from the fog nodes, Section 4.4 shows how to verify the correctness and completeness of the query result according to the verification objects and check the consistency of the query result based on the blockchain.
4.2. Data Outsourcing Process
The process of constructing the encrypted outsourced data will be illustrated based on the original database structure. For each keyword w related to a certain POI type and each set of description files containing the keyword w, the LBSP uses the pseudo-random function with the key k (i.e., ) and to form the encrypted retrieval index set and the ciphertext set . Moreover, to support the query result verification, the verification objects need to be constructed. Similar to the scheme proposed in [9], our scheme also adopts the Bloom filter to generate verification objects.
4.2.1. Design of the Fog Node Verification Object
For each fog node identifier , the LBSP first uses to obtain the corresponding ciphertext , where and s indicates the total number of fog nodes. Then, for each , the LBSP uses the pseudo-random function (i.e., ) to obtain the secret value and prepares a standard Bloom filter with m bits, where the initial value of each bit is 0. Further, the LBSP utilizes set H that is composed of l hash functions to hash and obtains the set of hashed values . Finally, the LBSP enabling these hashed values can be represented in the standard Bloom filter and sets the corresponding bit to be 1, where .
4.2.2. Design of Description File Verification Objects
For each set of description files containing the keyword (i.e., ), the LBSP prepares a counting Bloom filter with m counters, where the initial value of each counter is 0. Then, for each encrypted description file , the LBSP uses the pseudo-random function (i.e., ) to obtain the secret value and utilizes the set H composed of l hash functions to hash , obtaining the set of hashed values . Finally, the LBSP enabling these hashed values can be represented in the counting Bloom filter, adding the corresponding counter by 1, where , , and indicate the total number of keywords.
Problem statement: If the verification object is directly outsourced to the third party (i.e., the cloud side or the fog side), the number of description files represented in can be easily figured out by calculating , where l is the number of hash functions. Therefore, the scheme in [9] proposed a novel structure for the verification object to fix the above issue by adding a padding region, shown in Figure 3. In the structure, the number of counters is extended to n. The counters from 0 to are inserted corresponding to description files of by using and H, and the counters from m to n are inserted corresponding to random strings by using a pad function P with the range , where is the maximum number of description files containing the same keyword. The computed result , is not 0, the corresponding counter is added by 1.
Although the padding region can efficiently prevent the third party from calculating how many description files are contained in , the structure of the verification object is not perfect since this construction will leak some important information. For example, since each satisfies . Then, the structure of the verification object is an exceptional layout since all of the values of counters in the padding region are 0, where represents the verification object of . In other words, the value in the last m to n counters are all 0, as shown in Figure 4. Due to the layout shown in Figure 4, the third party can easily lock the verification object and further figure out the corresponding encrypted query. Consequently, the layout will support the third party to infer the meaning of the encrypted query index by investigating the data number of the POI type related to keyword w.
Improved construction process of verification objects: The main idea of our improved method is to set the sum of genuine description files and dummy description files of each keyword to be a fixed value , where is the maximum number of genuine description files and r is a random value. indicates the number of dummy description files. Suppose that denotes the number of genuine description files for each keyword , then the total number of description files that need to be represented (i.e., the number that needs to be inserted into the structure of the verification object) can be set as . Specifically, in the structure of the verification object , the verification region is inserted times and the padding region is inserted times. Finally, the sum of the inserted times (i.e., the sum of numbers in all counters) for each verification object is . An example of our verification object is shown in Figure 5. The improved construction process of the verification object is shown in Algorithm 1.
| Algorithm 1 Improved construction process of verification objects. |
Input: The ciphertext files sets and Output: The verification object sets and
|
4.2.3. Design of the Lookup Table
After the above settings, the encrypted retrieval index set (i.e., ), the encrypted query result set containing keywords (i.e., ), the verification object set of fog nodes (i.e., ), and the description file verification object set corresponding to the encrypted query result set (i.e., ) are obtained. Based on the above-encrypted data, the LBSP can outsource these data to a third party (i.e., the fog side). However, how to use the user’s encrypted query index to obtain the corresponding query result and the verification objects without leaking any useful information to the third party is an important problem that needs to be solved.
Problem statement. To overcome the disclosure of query privacy, it is common to use the user’s encrypted query index to support the secure query over the outsourced data. Although this way can prevent the third party from obtaining the plaintext information of the user’s query index (e.g., the plaintext information about the query keyword w in our scheme), it still exposes important information, such as the frequency or rarity of requests for outsourced data corresponding to the user’s encrypted query index, and accurate statistical information on the frequency of all encrypted outsourced data requested. Upon the above-exposed information, the third party may carry out some dishonest behaviors, such as deleting the outsourced data that are rarely requested or inferring the meaning of the encrypted query index (e.g., in our scheme).
Improved storage structure of the outsourced data. In brief, the reason that a third party can obtain the exposed information is that the relationship between the encrypted query index and the corresponding query objects is designed to be one-to-one in the storage structure. Therefore, to prevent the third party from implementing the inference attack based on the above one-to-one correspondence, our scheme designs the one-to-n lookup table as the storage structure of the outsourced data to disturb the corresponding relationship between the encrypted query index and the corresponding query objects. For example, Table 3 shows the improved storage structure with the one-to-two correspondence (i.e., the one-to-two lookup table). By using this storage structure, the relationship between the encrypted query index (i.e., ) and the corresponding query objects (e.g., ) stored in the fog node can achieve the goal of one-to-two. Note that each fog node only owns the encrypted outsourced data within its Voronoi cell (i.e., the LBSP outsources the lookup table that contains the ciphertext data to the corresponding fog node). In the lookup Table 3, a and b are two random numbers, where and . If , then . If , then . Moreover, is the identifier set of data items and each indicates the identifier of a data item. is the encrypted set of the number of genuine description files and each denotes the encrypted number of genuine description files corresponding to the set of encrypted description files (i.e.,), where indicates the number of genuine description files and it is obtained by encrypting the genuine number with . Based on the improved storage structure, the next subsection will show how to remedy the proposed problems with our scheme.
4.3. Data Retrieval Process
Since the process of the user registration in the LBSP is not the focal point of our scheme, we explain the data retrieval process based on the registered user who has obtained the key k of the pseudo-random function, the key of , the set of l hash functions H from the LBSP, and a hash function that used to verify the consistency of the query result in the registration process. When an authenticated user wants to request a query service, s/he could specify a query region by the client-side installed on his/her mobile device (e.g., an app) and send the query region to the LBSP. Subsequently, the LBSP sends the identifier set of fog nodes contained in the query region and a guide set that is used to fix the proposed problems, such as preventing the fog nodes from obtaining accurate statistical information about the frequency of the encrypted outsourced data. Upon receiving the identifiers of fog nodes and the guide set, the user begins to communicate with the corresponding fog nodes and enjoys the outsourced data retrieval service. Herein, since the interaction process between the user side and the fog side is the same, we focus on explaining the interaction process between one user and one fog node . In what follows, we first introduce how the LBSP designs a guide set based on the one-to-n lookup table and then shows how the user uses the guide set to request the encrypted outsourced data.
4.3.1. Design of Guide Set
Based on the one-to-n lookup table, the LBSP can set a guide set in the form of , where n is the redundancy of the one-to-n lookup table. Specifically, a guide set F consists of a series of binary digits and each element is a binary number. Herein, note that there is only one binary ’number 1’ in each guide set. For example, Table 3 is a one-to-two lookup table, then the guide set can be designed in the form of {1, 0} or {0, 1}. Note here that the form of the guide set sent from the LBSP to the user is random, i.e., the guide set received by the user may be {1, 0} or {0, 1}.
4.3.2. Query Request Submission
When a user wants to request a query service, the user should submit the query request in the form of to the fog node . In the query request Q, indicates a keyword of interest related to a POI type and is gained by encrypting with the shared key k of the pseudo-random function. Moreover, C is a ciphertext set composed of a series of encrypted data in the form of {}, in which represents encrypted data obtained by the public key and an element in the guide set F. Specifically, to obtain , the user encrypts the using the Paillier cryptosystem under the public key and a random number as follows:
Moreover, E represents encrypted data obtained by the public key and encrypted query index . Specifically, to obtain E, the user encrypts the using the Paillier cryptosystem under the public key and the set {} as follows:
4.3.3. Data Retrieval
Upon receiving the user’s query request , the fog node first scans the column of the lookup table and finds the corresponding data items that contain . According to the one-to-n lookup table, n data items can be found. For example, since Table 3 is a one-to-two lookup table, then two data items and can be found, where the column of is and the column of is , where . For each found data item, the fog node performs the computation as follows:
where .
Then, the fog node can find the target data item by checking whether is equal to E, i.e., when , the corresponding data item is the target data item . After finding the target data item, the fog node further computes:
After completing the above calculations, the fog node returns , , , and back to the user. Moreover, the fog uses sent from the LBSP to hash and sends to the blockchain. Upon receiving the returned data, the user can obtain , , , and with the private key and further obtain the available result set and the number of genuine description files with the shared key .
4.4. Data Verification Process
According to the returned data, the correctness, completeness, and consistency of the query result can be verified by the user.
4.4.1. Correctness Verification
To check the correctness of the fog node , the user first encrypts to obtain by using and further obtains with k. Then, with the set of l hash functions H, the user begins to calculate and checks the corresponding positions in . According to the above comparison, the user can confirm whether the returned data are sent by the fog node . To check the correctness of the query result , the user first calculates with the set of l hash functions H for each encrypted description file c. Then, the user makes a comparison between and . If one of the counters in is 0, this c is incorrect. The process of correctness verification is shown in Algorithm 2.
| Algorithm 2 Correctness verification. |
Input:, , k, H, , Output: The correctness of and
|
4.4.2. Completeness Verification
To check the completeness of the query result , the user first finds out the number which indicates the available description files from the available result set . Then, if is not equal to the number of genuine description files , the query result can be directly judged as incomplete. Otherwise, the user finds out the corresponding available encrypted description files based on . Further, for each available encrypted description file , the user calculates with the set of l hash functions H and the corresponding counters in are decreased by 1. Finally, the user can confirm whether the completeness of the query result by judging whether is equal to 0, where . The process of completeness verification is shown in Algorithm 3.
| Algorithm 3 Completeness verification. |
Input:, , , Output: The completeness of
|
4.4.3. Consistency Verification
To check the consistency of the query result , the user directly uses the hash function to hash sent from the fog node and further sends to the blockchain for the comparison between and . Since the data stored on the blockchain are obtained based on the consensus mechanisms, such as PBFT or Raft, if the comparison result shows that the hash value of is equal to the hash value of , the user can confirm that the received query result is consistent with the query result sent from the fog node . Moreover, the fog node cannot repudiate the incorrectness and incompleteness of the query result due to network problems. The process of consistency verification is shown in Algorithm 4.
| Algorithm 4 Consistency verification. |
Input:, , ChainGroup Output: The consistency of
|
Moreover, the scheme divides the cost the LBSP used to pay for the third-party storage into two parts, one part remains—the original storage cost—and the other part is given by the user incentivized by verifying the hash value of the data published by the fog node on the blockchain. The more times fog nodes return data honestly, the more incentive rewards they receive.
5. Security Analysis
In this section, we provide a comprehensive security analysis of the SEQRVS scheme, including the semantic security of verification objects and lookup table.
5.1. Security of Verification Objects
The purpose of the scheme containing the fog node verification object and the description file verification object proposed in this paper is the same as [9]; once the verification objects are constructed, for security’s sake, they reveal nothing about the characteristics of the fog node or the contents of the description files. That is to say, both the outside eavesdroppers and the inside data ’leakers’ can hardly acquire useful information from the verification objects. To reach such a goal, the proposed scheme focuses on two aspects: the meaninglessness of the verification objects themselves and the indistinguishability of the verification objects from each other.
According to Section 4.2, the fog node verification object consists of m bits with binary numbers and the description file verification objects consist of n counters with natural numbers. Due to the security of the hash function mapping process (i.e., the secrecy of the hash function), an attacker cannot obtain information related to the data itself from these sequences of numbers. Therefore, the verification objects themselves are meaningless. It is clear to see that guaranteeing the indistinguishability of verification objects means that their sizes and formats cannot be distinguished. The improved construction process mentioned in Section 4.2 set the length of the fog node verification object to m and the description file verification objects to n, solving the size problem. Inserting indistinguishable elements into the counters of the Bloom filter can further guarantee the indistinguishability of the inserted elements. In Algorithm 1, we used the pseudo-random function to guarantee the indistinguishability of the inserted elements.
Before proving the security of the verification objects, the definition of the pseudo-random function is given first.
Definition 3.
For a probabilistic polynomial time distinguisher with the advantage to distinguish from a string r of length s, where is a keyed function, is a random length string and and r are chosen uniformly and randomly from . This advantage can be defined as
Definition 3 means that no polynomial time algorithm can distinguish the output of a pseudo-random function from the output of a real random function [26]. If F is a pseudo-random function, then the advantage is negligible under the randomly chosen key k from .
The formal security proof is given as follows.
Theorem 1.
If is a pseudo-random function, then the fog node and description file verification objects are semantically secure and achieve indistinguishability in the random oracle model.
Proof.
For () and () given in Section 3.3, we define that adversary has a non-negligible advantage to win these two games. In the meantime, a distinguisher with a non-negligible advantage to distinguish the output between the pseudo-random function and the real random function can be constructed by .
As the function used in Algorithm 1 is , we introduce another algorithm Algorithm , which uses a random function to replace the pseudo-random function . We denote Algorithm 1 as and Algorithm as . In essence, the and are modeled as -accessible random oracles. emulates the game () and () for . According to whether adversary succeeds in the game, determines whether or , so that it accepts the algorithm . Specifically, if succeeds, then determines ; otherwise, .
chooses two keywords and to . uses the algorithm and chooses a bit randomly. The choice made influenced whether can succeed. However, the chances of and are uniformly . Then returns to . outputs a bit and outputs a guess for x. As defined above, has a non-negligible advantage to succeed in games () and () (i.e., ), we can easily conclude that also has a non-negligible advantage to determine the guess . This conclusion can also prove that can distinguish the output of (using the pseudo-random function under the key k) from (using the real random function ) with the non-negligible advantage . Since contains elements after padding, for each element c, assume that the advantage that distinguishes from is , we have
Since is non-negligible, the advantage is also non-negligible. Therefore, if wins games () and () with a non-negligible advantage , then has the non-negligible advantage to distinguish the output between the pseudo-random function and the real random function , which contradicts Definition 3. So that the security of verification objects can be proofed. □
5.2. Security of Lookup Table
Our scheme also adopts a secure outsourced data storage and query approach by designing a one-to-n lookup table so that multiple queries to the same POI by different users or by the same user at different times correspond to different contents of the fog node storage. By doing so, we completely break the traditional one-to-one storage structure of the lookup index and lookup content. To ensure the security of the proposed scheme, we will illustrate the security of the lookup table in the following ways: the security of stored content in the lookup table, the indistinguishability of individual data items in the lookup table, the security of the data request process.
Firstly, the files themselves are secure, because LBSP encrypts the description files before outsourcing them to the fog node with the keys that attackers cannot achieve. Secondly, as shown in Table 3, the data items in the lookup table are all composed of , , , , , and . Moreover, the data in the data items are all n-dimension (n = 2 in Table 3), attackers—even the fog node itself—cannot tell the difference between the different data items. Thirdly, when the same POI is queried, the description files and verification object returned by the fog node each time will likely be different data items (i.e., in different positions on the server) and that item will be unique in that query. As the generation of the guide set is random, the returned data from querying the same POI will be randomly assigned to multiple data entries in the lookup table, and the fog side cannot obtain the complete frequency information of the query index through traditional statistical analysis methods, enabling a secure query process. Moreover, queries against different POIs may return data from the same data item, which helps to confuse the one-to-one correspondence between the query index and the returned data.
6. Evaluation
To verify that our proposed query scheme for the description files in LBS is practical and feasible, we experimentally evaluated the scheme in the following ways.
6.1. Experimental Settings
Because of the large number of description files and the number of queries, we chose AES as the encryption algorithm for the description files. In addition, we used HMAC-SM3 with 256 bits key to instantiate the pseudo-random hash function . For the Hash function used to validate data on the blockchain, we used SHA-256, the same as Ethereum.
In our experiments, we used Java language to implement all programs. The client-side was an Inter i7-6700HQ 2.6 GHz computer with 16 GB RAM running Windows 10. The fog node was simulated by using the Linux CentosOS 7. As for the blockchain, we used the FISCO BCOS [27] consortium chain as the backbone of the blockchain and the system environment was also CentOS7. The compiler was the WeBASE IDE and the language was Solidity 0.4.24 (0.4.24 is upward compatible up to version 0.5).
6.2. Performance of Verification Objects
As a key technique in our query solution, the time to construct the verification objects greatly affects how well the solution works. Therefore, we first conducted experiments on the construction time of two types of verification objects.
To evaluate the performances of verification objects, we chose five representative types of POIs for this experiment: s, s, s, s, and s. Table 4 shows the amounts of these POIs in the regions. Moreover, we set the total inserted times S to 500, which is much more than any number of POIs in our experiments. The time required to construct the verification objects are shown in Figure 6. The graph should have consisted of the constructing time of the fog node verification object and the constructing time of the description file verification object. However, due to the difference in the construction method of the verification objects (i.e., the difference in the number of numbers inserted into the verification objects), the construction time of the fog node verification object was much less than that of the description file verification object and was negligible in the construction process for both types of verification objects.
The highest bar in the graph represents the construction time corresponding to the s, which is positively correlated with the number of POIs in the area; that is, the more POIs of the same type in the area, the more time it took to construct, which is in line with the common perception. However, the differences between the different categories were not very large, especially during the whole process of location-based services. Thus, it is not a concern for an attacker to infer from the construction time of a verification object on what it represents.
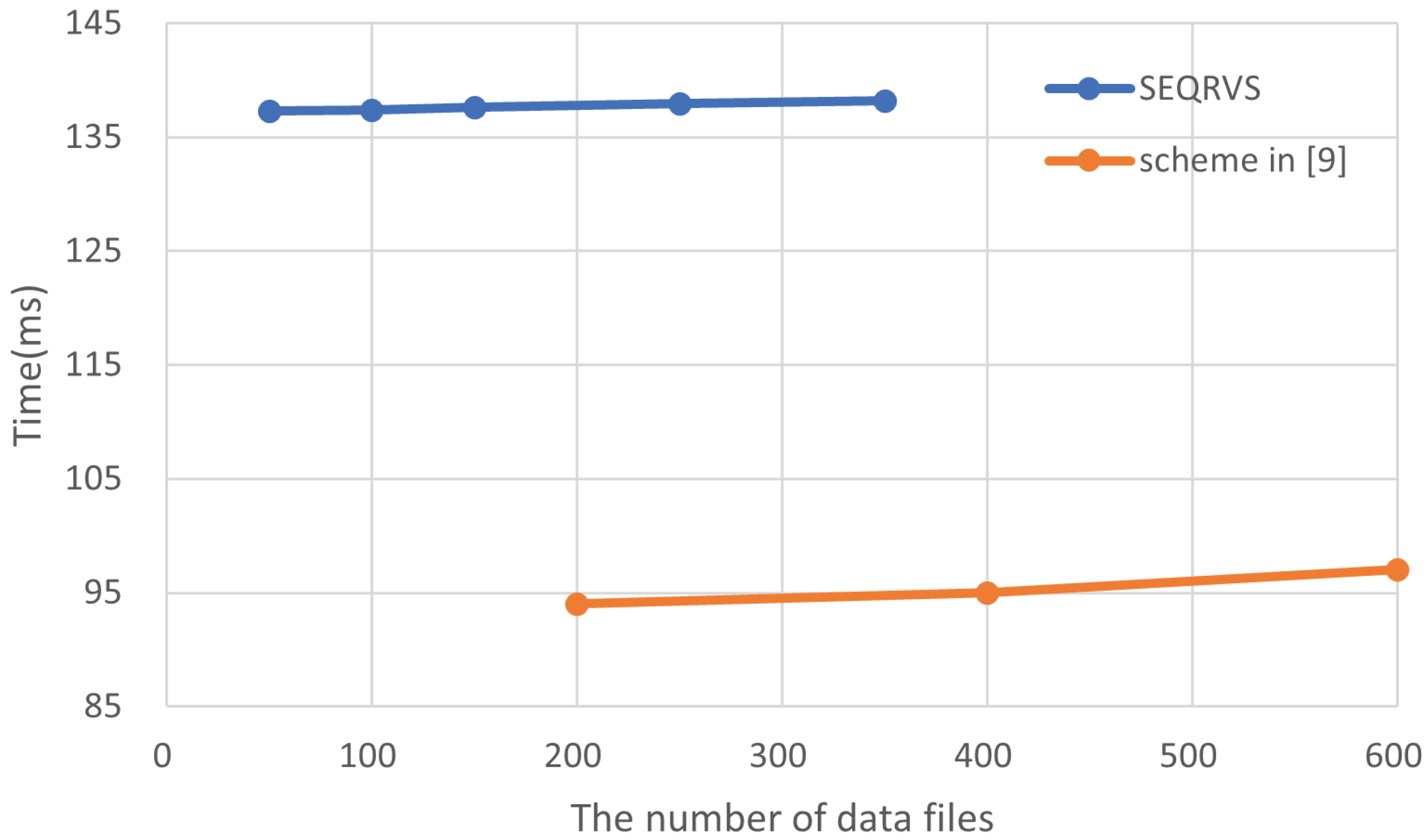
For the description file verification objects, although the POI numbers were distinguishably different, the numbers were five times more the numbers, and the time cost of s was only 6.3% (138.17 and 137.30 ms) more than the s; hence, not very different. The reason for this result is that the verification object construction time is mainly determined by the selected pseudo-random function. Moreover, as shown in Figure 7, we compare our verification object construction scheme with [9]. It is clear that our construction time is slightly higher, also because the pseudo-random function chosen is different. Compared to the HMAC-MD5 used in [9], our pseudo-random function key grew from 128 to 256 bits, addressing the potential security concerns associated with the use of an insecure cryptographic algorithm in the former, and the increase in construction time is within acceptable limits.
The construction time of the verification object affects the efficiency of the outsourced storage of description files; it is the verification time of the verification object that is critical for the user. Low latency is an important indicator to verify the feasibility of our solution. We made experiments on the verification time of the verification object.
Figure 8 shows the time cost increased with the number of data queried in our scheme. As our solution is similar to the data authenticity verification method in [9], we only made a comparison of the data completeness verification process. Figure 8 also shows the difference between our method and [9]. Since our solution stores the true number of description files corresponding to the verification objects in advance when constructing the verification object, we have a huge advantage in the data completeness verification process. As the grey line shows, if the data sent from the third party is incomplete, we can identify it in a short time and determine the amount of missing data, enabling the description file query solution to work more efficiently. Compared to the data query scheme in [9], the other main reason for our scheme, apart from the higher time consumption due to the introduction of pre-judgment, is a large amount of data we had to pad. The data verification objects in [9] were all padded to the data verification object corresponding to the keyword with the most data files, whereas our scheme was padded to T, which is greater than the maximum value of the former. The increased time cost was solely due to the security of the verification object. As a result, our verification time was slightly higher than [9], but still within acceptable limits.
6.3. Performance of Lookup Table
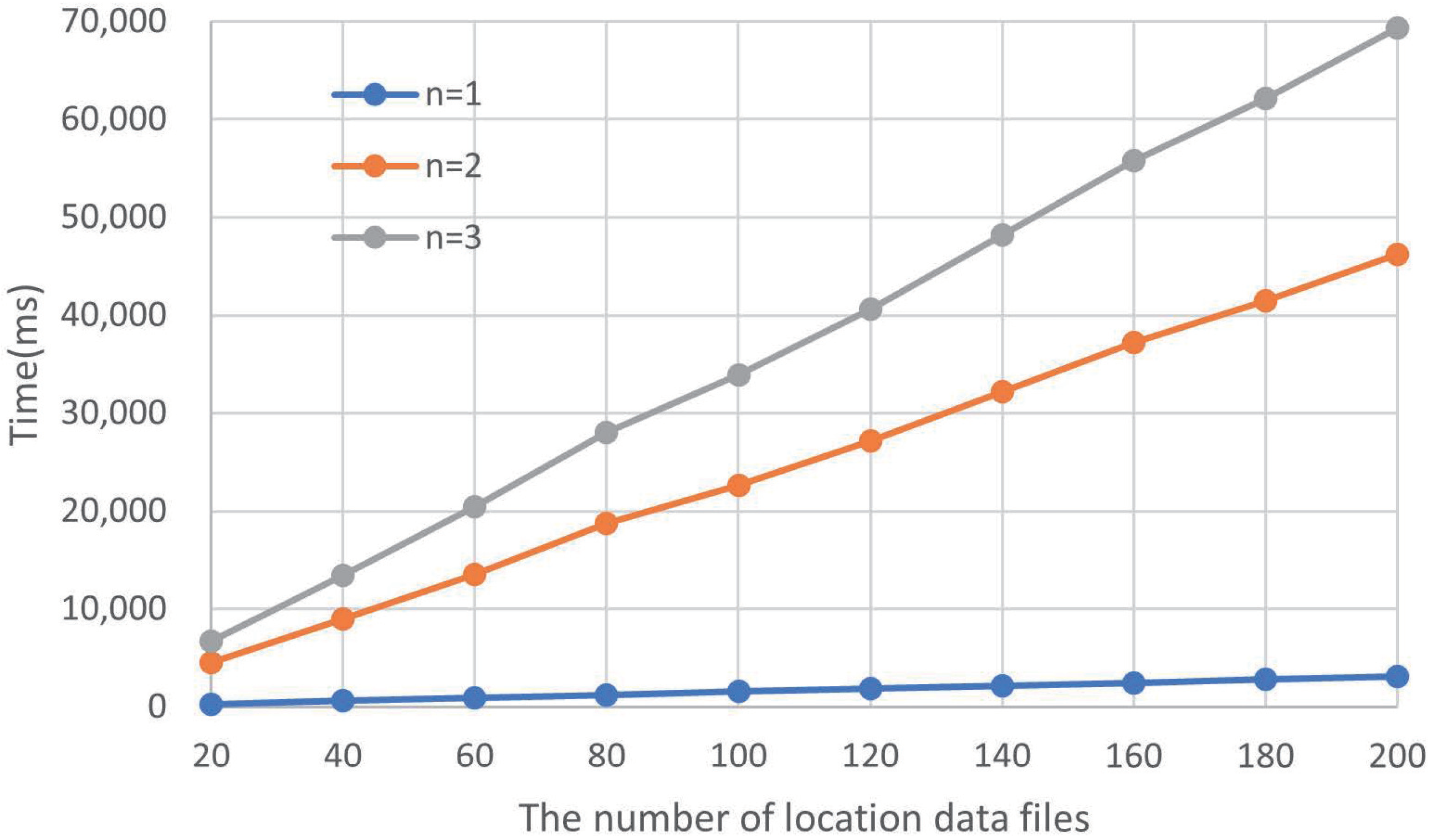
To better analyze the effectiveness of our proposed scheme, we also needed to further analyze the lookup table, and the data storage structure in the fog nodes, to ensure that our scheme was practical and feasible. We conducted experiments on the query time of the lookup table. With the increase in querying data files, the query time can be seen in Figure 9.
The blue line in Figure 9 represents the one-to-one lookup table method, and the red and grey lines represent the lookup tables for n = 2 and n = 3, respectively. It can be seen that the search time increases with the increase of search times. For n = 1, because the number of data files in the table is only one, the fog node can easily determine the important priority of data according to the access query times of each data and infer the meaning of the data representation (and even the encrypted data). At the same time, compared with n = 2 and n = 3, since the number of searches is determined, once a piece of datum is found, the search process will end immediately, which leads to a significant decrease in the average search time. When n = 2, it takes about 46 s to query the description files 200 times and the average time for each query is 0.23 s, which is within a reasonable limit. It can also be seen from the graph that the time spent on the look-up table corresponding to n = 3 has increased by approximately 50% compared to n = 2, but there is no improvement in terms of functional safety. Therefore, the one-to-two look-up table was ultimately chosen as the optimal choice.
6.4. Performance of Blockchain Incentive
We also experimented with the incentive benefits obtained by using blockchain in the fog node as part of the verification process, as shown in Figure 10.
The test results show that—with the increase of query times—if the fog node returns the description files required by users without error, its incentive income will also increase. The fog node can reach the service fee as discussed. Our plan is feasible.
6.5. Performance of Query Scheme
To verify the feasibility of the whole scheme and to simplify the whole process of querying description files, we visualized the area responsible for each fog node as a 10 × 10 matrix area, with one POI in each small area. Considering the practical situation, we designed 3 × 3 of matrix regions, which means that there were 9 fog nodes and 900 different small regions (for simplicity, we specify that each small region has only one POI attribute). The regions are shown in Figure 11.
We set the range of areas that the user is allowed to query to be a rectangular area of 5 × 5, locations beyond this range are not considered part of the query result. Since we used the k-anonymity algorithm to protect the privacy of the querying user, the query area was expanded accordingly. We set k to 9, which expanded the corresponding query area to a rectangular range of 7 × 7. The region surrounded by the red line in Figure 11 was the true area of the LBS user, and the region surrounded by the green line was the expanded area.
Regarding the size of the verification objects, only when the number of counters was more than 9585, the false positive was less than 0.01 [9]. So we set the number of counters in the fog node verification object to 10,000. To verify the impact of the verification and padding regions of the description file verification objects on the description file query, we designed two sets of comparison tests, i.e., the verification regions of the counting Bloom filter of the description file verification objects were designed to be 10,000 and 20,000, and the padding regions were designed to be 2500 and 5000. As mentioned above, the size of the fog node verification object was approximately 5 KB (10,000 × 4 bits) and the sizes of the description file verification objects were approximately 6 to 12 KB (12,500 × 4 bits to 25,000 × 4 bits).
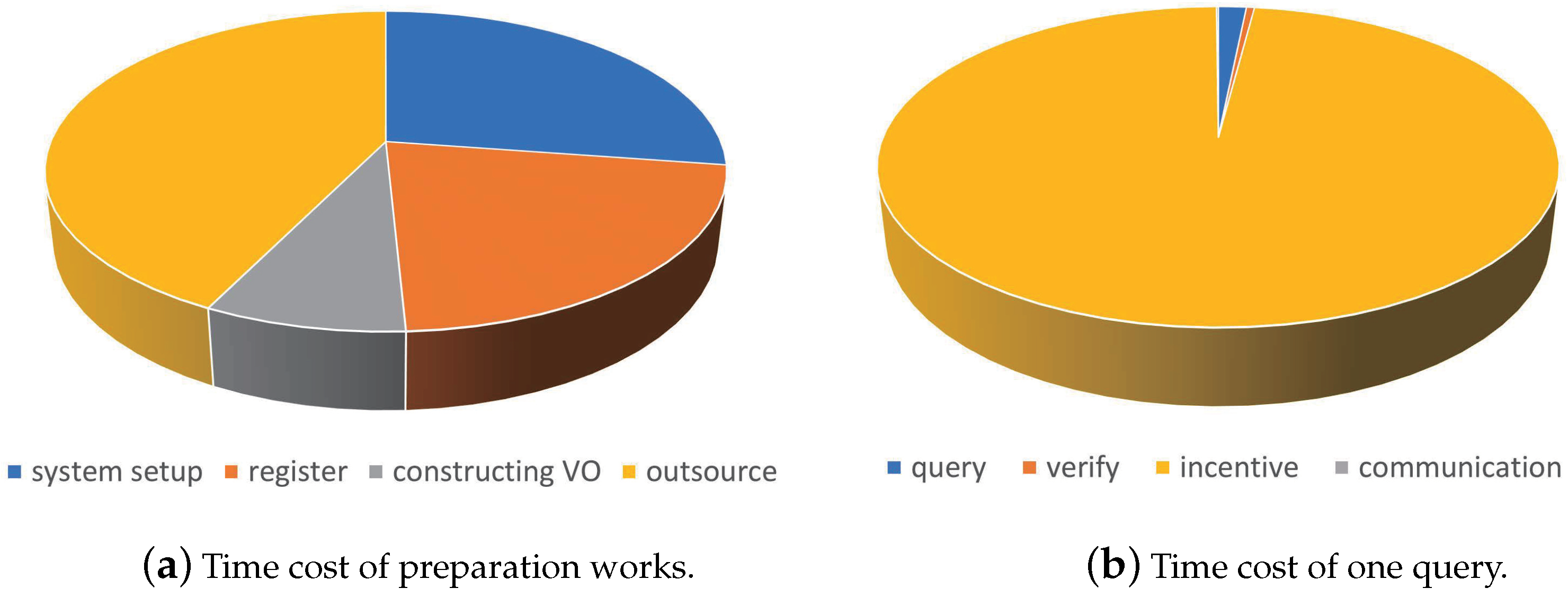
We conducted 100 experiments for each POI type data query, with each query location randomly selected. The results of the experiments are shown in Figure 12.
Figure 12a shows the time proportion of the preparation works of our scheme, including the construction of verification objects and the storage process. The time is about 1828 ms (100 description files). Figure 12b shows the time proportion of the one query. For most of them, it involves the incentive time for the fog node to reach the storage rewards. It takes about 14 s, which was determined by the time the blockchain generated a block. Indeed, the time the user obtained the required description files after querying and verifying was only about 307 ms.
From the above experimental results, it can be seen that the average query time for each description file is within acceptable limits. The experiments show that the scheme proposed in this paper is practical and feasible.
7. Conclusions
In this paper, we propose a security-enhanced query result verification scheme for outsourced data in location-based services. We corrected the mistake of the work in [9] to make the whole description file verification process unobstructed without missing the advantages of being ’fine-granted’ and secure. We used the one-to-n lookup table to confuse the corresponding relationship between the query index and the description files. Moreover, we solved the current problem of fog nodes exploiting vulnerabilities to deny dishonest behavior and optimize the current cost structure for third-party storage through blockchain technology. Performance and accuracy experiments demonstrate the validity and efficiency of our proposed scheme.
However, there are still some defects in our scheme. Compared with the previous works, our work has a certain improvement in security, but due to the complexity of using algorithms and technologies, the time consumption has increased slightly (still within a reasonable range). In addition, this scheme only considers the possible privacy disclosure caused by the fog node as a third-party storage object, but does not consider that LBSP may also disclose the user’s private information or analyze user queries to obtain improper benefits.
In the future, one research direction will be how to protect the user’s privacy under the consideration of taking LBSP as a dishonest entity. Moreover, the advantages of blockchain technology have not been fully brought into play, so another research direction will be to further use its characteristics to improve the security and feasibility of the scheme.
Author Contributions
Conceptualization, G.Y.; data curation, H.Z.; formal analysis, Y.H.; methodology, J.L.; software, C.L.; writing—original draft, J.L. and K.X.; writing—review and editing, G.Y. and Y.X. All authors have read and agreed to the published version of the manuscript.
Funding
This research was partially supported in part by the National Key R&D Program of China under grant 2020YFB1805403, the R&D Program of Beijing Municipal Education Commission under grant KM202010009010, the Yunnan Key Laboratory of Blockchain Application Technology (202105AG070005), the Beijing Municipal Natural Science Foundation under grant M21029, the National Key Research and Development Program of China under grant 2018YFB1800302, the Foundation of Guizhou Provincial Key Laboratory of Public Big Data under grant 2018BDKFJJ021, and the Talent special project (XN083).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used to support the finding of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare that there are no conflict of interest regarding the publication of this article.
References
- Adem, B.A.; Alrashdan, M.; Abdulnabi, M.; Jaradat, A.; Tubishat, M.; Ghanem, W.A.; Yusof, Y. A General Review on Location Based Services (LBS) Privacy Protection Using Centralized and Decentralized Approaches with Potential of Having a Hybrid Approach. Int. J. Future Gener. Commun. Netw. 2021, 14, 3057–3079. [Google Scholar]
- A Almusaylim, Z.; Jhanjhi, N. Comprehensive review: Privacy protection of user in location-aware services of mobile cloud computing. Wirel. Pers. Commun. 2020, 111, 541–564. [Google Scholar] [CrossRef]
- Yang, G.; He, Y.; Xiao, K.; Tang, Q.; Xin, Y.; Zhu, H. Privacy-Preserving Query Scheme (PPQS) for Location-Based Services in Outsourced Cloud. Secur. Commun. Netw. 2022, 2022, 9360899. [Google Scholar] [CrossRef]
- Li, D.; Wu, J.; Le, J.; Liao, X.; Xiang, T. A novel privacy-preserving location-based services search scheme in outsourced cloud. IEEE Trans. Cloud Comput. 2021. [Google Scholar] [CrossRef]
- Huang, H.; Gartner, G.; Krisp, J.M.; Raubal, M.; Van de Weghe, N. Location based services: Ongoing evolution and research agenda. J. Locat. Based Serv. 2018, 12, 63–93. [Google Scholar] [CrossRef]
- Yang, P.; Xiong, N.; Ren, J. Data security and privacy protection for cloud storage: A survey. IEEE Access 2020, 8, 131723–131740. [Google Scholar] [CrossRef]
- Chen, L.; Lee, W.K.; Chang, C.C.; Choo, K.K.R.; Zhang, N. Blockchain based searchable encryption for electronic health record sharing. Future Gener. Comput. Syst. 2019, 95, 420–429. [Google Scholar] [CrossRef]
- Wang, Y.; Sun, S.F.; Wang, J.; Liu, J.K.; Chen, X. Achieving searchable encryption scheme with search pattern hidden. IEEE Trans. Serv. Comput. 2020, 15, 1012–1025. [Google Scholar] [CrossRef]
- Yin, H.; Qin, Z.; Zhang, J.; Ou, L.; Li, K. Achieving secure, universal, and fine-grained query results verification for secure search scheme over encrypted cloud data. IEEE Trans. Cloud Comput. 2017, 9, 27–39. [Google Scholar] [CrossRef]
- Wu, Z.; Wang, R.; Li, Q.; Lian, X.; Xu, G.; Chen, E.; Liu, X. A location privacy-preserving system based on query range cover-up or location-based services. IEEE Trans. Veh. Technol. 2020, 69, 5244–5254. [Google Scholar] [CrossRef]
- Liu, Z.; Wu, L.; Meng, W.; Wang, H.; Wang, W. Accurate Range Query With Privacy Preservation for Outsourced Location-Based Service in IoT. IEEE Internet Things J. 2021, 8, 14322–14337. [Google Scholar] [CrossRef]
- Yadav, V.K.; Verma, S.; Venkatesan, S. Efficient and secure location-based services scheme in VANET. IEEE Trans. Veh. Technol. 2020, 69, 13567–13578. [Google Scholar] [CrossRef]
- Huang, Q.; Du, J.; Yan, G.; Yang, Y.; Wei, Q. Privacy-Preserving Spatio-Temporal Keyword Search for Outsourced Location-Based Services. IEEE Trans. Serv. Comput. 2021, 99, 1. [Google Scholar] [CrossRef]
- Wang, X.; Ma, J.; Miao, Y.; Liu, X.; Zhu, D.; Deng, R.H. Fast and Secure Location-based Services in Smart Cities on Outsourced Data. IEEE Internet Things J. 2021, 8, 17639–17654. [Google Scholar] [CrossRef]
- Zhang, H.; Guo, Z.; Zhao, S.; Wen, Q. Privacy-preserving linear region search service. IEEE Trans. Serv. Comput. 2017, 14, 207–221. [Google Scholar] [CrossRef]
- Guo, J.; Sun, J. Secure and Practical Group Nearest Neighbor Query for Location-Based Services in Cloud Computing. Secur. Commun. Netw. 2021, 2021, 5686506. [Google Scholar] [CrossRef]
- Manju, A.; Subramanian, S. Fog-Assisted Privacy Preservation Scheme for Location-Based Services Based on Trust Relationship. Int. J. Grid High Perform. Comput. 2020, 12, 48–62. [Google Scholar] [CrossRef]
- Zhu, X.; Ayday, E.; Vitenberg, R. A privacy-preserving framework for outsourcing location-based services to the cloud. IEEE Trans. Dependable Secur. Comput. 2019, 18, 384–399. [Google Scholar] [CrossRef]
- Zhou, J.; Cao, Z.; Qin, Z.; Dong, X.; Ren, K. LPPA: Lightweight privacy-preserving authentication from efficient multi-key secure outsourced computation for location-based services in VANETs. IEEE Trans. Inf. Forensics Secur. 2019, 15, 420–434. [Google Scholar] [CrossRef]
- Benarous, L.; Kadri, B. A novel privacy preserving scheme for cloud-enabled internet of vehicles users. In Security, Privacy and Trust in the IoT Environment; Springer: New York, NY, USA, 2019; pp. 227–254. [Google Scholar]
- Liao, D.; Sun, G.; Li, H.; Yu, H.; Chang, V. The framework and algorithm for preserving user trajectory while using location-based services in IoT-cloud systems. Clust. Comput. 2017, 20, 2283–2297. [Google Scholar] [CrossRef]
- Kuang, L.; Wang, Y.; Ma, P.; Yu, L.; Li, C.; Huang, L.; Zhu, M. An improved privacy-preserving framework for location-based services based on double cloaking regions with supplementary information constraints. Secur. Commun. Netw. 2017, 2017, 7495974. [Google Scholar] [CrossRef]
- Wan, S.; Zhao, Y.; Wang, T.; Gu, Z.; Abbasi, Q.H.; Choo, K.K.R. Multi-dimensional data indexing and range query processing via Voronoi diagram for internet of things. Future Gener. Comput. Syst. 2019, 91, 382–391. [Google Scholar] [CrossRef]
- Yang, C.; Tao, X.; Zhao, F.; Wang, Y. Secure data transfer and deletion from counting bloom filter in cloud computing. Chin. J. Electron. 2020, 29, 273–280. [Google Scholar] [CrossRef]
- Paillier, P. Public-key cryptosystems based on composite degree residuosity classes. In Proceedings of the International Conference on the Theory and Applications of Cryptographic Techniques, Prague, Czech Republic, 2–6 May 1999; Springer: New York, NY, USA, 1999; pp. 223–238. [Google Scholar]
- Bellare, M.; Rogaway, P. Introduction to Modern Cryptography; UCSD CSE: La Jolla, CA, USA, 2005; Volume 207, p. 207. [Google Scholar]
- FISCO BCOS Blockchain. Available online: https://fisco-bcos-documentation.readthedocs.io/zh_CN/latest/docs/introduction.html (accessed on 15 July 2022).
Figure 1.
Voronoi diagram based on fog nodes (for an example in a UK location).

Figure 2.
System model.

Figure 3.
The verification object with a padding region.

Figure 4.
The structure of the special verification object.

Figure 5.
The structure of the verification object in our scheme.

Figure 6.
Time costs of constructing the verification objects.

Figure 7.
The comparison of time costs in constructing verification objects.

Figure 8.
The comparison of time costs of data completeness verifications.

Figure 9.
Query time.

Figure 10.
Blockchain incentive.

Figure 11.
Region area.

Figure 12.
The time of our SEQRVS scheme.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Summary of notations.
| Notation | Description |
|---|---|
| G | The identifier set of fog nodes. |
| g | The identifier of a fog node. |
| W | The keyword set related to POI types. |
| w | A keyword in set W. |
| The set of description files containing all keywords. | |
| The set of description files containing keyword w. | |
| The corresponding ciphertext set of plaintext X. | |
| A pseudo-random function with the key k. | |
| c | A secure encryption algorithm, e.g., AES. |
| Key pair generated by Paillier cryptosystem. | |
| The verification object set of all fog nodes. | |
| The verification object of a fog node. | |
| The position in the verification object of a fog node. | |
| The verification object set of description files containing all keywords. | |
| The verification object of description files containing keyword w. | |
| The counter in the verification object of description files containing keyword w. | |
| H | The set of l hash functions. |
| h | A hash function. |
Table 2.
The original database structure of the LBSP.
| G | W | |
|---|---|---|
| ⋯ | ||
| ⋯ | ||
| ⋯ | ||
| ⋯ | ||
Table 3.
Improved storage structure with one-to-two correspondence.
| ⋯ | ||||||
| ⋯ | ||||||
| ⋯ | ||||||
| ⋯ | ||||||
Table 4.
The numbers and distribution of the POIs.
| Fog Node | Hotel | Restaurant | Supermarket | Gas Station | Attraction | Total |
|---|---|---|---|---|---|---|
| 29 | 41 | 18 | 7 | 5 | 100 | |
| 33 | 32 | 22 | 2 | 11 | 100 | |
| 30 | 38 | 16 | 4 | 12 | 100 | |
| 24 | 38 | 10 | 10 | 18 | 100 | |
| 29 | 36 | 18 | 6 | 11 | 100 | |
| 29 | 31 | 24 | 11 | 5 | 100 | |
| 22 | 43 | 11 | 8 | 16 | 100 | |
| 23 | 42 | 12 | 5 | 18 | 100 | |
| 24 | 41 | 13 | 10 | 12 | 100 | |
| total | 243 | 342 | 144 | 63 | 108 | 900 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yang, G.; Li, J.; He, Y.; Xiao, K.; Xin, Y.; Zhu, H.; Li, C. A Security-Enhanced Query Result Verification Scheme for Outsourced Data in Location-Based Services. Appl. Sci. 2022, 12, 8126. https://doi.org/10.3390/app12168126
AMA Style
Yang G, Li J, He Y, Xiao K, Xin Y, Zhu H, Li C. A Security-Enhanced Query Result Verification Scheme for Outsourced Data in Location-Based Services. Applied Sciences. 2022; 12(16):8126. https://doi.org/10.3390/app12168126
Chicago/Turabian StyleYang, Guangcan, Jiayang Li, Yunhua He, Ke Xiao, Yang Xin, Hongliang Zhu, and Chen Li. 2022. "A Security-Enhanced Query Result Verification Scheme for Outsourced Data in Location-Based Services" Applied Sciences 12, no. 16: 8126. https://doi.org/10.3390/app12168126
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.