
Support Vector Regression Model for Determining Optimal Parameters of HfAlO-Based Charge Trapping Memory Devices

 , and
, and
Abstract
:1. Introduction
2. Materials and Methods
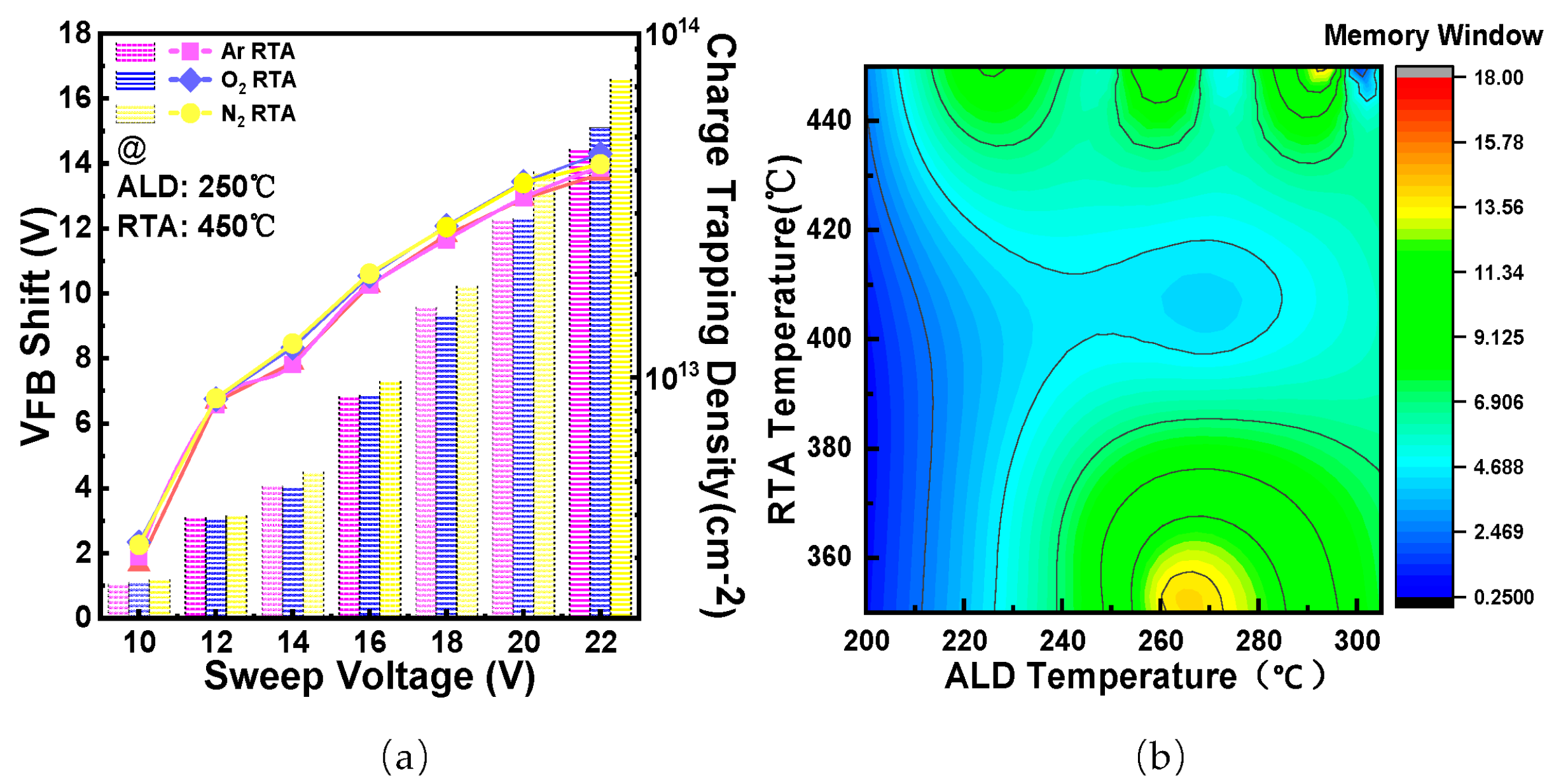
2.1. Experiment Methods
2.2. Data Pre-Processing
2.3. Optimization Methods
2.3.1. Whale Optimization Algorithm (WOA)
2.3.2. Pelican Optimization Algorithm (POA)
2.3.3. Grey Wolf Optimization (GWO)
2.3.4. Moth-Flame Optimization (MFO)
2.3.5. Particle Swarm Optimization (PSO)
2.3.6. Osprey Optimization Algorithm (OOA)
2.4. Model Error Detection
3. Results and Discussions
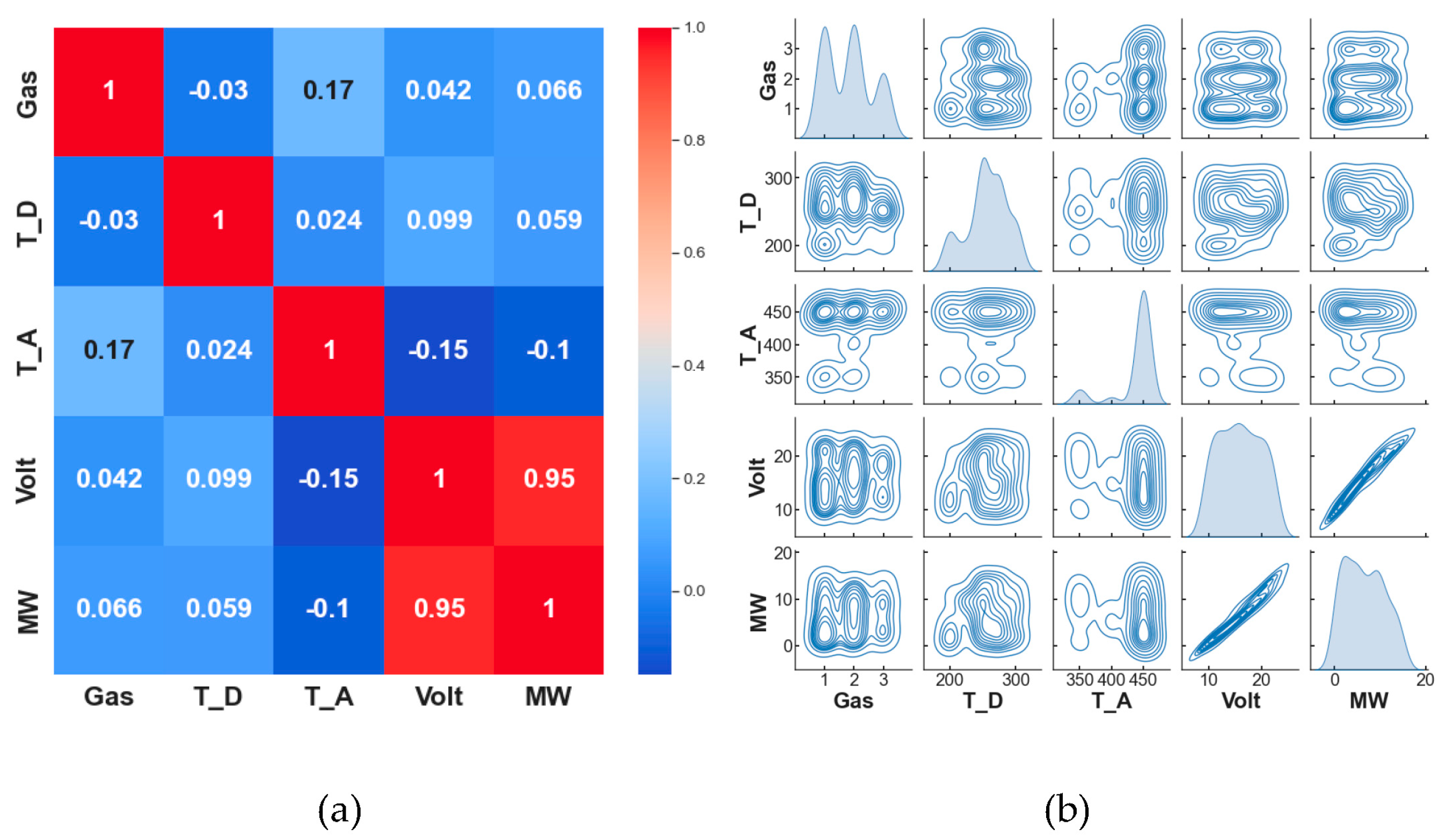
3.1. Dataset Pre-Analysis
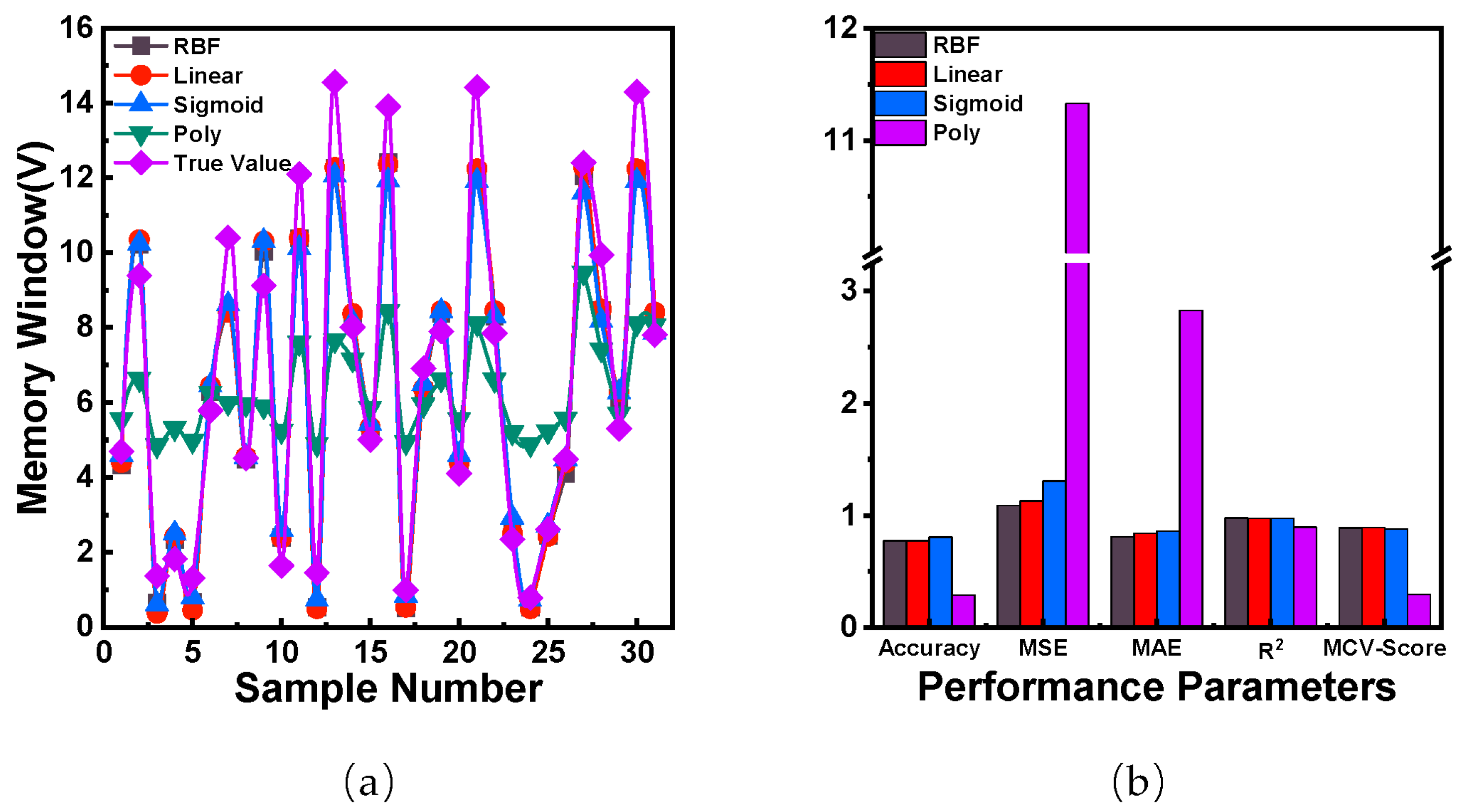
3.2. Comparison of Different Kernel Function
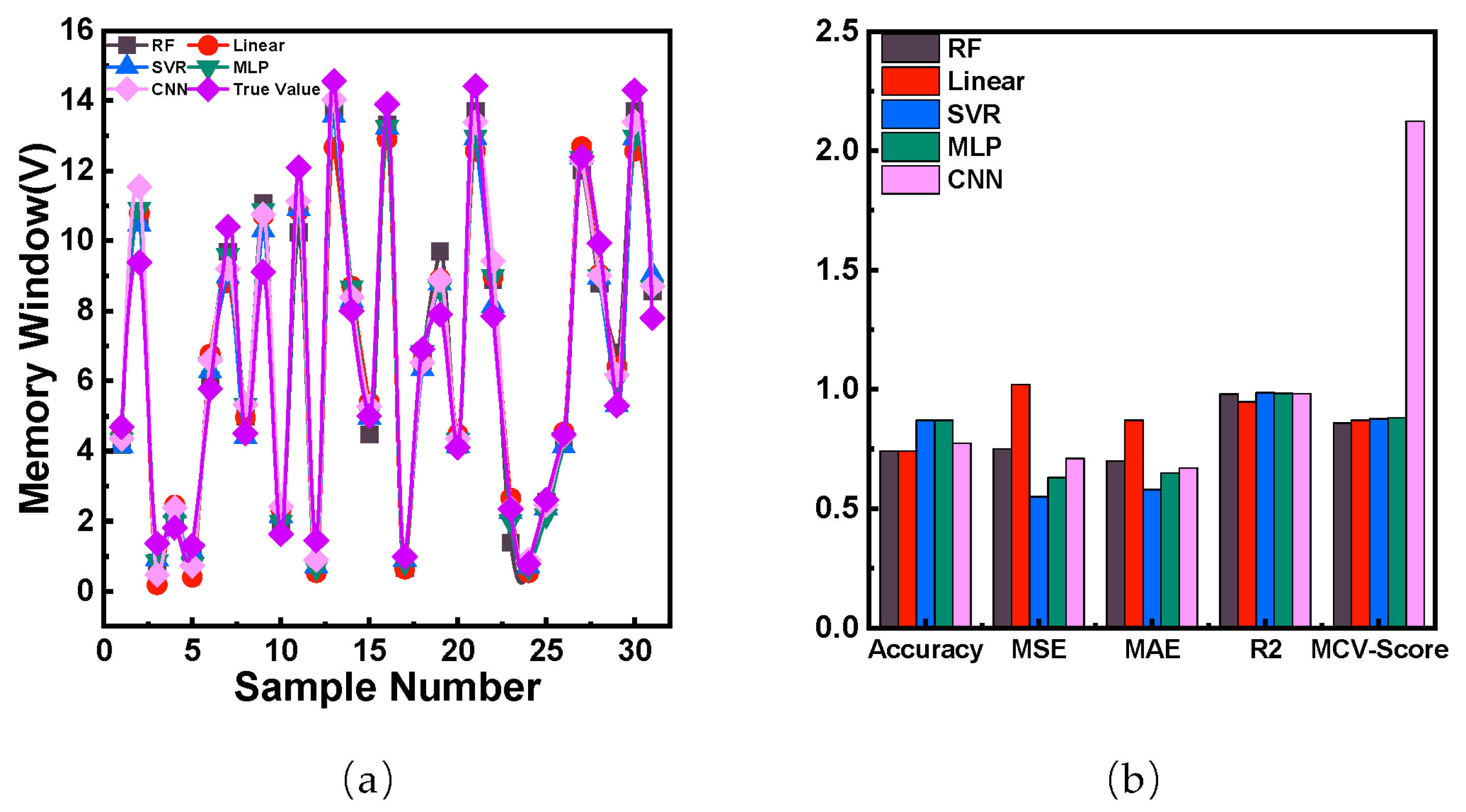
3.3. Comparison with Other Models
3.4. Different Swarm Algorithm Optimization
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Research, G.V. Next Generation Non Volatile Memory Market Size, Share & Trends Analysis Report by Product (FeRAM, PCM, MRAM, ReRAM), by Application, by Region, and Segment Forecasts, 2018–2024. In Market Analysis Report; Grand View Research: Pune, India, 2015. [Google Scholar]
- Nowak, E.; Chłopocka, E.; Szybowicz, M. ZnO and ZnO-Based Materials as Active Layer in Resistive Random-Access Memory (RRAM). Crystals 2023, 13, 416. [Google Scholar] [CrossRef]
- Hu, Y.; Rabelo, M.; Kim, T.; Cho, J.; Choi, J.; Fan, X.; Yi, J. Ferroelectricity Based Memory Devices: New-Generation of Materials and Applications. Trans. Electr. Electron. Mater. 2023, 24, 271–278. [Google Scholar] [CrossRef]
- Redaelli, A.; Petroni, E.; Annunziata, R. Material and Process Engineering Challenges in Ge-Rich GST for Embedded PCM. J. Mater. Sci. Semicond. Process. 2022, 137, 106184. [Google Scholar] [CrossRef]
- Alahmadi, A.; Chung, T.S. Crash Recovery Techniques for Flash Storage Devices Leveraging Flash Translation Layer: A Review. Electronics 2023, 12, 1422. [Google Scholar] [CrossRef]
- Shen, S.C.; Khare, E.; Lee, N.A.; Saad, M.K.; Kaplan, D.L.; Buehler, M.J. Computational Design and Manufacturing of Sustainable Materials through First-Principles and Materiomics. Chem. Rev. 2023, 123, 2242–2275. [Google Scholar] [CrossRef] [PubMed]
- Yoo, J.-H.; Park, W.-J.; Kim, S.-W.; Lee, G.-R.; Kim, J.-H.; Lee, J.-H.; Uhm, S.-H.; Lee, H.-C. Preparation of Remote Plasma Atomic Layer-Deposited HfO2 Thin Films with High Charge Trapping Densities and Their Application in Nonvolatile Memory Devices. Nanomaterials 2023, 13, 1785. [Google Scholar] [CrossRef] [PubMed]
- D’Acunto, G.; Tsyshevsky, R.; Shayesteh, P.; Gallet, J.-J.; Bournel, F.; Rochet, F.; Pinsard, I.; Timm, R.; Head, A.R.; Kuklja, M.; et al. Bimolecular Reaction Mechanism in the Amido Complex-Based Atomic Layer Deposition of HfO2. Chem. Mater. 2023, 35, 529–538. [Google Scholar] [CrossRef] [PubMed]
- Goh, G.D.; Lee, J.M.; Goh, G.L.; Huang, X.; Lee, S.; Yeong, W.Y. Machine Learning for Bioelectronics on Wearable and Implantable Devices: Challenges and Potential. Tissue Eng. Part A 2022, 29, 20–46. [Google Scholar] [CrossRef] [PubMed]
- Pradeep, D.; Vardhan, B.V.; Raiak, S.; Muniraj, I.; Elumalai, K.; Chinnadurai, S. Optimal Predictive Maintenance Technique for Manufacturing Semiconductors using Machine Learning. In Proceedings of the 2023 3rd International Conference on Intelligent Communication and Computational Techniques (ICCT), Jaipur, India, 19–20 January 2023; pp. 1–5. [Google Scholar]
- Szczepaniuk, H.; Szczepaniuk, E.K. Applications of Artificial Intelligence Algorithms in the Energy Sector. Energies 2023, 16, 347. [Google Scholar] [CrossRef]
- Bradshaw, T.J.; Huemann, Z.; Hu, J.; Rahmim, A. A Guide to Cross-Validation for Artificial Intelligence in Medical Imaging. Radiol. Artif. Intell. 2023, 5, e220232. [Google Scholar] [CrossRef]
- Van Thieu, N.; Mirjalili, S. MEALPY: An Open-Source Library for Latest Meta-Heuristic Algorithms in Python. J. Syst. Archit. 2023, 139, 102871. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Trojovský, P.; Dehghani, M.J.S. Pelican optimization algorithm: A novel nature-inspired algorithm for engineering applications. Sensors 2022, 22, 855. [Google Scholar] [CrossRef] [PubMed]
- Mirjalili, S.; Mirjalili, S.M.; Lewis, A. Grey Wolf Optimizer. Adv. Eng. Softw. 2014, 69, 46–61. [Google Scholar] [CrossRef] [Green Version]
- Mirjalili, S. Moth-Flame Optimization Algorithm: A Novel Nature-Inspired Heuristic Paradigm. J. Knowl.-Based Syst. 2015, 89, 228–249. [Google Scholar] [CrossRef]
- Kennedy, J.; Eberhart, R. Particle Swarm Optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; IEEE: Piscataway, NJ, USA, 1995; pp. 1942–1948. [Google Scholar]
- Trojovský, P.; Dehghani, M. Osprey Optimization Algorithm: A New Bio-Inspired Metaheuristic Algorithm for Solving Engineering Optimization Problems. J. Front. Mech. Eng. 2023, 8, 136. [Google Scholar]
- Huang, S.; Tian, L.; Zhang, J.; Chai, X.; Wang, H.; Zhang, H. Support Vector Regression Based on the Particle Swarm Optimization Algorithm for Tight Oil Recovery Prediction. ACS Omega 2021, 6, 32142–32150. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Accuracy *(%) | MSE | MAE | R2 | MCV-Score |
|---|---|---|---|---|---|
| Linear | 77.4 | 1.13 | 0.84 | 0.975 | 0.899 |
| Sigmoid | 80.6 | 1.31 | 0.86 | 0.975 | 0.880 |
| RBF | 87.1 | 0.55 | 0.58 | 0.987 | 0.876 |
| Poly | 80.6 | 0.59 | 0.58 | 0.987 | 0.858 |
| Model | Accuracy (%) | MSE | MAE | R2 | MCV-Score |
|---|---|---|---|---|---|
| SVR | 87.1 | 0.55 | 0.58 | 0.987 | 0.876 |
| RF | 74.2 | 0.75 | 0.7 | 0.980 | 0.859 |
| MLP | 87.1 | 0.63 | 0.65 | 0.984 | 0.881 |
| CNN | 77.4 | 0.71 | 0.67 | 0.982 | 2.123 |
| MLR | 74.2 | 1.02 | 0.87 | 0.947 | 0.871 |
| Model | Accuracy (%) | MSE | MAE | R2 | MCV-Score | Epsilon | C |
|---|---|---|---|---|---|---|---|
| SVR | 87.1 | 0.55 | 0.58 | 0.987 | 0.876 | 0.01 | 10 |
| MFO | 90.3 | 0.64 | 0.63 | 0.98445 | 0.88349 | 0.26495 | 31.66204 |
| GWO | 90.3 | 0.64 | 0.63 | 0.98856 | 0.88349 | 0.26479 | 31.52233 |
| POA | 90.3 | 0.64 | 0.63 | 0.98445 | 0.87317 | 0.265 | 31.62074 |
| WOA | 90.3 | 0.65 | 0.63 | 0.98419 | 0.88332 | 0.27517 | 29.11249 |
| PSO | 90.3 | 0.64 | 0.63 | 0.98446 | 0.87666 | 0.26474 | 31.52349 |
| OOA | 90.3 | 0.64 | 0.63 | 0.98447 | 0.88350 | 0.26473 | 31.4981 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, Y.; Wang, F.; Chen, J.; Dhungel, S.K.; Li, X.; Song, J.-K.; Kim, Y.-S.; Pham, D.P.; Yi, J. Support Vector Regression Model for Determining Optimal Parameters of HfAlO-Based Charge Trapping Memory Devices. Electronics 2023, 12, 3139. https://doi.org/10.3390/electronics12143139
Hu Y, Wang F, Chen J, Dhungel SK, Li X, Song J-K, Kim Y-S, Pham DP, Yi J. Support Vector Regression Model for Determining Optimal Parameters of HfAlO-Based Charge Trapping Memory Devices. Electronics. 2023; 12(14):3139. https://doi.org/10.3390/electronics12143139
Chicago/Turabian StyleHu, Yifan, Fucheng Wang, Jingwen Chen, Suresh Kumar Dhungel, Xinying Li, Jang-Kun Song, Yong-Sang Kim, Duy Phong Pham, and Junsin Yi. 2023. "Support Vector Regression Model for Determining Optimal Parameters of HfAlO-Based Charge Trapping Memory Devices" Electronics 12, no. 14: 3139. https://doi.org/10.3390/electronics12143139