Decentralized controllers have already proven to be an effective alternative for governing complex power systems [
22,
23]. They are based on the premise that numerous controllers can work independently, based on local measurements. Among all decentralization methods, Reinforcement Learning (RL)-based algorithms show promising results, including their dynamic response to new events, self-adaptation, and optimization, which eliminate the need for the time-consuming process of pre-tuning the key parameters. By interacting with the environment, an RL agent is modeled to make sequential decisions [
24,
25]. Typically, an infinite-horizon discounted Markov Decision Process (MDP) is used to model the environment. MDP has been widely used as a standard model to describe an agent’s decision-making process with complete system state observability [
26]. A branch of RL is called Multi-Agent Reinforcement Learning (MARL). The majority of effective applications include the interaction of several agents or players, which should be systematically represented as MARL issues [
27]. The sequential decision-making issue of numerous autonomous agents, operating in a shared environment, is specifically addressed by MARL [
28]. Each agent seeks to maximize its own long-term return by interacting with the environment and other agents. Also, it focuses on examining how different learning agents interact with one another in a common setting. Each agent acts to enlarge its own interests and is driven by its own rewards. In some contexts, these goals conflict with those of other agents, which leads to complicated group dynamics. Multi-agent systems, particularly repeated games and game theory, are all strongly connected to MARL.
2.1. Intelligent Switching System
While describing the MLI system as a MARL problem, the proposed approach, called Intelligent Switching System (ISS), attempts to find an appropriate solution to decrease high communication efforts in the MLI system, while also meeting the two most important system goals, namely, State of Charge (SoC) balancing and correct modulation of the desired output signal. The first and most important stage in defining a MARL problem is to identify the relevant participants and the environment in which they are able to interact.
There are two different categories of players in this particular MARL problem. The controller for the master module, simply called “master”, and the controller for each slave, simply called “cell”. The master interacts in “games” with several groups (packs), each made up of twelve cells.
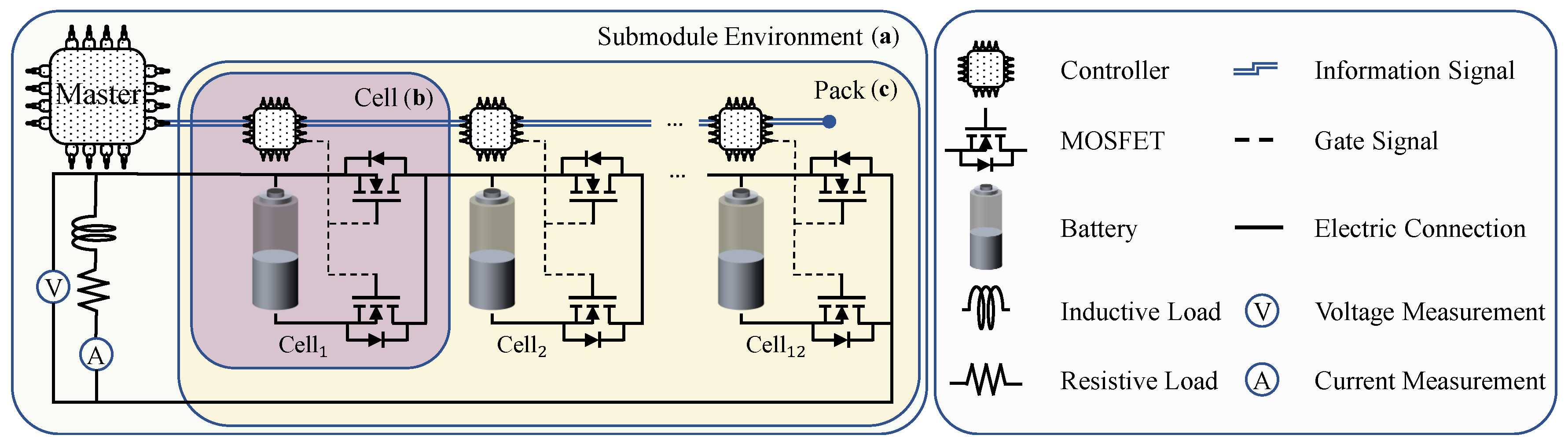
Figure 2 illustrates the submodule environment with the cell structure.
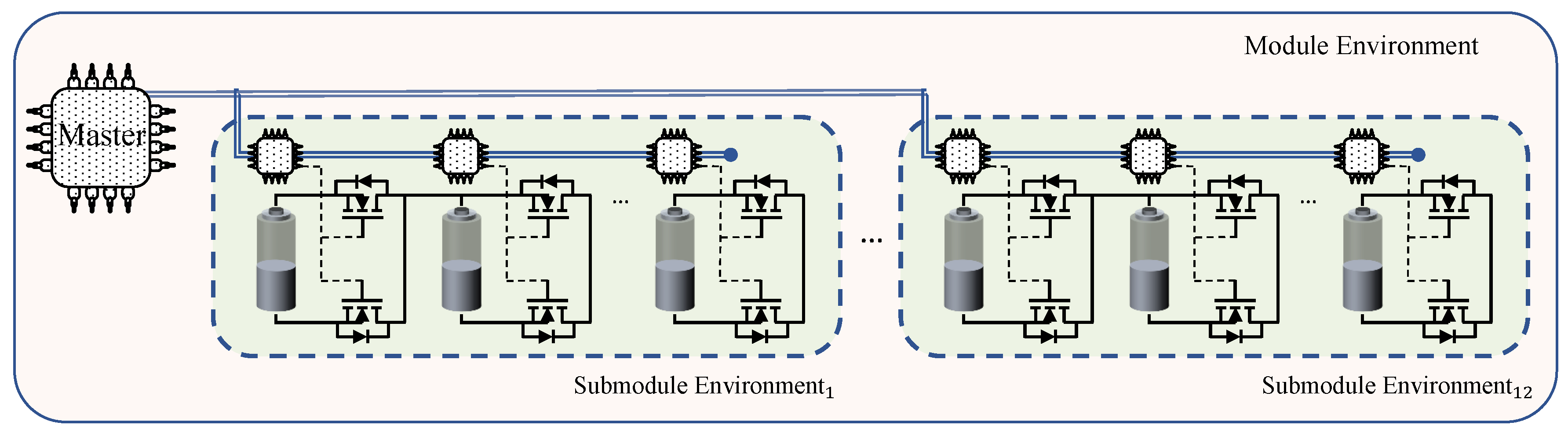
As a result, two environments can be defined. First, the interaction environment between the cells, known as submodules. In the submodule environment, participating cells actively strive to achieve a balanced SoC within the designated submodule. They rely on passive information received from the master to make decisions and take appropriate actions. Second, the environment between the submodules and the master is referred to as the module. The master actively works in the module environment to balance the SoC between packs. This is accomplished by continuously allocating the required charge among the participating packs based on their previous states and providing essential and relevant information to each submodule environment.
Figure 3 illustrates the module environment structure.
The initial step in developing the ISS involves identifying the individual goals of every player (following the establishment of the participants and the interaction environment). The master is responsible for ensuring that the desired output signal has the necessary modulation. Cells, on the other hand, are focused on achieving the specified switching strategy, which may include objectives such as SoC, temperature, or State of Health (SoH) balancing.
The next stage is to establish the communication protocols that govern the interactions among the various components. These details determine the methods by which data are shared between the players, the master, and the individual cells or packs.
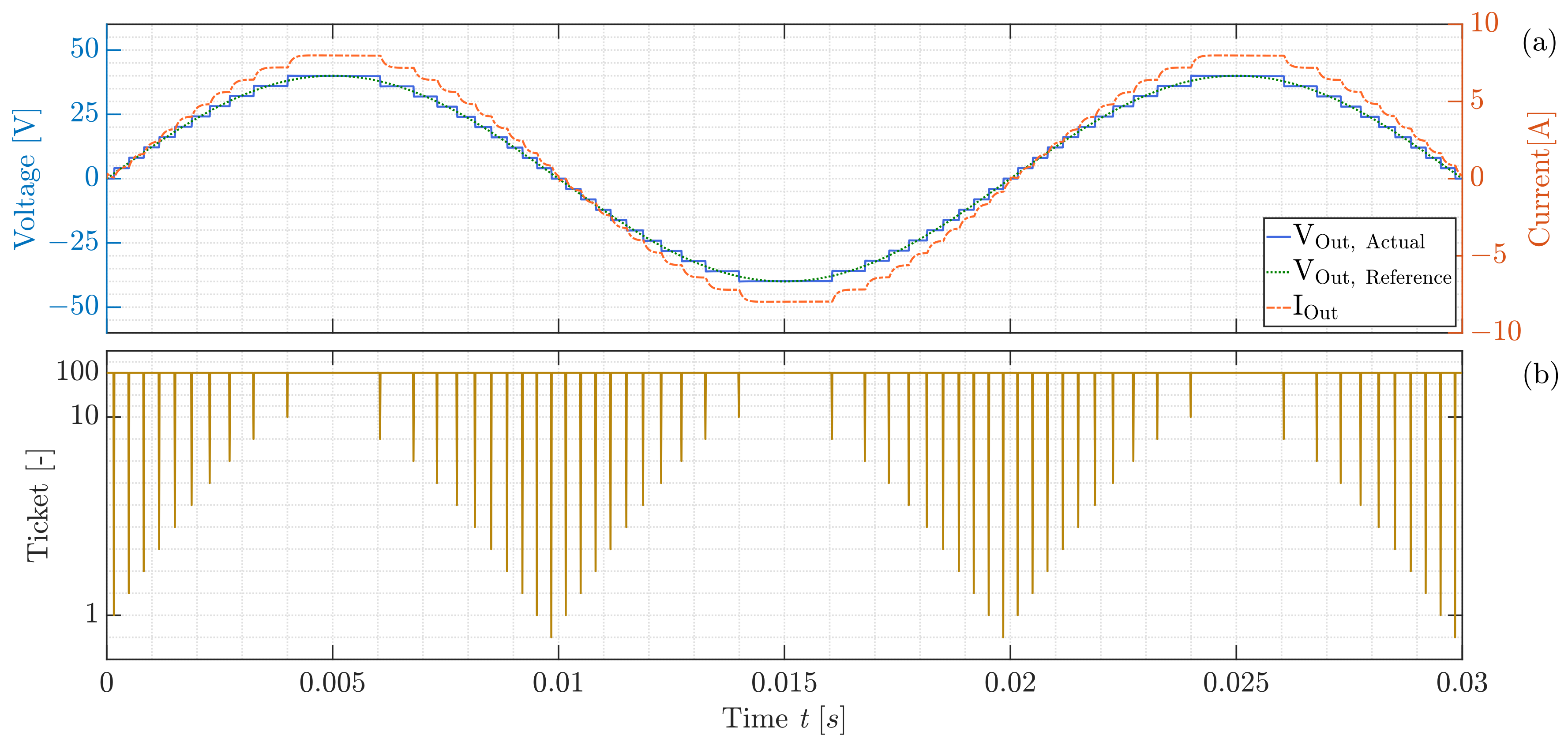
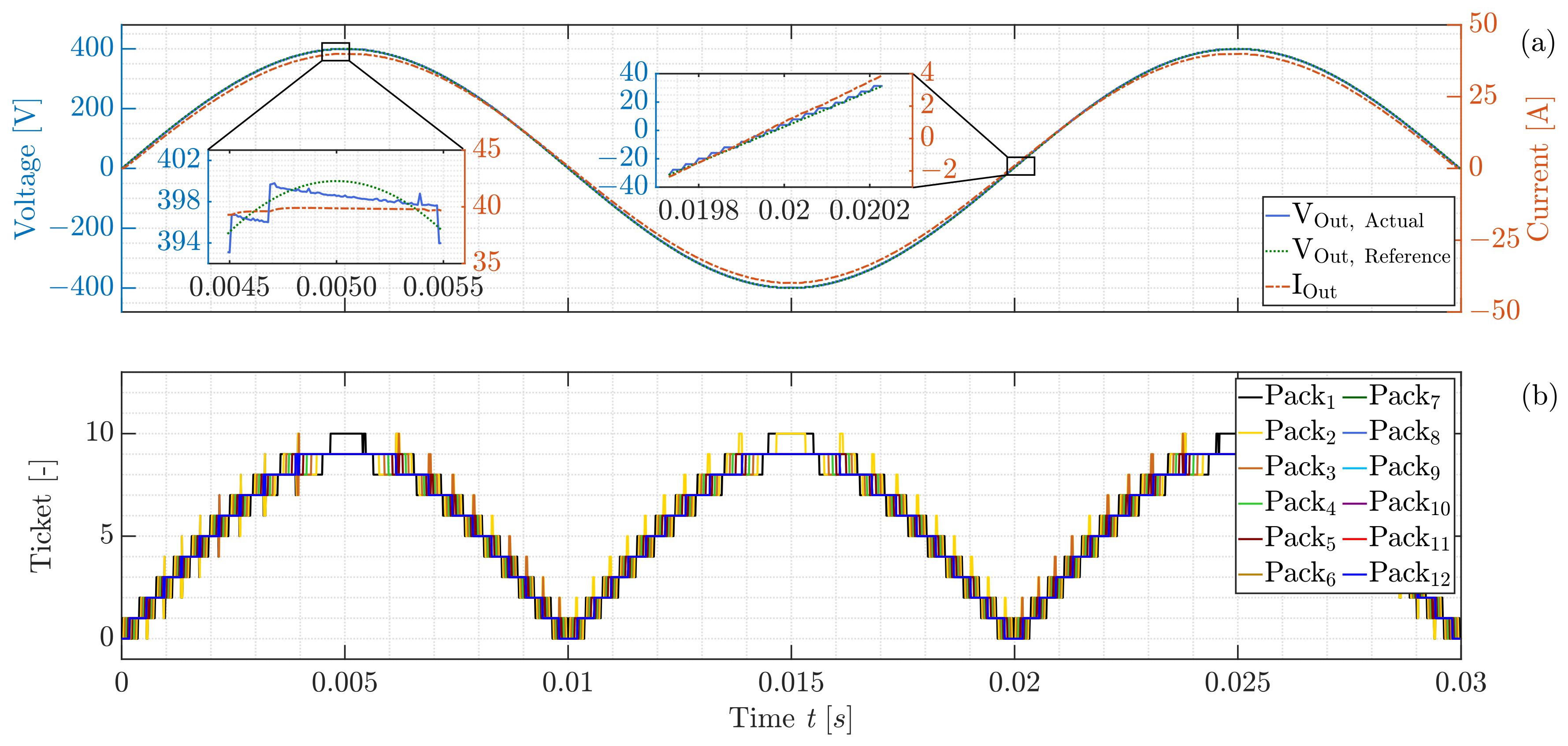
During the controlling of a conventional MLI system, the master has access to the output voltage and current in each cell and has to supply exact information to each one in order to achieve the desired switching behavior at a specific time. This requires the master to process and communicate a large amount of information in real time, which can place a significant strain on the communication bus and slow down the system’s response time. To overcome this limitation, the proposed MARL system utilizes a different approach. In this system, the master has access to the output voltage and current of each pack, rather than the information of a single cell. In other words, the master can process and broadcast information at a higher level, which is more efficient and less burdensome for the communication bus. Specifically, the master broadcasts two pieces of processed information to each cell in the pack, which are called “Reference” and “Ticket”. These terms are explained in more detail later in the system’s design.
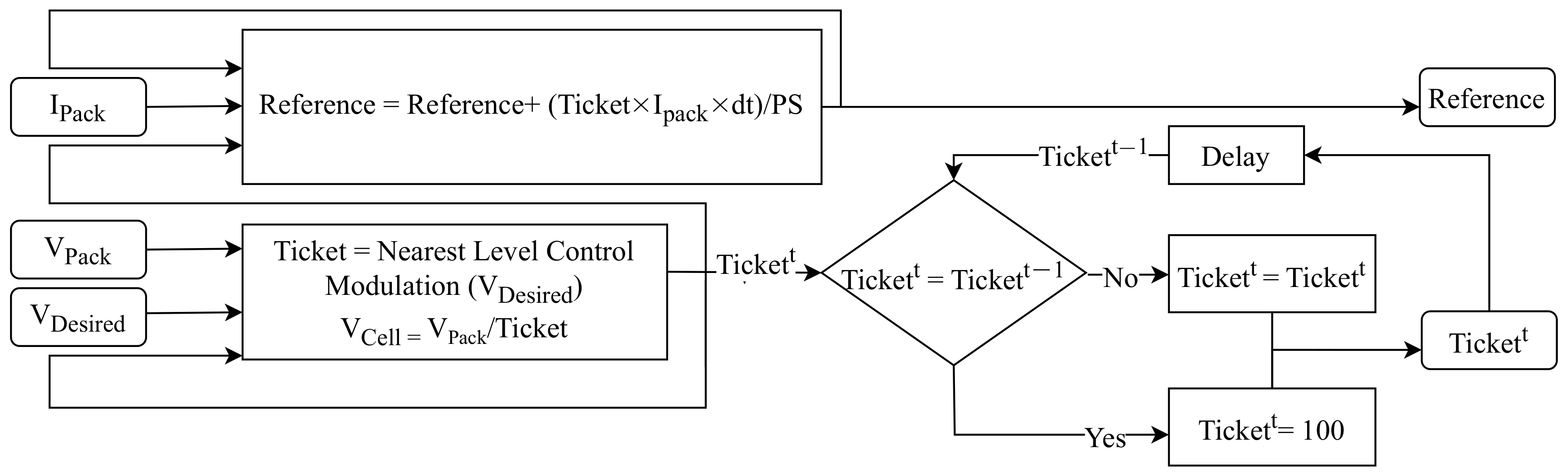
As mentioned before, the design of the MARL system allows only two distinct non-bidirectional signals to be used for communication between the master and the cells. The master has two main functions in the designed MARL system. Firstly, it attempts to generate the required number of in-series switched cells in each pack to achieve the desired output voltage using the nearest level modulation approach. This approach involves adjusting the sum of the output voltage of the participant’s cells to the nearest possible voltage level, in order to minimize the voltage error and ensure accurate voltage modulation [
32,
33]. Secondly, the master computes the permissible Average Depletion Charge (ADC) per pack regarding the Pack Size (PS), which the cells utilize as one of their decision-making reference values. The ADC is shown in Equation (
1). The cells continually examine the reference signal in order to have a better understanding of the interacting environment.
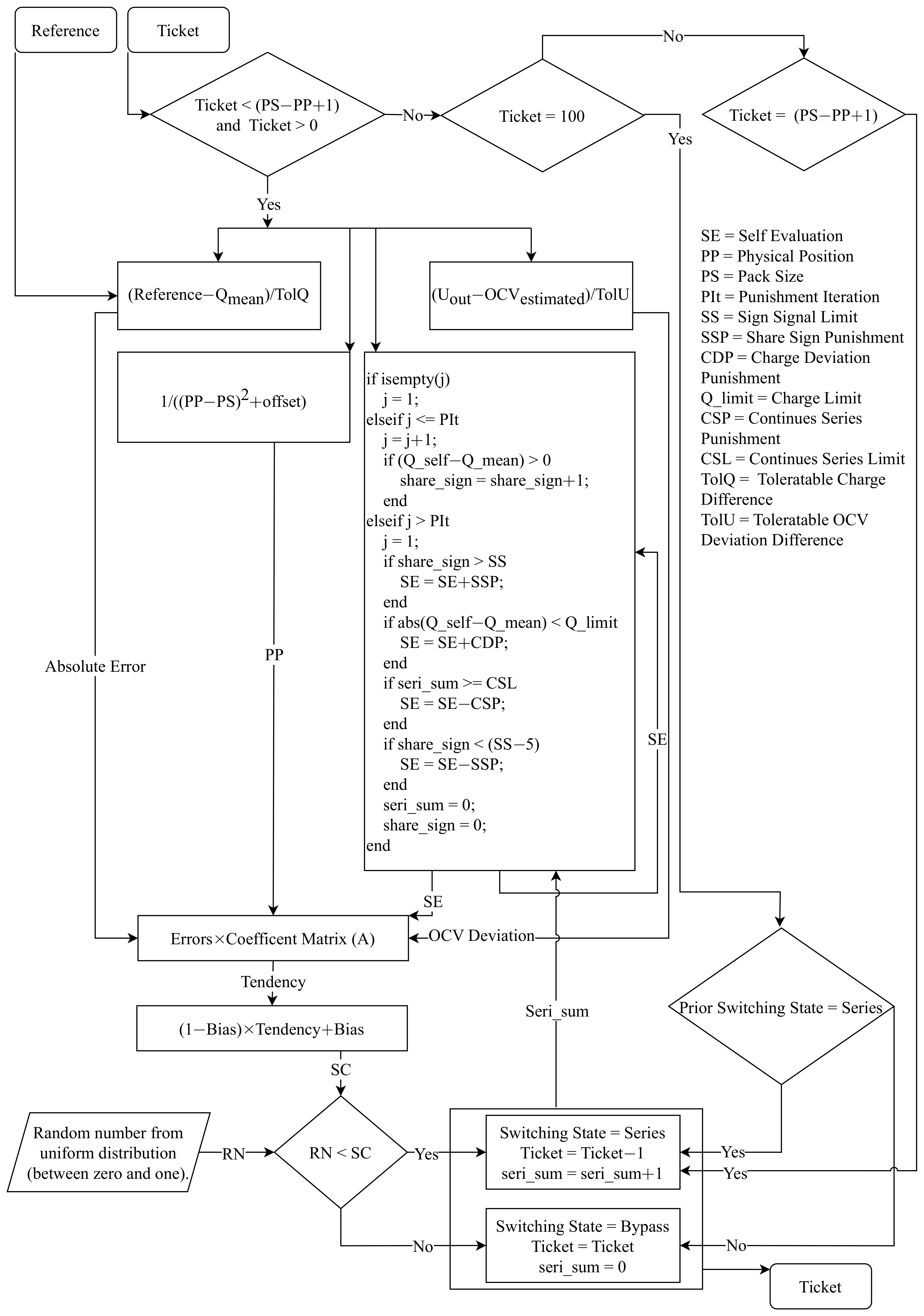
The decision-making process of the participants is the most important and complex part of the MARL system. The master generates the ticket signal to flag its decision. The ticket signal is broadcast to all cells in the system, and each cell must make a vital decision on its switching state based on this signal. This decision is based on the individual measurements of the cells as well as the received reference and ticket values, allowing each cell to synchronize its switching status with the master’s decision. Using these values, each cell attempts to make an informed judgment regarding its switching state, ensuring that the output voltage is modulated correctly, while it aims to keep its own calculated ADC aligned with the permitted ADC per cell (reference signal).
As a rational player in the game, each cell seeks to maximize the likelihood to reach its objective. The objective of each cell can be formulated as a Mixed Integer Linear Optimization (MILO). The goal of MILO is to identify the optimal decision variable values that minimize or maximize the objective function while satisfying a set of linear constraints. The decision variables can be a combination of continuous and discrete variables, where the discrete variables are typically limited to integer values [
34,
35]. Each cell in the system considers the calculated ADC values as a continuous variable. Furthermore, the cells can operate in one of two modes: series or bypass, which is represented as a binary variable. In addition, the objective function was selected as a Cartesian product to enable a full examination of the optimization issue. Additionally, it allows the objective function to represent the complex relationships and interdependence among the variables involved.
The optimization approach is designed to consider several constraints. First, it provides the maximum absolute difference permitted between the estimated ADC and the allowable ADC (referred to as TolQ). It also takes into account the maximum absolute difference between the estimated Open Circuit Voltage (OCV) and the measured terminal voltage (TolU). The second constraint that is taken into account is the consecutive participation of instances in order to reach the output voltage, which is known as the Continuous Series Limit (CSL). Finally, the framework includes the number of successive occurrences in which the computed ADC is either higher or lower than the permissible ADC over a certain period of time. This is referred to as the Sign Signal Limit (SSL). The values of the defined boundary conditions are given in
Table 1.
However, since cells have limited knowledge of the strategies of other players, every decision is made without complete information, which introduces an element of uncertainty to each decision. Despite this uncertainty, each cell will try to determine the probability of success associated with various decisions and then choose the one that appears most likely to lead to a favorable outcome. Even though each decision is made without adequate and comprehensive knowledge, the cells evaluate their choices at the next time step and the decision-making process is rewarded/punished based on the outcome. This feedback loop can be used to refine the strategies of each player over time, as the cells learn from their successes and failures. Overall, there is no definitive right or wrong choice; the cells will continuously adjust their strategies based on their observations of the available evidence and the outcomes of their decisions as a feedback loop.
The decision-making process is divided into three stages. The first step is to create a cost function or to translate evidence into knowledge or tendency. To summarize this process, four types of evidence are employed. The first category involves the absolute error (
), which is the difference between the computed ADC of each cell (calculated separately) and the master-determined permitted ADC, which is the reference signal. The second category contains the actual physical position of a cell with respect to the adjacent cells (
). The difference between the actual output voltage and the OCV of each cell is included in the third group as the OCV error (
). The last group incorporates the self-evaluation error (
) or a corresponding reward/punishment, depending on the consequences of previous actions. The tendency is summarized in Equation (
2), derived from observed evidence and the effectiveness matrix A, which determines the desire of a specific cell towards serial switching. Matrix A is a collection of optimized constant values that define the effectiveness of each individual piece of evidence. The values of the effectiveness matrix A are given in
Table 2.
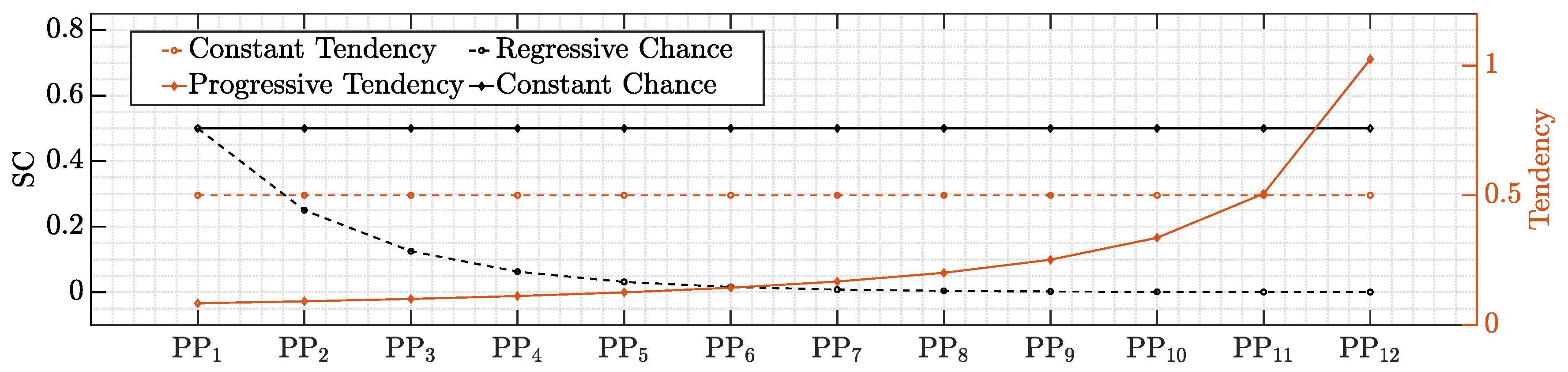
It should be emphasized that the goal of the cost function is not to give all players the same tendency, but rather to offer them an equal chance to reach the same conclusion. In other words, Switching Chance (SC) expresses the likelihood that the serial switching state is correct. Because each cell must make a choice in turn due to its physical positioning, the probability that two cells will make the same conclusion drops rapidly from prior to subsequent cells if the decisions are made based on equal tendency. This is shown in
Figure 4, where switching chance and tendency are plotted over the physical position.
In the second step of the decision-making process, the estimated tendency based on the cost function is applied to the option’s spectrum, which is presented with the probability of each decision. The goal of this step is to use probability theory to determine a boundary between two potential switching alternatives in the option’s spectrum.
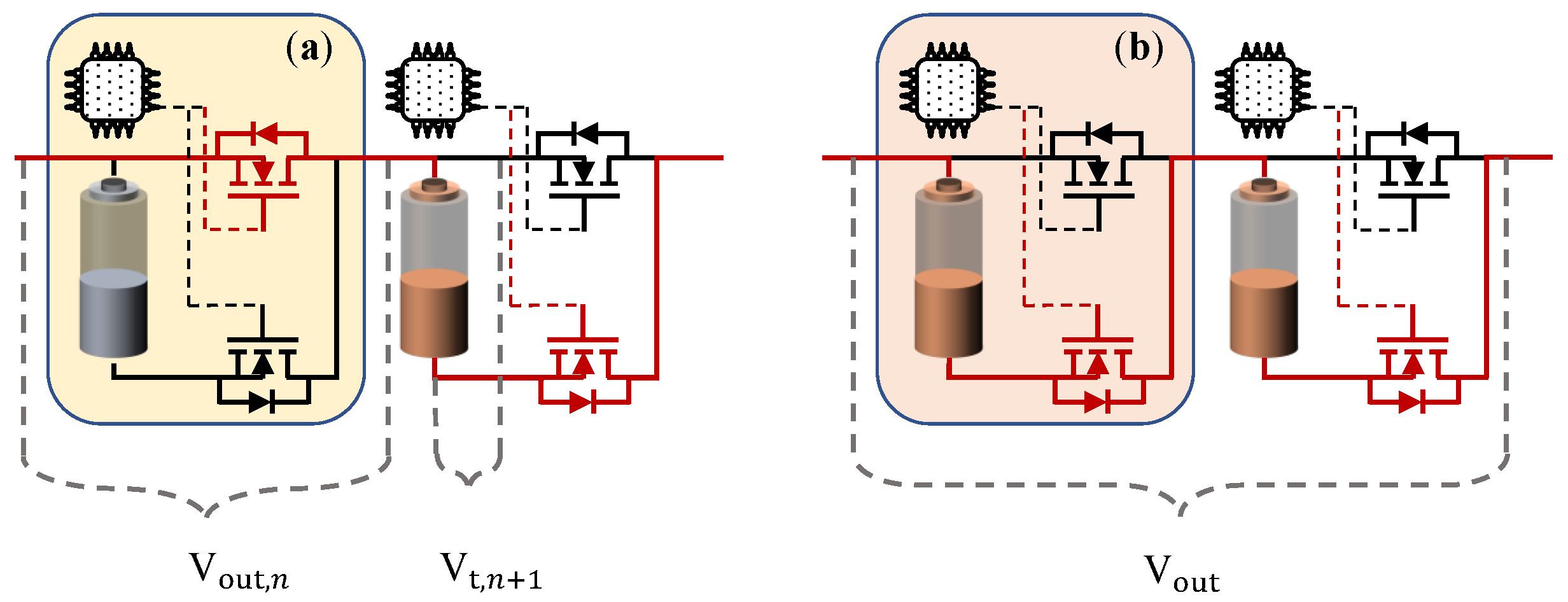
In the given system, each cell is equipped with a two-semiconductor switch topology, enabling them to switch between two distinct states: bypass and series, which are depicted in
Figure 5a,b, respectively. The “series” state implies that the cell is added to the output voltage of the entire pack (the cell is depicted in red), while the “bypass” state refers to the cell being excluded from the output voltage (the cell is depicted in gray). In other words, an individual cell can achieve two distinct output voltage levels according to Equation (
3), with
being the terminal voltage of the battery cell. Furthermore, the total output voltage (
) of a single-phase strand with
n cells can be described using Equation (
4), where
is the output voltage level of each individual cell [
14].
It is expected that the likelihood of the pack being in either one of these two states is equivalent to one, as these two states comprise the only possible options. A linear function (see Equation (
5)) was employed to scale the computed tendency from zero to one and transfer it to the SC. This ensures that the decision-making process remains intuitive. Furthermore, the bias value was incorporated into the decision-making process to add randomness and mutation. Regardless of a player’s physical position or previous behavior, they have the same initial minimum chance of making the same decision. This prevents the decision-making process from becoming overly predictable or repetitive, which could avoid converging at local minima. By incorporating instinct and mutation into the decision-making process, it becomes more adaptive and capable of dealing with a broader range of events and factors.
The final decision is made by generating a random number from a uniform distribution. As noted before, there is no single decision that is definitely right or wrong. On the contrary, choices are made based on their probability of being correct. By adapting to the environment through time, even options with a lower probability of success may still be a viable decision for the system. This approach can be seen as a modified response to a given event, as it results in a more nuanced and optimized approach to both the generalization and the cost function. By introducing randomness into the decision-making process, the system becomes better equipped to handle a range of possible outcomes and scenarios. This can lead to a better overall performance and a more robust decision-making process, as the system is not overly reliant on any single decision or strategy.
Once a decision has been made, the next step is to update the ticket signal accordingly. For example, if the decision is to change the cell’s status from bypass to serial, then the ticket signal should be decreased by one and passed on to the adjacent cell. This process of lowering the ticket signal refers to the action of occupying the necessary series switched option by the corresponding cell. It is important to note that the decision-making phase can only begin if the ticket signal is greater than zero but less than the actual location of the cell. If the ticket signal falls outside this range, then the decision is bypassed and the cell’s status remains unchanged or is converted to series, depending on the situation. If the ticket signal value exceeds the physical position of the relevant cell, it signifies a system problem or this value returns a special command to the cells, as the requested number of in-series switched cells exceeds the available number of cells. If the ticket signal is equal to zero, this can be interpreted as all remaining cells in the sequence needing to be switched to the bypass state. On the other hand, if the ticket signal is equal to the physical position of the cell, all cells must be switched to series, and no further processing is required.
The “ticket signal” has a dual purpose: it is not only used to communicate the precise number of switched cells in a battery pack, but it can also convey specific commands with specific values. For example, to minimize switching cases and losses, as well as to reduce computational effort, switching is intended to occur only once at each voltage level. As a result, the master always verifies whether the number of designated switching cases for a given submodule is the same as the previous command. If the required number of in-series switched cells is the same as the previous command, the master controller changes the ticket value to 100, indicating that each cell should maintain its prior switching state.
2.2. Self-Evaluation
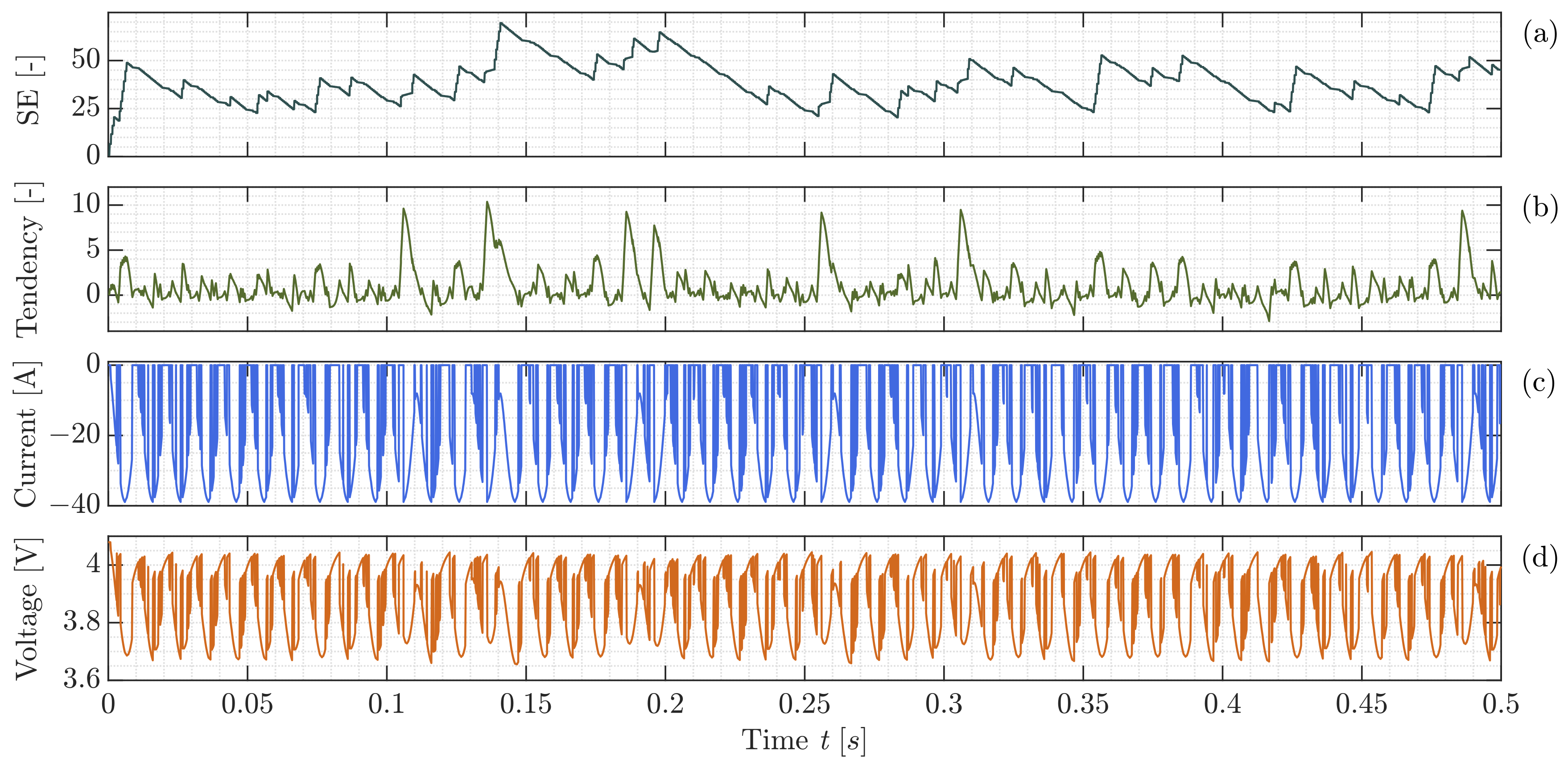
In the last step, each agent (cell) evaluates itself based on its interactions with the environment and the effect of its previous decisions is recorded. The assessment is then utilized to optimize the cost function by modifying the self-evaluation function ().
In essence, the agents’ behaviors and responses to their environment are constantly modified via a feedback loop that considers the knowledge gathered by each agent during past interactions. This feedback loop contributes to the overall optimization of the system performance by allowing agents to change their behavior based on current conditions and previous experiences. There are two types of post-action self-evaluation, which are a fixed and a floating reward/punishment. The fixed reward/punishment is designed to compensate for and avoid large errors that cause the tendency value to shift dramatically. Thus attempts to influence the agent’s persistent behavior by directly impacting the tendency to result in the opposite direction of the insistent action. The aim of this approach is to keep the agent’s performance within an acceptable range, even when the environment is changing and unpredictable.
The floating reward/punishment method achieves this by setting a target performance range and adjusting the reward/punishment signal depending on the agent’s current performance relative to that range. For instance, if the agent’s performance is within the acceptable range but has a diverging gradient from the goal range as compared to the previous time step, a floating reward/punishment is created to address this divergence gradually. However, as mentioned in
Section 2.1, the agent may continue to make the same decision despite changes in its tendency, displaying persistent behavior. When an agent performs persistent behavior or violates the allowed goal range, a fixed reward/punishment is created to shift the agent’s tendency towards the minimum or maximum, with the objective of changing its behavior in the opposite direction of the violation.
By adapting the reward/punishment signal in response to changes in the agent’s performance and the environment, the floating reward/punishment method can help to maintain high performance, even in dynamic and unpredictable situations. However, it is worth noting that this approach can be more complex to implement and may require more computational resources than fixed reward/punishment methods.
The last cell in each submodule faces unique challenges. While the cost function aims to ensure that all cells have equal decision-making opportunities, the last cell may not have the same options as the other cells. The last cell may need to compensate for the possible errors of the other cells, resulting in a switching state, regardless of its own preferences and self-evaluation. To reduce this effect, it is crucial to prioritize the performance of cells located earlier in the module. This can be accomplished by applying a higher punishment rate than rewards. The cell’s decision-making process is summarized in
Figure 6.
To avoid unforeseen events and maintain control over the output voltage, the master utilizes a feedback loop alongside the cells, which also helps to update its knowledge about the dynamic output voltage of the cells. Even though the master cannot access the output voltage of each individual cell, it plays an important role while controlling the output voltage. Through the feedback loop, the master agent estimates this information by dividing the output voltage of the entire pack by the number of cells participating (in this case, 12) and updates its estimation in each iteration. However, due to the constantly changing behavior of individual cells and the varying SoC and SoH conditions within a pack, it is impossible to estimate the output voltage of each cell with perfect accuracy. Nevertheless, the level of precision achieved is sufficient for effective modulation. The master’s decision-making process is summarized in the flowchart in
Figure 7.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}