
Distributed Cooperative Automatic Modulation Classification Using DWA-ADMM in Wireless Communication Networks
1
School of Information and Electronics, Beijing Institute of Technology, Beijing 100081, China
2
School of Electronic and Information Engineering, Beijing Jiaotong University, Beijing 100044, China
*
Author to whom correspondence should be addressed.
Electronics 2023, 12(14), 3002; https://doi.org/10.3390/electronics12143002
Submission received: 11 May 2023
/
Revised: 28 June 2023
/
Accepted: 6 July 2023
/
Published: 8 July 2023
Abstract
:Automatic modulation classification (AMC) is an important component in non-cooperative wireless communication networks to identify the modulation schemes of the received signals. In this paper, considering the multipath effect in practical propagation environments, a distributed cooperative AMC (Co-AMC) network based on machine learning is proposed to identify the modulation scheme in non-cooperative wireless communication networks. Specifically, feature vectors are first obtained by applying a cyclic spectrum to facilitate the feature extraction of the received signal. Then, a classifier based on the K-nearest neighbor (KNN) method is designed to obtain the local decision for modulation classification at each distributed node. Meanwhile, the reliability of the local decision is estimated by applying two loss functions to assess the quality of the local decision. Finally, the unified classification result is obtained to fuse the local decisions according to their reliabilities by applying a designed decision fusion algorithm based on the distributed weighted average alternating direction method of multipliers (DWA-ADMM). The simulation results demonstrate that the proposed Co-AMC network achieves superior classification accuracy compared to existing AMC methods across a range of modulation schemes and SNRs. More importantly, the proposed Co-AMC exhibits great flexibility and practicability since it is adaptive to wireless networks with various scales and topologies.
1. Introduction
Automatic modulation classification (AMC) is becoming increasingly important for its fundamental role in non-cooperative wireless communication networks to identify the modulation schemes [1]. However, AMC is a challenging issue for non-cooperative communications since there are unknown parameters such as carrier frequency and time delay of the received signals [2,3]. Generally, the AMC methods can be divided into two categories, namely likelihood-based (LB) and feature-based (FB) methods [4]. The LB methods, which employ a likelihood function value comparison of the received signal to determine the most probable classification results, are capable of achieving optimal solutions. However, this comes at the expense of high computational complexity [5]. In addition, the computation of the likelihood function is more difficult when there are unknown parameters [6]. Compared with the LB methods, FB methods exhibit greater prominence in practical implementations, which can achieve near-optimal performance while mitigating complexity [7]. For FB methods, there are mainly two crucial steps, i.e., feature extraction and classification. Recently, feature-based AMC has attracted significant attention while machine learning (ML) is widely used due to its superiority in feature extraction and classification accuracy [8]. For instance, in ref. [9], the signal modulation features are extracted by the time-frequency analysis and the classification is accomplished accurately by using a support vector machine (SVM). In ref. [10], a constellation density matrix is generated for the extraction of local information and a convolutional neural network (CNN)-based model is designed to obtain the high classification accuracy. It is worth noting that existing studies have predominantly focused on considering a single signal observation obtained from a single receiver. However, practical wireless channels commonly exhibit small-scale fading phenomena, which may degrade the classification performance. Hence, a cooperative AMC (Co-AMC) network should be designed to combat the multipath effects in wireless channels by receiving signals through multiple propagation paths.
The Co-AMC, which classifies the modulation schemes of the received signals by sharing data among multiple nodes, can improve the classification performance compared to a single receiver [11]. The Co-AMC algorithms can be categorized according to different criteria. For instance, the Co-AMC algorithms can be divided into two classes according to the cooperation architecture, i.e., centralized architecture and distributed architecture [12]. In the centralized architecture, a fusion center (FC) is presumed to exist, where each node shares its data. Subsequently, the FC combines the shared data to make a final decision. Alternatively, in the distributed architecture, each node obtains a unified classification result independently through the iterative exchange of its data. In ref. [13], an estimation of a priori probabilities is used for transmitting local decisions to the FC, which improves the classification accuracy. In ref. [14], a CNN-based Co-AMC method is proposed for the multiple-input multiple-output systems, which outperforms the high-order cumulant (HOC)-based traditional AMC methods. Although most of the Co-AMC methods proposed in the existing literature follow the centralized architecture, the AMC problem at FC has high computational complexity [15]. In addition, huge power for communications is required when all the observations received from nodes are transmitted to the FC.
In different Co-AMC algorithms, the fusion process can abstract data at the signal, feature, or decision level. At the signal level, each node transmits the received raw signals to the FC. The raw signals are combined to form a single signal, enabling the application of a conventional single AMC algorithm [15]. Although the signal-level combining preserves all the information of the signals, the raw signal exchange results in a huge overhead over the wireless networks, especially when the number of nodes is large. In the intermediate level of abstraction, local features are obtained at the individual nodes and then transmitted to the FC for combining. Feature-level combining reduces the overhead of the wireless networks compared with the signal-level combining [16]. However, the synchronization problem still needs to be considered due to the time delay of the received signals between nodes [17]. In the highest level of abstraction, local decisions are computed at the individual nodes by a single AMC algorithm, and the global decision is obtained by a centralized or distributed fusion algorithm. Decision-level combining minimizes network overhead but comes at the expense of losing all soft information contained in the raw signals [18].
As an attractive approach, distributed ML enables the Co-AMC to enhance the classification performance and reduce the computational complexity of distributed nodes. The key issue of distributed ML for the Co-AMC is how to obtain a uniform classification result to balance the trade-off between improving the classification accuracy and reducing the overhead of wireless networks [19]. To tackle this problem, in ref. [20], a temporary fusion center is assigned to reach an overall decision by a weighted voting mechanism. In ref. [21], a distributed learning-based AMC is proposed to reduce the computing overhead, which relies on the model averaging algorithm. In recent years, the alternating direction method of multipliers (ADMM) algorithm is widely used to solve the distributed optimization problem with faster convergence due to its simplicity and operator splitting capability [22]. Up to now, ADMM has been successfully applied in the signal detection [23], admission control [24], and resource allocation [25], but it has not yet been explored in the area of AMC.
Inspired by the aforementioned observations, we propose an ML-based Co-AMC for distributed wireless communication networks in this paper. At each distributed node, the signal features are extracted from the received signal based on the cyclic spectrum. Then, the individual classification decision, namely the local decision, is obtained by the K-nearest neighbor (KNN)-based classifier through the signal features. Finally, a distributed decision-level combing algorithm based on ADMM is designed to obtain the unified classification result on the modulation schemes of the unknown received signals. Simulation results show that the proposed network provides better performance than the existing AMC methods under various classification scenarios such as binary amplitude shift keying (BASK), binary phase shift keying (BPSK), quadrature phase shift keying (QPSK), binary frequency shift keying (BFSK) and minimum shift keying (MSK) modulation schemes, especially when the signal-to-noise ratio (SNR) is lower than 0dB. The major contributions of this paper can be summarized as follows.
- (1)
- A distributed Co-AMC network is proposed for non-cooperative wireless communication systems to identify the modulation schemes of the received signals with high classification accuracy. In addition, the proposed network is adaptive to the variation in the number of nodes and the topology of the architecture under the condition that each distributed node is connected to the others, thereby possessing high flexibility and practicability.
- (2)
- At each distributed node, the feature extraction method based on the cyclic spectrum is designed, in which the resampling and quantization algorithms can reduce the computational complexity significantly. Then, the local decision and its reliability are obtained by the KNN-based classifier through the extracted feature, which improves the accuracy of the subsequent decision fusion algorithm.
- (3)
- The distributed weighted average ADMM (DWA-ADMM) algorithm is designed for decision fusion to obtain a unified classification result, where the local decisions transmitted between distributed nodes are enhanced or weakened according to their reliabilities. Simulation results show that compared with traditional single-node AMC methods, the proposed algorithm can effectively improve the modulation classification accuracy under low SNR and reduce the negative impact of multipath fading channels.
2. System Model
Figure 1 shows the architecture of the distributed wireless transceiver platform. The target signals with unknown modulation schemes are transmitted at the transmitter via a radio antenna and received by each node in the distributed Co-AMC network. The local decisions are obtained through feature extraction and classifier in individual nodes. Then the unified classification result, which can be obtained by users at any node, is calculated by iteratively exchanging the local decisions via communication links in the distributed Co-AMC network.
The wireless channel model considered in this paper is a time-varying multipath channel, as depicted in Figure 1. This channel model exhibits two fundamental characteristics. Firstly, it entails different time delays for the received signals arriving at the receiver through multiple transmission paths. Secondly, it involves Doppler spread caused by the relative motion between the transmitter and receiver [26]. The received signal with additive noise of an individual node can be expressed as
where is the transmitted target signal with an unknown modulation scheme, and is the time impulse response. is applied to describe the multipath wireless channel [27], which can be expressed as
where the parameters , , and represent the channel fading coefficient, time delay, and direction of arrival (DOA), respectively. The maximum Doppler frequency is given by , where is the carrier frequency of the target signal, represents the speed of the distributed node, and c is the speed of light. The Dirac’s delta function is utilized. To facilitate further processing, the received signal is discretized into through sampling, i.e.,
where is the sample interval.
In the blind receiving system, modulation classification is an essential step before the signal is demodulated. In this paper, the local decision of the modulation scheme is obtained through feature extraction based on a cyclic spectrum and a KNN-based classifier. In addition, in order to simulate practical scenarios, we make the assumption that the carrier frequency and the time delay are unknown.
In order to integrate the local decisions of all nodes into a unified classification result, we consider the distributed Co-AMC network as a fully-distributed multi-agent network and represent it with an undirected network , where denotes the set of I nodes, and the edge set indicates the communication links between nodes as shown in Figure 1. We define the adjacency matrix of as W, where if and otherwise. Meanwhile, the neighborhood of the i-th node is denoted by and the diagonal degree matrix is defined as , where . The Laplacian matrix of is defined as , which is a symmetric positive semidefinite matrix [28]. For an undirected network, if the i-th smallest eigenvalue of the Laplacian matrix is with such that the first eigenvalue is zero, and is called the algebraic connectivity of , or the connectivity for short [29]. A higher value of indicates that more communication links exist among distributed nodes on average in the network.
In this paper, denotes the estimation of the local decision in the i-th node. Then, the i-th node and the j-th node agree in the network if and only if . When the nodes of the distributed Co-AMC network are all in agreement, the consensus equilibrium can be obtained as a unified classification. In this distributed optimization problem, each node aims to optimize the global objective function through exchanging information with others, which can be expressed as
where is the local objective function of the i-th node, and the consensus variable is used to guarantee . Two assumptions are made as follows [22].
Assumption 1.
The objective function is σ-strongly convex, i.e., such that
Assumption 2.
The communication of local decisions among nodes is considered as transmission without bit error. In addition, the unit communication cost among nodes is the same and remains constant for all iterations.
Assumption 1 is necessary for the convergence of the ADMM algorithm to solve problem (4). Assumption 2 guarantees that when optimizing the global objective function, we can only consider the importance of the local decisions and neglect the difference in the communication links among distributed nodes.
3. Distributed Co-AMC Network Design
3.1. Network Architecture
This section introduces the proposed distributed Co-AMC network, illustrated in Figure 1. The architecture of the network is depicted in Figure 2. Within this network, the received signals from each distributed node undergo signal feature extraction and classification to obtain a local decision and its corresponding reliability. This process involves a feature extraction module and a classifier module. Subsequently, these local decisions and their reliabilities are fused using the DWA-ADMM algorithm. This fusion enables the calculation of a unified classification result for the modulation scheme, which can then be transmitted to the user. Specifically, the network primarily consists of four modules: the feature extraction module, classifier module, reliability estimation module, and decision fusion module. Firstly, in the feature extraction module of each distributed node, the received signals are transformed into a cyclic spectrum to obtain the signal features. Subsequently, the classifier module employs a KNN structure to determine the local decision for each node. Meanwhile, two loss functions are used to evaluate the reliability of the local decision in each node. Finally, the decision fusion module fuses the local decisions and their reliabilities by iterative calculation and generates the final classification result for the user.
In the subsequent sections, we begin by constructing a dataset of received signals to simulate practical wireless signals in a multipath channel. Then, the feature extraction module, classifier module, reliability estimation module, and decision fusion module are introduced in detail.
3.2. Dataset
To ensure generality, a dataset of received signals is designed, and the specific parameters of the dataset are presented in Table 1. Multiple modulation schemes are considered to validate the effectiveness and adaptability of the proposed network. The Rayleigh channel model is employed to simulate the practical propagation environment based on Equation (2). Specifically, we assume that Hz, , is dB, and is s. The transmitted signal with an unknown modulation scheme can be expressed as
where is a binary or quaternary symbol sequence with random uniform distribution, is the carrier frequency, which is an unknown parameter for the receiver, is the symbol interval, and is a rectangular pulse that lasts for one symbol interval. In this paper, we assume that the received signal has a carrier frequency offset of −5 kHz∼5 kHz. In addition, in order to compare the classification performance under different network scales, the networks with different numbers of nodes are modeled, in which the received signals are generated according to (1).
3.3. Feature Extraction Module
In our proposed distributed Co-AMC network, each node utilizes a cyclic-spectrum-based feature extraction module. Firstly, the received signal is transformed into a normalized cyclic spectrum, as shown in Figure 3. Then, two cross-sections are extracted from the normalized cyclic spectrum as original features by setting the frequency to zero. Finally, the cross-section of the cyclic spectrum is resampled and quantified as the output of the feature extraction module. Specifically, in Figure 3a, for signals with cyclostationary characteristics, the synchronous averaging method with delay product form can be used to extract this periodicity according to [30,31]. The time-varying autocorrelation function of the received signal with samples is defined as
where is the sampling interval. is a periodic function whose period is with respect to time t, and can be denoted by the Fourier series as
The Fourier series coefficient, , is defined as
where is cyclic autocorrelation function, and is second-order cyclic frequency, or cyclic frequency for short. The cyclic spectrum is defined as the Fourier transform of , which can be expressed as
when , the cyclic autocorrelation function degenerates into the traditional autocorrelation function, the cyclic spectrum degenerates into the traditional power spectral density function.
For discrete signal , its cyclic autocorrelation function and cyclic spectrum are defined as
where is the sampling interval. The relationship between the cyclic autocorrelation function and its cyclic spectrum of the continuous signal and the discrete signal can be expressed as
When the signal is a band-limited random process in the mean square sense, i.e.,
where is the bandwidth of the signal , can be recovered from as follows:
It ensures that there will be no error in the digital processing of the received signal, and also restricts the range of spectral frequency in the cyclic spectrum processing method. The calculation of the cyclic autocorrelation function involves two variables: the cyclic frequency and the spectral frequency f. To ensure reliable spectral estimation, the resolution of the cyclic frequency and spectral frequency must satisfy the following reliability criteria [32].
where and represent the resolution of spectral frequency and cyclic frequency, respectively. Limited to the above constraints, the estimation of the cyclic autocorrelation function is generally obtained by soothing the cyclic periodic graph.
In this paper, to obtain the normalized cyclic spectrum, the fast Fourier transform (FFT) accumulation method (FAM) is employed, which utilizes a time-smoothing algorithm [33], as shown in Figure 3b. In Figure 3c, two cross-sections are extracted from the normalized cyclic spectrum by setting and as original features. As shown in Figure 3c, more sample points exist in the cross-section with than that with in the cyclic spectrum. Since is set to satisfy the reliability criteria of (17), it increases the amount of data calculation significantly. In order to reduce the computational complexity of subsequent processing, the cross-section with is resampled while retaining the main signal feature as follows:
where and represent the resolution of cyclic frequency before and after resampling, respectively, and is the decimation factor. Considering an original cross-section of the cyclic spectrum with samples, , the resampled cross-section, , is obtained by sampling every samples from the original cross-section, as shown in Figure 3d. In this paper, we set so that not only the signal features can be retained, but also the cross-section with after resampling has the same size as that with .
Then, resampled cross sections are quantified to further simplify the calculation and reduce the impact of spectral noise on classification as follows:
where a and are the amplitude of the cross-section before and after quantization, respectively. In this paper, the range of the normalized cyclic spectrum is . We divide it evenly into regions, i.e., , and take in each region as the quantization output of this region, as shown in Figure 3e. It is observed that the cross-section of the cyclic spectrum with quantization preserves the important features within the signal bandwidth and removes non-essential noise outside the bandwidth. In addition, the range of the quantized cyclic spectrum is converted from continuous interval to discrete values, which can effectively improve the calculation speed of digital signal processing modules deployed on distributed hardware. Finally, the feature vectors are obtained from the cross sections with resampling and quantization, which are two groups of discrete arrays with the same size, as shown in Figure 3f.
In Table 2, we take the multiple modulation schemes as an example to show the outputs of the feature extraction module, where the feature differences among five categories are demonstrated by the number and frequency of the peaks in the cross sections with and . In this experiment, we assume that 4 kHz, 8 kHz, 32 kHz, and the modulation frequency of BFSK 6 kHz, 10 kHZ. Table 2 lists the number and frequency of the peak in the cross-section under various modulation schemes. It is obvious that there are several distinct spectral lines with different frequencies both in the cross-sections with and under BASK and BFSK modulation schemes because their modulated signals are composed of complete periodic waves. In contrast, there are phase changes in a periodic waveform in the modulated signals of BPSK, QPSK, and MSK, which make the spectrum with a bandwidth appear in their cross-section with . However, there are peaks with different numbers and frequencies in the cross-section with , which makes them easier to be distinguished. Thus, all modulation schemes mentioned above can be classified by the extracted features based on the cyclic spectrum in theory.
3.4. Classifier Module
In this section, we introduce the classifier module based on the KNN algorithm. Compared with other prevalent classifiers such as CNN, the KNN-based classifier exhibits advantages in flexibility and interpretability. Specifically, KNN is a non-parametric algorithm, allowing it to handle complex and non-linear datasets without making assumptions about the data distribution. Furthermore, the classification results of KNN can be interpreted based on the voting outcomes of the nearest neighbors, which enhances the comprehensibility of the classification results. In our proposed distributed Co-AMC network, each node incorporates a KNN-based classifier module. The extracted feature vector is resized from to , two columns of which represent the cross sections of the spectral and cyclic frequencies, respectively, and act as the input testing sample for the classifier module. A general classifier module based on the KNN method, which is a popular classification method in data statistics because of its simple implementation and significant classification performance, is designed to obtain the local decision of the received signal in each node. Standard KNN classification predicts test data with its K-nearest neighbor in the training dataset, where the construction of distance function, classification rule, and value of K are key issues [34]. In this paper, we set the value of K to 13 by carrying out an m-fold cross-validation experiment, which is designed to compute an optimal K for training datasets [35]. The overall operations of the designed KNN-based classifier module are shown in Algorithm 1.
| Algorithm 1: KNN-Based Classifier |
Input: (1) The training dataset ; (2) The testing sampling ; (3) The parameter K for KNN classification. Output: The local decision Y of the input testing sampling .
|
Given a training dataset with training samples from class, where is the corresponding class label of , according to Section 3.2. The KNN classifier computes the Euclidean distances between the testing sample and each training sample as follows:
Then, the K-nearest neighbors of are computed and collected in ascending order in terms of their Euclidean distances, i.e.,
Finally, the testing sample is assigned to the local decision through a majority vote, i.e.,
where is the delta function with the value of ′1′ if or ′0′ otherwise. is an M-dimension vector, which represents the probability that the testing sample is classified as class according to KNN. It is obvious that the class corresponding to the maximum value in Y can be considered as the classification result of the individual node, i.e.,
In the proposed distributed Co-AMC network, the global classification result will be obtained through the following decision fusion module based on the local decision computed by each node.
3.5. Reliability Estimation Module
In this section, we introduce the reliability estimation module for the local decision obtained in Section 3.4. This module estimates the reliability of local decision based on two loss functions with the K-nearest neighbors of mentioned in the classifier module. The two loss functions, namely the loss of distance and exponential loss of the K-nearest neighbors, respectively, are mapped into reliability as the input of the decision fusion module with its corresponding local decision.
Specifically, the loss of distance measures the average distance between the testing sample and the training dataset, which can be expressed as
where represent the training samples in the whose class label is the result of local classification , represents the number of these training samples. Furthermore, is the sum of the distance between the testing sample and these training samples, which is calculated according to (20). The smaller the , the smaller the difference of received signal feature between the testing sample and the training samples is, which can be used as one of the parameters to evaluate the reliability of the local decision.
Meanwhile, another loss function, i.e., the exponential loss, which measures the maximum voting score of the local decision, can be expressed as
where is the local decision, in which represents the voting score of the class for the testing sample. The class corresponding to the maximum voting score is the result of local classification in each node. According to (25), the higher the maximum voting score, the smaller the exponential loss is. In addition, exponential loss ensures monotonic decline with the increase in the maximum voting score, and its lower bound is .
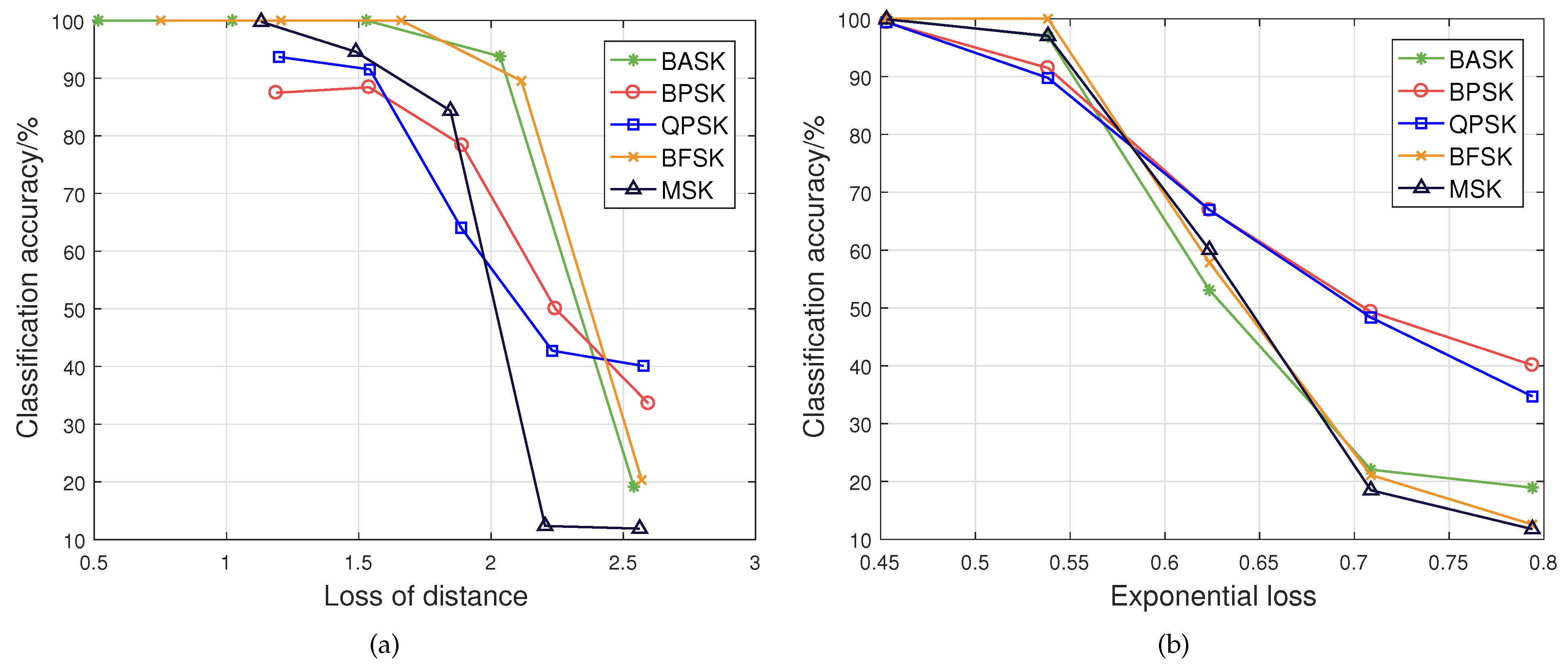
The values of the two loss functions under various modulation schemes and SNRs are shown in Figure 4. It is obvious that both the loss of distance and exponential loss decrease with the increase in the SNR of the received signal. This is because the signal features of the received signal are not significantly affected by noise under low SNR. In addition, it is observed that both the loss of distance and exponential loss of BASK and BFSK modulation schemes are smaller than those of other modulation schemes under the same SNR of the received signal. Since the unique signal features can be obtained at both spectral and cyclic frequencies under BASK and BFSK modulation schemes, the BASK and BFSK modulation schemes have less value of loss function and are easier to be classified than the other modulation schemes, as analyzed in Section 3.3. Then, the classification accuracies under different values of loss function are shown in Figure 5. It is obvious that the classification accuracy declines with the increase in the loss of distance or exponential loss under each modulation scheme. In particular, the classification accuracy decreases sharply when the loss of distance is greater than a certain threshold, which indicates that the signal feature cannot be distinguished accurately when the received signal is too weak.
In the proposed distributed Co-AMC network, the SNR of the received signal at each node is different and varies with time due to the geographical distribution of nodes and the impact of multipath fading channels. The classification performance of the whole network will be affected if the local decision is fused, which is obtained from the node with too low SNR of the current received signal. Thus, the reliability of the local decision is designed as the weighted value when that is fused according to the two loss functions. We set a threshold for loss of distance and exponential loss, respectively. When the values of loss functions are lower than their threshold, the current local decision is considered reliable, i.e., the weighted value is one, Otherwise, the weighted value is zero. Thus, we have
where represents the reliability of the i-th node, and represent the threshold of the loss of distance and the exponential loss, respectively. Finally, are the local decision and its corresponding reliability obtained by each node, which are iteratively exchanged for decision fusion in the proposed network.
3.6. Decision Fusion Module
In this section, we introduce the decision fusion module based on the designed DWA-ADMM algorithm. In Section 3.4 and Section 3.5, the local decision and the reliability of each node which can be transmitted to other connected nodes with communication links in the proposed network have been obtained through the KNN-based classifier. In order to compute the unified global classification result, the local decisions are weighted and averaged according to their reliabilities through their iterative exchange among connected nodes in the designed decision fusion module based on ADMM.
Considering problem (4) mentioned in Section 2, the core idea of the ADMM algorithm is the augmented Lagrange method (ALM) of the original dual algorithm [36]. In addition, in order to accelerate the convergence speed of the algorithm, the penalty function is applied. The augmented Lagrange function of problem (4) is
where and are Lagrange dual variables corresponding to the two constraints and , respectively, is the penalty parameter and the last term is the -norm of the two constraints which is used to promote robustness. The ADMM algorithm is solved iteratively by updating the variable , , and according to the following rule [36]:
At the t-th iteration and for , each variable is updated alternately by fixing other variables. In order to simplify the above update rule, it is worth noting that (29) is a quadratic unconstrained equation about , whose closed solution is
Meanwhile, it is obvious that and at any iteration. Thus, (32) can be further simplified as
At the t-th iteration and for , by substituting (35) into (28) and defining as the Lagrange multiplier with the initial condition , the update rule of the ADMM can be simplified as
In the above algorithm, each node stores the variable and the corresponding Lagrange multiplier . In each iteration, the i-th node receives the estimated variable from the connected nodes and optimizes the local objective function . Then the i-th node shares the updated estimated variables with the connected nodes for the next iteration. In this paper, the local objective function can be expressed as
where is the estimated variable, is the local decision obtained by the classifier in the i-th node, and is the corresponding reliability. Therefore, problem (4) can be specifically expressed as
The global optimization objective of (39) is to compute the weighted average of local decisions obtained by all nodes in the network according to their reliabilities. By substituting (39) into (36) and (37), the update rule of the DWA-ADMM can be expressed as
Meanwhile, we use the primal residuals and dual residuals as the variables to decide when the iteration stops, which can be expressed as
Note that the iteration of the proposed DWA-ADMM algorithm will stop when the -norm of primal residuals and dual residuals are lower than the predetermined thresholds in all nodes, which can be expressed as
where and represent the predetermined thresholds of the primal residual and dual residual, respectively. Finally, after the iteration, the estimated variables represent the possibility that the modulation scheme of the received signal belongs to class . In the proposed distributed Co-AMC network, the unified classification result of the received signal is the class corresponding to the maximum value in , which can be expressed as
The proposed DWA-ADMM procedure can be summarized in Algorithm 2.
| Algorithm 2: The Proposed DWA-ADMM |
Input: (1) The local decision ; (2) The reliability of the local decision ; (3) The penalty parameter . Output: The classification result .  |
In addition, we can also impose the following standard propositions on the optimization problem in (38).
Proposition 1.
(Convexity): Each of the objective functions is closed, proper and strictly convex.
Proposition 2.
(Existence of a Saddle Point): The unaugmented Lagrange function of problem (38), , has a saddle point, i.e., there exists a solution , not necessarily unique, for which .
The proof of the convexity is well known and can be found in [37] and the proof of the existence of the saddle point can be found in [38]. Since the objective function of (38) is affine, i.e., satisfying all those conditions, the algorithm is guaranteed to converge. Hence, this convergence property is independent of the network topology, and, in essence, it highlights the application of the proposed algorithm to the arbitrarily connected networks.
4. Experimental Results
In this section, we conduct experiments to verify the effectiveness of the key components in the proposed distributed Co-AMC network. Specifically, in Section 4.1, we focus on analyzing the complexity and convergence of the designed algorithm. In Section 4.2 and Section 4.3, the accuracy of the proposed network for modulation classification is evaluated by comparing with AMC of a single node and other existing methods. Furthermore, in Section 4.4, we analyze the impact of the number of nodes and the connectivity of the communication network on the performance of the proposed distributed Co-AMC network. For a fair comparison, all the algorithms are implemented using a Matlab 2019b/Windows 10 environment on a computer with a 2.10 GHz AMD-Ryzen-3500U.
4.1. Computational Complexity and Convergence Property of the Distributed Co-AMC Network
The overall computational complexity of each node in the proposed network consists of three parts. Firstly, the cyclic spectrum is calculated from the received signal with samples according to the FAM method. Then, the local decision and its reliability are obtained by computing and searching K-nearest neighbors in the training dataset, in which there are training samples with length . Thirdly, the classification result is obtained through -times iterative computation from the M-dimension local decision in the proposed network with I nodes. The complexity of the three steps can be expressed as , and , respectively.
Compared with the other two steps, the second step has the highest computational complexity, which mainly depends on the sizes of the training dataset and training sample. However, benefiting from the resampling and quantization in the feature extraction module, the size of the training sample is much less than the received signal, i.e., , and the training sample contains the values of zero, which significantly reduce the computational complexity in the second step. In addition, in the third step, the designed algorithm for decision fusion further reduces the computational complexity by reducing the amount of complex multiplication in each iteration.
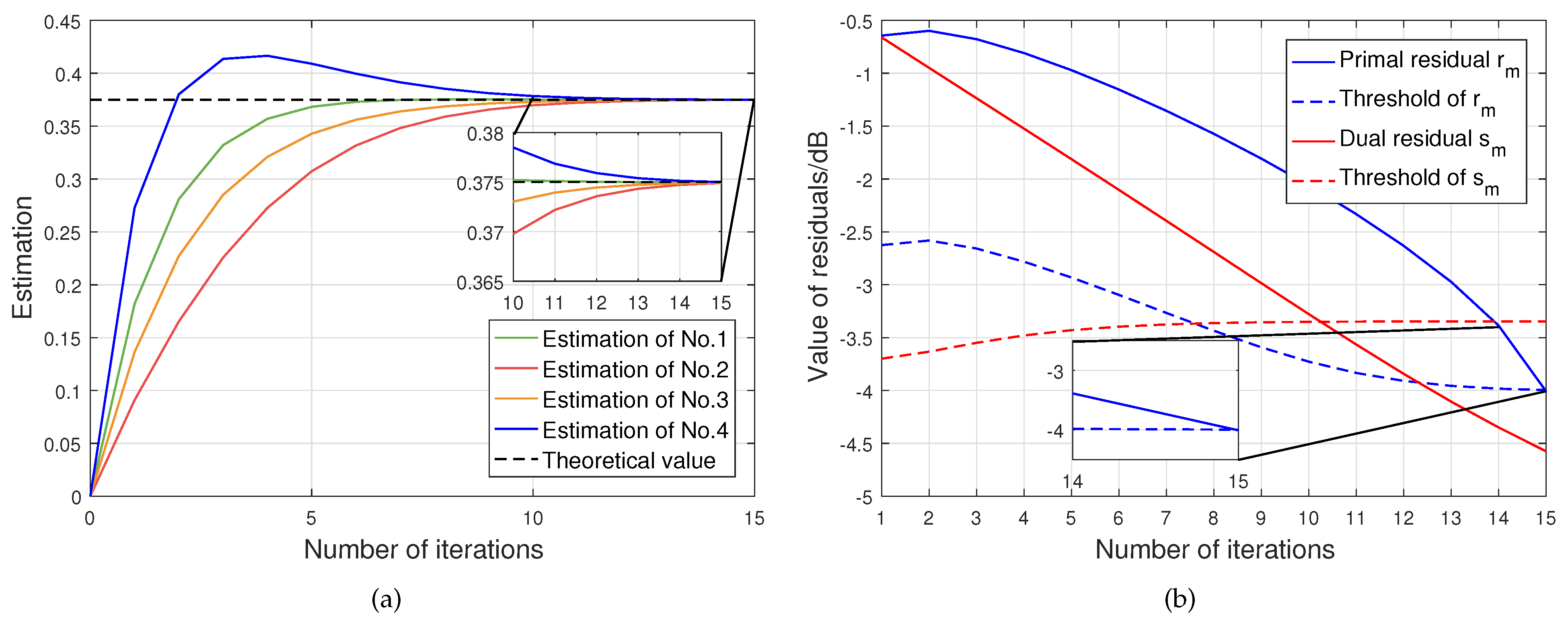
In addition, in order to evaluate the convergence property of the designed DWA-ADMM algorithm, we carry out a simulation experiment for the decision fusion module. We randomly generate the local decisions and their corresponding reliability for each node in the network, and fuse them by iterative computation according to the algorithm introduced in Section 3.6. In this experiment, we assume that the number of nodes and the network is fully connected, which means that each node can connect with all other nodes. According to (39), the theoretical value of the fused decision for the class is the weighted average of local decisions for each node, i.e., . The objective of each node is to make the estimation close to the theoretical value by iteration.
The convergence results of each node are presented in Figure 6. It can be observed that the estimations of all nodes in the network, whose initial values are zero, are almost equal to the theoretical value after fifteen iterations, as shown in Figure 6a. Furthermore, in Figure 6b, it can be observed that the iteration stops when the primal residual and dual residual of the estimation are both less than their respective thresholds according to (44) and (45).
4.2. Classification Effectiveness of the Distributed Co-AMC Network
To assess the effectiveness of the proposed distributed Co-AMC network, the following metrics are considered: accuracy, precision, and recall, as defined in Equations (47)–(49), respectively. These metrics are derived from the confusion matrix, which includes true positive (TP), false positive (FP), false negative (FN), and true negative (TN) indices. TP and TN represent the number of positive and negative samples correctly classified, while FP and FN represent the number of positive and negative samples incorrectly classified. In addition, we randomly generate 1000 sets of testing samples for each class under various SNRs to verify the performance of the proposed distributed Co-AMC network according to the dataset parameters in Section 3.2.
To measure the accuracy of the proposed distributed Co-AMC network, we employ the confusion matrix. The obtained confusion matrix is presented in Figure 7. In this figure, the first five diagonal cells show the number and percentage of correct classifications by the proposed network. For example, 1000 testing samples are correctly classified as a BASK modulation scheme, which corresponds to 20.0% of all 5000 testing samples. The observation reveals that the predicted and actual classes tend to cluster along the diagonal axes, indicating a high classification accuracy achieved by the proposed network. Meanwhile, the blue cells (except the diagonals) show the number and percentage of incorrect classifications. For example, 66 testing samples of the BPSK modulation scheme are incorrectly classified as the QPSK modulation scheme, which corresponds to 1.3% of all testing samples. In addition, the green cells on the right and bottom display the precision and recall metrics for each classification. Specifically, out of 1004 predictions of the BASK modulation scheme, 99.6% are correct and 0.4% are wrong, according to (48). Similarly, out of 1000 testing samples of the BPSK modulation scheme, 89.8% are correctly classified as the BPSK modulation scheme and 10.2% are classified as other modulation schemes, according to (49).
Overall, 92.7% of the predictions are classified correctly and 7.3% are wrong classifications, as shown in the green cell at the bottom right. The best-classified modulation schemes are BASK and BFSK with a recall of 100%, while the class classification error of the proposed network mainly occurs for the BPSK, QPSK, and MSK modulation schemes. This is because the extracted signal features of BASK and BFSK can be distinguished in both spectral frequency and cyclic frequency, while the extracted features of other classifications only have significant differences in cyclic frequency, especially under low SNRs.
4.3. Classification Accuracy of the Distributed Co-AMC Compared to the Single-Node AMC and Existing AMC Methods
To assess the classification accuracy of the proposed distributed Co-AMC network in comparison to the single-node AMC, an ablation study is conducted. In the single-node AMC, the local decision of a single node is considered to be the classification result. The accuracies of the Co-AMC and single-node AMC are compared and depicted in Figure 8. The results demonstrate that the proposed distributed Co-AMC network significantly outperforms the single-node AMC across various modulation schemes and SNRs. Notably, with the distributed Co-AMC network, the classification accuracy not only increases with the increase in SNR but also achieves near 100% when the SNR is as low as 0 dB for specific modulation schemes. Due to the geographical distribution of nodes and the impact of multipath fading channels in the Co-AMC network with multiple nodes, the SNR of the received signal at each node is different and varies with time, which will affect the classification accuracy if only the local decision from one node is used as the classification result of the whole network. Benefiting from the designed decision fusion module based on DWA-ADMM, the local decisions from all nodes are weighted and averaged based on their reliabilities, which filters those from the nodes with low SNR and improves the classification accuracy.
Furthermore, the classification accuracies of the proposed distributed Co-AMC network, as compared to other methods, are presented in Figure 9. The existing AMC method introduced in [39] is used as a baseline for comparison. The results demonstrate that the proposed distributed Co-AMC network outperforms existing methods significantly across various modulation schemes and SNRs. Remarkably, the proposed distributed Co-AMC network demonstrates a significant improvement in classification accuracy with increasing SNR. Particularly, under BFSK modulation schemes, the accuracy reaches nearly 100% even at an extremely low SNR of −15 dB. Similarly, under BPSK, QPSK, and MSK modulation schemes, the accuracy achieves 90% at a challenging SNR as low as −10 dB, which cannot be achieved by the existing method under such a low SNR. Thus, our proposed network is more suitable for AMC under the condition of low SNR.
4.4. Classification Effectiveness of the Distributed Co-AMC Network with Different Numbers of Nodes and Connectivity
To verify the robustness of our proposed network under different network scales and topologies, we apply the designed DWA-ADMM algorithm to the architecture with different numbers of nodes and connectivities, where the number of nodes and its connectivity correspond to the network scale and topology, respectively, as mentioned in Section 2.
The classification accuracy and the number of iterations of our proposed network with different numbers of nodes under various SNRs are shown in Figure 10. It can be observed that the classification accuracy of the network with a different number of nodes rises with the increase in SNR and reaches almost 100% when the SNR is as low as −5 dB∼0 dB. Noticeably, the classification accuracy of the network with a larger number of nodes is higher than those with fewer nodes when the SNR is lower than 0dB. In contrast, the number of iterations first decreases and then remains stable with the increase in SNR. Meanwhile, the number of iterations with a larger number of nodes is higher than those with fewer nodes when the SNR is small, which means that the expansion of the network scale increases the number of iterations while improving the classification performance, especially under low SNR. This is because the reliabilities of local decisions become one with the increase in the average SNR of all nodes in the network. The theoretical value of the fused decision degenerates from the weighted average to the arithmetic average, i.e., , which reduces the computational complexity of the optimization objective function and thus reduces the number of iterations.
In addition, the number of iterations of the network with a different number of nodes and its connectivity are shown in Figure 11. It is observed that the number of iterations gradually decreases and stabilizes with the increase in connectivity. This indicates that our proposed distributed Co-AMC network can achieve a reliable classification result with a few iterations without establishing too many communication connections among nodes. Therefore, the proposed distributed Co-AMC is adaptive to wireless networks with various scales and topologies.
5. Conclusions
In this paper, we have proposed a novel distributed Co-AMC network based on ML for wireless communication networks. The proposed network architecture consists of four essential modules: the feature extraction module, classifier module, reliability estimation module, and decision fusion module. Specifically, the feature vectors with resampling and quantization were calculated by applying the cyclic spectrum to the feature extraction module. The classifier module based on the KNN was designed to obtain the local decision according to the feature vectors at each distributed node. Then, the reliability of the local decision was estimated by applying two loss functions in the reliability estimation module. Finally, the classification result of the modulation scheme was obtained by applying the designed DWA-ADMM algorithm through iterative calculation among distributed nodes. Simulation results demonstrated that the proposed distributed Co-AMC network outperformed the existing AMC methods under various modulation schemes, especially when the SNR was low. In addition, our proposed Co-AMC is adaptive to the variations in the number of nodes and topologies of wireless networks, thereby possessing higher flexibility and practicability.
Author Contributions
Conceptualization, Q.Z.; methodology, Q.Z. and H.L.; software, Y.G.; validation, Q.Z.; investigation Y.G. and Z.S.; writing—original draft preparation Y.G.; writing—review and editing Y.G. and Z.S.; supervision H.L. and Z.S.; project administration Q.Z. and H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
No new data were created or analyzed in this study.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Qi, P.; Zhou, X.; Zheng, S.; Li, Z. Automatic modulation classification based on deep residual networks with multimodal information. IEEE Trans. Cogn. Commun. Netw. 2020, 7, 21–33. [Google Scholar] [CrossRef]
- Jafar, N.; Paeiz, A.; Farzaneh, A. Automatic modulation classification using modulation fingerprint extraction. J. Syst. Eng. Electron. 2021, 32, 799–810. [Google Scholar] [CrossRef]
- Kojima, S.; Maruta, K.; Feng, Y.; Ahn, C.J.; Tarokh, V. CNN-based joint SNR and Doppler shift classification using spectrogram images for adaptive modulation and coding. IEEE Trans. Commun. 2021, 69, 5152–5167. [Google Scholar] [CrossRef]
- Peng, S.; Sun, S.; Yao, Y.D. A survey of modulation classification using deep learning: Signal representation and data preprocessing. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 7020–7038. [Google Scholar] [CrossRef] [PubMed]
- Dobre, O.A.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. IET Commun. 2007, 1, 137–156. [Google Scholar] [CrossRef] [Green Version]
- Ozdemir, O.; Wimalajeewa, T.; Dulek, B.; Varshney, P.K.; Su, W. Asynchronous linear modulation classification with multiple sensors via generalized EM algorithm. IEEE Trans. Wirel. Commun. 2015, 14, 6389–6400. [Google Scholar] [CrossRef] [Green Version]
- Yan, X.; Feng, G.; Wu, H.C.; Xiang, W.; Wang, Q. Innovative robust modulation classification using graph-based cyclic-spectrum analysis. IEEE Commun. Lett. 2016, 21, 16–19. [Google Scholar] [CrossRef]
- Zhang, Q.; Guan, Y.; Li, H.; Xiong, K.; Song, Z. Distributed deep learning-based signal classification for time–frequency synchronization in wireless networks. Comput. Commun. 2023, 201, 37–47. [Google Scholar] [CrossRef]
- Wang, F.; Huang, S.; Wang, H.; Yang, C. Automatic modulation classification exploiting hybrid machine learning network. Math. Probl. Eng. 2018, 2018, 1–14. [Google Scholar] [CrossRef]
- Kumar, Y.; Sheoran, M.; Jajoo, G.; Yadav, S.K. Automatic modulation classification based on constellation density using deep learning. IEEE Commun. Lett. 2020, 24, 1275–1278. [Google Scholar] [CrossRef]
- Abdelbar, M.; Tranter, W.H.; Bose, T. Cooperative cumulants-based modulation classification in distributed networks. IEEE Trans. Cogn. Commun. Netw. 2018, 4, 446–461. [Google Scholar] [CrossRef]
- Abdelgawad, A.; Bayoumi, M. Resource-Aware Data Fusion Algorithms for Wireless Sensor Networks; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012; Volume 118. [Google Scholar]
- Hakimi, S.; Hodtani, G.A. Optimized distributed automatic modulation classification in wireless sensor networks using information theoretic measures. IEEE Sens. J. 2017, 17, 3079–3091. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, J.; Zhang, W.; Yang, J.; Gui, G. Deep learning-based cooperative automatic modulation classification method for MIMO systems. IEEE Trans. Veh. Technol. 2020, 69, 4575–4579. [Google Scholar] [CrossRef]
- Ozdemir, O.; Li, R.; Varshney, P.K. Hybrid maximum likelihood modulation classification using multiple radios. IEEE Commun. Lett. 2013, 17, 1889–1892. [Google Scholar] [CrossRef] [Green Version]
- Dulek, B.; Ozdemir, O.; Varshney, P.K.; Su, W. Distributed maximum likelihood classification of linear modulations over nonidentical flat block-fading Gaussian channels. IEEE Trans. Wirel. Commun. 2014, 14, 724–737. [Google Scholar] [CrossRef]
- Dulek, B. An online and distributed approach for modulation classification using wireless sensor networks. IEEE Sens. J. 2017, 17, 1781–1787. [Google Scholar] [CrossRef]
- Headley, W.C.; Reed, J.D.; da Silva, C.R.C.M. Distributed Cyclic Spectrum Feature-Based Modulation Classification. In Proceedings of the 2008 IEEE Wireless Communications and Networking Conference, Las Vegas, NV, USA, 31 March–3 April 2008; pp. 1200–1204. [Google Scholar] [CrossRef]
- Fu, X.; Gui, G.; Wang, Y.; Gacanin, H.; Adachi, F. Automatic modulation classification based on decentralized learning and ensemble learning. IEEE Trans. Veh. Technol. 2022, 71, 7942–7946. [Google Scholar] [CrossRef]
- Yan, X.; Rao, X.; Wang, Q.; Wu, H.C.; Zhang, Y.; Wu, Y. Novel Cooperative Automatic Modulation Classification Using Unmanned Aerial Vehicles. IEEE Sens. J. 2021, 21, 28107–28117. [Google Scholar] [CrossRef]
- Wang, Y.; Guo, L.; Zhao, Y.; Yang, J.; Adebisi, B.; Gacanin, H.; Gui, G. Distributed learning for automatic modulation classification in edge devices. IEEE Wirel. Commun. Lett. 2020, 9, 2177–2181. [Google Scholar] [CrossRef]
- Tian, Z.; Zhang, Z.; Wang, J.; Chen, X.; Wang, W.; Dai, H. Distributed ADMM with synergetic communication and computation. IEEE Trans. Commun. 2020, 69, 501–517. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, J.; Wang, Y. Efficient QAM signal detector for massive MIMO systems via PS/DPS-ADMM approaches. IEEE Trans. Wirel. Commun. 2022, 21, 8859–8871. [Google Scholar] [CrossRef]
- Manosha, K.S.; Joshi, S.K.; Codreanu, M.; Rajatheva, N.; Latva-aho, M. Admission control algorithms for QoS-constrained multicell MISO downlink systems. IEEE Trans. Wirel. Commun. 2017, 17, 1982–1999. [Google Scholar] [CrossRef] [Green Version]
- Leinonen, M.; Codreanu, M.; Juntti, M. Distributed joint resource and routing optimization in wireless sensor networks via alternating direction method of multipliers. IEEE Trans. Wirel. Commun. 2013, 12, 5454–5467. [Google Scholar] [CrossRef]
- Strom, E.G.; Malmsten, F. A maximum likelihood approach for estimating DS-CDMA multipath fading channels. IEEE J. Sel. Areas Commun. 2000, 18, 132–140. [Google Scholar] [CrossRef]
- Yi, Z.; Jiao, Y.; Dai, W.; Li, G.; Wang, H.; Xu, Y. A Stackelberg Incentive Mechanism for Wireless Federated Learning With Differential Privacy. IEEE Wirel. Commun. Lett. 2022, 11, 1805–1809. [Google Scholar] [CrossRef]
- Li, T.; Fu, M.; Xie, L.; Zhang, J.F. Distributed consensus with limited communication data rate. IEEE Trans. Autom. Control 2010, 56, 279–292. [Google Scholar] [CrossRef] [Green Version]
- Fiedler, M. Algebraic connectivity of graphs. Czechoslov. Math. J. 1973, 23, 298–305. [Google Scholar] [CrossRef]
- Gardner, W. Spectral correlation of modulated signals: Part I-analog modulation. IEEE Trans. Commun. 1987, 35, 584–594. [Google Scholar] [CrossRef]
- Gardner, W.; Brown, W.; Chen, C.K. Spectral correlation of modulated signals: Part II-digital modulation. IEEE Trans. Commun. 1987, 35, 595–601. [Google Scholar] [CrossRef]
- Gardner, W. Measurement of spectral correlation. IEEE Trans. Acoust. Speech Signal Process. 1986, 34, 1111–1123. [Google Scholar] [CrossRef]
- Tom, C. Cyclostionary Spectral Analysis of Typical Satcom Signals Using the fft Accumulation Method; Technical Report; Defence Research Establishment Ottawa (Ontario): Ottawa, ON, Canada, 1995. [Google Scholar]
- Zhang, S.; Li, X.; Zong, M.; Zhu, X.; Cheng, D. Learning k for knn classification. ACM Trans. Intell. Syst. Technol. (TIST) 2017, 8, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S. Challenges in KNN Classification. IEEE Trans. Knowl. Data Eng. 2022, 34, 4663–4675. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends® Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Goldsmith, A. Wireless Communications; Cambridge University Press: Cambridge, UK, 2005. [Google Scholar]
- Foukalas, F.; Shakeri, R.; Khattab, T. Distributed power allocation for multi-flow carrier aggregation in heterogeneous cognitive cellular networks. IEEE Trans. Wirel. Commun. 2018, 17, 2486–2498. [Google Scholar] [CrossRef]
- Ma, J.; Qiu, T. Automatic modulation classification using cyclic correntropy spectrum in impulsive noise. IEEE Wirel. Commun. Lett. 2018, 8, 440–443. [Google Scholar] [CrossRef]
Figure 1.
Architecture of the distributed wireless transceiver platform.

Figure 2.
Architecture of the proposed distributed Co-AMC network.

Figure 3.
Architecture of the feature extraction module.

Figure 4.
Two loss functions under various modulation schemes and SNRs. (a) Loss of distance. (b) Exponential loss.
Figure 4.
Two loss functions under various modulation schemes and SNRs. (a) Loss of distance. (b) Exponential loss.

Figure 5.
Classification accuracy under two loss functions. (a) Classification accuracy under different loss of distance. (b) Classification accuracy under different exponential loss.
Figure 5.
Classification accuracy under two loss functions. (a) Classification accuracy under different loss of distance. (b) Classification accuracy under different exponential loss.

Figure 6.
Convergence results of the designed DWA-ADMM algorithm. (a) Estimated result of the local decision in each node. (b) Residuals of estimation in each node.
Figure 6.
Convergence results of the designed DWA-ADMM algorithm. (a) Estimated result of the local decision in each node. (b) Residuals of estimation in each node.

Figure 7.
Confusion matrix of the classification result.

Figure 8.
Classification accuracy of Co-AMC compared with the single-node AMC.

Figure 9.
Classification accuracy of Co-AMC compared with the existing AMC methods.

Figure 10.
Classification accuracy and number of iterations for the network with different numbers of nodes.
Figure 10.
Classification accuracy and number of iterations for the network with different numbers of nodes.

Figure 11.
Number of iterations for the network with different numbers of nodes and connectivities.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Dataset parameters.
| Parameter | Description |
|---|---|
| Modulation Scheme | BASK, BPSK, QPSK BFSK, and MSK |
| Number of Samples per Symbol | 16 |
| Baud Rate () | 2 kHz or 4 kHz |
| Frequency Offset | −5 kHz∼5 kHz |
| Number of Distributed Nodes in Receiver | 4 or 8 or 16 |
| Time Delay of Received Signal | 0∼10 |
| SNR | −20 dB∼20 dB |
Table 2.
Dataset parameters.
| Modulation Scheme | Cross Section with | Cross Section with |
|---|---|---|
| BASK | Spectral line: | 2 peaks: |
| BPSK | Spectrum with bandwidth: | 6 peaks: and |
| QPSK | Spectrum with bandwidth: | No distinct peaks |
| BFSK | Spectral line: and | 4 peaks: and |
| MSK | Spectrum with bandwidth: | 4 peaks: |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, Q.; Guan, Y.; Li , H.; Song, Z. Distributed Cooperative Automatic Modulation Classification Using DWA-ADMM in Wireless Communication Networks. Electronics 2023, 12, 3002. https://doi.org/10.3390/electronics12143002
AMA Style
Zhang Q, Guan Y, Li H, Song Z. Distributed Cooperative Automatic Modulation Classification Using DWA-ADMM in Wireless Communication Networks. Electronics. 2023; 12(14):3002. https://doi.org/10.3390/electronics12143002
Chicago/Turabian StyleZhang, Qin, Yutong Guan, Hai Li , and Zhengyu Song. 2023. "Distributed Cooperative Automatic Modulation Classification Using DWA-ADMM in Wireless Communication Networks" Electronics 12, no. 14: 3002. https://doi.org/10.3390/electronics12143002
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.