



Systematic Review on Impact of Different Irradiance Forecasting Techniques for Solar Energy Prediction
 ,
,  ,
, 
Abstract
:1. Introduction
- This review work intends to give a clear and detailed understanding of different forecasting models used for solar radiation prediction and forecasting.
- It drafts a systematic understanding of the selection and application scopes of the various forecasting models. The forecasting models are classified into eight categories.
- The tabular literature summaries were made, which will provide a synopsis of the overall features of most of the significant research work developed in solar forecasting models. It also elaborates on details of various feature reduction techniques.
- The physical models, time series models, machine learning models, deep learning models, special artificial intelligence models, probabilistic models and hybrid and ensemble models, including the basic reference model, i.e., the persistence model, are the eight models explored in our discussion.
2. Classification of Forecasting Methods
2.1. Time Horizon
2.2. Spatial Resolution
2.3. Forecast Theme
2.4. Weather Factors
- Effect of primary weather elements determined from various PV analytical models and their contributions to the solar power forecast.
- Forecast of solar power ramping events caused by unexpected weather changes.
3. Survey on Solar Irradiance and Power Forecasting Models
3.1. Survey on Persistence Models
3.2. Survey on Physical Models
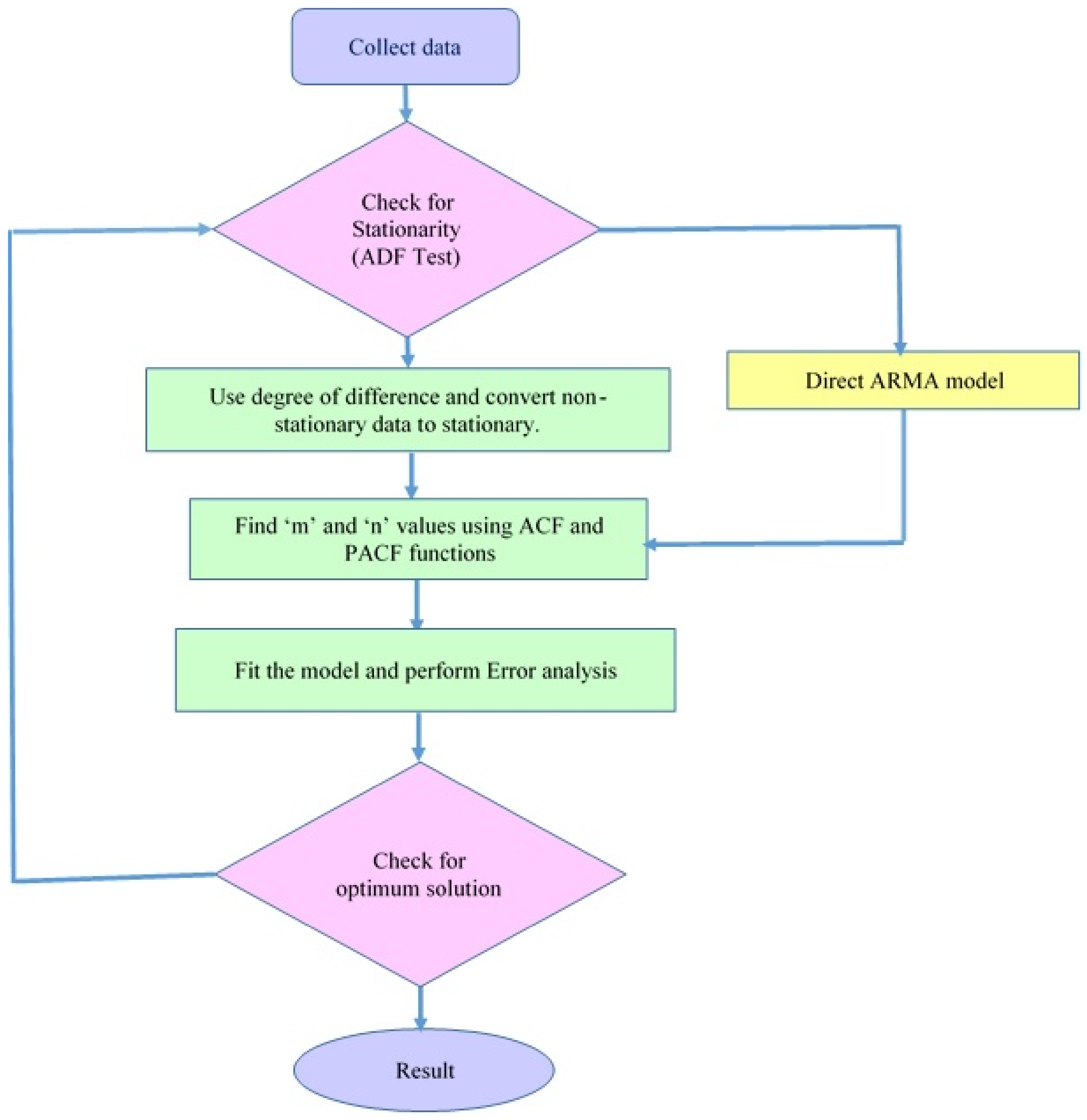
3.3. Survey on Time Series Models
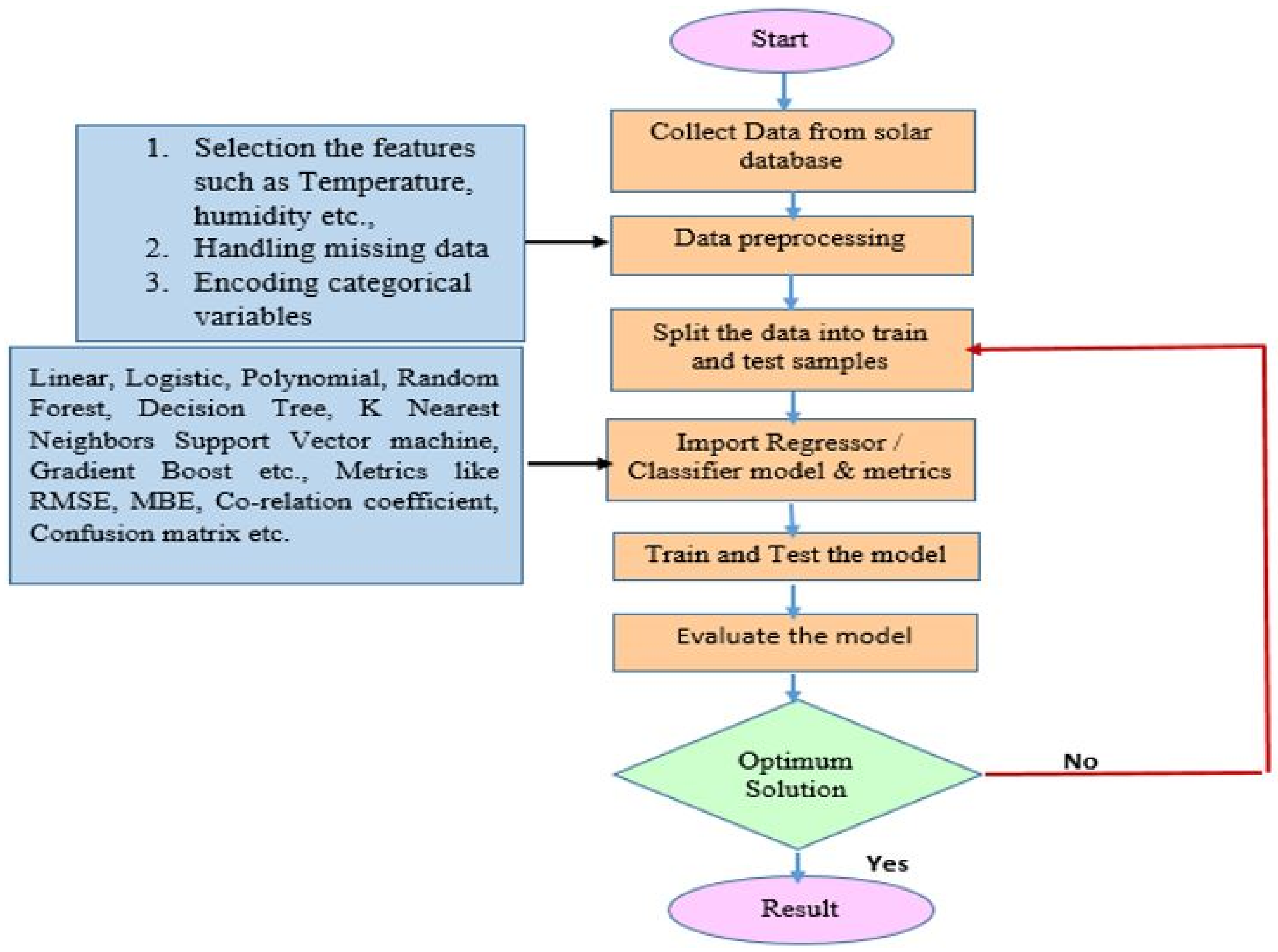
3.4. Survey on Machine Learning Models
3.5. Survey on Deep Learning Models
3.6. Survey on Special Artificial Intelligence Models
3.7. Survey on Hybrid and Ensemble Models
4. Statistical Metrics for Solar Power Forecasting
4.1. Pearson’s Correlation Coefficient ()
4.2. Root Mean Squared Error (RMSE)
4.3. Normalized Root Mean Squared Error (NRMSE)
4.4. Maximum Absolute Error (MaxAE)
4.5. Mean Absolute Error (MAE)
4.6. Mean Absolute Percentage Error (MAPE)
4.7. Mean Bias Error (MBE)
4.8. Kolmogorov–Smirnov Test Integral (KSI)
4.9. Confusion Matrix (CM)
4.10. Accuracy
4.11. Precision
4.12. Recall
4.13. Forecast Score
4.13.1. Score
4.13.2. Score
5. Solar Irradiance and Power Forecasting Methodologies
5.1. Persistence Model

| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion | Analysis |
|---|---|---|---|---|---|---|---|
| Yang et al. [52] | 2012 | Persistence | Orlando and Miami, USA | 1 h ahead | Orlando 2005 October, and Miami 2004 December | RMSE value of 156.81 W/m2 in Miami 160.61 W/m2 in Orlando | Features can be further added from specific to tropical climates to improve forecasting. |
| Voyant et al. [53] | 2012 | Persistence | Mediterranean, France | 1 h ahead | 6 years data | Average nRMSE is 26.2% | Complex and costly to implement in real time Gid connected systems |
| Marquez et al. [54] | 2013 | Persistence | Davis and Merced, USA | 30, 60, 90, and 120 min ahead | 1 year, (1 January 2011 to 6 June 2011 and 23 November 2011 to 31 January 2012) | RMSE value of 61.24 to 107.47 W/m2 | Low importance to the ANN architecture optimization analysis and to lag feature selection process. |

5.1.1. Persistence Model 1
5.1.2. Persistence Model 2
5.1.3. Smart Persistence Model
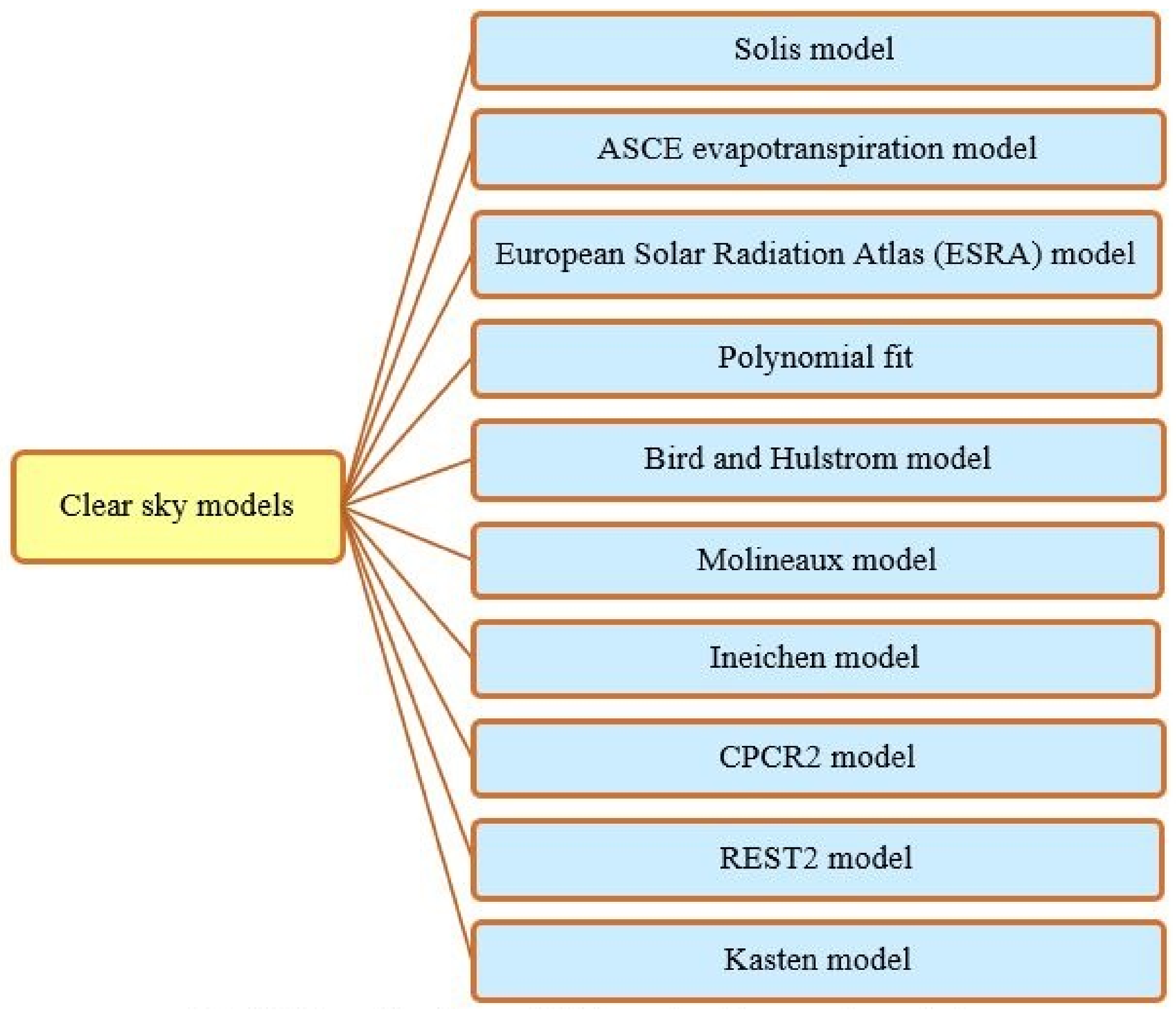
5.2. Physical Model
5.3. Time-Series-Based Forecast Models
5.4. Machine Learning Models
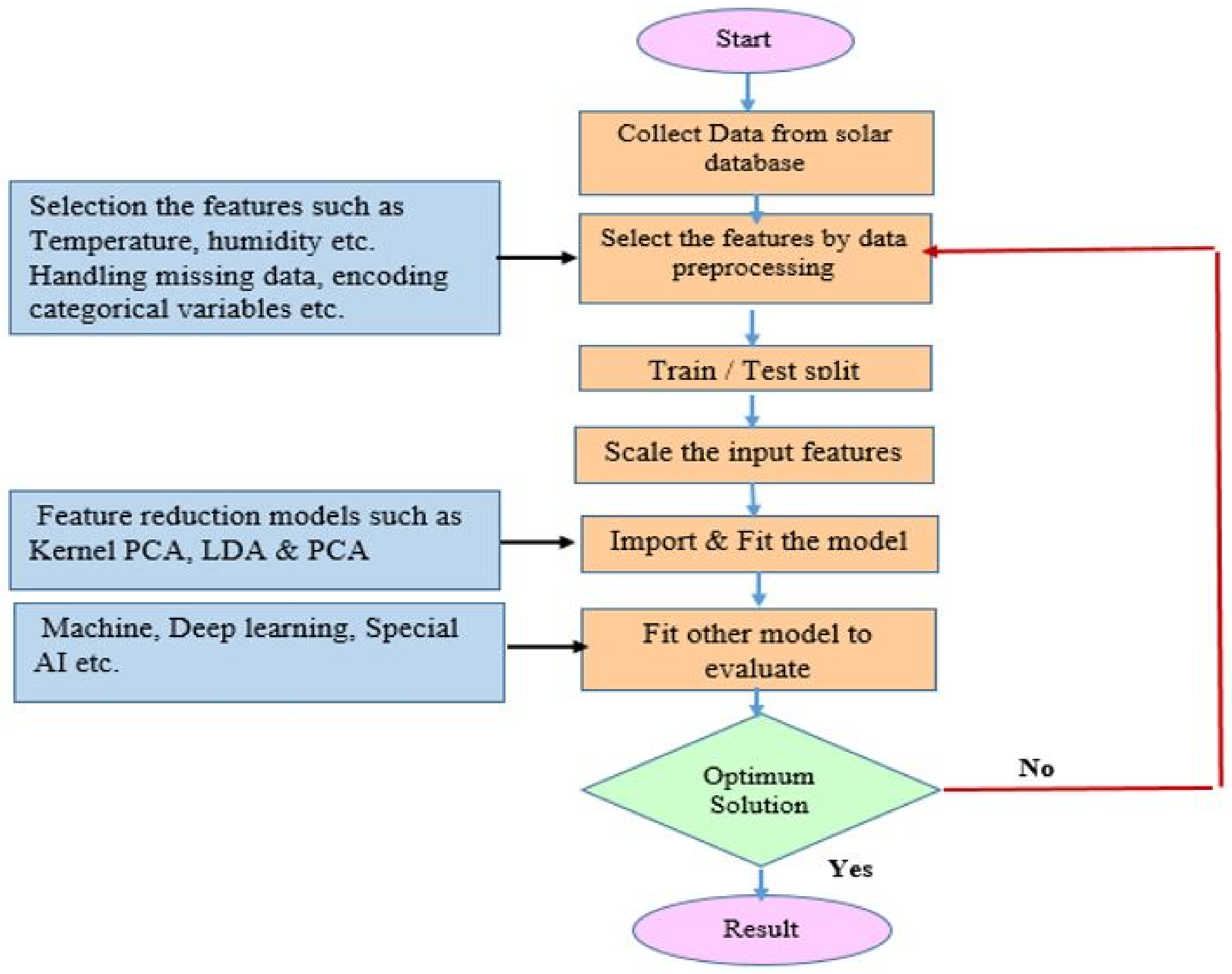
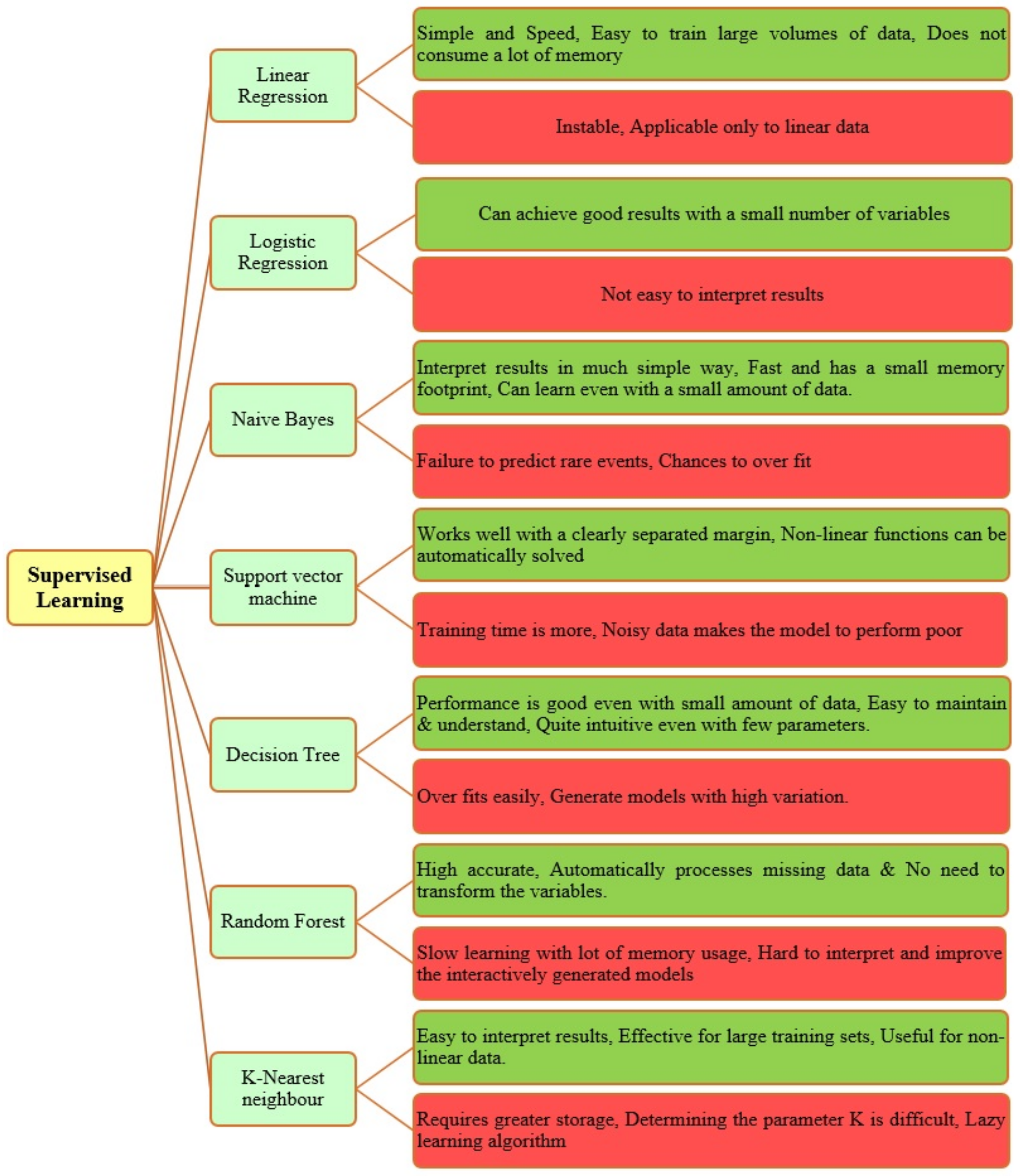
5.4.1. Supervised Learning
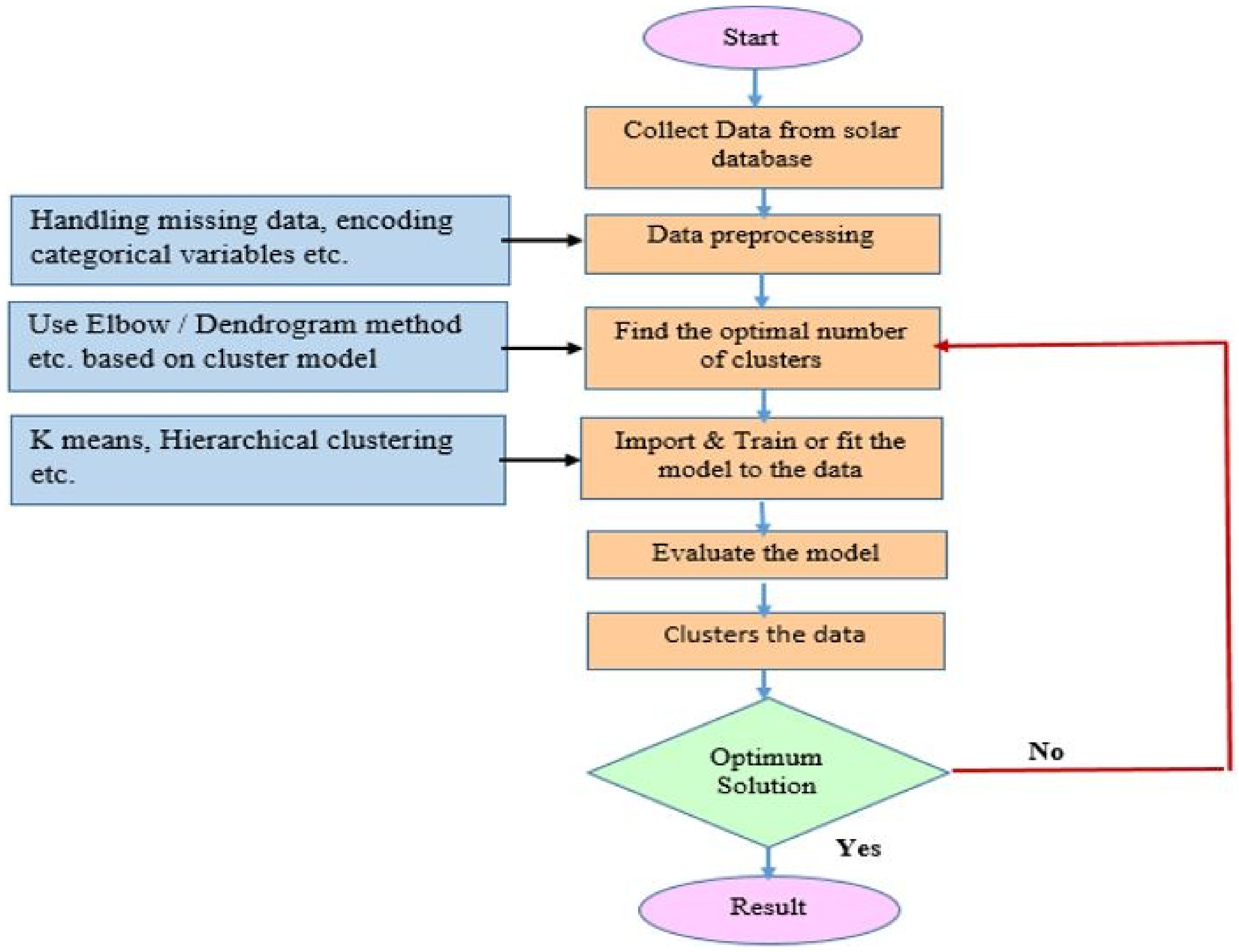
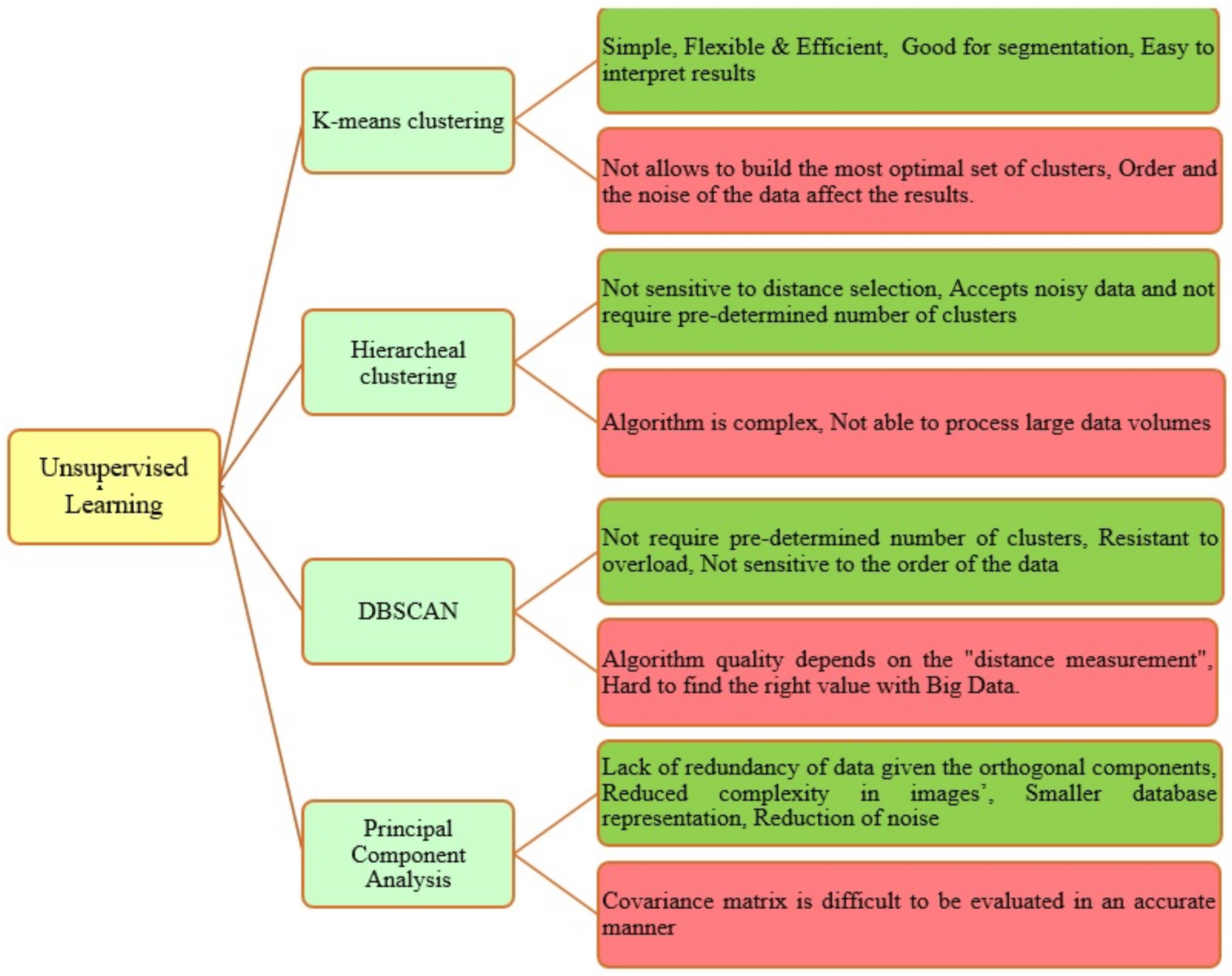
5.4.2. Unsupervised Learning
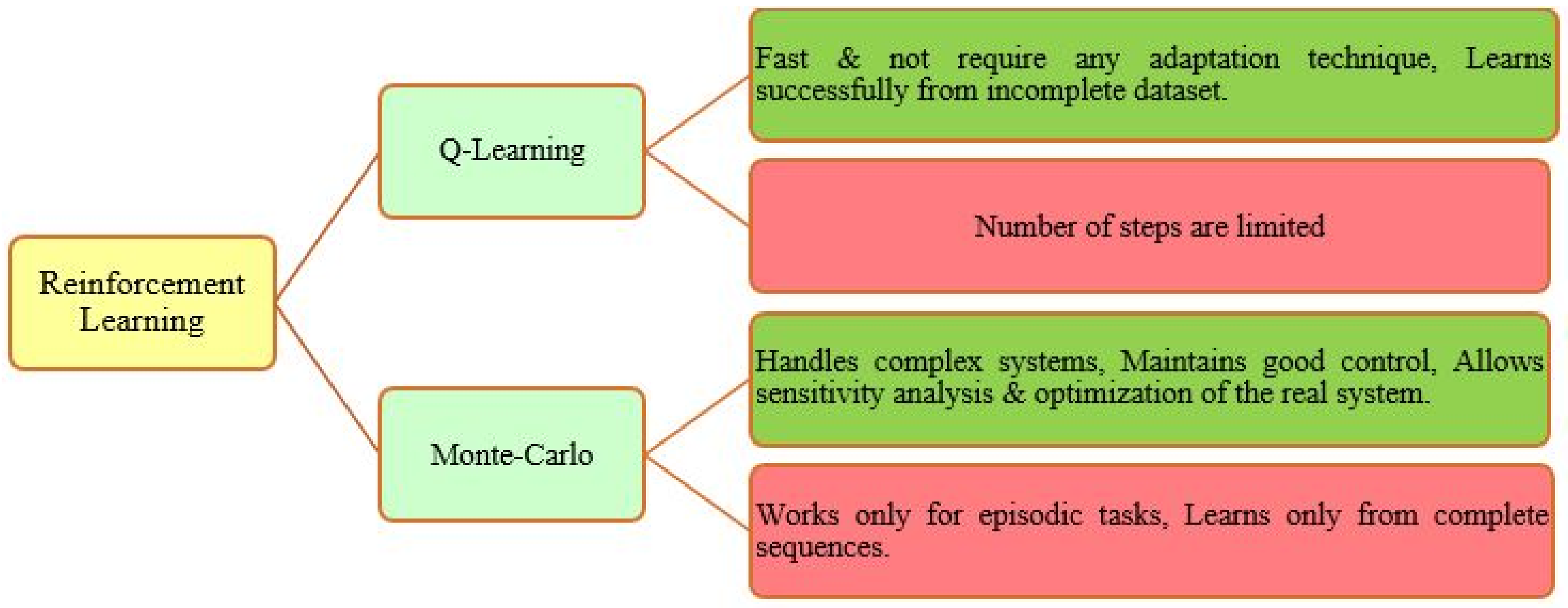
5.4.3. Reinforcement Learning
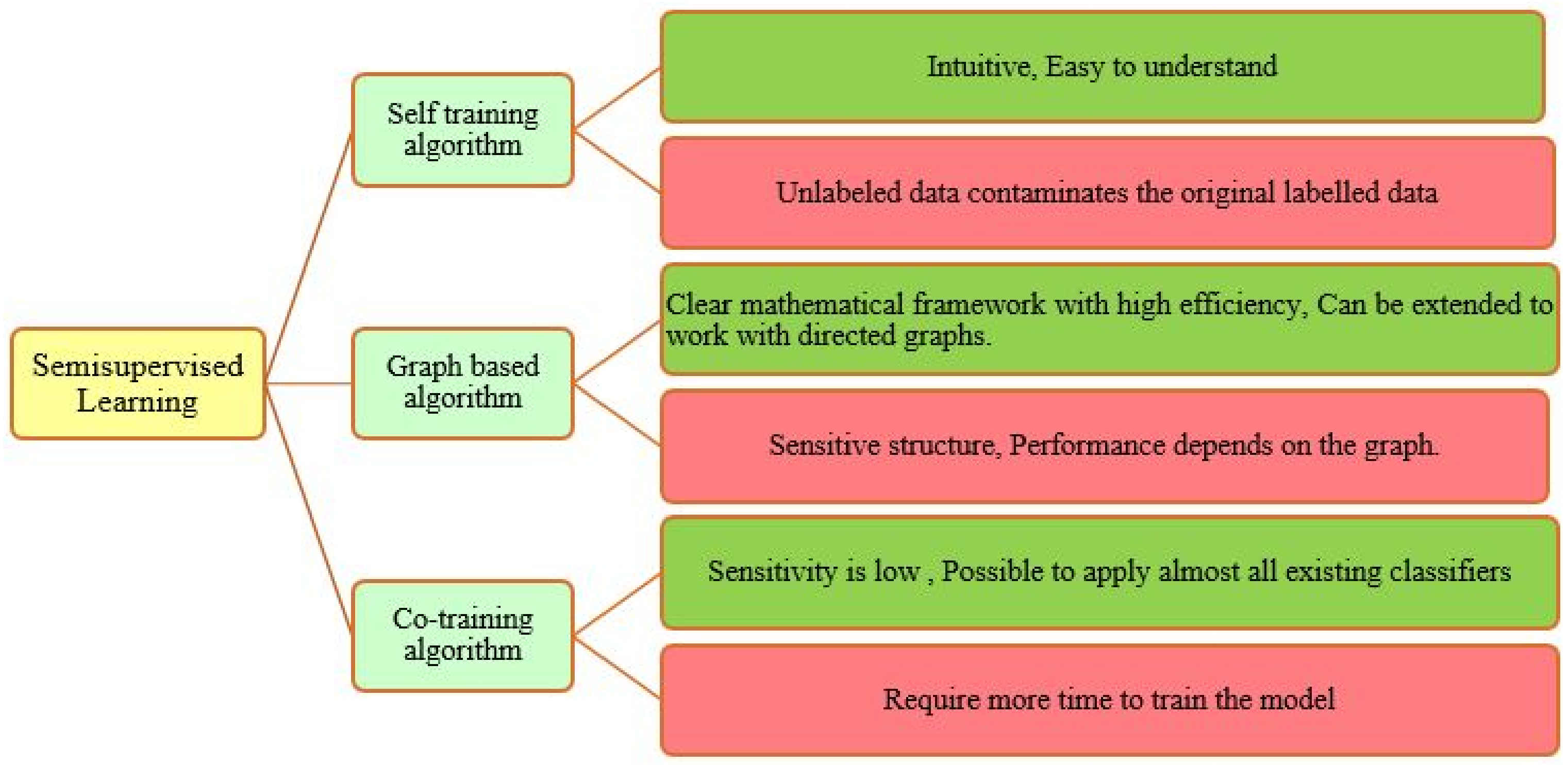
5.4.4. Semi-Supervised Learning
5.5. Deep Learning Models
- Deep multilayer perceptron.
- Convolutional neural networks.
- Recurrent neural networks.
- Auto encoder (AE).
- Restricted Boltzmann Machine (RBM).
- Self-Organizing Maps (SOM).
5.5.1. Supervised Deep Learning
5.5.2. Unsupervised Deep Learning
5.6. Probabilistic Models
5.7. Special AI Models
5.8. Hybrid & Ensemble Machine Learning Models
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lima, M.; Carvalho, P.; Fernández-Ramírez, L.; Braga, A. Improving solar forecasting using Deep Learning and Portfolio Theory integration. Energy 2020, 195, 117016. [Google Scholar] [CrossRef]
- Alkhayat, G.; Mehmood, R. A Review and Taxonomy of Wind and Solar Energy Forecasting Methods Based on Deep Learning. Energy AI 2021, 4, 100060. [Google Scholar] [CrossRef]
- Ahmed, R.; Sreeram, V.; Mishra, Y.; Arif, M. A review and evaluation of the state-of-the-art in PV solar power forecasting: Techniques and optimization. Renew. Sustain. Energy Rev. 2020, 124, 109792. [Google Scholar] [CrossRef]
- Marino, C.; Nucara, A.; Panzera, M.F.; Pietrafesa, M.; Pudano, A. Economic Comparison Between a Stand-Alone and a Grid Connected PV System vs. Grid Distance. Energies 2020, 13, 3846. [Google Scholar] [CrossRef]
- Liu, Y.; Qin, H.; Zhang, Z.; Pei, S.; Wang, C.; Yu, X.; Jiang, Z.; Zhou, J. Ensemble spatiotemporal forecasting of solar irradiation using variational Bayesian convolutional gate recurrent unit network. Appl. Energy 2019, 253, 113596. [Google Scholar] [CrossRef]
- Pazikadin, A.; Rifai, D.; Ali, K.; Malik, M.; Abdalla, A.; Faraj, M. Solar irradiance measurement instrumentation and power solar generation forecasting based on Artificial Neural Networks (ANN): A review of five years research trend. Sci. Total Environ. 2020, 715, 136848. [Google Scholar] [CrossRef] [PubMed]
- Akhter, M.N.; Mekhilef, S.; Mokhlis, H.; Mohamed Shah, N. Review on forecasting of photovoltaic power generation based on machine learning and metaheuristic techniques. IET Renew. Power Gener. 2019, 13, 1009–1023. [Google Scholar] [CrossRef]
- Singh, I. Solar Power Forecasting: A Review. Int. J. Comput. Appl. 2016, 145, 28–50. [Google Scholar] [CrossRef]
- Yang, B.; Zhu, T.; Cao, P.; Guo, Z.; Zeng, C.; Li, D.; Chen, Y.; Ye, H.; Shao, R.; Shu, H.; et al. Classification and summarization of solar irradiance and power forecasting methods: A thorough review. CSEE J. Power Energy Syst. 2021. [Google Scholar] [CrossRef]
- Wang, J.; Zhong, H.; Lai, X.; Xia, Q.; Wang, Y.; Kang, C. Exploring Key Weather Factors From Analytical Modeling Toward Improved Solar Power Forecasting. IEEE Trans. Smart Grid 2017, 10, 1417–1427. [Google Scholar] [CrossRef]
- Sreekumar, S.; Bhakar, R. Solar Power Prediction Models: Classification Based on Time Horizon, Input, Output and Application. In Proceedings of the 2018 International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 11–12 July 2018; pp. 67–71. [Google Scholar] [CrossRef]
- Gupta, P.; Singh, R. PV power forecasting based on data-driven models: A review. Int. J. Sustain. Eng. 2021, 14, 1733–1755. [Google Scholar]
- Antonanzas, J.; Osorio, N.; Escobar, R.; Urraca, R.; Ascacibar, F.J.; Antonanzas, F. Review of photovoltaic power forecasting. Solar Energy 2016, 136, 78–111. [Google Scholar] [CrossRef]
- Huang, R.; Huang, T.; Gadh, R.; Li, N. Solar generation prediction using the ARMA model in a laboratory-level micro-grid. In Proceedings of the 2012 IEEE Third International Conference on Smart Grid Communications (SmartGridComm), Tainan, Taiwan, 5–8 November 2012; pp. 528–533. [Google Scholar] [CrossRef]
- Prado-Rujas, I.I.; García-Dopico, A.; Serrano, E.; Pérez, M.S. A Flexible and Robust Deep Learning-Based System for Solar Irradiance Forecasting. IEEE Access 2021, 9, 12348–12361. [Google Scholar] [CrossRef]
- Mayer, M.; Grof, G. Extensive comparison of physical models for photovoltaic power forecasting. Appl. Energy 2020, 283, 116239. [Google Scholar] [CrossRef]
- Ayvazoğluyüksel Erol, Ö.; Başaran Filik, Ü. Estimation methods of global solar radiation, cell temperature and solar power forecasting: A review and case study in Eskişehir. Renew. Sustain. Energy Rev. 2018, 91, 639–653. [Google Scholar] [CrossRef]
- Singh, B.; Pozo, D. A Guide to Solar Power Forecasting using ARMA Models. In Proceedings of the 2019 IEEE PES Innovative Smart Grid Technologies Europe (ISGT-Europe), Bucharest, Romania, 29 September–2 October 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Mbaye, A.; Ndiaye, M.; Ndione, D.; Diaw, M.; Traore, V.; Amadou, N.; Sylla, M.; Aidara, M.; Diaw, V.; Traoré, A.; et al. ARMA model for short-term forecasting of solar potential ARMA model for short-term forecasting of solar potential: Application to a horizontal surface on Dakar site A. Mbaye et al, ARMA model for short-term forecasting of solar. OAJ Mat. Dev. 2019, 4, 1–8. [Google Scholar]
- As’ad, M. Finding the Best ARIMA Model to Forecast Daily Peak Electricity Demand. In Proceedings of the Fifth Annual ASEARC Conference-Looking to the Future-Programme and Proceedings, Hong Kong, 2–3 February 2012; p. 12. [Google Scholar]
- Colak, I.; Yesilbudak, M.; Genc, N.; Bayindir, R. Multi-period Prediction of Solar Radiation Using ARMA and ARIMA Models. In Proceedings of the 2015 IEEE 14th International Conference on Machine Learning and Applications (ICMLA), Miami, FL, USA, 9–11 December 2015; pp. 1045–1049. [Google Scholar] [CrossRef]
- Li, Y.; Su, Y.; Shu, L. An ARMAX model for forecasting the power output of a grid connected photovoltaic system. Renew. Energy 2014, 66, 78–89. [Google Scholar] [CrossRef]
- Guo, G.; Wang, H.; Bell, D.; Bi, Y.; Greer, K. KNN Model-Based Approach in Classification. Lect. Notes Comput. Sci. 2003, 2888, 986–996. [Google Scholar] [CrossRef]
- Leva, S.; Dolara, A.; Grimaccia, F.; Mussetta, M.; Ogliari, E. Analysis and validation of 24 hours ahead neural network forecasting of photovoltaic output power. Math. Comput. Simul. 2015, 131, 88–100. [Google Scholar] [CrossRef]
- Ahmad, M.; Mourshed, M.; Rezgui, Y. Tree-based ensemble methods for predicting PV power generation and their comparison with support vector regression. Energy 2018, 164, 465–474. [Google Scholar] [CrossRef]
- Feng, C.; Cui, M.; Hodge, B.M.; Lu, S.; Hamann, H.F.; Zhang, J. Unsupervised Clustering-Based Short-Term Solar Forecasting. IEEE Trans. Sustain. Energy 2019, 10, 2174–2185. [Google Scholar] [CrossRef]
- Hashemi, B.; Cretu, A.M.; Taheri, S. Snow Loss Prediction for Photovoltaic Farms Using Computational Intelligence Techniques. IEEE J. Photovolt. 2020, 10, 1044–1052. [Google Scholar] [CrossRef]
- Pan, C.; Tan, J. Day-Ahead Hourly Forecasting of Solar Generation Based on Cluster Analysis and Ensemble Model. IEEE Access 2019, 7, 112921–112930. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, Y. Forecast of photovoltaic power generation based on DBSCAN. E3S Web Conf. 2021, 236, 02016. [Google Scholar] [CrossRef]
- Chahboun, S.; Maaroufi, M. Principal Component Analysis and Machine Learning Approaches for Photovoltaic Power Prediction: A Comparative Study. Appl. Sci. 2021, 11, 7943. [Google Scholar] [CrossRef]
- Xiu, J.; Zhu, C.; Yang, Z. Prediction of solar power generation based on the principal components analysis and the BP neural network. In Proceedings of the 2014 IEEE 3rd International Conference on Cloud Computing and Intelligence Systems, Shenzhen, China, 27–29 November 2014; pp. 366–369. [Google Scholar] [CrossRef]
- Shojaeighadikolaei, A.; Ghasemi, A.; Bardas, A.G.; Ahmadi, R.; Hashemi, M. Weather-Aware Data-Driven Microgrid Energy Management Using Deep Reinforcement Learning. In Proceedings of the 2021 North American Power Symposium (NAPS), College Station, TX, USA, 14–16 November 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Huang, C.J.; Kuo, P.H. Multiple-Input Deep Convolutional Neural Network Model for Short-Term Photovoltaic Power Forecasting. IEEE Access 2019, 7, 74822–74834. [Google Scholar] [CrossRef]
- Alzahrani, A.; Shamsi, P.; Dagli, C.; Ferdowsi, M. Solar Irradiance Forecasting Using Deep Neural Networks. Procedia Comput. Sci. 2017, 114, 304–313. [Google Scholar] [CrossRef]
- Liu, J.; Fang, W.; Zhang, X.; Yang, C. An Improved Photovoltaic Power Forecasting Model with the Assistance of Aerosol Index Data. IEEE Trans. Sustain. Energy 2015, 6, 1–9. [Google Scholar] [CrossRef]
- Wen, S.; Zhang, C.; Lan, H.; Xu, Y.; Tang, Y.; Huang, Y. A Hybrid Ensemble Model for Interval Prediction of Solar Power Output in Ship Onboard Power Systems. IEEE Trans. Sustain. Energy 2021, 12, 14–24. [Google Scholar] [CrossRef]
- Lu, H.; Chang, G. A Hybrid Approach for Day-Ahead Forecast of PV Power Generation. IFAC-PapersOnLine 2018, 51, 634–638. [Google Scholar] [CrossRef]
- Ratshilengo, M.; Sigauke, C.; Bere, A. Short-Term Solar Power Forecasting Using Genetic Algorithms: An Application Using South African Data. Appl. Sci. 2021, 11, 4214. [Google Scholar] [CrossRef]
- Ospina, J.; Newaz, A.; Faruque, M.O. Forecasting of PV plant output using hybrid wavelet-based LSTM-DNN structure model. IET Renew. Power Gener. 2019, 13, 1087–1095. [Google Scholar] [CrossRef]
- Li, G.; Xie, S.; Wang, B.; Xin, J.; Li, Y.; Du, S. Photovoltaic Power Forecasting With a Hybrid Deep Learning Approach. IEEE Access 2020, 8, 175871–175880. [Google Scholar] [CrossRef]
- Jalali, S.M.J.; Khodayar, M.; Ahmadian, S.; Shafie-khah, M.; Khosravi, A.; Islam, S.M.S.; Nahavandi, S.; Catalão, J.P.S. A New Ensemble Reinforcement Learning Strategy for Solar Irradiance Forecasting using Deep Optimized Convolutional Neural Network Models. In Proceedings of the 2021 International Conference on Smart Energy Systems and Technologies (SEST), Vaasa, Finland, 6–8 September 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Bendali, W.; Saber, I.; Bourachdi, B.; Boussetta, M.; Mourad, Y. Deep Learning Using Genetic Algorithm Optimization for Short Term Solar Irradiance Forecasting. In Proceedings of the 2020 Fourth International Conference on Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 21–23 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Carneiro, T.; Rocha, P.; Carvalho, P.; Fernández-Ramírez, L. Ridge regression ensemble of machine learning models applied to solar and wind forecasting in Brazil and Spain. Appl. Energy 2022, 314, 118936. [Google Scholar] [CrossRef]
- Ahmad, T.; Manzoor, S.; Zhang, D. Forecasting high penetration of solar and wind power in the smart grid environment using robust ensemble learning approach for large-dimensional data. Sustain. Cities Soc. 2021, 75, 103269. [Google Scholar] [CrossRef]
- Bi, J.; Yuan, H.; Zhang, L.; Zhang, J. SGW-SCN: An integrated machine learning approach for workload forecasting in geo-distributed cloud data centers. Inf. Sci. 2019, 481, 57–68. [Google Scholar]
- Jensen; Fowler, T.; Brown, B.; Lazo, J.; Haupt, S. Metrics for Evaluation of Solar Energy Forecasts; Technical Report; National Center for Atmospheric Research: Boulder, CO, USA, 2016. [Google Scholar]
- Carriere, T.; Kariniotakis, G. An Integrated Approach for Value-Oriented Energy Forecasting and Data-Driven Decision-Making Application to Renewable Energy Trading. IEEE Trans. Smart Grid 2019, 10, 6933–6944. [Google Scholar] [CrossRef]
- Antonanzas, J.; Pozo-Vazquez, D.; Fernandez-Jimenez, L.; Ascacibar, F.J. The value of day-ahead forecasting for photovoltaics in the Spanish electricity market. Sol. Energy 2017, 158, 140–146. [Google Scholar] [CrossRef]
- Markoulidakis, I.; Rallis, I.; Georgoulas, I.; Kopsiaftis, G.; Doulamis, A.; Doulamis, N. Multiclass Confusion Matrix Reduction Method and Its Application on Net Promoter Score Classification Problem. Technologies 2021, 9, 81. [Google Scholar] [CrossRef]
- Yang, D.; Kleissl, J.; Gueymard, C.; Pedro, H.; Coimbra, C. History and trends in solar irradiance and PV power forecasting: A preliminary assessment and review using text mining. Sol. Energy 2018, 168, 60–101. [Google Scholar] [CrossRef]
- Prema, V.; Bhaskar, M.S.; Almakhles, D.; Gowtham, N.; Rao, K.U. Critical Review of Data, Models and Performance Metrics for Wind and Solar Power Forecast. IEEE Access 2022, 10, 667–688. [Google Scholar] [CrossRef]
- Yang, D.; Jirutitijaroen, P.; Walsh, W. Hourly solar irradiance time series forecasting using cloud cover index. Sol. Energy 2012, 86, 3531–3543. [Google Scholar] [CrossRef]
- Voyant, C.; Muselli, M.; Paoli, C.; Nivet, M.L. Numerical Weather Prediction (NWP) and hybrid ARMA/ANN model to predict global radiation. Energy 2012, 39, 341–355. [Google Scholar] [CrossRef]
- Marquez, R.; Pedro, H.; Coimbra, C. Hybrid solar forecasting method uses satellite imaging and ground telemetry as inputs to ANNs. Sol. Energy 2013, 92, 176–188. [Google Scholar] [CrossRef]
- Inman, R.; Pedro, H.; Coimbra, C. Solar forecasting methods for renewable energy integration. Prog. Energy Combust. Sci. 2013, 39, 535–576. [Google Scholar] [CrossRef]
- Nespoli, A.; Niccolai, A.; Ogliari, E.; Perego, G.; Collino, E.; Ronzio, D. Machine Learning techniques for solar irradiation nowcasting: Cloud type classification forecast through satellite data and imagery. Appl. Energy 2022, 305, 117834. [Google Scholar] [CrossRef]
- Ardiansyah Ramadhan, R.A.; Heatubun, Y.; Tan, S.; Lee, H.J. Comparison of physical and machine learning models for estimating solar irradiance and photovoltaic power. Renew. Energy 2021, 178, 1006–1019. [Google Scholar] [CrossRef]
- Feng, C.; Liu, Y. A taxonomical review on recent artificial intelligence applications to PV integration into power grids. Int. J. Electr. Power Energy Syst. 2021, 132, 107176. [Google Scholar] [CrossRef]
- Lin, F.; Zhang, Y.; Wang, J. Recent advances in intra-hour solar forecasting: A review of ground-based sky image methods. Int. J. Forecast. 2022. [Google Scholar] [CrossRef]
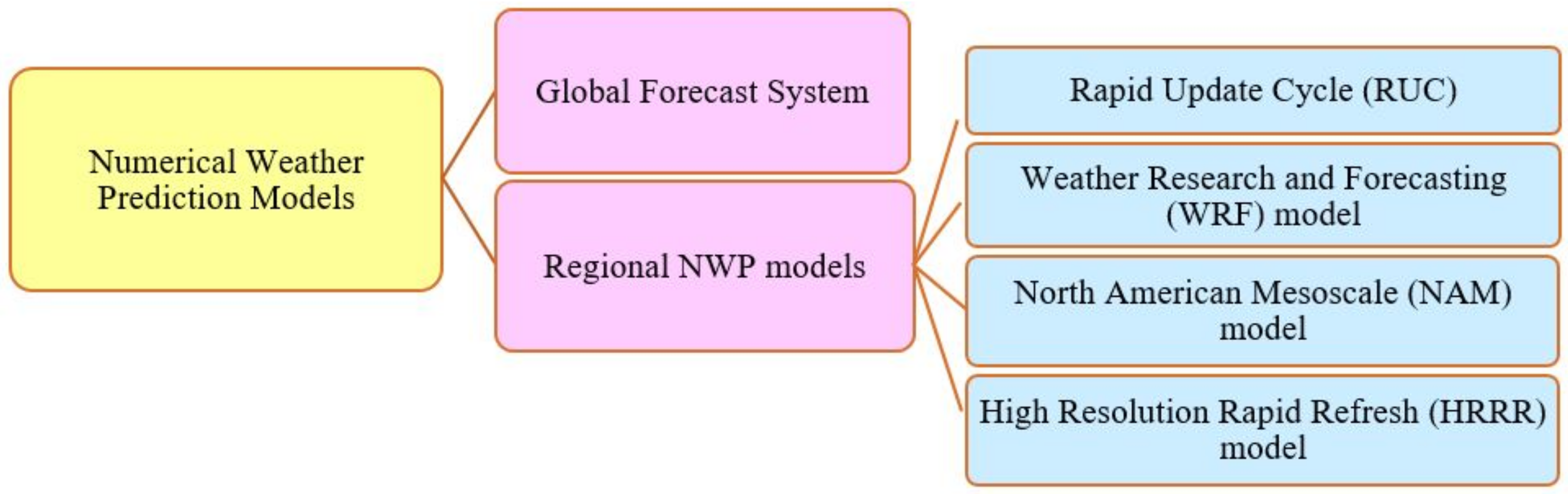
- Andrade, J.R.; Bessa, R.J. Improving Renewable Energy Forecasting with a Grid of Numerical Weather Predictions. IEEE Trans. Sustain. Energy 2017, 8, 1571–1580. [Google Scholar] [CrossRef]
- Yeom, J.M.; Park, S.; Chae, T.; Kim, J.Y.; Lee, C.S. Spatial Assessment of Solar Radiation by Machine Learning and Deep Neural Network Models Using Data Provided by the COMS MI Geostationary Satellite: A Case Study in South Korea. Sensors 2019, 19, 2082. [Google Scholar] [CrossRef]
- Putra, P.; Ardiansyah Ramadhan, R.A.; Lee, H.J. Application of Semi-Empirical Models Based on Satellite Images for Estimating Solar Irradiance in Korea. Appl. Sci. 2021, 11, 3445. [Google Scholar] [CrossRef]
- Pereira, S.; Canhoto, P.; Salgado, R.; Costa, M.J. Development of an ANN based corrective algorithm of the operational ECMWF global horizontal irradiation forecasts. Sol. Energy 2019, 185, 387–405. [Google Scholar] [CrossRef]
- Mathiesen, P.; Collier, C.; Kleissl, J. A high-resolution, cloud-assimilating numerical weather prediction model for solar irradiance forecasting. Sol. Energy 2013, 92, 47–61. [Google Scholar] [CrossRef]
- Fernandez-Jimenez, L.; Muñoz Jiménez, A.; Falces, A.; Mendoza-Villena, M.; Garcia-Garrido, E.; Lara-Santillan, P.; Zorzano Alba, E.; Zorzano-Santamaria, P. Short-term power forecasting system for photovoltaic plants. Renew. Energy 2012, 44, 311–317. [Google Scholar] [CrossRef]
- Prema, V.; Rao, U. Development of statistical time series models for solar power prediction. Renew. Energy 2015, 83, 100–109. [Google Scholar] [CrossRef]
- Moreno-Munoz, A.; de la Rosa, J.J.G.; Posadillo, R.; Bellido, F. Very short term forecasting of solar radiation. In Proceedings of the 2008 33rd IEEE Photovoltaic Specialists Conference, San Diego, CA, USA, 11–16 May 2008; pp. 1–5. [Google Scholar] [CrossRef]
- Russo, M.; Leotta, G.; Pugliatti, P.; Gigliucci, G. Genetic programming for photovoltaic plant output forecasting. Sol. Energy 2014, 105, 264–273. [Google Scholar] [CrossRef]
- Bacher, P.; Madsen, H.; Nielsen, H. Online Short-term Solar Power Forecasting. Sol. Energy 2009, 83, 1772–1783. [Google Scholar] [CrossRef]
- Bessa, R.; Trindade, A.; Silva, C.; Miranda, V. Solar power forecasting in smart grids using distributed information. Int. J. Electr. Power Energy Syst. 2015, 72, 16–23. [Google Scholar] [CrossRef]
- Sansa, I.; Najiba, m.b. Solar Radiation Prediction Using NARX Model; INTECH Open Science: London, UK, 2018. [Google Scholar] [CrossRef]
- Di Piazza, A.; Di Piazza, M.C.; Vitale, G. Solar and wind forecasting by NARX neural networks. Renew. Energy Environ. Sustain. 2016, 1, 39. [Google Scholar] [CrossRef]
- Voyant, C.; Randimbivololona, P.; Nivet, M.L.; Paoli, C.; Muselli, M. 24-hours ahead global irradiation forecasting using Multi-Layer Perceptron. Meteorl. Appl. 2014, 21, 644–655. [Google Scholar] [CrossRef]
- Shah, A.; Ahmed, K.; Han, X.; Saleem, A. A Novel Prediction Error Based Power Forecasting Scheme for Real PV System using PVUSA Model: A Grey Box Based Neural Network Approach. IEEE Access 2021, 9, 87196–87206. [Google Scholar] [CrossRef]
- Cao, J.C.; Cao, S.H. Study of forecasting solar irradiance using neural networks with preprocessing sample data by wavelet analysis. Energy 2006, 31, 3435–3445. [Google Scholar] [CrossRef]
- Bi, J.; Zhang, L.; Yuan, H.; Zhou, M. Hybrid task prediction based on wavelet decomposition and ARIMA model in cloud data center. In Proceedings of the 2018 IEEE 15th International Conference on Networking, Sensing and Control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Bi, J.; Li, S.; Yuan, H.; Zhao, Z.; Liu, H. Deep Neural Networks for Predicting Task Time Series in Cloud Computing Systems. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019; pp. 86–91. [Google Scholar] [CrossRef]
- AlMahamid, F.; Grolinger, K. Reinforcement Learning Algorithms: An Overview and Classification. In Proceedings of the 2021 IEEE Canadian Conference on Electrical and Computer Engineering (CCECE), Virtually, 12–17 September 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Lai, J.P.; Chang, Y.M.; Chen, C.H.; Pai, P.F. A Survey of Machine Learning Models in Renewable Energy Predictions. Appl. Sci. 2020, 10, 5975. [Google Scholar] [CrossRef]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Caballé, N.; Castillo-Sequera, J.; Gomez-Pulido, J.A.; Gómez, J.; Polo-Luque, M. Machine Learning Applied to Diagnosis of Human Diseases: A Systematic Review. Appl. Sci. 2020, 10, 5135. [Google Scholar] [CrossRef]
- Dineva, K.; Atanasova, T. Systematic Look at Machine Learning Algorithms—Advantages, Disadvantages and Practical Applications. In Proceedings of the 20th International Multidisciplinary Scientific Geoconference, Albena, Bulgaria, 18–24 August 2020; pp. 317–327. [Google Scholar] [CrossRef]
- Uhrig, R. Introduction to artificial neural networks. In Proceedings of the IECON ’95—21st Annual Conference on IEEE Industrial Electronics, Orlando, FL, USA, 6–10 November 1995; Volume 1, pp. 33–37. [Google Scholar] [CrossRef]
- Kaur, J.; Goyal, A.; Handa, P.; Goel, N. Solar power forecasting using ordinary least square based regression algorithms. In Proceedings of the 2022 IEEE Delhi Section Conference (DELCON), New Delhi, India, 11–13 February 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Taunk, K.; De, S.; Verma, S.; Swetapadma, A. A Brief Review of Nearest Neighbor Algorithm for Learning and Classification. In Proceedings of the 2019 International Conference on Intelligent Computing and Control Systems (ICCS), Madurai, India, 15–17 May 2019; pp. 1255–1260. [Google Scholar] [CrossRef]
- Schmitz, G.; Aldrich, C.; Gouws, F. ANN-DT: An algorithm for extraction of decision trees from artificial neural networks. IEEE Trans. Neural Netw. 1999, 10, 1392–1401. [Google Scholar] [CrossRef] [PubMed]
- McCandless, T.; Jiménez, P.A. Examining the Potential of a Random Forest Derived Cloud Mask from GOES-R Satellites to Improve Solar Irradiance Forecasting. Energies 2020, 13, 1671. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.T.; Huang, C.M.; Huang, Y.C.; Pai, Y.S. A Weather-Based Hybrid Method for 1-Day Ahead Hourly Forecasting of PV Power Output. IEEE Trans. Sustain. Energy 2014, 5, 917–926. [Google Scholar] [CrossRef]
- Wang, Y.; Xia, Q.; Kang, C. Secondary Forecasting Based on Deviation Analysis for Short-Term Load Forecasting. IEEE Trans. Power Syst. 2011, 26, 500–507. [Google Scholar] [CrossRef]
- Park, J.; Moon, J.; Jung, S.; Hwang, E. Multistep-Ahead Solar Radiation Forecasting Scheme Based on the Light Gradient Boosting Machine: A Case Study of Jeju Island. Remote Sens. 2020, 12, 2271. [Google Scholar] [CrossRef]
- Gunasekaran, V.; Kovi, K.; Arja, S.; Chimata, R. Solar Irradiation Forecasting Using Genetic Algorithms. arXiv 2021, arXiv:2106.13956. [Google Scholar]
- Kang, M.C.; Sohn, J.M.; Park, J.; Lee, S.K.; Yoon, Y.T. Development of algorithm for day ahead PV generation forecasting using data mining method. Midwest Symp. Circuits Syst. 2011, 7, 1–4. [Google Scholar] [CrossRef]
- Li, J.; Shao, B.; Li, T.; Ogihara, M. Hierarchical Co-Clustering: A New Way to Organize the Music Data. IEEE Trans. Multimed. 2012, 14, 471–481. [Google Scholar] [CrossRef]
- Zhou, S.; Xu, Z.; Liu, F. Method for Determining the Optimal Number of Clusters Based on Agglomerative Hierarchical Clustering. IEEE Trans. Neural Netw. Learn. Syst. 2017, 28, 3007–3017. [Google Scholar] [CrossRef]
- Karamizadeh, S.; Abdullah, S.; Manaf, A.; Zamani, M.; Hooman, A. An Overview of Principal Component Analysis. J. Signal Inf. Process. 2013, 4, 173–175. [Google Scholar] [CrossRef]
- Naeem, M.; Rizvi, S.T.H.; Coronato, A. A Gentle Introduction to Reinforcement Learning and its Application in Different Fields. IEEE Access 2020, 8, 209320–209344. [Google Scholar] [CrossRef]
- Muhammad, A.; Lee, J.M.; Kim, H.S.; Lee, S.; Hong, S. Deep Learning Models for Long-Term Solar Radiation Forecasting Considering Microgrid Installation: A Comparative Study. Energies 2019, 13, 147. [Google Scholar] [CrossRef] [Green Version]
- Mohammadi, K.; Shamshirband, S.; Chong, W.T.; Arif, M.; Petkovic, D.; Chintalapati, D.S. A new hybrid Support Vector Machine-Wavelet Transform approach for estimation of horizontal global solar radiation. Energy Convers. Manag. 2015, 92, 162–171. [Google Scholar] [CrossRef]
- Sanjari, M.J.; Gooi, H.B. Probabilistic Forecast of PV Power Generation Based on Higher Order Markov Chain. IEEE Trans. Power Syst. 2017, 32, 2942–2952. [Google Scholar] [CrossRef]
- Torres-Barrán, A.; Alonso, Á.; Dorronsoro, J. Regression Tree Ensembles for Wind Energy and Solar Radiation Prediction. Neurocomputing 2017, 326–327, 151–160. [Google Scholar] [CrossRef]
- Wang, J.; Li, P.; Ran, R.; Che, Y.; Zhou, Y. A Short-Term Photovoltaic Power Prediction Model Based on the Gradient Boost Decision Tree. Appl. Sci. 2018, 8, 689. [Google Scholar] [CrossRef]
- Yap, K.; Karri, V. Comparative Study in Predicting the Global Solar Radiation for Darwin, Australia. J. Sol. Energy Eng. 2012, 134, 034501. [Google Scholar] [CrossRef]
- Lamara, B.; Notton, G.; Fouilloy, A.; Voyant, C.; Rabah, D. Solar Radiation Forecasting using Artificial Neural Network and Random Forest Methods: Application to Normal Beam, Horizontal Diffuse and Global Components. Renew. Energy 2018, 132, 871–884. [Google Scholar] [CrossRef]
- Liu, L.; Zhan, M.; Bai, Y. A recursive ensemble model for forecasting the power output of photovoltaic systems. Sol. Energy 2019, 189, 291–298. [Google Scholar] [CrossRef]
- Jiménez-Pérez, P.; López, L. Modeling and forecasting hourly global solar radiation using clustering and classification techniques. Sol. Energy 2016, 135, 682–691. [Google Scholar] [CrossRef]
- Basaran, K.; Ozcift, A.; Kilinç, D. A New Approach for Prediction of Solar Radiation with Using Ensemble Learning Algorithm. Arab. J. Sci. Eng. 2019, 44, 7759–7771. [Google Scholar] [CrossRef]
- Sun, S.; Wang, S.; Zhang, G.; Zheng, J. A decomposition-clustering-ensemble learning approach for solar radiation forecasting. Sol. Energy 2018, 163, 189–199. [Google Scholar] [CrossRef]
- Bae, K.Y.; Jang, H.S.; Sung, D.K. Hourly Solar Irradiance Prediction Based on Support Vector Machine and Its Error Analysis. IEEE Trans. Power Syst. 2017, 32, 935–945. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Deep learning models for solar irradiance forecasting: A comprehensive review. J. Clean. Prod. 2021, 318, 128566. [Google Scholar] [CrossRef]
- Kisi, O.; Zounemat-Kermani, M.; Salazar, G.; Zhu, Z.; Gong, W. Solar radiation prediction using different techniques: Model evaluation and comparison. Renew. Sustain. Energy Rev. 2016, 61, 384–397. [Google Scholar] [CrossRef]
- Si, Z.; Yang, M.; Yu, Y. Hybrid Solar Forecasting Method Using Satellite Visible Images and Modified Convolutional Neural Networks. IEEE Trans. Ind. Appl. 2021, 57, 5–16. [Google Scholar] [CrossRef]
- Zang, H.; Liu, L.; Sun, L.; Cheng, L.; Wei, Z.; Sun, G. Short-term global horizontal irradiance forecasting based on a hybrid CNN-LSTM model with spatiotemporal correlations. Renew. Energy 2020, 160, 26–41. [Google Scholar] [CrossRef]
- Wang, F.; Zhang, Z.; Chai, H.; Yu, Y.; Lu, X.; Wang, T.; Lin, Y. Deep Learning Based Irradiance Mapping Model for Solar PV Power Forecasting Using Sky Image. In Proceedings of the 2019 IEEE Industry Applications Society Annual Meeting, Baltimore, MD, USA, 29 September–3 October 2019; pp. 1–9. [Google Scholar] [CrossRef]
- Xu, C.; Shen, J.; Du, X.; Zhang, F. An Intrusion Detection System Using a Deep Neural Network With Gated Recurrent Units. IEEE Access 2018, 6, 48697–48707. [Google Scholar] [CrossRef]
- Wang, F.; Xuan, Z.; Zhen, Z.; Li, K.; Wang, T.; Shi, M. A day-ahead PV power forecasting method based on LSTM-RNN model and time correlation modification under partial daily pattern prediction framework. Energy Convers. Manag. 2020, 212, 112766. [Google Scholar] [CrossRef]
- Liu, C.H.; Gu, J.C.; Yang, M.T. A Simplified LSTM Neural Networks for One Day-ahead Solar Power Forecasting. IEEE Access 2021, 9, 17174–17195. [Google Scholar] [CrossRef]
- Sibtain, M.; Li, X.; Saleem, S.; Mansoor, Q.; Saqlain, M.; Tahir, T.; Apaydin, H. A Multistage Hybrid Model ICEEMDAN-SE-VMD-RDPG for a Multivariate Solar Irradiance Forecasting. IEEE Access 2021, 9, 37334–37363. [Google Scholar] [CrossRef]
- Li, S.; Bi, J.; Yuan, H.; Zhou, M.; Zhang, J. Improved LSTM-based Prediction Method for Highly Variable Workload and Resources in Clouds. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 1206–1211. [Google Scholar] [CrossRef]
- Dabbaghjamanesh, M.; Kavousi-Fard, A.; Zhang, J. Stochastic Modeling and Integration of Plug-In Hybrid Electric Vehicles in Reconfigurable Microgrids With Deep Learning-Based Forecasting. IEEE Trans. Intell. Transp. Syst. 2021, 22, 4394–4403. [Google Scholar] [CrossRef]
- Huang, Z.; Yang, F.; Xu, F.; Song, X.; Tsui, K.L. Convolutional Gated Recurrent Unit–Recurrent Neural Network for State-of-Charge Estimation of Lithium-Ion Batteries. IEEE Access 2019, 7, 93139–93149. [Google Scholar] [CrossRef]
- Hao, Y.; Sheng, Y.; Wang, J. Variant Gated Recurrent Units With Encoders to Preprocess Packets for Payload-Aware Intrusion Detection. IEEE Access 2019, 7, 49985–49998. [Google Scholar] [CrossRef]
- Gupta, A.; Gupta, K.; Saroha, S. A review and evaluation of solar forecasting technologies. Mater. Today Proc. 2021, 47, 2420–2425. [Google Scholar] [CrossRef]
- Feng, C.; Zhang, J. SolarNet: A Deep Convolutional Neural Network for Solar Forecasting via Sky Images. In Proceedings of the 2020 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 17–20 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Sun, Y.; Venugopal, V.; Brandt, A. Short-term solar power forecast with deep learning: Exploring optimal input and output configuration. Sol. Energy 2019, 188, 730–741. [Google Scholar] [CrossRef]
- Mishra, S.; Palanisamy, P. Multi-time-horizon Solar Forecasting Using Recurrent Neural Network. In Proceedings of the 2018 IEEE Energy Conversion Congress and Exposition (ECCE), Portland, OR, USA, 23–27 September 2018; pp. 18–24. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, J.; Zhu, J. An LSTM Short-Term Solar Irradiance Forecasting Under Complicated Weather Conditions. IEEE Access 2019, 7, 145651–145666. [Google Scholar] [CrossRef]
- Qing, X.; Niu, Y. Hourly day-ahead solar irradiance prediction using weather forecasts by LSTM. Energy 2018, 148, 461–468. [Google Scholar] [CrossRef]
- Guermoui, M.; Melgani, F.; Danilo, C. Multi-step Ahead Forecasting of Daily Global and Direct Solar Radiation: A Review and Case Study of Ghardaia Region. J. Clean. Prod. 2018, 201, 716–734. [Google Scholar] [CrossRef]
- Jeon, B.K.; Kim, E.J. Next-Day Prediction of Hourly Solar Irradiance Using Local Weather Forecasts and LSTM Trained with Non-Local Data. Energies 2020, 13, 5258. [Google Scholar] [CrossRef]
- Obiora, C.N.; Ali, A.; Hasan, A.N. Estimation of Hourly Global Solar Radiation Using Deep Learning Algorithms. In Proceedings of the 2020 11th International Renewable Energy Congress (IREC), Hammamet, Tunisia, 29–31 October 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Mukherjee, A.; Ain, A.; Dasgupta, P. Solar Irradiance Prediction from Historical Trends Using Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Smart Energy Grid Engineering (SEGE), Oshawa, ON, Canada, 12–15 August 2018; pp. 356–361. [Google Scholar] [CrossRef]
- de Guia, J.D.; Concepcion, R.S.; Calinao, H.A.; Alejandrino, J.; Dadios, E.P.; Sybingco, E. Using Stacked Long Short Term Memory with Principal Component Analysis for Short Term Prediction of Solar Irradiance based on Weather Patterns. In Proceedings of the 2020 IEEE Region 10 Conference (TENCON), Osaka, Japan, 16–19 November 2020; pp. 946–951. [Google Scholar] [CrossRef]
- Rai, A.; Shrivastava, A.; Jana, K. A Robust Auto Encoder-Gated Recurrent Unit (AE-GRU) Based Deep Learning Approach for Short Term Solar Power Forecasting. Optik 2021, 252, 168515. [Google Scholar] [CrossRef]
- Li, B. A review on the integration of probabilistic solar forecasting in power systems. Sol. Energy 2020, 207, 777–795. [Google Scholar] [CrossRef]
- Panamtash, H.; Mahdavi, S.; Zhou, Q. Probabilistic Solar Power Forecasting: A Review and Comparison. In Proceedings of the 52nd North American Power Symposium, Virtual, 11–14 April 2021; pp. 1–6. [Google Scholar] [CrossRef]
- Wang, H.Z.; Yi, H.; Peng, J.; Wang, G.; Liu, Y.; Jiang, H.; Liu, W. Deterministic and probabilistic forecasting of photovoltaic power based on deep convolutional neural network. Energy Convers. Manag. 2017, 153, 409–422. [Google Scholar] [CrossRef]
- Garg, S.; Agrawal, A.; Goyal, S.; Verma, K. Day Ahead Solar Irradiance Forecasting using Markov Chain Model. In Proceedings of the 2020 IEEE 17th India Council International Conference (INDICON), New Delhi, India, 11–13 December 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Yona, A.; Senjyu, T.; Funabashi, T.; Kim, C.H. Determination Method of Insolation Prediction with Fuzzy and Applying Neural Network for Long-Term Ahead PV Power Output Correction. IEEE Trans. Sustain. Energy 2013, 4, 527–533. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, Y.; Mao, S.; Cao, G.; Nelms, R.M. Adaptive Learning Hybrid Model for Solar Intensity Forecasting. IEEE Trans. Ind. Inform. 2018, 14, 1635–1645. [Google Scholar] [CrossRef]
- Van Deventer, W.; Jamei, E.; Thirunavukkarasu, G.; Seyedmahmoudian, M.; Tey, K.S.; Horan, B.; Mekhilef, S.; Stojcevski, A. Short-term PV power forecasting using hybrid GASVM technique. Renew. Energy 2019, 140, 367–379. [Google Scholar] [CrossRef]
- Tao, Y.; Chen, Y. Distributed PV Power Forecasting Using Genetic Algorithm Based Neural Network Approach. In Proceedings of the 2014 International Conference on Advanced Mechatronic Systems, Kumamoto, Japan, 10–12 August 2014; pp. 557–560. [Google Scholar] [CrossRef]
- B Gururaj, M.P.; Amani, A. An Identification and Estimation of Solar Energy in India Using Fuzzy Logic (AI) Technique. Int. J. Core Eng. Manag. 2017, 72–79. [Google Scholar]
- Tawn, R.; Browell, J. A review of very short-term wind and solar power forecasting. Renew. Sustain. Energy Rev. 2022, 153, 111758. [Google Scholar] [CrossRef]
- Mitrentsis, G.; Lens, H. An interpretable probabilistic model for short-term solar power forecasting using natural gradient boosting. Appl. Energy 2022, 309, 118473. [Google Scholar] [CrossRef]
- Alessandrini, S.; Delle Monache, L.; Sperati, S.; Cervone, G. An analog ensemble for short-term probabilistic solar power forecast. Appl. Energy 2015, 157, 95–110. [Google Scholar] [CrossRef]
- Doubleday, K.; Jascourt, S.; Kleiber, W.; Hodge, B.M. Probabilistic Solar Power Forecasting Using Bayesian Model Averaging. IEEE Trans. Sustain. Energy 2021, 12, 325–337. [Google Scholar] [CrossRef]
- Khodayar, M.; Mohammadi, S.; Khodayar, M.E.; Wang, J.; Liu, G. Convolutional Graph Autoencoder: A Generative Deep Neural Network for Probabilistic Spatio-Temporal Solar Irradiance Forecasting. IEEE Trans. Sustain. Energy 2020, 11, 571–583. [Google Scholar] [CrossRef]
- Huang, X.; Shi, J.; Gao, B.; Tai, Y.; Chen, Z.; Zhang, J. Forecasting Hourly Solar Irradiance Using Hybrid Wavelet Transformation and Elman Model in Smart Grid. IEEE Access 2019, 7, 139909–139923. [Google Scholar] [CrossRef]
- Perveen, G.; Rizwan, M.; Goel, N. An ANFIS-based model for solar energy forecasting and its smart grid application. Eng. Rep. 2019, 1, e12070. [Google Scholar] [CrossRef]
- Shuaixun, C.; Gooi, H.; Wang, M. Solar radiation forecast based on fuzzy logic and neural networks. Renew. Energy 2013, 60, 195–201. [Google Scholar] [CrossRef]
- Yeom, J.M.; Deo, R.; Adamowski, J.; Park, S.; Lee, C.S. Spatial mapping of short-term solar radiation prediction incorporating geostationary satellite images coupled with deep convolutional LSTM networks for South Korea. Environ. Res. Lett. 2020, 15, 094025. [Google Scholar] [CrossRef]
- Yang, D.; Yagli, G.; Srinivasan, D. Sub-minute probabilistic solar forecasting for real-time stochastic simulations. Renew. Sustain. Energy Rev. 2022, 153, 111736. [Google Scholar] [CrossRef]
- Zhang, X.; Fang, F.; Wang, J. Probabilistic Solar Irradiation Forecasting Based on Variational Bayesian Inference with Secure Federated Learning. IEEE Trans. Ind. Inform. 2021, 17, 7849–7859. [Google Scholar] [CrossRef]
- Bi, J.; Zhang, K.; Yuan, H. Workload and Renewable Energy Prediction in Cloud Data Centers with Multi-scale Wavelet Transformation. In Proceedings of the 2021 29th Mediterranean Conference on Control and Automation (MED), virtually, 22–25 June 2021; pp. 506–511. [Google Scholar] [CrossRef]
- Bi, J.; Zhang, X.; Yuan, H.; Zhang, J.; Zhou, M. A Hybrid Prediction Method for Realistic Network Traffic With Temporal Convolutional Network and LSTM. IEEE Trans. Autom. Sci. Eng. 2022, 19, 1869–1879. [Google Scholar] [CrossRef]
- A novel clustering approach for short-term solar radiation forecasting. Sol. Energy 2015, 122, 1371–1383. [CrossRef]
- Cannizzaro, D.; Aliberti, A.; Bottaccioli, L.; Macii, E.; Acquaviva, A.; Patti, E. Solar radiation forecasting based on convolutional neural network and ensemble learning. Expert Syst. Appl. 2021, 181, 115167. [Google Scholar] [CrossRef]
- Kumari, P.; Toshniwal, D. Extreme gradient boosting and deep neural network based ensemble learning approach to forecast hourly solar irradiance. J. Clean. Prod. 2020, 279, 123285. [Google Scholar] [CrossRef]
- Sharma, N.; Mangla, M.; Yadav, S.; Goyal, N.; Singh, A.; Verma, S.; Saber, T. A sequential ensemble model for photovoltaic power forecasting. Comput. Electr. Eng. 2021, 96, 107484. [Google Scholar] [CrossRef]
- Rodríguez, F.; Martín, F.; Fontan, L.; Galarza, A. Ensemble of machine learning and spatiotemporal parameters to forecast very short-term solar irradiation to compute photovoltaic generators’ output power. Energy 2021, 229, 120647. [Google Scholar] [CrossRef]
- Khan, W.; Walker, S.; Zeiler, W. Improved solar photovoltaic energy generation forecast using deep learning-based ensemble stacking approach. Energy 2022, 240, 122812. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
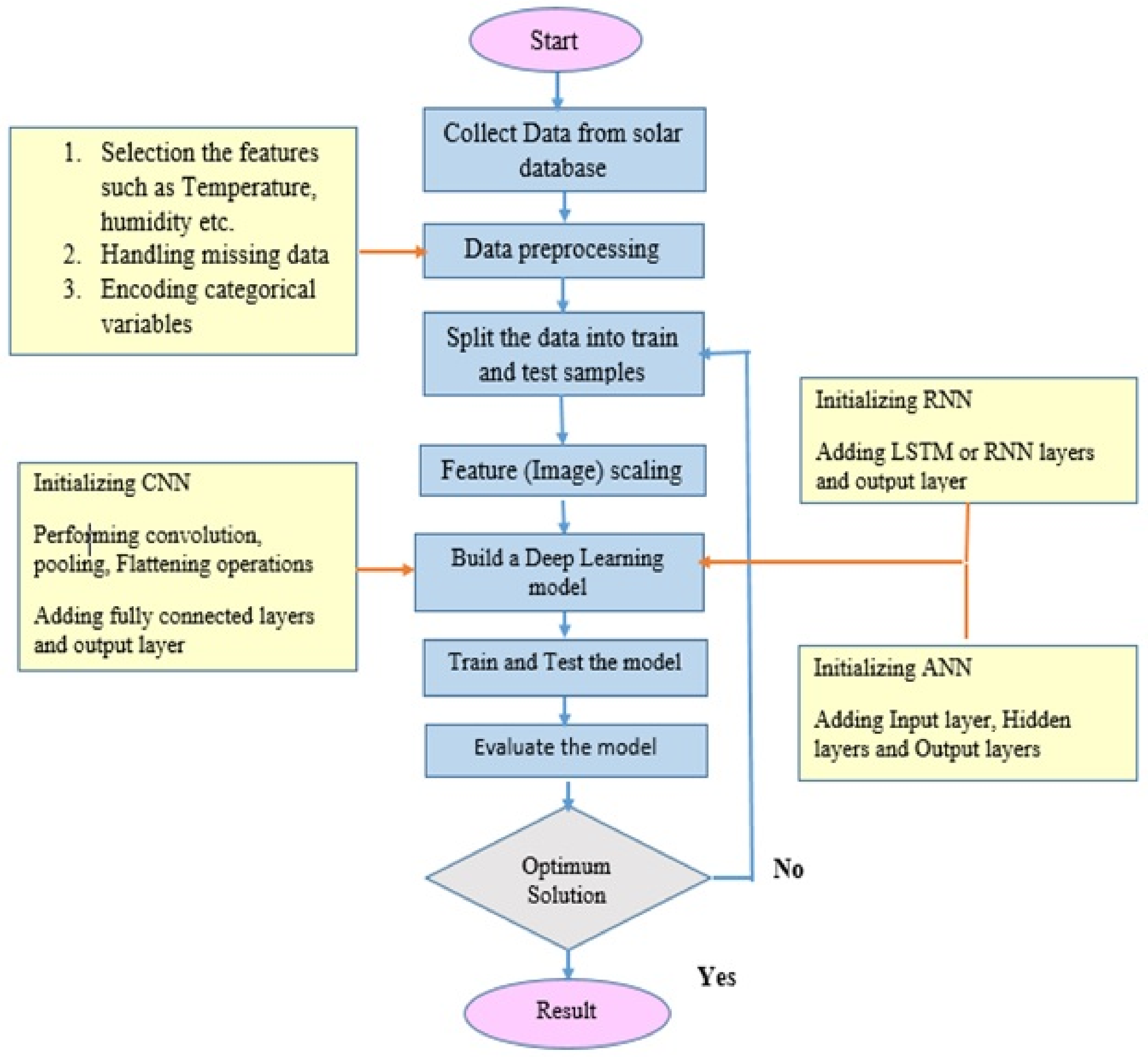{kind=link}
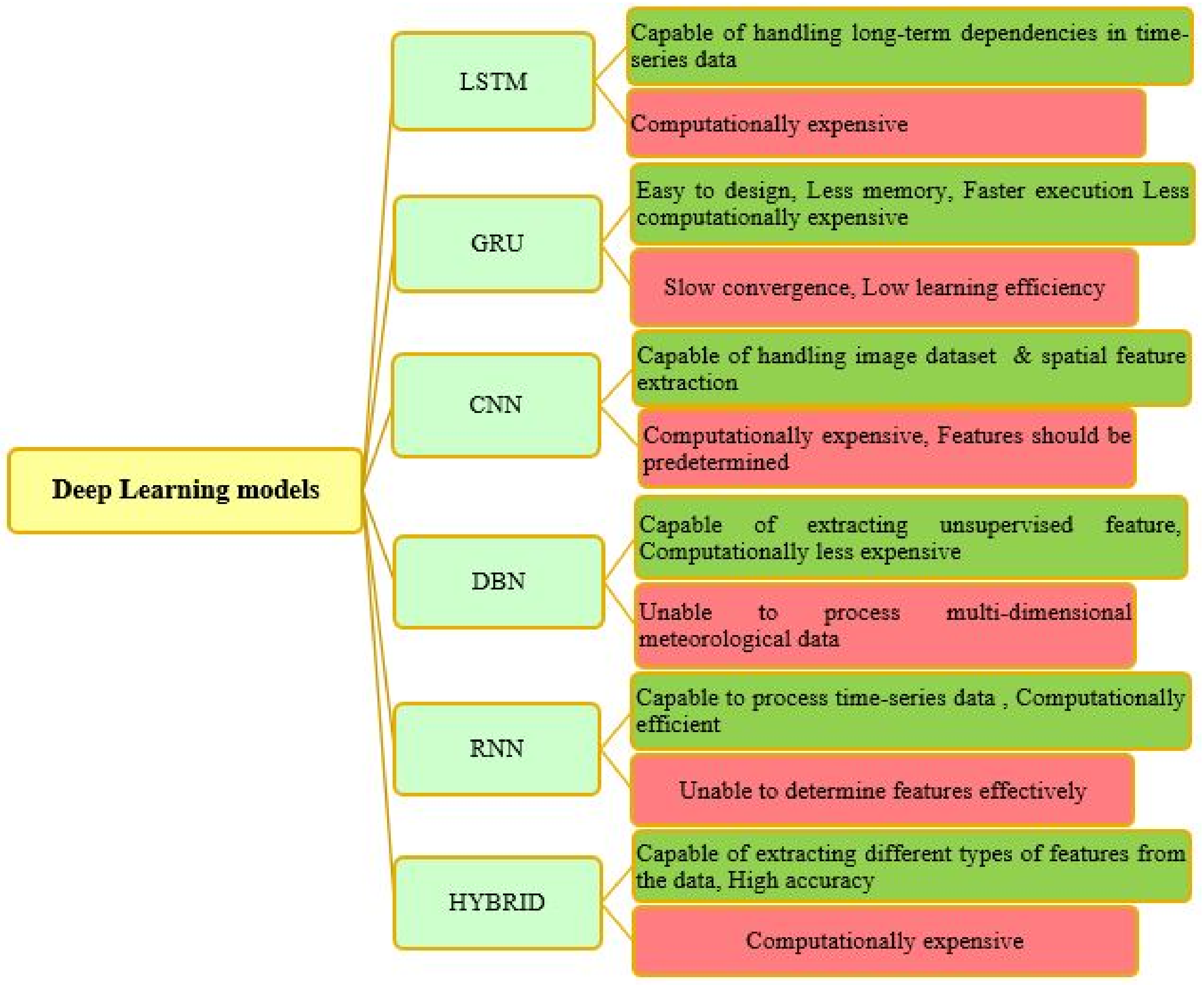{kind=link}
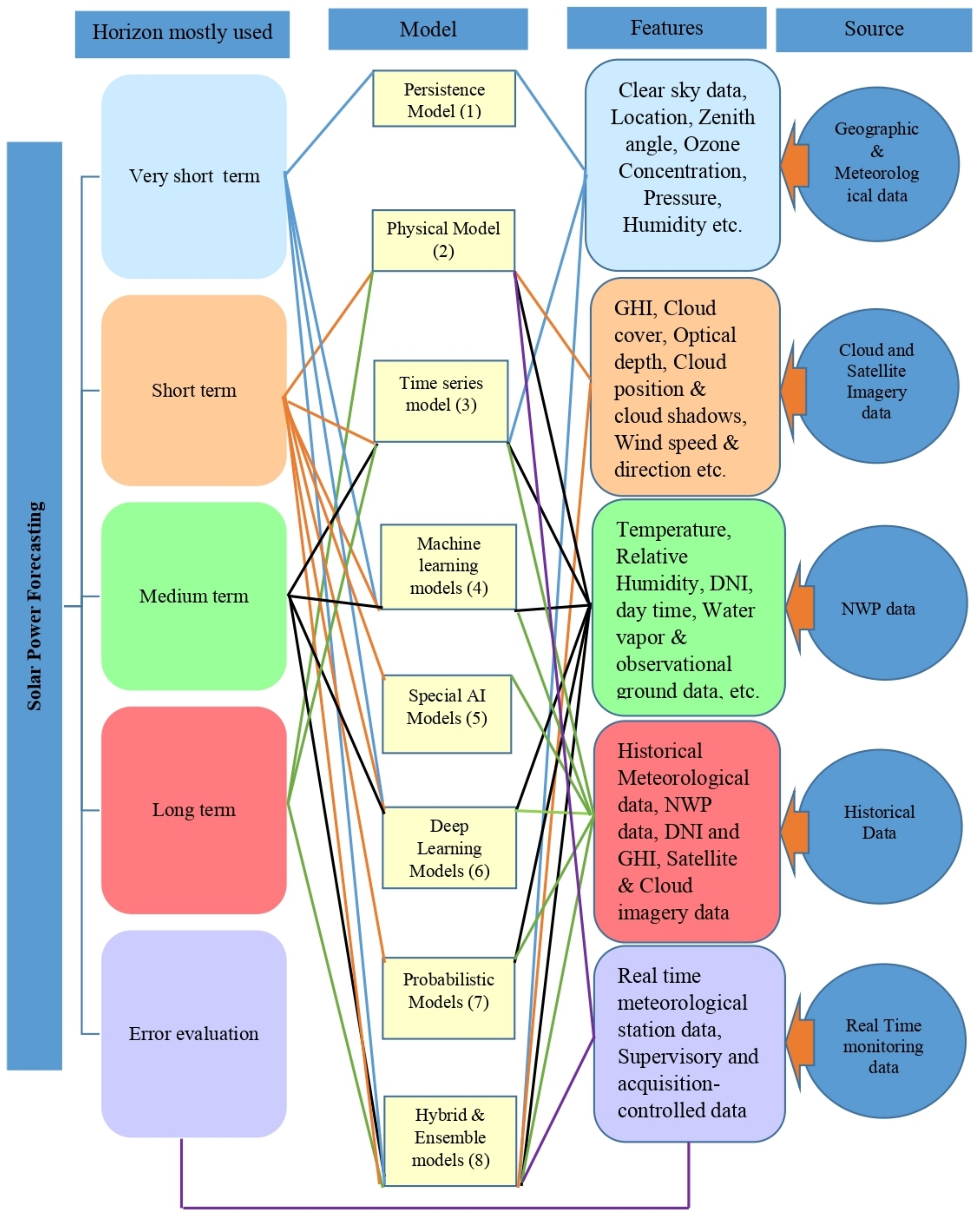{kind=link}




| Reference | Title of the Paper | Year | Summary |
|---|---|---|---|
| S. Sreekumar et al. [11] | Solar power prediction models: classification based on time horizon, input, output and application | 2018 | Presents the classification of solar power forecast models majorly by type of inputs |
| Priya Gupta et al. [12] | PV power forecasting based on data-driven models: a review | 2021 | Presents the classification of solar power forecast models based on theme i.e., direct forecasting and indirect forecasting |
| J. Antonanzas et al. [13] | Review of photovoltaic power forecasting | 2016 | Presents the classification of solar power forecast models based on spatial region with single and regional solar power forecasts. |
| Muhammad Naveed Akhter et al. [7] | Review on forecasting of photovoltaic power generation based on machine learning and meta-heuristic techniques. | 2019 | Presents the classification of solar power forecast models based on time horizon of forecast. |
| Actual Values | |||
|---|---|---|---|
| T/F | 1 | 0 | |
| Predicted values | 1 | TP | FP |
| 0 | FN | TN | |
| Reference | Year | Model | Location | Forecast horizon | Data | Conclusion | Analysis |
|---|---|---|---|---|---|---|---|
| Yeom et al. [61] | 2019 | Kawamura | Korea | 1 h ahead | April 2011 to December 2017 | RMSE of 91.79 W/m2 | Misclassified results affect the forecast performance of solar radiation |
| Garniwa et al. [62] | 2021 | Beyer | Seoul, Korea | 1 h ahead | 2018 year data | RMSE of 118.95 W/m2 | LSTM performs well than physical model |
| Garniwa et al. [62] | 2021 | Perez | Seoul, Korea | 1 h ahead | 2018 year data | RMSE of 89.67 W/m2 | LSTM performs well than physical model |
| Pereira et al. [63] | 2019 | NWP | Evora and Sines, Portugal | 1 h ahead | 2015 year data | RMSE = 57.8–164.4 W/m2 based on sky condition | Increase in data can further improve forecast performance. |
| Mathiesen et al. [64] | 2013 | NWP | USA | 1 h to 1 day ahead | Hourly GHI from the SURFRAD network | rMBE 17.8% and rMAE 25.4% | Based on the cloud parameters, resolution and ramp rate, the result can be further improved |
| Alfredo et al. [65] | 2012 | NWP | Spain | 6 to 39 h ahead | 362 days (2 June 2007 to 27 May 2008) | RMSE error of 11.79% of rated power output | Addition of new input parameters in the third module may increase further performance |
| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion | Analysis |
|---|---|---|---|---|---|---|---|
| Moreno-Munoz et al. [67] | 2008 | Auto Regressive | south Spain | 5 min ahead | 4 years data, (1994–1997) | Best Fit: 65% | The use of AI models enhance better prediction performance |
| Y. Li et al. [68] | 2014 | Moving average | Coloane island, Macau | 1 day ahead | 1 January 2011 to 30 June 2012. | RMSE value of 196.22 W/m2 | Analysis of cloud further enhance the performance |
| Bacher et al. [69] | 2009 | ARX | Small village in Denmark | Up to 36 h ahead | 1 year data | RMSE improvement of 35% in ARX model over naïve predictor model. | Further forecast can be improved with other Time series and AI models Analysis of cloud further enhance the performance |
| Y. Li et al. [68] | 2014 | ARIMA | Coloane island of Macau | 1 day ahead | 1 January 2011 to 30 June 2012. | RMSE value of 171.73 W/m2 | Analysis of cloud further enhance the performance |
| Yang et al. [52] | 2012 | ARIMA | Orlando and Miami, USA | 1 h ahead | Orlando 2005 October, and Miami 2004 December | RMSE value of 29.73 W/m2 in Miami and 32.80 W/m2 in Orlando | Features can be further added from specific to tropical climates to improve forecasting. |
| Y. Li et al. [68] | 2014 | ARMAX | Coloane island of Macau | 1 day ahead | 1 January 2011 to 30 June 2012. | RMSE value of 125.84 W/m2 | Analysis of cloud further enhance the performance |
| Ricardo et al. [70] | 2015 | VAR | Evora, Portugal | Six hours ahead | 1 February 2011 and 6 March 2013 | Improvement of 8% to 1.5% over AR model | The algorithms like GA, PCA for future selection can achieve better performance. |
| Ricardo et al. [70] | 2015 | VARX | Evora, Portugal | Six hours ahead | 1 February 2011 and 6 March 2013 | Improvement of 10% to 5.5% over AR model. | Addition of Weather station and NWP data enhance prediction accuracy. |
| Ines et al. [71] | 2017 | NARX | North of Barcelona | Any time | 1 year 2010 | RMSE value of 18.64% | The results should be compared with high solar radiation fluctuations. |
| Piazza et al. [72] | 2016 | NARX | Palemo, Silicy, Italy | 1 h ahead | 2002 to 2008 | nRMSE value of 6.1% | The exogeneous variable has to be changed to new parameter from temperature to increase accuracy. |
| Voyant et al. [73] | 2014 | ARMA | Mediterranean, France | 24 h ahead | 10 years data | nRMSE ranges from 28.6 to 32.8% | The use of exogenous input increases the performance. Additionally, the deep and machine learning models can be applied to improve the result. |
| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion |
|---|---|---|---|---|---|---|
| Aslam et al. [97] | 2020 | FFNN | Seoul/Korea | Hourly | 2000 to 2017 | RMSE of 109.11 W/m2 |
| Mohammadi et al. [98] | 2015 | SVM | Bandar Abbas, Iran | Daily and Monthly ahead | 1992–2005 | MAPE = 3.2601–6.9996% |
| SANJARI et al. [99] | 2017 | ANN | Australia | 15-min ahead | Two year data 2014 and 2015 | CRPS score = 3.81 |
| Marquez et al. [54] | 2013 | ANN | Davis and Merced, USA | 30, 60, 90, and 120 min ahead | 1 year (1 January 2011 to 31 January 2012) | RMSE value of 55 to 80 W/m2 |
| Torres et al. [100] | 2019 | SVR | Oklahoma, USA | 3 h ahead | 1994 to 2007 | MAE = 2225.2 KJ |
| Wang, J et al. [101] | 2018 | GBDT | Oregon, USA | 1 day ahead | Random 240 day data from the 2015 and 2016 years. | nRMSE varies from 6.96 to 7.72% based on monthly test data |
| Torres et al. [100] | 2019 | XGB | Oklahoma, USA | 3 h ahead | 1994 to 2007 | MAE = 2190.9 KJ |
| Yap et al. [102] | 2012 | Linear regression | Darwin, Australia | 1 h ahead | 2008 to 2010 | RMSE of 6.72% |
| Benali et al. [103] | 2019 | Random Forest | Odeillo, France | hourly | 3 years | nRMSE of 19.65% to 27.78% |
| Liu et al. [104] | 2020 | SVM | 80 sites in China | Daily | 1957–2017 | = 0.613–0.933 for different sites |
| Jimenez Perez et al. [105] | 2016 | EM model | Malaga, Spain | Hourly | 2010–2013 | rMABE = 15.2% |
| Basaran et al. [106] | 2019 | EM model | Afyon, Agri, Sinop, and Hakkari in Turkey | Hourly data | 2012–2016 | RMSE varies from 4.6–14.6% |
| Sun et al. [107] | 2018 | K-means and LSSVM | Beijing, China | Day ahead | 2009–2015 | MAPE 3.27% to 4.65% from single to multi-step |
| Bae et al. [108] | 2017 | SVM RBF | Daejeon, South Korea | 1 h ahead | 26 months (January 2012 to April 2014) | RMSE = (49.26–62.57) W/m2 |
| Reference | Year | Model | Location | Forecast horizon | Data | Conclusion |
|---|---|---|---|---|---|---|
| Voyant et al. [73] | 2014 | MLP | Mediterranean, France | 24 h ahead | 10 years data | nRMSE ranges from 28.6 to 31.9% |
| F. Wang, et al. [115] | 2020 | BPNN | Nevada. | Day-ahead | 2011 to 2016 | RMSE of 10.31% |
| C. Fang et al. [123] | 2020 | CNN | Golden, Colorado, USA | 10 min ahead | Ten years data 1 January 2008 to 31 December 2017 | RMSE of 80.14 W/m2 |
| Yuchi Sun et al. [124] | 2019 | CNN | USA | 15 min ahead | 1 year (March 1st 2017 to March 1st 2018) | RMSE: 2.1 kW/25 kW |
| S. Mishra et al. [125] | 2018 | RNN | Boulder, Desert Rock, Fort Peck, Sioux Falls, Bondville, Goodwin Creek, and Penn State | 1, 2, 3 and 4 h ahead | 2009, 2010, 2011, 2015, 2016 and 2017 year data | Mean RMSE of 9.713 to 39.812% |
| Yu et al. [126] | 2019 | LSTM | Atlanta, New York, and Hawaii in USA. | 1 h ahead | 2013 to 2017 | RMSE in a range of 45.84 W/m2 and 41.37 W/m2 in two different locations. |
| Qing et al. [127] | 2018 | LSTM | Santiago, Cape Verde. | 1 h ahead | 2.5 years (March 2011 to August 2012 and January 2013 to December 2013) | RMSE value of 76.245 W/m2 |
| Chandola et al. [128] | 2020 | LSTM | Arid zones of India | 3, 6, 24 h ahead | Five years dataset (2010 to 2014) | MAPE values ranging 6.79% to 10.47%. |
| Jeon and Kim [129] | 2020 | LSTM | Korea Meteorological Administration. | 24 h ahead | 1825 days | RMSE of 30 W/m2 |
| Obiora et al. [130] | 2020 | LSTM | Johannesburg city | 1 h ahead | Ten years data 2009 and 2019 | Improvement of 3.2% NRMSE over the SVR model |
| Mukherjee et al. [131] | 2018 | LSTM | Kharagpur, India | 1 h ahead | Fifteen years of recorded data from 2000 to 2014 | RMSE value of 57.249 W/m2 |
| Justin et al. [132] | 2020 | LSTM | Weather station, Rizal | Any time | Six months data (September 2019 to February 2020) | value 0.953 and MAE value 41.738 W/m2 |
| A. Rai et al. [133] | 2021 | GRU | New Delhi, India | 24 h, 48 h, and 360 h | 31-December–2015 to 31–December–2016 | MAE of 0.0321, 0.0332 and 0.0377 |
| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion |
|---|---|---|---|---|---|---|
| M. Russo et al. [68] | 2014 | Genetic Algorithm | ENEL Catania site, Italy | 15 min | 1 whole year 2010 | RMSE: 67.6 W/1000 W |
| S.Garg et al. [137] | 2020 | Markov Chains | Bhadla, Jodhpur, Rajasthan, India | Day ahead | 5 years (2010–2014) | MAPE value of 5.04 to 26.56 varies from month to month. |
| V. Gunasekaran et al. [91] | 2021 | Genetic Algorithm | Bondville IL, Pennstate, PA and Desertrock, NV. | 1 min. ahead GHI | 2018 to 2020 | MAE of 4.64, 3.08 and 4.58 respectively |
| Yona et al. [138] | 2013 | Fuzzy Logic | Okinawa, Japan | 24 h ahead | 1 year of data | Average MAE of 0.22 |
| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion |
|---|---|---|---|---|---|---|
| Mitrentsis et al. [144] | 2021 | Natural Gradient Boosting | Germany | day-ahead | February 2018 to October 2019 | RMSE of 5.77 to 6.17% from reduced to full features |
| S. Alessandrini et al. [145] | 2015 | Quantile Regression | Milano, Catania, and Calabria in Italy | 0–72-h ahead | January 2010 to December 2011 (Catania), July 2010 to December 2011 (Milano), and April 2011 to March 2013 (Calabria) | CATANIA MRE = 5.92% CALABRIA MRE = 7.72% MILANO MRE = 8.03% |
| DOUBLEDAY et al. [146] | 2021 | Bayesian Model Averaging | Texas | 1, 4, 12, and 24 h ahead | Two-plus years of data November 2016 to December, 2018. | CRPS score of 5.18 to 7.47 varies from site to site. |
| KHODAYAR et al. [147] | 2020 | Convolutional Graph Auto encoder | USA | 30-min up to 6 h ahead GHI | 1998 up to 2016 | CGAE obtains 2.53% better CRPS than ST-QR-Lasso |
| Reference | Year | Model | Location | Forecast Horizon | Data | Conclusion |
|---|---|---|---|---|---|---|
| SANJARI et al. [99] | 2017 | Markov Chain, Gaussian mixture and Genetic algorithm | Australia | 15-min ahead | Two year (2014 and 2015) | CRPS 2.16 |
| Yona et al. [138] | 2013 | Fuzzy theory, RNN | Okinawa, Japan | 24 h head | 1 year of data | Average MAE of 0.1327 |
| Voyant et al. [53] | 2012 | ANN and ARMA | Mediterranean, France | 1 h ahead | 6 years data | average nRMSE is 14.9% |
| Marzouq et al. [54] | 2013 | GA-MLP | Fez in Morocco | Daily | 7 years (2009 to 2015 | = 0.975 |
| Perveen et al. [149] | 2019 | ANFIS | India | 10 min ahead | 15 years (2002 to 2016) | Average MAPE = 0.00000021% |
| Chen et al [150] | 2013 | Fuzzy logic, MLP | Singapore | Hourly | One month | MAPE = 6.03–9.65% |
| Yeom et al. [151] | 2020 | CNN- LSTM network | Korean Peninsula. | 1 h ahead | 1 April 2011 to 31 December 2015 | RMSE value of 71.334 W/m2 and value of 0.895. |
| D. Yang et al. [152] | 2021 | AnEn+LPQR | Oahu Solar Measurement Grid, Hawaii. | 4 s to 1 min ahead | 2010 March to 2011 October | CRPS score of 24.7 to 64.5 and Average skill score is 27.80% |
| A. Rai et al. [133] | 2021 | AE-GRU | New Delhi, India | 24 h, 48 h, and 360 h ahead | 1 year (31-December–2015 to 31–December–2016) | Coefficient of 0.8976247 to 0.937336 |
| F. Wang, et al. [115] | 2020 | LSTM-RNN | Nevada. | Day-ahead | 6 years (2011 to 2016) | RMSE value of 8.83% |
| ZHANG et al. [153] | 2021 | Federated BayesLSTM-NN | Ningxia, China | Intra hour, Intraday and day ahead | July 2006 to November 2018 | MAE of 49.1, 53.1 and 71.6 W/m2 |
| Ratshilengo et al. [38] | 2019 | GA-SVM | Victoria, Australia | 1 h ahead | 278 days | RMSE of 11.226 W and MAPE of 1.70% |
| Jing Bi et. Al [154] | 2021 | Wavelet Transformation—LSTM | US Virgin Islands | 5 min. | 19 October 2013 to 19 November 2013 | = 0.98 |
| Jing Bi et. Al [154] | 2021 | Wavelet Transformation—BPNN | US Virgin Islands | 5 min. | 19 October 2013 to 19 November 2013 | = 0.99 |
| Jing Bi et. Al [155] | 2022 | ST-LSTM | Spanish Wikipedia | 1 h | 1 July 2015 to 1 July 2016. | = 0.99 |
| M. Ghayekhloo [156] | 2015 | Game Theory (GT)-SOM | Ames, Iowa, United States | 1 h, 2 h, 3 h and 1 day ahead | 2011 and 2013 | RMSE value of 67.921, 82.506, 113.4 and 119.75 W/m2 respectively |
| Monjoly et. Al [79] | 2017 | WD–AR | Le Raizet, France | 1 h | January 2012 to December 2013 | RMSE value of 19.57% |
| Monjoly et. Al [79] | 2017 | WD–AR–ANN | Le Raizet, France | 1 h | January 2012 to December 2013 | RMSE value of 7.90% |
| Reference | Year | Model | Location | Forecast Horizon | Data | Training/Test Split Ratio | Conclusion |
|---|---|---|---|---|---|---|---|
| Yongqi Liu et al. [5] | 2019 | CNN and GRU | United States | 3 h-ahead GHI | 2 years (1 January 2013 to 31 December 2014) | 8760 h / 8760 h | Mean RMSE of 69.5 W/m2 |
| Davide Cannizzaro et al. [157] | 2021 | Convolutional Neural Networks (CNN) and Random Forest (RF) | University Campus in Turin, Italy, | Next 15 min up to next 24 h GHI | December 2009 to November 2015 | (6 years) December 2009 to November 2014/December 2014 to November 2015 | coefficient of 0.936 to 0.908 |
| Davide Cannizzaro et al. [157] | 2021 | Convolutional Neural Networks (CNN) and Long Short Term Memory (LSTM) | University Campus in Turin, Italy | Next 15 min up to next 24 h GHI | December 2009 to November 2015 with a time- resolution of 15 min (6 years) | December 2009 to November 2014/December 2014 to November 2015 | coefficient of 0.937 to 0.908 |
| Pratima Kumari et al. [158] | 2020 | Extreme gradient boosting forest and Deep neural networks (XGBF-DNN) | New Delhi, Jaipur and Gangtok in India | 1 h GHI ahead | Ten years (from 2005 to 2014) | First eight years of data/Two years of data. | RMSE of 56.68 W/m2, 53.78 W/m2 and 91.86 W/m2 of Jaipur, New Delhi, and Gangtok respectively. |
| Nonita Sharma et al. [159] | 2021 | Long Short Term Memory (LSTM) Layer and Maximal Overlap Discrete Wavelet Transform (MODWT) | Yulara Solar System, Australia | 1 day, 10 days, and 1 month ahead GHI | January 2016 (12:00:00 a.m.) to 10 June 2020 (4:50:00 a.m.) | 2016–2019/2020 | RMSE of 0.1109, 0.1231, and 0.1231 kW for 1 day, 10 days, and 1 month, respectively |
| Fermín Rodríguez et al. [160] | 2021 | Feed forward neural network and a Spatio-temporal approach | Vitoria–Gasteiz, Spain | 10 min ahead GHI | 2015–2017 (3 years) | 2015–2016/2017 | RMSE of 50.80 W/m2 |
| Waqas Khan et al. [161] | 2021 | DSE-XG (ANN, LSTM and XGBoost) | Bunnik, Netherlands | 15 min and 1 h ahead GHI | 2016 to 2019 years data by solar gis | Four folds/One fold | RMSE of 0.35, and 0.26 kW for 15 min. and 1 h respectively |
| Liping Liu et al. [104] | 2019 | SVM, MLP and MARS | Australia Solar Centre (DKASC), Australia | 1 day ahead GHI | 15 August 2013 up to 17 June 2018 | 4 months of each year (from 2014 to 2018), with a total of 600/4 days in 2018 | RMSE of 0.1248 to 0.53 kW |
| Horizon Mostly Used—Model | Source—Model |
|---|---|
| Very short term—Blue—1,4,6,8 | Geographical & Meteorological data—Blue—1,3,8 |
| Short term—Brown—2,3,4,5,6,7,8 | Cloud & Satellite Imagery data—Brown—2,8 |
| Medium term—Black—3,4,6,8 | NWP data—Black—2,3,4,6,7,8 |
| Long term—Green—2,3,8 | Historical data—Green—3,4,5,6,7,8 |
| Error evaluation—Violet | Real time monitoring data—2,8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sudharshan, K.; Naveen, C.; Vishnuram, P.; Krishna Rao Kasagani, D.V.S.; Nastasi, B. Systematic Review on Impact of Different Irradiance Forecasting Techniques for Solar Energy Prediction. Energies 2022, 15, 6267. https://doi.org/10.3390/en15176267
Sudharshan K, Naveen C, Vishnuram P, Krishna Rao Kasagani DVS, Nastasi B. Systematic Review on Impact of Different Irradiance Forecasting Techniques for Solar Energy Prediction. Energies. 2022; 15(17):6267. https://doi.org/10.3390/en15176267
Chicago/Turabian StyleSudharshan, Konduru, C. Naveen, Pradeep Vishnuram, Damodhara Venkata Siva Krishna Rao Kasagani, and Benedetto Nastasi. 2022. "Systematic Review on Impact of Different Irradiance Forecasting Techniques for Solar Energy Prediction" Energies 15, no. 17: 6267. https://doi.org/10.3390/en15176267