
Study of Quantized Hardware Deep Neural Networks Based on Resistive Switching Devices, Conventional versus Convolutional Approaches

 , , , and
, , , and
Abstract
:1. Introduction
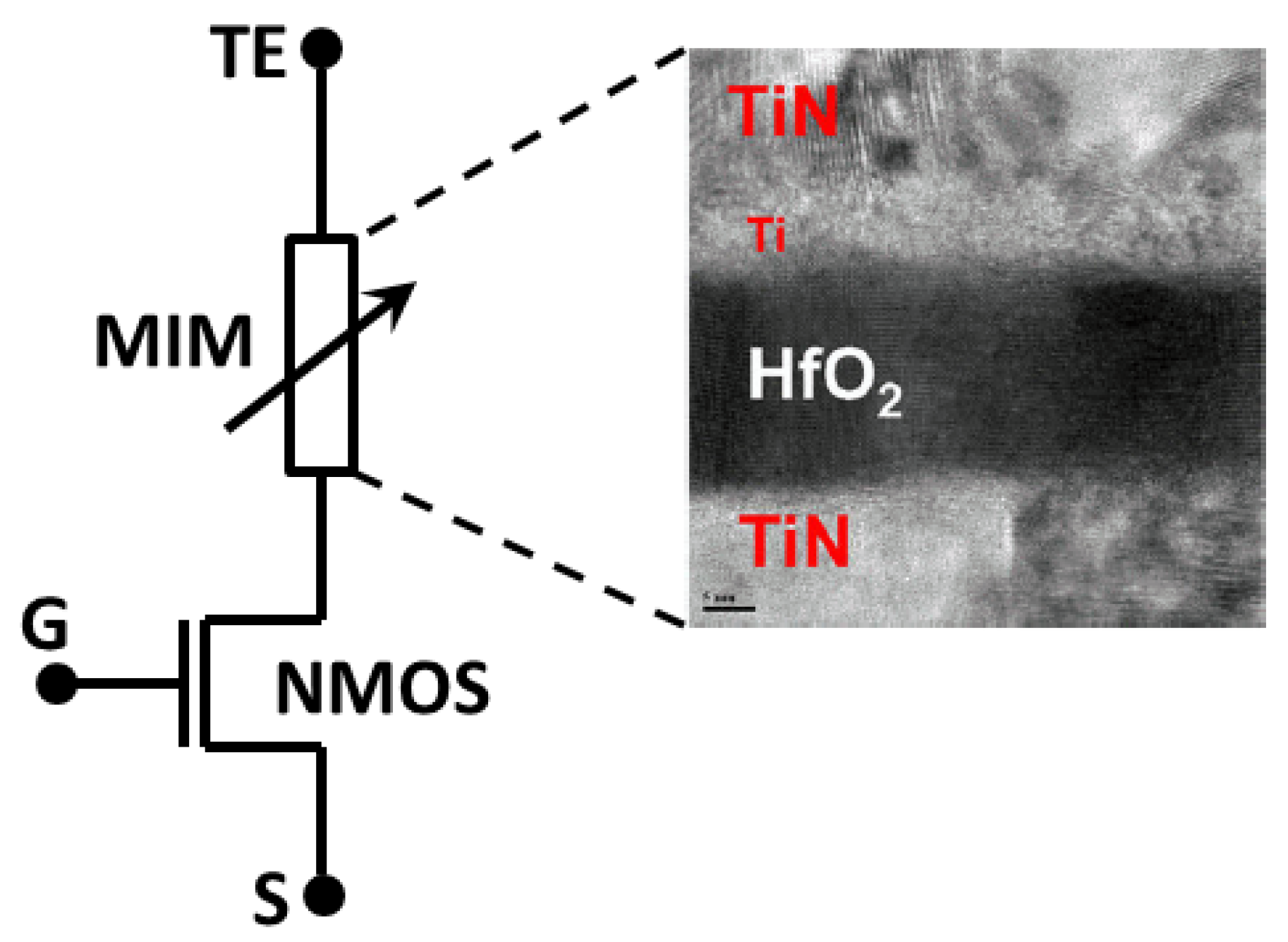
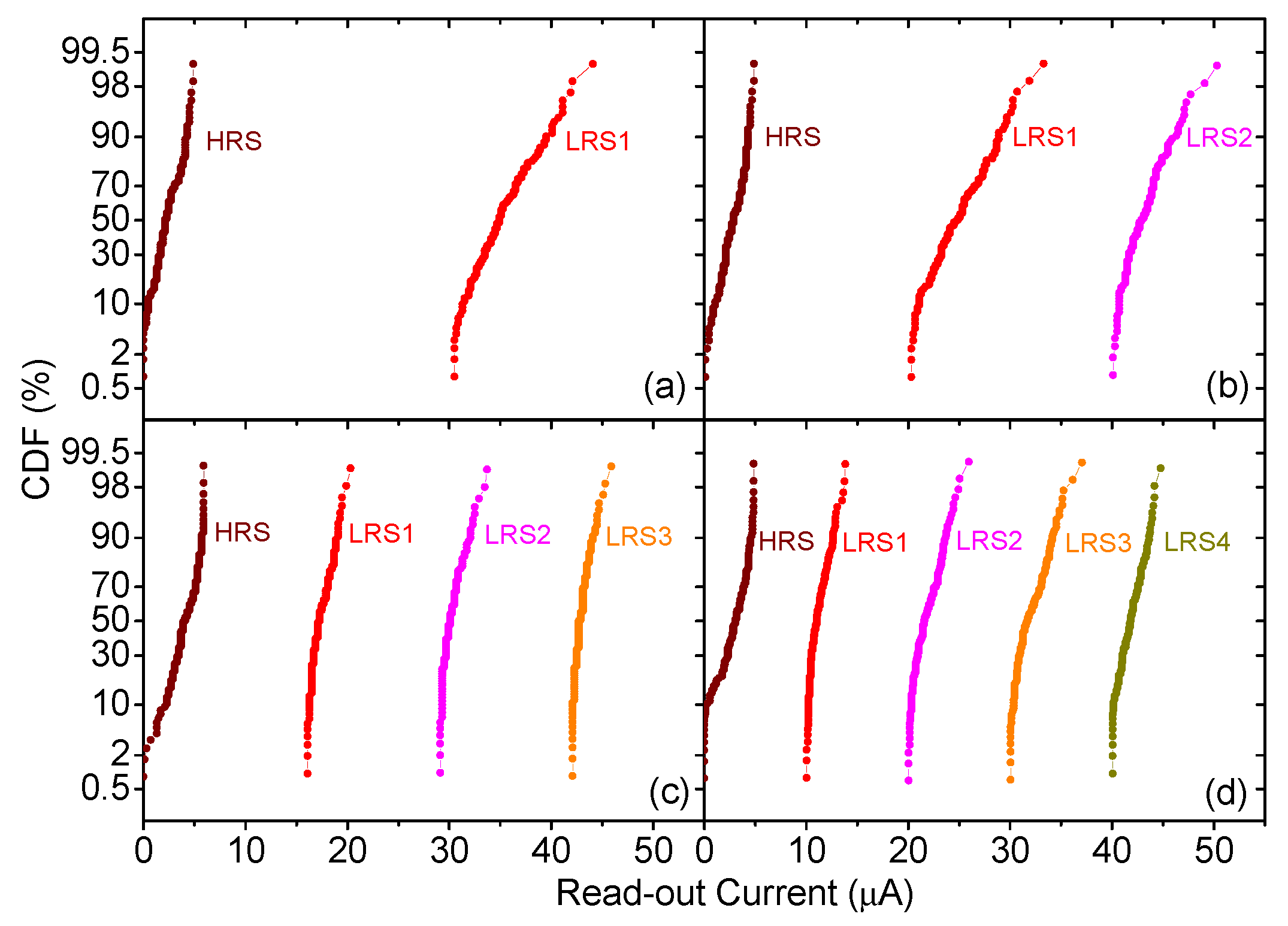
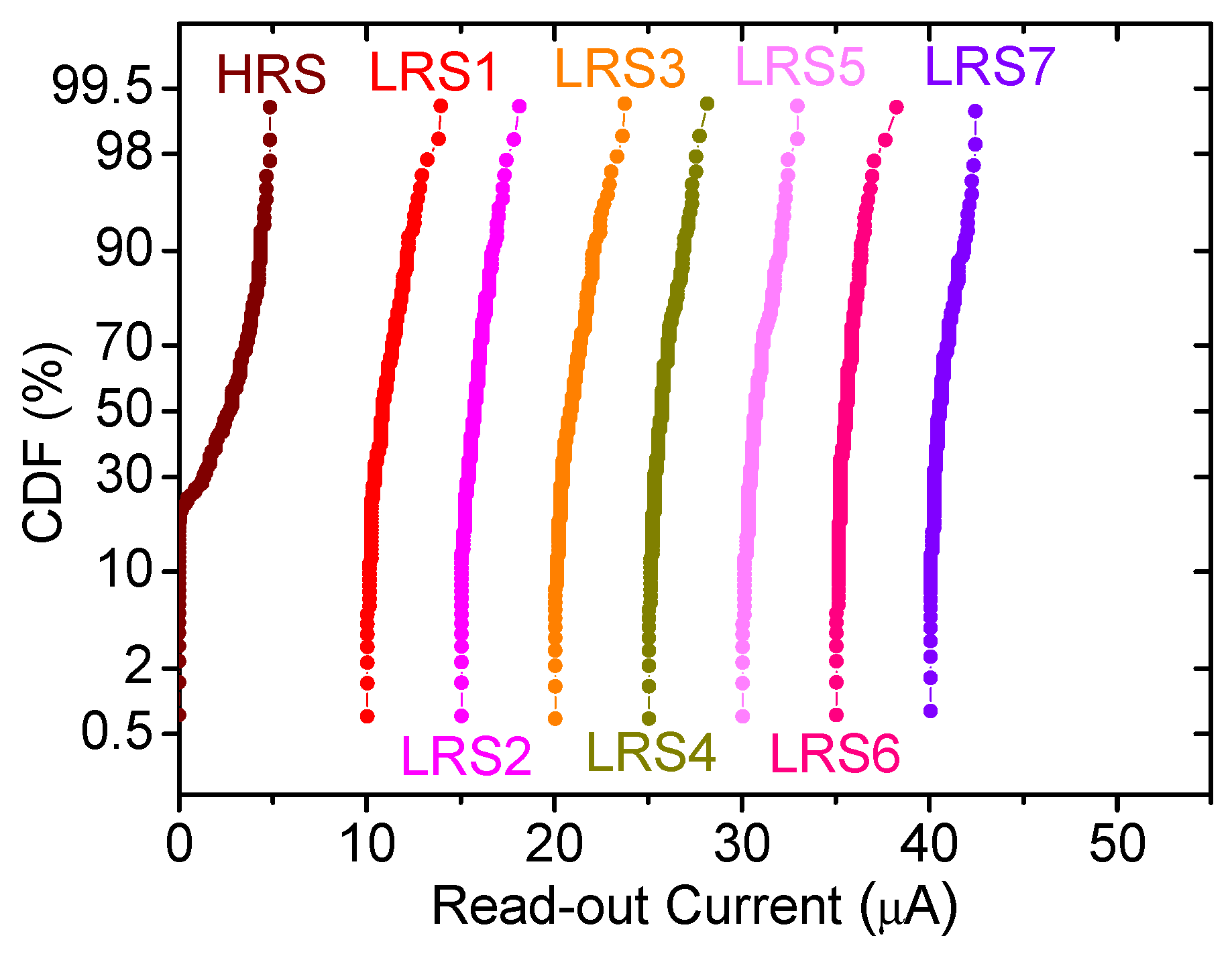
2. Device Fabrication and Measurement Set-Up, a Multilevel Approach
3. ANN Architecture Analysis, the Role of Quantization
3.1. Convolutional Neural Networks
3.2. Quantization Process
4. Experiments and Results
4.1. MLP Architecture
4.2. CNN Architecture
4.3. Datasets
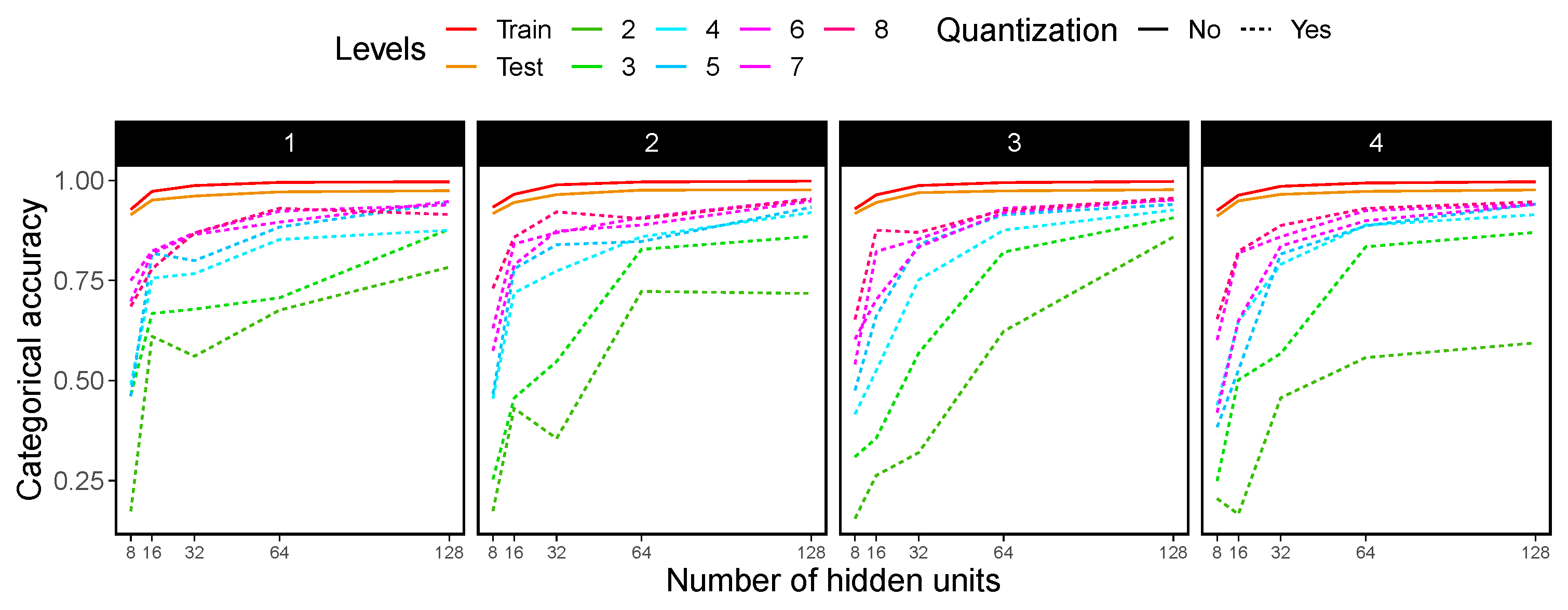
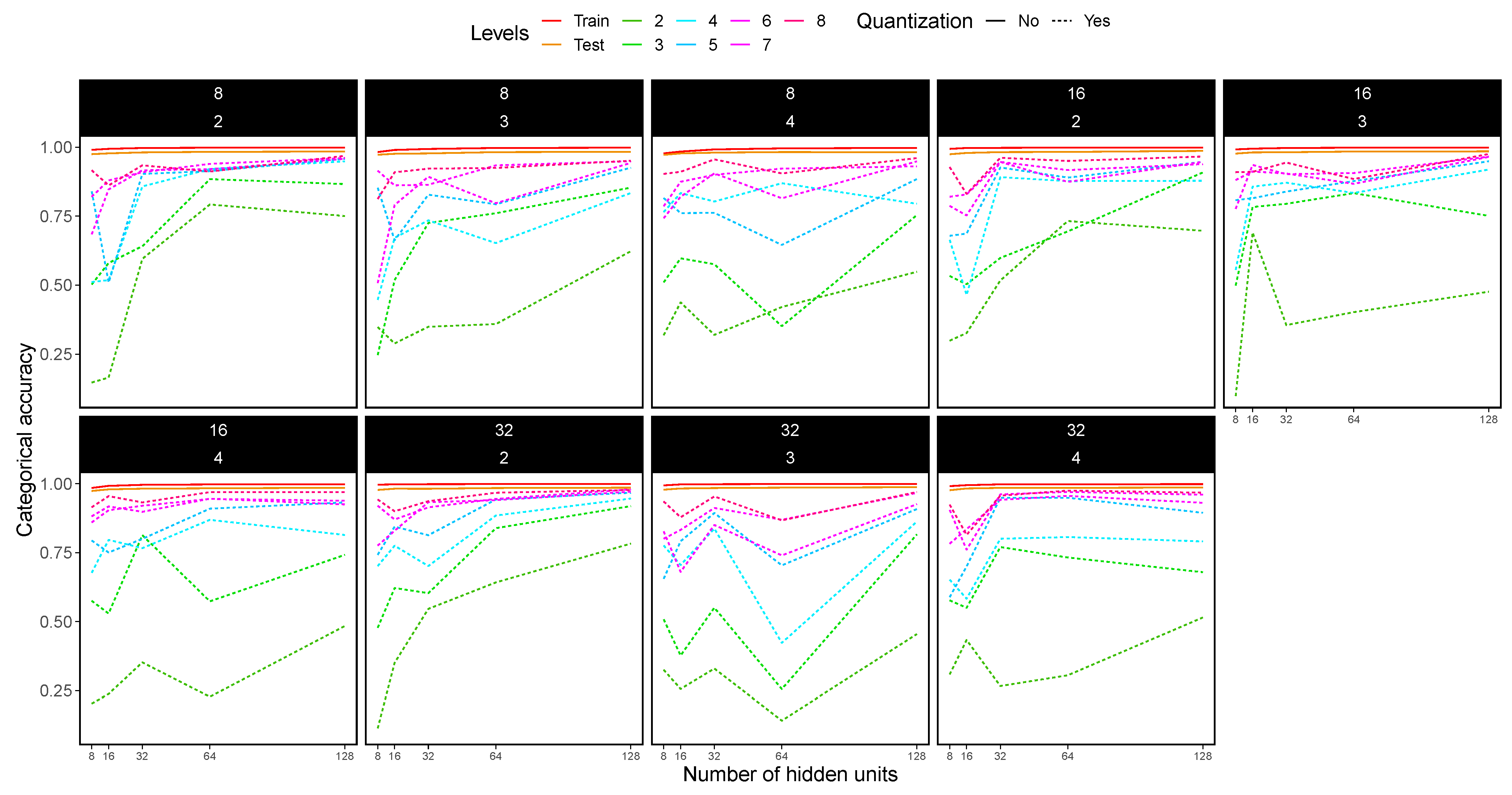
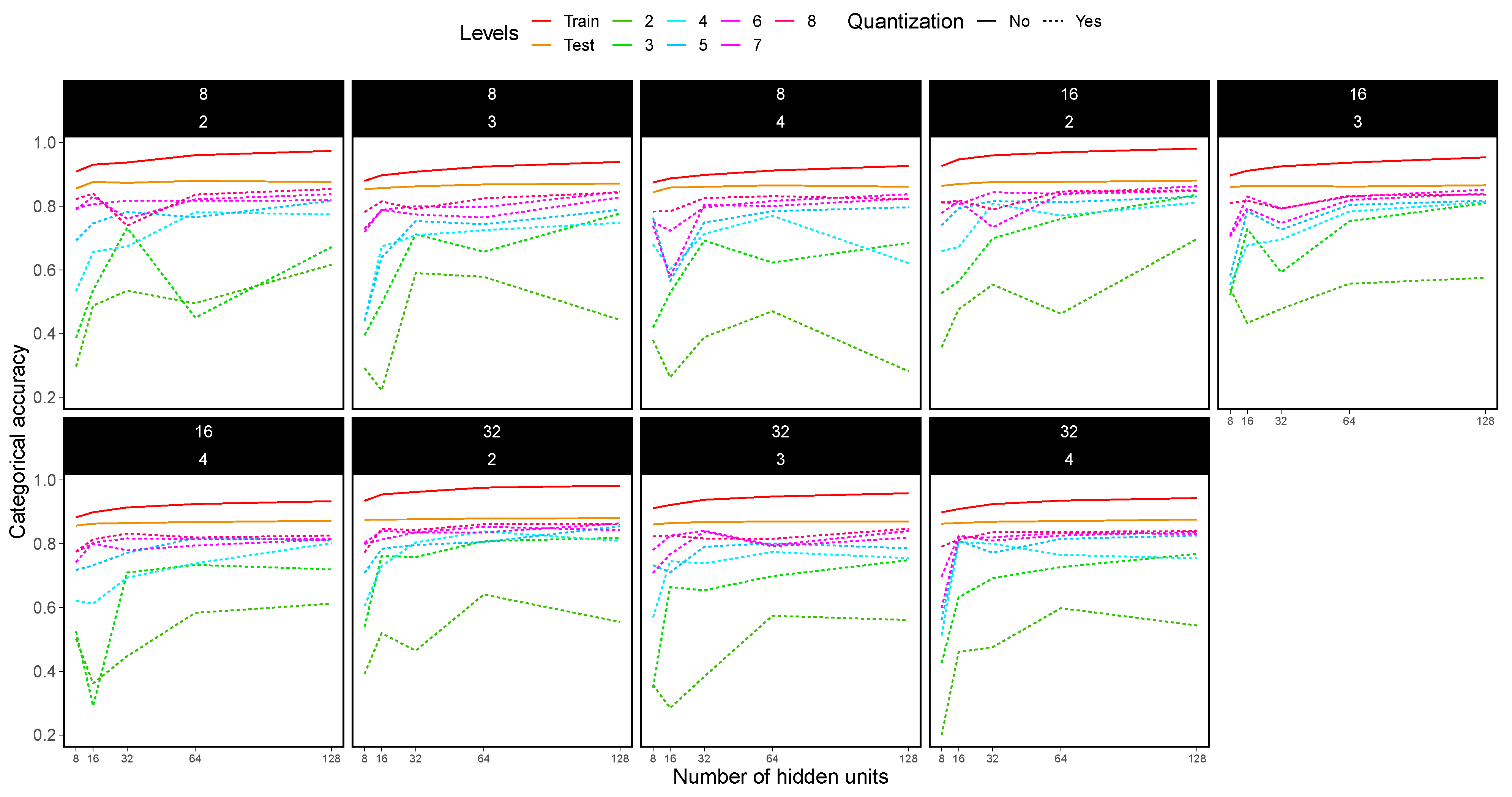
4.4. MLP Experimental Results
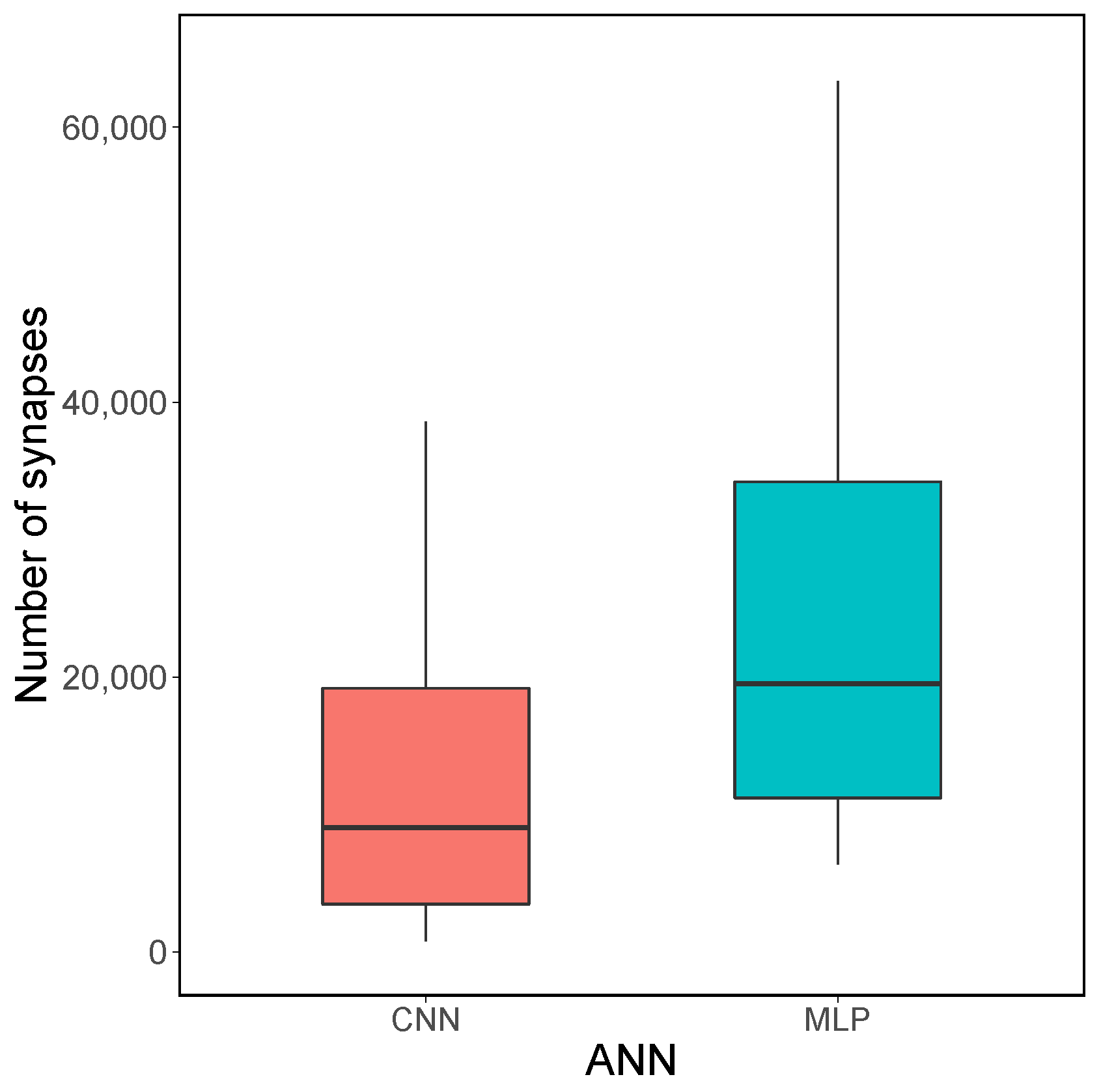
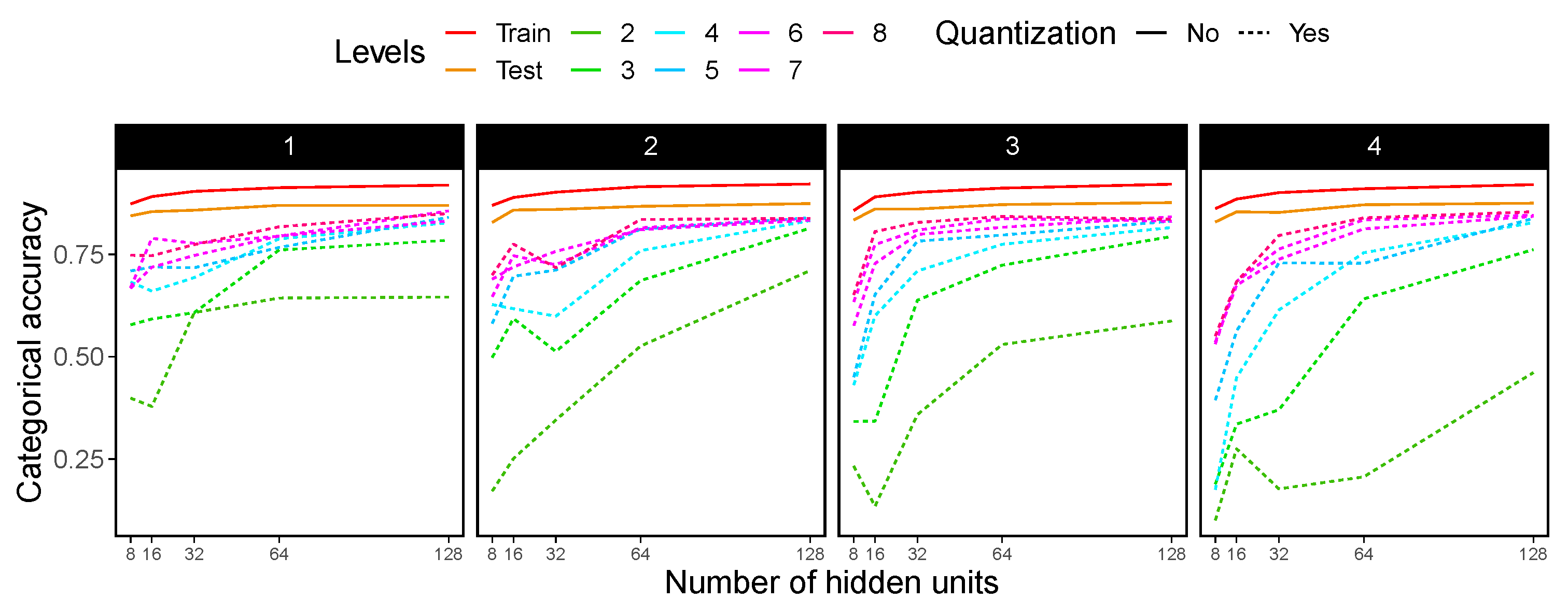
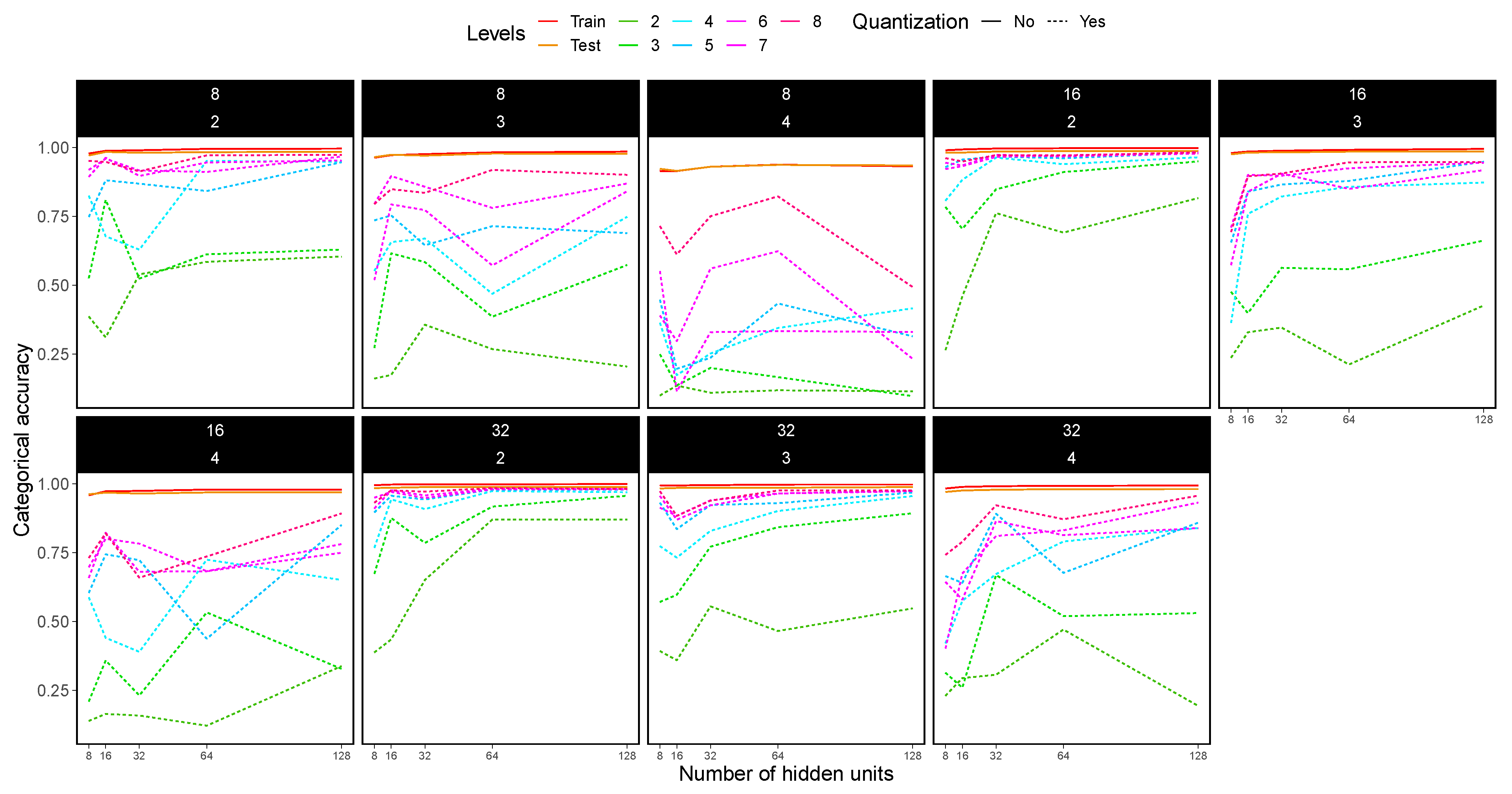
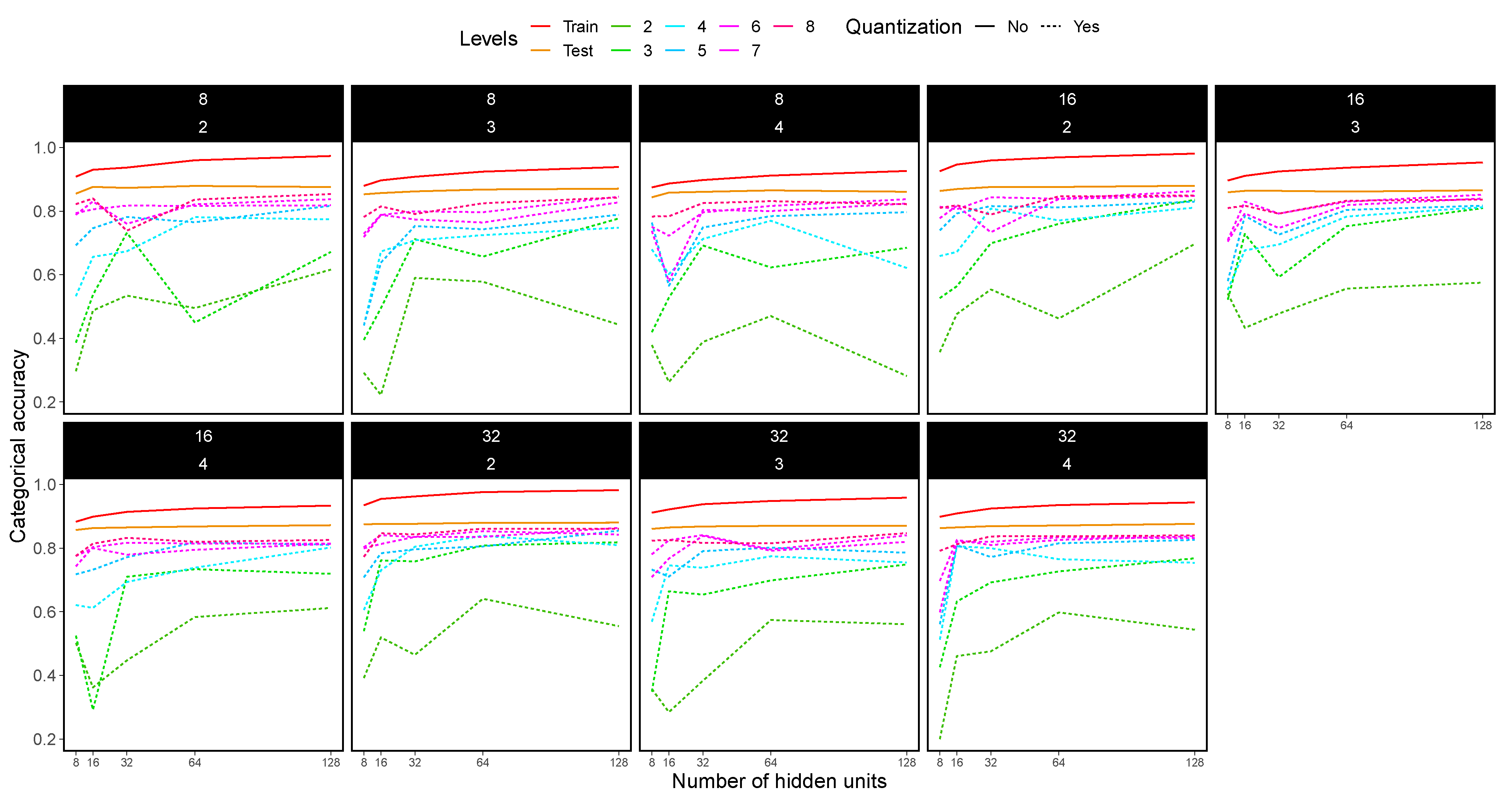
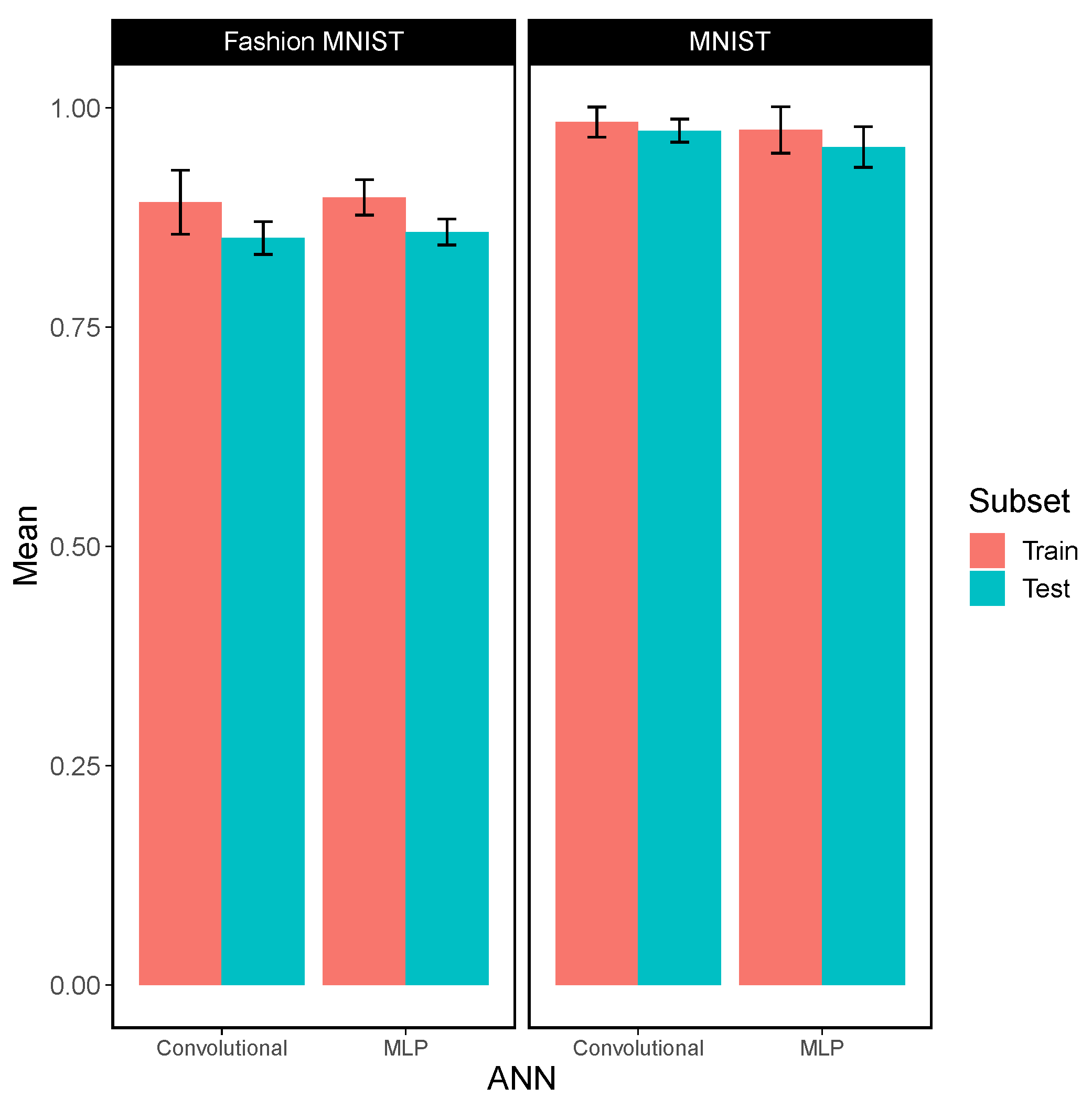
4.5. CNN Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krestinskaya, O.; James, A.P.; Chua, L.O. Neuromemristive Circuits for Edge Computing: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2020, 31, 4–23. [Google Scholar] [CrossRef] [Green Version]
- Jeong, H.; Shi, L. Memristor devices for neural networks. J. Phys. Appl. Phys. 2018, 52, 023003. [Google Scholar] [CrossRef]
- Prezioso, M.; Merrikh-Bayat, F.; Hoskins, B.; Adam, G.; Likharev, K.; Strukov, D. Training and operation of an integrated neuromorphic network based on metal-oxide memristors. Nature 2015, 521, 7550. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lanza, M.; Wong, H.S.P.; Pop, E.; Ielmini, D.; Strukov, D.; Regan, B.C.; Larcher, L.; Villena, M.A.; Yang, J.J.; Goux, L.; et al. Recommended Methods to Study Resistive Switching Devices. Adv. Electron. Mater. 2019, 5, 1800143. [Google Scholar] [CrossRef] [Green Version]
- Tang, J.; Yuan, F.; Shen, X.; Wang, Z.; Rao, M.; He, Y.; Sun, Y.; Li, X.; Zhang, W.; Li, Y.; et al. Bridging Biological and Artificial Neural Networks with Emerging Neuromorphic Devices: Fundamentals, Progress, and Challenges. Adv. Mater. 2019, 31, 1902761. [Google Scholar] [CrossRef] [PubMed]
- Xia, Q.; Berggren, K.K.; Likharev, K.; Strukov, D.B.; Jiang, H.; Mikolajick, T.; Querlioz, D.; Salinga, M.; Erickson, J.; Pi, S.; et al. Roadmap on emerging hardware and technology for machine learning. Nanotechnology 2020, 32, 012002. [Google Scholar]
- Yan, B.; Li, B.; Qiao, X.; Xue, C.X.; Chang, M.F.; Chen, Y.; Li, H.H. Resistive Memory-Based In-Memory Computing: From Device and Large-Scale Integration System Perspectives. Adv. Intell. Syst. 2019, 1, 1900068. [Google Scholar] [CrossRef] [Green Version]
- Manukian, H.; Traversa, F.L.; Ventra, M.D. Accelerating Deep Learning with Memcomputing. Neural Netw. 2019, 110, 1–7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Carbajal, J.P.; Dambre, J.; Hermans, M.; Schrauwen, B. Memristor Models for Machine Learning. Neural Comput. 2015, 27, 725–747. [Google Scholar] [CrossRef]
- Caravelli, F.; Carbajal, J. Memristors for the Curious Outsiders. Technologies 2018, 6, 118. [Google Scholar] [CrossRef] [Green Version]
- Aldana, S.; Pérez, E.; Jiménez-Molinos, F.; Wenger, C.; Roldán, J.B. Kinetic Monte Carlo analysis of data retention in Al:HfO2-based resistive random access memories. Semicond. Sci. Technol. 2020, 35, 115012. [Google Scholar] [CrossRef]
- Villena, M.; Roldan, J.; Jimenez-Molinos, F.; Miranda, E.; Suñé, J.; Lanza, M. SIM2RRAM: A physical model for RRAM devices simulation. J. Comput. Electron. 2017, 16, 1095–1120. [Google Scholar] [CrossRef]
- Pérez, E.; Maldonado, D.; Acal, C.; Ruiz-Castro, J.; Alonso, F.; Aguilera, A.; Jiménez-Molinos, F.; Wenger, C.; Roldán, J. Analysis of the statistics of device-to-device and cycle-to-cycle variability in TiN/Ti/Al:HfO2/TiN RRAMs. Microelectron. Eng. 2019, 214, 104–109. [Google Scholar] [CrossRef]
- Roldán, J.B.; Alonso, F.J.; Aguilera, A.M.; Maldonado, D.; Lanza, M. Time series statistical analysis: A powerful tool to evaluate the variability of resistive switching memories. J. Appl. Phys. 2019, 125, 174504. [Google Scholar] [CrossRef]
- Acal, C.; Ruiz-Castro, J.; Aguilera, A.; Jiménez-Molinos, F.; Roldán, J. Phase-type distributions for studying variability in resistive memories. J. Comput. Appl. Math. 2019, 345, 23–32. [Google Scholar] [CrossRef]
- Zheng, N.; Mazumder, P. Learning in Energy-Efficient Neuromorphic Computing: Algorithm and Architecture Co-Design; Wiley: Hoboken, NJ, USA, 2019. [Google Scholar]
- Chen, J.; Wu, H.; Gao, B.; Tang, J.; Hu, X.S.; Qian, H. A Parallel Multibit Programing Scheme With High Precision for RRAM-Based Neuromorphic Systems. IEEE Trans. Electron Devices 2020, 67, 2213–2217. [Google Scholar] [CrossRef]
- Wenger, C.; Zahari, F.; Mahadevaiah, M.K.; Pérez, E.; Beckers, I.; Kohlstedt, H.; Ziegler, M. Inherent Stochastic Learning in CMOS-Integrated HfO2 Arrays for Neuromorphic Computing. IEEE Electron Device Lett. 2019, 40, 639–642. [Google Scholar] [CrossRef]
- Woo, J.; Moon, K.; Song, J.; Kwak, M.; Park, J.; Hwang, H. Optimized Programming Scheme Enabling Linear Potentiation in Filamentary HfO2 RRAM Synapse for Neuromorphic Systems. IEEE Trans. Electron Devices 2016, 63, 5064–5067. [Google Scholar] [CrossRef]
- Sun, S.; Wu, H.; Xiang, L. City-Wide Traffic Flow Forecasting Using a Deep Convolutional Neural Network. Sensors 2020, 20, 421. [Google Scholar] [CrossRef] [Green Version]
- Geng, Z.; Wang, Y. Automated design of a convolutional neural network with multi-scale filters for cost-efficient seismic data classification. Nat. Commun. 2020, 11, 3311. [Google Scholar] [CrossRef] [PubMed]
- Bhattacharya, S.; Somayaji, S.R.K.; Gadekallu, T.R.; Alazab, M.; Maddikunta, P.K.R. A review on deep learning for future smart cities. Internet Technol. Lett. 2020, e187. [Google Scholar] [CrossRef]
- Kattenborn, T.; Eichel, J.; Fassnacht, F.E. Convolutional Neural Networks enable efficient, accurate and fine-grained segmentation of plant species and communities from high-resolution UAV imagery. Sci. Rep. 2019, 9, 17656. [Google Scholar] [CrossRef] [PubMed]
- Webb, S. Deep learning for biology. Nature 2018, 554, 555–557. [Google Scholar] [CrossRef] [Green Version]
- Tang, B.; Pan, Z.; Yin, K.; Khateeb, A. Recent Advances of Deep Learning in Bioinformatics and Computational Biology. Front. Genet. 2019, 10, 214. [Google Scholar] [CrossRef] [Green Version]
- Wu, S.; Zhao, W.; Ghazi, K.; Ji, S. Convolutional neural network for efficient estimation of regional brain strains. Sci. Rep. 2019, 9, 17326. [Google Scholar] [CrossRef] [Green Version]
- Esteva, A.; Robicquet, A.; Ramsundar, B.; Kuleshov, V.; DePristo, M.; Chou, K.; Cui, C.; Corrado, G.; Thrun, S.; Dean, J. A guide to deep learning in healthcare. Nat. Med. 2019, 25, 24–29. [Google Scholar] [CrossRef]
- Piccialli, F.; Somma, V.D.; Giampaolo, F.; Cuomo, S.; Fortino, G. A survey on deep learning in medicine: Why, how and when? Inf. Fusion 2021, 66, 111–137. [Google Scholar] [CrossRef]
- Zhang, Y.; Cui, M.; Shen, L.; Zeng, Z. Memristive Quantized Neural Networks: A Novel Approach to Accelerate Deep Learning On-Chip. IEEE Trans. Cybern. 2019, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Hu, X.; Duan, S.; Chen, G.; Chen, L. Modeling affections with memristor-based associative memory neural networks. Neurocomputing 2017, 223, 129–137. [Google Scholar] [CrossRef]
- Zambelli, C.; Grossi, A.; Olivo, P.; Walczyk, D.; Bertaud, T.; Tillack, B.; Schroeder, T.; Stikanov, V.; Walczyk, C. Statistical analysis of resistive switching characteristics in ReRAM test arrays. In Proceedings of the 2014 International Conference on Microelectronic Test Structures (ICMTS), Udine, Italy, 24–27 March 2014; pp. 27–31. [Google Scholar] [CrossRef]
- Grossi, A.; Perez, E.; Zambelli, C.E.A. Impact of the precursor chemistry and process conditions on the cell-to-cell variability in 1T-1R based HfO2 RRAM devices. Sci. Rep. 2018, 8, 11160. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Milo, V.; Zambelli, C.; Olivo, P.; Pérez, E.; Mahadevaiah, M.K.; Ossorio, O.G.; Wenger, C.; Ielmini, D. Multilevel HfO2-based RRAM devices for low-power neuromorphic networks. APL Mater. 2019, 7, 081120. [Google Scholar] [CrossRef] [Green Version]
- Pérez, E.; Ossorio, O.G.; Dueñas, S.; Castán, H.; García, H.; Wenger, C. Programming Pulse Width Assessment for Reliable and Low-Energy Endurance Performance in Al: HfO2-Based RRAM Arrays. Electronics 2020, 9, 864. [Google Scholar] [CrossRef]
- Pérez, E.; Zambelli, C.; Mahadevaiah, M.K.; Olivo, P.; Wenger, C. Toward Reliable Multi-Level Operation in RRAM Arrays: Improving Post-Algorithm Stability and Assessing Endurance/Data Retention. IEEE J. Electron Devices Soc. 2019, 7, 740–747. [Google Scholar] [CrossRef]
- Milo, V.; Anzalone, F.; Zambelli, C.; Pérez, E.; Mahadevaiah, M.; Ossorio, O.; Olivo, P.; Wenger, C.; Ielmini, D. Optimized programming algorithms for multilevel RRAM in hardware neural networks. In Proceedings of the 2021 IEEE International Reliability Physics Symposium (IRPS), Monterey, CA, USA, 21–25 March 2021. [Google Scholar]
- González-Cordero, G.; Jiménez-Molinos, F.; Roldán, J.B.; González, M.B.; Campabadal, F. In-depth study of the physics behind resistive switching in TiN/Ti/HfO2/W structures. J. Vac. Sci. Technol. B 2017, 35, 01A110. [Google Scholar] [CrossRef]
- Aldana, S.; García-Fernández, P.; Romero-Zaliz, R.; González, M.B.; Jiménez-Molinos, F.; Gómez-Campos, F.; Campabadal, F.; Roldán, J.B. Resistive switching in HfO2 based valence change memories, a comprehensive 3D kinetic Monte Carlo approach. J. Phys. Appl. Phys. 2020, 53, 225106. [Google Scholar] [CrossRef]
- Bashar, A. Survey on Evolving Deep Learning Neural Network Architectures. J. Artif. Intell. Capsul. Netw. 2019, 1, 73–82. [Google Scholar] [CrossRef]
- Nassif, A.B.; Shahin, I.; Attili, I.; Azzeh, M.; Shaalan, K. Speech recognition using deep neural networks: A systematic review. IEEE Access 2019, 7, 19143–19165. [Google Scholar] [CrossRef]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Zou, L.; Yu, S.; Meng, T.; Zhang, Z.; Liang, X.; Xie, Y. A technical review of convolutional neural network-based mammographic breast cancer diagnosis. Comput. Math. Methods Med. 2019, 2019. [Google Scholar] [CrossRef] [Green Version]
- Liu, C.; Chen, H.; Wang, S.; Liu, Q.; Jiang, Y.G.; Zhang, D.W.; Liu, M.; Zhou, P. Two-dimensional materials for next-generation computing technologies. Nat. Nanotechnol. 2020, 15, 545. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, C.C. Neural Networks and Deep Learning: A Textbook; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Astudillo, N.M.; Bolman, R.; Sirakov, N.M. Classification with Stochastic Learning Methods and Convolutional Neural Networks. SN Comput. Sci. 2020, 1, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2016, arXiv:1603.04467. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 7 January 2021).
- LeCun, Y.; Cortes, C.; Burges, C. MNIST handwritten Digit Database. ATT Labs [Online]. 2010. Available online: http://yann.lecun.com/exdb/mnist (accessed on 7 January 2021).
- Xiao, H.; Rasul, K.; Vollgraf, R. Fashion-MNIST: A Novel Image Dataset for Benchmarking Machine Learning Algorithms. arXiv 2017, arXiv:1708.07747. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Name | Value |
|---|---|
| Optimizer | Stochastic Gradient Descent (SGD) |
| Learning rate | 0.1 |
| Momentum | 0.9 |
| Number of epochs | 30 |
| Batch Size | 32 |
| Validation set | 10% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Romero-Zaliz, R.; Pérez, E.; Jiménez-Molinos, F.; Wenger, C.; Roldán, J.B. Study of Quantized Hardware Deep Neural Networks Based on Resistive Switching Devices, Conventional versus Convolutional Approaches. Electronics 2021, 10, 346. https://doi.org/10.3390/electronics10030346
Romero-Zaliz R, Pérez E, Jiménez-Molinos F, Wenger C, Roldán JB. Study of Quantized Hardware Deep Neural Networks Based on Resistive Switching Devices, Conventional versus Convolutional Approaches. Electronics. 2021; 10(3):346. https://doi.org/10.3390/electronics10030346
Chicago/Turabian StyleRomero-Zaliz, Rocío, Eduardo Pérez, Francisco Jiménez-Molinos, Christian Wenger, and Juan B. Roldán. 2021. "Study of Quantized Hardware Deep Neural Networks Based on Resistive Switching Devices, Conventional versus Convolutional Approaches" Electronics 10, no. 3: 346. https://doi.org/10.3390/electronics10030346