1. Introduction
Neuromorphic engineering is a booming research field, taking into consideration its connections to Artificial Intelligence (AI) applications [
1]. The current data centric context where the amount of data generated is continuously growing due to Internet, 5G, edge and cloud computing, etc., is pushing forward the need for neural networks (NNs), which are getting deeper and deeper to be able to deal with continuously increasing datasets in complexity and size and the efficiency requirements of today’s technological companies. The resources available at current data centers allow the lengthy training processes of these networks. Nevertheless, two main hurdles, among others, affect the advances in the computing frameworks for AI. On the one hand, the limitations of computing architectures, influenced by the slowing down of Moore’s law for device scaling, and mostly, by the physical separation of processor and memory units (von Neumann’s bottleneck), that causes an enormous burden to the computer operation since data have to shuttle back and forth between these units. The memory wall problem (the rising performance gap between memory and processors) also contributes to slow down AI-oriented applications [
1,
2]. On the other hand, the training process of state-of-the-art NNs has a huge carbon footprint, as shown in Ref. [
3].
Different general purpose neuromorphic frameworks have been developed so far, both at the industry and academia, to overcome the hurdles described above in relation to AI computing [
4]. Among them, the following can be highlighted: the neurogrid developed at Stanford University [
1], SpiNNaker created at the University of Manchester [
5], TrueNorth developed at IBM [
6] and Loihi made at INTEL [
7]. In line with these developments, new advances are being produced to accelerate AI. Certain operations at the core of this computing paradigm, such as the vector-matrix multiplication (VMM), can be improved if memristors are employed in crossbar structures [
8]. Resistive switching devices based on the conductance modulation of their layer structure are one of the most promising types of memristors [
9] for this purpose, since they are CMOS-compatible technology, have good endurance [
10] and retention behavior and low power operation features [
2,
8,
11,
12,
13]. Memristor mimic synapses in the implementation of conventional NNs; also, their intrinsic non-volatility adds a clear advantage in comparison with chips where SRAM and DRAM (volatile memories) are employed; the low power consumption and scalability are also key issues to take into account [
12,
13,
14,
15]. The key architecture of the circuits based on memristors for neuromorphic engineering leads to In-Memory Computing (IMC), where computational tasks are performed in place in the memory itself [
16]. The idea behind IMC is that introducing physical coupling between memory devices, the computational time could be reduced [
16]. The advances in neuromorphic computing are essential since they can help on the development of the technology for edge computing linked to the Internet of Things era [
13,
14,
17,
18,
19].
In spite of the clear advances in this field, there are open issues that are currently under intense research efforts. For instance, the different programming algorithms to obtain device conductance multilevels (needed for the implementation of synaptic weight quantization), the role of cycle-to-cycle variability on final circuits, the efficiency of training processes when synaptic weight quantization is considered, etc., are under scrutiny nowadays. In addition, the details of the circuits needed for each type of memristor [
16] and the auxiliary circuitry for different types of crossbar arrays are a subject of investigation [
20]. In particular, variability and multilevel operation [
21,
22,
23,
24,
25] are in need of new adapted NN architectures and training strategies [
18]. There have been results related to these issues linked to row-by-row parallel program-verify schemes [
26], binary synaptic learning that takes advantage from the set and reset voltage variability in CMOS integrated 1T1R structures [
27], etc.
The role of quantization and variability in different types of NNs has been analyzed. The consequences of weight precision reduction have been described previously [
18,
19]; the variability on the quantization process was tackled from the perspective of device modeling [
28], circuit implementation [
29] and NN architecture [
30]; however, in all these issues there is a long way to go till industrial maturity is reached. In this manuscript, we have characterized the influence of the NN architecture (fully dense/connected or convolutional), the number of synaptic weights (NN size) for different configurations of the NN hidden layers, and the number of memristor quantized conductance levels on the recognition accuracy achieved over different datasets.
The memristor-based array developed to implement all the different NNs proposed is a 4-kbit 1T1R ReRAM array based on
dielectrics, which show a clear bipolar operation where conductive filaments are made of oxygen vacancies. The multilevel conductance modulation is achieved by using the Incremental Gate Voltage with Verify Algorithm (IGVVA), which can provide any combination of levels between 2 and 8 [
31]. We have kept in mind that it has been proven that only a 3-bit precision was needed to correctly encode state-of-the-art networks [
18]. This corresponds to the higher number of levels analyzed here. From another viewpoint, quantization could be beneficial to deal with common problems in the NN realm, such as overfitting. We have dealt with all these issues as the manuscript unfolded; in
Section 2 the technological features of the devices employed are described, the NN architecture and the basis of the study performed are given in
Section 3, finally, the main results and corresponding discussions are explained in
Section 4.
2. Experimental Description
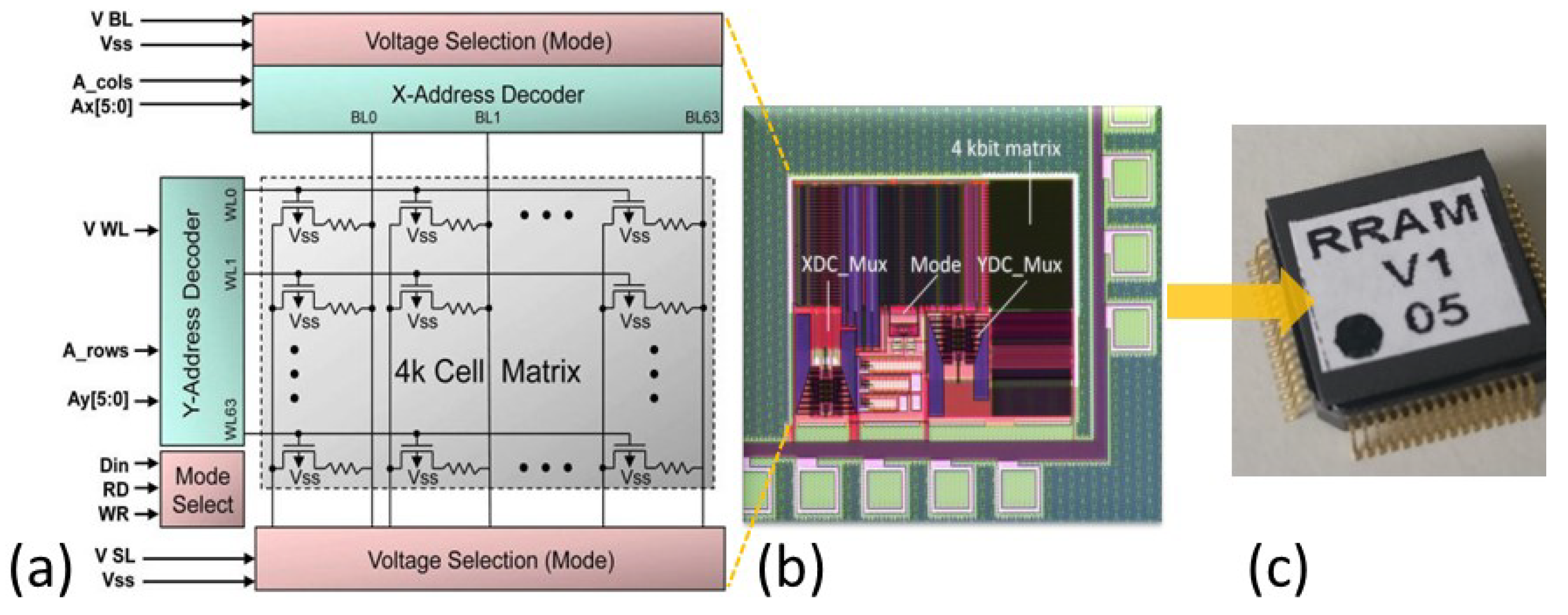
The crossbar arrays utilized in this work are 4-kbit 1T1R ReRAM arrays integrated together with basic circuit periphery and encapsulated in memory chips [
32], as shown in
Figure 1. Each ReRAM cell is constituted by a NMOS transistor (manufactured in 0.25
m CMOS technology) connected in series to a metal–insulator–metal (MIM) structure placed on the metal line 2 of the CMOS process [
29]. The MIM structure consists of a
stack with 150 nm TiN top and bottom electrode layers deposited by magnetron sputtering, a 7 nm Ti layer (under the TiN top electrode) and an 8 nm
layer grown by atomic layer deposition (ALD) [
33].
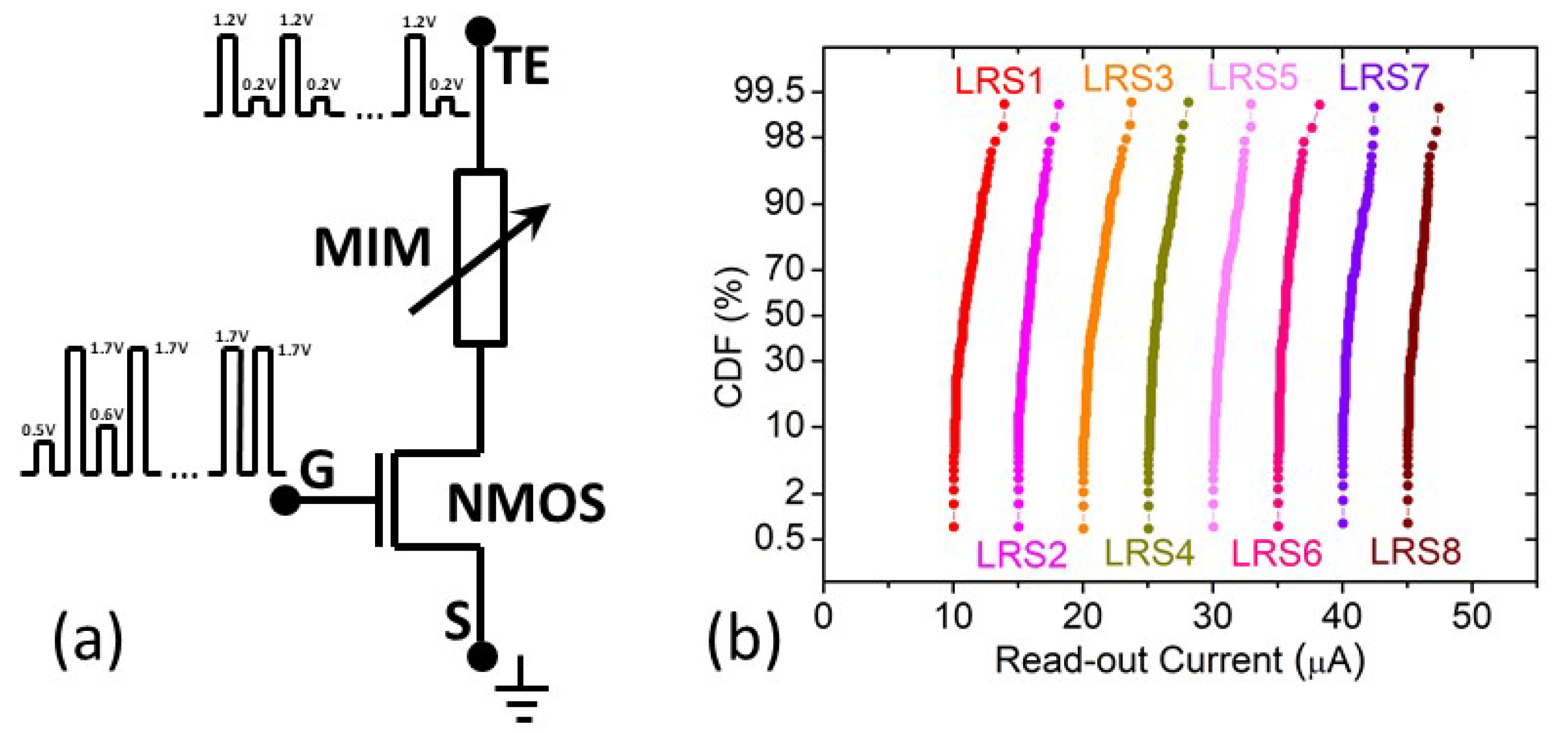
In order to implement the quantized weight values in the NN architectures considered here, a write-verify programming algorithm was employed, namely, the IGVVA. This algorithm, tested on our technology for the first time in [
31], keeps constant the pulse amplitude applied on the terminal connected to the top electrode (TE) of the MIM structure during set operations and increases step by step the gate voltage (
) value until a desired readout (at 0.2 V) current target (
) is achieved (see
Figure 2a). The cumulative distribution functions (CDFs) of the readout currents measured on 128 ReRAM cells for eight different conductive levels are shown in
Figure 2b. Therefore, this programming approach provides the right tool to define all different quantization levels tested in this work.
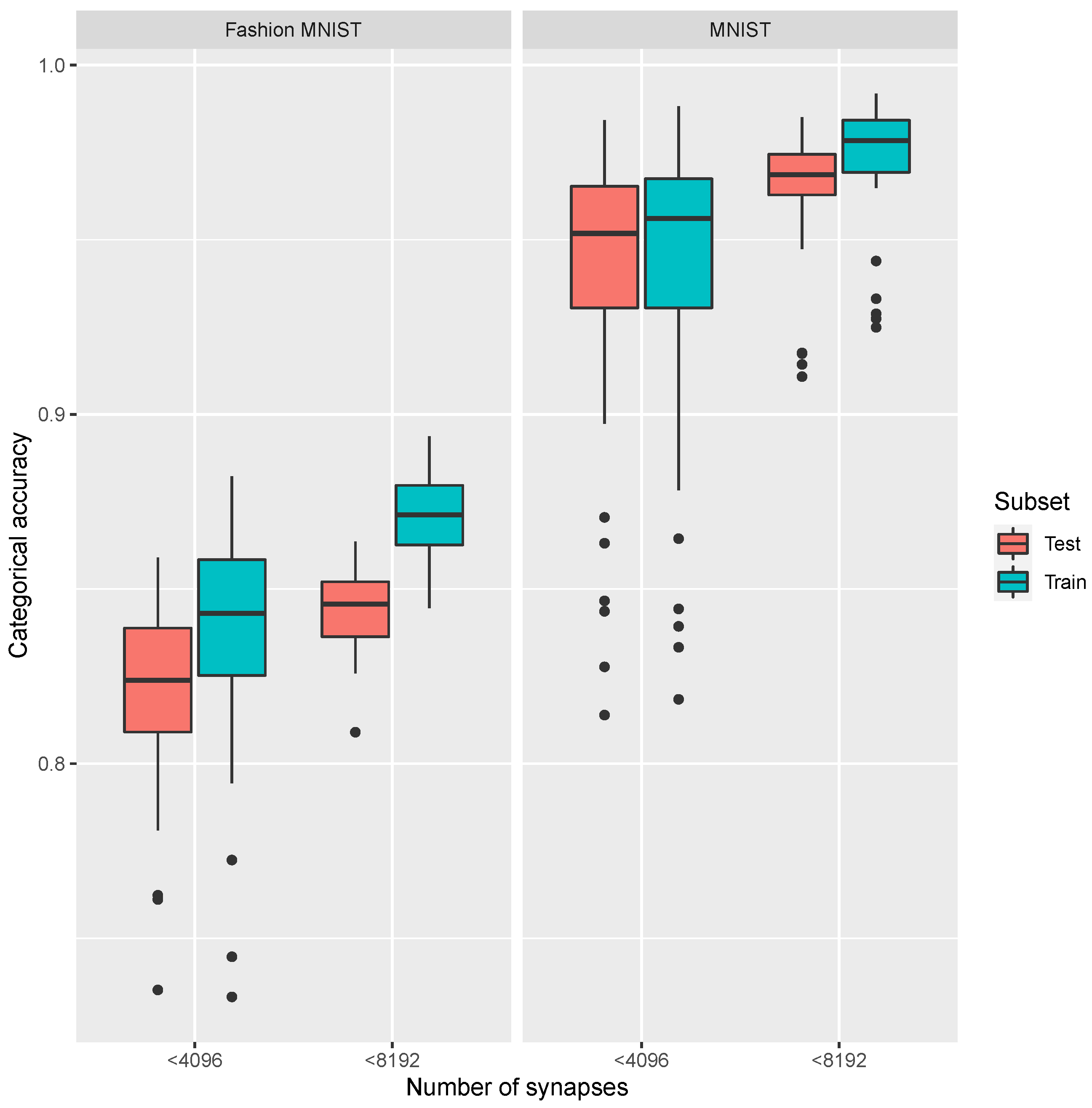
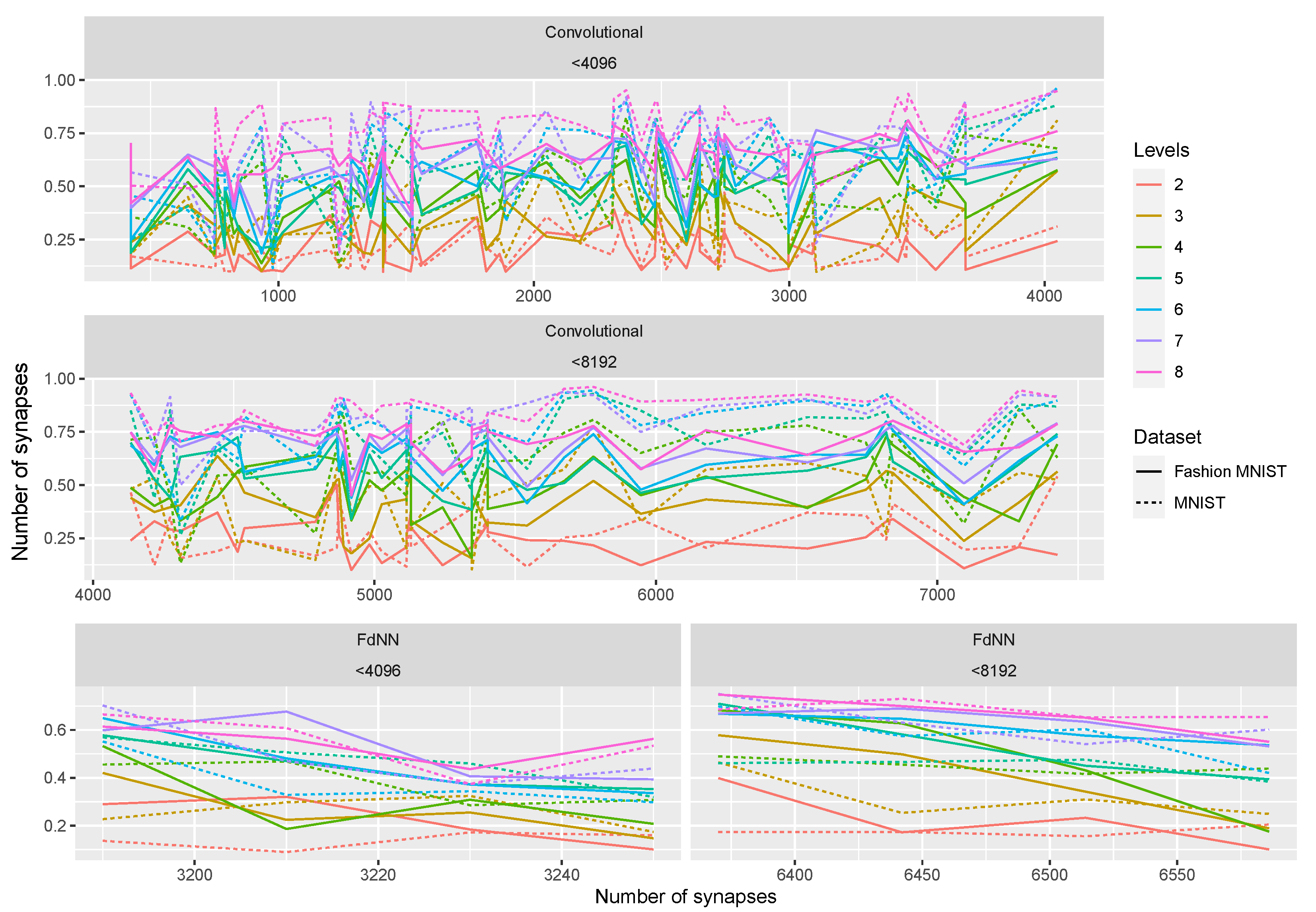
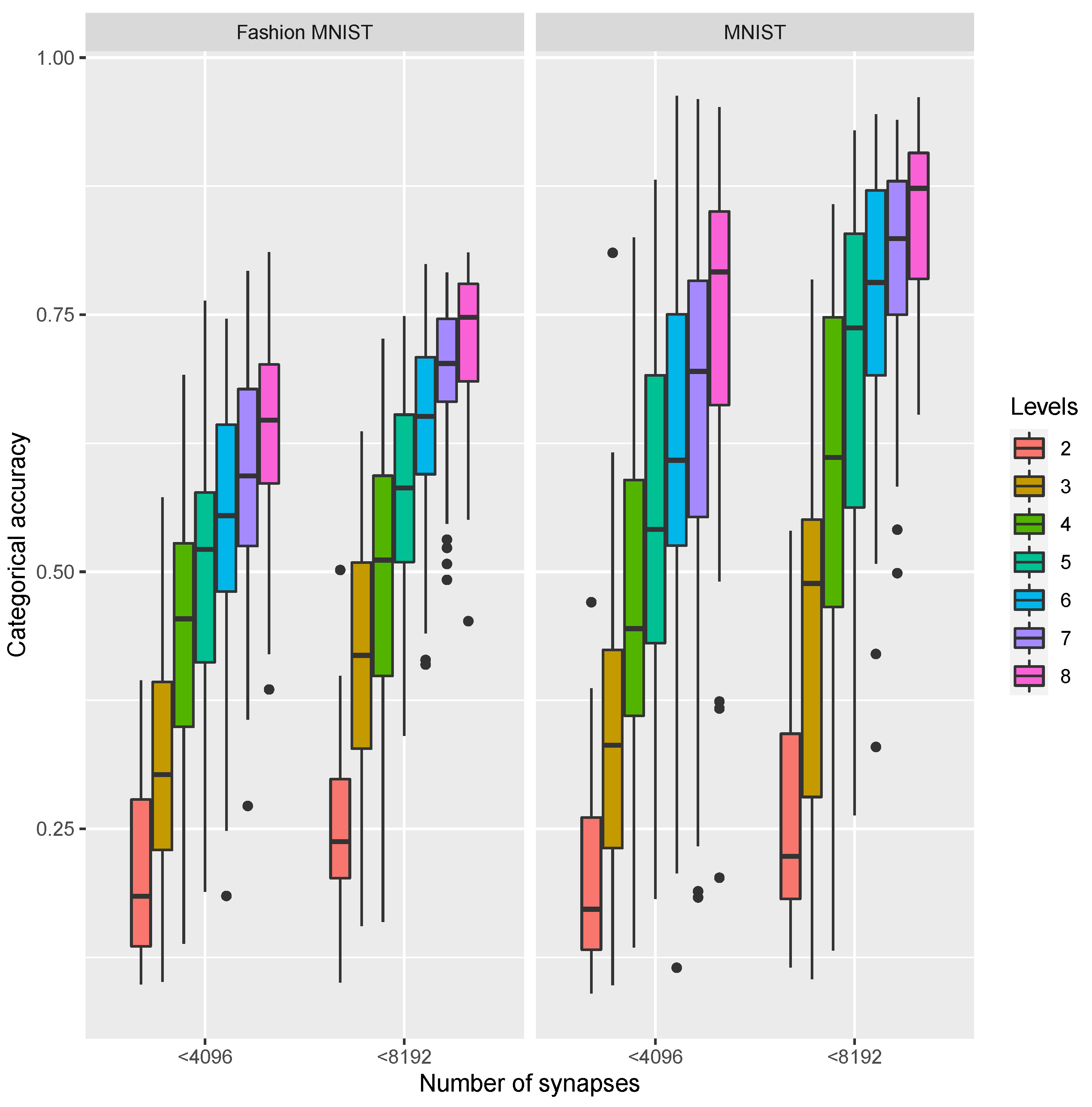
Our arrays exactly contain 4096 cells, so this is the number we have considered in our study as the reference for the number of synaptic weights of the NN analyzed (we have considered mainly one and two arrays). We have studied NNs with a low number of synapses, trying to optimize the NN recognition accuracy and considering the possibility of implementing the NN in this technology and with the crossbar arrays described above.
3. Neural Network Architecture
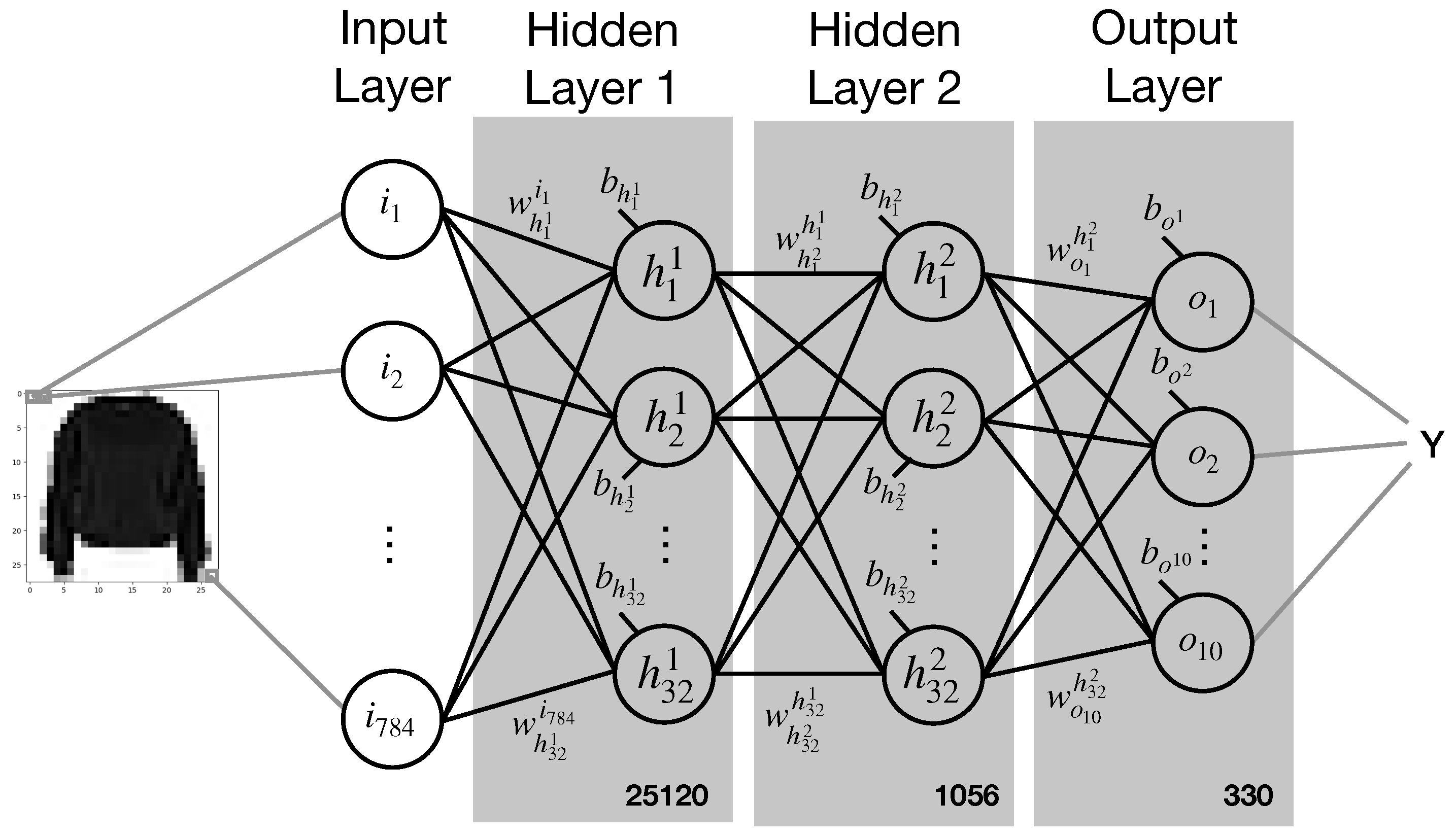
Different architectures have been considered here; in particular, as highlighted above, fully dense and convolutional NNs. In
Figure 3, the scheme of FdNN is shown, the number of weights employed in this particular configuration is described. It is clear that if we vary the number of hidden layers, the NN amount of weights can be changed for the study we present below. Notice that deepening in a fully dense NN will highly increase the number of synaptic weights as all units from a layer are connected to all units in the next layer.
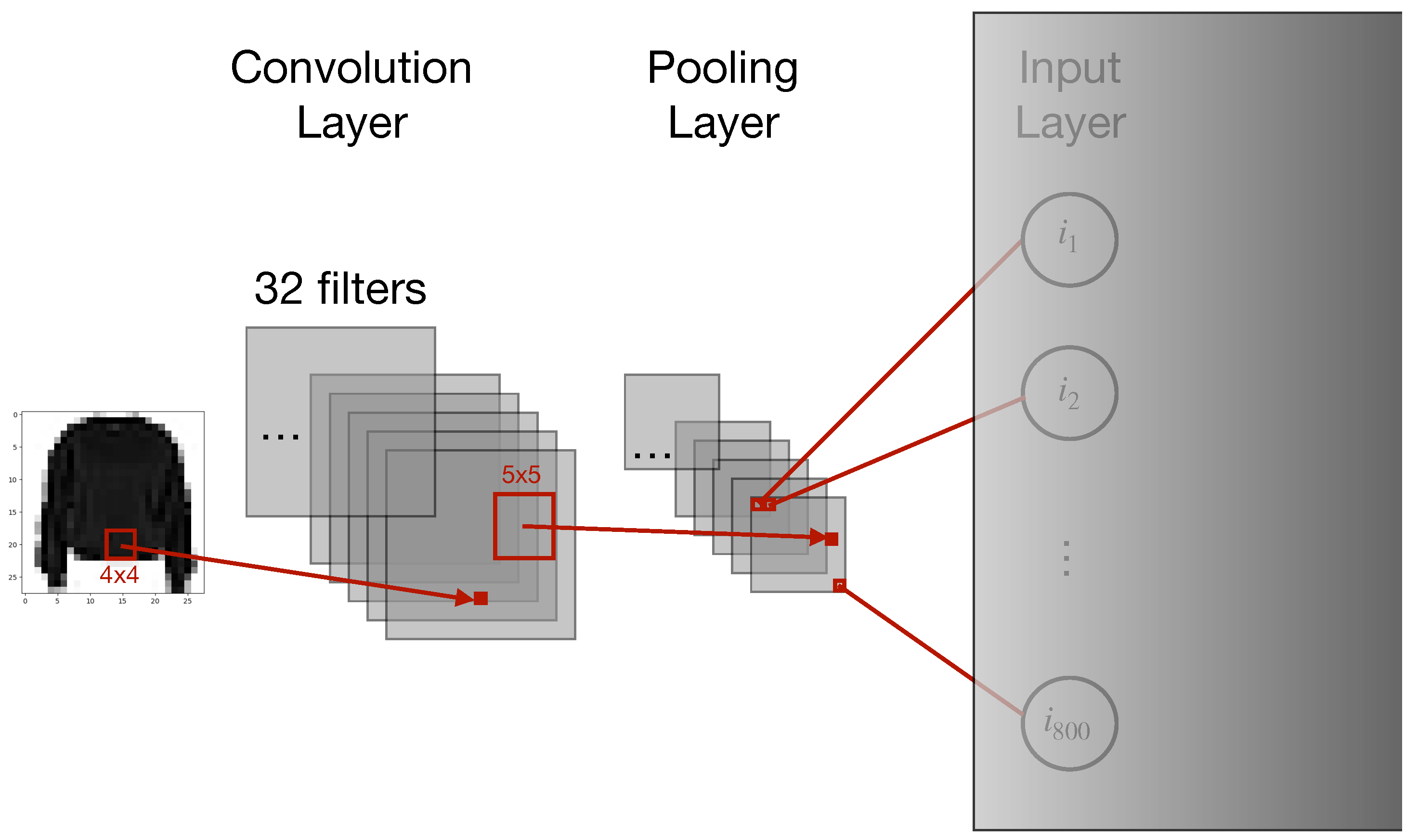
In
Figure 4, the architecture of a Convolutional Neural Network (CNN) is described. They are widely employed for image recognition issues in perception activities; at this task, they perform a fast and highly parallel data processing [
34]. In a CNN, preprocessing layers are used before the final FdNN. These special layers are called convolution layers and pooling layers. The former apply a set of filters to the input data in order to create maps that summarize the presence of detected features. The latter down-sample those features, reducing the number of units needed to process the input data. We have employed this somewhat general scheme to build the CNN architecture following a previous work [
30], to be able to change the number of synaptic weights for our study.
For both types of networks we have assumed a deep NN approach (we assume “deep” as the use of two or more hidden layers in fully dense NNs; CNNs are considered always deep) since these type of NNs have shown the correct features to fulfill a high degree of accuracy in learning complex and massive datasets [
35,
36,
37,
38]. We have focused our study in the influence of the number of synaptic weights on the accuracy of the networks. To do so, we have changed the network architecture using the NNs explained above as a starting point and increasing the number of hidden layers, neurons per layer, number of filters, etc. The motivation behind this analysis stands on the limited size of the available ReRAM crossbar arrays, namely, 4096 1T1R cells in our technology. This is a first approach in this type of study, based on the NN size, calculated in terms of the number of the most representative elements. There is still the possibility of using several crossbar arrays on a tiled architecture in order to provide a larger number of synaptic devices for the NN implementation. However, it is important to highlight that the optimization process of the hardware-based NN stands upon the use of the lowest number of crossbar arrays, obtaining a reasonable accuracy. The tiled structure design details are out of the scope of the study presented here. At this point, notice that our approach is much different to the conventional studies performed in the context of software engineering, where gigantic NN are considered to achieve recognition accuracy top figures. In this respect, we make clear that, in the latter context, obviously, the state of the art for the NN under consideration is different to what we obtain here [
39,
40].
For our study, we have used two datasets: the MNIST [
41] and Fashion MNIST [
42]. The MNIST image dataset [
41] consist of 70,000 grayscale pixel images; they represent handwritten digits (labeled in the interval
), divided into a training set of size 60,000 and a test set of size 10,000. The Fashion MNIST dataset [
42] has 70,000 28 × 28 grayscale images in 10 classes (T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag and Ankle boot). The training set has 60,000 images and a test set 10,000 (see Figure 7 in [
30]), this dataset is more complex to learn than the original MNIST, and for image recognition purposes, it represents a more real-world approach [
42].
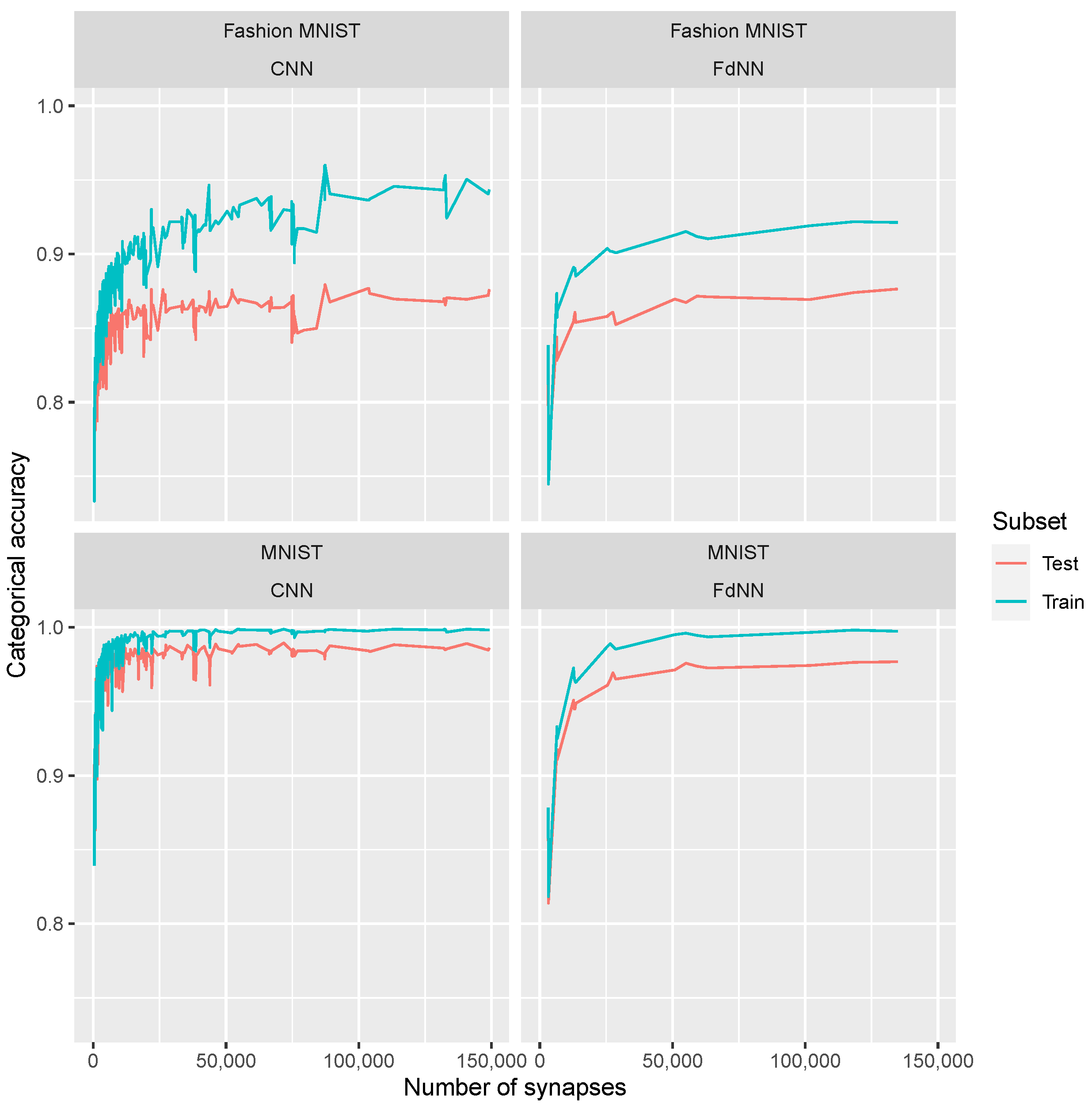
For each dataset, we have run several simulation experiments for the two types of NNs described above. The NNs were trained using the default parameter values of the keras/tensorflow implementation (some hyperparameters employed were linked to the stochastic gradient descend algorithm with
and
). We utilized the categorical accuracy as the comparison metric. It obtains the relative frequency in which the prediction matches the labeled data, and this frequency is then returned as categorical accuracy [
43,
44]. The main goal of this work is to study the effect of synaptic weight quantization in hardware neural networks with different configurations that come up because of the number of synapses constraints imposed by the use of memristor-based arrays of 4-kbit 1T1R cells. Although we have not performed multiple simulation runs for all the NN analyzed, we have considered a representative example (a CNN with three convolution layers, 16 filters, 2 × 2 pooling layers and a hidden layer with 32 neurons in the fully dense section of the network) and analyzed the random deviations among different simulations. We obtained an average accuracy of 0.909 and standard deviation of 0.035 for 10 simulation runs. In this respect, we expect, taking into consideration the similitude of the different NN architectures, that the results within our work could be accurate within a margin of
.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}