
Predicting Serum Levels of Lithium-Treated Patients: A Supervised Machine Learning Approach

 ,
,  , , ,
, , ,
Abstract
:1. Introduction
2. Materials and Methods
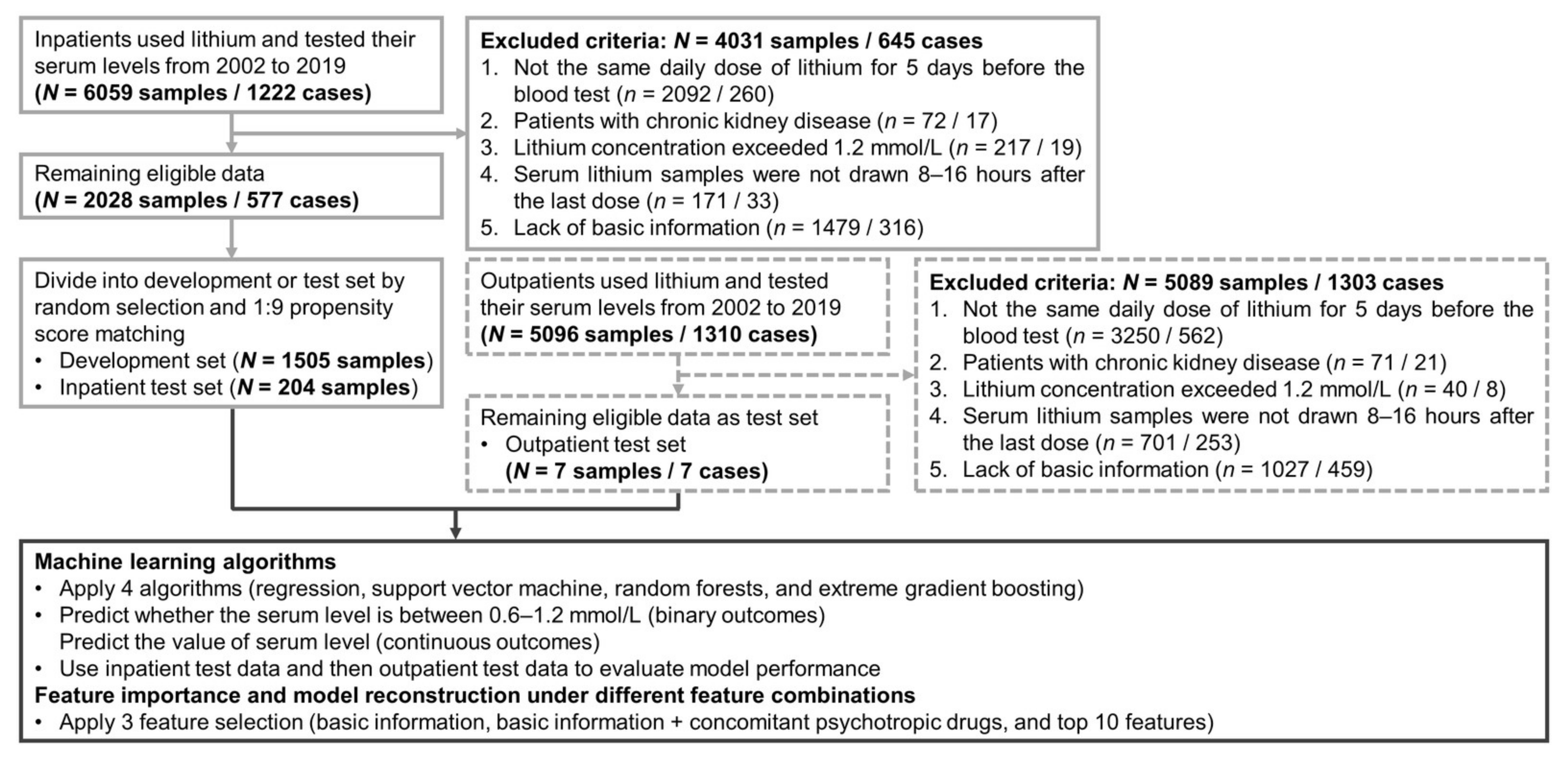
2.1. Data Source and Study Subjects
2.2. Definition of Outcome Targets, Predictive Features, and Analysis Subject
2.3. Machine Learning Models and Model Evaluation
2.4. Model Interpretation and Statistical Analysis
3. Results
3.1. Characteristics of Study Participants
3.2. Predictive Model Performance
3.3. Feature Importance and Model Performance under Different Feature Combinations
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Carvalho, A.F.; Firth, J.; Vieta, E. Bipolar Disorder. N. Engl. J. Med. 2020, 383, 58–66. [Google Scholar] [CrossRef]
- Leucht, S.; Helfer, B.; Dold, M.; Kissling, W.; McGrath, J.J. Lithium for schizophrenia. Cochrane Database Syst. Rev. 2015, 2015, Cd003834. [Google Scholar] [CrossRef] [PubMed]
- Carvalho, A.F.; Solmi, M.; Husain, M.I.; Berk, M.; Vieta, E. The rebirth of lithium as the archetypal mood stabilizer. Bipolar Disord. 2021, 23, 211–212. [Google Scholar] [CrossRef]
- Yatham, L.N.; Kennedy, S.H.; Parikh, S.V.; Schaffer, A.; Bond, D.J.; Frey, B.N.; Sharma, V.; Goldstein, B.I.; Rej, S.; Beaulieu, S.; et al. Canadian Network for Mood and Anxiety Treatments (CANMAT) and International Society for Bipolar Disorders (ISBD) 2018 guidelines for the management of patients with bipolar disorder. Bipolar Disord. 2018, 20, 97–170. [Google Scholar] [CrossRef] [PubMed]
- Fountoulakis, K.N.; Grunze, H.; Vieta, E.; Young, A.; Yatham, L.; Blier, P.; Kasper, S.; Moeller, H.J. The International College of Neuro-Psychopharmacology (CINP) Treatment Guidelines for Bipolar Disorder in Adults (CINP-BD-2017), Part 3: The Clinical Guidelines. Int. J. Neuropsychopharmacol. 2017, 20, 180–195. [Google Scholar] [CrossRef] [PubMed]
- Hsu, C.W.; Carvalho, A.F.; Tsai, S.Y.; Wang, L.J.; Tseng, P.T.; Lin, P.Y.; Tu, Y.K.; Vieta, E.; Solmi, M.; Hung, C.F.; et al. Lithium concentration and recurrence risk during maintenance treatment of bipolar disorder: Multicenter cohort and meta-analysis. Acta Psychiatr. Scand. 2021, 144, 368–378. [Google Scholar] [CrossRef]
- Dugas, J.E. Slowly titrated lithium doses delay therapeutic response. Clin. Pharm. 1984, 3, 236–238. [Google Scholar]
- Collins, N.; Barnes, T.R.; Shingleton-Smith, A.; Gerrett, D.; Paton, C. Standards of lithium monitoring in mental health Ttrusts in the UK. BMC Psychiatry 2010, 10, 80. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Nederlof, M.; Egberts, T.C.; van Londen, L.; de Rotte, M.C.; Souverein, P.C.; Herings, R.M.; Heerdink, E.R. Compliance with the guidelines for laboratory monitoring of patients treated with lithium: A retrospective follow-up study among ambulatory patients in the Netherlands. Bipolar Disord. 2019, 21, 419–427. [Google Scholar] [CrossRef]
- Sienaert, P.; Geeraerts, I.; Wyckaert, S. How to initiate lithium therapy: A systematic review of dose estimation and level prediction methods. J. Affect. Disord. 2013, 146, 15–33. [Google Scholar] [CrossRef]
- Abou-Auda, H.S.; Al-Yamani, M.J.; Abou-Shaaban, R.R.; Khoshhal, S.I. A new accurate method for predicting lithium clearance and daily dosage requirements in adult psychiatric patients. Bipolar Disord. 2008, 10, 369–376. [Google Scholar] [CrossRef] [PubMed]
- Terao, T.; Okuno, K.; Okuno, T.; Nakano, H.; Shinkai, T.; Ohmori, O.; Yoshimura, R.; Suzuki, T.; Abe, K. A simpler and more accurate equation to predict daily lithium dose. J. Clin. Psychopharmacol. 1999, 19, 336–340. [Google Scholar] [CrossRef]
- Jermain, D.M.; Crismon, M.L.; Martin, E.S., 3rd. Population pharmacokinetics of lithium. Clin. Pharm. 1991, 10, 376–381. [Google Scholar]
- Radhakrishnan, R.; Kanigere, M.; Menon, J.; Calvin, S.; Srinivasan, K. Comparison of three a-priori models in the prediction of serum lithium concentration. Indian J. Pharmacol. 2012, 44, 234–237. [Google Scholar] [CrossRef] [PubMed]
- Chekroud, A.M.; Bondar, J.; Delgadillo, J.; Doherty, G.; Wasil, A.; Fokkema, M.; Cohen, Z.; Belgrave, D.; DeRubeis, R.; Iniesta, R.; et al. The promise of machine learning in predicting treatment outcomes in psychiatry. World Psychiatry 2021, 20, 154–170. [Google Scholar] [CrossRef] [PubMed]
- Radua, J.; Carvalho, A.F. Route map for machine learning in psychiatry: Absence of bias, reproducibility, and utility. Eur. Neuropsychopharmacol. 2021, 50, 115–117. [Google Scholar] [CrossRef]
- Lin, E.; Lin, C.-H.; Lane, H.-Y. Precision Psychiatry Applications with Pharmacogenomics: Artificial Intelligence and Machine Learning Approaches. Int. J. Mol. Sci. 2020, 21, 969. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eugene, A.R.; Masiak, J.; Eugene, B. Predicting lithium treatment response in bipolar patients using gender-specific gene expression biomarkers and machine learning. F1000Research 2018, 7, 474. [Google Scholar] [CrossRef] [PubMed]
- Manchia, M.; Vieta, E.; Smeland, O.B.; Altimus, C.; Bechdolf, A.; Bellivier, F.; Bergink, V.; Fagiolini, A.; Geddes, J.R.; Hajek, T.; et al. Translating big data to better treatment in bipolar disorder—A manifesto for coordinated action. Eur. Neuropsychopharmacol. 2020, 36, 121–136. [Google Scholar] [CrossRef]
- Shao, S.C.; Chan, Y.Y.; Kao Yang, Y.H.; Lin, S.J.; Hung, M.J.; Chien, R.N.; Lai, C.C.; Lai, E.C. The Chang Gung Research Database-A multi-institutional electronic medical records database for real-world epidemiological studies in Taiwan. Pharmacoepidemiol. Drug Saf. 2019, 28, 593–600. [Google Scholar] [CrossRef]
- Tsai, M.S.; Lin, M.H.; Lee, C.P.; Yang, Y.H.; Chen, W.C.; Chang, G.H.; Tsai, Y.T.; Chen, P.C.; Tsai, Y.H. Chang Gung Research Database: A multi-institutional database consisting of original medical records. Biomed. J. 2017, 40, 263–269. [Google Scholar] [CrossRef] [PubMed]
- Ward, M.E.; Musa, M.N.; Bailey, L. Clinical pharmacokinetics of lithium. J. Clin. Pharmacol. 1994, 34, 280–285. [Google Scholar] [CrossRef] [PubMed]
- Peralta, C.A.; Shlipak, M.G.; Judd, S.; Cushman, M.; McClellan, W.; Zakai, N.A.; Safford, M.M.; Zhang, X.; Muntner, P.; Warnock, D. Detection of chronic kidney disease with creatinine, cystatin C, and urine albumin-to-creatinine ratio and association with progression to end-stage renal disease and mortality. JAMA 2011, 305, 1545–1552. [Google Scholar] [CrossRef] [Green Version]
- Nichols, T.A.; Drayton, S.J.; Borckardt, J.; Taber, D.J. Lithium dosing equations: Are they accurate? Ann. Pharmacother. 2014, 48, 596–600. [Google Scholar] [CrossRef]
- Yoshida, K.; Uchida, H.; Suzuki, T.; Watanabe, M.; Yoshino, N.; Houchi, H.; Mimura, M.; Fukuoka, N. Prediction Model of Serum Lithium Concentrations. Pharmacopsychiatry 2018, 51, 82–88. [Google Scholar] [CrossRef] [PubMed]
- Cooper, T.B.; Bergner, P.E.; Simpson, G.M. The 24-h serum lithium level as a prognosticator of dosage requirements. Am. J. Psychiatry 1973, 130, 601–603. [Google Scholar] [CrossRef]
- Nolen, W.A.; Licht, R.W.; Young, A.H.; Malhi, G.S.; Tohen, M.; Vieta, E.; Kupka, R.W.; Zarate, C.; Nielsen, R.E.; Baldessarini, R.J.; et al. What is the optimal serum level for lithium in the maintenance treatment of bipolar disorder? A systematic review and recommendations from the ISBD/IGSLI Task Force on treatment with lithium. Bipolar Disord. 2019, 21, 394–409. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Finley, P.R. Drug Interactions with Lithium: An Update. Clin. Pharmacokinet. 2016, 55, 925–941. [Google Scholar] [CrossRef]
- Hsu, C.W.; Lee, S.Y.; Yang, Y.H.; Wang, L.J. Brand-Name Antidepressants Outperform Their Generic Counterparts in Preventing Hospitalization for Depression: The Real-World Evidence from Taiwan. Int. J. Neuropsychopharmacol. 2020, 23, 653–661. [Google Scholar] [CrossRef]
- Jonsson, P.; Wohlin, C. An evaluation of k-nearest neighbour imputation using Likert data. In Proceedings of the 10th International Symposium on Software Metrics, Washington, DC, USA, 11–17 September 2004; pp. 108–118. [Google Scholar]
- Rassen, J.A.; Shelat, A.A.; Myers, J.; Glynn, R.J.; Rothman, K.J.; Schneeweiss, S. One-to-many propensity score matching in cohort studies. Pharmacoepidemiol. Drug Saf. 2012, 21 (Suppl. 2), 69–80. [Google Scholar] [CrossRef]
- Baştanlar, Y.; Ozuysal, M. Introduction to machine learning. Methods Mol. Biol. 2014, 1107, 105–128. [Google Scholar] [CrossRef] [Green Version]
- Tomasik, J.; Han, S.Y.S.; Barton-Owen, G.; Mirea, D.-M.; Martin-Key, N.A.; Rustogi, N.; Lago, S.G.; Olmert, T.; Cooper, J.D.; Ozcan, S.; et al. A machine learning algorithm to differentiate bipolar disorder from major depressive disorder using an online mental health questionnaire and blood biomarker data. Transl. Psychiatry 2021, 11, 41. [Google Scholar] [CrossRef] [PubMed]
- Nunes, A.; Ardau, R.; Berghöfer, A.; Bocchetta, A.; Chillotti, C.; Deiana, V.; Garnham, J.; Grof, E.; Hajek, T.; Manchia, M.; et al. Prediction of lithium response using clinical data. Acta Psychiatr. Scand. 2020, 141, 131–141. [Google Scholar] [CrossRef]
- Li, M.; Das, T.; Deng, W.; Wang, Q.; Li, Y.; Zhao, L.; Ma, X.; Wang, Y.; Yu, H.; Li, X.; et al. Clinical utility of a short resting-state MRI scan in differentiating bipolar from unipolar depression. Acta Psychiatr. Scand. 2017, 136, 288–299. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Tin Kam, H. The random subspace method for constructing decision forests. IEEE 1998, 20, 832–844. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, S.; Golbraikh, A.; Oloff, S.; Kohn, H.; Tropsha, A. A novel automated lazy learning QSAR (ALL-QSAR) approach: Method development, applications, and virtual screening of chemical databases using validated ALL-QSAR models. J. Chem. Inf. Model. 2006, 46, 1984–1995. [Google Scholar] [CrossRef] [Green Version]
- Varsou, D.D.; Melagraki, G.; Sarimveis, H.; Afantitis, A. MouseTox: An online toxicity assessment tool for small molecules through Enalos Cloud platform. Food Chem. Toxicol. 2017, 110, 83–93. [Google Scholar] [CrossRef] [PubMed]
- Tibshirani, R. Regression Shrinkage and Selection Via the Lasso. JSTOR 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Kosmicki, J.A.; Sochat, V.; Duda, M.; Wall, D.P. Searching for a minimal set of behaviors for autism detection through feature selection-based machine learning. Transl. Psychiatry 2015, 5, e514. [Google Scholar] [CrossRef] [Green Version]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Zetin, M.; Garber, D.; De Antonio, M.; Schlegel, A.; Feureisen, S.; Fieve, R.; Jewett, C.; Reus, V.; Huey, L.Y. Prediction of lithium dose: A mathematical alternative to the test-dose method. J. Clin. Psychiatry 1986, 47, 175–178. [Google Scholar] [PubMed]
- Stip, E.; Dufresne, J.; Boulerice, B.; Elie, R. Accuracy of the Pepin method to determine appropriate lithium dosages in healthy volunteers. J. Psychiatry Neurosci. 2001, 26, 330–335. [Google Scholar] [PubMed]
- Higuchi, S.; Fukuoka, R.; Aoyama, T.; Horioka, M. Predicting serum lithium concentration using Bayesian method: A comparison with other methods. J. Pharmacobiodyn. 1988, 11, 158–174. [Google Scholar] [CrossRef] [PubMed]
- Malhi, G.S.; Gessler, D.; Outhred, T. The use of lithium for the treatment of bipolar disorder: Recommendations from clinical practice guidelines. J. Affect. Disord 2017, 217, 266–280. [Google Scholar] [CrossRef] [PubMed]
- Malhi, G.S.; Tanious, M.; Das, P.; Berk, M. The science and practice of lithium therapy. Aust. N. Z. J. Psychiatry 2012, 46, 192–211. [Google Scholar] [CrossRef] [PubMed]
- Eagles, J.M.; McCann, I.; MacLeod, T.N.; Paterson, N. Lithium monitoring before and after the distribution of clinical practice guidelines. Acta Psychiatr. Scand. 2000, 101, 349–353. [Google Scholar] [CrossRef] [PubMed]
- Chan, B.S.; Cheng, S.; Isoardi, K.Z.; Chiew, A.; Siu, W.; Shulruf, B.; Vecellio, E.; Buckley, N.A. Effect of age on the severity of chronic lithium poisoning. Clin. Toxicol. 2020, 58, 1023–1027. [Google Scholar] [CrossRef]
- Bocchetta, A.; Ardau, R.; Fanni, T.; Sardu, C.; Piras, D.; Pani, A.; Del Zompo, M. Renal function during long-term lithium treatment: A cross-sectional and longitudinal study. BMC Med. 2015, 13, 12. [Google Scholar] [CrossRef] [Green Version]
- Potkin, S.G.; Thyrum, P.T.; Bera, R.; Carreon, D.; Alva, G.; Kalali, A.H.; Yeh, C. Open-label study of the effect of combination quetiapine/lithium therapy on lithium pharmacokinetics and tolerability. Clin. Ther. 2002, 24, 1809–1823. [Google Scholar] [CrossRef]
- Granneman, G.R.; Schneck, D.W.; Cavanaugh, J.H.; Witt, G.F. Pharmacokinetic interactions and side effects resulting from concomitant administration of lithium and divalproex sodium. J. Clin. Psychiatry 1996, 57, 204–206. [Google Scholar]
- Amerio, A.; Russo, D.; Miletto, N.; Aguglia, A.; Costanza, A.; Benatti, B.; Odone, A.; Barroilhet, S.A.; Brakoulias, V.; Dell’Osso, B.; et al. Polypharmacy as maintenance treatment in bipolar illness: A systematic review. Acta Psychiatr. Scand. 2021, 144, 259–276. [Google Scholar] [CrossRef]
- Altamura, A.C.; Mundo, E.; Dell’Osso, B.; Tacchini, G.; Buoli, M.; Calabrese, J.R. Quetiapine and classical mood stabilizers in the long-term treatment of Bipolar Disorder: A 4-year follow-up naturalistic study. J. Affect. Disord. 2008, 110, 135–141. [Google Scholar] [CrossRef] [PubMed]
- Colvard, M.D.; Gentry, J.D.; Mullis, D.M. Neurotoxicity with combined use of lithium and haloperidol decanoate. Prim. Care Companion CNS Disord. 2013, 15, PCC13l01563. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hsu, C.-W.; Lee, Y.; Lee, C.-Y.; Lin, P.-Y. Neurotoxicity and nephrotoxicity caused by combined use of lithium and risperidone: A case report and literature review. BMC Pharmacol. Toxicol. 2016, 17, 59. [Google Scholar] [CrossRef] [Green Version]
- Netto, I.; Phutane, V.H.; Ravindran, B. Lithium Neurotoxicity Due to Second-Generation Antipsychotics Combined With Lithium: A Systematic Review. Prim. Care Companion CNS Disord. 2019, 21, 17r02225. [Google Scholar] [CrossRef] [PubMed]
- McCoy, S.N.; Thavundayil, J.X.; Schwartz, G.; Etienne, P. Lithium ratio and hypertension in manic-depressive patients. Am. J. Psychiatry 1982, 139, 247–248. [Google Scholar] [CrossRef] [PubMed]
- Cirillo, M.; Laurenzi, M.; Panarelli, W.; Trevisan, M.; Dyer, A.R.; Stamler, R.; Stamler, J. Sodium-lithium countertransport and blood pressure change over time: The Gubbio study. Hypertension 1996, 27, 1305–1311. [Google Scholar] [CrossRef] [PubMed]
- Anton, R.F.; Paladino, J.A.; Morton, A.; Thomas, R.W. Effect of acute alcohol consumption on lithium kinetics. Clin. Pharmacol. Ther. 1985, 38, 52–55. [Google Scholar] [CrossRef] [PubMed]
- Vrontaki, E.; Melagraki, G.; Mavromoustakos, T.; Afantitis, A. Searching for anthranilic acid-based thumb pocket 2 HCV NS5B polymerase inhibitors through a combination of molecular docking, 3D-QSAR and virtual screening. J. Enzyme Inhib. Med. Chem. 2016, 31, 38–52. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Characteristics | Development (n = 1505) | Test (n = 204) | t or χ² | p |
|---|---|---|---|---|
| Lithium serum levels, mmol/L | 0.69 ± 0.21 | 0.70 ± 0.22 | −0.51 | 0.612 |
| Basic Information | ||||
| Age, year | 43.13 ± 13.70 | 42.95 ± 13.82 | 0.18 | 0.856 |
| Sex, female | 696 (46.25) | 87 (42.65) | 0.94 | 0.333 |
| Clinical Characteristics | ||||
| Height, m | 1.64 ± 0.08 | 1.64 ± 0.09 | −0.90 | 0.370 |
| Weight, kg | 69.64 ± 14.73 | 70.35 ± 14.54 | −0.65 | 0.517 |
| Systolic blood pressure, mmHg | 122.00 ± 10.86 | 122.30 ± 10.42 | −0.38 | 0.706 |
| Diastolic blood pressure, mmHg | 76.28 ± 7.48 | 76.21 ± 7.76 | 0.14 | 0.890 |
| Lithium Prescription | ||||
| Daily dose, mg/day | 867.70 ± 266.70 | 896.30 ± 257.20 | −1.44 | 0.148 |
| Dosing frequency, time/day | 2.57 ± 0.78 | 2.60 ± 0.73 | −0.57 | 0.568 |
| Last dose, mg | 354.60 ± 125.20 | 362.50 ± 131.30 | −0.84 | 0.401 |
| Time interval, hour | 13.08 ± 1.44 | 13.11 ± 1.32 | −0.26 | 0.796 |
| Concomitant Psychotropic Drugs | ||||
| Mood Stabilizers | ||||
| Carbamazepine | 73 (4.85) | 11 (5.39) | 0.11 | 0.737 |
| Lamotrigine | 64 (4.25) | 7 (3.43) | 0.30 | 0.581 |
| Topiramate | 110 (7.31) | 15 (7.35) | 0.001 | 0.982 |
| Valproic acid | 524 (34.82) | 67 (32.84) | 0.31 | 0.578 |
| Antidepressants | ||||
| SSRI | 175 (11.63) | 24 (11.76) | 0.003 | 0.954 |
| SNRI | 88 (5.85) | 10 (4.90) | 0.30 | 0.586 |
| Trazodone | 38 (2.52) | 4 (1.96) | 0.24 | 0.625 |
| Mirtazapine | 45 (2.99) | 7 (3.43) | 0.12 | 0.731 |
| Bupropion | 62 (4.12) | 8 (3.92) | 0.02 | 0.894 |
| Agomelatine | 48 (3.19) | 7 (3.43) | 0.03 | 0.854 |
| Antipsychotics | ||||
| Typical antipsychotics | 177 (11.76) | 23 (11.27) | 0.04 | 0.839 |
| The benzamides | 49 (3.26) | 7 (3.43) | 0.02 | 0.895 |
| The -dones | 295 (19.60) | 49 (24.02) | 2.18 | 0.140 |
| The -pines | 1033 (68.64) | 129 (63.24) | 2.41 | 0.121 |
| Aripiprazole | 157 (10.43) | 23 (11.27) | 0.14 | 0.713 |
| Anxiolytics, Sedatives, or Hypnotics | ||||
| Benzodiazepines | 1252 (83.19) | 169 (82.84) | 0.02 | 0.901 |
| Non-benzodiazepines | 208 (13.82) | 32 (15.69) | 0.52 | 0.472 |
| Acetylcholinesterase inhibitors | 12 (0.80) | 1 (0.49) | 0.22 | 0.636 |
| Mental Disorders | ||||
| Bipolar disorders | 1108 (73.62) | 150 (73.53) | 0.001 | 0.978 |
| Laboratory Data | ||||
| Serum creatinine, mg/dL | 0.79 ± 0.16 | 0.80 ± 0.16 | 0.12 | 0.469 |
| BUN, mg/dL | 9.99 ± 2.64 | 9.97 ± 2.58 | −0.72 | 0.902 |
| Binary | LogR | SVM | RF | XGBoost |
|---|---|---|---|---|
| Sensitivity | 0.89 (0.84–0.93) | 0.94 (0.91–0.97) | 0.96 (0.95–0.97) | 0.90 (0.87–0.94) |
| Specificity | 0.43 (0.36–0.51) | 0.32 (0.24–0.41) | 0.22 (0.13–0.31) | 0.38 (0.34–0.41) |
| AUC-ROC | 0.75 (0.73–0.76) | 0.76 (0.74–0.77) | 0.78 (0.75–0.81) | 0.78 (0.74–0.81) |
| Accuracy | 0.73 (0.71–0.75) | 0.73 (0.71–0.75) | 0.70 (0.68–0.73) | 0.72 (0.70–0.74) |
| Continuous | LinR | SVM | RF | XGBoost |
| MAE | 0.16 (0.16–0.16) | 0.14 (0.13–0.15) | 0.15 (0.15–0.16) | 0.15 (0.15–0.16) |
| MSE | 0.04 (0.04–0.04) | 0.03 (0.03–0.03) | 0.04 (0.03–0.04) | 0.04 (0.04–0.04) |
| RMSE | 0.20 (0.19–0.20) | 0.17 (0.17–0.18) | 0.19 (0.18–0.19) | 0.19 (0.19–0.20) |
| Accuracy | 0.69 (0.68–0.70) | 0.75 (0.71–0.79) | 0.68 (0.67–0.70) | 0.68 (0.67–0.70) |
| Binary | Ensemble | LogR | SVM | RF | XGBoost |
|---|---|---|---|---|---|
| Top 1 | Daily dose * | Daily dose | Daily dose | Daily dose | Daily dose |
| Top 2 | Age * | MCHC | Topiramate | MCHC | Age |
| Top 3 | Last dose * | Valproic acid | NSAIDs | Last dose | Valproic acid |
| Top 4 | The -pines * | Renal diseases | Hyperlipidemia | Dosing frequency | Height |
| Top 5 | Valproic acid * | Age | Elimination disorders | Age | Time interval |
| Top 6 | Weight | Weight | Age | The -pines | Benzodiazepines |
| Top 7 | SBP * | Substance use disorders | The -pines | Valproic acid | RBC |
| Top 8 | Hypertension | Hypertension | Time interval | Benzodiazepines | WBC |
| Top 9 | MCHC | The -pines | Sleep-wake disorders | Hemoglobin | MCHC |
| Top 10 | Substance use disorders * | Last dose | Last dose | Serum creatinine | RDW-SD |
| Continuous | Ensemble | LinR | SVM | RF | XGBoost |
| Top 1 | Daily dose * | Daily dose | Daily dose | Daily dose | Daily dose |
| Top 2 | Age * | Valproic acid | Age | Age | Age |
| Top 3 | Valproic acid * | Age | Beta blockers | Valproic acid | Valproic acid |
| Top 4 | The -pines * | Weight | Hyperlipidemia | Weight | The -pines |
| Top 5 | Substance use disorders * | Topiramate | Depressive disorders | RBC | SBP |
| Top 6 | SBP * | ARB | SBP | Height | Weight |
| Top 7 | Beta blockers | MCHC | Valproic acid | RDW-SD | Height |
| Top 8 | Last dose * | Hypertension | Mild DM | SBP | Time interval |
| Top 9 | Potassium | Ocular bleeding | Sex | Last dose | Topiramate |
| Top 10 | NSAIDs | Substance use disorders | Sleep-wake disorders | Topiramate | Benzodiazepines |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hsu, C.-W.; Tsai, S.-Y.; Wang, L.-J.; Liang, C.-S.; Carvalho, A.F.; Solmi, M.; Vieta, E.; Lin, P.-Y.; Hu, C.-A.; Kao, H.-Y. Predicting Serum Levels of Lithium-Treated Patients: A Supervised Machine Learning Approach. Biomedicines 2021, 9, 1558. https://doi.org/10.3390/biomedicines9111558
Hsu C-W, Tsai S-Y, Wang L-J, Liang C-S, Carvalho AF, Solmi M, Vieta E, Lin P-Y, Hu C-A, Kao H-Y. Predicting Serum Levels of Lithium-Treated Patients: A Supervised Machine Learning Approach. Biomedicines. 2021; 9(11):1558. https://doi.org/10.3390/biomedicines9111558
Chicago/Turabian StyleHsu, Chih-Wei, Shang-Ying Tsai, Liang-Jen Wang, Chih-Sung Liang, Andre F. Carvalho, Marco Solmi, Eduard Vieta, Pao-Yen Lin, Chien-An Hu, and Hung-Yu Kao. 2021. "Predicting Serum Levels of Lithium-Treated Patients: A Supervised Machine Learning Approach" Biomedicines 9, no. 11: 1558. https://doi.org/10.3390/biomedicines9111558